
Restoration of Motion Blurred Image by Modified DeblurGAN for Enhancing the Accuracies of Finger-Vein Recognition



Abstract
:1. Introduction
- This is the first study on motion blur finger-vein image restoration that can occur in actual environments.
- For restoration of motion blur finger-vein image, we propose a modified DeblurGAN. The proposed modified DeblurGAN has differences in comparison with the original DeblurGAN, (1) dropout layer removal, (2) number of trainable parameters reduction by modifying the number of the residual block structure, (3) and uses feature-based perceptual loss in the first residual block.
- Training is conducted by separating the modified DeblurGAN and the deep CNN, therefore, reducing training complexity while improving convergence.
- The modified DeblurGAN, a deep CNN, and a non-uniform motion blurred image database are published in [16] to allow other researchers to perform fair performance evaluations.
2. Related Works
2.1. Finger-Vein Recognition without Blur Restoration
2.2. Finger-Vein Recognition with Skin Scattering Blur Restoration
2.3. Finger-Vein Recognition with Optical Blur Restoration
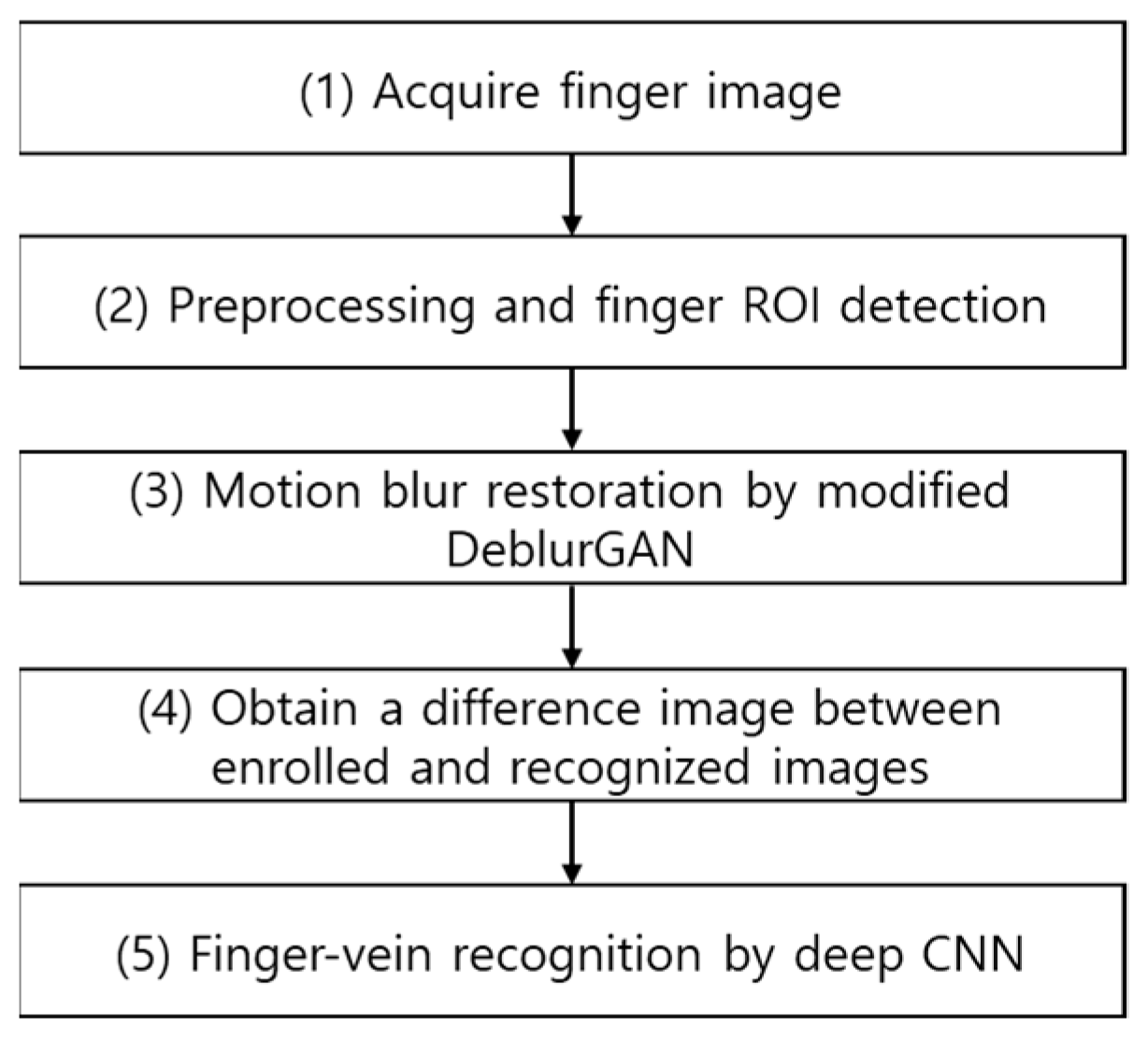
