A Frequency-Based Approach for the Detection and Classification of Structural Changes Using t-SNE †



Control, Modeling, Identification and Applications (CoDAlab), Department of Mathematics, Escola d’Enginyeria de Barcelona Est (EEBE), Universitat Politècnica de Catalunya (UPC), Campus Diagonal-Besòs (CDB), Eduard Maristany, 16, 08019 Barcelona, Spain
*
Author to whom correspondence should be addressed.
†
This paper is an extended version of our paper published in International Conference on Structural Engineering Dynamics (ICEDyn 2019).
Sensors 2019, 19(23), 5097; https://0-doi-org.brum.beds.ac.uk/10.3390/s19235097
Submission received: 24 October 2019
/
Revised: 20 November 2019
/
Accepted: 20 November 2019
/
Published: 21 November 2019
(This article belongs to the Special Issue Sensors for Structural Health Monitoring and Condition Monitoring)
Abstract
:This work presents a structural health monitoring (SHM) approach for the detection and classification of structural changes. The proposed strategy is based on t-distributed stochastic neighbor embedding (t-SNE), a nonlinear procedure that is able to represent the local structure of high-dimensional data in a low-dimensional space. The steps of the detection and classification procedure are: (i) the data collected are scaled using mean-centered group scaling (MCGS); (ii) then principal component analysis (PCA) is applied to reduce the dimensionality of the data set; (iii) t-SNE is applied to represent the scaled and reduced data as points in a plane defining as many clusters as different structural states; and (iv) the current structure to be diagnosed will be associated with a cluster or structural state based on three strategies: (a) the smallest point-centroid distance; (b) majority voting; and (c) the sum of the inverse distances. The combination of PCA and t-SNE improves the quality of the clusters related to the structural states. The method is evaluated using experimental data from an aluminum plate with four piezoelectric transducers (PZTs). Results are illustrated in frequency domain, and they manifest the high classification accuracy and the strong performance of this method.

1. Introduction
Structural health monitoring (SHM) is a crucial process for engineering structures because it checks the correct behavior of the structure and determines whether it needs some type of maintenance. The healthy state of the structure has to remain between the specified limits or threshold, but these limits may change due to the aging of the structure and its use, or due to the environmental and operational conditions (EOC). Hence, in SHM systems, detection and classification of structural changes are essential in order to know the current state of the structure for security and to reduce costs of inspection and maintenance. If damage is detected and classified precisely at the time it occurs, some action may be taken before a human and/or economic disaster occurs, thus reducing the probability of accidents and the maintenance costs. SHM has been applied in many structures such as wind turbines [1,2,3], buildings [4,5], and aircraft [6,7], among others, and a review of the state-of-the-art manifests that SHM is a very active research field.
With the goal of obtaining information about the state of the structure, data are collected by a sensor network, which is placed along the structure. The information obtained from multi-sensor signals creates a high-dimensional data set with a large volume of data due to continuous measurements of the monitoring system. Various methods have been proposed for the handling of high-dimensional, big, and complex data. Among these methods, plane or spatial representation techniques stick out as they offer a way to handle this type of data by means of an interface that allows an easy detection of natural clusters, identifying hidden patterns, et cetera [8]. Plane or spatial representation techniques are also somehow related to dimensionality reduction. Dimensionality reduction is the mechanism of reducing the dimension of the original data, while keeping mostly the same intrinsic information [9]. One of the proposed dimensionality reduction methods in the literature is t-distributed stochastic neighbor embedding (t-SNE), a technique developed by L. van der Maaten and G. Hinton [10], which is able to represent the local structure of original high-dimensional data in a low-dimensional space (for example, a simple 2-D plot). This technique detects patterns by identifying clusters based on similarity of data points. t-SNE is widely used in the literature as a dimensionality reduction technique, as a classification or pattern recognition method, or as a visualization and compression method of big data sets, but although t-SNE has been applied in several applications, this is one of the first approaches of t-SNE in the field of SHM [11].
In the present approach, t-SNE is applied in the frequency domain. In the field of SHM and condition monitoring (CM) this is sometimes common, and the combination of time-frequency domain is also used. Some examples are Tsogka et al. [12], who propose a novel vibration-based SHM method for damage detection in the frequency domain, which illustrates its practical application in the case of a historic bell tower. Xu et al. [13] propose a clustering method based on ensemble empirical mode decomposition and affinity propagation for bearing performance degradation assessment. To prove the superiority of the approach, the proposed methodology is compared to various popular clustering methods and commonly used time-domain indicators. The results show that the proposed method outperforms these popular clustering methods and time-domain indicators. Cheng et al. [14] propose a multisensory data-driven health degradation monitoring system by using a generalized multiclass support vector machine. In this method, multidimensional feature extraction is implemented in the time domain, frequency domain, and time-frequency domain.
In this work, a SHM strategy for detection and classification of structural changes based on a two-step data integration (type E unfolding [15] and the so-called mean-centered group scaling (MCGS)), data transformation using PCA, and a two-step data reduction combining PCA and t-SNE has been proposed. PCA is an extensively used technique that is mainly used for dimensionality reduction or feature extraction in the framework of pattern recognition [16], and it can be applied differently to detect and classify structural changes or faults [17]. In some cases, however, it can be observed that the projection into the first principal components does not allow a visual grouping, clustering, or separation. For this reason, we propose the damage or fault detection based on the combination of PCA and t-SNE. As a consequence, the basic steps of the detection and classification procedure that we apply are: (i) the data collected, in the frequency domain, are first scaled using MCGS due to the different scales and magnitudes in the measurements; (ii) then PCA is applied to obtain a better representation of the original data, by reducing the dimensionality of the scaled data and projecting the scaled data into the vectorial space spanned by the principal components; and (iii) t-SNE is finally applied to the projected data to represent these points as points in a plane. It will be shown that, with respect to the time domain, the quality of the clusters related to the different structural states is significantly improved. More precisely, the current structure to be diagnosed will then be associated with a structural state based on three different strategies: (i) the smallest point-centroid distance, i.e., when a single actuation phase is considered; (ii) majority voting; and (iii) sum of the inverse distances, i.e., when several actuation phases are combined. Therefore, in this work, t-SNE is used, in combination with a particular data integration, data transformation, and data reduction, for the first time in the field of SHM in a frequency-based approach. In comparison to previous strategies found in the literature, this novel method is able to yield a best detection and classification of structural changes, thus leading to a best performance.
The proposed method for the detection and classification of structural changes is assessed using experimental data from a plate with four piezoelectric transducers (PZTs). Since guided wave propagation-based SHM strategies have proven their ability to adequately identify defects in structures [18,19,20,21], in the present work, we have also considered the paradigm of guided waves. In this paradigm, the structure is excited by a signal and the response is measured to create a baseline pattern. When a new structure has to be diagnosed, it has to be excited by the exact same signal and the response is measured and compared with the baseline pattern. Results reveal the high classification accuracy and the strong performance of this methodology, with a percentage of correct decisions of about in various scenarios. In the present work, the environmental conditions were not considered, as it will be the topic for further developments.
The structure of the paper is as follows: Section 2 describes the objective of t-SNE and how the plane or spatial representation is obtained. Section 3 includes how the baseline data are collected and pre-processed, how the global dimension of the data is reduced, and how the clusters are created using t-SNE. The damage detection and classification procedure of a structure that has to be diagnosed is presented in Section 4. The experimental case study is described in Section 5. In Section 6, the results are shown. Finally, in Section 7, some conclusions are drawn.
2. t-Distributed Stochastic Neighbor Embedding (t-SNE)
2.1. The Objective of t-SNE
t-SNE is an improved variation of the technique so-called stochastic neighbor embedding (SNE) [22]. With respect to SNE, t-SNE is much easier to optimize and yields better plane or spatial representations of the high-dimensional data, since it reduces the tendency to crowd points in the center of the distribution (the so-called crowding problem). Part of the enhancements of t-SNE with respect to SNE are due to the fact that the cost function used by t-SNE differs from the one used by SNE in two features: (i) t-SNE uses a symmetrized version of the SNE cost function with simpler gradients; and (ii) t-SNE uses a Student’s t-distribution, instead of a Gaussian, to calculate the similarity between two points in the low-dimensional space.
Given a collection of high-dimensional data points:
the aim is to find a collection of low-dimensional map points
that form a faithful representation of the original points in a lower-dimensional space. Typical values for d are 2 (plane representation) or 3 (spatial representation), where . By saying faithful representation, we mean that the points in the lower-dimensional space preserve, as much as possible, the local structure of the original data .
