
Mobile Edge Computing Task Offloading Strategy Based on Parking Cooperation in the Internet of Vehicles

1
Guangxi Key Laboratory of Embedded Technology and Intelligent Information Processing College of Information Science and Engineering, Guilin University of Technology, Guilin 541006, China
2
School of Mechanical and Electrical Engineering, Beijing University of Technology, Beijing 100081, China
*
Author to whom correspondence should be addressed.
Sensors 2022, 22(13), 4959; https://0-doi-org.brum.beds.ac.uk/10.3390/s22134959
Submission received: 19 May 2022
/
Revised: 24 June 2022
/
Accepted: 28 June 2022
/
Published: 30 June 2022
(This article belongs to the Section Sensor Networks)
Abstract
:Due to the limited computing capacity of onboard devices, they can no longer meet a large number of computing requirements. Therefore, mobile edge computing (MEC) provides more computing and storage capabilities for vehicles. Inspired by a large number of roadside parking vehicles, this paper takes the roadside parking vehicles with idle computing resources as the task offloading platform and proposes a mobile edge computing task offloading strategy based on roadside parking cooperation. The resource sharing and mutual utilization among roadside vehicles, roadside units (RSU), and cloud servers (cloud servers) were established, and the collaborative offloading problem of computing tasks was transformed into a constraint problem. The hybrid genetic algorithm (HHGA) with a mountain-climbing operator was used to solve the multi-constraint problem, to reduce the delay and energy consumption of computing tasks. The simulation results show that when the number of tasks is 25, the delay and energy consumption of the HHGA algorithm is improved by 24.1% and 11.9%, respectively, compared with Tradition. When the task size is 1.0 MB, the HHGA algorithm reduces the system overhead by 7.9% compared with Tradition. Therefore, the proposed scheme can effectively reduce the total system cost during task offloading.
1. Introduction
In recent years, with the increase in the number of cars on the road and the progress of science and technology, cars are also moving in the direction of intelligence. The Internet of vehicles (IOV) is the application of the Internet of Things in the field of intelligent transportation and is also an important organic part of intelligent transportation systems [1]. However, intelligent vehicles on the Internet of vehicles have a large number of mobile applications, such as vehicle-mounted information communication systems and ABS. These mobile applications present some challenges for intelligent vehicles that require real-time information collection and a large number of computing resources. Due to the limited computing resources on the current intelligent vehicles, they cannot meet the requirements of low latency and high Quality of Service (QoS) [2,3,4] and may have problems in real-time and accuracy provided by mobile applications, thus increasing the potential hidden dangers in the process of driving [5,6].
In order to solve the above problems, researchers put forward the concept of mobile edge computing (MEC) [7]. Mobile edge computing provides cloud-like functionality to the end-user by equipping the edge of the network with computing and storage resources. Mobile edge computing can significantly improve the computing capacity of users, but due to the limited hardware resources of edge servers, it is still difficult to develop a better method of computing offloading [8]. When many users try to offload a task at the same time, the edge server and wireless channel take up too many resources, resulting in a long task response time [9,10]. Therefore, it is critical to design an effective offload strategy to determine which tasks to offload, which tasks to edge servers or other platforms, and how those tasks offload platforms allocate computing resources.
The composition of this article is as follows. Section 2 introduces the existing research related to offloading of mobile edge computing tasks. Section 3 introduces the system model used in this paper in detail. Section 4 introduces the algorithm used in detail. Section 5 compares its performance with existing methods. Section 6 discusses the conclusion of this paper and the future research direction.
2. Related Works
As a key technology in edge computing, computational offloading has been widely studied. Zhang et al. [11] proposed an offloading framework of vehicular edge computing based on a layered cloud to solve the problem of limited computing resources of MEC servers by introducing backup servers in the neighborhood. T. X. Tran et al. [12] studied joint task offloading and resource allocation in order to maximize user offloading gain. There is a need for the literature [11,12] to address the lack of computing resources for user terminals and how to optimize the resource allocation algorithm to ensure the maximum benefit of user terminals. However, there are few studies on task-specific offloading strategies.
Regarding the related research on the platform of task offloading, Mahenge et al. [13] proposed a MEC-assisted offloading scheme for energy-saving tasks, which mainly utilized the framework of cooperation between multiple MECs. This was conducted to achieve the goal of energy-saving and then propose a new wolf optimization algorithm based on the particle swarm optimization algorithm and the hybrid method to solve the optimization problems; the proposed method takes into account the effective allocation of resources, such as those for offloading subcarrier and power and bandwidth, to ensure the minimum energy consumption and latency requirements. Elham Karimi et al. [14] studied the response time required by resource allocation to ensure task offloading. However, MEC resources are limited and cannot handle the high mobility of many different applications. Therefore, the cooperation between MEC and central cloud decisions is proposed for offloading different onboard applications. Deep reinforcement learning, an appropriate computational model, is used to automatically learn the dynamics of the network state and quickly capture the best solution. Kuang et al. [15] proposed the calculation of offloading decision, cooperative selection, power allocation, and CPU cycle frequency allocation to solve the problem of minimization delay optimization while ensuring transmission power, energy consumption, and CPU cycle frequency constraints. Ni Zhang et al. [16] conceived and implemented an algorithm for calculating the combination of offloading and data cache for the MEC network cooperative system. The queuing theory was used to analyze the processing delay and transmission delay. In addition, an efficient online algorithm based on a genetic algorithm is proposed, which can customize the data cache decision according to the Spatio-temporal task popular pattern.
