Recognition of Typical Locomotion Activities Based on the Sensor Data of a Smartphone in Pocket or Hand


Abstract
:1. Introduction
2. Related Work
3. Sensors and Locomotion Activities
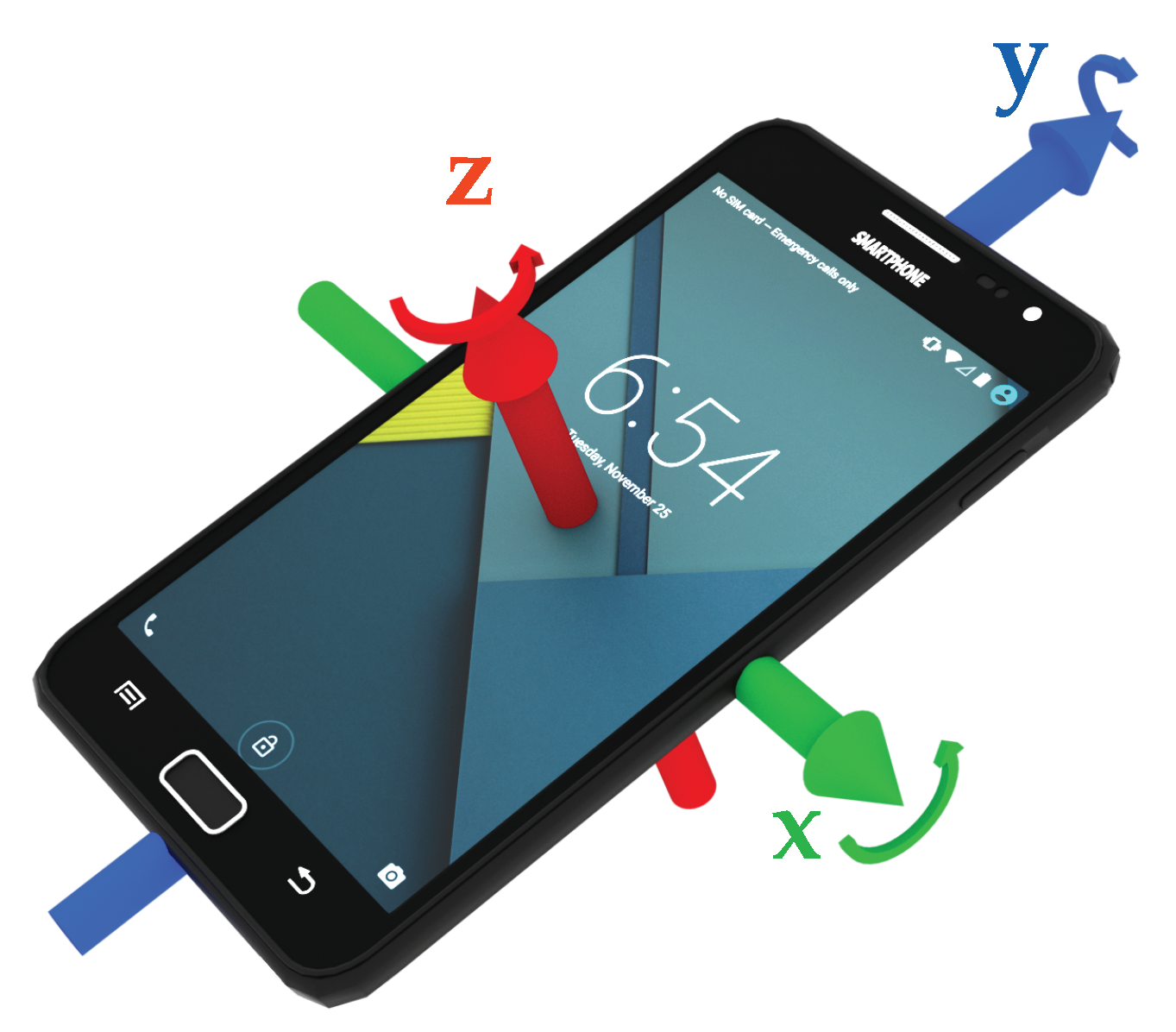
3.1. Sensors
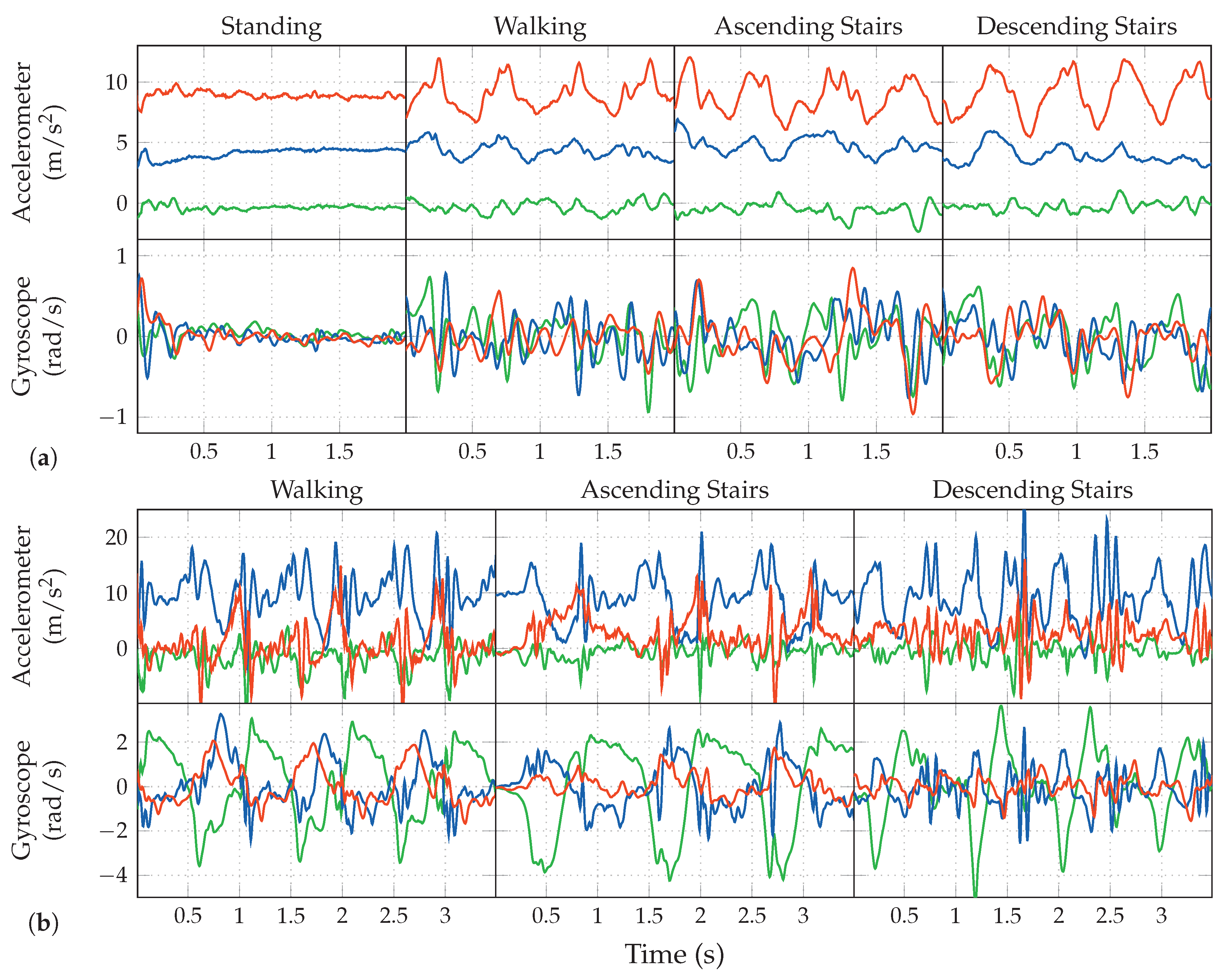
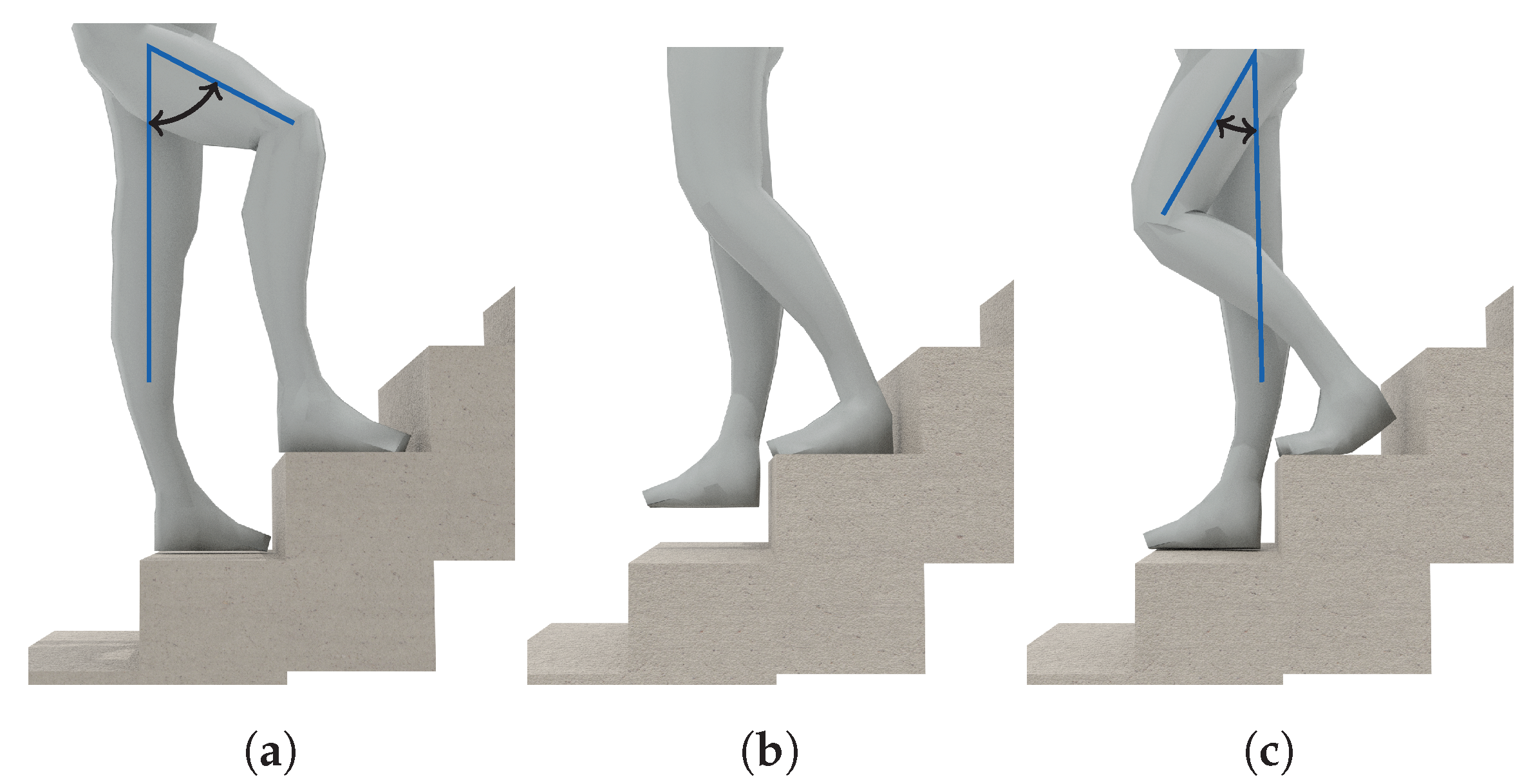
3.2. Locomotion Activities
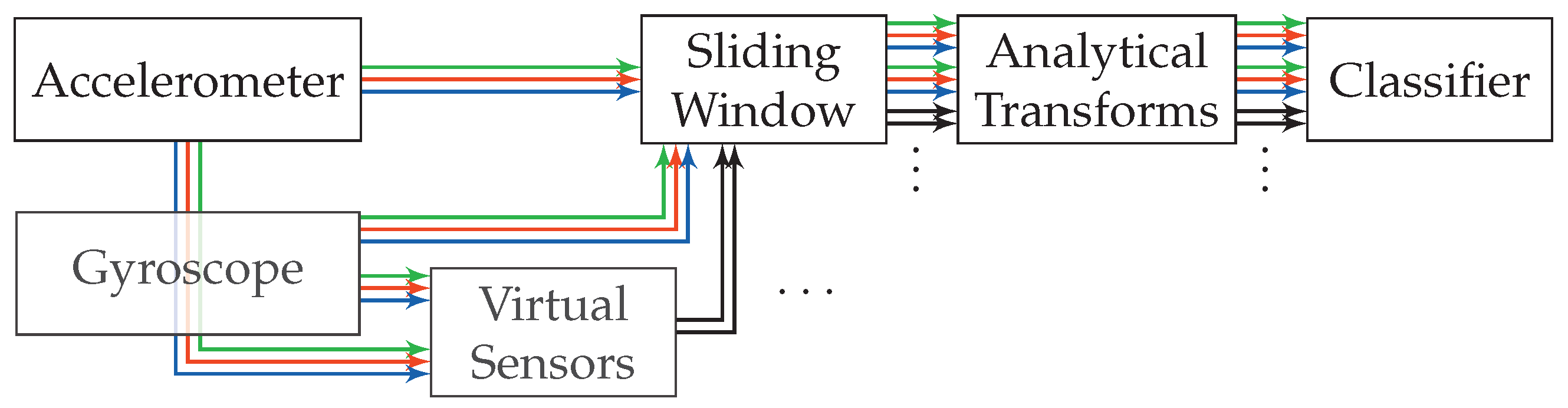
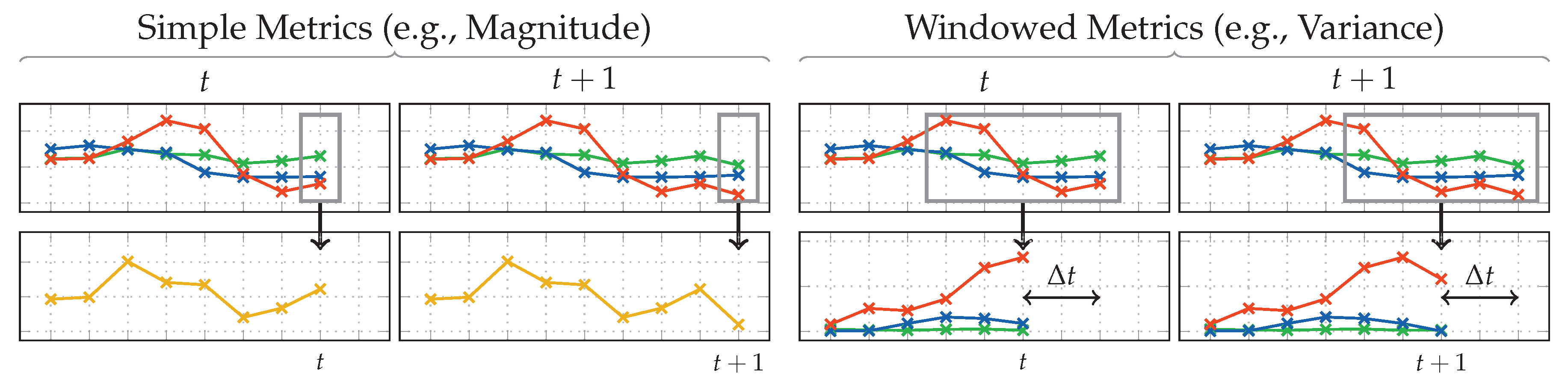
4. Activity Recognition
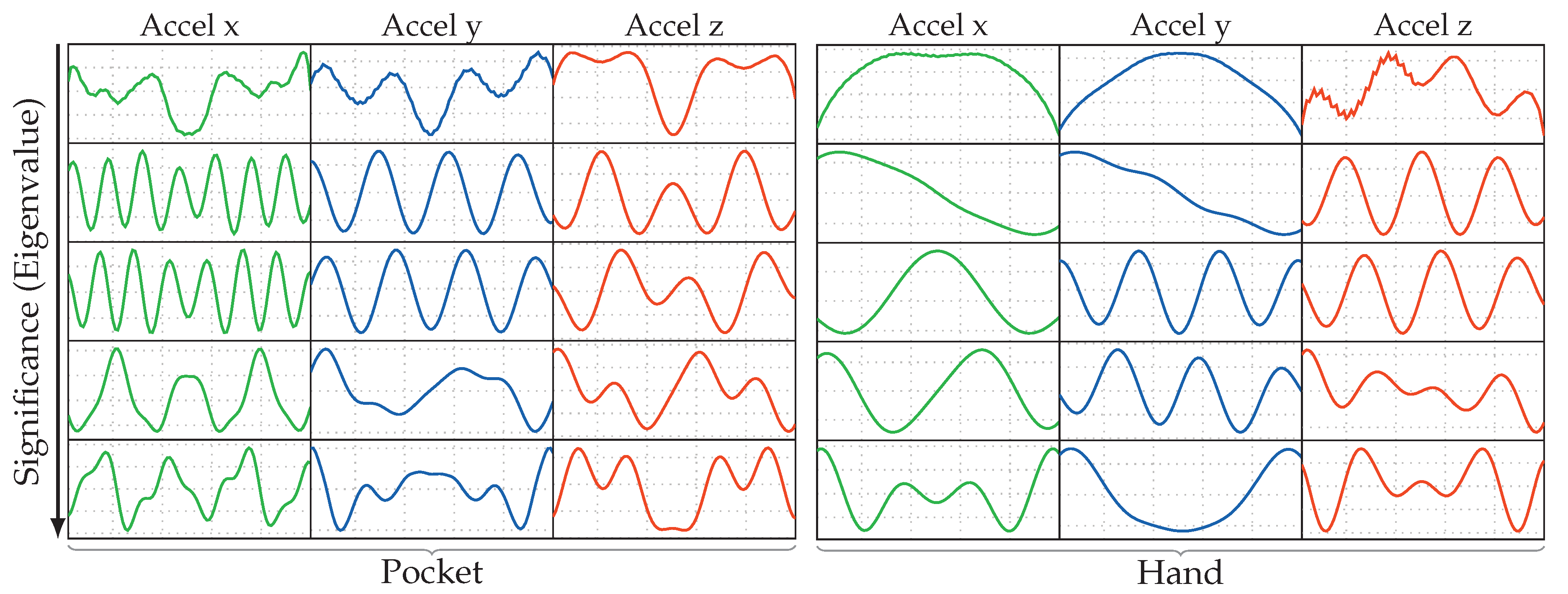
4.1. Analytical Transformations
Outlier Detection
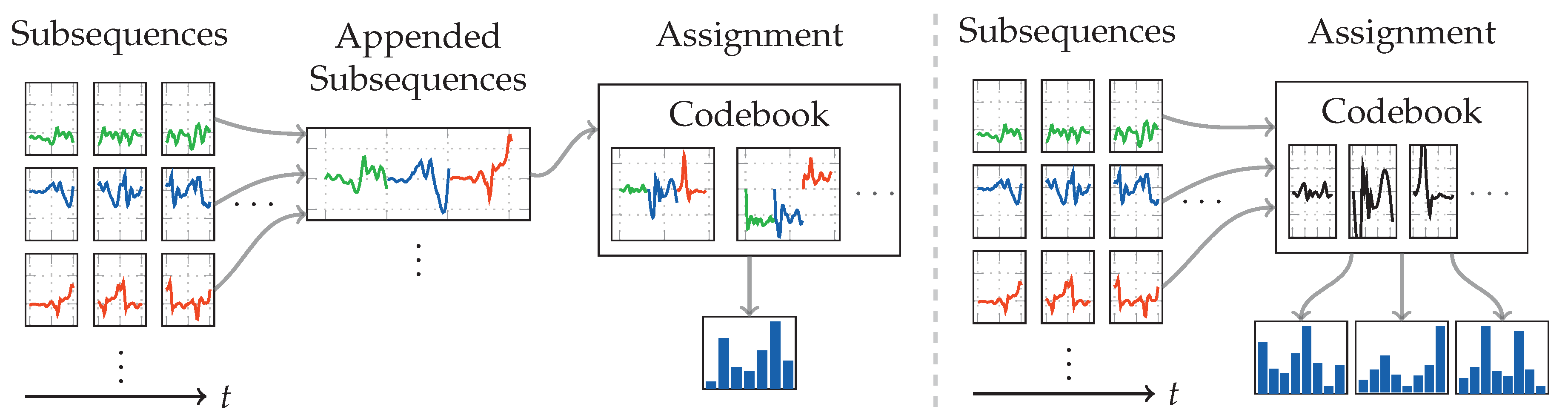
4.2. Codebook
Outlier Detection
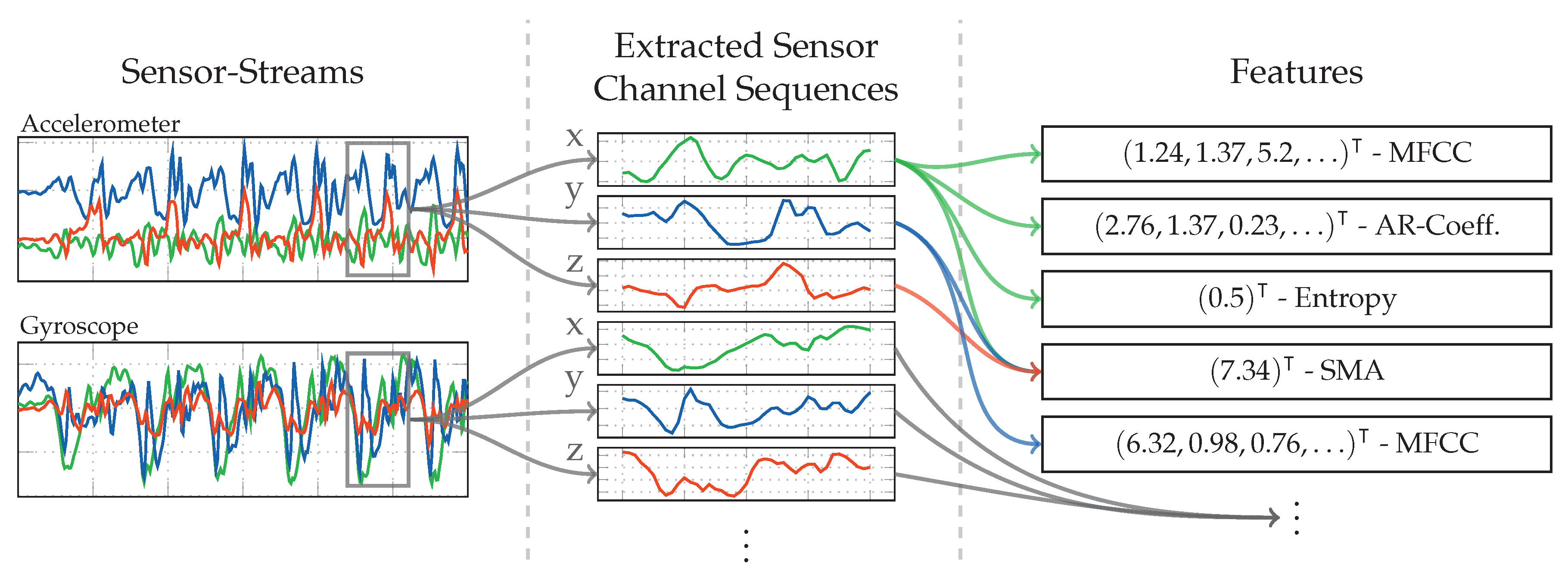
4.3. Statistical Features
Outlier Detection
5. Experiments
5.1. Dataset and Measuring Setup
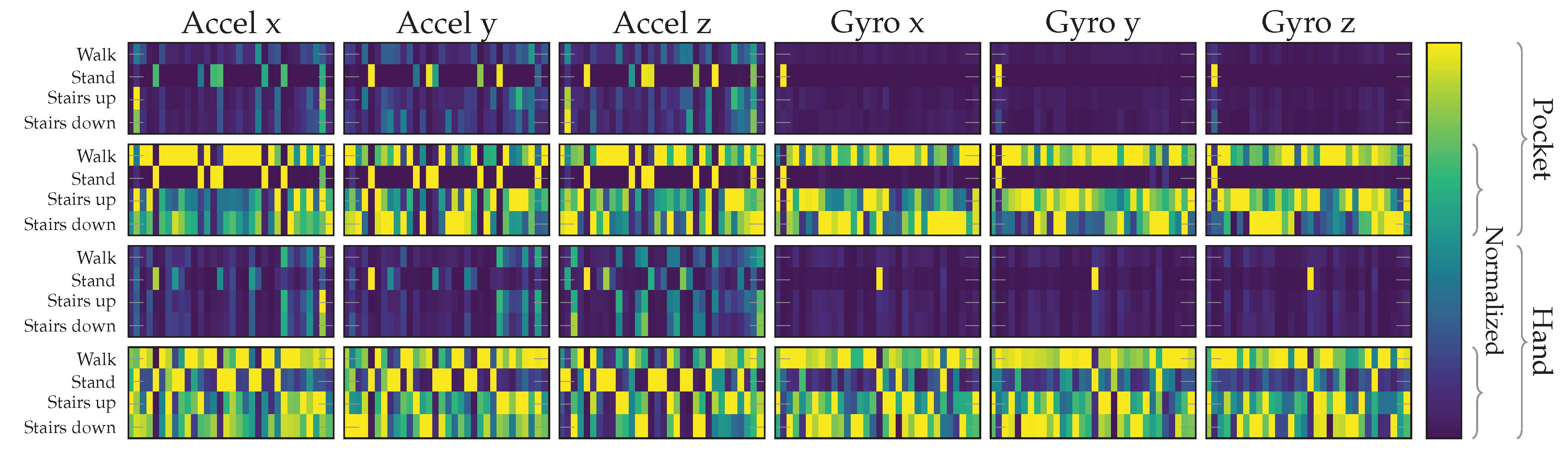
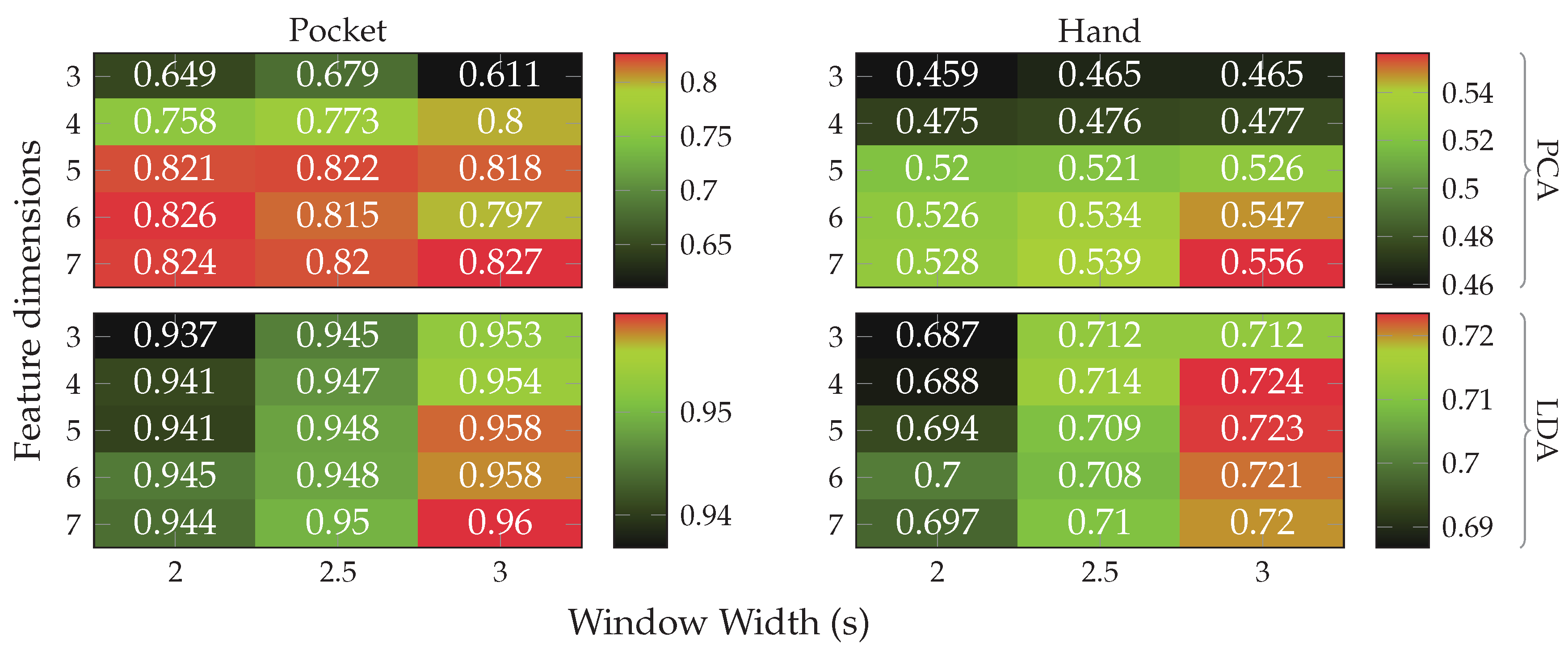
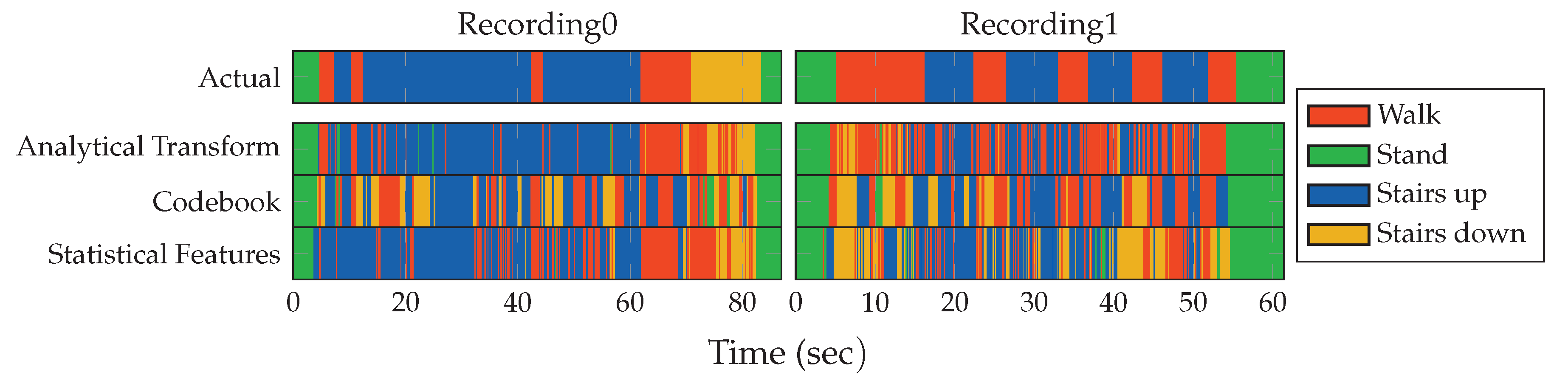
5.2. Results for Analytical Transformations
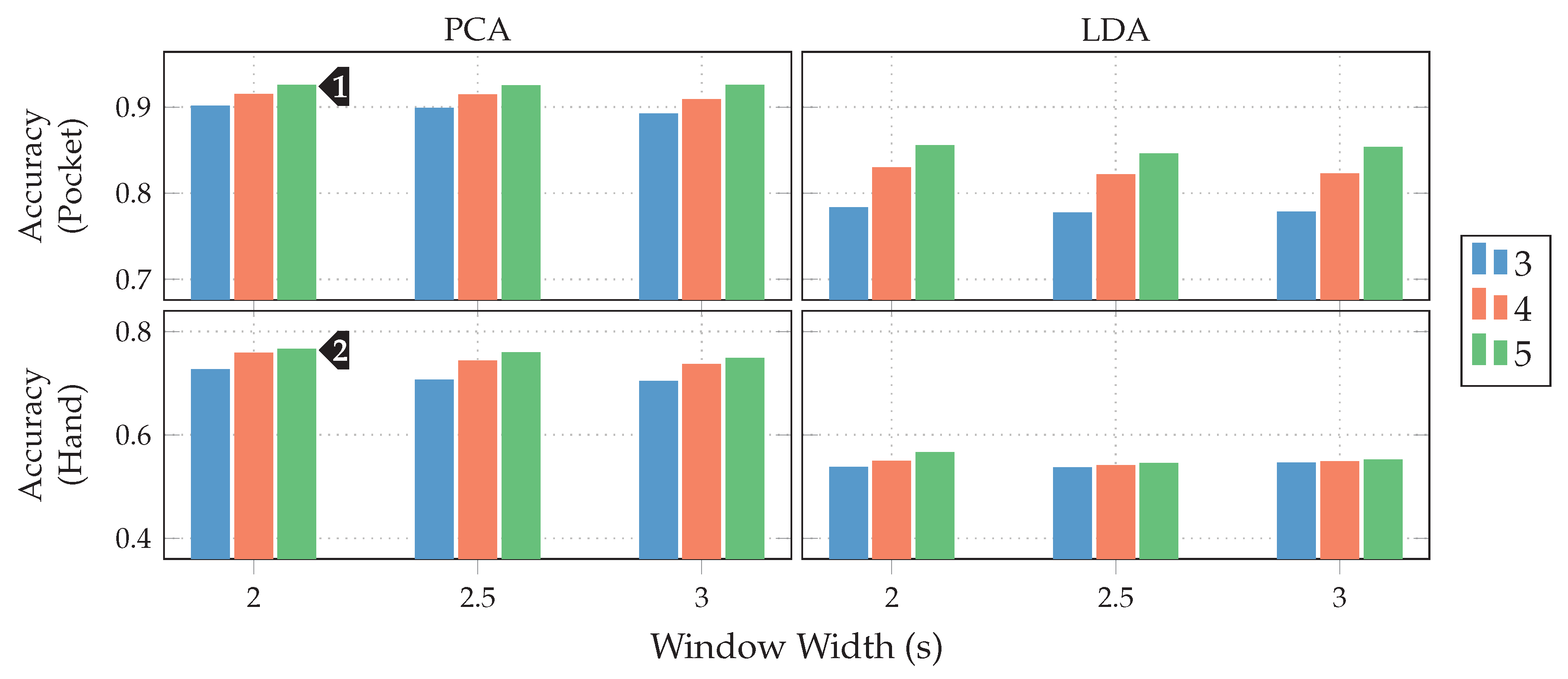
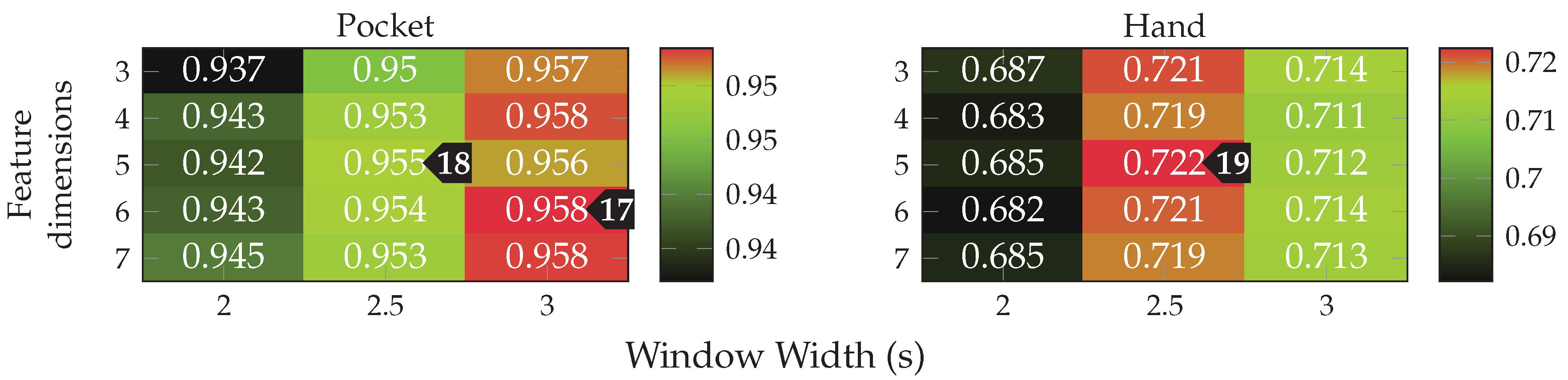
 at 5 remaining dimensions with a window length of for the pocket-case, and %(%)
at 5 remaining dimensions with a window length of for the pocket-case, and %(%)  for the hand-case at the same configuration. Between window lengths, again, there is not much difference, with a slight tendency to be better for smaller window lengths. Especially for the hand-case, with more realistic recordings, this could be due to fewer misclassifications at the borders between two adjacent activities. A fundamental question arising from these results is, however, why the LDA performs much worse than the PCA across all tests, even