2.2. Pairwise Similarities
To preserve local similarities of the original data by this embedding, t-SNE first converts the high-dimensional Euclidean distances between data points and into conditional probabilities by centering a Gaussian distribution at , computing the density of under this Gaussian distribution, and renormalizing:
where (affinity or scaled squared Euclidean distance) is the dissimilarity between data points and . The variance of the Gaussian distribution, , is computed automatically. Since only pairwise similarities between data points are of interest, t-SNE imposes . This conditional probability measures the similarity of to . If two data points are close, will be large. However, if two data points are far, will be small.
Then, by symmetrizing the conditional probability in Equation (2), the joint probability is defined as follows:
The joint probability also measures the pairwise similarity between data points and . As a result, let us define the similarity matrix for the high-dimensional data points as .
When the similarity matrix for the data points in Equation (1) is obtained, t-SNE also defines the similarity matrix for the map points . Essentially, we build matrix following the same idea as for the similarity matrix with respect to original data points. The one and only difference is that we use for matrix a renormalized Student’s t-distribution with one degree of freedom and for all i, instead of a Gaussian distribution:
where represents the local structure of the data points in the low-dimensional space.
2.3. Comparing Similarity Matrices: Cost Function
The goal is to select the map points so that the two similarity matrices, and , are as similar as possible. The similarity between these two matrices will be defined in terms of the Kullback–Leibler (KL) divergence. The KL divergence between the joint probability distributions and is a measure of the distance between the two similarity matrices, and it can be defined as [10,22,23]:
Therefore, minimizing the KL divergence reduces the distance between these two matrices. And to minimize the cost function , the gradient descent method is used: . It is worth noting that the gradient descent is an iterative optimization algorithm and therefore it updates the map point at each step.
For more details, see the original t-SNE paper [10].
3. Data Collection, Pre-Processing, and Clustering: Baseline Data
3.1. Data Collection and Pre-Processing
The data collected are made up of different response signals measured, in the time domain, by sensors on a vibrating structure. Multiple realizations of these responses are measured, under different structural states. Coming up next, these responses signals are transformed into the frequency domain using the fast Fourier transform (FFT) algorithm, and features are extracted from the spectrum to reduce the data dimension, dividing by two and adding one to the number of components in each signal. A matrix which collects all the realizations under different structural states in the frequency domain is defined as:
where is the number of sensors and identifies the sensor that is measuring; is the number of components in each signal and indicates the j-th measurement in the frequency domain; is the number of different structural states that are considered and represents the structural state that is been measured; and finally, , is the number of realizations per structural state and is the i-th realization related to the l-th structural state. Note that matrix in Equation (7) is formed by E horizontal blocks, , each one of them related to the different structural states. At the same time, this matrix can also be viewed as formed by N vertical blocks, , each one of them related to the different sensors. Due to the different scales and magnitudes in the measurements, the matrix in Equation (7) is rescaled using MCGS, which is suggested by Pozo et al. [24].
3.2. Dimensionality Reduction
One of the main reasons of using the MCGS is that the covariance matrix of matrix , i.e., the scaled data set, can be computed in a very simple way as:
The eigenvectors and eigenvalues of the covariance matrix define the subspaces in the PCA model. The eigenvalues are then ordered in decreasing order as
and the matrix contains, written as columns, their corresponding eigenvectors . These eigenvectors are known as the principal components. The eigenvalues define the partial variance of each eigenvector. When the column scaling is applied to matrix in Equation (7), although not not the case of this paper, we have that the trace of the covariance matrix , which is the sum of the eigenvalues, is equal to the number of columns of , that is, . This means that the proportion of the variance directed along the first principal components is given by . However, when the MCGS is applied to scale the raw data in matrix in Equation (7), the trace of the covariance matrix is no longer necessarily equal to . As a consequence, the proportion of the variance explained by the first ℓ principal components is given by:
In this work, we use PCA to reduce the dimensionality of the scaled data set by selecting a reduced, but still significant, number of principal components. This dimensionality reduction is performed through the reduced matrix
which is composed by the concatenation of the eigenvectors related to the highest eigenvalues. Matrix in Equation (10) is the model or PCA model. The scaled data set is then projected into the vectorial space spanned by the first principal components through the premultiplication of by . More precisely,
in Equation (10) has been defined as the PCA model that includes multiple realizations under different structural states. At the same time, in Equation (11) is the projection of the scaled data set into the subspace spanned by the PCA model. The number of principal components is chosen so that the proportion of the variance explained is greater than or equal to .
3.3. Clustering Effect
In Section 3.2, the dimensionality reduction has been performed. More precisely, n realizations under different structural states (the rows of matrix in Equation (7)), that may be seen as dimensional vectors, are projected and transformed into dimensional vectors. This reduction of the dimension of the original data is performed with a small loss of information, less than , and it is also expected that ℓ is much smaller than .
A second transformation is performed to the projected data in matrix in Equation (11) using the t-SNE presented in Section 2. Let us define
as the i-th row of matrix in Equation (11). The vector is the i-th element of the canonical basis. Let us also define
as a collection of high-dimensional data points. The objective is to find a collection of dimensional map points
that represent the original set with no explicit loss of information and preserving the local structure of this set. After the application of t-SNE, we expect E clusters to be observed, related to the E different structural states. These clusters are formed by the map points:
4. Damage Detection and Classification Procedure: Structure to Diagnose
In Section 3.3, we have seen how the original realizations under different structural states are finally projected on a plane to define a set of clusters. In this section, we will present the damage detection and classification procedure of a structure that has to be diagnosed.
A single realization of the current structure to diagnose is needed. The data collected are made up, in this case, of different response signals measured by the same number of sensors N and the same number of components in each signal L, as in Equation (7). When these measures are obtained and they are transformed into the frequency domain, a new data vector is constructed:
4.1. Scaling (MCGS)
Before the collected data coming from the structure to diagnose is projected into the space spanned by the principal components, the row vector has to be scaled to define a scaled row vector :
where is the arithmetic mean of all the elements in the -th column of matrix in Equation (6) i.e., the j-th column of the vertical block in Equation (8); and is the standard deviation of all the elements in the vertical block in Equation (8) with respect to the mean value (the arithmetic mean of all the elements in the vertical block in Equation (8)).
4.2. Projection (PCA)
The projection of the scaled row vector into the space spanned by the ℓ first principal components in is performed through the following vector to matrix multiplication:
It is worth noting that the dimensional vector that contains the collected data coming from the structure to be diagnosed in now transformed into an dimensional vector. This new point will be added to the data set in Equation (12) to define a new set:
4.3. t-SNE and Final Classification
t-SNE is applied to the dimensional data set in Equation (15) to find a collection of dimensional map points:
that represent the original set with no explicit loss of information and preserving the local structure of this set, as well as including the map point associated to the data point . The same E clusters have to be observed, related to the E different structural states. As in Section 3.3, these clusters are formed by the map points in Equation (13).
For each cluster, we compute its centroid, that is, the mean of the values of the points of data in the cluster. For instance, the centroid associated with the first structural state is:
whereas the centroid associated with the second structural state is:
In general, the centroid associated with the l-th structural state, , is the point of the plane defined as
where . Therefore, the current structure to diagnose is associated to the l-th structural state if
that is, if the minimum distance between and each one of the centroids corresponds to the Euclidean distance between and . We call this approach the smallest point-centroid distance (see Figure 1).
A flowchart of the proposed approach and how it is applied is given in Figure 2.
5. Case Study: Aluminum Plate with Four PZTs
5.1. Structure
In this section, a square aluminum plate with an area of 1600 cm (40 cm cm, and a thickness of cm) and instrumented with four PZTs is considered to demonstrate the reliability of the damage detection and classification methodology introduced in Section 3 and Section 4. The piezoelectric transducer discs are attached to the surface and their location is shown in Figure 3. Assuming that the lower left corner of the plate in Figure 3 represents the origin of coordinates, the PZTs are installed at these positions (units in centimeters):
- PZT1 at
- PZT2 at
- PZT3 at
- PZT4 at
These PZTs are able to work both in actuator mode and in sensor mode. In actuator mode, the burst signal in Figure 4 is applied to the PZTs, and they produce a mechanical vibration; and in sensor mode, they detect time varying mechanical response. It is worth keeping in mind that the distance between the four sensors is not the same. More precisely, for example, the distance between sensor 1 and sensor 2 and the distance between sensor 1 and sensor 4 is equal. However, the distance between sensor 1 and sensor 3 is relatively larger.
