
Fast and Efficient Method for Optical Coherence Tomography Images Classification Using Deep Learning Approach

 ,
,
Abstract
:1. Introduction
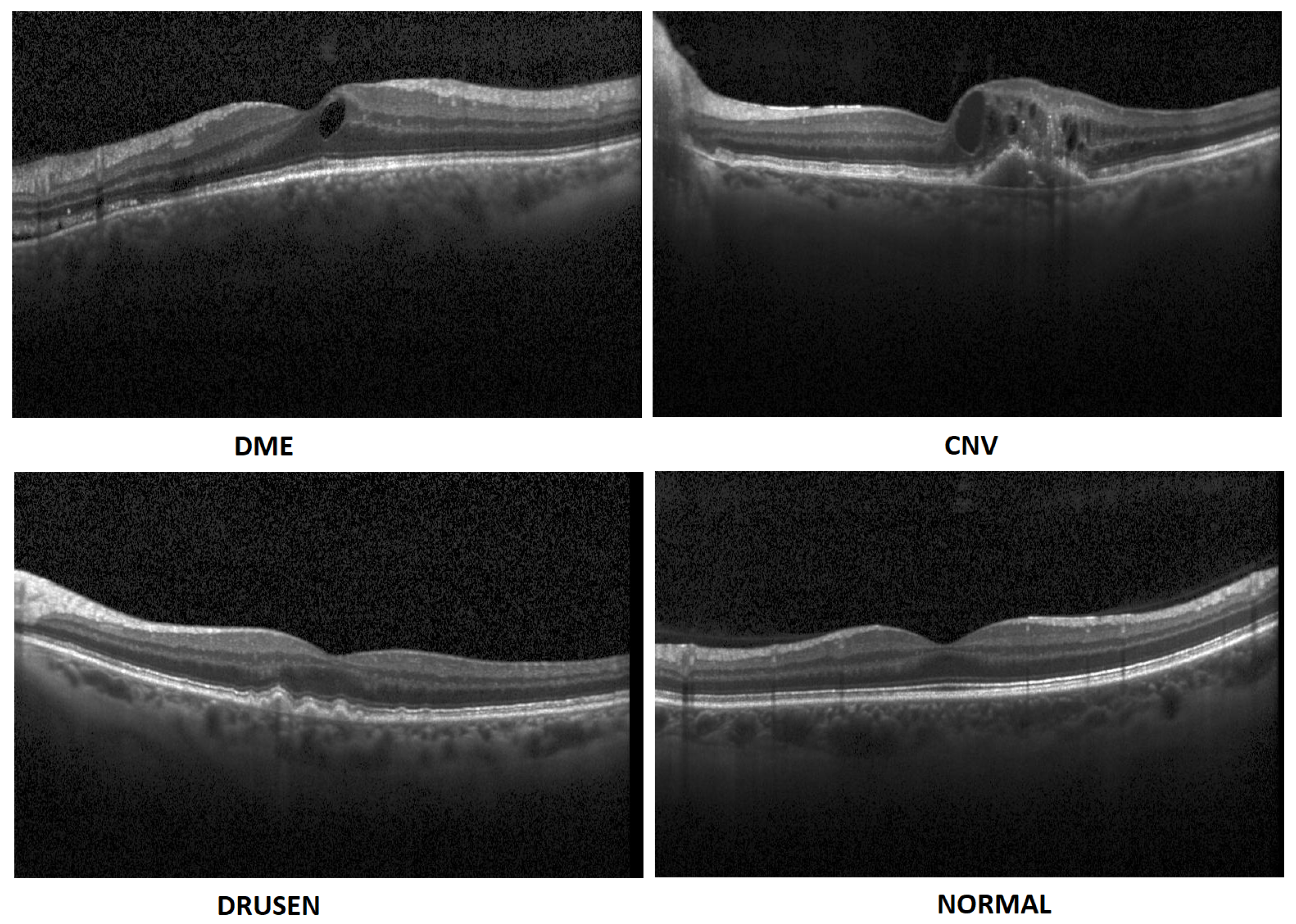
- In this paper, we propose an artificial intelligence aid solution for medical image classification. We deal with multiple classifications among four classes of images: DME, CNV, Drusen, and Normal (without visible pathology). Figure 1 presents images from the dataset used in the research taken from a publicly available dataset [7].
