Improving GNSS Ambiguity Acceptance Test Performance with the Generalized Difference Test Approach

 ,
,  , ,
, , 
 and
and
Abstract
:1. Introduction
- Estimating and using a least-squares estimator or Kalman filter. The integer nature of is not considered in this step and corresponding estimated parameters are regarded as the ’float solution’. The float solution and its variance-covariance matrix are denoted as:
- Mapping the real-valued ambiguity to integer with the integer estimator. The integer estimation procedure can be described as, with .
- Performing ambiguity acceptance test. The fixed integer is validated with ambiguity acceptance tests. If is rejected by the test, the procedure is finished and the float solution will be used as the final solution
- Updating real-valued parameters by if is accepted by the ambiguity acceptance test.
2. The Sub-Optimality of the Difference test
2.1. The Difference Test
2.2. The Optimal Integer Aperture Estimation
2.3. The Discrepancy between the DTIA and the OIA
3. Generalized Difference Test
3.1. Definition of the Generalized Difference test
3.2. The Acceptance Region of the GDT
3.3. The Optimal Term Number of GDT
3.4. Rapid Determination of the Threshold of the GDT
3.5. The Procedure of Applying GDT
- Finding the best m integer candidates. The optimal integer estimator, the integer least-squares, can intermediately give an arbitrary number of best integer candidate sets. Hence, getting m best sets of integer candidates is just a sorting procedure.
- Constructing the test statistics of GDT. For example, the test statistics of GDT3 can be computed as:where denotes for the computed test statistics of GDT3. , , are the best, second best, third best sets of integer candidates. The squared Mahalanobis distances can also be obtained with the integer least-squares searching procedure.
- Computing IB success rate with Equation (26), then determining the threshold of GDT using the threshold function with specified IB success rate and failure rate tolerance. The threshold is a non-negative value, so the threshold is set to be zero if the computed threshold is negative.
- Performing ambiguity acceptance test. If , or equivalently , then the best integer candidate can be accepted by the ambiguity acceptance test, otherwise, reject it. Since the threshold function gives , it is necessary to recover the with an exponential function.