A grams mass is added to simulate the damage, in a non-destructive way, in the aluminum plate. This mass is an attached magnet in both sides of the plate, since aluminum is non-magnetic metal. This kind of damage is used to change the properties of the structure and to produce changes in the propagated wave, therefore providing different scenarios for validating the proposed method. The location of the mass defines each damage. These locations are (units in centimeters):
- damage 1 at
- damage 2 at
- damage 3 atstructural states are considered here:
- the first structural state corresponds to the healthy state of the structure, that is, the square aluminum plate with no damage;
- the second, third, and fourth structural states correspond to the plate with an added mass at the positions indicated in Figure 3 as damage 1, damage 2, and damage 3, respectively.
The aluminum plate is isolated from the vibration and noise that could affect the laboratory, as can be observed in Figure 5.
5.2. Scenarios and Actuation Phases
The experimental setup includes three different scenarios to determine the behavior of the methodology under the presence of white Gaussian noise, filters, and with respect to the length of the wire that is used from the digitizer to the sensors:
- Scenario 1. The signals are obtained using a short wire ( m) from the digitizer to the PZTs, and these signals are filtered with a Savitzky–Golay (SG) [25] filter algorithm after adding white Gaussian noise. The filter is applied for the intention of smoothing the data.
- Scenario 2. The signals are obtained using a short wire ( m) from the digitizer to the PZTs, but these signals are not filtered.
- Scenario 3. The signals are obtained using a long wire ( m) from the digitizers to the PZTs. Signals are also filtered with the SG algorithm.
In this manner, we can observe the effect of the attenuation with short and long wires, the effect of adding white Gaussian noise to the measured signals, and the effect of the use of a SG filter in the detection and classification procedure.
As stated in Section 5.1, four PZTs (PZT1, PZT2, PZT3, and PZT4) are used to excite the aluminum plate and collect the measured response. This sensor network works in what we call actuation phases. In each actuation phase, a single PZT is used as an actuator (active sensor: the PZT excites the structure with a given excitation signal), and the rest of the PZTs are used as sensors (passive sensors: PZTs measure signals). Therefore, we have as many actuation phases as sensors:
- Actuation phase 1. PZT1 is used as the actuator, and PZT2, PZT3, and PZT4 are used as sensors.
- Actuation phase 2. PZT2 is used as the actuator, and PZT1, PZT3, and PZT4 are used as sensors.
- Actuation phase 3. PZT3 is used as the actuator, and PZT1, PZT2, and PZT4 are used as sensors.
- Actuation phase 4. PZT4 is used as the actuator, and PZT1, PZT2, and PZT3 are used as sensors.
It is very common in the literature, when using a sensor data fusion as in J. Vitola et al. [26,27], to merge the data that come from the different actuation phases in a single data matrix. In this paper, the approach with a single data matrix is also considered, but the case where each actuation phase is used as a classifier is additionally examined in Section 5.5.
5.3. Data Collection
Given a particular scenario, as the three defined in Section 5.2, four matrices , one for each actuation phase, are obtained. Each matrix , is organized as follows:
- experiments or realizations are performed for each structural state. Consequently, each matrix , consists of 100 rows, that is . More precisely, the first 25 rows represent the structure with no damage, the next 25 are realization where damage 1 is present in the structure, and so on.
- For each actuation phase , we measure PZTs working as sensors during 60000 time instants. Then, these measurements are transformed into the frequency domain. Therefore, the number of columns of matrix , is equal to .
Therefore, the matrix that collects all the realizations under the four different structural states in the frequency domain is (see Equation (6): here and ):
The damage detection and classification procedure introduced in Section 3 and Section 4 can be applied to each one of the matrices , in Equation (17), thus leading to one classification per actuation phase. But we can also use the horizontal concatenation of the four matrices , to obtain the matrix:
If matrix in Equation (18) is used for the damage detection and classification procedure introduced in Section 3 and Section 4, which this allows analyzation of the information of all the actuation phases at one time, a single classification is obtained that combines these four phases. Finally, we can also use the separate classification obtained for each actuation phase so that each actuation phase casts a vote thus leading to a final decision based on the four actuation phases. These strategies will be explained in detail in Section 5.5.
5.4. Fold Non-Exhaustive Leave-p-Out Cross Validation
The analysis of the proposed approach is done by comparing test data, i.e., the new experiments in unknown state under the same conditions, with baseline data, which is data from the structure under different structural states. To this end, we use the fold non-exhaustive leave-p-out cross validation described in the subsequent paragraphs.
For the sake of clarity, let us write to refer to both matrix in Equation (17) and matrix in Equation (18). Some of the rows in will be used as the baseline data to build the model and the clusters, i.e., rows per structural state, and the rest of the rows are used for the validation. More precisely, we will perform five iterations () of a non-exhaustive leave-p-out cross validation, where , to estimate the overall accuracy and avoid overfitting. Let us define, for each structural state , the permutation :
In this particular case, . Therefore, in the first iteration, the baseline data to build the model are the matrix:
where is the j-th element of the canonical basis of the real vector space , and is the selector matrix. Basically, matrix in Equation (19) has been built by randomly selecting rows per structural state. The rows of matrix that are not used to build the model are used for the validation.
In the i-th iteration, , the baseline data to build the model are the matrix:
where, as in Equation (19), is the j-th element of the canonical basis of the real vector space and, as in Equation (20), is the selector matrix. Since rows of matrix will be used for the validation step and with respect to iterations, the sum of all the elements in the confusion matrices that we will present in Section 6 is equal to .
5.5. Application of the Damage Detection and Classification Procedure
In this section, two strategies are presented to apply the damage detection and classification procedure. These two strategies are:
- (1)
- (2)
- the classification is based on the four matrices and , defined in Equation (17), with respect to the four actuation phases, with fold non-exhaustive leave-p-out cross validation. Each actuation phase will cast a vote and a final decision is taken.
In the first case, in a succinct way, the following seven steps are performed:
- Step 1. The data in matrix are scaled using MCGS to define a new matrix .
- Step 2. PCA is applied to to obtain the PCA model .
- Step 3. The number of principal components is chosen so that the proportion of variance explained is greater than or equal to . Therefore, the reduced PCA model is .
- Step 4. A realization —for and — or —for — of the current structure to diagnose is needed. Then, vector is scaled as in Equation (14) to define .
- Step 5. The data points set is defined as:whereSubsequently, t-SNE is applied to this dimensional data set to find a collection of dimensional map points:
- Step 6. clusters are obtained, that are related to the different structural states. These clusters are formed by the map points:The centroid , associated with the l-th structural state is computed as in Equation (16).
- Step 7. Finally, the current structure to diagnose is associated to the l-th structural state if
In the second case, we follow Step 1 to Step 6 above for the four matrices , related to the four actuation phases. With the information provided by the four actuation phases, several approaches can be considered to finally classify the structure that has to be diagnosed. One of these approaches, majority voting, is widely used in standard fusion schemes [28], as well as weighted majority vote or soft voting. For our case of the small aluminum plate, the majority voting will be used, as well as an approach based on the sum of the inverse distances between the centroids and the map point, which is somehow related to a weighted majority vote. Here are the details of both approaches:
- Majority voting. In this case, the strategy of the smallest point-centroid distance is performed four times, one per actuation phase. Therefore, four classifications are obtained for a single structure to diagnose. More precisely, each actuation phase acts as a classifier. Figure 6 illustrates this idea with respect to three actuation phases.The current structure to diagnose, in the -th actuation phase, , is associated to the -th structural state ifIt is worth remembering that is the map point associated to the realization of the current structure to diagnose. The structure is finally classified according to the most repeated classification. That is, the current structure to diagnose is associated to the l-th structural state ifin the case of a unimodal set. In the case of a bi-modal set, if the two modal values are and , the current structure to diagnose is associated to the l-th structural state ifFinally, if the set is a set with no mode, the structure is associated to the l-th structural state if
- Sum of the inverse distances. In this case, for a given structural state, we sum the inverse of the distances between the centroids and the map point , for all the actuation phases . The assigned structural state is the one that obtains the highest sum. More precisely, the current structure to diagnose is associated to the l-th structural state ifIt is worth remarking that the arguments of the maxima of the sum of the inverse distances is equivalent to the arguments of the minima of the harmonic mean of these distances. More precisely, for a given structural state, the harmonic mean of the distances between the centroids and the map point , for all the actuation phases isTherefore,S. Mehta et al. [29] also uses the harmonic distance to define a pattern classification technique similar to k-nearest neighbors classifier.