though its primary task is to improve class separability. Since the LDA is especially crafted for classification problems, one would expect it to yield better results than the PCA, which is solely based on variances. Multiple possible reasons for this come to mind. One being that the original Fisher Discriminant Analysis was only specified for two classes. The variant deployed in this work is actually a modification called Multiclass LDA, introduced by Rao in [60]. This variant assumes a normal distribution of the classes, as well as equal class covariances. Another possible reason is that, in comparison to the PCA, the LDA’s kernel is not guaranteed to be positive semi-definite, since it is a combination of multiple covariance matrices. An implication of this are negative eigenvalues, and thus imaginary components in the corresponding eigenvectors. A short test with the trained transformations, however, did not confirm this problem. Another short experiment with training data containing an equal amount of samples per class, instead of the unevenly distributed default, was able to dismiss the distribution of class-samples as another possible implication. to %(%)
for the hand-case at the same configuration. Between window lengths, again, there is not much difference, with a slight tendency to be better for smaller window lengths. Especially for the hand-case, with more realistic recordings, this could be due to fewer misclassifications at the borders between two adjacent activities. A fundamental question arising from these results is, however, why the LDA performs much worse than the PCA across all tests, even though its primary task is to improve class separability. Since the LDA is especially crafted for classification problems, one would expect it to yield better results than the PCA, which is solely based on variances. Multiple possible reasons for this come to mind. One being that the original Fisher Discriminant Analysis was only specified for two classes. The variant deployed in this work is actually a modification called Multiclass LDA, introduced by Rao in [60]. This variant assumes a normal distribution of the classes, as well as equal class covariances. Another possible reason is that, in comparison to the PCA, the LDA’s kernel is not guaranteed to be positive semi-definite, since it is a combination of multiple covariance matrices. An implication of this are negative eigenvalues, and thus imaginary components in the corresponding eigenvectors. A short test with the trained transformations, however, did not confirm this problem. Another short experiment with training data containing an equal amount of samples per class, instead of the unevenly distributed default, was able to dismiss the distribution of class-samples as another possible implication. to %(%)  at the same configuration as previously, while the hand-case’s best accuracy has deteriorated from %(%) to %(%)
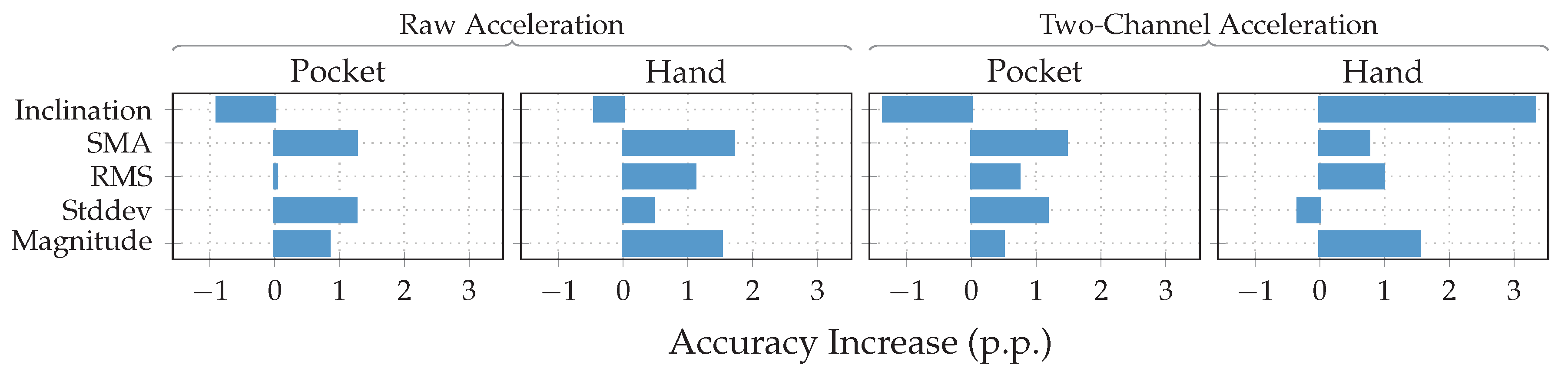
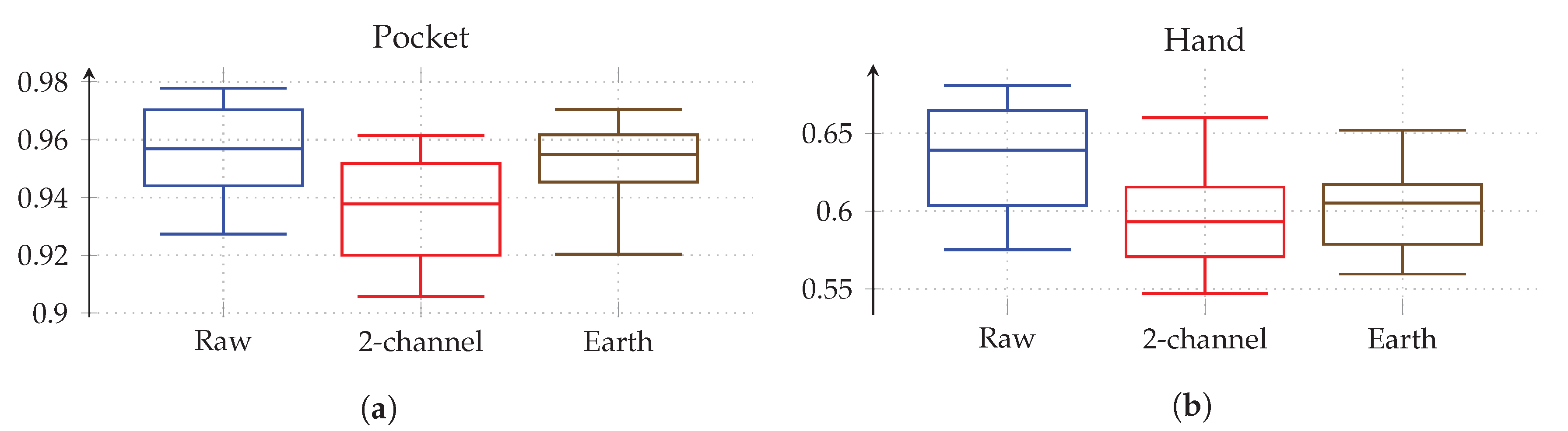