3. Proposed Method
3.1. Overview of the Proposed Method
3.2. Preprocessing the Finger-Vein Image
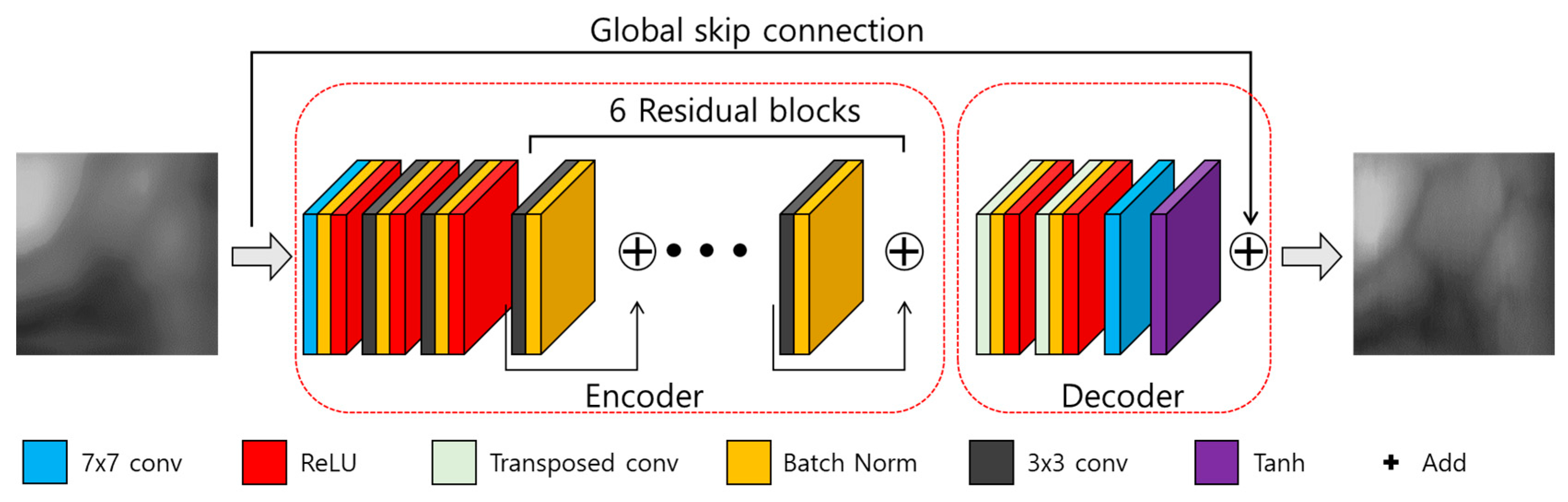
3.3. Modified DeblurGAN-Based Finger-Vein Image Restoration
3.3.1. Generator
3.3.2. Discriminator
3.3.3. Loss
3.3.4. Summarized Differences between Original DeblurGAN and Proposed Modified DeblurGAN
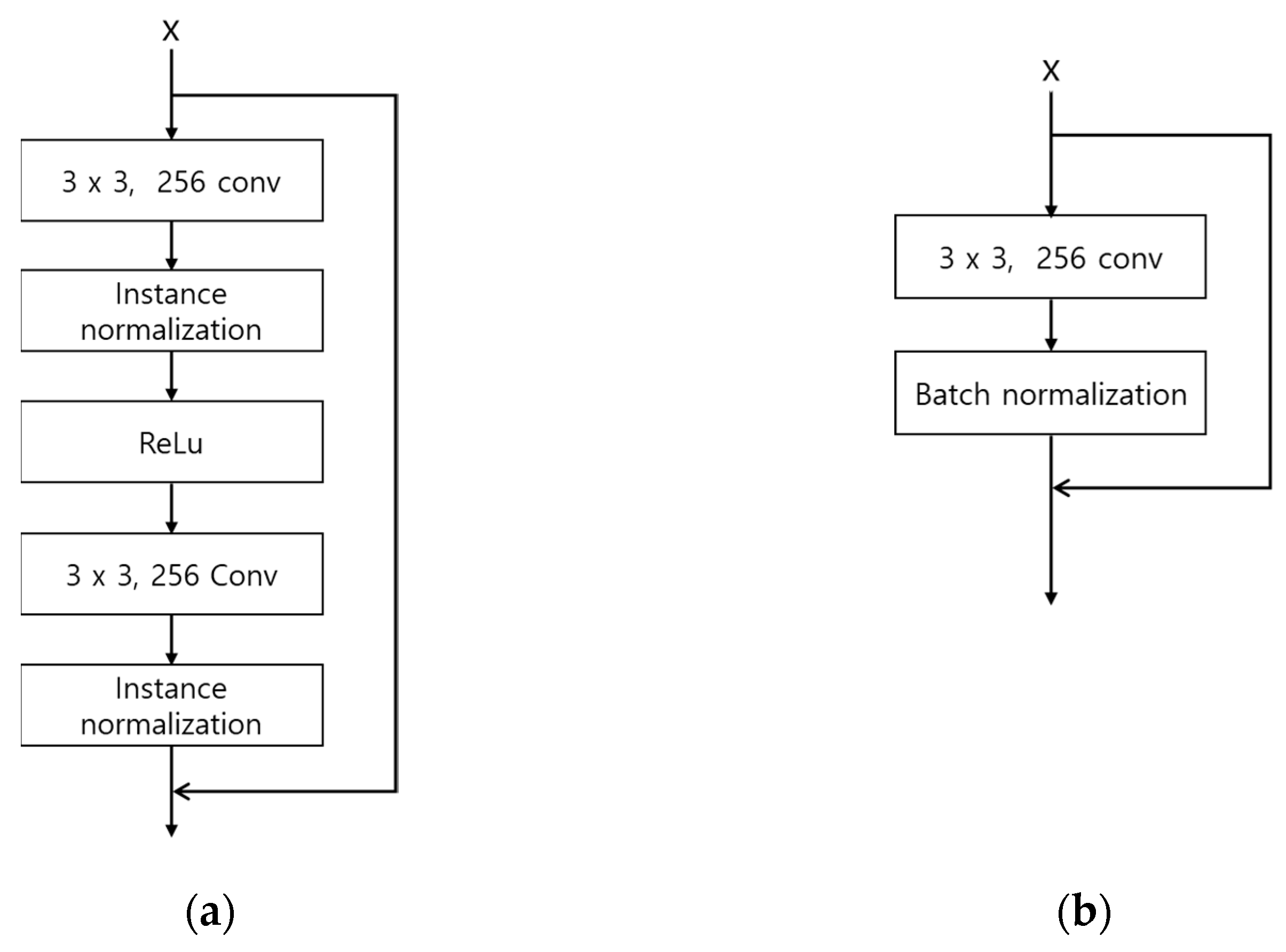
- A dropout is applied to the generator of the original DeblurGAN, whereas a dropout is not applied to the generator of the modified DeblurGAN because the vein patterns of the restored image can be modified. The dropout layer usually helps avoiding overfitting. However, the dropout layer can also bring about the excessive sparsity of activation and features with coarser features compared to the case without the dropout layer [34,43], which can cause the consequent modification of a vein pattern in the restored output image. Therefore, we do not use the dropout layer in the generator of proposed modified DeblurGAN.
