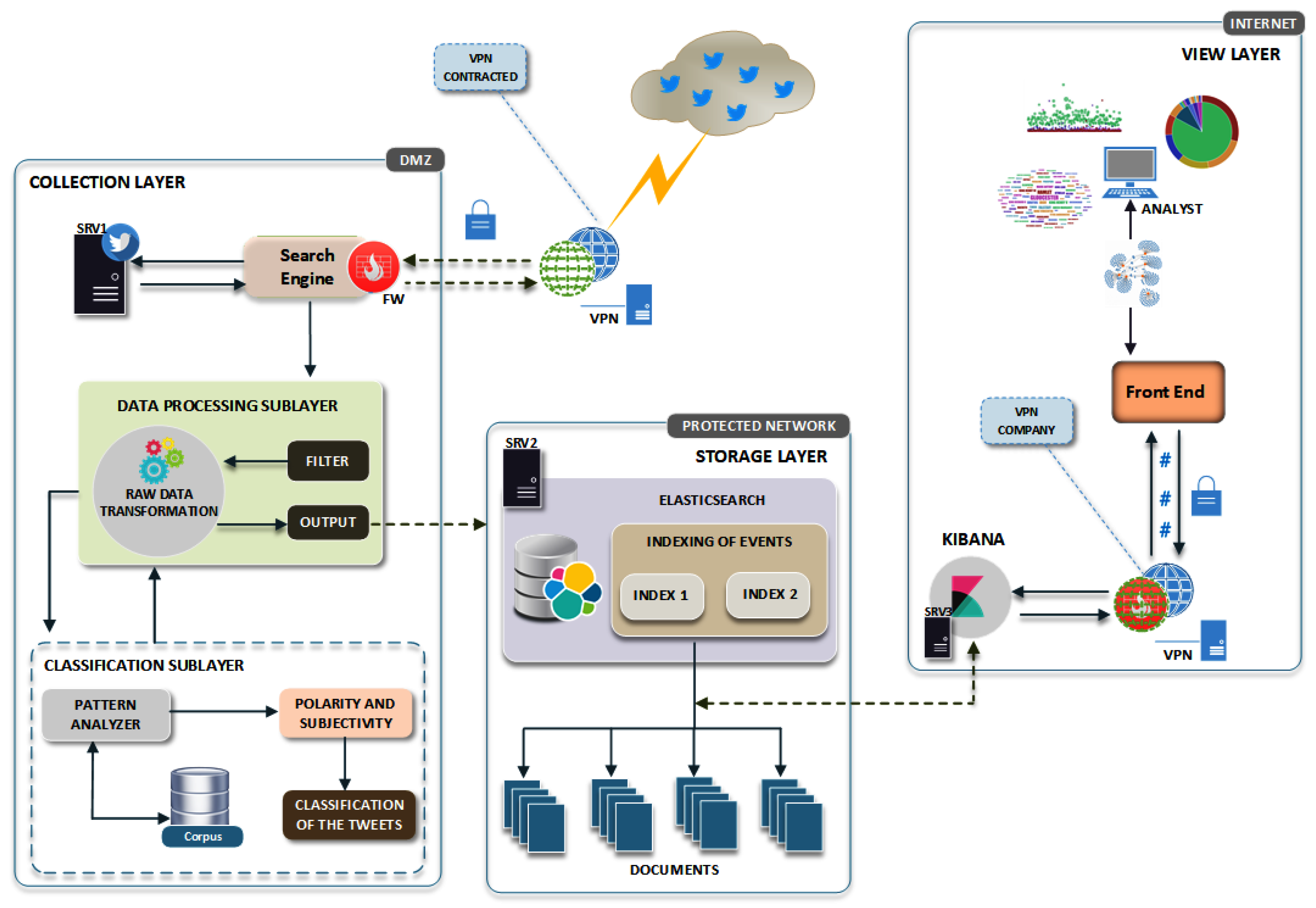
Figure 1.
OctopusViz architecture.
Figure 1.
OctopusViz architecture.
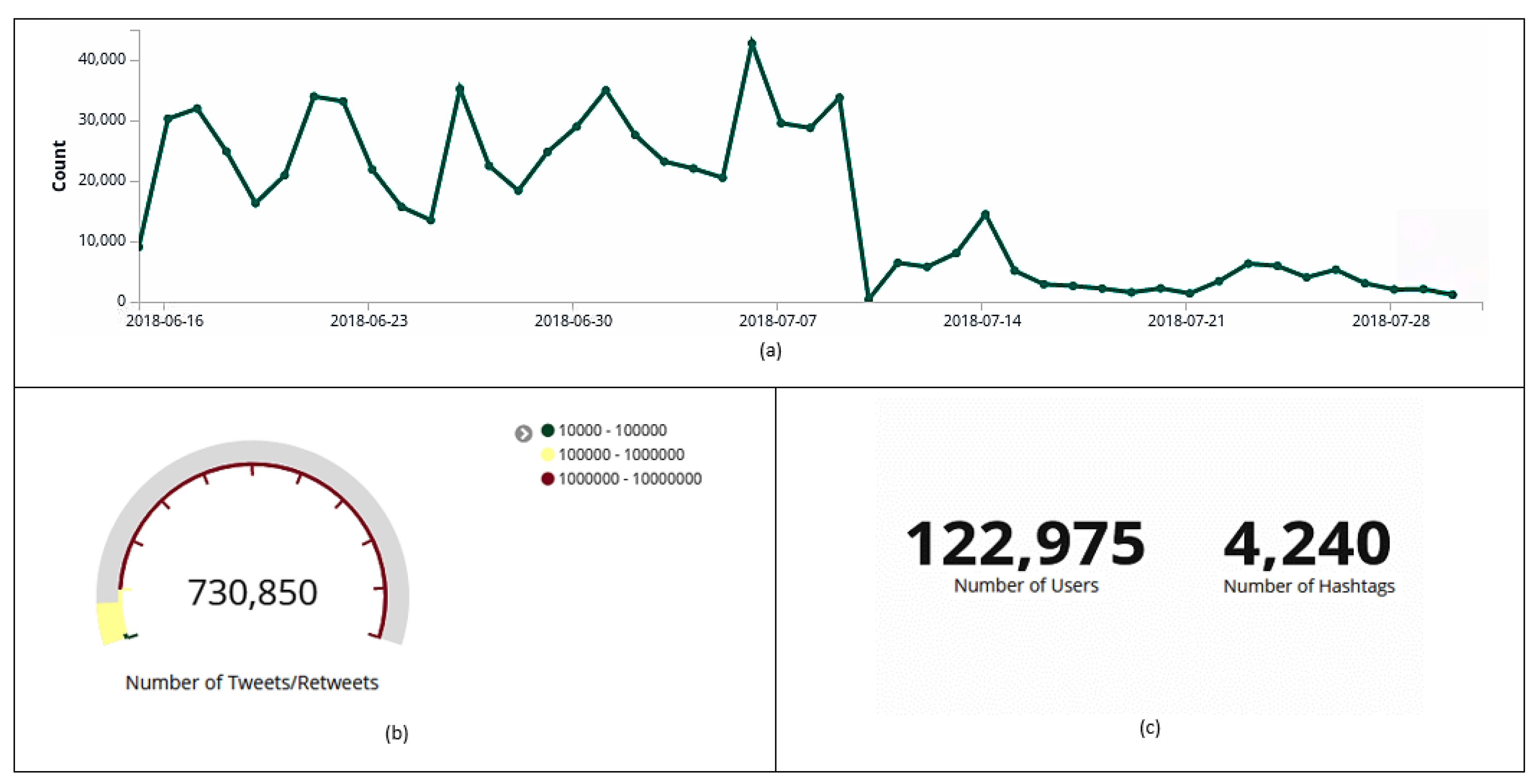
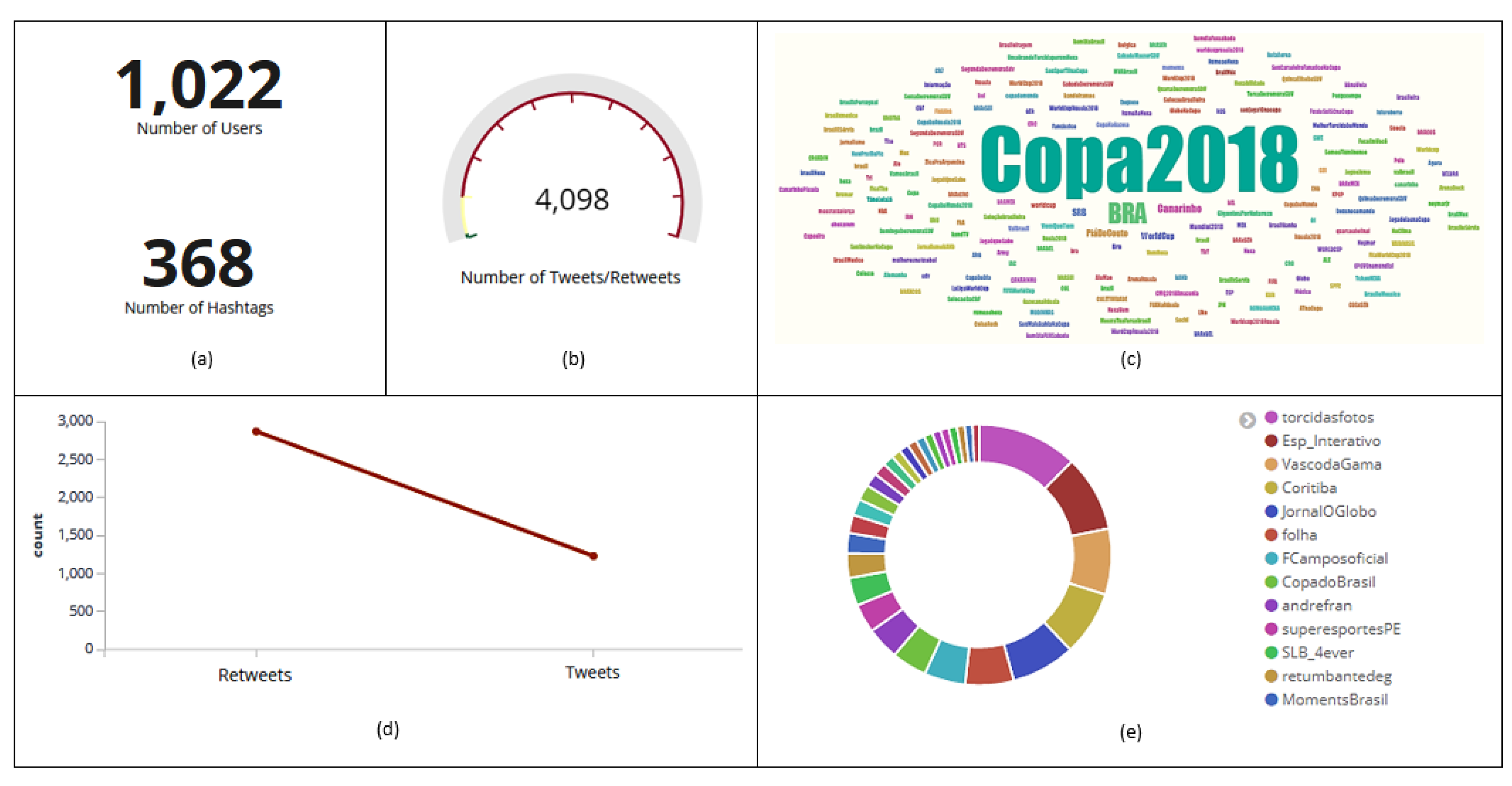
Figure 2.
Data collected on Twitter between 15 June and 31 July 2018. Histogram with the amount of tweets and retweets collected per day (a). Total amount of tweets and retweets (b). Total number of users and hashtags (c).
Figure 2.
Data collected on Twitter between 15 June and 31 July 2018. Histogram with the amount of tweets and retweets collected per day (a). Total amount of tweets and retweets (b). Total number of users and hashtags (c).
Figure 3.
Data collected on Twitter between 15 June and 31 July 2018. Message classification into tweets and retweets (a). Histogram with the messages’ classification into tweets and retweets collected per day (b).
