
Estimating Player Positions from Padel High-Angle Videos: Accuracy Comparison of Recent Computer Vision Methods

 , , , and
, , , and
Abstract
:
1. Introduction
2. Materials and Methods
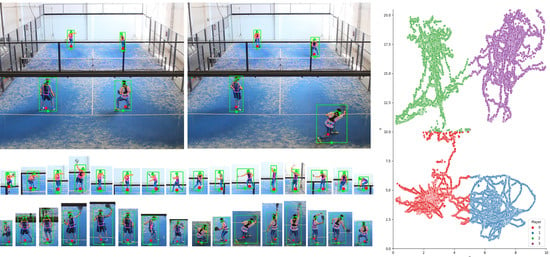
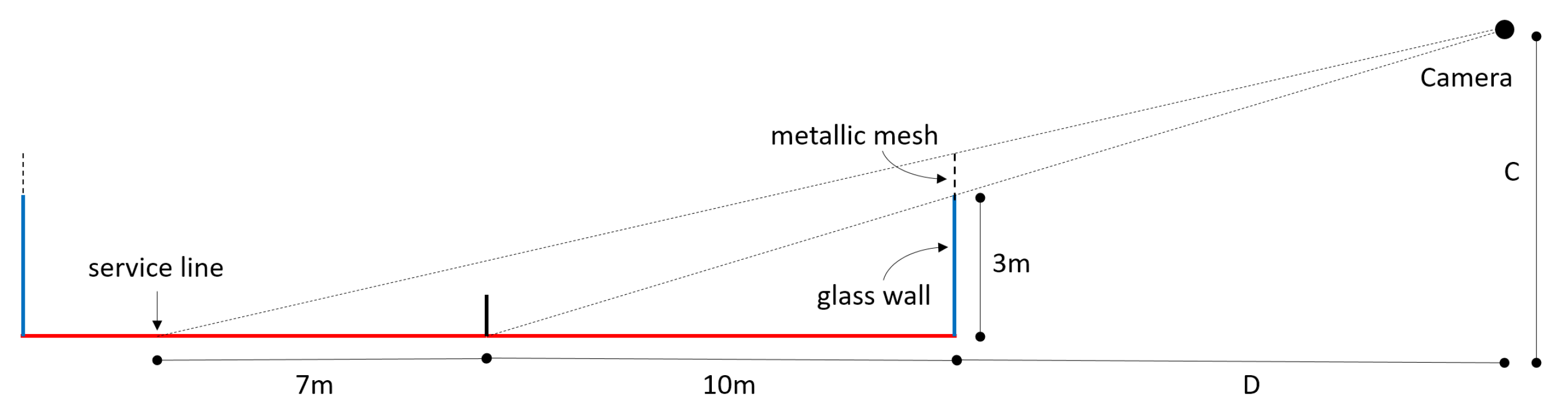
2.1. Dataset Description
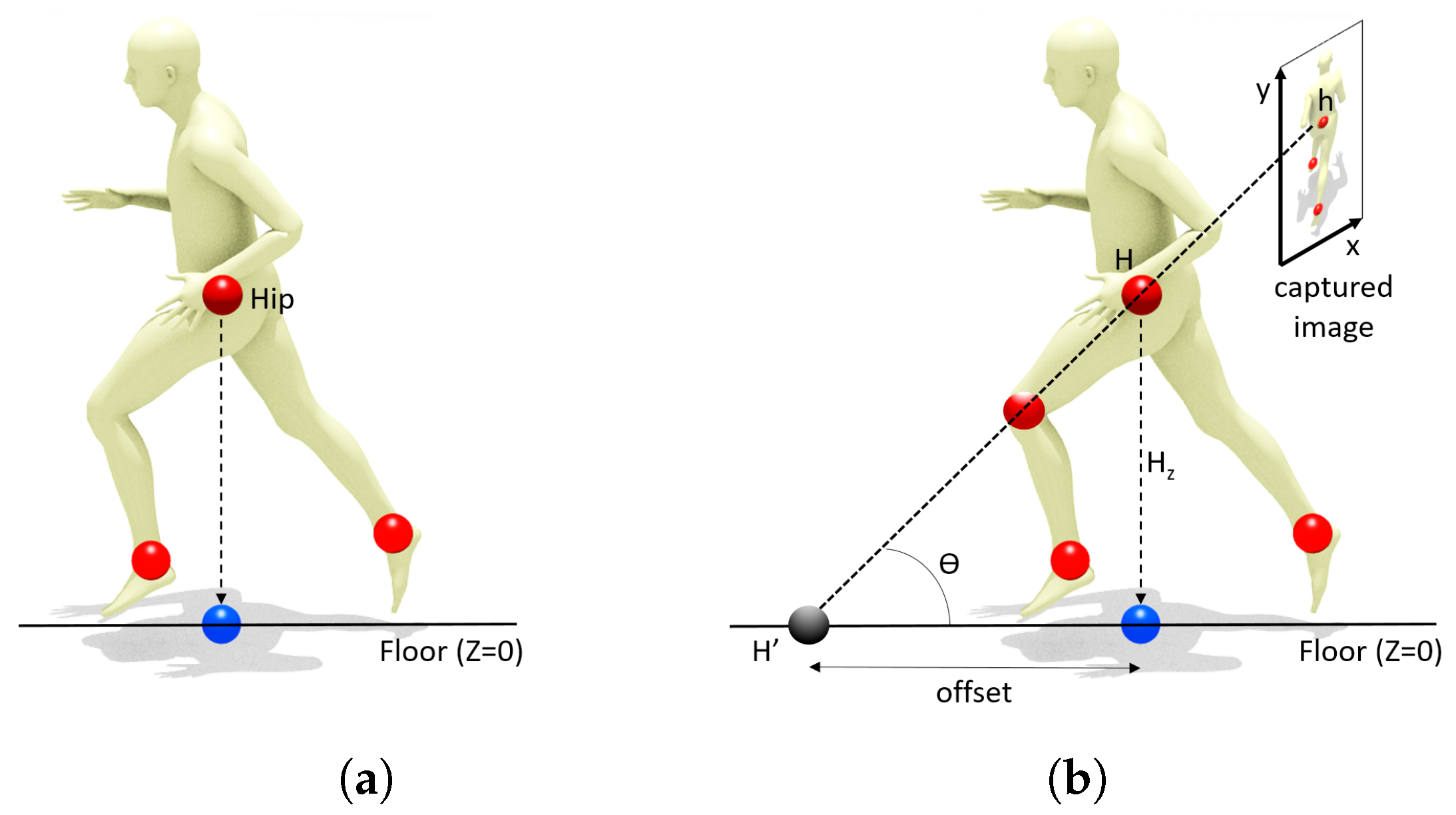
2.2. Defining 2D Court-Space Positions
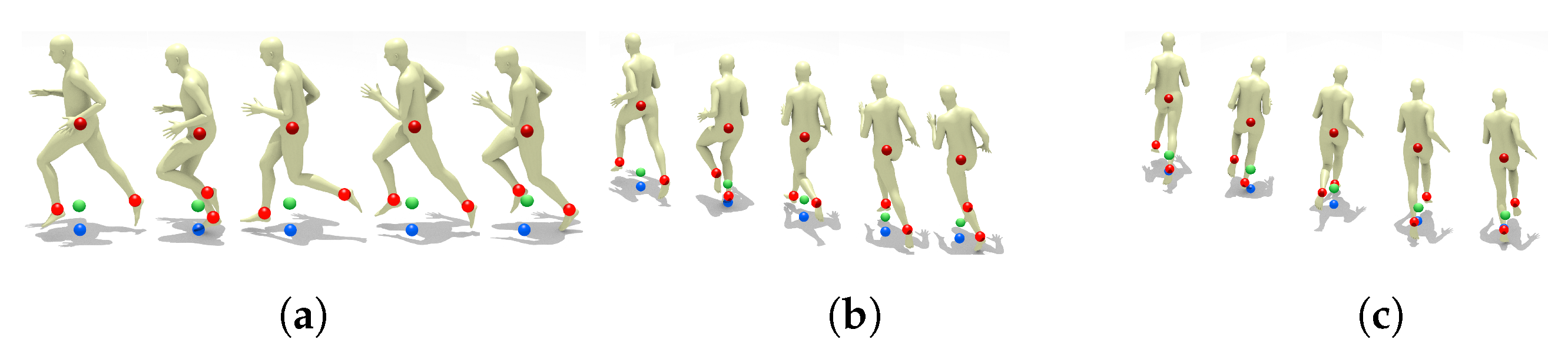
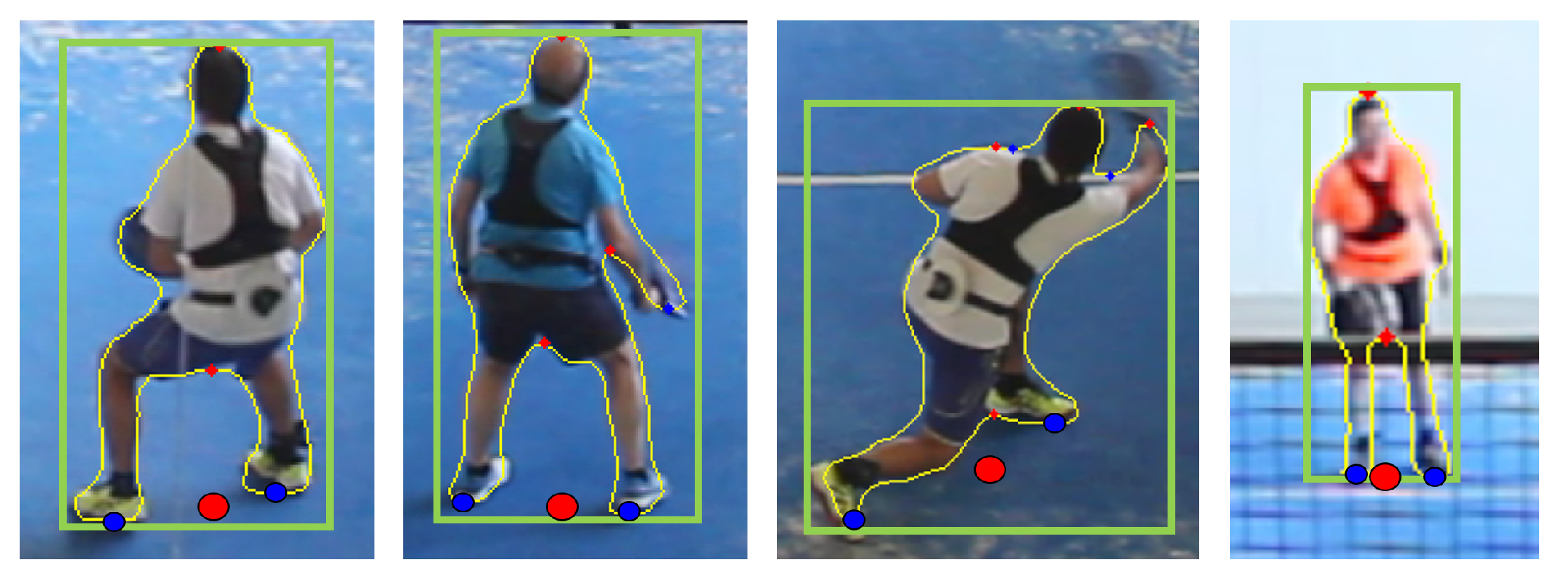
2.3. Court-Space Positions from Image-Space Joints
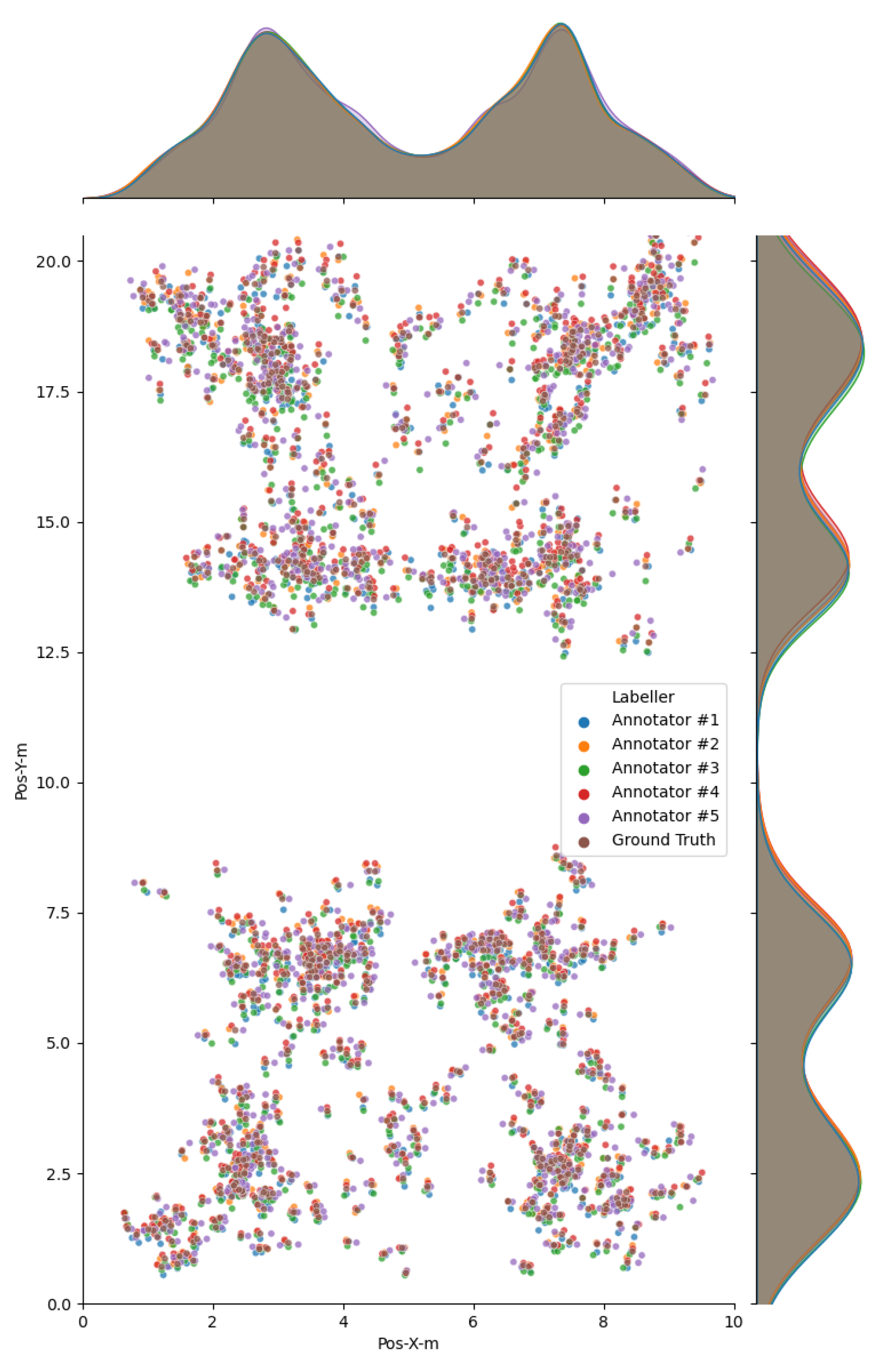
2.4. Manual Player Annotation
2.5. Selected Position Estimation Methods
3. Results
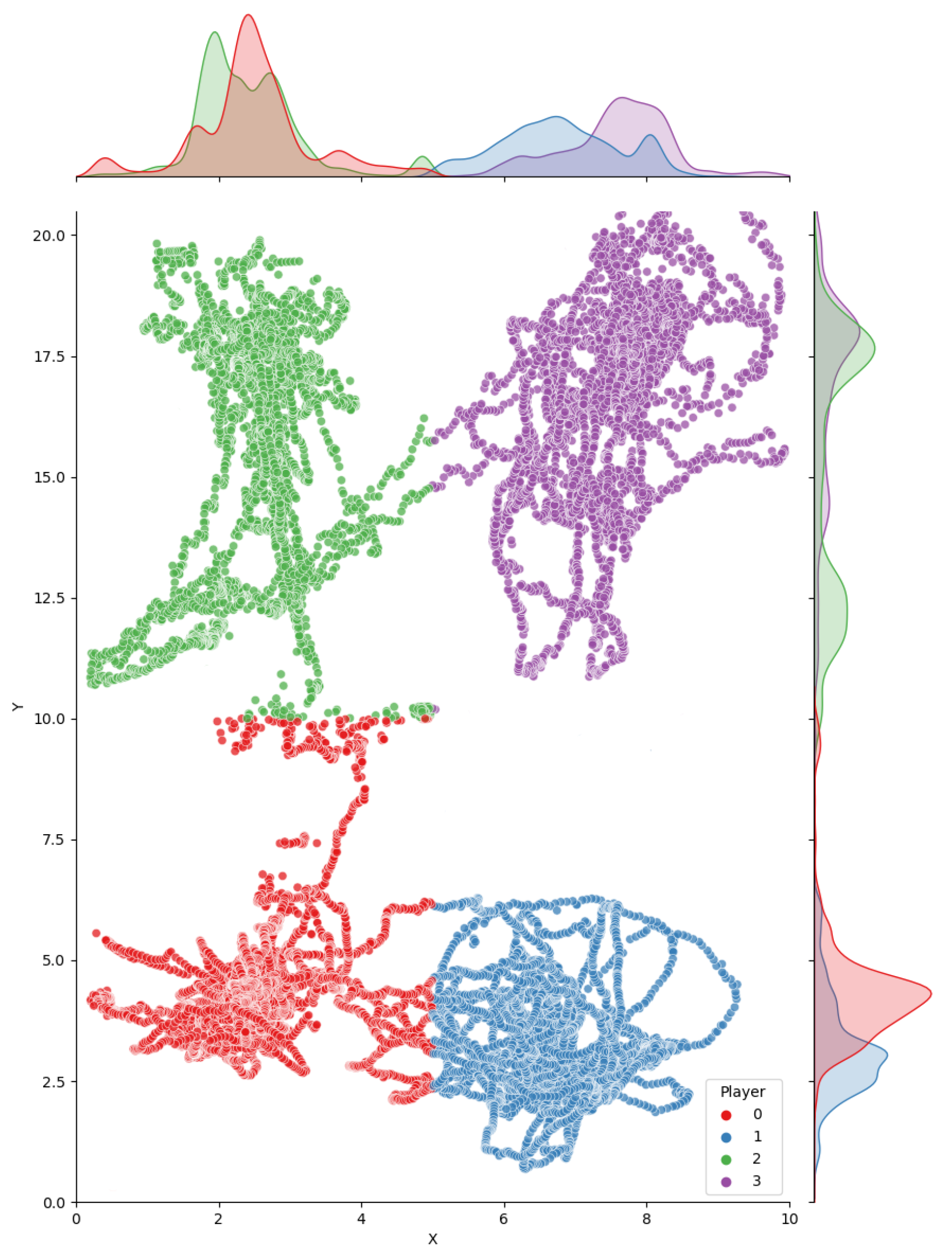
3.1. Test 1
3.2. Test 2
3.3. Amateur Video
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Santiago, C.B.; Sousa, A.; Estriga, M.L.; Reis, L.P.; Lames, M. Survey on team tracking techniques applied to sports. In Proceedings of the 2010 International Conference on Autonomous and Intelligent Systems, Povoa de Varzim, Portugal, 21–23 June 2010; pp. 1–6. [Google Scholar]
- Shih, H.C. A survey of content-aware video analysis for sports. IEEE Trans. Circuits Syst. Video Technol. 2017, 28, 1212–1231. [Google Scholar] [CrossRef] [Green Version]