- In the original DeblurGAN, nine residual blocks (convolutional layer—normalization layer—activation layer—convolutional layer—normalization layer) were used for the generator. In the modified DeblurGAN, to reduce the inference time, the number of parameters was reduced by reducing the structure of the residual block (convolutional layer-normalization layer) and reducing the total number of residual blocks to six.
- In the original DeblurGAN, high-level feature maps extracted from the third convolution layer prior to the third max-pooling layer of the ImageNet-pretrained VGG-19 were applied to a perceptual loss. However, it is equally important to restore the information of low-level features, such as color, corner, edge, and texture, during finger-vein restoration. Hence, a perceptual loss was applied to the first residual block (conv2_x) using the ImageNet-pretrained ResNet-34 in the modified DeblurGAN.
3.4. Finger-Vein Recognition by Deep CNN
4. Experimental Results
4.1. Two Open Databases for Experiments
4.2. Motion Blur Datasets for Finger-Vein Image Restoration
4.3. Data Augmentation and Experimental Setup
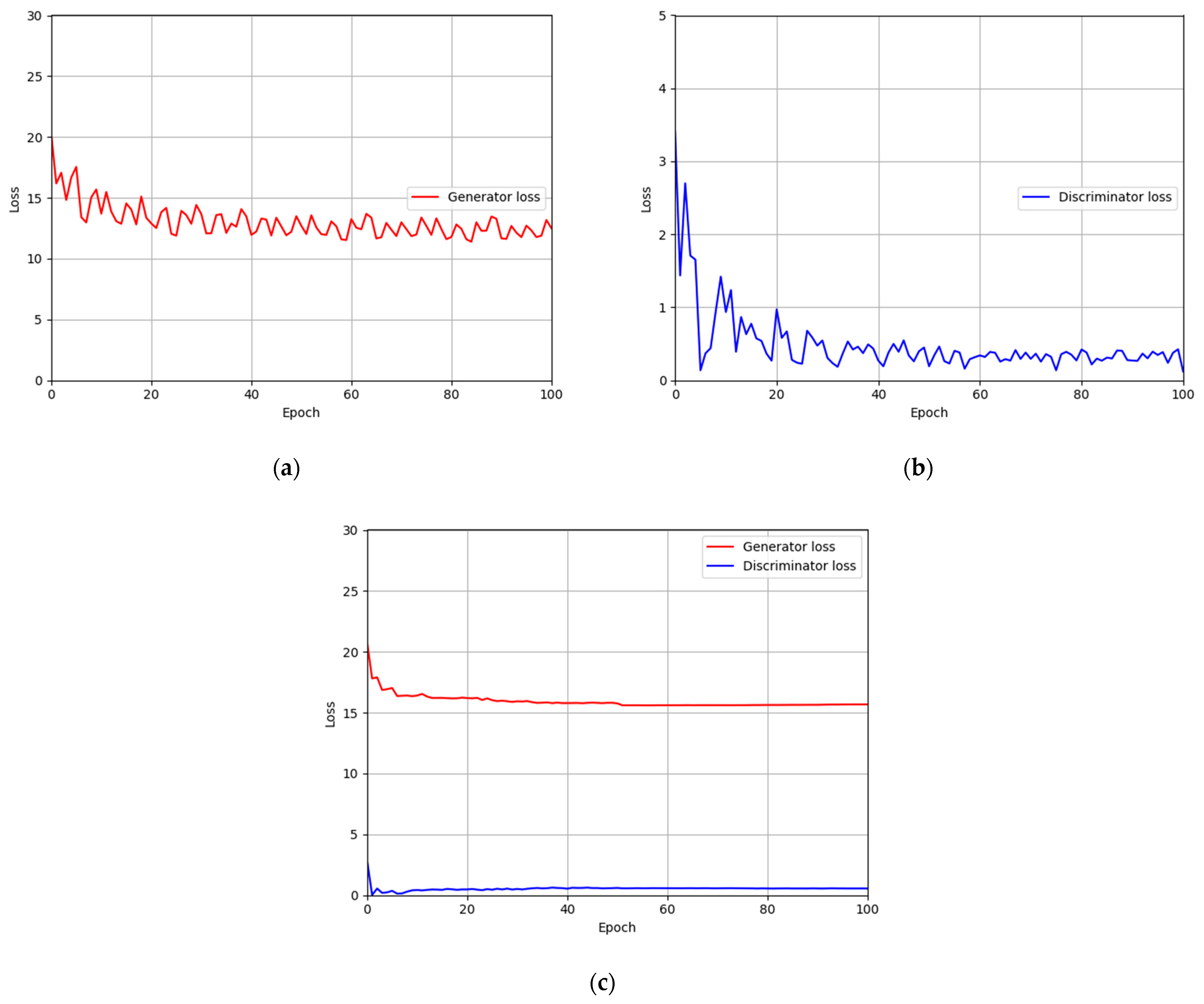
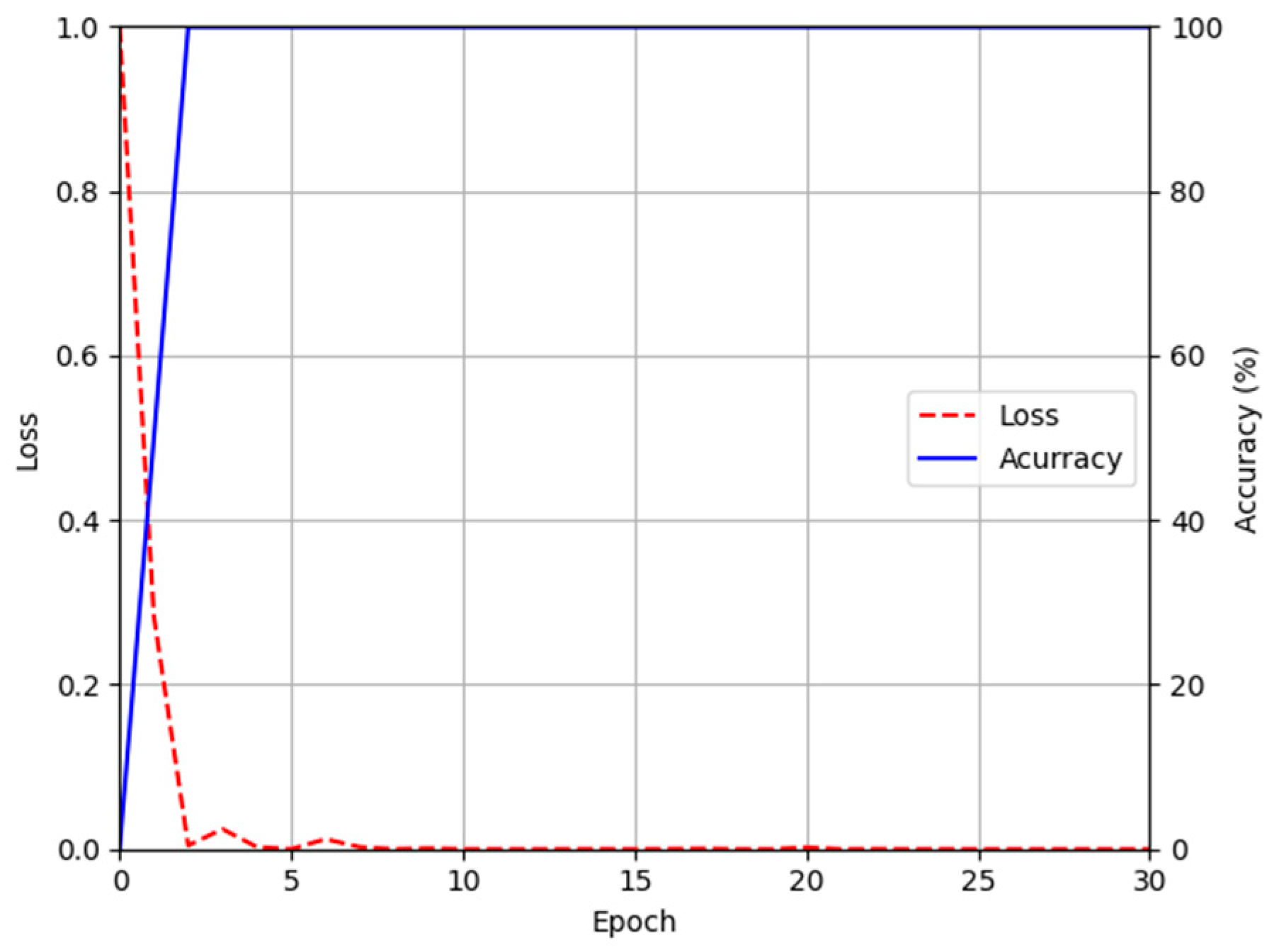
4.4. Training of Modified DeblurGAN Model for Motion Blur Restoration
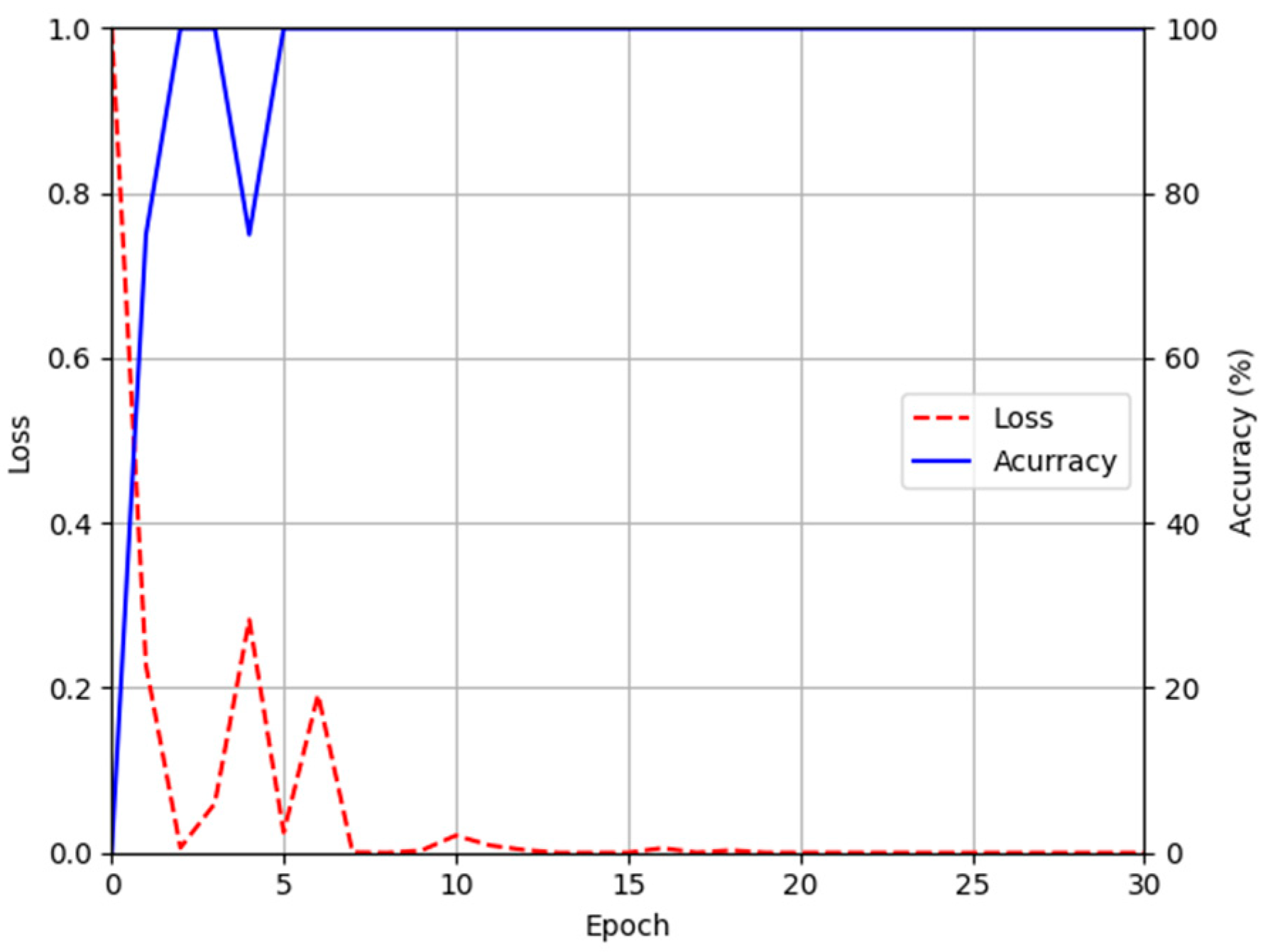
