The plant health estimation method described here, makes use of portable multispectral technology to obtain VHR images in order to properly identify objects of interest at crop fields using several AI algorithms. Additionally, individual spectral signatures of objects of interest and soil samples were taken to be analyzed in laboratory. The procedure presented can be applied to a wide variety of crops in order to evaluate plant health levels in a parcel, by means of the analysis of high resolution multispectral images which could be acquired by UAVs, manned flights, or even by satellites. To describe them in a very specific manner, we choose a study case consisting on the plant health evaluation of a parcel of C. annuum crop. The corresponding details are described in the following subsections.
2.2. Data Acquisition and Image Preprocessing
For the data acquisition, two Phantom III Standard
® (SZ DJI Technology Co., Ltd., Shenzhen, China) multirotor UAVs, adapted with a Parrot Sequoia
® (Parrot SA, Paris, France) multispectral camera were used to obtain multispectral images with the resolution needed to identify crop objects. Automated flight missions were programmed using the Pix4D Capture
® (Pix4D, Lucerne, Switzerland) software. ground control points (GCPs) were placed every 3 m along ploughing direction. The flights were performed at 15 m above ground level covering an area of 5000 m
at a speed of 10 m/s. In this way, 15 GB of multispectral imagery were gathered with an overall resolution of 2 cm/px in the wavelengths green (G) 550 nm, red (R) 660 nm, red edge (RE) 735 nm, and near infrared (NIR) 790 nm, with respective bandwidths of 40, 40, 10, and 40 nm. Image pixel levels had a 14-bit precision in GEOTIFF format. RGB images with a standard camera were also taken. Generation of RGB and multispectral point clouds and orthomosaics were executed with the Pix4D Mapper
® (Pix4D, Lucerne, Switzerland)) software. After this preprocessing, resolution dropped to 4 cm/px and the effective area covered by orthomosaics was reduced to 2250 m
, in order to discard border images and non-crop objects. The Parrot Sequoia
® multispectral camera integrates an irradiance sensor that was calibrated with a Micasense
® (MicaSense Inc., Seattle, WA, USA) reflectance panel before each flight mission of the UAVs. The firmware of the multispectral camera writes irradiance calibration measurement parameters at the EXIF headers in the GEOTIFF files, along with other photogrammetric data, inside each image corresponding to G, R, RE, and NIR bands. Polynomial coefficients for vignetting correction, camera pose angles, and GPS coordinates are also registered in the EXIF headers. The Pix4D Mapper
® software works by looking at this information to automatically convert digital numbers (DN) into radiance values, and to generate the respective orthomosaics. Poncet et al. show in [
24] that this setup is able to produce radiometric indices with an accuracy comparable to some empirical calibration methods. Note that radiometric correction and camera pose parameters are not written for images from the RGB sensor. Therefore, only G, R, RE, and NIR orthomosaics are used in the calculations of the workflow described below.
Figure 1 shows non calibrated RGB and calibrated NIR orthomosaics of the study parcel, it also shows a portion of a zoomed area, to give a visual representation for the detail level of the orthomosaics. A digital elevation model (DEM) was also generated from the same point clouds used to create the orthomosaics.