Regarding the research on time delay and energy consumption, L. T. Tan et al. [17] proposed a multi-time scale framework to jointly allocate cache and computing resources on the Internet of vehicles to minimize energy consumption, considering the time delay requirements of vehicle applications. Yang et al. [18] modeled the energy consumption of computational offloading from the aspects of computational task and communication and used artificial fish swarm algorithm to solve the problem of minimizing the energy consumption of computational offloading. Ning et al. [19] proposed that a cloud server collaborates with several edge servers to perform computationally intensive tasks. Qiao et al. [20] introduced the vehicle edge multi-access network to combine resource-rich vehicles with cloud servers to build a collaborative computing architecture.
C. Ma et al. [21] organized parked vehicles outside into parking clusters as virtual edge servers to assist edge servers in processing tasks. Additionally, a new task scheduling algorithm was designed to jointly determine the resource allocation of edge servers.
The offloading strategy in the literature [13] only considers offloading tasks to edge servers, and the platform of offloading tasks is single. Although collaborative offloading has been studied in the literature [14,15,16], the communication range of RSU is limited at present, leading to the failure of moving vehicles in some sections to communicate in time, and the main goal is only to reduce computational delay. Refs. [17,18] only studied the energy consumption of task unloading and Refs. [19,20] only studied the delay of task unloading. Ref. [21] proposed a new framework but mainly studied the task scheduling and task completion rate between parked vehicles and moving vehicles and took the reduction in total delay as the goal. At present, there are few studies on the time delay and energy consumption of mobile edge computing task offloading on the Internet of vehicles.
According to the investigation [22], there are always parked vehicles on both sides of urban roads, and the parking time is more than 18 h on average. Inspired by this, roadside parked vehicles have idle computing resources, which can be used as a platform for offloading mobile edge computing tasks.
The contributions of this paper are as follows:
- A moving edge computing framework based on roadside parking cooperation is proposed. In the case of no RSU or insufficient vehicle local computing resources, roadside parking was added as an offloading platform;
- After the global optimal solution was generated by the crossover and variation in the traditional genetic algorithm, a mountain-climbing algorithm was added to search for the local optimal solution, which improves the convergence speed and reduces the system overhead;
- In order to evaluate the proposed task offloading scheme based on a hybrid genetic algorithm, it was compared and analyzed with Local, ATM, Random, and Tradition task offloading methods in aspects of system overhead, delay, and energy consumption;
- Finally, we evaluated our method in detail from two aspects: task number and task size. Our scheme is superior to the other four offloading schemes in system overhead, delay, and energy consumption. In other words, our method produces less system cost for the same task guarantee, or equivalently, it provides a higher quality of service guarantee for the same system cost.
3. System Model
3.1. Network Model
As shown in Figure 1, in the scenario of ordinary roads, there are N mobile vehicles V, M RSUs, roadside parked vehicles, and cloud servers in total. MEC servers are deployed in each RSU to provide computing resources for vehicles. Computing resources between vehicles, RSUs, and cloud servers can be shared and used with each other. Roadside parked vehicles with no computing tasks, RSUs, and cloud servers can assist vehicles that need computing. Tasks on a moving vehicle can be calculated locally, offloaded to off-road parking, migrated to an RSU, or loaded into a cloud server over a cellular network for processing.
3.2. Communication Model
Assume that all vehicles are traveling at a constant speed S. Each car has a computational task; define the task as , . Here, represents the size of the input data used in the calculation, and indicates the computing resources required to complete the task . indicates the computing resource of the vehicle, indicates the maximum delay constraint of the task, the computing resource of MEC is . Assuming that all vehicles have the same transmitting power, the data transmission rate between moving vehicles, roadside vehicles, and RSU is as follows:
where represents the channel bandwidth, represents the transmitting power of vehicles on the channel, represents the channel gain of moving vehicles on the channel to RSU, and represents the white noise power.
Since tasks can be calculated locally, on MEC servers, on cloud servers, and on roadside parked vehicles, it is necessary to divide tasks and determine which platforms to offload to. This paper defines as the offloading decision of the vehicle. , , , and indicates that the task is offloaded to the local server, MEC server, cloud server, and parked vehicle, respectively.
