
On the Optimization of Regression-Based Spectral Reconstruction †


School of Computing Sciences, University of East Anglia, Norwich NR4 7TJ, UK
*
Author to whom correspondence should be addressed.
†
This paper is an extended version of our papers published in (1) Lin Y.-T. and Finlayson G.D. Per-channel regularization for regression-based spectral reconstruction. In Proceedings of the 10th Colour and Visual Computing Symposium, CEUR Workshop Proceedings, Gjøvik, Norway, 16–17 September 2020 (online open access: http://ceur-ws.org/Vol-2688/ ). (2) Lin Y.-T. and Finlayson G.D. Reconstructing spectra from RGB images by relative error least squares regression. In Proceedings of the 28th Color and Imaging Conference, Online, 4–19 November 2020; pp. 264–269.
Sensors 2021, 21(16), 5586; https://0-doi-org.brum.beds.ac.uk/10.3390/s21165586
Submission received: 16 June 2021
/
Revised: 14 August 2021
/
Accepted: 15 August 2021
/
Published: 19 August 2021
(This article belongs to the Collection Advances in Spectroscopy and Spectral Imaging)
Abstract
:Spectral reconstruction (SR) algorithms attempt to recover hyperspectral information from RGB camera responses. Recently, the most common metric for evaluating the performance of SR algorithms is the Mean Relative Absolute Error (MRAE)—an relative error (also known as percentage error). Unsurprisingly, the leading algorithms based on Deep Neural Networks (DNN) are trained and tested using the MRAE metric. In contrast, the much simpler regression-based methods (which actually can work tolerably well) are trained to optimize a generic Root Mean Square Error (RMSE) and then tested in MRAE. Another issue with the regression methods is—because in SR the linear systems are large and ill-posed—that they are necessarily solved using regularization. However, hitherto the regularization has been applied at a spectrum level, whereas in MRAE the errors are measured per wavelength (i.e., per spectral channel) and then averaged. The two aims of this paper are, first, to reformulate the simple regressions so that they minimize a relative error metric in training—we formulate both and relative error variants where the latter is MRAE—and, second, we adopt a per-channel regularization strategy. Together, our modifications to how the regressions are formulated and solved leads to up to a 14% increment in mean performance and up to 17% in worst-case performance (measured with MRAE). Importantly, our best result narrows the gap between the regression approaches and the leading DNN model to around 8% in mean accuracy.
1. Introduction
A consumer RGB camera captures light signals with three types of color sensors. Yet the light is physical radiance—a continuous spectral function of wavelength—which, intuitively, can hardly be described by a 3-dimensional color representation. Indeed, many researchers have found that real-world spectra should be at least 5- to 8-dimensional [1,2,3,4,5]. Consequently, with RGB imaging we can only acquire limited information encoded in the light spectrum.
Using a hyperspectral camera [6,7,8,9,10,11,12,13,14,15,16,17,18,19], we can record scene radiance at high spectral and spatial resolution. This technique has been widely used in machine vision applications such as remote sensing [20,21,22,23,24,25,26,27], medical imaging [28,29,30,31], food processing [32,33,34,35,36,37], and anomaly detection [38,39,40,41,42,43,44], as well as in the spectral characterization domain, including the calibration of color devices (e.g., cameras [45] and scanners [46]), scene relighting [47,48], and art conservation and archiving [49,50,51]. While useful, hyperspectral cameras are usually much more expensive than the RGB cameras. Moreover, the extra spectral information is often captured with reduced spatial and/or temporal resolution, which limits their usefulness.
Spectral reconstruction (SR) seeks to recover spectral information from the RGB data of a single camera [52,53,54,55,56,57,58,59,60,61,62,63,64,65,66]. Assuming the recovery error of SR is low enough (regarding the results in the literature and in this paper), we can essentially measure spectra using an RGB camera.
Historically, SR is most efficiently solved by Linear Regression (LR) [52], where the map from RGBs to spectra is described by a simple linear transformation. Considering a nonlinear map, the Polynomial Regression (PR) [53] and Root-Polynomial Regression (RPR) [56] methods expand the RGBs into a set of polynomial/root-polynomial terms—which are then mapped to spectra via a linear transform. More recent regression models, including the Radial Basis Function Network (RBFN) [54] and the A+ sparse coding algorithm [55], use clustering techniques to define the local neighborhood (in the color or spectral space) in which each RGB is regressed.
On the other hand, we see most of the recent SR algorithms are not based on simple regressions but based on Deep Neural Networks (DNN) [60,61,62,63,64,65,66] which embrace the idea of regressing RGB image patches as a whole (as oppose to regressing each pixel independently in regressions). This approach hypothesizes that object-level descriptions of the RGBs can—though requiring much more computational resources—aid the recovery of spectra. However, DNN-based models do not always perform better than simple regressions [55] and often suffer from instability issue when recovering spectra at different brightness scales [56,57,58]. Furthermore, spectra recovered by DNNs are shown to be less accurate in color [57,59] and do not necessarily provide more accurate cross-illumination or cross-device color reproductions [57].
In this paper, we aim to further optimize the existing regression-based SR methods. First, we noticed that in recent works, DNN-based models are evaluated and ranked by Mean Relative Absolute Error (MRAE) [63,64]. Most top DNN models are also designed to minimize MRAE directly [60,61,62,63,64]. However, all regressions used in SR are optimized by convention for Root Mean Square Error (RMSE) while evaluated using MRAE (or other similar relative errors) when compared with the DNNs [55,56,57,60,61]. In other words, these regressions are optimized for one metric, and then how well they work is evaluated with another.
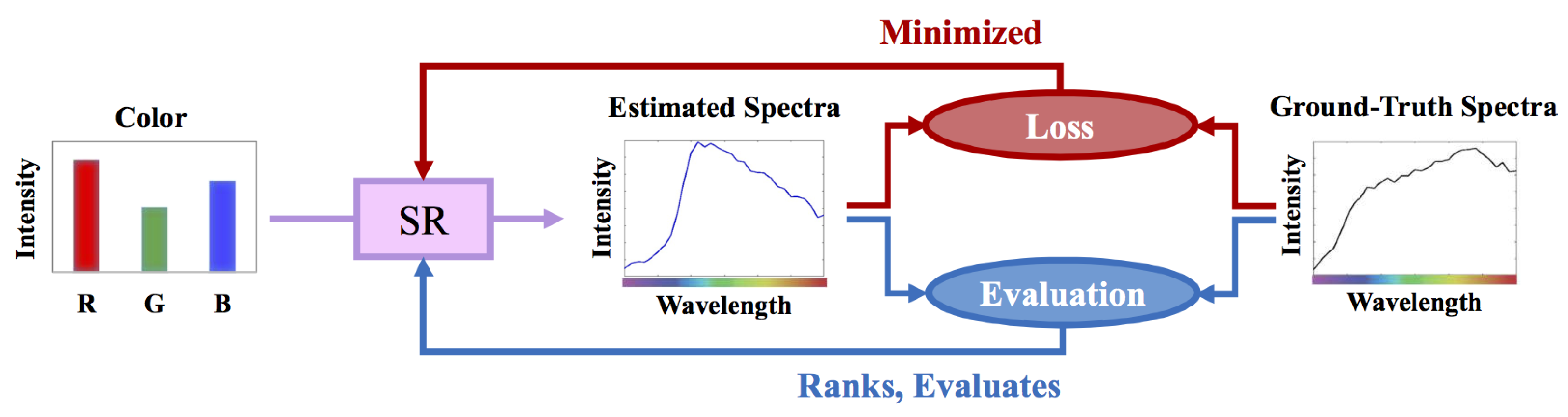
In Figure 1, we illustrate the standard experimental framework of SR. In training, the parameters of the SR model are tuned such that the “losses”—the differences between the ground-truths and estimations measured by a given loss metric—are statistically minimized. After the SR models are trained, we evaluate them based on a desired evaluation metric. Ideally, the loss and evaluation metrics should match (i.e., the same or similar in nature). Indeed, a model that is optimized for one metric but evaluated by another will surely lead to sub-optimal results.
Based on this insight, we propose two new minimization approaches for simple regressions—the Relative Error Least Squares (RELS) and Relative Error Least Absolute Deviation (RELAD). While the former minimizes an error similar to MRAE and is solved in closed form, the latter explicitly minimizes the MRAE metric but has the disadvantage of requiring an iterative minimization.
The second contribution of this paper is to propose a new way of regularizing the regression-based spectral reconstruction. Most regressions are necessarily trained using a regularization constraint [67], both to prevent overfitting and to make the system equations more “stable” [68] (a system of equations is stable if small perturbations appear in the training data results in a small perturbation in the solved-for model parameters). However, we observe that hitherto in regression-based spectral reconstruction all spectral channels are regularized altogether—e.g., in [52,53,54,55,56]. That is the regularization constraint is effectively applied at the spectrum level. Yet, fundamentally, error metrics such as MRAE measure the errors at all spectral channels independently and then average them to give a spectral error measure. Thus, we propose a “per-channel” regularization methodology which ensures optimized regularization for each spectral channel independently.