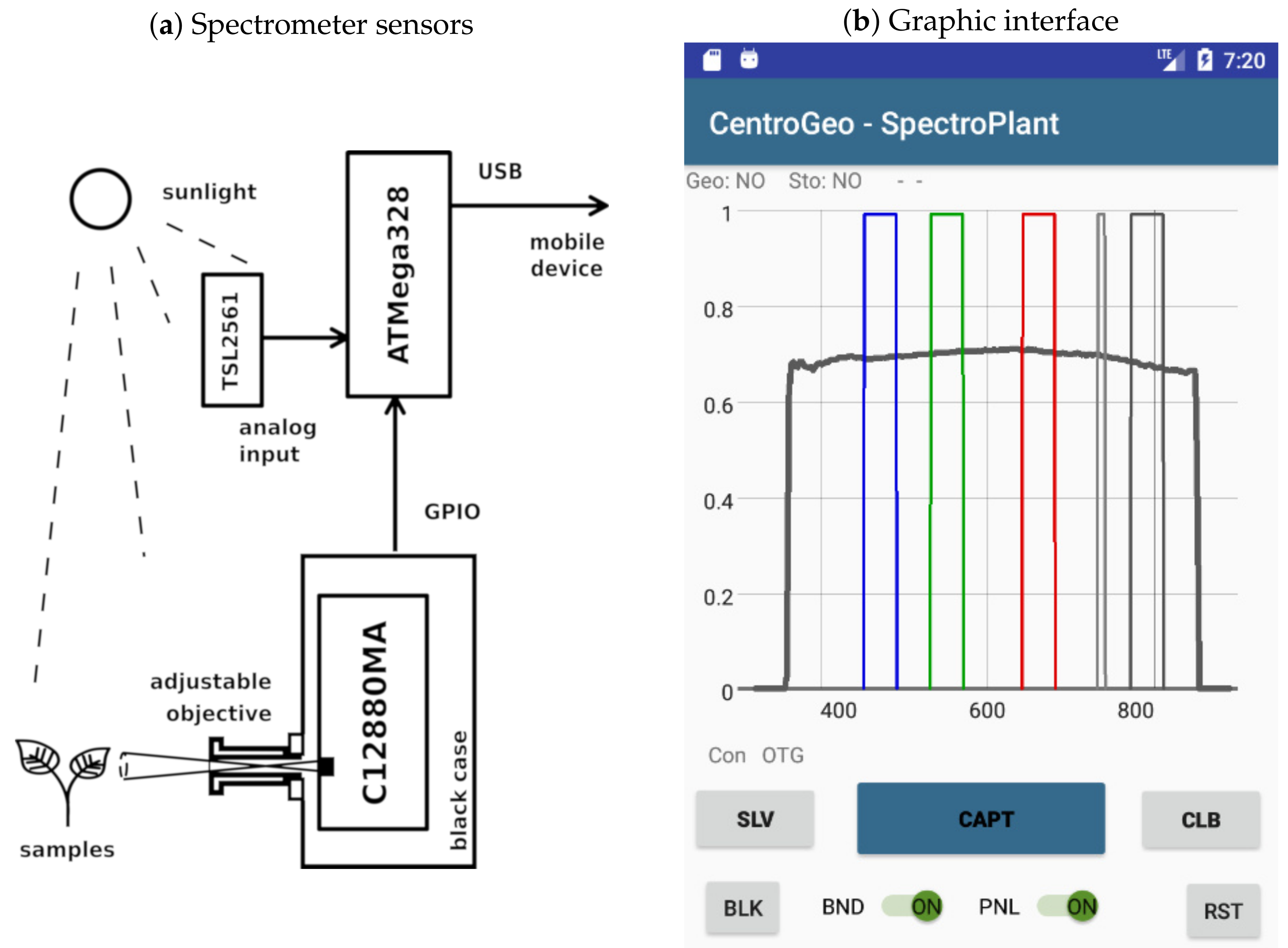
Spectral signatures for objects of interest were also taken in the field. To this end, we designed a low cost portable spectrometer, which was used to obtain georeferenced signatures of different crop samples. It also features an interface with a mobile application that makes possible to visualize a real-time graphic representation of reflectance curves and calibration parameters. We implemented the portable spectrometer with a printed circuit board based on the C12880MA (Hamamatsu Photonics K.K., Shizuoka, Japan) sensor which detects 288 wavelengths. C12880MA signals were collected trough a digital general purpose input output (GPIO) port using a generic ATMega328
® (Atmel Corp., San Jose, CA, USA) microcontroller which sends signal level values to a mobile device via an universal serial bus (USB) connection. A custom software written in Java programming language for controlling the C12880MA sensor with a mobile device was developed using the Android Studio SDK
® (Google Inc., Mountain View, CA, USA) environment. The software developed was responsible for dynamic sensor calibration, user interface controls, real-time graphic representation of reflectance spectra, geolocation, and data storage. The C12880MA chip has a typical full width at half maximum (FWHM) of 12 nm and a maximal FWHM of 15 nm [
25]. The spectral resolution of the C12880MA sensor is not linear throughout its operational bandwidth, but rather can be modeled by the polynomial
where
x is the index of the pixel measured as an output signal level, and
,
are coefficients determined at factory tests [
26]. The specific coefficients for the device used are shown in
Table 1. The Java program developed for the mobile device interface, uses these coefficients to interpret the signals generated by the C12880MA chip, and rounds the results of the evaluation of
to the nearest integer to graphically represent the measured reflectance values at the mobile device screen.