3.3. Calculation Model
3.3.1. Local Computing Model
When the task of moving the vehicle is calculated locally, let represent the local execution delay of the moving vehicle. indicates the local processing delay, and indicates the local processing power consumption.
where represents the equipment power of moving vehicle .
3.3.2. MEC Calculation Model
When a vehicle chooses to offload its tasks onto the MEC server, the delay can be divided into three parts. The first part is the transmission delay required by the task offloaded by the moving vehicle to reach the MEC server. Since the MEC server is equipped on the RSU, this part of the time is equal to the delay of the task to reach the RSU.
The second part is the execution delay of this task on the MEC server.
where represents the number of resources allocated from the MEC server to the vehicle to offload the task.
The third part is the return delay of the task file from RSU to the moving vehicle.
where λ is the coefficient of output data quantity, representing the relationship between output data quantity and input data quantity.
The total delay and total energy consumption of offloading tasks from mobile vehicles to MEC servers are as follows:
where represents the power of moving vehicles to upload tasks, and represents the power of moving edge computing servers.
3.3.3. Cloud Server Computing Model
Mobile vehicles offload their computing tasks to cloud servers thousands of miles away via fiber optics and core networks [23]. Therefore, the upload time for transferring input data from the RSU to the cloud server must be considered. In addition, although the amount of output data is much smaller than the amount of input data, the download time to send the results from the cloud server back to the RSU is not negligible. In this case, let represent the execution time of the task in the cloud server, represent the transmission delay of the task to RSU, represent the return delay of the calculation result from RSU to the mobile vehicle. On the optical fiber line, the average transmission wait delay of tasks is calculated as , represents the total delay of offloading tasks from the moving vehicle to the cloud server, and represents the total energy consumption of offloading tasks from the moving vehicle to the cloud server.
where represents computing resources provided by the cloud server for mobile vehicles, represents device power of the cloud server, and represents RSU transmitting power.
3.3.4. Calculation Model of Roadside Parking
When a moving vehicle chooses to offload its task onto a roadside stop, the delay can be divided into three parts.
The first part is the task execution delay of roadside parking.
where represents the computing resources provided by roadside parking.
The second part is the transmission delay of the task from moving vehicles to roadside parking.
The third part is the delay of sending the result to the moving vehicle after the task is processed.
The total time delay and total energy consumption of offloading tasks from moving vehicles to roadside parking are as follows:
where represents the power of roadside parking equipment.
In summary, the total delay for processing the whole task in this strategy can be given by the following formula:
Similarly, calculating the total energy consumption of a task can be given by the following formula:
3.4. Problem Expression
This paper attempted to minimize the delay and energy consumption of the entire system and analyze the impact of task and task offloading to find a solution that makes the total cost more suitable for the real scenario. The linear combination of time delay and energy consumption provides a flexible method for system cost measurement by adaptively adjusting the linear weight factor when performing complex calculation tasks. Specifically, when the weighting factor is 0 or 1, only delay or energy consumption is considered. In this paper, the weighted sum of delay and energy consumption of the whole system was considered, and a weight factor: was introduced, so different weights can be given according to specific needs.
where represents the cost of the collaborative offloading system.
In this paper, task offloading and resource allocation were formulated as optimization problems to minimize . The optimization problem is expressed as:
where indicates the offloading decision of the vehicle, and indicates the allocation of computing resources, that is, . indicates that only one uninstallation platform can be selected for each task. indicates that the time to complete the task of each vehicle shall not exceed the maximum allowable delay; indicates the constraint on the total computing resources of the MEC server.
4. A Hybrid Algorithm Based on Hill-Climbing Algorithm and Genetic Algorithm (HHGA)
The Genetic Algorithm (GA) [24] is an Evolutionary Algorithm. In nature, individuals who can adapt to changing conditions can survive, while others cannot, and individual characteristics are written on genes stored on chromosomes. Compared with individuals with poor environmental adaptability, individuals with good environmental adaptability are more likely to survive. Hill-climbing algorithm [25] is a local search method. It is an iterative algorithm, and the hill-climbing algorithm is suitable for finding local optimal values, but it cannot guarantee to find global optimal values outside the search space, especially when there are multiple local optimal values.
However, a mountain-climbing algorithm can be used as an assistant to find local optimal when the genetic algorithm is dealing with complex problems. The mountain-climbing algorithm is regarded as an operator and placed in a genetic algorithm to increase the local search ability of the genetic algorithm and to improve the convergence and stability of the algorithm. Therefore, in this paper, a hybrid algorithm based on a hill-climbing algorithm and genetic algorithm HHGA (a hybrid algorithm based on a hill-climbing algorithm and genetic algorithm) was introduced to solve the multi-constraint problem. Figure out the best strategy.