at the same configuration as previously, while the hand-case’s best accuracy has deteriorated from %(%) to %(%)  . Main motivation for the aligned coordinate systems is an improved orientation-independence, same of which inspired the use of virtual sensors. Acceleration in the two-channel coordinate system could have reduced the information content, such that it is hindering the calculated virtual sensor’s effectiveness. To test this assumption, the comparison between raw and aligned acceleration was repeated without virtual sensors, only making use of accelerometer and gyroscope. And indeed, with hardware sensors only, the two-channel coordinate system was able to improve the best performance from % to % for the pocket-case, and from % to % for the hand-case. to %(%)
. Main motivation for the aligned coordinate systems is an improved orientation-independence, same of which inspired the use of virtual sensors. Acceleration in the two-channel coordinate system could have reduced the information content, such that it is hindering the calculated virtual sensor’s effectiveness. To test this assumption, the comparison between raw and aligned acceleration was repeated without virtual sensors, only making use of accelerometer and gyroscope. And indeed, with hardware sensors only, the two-channel coordinate system was able to improve the best performance from % to % for the pocket-case, and from % to % for the hand-case. to %(%)  for the pocket-case, and from %(%) to %(%)
for the pocket-case, and from %(%) to %(%)  in the hand-case. This improvement can probably be mostly attributed to the small neighborhood size of , which was chosen for performance reasons. As was to be expected from the discussion in Section 3.2, most misclassifications in the hand-case happen between the gait-involving activities.