- Priego, J.I.; Melis, J.O.; Belloch, S.L.; Soriano, P.P.; García, J.C.G.; Almenara, M.S. Padel: A Quantitative study of the shots and movements in the high-performance. J. Hum. Sport Exerc. 2013, 8, 925–931. [Google Scholar] [CrossRef] [Green Version]
- Yazaki, S.; Yamamoto, O. Analyzing Movements of Tennis Players by Dynamic Image Processing. IEEJ Trans. Electron. Inf. Syst. 2007, 127, 2005–2010. [Google Scholar]
- Mukai, R.; Araki, T.; Asano, T. Quantitative Evaluation of Tennis Plays by Computer Vision. IEEJ Trans. Electron. Inf. Syst. 2013, 133, 91–96. [Google Scholar] [CrossRef]
- Lara, J.P.R.; Vieira, C.L.R.; Misuta, M.S.; Moura, F.A.; Barros, R.M.L.D. Validation of a video-based system for automatic tracking of tennis players. Int. J. Perform. Anal. Sport 2018, 18, 137–150. [Google Scholar] [CrossRef]
- Pingali, G.; Opalach, A.; Jean, Y. Ball tracking and virtual replays for innovative tennis broadcasts. In Proceedings of the 15th International Conference on Pattern Recognition, ICPR-2000, Barcelona, Spain, 3–7 September 2000; Volume 4, pp. 152–156. [Google Scholar]
