The two-stage method conducted in this paper follows the classical framework for multi-model fitting, which firstly generates large amount hypotheses, then makes preference for the hypotheses, and finally segments the inliers belonging to different models. Both stages make use of the quantized residual and contain a linkage cluster process, the difference is that the objects used for clustering are not the same.
In the model selection stage, a large amount of hypotheses will be generated and the sum of several minimum residuals (hypothesis cost) will be calculated for every hypothesis to measure the quality of the hypotheses. Then quantized residual preference will be made for the hypotheses to propose linkage clustering, which is iteratively merging two hypotheses with minimum distance and updating with the one of smaller sum of residuals. Finally hypotheses retained with small hypothesis cost and considerable number of cluster members will be selected as the model selection results.
The inlier segmentation stage will be entered after the models are selected, quantized residual preferences are generated based on the initial inliers of the selected hypotheses for the points, which will be used to separate inliers and outliers for each selected models by linkage clustering. In addition, an alternate sampling and clustering framework is proposed to make sure optimum division of the inliers and outliers can be found.
In this section, we will first introduce how to calculate the quantized residual preference after generating several hypotheses for linkage clustering to select models, and then we will carefully explain how the quantized residual preference is used in linkage clustering under alternate sampling and clustering framework to separate the inliers and outliers for each selected model one by one.
2.1. Model Selection
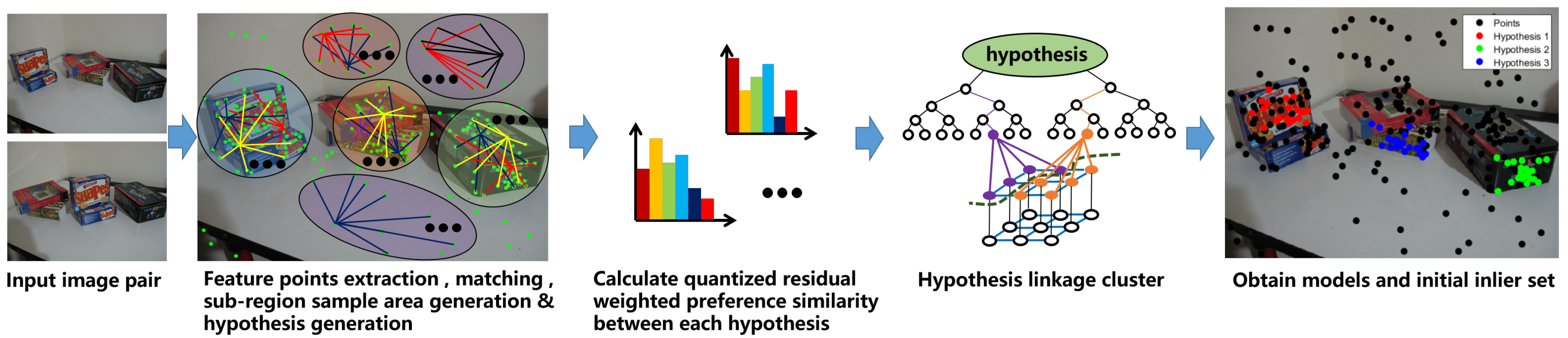
The model selection algorithm is proposed to obtain all the valid models in the scene. The flow chat of model selection is shown in
Figure 1. Like most of the model fitting methods, a sampling process to generate a great number of hypotheses will be conducted firstly. In addition, in order to take advantage of the prior knowledge that inliers belonging to one model tend to be neighbours, the hypotheses generation follows the random sampling process, but within a region. All the data points are segmented into several subregions with the same size by Euclidean distance, and then hypotheses are generated by random sampling within each subregion.
Given the data point set , the hypotheses set after the hypothesis generation, and then the residual matrix , where refers to the residuals of hypothesis to all the data points in X, N is the data number, and M is the number of hypotheses.
To calculate the hypothesis cost, we first need to sort the residuals of the hypothesis in ascending order. If
is the ascending sorted residuals of hypothesis
, then the hypothesis cost
of
is calculated by Equation (
1).
in which
, and usually
.
Hypotheses with lower cost will be used in the quantized residual preference linkage clustering for selecting hypotheses with good quality. The quantized residual preference is actually the quantization on
R by Equation (
2).
where
refers to the quantization level. When using the quantized residuals to represent the hypotheses or the data points, a valid quantization length
is needed to decrease the complexity of the quantized residual preferences.