- We present an optimized implementation of the CNN model for medical image (OCT) analysis. We conduct experiments on public datasets [7]. Experimental results show that the proposed approach achieves high accuracy compared to the state-of-the-art algorithms.
- It is a novel study that emphasizes the importance of using augmented data in the training of the OCT images rather than increasing the depth (number of hidden layers) and width (number of filters) of the model.
2. Related Works
3. Database and Augmentation
- Mirror image. Symmetrical reflection of the image in relation to the vertical description of the symmetry of the image. Reflection in relation to the horizontal axis would cause the layers to be inverted, hence it was not used.
- Rotation. Rotation of the image relative to the center of symmetry of the image. Rotation was carried out in the range of (counterclockwise) to (clockwise) with an interval of 5°.
- Aspect ratio change. Expanding the image in the range from 105 to 130 percent taking into account the horizontal and vertical axis of the photo separately. Changing both axes simultaneously would only change the image size.
- Histogram equalization. Equalizing the pixel value histogram. The dependence of the image acquisition on different tissue permeability is reduced.
- Gaussian blur. Blur with the kernel parameter (5, 5). The operation is to increase the number of samples and add distorted samples-less sharp-based on the original.
- Sharpen filter. Edge sharpening operation, inverse to blurring, according to:[[-1, -1, -1],[-1, 9, -1],[-1, -1, -1]]
4. Proposed Models
- Image size = 128 × 128 × 3
- Batch size = 32
- Epochs = 10
- Kernel size (v1) = 3 × 3
- Kernel size (v2) = 3 × 3 & 5 × 5
- Max pooling = 3 × 3 & 2 × 2
- Activation function = ReLU (Rectified Linear Unit)
- Dropout (v1): 25% & 50%
- Dropout (v2): 15% & 15% & 15% & 25% & 10% & 10% & 10%
- Adam optimizer = 0.001 (v1), 0.002 (v2)
- Loss function = Categorical Cross-Entropy
- Dense (v1): 1024
- Dense (v2): 256 & 128 & 64 & 32
- Output layer activation function = Softmax
- Number of training images = 28,000
- Number of validation images = 6488
- Number of test images = 968
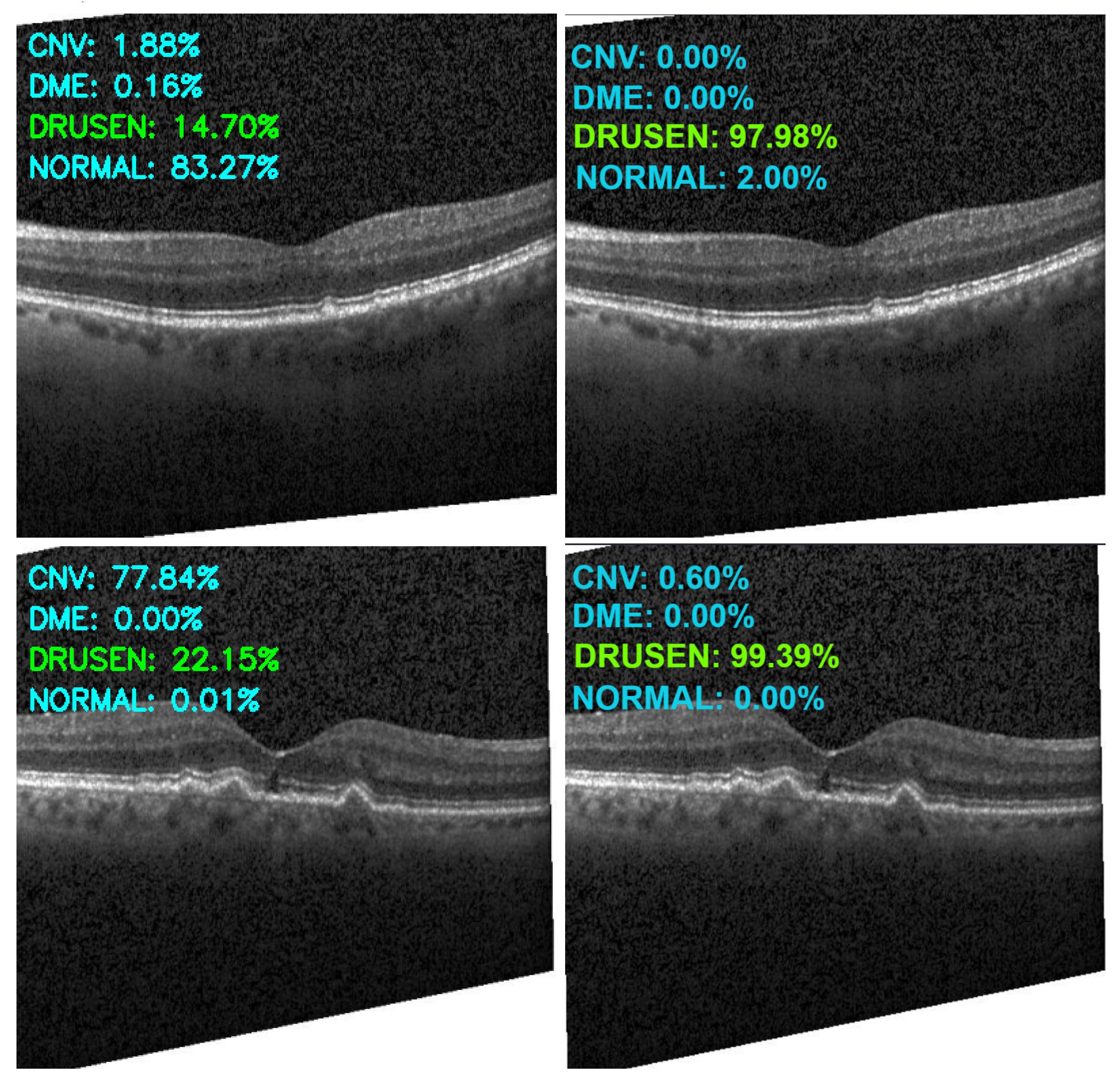
5. Experiments and Evaluation
6. Discussion and Significance of Proposed Work
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AMD | Age-related macular degeneration |
| CNN | Convolutional Neural Network |
| CNV | Choroidal NeoVascularization |
| DME | Diabetic Macular Edema |
| DR | Diabetic Retinopathy |
| ERM | Epiretinal Membrane |
| JPEG | Joint Photographic Experts Group image format |