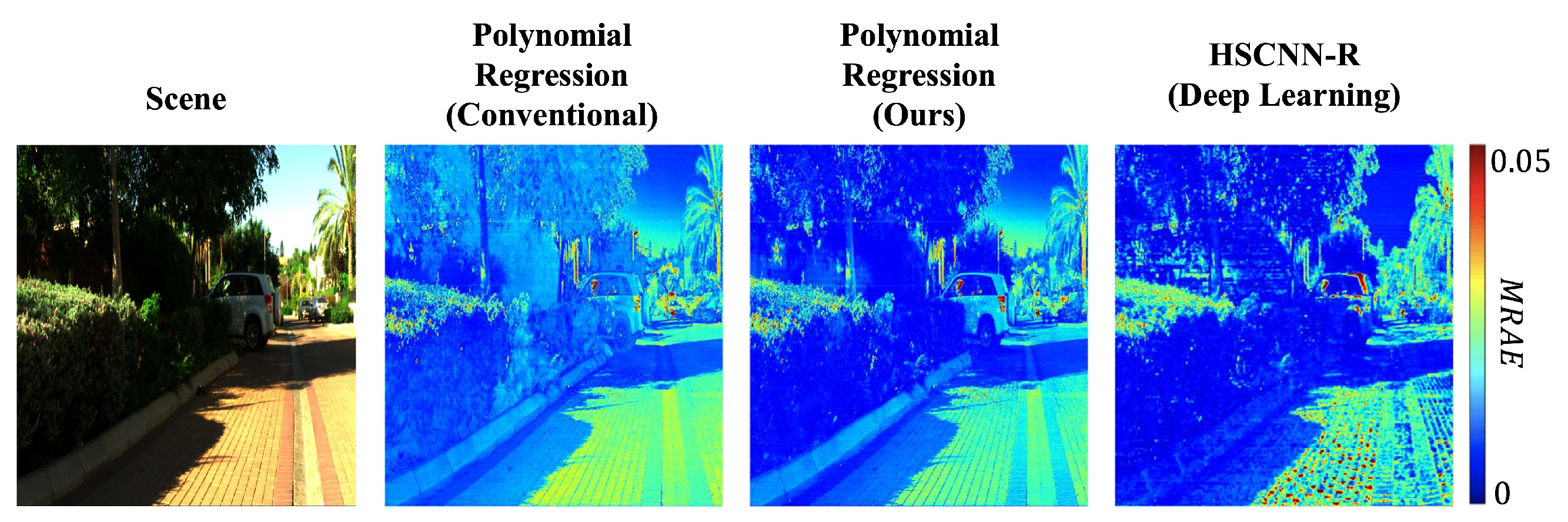
Combined, we find that training the simple regressions to minimize the same error as used in testing and adopting a per-channel regularization approach lead to a significant uptick in performance. Moreover, as shown in the example hyperspectral image reconstruction results in Figure 2, our new regression methods deliver performance that is similar to one of the best (but much more complex) DNN approaches.
The rest of the paper is organized as follows. In Section 2, we will introduce the prerequisites of regression-based spectral reconstruction. Our new methods are introduced in Section 3. Section 4 details the experimental procedures, and Section 5 discusses the experimental results. This paper concludes in Section 6.
2. Background
2.1. Regression-Based Spectral Reconstruction
A simple mathematical model of RGB formation is written as [69]
where denotes the radiance spectrum, is the set of three spectral sensitivities of the color sensors, and is the derived color vector (the superscript denotes the transpose operator). In the case of color imaging, the range of integration, , is the visible range. In this paper, we consider this range to be the interval from 400 to 700 nanometers (nm).
Further, we assume and are measured by a hyperspectral device at every 10 nm (in accordance with the recent SR challenge datasets [63,64]). As such, we can approximate the integration in Equation (1) by inner products [69]:
where is the 31-component vectorized spectrum, and is the spectral sensitivity matrix (one spectral sensitivity per column).
In SR, we study the inverse problem: we wish to recover using the information of . A general definition of SR (considering both regressions and DNNs) can be written as
where denotes the hyperspectral data at the location of interest (the pixel), denotes an SR algorithm, and the neighborhood set includes the RGBs in the spatial neighborhood of pixel k (the subscripts indexing the pixel in the proximity of pixel k). Note that also contains the RGB at the location of interest i.e., .
In regression we normally do not use the neighborhood information to recover spectra (though small neighborhoods are occasionally admitted [55,56]). Rather, we attempt to map each RGB uniquely to a corresponding spectrum, i.e., .
2.1.1. Linear Regression
The simplest Linear Regression (LR) approach [52] models the SR algorithm by a linear transformation:
where is a matrix.
Considering the whole database of N spectra and their matching RGBs (regardless of which images they are in and their pixel locations), let us arrange them into the spectral data matrix and the matching RGB data matrix . Based on this nomenclature, we can rewrite Equation (4) as
That is, all spectra (the rows of ) are estimated from their corresponding RGBs (the rows of ) using the same linear transformation matrix .
2.1.2. Nonlinear Regressions
The regression problem summarized in Equation (5) is, by construction, linear. In a general case where we may wish to pose the SR problem as a non-linear regression, we might transform each row of (each RGB) to an s-component counterpart using a given nonlinear function :
This transformed RGB matrix is then regressed to estimate the spectral data using a new linear transformation matrix :
Here, the dimension of is .
Examples of nonlinear regressions in the literature include Polynomial Regression (PR) [53], Root-Polynomial Regression (RPR) [56], and Radial Basis Function Network (RBFN) [54]. For instance, if we consider the 2nd-order RPR, we will have , in which case is an matrix and the regression matrix is [56].
2.1.3. A+ Sparse Coding
So far, both linear and nonlinear regressions assume a single regression matrix that is used to estimate spectra for all RGBs. Yet in A+ sparse coding (i.e., adjusted anchored neighborhood regression) [55], it is considered that the SR mapping should be done locally [55,59]. Fundamentally, in sparse coding one assumes that all spectra can be represented by linear combinations of a small number of anchor spectra (hence it is “sparse”) [55,70].
In training, the A+ algorithm runs the K-SVD clustering algorithm [71] and assigns the clusters’ centers as the set of anchor spectra. Around the corresponding RGB value of each anchor, a fixed number of nearest RGB neighbors in the training dataset and their corresponding radiance spectra are recorded. These neighboring data points are then used to create a bespoke Linear Regression mapping (Equation (5)) that should be only used by the RGBs in the testing set that are around the same neighborhood [59]. That is, in the reconstruction stage of A+, we first find the anchor spectrum whose matching RGB is closest to the query RGB, and second we map the query RGB to spectrum using the regression mapping associated with that neighborhood.
We note that all the discussed regression models can be formulated by either Equations (5) or (7), while the structure of both are essentially the same. Thus, to simplify the notation we will adopt the regression notation of Equation (5), i.e., we drop the subscript of Equation (7). As such, in later discussions the data we are regressing can be the RGBs or their non-linear expansions thereof.
2.2. Least-Squares Minimization
Now let us consider how we solve for the regression matrix . In essence, we must define what we meant by the ≈ symbol in Equation (5).
Most commonly, we seek to minimize the “sum-of-squares” between the estimations and ground-truths:
Here, calculates the sum of all components squared. Equivalently, is sometimes written as denoting the Frobenius norm.
Regressions solved in this manner are called the Least-Squares (LS) regression. Advantageously, the solution of LS minimization can be solved in closed form [72].
2.2.1. The Overfitting Problem and Regularized Least Squares
However, the solution of Equation (8) often cannot be directly used in practice—given that the solved regression matrix is optimized for minimizing the errors in the training set, we often find that this matrix does not work for unseen data. In other words, denoting a set of unseen RGB and spectral data as and , we often get . This problem is so-called “overfitting” [67,68].
One of the biggest problems for an overfitted regression is that it might not work in the presence of noise. As a thought experiment, we may consider to recover (the same set of training spectral data) from the “perturbed” training RGB data, , where is a matrix of very small numbers, representing the noise occurs in the RGB imaging process. It follows that an overfitted can very possibly suggest , that is, it fails to plausibly recover .
Another facet of this problem is that if we actually attempt to find the best regression matrix for the noisy data , we can end up having the optimal regression matrix that is very different from the original one. That is, as we perturb our RGB data, we can arrive at very different regressions.
To mitigate the overfitting problem, the tool of ridge regularization (a.k.a. Tikhonov regularization) [67] is often incorporated when training a regression. While solving the minimization in Equation (8), we add another penalty term which bounds the magnitude of the regression matrix :
where the solution of can still be written in closed form [52].
Here, the parameter—which is set by the user—controls how mitigates the minimization of the sum-of-squares fitting error. Clearly, if , the equation resorts to the simple LS (Equation (8)), and as becomes large, the need to solve for an that has a small (bounded) norm becomes imperative and the requirement to reduce the sum-of-squares fitting error is less important.
When the solved has a bounded norm, the regression has the stability property we desire. That is, if we perturb by a small amount we will still get the same (or very similar) , and this in turn implies that albeit the perturbation in the input RGBs we will still get similar spectral estimations. We refer the readers to the work in [67] for a fuller discussion of how regularization is used and why it solves the instability problem.