In this way, we can obtain the quantized residual matrix , where each column of Q is the quantized residual preference for the hypothesis, and each row of Q is the quantized residual preference for the data point. That is, the quantized residual preference for hypothesis is the jth column of Q, i.e., .
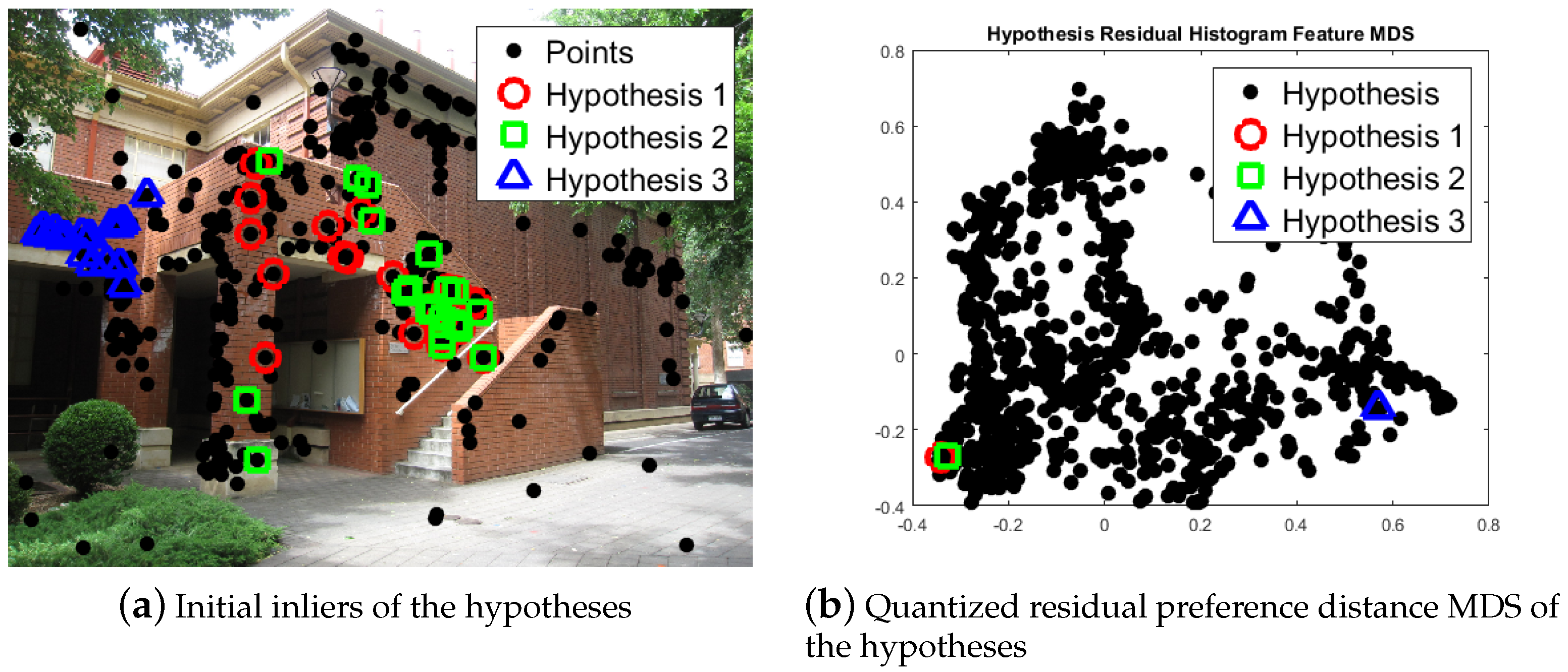
Considering the impact of the inliers will be greater than the outliers for hypotheses, especially when comparing two quantized residual preferences. The quantized residual weighted preference similarity is defined by Equation (
4), in which the more common elements between two quantized residual preferences, the more similar they are, and the smaller the common quantized value (except 0), the closer they are to a common model. A sample plot is presented in
Figure 2 to show the effectiveness of weighted preference similarity for comparing two hypotheses.