- Mao, J. Tracking a Tennis Ball Using Image Processing Techniques. Ph.D. Thesis, University of Saskatchewan, Saskatoon, SK, Canada, 2006. [Google Scholar]
- Qazi, T.; Mukherjee, P.; Srivastava, S.; Lall, B.; Chauhan, N.R. Automated ball tracking in tennis videos. In Proceedings of the 2015 Third International Conference on Image Information Processing (ICIIP), Waknaghat, India, 21–24 December 2015; pp. 236–240. [Google Scholar]
- Kamble, P.R.; Keskar, A.G.; Bhurchandi, K.M. Ball tracking in sports: A survey. Artif. Intell. Rev. 2019, 52, 1655–1705. [Google Scholar] [CrossRef]
- Sudhir, G.; Lee, J.C.M.; Jain, A.K. Automatic classification of tennis video for high-level content-based retrieval. In Proceedings of the 1998 IEEE International Workshop on Content-Based Access of Image and Video Database, Bombay, India, 3 January 1998; pp. 81–90. [Google Scholar]
- Dahyot, R.; Kokaram, A.; Rea, N.; Denman, H. Joint audio visual retrieval for tennis broadcasts. In Proceedings of the 2003 IEEE International Conference on Acoustics, Speech, and Signal Processing, Hong Kong, China, 6–10 April 2003; Volume 3, p. III-561. [Google Scholar]