Figure 3.
Data collected on Twitter between 15 June and 31 July 2018. Message classification into tweets and retweets (a). Histogram with the messages’ classification into tweets and retweets collected per day (b).
Figure 4.
Cloud of words with the identification from the most referenced hashtags in tweets and retweets.
Figure 4.
Cloud of words with the identification from the most referenced hashtags in tweets and retweets.
Figure 5.
Cloud with the most referenced hashtags. (a) indicates tweets and (b) retweets.
Figure 5.
Cloud with the most referenced hashtags. (a) indicates tweets and (b) retweets.
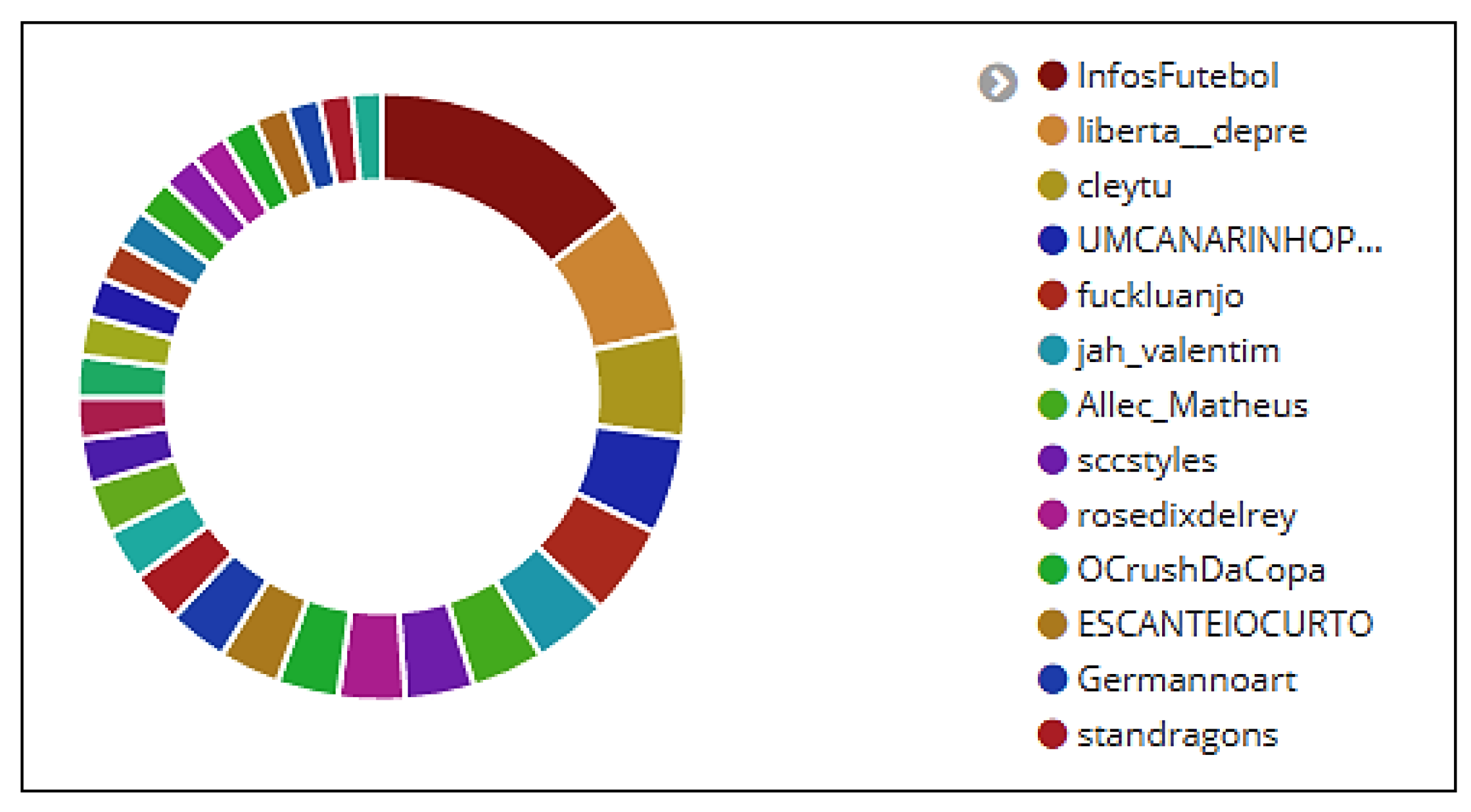
Figure 6.