An auxiliary TSL2561 (AMS AG, Premstaetten, Austria) sensor was added as an analog input to the ATMega328
® microcontroller to perform dynamic calibration of the C12880MA chip output levels under different sunlight conditions. The calibration reference taken was the Micasense
® reflectance panel for wavelengths between 360 nm and 850 nm in bandwidth center increments of 1 nm.
Figure 2a shows a diagram of the device implemented to obtain georeferenced spectral signatures on field,
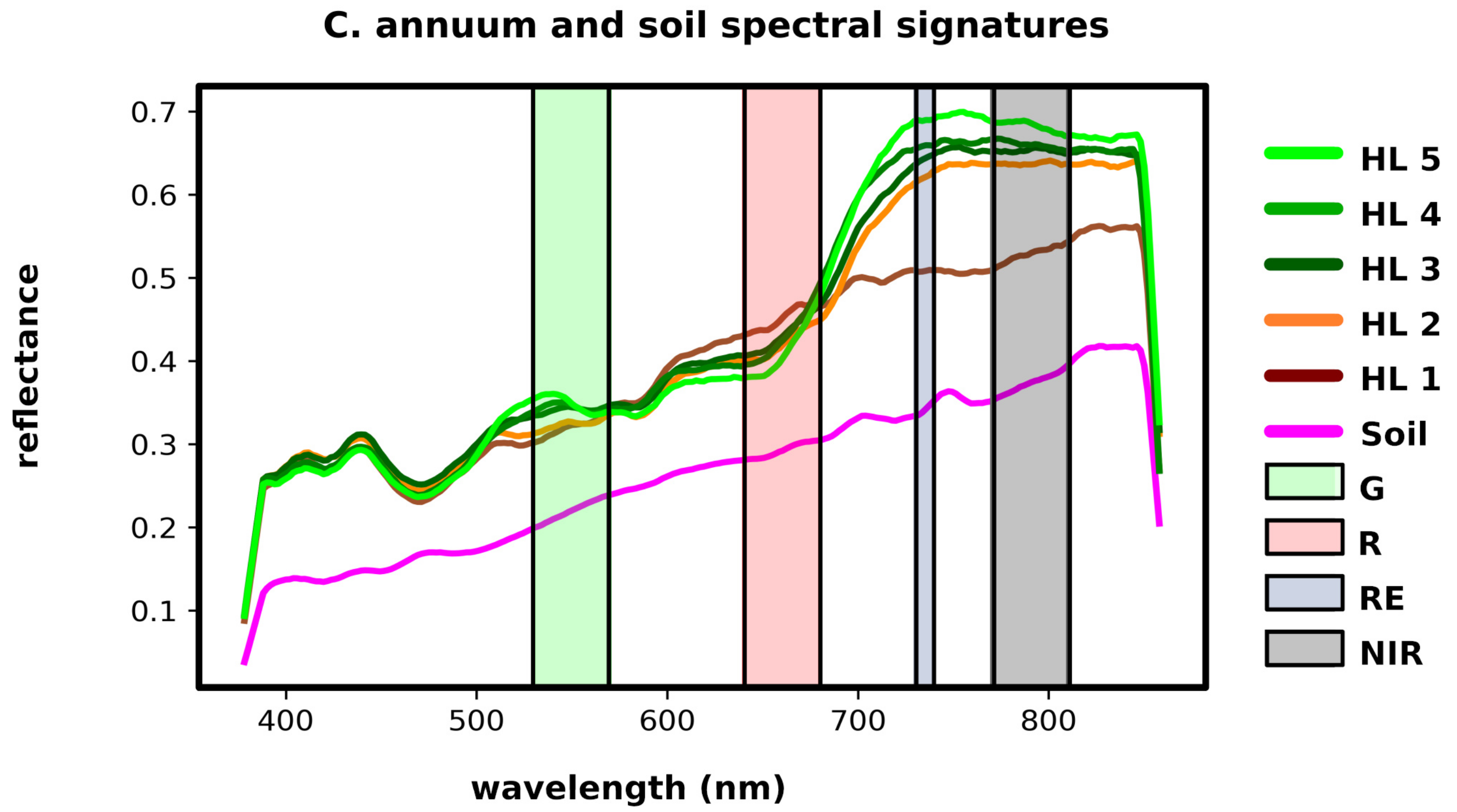
Figure 2b presents a view of the program interface. The gray plot shown in this figure corresponds to the coefficients from the reflectance panel for dynamic calibration, the vertical bars represent the B, G, R, RE, and NIR bands detected by the multispectral camera. The portable spectrometer was built in order to be able to obtain in field a set of georeferenced spectral signatures of portions of crop objects with enough spatial resolution to appear as endmember pixels in the VHR multispectral images gathered by the UAVs. The spectral signatures were taken at regularly spaced points, and then mapped to image segments belonging to vegetation to assign the labels to segments used for training and validation of a supervised classifier.
2.3. Algorithmic Pipeline
The processing stack proposed in this paper with the aim of identifying plant health states, starts with an a priori definition of health categories defined by
C. annuum phenotype features evaluated after six months of plant growth. Five health categories were determined, based on their principal phenotypical characteristics: Height
, canopy surface
, and on the percentage of observed change in leaf morphology; namely curly leaves, spotted leaves, and yellowing (chlorotic leaves). The respective plant health category labels are identified as
from the lowest to highest as shown in
