1. Introduction
During communication, emotion recognition skills help us understand the attitude, feeling, and intention of the partner, and therefore guide our behavior to make the communication successful. However, the ability of emotion recognition is different from person to person, and we sometimes fail to recognize the emotion of the interlocutor. This kind of mistake can lead to mutual misunderstandings, impeded communication, and deterioration in relationships [
1]. To avoid such failures and improve communication, one solution here is to use the power of machine learning.
Thanks to the significant development in the field of machine learning, recently we have obtained many software programs that can automatically recognize human emotion [
2,
3,
4,
5]. Although the methods of automatic emotion recognition emerge, their performance is still unsatisfactory [
6,
7]. Therefore, we hope to propose a possible method to achieve a better performance.
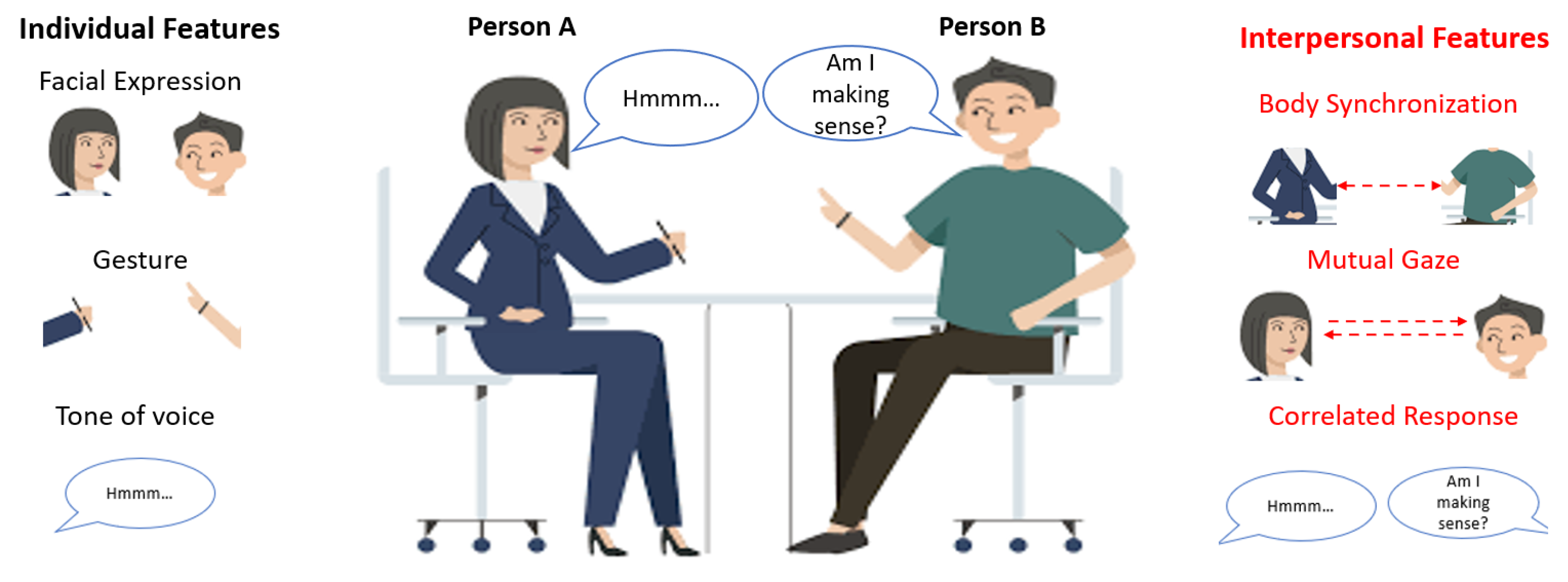
As illustrated in
Figure 1, humans recognize others’ emotions through both individual features and interpersonal features. Studies [
8,
9,
10] have shown that the individual features such as facial expression [
11,
12], gesture [
13,
14], and tone of the voice [
15] help us to recognize others’ emotions. For example, if a man clenches his fist, it may mean he is angry. If a man frowns, it may mean sorrow.