| MDFF | Multi-scale Deep Features Fusion |
| OCT | Optical Coherence Tomography |
References
- Krause, J.; Gulshan, V.; Rahimy, E.; Karth, P.; Widner, K.; Corrado, G.S.; Peng, L.; Webster, D.R. Grader Variability and the Importance of Reference Standards for Evaluating Machine Learning Models for Diabetic Retinopathy. Ophthalmology 2018, 125, 1264–1272. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Edison Artificial Intelligence Analytics. GE Healthcare (United States). Available online: https://www.gehealthcare.com/products/edison (accessed on 1 May 2022).
- García, P.H.; Simunic, D. Regulatory Framework of Artificial Intelligence in Healthcare. In Proceedings of the 2021 44th International Convention on Information, Communication and Electronic Technology (MIPRO), Opatija, Croatia, 27 September–1 October 2021; pp. 1052–1057. [Google Scholar] [CrossRef]
- Pesapane, F.; Codari, M.; Sardanelli, F. Artificial intelligence in medical imaging: Threat or opportunity? Radiologists again at the forefront of innovation in medicine. Eur. Radiol. Exp. 2018, 2, 35. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Trichonas, G.; Kaiser, P.K. Optical coherence tomography imaging of macular oedema. Br. J. Ophthalmol. 2014, 98, ii24–ii29. [Google Scholar] [CrossRef]
- Stahl, A. The Diagnosis and Treatment of Age-Related Macular Degeneration. Dtsch. Arztebl. Int. 2020, 117, 513–520. [Google Scholar] [CrossRef] [PubMed]
- Kermany, D.; Goldbaum, M.; Cai, W.; Valentim, C.; Liang, H.Y.; Baxter, S.; McKeown, A.; Yang, G.; Wu, X.; Yan, F.; et al. Identifying Medical Diagnoses and Treatable Diseases by Image-Based Deep Learning. Cell 2018, 172, 1122–1131.e9. [Google Scholar] [CrossRef]
- Sánchez Brea, L.; Andrade De Jesus, D.; Shirazi, M.F.; Pircher, M.; van Walsum, T.; Klein, S. Review on Retrospective Procedures to Correct Retinal Motion Artefacts in OCT Imaging. Appl. Sci. 2019, 9, 2700. [Google Scholar] [CrossRef] [Green Version]
- Phadikar, S.; Sinha, N.; Ghosh, R.; Ghaderpour, E. Automatic Muscle Artifacts Identification and Removal from Single-Channel EEG Using Wavelet Transform with Meta-Heuristically Optimized Non-Local Means Filter. Sensors 2022, 22, 2948. [Google Scholar] [CrossRef]
- Ahmad, M.; Qadri, S.F.; Qadri, S.; Saeed, I.A.; Zareen, S.S.; Iqbal, Z.; Alabrah, A.; Alaghbari, H.M.; Mizanur Rahman, S.M. A Lightweight Convolutional Neural Network Model for Liver Segmentation in Medical Diagnosis. Comput. Intell. Neurosci. 2022, 2022, 7954333. [Google Scholar] [CrossRef]