Table 2. Figures presented at this table were determined by visual inspection an counting of features at seeding points inside crop areas designated for training and validation of the algorithms, and some manual labor was required to obtain such data. In this way, we have a classification of plants based on a combination of different observed features related to the presence of plant disease symptoms, or otherwise, their absence.
The next step consists in applying the large scale mean shift segmentation (LSMSS) algorithm [
27] on the multispectral images. It is convenient to have the input images rectified and stitched as an orthomosaic as described in the preprocessing section. LSMSS was presented by Michel et al. as an efficient version of the spatial extension of the mean shift segmentation (MSS), a non-parametric clustering procedure by Comaniciu and Meer [
28]. The MSS algorithm takes an image with pixels
and produces another image where the pixel values of
have been assigned to be equal to the local maxima of the clusters found by the iterative procedure on
defined by:
where
is the
j-th approximation to the mode corresponding to pixel
,
represents the neighboring pixels of
at spatial range
and spectral range
,
t stands for a convergence threshold and
is a kernel function. In [
28] a radially symmetric kernel
K derived from the Epanechnikov kernel [
29] is used, although Gaussian kernels are also applicable. Superscripts
s and
r refer to spatial and spectral components, respectively. After the last iteration, adjacent
points converging to the same modal values are labeled as part of the same segment. The use of LSMSS here is introduced to help us to model the boundaries between contiguous vegetation pixels, as the shapes of the segments generated in vegetation areas tend to follow the contours of leaves and branches of plants. The implementation of the stable version of [
27] provided by the Orfeo Toolbox (OTB) library was used to apply LSMSS in our procedure. The spatial and spectral parameters were fixed to
and
, respectively, based on plant object sizes and their spectral variations.
Figure 3 shows a section of the crop’s multispectral images segmented by the LSMSS algorithm in a background of false colors combining G, R, RE, and NIR spectral bands.