Users who posted the most tweets and retweets.
Figure 6.
Users who posted the most tweets and retweets.
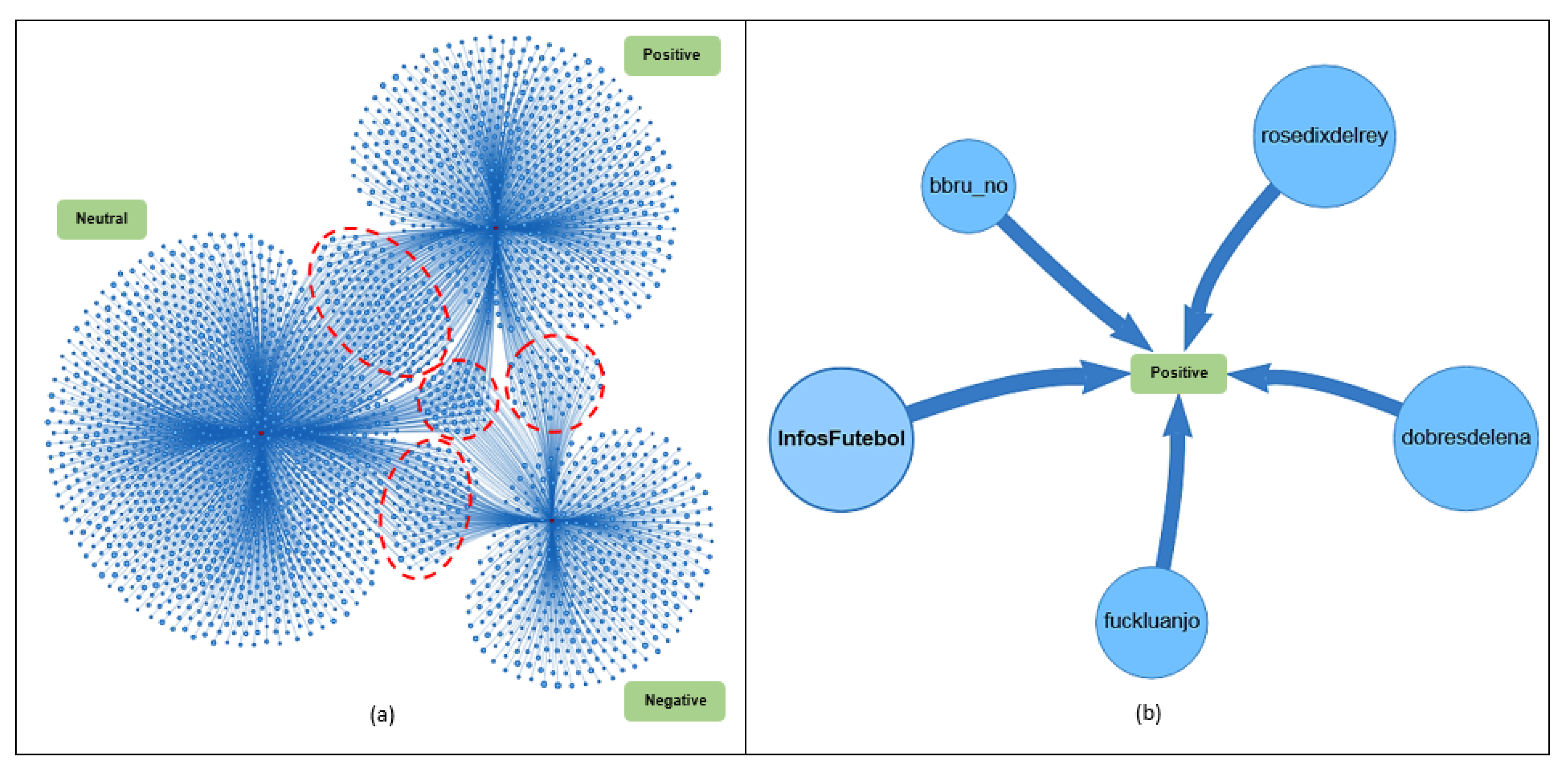
Figure 7.
Retweets published by user InfosFutebol.