The model selection process is actually a linkage clustering, which is aimed at clustering similar hypotheses and selecting hypotheses close to the model in represent of each cluster. When conducting linkage clustering, we iteratively merge the two hypotheses with the maximum similarity (minimum weighted preference distance) and update the similarity matrix and clusters, until the maximum similarity is less than a threshold. This threshold depends on the given valid quantization length. If the two hypotheses have only one common item at the end of the valid quantization length, then the two hypotheses are considered to be disrelated with high probability. Therefore, if the valid quantization length is taken as 20, then according to Equation (
4), the threshold should be 0.05. For the similarity matrix updating, we preserve the similarity value of the hypothesis with the best quality (smaller hypothesis cost) and set the similarity values of the other hypotheses to 0 to avoid repetitive clustering. After the linkage clustering, models very different from each other are clustered into different classes, and hypotheses with the minimum hypothesis cost are left to represent each cluster. As there will also be some clusters consisting of bad hypotheses, we set a threshold(1% of the hypothesis number) for the size of cluster to remove these clusters by taking advantage of the random sample consensus, i.e., a good model will be more likely to be sampled repeatedly. The detailed model selection algorithm is presented in Algorithm 1.
| Algorithm 1 |
| 1: | Calculate hypothesis cost for each hypothesis by Equation (1); |
| 2: | Calculate quantized residual preference for hypotheses by Equations (2) and (3); |
| 3: | Calculate the weighted preference similarity by Equation (4) between every two hypotheses, and obtained similarity matrix; |
| 4: | Define each hypothesis as a cluster; |
| 5: | Merge the two cluster with maximum weighted preference similarity into one cluster; |
| 6: | Update the merged cluster with the quantized residual preference of smaller hypothesis, and replace the cluster similarity, while set the similarity of the other cluster to 0; |
| 7: | Repeat from step 5, until the maximum weighted preference similarity is less ; |
| 8: | remove the clusters whose size is less than hypothesis number. |
2.2. Inlier Segmentation
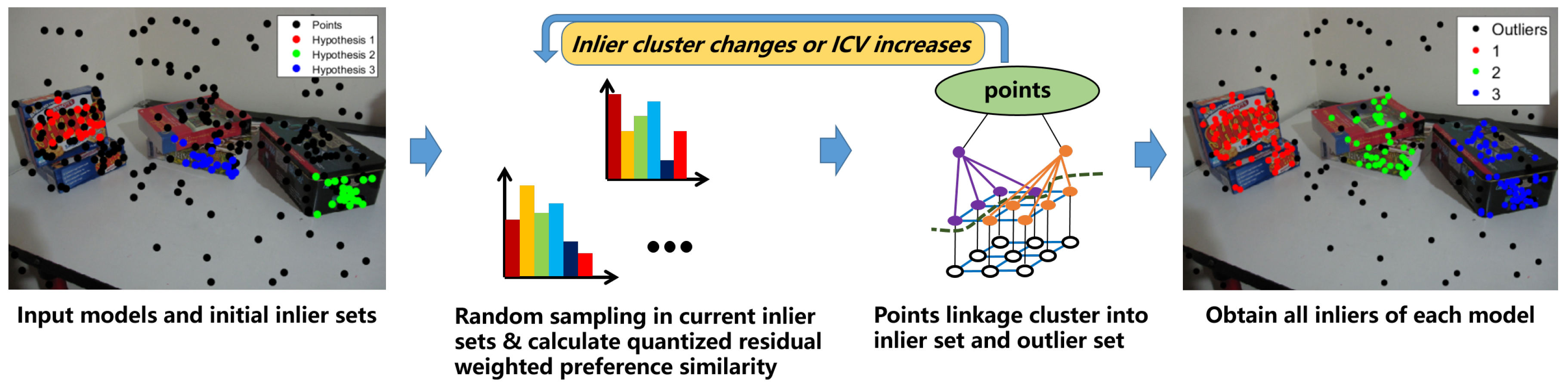
The model selection process usually makes it possible for us to find all the models in the data set, except for the fact that the sampling is not sufficient. Meanwhile, through the model selection process, we just obtain the model inlier sets with a fixed size and the hypothesis clusters, and most of the time we need to obtain all the inliers of each model, so that we can perfectly separate the inliers and outliers for each model. As a result, inlier segmentation is proposed to obtain all the inliers of each model, under the circumstance that the parameters of each model are estimated. Similar to the model selection algorithm, it also includes a random sampling process and a hierarchical clustering operation. The difference is that the model selection algorithm randomly samples the sub-regions and clusters the hypotheses to obtain multiple models, while the inlier segmentation algorithm randomly samples the current inlier set and clusters each point to obtain all inliers belonging to each model.
