In the presence of outliers, several strategies have been proposed. Robust methods aim at automatically mitigating the weight of these outliers in the estimation. For instance, PF or its variants belonging to the class of robust estimators can theoretically cope with outliers simply by giving a very small weight to the generated particles. However, if this filter has proven its efficiency against noise, we will see that too many outliers jeopardize the filter stability. Then, in the case of GPS data processing, some statistical tests have been proposed to detect the outliers, e.g., [
31]. The most simple to cope with these outliers is simply to discard them from the data measurements (just as if the corresponding satellites were blocked). This is the strategy of the standard Fault Detection and Exclusion (FDE) technique implemented in the GPS receivers (even if they can only cope with at most one erroneous measurement [
32]). More sophisticated strategies have also been proposed, e.g., [
15,
33], that aim at correcting the outliers. However, in this study, we do not consider such strategies, because we focus on the following basic main questions:
For the localization problem, are Doppler measurements less subject to outliers than PR measurements?
Does the presence of outliers also impact robust localization algorithms, such as PF or the Rao–Blackwell Particle Filter?
In the affirmative case, is it worth detecting and discarding these outliers?
Then, in the localization algorithm, we add an outlier detection step that will select the data (among those available) involved in the location estimation. Specifically, considering filtering algorithms with two steps, prediction and estimation, the outlier detection step is inserted before the estimation step.
3.1. Outlier Detection
The outlier detection is performed using the
a contrario approach that we proposed in [
23] extended to the case of (PR,Dp). The
a contrario approach detects the inliers as observations that are “too regular to occur by chance”. “Chance” is measured through the Number of False Alarms (NFA), based on two items: a model, called the “naive” model, that represents the statistics of the outliers (the
hypotheses in statistical decision theory) and a measurement that will allow the distinction of inlier and outlier sets under the “naive” model assumption. In [
23], we have proposed and compared two “naive” models leading to two NFA criteria for partitioning the data between inliers and outliers. However, these models only deal with PR measurements. In this study, we extend to (PR,Dp) the first NFA criterion that experimentally leads to slightly better results than the second NFA criterion.
Before presenting the extended algorithm, let us specify the equations used and the notations. Assuming a value of
denoted
and the satellite features (location and velocity), we are able to compute using Equations (8) and (9) the expected value of PR or Doppler measurement. Then, we can compare these expected ones to the actually observed ones. By definition, the residues are the differences between computed measurements (under the
hypothesis) and the observed ones:
associated with the PR observation at
,
, is:
where
is computed using Equation (8), and
associated with Doppler observation at
,
, is:
where
is computed using Equation (9).
In order to give the same weight to both kinds of measurements, PR and Doppler ones,
and
are normalized by their standard deviation,
and
, respectively, and gathered into vector
:
with
M the cardinality of (PR,Dp) set.
As for Equations (10) and (11), several epochs are considered. This allows us to increase the number of available data, as well as the quality of the estimation, provided that the dynamic model (Equations (8) and (9)) used to ‘align’ the data acquired at different epochs is sufficiently accurate. The number of considered epochs, , is then a compromise between data availability and dynamic model approximation. In the following, and denote the sets of available observations (PR and Doppler measurements, respectively) over the considered interval of epochs .
Let us now consider a subset of measurements noted
in the whole set of observations
. Given
and
(Equation (14)),
is defined as the sum of the squares of
components for indices
j belonging to
(indeed,
measurements being indexed,
also corresponds to a set of indices). Then, according to [
23],
allows us to quantify the consistency of
through the NFA measure (associated with the Gaussian naive model
):
where Γ is the Gamma function,
is the cardinality set operator and
is a normalization term that allows us to control the average number of false alarms [
17].
The
test using the SSE (Sum of Squared Error) is used in the classical RAIM (Receiver Autonomous Integrity Monitoring) method [
10,
34] to detect the presence of erroneous data. However, it requires an
a priori parameter, namely the probability of false alarm
, to threshold the values of SSE. Conversely, using the NFA criterion, we are free from the fitting of a threshold parameter, since the solution is derived by optimization of the NFA function: the subset of inliers is the subset of measurements that allows us to reach the minimal value of NFA. Let us underline the difference between the parameter
σ involved in the naive model and a threshold parameter: whereas a set of inliers obtained by thresholding will be very sensitive to the used threshold value, we have shown [
23] that the subset
that minimizes the NFA value is very robust to naive model parameter
σ.
Algorithm 1 presents the extended version of Algorithm 1 of [
23] that allows us to find the subset
minimizing the NFA criterion. Here, the input parameters are the observation sets
and
(possibly empty if Doppler measurements are not considered), the number of iterations
, the parameter
σ of naive model
, the standard deviations,
and
, for the residue normalization and the binary parameter
that is equal to zero or one, depending on the kind of processed data: only PR data or (PR,Dp), respectively. The output parameters are the subset
of the inliers and the estimation of
.