6. Results
In this section, the results of the application of the damage detection and classification procedure, introduced in Section 3 and Section 4 and detailed in Section 5.3, Section 5.4 and Section 5.5, to the aluminum plate are presented in terms of the confusion matrices and with respect to the scenarios defined in Section 5.2. The results for each scenario are presented in a different section. More precisely, in Section 6.1 the results with respect to Scenario 1 are presented. Equivalently, Section 6.2 and Section 6.3 present the results with respect to Scenario 2 and Scenario 3, respectively. In the three scenarios, four different structural states have been considered:
- the first structural state corresponds to the healthy state of the structure, that is, the square aluminum plate with no damage, noted as ;
To validate the damage detection and classification detailed in Section 5.3, Section 5.4 and Section 5.5, we will perform five iterations () of a non-exhaustive leave-p-out cross validation, where , as described in Section 5.4. At each iteration, a total of 80 realizations have been considered, according to the following distribution: 20 realization per structural state (, and ). Since 80 realizations have been used for the validation step and with respect to iterations, the sum of all the elements in the confusion matrices that we will present in Section 6.1, Section 6.2 and Section 6.3 is equal to .
Again, for the three scenarios, seven different confusion matrices are presented:
- Actuation phase 1. The damage detection and classification procedure is applied to a single matrix, , as in Equation (17), using the smallest point-centroid distance.
- Actuation phase 2. The damage detection and classification procedure is applied to a single matrix, , as in Equation (17), using the smallest point-centroid distance.
- Actuation phase 3. The damage detection and classification procedure is applied to a single matrix, , as in Equation (17), using the smallest point-centroid distance.
- Actuation phase 4. The damage detection and classification procedure is applied to a single matrix, , as in Equation (17), using the smallest point-centroid distance.
- Actuation phases 1–4. The damage detection and classification procedure is applied to a single matrix, i.e., the horizontal concatenation of the four matrices , , as in Equation (18), using the smallest point-centroid distance.
- Majority voting. The damage detection and classification procedure is applied to the four . Each actuation phase casts a vote, and a final decision is taken based on majority voting (Section 5.5).
- Sum of the inverse distances. The damage detection and classification procedure is applied to the four . Each actuation phase casts a vote and a final decision is taken based on the maximum sum of the inverse distances (Section 5.5).
Finally, in some cases, and with the purpose of comparing the performance of the current damage detection and classification approach, confusion matrices in the frequency and time domains have been included.
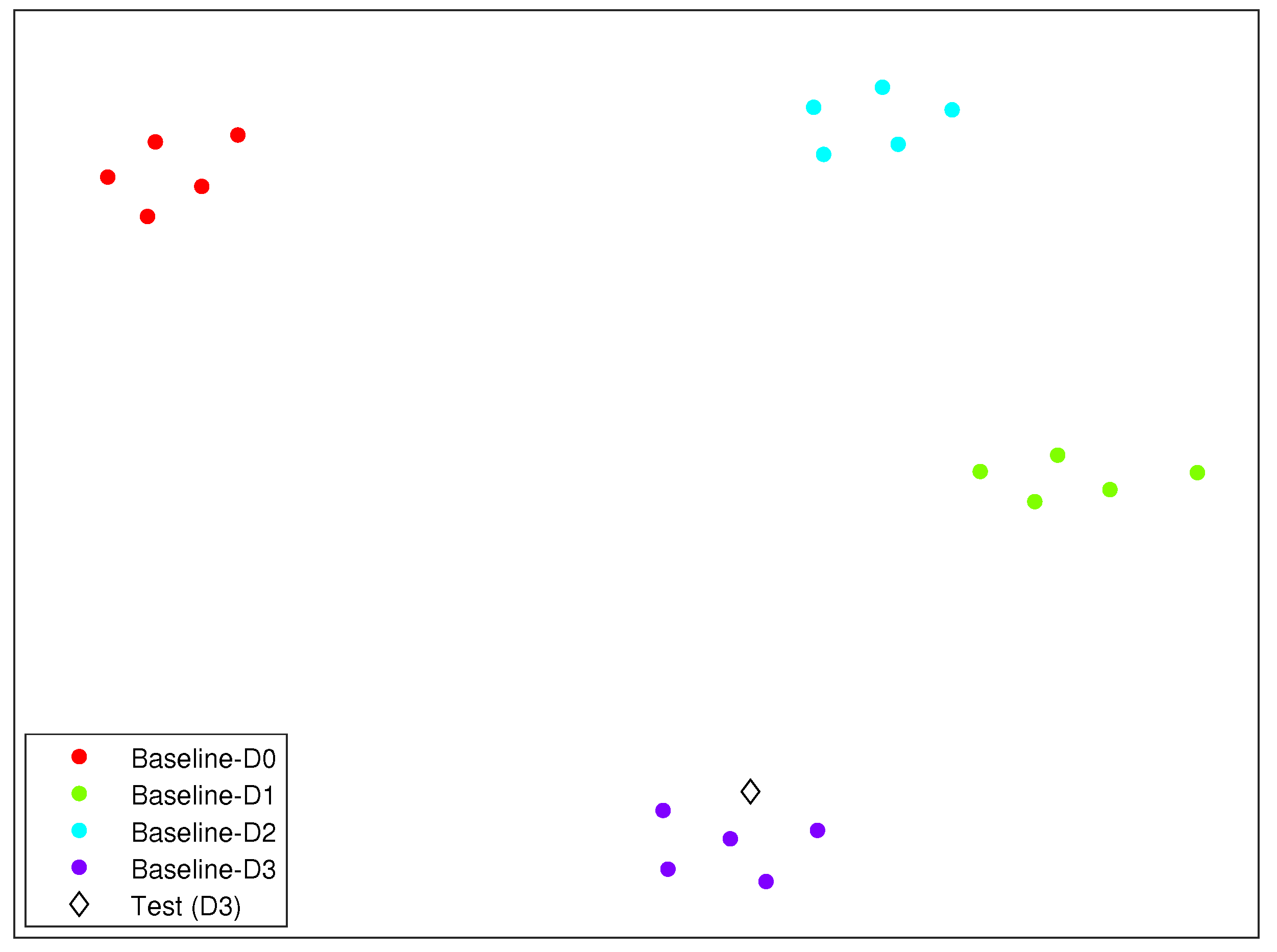
As an illustrating example, we have included in Figure 7 the clusters formed by the different structural states described in this section and in the case of Scenario 3. In this figure, the diamond represents the structure to diagnose. It can be clearly observed how the diamond is close to the cluster related to damage 3.
6.1. Scenario 1
In this section, the results with respect to Scenario 1 are presented. It is worth noting that, in this scenario, a short wire has been used, and the measured signals are filtered with a SG algorithm. The seven confusion matrices can be found in Table 1 and Table 2. When the decision is based on a single actuation phase (Table 1), the overall accuracy is quite good. More precisely, with 397 in the actuation phase 1, 399 in the actuation phase 2, 395 in the actuation phase 3, and 397 in the actuation phase 4, realizations have been correctly classified out of 400 cases, which represents an overall accuracy of , , , and , respectively. When the four actuation phases are used at the same time (actuation phases 1–4, Equation (18), majority voting, and sum of the inverse distances), an overall accuracy of 99–100% is achieved, as it can be observed from Table 2.
6.2. Scenario 2
In this section, the results with respect to Scenario 2 are presented. In this case, a short wire has been used but the measured signals are not filtered. The seven confusion matrices can be found in Table 3 and Table 4. When the decision is based on a single actuation phase (Table 3), the overall accuracy is very remarkable. More precisely, with respect to actuation phase 1, 2, and 3, 400 realizations have been correctly classified out of 400 cases, which represents an overall accuracy of . With respect to actuation phase 4, 399 realizations have been correctly classified out of 400 cases, that is to say, an overall accuracy of . When the four actuation phases are used at the same time (actuation phases 1–4, Equation (18), majority voting, and sum of the inverse distances), an overall accuracy of is achieved, as it can be observed from Table 4.