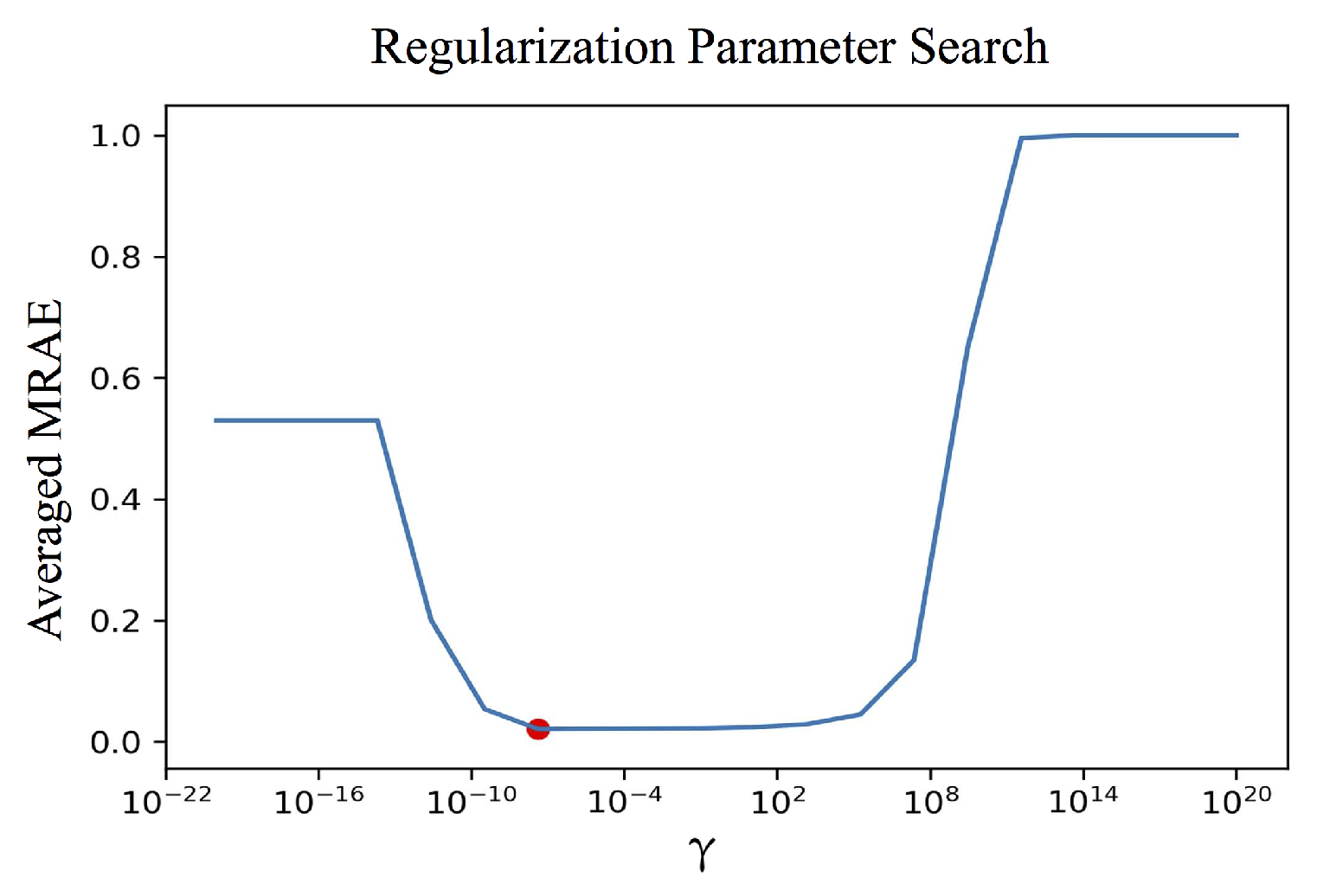
In practice, we choose the parameter empirically to best trade-off the need for a stable solution and to lower the fitting spectral errors. Figure 3 illustrates a typical cross-validation parameter selection methodology [73]. First, a wide range of different ’s are tried, and the solved ’s depending on these values are used to recover spectra in an unseen “validation set”, which are then evaluated using the desired evaluation metric (here, we use the MRAE metric). Usually, a “U-shaped” curve is obtained when plotting the averaged validation-set MRAE against , where the minimal point (the red dot in the plot) indicates the selected parameter.
We note that the regularization parameter (the red dot in Figure 3) is not “fixed”, that is we search for independent regularization parameter in every minimization instance encountered.
While the ridge regularization approach introduced here (adding an penalty term) is the most widely used approach (not only for SR but for learning problems in general), there are other regularization approaches used in the literature, including the LASSO [74] (where the penalty term is used) and Elastic Net approach [75] (where both and penalty terms are added, with dependent or independent regularization parameters). It is known that LASSO provides more robust regularization compared to the ridge regularization, while the Elastic Net provides the possibility to swing more towards LASSO or ridge regression depending on the relative dominance between the two methods in each specific learning circumstances. For more information of these two methods, interested readers are pointed to the works in [74,75], respectively.
2.3. RMSE versus MRAE Error Measures
In the prior art of SR, most (if not all) regression-based methods are based on LS minimization with a ridge regularization setting (see, e.g., in [52,53,54,55,56]). As the LS minimization uses sum-of-squares as its loss metric (see Equations (8) and (9)), a natural metric for evaluating LS-based regressions is Root Mean Square Error (RMSE):
(because the sum-of-squares is essentially the sum of squared RMSE). Here, we denote as the estimation (returned by, e.g., regressions or DNNs) of the ground-truth .
Of course, the physical radiance spectra may have greater or lesser magnitudes depending on the imaging conditions [56]. However, if we model the change in brightness by a scalar k, we get . Which means, for a ground-truth spectrum that is k times brighter than , when compared with the recovered spectrum also scaled by k (i.e., ), we will get k times larger RMSE than the original case.
This biased nature of RMSE evaluation can as well influence the training process of regressions. Indeed, we can expect that the standard LS minimization can overestimate the squared-RMSE (i.e., sum-of-squares) losses of the bright spectra and consequently place more importance on minimizing their errors compared to the dim ones.
This brightness bias is part of the motivation underpinning the Mean Relative Absolute Error (MRAE) metric for spectral recovery [63,64]. This MRAE metric almost universally adopted in the recent literature is defined as
where the spectral difference is divided by (component-wise) the ground-truth spectral values. As such, the effect of brightness level is discounted when measuring spectral differences, i.e., .
Arguably, the MRAE makes more sense as a performance metric as the SR algorithm might be used where the absolute/maximum intensity of the tested spectra is not known or controlled. Therefore, the main goal of this paper is to consider how to modify the SR regression to minimize a relative recovery error (in general and MRAE in particular).
We would also like to emphasize that the development of our new methods (presented in the following sections) are, of course, tailored to the assumption that MRAE is used as the evaluation error metric. Moreover, again, MRAE is certainly the most commonly used metric adopted for DNNs in the literature at this time, see, e.g., in [60,61,63,64].
3. Rethinking the Optimization of Regression for Spectral Reconstruction
The first part of our contributions concerns the regularization method used in the standard case (Equation (9)), where the regularization takes place at the spectrum level with all spectral channels being regularized together. Here, we will argue—and develop the requisite mathematics—that the regularization should be done per spectral channel.
In our second contribution, we alter the form of the regression. Following that recently MRAE is used to evaluate and rank new methods, and that this metric is optimized directly in modern DNN solutions but not in regression-based methods, we reformulate the regressions to optimize for fitting errors that are “relative” in nature (spectral differences relative to the ground-truth values). We develop solutions based on both and relative error minimizations.
3.1. Per-Channel Regularization
Returning to the conventional regression formulation in Equation (5), let us split the regression matrix and the ground-truth spectral data by columns:
Here, denotes the column of . Remember that each row of is a single radiance spectrum, thus the numbers in are the -channel spectral intensities of all the spectra in the database.
Now, we observe that the original multivariate regression is in fact a collection of 31 independent regressions:
Notice that Equation (13) is equivalent to the original formulation in Equation (5), only that it explicitly shows there is no “inter-channel” dependence. In other words, for all regression-based SR in the literature, it has been always the case that each column of is only used for recovering the corresponding column of while irrelevant to the recoveries for other spectral channels.
Curiously, as we solve for using the standard LS minimization in Equation (9), the strength of the penalty term, , is controlled by a single parameter , meaning that all columns of , that is, the 31 ’s, are regularized using the same parameter despite the fact that each of them works independently of others. Essentially, by regularizing as a whole, we are “asserting” such an interdependence among channels.
From a mathematical viewpoint (regarding how the regression is formulated), it makes more sense to regularize each per-channel regression independently. Following Equation (13), we rewrite Equation (9) in a per-channel fashion:
Here, the per-channel regularization parameter (again to be optimized by a cross-validation procedure, see Section 2.2.1) is used specifically for regularizing the regression of the spectral channel. That is, we select different regularization parameters for different spectral channels.
We would like to remark that, although our per-channel approach matches the assumption made by the regression’s formulation (that there is no inter-spectral-channel dependence), we shall admit the possibility that there might be better ways to formulate the regression which factors in “reasonable interdependence” between channels. For example, we may consider to impose a “smoothness” constraint used in the literature (see, e.g., in [76]) on the recovered spectra, though we note that this assumption would be more important for the recovery of “reflectance” spectra (which are intrinsically smooth) instead of the “radiance” spectra we are recovering (because the illumination spectrum is part of the radiance, which can occasionally make the radiance far from smooth, especially for indoor illuminations).
3.2. Relative-Error Least Squares Minimization
Now, let us minimize an error that is more similar to MRAE. First, we consider to formulate an -minimization problem so as to ensure a closed-form solution.
From Equation (5), we can remodel the approximation as the following minimization:
where all the divisions are component-wise. Here, the square of an relative error (referred to as the “relative-RMSE” in some works [55,70]) is minimized. We call this new minimization approach the Relative Error Least Squares (RELS).