Figure 7.
Retweets published by user InfosFutebol.
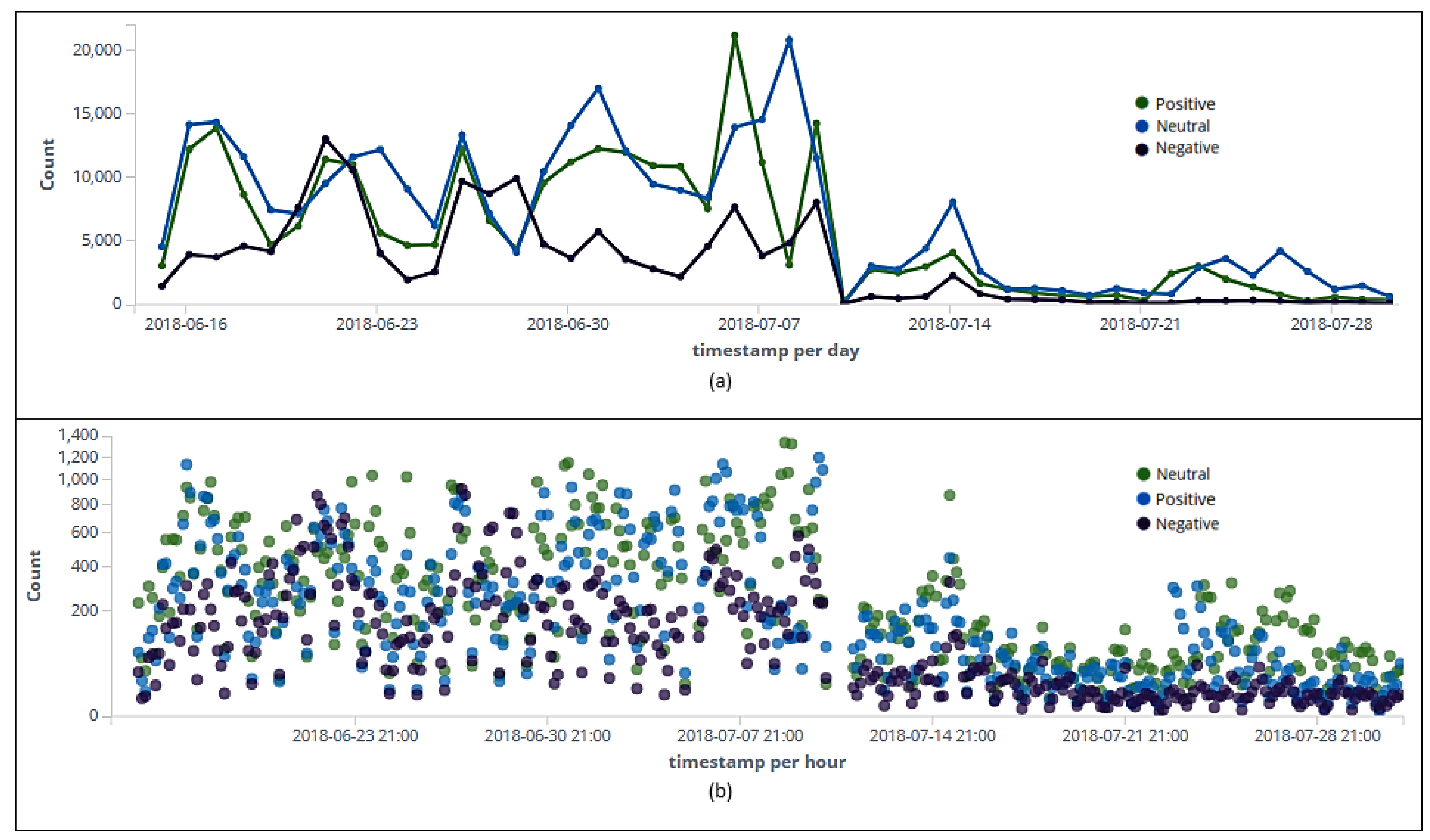
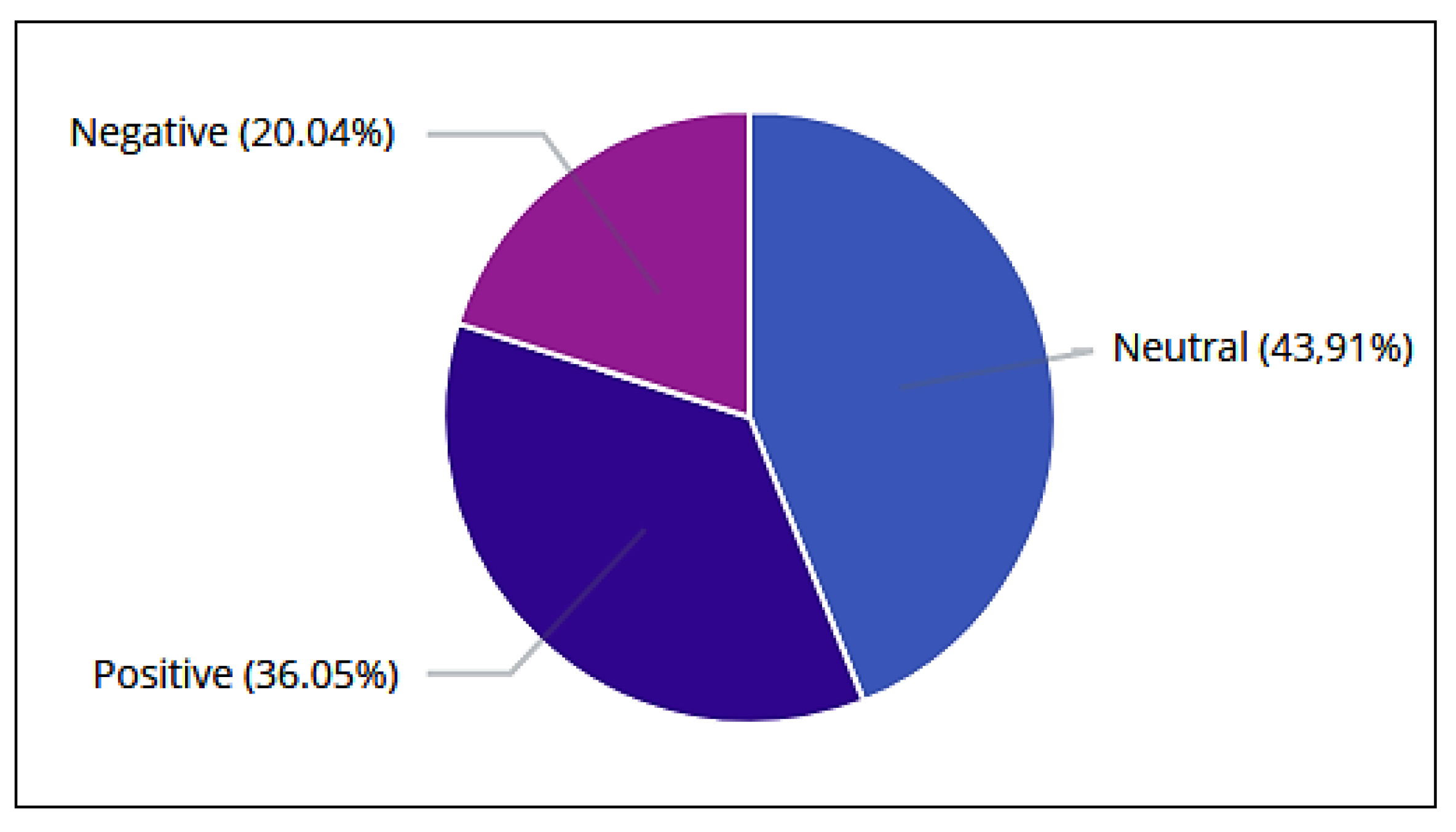
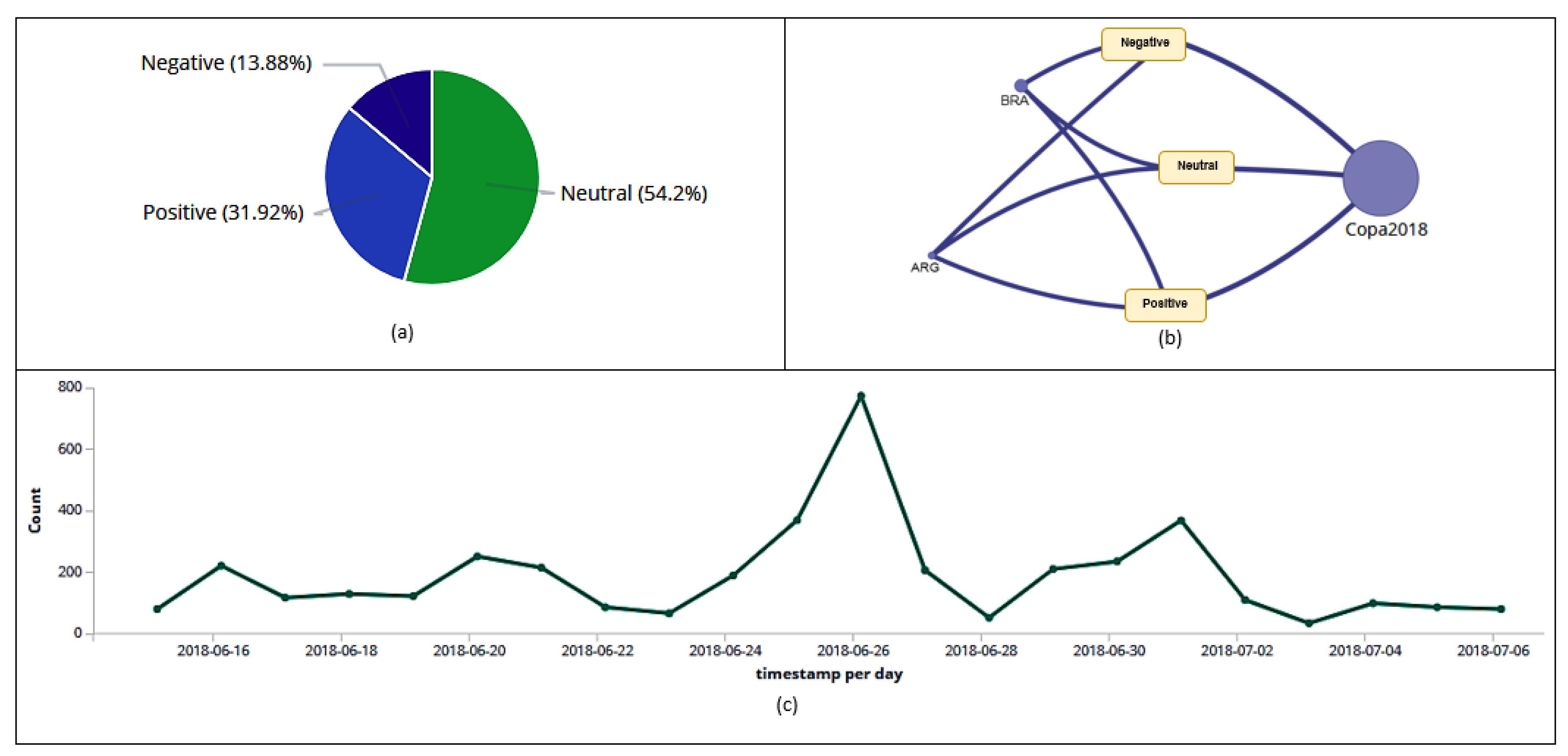
Figure 8.