6.3. Scenario 3
The results with respect to Scenario 3 are finally presented in this section. In the two previous scenarios, a short wire was used. However, in this case, the signals are acquired using a m long wire. Table 5 and Table 6 include the seven confusion matrices. When the decision is based on a single actuation phase (Table 5), the overall accuracy is quite good, too. More precisely, with 384 in the actuation phase 1, 395 in the actuation phase 2, 395 in the actuation phase 3, and 398 in the actuation phase 4, realizations have been correctly classified, which represents an overall accuracy of , , , and , respectively. When the four actuation phases are used at the same time (actuation phases 1–4, Equation (18), majority voting, and sum of the inverse distances), an overall accuracy of 99.5–100% is achieved, as it can be observed from Table 6.
The potential of the approaches where the four actuation phases are used can be observed in this last scenario, see Table 6:
- When the four actuation phases are merged in a single matrix as in Equation (18), 398 realizations have been correctly classified out of 400 cases, which represents an overall accuracy of .
- When each actuation phase casts a vote and a final decision is taken based on majority voting, the overall accuracy is increased to .
- Finally, when each actuation phase casts a vote and a final decision is taken based on the maximum sum of the inverse distances, the overall accuracy is increased to , too.
In addition, in this scenario, the results in the frequency domain are compared to those in the time domain [11]. In the time domain, when the decision is based on a single actuation phase (Table 7), with 244 in the actuation phase 1, 398 in the actuation phase 2, 280 in the actuation phase 3, and 277 in the actuation phase 4, realizations have been correctly classified out of 400 cases. This represents an overall accuracy of , , , and , respectively. Clearly, the strategy in the frequency domain, i.e., the overall accuracy fluctuates between and , outperforms the approach in the time domain. In addition, the false positive rate (FPR), i.e., the number of false positives with respect to the total number of negatives, and the false negative rate (FNR), i.e., the number of false negatives with respect to the total number of positives, are clearly unsatisfactory in the time domain. However, FPR and FNR are significantly reduced to values close to in the frequency domain. It is worth noting that in the computation of the FNR, the three different types of damage , and are considered as a single category, just the opposite of the healthy state of the structure. In the time domain, when the four actuation phases are used at the same time (Table 8), the overall accuracy is of in actuation phases 1–4, of in majority voting, and of in sum of the inverse distances, whereas the overall accuracy is increased to , , and , respectively, in the frequency domain. At the same time, FPR and FNR are reduced to in the frequency domain, while they are slightly increased in the time domain. All this is an indication of the better quality of the clusters created in the frequency domain than the ones created in the time domain. Table 9 summarizes the values for the overall accuracy, the FPR, and the FNR in this scenario and in the time and frequency domains.
6.4. General Comments
The results presented in Section 6.1, Section 6.2 and Section 6.3 reveal that it is better to make a decision considering all of the actuation phases (assembling theses phases or using them to cast a vote) rather than working with the phases separately. On the other hand, the results also show that both strategies majority voting and sum of the inverse distances slightly outperform the horizontal concatenation of the four actuation phases in the frequency domain. However, in the time domain (Scenario 3, Table 8), the results reveal (i) the strong performance of the sum of the inverse distances strategy, which clearly classifies the practical totality of the kinds of damage that we have considered, compared to majority voting or the horizontal concatenation of the four actuation phases; and (ii) that the majority voting outperforms the horizontal concatenation of the four actuation phases, but it cannot completely classify damage .
It is worth noting that, in general, the healthy state of the structure is confused with the structure with damage in just a few cases. Similarly, the structure with damage is identified as a structure with no damage in a very limited number of realizations.
In general, the performance of the proposed methodology is very satisfactory when the signals are acquired using a short wire, with or without adding white Gaussian noise. In these two cases, using PCA as a pre-processing step, the noise is canceled. The third scenario presents the worst case because it used a long cable ( m) from the digitizers to the sensors. In this scenario, the signals were badly digitized due to the impedance of the cable, the low voltage of the stimulus, and other experimental features. Therefore, it can be observed that the use of a long cable from the digitizer to the sensors affects in the detection and classification method. However, combining the four actuation phases with
- (i)
- the sum of the inverse distances strategy, in the time domain; or
- (ii)
- the majority voting strategy or the sum of the inverse distances strategy, in the frequency domain,
very accurate results can be obtained.
It should be noted that, in general, it is better to work in the frequency domain than in the time domain because the obtained results are significantly improved, as it can be clearly observed in the third scenario.
7. Conclusions
In this work, a SHM strategy for detection and classification of structural changes based on a two-step data integration (type E unfolding and MCGS), data transformation using PCA, and a two-step data reduction combining PCA and t-SNE has been proposed. The proposed approach is evaluated using experimental data. In general, the results obtained show that the performance of the proposed methodology is very satisfactory, given its high classification accuracy; and its behavior is very good and similar in all the data sets.
In the case study, very accurate results are obtained with or without adding white Gaussian noise, since PCA cancels the noise. However, the use of a long wire ( m) from the digitizers to the sensors negatively affects the detection and classification method. But combining the four actuation phases with the sum of the inverse distances strategy, in the time domain, and with the majority voting strategy or the sum of the inverse distances strategy, in the frequency domain, accurate results can be obtained. Results also show that the quality of the two-dimensional clusters created with t-SNE in the frequency domain is better than the quality of the two-dimensional clusters created with t-SNE in the time domain, thus leading to a better classification. Therefore, the strategy in the frequency domain significantly outperforms the approach in the time domain.
Some aspects to highlight in the proposed methodology are: the t-SNE technique has been extended and adapted to the field of SHM, in the detection and classification of structural changes; the method classifies the current state of the structure by means of a data-driven analysis, that is, using collected data from the structure under different structural states and without the use of complex mathematical models; it is better to make a decision considering all of the actuation phases (assembling theses phases or using them to cast a vote) rather than working with the phases separately; both strategies, majority voting and sum of the inverse distances, slightly outperform the horizontal concatenation of the four actuation phases in the frequency domain; in the time domain, sum of the inverse distances strategy outperforms majority voting, and this last strategy outperforms the horizontal concatenation of the four actuation phases; it is better to work in the frequency domain than in the time domain because better results are obtained; and finally, in general, the healthy state of the structure is confused with the structure with damage in just a few cases, and similarly, the structure with damage is identified as a structure with no damage in a very limited number of realizations. With respect to the possible fields of application, similar aluminum plates have been used to represent parts of a plane (wings or fuselage). We think that we can also apply this approach for the damage and fault detection of wind turbines. In general, there is no a prescribed field of application: if a sensor network can be installed in a structure, and several actuation phases can be considered, the proposed approach can be implemented a priori.
As a future work, we plan to develop further the proposed method for different EOC to determine its effectiveness, as well as to handle imbalanced data. In addition, we aim to investigate the parametric version of t-SNE.
Author Contributions
D.A. and F.P. developed the idea and designed the exploration framework; D.A. developed the algorithms; F.P. supervised the results of the validation; D.A. and F.P. drafted the manuscript.
Funding
This work has been partially funded by the Spanish Agencia Estatal de Investigación (AEI) - Ministerio de Economía, Industria y Competitividad (MINECO), and the Fondo Europeo de Desarrollo Regional (FEDER) through the research project DPI2017-82930-C2-1-R; and by the Generalitat de Catalunya through the research project 2017 SGR 388.
Acknowledgments
We gratefully acknowledge the support of NVIDIA Corporation with the donation of the Titan Xp GPU used for this research. We thank the Universitat Politècnica de Catalunya (UPC) for pre-doctoral fellowship (to David Agis). We also thank Jaime Vitola and Diego A. Tibaduiza for useful discussions with respect to the experimental set-up.
Conflicts of Interest
The authors declare no conflict of interest.