Equation (16) can be rewritten in a per-channel fashion:
(these two minimizations are equivalent because the divisions are component-wise). Or equivalently, we write
where is an N-component vector of ones.
We can further define a matrix of RGBs weighted by the reciprocals of :
where . Using this nomenclature, let us again rewrite Equation (18) into
Clearly, Equation (20) shows that RELS is in effect another least-squares problem which regresses to fit the vector .
3.3. Relative-Error Least Absolute Deviation Minimization
Finally, let us consider to minimize MRAE directly. Analogous to Equation (16), we are now going to solve the following minimization:
In the literature, regressions solved via an minimization is called the Least Absolute Deviation (LAD) [78,79]. As here the MRAE we are minimizing is a relative error, we call this new approach the Relative Error Least Absolute Deviation (RELAD).
Notice that for the regularization penalty term in Equation (24) we also adopted an norm, which refers to the LASSO regularization [74] (see Section 2.2.1).
Unlike RELS, RELAD does not have a closed-form solution. For a small amount of data, a globally optimal solution can be found using a linear-programming solution [78,80]. However, in our application the amount of data is large—where the Iterative Reweighted Least Squares (IRLS) [79] algorithm is more appropriate and is thus used here.
The IRLS process approaches RELAD minimization by repeatedly solving Weighted Least Squares (WLS) [81] while updating the weights on every iteration depending on the losses and mapping functions obtained in the previous iteration, until the solution converges.
The detailed algorithm is given in Algorithm 1. The iteration number is indicated by the superscript . All min, division, and absolute operations shown in Algorithm 1 are component-wise to the vectors, while the median function in Step 8 and the mean functions in Step 11 calculate the median and mean of components of (the resulting scalar in Step 8 is a preliminary estimate of the standard deviation of absolute losses commonly used in the literature, see, e.g., in [79,82]). Furthermore, the min functions used in Step 9 and 10 are to clip the reciprocal values at so as to prevent overly large numbers. Finally, in Step 11, we set the tolerance and the stopping iteration .
| Algorithm 1: Solving RELAD regression (Equation (24)) by IRLS algorithm. |
|
4. Experiment
4.1. The Regression Models
The regression models we consider in this paper (introduced in Section 2.1) are listed in Table 1. For each of these regressions, we train the model under the 4 minimization criteria listed in Table 2. That is, we benchmark 5 models paired with 4 minimization approaches; but, irrespective of which minimization we are using, we evaluate the performance of all algorithms using MRAE.
For reference, we benchmark against HSCNN-R [60]—the 2nd place winner of the NTIRE 2018 challenge [63]. HSCNN-R is DNN-based (orders of magnitude more parameters compared to all considered regressions), and it minimizes MRAE directly.
All implemented codes are provided as the Supplementary Materials.
4.2. Preparing Ground-Truth Datasets
In this paper, we adopt the ICVL hyperspectral image database [70], which was the database used for the NTIRE 2018 Spectral Reconstruction Challenge [63]. Each spectral image from the database (200 in total) has a spatial dimension of —that is, approximately 1.8 M spectra per image—with 31 spectral channels (referring to 10-nm spectral samplings between 400 and 700 nm).
For each spectral image, we calculate the corresponding RGB image following Equation (2), using the CIE 1964 color matching functions [83,84] as the camera’s spectral sensitivities , i.e., the resulting RGBs are the CIEXYZ tristimulus values [84]. This setting corresponds to the “Clean Track” methodology of NTIRE 2018 and 2020 Spectral Reconstruction Challenge [63,64].
4.3. Training, Validation, and Testing
We follow a 4-trial cross-validation process. First, we randomly separated all images (pairs of hyperspectral and corresponding RGB images) into 4 data subsets—denoted as image subset , , , and ; each consists 50 scenes. Then, in each trial, 2 subsets were used for training, 1 subset was used for validation, and 1 subset was used for testing, and the roles for each subset in different trials were permuted as follows:
- Trial #1—Training: & , Validation: , Testing:
- Trial #2—Training: & , Validation: , Testing:
- Trial #3—Training: & , Validation: , Testing:
- Trial #4—Training: & , Validation: , Testing: .
In the training process of each trial, the training set was used to minimize for either the LS, LS, RELS, or RELAD criteria.
Then, the validation set was used to determine the unknown regularization parameters following the procedure introduced in Section 2.2.1. More specifically, we first coarsely tried a wide range of magnitudes: or , and then selected the magnitude that returns the lowest averaged validation-set MRAE. Next, we conducted a finer search at 1000 points (equidistant on the log scale) between the two adjacent magnitudes of the coarsely selected one, which determines the final selection of or .
For the deep learning-based HSCNN-R, the validation step is different. In HSCNN-R, we use the validation set to determine the termination epoch of the training [60]. The actual termination epochs adopted differ among the 4 cross-validation trials, but all of them are between 315 and 350 epochs.
Finally, we evaluated all models and minimization criteria using the testing-set images. The resulting statistics presented in the next section are the averaged testing results over the 4 cross-validation trials.
5. Results
5.1. Mean and Worst-Case Performance
In Table 3, we present the mean statistics of per-image-mean and per-image-99-percentile (worst-case) MRAE over the 200 tested images. Let us first look at the numbers in the first row, which are results of variations of LR (i.e., Linear Regression). The mean results (under the headline “Mean per-image-mean MRAE”) show that LR trained using all of our three new approaches outperform the standard LS (least-squares), among which the RELAD method performs the best—returning 14% lower MRAE compared to LS. On the right side of Table 3 (headlined “Mean per-image-99-percentile MRAE”), we see that RELS-based LR provides 17% lower worst-case MRAE compared to using the standard LS. Likewise, observing all other regression models, we found that the best minimization criterion in terms of mean MRAE is either RELS or RELAD depending on the model.
To further examine the robustness of the best minimization approach against other tested approaches, we present the “paired” (or “dependent”) two-sample Student’s t-test scores [85] in Table 4. The t-test scores are calculated based on the observed 200 pairs of per-image-mean MRAEs delivered by two compared minimization criteria. For example, let us look at the top-left number of the table, where 9.46 is the t-test score when comparing the “Best” approach for LR (i.e., RELAD, which delivers the lowest mean per-image-mean MRAE for LR) versus the conventional LS minimization. In the same row, we also see the t-test scores comparing the Best approach with LS and RELS, respectively, but not RELAD (because RELAD is the Best criterion itself).
In essence, the larger the absolute value of the t-test score, the more significant the two distributions are apart (i.e., the advantageous mean performance of the Best criterion has statistical significance). In our case, all tests have a degree of freedom of (200 is the number of dependent sample pairs). Accordingly, with a “one-sided” hypothesis (as we only want to test if the mean of the Best criterion is smaller), a 5% level of significance (so-called the “p-value” in most literature) corresponds to a t-score of 1.65 (according to the t-distribution table in [86]). Evidently, we see that the t-scores of all our tests are greater than the 1.65 threshold. In a practical sense, this result suggests that for each regression model, using the corresponding best minimization criterion can consistently deliver the lowest per-image-mean MRAEs of all.
Still, it is somewhat counterintuitive that RELAD performs worse than RELS in some cases. Indeed, as RELAD directly minimizes MRAE, we might expect that RELAD would always provide the lowest mean MRAE. This outcome likely originates from the imprecision problem of IRLS specifically when solving LAD (i.e., the Least Absolute Deviation) minimizations [79,87,88]. Another possible cause which might result in suboptimal optimization is that the IRLS algorithm might, in some cases, fail to converge after 20 iterations (remember that we set the stopping iteration in Step 11 of Algorithm 1). We stopped iterating after 20 iterations to keep limit the computational complexity of the problem.
In contrast, it is not entirely surprising that RELS has better worst-case performance than RELAD (and consequently RELS is the best method for all tested regressions in terms of the worst-case MRAE). Indeed, it is well known that minimizations tend to be less sensitive to outliers compared to their counterparts [78,79]. Which means, in RELAD these 99-percentile pixels might be treated as outliers during training—i.e., minimization of these pixels are less important—and thus perform worse in testing.
Finally, it is shown that our best performing regression model—the RELS-based PR—is only 8.7% worse than HSCNN-R in terms of mean MRAE. We remind the reader that HSCNN-R is one of the top models in the NTIRE 2018 challenge [63] in which all finalists are based on DNNs. Given that most of the reported challenge entries were much more than 10% worse than HSCNN-R under the MRAE evaluation, we can expect that some of our further optimized regression models can be on par with—or even better than—many DNN models in the challenge.
This result contradicts the assumption taken by many DNN approaches that mapping large image patches is necessary for achieving top performances—as all tested regressions in our experiment are pixel-based. Furthermore, regarding how much fewer model parameters the regressions use in comparison to the DNNs (e.g., the PR regression model has 2573 parameters, whereas HSCNN-R has approximately parameters), it is surprising to see that regression methods can achieve comparable performance to the DNNs (let alone being better than some). As DNNs have millions of parameters, it is likely that the training data is insufficient to robustly optimize these parameters (the ICVL database [70] used in our study and in NTIRE 2018 challenge [63] is already one of the largest available hyperspectral image databases so far).
5.2. Computational Time
The training and reconstruction time of all tested models are presented in Table 5. We calculate the training time as the average time used for each cross-validation trial, and the reconstruction time as the average time used to reconstruct each tested image.