4.5. Training of DenseNet-161 for Finger-Vein Recognition
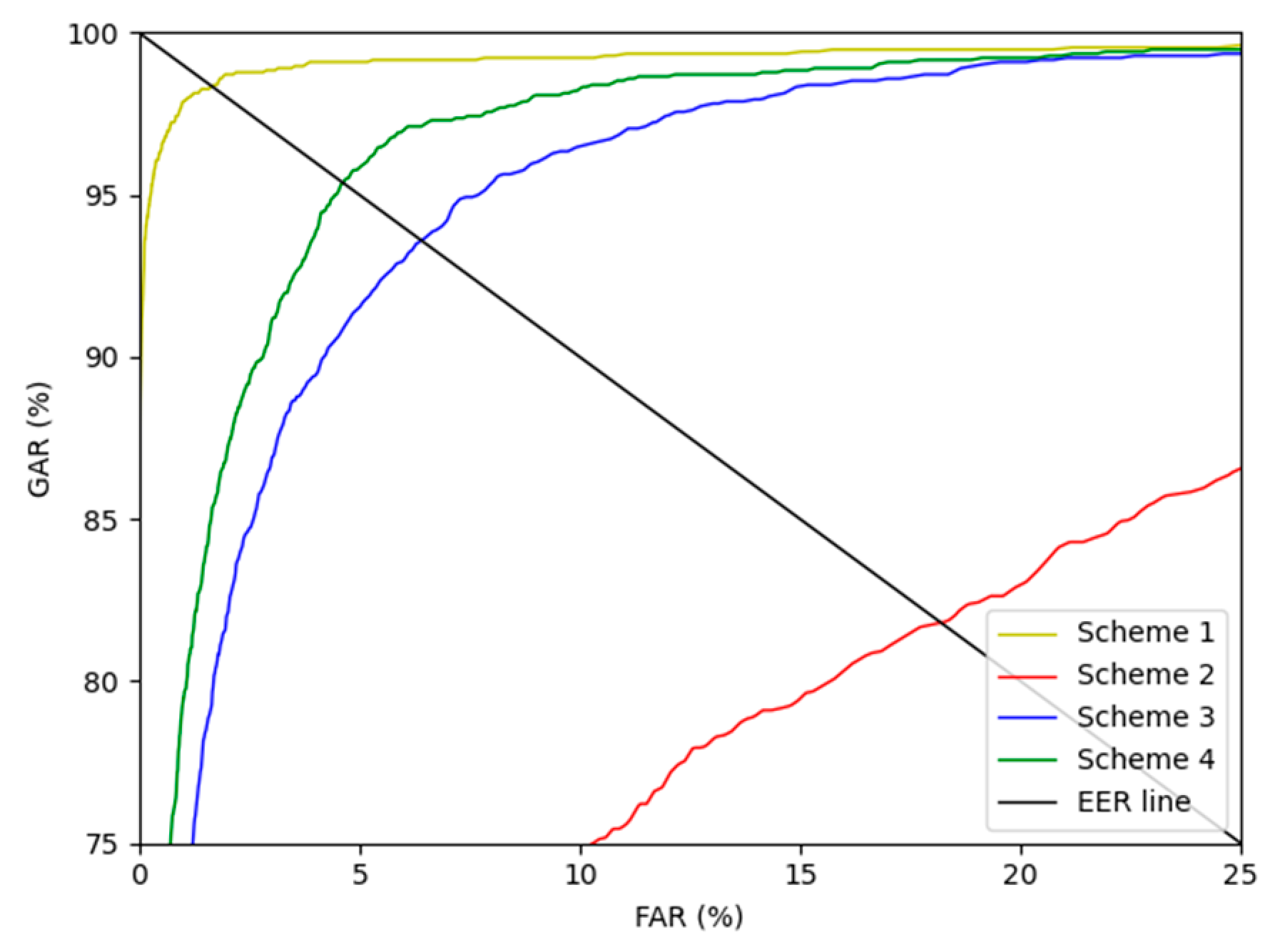
4.6. Testing Results of Proposed Method
4.6.1. Ablation Studies
4.6.2. Comparisons with the State-of-the-Art Methods
4.7. Processing Time of Proposed Method
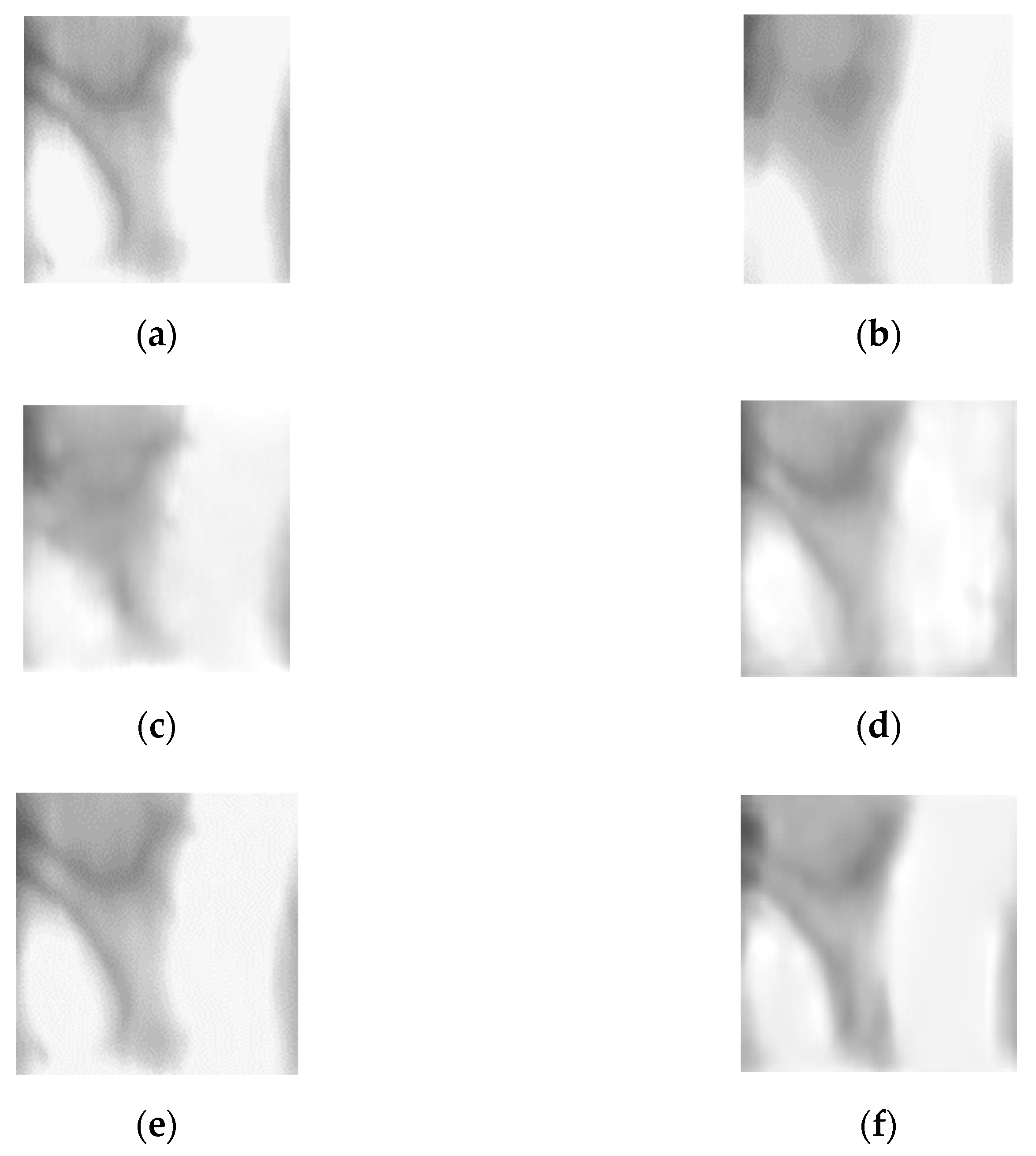
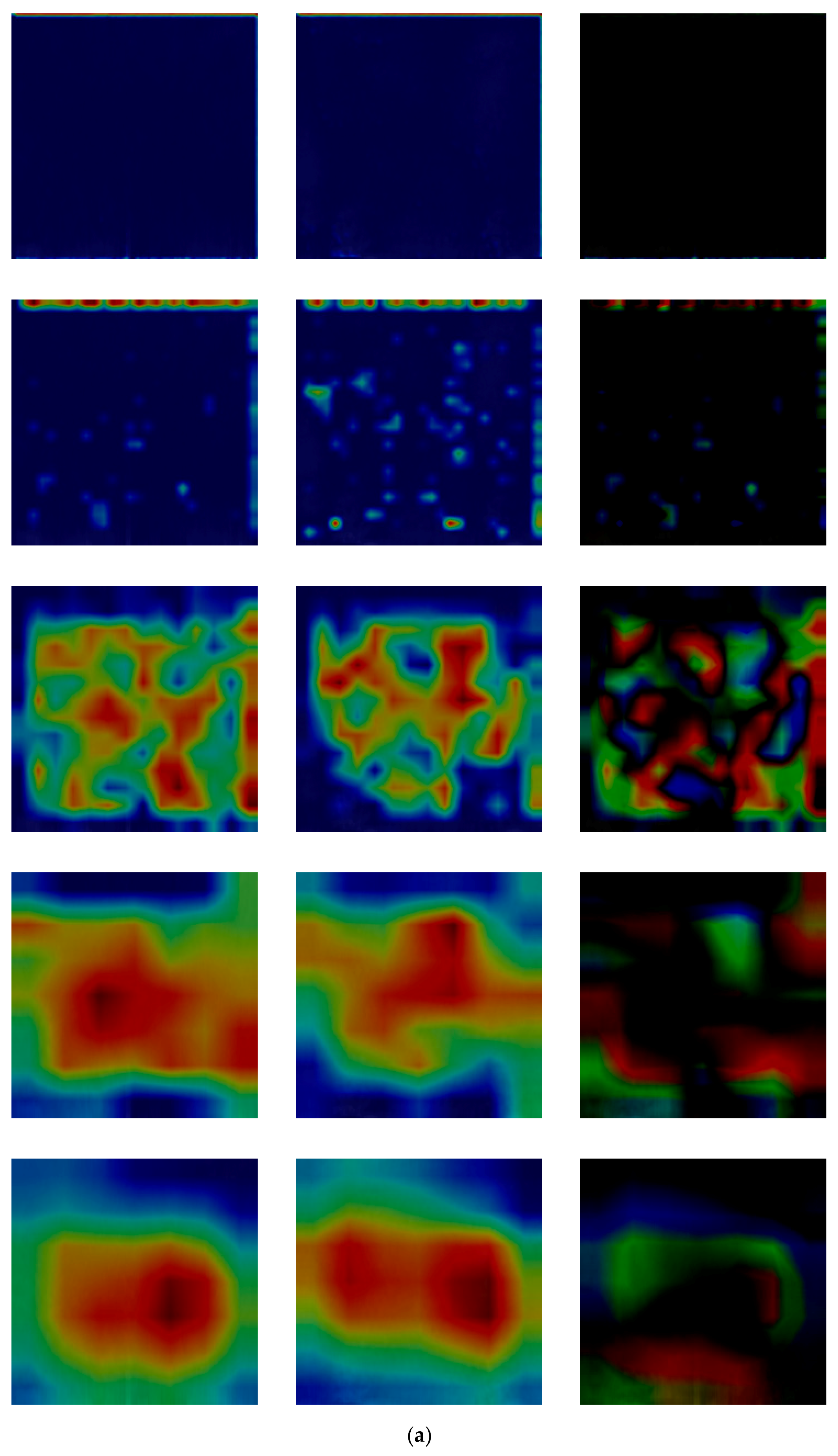
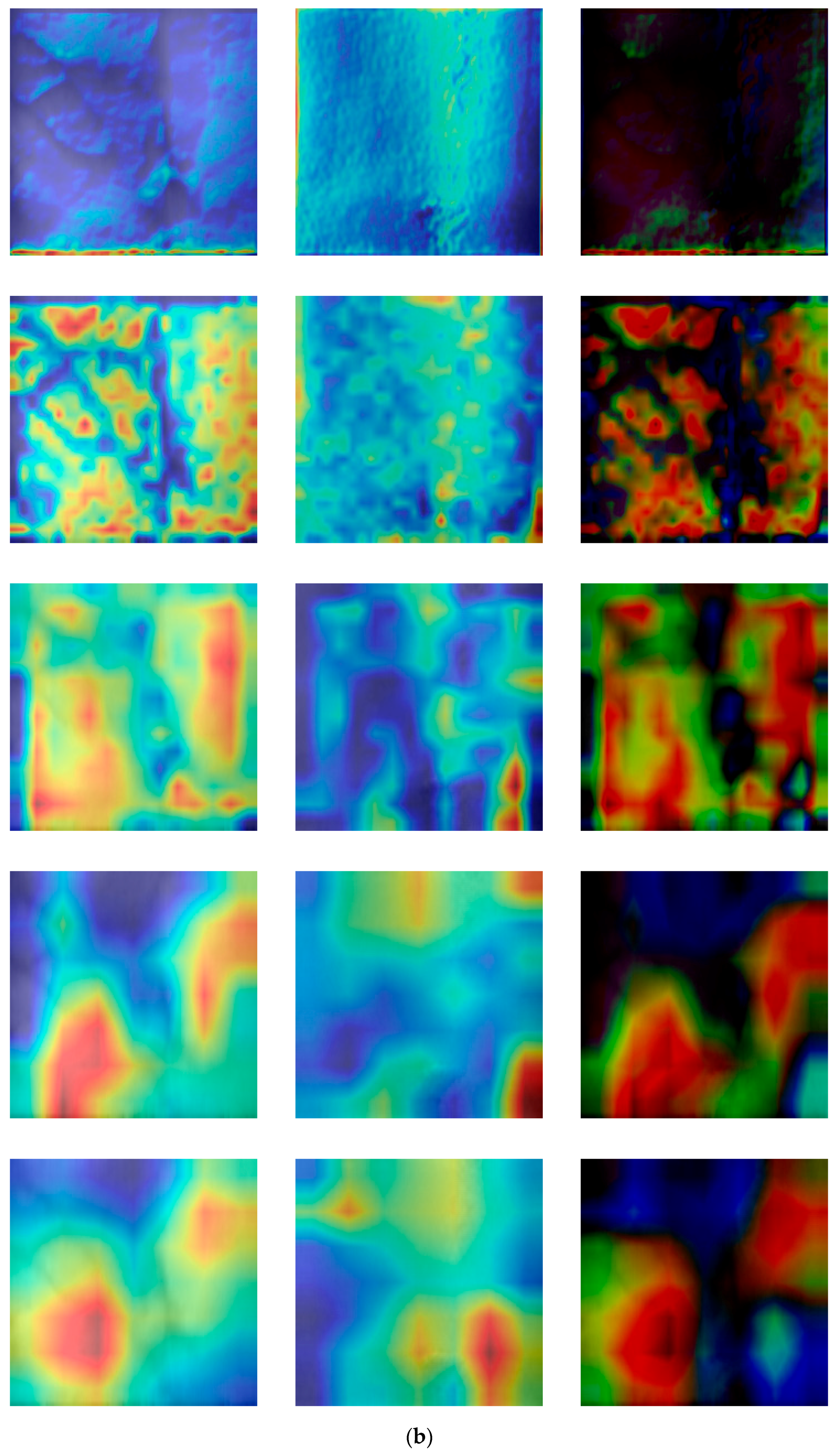
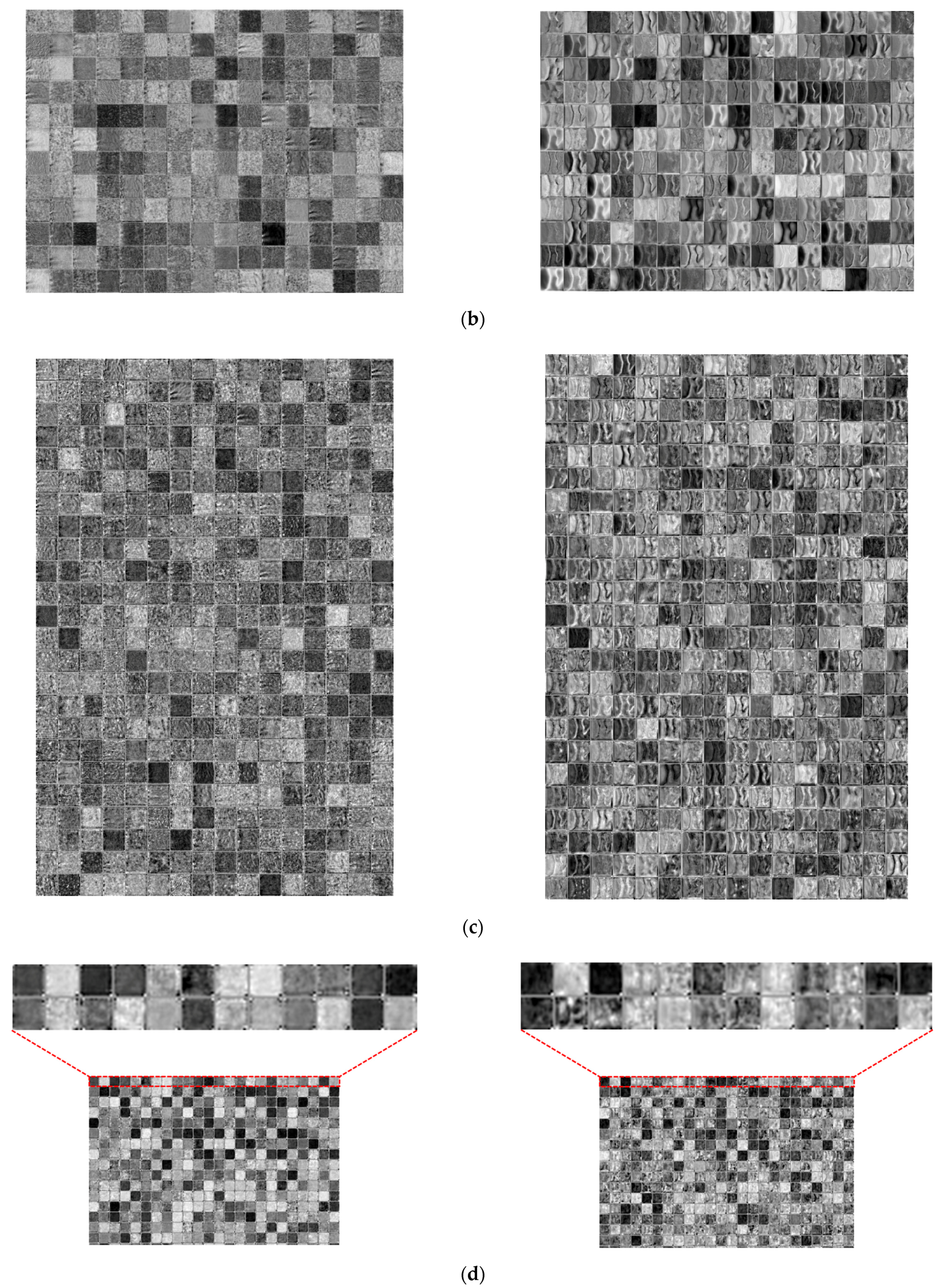
4.8. Analysis of Feature Map
4.8.1. Class Activation Map of Restored Image
4.8.2. Feature Maps of Difference Image
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Liu, Z.; Yin, Y.; Wang, H.; Song, S.; Li, Q. Finger vein recognition with manifold learning. J. Netw. Comput. Appl. 2010, 33, 275–282. [Google Scholar] [CrossRef]
- Lee, E.C.; Park, K.R. Restoration method of skin scattering blurred vein image for finger vein recognition. Electron. Lett. 2009, 45, 1074–1076. [Google Scholar] [CrossRef]
- Yang, J.; Zhang, B.; Shi, Y. Scattering removal for finger-vein image restoration. Sensors 2012, 12, 3627–3640. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yang, J.; Zhang, B. Scattering removal for finger-vein image enhancement. In Proceedings of the International Conference on Hand-Based Biometrics (ICHB), Hong Kong, China, 17–18 November 2011; pp. 1–5. [Google Scholar]