Nomenclature
| High-dimensional data set. | |
| High-dimensional data set including the data point to diagnose. | |
| Low-dimensional map points. | |
| Low-dimensional map points including the map point to diagnose. | |
| Centroid associated with the l-th structural state. | |
| Similarity matrix for the high-dimensional data points. | |
| Similarity matrix for the low-dimensional map points. | |
| KL divergence. | |
| Learning rate. | |
| Momentum term at iteration t. | |
| p | Perplexity. |
| Matrix that collects all the realizations under different structural states. | |
| Scaled original —in the frequency domain— data matrix. | |
| N | Number of sensors. |
| L | Number of components in each signal. |
| E | Number of different structural states. |
| Covariance matrix of . | |
| Eigenvalues. | |
| Eigenvectors. | |
| Eigenvalues in a diagonal matrix. | |
| PCA model (full case). | |
| PCA model (reduced). | |
| Projection of the scaled data set into the subspace spanned by the PCA model. | |
| i-th element of the canonical basis. | |
| Current original —in the frequency domain— data vector to diagnose. | |
| Current scaled original —in the frequency domain— data vector to diagnose. | |
| -th actuation phase. | |
| Selector matrix |
Abbreviations
| CM | Condition monitoring |
| EOC | Environmental and operational conditions |
| FFT | Fast Fourier transform |
| FNR | False negative rate |
| FPR | False positive rate |
| KL | Kullback-Leibler |
| MCGS | Mean-centered group scaling |
| PCA | Principal component analysis |
| PZT | Piezoelectric transducer |
| SG | Savitzky–Golay |
| SHM | Structural health monitoring |
| SNE | Stochastic neighbor embedding |
| t-SNE | t-distributed stochastic neighbor embedding |
References
- Rolfes, R.; Zerbst, S.; Haake, G.; Reetz, J.; Lynch, J.P. Integral SHM-system for offshore wind turbines using smart wireless sensors. In Proceedings of the 6th International Workshop on Structural Health Monitoring, Stanford, CA, USA, 11–13 September 2007; pp. 11–13. [Google Scholar]
- Ciang, C.C.; Lee, J.R.; Bang, H.J. Structural health monitoring for a wind turbine system: A review of damage detection methods. Meas. Sci. Technol. 2008, 19, 122001. [Google Scholar] [CrossRef]
- Loh, C.H.; Loh, K.J.; Yang, Y.S.; Hsiung, W.Y.; Huang, Y.T. Vibration-based system identification of wind turbine system. Struct. Control Health Monit. 2017, 24, e1876. [Google Scholar] [CrossRef]
- Raju, K.S.; Pratap, Y.; Sahni, Y.; Babu, M.N. Implementation of a WSN system towards SHM of civil building structures. In Proceedings of the IEEE 9th International Conference on Intelligent Systems and Control (ISCO), Coimbatore, India, 9–10 January 2015; pp. 1–7. [Google Scholar]
- Blanco, H.; Boffill, Y.; Lombillo, I.; Villegas, L. An integrated structural health monitoring system for determining local/global responses of historic masonry buildings. Struct. Control Health Monit. 2018, 25, e2196. [Google Scholar] [CrossRef]
- Nisha, M. Structural health monitoring of aircraft wing using wireless network. Int. J. Technol. Explor. Learn. Www. Ijtel. Org Struct 2014, 3, 341–343. [Google Scholar]
- Ochôa, P.; Groves, R.M.; Benedictus, R. Systematic multiparameter design methodology for an ultrasonic health monitoring system for full-scale composite aircraft primary structures. Struct. Control Health Monit. 2019, 26, e2340. [Google Scholar] [CrossRef]
- Ward, M.O.; Grinstein, G.; Keim, D. Interactive Data Visualization: Foundations, Techniques, and Applications; AK Peters/CRC Press: Boca Raton, FL, USA, 2015. [Google Scholar]
- Tenenbaum, J.B.; De Silva, V.; Langford, J.C. A global geometric framework for nonlinear dimensionality reduction. Science 2000, 290, 2319–2323. [Google Scholar] [CrossRef]
- van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Agis, D.; Pozo, F. Detection and classification of structural changes using t-distributed stochastic neighbor embedding. In Proceedings of the International Conference on Structural Engineering Dynamics, Viana do Castelo, Portugal, 24–26 June 2019; pp. 1–10. [Google Scholar]
- Tsogka, C.; Daskalakis, E.; Comanducci, G.; Ubertini, F. The stretching method for vibration-based structural health monitoring of civil structures. Comput. Aided Civ. Infrastruct. Eng. 2017, 32, 288–303. [Google Scholar] [CrossRef]
- Xu, F.; Song, X.; Tsui, K.L.; Yang, F.; Huang, Z. Bearing performance degradation assessment based on ensemble empirical mode decomposition and affinity propagation clustering. IEEE Access 2019, 7, 54623–54637. [Google Scholar] [CrossRef]
- Cheng, Y.; Zhu, H.; Hu, K.; Wu, J.; Shao, X.; Wang, Y. Multisensory data-driven health degradation monitoring of machining tools by generalized multiclass support vector machine. IEEE Access 2019, 7, 47102–47113. [Google Scholar] [CrossRef]
- Westerhuis, J.A.; Kourti, T.; MacGregor, J.F. Comparing alternative approaches for multivariate statistical analysis of batch process data. J. Chemom. A J. Chemom. Soc. 1999, 13, 397–413. [Google Scholar] [CrossRef]
- Mujica, L.; Rodellar, J.; Fernandez, A.; Güemes, A. Q-statistic and T2-statistic PCA-based measures for damage assessment in structures. Struct. Health Monit. 2011, 10, 539–553. [Google Scholar] [CrossRef]
- Vidal, Y.; Pozo, F.; Tutivén, C. Wind turbine multi-fault detection and classification based on SCADA data. Energies 2018, 11, 3018. [Google Scholar] [CrossRef]
- Sikdar, S.; Kundu, A.; Jurek, M.; Ostachowicz, W. Nondestructive analysis of debonds in a composite structure under variable temperature conditions. Sensors 2019, 19, 3454. [Google Scholar] [CrossRef]
- Yan, J.; Jin, H.; Sun, H.; Qing, X. Active monitoring of fatigue crack in the weld zone of bogie frames using ultrasonic guided waves. Sensors 2019, 19, 3372. [Google Scholar] [CrossRef]
- Cho, H.; Hasanian, M.; Shan, S.; Lissenden, C.J. Nonlinear guided wave technique for localized damage detection in plates with surface-bonded sensors to receive Lamb waves generated by shear-horizontal wave mixing. NDT E Int. 2019, 102, 35–46. [Google Scholar] [CrossRef]
- Jiménez, A.A.; Muñoz, C.Q.G.; Márquez, F.P.G. Dirt and mud detection and diagnosis on a wind turbine blade employing guided waves and supervised learning classifiers. Reliab. Eng. Syst. Saf. 2019, 184, 2–12. [Google Scholar] [CrossRef]
- Hinton, G.; Roweis, S.T. Stochastic neighbor embedding. Adv. Neural Inf. Process. Syst. 2003, 15, 857–864. [Google Scholar]
- Min, R. A Non-Linear Dimensionality Reduction Method for Improving Nearest Neighbour Classification; University of Toronto: Toronto, ON, Canada, 2005. [Google Scholar]
- Pozo, F.; Vidal, Y.; Salgado, Ó. Wind turbine condition monitoring strategy through multiway PCA and multivariate inference. Energies 2018, 11, 749. [Google Scholar] [CrossRef]
- Orfanidis, S.J. Introduction to Signal Processing; Prentice-Hall, Inc.: Upper Saddle River, NJ, USA, 1995. [Google Scholar]
- Vitola, J.; Pozo, F.; Tibaduiza, D.A.; Anaya, M. A sensor data fusion system based on k-nearest neighbor pattern classification for structural health monitoring applications. Sensors 2017, 17, 417. [Google Scholar] [CrossRef]
- Vitola, J.; Pozo, F.; Tibaduiza, D.A.; Anaya, M. Distributed piezoelectric sensor system for damage identification in structures subjected to temperature changes. Sensors 2017, 17, 1252. [Google Scholar] [CrossRef] [PubMed]
- Tardy, B.; Inglada, J.; Michel, J. Assessment of optimal transport for operational land-cover mapping using high-resolution satellite images time series without reference data of the mapping period. Remote Sens. 2019, 11, 1047. [Google Scholar] [CrossRef]
- Mehta, S.; Shen, X.; Gou, J.; Niu, D. A new nearest centroid neighbor classifier based on k local means using harmonic mean distance. Information 2018, 9, 234. [Google Scholar] [CrossRef] [Green Version]
Figure 1.
The current structure to diagnose is associated to the structural state with the smallest point-centroid distance.
Figure 1.
The current structure to diagnose is associated to the structural state with the smallest point-centroid distance.

Figure 2.