Classification (positive, negative, and neutral) of tweets and retweets per day (a). Classification (positive, negative, and neutral) of tweets and retweets per hour (b).
Figure 8.
Classification (positive, negative, and neutral) of tweets and retweets per day (a). Classification (positive, negative, and neutral) of tweets and retweets per hour (b).
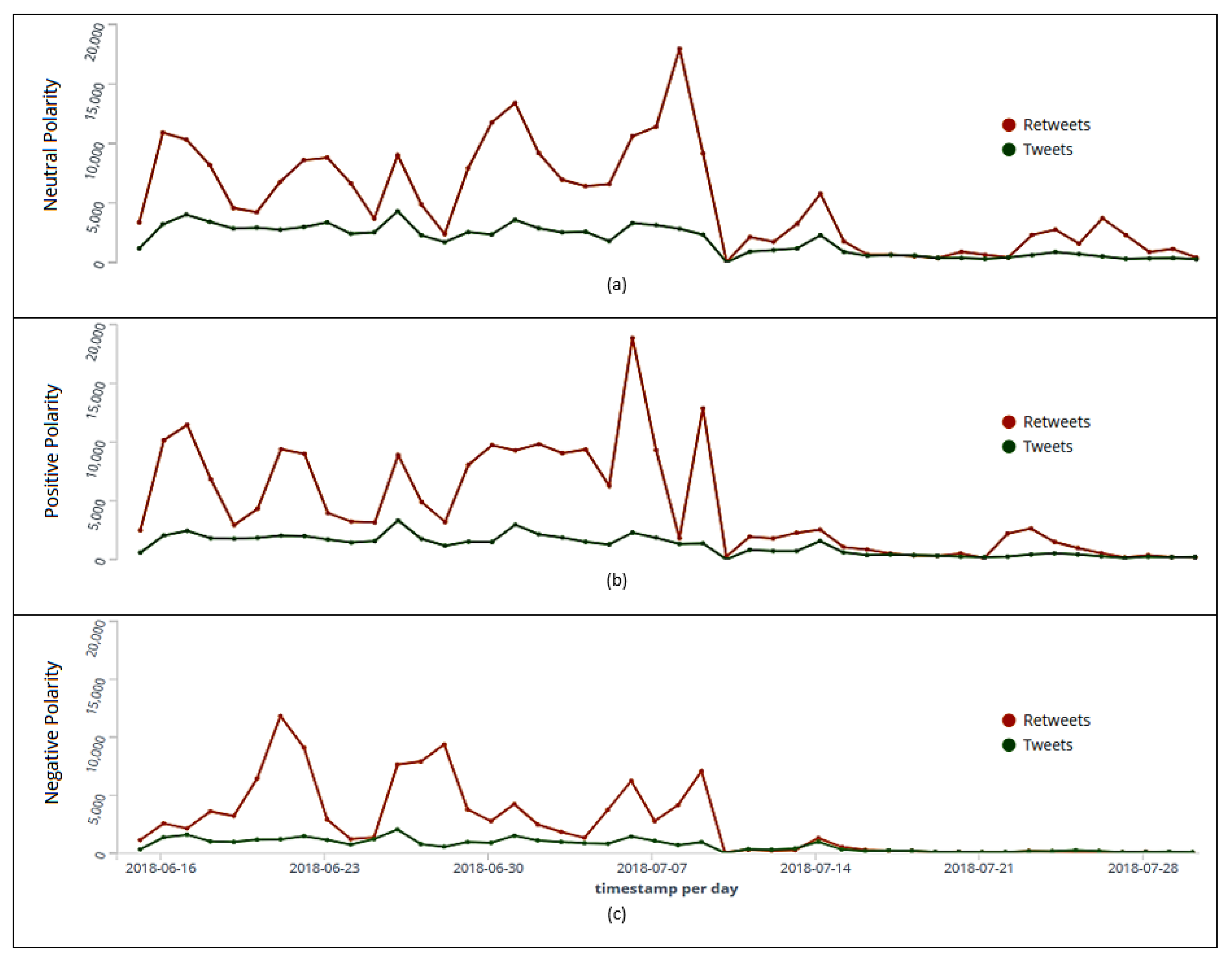
Figure 9.
Ranking of tweets and retweets per day with neutral (a), positive (b), and negative (c) polarities.
Figure 9.
Ranking of tweets and retweets per day with neutral (a), positive (b), and negative (c) polarities.
Figure 10.
Overall ranking of tweets and retweets by the algorithm Pattern Analyzer.
Figure 10.
Overall ranking of tweets and retweets by the algorithm Pattern Analyzer.
Figure 11.
Relationship among the entities’ polarity (positive, negative, and neutral) and the user (a). Users who published the most tweets and retweets with positive polarity (b).
Figure 11.
Relationship among the entities’ polarity (positive, negative, and neutral) and the user (a). Users who published the most tweets and retweets with positive polarity (b).
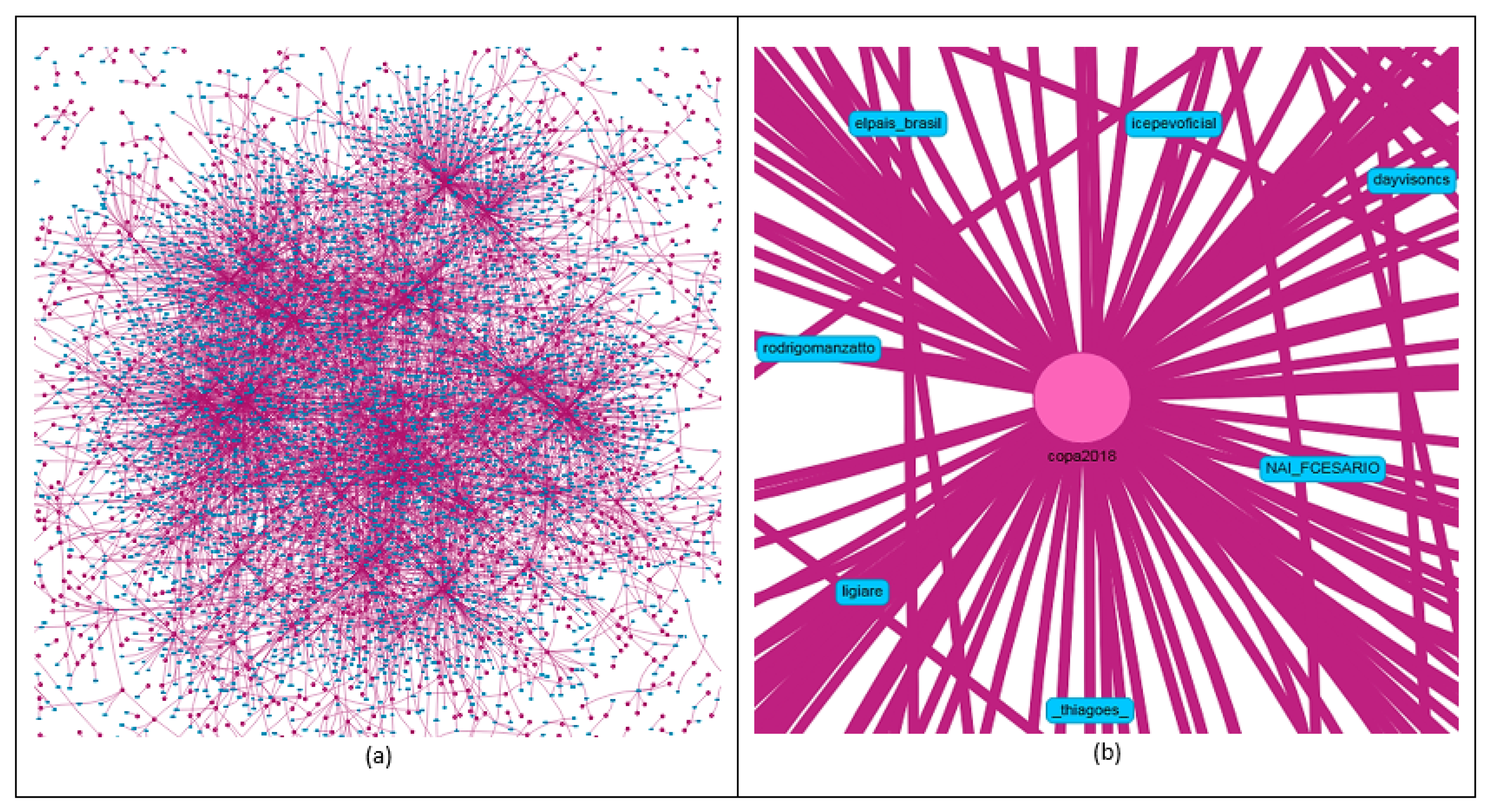
Figure 12.