- Qadri, S.F.; Shen, L.; Ahmad, M.; Qadri, S.; Zareen, S.S.; Khan, S. OP-convNet: A Patch Classification-Based Framework for CT Vertebrae Segmentation. IEEE Access 2021, 9, 158227–158240. [Google Scholar] [CrossRef]
- Ahmed, M.Z.I.; Sinha, N.; Phadikar, S.; Ghaderpour, E. Automated Feature Extraction on AsMap for Emotion Classification Using EEG. Sensors 2022, 22, 2346. [Google Scholar] [CrossRef]
- Zhang, R.; Xu, L.; Yu, Z.; Shi, Y.; Mu, C.; Xu, M. Deep-IRTarget: An Automatic Target Detector in Infrared Imagery Using Dual-Domain Feature Extraction and Allocation. IEEE Trans. Multimed. 2022, 24, 1735–1749. [Google Scholar] [CrossRef]
- Ran, A.; Cheung, C.Y. Deep Learning-Based Optical Coherence Tomography and Optical Coherence Tomography Angiography Image Analysis: An Updated Summary. Asia-Pac. J. Ophthalmol. 2021, 10, 3. [Google Scholar] [CrossRef]
- Schmidt-Erfurth, U.; Sadeghipour, A.; Gerendas, B.S.; Waldstein, S.M.; Bogunović, H. Artificial intelligence in retina. Prog. Retin. Eye Res. 2018, 67, 1–29. [Google Scholar] [CrossRef] [PubMed]
- Ting, D.S.W.; Pasquale, L.R.; Peng, L.; Campbell, J.P.; Lee, A.Y.; Raman, R.; Tan, G.S.W.; Schmetterer, L.; Keane, P.A.; Wong, T.Y. Artificial intelligence and deep learning in ophthalmology. Br. J. Ophthalmol. 2019, 103, 167–175. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lee, C.S.; Baughman, D.M.; Lee, A.Y. Deep Learning Is Effective for Classifying Normal versus Age-Related Macular Degeneration OCT Images. Ophthalmol. Retin. 2017, 1, 322–327. [Google Scholar] [CrossRef]
- Seeböck, P.; Waldstein, S.M.; Klimscha, S.; Bogunovic, H.; Schlegl, T.; Gerendas, B.S.; Donner, R.; Schmidt-Erfurth, U.; Langs, G. Unsupervised Identification of Disease Marker Candidates in Retinal OCT Imaging Data. IEEE Trans. Med. Imaging 2019, 38, 1037–1047. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Huang, L.; He, X.; Fang, L.; Rabbani, H.; Chen, X. Automatic Classification of Retinal Optical Coherence Tomography Images With Layer Guided Convolutional Neural Network. IEEE Signal Process. Lett. 2019, 26, 1026–1030. [Google Scholar] [CrossRef]
- Chowdhary, C.L.; Acharjya, D. Clustering Algorithm in Possibilistic Exponential Fuzzy C-Mean Segmenting Medical Images. J. Biomimetics Biomater. Biomed. Eng. 2017, 30, 12–23. [Google Scholar] [CrossRef]
- Chowdhary, C.L.; Acharjya, D.P. Segmentation of Mammograms Using a Novel Intuitionistic Possibilistic Fuzzy C-Mean Clustering Algorithm. In Nature Inspired Computing; Panigrahi, B.K., Hoda, M.N., Sharma, V., Goel, S., Eds.; Springer: Singapore, 2018; pp. 75–82. [Google Scholar]
- Das, V.; Dandapat, S.; Bora, P. Multi-scale deep feature fusion for automated classification of macular pathologies from OCT images. Biomed. Signal Process. Control 2019, 54, 101605. [Google Scholar] [CrossRef]