Studies also have shown that interpersonal features such as mutual gaze [
16,
17], body synchronization [
18] and the synchronization of speech [
19] will help us to recognize others’ emotions. Here, the interpersonal features used in this study are defined as the interpersonal interaction activities (verbal or nonverbal) that happen consciously or unconsciously during communication. It is important for the emotion recognition task because first- and third-person emotion recognitions will be influenced by these features [
20]. For example, during an interaction, if you have a mutual gaze and touch your partner, greater positive emotion will be observed [
21]. If the partner synchronizes with your action, the positive emotion will increase [
18]. Furthermore, sometimes interpersonal features play a crucial role in recognizing emotion. For example, when one interlocutor is not very expressive, it will be hard to recognize his/her emotion from the individual features only. However, the synchronization of body movement with the interlocutor may help humans recognize the emotion. (E.g., if the synchronization is high, the possibility of positive emotion is high. See [
22] for a review.)
However, to the best of our knowledge, most current automatic emotion recognition technologies either only use the individual features or just simply combine individual features to capture interpersonal features (see Related Work below). They overlooked the importance of synchronization features. Therefore, we aim to explore the following questions in this study: Are the interpersonal features, especially time-lagged synchronization features, beneficial for automatic emotion recognition tasks? Here, time-lagged synchronization includes both concurrent (i.e., zero-lag) interpersonal features such as mutual gaze and mirroring of facial expressions, and action–reaction (i.e., lagged) interpersonal features such as utterances and responses or smile to smile.
We addressed this question using the K-EmoCon [
23] dataset, a publicly available multimodal dataset of naturalistic conversations with continuous annotation of emotions by the participant themselves, as well as external emotion annotation. Using visual, audio, and audio-visual cross-modal features, respectively, we built two types of emotion recognition models: an individual model and interpersonal model. The individual model serves as a control condition using only individual features. The interpersonal model serves as an experimental condition, using both the individual and interpersonal features. We compared the performance of the models to judge whether interpersonal features are beneficial or not. Based on the findings on the importance of interpersonal features, we hypothesized that the interpersonal models would outperform the individual models with either unimodal or cross-modal features.
2. Related Work
Emotion recognition is a challenging task due to the difficulty of discrimination [
24] and diverse expression modalities [
25]. To solve the challenge of abstraction of emotion, researchers tried to use different features to discriminate different emotions. However, most of them are individual features.
A common feature used in visual modalities is facial expression [
26,
27,
28,
29,
30,
31,
32]. Given a raw image, researchers used face detection methods [
33,
34,
35] to find the position of the face first. Then, they cropped the face and extracted the feature of facial expressions. Finally, they fed these features into the classifier [
36,
37] to obtain the emotion. Some popular methods include DTAGN [
38], FN2EN [
39], LPQ-SLPM-NN [
32], and so on. In addition to facial expression, gestures are also a common feature [
40,
41,
42,
43]. The researchers first used pose estimation methods [
44,
45,
46] to obtain the pose of humans. Then, they fed the pose into a classifier to obtain the emotion. Pupil size [
47] and gaze [
48] are also important features used for recognizing emotion.
For the audio modality, the speech features [
49,
50,
51,
52,
53] include qualitative features, such as voice quality, harshness, tense and breathy; continuous features, such as energy, pitch, formant, zero-cross rate (ZCR), and speech rate; spectral features, such as Mel-frequency cepstral coefficients (MFCC), linear predictor coefficients (LPC), perceptual linear prediction (PLP), and linear predictive cepstral coefficients (LPCC); Teager energy operator (TEO)-based features, such as TEO-decomposed frequency modulation variation (TEO-FM-Var), normalized TEO autocorrelation envelope area (TEO-Auto-Env), and critical band based TEO autocorrelation envelope (TEO-CB-Auto-Env). Similar to the visual modality, given the raw speech signal, researchers first extracted their desired features such as above, then fed them into the classifier. Different from the above individual features methods, Lin [
54], Lee [
55], and Yeh [
56] tried to use interpersonal features in audio modality to boost the performance of automatic emotion recognition. However, they did not explore whether synchronization will be beneficial or not, which is the main target of this study.
Although researchers have spent decades on emotion recognition tasks using unimodal features, the performance is still not satisfactory. To achieve a better performance, researchers proposed to fuse visual and audio modalities [
57,
58]. To further improve the performance, others tried to fuse not only the audio and visual modality but also the context modality [
59,
60]. This fusing strategy improved the performance of the emotion recognition task further, because multimodality can give mutually supplementary information that is missed in the unimodal approaches.