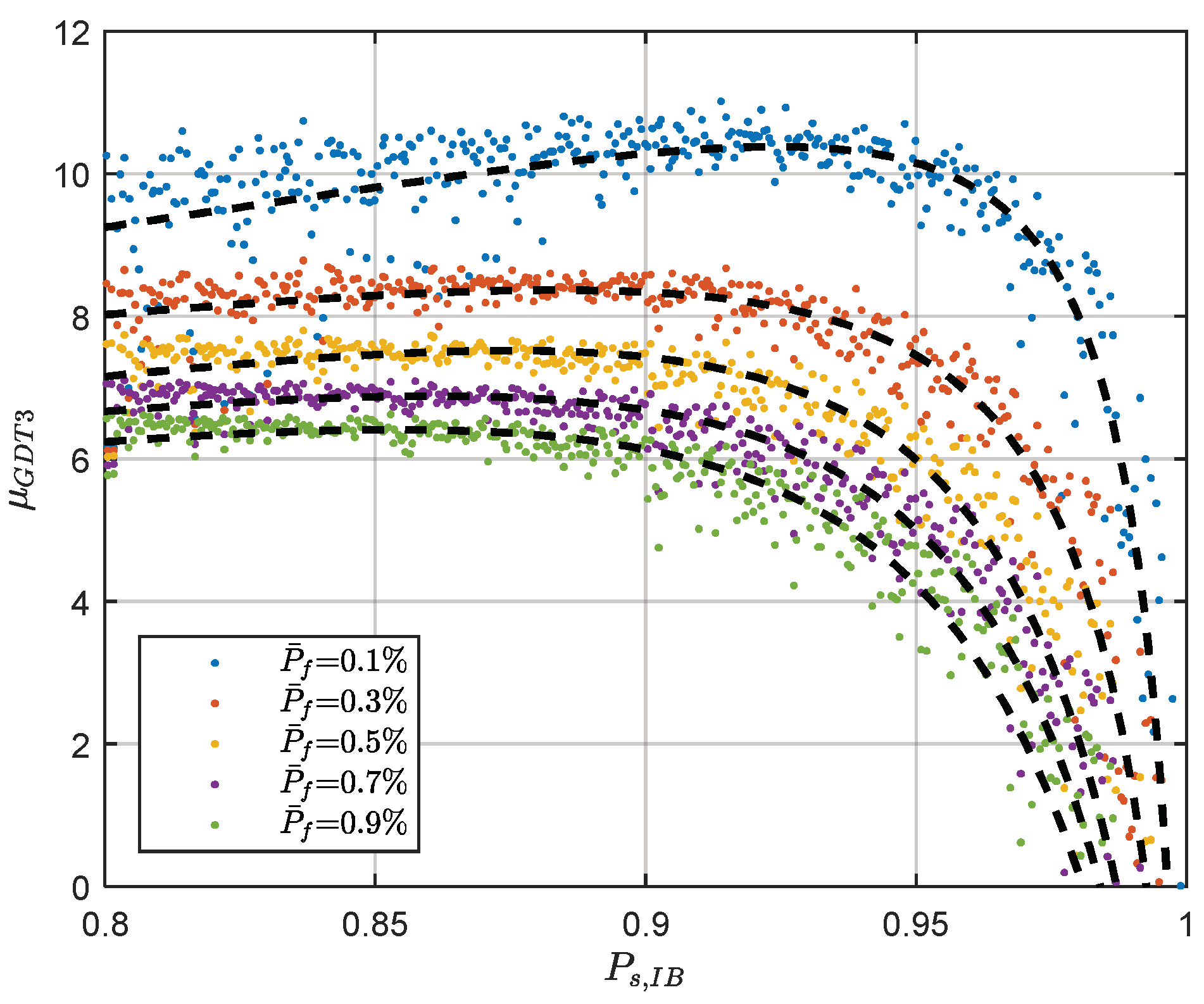
4. Performance Evaluation of the GDT
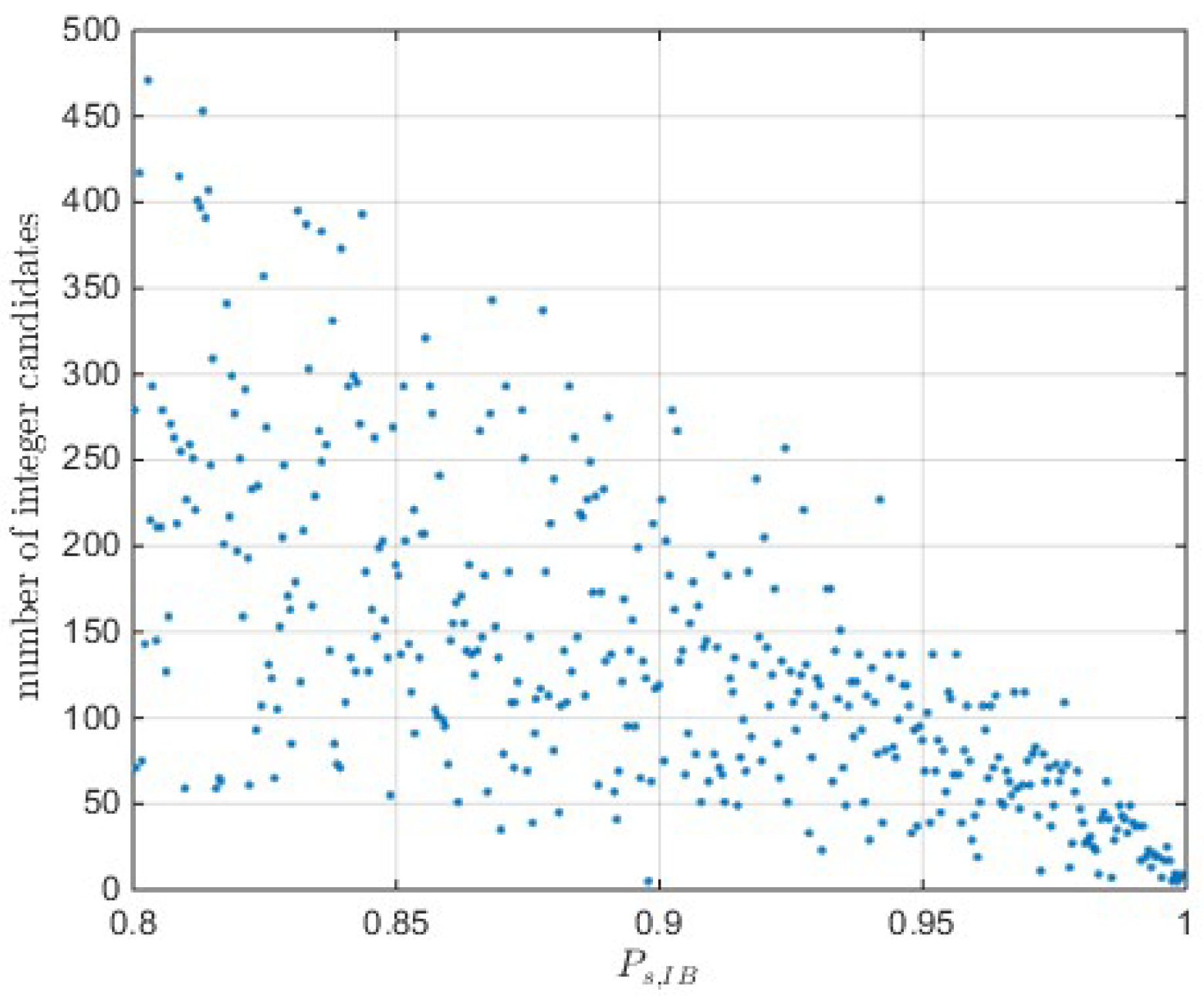
5. Numerical Results from GNSS Baseline Data
- The ionosphere weighted model is used to capture the ionosphere biases. The elevation dependent and baseline dependent stochastic model is used for the priori ionospheric noise. With strong priori ionosphere constraint, the short-baseline is equivalent to the ionosphere-fixed model.
- The elevation dependent weighting model is used to reflect the observation noise.
- The posterior variance factor is estimated on epoch basis to adapt the temporal variation of observation noise. Since the difference test and GDT are sensitive to the variance factor, so capture the temporal variation of variance factor is important. A more detailed stochastic modeling strategies can be found in the work [14].
6. Concluding Remarks
Author Contributions
Funding
Conflicts of Interest
References
- Teunissen, P.J.G. Least-Square Estimation of the Integer GPS Ambiguities. In Proceedings of the International Association of Geodesy, Beijing, China, 8–13 August 1993. [Google Scholar]
- Wang, L.; Verhagen, S. A new ambiguity acceptance test threshold determination method with controllable failure rate. J. Geod. 2015, 89, 361–375. [Google Scholar] [CrossRef] [Green Version]
- Teunissen, P.J.G. The least-squares ambiguity decorrelation adjustment: A method for fast GPS integer ambiguity estimation. J. Geod. 1995, 70, 65–82. [Google Scholar] [CrossRef]
- Verhagen, S.; Teunissen, P.J.G. On the probability density function of the GNSS ambiguity residuals. GPS Solutions 2006, 10, 21–28. [Google Scholar] [CrossRef]
- Shen, L.; Guo, J.; Wang, L. A self-organizing spatial clustering approach to support large-scale network RTK system. Sensors 2018, 18, 1855. [Google Scholar] [CrossRef] [PubMed]
- Mahalanobis, P.C. On the generalised distance in statistics. Proc. National Inst. Sci. India 1936, 2, 49–55. [Google Scholar]
- Teunissen, P.J.G. Integer aperture GNSS ambiguity resolution. Artif. Satell. 2003, 38, 79–88. [Google Scholar]