4.1. Integer Coding and Initial Population
In this paper, each offloading strategy was regarded as a chromosome by integer coding, and each chromosome has N genes. The genes on the chromosome have three possible values −1, 0, 1, and 2, corresponding to local calculation, MEC server calculation, cloud server calculation, and roadside parking calculation, respectively. The encoding is shown in Figure 2.
M individuals were randomly generated as the initial population .
4.2. Fitness Function
In searching for an optimal solution, a fitness function was used to evaluate a possible solution (individual). The fitness function determines the strongest individuals with high fitness values, and these strongest individuals are selected as the parents of the next generation. Let the reciprocal of Equation (21) be the fitness function. When the value of Equation (23) is higher, it means that the delay and energy consumption of this offloading scheme is smaller; that is, the offloading scheme is better.
4.3. Select Operations
The selection operation is the basic method of genetic algorithm to achieve good gene transfer. In this paper, the roulette selection method was used [26]. In this selection, the fitness of each chromosome was assessed by the fitness function described above. The steps to solve the maximization problem with this selection method are as follows:
- (1)
- The fitness value of individuals in the population is superimposed on the total fitness value of 1;
- (2)
- The fitness value of each divided by the total fitness is worth the probability of individual selection;
- (3)
- Calculate the cumulative probability of individuals to construct a roulette wheel;
- (4)
- Generate a random number within the interval of [0, 1]. If the random number is less than or equal to the cumulative probability of the individual and greater than the cumulative probability of individual 1, select the individual to enter the offspring population.
Repeat step (4) times and the obtained individuals constitute a new-generation population.
4.4. Cross Operations
This paper chose a method of uniform crossover [27]. For each gene of the first offspring, a number is uniformly generated in order to determine which parent it will inherit the gene from according to the following conditions.
where represents the th position of the offspring chromosome, of is the th position on the paternal chromosome . is named crossover rate, indicating the threshold selected. Normally, each gene of the first progeny is selected with probability from either parent, and each gene of the second progeny is selected from the corresponding parent selected by the first progeny gene. The uniform crossover process is shown in Figure 3.
4.5. Mutation Operation
Adaptive variation is adopted in this paper [28], and the formula is as follows:
where represents the first-generation variation rate, represents the variation rate of the generation, represents the variation rate of the generation, represents the fitness value of the generation individual, represents the highest fitness value of the generation, and is the adjustment coefficient.
4.6. Climbing Operation and Termination Rules
Mountain climbing is a search algorithm with a good local optimization effect. First, add random point in the search space as the initial iteration point, then randomly generate within their neighborhood, calculating the function value; if the function value is superior to the point at which the current point, the initial points are replaced with the current point as a new initial point continue to search in the neighborhood, or continue to another point in the neighborhood randomly generated comparing with the initial point. The search process terminates until it finds a point that is better than it or fails to find a point that is better than it for several consecutive times. The mountain climbing method can quickly converge to the local optimal point when dealing with problems, but the multi-peak problem has multiple peak points, and the mountain climbing method can only find one of the local optimal points, not necessarily the global optimal point, so the global optimal point cannot be determined. Although global optimization cannot be a mountain-climbing method, the climbing method has the advantage that traditional optimization algorithm does not have, which is that the climbing method can handle non-micro unimodal functions because the climbing method by random individual optimization in the neighborhood does not need to use gradient, so the climbing method can deal with complex problems in the genetic algorithm (ga) that play a role of local optimization.
The new generation population selected after mutation is optimized by a mountain-climbing algorithm so that individuals can achieve a better local optimal.
The condition of ending the algorithm is that the value of the fitness function remains unchanged or reaches the specified number of iterations. Otherwise, the algorithm starts to search for a new population and starts a new iteration until the algorithm terminates. The process of Algorithm 1 is shown below.
| Algorithm 1: HHGA algorithm |
| Input: Population size, M Selection probability, Crossover probability, Mutation probability, Number of iterations, gen Output: W |
| 1.t = 0; |
| 2.Initialize ; |
| 3.Repair ; |
| 4.Calculate |
| 5.Store best solutions of in old ; |
| 6.while t < gen do |
| 7. Selection operation , to ; |
| 8. Crossover operation to ; |
| 9. Mutation operation to ; |
| 10. hill-climbing operation to ; |
| 11. Store the best fitness individuals of in new ; |
| 12. if (old ) > (new )then |
| new ld |
| 13. end if |
| 14. old = new |
| 15. find the worst fitness value in and replace it with new ; |
| 16. t = t + 1; |
| 17.end while |
5. Simulation Verification and Analysis
5.1. Simulation Parameter Setting
The simulation scene of this paper was on the highway, which is 2100 m long and has two lanes. Each lane was 3.75 m wide. Vehicles were randomly distributed on the road, traveling at speeds of 30 to 50 kilometers per hour. By default, there were 30 vehicles on the road and the task size ranged from 0 to 2 MB, the maximum delay constraint was 5 s. This paper carried out the simulation through MATLAB. The relevant parameters in this paper were set under the constraints of the IEEE 802.11P standard and the mobile edge computing white paper, and some adjustments were made according to the simulation environment. In order to simplify the model, we consider that only the Gaussian white noise value was −100 dBm, and there are no other interference factors. Specific simulation experiment parameters are shown in Table 1.