- Hwang, D.K.; Hsu, C.C.; Chang, K.J.; Chao, D.; Sun, C.H.; Jheng, Y.C.; Yarmishyn, A.A.; Wu, J.C.; Tsai, C.Y.; Wang, M.L.; et al. Artificial intelligence-based decision-making for age-related macular degeneration. Theranostics 2019, 9, 232–245. [Google Scholar] [CrossRef]
- Tasnim, N.; Hasan, M.; Islam, I. Comparisonal study of Deep Learning approaches on Retinal OCT Image. arXiv 2019, arXiv:1912.07783. [Google Scholar]
- Kaymak, S.; Serener, A. Automated Age-Related Macular Degeneration and Diabetic Macular Edema Detection on OCT Images using Deep Learning. In Proceedings of the 2018 IEEE 14th International Conference on Intelligent Computer Communication and Processing (ICCP), Cluj-Napoca, Romania, 6–8 September 2018; pp. 265–269. [Google Scholar] [CrossRef]
- Li, F.; Chen, H.; Liu, Z.; dian Zhang, X.; shan Jiang, M.; zheng Wu, Z.; qian Zhou, K. Deep learning-based automated detection of retinal diseases using optical coherence tomography images. Biomed. Opt. Express 2019, 10, 6204–6226. [Google Scholar] [CrossRef] [PubMed]
- Lo, Y.C.; Lin, K.H.; Bair, H.; Sheu, W.H.H.; Chang, C.S.; Shen, Y.C.; Hung, C.L. Epiretinal Membrane Detection at the Ophthalmologist Level using Deep Learning of Optical Coherence Tomography. Sci. Rep. 2020, 10, 8424. [Google Scholar] [CrossRef]
- Tsuji, T.; Hirose, Y.; Fujimori, K.; Hirose, T.; Oyama, A.; Saikawa, Y.; Mimura, T.; Shiraishi, K.; Kobayashi, T.; Mizota, A.; et al. Classification of optical coherence tomography images using a capsule network. BMC Ophthalmol. 2020, 20, 114. [Google Scholar] [CrossRef] [Green Version]
- Prabhakaran, S.; Kar, S.; Sai Venkata, G.; Gopi, V.; Ponnusamy, P. OctNET: A Lightweight CNN for Retinal Disease Classification from Optical Coherence Tomography Images. Comput. Methods Programs Biomed. 2020, 200, 105877. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T.M. A survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Rosebrock, A. MiniVGGNet: Going Deeper with CNNs. 2021. Available online: https://pyimagesearch.com/2021/05/22/minivggnet-going-deeper-with-cnns (accessed on 1 May 2022).
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Panahi, A.H.; Rafiei, A.; Rezaee, A. FCOD: Fast COVID-19 Detector based on deep learning techniques. Inform. Med. Unlocked 2021, 22, 100506. [Google Scholar] [CrossRef]
- Chi-Feng, W. A Basic Introduction to Separable Convolutions. 2018. Available online: https://towardsdatascience.com/a-basic-introduction-to-separable-convolutions-b99ec3102728 (accessed on 1 May 2022).