Our hardware specification includes Intel Core i7-9700 CPU and NVIDIA GeForce RTX 2080 SUPER GPU. Note that the GPU is only used to run the training process of the HSCNN-R model. All testing (reconstruction) processes and the training of the regressions use solely the CPU.
Let us look at the training time (the left side of Table 5). First, we see that regardless of the regression model, the closed-form LS, LS and RELS approaches show absolute dominance over the iteratively solved RELAD approach and HSCNN-R for shorter training time. Then, although it appears that the RELAD minimization in general takes longer than training HSCNN-R, we remark that HSCNN-R is GPU-accelerated (which is highly based on parallel programming), yet our implementation of RELAD does not use any apparent parallel programming technique.
As for the reconstruction time results (the right side of Table 5), we see that all tested regression methods require much less time to reconstruct a spectral image compared to HSCNN-R. Additionally, we notice that the reconstruction time for regression models does not depend on the adopted minimization approach—this result makes sense because after all, no matter how we optimized the regression matrix, the reconstruction procedure is the same. Consequently, in the case that longer “offline” training time is permitted, the RELAD-optimized regression can still support fast reconstruction as LS, LS, and RELS.
5.3. Brightness Dependence
Let us further investigate the performance discrepancy within an image. In Figure 4, we show for each regression approach the MRAE recovery error map of a given example scene. We see that RELS and RELAD tend to improve the spectral recoveries for the foreground objects particularly e.g., trees and grass in the LR results, flowers in the RPR results, leaves in the A+ results, bonsai pot in the RBFN results, and the green peppers in the PR results. Yet, it seems that in the background and/or highlight regions (e.g., sandy grounds and the blue sky), LS and LS in turn outperform RELS and RELAD.
We observe that generally in scenes included in the ICVL database the foregrounds are dimmer than the backgrounds, therefore we presume the reason that LS and LS tend to recover spectra of the background and highlights more accurately (yet perform much worse in the foreground) is due to the brightness bias of least-squares minimization (see Section 2.3).
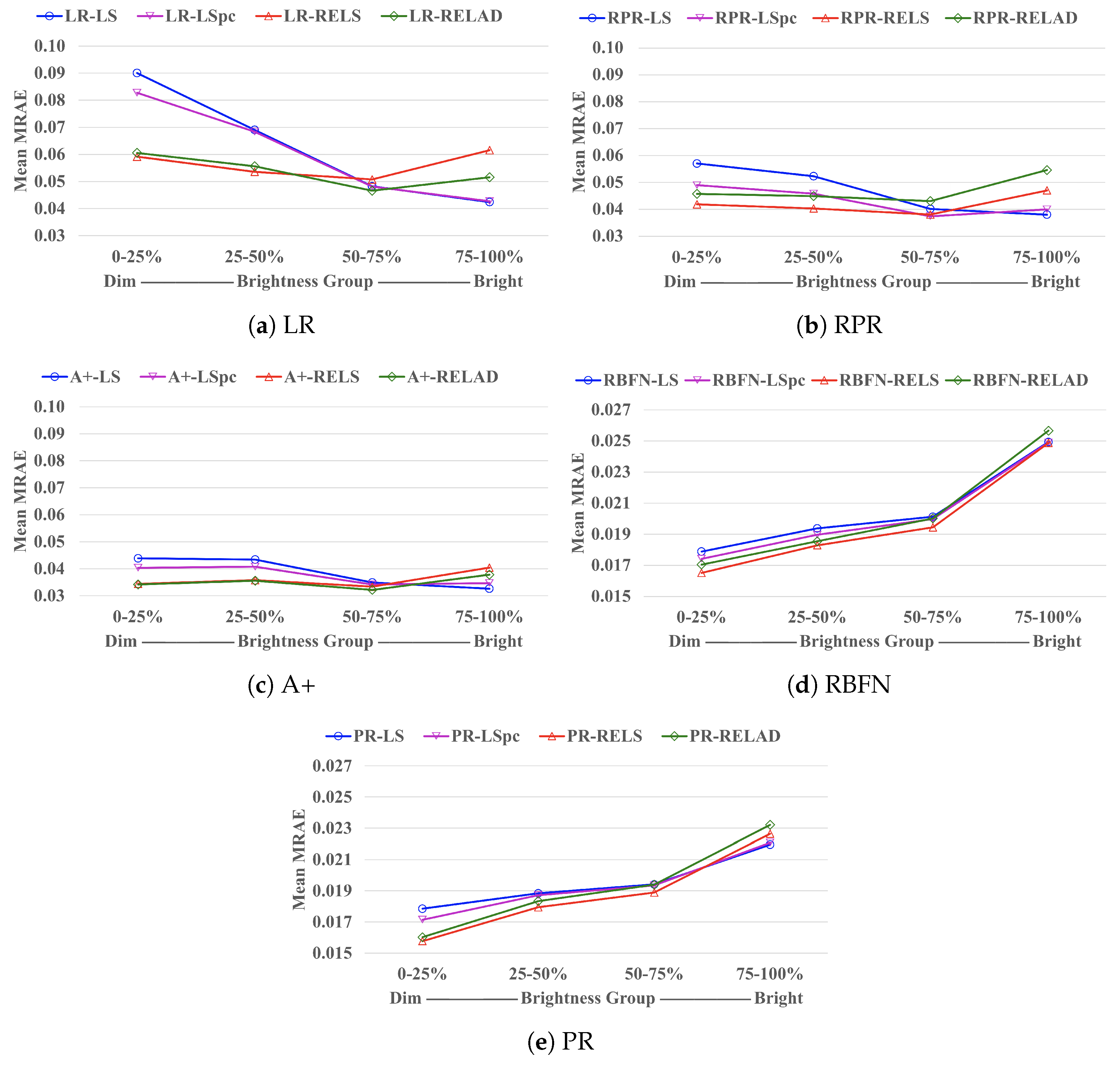
In Figure 5, we exhibit how the mean MRAE performance of each regression approach is related to the pixels’ brightness. Here, “brightness” is defined as the norm of the ground-truth spectrum. For each image we separated all pixels into 4 different brightness groups—0–25 percentile (the dimmest group), 25–50 percentile, 50–75 percentile, and 75–100 percentile (the brightest group). Then, for pixels belonging to the same brightness group (from all testing-set images) we calculated their mean MRAE, which is presented in the plots.
Clearly, we observe that while LS and LS generally provide lower MRAE for the brightest group in an image (75–100%), RELS and RELAD demonstrate great advantages over LS and LS in the two dimmest groups (0–25% and 25–50%), which eventually leads to better overall performance.
6. Conclusions
Spectral reconstruction (SR) recovers high-resolution radiance spectra from RGB images. Many methods are regression-based, with simple formulations and usually closed-form solutions, while the current state-of-the-art spectral recovery is delivered by the much more sophisticated Deep Neural Network (DNN) solutions.
Recently, the top DNN models are trained and evaluated based on Mean Relative Absolute Error (MRAE)—a relative error which measures the spectral difference as a percentage of the ground-truth spectral value. Comparatively, all regressions are still trained based on the Least Squares (LS) minimization, which does not suggest a minimized MRAE result. This problem is further compounded by the sub-optimal regularization setting used in conventional regressions where all spectral channels are jointly regularized by a single penalty parameter.
In this paper, we developed new regression approaches that minimize relative errors and are regularized per spectral channel, including the closed-form Relative-Error Least Squares (RELS) and the Relative-Error Least Absolute Deviation (RELAD) approach (which directly minimizes MRAE and was solved by an iterative method).
Our results showed that the new minimization approaches significantly improve the conventional regressions especially in the darker regions of the images. Consequently, our best improved regression model narrows the performance gap with the leading DNNs to only 8% under the MRAE evaluation.
Supplementary Materials
The code of the methods introduced in this paper is available at https://github.com/EthanLinYitun/On_the_Optimization_of_Regression_Based_Spectral_Reconstruction.
Author Contributions
Conceptualization, Y.-T.L. and G.D.F.; Data curation, Y.-T.L.; Formal analysis, Y.-T.L.; Funding acquisition, G.D.F.; Investigation, Y.-T.L.; Methodology, Y.-T.L. and G.D.F.; Project administration, G.D.F.; Resources, G.D.F.; Software, Y.-T.L.; Supervision, G.D.F.; Validation, Y.-T.L.; Visualization, Y.-T.L.; Writing—original draft, Y.-T.L.; Writing—review and editing, Y.-T.L. and G.D.F. Both authors have read and agreed to the published version of the manuscript.