5.2. Comparison Scheme Settings
In order to better evaluate the algorithm, the task offloading strategy based on roadside parking cooperative moving edge computing was compared with other the four task offloading strategies:
- Strategy 1:
- Moving Vehicle Local Execution Policy (Local): all tasks need to be executed only on the moving vehicle;
- Strategy 2:
- MEC Server Policy (ATM): all tasks need to be offloaded and executed on the MEC server;
- Strategy 3:
- Random Offloading Policy (Random): tasks are randomly offloaded on moving vehicles, MEC servers, roadside vehicles, and cloud servers;
- Strategy 4:
5.3. Impact of Number of Tasks on Algorithm Performance
Figure 4 shows the changes in system overhead of five offloading schemes as the number of iterations increases. As it can be seen from Figure 4, the system overhead of the HHGA algorithm is lower than that of the GA algorithm. Since the GA algorithm tends to fall into local optimum, the HHGA algorithm added to a mountain-climbing algorithm can improve this problem well. Both HHGA genetic algorithm and GA algorithm are superior to Local, ATM, and Random. Even though the system overhead of the Random algorithm is lower in rare cases, the overall overhead of the Random algorithm was much higher than that of the HHGA algorithm in this paper. Because the Random algorithm offloads tasks to the cloud through Random selection, tasks were randomly offloaded to mobile vehicles, MEC servers, roadside vehicles, and cloud servers for execution, which has certain randomness. As the number of iterations increases, the Local algorithm stays the same because all tasks are executed locally with no transport costs, but the system overhead is still high. Compared with the other four offloading schemes, the task offloading strategy proposed in this paper was based on roadside parking cooperative moving edge computing achieves the minimum system overhead.
Figure 5 shows the delay changes of five offloading schemes as the number of tasks increases. It can be seen from Figure 5 that the Local algorithm has the highest latency, which indicates that the offloading of computational load can reduce the execution time of the task. When the number of tasks is 20, the delay of the ATM algorithm suddenly increases because when the number of tasks reaches a certain value, the computing resources allocated by MEC to vehicles carrying tasks are not as much as the local resources, so the delay of ATM algorithm is higher than the Local delay. When the number of tasks is 25, the delay performance of the HHGA algorithm improves by 52.1%, 27.6%, 28.8%, and 24.1%. It can be seen that with the increase in the number of tasks, the delay of different strategies increases. Due to the limited computing capacity of terminal devices, channel band resources are limited. As the number of tasks increases, the load of computing equipment increases, and the limited wireless resources cannot cope with the increase in the number of tasks. Because the HHGA algorithm can quickly make offloading decisions and effectively optimize the system costs, the delay of the HHGA algorithm is minimal, respectively, compared with Local, ATM, Random, and Tradition. Therefore, the HHGA algorithm in this paper had the minimum delay compared with other offloading schemes.
As it can be seen from Figure 6, the energy consumption of the ATM algorithm increases rapidly as the number of tasks increases. This is because the ATM algorithm does not consider the computing resources of a cloud server, which brings greater energy consumption to the moving vehicle. Compared with ATM algorithms, Random, HHGA, and Tradition algorithms of cloud servers have obvious energy consumption reduction. As the number of tasks increases, the offloading scheme proposed in this paper has smaller energy consumption compared with other schemes.