- Yang, J.; Shi, Y. Towards finger-vein image restoration and enhancement for finger-vein recognition. Inf. Sci. 2014, 268, 33–52. [Google Scholar] [CrossRef]
- Shi, Y.; Yang, J.; Yang, J. A new algorithm for finger-vein image enhancement and segmentation. Inf. Sci. Ind. Appl. 2012, 4, 139–144. [Google Scholar]
- Yang, J.; Bai, G. Finger-vein image restoration based on skin optical property. In Proceedings of the 11th International Conference on Signal Processing (ICSP), Beijing, China, 21–25 October 2012; pp. 749–752. [Google Scholar]
- Yang, J.; Shi, Y.; Yang, J. Finger-vein image restoration based on a biological optical model. In New Trends and Developments in Biometrics; IntechOpen: London, UK, 2012; pp. 59–76. [Google Scholar]
- You, W.; Zhou, W.; Huang, J.; Yang, F.; Liu, Y.; Chen, Z. A bilayer image restoration for finger vein recognition. Neurocomputing 2019, 348, 54–65. [Google Scholar] [CrossRef]
- Lee, E.C.; Park, K.R. Image restoration of skin scattering and optical blurring for finger vein recognition. Opt. Lasers Eng. 2011, 49, 816–828. [Google Scholar] [CrossRef]
- Choi, J.H.; Noh, K.J.; Cho, S.W.; Nam, S.H.; Owais, M.; Park, K.R. Modified conditional generative adversarial network-based optical blur restoration for finger-vein recognition. IEEE Access 2020, 8, 16281–16301. [Google Scholar] [CrossRef]
- Kupyn, O.; Budzan, V.; Mykhailych, M.; Mishkin, D.; Matas, J. DeblurGAN: Blind motion deblurring using conditional adversarial networks. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 8183–8192. [Google Scholar]
- Szeliski, R. Computer Vision: Algorithms and Applications, 1st ed.; Springer: London, UK, 2010. [Google Scholar]
- Kupyn, O.; Martyniuk, T.; Wu, J.; Wang, Z. Deblurgan-v2: Deblurring (orders-of-magnitude) faster and better. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 8878–8887. [Google Scholar]
- Tao, X.; Gao, H.; Shen, X.; Wang, J.; Jia, J. Scale-recurrent network for deep image deblurring. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 8174–8182. [Google Scholar]
- Dongguk Modified DeblurGAN and CNN for Recognition of Blurred Finger-Vein Image with Motion Blurred Image Database. Available online: https://github.com/dongguk-dm/MDG_CNN (accessed on 29 June 2021).