Despite all these efforts, we believe that there still is room for improvement. We were motivated by psychological studies that indicated that humans also use interpersonal features to recognize others’ emotions [
16,
17,
18,
19]. According to our best knowledge, although the previous automatic emotion recognition research paid great attention to the individual features, most studies did not pay attention to the interpersonal features, especially the time-lagged synchronization. Therefore, we constructed an interpersonal model in the present study to explore whether interpersonal features are beneficial for emotion recognition or not.
3. Methods
The present study has two aims. First, we aimed to establish the usefulness of interpersonal features for an emotion recognition task. To achieve this, we constructed two models for comparison. One is the individual model using only individual features. Another one is the interpersonal model using both individual and interpersonal features. The only difference in structure between the two models is that the interpersonal model includes the synchronization model (the red block in
Figure 2). Second, we aimed to show the power of interpersonal features in multiple modalities. Therefore, we built the models that use visual, audio, and audio-visual cross-modality features, respectively.
Figure 2 shows the general framework of our individual and interpersonal models using visual (
Figure 2a), audio (
Figure 2b), and cross-modality (
Figure 2c). We note that we detected the emotions of both individuals (person A and B) in dyadic communication using visual, audio, and cross-modality. However, to explain our methods concisely, we use the scenario of predicting person A’s emotion as an example.
3.1. K-EmonCon Dataset
To compare the individual model with the interpersonal model in different modalities, and to perform our experiments with minimum human intervention, we decided to use the K-EmoCon dataset [
23] to test the usefulness of interpersonal features because, to our best knowledge, the K-EmoCon is the
only dyadic dataset in which the subjects show
spontaneous emotions during
naturalistic conversations.
Other datasets are not suitable for our experiments due to posed or induced emotions and limited situation. For example, the IEMOCAP [
61] is a popular dataset used for the emotion recognition task. However, IEMOCAP was considered to contain induced emotion and posed emotion by actors. As we aim to achieve the recognition of natural (spontaneous) emotions during dialogue communication, containing induced emotions and especially the posed emotions violates our purpose. Unlike IEMOCAP, the content in K-EmoCon is the natural debate between individuals without professional training in acting, which means it is more like an in-the-wild challenging situation.
Figure 3 shows scenario and a sample image in the K-EmoCon dataset. The original K-EmoCon dataset includes 32 participants. However, for the complete audiovisual recording, there are 16 participants (Person IDs: 3, 4, 7, 8, 9, 10, 19, 20, 21, 22, 23, 24, 25, 26, 29, 30) available in the dataset. The 16 participants are paired into eight sessions. For example, Person IDs 3 and 4 are in one session. Each session contains an approximately 10-min-long paired debate on a social issue. The video (frame rate (
): 30 fps) is re-sized into 112 × 112 and records participants’ facial expressions, upper body, and speeches (sampling rate: 22 kHz).
The original K-EmoCon dataset contains emotion annotations by the subjects themselves, by the partner, and by external raters. Since our purpose in this study was to test the utility of interpersonal feature in recognizing subjectively experienced emotions rather than the observed/inferred emotions by others, we decided to use self-reported annotations as the label. Although the K-EmoCon dataset also contains the labels of “cheerful”, “happy”, “angry”, “nervous”, and “sad”, their values are heavily imbalanced (see Figure 3 in [
23]) compared to the more normally distributed arousal and valence. Furthermore, arousal and valence are the two affective dimensions of the well-known circumplex model of emotion by James Russell [
62], which can cover more subtle changes in emotions. Thus, we used the arousal and valence labels for our emotion recognition task.
Specifically, we chose to use the self-reported arousal and valence which were rated on a five-level scale (from 1: very low to 5: very high) for every 5 s as emotion labels. Therefore, for the recognition of each 5 s segment of emotional state, the original input size of individual video clips (
) was
, and the original size of individual speech data (
) was
. In extracting MFCC features for audio data, we framed the audio data into the same temporal size as the visual data. That is, the temporal dimension for audio data after MFCC was 150, which is equal to
(visual temporal dimension). We formalized the emotion recognition as a classification task, similarly to [
63], because the annotated emotion labels in K-EmoCon are limited to five-level scale instead of continuous values in an interval. Moreover, the labels changed by steps at intervals of every 5 s instead of changing continuously frame by frame, which made the task more like qualitative task rather than quantitative task.