After executing the LSMSS segmentation, the next step performs a supervised classification operation. We selected the maximum likelihood classifier (MLC), a commonly used procedure in many remote sensing applications [
30,
31]. In MLC, the probability for an element
with a feature vector
to belong to a class C is given by:
where
is the class conditional density for
,
is the a priori probability of any element to belong to class C, and the divisor is the likelihood of observing
as data. Assuming a multivariate Gaussian distribution, the class conditional density
can be modeled by the following logarithmic likelihood function:
where
N is the number of classes,
is the mean of the distribution, and
is the covariance matrix. MLC chooses the values for
, and the entries of
that maximize
by equating its derivatives to zero. An element
is assigned to class C if:
For the input of MLC, segments obtained at the LSMSS stage were taken as elements
and the spectral modes
in Equation (
2) were used as feature vectors
. Then MLC was applied to segments instead of pixels. Each of the training segments with class labels belonging to vegetation and soil in selected crop areas were identified and geolocated. In the case of plants, the corresponding segments were cataloged into one of the
health levels. There were some areas at which soil and vegetation signatures where heavily mixed, mainly at the edges of plants where soil was partially covered by vegetation and their silhouettes. Segments in these areas were labeled as shadows. Additionally, the spectral signatures of objects of interest were registered with the spectrometer device described in a previous section, which also provided latitude and longitude coordinates through the GPS unit integrated in the mobile device, allowing in this way to obtain georeferenced labels of segments for identified objects. The MLC operation was executed by making use of the System for Automated Geoscientific Analyses (SAGA) [
32]. In particular, MLC was chosen as it gave the best precision among other supervised classifiers from the SAGA library, including minimum distance to means classifier (MDM) [
33], spectral angle mapping (SAM) [
34], nearest neighbor classifier (NNC) [
35], and the parallelepiped classifier (PC) [
36]. A comparison of the average precision of these methods at the classification of all labels for the segments obtained by LSMSS is shown at the results section in
Table 3.
Figure 4 shows an area at which the MLC step has been applied. In this figure, segments classified with the label ‘Shadow’, correspond to adjacent pixels with very low reflectance levels that could not be matched with vegetation or soil.
Once each segment had been labeled, all polygons representing vegetation were grouped together and saved into a file with shapefile (.shp) format for its processing in QGIS [
37]. In order to calculate seeding point center locations, we considered the pixels under these regions and estimated the number and position of inscribed circles of diameter
m, which is the mean distance of seeding points separation, by doing so we took an approach of a clustering problem [
38]. A convenient option for solving this grouping step is the employment of the KMeans algorithm [
39]. With the purpose of preserving the separation distance specified by
d, we set the number of classes
k in the KMeans algorithm to
, where
a denotes the area of the polygons enclosing each connected vegetation region. To efficiently determine which pixels have to be considered while evaluating
k and
a, instead of querying polygon boundaries of segments directly from the shapefiles, we applied the function ‘cv2.connectedComponents’ included in the OpenCV library [
40] to assign connected component labeling (CCL) markers [
41] on a binary mask consisting of pixels corresponding to vegetation areas. This binary mask can be built by joining the pixels inside vegetation segments labeled at the classification step. Then, by calculating KMeans centroids, the grouped areas were not limited to round shapes, but they were rather defined by a two-dimensional Voronoi tessellation [
42]. KMeans is not used for classification purposes in this step of the pipeline. It is instead applied to approximate the center locations of regions formed by segments belonging to vegetation emerging from the same point. The election of the parameter
k is thus defined for the recognition of segments belonging to same plants. The implementation of the KMeans clustering algorithm was the included in OpenCV. A custom script was written in Python programming language [
43] to feed the OpenCV API functions with the geographic coordinates of each vegetation region. It is worth noting that in the KMeans clustering, only spatial information of the pixels inside vegetation segment regions was used, and spectral data were discarded. That is, only the
vectors of Equation (
2) were involved in this phase.
With the estimation of seeding point center locations, the next stage of the pipeline consists in determining health indices associated to each seeding point. We propose an index based on the assignation of
classes defined in
Table 2, mapped to the corresponding integer value in the set
. Then, at each detected seeding point
p, a neighborhood
with center in
p and radius
r, is considered to define a set of segments
as:
where
is the set containing all segments generated by LSMSS. The health level index for a seeding point is then defined by:
with
denoting the health level associated to the classification made by MLC for segment
, and
n representing the cardinality of
. By defining this indexing scheme, we aim to compensate for centroid estimation errors, spectral signature mixing of soil and vegetation at leaf and branch edges, irregular plant shapes, and reflectance variations of plant leaves originated at the same seeding point.