5.4. Impact of Task Size on Algorithm Performance
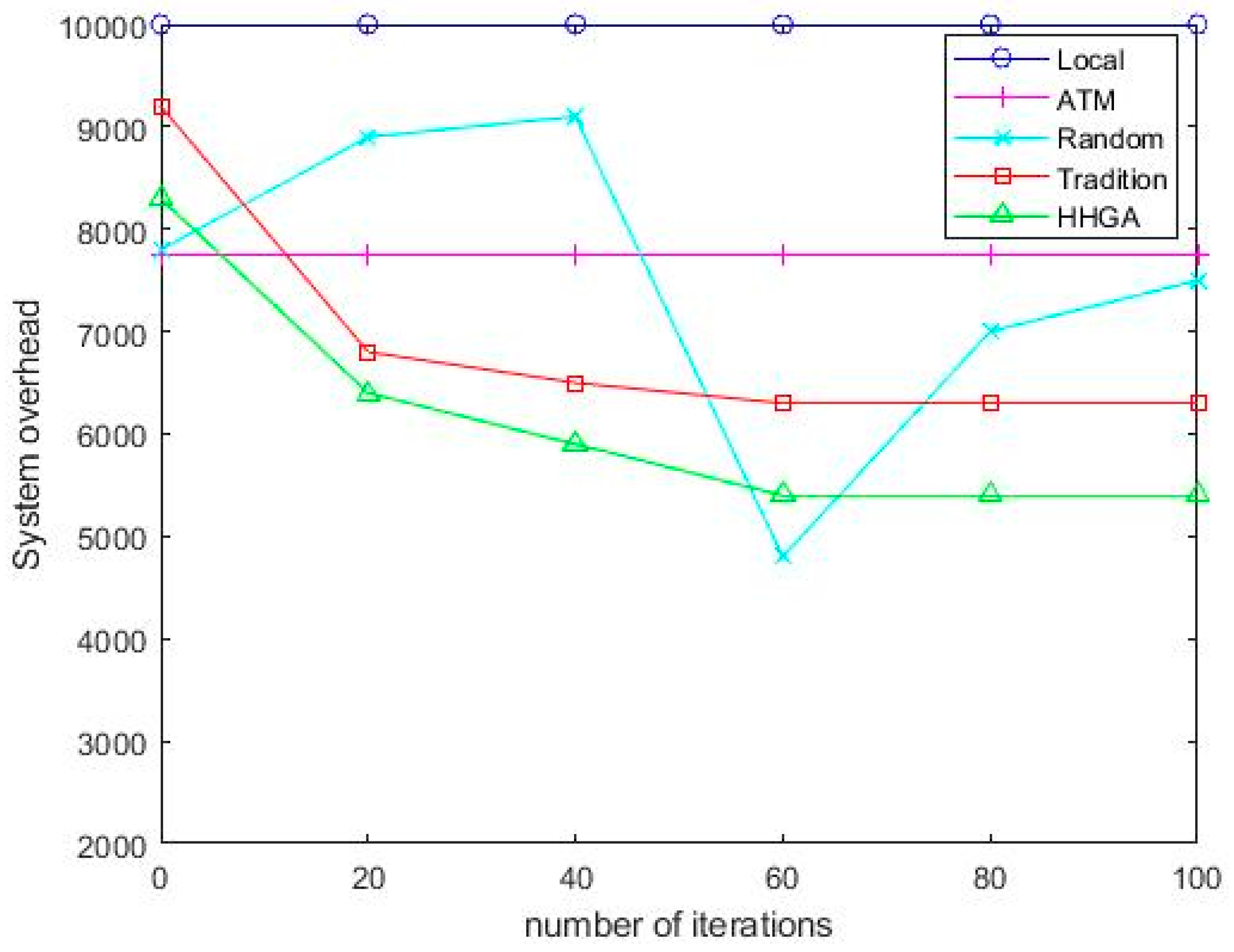
Figure 7 shows the system overhead of different task sizes, and it can be seen that the Random algorithm has fluctuations because it can be randomly offloaded to mobile vehicles, MEC servers, roadside vehicles, and cloud servers for execution. For the other four algorithms, when the task input data increases, the system overhead increases with the task input data. When the task size is 1.0 MB, the system overhead of the HHGA algorithm is reduced by 42.4%, 41.3%, 39.3%, and 7.9%, respectively, compared with Local, ATM, Random, and Tradition. Therefore, the HHGA algorithm proposed in this paper had the minimum system overhead, and the speed of rising was relatively slow.
6. Conclusions
This paper proposed an offloading strategy for roadside parking coordinated moving edge computing tasks. In this scheme, roadside parking was added as the tasks offloading platform, and three tasks offloading platforms, including local, RSU, and cloud servers, were combined for task processing. An HHGA algorithm was proposed, and a mountain-climbing algorithm was introduced based on the GA algorithm to improve the problem that the GA algorithm falls into local optimal. Experimental results show that compared with other offloading schemes, the proposed scheme can effectively reduce system overhead, delay, and energy consumption based on the number of tasks or task size and was superior to the other four offloading schemes. Therefore, the task offloading strategy scheme of moving edge computing coordinated with roadside parking can reduce the total system cost during task offloading more effectively.
In the future, the density of roadside parked vehicles and the moving speed of moving vehicles will be considered, and new heuristic algorithms will continue to be explored for offloading processing of collaborative moving edge computing.
Author Contributions
Pre-research data collection for this article was done by X.S. and Z.C. Software was done by Z.C., X.S. and Z.C. were responsible for writing and editing the article. S.N. was responsible for project management, obtaining funding and reviewing the article. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Natural Science Foundation of China (No.61961010), Guangxi Science and technology major special projects (No.AA19046004), Innovation Project of Guangxi Graduate Education (Grant no. YCSW2022314).