in the hand-case. This improvement can probably be mostly attributed to the small neighborhood size of , which was chosen for performance reasons. As was to be expected from the discussion in Section 3.2, most misclassifications in the hand-case happen between the gait-involving activities.Outlier Detection
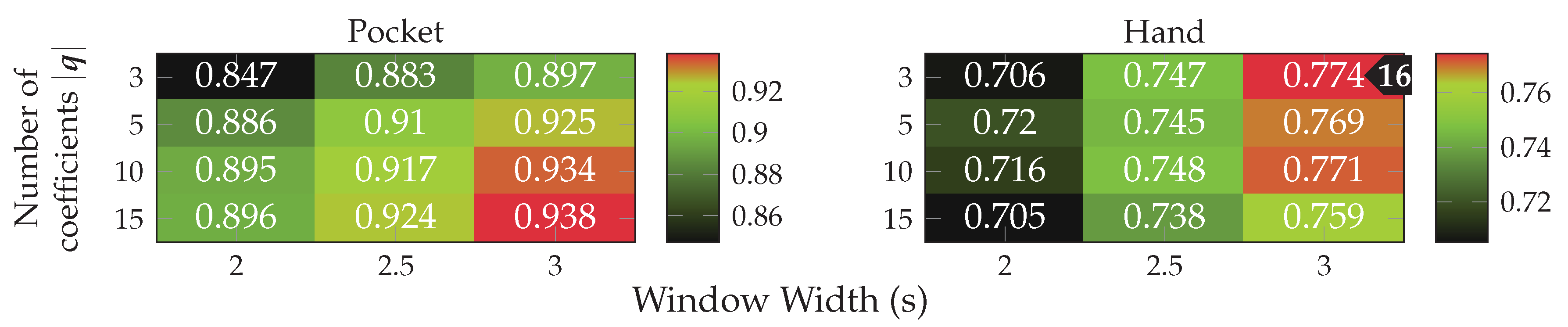
5.3. Results for Codebook
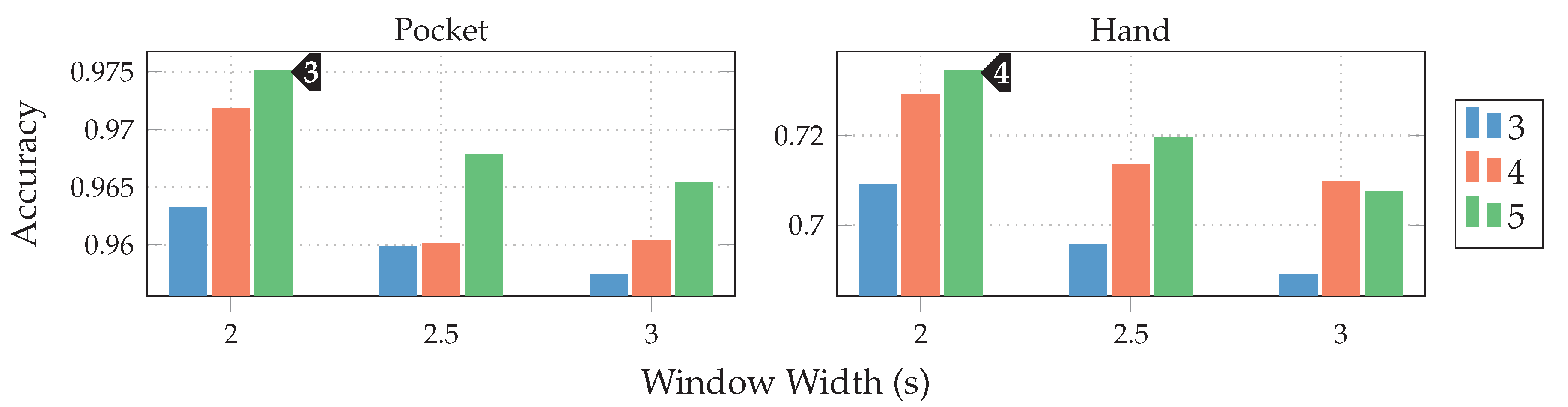
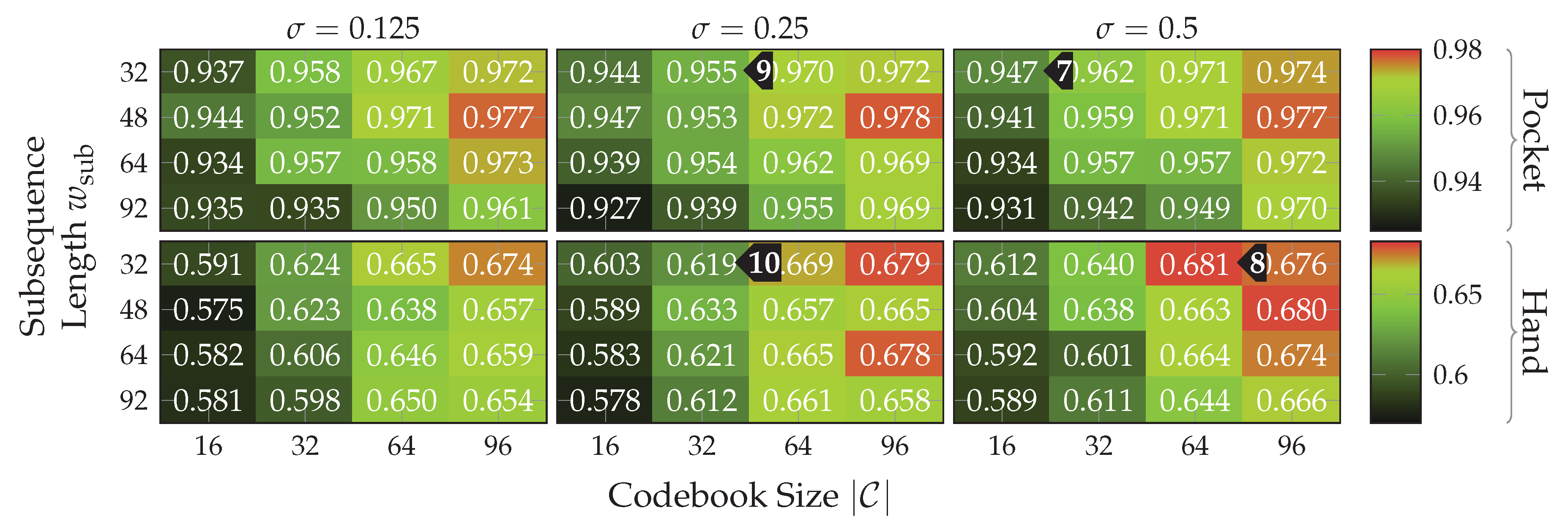
 , with only 16 codewords for the pocket-case. Further increases in classification accuracy would not be worth the increased computational complexity, for the pocket-case at least. The sweet spot for the used subsequence length here seems to be at 48 samples. With the highest classification accuracy of %(%)
, with only 16 codewords for the pocket-case. Further increases in classification accuracy would not be worth the increased computational complexity, for the pocket-case at least. The sweet spot for the used subsequence length here seems to be at 48 samples. With the highest classification accuracy of %(%)  for the hand-case at , , and , however, the accuracies are mostly insufficient for practical uses. Improvements of the classification accuracy achieved by increasing the number of codewords in a codebook, is 3 percentage points on average, over the tested codebook sizes. This improvement is clearly more significant than the one observed for the pocket-case above, but still only marginal for practical uses. The sweet spot for the subsequence length seems to be somewhere between 32 samples and 48 samples, instead of 48 observed for the pocket-case results. This may be connected with the main difference between pocket-case data and hand-case data, which was discussed in Section 3.2. Since the smartphone can only measure movements of the leg to which the pocket is attached, the exhibited base frequency in the data recorded for the pocket-case is roughly half that of the hand-case. Most repetitive behavior in the recorded signals for the hand-case thus have smaller periods, which could be advantaged by a smaller subsequence length .
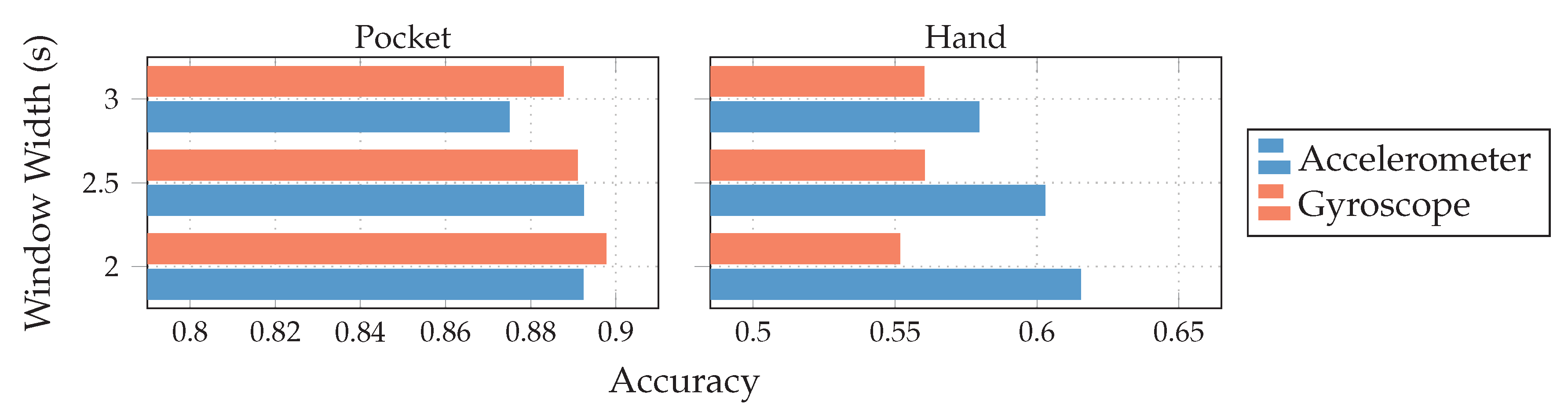
for the hand-case at , , and , however, the accuracies are mostly insufficient for practical uses. Improvements of the classification accuracy achieved by increasing the number of codewords in a codebook, is 3 percentage points on average, over the tested codebook sizes. This improvement is clearly more significant than the one observed for the pocket-case above, but still only marginal for practical uses. The sweet spot for the subsequence length seems to be somewhere between 32 samples and 48 samples, instead of 48 observed for the pocket-case results. This may be connected with the main difference between pocket-case data and hand-case data, which was discussed in Section 3.2. Since the smartphone can only measure movements of the leg to which the pocket is attached, the exhibited base frequency in the data recorded for the pocket-case is roughly half that of the hand-case. Most repetitive behavior in the recorded signals for the hand-case thus have smaller periods, which could be advantaged by a smaller subsequence length . with both sensors in combination. While the gyroscope does seem to be more suited for the recognition of pocket-case data, it is only a marginal lead.+ Since the combined accuracy is higher, the accelerometer does seem to still have valuable information to contribute. On the hand-case dataset, the accuracies % and % were achieved for accelerometer and gyroscope respectively. This can be explained by the exhibited shapes in the analysis done in Section 3.2. It makes sense that the accelerometer is taking the leading role for the hand-case, since, as discussed in the mentioned section, barely any characteristic rotations should reach the smartphone when carried in hand. With a classification accuracy of %(%)
with both sensors in combination. While the gyroscope does seem to be more suited for the recognition of pocket-case data, it is only a marginal lead.+ Since the combined accuracy is higher, the accelerometer does seem to still have valuable information to contribute. On the hand-case dataset, the accuracies % and % were achieved for accelerometer and gyroscope respectively. This can be explained by the exhibited shapes in the analysis done in Section 3.2. It makes sense that the accelerometer is taking the leading role for the hand-case, since, as discussed in the mentioned section, barely any characteristic rotations should reach the smartphone when carried in hand. With a classification accuracy of %(%)  , with the combination of accelerometer and gyroscope it seems that the gyroscope is actually obstructive for classification.