Figure 5 shows health levels I(p) for estimated seeding points obtained by applying Equation (
7) with
cm over a crop’s image region. Note that many vegetation segments classified as soil that can be appreciated at
Figure 5 were composed of decayed foliage that was no longer performing photosynthetic processes. In consequence, they presented very low reflectance values at NIR wavelengths. Some other segments were definitely misclassified. The number of erroneously labeled segments are shown in the form of a confusion matrix at
Table 4 in the results section.
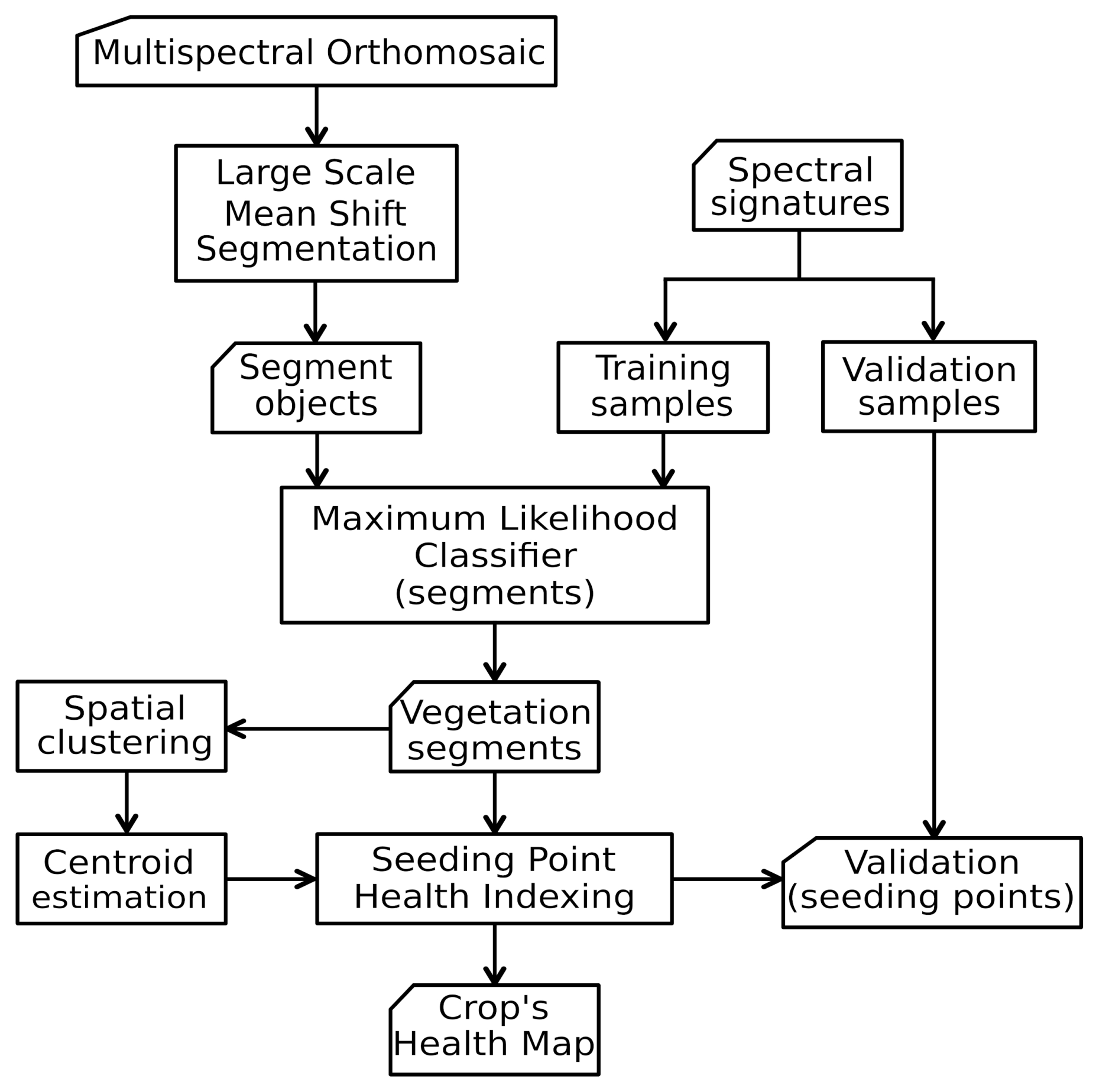
Figure 6 depicts a flowchart for the entire pipeline starting with preprocessed multispectral images into the form of orthomosaics. Besides the stitching and orthorectification of the images, the rest of the processing pipeline was performed using open source software and libraries, complemented with custom scripts. A concise step-by-step description of the procedure is presented in Algorithm 1.