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Qureshi, K.N.; Alhudhaif, A.; Haidar, S.W.; Majeed, S.; Jeon, G. Secure data communication for wireless mobile nodes in intelligent transportation systems. Microprocess. Microsyst. 2022, 90, 104501. [Google Scholar] [CrossRef]
- Xu, X.; Li, Y.; Huang, T.; Xue, Y.; Peng, K.; Qi, L.; Dou, W. An energy-aware computation offloading method for smart edge computing in wireless metropolitan area networks. J. Netw. Comput. Appl. 2020, 133, 75–85. [Google Scholar] [CrossRef]
- Zhang, K.; Mao, Y.; Leng, S.; He, Y.; Zhang, Y. Mobile-Edge Computing for Vehicular Networks: A Promising Network Paradigm with Predictive Off-Loading. IEEE Veh. Technol. Mag. 2017, 12, 36–44. [Google Scholar] [CrossRef]
- Li, Q.; Wang, S.; Zhou, A.; Ma, X.; Yang, F.; Liu, A.X. QoS Driven Task Offloading with Statistical Guarantee in Mobile Edge Computing. IEEE Trans. Mob. Comput. 2022, 21, 278–290. [Google Scholar] [CrossRef]
- Karim, A. Development of secure Internet of Vehicle Things (IoVT) for smart transportation system. Comput. Electr. Eng. 2022, 102, 108101. [Google Scholar] [CrossRef]
- Sharma, S.; Kaushik, B. A survey on internet of vehicles: Applications, security issues & solutions. Veh. Commun. 2019, 20, 100182. [Google Scholar] [CrossRef]
- Fang, J.; Zhang, M.; Ye, Z.; Shi, J.; Wei, J. Smart collaborative optimizations strategy for mobile edge computing based on deep rein forcement learning. Comput. Electr. Eng. 2021, 96, 107539. [Google Scholar] [CrossRef]
- Feng, C.; Han, P.; Zhang, X.; Yang, B.; Liu, Y.; Guo, L. Computation offloading in mobile edge computing networks: A survey. J. Netw. Comput. Appl. 2022, 202, 103366–103402. [Google Scholar] [CrossRef]
- Huang, X.; Zhang, W.; Yang, J.; Yang, L.; Yeo, C.K. Market-based dynamic resource allocation in Mobile Edge Computing systems with multi-server and multi-user. Comput. Commun. 2021, 165, 43–52. [Google Scholar] [CrossRef]
- Lu, J.; Jiang, J. Deep reinforcement learning-based multi-objective edge server placement in Internet of Vehicles. Comput. Commun. 2022, 187, 172–180. [Google Scholar] [CrossRef]
- Zhang, K.; Mao, Y.; Leng, S.; Maharjan, S.; Zhang, Y. Optimal delay constrained offloading for vehicular edge computing networks. In Proceedings of the 2017 IEEE International Conference on Communications, Paris, France, 21–25 May 2017; pp. 1–6. [Google Scholar]
- Tran, T.X.; Pompili, D. Joint Task Offloading and Resource Allocation for Multi-Server Mobile-Edge Computing Networks. IEEE Trans. Veh. Technol. 2019, 68, 856–868. [Google Scholar] [CrossRef] [Green Version]
- Mahenge, M.P.J.; Li, C.; Sanga, C.A. Energy-efficient task offloading strategy in mobile edge computing for resource-intensive mobile applications. Digit. Commun. Netw. 2022; in press. [Google Scholar] [CrossRef]
- Karimi, E.; Chen, Y.; Akbari, B. Task offloading in vehicular edge computing networks via deep reinforcement learning. Comput. Commun. 2022, 189, 193–204. [Google Scholar] [CrossRef]
- Kuang, Z.; Ma, Z.; Li, Z.; Deng, X. Cooperative computation offloading and resource allocation for delay minimization in mobile edge computing. J. Syst. Arch. 2021, 118, 102167. [Google Scholar] [CrossRef]
- Zhang, N.; Guo, S.; Dong, Y.; Liu, D. Joint task offloading and data caching in mobile edge computing networks. Comput. Netw. 2020, 182, 107446. [Google Scholar] [CrossRef]
- Tan, L.T.; Hu, R.Q.; Hanzo, L. Twin-Timescale Artificial Intelligence Aided Mobility-Aware Edge Caching and Computing in Vehicular Networks. IEEE Trans. Veh. Technol. 2019, 68, 3086–3099. [Google Scholar] [CrossRef] [Green Version]
- Yang, L.; Zhang, H.; Li, M.; Guo, J.; Ji, H. Mobile Edge Computing Empowered Energy Efficient Task Offloading in 5G. IEEE Trans. Veh. Technol. 2018, 67, 6398–6409. [Google Scholar] [CrossRef]
- Guo, H.; Liu, J. Collaborative Computation Offloading for Multiaccess Edge Computing Over Fiber–Wireless Networks. IEEE Trans. Veh. Technol. 2018, 67, 4514–4526. [Google Scholar] [CrossRef]