- Yan, F.; Christmas, W.; Kittler, J. A tennis ball tracking algorithm for automatic annotation of tennis match. In Proceedings of the British Machine Vision Conference, Oxford, UK, 5–8 September 2005; Volume 2, pp. 619–628. [Google Scholar]
- Ramón-Llin, J.; Guzmán, J.; Martínez-Gallego, R.; Muñoz, D.; Sánchez-Pay, A.; Sánchez-Alcaraz, B.J. Stroke Analysis in Padel According to Match Outcome and Game Side on Court. Int. J. Environ. Res. Public Health 2020, 17, 7838. [Google Scholar] [CrossRef]
- Mas, J.R.L.; Belloch, S.L.; Guzmán, J.; Vuckovic, G.; Muñoz, D.; Martínez, B.J.S.A. Análisis de la distancia recorrida en pádel en función de los diferentes roles estratégicos y el nivel de juego de los jugadores (Analysis of distance covered in padel based on level of play and number of points per match). Acción Motriz 2020, 25, 59–67. [Google Scholar]
- Vučković, G.; Perš, J.; James, N.; Hughes, M. Measurement error associated with the SAGIT/Squash computer tracking software. Eur. J. Sport Sci. 2010, 10, 129–140. [Google Scholar] [CrossRef]
- Ramón-Llin, J.; Guzmán, J.F.; Llana, S.; Martínez-Gallego, R.; James, N.; Vučković, G. The Effect of the Return of Serve on the Server Pair’s Movement Parameters and Rally Outcome in Padel Using Cluster Analysis. Front. Psychol. 2019, 10, 1194. [Google Scholar] [CrossRef] [Green Version]
- Baclig, M.M.; Ergezinger, N.; Mei, Q.; Gül, M.; Adeeb, S.; Westover, L. A Deep Learning and Computer Vision Based Multi-Player Tracker for Squash. Appl. Sci. 2020, 10, 8793. [Google Scholar] [CrossRef]
- Cao, Z.; Hidalgo, G.; Simon, T.; Wei, S.E.; Sheikh, Y. OpenPose: Realtime multi-person 2D pose estimation using Part Affinity Fields. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 172–186. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J.; et al. MMDetection: Open MMLab Detection Toolbox and Benchmark. arXiv 2019, arXiv:cs.CV/1906.07155. [Google Scholar]
- Xiao, B.; Wu, H.; Wei, Y. Simple baselines for human pose estimation and tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 466–481. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: High Quality Object Detection and Instance Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2019. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wu, Y.; Kirillov, A.; Massa, F.; Lo, W.Y.; Girshick, R. Detectron2. 2019. Available online: https://github.com/facebookresearch/detectron2 (accessed on 1 February 2021).