| Algorithm 1:Geobia-based steps for plant health indexing of crops |
Input: Multispectral orthomosaic. Georreferenced spectral signatures. |
Output: Plant health indexing and location of seeding points. - Step 1:
Segmentation. Execute the LSMSS algorithm on the multispectral orthomosaic of the region of interest, using spatial and spectral range parameters according to the size of the objects to be identified and their spectral variations. - Step 2:
Training. Create a table with the characteristics that properly define the most representative categories. Take the average spectral signatures of objects at such categories. Geolocate these signatures and assign labels to the corresponding segments on specific training areas. - Step 3:
Segment classification. Apply the supervised machine learning algorithm MLC to classify the segments obtained by LSMSS. Other supervised algorithms can also be used at this step, as long as they provide a good accuracy level. - Step 4:
Clustering. Calculate plant or seeding point locations by the use of a clustering algorithm over pixels belonging to vegetation segments. For this, consider the average plant size and separation of seeding points. The KMeans algorithm applied on the spatial components of pixels can do the work required by this step. - Step 5:
Indexing. Evaluate the health index at each seeding point by assigning a numeric value to every category determined at Step 2. Then, take the average of the corresponding values of the pixels inside all segments that intersect a neighborhood of an specific radius from each seeding point by using Equation 7. - Step 6:
Validation. Estimate the precision of the health indices calculated at Step 5 by using georeferenced spectral measurements and observations on specific validation areas. This will give an insight on the precision of the results obtained.
|
2.5. Performance and Parallel Execution
To get a measure for the performance of the proposed workflow, the computational complexity of the algorithms involved can be done by tracing the main operations inside their loops [
44]. Step 1 is based on MSS, which relies on kernel density estimation [
28]. According to Equation (
2) this can be performed in
time, with
being the number of pixels in the image, and
m the size of the neighborhood taken to evaluate kernel modes. Step 2 is a manual process assisted by the portable spectrometer and GIS tools. When the classification at Step 3 is performed with MLC, the temporal complexity is determined by Equation (
4), from which we can see that the sum of the computational complexities associated to each term of the right side of Equation (
4) multiplied by the number of classes
is:
where
is the number of training segments and
is the dimension of the covariance matrix
at Equation (
4) which is given by the number of bands used in the classification step. Additionally, probability comparisons at Equation (
5) are done in
time, where
is the number of segments produced in Step 1. Therefore, the complexity
for the classification stage have the form:
Step 4 involves the use of the clustering algorithm KMeans, for which finding an optimal solution is known to be a NP-hard problem [
45]. However, the iterative Lloyd’s procedure [
46] gives approximate solutions of the KMeans problem for
d-dimensional vectors and
k clusters in complexity time
, with
i representing the number of its iterations. In the present work, only spatial components of the vegetation associated pixels
were considered at the clustering stage, thus, the corresponding dimension is
. Moreover, the number of iterations was limited to
to manage the clustering complexity in the worst case. The time complexity of the CCL algorithm used for determining the number of clusters
k is
[
41], therefore, the complexity
for the clustering stage is given by:
Step 5 queries
location vectors of the detected seeding points against
segments containing vegetation pixels. Spatial queries in this work were scripted in Python for the POSTGIS database running under QGIS. A spatial query on
N elements has a typical time complexity of
[
47], consequently the complexity
of the queries needed to evaluate
at the indexing step can be expressed as:
Hence, time complexity
of the entire workflow can be expressed as:
Taking into account that
m,
, and