When we obtain the exact model parameters, a direct and easy way to separate the inliers is to set an inlier threshold to obtain the data points with residuals less than the threshold as the inliers. However, most of the time, this direct method works poorly, in which only some of the inliers can be separated. The exact true model parameters are very hard to find, and most of the time the parameters we find are only approximate, so the inliers within the threshold make it difficult to fully separate the inliers and outliers. In addition, when there is more than one model, one single threshold will not be enough to separate all the models’ inliers. Although some scale estimators claim to estimate the inlier scale, they have many limitations and require the noise distribution, which will usually fail in a real data set, and they work poorly when the model is complicated (such as homography matrix estimation and fundamental matrix estimation) and the data contain pseudo-outliers and noise. In contrast, a clustering method, taking advantage of the consensus representation, can separate the inliers and outliers without an inlier threshold or scale estimator. The use of the quantized residual preference for the hypotheses is very robust and efficient for linkage clustering in the model selection process to cluster similar hypotheses, and it can also be used to represent data points to separate the inliers from the outliers. The flow chat of inlier segmentation is shown in
Figure 3.
For a better representation, we use the k points with minimum residuals of each selected model by Algorithm 1, to generate hypotheses and make quantized residual preference for the data points. We then conduct linkage clustering to generate only two clusters—inlier cluster and outlier cluster for each selected model one by one. When conducting inlier and outlier clustering, an iterative sampling and clustering framework is introduced to get a optimum result, which iteratively samples the hypotheses from the inlier cluster and extract the quantized residual preference for the points for inlier and outlier clustering, until the clustering result unchanged.
Given we get the selected models after model selection in Algorithm 1, and the residual matrix of all the selected models, where refers to the residuals of model to all the data points in X, N is the data number, and m is the number of selected models. Then for each selected model we collect its initial inlier set consisting of k points with minimum residuals. Since the proposed inlier segmentation is actually to separate the inliers from the outliers for each selected model one by one, the following will take model as example to further explain our method.
When collecting the initial inlier set of model , firstly the residuals of model are sorted in ascending order . Then we collect as the initial inlier set for selected model .
Then, several hypotheses will be generated through random sampling on initial inlier set
, which will be soon used to make quantized residual preference for the data points the same way as the model selection process by Equations (
2) and (
3). As a consequence, more good hypotheses close to the model