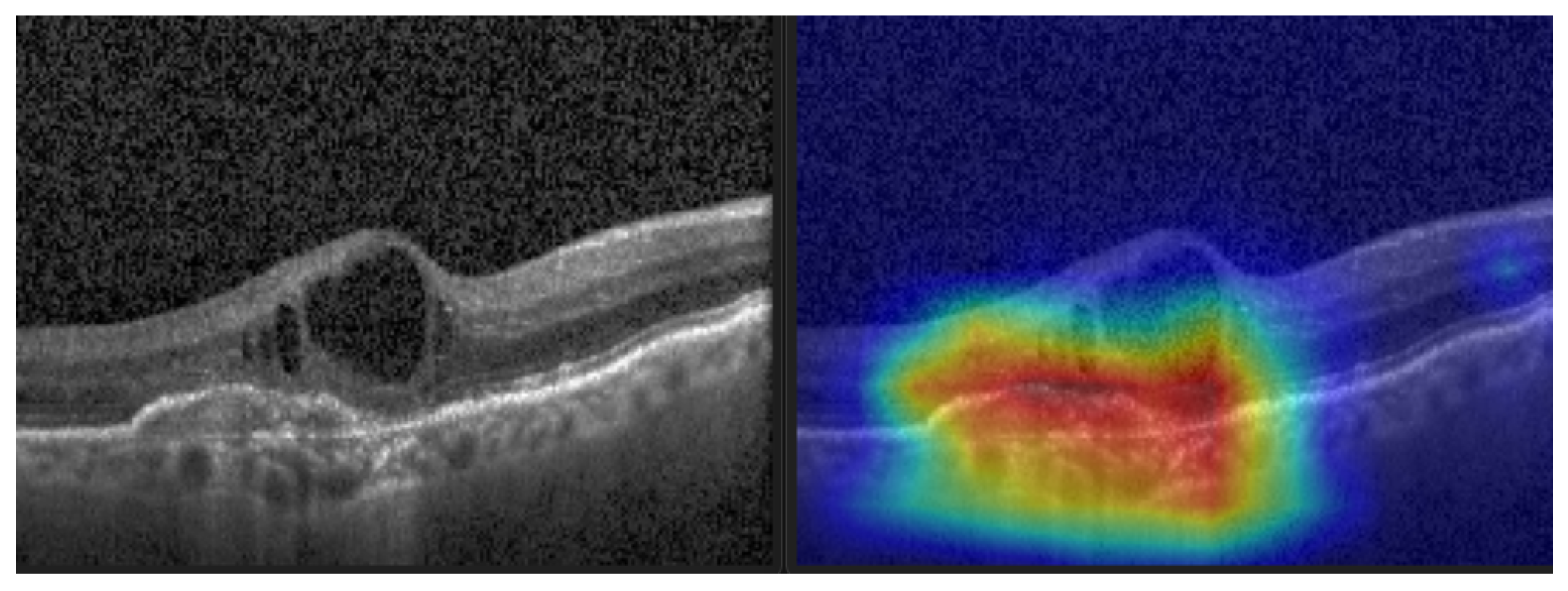
- Selvaraju, R.R.; Das, A.; Vedantam, R.; Cogswell, M.; Parikh, D.; Batra, D. Grad-CAM: Why did you say that? Visual Explanations from Deep Networks via Gradient-based Localization. arXiv 2016, arXiv:1611.07450. [Google Scholar]
- Weiss, G. Mining with rarity: A unifying framework. SIGKDD Explor. 2004, 6, 7–19. [Google Scholar] [CrossRef]
- Espíndola, R.; Ebecken, N. On extending f-measure and g-mean metrics to multi-class problems. WIT Trans. Inf. Commun. Technol. 2005, 35, 25–34. [Google Scholar]
- Vakili, M.; Ghamsari, M.; Rezaei, M. Performance Analysis and Comparison of Machine and Deep Learning Algorithms for IoT Data Classification. arXiv 2020, arXiv:2001.09636. [Google Scholar]
- Kulkarni, A.; Chong, D.; Batarseh, F.A. 5-Foundations of data imbalance and solutions for a data democracy. In Data Democracy; Batarseh, F.A., Yang, R., Eds.; Academic Press: Cambridge, MA, USA, 2020; pp. 83–106. [Google Scholar] [CrossRef]
- Stockman, G.; Shapiro, L.G. Computer Vision; Prentice Hall PTR: Upper Saddle River, NJ, USA, 2001. [Google Scholar]
- Wikipedia Contributors. Gaussian Blur—Wikipedia, The Free Encyclopedia 2022. Available online: https://en.wikipedia.org/wiki/Gaussian_blur (accessed on 3 May 2022).