Following the
a contrario RANSAC principle (e.g., [
35]), the algorithm performs different estimations or tests (loop until
) in order to select the best one according to the NFA criterion. Then, for each test, it performs the three following steps. First, the data selection step consists of randomly drawing
elements in
(the set of PR observations) or, if
,
elements in
and
(the set of Doppler measurements). The numbers eight and 10 correspond to the minimum number of observations to estimate
or
further.
and
include any available observations performed during the considered interval of
last epochs. According to [
23], the random drawing of observations is biased in order to favor the drawing of favorable configurations of satellites. Since we use a sliding window over epochs, there is an overlapping between the sets of considered epochs for the estimation at two successive instants. Therefore, from the processing of the previous instant, we know the inliers corresponding to previous
epochs. Then, like in [
23], random drawing is constrained, such that: (i) there is at least one measurement per epoch; (ii) for epochs before the last one, the PR Doppler measurements are chosen among the already detected inliers; (iii) the selection of different satellites is favored.
These
d observations are used to derive a preliminary solution
or
(depending on the
value). To derive this solution, a regularization term may be added to Equation (8) or Equation (9), allowing both better conditioning of the problem and the receiver trajectory being smoother. Considering the regularization term, instead of Equation (10), we have to solve Equation (16):
and instead of Equation (11), we have to solve Equation (17):
In Equation (16) and Equation (17),
, is the predicted vector state according to dynamic Model (7);
returns the vector of the absolute values of
v components; and
is the vector of the regularization parameters (
λ weights the importance of the deviation between estimated
and predicted state vector
). The
Appendix specifies the derivation of
.
![Sensors 16 00580 i001]() |
The second part of the algorithm computes the non-null residues for all of the other (not drawn) observations, either only PR or (PR,Dp). Having increasingly sorted the vector of residues, the last part of the algorithm computes the minimum NFA values by varying the cardinality of
(increasing from
to
M).
is a vector that stores the values of the minimal quadratic errors (sum of the squares of the residues) for every cardinality of subset
. Indeed, for a given cardinality of
, the
value is minimum for minimum value of quadratic error
that is achieved considering the
lowest values of residues (hence, the sorting of
). Then,
is a vector that stores the
values corresponding to
;
is the minimum among
. The inlier subset is the set
achieving the
value. Finally, state vector
or
is estimated from
and Equation (18):
where
is the residue provided by Equation (14).
Algorithm 1 has a linear complexity with
. For one iteration, the complexity mainly comes from state vector estimation (Algorithm A1,
Appendix). The complexity of this latter depends on
d: matrix inversion and matrix multiplication are in
. Then, the complexity of the sorting of
is in
. For NFA(PR,Dp),
, and
M varies in
considering a temporal window of three epochs. Therefore, to control the computation time, one should fit the parameter
.
Finally, note that, even if Algorithm 1 provides estimations of GNSS receiver localization parameters, the proposed coupling between Algorithm 1 and the robust localization algorithm (PF/RBPF presented in the next section) is only done in terms of data selection. Indeed, in Algorithm 1, the provided estimation only aims at evaluating the consistency of a subset of data, whereas PF/RBPF allows for non-linear/non-Gaussian data filtering that exploits some classic a priori parameteron the smoothness of the trajectories. Such an independence between the detection step (Algorithm 1) and the filtering step (PF/RBPF) increases the robustness of the global localization algorithm.
3.2. Localization Algorithm
The particle filter, also called the Sequential Monte Carlo (SMC) method, is a numerical method that consists of approximating the posterior probability (probability of the state given the set of observations ) using a sufficient number of particles . A particle represents a state vector solution, and the associated weight represents its likelihood. Such a representation based on samples/particles allows us to approximate and deal with any statistical distribution of error, especially non-parametric ones and non-Gaussian ones.
3.2.1. SIR-PF
The Sequential Importance Resampling (SIR) particle filter [
13], also known as the “bootstrap filter”, is the most popular method to solve the non-linear filtering problem.
For SIR-PF, the number of the required particles is directly linked to the dimensionality of the state vector. In order to keep a reasonable number of particles (bounded to a few thousands), we assume that either the altitude is constant, as is often in urban environments, or it is known as in our case from the output of Algorithm 1, so that it has not been introduced in the state vector. For the same reasons, velocity is also excluded from the state vector (conversely to the RBPF state vector presented in the next section). Then, the SIR-PF particles are , where i denotes the particle index and t is the epoch.
At each epoch, the SIR-PF iterates the three steps “prediction”, “estimation” and “resampling”.