- Verhagen, S. The GNSS Integer Ambiguities: Estimation and Validation. Ph.D. Thesis, Delft Institute of Earth Observation and Space Systems, Delft University of Technology, Delft, The Netherland, 2005. [Google Scholar]
- Teunissen, P.J.G. A carrier phase ambiguity estimator with easy-to-evaluate fail-rate. Artif. Satell. 2003, 38, 89–96. [Google Scholar]
- Wang, L. Reliability Control of GNSS Carrier-Phase Integer Ambiguity Resolution. Ph.D. Thesis, School of Electrical Engineering and Computer Science, Queensland University of Technology, Brisbane, Australia, 2015. [Google Scholar]
- Teunissen, P.J.G.; Verhagen, S. The GNSS ambiguity ratio-test revisited: A better way of using it. Surv. Rev. 2009, 41, 138–151. [Google Scholar] [CrossRef]
- Verhagen, S.; Teunissen, P.J.G. The ratio test for future GNSS ambiguity resolution. GPS Solutions 2013, 17, 535–548. [Google Scholar] [CrossRef]
- Wang, L.; Verhagen, S.; Feng, Y. A Novel Ambiguity Acceptance Test. Threshold Determination Method with Controllable Failure Rate. In Proceedings of the ION GNSS+ 2014, Tampa, FL, USA, 8–12 September 2014; pp. 2494–2502. [Google Scholar]
- Wang, L.; Feng, Y.; Guo, J. Reliability control of single-epoch RTK ambiguity resolution. GPS Solutions 2016, 21, 591–604. [Google Scholar] [CrossRef]
- Landau, H. On-the-Fly Ambiguity Resolution for Precise Differential Positioning. In Proceedings of the ION GPS 1992, Albuquerque, NM, USA, 16–18 September 1992; pp. 607–613. [Google Scholar]
- Abidin, H.Z.; Subari, M.D. On the discernibility of the ambiguity sets during on-the-fly ambiguity resolution. Aust. J. Geod. Photogramm. Surv. 1994, 61, 17–40. [Google Scholar]
- Euler, H.J.; Schaffrin, B. On a Measure for the Discernibility Between Different Ambiguity Solutions in the Static-Kinematic GPS-Mode. In Proceedings of the International Association of Geodesy Symposia, New York, NY, USA, 10–13 September 1991; pp. 285–295. [Google Scholar]
- Tiberius, C.C.J.M.; De Jonge, P. Fast Positioning Using the LAMBDA Method. In Proceedings of the International Symposium on Differential Satellite Navigation Systems, Bergen, Norway, 24–28 April 1995; pp. 24–28. [Google Scholar]
- Han, S. Quality-control issues relating to instantaneous ambiguity resolution for real-time GPS kinematic positioning. J. Geod. 1997, 71, 351–361. [Google Scholar] [CrossRef]