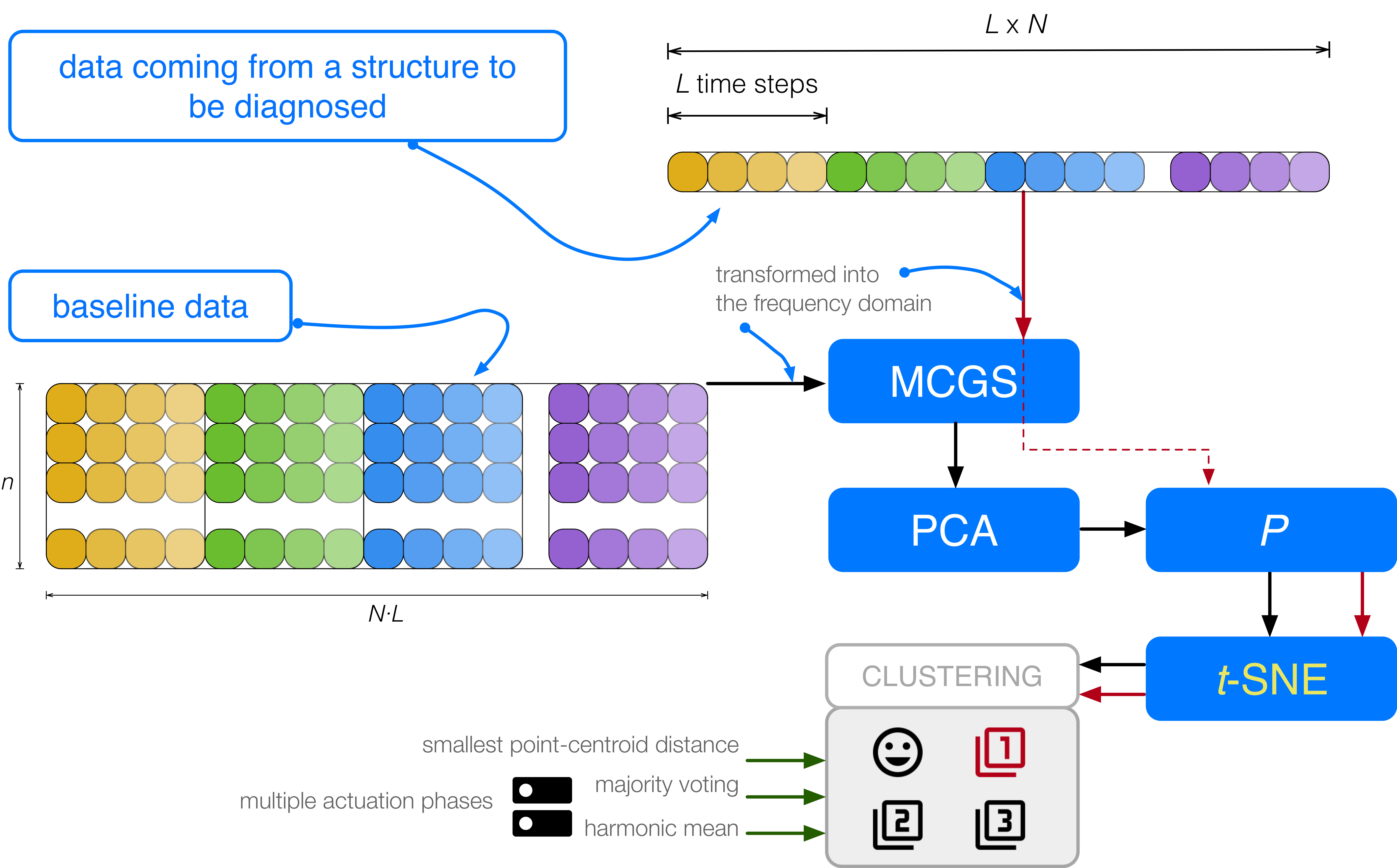
Flowchart of the proposed approach. Data coming from a structure are first transformed into the frequency domain and scaled, and then projected into the principal component analysis (PCA) model. Finally, t-distributed stochastic neighbor embedding (t-SNE) is used to create the clusters that will be used in the detection and classification of structural changes. MCGS = mean-centered group scaling.
Figure 2.
Flowchart of the proposed approach. Data coming from a structure are first transformed into the frequency domain and scaled, and then projected into the principal component analysis (PCA) model. Finally, t-distributed stochastic neighbor embedding (t-SNE) is used to create the clusters that will be used in the detection and classification of structural changes. MCGS = mean-centered group scaling.

Figure 3.
Aluminum plate instrumented with four piezoelectric sensors (, and ).

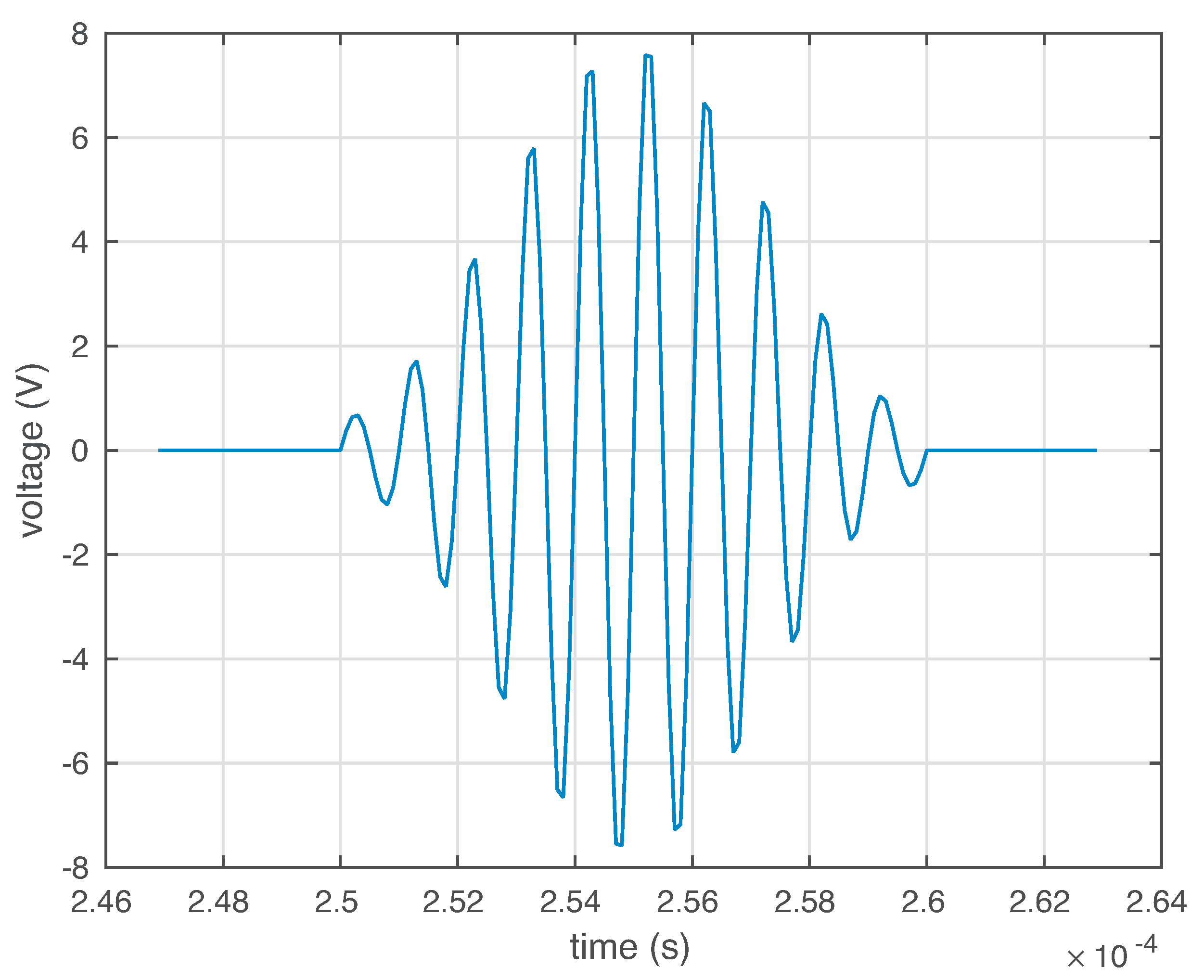
Figure 4.
In actuator mode, this burst signal is applied to the piezoelectric transducers (PZTs) to produce a mechanical vibration.
Figure 4.
In actuator mode, this burst signal is applied to the piezoelectric transducers (PZTs) to produce a mechanical vibration.

Figure 5.
Aluminum plate with four PZTs and with four different structural states.

Figure 6.
In the majority voting, the strategy of the smallest point-centroid distance is performed per actuation phase. The current structure to diagnose is associated to the most voted structural state.
Figure 6.
In the majority voting, the strategy of the smallest point-centroid distance is performed per actuation phase. The current structure to diagnose is associated to the most voted structural state.

Figure 7.
Clusters formed by the different structural states described in Section 6, for Scenario 3. The diamond represents the structure to diagnose.