Prediction Step
This step, sometimes called PF time update, aims at providing an estimation of the state vector at the next time step. Note that if here, we place it at the beginning of iteration at time t, it can equivalently be placed at the end of iteration at .
To predict the next position of the particle, we need an estimation of the velocity
. Since,
is not part of the state vector, it should be provided by external data. Using GPS-only data, we consider Doppler measurements to derive
: Doppler measurements at time
provide PR rates from which we derive the receiver velocity
using Equation (3). In order to comply with common notations in the transportation and navigation community,
can be equivalently represented in terms of norm and orientation:
and
, respectively. Then, we predict the next state at
t of the
i-th particle according to:
where the time step
is equal to one and
ν is the prediction noise associated with each component of the state vector. Indeed, as a stochastic approach, PF is based on stochastic simulations provided here by the addition (to the deterministic predictions state vectors) of a Gaussian noise with zero mean and standard deviation
.
Note that in our case, the velocity used for prediction is estimated from
at
. Instead of using Doppler measurements at
, we could have used those acquired at
t. However, since the prediction is between
and
t, it will not provide necessarily a more accurate prediction. In comparison with the RBPF (presented in
Section 3.2.2), let us underline that the velocity estimation is performed as an external process to the SIR-PF itself, since velocity is not a part of the state vector.
Estimation Step
This step, sometimes called PF measurement update, aims at correcting the prediction step estimate according to the observations. Since velocity is not represented in the state vector , the posterior probability of our SIR-PF is only computed relatively to the PR measurements. It is denoted with the vector of observed at t.
The update process of weights
is a weighting function of their previous values [
36] by the observation likelihood function
:
∝
. In most cases, because of computational constraints, the likelihood function
is approximated by a multivariate Gaussian density. Finally, normalization of the weights is performed so that
.
Having updated the weights, the ‘optimal’ state vector
is derived as the weighted sum of all particles:
Resampling
This step aims at preventing the degeneracy of the algorithm, in particular to avoid that computer resources are consumed by “unlikely” particles. During this step, a threshold is computed [
36] to partition the set of the particles according to their weight [
13]. Having removed the particles that present lower weight than the considered threshold, the remaining particles are duplicated in order to keep a constant number of particles, and all of the weights are reinitialized to a constant value (reciprocal of the total number of particles).
3.2.2. Rao-Blackwellised PF
In previous PF, the velocity was estimated directly from Doppler measurements (being ‘outside’ of the PF estimation step, it does not take into account previous estimations of the PF prediction step). This boils down to assuming no noise on Doppler measurements. In order to avoid such an assumption and to be more realistic, we extend the state vector from to , i.e., its dimensionality increases from three to eight.
However, standard PF would require a very important number of particles to explore the whole space of solutions, and the PF would become intractable. On the other hand, the Rao-Blackwellization approach [
37,
38] was proposed both to reduce the complexity and to better approximate the solution in case of convex functions. It is based on the idea that splitting the state vector allows us to decrease the approximate error by exploiting linear substructures [
25]. A classic case corresponds to the splitting of the initial state vector into two sub-vectors, one being estimated analytically and the other one by importance sampling (e.g., PF). Thus, the number of particles required for precise estimation remains tractable thanks to the lower dimensionality of the non-linear subsystem [
25,
38].
Considering our problem, we split the system of eight components describing the prediction step equations into two sub-systems, a linear and a non-linear one, as follows. The equations involving PR observations (Equation (1)) are non-linear leading to a non-linear system for deriving GPS position. On the other hand, the velocity estimation knowing the position of the receiver and the Doppler measurements is achieved solving a linear system (Equation (3)). Thus, we define the two state vectors and .
The posterior probability of the RBPF is factorized:
where
still denotes the set of observations. The first term is solved analytically using EKF, and the second term is estimated by Monte Carlo sampling using PF. Then, in RBPF, we can keep the same number of particles as in
Section 3.2.1, while considering also the receiver velocity in the state vector and filtering it. The proposed model for RBPF is triangular:
where
is the square identity matrix of dimensionality
n,
is the rectangular zero matrix of dimensionality
,
and
are the covariance matrices of the noise, which is assumed zero mean Gaussian (for notation shortness, we omitted the time dependency for covariance matrices) and
and
are the transition matrices defined as follows:
The non-linear part is processed using the same PF presented in
Section 3.2.1 to estimate the state vector of each particle
and its associated weight
. The linear part is processed using an EKF applied to the state vector
of each particle recursively. EKF involves two main steps:
Prediction Step
This step occurs between the prediction step and the estimation step of the SIR-PF. We define intermediate variables,
where
is interpreted as an error measurement and
and
are intermediate matrices modeling the impact of the non-linear system on the linear estimation. Then,
where
is the covariance matrix of
. Note that if the
matrix is null, previous equations boil down to Kalman’s filter prediction step. Note that, since the prediction step presented in
Section 3.2.1 is involved in Equation (27), the current prediction step occurs after the prediction of the non-linear part of RBPF.