Relationship between hashtag and user entities (a). Hashtag most referenced in tweets and retweets (b).
Figure 12.
Relationship between hashtag and user entities (a). Hashtag most referenced in tweets and retweets (b).
Figure 13.
Number of users and hashtags (a), tweets and retweets (b). Most commented on hashtag (c). Rating of posts that have been included with that hashtag in tweets and retweets (d). Users who sent the most messages with that hashtag (e).
Figure 13.
Number of users and hashtags (a), tweets and retweets (b). Most commented on hashtag (c). Rating of posts that have been included with that hashtag in tweets and retweets (d). Users who sent the most messages with that hashtag (e).
Figure 14.
Polarity of tweets and retweets (a). Graph with the relationship between hashtag and polarity entities (b). Histogram with the amount of tweets and retweets collected per day with that hashtag (c).
Figure 14.
Polarity of tweets and retweets (a). Graph with the relationship between hashtag and polarity entities (b). Histogram with the amount of tweets and retweets collected per day with that hashtag (c).
Figure 15.
Data collected from Twitter between 15 June and 21 June 2018. Discrepant users.
Figure 15.
Data collected from Twitter between 15 June and 21 June 2018. Discrepant users.
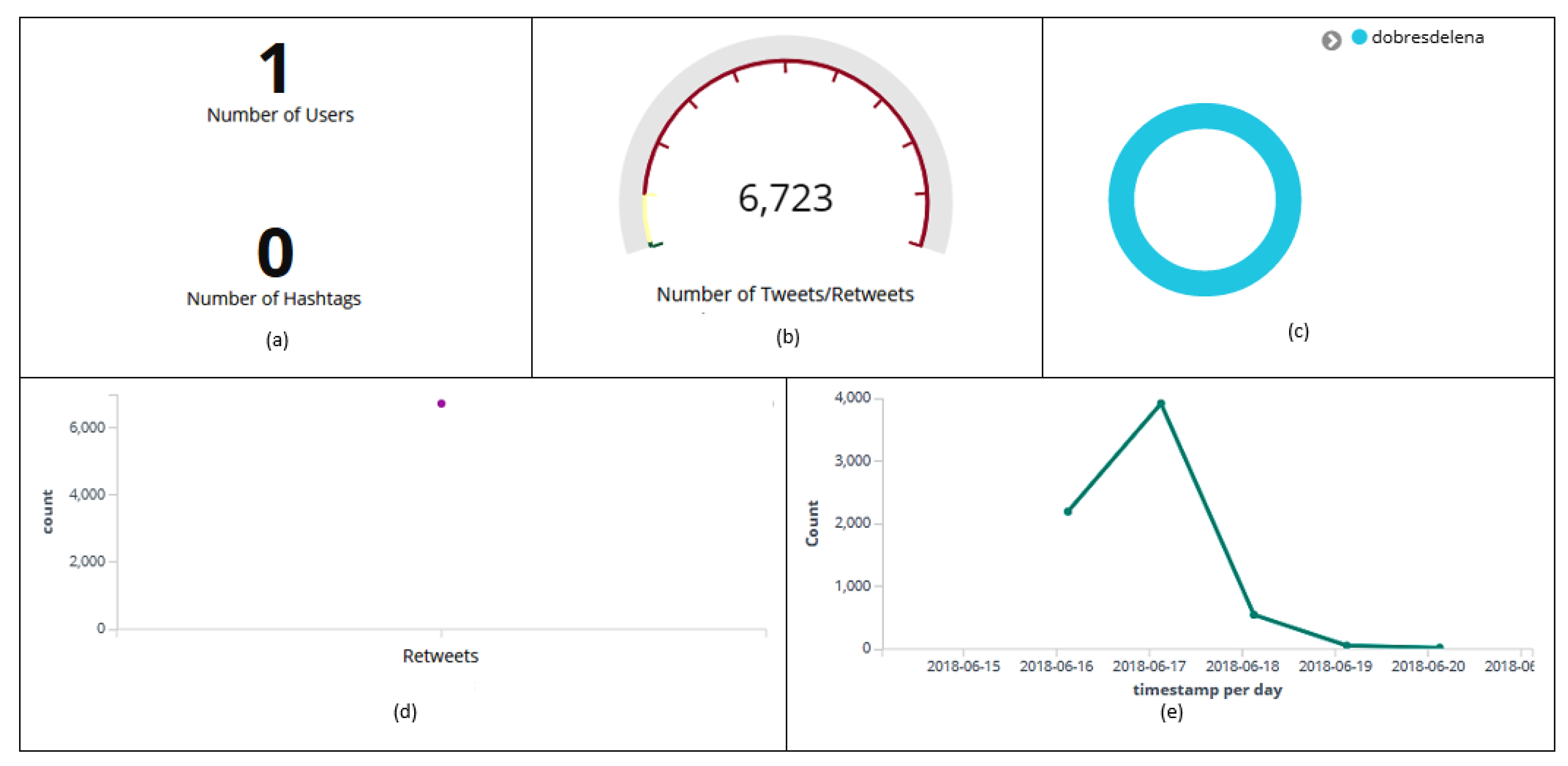
Figure 16.
Dashboard with information about user dobresdelena. Number of hashtags (a), tweets and retweets (b). Discrepant user (c). Number of messages classified as retweets (d). Histogram with the amount of retweets collected per day (e).
Figure 16.
Dashboard with information about user dobresdelena. Number of hashtags (a), tweets and retweets (b). Discrepant user (c). Number of messages classified as retweets (d). Histogram with the amount of retweets collected per day (e).