- Chen, K.; Pang, J.; Wang, J.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Shi, J.; Ouyang, W.; et al. Hybrid task cascade for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Newell, A.; Yang, K.; Deng, J. Stacked hourglass networks for human pose estimation. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 483–499. [Google Scholar]
- Huang, J.; Zhu, Z.; Guo, F.; Huang, G. The Devil Is in the Details: Delving Into Unbiased Data Processing for Human Pose Estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Zhang, F.; Zhu, X.; Dai, H.; Ye, M.; Zhu, C. Distribution-aware coordinate representation for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 7093–7102. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 5693–5703. [Google Scholar]
- Cheng, B.; Xiao, B.; Wang, J.; Shi, H.; Huang, T.S.; Zhang, L. HigherHRNet: Scale-Aware Representation Learning for Bottom-Up Human Pose Estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5386–5395. [Google Scholar]
- Zhao, Z.Q.; Zheng, P.; Xu, S.T.; Wu, X. Object detection with deep learning: A review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [Green Version]
- Loper, M.; Mahmood, N.; Romero, J.; Pons-Moll, G.; Black, M.J. SMPL: A Skinned Multi-Person Linear Model. ACM Trans. Graphics (Proc. SIGGRAPH Asia) 2015, 34, 248:1–248:16. [Google Scholar] [CrossRef]
- Raykar, V.C.; Yu, S.; Zhao, L.H.; Valadez, G.H.; Florin, C.; Bogoni, L.; Moy, L. Learning from crowds. J. Mach. Learn. Res. 2010, 11, 1297–1322. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1492–1500. [Google Scholar]
- Zhu, X.; Hu, H.; Lin, S.; Dai, J. Deformable ConvNets v2: More Deformable, Better Results. arXiv 2018, arXiv:1811.11168. [Google Scholar]
- Skublewska-Paszkowska, M.; Powroznik, P.; Lukasik, E. Learning Three Dimensional Tennis Shots Using Graph Convolutional Networks. Sensors 2020, 20, 6094. [Google Scholar] [CrossRef]
- Steels, T.; Van Herbruggen, B.; Fontaine, J.; De Pessemier, T.; Plets, D.; De Poorter, E. Badminton Activity Recognition Using Accelerometer Data. Sensors 2020, 20, 4685. [Google Scholar] [CrossRef] [PubMed]
- Yu, C.H.; Wu, C.C.; Wang, J.S.; Chen, H.Y.; Lin, Y.T. Learning tennis through video-based reflective learning by using motion-tracking sensors. J. Educ. Technol. Soc. 2020, 23, 64–77. [Google Scholar]
- Delgado-García, G.; Vanrenterghem, J.; Ruiz-Malagón, E.J.; Molina-García, P.; Courel-Ibáñez, J.; Soto-Hermoso, V.M. IMU gyroscopes are a valid alternative to 3D optical motion capture system for angular kinematics analysis in tennis. Proc. Inst. Mech. Eng. Part J. Sport. Eng. Technol. 2020, 235, 1754337120965444. [Google Scholar] [CrossRef]
- Zhu, X.; Xiong, Y.; Dai, J.; Yuan, L.; Wei, Y. Deep feature flow for video recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2349–2358. [Google Scholar]
- Zhu, X.; Wang, Y.; Dai, J.; Yuan, L.; Wei, Y. Flow-guided feature aggregation for video object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 408–417. [Google Scholar]
- Wu, H.; Chen, Y.; Wang, N.; Zhang, Z. Sequence level semantics aggregation for video object detection. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 9217–9225. [Google Scholar]
- Wojke, N.; Bewley, A.; Paulus, D. Simple online and realtime tracking with a deep association metric. In Proceedings of the 2017 IEEE international conference on image processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3645–3649. [Google Scholar]
- Bergmann, P.; Meinhardt, T.; Leal-Taixe, L. Tracking without bells and whistles. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 941–951. [Google Scholar]
- Uzu, R.; Shinya, M.; Oda, S. A split-step shortens the time to perform a choice reaction step-and-reach movement in a simulated tennis task. J. Sport. Sci. 2009, 27, 1233–1240. [Google Scholar] [CrossRef] [PubMed]