Figure 7.
Clusters formed by the different structural states described in Section 6, for Scenario 3. The diamond represents the structure to diagnose.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Confusion matrix of the application of the t-SNE based damage detection and classification procedure presented in Section 3 and Section 4 to the case of the aluminum plate in Scenario 1, in the frequency domain. Rows represent true values, while columns represent predicted values.
| Actuation Phase 1 | Actuation Phase 2 | Actuation Phase 3 | Actuation Phase 4 | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 97 | 0 | 2 | 1 | 100 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | |
| 0 | 100 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 100 | 0 | 0 | |
| 0 | 0 | 100 | 0 | 0 | 0 | 100 | 0 | 3 | 0 | 96 | 1 | 0 | 0 | 98 | 2 | |
| 0 | 0 | 0 | 100 | 0 | 0 | 1 | 99 | 1 | 0 | 0 | 99 | 0 | 0 | 1 | 99 | |
Table 2.
Confusion matrix of the application of the t-SNE based damage detection and classification procedure presented in Section 3 and Section 4 to the case of the aluminum plate in Scenario 1, when the four actuation phases are used at the same time, in the frequency domain. Rows represent true values, while columns represent predicted values.
Table 2.
Confusion matrix of the application of the t-SNE based damage detection and classification procedure presented in Section 3 and Section 4 to the case of the aluminum plate in Scenario 1, when the four actuation phases are used at the same time, in the frequency domain. Rows represent true values, while columns represent predicted values.
| Phases 1–4 | Majority Voting | Inverse Distances | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 100 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | |
| 0 | 99 | 1 | 0 | 0 | 100 | 0 | 0 | 0 | 100 | 0 | 0 | |
| 1 | 0 | 99 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 100 | 0 | |
| 0 | 0 | 0 | 100 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 100 | |
Table 3.
Confusion matrix of the application of the t-SNE based damage detection and classification procedure presented in Section 3 and Section 4 to the case of the aluminum plate in Scenario 2, in the frequency domain. Rows represent true values, while columns represent predicted values.
| Actuation Phase 1 | Actuation Phase 2 | Actuation Phase 3 | Actuation Phase 4 | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 100 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | |
| 0 | 100 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 100 | 0 | 0 | |
| 0 | 0 | 100 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 100 | 0 | |
| 0 | 0 | 0 | 100 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 100 | 0 | 0 | 1 | 99 | |
Table 4.
Confusion matrix of the application of the t-SNE based damage detection and classification procedure presented in Section 3 and Section 4 to the case of the aluminum plate in Scenario 2, when the four actuation phases are used at the same time, in the frequency domain. Rows represent true values, while columns represent predicted values.
Table 4.
Confusion matrix of the application of the t-SNE based damage detection and classification procedure presented in Section 3 and Section 4 to the case of the aluminum plate in Scenario 2, when the four actuation phases are used at the same time, in the frequency domain. Rows represent true values, while columns represent predicted values.
| Phases 1–4 | Majority Voting | Inverse Distances | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 100 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | |
| 0 | 100 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 100 | 0 | 0 | |
| 0 | 0 | 100 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 100 | 0 | |
| 0 | 0 | 0 | 100 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 100 | |
Table 5.
Confusion matrix of the application of the t-SNE based damage detection and classification procedure presented in Section 3 and Section 4 to the case of the aluminum plate in Scenario 3, in the frequency domain. Rows represent true values, while columns represent predicted values.
| Actuation Phase 1 | Actuation Phase 2 | Actuation Phase 3 | Actuation Phase 4 | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 98 | 2 | 0 | 0 | 99 | 0 | 1 | 0 | 100 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | |
| 6 | 90 | 2 | 2 | 0 | 99 | 1 | 0 | 0 | 95 | 5 | 0 | 1 | 99 | 0 | 0 | |
| 1 | 1 | 97 | 1 | 0 | 1 | 97 | 2 | 0 | 0 | 100 | 0 | 0 | 0 | 100 | 0 | |
| 0 | 1 | 0 | 99 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 100 | 0 | 0 | 1 | 99 | |
Table 6.
Confusion matrix of the application of the t-SNE based damage detection and classification procedure presented in Section 3 and Section 4 to the case of the aluminum plate in Scenario 3, when the four actuation phases are used at the same time, in the frequency domain. Rows represent true values, while columns represent predicted values.
Table 6.
Confusion matrix of the application of the t-SNE based damage detection and classification procedure presented in Section 3 and Section 4 to the case of the aluminum plate in Scenario 3, when the four actuation phases are used at the same time, in the frequency domain. Rows represent true values, while columns represent predicted values.
| Phases 1–4 | Majority Voting | Inverse Distances | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 100 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | |
| 0 | 99 | 0 | 1 | 0 | 100 | 0 | 0 | 0 | 100 | 0 | 0 | |
| 0 | 1 | 99 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 100 | 0 | |
| 0 | 0 | 0 | 100 | 0 | 0 | 0 | 100 | 0 | 0 | 0 | 100 | |
Table 7.
Confusion matrix of the application of the t-SNE based damage detection and classification procedure presented in Section 3 and Section 4 to the case of the aluminum plate in textbfScenario 3, in the time domain. Rows represent true values, while columns represent predicted values.
| Actuation Phase 1 | Actuation Phase 2 | Actuation Phase 3 | Actuation Phase 4 | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 50 | 6 | 19 | 25 | 100 | 0 | 0 | 0 | 93 | 1 | 3 | 3 | 53 | 21 | 1 | 25 | |
| 19 | 66 | 11 | 4 | 0 | 100 | 0 | 0 | 16 | 50 | 23 | 11 | 17 | 61 | 2 | 20 | |
| 14 | 3 | 73 | 10 | 0 | 1 | 98 | 1 | 5 | 19 | 70 | 6 | 5 | 3 | 76 | 16 | |
| 15 | 9 | 21 | 55 | 0 | 0 | 0 | 100 | 0 | 23 | 10 | 67 | 10 | 3 | 0 | 87 | |
Table 8.
Confusion matrix of the application of the t-SNE based damage detection and classification procedure presented in Section 3 and Section 4 to the case of the aluminum plate in Scenario 3, when the four actuation phases are used at the same time, in the time domain. Rows represent true values, while columns represent predicted values.
Table 8.
Confusion matrix of the application of the t-SNE based damage detection and classification procedure presented in Section 3 and Section 4 to the case of the aluminum plate in Scenario 3, when the four actuation phases are used at the same time, in the time domain. Rows represent true values, while columns represent predicted values.
| Phases 1–4 | Majority voting | Inverse distances | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 86 | 1 | 7 | 6 | 98 | 0 | 0 | 2 | 99 | 0 | 1 | 0 | |
| 8 | 88 | 4 | 0 | 12 | 85 | 2 | 1 | 1 | 99 | 0 | 0 | |
| 1 | 8 | 89 | 2 | 6 | 2 | 90 | 2 | 1 | 1 | 95 | 3 | |
| 3 | 4 | 2 | 91 | 0 | 3 | 5 | 92 | 1 | 2 | 2 | 95 | |
Table 9.
Overall accuracy, false positive rate (FPR) and false negative rate (FNR) of the application of the t-SNE-based damage detection and classification procedure presented in Section 3 and Section 4 to the case of the aluminum plate in Scenario 3, when the four actuation phases are used separately and at the same time, in both domains, time and frequency.
Table 9.
Overall accuracy, false positive rate (FPR) and false negative rate (FNR) of the application of the t-SNE-based damage detection and classification procedure presented in Section 3 and Section 4 to the case of the aluminum plate in Scenario 3, when the four actuation phases are used separately and at the same time, in both domains, time and frequency.
| Accuracy | FPR | FNR | ||||
|---|---|---|---|---|---|---|
| Time | Frequency | Time | Frequency | Time | Frequency | |
| Actuation phase 1 | ||||||
| Actuation phase 2 | ||||||
| Actuation phase 3 | ||||||
| Actuation phase 4 | ||||||
| Phases 1-4 | ||||||
| Majority voting | ||||||
| Inverse distances | ||||||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Agis, D.; Pozo, F.
A Frequency-Based Approach for the Detection and Classification of Structural Changes Using t-SNE
AMA Style
Agis D, Pozo F.
A Frequency-Based Approach for the Detection and Classification of Structural Changes Using t-SNE
Agis, David, and Francesc Pozo.
2019. "A Frequency-Based Approach for the Detection and Classification of Structural Changes Using t-SNE
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.