, with the combination of accelerometer and gyroscope it seems that the gyroscope is actually obstructive for classification. and %(%)
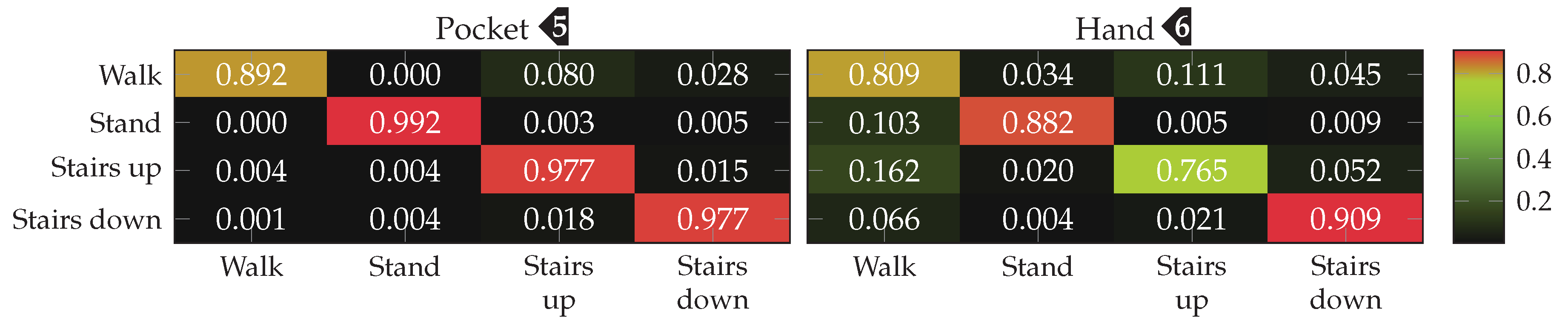
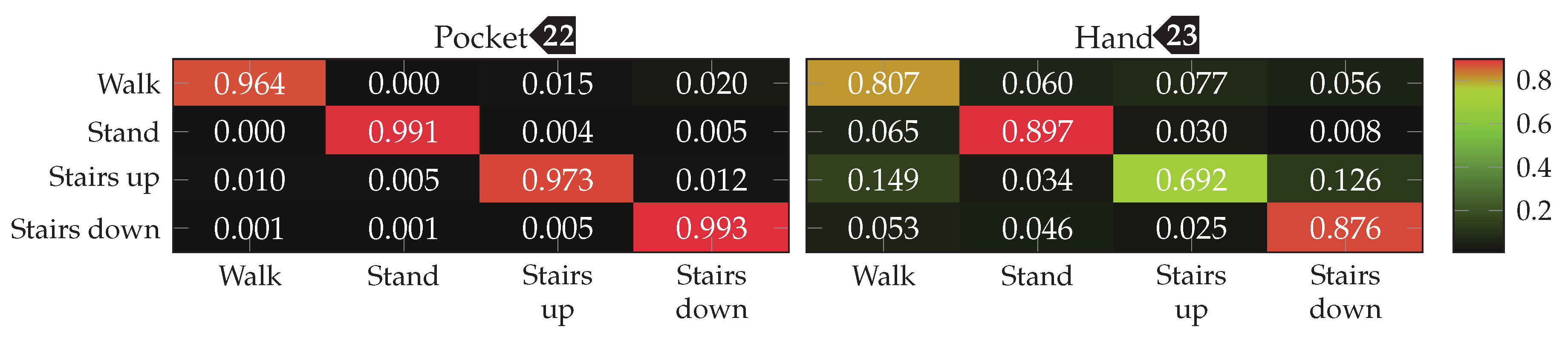
and %(%)  for pocket-case and hand-case respectively. The minor improvement of accuracy for the pocket-case can be mostly assigned to measurement errors. Nevertheless, the classification shows an accuracy for the pocket-case, which is at least on par with the classification for , even though the sweet spot for the pocket-case seemed to be around the latter from the previous benchmark results. With and the k-Nearest Neighbor classifier, this configuration previously achieved the classification accuracies %(%) and %(%) for pocket-case and hand-case respectively. The resulting confusion matrices when using the SVM classifier with for pocket-case and hand-case, are shown in Figure 20. To no surprise, the most common misclassifications are found between the activities that involve gait.
for pocket-case and hand-case respectively. The minor improvement of accuracy for the pocket-case can be mostly assigned to measurement errors. Nevertheless, the classification shows an accuracy for the pocket-case, which is at least on par with the classification for , even though the sweet spot for the pocket-case seemed to be around the latter from the previous benchmark results. With and the k-Nearest Neighbor classifier, this configuration previously achieved the classification accuracies %(%) and %(%) for pocket-case and hand-case respectively. The resulting confusion matrices when using the SVM classifier with for pocket-case and hand-case, are shown in Figure 20. To no surprise, the most common misclassifications are found between the activities that involve gait.Outlier Detection
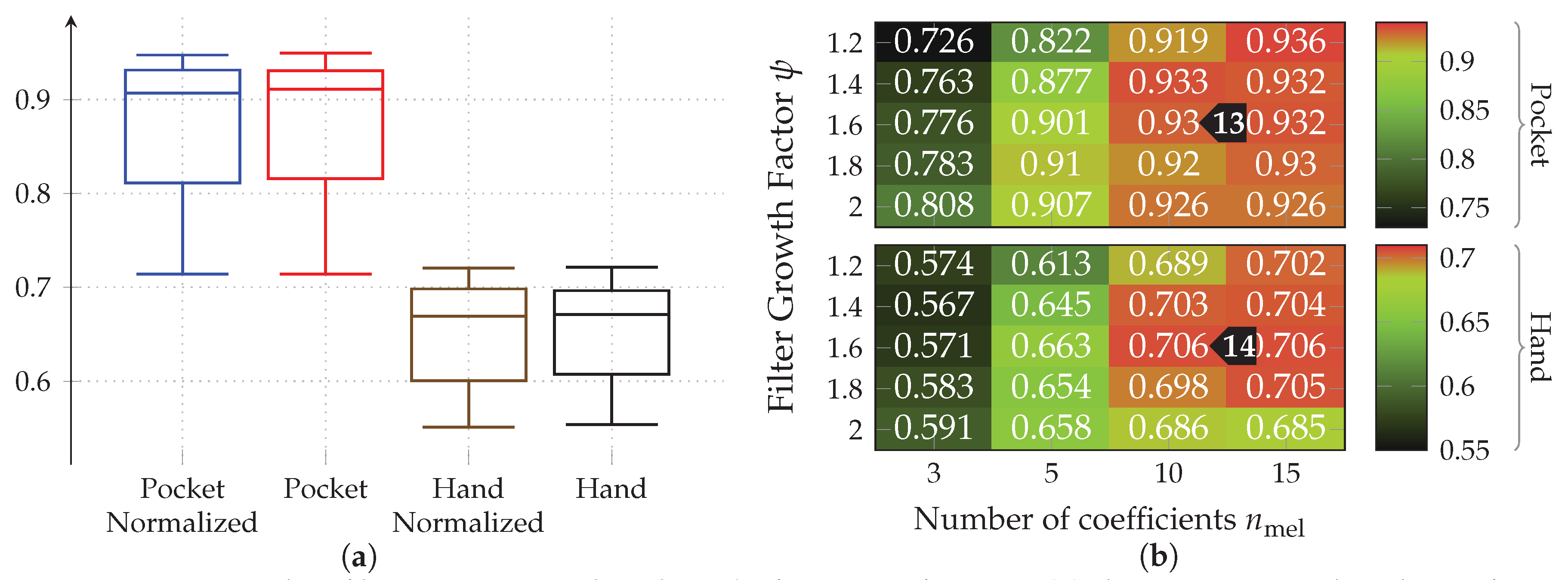
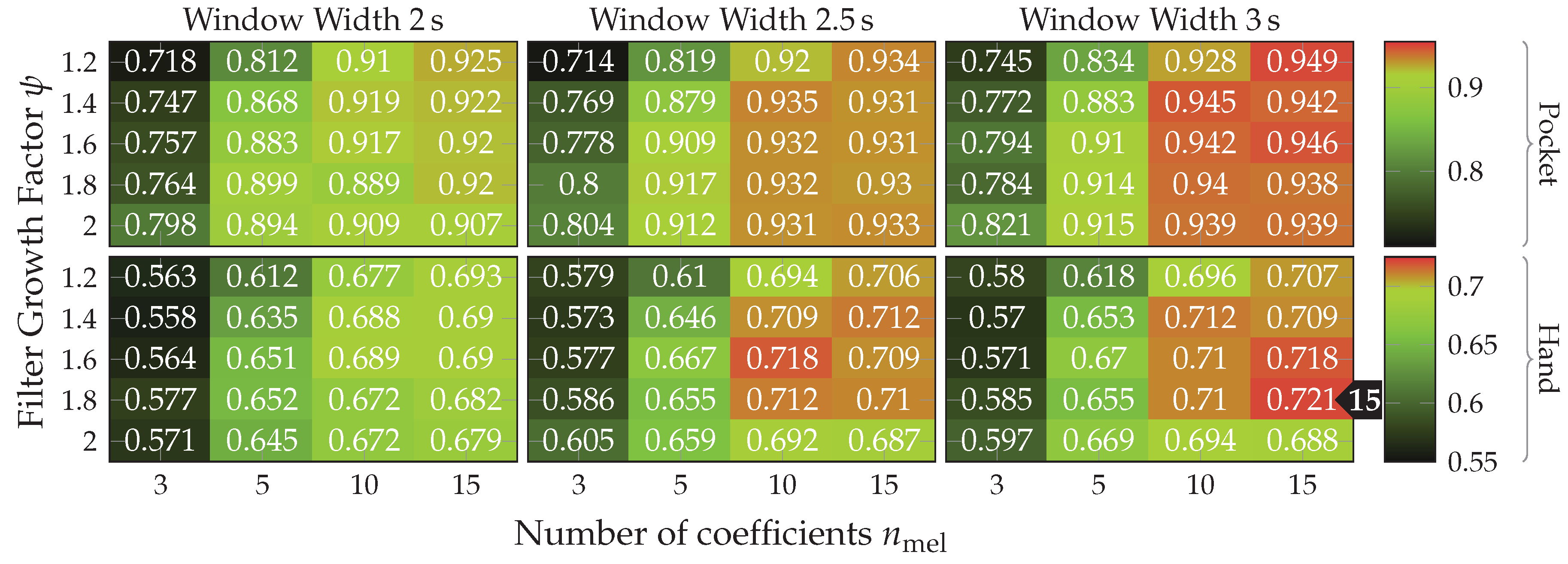
5.4. Results for Statistical Features
 for the pocket-case, and %(%)
for the pocket-case, and %(%)  for the hand-case. The benchmark results for the tested window lengths can be seen in Figure 22. The patterns exhibited across the tested window lengths, as well as across cases are very similar. Here, the improvements for accuracy, reached by increasing the number of calculated MFC coefficients , declines with each step. The average difference between and roughly equals for the pocket-case, and for the hand-case. Despite being a larger step, increases between and only amount to , and for pocket-case and hand-case respectively. If the accuracies achieved are considered to be a function of the tested growth factors , only minor differences are to be found for . The greatest influence of the tested growth factors can be seen for . Here, the accuracy is better, the larger the growth factors are chosen. This can be interpreted as an indication of the importance of low frequencies, as larger growth factors lead to more and smaller filters in the lower frequency ranges. This causes the calculated feature’s to have a higher resolution in the lower frequency ranges. Due to the relatively slow nature of gait, this seems plausible.
for the hand-case. The benchmark results for the tested window lengths can be seen in Figure 22. The patterns exhibited across the tested window lengths, as well as across cases are very similar. Here, the improvements for accuracy, reached by increasing the number of calculated MFC coefficients , declines with each step. The average difference between and roughly equals for the pocket-case, and for the hand-case. Despite being a larger step, increases between and only amount to , and for pocket-case and hand-case respectively. If the accuracies achieved are considered to be a function of the tested growth factors , only minor differences are to be found for . The greatest influence of the tested growth factors can be seen for . Here, the accuracy is better, the larger the growth factors are chosen. This can be interpreted as an indication of the importance of low frequencies, as larger growth factors lead to more and smaller filters in the lower frequency ranges. This causes the calculated feature’s to have a higher resolution in the lower frequency ranges. Due to the relatively slow nature of gait, this seems plausible. ) and MFCC features (max %(%)
) and MFCC features (max %(%)  ), the AR-Coefficients prove to be superior. Situation for the pocket-case is more complex. Here, the AR-Coefficients tend to perform better than the MFCC coefficients when only calculating 3 coefficients for both approaches, reducing in performance for a larger model order . To summarize, AR-Coefficients seem to be more efficient by producing higher accuracies for smaller numbers of coefficients, and thus smaller feature vectors. In addition, AR-Coefficients also have the advantage of being dependent on only one hyperparameter, while MFCC features must also be adjusted to each use-case, by tuning the filter growth factor for their underlying filter-bank.
