Digital Forensics of Scanned QR Code Images for Printer Source Identification Using Bottleneck Residual Block

 , ,
, ,
Abstract
:1. Introduction
2. Materials and Methods
2.1. The Printer Source Identification of QR Codes Using CNNs
- (1)
- Printing process. Eight printers were used to print the same batch of QR code documents.
- (2)
- Scanning process. The printed QR code paper documents were scanned by the same scanner to generate digital images.
- (3)
- QR code extraction. It can be seen from Figure 1 that there are many QR codes in the scanned digital images and a single QR code needs to be extracted. In this study, OpenCV, a cross-platform computer vision and machine learning software library based on Berkeley Software Distribution (BSD) license, is used; the main extraction steps include graying, binarization, morphological opening operation, image reverse operation, finding contours, and setting the threshold range to extraction QR code contour area. These operations are well known in the field of image processing and are described in detail in Section 2.2.
- (4)
- Dataset production. Adjust the size of all the extracted QR codes to 256 × 256, and then make the calibration dataset, validation set, and prediction set in the ration of 3:1:1. Then, block all the QR code images in the data set to a size of M × N.
- (5)
- Training and testing of CNNs. Design PSINet, then the QR code blocks are input for training and testing.

2.2. QR Code Extraction
- (1)
- Grayscale.
- (2)
- Otsu’s segmentation.
- (3)
- Morphological opening operation.
- (4)
- Image reversal.
- (5)
- QR code extraction.
2.3. PSINet: A Printer Source Identification Network for QR Codes Based on Bottleneck Residual Block
3. Experimental Results and Analysis
3.1. Development Environment and Tools
3.2. Dataset Production
3.3. Determination of the Specific Structure of PSINet
3.4. Comparison of PSINet with Other Deep Learning Methods
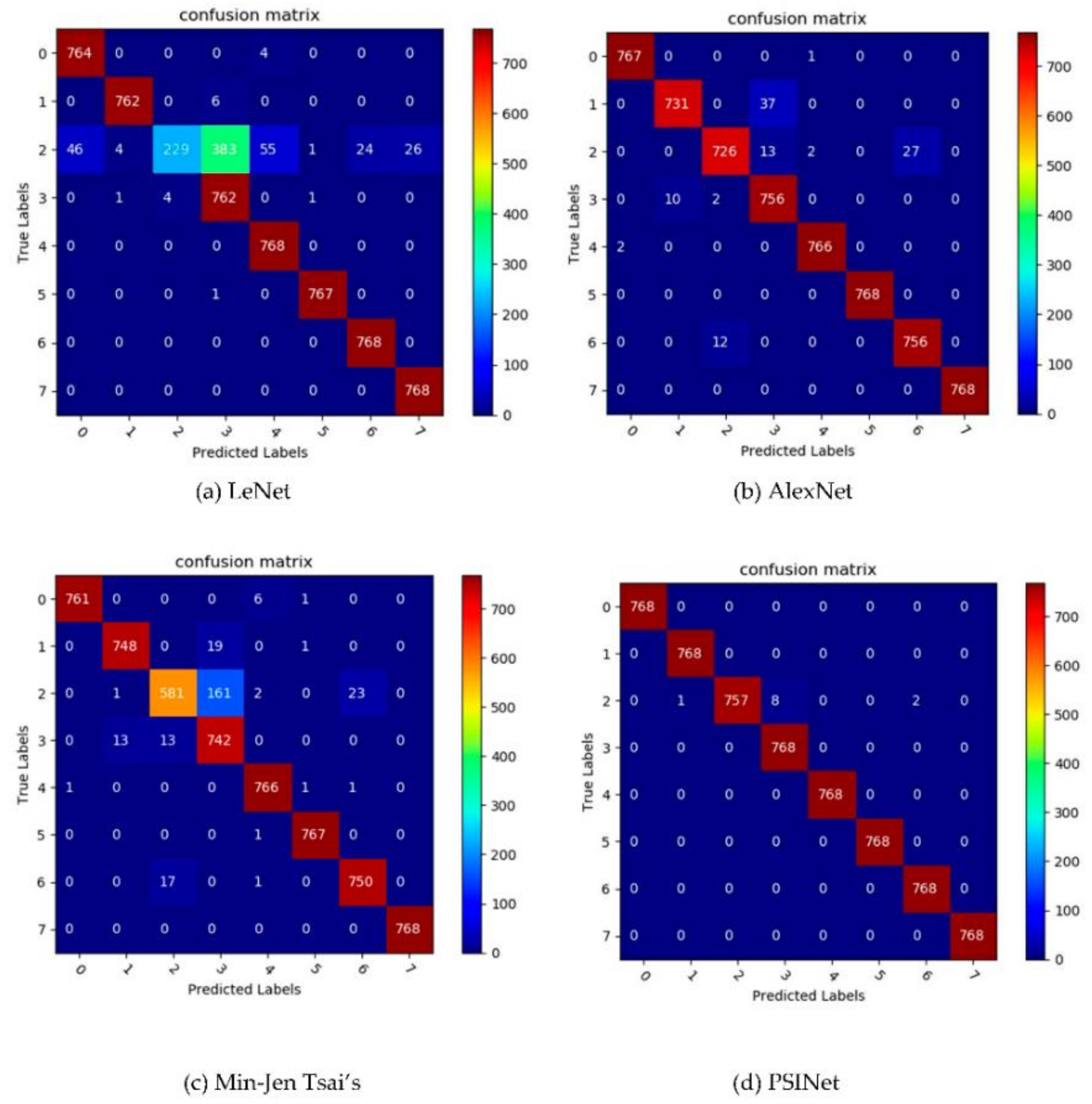
3.4.1. Accuracy Comparison of Different CNNs
3.4.2. Comparison of Inference Time of Four CNN Models
3.4.3. Comparison of Computational Cost of Four CNN Models
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Nofal, R.M. Initiating android phone technology using QR codes to make innovative functional clothes. Int. J. Cloth. Sci. Technol. 2020. [Google Scholar] [CrossRef]
- Tara Spalla, K. Using QR Codes on Professional Posters to Increase Engagement and Understanding. Nurs. Educ. 2020, 45, 219. [Google Scholar]
- Li, H.-S.; Xue, F.; Xia, H.-Y. Style transfer for QR code. Multimed. Tools Appl. 2020, 1–14. [Google Scholar] [CrossRef]
- Yuan, T.; Wang, Y.; Xu, K.; Martin, R.R.; Hu, S.-M. Two-Layer QR Codes. IEEE Trans. Image Process. 2019, 28, 4413–4428. [Google Scholar] [CrossRef] [PubMed]