Funding
This research is funded by EPSRC grant EP/S028730/1. We also thank Apple Inc. for additional support.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Publicly available datasets were analyzed in this study. This data can be found here: http://icvl.cs.bgu.ac.il/hyperspectral/.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Hardeberg, J.Y. On the spectral dimensionality of object colours. In Proceedings of the Conference on Colour in Graphics, Imaging, and Vision, Poitiers, France, 2–5 April 2002; Society for Imaging Science and Technology: Scottsdale, AZ, USA, 2002; Volume 2002, pp. 480–485. [Google Scholar]
- Romero, J.; Garcıa-Beltrán, A.; Hernández-Andrés, J. Linear bases for representation of natural and artificial illuminants. J. Opt. Soc. Am. A 1997, 14, 1007–1014. [Google Scholar] [CrossRef]
- Lee, T.W.; Wachtler, T.; Sejnowski, T.J. The spectral independent components of natural scenes. In Proceedings of the International Workshop on Biologically Motivated Computer Vision, Seoul, Korea, 15–17 May 2000; Springer: Berlin/Heidelberg, Germany, 2000; pp. 527–534. [Google Scholar]
- Marimont, D.H.; Wandell, B.A. Linear models of surface and illuminant spectra. J. Opt. Soc. Am. A 1992, 9, 1905–1913. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Parkkinen, J.P.; Hallikainen, J.; Jaaskelainen, T. Characteristic spectra of Munsell colors. J. Opt. Soc. Am. A 1989, 6, 318–322. [Google Scholar] [CrossRef]
- Riihiaho, K.A.; Eskelinen, M.A.; Pölönen, I. A Do-It-Yourself Hyperspectral Imager Brought to Practice with Open-Source Python. Sensors 2021, 21, 1072. [Google Scholar] [CrossRef] [PubMed]
- Stuart, M.B.; McGonigle, A.J.; Davies, M.; Hobbs, M.J.; Boone, N.A.; Stanger, L.R.; Zhu, C.; Pering, T.D.; Willmott, J.R. Low-Cost Hyperspectral Imaging with A Smartphone. J. Imaging 2021, 7, 136. [Google Scholar] [CrossRef]
- Zhao, Y.; Guo, H.; Ma, Z.; Cao, X.; Yue, T.; Hu, X. Hyperspectral Imaging With Random Printed Mask. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 10149–10157. [Google Scholar]
- Garcia, H.; Correa, C.V.; Arguello, H. Multi-resolution compressive spectral imaging reconstruction from single pixel measurements. IEEE Trans. Image Process. 2018, 27, 6174–6184. [Google Scholar] [CrossRef] [PubMed]
- Takatani, T.; Aoto, T.; Mukaigawa, Y. One-shot hyperspectral imaging using faced reflectors. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4039–4047. [Google Scholar]
- Galvis, L.; Lau, D.; Ma, X.; Arguello, H.; Arce, G.R. Coded aperture design in compressive spectral imaging based on side information. Appl. Opt. 2017, 56, 6332–6340. [Google Scholar] [CrossRef]
- Wang, L.; Xiong, Z.; Gao, D.; Shi, G.; Zeng, W.; Wu, F. High-speed hyperspectral video acquisition with a dual-camera architecture. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4942–4950. [Google Scholar]
- Rueda, H.; Arguello, H.; Arce, G.R. DMD-based implementation of patterned optical filter arrays for compressive spectral imaging. J. Opt. Soc. Am. A 2015, 32, 80–89. [Google Scholar] [CrossRef]
- Correa, C.V.; Arguello, H.; Arce, G.R. Snapshot colored compressive spectral imager. J. Opt. Soc. Am. A 2015, 32, 1754–1763. [Google Scholar] [CrossRef]
- Arguello, H.; Arce, G.R. Colored coded aperture design by concentration of measure in compressive spectral imaging. IEEE Trans. Image Process. 2014, 23, 1896–1908. [Google Scholar] [CrossRef]
- Lin, X.; Liu, Y.; Wu, J.; Dai, Q. Spatial-spectral encoded compressive hyperspectral imaging. ACM Trans. Graph. 2014, 33, 233. [Google Scholar] [CrossRef]
- Cao, X.; Du, H.; Tong, X.; Dai, Q.; Lin, S. A prism-mask system for multispectral video acquisition. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 2423–2435. [Google Scholar]
- Gat, N. Imaging spectroscopy using tunable filters: A review. In Proceedings of the Wavelet Applications VII, Orlando, FL, USA, 26–28 April 2000; International Society for Optics and Photonics: Bellingham, WA, USA, 2000; Volume 4056, pp. 50–64. [Google Scholar]
- Green, R.O.; Eastwood, M.L.; Sarture, C.M.; Chrien, T.G.; Aronsson, M.; Chippendale, B.J.; Faust, J.A.; Pavri, B.E.; Chovit, C.J.; Solis, M.; et al. Imaging spectroscopy and the airborne visible/infrared imaging spectrometer (AVIRIS). Remote Sens. Environ. 1998, 65, 227–248. [Google Scholar] [CrossRef]
- Wang, W.; Ma, L.; Chen, M.; Du, Q. Joint Correlation Alignment-Based Graph Neural Network for Domain Adaptation of Multitemporal Hyperspectral Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 3170–3184. [Google Scholar] [CrossRef]
- Torun, O.; Yuksel, S.E. Unsupervised segmentation of LiDAR fused hyperspectral imagery using pointwise mutual information. Int. J. Remote Sens. 2021, 42, 6465–6480. [Google Scholar] [CrossRef]
- Tu, B.; Zhou, C.; Liao, X.; Zhang, G.; Peng, Y. Spectral–spatial hyperspectral classification via structural-kernel collaborative representation. IEEE Geosci. Remote Sens. Lett. 2020, 18, 861–865. [Google Scholar] [CrossRef]
- Inamdar, D.; Kalacska, M.; Leblanc, G.; Arroyo-Mora, J.P. Characterizing and mitigating sensor generated spatial correlations in airborne hyperspectral imaging data. Remote Sens. 2020, 12, 641. [Google Scholar] [CrossRef] [Green Version]
- Alcolea, A.; Paoletti, M.E.; Haut, J.M.; Resano, J.; Plaza, A. Inference in supervised spectral classifiers for on-board hyperspectral imaging: An overview. Remote Sens. 2020, 12, 534. [Google Scholar] [CrossRef] [Green Version]
- Gholizadeh, H.; Gamon, J.A.; Helzer, C.J.; Cavender-Bares, J. Multi-temporal assessment of grassland α-and β-diversity using hyperspectral imaging. Ecol. Appl. 2020, 30, e02145. [Google Scholar] [CrossRef]
- Veganzones, M.; Tochon, G.; Dalla-Mura, M.; Plaza, A.; Chanussot, J. Hyperspectral image segmentation using a new spectral unmixing-based binary partition tree representation. IEEE Trans. Image Process. 2014, 23, 3574–3589. [Google Scholar] [CrossRef]
- Ghamisi, P.; Dalla Mura, M.; Benediktsson, J. A survey on spectral–spatial classification techniques based on attribute profiles. IEEE Trans. Geosci. Remote Sens. 2014, 53, 2335–2353. [Google Scholar] [CrossRef]
- Lv, M.; Chen, T.; Yang, Y.; Tu, T.; Zhang, N.; Li, W.; Li, W. Membranous nephropathy classification using microscopic hyperspectral imaging and tensor patch-based discriminative linear regression. Biomed. Opt. Express 2021, 12, 2968–2978. [Google Scholar] [CrossRef]
- Courtenay, L.A.; González-Aguilera, D.; Lagüela, S.; del Pozo, S.; Ruiz-Mendez, C.; Barbero-García, I.; Román-Curto, C.; Cañueto, J.; Santos-Durán, C.; Cardeñoso-Álvarez, M.E.; et al. Hyperspectral imaging and robust statistics in non-melanoma skin cancer analysis. Biomed. Opt. Express 2021, 12, 5107–5127. [Google Scholar] [CrossRef]
- Zhang, Y.; Xi, Y.; Yang, Q.; Cong, W.; Zhou, J.; Wang, G. Spectral CT reconstruction with image sparsity and spectral mean. IEEE Trans. Comput. Imaging 2016, 2, 510–523. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, Y.; Mou, X.; Wang, G.; Yu, H. Tensor-based dictionary learning for spectral CT reconstruction. IEEE Trans. Med Imaging 2016, 36, 142–154. [Google Scholar] [CrossRef] [Green Version]
- Chen, Z.; Wang, J.; Wang, T.; Song, Z.; Li, Y.; Huang, Y.; Wang, L.; Jin, J. Automated in-field leaf-level hyperspectral imaging of corn plants using a Cartesian robotic platform. Comput. Electron. Agric. 2021, 183, 105996. [Google Scholar] [CrossRef]
- Gomes, V.; Mendes-Ferreira, A.; Melo-Pinto, P. Application of Hyperspectral Imaging and Deep Learning for Robust Prediction of Sugar and pH Levels in Wine Grape Berries. Sensors 2021, 21, 3459. [Google Scholar] [CrossRef] [PubMed]
- Pane, C.; Manganiello, G.; Nicastro, N.; Cardi, T.; Carotenuto, F. Powdery Mildew Caused by Erysiphe cruciferarum on Wild Rocket (Diplotaxis tenuifolia): Hyperspectral Imaging and Machine Learning Modeling for Non-Destructive Disease Detection. Agriculture 2021, 11, 337. [Google Scholar] [CrossRef]
- Hu, N.; Li, W.; Du, C.; Zhang, Z.; Gao, Y.; Sun, Z.; Yang, L.; Yu, K.; Zhang, Y.; Wang, Z. Predicting micronutrients of wheat using hyperspectral imaging. Food Chem. 2021, 343, 128473. [Google Scholar] [CrossRef]
- Weksler, S.; Rozenstein, O.; Haish, N.; Moshelion, M.; Wallach, R.; Ben-Dor, E. Detection of Potassium Deficiency and Momentary Transpiration Rate Estimation at Early Growth Stages Using Proximal Hyperspectral Imaging and Extreme Gradient Boosting. Sensors 2021, 21, 958. [Google Scholar] [CrossRef]
- Qin, J.; Chao, K.; Kim, M.S.; Lu, R.; Burks, T.F. Hyperspectral and multispectral imaging for evaluating food safety and quality. J. Food Eng. 2013, 118, 157–171. [Google Scholar] [CrossRef]
- Xie, W.; Fan, S.; Qu, J.; Wu, X.; Lu, Y.; Du, Q. Spectral Distribution-Aware Estimation Network for Hyperspectral Anomaly Detection. IEEE Trans. Geosci. Remote Sens. 2021. [Google Scholar] [CrossRef]
- Zhang, L.; Cheng, B. A combined model based on stacked autoencoders and fractional Fourier entropy for hyperspectral anomaly detection. Int. J. Remote Sens. 2021, 42, 3611–3632. [Google Scholar] [CrossRef]
- Li, X.; Zhao, C.; Yang, Y. Hyperspectral anomaly detection based on the distinguishing features of a redundant difference-value network. Int. J. Remote Sens. 2021, 42, 5459–5477. [Google Scholar] [CrossRef]
- Zhang, X.; Ma, X.; Huyan, N.; Gu, J.; Tang, X.; Jiao, L. Spectral-Difference Low-Rank Representation Learning for Hyperspectral Anomaly Detection. IEEE Trans. Geosci. Remote Sens. 2021. [Google Scholar] [CrossRef]