will be used to produce the quantized residual preference for the data points, and it will make the quantized residual preferences for the inliers to have more smaller quantized values, and the quantized residual preferences for the outliers to have more bigger quantized values (or 0), which will make it possible to separate inliers from the outliers for model
. Supposing we obtain the quantized residual preference matrix
, where each row of
is the quantized residual preference for the data point. That is, the quantized residual preference for data point
is the
ith row of
, i.e.,
. When comparing two quantized residual preferences
and
, the distance measurement defined by Equation (
5) is used.
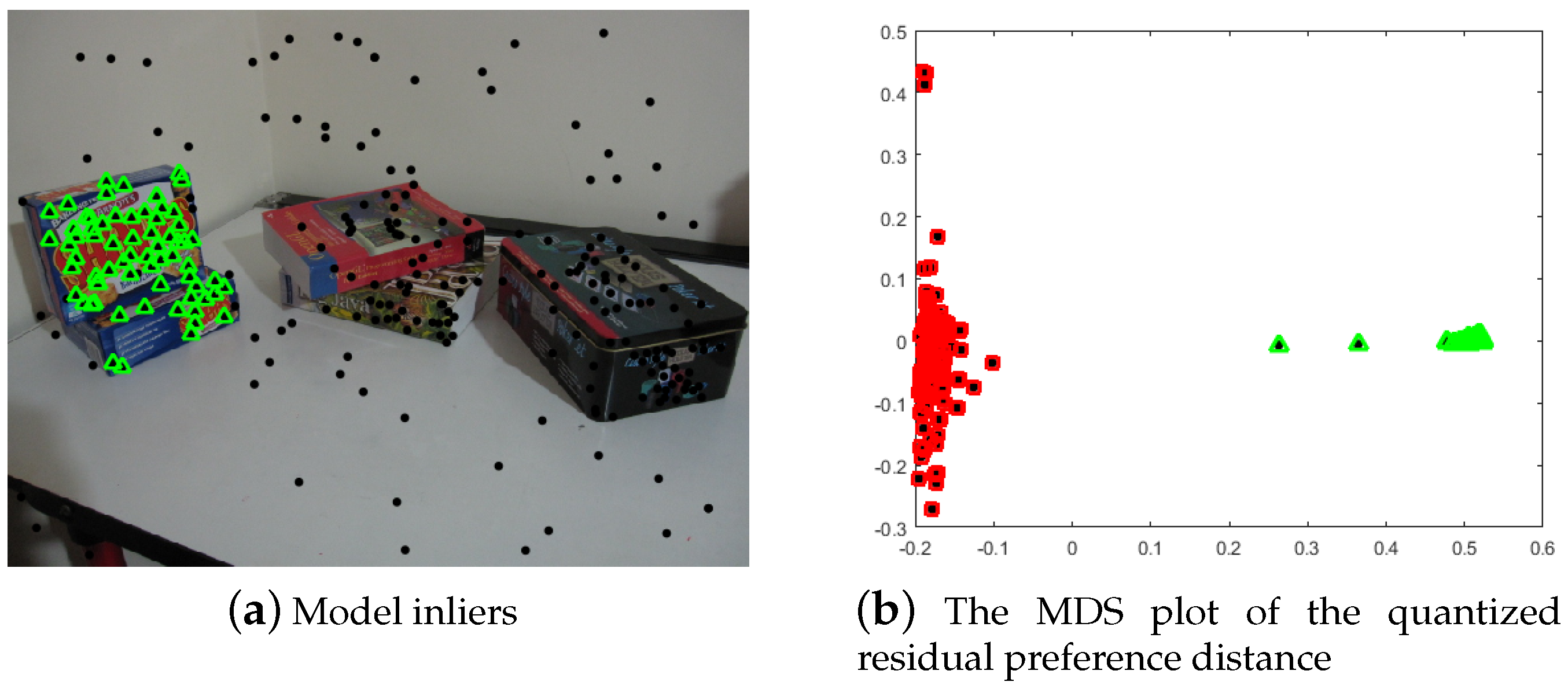
Figure 4 presents the MDS plot of the quantized residual preference for the data points, from which we can see the inliers and outliers are well separated.
From
Figure 4, we can see that the quantized residual preference for the points can separate the inliers from the outliers easily. In addition, we then undertake linkage clustering with a fixed cluster number of two to only cluster the inliers and outliers. To make the effect of the random hypothesis sampling in the inlier set stable and ensure that it can easily reach convergence, an iterative sampling and clustering framework is proposed to iteratively conduct the hypothesis sampling and linkage clustering. Furthermore, in order to avoid non-convergence and instability of the sampling, we use the inter-class variance (
) (Equation (
6)) to measure the quality of the inlier cluster, i.e., good inlier separation presents bigger inter-class variance. Please note that
refers inlier cluster and
is outlier cluster, and
represents the residual of
to the model calculated from the inlier set
in Equation (
6). The bigger the
value, the better the clustering result will be.
Then the whole inlier segmentation process for model
under iterative sampling and clustering framework can be summarized. We first sample several hypotheses in the initial inlier set
, and then extract the quantized residual preference
and calculate the distance matrix for every two points. We undertake linkage clustering with a fixed cluster number of two to cluster the inliers
and outliers
, and then calculate the inter-class variance by Equation (
6). We then replace the initial inlier set
with inliers
, and again conduct hypothesis sampling on the inlier set in turn, this way we iteratively perform clustering then sampling, until the inlier set is unchanged or inter-class variance decreases. The detailed algorithm is presented in Algorithm 2.
| Algorithm 2 |
- 1:
Calculate residuals for selected model ; - 2:
Collect initial inlier set; - 3:
Generate hypotheses on inlier set, and Calculate residuals; - 4:
Calculate quantized residual preference for data points and preference distance between every two data points; - 5:
Conduct linkage clustering to generate two clusters, take cluster more intersected with initial inlier set as inlier set; - 6:
Calculate the inter-class variance ; - 7:
if The inlier cluster unchanged or the inter-class variance decreases then - 8:
go to step 12; - 9:
else - 10:
Replace the initial inlier set with inlier set, and go back to step 3; - 11:
end if - 12:
Conduct step 1 to 11, until all the selected models are processed.
|











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}