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar] [CrossRef] [Green Version]
- Paradisa, R.H.; Bustamam, A.; Victor, A.A.; Yudantha, A.R.; Sarwinda, D. Diabetic Retinopathy Detection using Deep Convolutional Neural Network with Visualization of Guided Grad-CA. In Proceedings of the 2021 4th International Conference of Computer and Informatics Engineering (IC2IE), Depok, Indonesia, 14–15 September 2021; pp. 19–24. [Google Scholar] [CrossRef]
- Pinciroli Vago, N.O.; Milani, F.; Fraternali, P.; da Silva Torres, R. Comparing CAM Algorithms for the Identification of Salient Image Features in Iconography Artwork Analysis. J. Imaging 2021, 7, 106. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Original | Augmented |
|---|---|---|
| CNV | 37,205 | 1,785,840 |
| DME | 11,348 | 544,704 |
| Drusen | 8616 | 413,568 |
| Normal | 26,315 | 1,263,120 |
| Model | f1 | f2 | f3 | f4 | f5 | f6 | f7 | f8 | f9 | f10 | f11 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 3 Layers | 32 | 64 | 128 | ||||||||
| 5 Layers | 32 | 64 | 128 | 256 | 512 | ||||||
| 7 Layers | 32 | 32 | 64 | 64 | 128 | 256 | 512 | ||||
| 9 Layers | 32 | 32 | 64 | 64 | 128 | 128 | 128 | 512 | 512 | ||
| 11 Layers | 32 | 32 | 64 | 64 | 128 | 128 | 256 | 256 | 512 | 512 | 512 |
| Layer (Type) | Output Shape | Param # |
|---|---|---|
| Separable Conv2D | (None, 126, 126, 128) | 539 |
| Batch_Normalization | (None, 126, 126, 128) | 512 |
| Max_Pooling2D | (None, 42, 42, 128) | 0 |
| Dropout | (None, 42, 42, 128) | 0 |
| Separable Conv2D | (None, 40, 40, 128) | 17,664 |
| Batch_Normalization | (None, 40, 40, 128) | 512 |
| Separable Conv2D | (None, 36, 36, 128) | 19,712 |
| Batch_Normalization | (None, 36, 36, 128) | 512 |
| Max_Pooling2D | (None, 18, 18, 128) | 0 |
| Dropout | (None, 18, 18, 128) | 0 |
| Separable Conv2D | (None, 16, 16, 256) | 34,176 |
| Batch_Normalization | (None, 16, 16, 256) | 1024 |
| Separable Conv2D | (None, 12, 12, 256) | 72,192 |
| Batch_Normalization | (None, 12, 12, 256) | 1024 |
| Max_Pooling2D | (None, 6, 6, 256) | 0 |
| Dropout | (None, 6, 6, 256) | 0 |
| Flatten | (None, 9216) | 0 |
| Dense | (None, 256) | 2,359,552 |
| Batch_Normalization | (None, 256) | 1024 |
| Dropout | (None, 256) | 0 |
| Dense | (None, 128) | 32,896 |
| Batch_Normalization | (None, 128) | 512 |
| Dropout | (None, 128) | 0 |
| Dense | (None, 64) | 8256 |
| Batch_Normalization | (None, 64) | 256 |
| Dropout | (None, 64) | 0 |
| Dense | (None, 32) | 2080 |
| Batch_Normalization | (None, 32) | 128 |
| Dropout | (None, 32) | 0 |
| Dense | (None, 4) | 132 |
| Total Pramas: | 2,552,703 | |
| Trainable Pramas: | 2,549,951 | |
| Non-Trainable Pramas | 2752 |
| Recall | Precision | F1-Score | |
|---|---|---|---|
| CNV | 0.9876 | 0.9122 | 0.9484 |
| DME | 0.9298 | 0.9912 | 0.9595 |
| Drusen | 0.9380 | 0.9827 | 0.9598 |
| Normal | 0.9876 | 0.9637 | 0.9755 |
| Recall | Precision | F1-Score | |
|---|---|---|---|
| CNV | 0.9256 | 0.9739 | 0.9492 |
| DME | 0.9917 | 0.9302 | 0.9600 |
| Drusen | 0.9793 | 0.9634 | 0.9713 |
| Normal | 0.9628 | 0.9957 | 0.9790 |
| Recall | Precision | F1-Score | |
|---|---|---|---|
| CNV | 0.9669 | 0.9710 | 0.9689 |