- Alan, C.; Gustavo, M.; Leire, M.B. QRcode, hashtag or audio watermark? A case study on second screening. Multimed. Tools. Appl. 2017, 76, 7519–7534. [Google Scholar]
- Yu, R.; Duan, X.; Jiao, B. Design and implement of mobile equipment management system based on QRcode. J. Phys. Conf. Ser. 2017, 887. [Google Scholar] [CrossRef] [Green Version]
- Li, C.; Shao, P. Precision UAV Parcel Delivery Using QR Code Recognition. J. Aeronaut. Astronaut. Aviat. 2019, 51, 275–289. [Google Scholar]
- Chen, R.; Yu, Y.; Xu, X.; Wang, L.; Zhao, H.; Tan, H.-Z. Adaptive Binarization of QR Code Images for Fast Automatic Sorting in Warehouse Systems. Sensors 2019, 19, 5466. [Google Scholar] [CrossRef] [Green Version]
- Gammer, N.; Cherrett, T.; Gutteridge, C. Disseminating real-time bus arrival information via QRcode tagged bus stops: A case study of user take-up and reaction in Southampton, UK. J. Transp. Geogr. 2014, 34, 254–261. [Google Scholar] [CrossRef]
- Ferreira, A.; Bondi, L.; Baroffio, L.; Bestagini, P.; Huang, J.; Dos Santos, J.A.; Tubaro, S.; Rocha, A.D.R. Data-Driven Feature Characterization Techniques for Laser Printer Attribution. IEEE Trans. Inf. Forensics Secur. 2017, 12, 1860–1872. [Google Scholar] [CrossRef]
- Mikkilineni, A.K.; Chiang, P.-J.; Ali, G.N.; Chiu, G.T.C.; Allebach, J.P.; Iii, E.J.D. Printer identification based on graylevel co-occurrence features for security and forensic applications. In Proceedings of the International Conference on Security, Steganography, and Watermarking of Multimedia Contents VII, San Jose, CA, USA, 17–20 January 2005; Volume 5681, pp. 430–440. [Google Scholar]
- Mikkilineni, A.; Arslan, O.; Chiang, P. Printer Forensics using SVM Techniques. In Proceedings of the NIP21: 21st International Conference on Digital Printing Technologies—Final Program and Proceedings, Baltimore, MD, USA, 18–23 September 2005; pp. 223–226. [Google Scholar]
- Tsai, M.-J.; Yuadi, I. Digital forensics of microscopic images for printed source identification. Multimed. Tools Appl. 2018, 77, 8729–8758. [Google Scholar] [CrossRef]
- Tsai, M.-J.; Liu, J.; Yin, J.-S.; Yuadi, I. Digital Forensics of Printed Source Identification for Chinese Characters. Multimed. Tools Appl. 2014, 73, 2129–2155. [Google Scholar] [CrossRef]
- Choi, J.-H.; Lee, H.-Y.; Lee, H.-K. Color laser printer forensic based on noisy feature and support vector machine classifier. Multimed. Tools Appl. 2013, 67, 363–382. [Google Scholar] [CrossRef]
- Zhou, Q.; Yan, Y.; Fang, T.; Luo, X.; Chen, Q. Text-independent printer identification based on texture synthesis. Multimed. Tools Appl. 2016, 75, 5557–5580. [Google Scholar] [CrossRef]