- Lee, E.C.; Lee, H.C.; Park, K.R. Finger vein recognition using minutia-based alignment and local binary pattern-based feature extraction. Int. J. Imaging Syst. Technol. 2009, 19, 179–186. [Google Scholar] [CrossRef]
- Peng, J.; Wang, N.; El-Latif, A.A.A.; Li, Q.; Niu, X. Finger-vein verification using Gabor filter and SIFT feature matching. In Proceedings of the International Conference on Intelligent Information Hiding and Multimedia Signal Processing (IIHMSP), Piraeus, Greece, 18–20 July 2012; pp. 45–48. [Google Scholar]
- Wu, J.-D.; Liu, C.-T. Finger-vein pattern identification using SVM and neural network technique. Expert Syst. Appl. 2011, 38, 14284–14289. [Google Scholar] [CrossRef]
- Hong, H.G.; Lee, M.B.; Park, K.R. Convolutional neural network-based finger-vein recognition using NIR image sensors. Sensors 2017, 17, 1297. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kim, W.; Song, J.M.; Park, K.R. Multimodal biometric recognition based on convolutional neural network by the fusion of finger-vein and finger shape using near-infrared (NIR) camera sensor. Sensors 2018, 18, 2296. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Qin, H.; El-Yacoubi, M.A. Deep representation-based feature extraction and recovering for finger-vein verification. IEEE Trans. Inf. Forensic Secur. 2017, 12, 1816–1829. [Google Scholar] [CrossRef]
- Song, J.M.; Kim, W.; Park, K.R. Finger-vein recognition based on deep DenseNet using composite image. IEEE Access 2019, 7, 66845–66863. [Google Scholar] [CrossRef]
- Noh, K.J.; Choi, J.; Hong, J.S.; Park, K.R. Finger-vein recognition based on densely connected convolutional network using score-level fusion with shape and texture images. IEEE Access 2020, 8, 96748–96766. [Google Scholar] [CrossRef]
- Noh, K.J.; Choi, J.; Hong, J.S.; Park, K.R. Finger-vein recognition using heterogeneous databases by domain adaption based on a cycle-consistent adversarial network. Sensors 2021, 21, 524. [Google Scholar] [CrossRef]
- Qin, H.; Wang, P. Finger-vein verification based on LSTM recurrent neural networks. Appl. Sci. 2019, 9, 1687. [Google Scholar] [CrossRef] [Green Version]
- Gonzalez, R.C.; Woods, R.E. Digital Image Processing, 2nd ed.; Prentice-Hall: Upper Saddle River, NJ, USA, 2002. [Google Scholar]
- Gonzalez, R.C.; Woods, R.E. Digital Image Processing, 3rd ed.; Prentice-Hall: Upper Saddle River, NJ, USA, 2010. [Google Scholar]
- Kumar, A.; Zhou, Y. Human identification using finger images. IEEE Trans. Image Process. 2012, 21, 2228–2244. [Google Scholar] [CrossRef]
- Kumar, A.; Zhang, D. Personal recognition using hand shape and texture. IEEE Trans. Image Process. 2006, 15, 2454–2461. [Google Scholar] [CrossRef] [Green Version]
- Yin, Y.; Liu, L.; Sun, X. SDUMLA-HMT: A Multimodal Biometric Database. In Proceedings of the Chinese Conference on Biometric Recognition (CCBR), Beijing, China, 3–4 December 2011; pp. 260–268. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted Boltzmann machines. In Proceedings of the 27th International Conference on International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn Res. 2014, 15, 1929–1958. [Google Scholar]
- Nah, S.; Kim, T.H.; Lee, K.M. Deep multi-scale convolutional neural network for dynamic scene deblurring. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3883–3891. [Google Scholar]
- Köhler, R.; Hirsch, M.; Mohler, B.; Schölkopf, B.; Harmeling, S. Recording and playback of camera shake: Benchmarking blind deconvolution with a real-world database. In Proceedings of the Europe Conference Computer Vision (ECCV), Florence, Italy, 7–13 October 2012; pp. 27–40. [Google Scholar]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A.C. Improved training of Wasserstein GANs. arXiv 2017, arXiv:1704.00028. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved techniques for training GANs. In Proceedings of the 30th International Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 2234–2242. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 818–833. [Google Scholar]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 694–711. [Google Scholar]
- Molchanov, D.; Ashukha, A.; Vetrov, D. Variational dropout sparsifies deep neural networks. arXiv 2017, arXiv:1701.05369v3. [Google Scholar]
- Image Differencing. Available online: https://en.wikipedia.org/wiki/Image_differencing (accessed on 20 December 2020).
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- NVIDIA GeForce GTX 1070. Available online: https://www.geforce.com/hardware/desktop-gpus/geforce-gtx-1070/specifications (accessed on 27 December 2020).
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Bottou, L. Large-scale machine learning with stochastic gradient descent. In Proceedings of the International Conference on Computational Statistics, Paris, France, 22–27 August 2010; pp. 177–186. [Google Scholar]
- Xie, S.; Girshick, R.; Dollar, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5987–5995. [Google Scholar]
- Stathaki, T. Image Fusion: Algorithms and Applications; Academic: Cambridge, MA, USA, 2008. [Google Scholar]
- Salomon, D. Data Compression: The Complete Reference, 4th ed.; Springer: New York, NY, USA, 2006. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality evaluation: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jetson TX2 Module. Available online: https://developer.nvidia.com/embedded/jetson-tx2 (accessed on 2 January 2021).