- Yang, Y.; Song, S.; Liu, D.; Chan, J.C.W.; Li, J.; Zhang, J. Hyperspectral anomaly detection through sparse representation with tensor decomposition-based dictionary construction and adaptive weighting. IEEE Access 2020, 8, 72121–72137. [Google Scholar] [CrossRef]
- Lei, J.; Fang, S.; Xie, W.; Li, Y.; Chang, C.I. Discriminative reconstruction for hyperspectral anomaly detection with spectral learning. IEEE Trans. Geosci. Remote Sens. 2020, 58, 7406–7417. [Google Scholar] [CrossRef]
- Jablonski, J.A.; Bihl, T.J.; Bauer, K.W. Principal component reconstruction error for hyperspectral anomaly detection. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1725–1729. [Google Scholar] [CrossRef]
- Cheung, V.; Westland, S.; Li, C.; Hardeberg, J.; Connah, D. Characterization of trichromatic color cameras by using a new multispectral imaging technique. J. Opt. Soc. Am. A 2005, 22, 1231–1240. [Google Scholar] [CrossRef]
- Shen, H.L.; Xin, J.H. Spectral characterization of a color scanner by adaptive estimation. J. Opt. Soc. Am. A 2004, 21, 1125–1130. [Google Scholar] [CrossRef] [Green Version]
- Jaspe-Villanueva, A.; Ahsan, M.; Pintus, R.; Giachetti, A.; Marton, F.; Gobbetti, E. Web-based Exploration of Annotated Multi-Layered Relightable Image Models. ACM J. Comput. Cult. Herit. 2021, 14, 1–29. [Google Scholar] [CrossRef]
- Lam, A.; Sato, I. Spectral modeling and relighting of reflective-fluorescent scenes. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 1452–1459. [Google Scholar]
- Picollo, M.; Cucci, C.; Casini, A.; Stefani, L. Hyper-spectral imaging technique in the cultural heritage field: New possible scenarios. Sensors 2020, 20, 2843. [Google Scholar] [CrossRef]
- Grillini, F.; Thomas, J.B.; George, S. Mixing models in close-range spectral imaging for pigment mapping in cultural heritage. In Proceedings of the International Colour Association (AIC) Conference, Online, 20 & 26–27 November 2020; pp. 372–376. [Google Scholar]
- Xu, P.; Xu, H.; Diao, C.; Ye, Z. Self-training-based spectral image reconstruction for art paintings with multispectral imaging. Appl. Opt. 2017, 56, 8461–8470. [Google Scholar] [CrossRef]
- Heikkinen, V.; Lenz, R.; Jetsu, T.; Parkkinen, J.; Hauta-Kasari, M.; Jääskeläinen, T. Evaluation and unification of some methods for estimating reflectance spectra from RGB images. J. Opt. Soc. Am. A 2008, 25, 2444–2458. [Google Scholar] [CrossRef]
- Connah, D.; Hardeberg, J. Spectral recovery using polynomial models. In Color Imaging X: Processing, Hardcopy, and Applications in Proceedings of the Electronic Imaging, San Jose, CA, USA, 16–20 January 2005; International Society for Optics and Photonics: Bellingham, WA, USA, 2005; Volume 5667, pp. 65–75. [Google Scholar]
- Nguyen, R.; Prasad, D.; Brown, M. Training-based spectral reconstruction from a single RGB image. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; pp. 186–201. [Google Scholar]
- Aeschbacher, J.; Wu, J.; Timofte, R. In defense of shallow learned spectral reconstruction from RGB images. In Proceedings of the International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 471–479. [Google Scholar]
- Lin, Y.T.; Finlayson, G.D. Exposure Invariance in Spectral Reconstruction from RGB Images. In Proceedings of the Color and Imaging Conference, Paris, France, 21–25 October 2019; Society for Imaging Science and Technology: Scottsdale, AZ, USA, 2019; Volume 2019, pp. 284–289. [Google Scholar]
- Lin, Y.T.; Finlayson, G.D. Physically Plausible Spectral Reconstruction. Sensors 2020, 20, 6399. [Google Scholar] [CrossRef]
- Stiebel, T.; Merhof, D. Brightness Invariant Deep Spectral Super-Resolution. Sensors 2020, 20, 5789. [Google Scholar] [CrossRef] [PubMed]
- Lin, Y.T. Colour Fidelity in Spectral Reconstruction from RGB Images. In Proceedings of the London Imaging Meeting, London, UK, 29 September–1 October 2020; Society for Imaging Science and Technology: Scottsdale, AZ, USA, 2020; Volume 2020, pp. 144–148. [Google Scholar]
- Shi, Z.; Chen, C.; Xiong, Z.; Liu, D.; Wu, F. Hscnn+: Advanced cnn-based hyperspectral recovery from RGB images. In Proceedings of the Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 939–947. [Google Scholar]
- Li, J.; Wu, C.; Song, R.; Li, Y.; Liu, F. Adaptive weighted attention network with camera spectral sensitivity prior for spectral reconstruction from RGB images. In Proceedings of the Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 462–463. [Google Scholar]
- Zhao, Y.; Po, L.M.; Yan, Q.; Liu, W.; Lin, T. Hierarchical regression network for spectral reconstruction from RGB images. In Proceedings of the Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 422–423. [Google Scholar]
- Arad, B.; Ben-Shahar, O.; Timofte, R. NTIRE 2018 challenge on spectral reconstruction from RGB images. In Proceedings of the Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 929–938. [Google Scholar]
- Arad, B.; Timofte, R.; Ben-Shahar, O.; Lin, Y.T.; Finlayson, G.D. NTIRE 2020 challenge on spectral reconstruction from an RGB Image. In Proceedings of the Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Arun, P.; Buddhiraju, K.; Porwal, A.; Chanussot, J. CNN based spectral super-resolution of remote sensing images. Signal Process. 2020, 169, 107394. [Google Scholar] [CrossRef]
- Joslyn Fubara, B.; Sedky, M.; Dyke, D. RGB to Spectral Reconstruction via Learned Basis Functions and Weights. In Proceedings of the Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 480–481. [Google Scholar]
- Tikhonov, A.; Goncharsky, A.; Stepanov, V.; Yagola, A. Numerical Methods for the Solution of Ill-Posed Problems; Springer: New York, NY, USA, 2013; Volume 328. [Google Scholar]
- Webb, G.I. Overfitting. In Encyclopedia of Machine Learning; Sammut, C., Webb, G.I., Eds.; Springer: Boston, MA, USA, 2010; p. 744. [Google Scholar]
- Wandell, B.A. The synthesis and analysis of color images. IEEE Trans. Pattern Anal. Mach. Intell. 1987, PAMI-9, 2–13. [Google Scholar] [CrossRef] [Green Version]
- Arad, B.; Ben-Shahar, O. Sparse recovery of hyperspectral signal from natural RGB images. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Cham, Switzerland, 2016; pp. 19–34. [Google Scholar]
- Aharon, M.; Elad, M.; Bruckstein, A. K-SVD: An algorithm for designing overcomplete dictionaries for sparse representation. IEEE Trans. Signal Process. 2006, 54, 4311–4322. [Google Scholar] [CrossRef]
- Penrose, R. A generalized inverse for matrices. In Mathematical Proceedings of the Cambridge Philosophical Society; Cambridge University Press: Cambridge, UK, 1955; Volume 51, pp. 406–413. [Google Scholar]
- Galatsanos, N.; Katsaggelos, A. Methods for choosing the regularization parameter and estimating the noise variance in image restoration and their relation. IEEE Trans. Image Process. 1992, 1, 322–336. [Google Scholar] [CrossRef] [PubMed]
- Tibshirani, R. Regression shrinkage and selection via the lasso. J. R. Stat. Soc. Ser. B (Methodol.) 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Zou, H.; Hastie, T. Regularization and variable selection via the elastic net. J. R. Stat. Soc. Ser. B (Stat. Methodol.) 2005, 67, 301–320. [Google Scholar] [CrossRef] [Green Version]
- Van Trigt, C. Smoothest reflectance functions. II. Complete results. J. Opt. Soc. Am. A 1990, 7, 2208–2222. [Google Scholar] [CrossRef]
- Tofallis, C. Least squares percentage regression. J. Mod. Appl. Stat. Methods 2008, 7, 526–534. [Google Scholar] [CrossRef]
- Wang, L.; Gordon, M.D.; Zhu, J. Regularized least absolute deviations regression and an efficient algorithm for parameter tuning. In Proceedings of the International Conference on Data Mining, Hong Kong, China, 18–22 December 2006; pp. 690–700. [Google Scholar]
- Chen, K.; Lv, Q.; Lu, Y.; Dou, Y. Robust regularized extreme learning machine for regression using iteratively reweighted least squares. Neurocomputing 2017, 230, 345–358. [Google Scholar] [CrossRef]
- Wagner, H.M. Linear programming techniques for regression analysis. J. Am. Stat. Assoc. 1959, 54, 206–212. [Google Scholar] [CrossRef]
- Carroll, R.J.; Ruppert, D. Transformation and Weighting in Regression; CRC Press: Boca Raton, FL, USA, 1988; Volume 30. [Google Scholar]
- Deng, W.; Zheng, Q.; Chen, L. Regularized extreme learning machine. In Proceedings of the Symposium on Computational Intelligence and Data Mining, Nashville, TN, USA, 30 March–2 April 2009; pp. 389–395. [Google Scholar]
- Commission Internationale de L’eclairage. CIE Proceedings (1964) Vienna Session, Committee Report E-1.4. 1; Commission Internationale de L’eclairage: Paris, France, 1964. [Google Scholar]
- Wyszecki, G.; Stiles, W.S. Color Science; Wiley: New York, NY, USA, 1982; Volume 8. [Google Scholar]
- Snedecor, G.W.; Cochran, W. Statistical Methods, 6th ed.; The Iowa State University: Ames, IA, USA, 1967; pp. 91–119. [Google Scholar]
- Kokoska, S.; Zwillinger, D. CRC Standard Probability and Statistics Tables and Formulae; CRC Press: Boca Raton, FL, USA, 2000; pp. 152–153. [Google Scholar]
- Schlossmacher, E. An iterative technique for absolute deviations curve fitting. J. Am. Stat. Assoc. 1973, 68, 857–859. [Google Scholar] [CrossRef]
- Gentle, J.E. Matrix Algebra; Springer Texts in Statistics; Springer: Cham, Switzerland, 2007; Volume 10, pp. 232–233. [Google Scholar]
Figure 1.
