Most proposed CNN-based methods have complicated architectures or a vast number of trainable parameters, which increase the difficulty of model training or make the model feedforward process more time-consuming. For example, some models (e.g., CSRNet [
13] and CP-CNN [
9]) inherit many parameters from the VGG network [
41] for transfer learning. Although these parameters may be frozen during model training, they still dilate the whole model and slow down the speed of this method. Multi-column or multi-branch approaches are synonymous with huge floating-point operations. More attention should be paid to the right-sized architecture. In this paper, the single-column network achieves good performance with less computation and fewer trainable parameters.
Due to the lack of external perspective information about crowds and the presence of multiple scales in an image, it is difficult to estimate crowd counts under a single standard or generate a high-quality density map without spatial distribution information. Conceptually, CNNs need larger receptive fields to recognize the same kind of crowd in a close shot than in a vista. In other words, fusing contextual details or dilating receptive fields is the key factor for a successful crowd counting method. Further-more, context information and multi-scale feature representation play an active part in distinguishing crowd from other objects. Nevertheless, the huge amount of computation cost and parameters restrict the deployment of such applications.
In the following subsections, we design the architecture under the guidance of three key strategies:
3.1.1. Backbone
In recent years, different types of efficient convolutional neural network architectures for eliminating the redundancy in convolution kernels have been published. SqueezeNet [
43] achieves AlexNet-level accuracy on ImageNet with 50× fewer parameters. Another notable work in this direction is the DarkNet Reference network [
23], which is optimized for not only parameter count, but also inference speed. MobileNet [
44], which uses depth-wise convolution for spatial convolutions, exceeds AlexNet’s performance with only 1.32 million parameters. This idea is extended to pointwise group convolution along with channel shuffling by ShuffleNet [
45]. Furthermore, SqueezeNext [
46], whose design was guided by considering previous architectures, achieves better classification accuracy with fewer parameters, but avoids using depth-wise-separable convolutions, which are inefficient on some mobile processor platforms. The difference between the performance of these works should not attract too much attention. In a real scenario, better automation capabilities and ease of implementation are more efficient.
Although the above works have studied convolution in-depth, additional complexity may be injected into our experimental comparison. Considering the design of previous works for crowd counting, slightly fine-tuning the architecture composed of traditional convolutional layers may cause impartial competition among such works. Due to our modular design, it is also easy to enhance our model based on the components proposed in the above works for better accuracy or better real-time ability.
The design philosophy of the proposed model comes from Tiny Darknet, which is the front-end of the famous object detection network YOLO [
23]. As shown in
Figure 1, the backbone is repeatedly stacked with a block composed of a
bottleneck layer and a
ordinary convolutional layer. In particular, the compression factor (
) and the 1 × 1 filter kernel in the bottleneck layer contribute to limiting the quantity of parameters in this lightweight architecture. In other words, the compression factor (
) and the filters of the unit (
) jointly determine the number of filters in each layer. A parameter-free shortcut connection is also used to help all information pass through the blocks.
In this paper, the proposed backbone was YOLO style. To further reduce computation, the max-pooling layer was also replaced with a convolutional layer with a stride of 2. However, modern approaches usually compromise spatial resolution to achieve faster inference speed, which leads to poor performance. Due to the importance of the density map resolution and the hard work required to remedy the loss of spatial details, the backbone only reduced the spatial resolution of feature maps twice to obtain the 1/4 feature map. In
Table 1, the configuration of the proposed network is presented. The parameters in the convolutional layers are denoted as “(kernel size), (number of filters), (stride), (dilation rate)”. Unless otherwise stated, the stride and dilation rate were all set to 1 by default.