), the AR-Coefficients prove to be superior. Situation for the pocket-case is more complex. Here, the AR-Coefficients tend to perform better than the MFCC coefficients when only calculating 3 coefficients for both approaches, reducing in performance for a larger model order . To summarize, AR-Coefficients seem to be more efficient by producing higher accuracies for smaller numbers of coefficients, and thus smaller feature vectors. In addition, AR-Coefficients also have the advantage of being dependent on only one hyperparameter, while MFCC features must also be adjusted to each use-case, by tuning the filter growth factor for their underlying filter-bank. , the best accuracy for the pocket-case here is reached for 6 remaining dimensions and a window of . The hand-case achieved a maximum classification accuracy of %(%)
, the best accuracy for the pocket-case here is reached for 6 remaining dimensions and a window of . The hand-case achieved a maximum classification accuracy of %(%)  at 5 remaining dimensions and a window of . Like when using unaligned acceleration, this result is much worse for the hand-case when compared to using only AR-Coefficients . The assumption is therefore that some of the included features confuse the classifier, even though the LDA acts as a kind of simple feature selector when paired with a reduction in dimensionality. Acceleration in the two-channel acceleration was chosen as best configuration, since it achieves similar performance to unaligned acceleration at smaller window sizes, thus reducing delay while also operating with fewer dimensions.
at 5 remaining dimensions and a window of . Like when using unaligned acceleration, this result is much worse for the hand-case when compared to using only AR-Coefficients . The assumption is therefore that some of the included features confuse the classifier, even though the LDA acts as a kind of simple feature selector when paired with a reduction in dimensionality. Acceleration in the two-channel acceleration was chosen as best configuration, since it achieves similar performance to unaligned acceleration at smaller window sizes, thus reducing delay while also operating with fewer dimensions. and %(%) for pocket-case and hand-case respectively. When using the SVM classifier, this configuration achieves %(%)
and %(%) for pocket-case and hand-case respectively. When using the SVM classifier, this configuration achieves %(%)  and %(%)
and %(%)  , with the corresponding confusion matrices depicted in Figure 26. The difference for the pocket-case can here be assigned to measuring errors, while the result for the hand-case with the SVM changes little for the low overall practicability of the approach. For comparison, using only AR-Coefficients as feature with an SVM classifier, a window length of and 4 dimensions after the LDA, achieved the classification accuracies % and % for pocket-case and hand-case respectively.
, with the corresponding confusion matrices depicted in Figure 26. The difference for the pocket-case can here be assigned to measuring errors, while the result for the hand-case with the SVM changes little for the low overall practicability of the approach. For comparison, using only AR-Coefficients as feature with an SVM classifier, a window length of and 4 dimensions after the LDA, achieved the classification accuracies % and % for pocket-case and hand-case respectively.Outlier Detection
5.5. Comparison and Discussion
 , the model was able to preserve its high classification accuracy for the pocket-case of previously %(%) . For the hand-case, the classification accuracy dropped to %(%)
, the model was able to preserve its high classification accuracy for the pocket-case of previously %(%) . For the hand-case, the classification accuracy dropped to %(%)  from the %(%) achieved with separate training on both cases. When comparing the results with the separately trained counterpart depicted in Figure 26, the walking upstairs activity can be identified as main loser of this combination for the hand-case. The loss in accuracy incurred by the combined training is less pronounced than expected. Though with roughly % for the hand-case, the accuracy still has room for improvement.
from the %(%) achieved with separate training on both cases. When comparing the results with the separately trained counterpart depicted in Figure 26, the walking upstairs activity can be identified as main loser of this combination for the hand-case. The loss in accuracy incurred by the combined training is less pronounced than expected. Though with roughly % for the hand-case, the accuracy still has room for improvement.6. Conclusions
Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Labrador, M.A.; Yejas, O.D.L. Human Activity Recognition: Using Wearable Sensors and Smartphones; CRC Press: Boca Raton, FL, USA, 2013. [Google Scholar]
- Lara, O.D.; Labrador, M.A. A Survey on Human Activity Recognition using Wearable Sensors. Commun. Surv. Tutor. 2012, 15, 1192–1209. [Google Scholar] [CrossRef]
- Bao, L.; Intille, S.S. Activity Recognition from User-Annotated Acceleration Data. In International Conference on Pervasive Computing; Springer: Berlin/Heidelberg, Germany, 2004; pp. 1–17. [Google Scholar]
- Maurer, U.; Smailagic, A.; Siewiorek, D.P.; Deisher, M. Activity Recognition and Monitoring Using Multiple Sensors on Different Body Positions. In Proceedings of the International Workshop on Wearable and Implantable Body Sensor Networks, Cambridge, MA, USA, 3–5 April 2006. [Google Scholar]
- Zhou, B.; Li, Q.; Mao, Q.; Tu, W.; Zhang, X. Activity Sequence-Based Indoor Pedestrian Localization Using Smartphones. Trans. Hum.-Mach. Syst. 2014, 45, 562–574. [Google Scholar] [CrossRef]
- Liu, H.; Darabi, H.; Banerjee, P.; Liu, J. Survey of Wireless Indoor Positioning Techniques and Systems. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2007, 37, 1067–1080. [Google Scholar] [CrossRef]
- Ebner, F.; Deinzer, F.; Köping, L.; Grzegorzek, M. Robust Self-Localization using Wi-Fi, Step/Turn-Detection and Recursive Density Estimation. In Proceedings of the International Conference on Indoor Positioning and Indoor Navigation (IPIN), Busan, Korea, 27–30 October 2014; pp. 1–9. [Google Scholar]
- Fetzer, T.; Ebner, F.; Bullmann, M.; Deinzer, F.; Grzegorzek, M. Smartphone-Based Indoor Localization within a 13th Century Historic Building. Sensors 2018, 18, 4095. [Google Scholar] [CrossRef] [Green Version]
- Ebner, F.; Fetzer, T.; Deinzer, F.; Grzegorzek, M. On Wi-Fi Model Optimizations for Smartphone-Based Indoor Localization. ISPRS Int. J. Geo-Inf. 2017, 6, 233–250. [Google Scholar] [CrossRef] [Green Version]
- Davidson, P.; Piché, R. A Survey of Selected Indoor Positioning Methods for Smartphones. IEEE Commun. Surv. Tutor. 2016, 19, 1347–1370. [Google Scholar] [CrossRef]
- Ebner, F.; Fetzer, T.; Deinzer, F.; Köping, L.; Grzegorzek, M. Multi Sensor 3D Indoor Localisation. In Proceedings of the International Conference on Indoor Positioning and Indoor Navigation (IPIN), Banff, AB, Canada, 13–16 October 2015; pp. 1–11. [Google Scholar]
- Ebner, F.; Fetzer, T.; Deinzer, F.; Grzegorzek, M. On Prior Navigation Knowledge in Multi Sensor Indoor Localisation. In Proceedings of the 19th International Conference on Information Fusion (FUSION), Heidelberg, Germany, 5–8 July 2016; pp. 557–564. [Google Scholar]
- Fetzer, T.; Ebner, F.; Deinzer, F.; Köping, L.; Grzegorzek, M. On Monte Carlo Smoothing in Multi Sensor Indoor Localisation. In Proceedings of the International Conference on Indoor Positioning and Indoor Navigation (IPIN), Alcala de Henares, Spain, 4–7 October 2016; pp. 1–8. [Google Scholar]
- Guo, X.; Ansari, N.; Hu, F.; Shao, Y.; Elikplim, N.R.; Li, L. A Survey on Fusion-Based Indoor Positioning. IEEE Commun. Surv. Tutor. 2019, 22, 566–594. [Google Scholar] [CrossRef]
- Foerster, F.; Smeja, M.; Fahrenberg, J. Detection of Posture and Motion by Accelerometry: A Validation Study in Ambulatory Monitoring. Comput. Hum. Behav. 1999, 15, 571–583. [Google Scholar] [CrossRef]
- Bulling, A.; Blanke, U.; Schiele, B. A Tutorial on Human Activity Recognition Using Body-worn Inertial Sensors. ACM Comput. Surv. (CSUR) 2014, 46. [Google Scholar] [CrossRef]
- Ordóñez, F.J.; Roggen, D. Deep Convolutional and LSTM Recurrent Neural Networks for Multimodal Wearable Activity Recognition. Sensors 2016, 16, 115. [Google Scholar] [CrossRef] [Green Version]
- Shirahama, K.; Köping, L.; Grzegorzek, M. Codebook Approach for Sensor-based Human Activity Recognition. In Proceedings of the International Joint Conference on Pervasive and Ubiquitous Computing: Adjunct; ACM: New York, NY, USA, 2016. [Google Scholar]
- Shirahama, K.; Grzegorzek, M. On the Generality of Codebook Approach for Sensor-Based Human Activity Recognition. Electronics 2017, 6, 44. [Google Scholar] [CrossRef] [Green Version]
- Lester, J.; Choudhury, T.; Borriello, G. A Practical Approach to Recognizing Physical Activities. In International Conference on Pervasive Computing; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Quaid, M.A.K.; Jalal, A. Wearable Sensors Based Human Behavioral Pattern Recognition Using Statistical Features and Reweighted Genetic Algorithm. Multimed. Tools Appl. 2020, 79, 6061–6083. [Google Scholar] [CrossRef]
- Su, X.; Tong, H.; Ji, P. Activity Recognition with Smartphone Sensors. Tsinghua Sci. Technol. 2014, 19, 235–249. [Google Scholar]
- Morales, J.; Akopian, D. Physical Activity Recognition by Smartphones, a Survey. Biocybern. Biomed. Eng. 2017, 37, 388–400. [Google Scholar] [CrossRef]
- Saeedi, S.; El-Sheimy, N. Activity Recognition Using Fusion of Low-Cost Sensors on a Smartphone for Mobile Navigation Application. Micromachines 2015, 6, 1100–1134. [Google Scholar] [CrossRef]
- Yang, J. Toward Physical Activity Diary: Motion Recognition Using Simple Acceleration Features with Mobile Phones. In Proceedings of the International Workshop on Interactive Multimedia for Consumer Electronics; ACM: New York, NY, USA, 2009. [Google Scholar]
- Ustev, Y.E.; Durmaz Incel, O.; Ersoy, C. User, Device and Orientation Independent Human Activity Recognition on Mobile Phones: Challenges and a Proposal. In Proceedings of the Conference on Pervasive and Ubiquitous Computing Adjunct Publication; ACM: New York, NY, USA, 2013. [Google Scholar]
- Siirtola, P.; Röning, J. Recognizing Human Activities User-independently on Smartphones Based on Accelerometer Data. IJIMAI 2012, 1, 38–45. [Google Scholar] [CrossRef]
- Shoaib, M.; Scholten, H.; Havinga, P.J. Towards Physical Activity Recognition Using Smartphone Sensors. In Proceedings of the International Conference on Ubiquitous Intelligence and Computing, Vietri sul Mere, Italy, 18–21 December 2013. [Google Scholar]