- Pons, E.; Ponce-Bordón, J.C.; Díaz-García, J.; López del Campo, R.; Resta, R.; Peirau, X.; García-Calvo, T. A Longitudinal Exploration of Match Running Performance during a Football Match in the Spanish La Liga: A Four-Season Study. Int. J. Environ. Res. Public Health 2021, 18, 1133. [Google Scholar] [CrossRef] [PubMed]
- Cust, E.E.; Sweeting, A.J.; Ball, K.; Robertson, S. Machine and deep learning for sport-specific movement recognition: A systematic review of model development and performance. J. Sport. Sci. 2019, 37, 568–600. [Google Scholar] [CrossRef] [PubMed]
- Passos, P.; Lacasa, E.; Milho, J.; Torrents, C. Capturing Interpersonal Synergies in Social Settings: An Example within a Badminton Cooperative Task. Nonlinear Dyn. Psychol. Life Sci. 2020, 24, 59–78. [Google Scholar]
- Linke, D.; Link, D.; Lames, M. Validation of electronic performance and tracking systems EPTS under field conditions. PLoS ONE 2018, 13, e0199519. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yan, S.; Xiong, Y.; Lin, D. Spatial temporal graph convolutional networks for skeleton-based action recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Detector Config | Pose Estimator Config | Core Method(s) |
|---|---|---|
| faster rcnn r50 fpn person | hrnet w48 384 × 288 | HRNet [30] Faster R-CNN [22] ResNet [35] |
| faster rcnn x101 64 × 4d fpn | hrnet w48 384 × 288 | HRNet [30] Faster R-CNN [22] ResNeXt [36] |
| faster rcnn r50 fpn | hrnet w48 384 × 288 dark | HRNet [30] DarkPose [29] Faster R-CNN [22] ResNet [35] |
| faster rcnn r50 fpn | hourglass52 384 × 384 | Hourglass [27] Faster R-CNN [22] ResNet [35] |
| faster rcnn r50 fpn | hrnet w48 384 × 288 | HRNet [30] Faster R-CNN [22] ResNet [35] |
| cascade mask rcnn x101 64 × 4d fpn | hrnet w48 256 × 192 | HRNet [30] ResNeXt [36] Cascade Mask R-CNN [23] |
| htc x101 64 × 4d fpn | hrnet w48 256 × 192 | HRNet [30] ResNeXt [36] Hybrid Task Cascade [25] |
| dcn/cascade mask rcnn x101 32 × 4d fpn | hrnet w48 256 × 192 | HRNet [30] ResNeXt [36] Cascade Mask R-CNN [23] Deformable ConvNets [37] |
| Configuration | Core Method(s) |
|---|---|
| higherhrnet/higher hrnet32 512 × 512 | Higher HRNet [31] |
| higherhrnet/higher hrnet32 640 × 640 | Higher HRNet [31] |
| higherhrnet/higher hrnet48 512 × 512 | Higher HRNet [31] |
| hrnet w32 512 × 512 | HRNet [30] |
| hrnet w48 512 × 512 | HRNet [30] |
| mobilenetv2 512 × 512 | MobileNetv2 [26] |
| resnet/res50 512 × 512 | ResNet [21] |
| resnet/res50 640 × 640 | ResNet [21] |
| resnet/res101 512 × 512 | ResNet [21] |
| resnet/res152 512 × 512 | ResNet [21] |
| hrnet w32 512 × 512 udp | HRNet [30] UDP [28] |
| higher hrnet32 512 × 512 udp | Higher HRNet [31] UDP [28] |
| Method | AP | AP | AP | AP | AP | ||||
|---|---|---|---|---|---|---|---|---|---|
| DT-htc-x101-64 × 4d | 10.87 | 13.48 | 54.3 | 86.1 | 59.41 | 18.71 | 0.3 | 0.3 | 0.6 |
| DT-faster-rcnn-r50-1x | 10.83 | 13.49 | 55.6 | 87.0 | 58.19 | 21.48 | 0.7 | 1.0 | 1.2 |
| MK-Detectron2 | 9.25 | 12.67 | 66.9 | 87.7 | 40.86 | 23.51 | 3.0 | 3.8 | 5.5 |
| BU-openpose | 4.03 | 5.50 | 92.3 | 99.1 | 22.59 | 23.85 | 40.0 | 63.3 | 73.6 |
| BU-mobilenetv2-512 × 512 | 4.62 | 8.93 | 91.4 | 98.6 | 21.59 | 25.38 | 58.1 | 75.7 | 85.5 |
| BU-res50-640 × 640 | 3.73 | 6.33 | 95.1 | 98.9 | 19.41 | 20.48 | 52.8 | 76.7 | 87.5 |
| BU-hrnet-w32-512 × 512 | 3.06 | 4.54 | 97.9 | 99.8 | 17.38 | 15.98 | 51.7 | 75.9 | 88.6 |
| BU-res152-512 × 512 | 3.14 | 4.14 | 97.7 | 99.8 | 17.67 | 18.74 | 62.3 | 81.1 | 88.9 |
| BU-higher-hrnet32-512 × 512 | 2.55 | 3.29 | 98.9 | 100.0 | 16.48 | 13.87 | 53.1 | 78.0 | 91.2 |
| BU-higher-hrnet32-640 × 640 | 2.68 | 3.45 | 98.7 | 100.0 | 15.60 | 13.29 | 60.6 | 83.3 | 94.1 |
| TD-faster-rcnn-r50-1x—resnetv1d152-384 × 288 | 2.80 | 3.45 | 98.6 | 99.9 | 15.41 | 12.76 | 59.5 | 85.1 | 94.9 |
| TD-faster-rcnn-r50-1x—hourglass52-384 × 384 | 2.82 | 3.54 | 98.0 | 99.9 | 15.00 | 12.41 | 61.4 | 87.9 | 95.3 |