3.2. Visual Modality
3.2.1. Individual Model
Let us begin with the individual model for the visual modality. In general, our individual model includes three stages (
Figure 2a).
The first stage is to feed the individual video clips ( or ) into the backbone to extract spatial information and obtain individual features;
The second stage is to feed the individual features into the Temporal Net to extract temporal information;
The final stage is to feed the output from the Temporal Net into a fully connected layer to predict the value of arousal or valence. Now, we explain the detail of each component.
The backbone (
Figure 4) for visual modality includes a convolutional neural network (CNN) [
64] and transpose CNN [
65]. It is a structure similar to Resnet [
66]. A CNN was used to extract the local information first. A transpose CNN was used to extract further information and reshape the output to make its size equal to the size of the input. To obtain the general information, max-pooling was used to down-sample and summarize the local information. In the backbone, CNN plus transpose CNN were used for a total of four times. The first three times were used in the Resnet structure (purple line in
Figure 4) to deepen our network because the mapping from the input features to emotional states requires heavy nonlinear transformation. The fourth time is slightly different from the first three times. The CNN was not connected with the transpose CNN directly. The max-pooling was inserted between the CNN and transpose CNN to reduce computing complexity. The Temporal Net (
Figure 5) here is a structure similar to the temporal CNN [
67]. Dilation CNN and Resnet were used to extract temporal information. As the backbone for visual modality is deep enough, only one layer was used in Temporal Net to prevent overfitting.
3.2.2. Interpersonal Model
Next, we used the task of predicting Person A’s emotion as an example to explain the process to obtain interpersonal feature
. (When predicting person B’s emotion, the process is symmetrical.) In general, the interpersonal feature
was obtained by feeding the respective individual features (
and
) into the synchronization model
as shown in
Figure 6. Specifically
as shown in Equation (
1). As for person B, we obtained
with a different backbone model
as shown in Equation (
2). Then, the pair of individual features (
and
) were fed into the synchronization model
(Equation (
3)) to obtain interpersonal features
. Finally, the interpersonal features were combined with individual features and fed into the fully connected layer to predict the value of emotion.
We note that
processed the spatial dimension, which means it conserves the temporal order of video clips. For example, the size of the original input
is
, where
T represents the time length of clips,
C represents the RGB channel,
W represents the frame image width, and
H represents the frame image height. After the processing of
, the size of
is
, where
T keeps the same and
F represents the length of the individual feature vector. The specific values used in the experiment are specified in
Section 3.1.
The synchronization model consists of two parts. The first part is the computation of time-lagged synchronization similarly to the time-lagged detrended cross-correlation analysis (DCCA) cross-correlation coefficient computing process [
68]. The second part is to use 1D CNN to further extract information.
The detailed algorithm is shown in Algorithm 1. When computing time-lagged synchronization
, the individual features (
and
) were first divided into several temporal blocks (
R and
). The number of blocks is
. Then the cosine similarity was computed with
R and
as shown in Equation (
4). During this computing, the decay weight
was used for the output to emphasize the time-lagged feature. We design
, because as
increases, the
decreases, which is similar to our memory that will forget information along with time. Finally, the mean of the output (
) was calculated. The calculated
Means (
) were combined as
. Specifically, the size of
is
, where
represents the number of calculated
and
L represents the features length for each
.
| Algorithm 1 Time-Lagged Synchronization |
| Input: Individural Features , |
| Parameters: Time block size n, Time lag length , Decay weight , Clips time length N |
| |
| for i init 0 to by n do |
| |
| |
| |
| for init 0 to by 1 do |
| |
| |
| |
| end for |
| |
| end for |
| return |
To further extract the information between each , the 1D CNN was used to obtain interpersonal features .