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Rarikh, D.; Batra, D. Grad-CAM: Visual explanations from deep networks through gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Zhu, Y.-C.; AlZoubi, A.; Jassim, S.; Jiang, Q.; Zhang, Y.; Wang, Y.-B.; Ye, X.-D.; DU, H. A generic deep learning framework to classify thyroid and breast lesions in ultrasound images. Ultrasonics 2021, 110, 1–8. [Google Scholar] [CrossRef] [PubMed]
- Robb, E.; Chu, W.-S.; Kumar, A.; Huang, J.-B. Few-shot adaptation of generative adversarial networks. arXiv 2020, arXiv:2010.11943v1. [Google Scholar]



























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Methods | Advantages | Disadvantages | |
|---|---|---|---|---|
| Without considering blur restoration | Handcrafted feature-based | LBP-based feature extraction + Hamming distance [17] | Recognition performance is improved when an optimal filter is accurately modeled |
|
| Gabor filter + SIFT feature matching [18] | ||||
| Deep feature-based | PCA + LDA + SVM [19] |
|
| |
| Difference image + CNN [20,21] | ||||
| Vein-pattern maps + CNN [22] | ||||
| Composite image + shift matching + CNN [23,24,25] | ||||
| SCNN-LSTM [26] | ||||
| Skin scattering blur restoration | Handcrafted feature-based | PSF + CLS filter [2] | Performance is significantly improved if scattering blur parameters are accurately estimated |
|
| BOM [3,4] | ||||
| WBOM + ADAGC + NSTM + Gabor wavelets [5] | ||||
| Haze removal techniques [6] | ||||
| Multilayered PSF + BOM [7] | ||||
| Optical model-based scattering removal [8] | ||||
| Bilayer diffusion model + blur-SURE + multi-Wiener SURE-LET [9] | ||||
| Optical-blur restoration | Handcrafted feature-based | PSF for optical blur + PSF for scattering blur + CLS filter [10] | Image restoration considering both optical and skin scattering blur |
|
| Deep feature-based | Conditional GAN + CNN [11] | Applicable to images captured from various environments | Did not consider the motion blur | |
| Motion blur restoration | Deep feature-based | Modified DeblurGAN-based method + CNN (Proposed method) | Recognition performance improved after restoration considering a motion blur that may occur when capturing finger-vein images | Networks for restoration and recognition require large data and take a long time to train. |
| Layer | Number of Filters | Size of Feature Map (Height × Width × Channel) | Size of Kernel (Height × Width × Channel) | Number of Strides (Height × Width) | Number of Paddings (Height × Width) | |
|---|---|---|---|---|---|---|
| Image input layer | 256 × 256 × 3 | |||||
| Encoder | 1st convolutional layer Batch normalization ReLU | 64 | 256 × 256 × 64 | 7 × 7 × 3 | 1 × 1 | 3 × 3 |
| 2nd convolutional layer Batch normalization ReLU | 128 | 128 × 128 × 128 | 3 × 3 × 64 | 2 × 2 | 1 × 1 | |
| 3rd convolutional layer Batch normalization ReLU | 256 | 64 × 64 × 256 | 3 × 3 × 128 | 2 × 2 | 1 × 1 | |
| Residual Blocks × 6 [3 × 3 conv, Batch normalization] | 256 | 64 × 64 × 256 | 3 × 3 × 256 | 1 × 1 | 1 × 1 | |
| Decoder | 1st transposed layer Batch normalization ReLU | 128 | 128 × 128 × 128 | 3 × 3 × 256 | 2 × 2 | |
| 2nd transposed layer Batch normalization ReLU | 64 | 256 × 256 × 64 | 3 × 3 × 128 | 2 × 2 | ||
| 4th convolutional layer Batch normalization ReLU | 3 | 256 × 256 × 3 | 7 × 7 × 64 | 1 × 1 | 3 × 3 | |
| Output (input + 4th convolutional layer) | 256 × 256 × 3 | |||||
| Layer | Number of Filters | Size of Feature Map (Height × Width × Channel) | Size of Kernel (Height × Width × Channel) | Number of Strides (Height × Width) | Number of Paddings (Height × Width) |
|---|---|---|---|---|---|
| * Image input layer | 256 × 256 × 3 | ||||
| 1st convolutional layer Leaky ReLU | 64 | 129 × 129 × 64 | 4 × 4 × 3 | 2 × 2 | 2 × 2 |
| 2nd convolutional layer Batch normalization Leaky ReLU | 128 | 65 × 65 × 128 | 4 × 4 × 64 | 2 × 2 | 2 × 2 |
| 3rd convolutional layer Batch normalization Leaky ReLU | 256 | 33 × 33 × 256 | 4 × 4 × 128 | 2 × 2 | 2 × 2 |
| 4th convolutional layer Batch normalization Leaky ReLU | 512 | 34 × 34 × 512 | 4 × 4 × 256 | 1 × 1 | 2 × 2 |
| 5th convolutional layer | 1 | 35 × 35 × 1 | 4 × 4 × 512 | 1 × 1 | 2 × 2 |
| SDU-DB | PolyU-DB | |||
|---|---|---|---|---|
| Original images | # of images | 3816 | 1872 | |
| # of people | 106 | 156 | ||
| # of hands | 2 | 1 | ||
| # of fingers | 3 (index, middle, and ring fingers) | 2 (index and middle fingers) | ||
| # of classes (# of images per class) | 636 (6) | 312 (6) | ||
| Training for 1st or 2nd fold cross validation | Training of modified DeblurGAN | # of images (original + augmented data) | 17,172 (6 images × 9 times × 318 classes) | 8424 (6 images × 9 times × 156 classes) |
| Training of CNN for finger-vein recognition | # of images for genuine matching | 16,854 ((6 images × 9 times − 1) × 318 classes) | 8268 ((6 images × 9 times − 1) × 156 classes) | |
| # of images for imposter matching | 16,854 (Random selection) | 8268 (Random selection) | ||
| Training & Testing with Original Images (Scheme 1) | Testing Blurred Images without Training (Scheme 2) | Training & Testing with Blurred Images (Scheme 3) | Training & Testing with Restored Images (Scheme 4) (Proposed Method) |
|---|---|---|---|
| 2.932 | 14.618 | 6.420 | 5.270 |
| Training & Testing with Original Images (Scheme 1) | Testing Blurred Images without Training (Scheme 2) | Training & Testing with Blurred Images (Scheme 3) | Training & Testing with Restored Images (Scheme 4) (Proposed Method) |
|---|---|---|---|
| 1.534 | 18.303 | 5.886 | 4.536 |
| VGG-19 [40] (Original DeblurGAN) | VGG-19 [40] (Conv3.1) | ResNeXt-101 [51] (Conv2) | ResNet-34 [32] (Conv2_x) |
|---|---|---|---|
| 6.049 | 6.503 | 5.281 | 5.270 |
| VGG-19 [40] (Original DeblurGAN) | VGG-19 [40] (Conv3.1) | ResNeXt-101 [51] (Conv2) | ResNet-34 [32] (Conv2_x) |
|---|---|---|---|
| 4.777 | 4.536 | 4.764 | 4.983 |
| Methods | PSNR | SNR | SSIM |
|---|---|---|---|
| Original DeblurGAN [12] | 28.98 | 21.45 | 0.90 |
| DeblurGANv2 [14] | 26.84 | 19.32 | 0.87 |
| SRN-DeblurNet [15] | 37.22 | 29.69 | 0.95 |
| Modified DeblurGAN (proposed method) VGG-19 (conv3.1) | 26.90 | 19.37 | 0.88 |
| Modified DeblurGAN (proposed method) ResNet-34 | 27.70 | 20.17 | 0.90 |
| Methods | PSNR | SNR | SSIM |
|---|---|---|---|
| Original DeblurGAN [12] | 30.84 | 20.95 | 0.81 |
| DeblurGANv2 [14] | 29.63 | 19.73 | 0.82 |
| SRN-DeblurNet [15] | 39.17 | 29.28 | 0.90 |
| Modified DeblurGAN (proposed method) VGG-19(conv3.1) | 28.50 | 18.60 | 0.82 |
| Modified DeblurGAN (proposed method) ResNet-34 | 32.64 | 22.75 | 0.85 |
| Original DeblurGAN [12] | DeblurGANv2 [14] | SRN-DeblurNet [15] | Modified DeblurGAN |
|---|---|---|---|
| 6.049 | 6.077 | 6.032 | 5.270 |
| Original DeblurGAN [12] | DeblurGANv2 [14] | SRN-DeblurNet [15] | Modified DeblurGAN |
|---|---|---|---|
| 4.777 | 5.507 | 7.105 | 4.536 |
| Modified DeblurGAN for Restoration | DenseNet-161 for Finger-Vein Recognition | Total | |
|---|---|---|---|
| Desktop computer | 3.4 | 12.8 | 16.2 |
| Jetson TX2 | 6.1 | 226.2 | 232.3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Choi, J.; Hong, J.S.; Owais, M.; Kim, S.G.; Park, K.R. Restoration of Motion Blurred Image by Modified DeblurGAN for Enhancing the Accuracies of Finger-Vein Recognition. Sensors 2021, 21, 4635. https://0-doi-org.brum.beds.ac.uk/10.3390/s21144635
Choi J, Hong JS, Owais M, Kim SG, Park KR. Restoration of Motion Blurred Image by Modified DeblurGAN for Enhancing the Accuracies of Finger-Vein Recognition. Sensors. 2021; 21(14):4635. https://0-doi-org.brum.beds.ac.uk/10.3390/s21144635
Chicago/Turabian StyleChoi, Jiho, Jin Seong Hong, Muhammad Owais, Seung Gu Kim, and Kang Ryoung Park. 2021. "Restoration of Motion Blurred Image by Modified DeblurGAN for Enhancing the Accuracies of Finger-Vein Recognition" Sensors 21, no. 14: 4635. https://0-doi-org.brum.beds.ac.uk/10.3390/s21144635