are small and fixed, and considering the relations:
we have that the complexity in Equation (
12) is dominated by the term
, associated to spatial clustering operations. Therefore:
To speed up the execution of the spatial clustering, the vegetation regions were divided into polygons belonging to the same plowing row, by querying their spatial coordinates. It is worth to note that by partitioning vegetation areas in this way, there is no data dependency for the input vectors to the KMeans algorithm, as all of them belong to different unconnected pixel areas. Therefore, it was possible to send the corresponding areas of each row to a different parallel execution process, as presented in
Figure 8, which was implemented by making use of the ‘multiprocessing.Pool’ interface included in the standard Python libraries. The scheduling scripts were run on a HP Z440 workstation with an Intel Xeon E5-2630 CPU (Intel Corp.) at
GHz, with 32 GB of RAM, featuring 8 physical cores and 16 logical cores. In order to obtain performance metrics of the parallelization of Step 4, five executions of the workflow were performed over the same orthomosaic varying the number of parallel processes
and averaging execution times obtained using the
time package included in Phyton. Amdahl’s law [
48] was used to determine the speedup
, the portion of code
P that was effectively executed in parallel, given a constant workload, and the complementary non-parallelizable portion
with the expression:
2.6. Phytosanitary Soil Analysis
With the purpose of searching for correlations between canopy reflectance properties and plant root health states, microbiological analysis of soil samples were performed at uniformly sparsed points in the training and validation areas, in order to search for pathogens that might be affecting the crop. Previous studies reported that in regions near the area where the experiment was conducted, one of the main pathogen that affects
C. annuum crops is
Phytophthora capsici Leonian [
49]. Then, soil samples were analysed under laboratory conditions to determine the presence of fungal pathogens. The analysis included soil samples of 100 g that were collected from alternating rows and two
C. annuum plants were considered per point, the process was repeated each 20 m until complete 14 samples were gathered throughout a field area of 120 m long with four double-rows of 3 m width, a space of 10 m to the borders of the crop was left between the initial and final soil sample. The soil samples were taken near plant roots at 10 cm below ground surface and were individually stored in sterile plastic bags. Then, they were labeled and transported for processing. Soil isolation and identification of microorganism strains procedures were executed as follows. These soil samples were homogenized and 1 g (3 replications/sample) was deposited in a Falcon
® tube. Next, 10 mL of deionized water was added and were put in a vortex mixer for 10 minutes (Maxi Mix II, Thermo Scientific). The resulting suspension was used to prepare a
dilution and
L were seeded in Petri dishes with
-Agar medium supplemented with PCNB (
g/mL), benomyl (
g/mL), hymexazole (
g/mL) and ampicillin (
g/mL) [
50]. The Petri dishes were incubated at
C under dark conditions and were inspected every 12 hours under a stereomicroscope (
) to detect the mycelial growing of colonies. Observations were counted to register the colony forming units per gram (CFU/g) of soil. The mycelial growths were transferred to
-Agar medium for maintenance and observation. The identification was done considering its morphological characteristics [
51], and pure isolated strains were molecularly analyzed by extraction of genomic DNA using the CTAB method [
52]. PCR amplification was done analyzing the internal transcriber spacer (ITS) regions of fungal ribosomal DNA (rDNA) with oligonucleotides ITS1 (5
-tccgtaggtgaacctgcgg-3
) and ITS4 (5
-tcctccgcttattattgatatgc-3
) according to White et al. [
53], under the following PCR conditions:
C 5 min, 30 cycles
C 1 min,
C
s,
C 2 min, and
C 2 min final extension. PCR products of expected sizes (650–700 bp) were purified and sequenced. The BLASTn algorithm was used to search the NCBI GenBank database [
54] to confirm taxonomical assignment.

 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}