| TD-faster-rcnn-r50-1x—hrnet-w48-384 × 288-dark | 2.78 | 4.11 | 98.1 | 99.8 | 14.29 | 11.80 | 67.4 | 88.4 | 95.9 |
| TD-faster-rcnn-r50-1x—hrnet-w48-384 × 288 | 2.68 | 3.26 | 98.7 | 100.0 | 14.40 | 11.55 | 65.2 | 89.9 | 97.0 |
| TD-cascade-mask-rcnn-x101-64 × 4d—hrnet-w48-256 × 192 | 2.67 | 3.37 | 98.1 | 99.9 | 14.16 | 11.42 | 67.9 | 90.0 | 97.2 |
| TD-cascade-mask-rcnn-x101-32 × 4d—hrnet-w48-256x192 | 2.66 | 3.39 | 98.2 | 99.8 | 14.27 | 11.42 | 66.5 | 89.0 | 97.2 |
| TD-htc-x101-64 × 4d—hrnet-w48-256 × 192 | 2.70 | 3.37 | 98.5 | 99.9 | 14.20 | 11.30 | 67.5 | 89.7 | 97.5 |
| TD-faster-rcnn-r50-1x—hrnet-w48-256 × 192-person | 2.75 | 4.23 | 98.3 | 99.7 | 11.12 | 10.93 | 87.6 | 96.9 | 98.2 |
| TD-faster-rcnn-x101-64 × 4d-1x—hrnet-w48-256 × 192 | 2.63 | 3.23 | 98.5 | 100.0 | 11.10 | 10.66 | 88.0 | 96.9 | 98.7 |
| TD-faster-rcnn-r50-1x—hrnet-w48-256 × 192 | 2.71 | 4.13 | 98.4 | 99.9 | 11.34 | 11.47 | 87.3 | 95.9 | 98.7 |
| Method | AP | AP | AP | AP | AP | ||||
|---|---|---|---|---|---|---|---|---|---|
| DT-htc-x101-64 × 4d | 11.67 | 14.21 | 49.2 | 84.1 | 51.73 | 12.87 | 0.0 | 0.0 | 0.2 |
| DT-faster-rcnn-r50-1x | 11.77 | 14.35 | 48.4 | 84.5 | 50.29 | 13.37 | 0.0 | 0.0 | 0.2 |
| MK-Detectron2 | 10.13 | 13.62 | 63.1 | 83.8 | 33.43 | 16.23 | 1.9 | 2.6 | 6.2 |
| BU-mobilenetv2-512 × 512 | 4.02 | 9.99 | 96.8 | 98.2 | 17.66 | 22.44 | 72.3 | 89.7 | 93.1 |
| BU-res50-640 × 640 | 3.22 | 5.71 | 97.4 | 99.3 | 14.69 | 17.00 | 83.5 | 93.5 | 97.1 |
| BU-res152-512 × 512 | 2.70 | 3.36 | 99.0 | 100.0 | 12.36 | 10.39 | 83.6 | 96.0 | 99.0 |
| TD-faster-rcnn-r50-1x—hrnet-w48-256 × 192 | 2.57 | 4.53 | 99.0 | 99.8 | 7.31 | 7.30 | 98.7 | 99.6 | 99.6 |
| BU-openpose | 3.04 | 3.84 | 98.1 | 100.0 | 10.53 | 11.95 | 95.4 | 99.2 | 99.6 |
| BU-hrnet-w32-512 × 512 | 2.57 | 3.14 | 99.6 | 100.0 | 10.56 | 8.91 | 91.9 | 99.0 | 99.6 |
| BU-higher-hrnet32-512 × 512 | 2.36 | 2.87 | 99.8 | 100.0 | 10.03 | 7.72 | 94.7 | 99.5 | 99.8 |
| TD-cascade-mask-rcnn-x101-32 × 4d—hrnet-w48-256 × 192 | 2.47 | 2.91 | 99.2 | 100.0 | 9.31 | 7.21 | 97.5 | 99.8 | 99.8 |
| TD-faster-rcnn-r50-1x—hrnet-w48-384 × 288 | 2.55 | 2.94 | 98.8 | 100.0 | 9.67 | 7.29 | 96.2 | 99.8 | 99.8 |
| TD-faster-rcnn-r50-1x—hrnet-w48-384 × 288-dark | 2.64 | 4.37 | 98.5 | 99.8 | 8.86 | 7.12 | 98.1 | 99.6 | 99.8 |
| TD-faster-rcnn-r50-1x—resnetv1d152-384 × 288 | 2.58 | 2.99 | 99.2 | 100.0 | 9.47 | 7.66 | 97.3 | 99.6 | 99.8 |
| TD-cascade-mask-rcnn-x101-64 × 4d—-hrnet-w48-256 × 192 | 2.53 | 3.00 | 99.0 | 100.0 | 9.07 | 6.82 | 98.3 | 100.0 | 100.0 |
| BU-higher-hrnet32-640 × 640 | 2.46 | 3.08 | 99.0 | 100.0 | 9.45 | 7.60 | 97.7 | 100.0 | 100.0 |
| TD-faster-rcnn-r50-1x—hourglass52-384 × 384 | 2.66 | 3.12 | 98.3 | 100.0 | 9.74 | 7.55 | 96.0 | 99.6 | 100.0 |
| TD-faster-rcnn-r50-1x—hrnet-w48-256 × 192-person | 2.51 | 3.88 | 99.0 | 99.8 | 7.11 | 6.67 | 98.8 | 99.8 | 100.0 |
| TD-faster-rcnn-x101-64 × 4d-1x—hrnet-w48-256 × 192 | 2.43 | 2.84 | 99.0 | 100.0 | 7.10 | 6.52 | 99.0 | 100.0 | 100.0 |
| TD-htc-x101-64 × 4d—hrnet-w48-256 × 192 | 2.54 | 3.01 | 99.2 | 100.0 | 9.22 | 6.88 | 98.1 | 99.8 | 100.0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Javadiha, M.; Andujar, C.; Lacasa, E.; Ric, A.; Susin, A. Estimating Player Positions from Padel High-Angle Videos: Accuracy Comparison of Recent Computer Vision Methods. Sensors 2021, 21, 3368. https://0-doi-org.brum.beds.ac.uk/10.3390/s21103368
Javadiha M, Andujar C, Lacasa E, Ric A, Susin A. Estimating Player Positions from Padel High-Angle Videos: Accuracy Comparison of Recent Computer Vision Methods. Sensors. 2021; 21(10):3368. https://0-doi-org.brum.beds.ac.uk/10.3390/s21103368
Chicago/Turabian StyleJavadiha, Mohammadreza, Carlos Andujar, Enrique Lacasa, Angel Ric, and Antonio Susin. 2021. "Estimating Player Positions from Padel High-Angle Videos: Accuracy Comparison of Recent Computer Vision Methods" Sensors 21, no. 10: 3368. https://0-doi-org.brum.beds.ac.uk/10.3390/s21103368