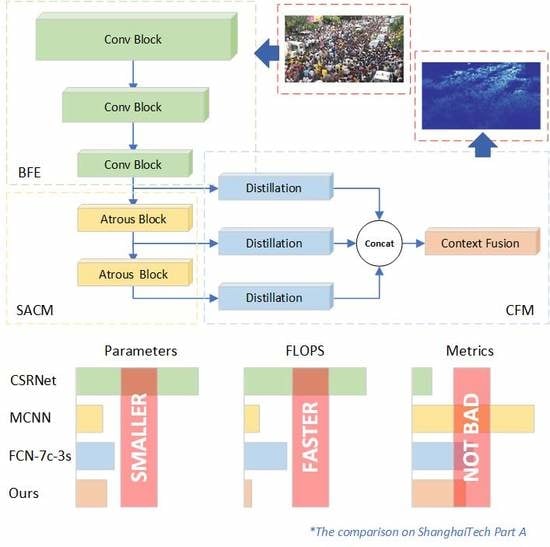
A basic feature extractor (BFE) consisting of three convolutional blocks was employed, which is a fast down-sampling strategy. Following the above extractor, a transition layer was used to compress the depth of the feature maps. This layer provided a “soft landing” to reduce information loss from channel truncation.
Another critical component of our design was the stacked à trous convolution module (SACM). Similar to the component reported in [
13], à trous convolution helps the network enlarge the receptive field without extra trainable parameters or any loss of spatial resolution of features. For example, the receptive size of the last layer in the first à trous block {117} is almost three-times larger than the receptive size of the layer above this block {37} in
Table 1. In addition, the main idea of à trous convolution is to insert “holes” in basic convolutional kernels, thus enabling employing them easily without other by-products.
Only three à trous convolutional layers with the same dilation rate were deployed in [
13], which had the same number of parameters as traditional convolution (same filter size, rate = 1). In contrast to CSRNet, we grouped together three layers as a block with an increasing dilation rate 2, 3, 5 to avoid the “gridding” problem in [
47]. At the same time, the receptive sizes of these feature maps increased more efficiently. To ensure an appropriate receptive size of the network, a SACM composed of two consecutive blocks was deployed in this paper.
The final context fusion layer used ReLU activation without batch normalization, while the other convolutional layers were followed with a batch normalization layer and leaky ReLU activation (the slope of the negative section was 0.1).
3.1.2. Context Fusion Module
Several context fusion architectures have been presented: the multi-column architecture was an initial attempt to fuse local context, while CP-CNN [
9] and Hydra CNN [
11] have further applications. In [
10], the classic image pyramid also helped the FCN handle context fusion attributed to multiple scales.
Inspired by the success of spatial pyramid pooling [
48], which fuses information of various arbitrary scales, à trous spatial pyramid pooling (ASPP) effectively resamples features at different scales to classify regions of arbitrary scale accurately and efficiently. Various pooling layers (e.g., max pooling) are widely used in current image-to-image models because they can multiply the receptive field in addition to providing other benefits, despite reducing the spatial resolution of feature maps. Attenuation of spatial resolution is a serious problem that leads to loss of information in image-to-image tasks.
In many proposed models [
47,
49], deconvolution or other upsampling components, which certainly add extra complexity to the original model, are used to recover the resolution. In particular, à trous convolution enlarges the receptive field without loss of spatial details or increasing the number of trainable parameters. This means that CNNs can appear wider with fewer layers, and little attention will be paid to handling feature resolution at different contextual scales.
Multiple parallel à trous convolutional layers with different sampling rates are used in ASPP to generate different scale information in separate branches. The above outputs are joined for final feature fusion. However, the parallel branches in ASSP slow down the inference speed.
In the context fusion module (CFM) we proposed, different contextual features were extracted from different parts of the backbone for further isolated distillation. In other words, various contextual information will not be fused until the last few layers. The experiments in
Section 4.2 demonstrate that this design not only improved context fusion, but also reduced the number of parameters and increased the inference speed.
Figure 2 presents the completed scheme of the proposed network for crowd counting. The network extracted common feature maps with reduced spatial resolution using BFE. To ensure the diversity of the contextual features, SACM enlarged the gap between the receptive sizes of feature maps. CFM distilled different contextual information and fused it to estimate the density map.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}