The standard spectral reconstruction (SR) training and evaluation scheme.

Figure 2.
Example hyperspectral image reconstruction error heat maps (in MRAE) by the conventional Polynomial Regression [53] (left), Polynomial Regression based on our new RELS method (middle), and the deep learning-based HSCNN-R [60] (right).

Figure 3.
An illustration of searching for the regularization parameter. The averaged MRAE (vertical axis) is calculated over the validation set (a separate data set that is not the training set). The red dot in the graph indicates the minimal error and the suggested regularization parameter.
Figure 3.
An illustration of searching for the regularization parameter. The averaged MRAE (vertical axis) is calculated over the validation set (a separate data set that is not the training set). The red dot in the graph indicates the minimal error and the suggested regularization parameter.

Figure 4.
The MRAE error heat maps for the considered regression models optimized for LS, LS, RELS, and RELAD criteria.
Figure 4.
The MRAE error heat maps for the considered regression models optimized for LS, LS, RELS, and RELAD criteria.

Figure 5.
The mean MRAE performance for pixels belonging to 4 different percentile groups (based on their brightness) in each image. For display purposes, in plot (a–c) the Mean MRAE (the vertical axes) is shown between the interval of , while in plot (d,e) it is shown between .
Figure 5.
The mean MRAE performance for pixels belonging to 4 different percentile groups (based on their brightness) in each image. For display purposes, in plot (a–c) the Mean MRAE (the vertical axes) is shown between the interval of , while in plot (d,e) it is shown between .


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
List of considered regression models.
| Model | Abbreviation |
|---|---|
| Linear Regression [52] | LR |
| Root-Polynomial Regression ( order) [56] | RPR |
| A+ Sparse Coding [55] | A+ |
| Radial Basis Function Network [54] | RBFN |
| Polynomial Regression ( order) [53] | PR |
Table 2.
List of minimization approaches.
| Approach | Abbreviation | Per-Channel Regularization | Loss Metric |
|---|---|---|---|
| Least Squares | LS | ✗ | squared RMSE |
| Per-Channel Least Squares | LS | ✓ | squared RMSE |
| Relative Error Least Squares | RELS | ✓ | squared relative-RMSE |
| Relative Error Least Absolute Deviation | RELAD | ✓ | MRAE |
Table 3.
The mean per-image-mean and per-image-99-percentile MRAE for all tested spectral reconstruction models. The result of HSCNN-R (the reference DNN model) is given in the last row. For all regression approaches (all except HSCNN-R), best results among the 4 training criteria—LS, LS, RELS, and RELAD—are underlined.
Table 3.
The mean per-image-mean and per-image-99-percentile MRAE for all tested spectral reconstruction models. The result of HSCNN-R (the reference DNN model) is given in the last row. For all regression approaches (all except HSCNN-R), best results among the 4 training criteria—LS, LS, RELS, and RELAD—are underlined.
| Mean Per-Image-Mean MRAE | Mean Per-Image-99-Percentile MRAE | |||||||
|---|---|---|---|---|---|---|---|---|
| LS | LS | RELS | RELAD | LS | LS | RELS | RELAD | |
| LR | 0.0624 | 0.0605 | 0.0563 | 0.0536 | 0.1695 | 0.1779 | 0.1409 | 0.1656 |
| RPR | 0.0469 | 0.0431 | 0.0418 | 0.0471 | 0.1548 | 0.1498 | 0.1294 | 0.1432 |
| A+ | 0.0387 | 0.0375 | 0.0360 | 0.0349 | 0.1526 | 0.1428 | 0.1350 | 0.1402 |
| RBFN | 0.0206 | 0.0203 | 0.0198 | 0.0203 | 0.0789 | 0.0793 | 0.0740 | 0.0799 |
| PR | 0.0195 | 0.0193 | 0.0188 | 0.0192 | 0.0710 | 0.0709 | 0.0703 | 0.0734 |
| HSCNN-R | 0.0173 | 0.0653 | ||||||
Table 4.
The paired two-sample Student’s t-test scores of the mean per-image-mean MRAE results. For each regression model, the best minimization criterion (the one has the lowest number in Table 3) is tested against each of the other criteria.
Table 4.
The paired two-sample Student’s t-test scores of the mean per-image-mean MRAE results. For each regression model, the best minimization criterion (the one has the lowest number in Table 3) is tested against each of the other criteria.
| Student’s t-Test Score of Mean Per-Image-Mean MRAE | |||||
|---|---|---|---|---|---|
| Best Approach | Best vs. LS | Best vs. LS | Best vs. RELS | Best vs. RELAD | |
| LR | RELAD | 9.46 | 9.54 | 4.18 | N/A |
| RPR | RELS | 7.70 | 2.65 | N/A | 13.28 |
| A+ | RELAD | 6.93 | 7.19 | 7.69 | N/A |
| RBFN | RELS | 4.42 | 3.01 | N/A | 5.33 |
| PR | RELS | 4.59 | 4.18 | N/A | 4.33 |
Table 5.
The training and reconstruction time measurements. The size of the reconstructed images (from the ICVL database) is with 31 spectral channels, and the training set (for each cross-validation trial) is composed of 100 images.
Table 5.
The training and reconstruction time measurements. The size of the reconstructed images (from the ICVL database) is with 31 spectral channels, and the training set (for each cross-validation trial) is composed of 100 images.
| Training Time | Reconstruction Time | |||||||
|---|---|---|---|---|---|---|---|---|
| (Per Cross-Validation Trial) | (Per Image) | |||||||
| LS | LS | RELS | RELAD | LS | LS | RELS | RELAD | |
| LR | 6.7 min | 6.1 min | 6.2 min | 36.0 h | 3.3 s | 3.3 s | 3.3 s | 3.3 s |
| RPR | 17.0 min | 16.9 min | 35.9 min | 47.8 h | 10.8 s | 10.8 s | 10.8 s | 10.9 s |
| A+ | 26.9 min | 52.8 min | 54.6 min | 46.2 h | 1.5 min | 1.5 min | 1.5 min | 1.5 min |
| RBFN | 1.0 h | 1.0 h | 1.2 h | 36.8 h | 7.0 s | 7.0 s | 7.0 s | 7.0 s |
| PR | 15.1 min | 15.4 min | 42.2 min | 44.6 h | 9.8 s | 10.0 s | 10.0 s | 9.8 s |
| HSCNN-R | 35.5 h (GPU-accelerated) | 3.4 min | ||||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Lin, Y.-T.; Finlayson, G.D. On the Optimization of Regression-Based Spectral Reconstruction. Sensors 2021, 21, 5586. https://0-doi-org.brum.beds.ac.uk/10.3390/s21165586
AMA Style
Lin Y-T, Finlayson GD. On the Optimization of Regression-Based Spectral Reconstruction. Sensors. 2021; 21(16):5586. https://0-doi-org.brum.beds.ac.uk/10.3390/s21165586
Chicago/Turabian StyleLin, Yi-Tun, and Graham D. Finlayson. 2021. "On the Optimization of Regression-Based Spectral Reconstruction" Sensors 21, no. 16: 5586. https://0-doi-org.brum.beds.ac.uk/10.3390/s21165586
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.