- Qiao, G.; Leng, S.; Zhang, K.; He, Y. Collaborative Task Offloading in Vehicular Edge Multi-Access Networks. IEEE Commun. Mag. 2018, 56, 48–54. [Google Scholar] [CrossRef]
- Ma, C.; Zhu, J.; Liu, M.; Zhao, H.; Liu, N.; Zou, X. Parking Edge Computing: Parked-Vehicle-Assisted Task Offloading for Urban VANETs. IEEE Internet Things J. 2021, 8, 9344–9358. [Google Scholar] [CrossRef]
- Li, B.; Hou, F.; Ding, H.; Wu, H. Community based parking: Finding and predicting available parking spaces based on the Internet of Things and crowdsensing. Comput. Ind. Eng. 2021, 162, 107755. [Google Scholar] [CrossRef]
- Chen, M.; Wang, T.; Zhang, S.; Liu, A. Deep reinforcement learning for computation offloading in mobile edge computing environment. Comput. Commun. 2021, 175, 1–12. [Google Scholar] [CrossRef]
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef] [Green Version]
- Jately, V.; Azzopardi, B.; Joshi, J.; Balaji, V.V.; Sharma, A.; Arora, S. Experimental Analysis of hill-climbing MPPT algorithms under low irradiance levels. Renew. Sustain. Energy Rev. 2021, 150, 111467. [Google Scholar] [CrossRef]
- Hameed, M.A.; Jamsheela, O.; Robert, B.S. Relative performance of Roulette wheel GA and Rank GA is dependent on chromosome parity. Mater. Today Proc. 2021; in press. [Google Scholar] [CrossRef]
- Magoula, L.; Barmpounakis, S.; Stavrakakis, I.; Alonistioti, N. A genetic algorithm approach for service function chain placement in 5G and beyond, virtualized edge networks. Comput. Netw. 2021, 195, 108157. [Google Scholar] [CrossRef]
- Zhang, Y.; Wei, C.; Zhao, J.; Qiang, Y.; Wu, W.; Hao, Z. Adaptive mutation quantum-inspired squirrel search algorithm for global optimization problems. Alex. Eng. J. 2022, 61, 7441–7476. [Google Scholar] [CrossRef]
- Wang, H.; Li, X.; Ji, H.; Zhang, H. Federated Offloading Scheme to Minimize Latency in MEC-Enabled Vehicular Networks. In Proceedings of the 2018 IEEE Globecom Workshops (GC Wkshps), Abu Dhabi, United Arab Emirates, 9–13 December 2018; pp. 1–6. [Google Scholar]
- Gao, J.X.; Wang, J. Multi-edge Collaborative Computing Unloading Scheme Based on Genetic Algorithm. Comput. Sci. 2021, 48, 9. [Google Scholar]
Figure 1.
Collaborative mobile edge computing task offloading model for roadside parking.

Figure 2.
Coding.

Figure 3.
Uniform crossing.

Figure 4.
Comparison of offloading schemes.

Figure 5.
Delay comparison of various algorithms under different number of tasks.

Figure 6.
Comparison of energy consumption of various algorithms under different number of tasks.

Figure 7.
Comparison of system overhead of various algorithms under different task sizes.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Simulation experiment parameters.
| Experimental Parameters | Numerical |
|---|---|
| The launch rate at which a moving vehicle uploads a task | 5 W |
| Computing resources for moving vehicles | 1G cycles/s |
| Computing resources for MEC | 4G cycles/s |
| Computing resources provided by the cloud server | 10G cycles/s |
| Curbside parking provides computing resources | 1G cycles/s |
| Equipment power for moving vehicles/roadside parking | 8 W |
| Device power of the MEC server | 30 W |
| Device power of the cloud server | 70 W |
| Populations M | 60 |
| Maximum number of iterations | 100 |
| Crossover rate | 0.85 |
| Mutation rate | 0.02 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Shen, X.; Chang, Z.; Niu, S. Mobile Edge Computing Task Offloading Strategy Based on Parking Cooperation in the Internet of Vehicles. Sensors 2022, 22, 4959. https://0-doi-org.brum.beds.ac.uk/10.3390/s22134959
AMA Style
Shen X, Chang Z, Niu S. Mobile Edge Computing Task Offloading Strategy Based on Parking Cooperation in the Internet of Vehicles. Sensors. 2022; 22(13):4959. https://0-doi-org.brum.beds.ac.uk/10.3390/s22134959
Chicago/Turabian StyleShen, Xianhao, Zhaozhan Chang, and Shaohua Niu. 2022. "Mobile Edge Computing Task Offloading Strategy Based on Parking Cooperation in the Internet of Vehicles" Sensors 22, no. 13: 4959. https://0-doi-org.brum.beds.ac.uk/10.3390/s22134959
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.