- Wang, J.; Stewart, M.P.; Tsakiri, M. A discrimination test procedure for ambiguity resolution on-the-fly. J. Geod. 1998, 72, 644–653. [Google Scholar] [CrossRef]
- Teunissen, P.J.G. Some Remarks on GPS Ambiguity Resolution. Artif. Satell. 1998, 32, 119–130. [Google Scholar]
- Teunissen, P.J.G. Integer aperture bootstrapping: A new GNSS ambiguity estimator with controllable fail-rate. J. Geod. 2005, 79, 389–397. [Google Scholar] [CrossRef]
- Teunissen, P.J.G. Integer aperture least-squares estimation. Artif. Satell. 2005, 40, 219–227. [Google Scholar]
- Teunissen, P.J.G. Penalized GNSS Ambiguity Resolution. J. Geod. 2004, 78, 235–244. [Google Scholar] [CrossRef] [Green Version]
- Teunissen, P.J.G. GNSS ambiguity resolution with optimally controlled failure-rate. Artif. Satell. 2005, 40, 219–227. [Google Scholar]
- Wang, L.; Verhagen, S.; Feng, Y. Ambiguity Acceptance Testing: A Comparison of the Ratio Test. And Difference Test. In Proceedings of the China Satellite Navigation Conference (CSNC) 2014, Nanjing, China, 21–23 May 2014. [Google Scholar]
- Li, T.; Zhang, J.; Wu, M.; Zhu, J. Integer aperture estimation comparison between ratio test and difference test: From theory to application. GPS Solutions 2016, 20, 539–551. [Google Scholar] [CrossRef]
- Neyman, J.; Pearson, E.S. On the problem of the most efficient tests of statistical hypotheses. Philos. Trans. R. Soc. London 1933, 231, 289–337. [Google Scholar] [CrossRef]
- Wang, L.; Feng, Y. Fixed Failure Rate Ambiguity Validation Methods for GPS and COMPASS. In Proceedings of the China Satellite Navigation Conference (CSNC) 2013, Wuhan, China, 15–17 May 2013. [Google Scholar]
- De Jonge, P.J.; Tiberius, C.C.J.M. The LAMBDA Method for Integer Ambiguity Estimation: Implementation Aspects; Delft University of Technology: Delft, The Netherlands, 1996; pp. 1–47. [Google Scholar]
- Wu, Z.; Bian, S. GNSS integer ambiguity validation based on posterior probability. J. Geod. 2015, 89, 961–977. [Google Scholar] [CrossRef]
- Chen, Y. An approach to validate the resolved ambiguities in GPS rapid positioning. J. Wuhan Tech. Univ. Surv. Mapping 1997, 22, 41–44. [Google Scholar]
- Hou, Y.; Verhagen, S.; Wu, J. An efficient implementation of fixed failure-rate ratio test for GNSS ambiguity resolution. Sensors 2016, 16, 945. [Google Scholar] [CrossRef] [PubMed]