3.3. Audio Modality
3.3.1. Preprocess
The mixture of speech from two speakers in a single audio data file brings a challenge to the audio modality. To overcome this challenge, several preprocessing steps were performed to obtain individual speech features. Given the obtained speech features, we shifted them by different time lengths, because we aimed to capture the action–reaction relationship between the speaker and interlocutor. We predicted Person A’s emotion here as an example. (When predicting person B’s emotion, the process is symmetrical.) Specifically, first, we manually segmented the raw audio data (
) to obtain each speaker’s data (
and
) as shown in Equation (
5).
Then, to synthesize the interpersonal features between
and
, we shifted person B’s individual speech data
with different time lengths
. For example,
represents the audio data from time 0 to 5 s, and the
is from time 0 s to 5 s. If we shift time-lagged length
, the shifted
will be the data from time
to
. Finally, we extracted MFCC features for
and
to obtain individual speech features (
and
) in
Figure 2b.
3.3.2. Individual Model
Similar to the visual modality, we built both the individual model and interpersonal model (
Figure 2b). The individual model is similar to the visual modality. The rough information is extracted by the backbone. Then, the temporal information is further extracted by the Temporal Net (
Figure 5). The backbone here is CNN plus Transformer [
69] as shown in
Figure 7. Specifically, we use da kernel size of
for the first layer, and the kernel size of
for the second layer. The different kernel size helps our model extract more different degree local information. With a two-layer CNN, the max-pooling was used to summarize the local information. The output was fed into the Transformer to extract further information. The Temporal Net is the same as the visual modality.
3.3.3. Interpersonal Model
For the interpersonal model, first, the backbone
was used to obtain
individual features of the target speaker (Person A in
Figure 2b). Then, the backbone
was used to obtain
.
are different time-lagged individual speech features of the interlocutor (Person B in
Figure 2b). Next, the cosine similarity between the speaker feature vector
and different time-lagged interlocutor vectors
was computed to obtain similarity vectors
as shown in Equation (
6).
These similarity vectors were combined as
with a decay weight
as shown in Equation (
8). The
was fed into the CNN to obtain our target—interpersonal features
. The decay weight
here was calculated with decay parameter
as Equation (
7). As
increases the
will decrease. We also used
to represent the a priori knowledge, which makes sure the
percent of
will contribute.
Finally, the interpersonal features were combined with extracted individual features and fed into a fully connected layer to obtain the emotion value of the target speaker.
3.4. Cross Modality
3.4.1. Individual Model
The cross-modality is similar to visual and audio modality, including individual models and interpersonal models (
Figure 2c). For the individual model, individual features were extracted from the structure of visual and audio modality as in
Section 3.2 and
Section 3.3. Then the two modality features were combined and fed into a fully connected layer to predict emotion value.
3.4.2. Interpersonal Model
For the interpersonal model, we incorporated both the audio-visual interpersonal feature and visual-audio interpersonal feature . We used the prediction of Person A’s emotion as an example.
The audio-visual interpersonal features
were obtained by computing cosine-similarity between interlocutor visual modality
and time-lagged speaker audio features
as shown in Equation (
9). Then,
were combined together with decay weight
to obtain visual-audio interpersonal feature
as shown in Equation (
10).
The visual-audio interpersonal features
were obtained by computing the cosine-similarity between speaker visual modality
and time-lagged interlocutor audio features
as shown in Equation (
11). Then,
were combined together with decay weight
to obtain visual-audio interpersonal feature
as shown in Equation (
12).
Finally, these two interpersonal features ( and ) were combined with individual features ( and ) and fed into the final layer to predict emotion value.
We note that the computing of the cosine-similarity requires the data to share the same shape in both temporal and feature dimensions. For example, the size of a visual individual feature of speaker
is
, and the size of an audio individual feature of interlocutor
is
. The temporal dimension of the individual feature is the same (
) via the neural network that we built. The feature dimension of the individual feature of different modalities was reshaped to the same size
F with interpolating methods such as Equation (
13). Thus, the size of the feature (
and
) satisfied the required conditions
and
.