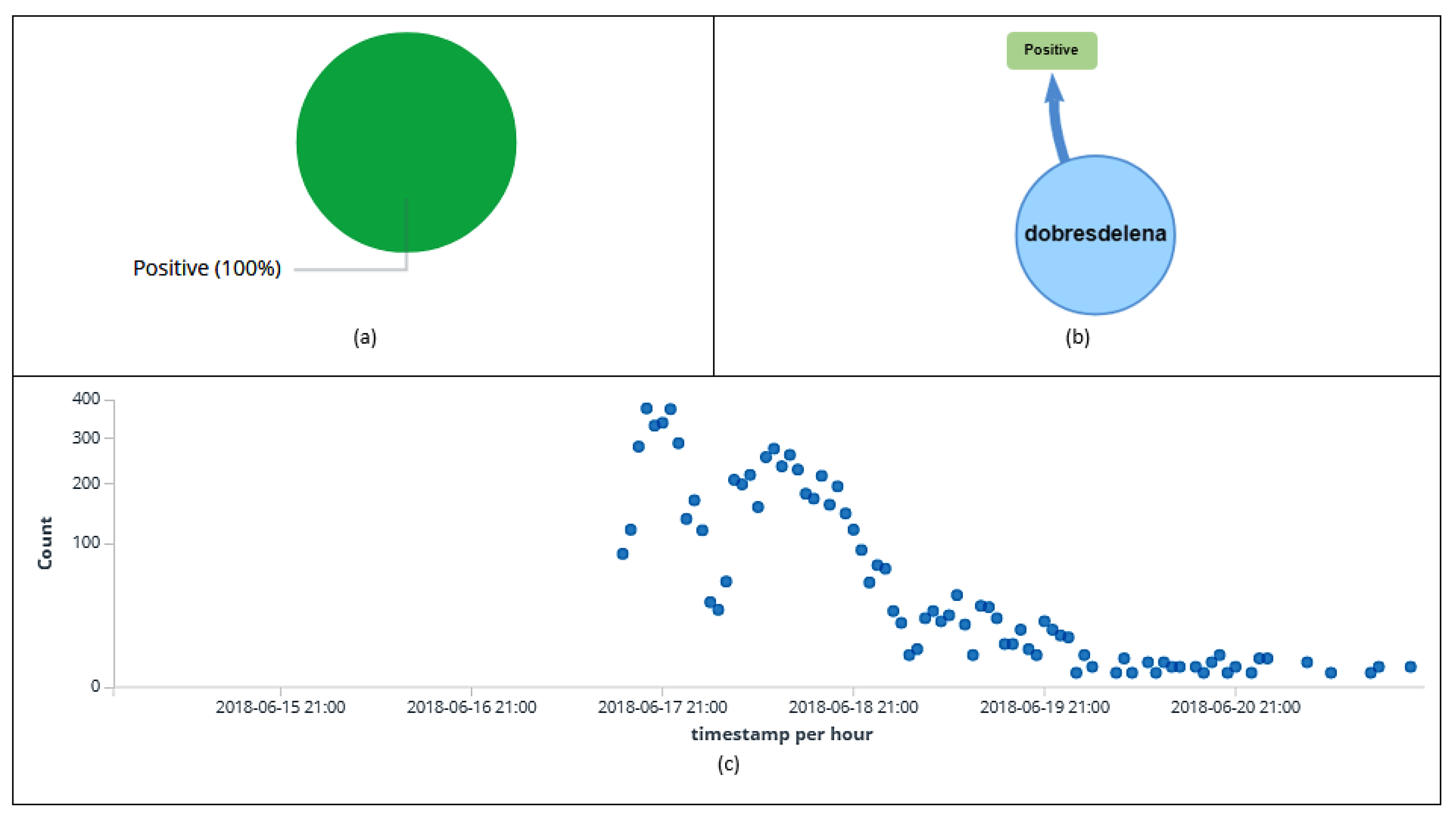
Figure 17.
Information about dobresdelena’s retweet polarity (a). Relationship among the entities’ polarity (positive) and the user (b). Classification (positive) of retweets per hour (c).
Figure 17.
Information about dobresdelena’s retweet polarity (a). Relationship among the entities’ polarity (positive) and the user (b). Classification (positive) of retweets per hour (c).
Figure 18.
Retweets posted by the user dobresdelena.
Figure 18.
Retweets posted by the user dobresdelena.
Figure 19.
Reverse image analysis with the tools TinEye (a) and Google Images (b).
Figure 19.
Reverse image analysis with the tools TinEye (a) and Google Images (b).
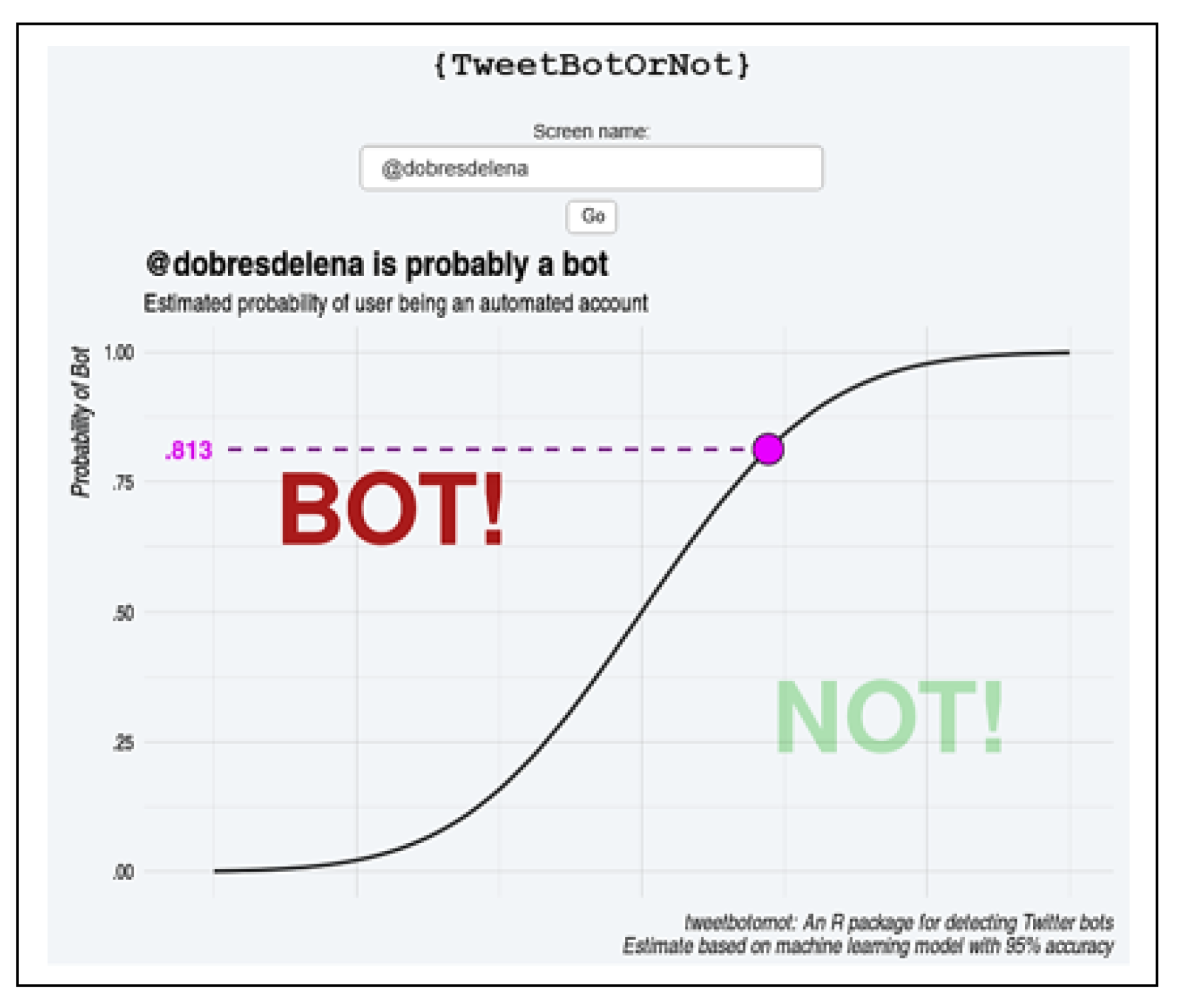
Figure 20.
Analysis through the TweetBotOrNot tool.
Figure 20.
Analysis through the TweetBotOrNot tool.
Table 1.
OctopusViz highlighted features compared to related works.
Table 1.
OctopusViz highlighted features compared to related works.
| | Anonymization | Sentiment | Real Time | Distributed | Visualization |
|---|
| Analysis | Operation | Storage |
|---|
| OctopusViz | x | x | x | x | x |
| [12] | – | x | x | – | – |
| [29] | – | x | – | – | – |
| [30] | – | x | – | – | – |
| [31] | – | x | x | – | – |
| [32] | – | x | – | – | – |
| [33] | – | x | – | – | – |
| [34] | – | x | – | – | – |
| [35] | – | x | x | x | x |
| [36] | – | x | – | – | x |
| [37] | – | – | x | x | x |
| [38] | – | – | – | x | x |
Table 2.
Host features.
| Server | Configuration |
|---|
| Dell PowerEdge R730 | Intel Xeon processor E5-2690 v3 @ X5560 2.6 GHz, 48 cores with Intel VT technology, 128 GB RAM, 6 disks with 1TB configured with RAID 5, and 6 network cards 10/100/1000. |
| Hypervisor | XenServer 7.4, DBV 2018.0223. |
Table 3.