- Feng, Y.; Wang, J. Computed success rates of various carrier phase integer estimation solutions and their comparison with statistical success rates. J. Geod. 2011, 85, 93–103. [Google Scholar] [CrossRef]
- Teunissen, P.J.G. An optimality property of the integer least-squares estimator. J. Geod. 1999, 73, 587–593. [Google Scholar] [CrossRef]
- Wang, L.; Feng, Y.; Guo, J.; Wang, C. Impact of decorrelation on success rate bounds of ambiguity estimation. J. Navig. 2016, 69, 1061–1081. [Google Scholar] [CrossRef]
- Teunissen, P.J.G. The invertible GPS ambiguity transformations. Manuscr. Geod. 1995, 20, 489–497. [Google Scholar]
- Gavin, H. The Levenberg-Marquardt Method for Nonlinear Least Squares Curve-Fitting Problems. Available online: http://een.iust.ac.ir/profs/Farrokhi/Neural%20Networks/Levenberg-Marquardt/lm.pdf (accessed on 10 July 2018).
- Marquardt, D.W. An algorithm for least-squares estimation of nonlinear parameters. J. Soc. Ind. Appl. Math. 1963, 11, 431–441. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 0.1 | 1.6691 | −1.6660 | −1.7798 | 0.7849 |
| 0.2 | 1.6957 | −1.6990 | −1.7434 | 0.7492 |
| 0.3 | 1.6277 | −1.6333 | −1.7419 | 0.7491 |
| 0.4 | 1.5834 | −1.5899 | −1.7383 | 0.7471 |
| 0.5 | 1.4711 | −1.4775 | −1.7617 | 0.7723 |
| 0.6 | 1.4260 | −1.4314 | −1.7653 | 0.7780 |
| 0.7 | 1.3723 | −1.3796 | −1.7740 | 0.7875 |
| 0.8 | 1.3850 | −1.3959 | −1.7589 | 0.7726 |
| 0.9 | 1.2930 | −1.3041 | −1.7851 | 0.8001 |
| 1.0 | 1.2639 | −1.2771 | −1.7881 | 0.8035 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, L.; Chen, R.; Shen, L.; Feng, Y.; Pan, Y.; Li, M.; Zhang, P. Improving GNSS Ambiguity Acceptance Test Performance with the Generalized Difference Test Approach. Sensors 2018, 18, 3018. https://0-doi-org.brum.beds.ac.uk/10.3390/s18093018
Wang L, Chen R, Shen L, Feng Y, Pan Y, Li M, Zhang P. Improving GNSS Ambiguity Acceptance Test Performance with the Generalized Difference Test Approach. Sensors. 2018; 18(9):3018. https://0-doi-org.brum.beds.ac.uk/10.3390/s18093018
Chicago/Turabian StyleWang, Lei, Ruizhi Chen, Lili Shen, Yanming Feng, Yuanjin Pan, Ming Li, and Peng Zhang. 2018. "Improving GNSS Ambiguity Acceptance Test Performance with the Generalized Difference Test Approach" Sensors 18, no. 9: 3018. https://0-doi-org.brum.beds.ac.uk/10.3390/s18093018