5. Conclusions
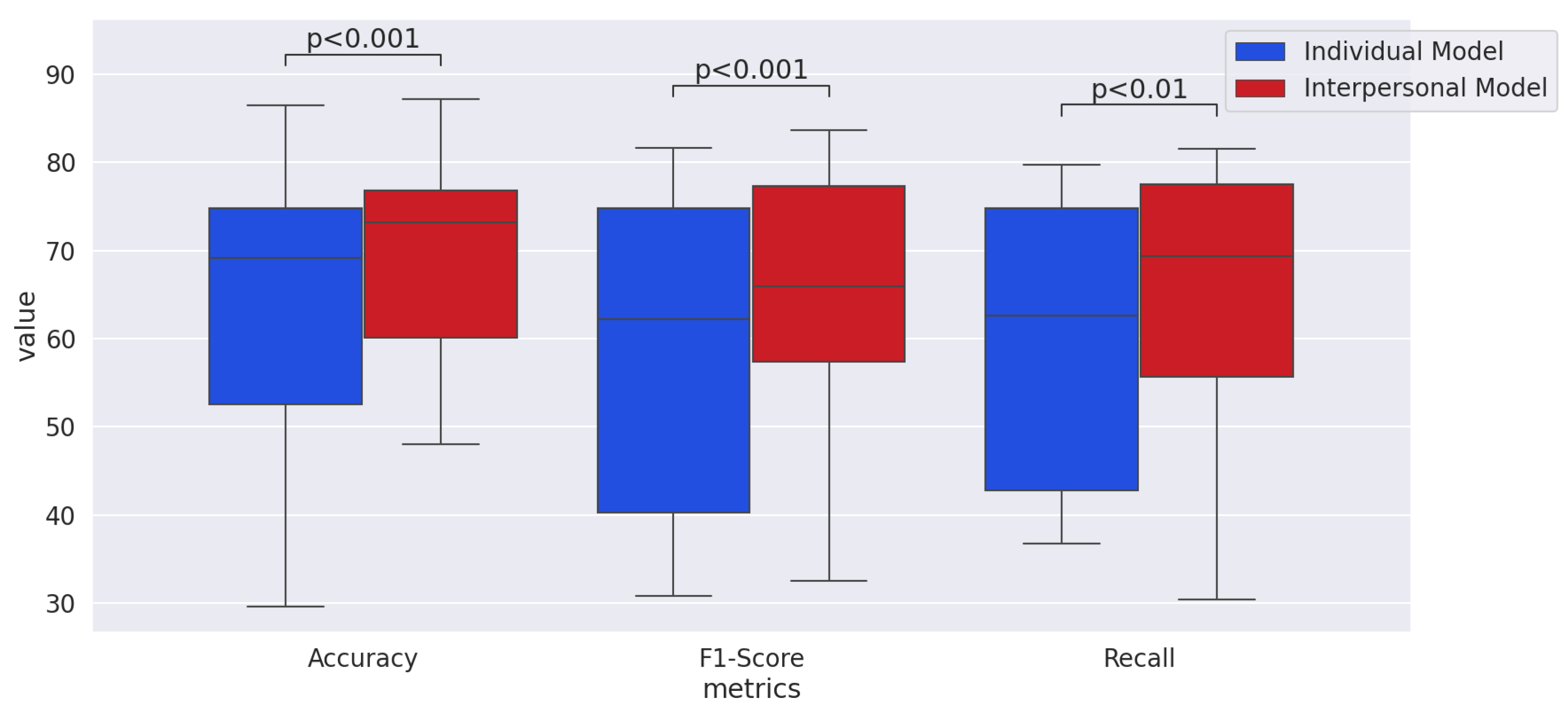
Inspired by the fact the humans recognize emotion via individual features and interpersonal features, we explored whether interpersonal features are beneficial for automatic emotion recognition in this study. Specifically, we constructed the individual model and interpersonal model in visual, audio, cross-modality respectively. Then, we compared these two models using the K-EmoCon dataset with the main experiment and supplementary experiment. Our main experiment results showed that the performance of the interpersonal model was higher than the individual model. Our supplementary experiment results showed—even for unknown communication pairs—that the interpersonal model outperformed the individual model. Therefore, we advocate incorporating interpersonal features for automatic emotion recognition in communication settings.
The framework used in this study was a “black box”. We cannot identify what specific synchronization contributed to better emotion recognition performance. The “black box” nature impeded us from further improving the algorithm, and more importantly impeded us from understanding the mechanism about how humans recognize emotion in nature. In the future, we hope to resolve this issue with the eXplainable Artificial Intelligence (XAI) approach [
81].













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}