- Mikkilineni, A.; Khanna, N.; Delp, E. Texture Based Attacks on Intrinsic Signature Based Printer Identification. In Proceedings of the Media Forensics and Security II, Part of the IS&T-SPIE Electronic Imaging Symposium, San Jose, CA, USA, 18–20 January 2010. [Google Scholar]
- Gebhardt, J.; Goldstein, M.; Shafait, F.; Dengel, A. Document Authentication Using Printing Technique Features and Unsupervised Anomaly Detection. In Proceedings of the 2013 12th International Conference on Document Analysis and Recognition, Washington, DC, USA, 25–28 August 2013; pp. 479–483. [Google Scholar]
- Fang, T.; Chen, Q.; Yan, Y. Laser Print Document Identification Based on Gabor Feature and Sparse Representation Classification. Geomat. Inf. Sci. Wuhan Univ. 2016, 41, 1550–1555. [Google Scholar]
- Lecun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Sun, Y.; Wang, X.; Tang, X. Deep Learning Face Representation by Joint Identification-Verification. Adv. Neural Inf. Process. Syst. 2014, 27, 1988–1996. [Google Scholar]
- Theodoridis, S. Neural Networks and Deep Learning. In Machine Learning; Theodoridis, S., Ed.; Department of Informatics and Telecommunications, National and Kapodistrian University of Athens: Athens, Greece, 2015; pp. 875–936. [Google Scholar]
- Sun, M.; Deng, Y.; Li, M.; Jiang, H.; Huang, H.; Liao, W.; Liu, Y.; Yang, J.; Li, Y. Extraction and Analysis of Blue Steel Roofs Information Based on CNN Using Gaofen-2 Imageries. Sensors 2020, 20, 4655. [Google Scholar] [CrossRef] [PubMed]
- Tsai, C.-Y.; Chen, H.-W. SurfNetv2: An Improved Real-Time SurfNet and Its Applications to Defect Recognition of Calcium Silicate Boards. Sensors 2020, 20, 4356. [Google Scholar] [CrossRef]
- Voulodimos, A.; Doulamis, N.; Doulamis, A.; Protopapadakis, E. Deep Learning for Computer Vision: A Brief Review. Comput. Intell. Neurosci. 2018, 2018, 7068349. [Google Scholar] [CrossRef] [PubMed]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martínez, V.; Garcia-Rodriguez, J. A Review on Deep Learning Techniques Applied to Semantic Segmentation. arXiv 2017, arXiv:1704.06857. [Google Scholar]
- Alessandro, P. An Overview on Image Forensic. ISRN Signal Process. 2013, 2013, 1–22. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet Classification with Deep Convolutional Neural Networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2014; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Kim, D.-G.; Hou, J.-U.; Lee, H.-K. Learning deep features for source color laser printer identification based on cascaded learning. Neurocomputing 2019, 365, 219–228. [Google Scholar] [CrossRef] [Green Version]
- Tsai, M.-J.; Tao, Y.-H.; Yuadi, I. Deep learning for printed document source identification. Signal. Process. Image Commun. 2019, 70, 184–198. [Google Scholar] [CrossRef]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional Architecture for Fast Feature Embedding. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 675–678. [Google Scholar]