| DME | 0.9917 | 0.9796 | 0.9856 |
| Drusen | 0.9752 | 0.9793 | 0.9772 |
| Normal | 0.9917 | 0.9959 | 0.9938 |
| Recall | Precision | F1-Score | |
|---|---|---|---|
| CNV | 0.9835 | 0.9917 | 0.9876 |
| DME | 0.9917 | 0.9877 | 0.9897 |
| Drusen | 0.9959 | 0.9837 | 0.9897 |
| Normal | 0.9876 | 0.9958 | 0.9917 |
| Recall | Precision | F1-Score | |
|---|---|---|---|
| CNV | 0.9545 | 0.9957 | 0.9747 |
| DME | 0.9835 | 0.9714 | 0.9774 |
| Drusen | 1.0000 | 0.9565 | 0.9778 |
| Normal | 0.9752 | 0.9916 | 0.9833 |
| Number of Convolutions | Recall | Precision | F1-Score | G-Measure |
|---|---|---|---|---|
| 3-Layers | 0.9607 | 0.9624 | 0.9608 | 0.9615 |
| 5-Layers | 0.9649 | 0.9658 | 0.9649 | 0.9653 |
| 7-Layers | 0.9814 | 0.9814 | 0.9814 | 0.9814 |
| 9-Layers | 0.9897 | 0.9897 | 0.9897 | 0.9897 |
| 11-Layers | 0.9783 | 0.9788 | 0.9783 | 0.9785 |
| Recall | Precision | F1-Score | |
|---|---|---|---|
| CNV | 1.0000 | 1.0000 | 1.0000 |
| DME | 1.0000 | 1.0000 | 1.0000 |
| Drusen | 0.9959 | 1.0000 | 0.9979 |
| Normal | 1.0000 | 0.9959 | 0.9979 |
| Algorithms | Recall | Precision | F1-Score | Accuracy |
|---|---|---|---|---|
| Proposed Method | 0.9990 | 0.9990 | 0.9990 | 0.9990 |
| A.P. Sunija et al. [29] | 0.9969 | 0.9969 | 0.9968 | 0.9969 |
| D.S. Kermany et al. [7] | 0.9780 | N/A | N/A | 0.9660 |
| L. Huang et al. [19] | N/A | N/A | N/A | 0.8990 |
| S. Kaymak et al. [25] | 0.9960 | N/A | N/A | 0.9710 |
| V. Das et al. [22] | 0.9960 | 0.9960 | 0.9960 | 0.9960 |
| D.K. Hwang. [23] | N/A | N/A | N/A | 0.9693 |
| Algorithms | Resolution | Recall | Precision | F1-Score | Accuracy |
|---|---|---|---|---|---|
| Proposed Method | 128 × 128 × 3 | 0.9990 | 0.9990 | 0.9990 | 0.9990 |
| CNN | 150 × 150 × 3 | 0.98 | 0.98 | 0.98 | 0.98 |
| Xception | 150 × 150 × 3 | 0.99 | 0.99 | 0.99 | 0.99 |
| ResNet-50 | 150 × 150 × 3 | 0.97 | 0.97 | 0.97 | 0.97 |
| MobileNet-V2 | 150 × 150 × 3 | 0.99 | 0.99 | 0.99 | 0.99 |
| CNN Model | Dataset Distribution | Recall | Precision | F1-Score |
|---|---|---|---|---|
| 5-Layers-v1 | (imbalanced) | 0.9804 | 0.9806 | 0.9804 |
| 5-Layers-v1 | (balanced) | 0.9752 | 0.9754 | 0.9752 |
| 5-Layers-v2 | (imbalanced) | 0.9783 | 0.9794 | 0.9784 |
| 5-Layers-v2 | (balanced) | 0.9886 | 0.9887 | 0.9886 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ara, R.K.; Matiolański, A.; Dziech, A.; Baran, R.; Domin, P.; Wieczorkiewicz, A. Fast and Efficient Method for Optical Coherence Tomography Images Classification Using Deep Learning Approach. Sensors 2022, 22, 4675. https://0-doi-org.brum.beds.ac.uk/10.3390/s22134675
Ara RK, Matiolański A, Dziech A, Baran R, Domin P, Wieczorkiewicz A. Fast and Efficient Method for Optical Coherence Tomography Images Classification Using Deep Learning Approach. Sensors. 2022; 22(13):4675. https://0-doi-org.brum.beds.ac.uk/10.3390/s22134675
Chicago/Turabian StyleAra, Rouhollah Kian, Andrzej Matiolański, Andrzej Dziech, Remigiusz Baran, Paweł Domin, and Adam Wieczorkiewicz. 2022. "Fast and Efficient Method for Optical Coherence Tomography Images Classification Using Deep Learning Approach" Sensors 22, no. 13: 4675. https://0-doi-org.brum.beds.ac.uk/10.3390/s22134675