Estimation Step
This step occurs between the estimation step and the resampling of the SIR-PF. It is the classical correction step of the extended Kalman filter.
where
is the observation matrix of Doppler measurements derived from Equation (3).
This analytical correction of the
subvector is independent from the estimation of
that is performed according to the estimation step presented in
Section 3.2.1 (Equation (20)).
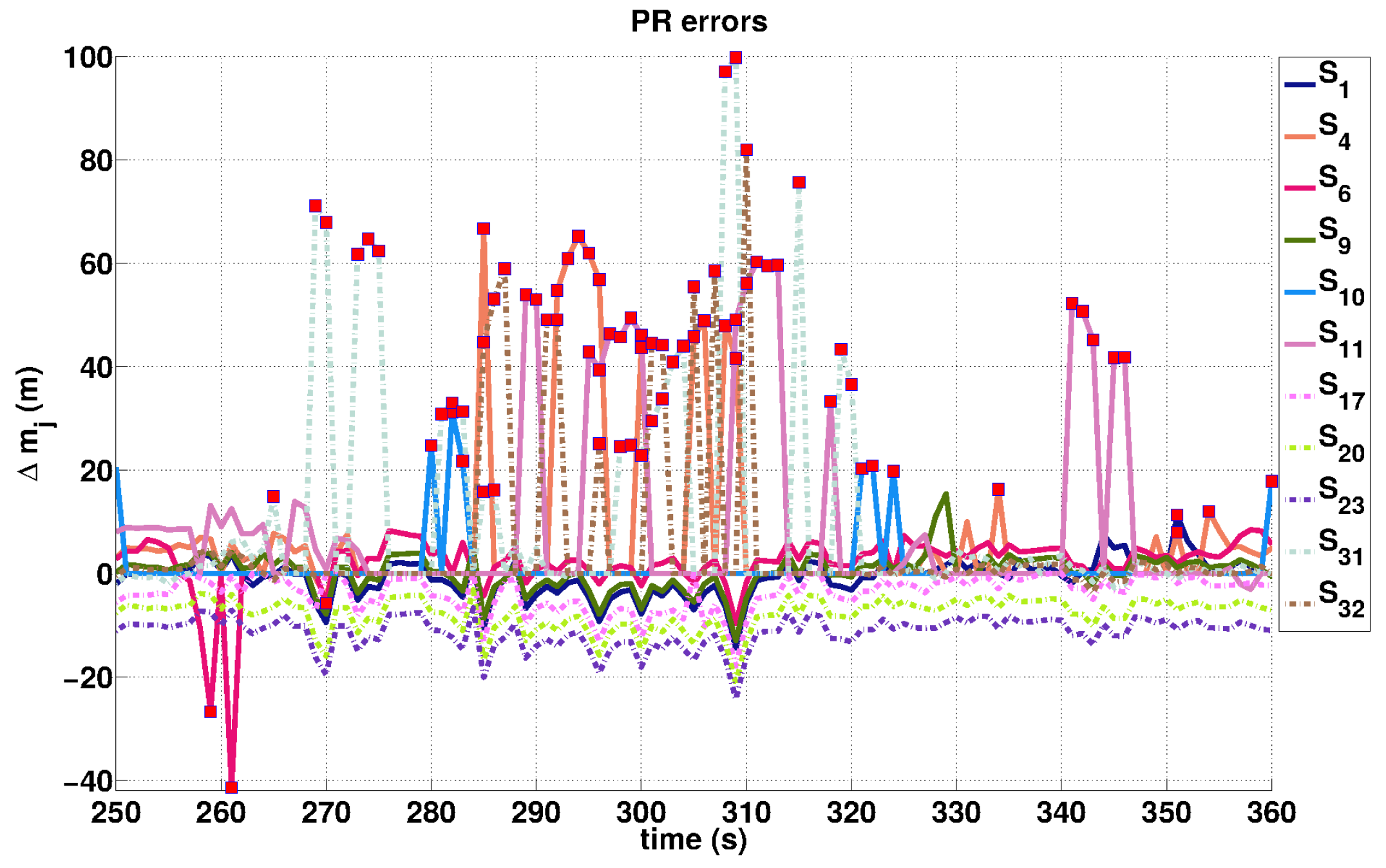
One of the objectives of this study was to check the interest of removing outliers from the datasets, either PR or (PR,Dp). This can be achieved by comparing the localization results obtained using outlier detection coupled with PF or RBPF.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}