- Shoaib, M.; Bosch, S.; Incel, O.; Scholten, H.; Havinga, P. Fusion of Smartphone Motion Sensors for Physical Activity Recognition. Sensors 2014, 14, 10146–10176. [Google Scholar] [CrossRef]
- Sun, L.; Zhang, D.; Li, B.; Guo, B.; Li, S. Activity Recognition on an Accelerometer Embedded Mobile Phone with Varying Positions and Orientations. In International Conference on Ubiquitous Intelligence and Computing; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Tran, D.N.; Phan, D.D. Human Activities Recognition in Android Smartphone Using Support Vector Machine. In Proceedings of the International Conference on Intelligent Systems, Modelling and Simulation (ISMS), Bangkok, Thailand, 25–27 January 2016. [Google Scholar]
- Anguita, D.; Ghio, A.; Oneto, L.; Parra, X.; Reyes-Ortiz, J.L. Human Activity Recognition on Smartphones Using a Multiclass Hardware-Friendly Support Vector Machine. In Ambient Assisted Living and Home Care; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Anjum, A.; Ilyas, M.U. Activity Recognition Using Smartphone Sensors. In Proceedings of the Consumer Communications and Networking Conference (CCNC), Las Vegas, NV, USA, 11–14 January 2013. [Google Scholar]
- Figo, D.; Diniz, P.C.; Ferreira, D.R.; Cardoso, J.M. Preprocessing Techniques for Context Recognition from Accelerometer Data. Pers. Ubiquitous Comput. 2010, 14, 645–662. [Google Scholar] [CrossRef]
- Lee, Y.S.; Cho, S.B. Activity recognition using hierarchical hidden markov models on a smartphone with 3D accelerometer. In International Conference on Hybrid Artificial Intelligence Systems; Springer: Berlin/Heidelberg, Germany, 2011; pp. 460–467. [Google Scholar]
- Euston, M.; Coote, P.; Mahony, R.; Kim, J.; Hamel, T. A Complementary Filter for Attitude Estimation of a Fixed-Wing UAV. In Proceedings of the International Conference on Intelligent Robots and Systems, Nice, France, 22–26 September 2008. [Google Scholar]
- Mahony, R.; Hamel, T.; Pflimlin, J.M. Complementary Filter Design on the Special Orthogonal Group SO(3). In Proceedings of the Conference on Decision and Control, Seville, Spain, 15 December 2005. [Google Scholar]
- Madgwick, S. An Efficient Orientation Filter for Inertial and Inertial/Magnetic Sensor Arrays. Rep. X-Io Univ. Bristol (UK) 2010, 25, 113–118. [Google Scholar]
- Madgwick, S.O.; Harrison, A.J.; Vaidyanathan, R. Estimation of Imu and Marg Orientation Using a Gradient Descent Algorithm. In Proceedings of the International Conference on Rehabilitation Robotics, Zurich, Switzerland, 29 June–1 July 2011. [Google Scholar]
- Yang, J.; Lu, H.; Liu, Z.; Boda, P.P. Physical Activity Recognition with Mobile Phones: Challenges, Methods, and Applications. In Multimedia Interaction and Intelligent User Interfaces; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Mohd-Yasin, F.; Nagel, D.; Korman, C. Noise in MEMS. Meas. Sci. Technol. 2009, 21, 012001. [Google Scholar] [CrossRef]
- Pedley, M. High Precision Calibration of a Three-Axis Accelerometer. Free Semicond. Appl. Note 2013, 1–41. [Google Scholar]
- Maxwell Donelan, J.; Kram, R.; Arthur D, K. Mechanical and Metabolic Determinants of the Preferred Step Width in Human Walking. Proc. R. Soc. Lond. Ser. B Biol. Sci. 2001, 268, 1985–1992. [Google Scholar] [CrossRef] [Green Version]
- Wu, W.; Dasgupta, S.; Ramirez, E.E.; Peterson, C.; Norman, G.J. Classification Accuracies of Physical Activities Using Smartphone Motion Sensors. J. Med. Internet Res. 2012, 14, e130. [Google Scholar] [CrossRef] [PubMed]
- Preece, S.J.; Goulermas, J.Y.; Kenney, L.P.; Howard, D. A Comparison of Feature Extraction Methods for the Classification of Dynamic Activities From Accelerometer Data. Trans. Biomed. Eng. 2008, 56, 871–879. [Google Scholar] [CrossRef] [PubMed]
- Pearson, K. On Lines and Planes of Closest Fit to Systems of Points in Space. Lond. Edinb. Dublin Philos. Mag. J. Sci. 1901, 2, 559–572. [Google Scholar] [CrossRef] [Green Version]
- Fisher, R.A. The Use of Multiple Measurements in Taxonomic Problems. Ann. Eugen. 1936, 7, 179–188. [Google Scholar] [CrossRef]
- Khan, A.M.; Lee, Y.K.; Lee, S.Y.; Kim, T.S. Human Activity Recognition via an Accelerometer-Enabled-Smartphone Using Kernel Discriminant Analysis. In Proceedings of the International Conference on Future Information Technology, Busan, Korea, 21–23 May 2010. [Google Scholar]
- Mika, S.; Ratsch, G.; Weston, J.; Scholkopf, B.; Mullers, K.R. Fisher Discriminant Analysis with Kernels. In Proceedings of the Neural Networks for Signal Processing IX: Proceedings of the 1999 IEEE Signal Processing Society Workshop, Madison, WI, USA, 25 August 1999; pp. 41–48.
- Ravi, N.; Dandekar, N.; Mysore, P.; Littman, M.L. Activity Recognition from Accelerometer Data. In Proceedings of the Conference on Artificial Intelligence (AAAI), Pittsburgh, Pennsylvania, 9–13 July 2005; Volume 5. [Google Scholar]
- Dernbach, S.; Das, B.; Krishnan, N.C.; Thomas, B.L.; Cook, D.J. Simple and Complex Activity Recognition through Smart Phones. In Proceedings of the International Conference on Intelligent Environments, Guanajuato, Mexico, 26–29 June 2012. [Google Scholar]
- Kwapisz, J.R.; Weiss, G.M.; Moore, S.A. Activity Recognition Using Cell Phone Accelerometers. SigKDD Explor. Newsl. 2011, 12, 74–82. [Google Scholar] [CrossRef]
- Morales, J.; Akopian, D.; Agaian, S. Human Activity Recognition by Smartphones Regardless of Device Orientation. In Mobile Devices and Multimedia: Enabling Technologies, Algorithms, and Applications; International Society for Optics and Photonics (SPIE): Toulouse, France, 2014; Volume 9030. [Google Scholar]
- Cano, P.; Batle, E.; Kalker, T.; Haitsma, J. A Review of Algorithms for Audio Fingerprinting. In Proceedings of the Workshop on Multimedia Signal Processing, St. Thomas, VI, USA, 9–11 December 2002. [Google Scholar]
- Miluzzo, E.; Lane, N.D.; Fodor, K.; Peterson, R.; Lu, H.; Musolesi, M.; Eisenman, S.B.; Zheng, X.; Campbell, A.T. Sensing Meets Mobile Social Networks: The Design, Implementation and Evaluation of the CenceMe Application. In Proceedings of the Conference on Embedded Network Sensor Systems; ACM: New York, NY, USA, 2008. [Google Scholar]
- Vavoulas, G.; Chatzaki, C.; Malliotakis, T.; Pediaditis, M.; Tsiknakis, M. The MobiAct Dataset: Recognition of Activities of Daily Living using Smartphones. ICT4AgeingWell 2016, 143–151. [Google Scholar]
- Ebner, M.; Ebner, F.; Fetzer, T.; Bullmann, M.; Köping, L. SensorReadoutApp. 2020. Available online: https://github.com/simpleLoc/SensorReadoutApp (accessed on 24 April 2020).
- Ebner, M.; Ebner, F.; Fetzer, T.; Bullmann, M.; Köping, L. Recording Walks With the simpleLoc SensorReadout App. 2020. Available online: https://youtu.be/2Ea_crH0Ds4 (accessed on 15 September 2020).
- Bishop, C.M. Pattern Recognition and Machine Learning; Information Science and Statistics; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Rao, C.R. The Utilization of Multiple Measurements in Problems of Biological Classification. J. R. Stat. Soc. Ser. B (Methodol.) 1948, 10, 159–203. [Google Scholar] [CrossRef]
- Martínez, A.M.; Kak, A.C. PCA versus LDA. Trans. Pattern Anal. Mach. Intell. 2001, 23, 228–233. [Google Scholar] [CrossRef] [Green Version]
- Pires, I.M.; Marques, G.; Garcia, N.M.; Flórez-Revuelta, F.; Canavarro Teixeira, M.; Zdravevski, E.; Spinsante, S.; Coimbra, M. Pattern Recognition Techniques for the Identification of Activities of Daily Living Using a Mobile Device Accelerometer. Electronics 2020, 9, 509. [Google Scholar] [CrossRef] [Green Version]
- Wu, T.F.; Lin, C.J.; Weng, R.C. Probability Estimates for Multi-class Classification by Pairwise Coupling. J. Mach. Learn. Res. 2004, 5, 975–1005. [Google Scholar]
- Lara, O.D.; Pérez, A.J.; Labrador, M.A.; Posada, J.D. Centinela: A Human Activity Recognition System Based on Acceleration and Vital Sign Data. Pervasive Mob. Comput. 2012, 8, 717–729. [Google Scholar] [CrossRef]
- Wang, A.; Chen, G.; Yang, J.; Zhao, S.; Chang, C.Y. A Comparative Study on Human Activity Recognition Using Inertial Sensors in a Smartphone. Sens. J. 2016, 16, 4566–4578. [Google Scholar] [CrossRef]
- Kaiser, S.; Lang, C. Detecting Elevators and Escalators in 3D Pedestrian Indoor Navigation. In Proceedings of the International Conference on Indoor Positioning and Indoor Navigation (IPIN), Alcala de Henares, Spain, 4–7 October 2016. [Google Scholar]





























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Virtual Sensor (Metric) | For Accelerometer | For Gyroscope | Calculated per Sample | Calculated per Channel | Channels (Dimensions) |
|---|---|---|---|---|---|
| Magnitude | ✓ | - | ✓ | - | 1 |
| Standard Deviation | ✓ | ✓ | - | ✓ | 3 |
| Root mean square | ✓ | ✓ | ✓ | ✓ | 3 |
| Inclination | ✓ | - | ✓ | - | 2 |
| Features | Calculated per Channel | Calculated on Sensor | Channels (Dimensions) |
|---|---|---|---|
| MFCC | yes | Accelerometer | |
| Gyroscope | |||
| Accelerometer Magnitude | |||
| Gyroscope Magnitude | |||
| AR-Coefficients | yes | Accelerometer | |
| SMA | no | Accelerometer | 1 |
| Gyro | 1 | ||
| Integration | yes | Gyroscope | 3 |
| Variance | yes | Inclination | 2 |
| Acceleration Magnitude | 1 | ||
| Gyroscope Magnitude | 1 | ||
| Max | yes | Inclination | 2 |
| Inclination Gradient | 2 | ||
| Min | yes | Inclination | 2 |
| Inclination Gradient | 2 | ||
| Entropy | yes | Acceleration | |
| Gyroscope | 3 | ||
| Correlation | no | Acceleration | |
| Gyroscope | 3 | ||
| 75th Percentile | yes | Acceleration Magnitude | 1 |
| Gyroscope Magnitude | 1 |
| Approach | KNN | SVM | Outlier Detect | Configuration | ||
|---|---|---|---|---|---|---|
| Hand | Hand | |||||
| Analytical Transform | % (%) | % (%) | % (%) | % (%) | % | PCA 5-dim, , raw acceleration |
| Codebook | % (%) | % (%) | % (%) | % (%) | % | , , , raw acceleration |
| Statistical Features | % (%) | % (%) | % (%) | % (%) | % | LDA 5-dim, , , , , two-channel acceleration |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ebner, M.; Fetzer, T.; Bullmann, M.; Deinzer, F.; Grzegorzek, M. Recognition of Typical Locomotion Activities Based on the Sensor Data of a Smartphone in Pocket or Hand. Sensors 2020, 20, 6559. https://0-doi-org.brum.beds.ac.uk/10.3390/s20226559
Ebner M, Fetzer T, Bullmann M, Deinzer F, Grzegorzek M. Recognition of Typical Locomotion Activities Based on the Sensor Data of a Smartphone in Pocket or Hand. Sensors. 2020; 20(22):6559. https://0-doi-org.brum.beds.ac.uk/10.3390/s20226559
Chicago/Turabian StyleEbner, Markus, Toni Fetzer, Markus Bullmann, Frank Deinzer, and Marcin Grzegorzek. 2020. "Recognition of Typical Locomotion Activities Based on the Sensor Data of a Smartphone in Pocket or Hand" Sensors 20, no. 22: 6559. https://0-doi-org.brum.beds.ac.uk/10.3390/s20226559