- Luke, Y.; Julie, B. DIGITS: The Deep learning GPU Training System. In Proceedings of the International Conference on Machine Learning (ICML), Lille, France, 6–11 July 2015; pp. 1–4. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Brand | Model |
|---|---|---|
| 0 | Canon | iR-ADV C50455051 UFR 2 |
| 1 | Canon | iR-ADV C7260270 UFR 2 |
| 2 | Epson | L310 Series |
| 3 | Fuji | XEROX DocuCentre S2110 |
| 4 | RICOH | Aficio MP7502 |
| 5 | RICOH | Pro 8100s |
| 6 | Samsung | K2200 series |
| 7 | TOSHIBA | e-STUDIO2051C-11606695 |
| Image Size | 7 Layers | 11 Layers | 15 Layers | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 3 × 3 | 5 × 5 | 7 × 7 | 3 × 3 | 5 × 5 | 7 × 7 | 3 × 3 | 5 × 5 | 7 × 7 | |
| 48 × 48 | 99.90% | 99.49% | 99.77% | 99.84% | 99.77% | 99.59% | 97.75% | 98.41% | 96.76% |
| 56 × 56 | 99.92% | 99.89% | 99.93% | 99.85% | 99.71% | 99.66% | 98.00% | 98.93% | 99.06% |
| 64 × 64 | 99.89% | 99.82% | 99.71% | 99.46% | 99.63% | 99.72% | 99.69% | 98.36% | 99.73% |
| Methods | Identification Accuracy (%) | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | Ave | |
| LeNet | 99.48% | 99.22% | 29.82% | 99.22% | 100.00% | 99.87% | 100.00% | 100.00% | 90.95% |
| AlexNet | 99.87% | 95.18% | 94.53% | 98.44% | 99.74% | 100.00% | 98.44% | 100.00% | 98.27% |
| Min-Jen Tsai’s | 99.09% | 97.40% | 75.65% | 96.61% | 99.74% | 99.87% | 97.66% | 100.00% | 95.75% |
| PSINet (ours) | 100.00% | 100.00% | 98.57% | 100.00% | 100.00% | 100.00% | 100.00% | 100.00% | 99.82% |
| CNNs | LeNet | AlexNet | Min-Jen Tsai’s | PSINet |
|---|---|---|---|---|
| Inference Time(s) | 13 | 24 | 11 | 13 |
| CNNs | LeNet | AlexNet | PSDI | PSINet |
|---|---|---|---|---|
| Size (MB) | 16.2 | 77.0 | 0.43 | 5.18 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, Z.; Zheng, H.; You, C.; Xu, X.; Wu, X.; Zheng, Z.; Ju, J. Digital Forensics of Scanned QR Code Images for Printer Source Identification Using Bottleneck Residual Block. Sensors 2020, 20, 6305. https://0-doi-org.brum.beds.ac.uk/10.3390/s20216305
Guo Z, Zheng H, You C, Xu X, Wu X, Zheng Z, Ju J. Digital Forensics of Scanned QR Code Images for Printer Source Identification Using Bottleneck Residual Block. Sensors. 2020; 20(21):6305. https://0-doi-org.brum.beds.ac.uk/10.3390/s20216305
Chicago/Turabian StyleGuo, Zhongyuan, Hong Zheng, Changhui You, Xiaohang Xu, Xiongbin Wu, Zhaohui Zheng, and Jianping Ju. 2020. "Digital Forensics of Scanned QR Code Images for Printer Source Identification Using Bottleneck Residual Block" Sensors 20, no. 21: 6305. https://0-doi-org.brum.beds.ac.uk/10.3390/s20216305