Guest systems and their settings.
Table 3.
Guest systems and their settings.
| Guest Systems | Configuration |
|---|
Fw
(Firewall) | 2 core processor, 4 GB RAM, one 50 GB virtual disk, and 3 virtual network interfaces.
pfSense-2.4.3-RELEASE version based on the FreeBSD Operating System. |
Srv1
(Collection) | 12 core processor, 16 GB RAM, one 50 GB virtual disk, and one virtual network interface.
Operating system: Linux Debian Stretch 9.0 with the Python 3 programming language and libraries tweepy, json, time, elasticsearch, datatime, os, re, and textblob. |
Srv2
(Storage) | 12 core processor, 32 GB RAM, one 400 GB virtual disk, and one virtual network interface.
Operating system: Linux Debian Stretch 9.0 with thee elasticsearch-6.2.4 service. |
Srv3
(Visualization) | 8 core processor, 8 GB RAM, one 50 GB virtual disk, and one virtual network interface.
Operating system: Linux Debian Stretch 9.0 with kibana-6.2.4 service. |
Table 4.
Function for translation and correction of tweets.
Table 4.
Function for translation and correction of tweets.
| Example of Data Input in Portuguese | O Brasil jogou muito bem contra a Costa Rica |
| | tweet = TextBlob(“O Brasil jogou muito bem contra a Costa Rica") |
| | if tweet.detect_language() != ’en’: |
| | translate_to_english = TextBlob(str(tweet.translate(to=’en’))) |
| Data Preprocessing | correct_tweet = translate_to_english.correct() |
| (Translation and Correction) | print (correct_tweet) |
| | else: |
| | tweet.correct() |
| | print (tweet.correct()) |
| Data Output | Brazil played very well against Costa Rich |
Table 5.
Corpus words stop words and special characters.
Table 5.
Corpus words stop words and special characters.
| Methods | Method Description | Data Output |
|---|
stopWords = set(stopwords.words(’english’))
print(stopWords) | Corpus words stop words | [’i’, ’me’, ’my’, ’we’, ’our’, ’ours’, ’his’, ’y’, ’your’, ’it’] |
| string.punctuation | Scores and special characters | ’!"#$%&’()*+,-./:; <=>?@[]‘{|} ’ |
Table 6.
Function for cleaning tweets.
Table 6.
Function for cleaning tweets.
| Example of Data Input | Brazil is an excellent soccer team:) !!! |
| | tweet = TextBlob(“Brazil is an excellent soccer team:) !!!") |
| | translation_correction(tweet) |
| | stopwords_english = stopwords.words(’english’) |
| | words = tweet.words |
| Data Preprocessing | words_clean = [] |
| (Stop Words and Special Characters) | for word in words: |
| | if word not in stop words_english: |
| | if word not in string.punctuation: |
| | words_clean.append(word) |
| | print (words_clean) |
| Data Output | [’Brazil’, ’excellent’, ’soccer’, ’team’] |
Table 7.
Function for tokenization of tweets.
Table 7.
Function for tokenization of tweets.
| Example of Data Input | Brazil played very well against Costa Rica |
| | tweet = TextBlob(“Brazil played very well against Costa Rica") |
| Data Preprocessing | translation_correction(tweet) |
| (Tokenization) | tweet_clean_stop words(tweet) |
| | print (tweet.words) |
| Data Output | [’Brazil’, ’played’, ’very’, ’well’, ’against’, ’Costa’, ’Rica’] |
Table 8.
Function for tweets’ classification.
Table 8.
Function for tweets’ classification.
| Example of Data Input | Brazil is an excellent soccer team:) !!! |
| | tweet = TextBlob(“Brazil is an excellent soccer team:) !!!") |
| | translation_correction(tweet) |
| | tweet_clean_stop words(tweet) |
| | tokenization(tweet) |
| | if tweet.sentiment.polarity > 0: |
| | print (tweet.sentiment) |
| Data Classification | print (’Polarity: Positive’) |
| (Polarity and Subjectivity) | elif tweet.sentiment.polarity == 0: |
| | print (tweet.sentiment) |
| | print (’Polarity: Neutral’) |
| | else: |
| | print (tweet.sentiment) |
| | print (’Polarity: Negative’) |
| Data Output | Sentiment(polarity = 0.98828125, subjectivity = 1.0) |
| | Polarity: Positive |
Table 9.
The five most referenced hashtags between 15 June and 31 July 2018.
Table 9.
The five most referenced hashtags between 15 June and 31 July 2018.
| Hashtags | Tweets | Retweets | Total |
|---|
| #Copa2018 | 1356 | 3193 | 4549 |
| #BRA | 575 | 2701 | 3276 |
| #VaiBrasil | 100 | 1062 | 1162 |
| #BrasilGanha | 95 | 960 | 1055 |
| #BRAMEX | 123 | 821 | 944 |
Table 10.
Hashtags most referenced by tweets or retweets.
Table 10.
Hashtags most referenced by tweets or retweets.
| Hashtags | Tweets | Hashtags | Retweets |
|---|
| #Copa2018 | 1356 | #Copa2018 | 3193 |
| #BRA | 575 | #BRA | 2701 |
| #WorldCup | 277 | #VaiBrasil | 1062 |
| #expedientefutebol | 273 | #BrasilGanha | 960 |
| #Brasil | 238 | #soujoga10nacopa | 923 |
Table 11.
Rating of tweets and retweets by user.
Table 11.
Rating of tweets and retweets by user.
| Users | Tweets | Retweets | Total |
|---|
| InfosFuteboI | 34 | 35,504 | 35,538 |
| liberta_depre | 16 | 17,575 | 17,591 |
| cleytu | 2 | 13,856 | 13,858 |
| UMCANARINHOPUTO | 7 | 12,799 | 12,806 |
| fuckluanjo | 1 | 11,997 | 11,998 |
| jah_valentim | 2 | 9899 | 9901 |
| Allec_Matheus | 0 | 9529 | 9529 |
| sccstyles | 4 | 9046 | 9050 |
| rosedixdelrey | 0 | 8776 | 8776 |
| OCrushDaCopa | 1 | 8073 | 8074 |
| ESCANTEIOCUTO | 3 | 7986 | 7989 |
| Germannoart | 1 | 7901 | 7902 |
| standragons | 14 | 6971 | 6985 |
Table 12.
Peak polarities of tweets and retweets per day.
Table 12.
Peak polarities of tweets and retweets per day.
| Polarity | Day | Tweets | Retweets | Total |
|---|
| Neutral | July 9th | 2824 | 17,946 | 20,770 |
| Positive | July 7th | 2291 | 18,855 | 21,146 |
| Negative | June 22nd | 1196 | 11,811 | 13,007 |
Table 13.
Polarity of tweets and retweets.
Table 13.
Polarity of tweets and retweets.
| Polarity | Tweets | Retweets | Total |
|---|
| Positive | 53,993 | 209,492 | 263,485 |
| Negative | 31,230 | 115,215 | 146,445 |
| Neutral | 83,286 | 237,634 | 320,920 |
Table 14.
Numbers of tweets and retweets by user.
Table 14.
Numbers of tweets and retweets by user.
| Users | Tweets | Retweets | Total |
|---|
| dobresdelena | 0 | 6723 | 6723 |
| lorenzopaag | 0 | 4877 | 4877 |
| whindersson | 0 | 4526 | 4526 |
| cleytu | 0 | 4003 | 4003 |
| PAPAIDIDICOLIFE | 2 | 3481 | 3483 |
| frasesdebebada | 1 | 3170 | 3171 |
| moniqueppaes | 1 | 2299 | 2300 |
| QuebrandoOTabu | 1 | 2279 | 2280 |
| liberta_depre | 5 | 1686 | 1691 |
| adrianowilkson | 0 | 1388 | 1388 |
| petermaxiff | 1 | 1385 | 1386 |
| lacaxarruda | 0 | 1296 | 1296 |
| InfosFutebol | 5 | 1287 | 1292 |

 ,
, 






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}