3.1. Datasets Description
The applicability of the proposed mechanism was measured by evaluating all the different ML algorithms on six diverse datasets selected from various available data repositories, referring to different health anomalies and scenarios (i.e., diabetes [
91], stroke [
92], heart failure [
93], COVID-19 [
94], breast cancer [
95], kidney disease [
96]). More specifically, diabetes data were chosen because diabetes refers to a set of metabolic disorders from which millions of people suffer worldwide and, as a result, it is imperative to find the best prediction model to avoid implications and provide the best treatment possible. In the case of the stroke-related dataset, as well as the heart-failure-related dataset, those were chosen since both stroke and heart failure events occur regularly and are fatal in about 20% of the cases [
97]. COVID-19 data were chosen because the COVID-19 pandemic radically changed the ordinary way of life and ML models are needed to predict the short-term (i.e., Intensive Care Units (ICU) visits) and long-term implications of this disease (i.e., other medical conditions such as heart failure). Breast cancer data were used because breast cancer is one of the most common types of cancer in women, and ML models could help physicians to determine whether a tumor is malignant or not. Finally, kidney disease is also a chronic disease for which, even though it mostly affects older people, its symptoms may occur in an earlier stage in life. To predict the occurrence of kidney disease, ML models can also be utilized, and that is why a kidney disease-related dataset was also used in this study.
The selection of the aforementioned diseases, apart from the COVID-19 case, regards the selection of some of the major chronic diseases in which patients are subject to multiple drug regimens. More specifically, two of the four main categories of chronic non-communicable diseases as indicated by WHO [
98] have been selected, referring to cardiovascular diseases (stroke, heart failure) and diabetes mellitus (diabetes). In addition to these categories, there are also breast cancer and kidney disease, which do not belong to any of the four categories but belong to the wide range of chronic diseases. In addition, the choice of the COVID-19 case is due to the fact that it is a recent healthcare topic studied by the entire research community to interpret its possible linking with chronic diseases. At this point, it is necessary to clarify that chronic diseases share common factors (common characteristics) and risk situations. While some risk factors, such as age and sex, cannot be changed, many behavioral risk factors can be changed, as well as several intermediate biological factors such as high blood pressure or body mass index. Additionally, economic (e.g., working status) and physical conditions (e.g., place of residence) influence and shape behavior and indirectly influence other biological factors (e.g., single or married, smoker or non-smoker). Identification of these common risk factors and conditions is the conceptual basis for a comprehensive approach to any chronic disease being studied. Equally important is the contribution of laboratory data, such as red or white blood cells and other data, which help clinicians to provide a better picture of the control and prevention of potential patients’ health-related risks.
In further detail, the diabetes dataset spans ten years (1999–2008) of clinical treatment across 130 US hospitals and integrated delivery networks, including more than 50 variables characterizing patient and hospital outcomes. However, for the current experimentation, the main features that were selected were race, gender, age, admission type, discharge disposition, admission source, time in hospital, number of procedures, number of medications, number of inpatient visits, number of diagnoses, glucose serum test result, A1c test result, and change of medications (
Table 1). The characteristics were chosen because they reflect the main features of a patient’s background and main clinical features.
Regarding the stroke event dataset, it consists of clinical features for predicting stroke events, like gender, age, and various diseases. Indicatively, some of the chosen features of the above dataset were gender, age, hypertension, heart disease, and smoking status (
Table 2). The selected features were considered necessary for the final prediction result, because in the case that a patient has hypertension or not, it is a feature with significant role. Knowing whether the patient is married or not, whether he/she lives in a city or the suburbs, as well as his/her occupation, also are of great importance. Equally important are the body mass index metrics or glucose levels, as well as smoking category.
As for the heart failure dataset, it is made up of 299 heart failure patients’ medical records obtained from the Faisalabad Institute of Cardiology. The patients ranged in the age from 40 to 95 years old and included 105 women and 194 men. For this dataset, the following features were selected for the experimentation: age, anemia, creati-nine_phosphokinase, diabetes, and ejection_fraction (
Table 3). The features reported to make the ML models are general patient targets, such as age, gender, and smoking habits. Additionally, there included data from clinical laboratory tests that are considered necessary metrics for the state of a patient’s indicators.
As for the COVID-19 dataset, ML models were created exploiting train-test split techniques using 18 laboratory data features from 600 individuals. Hence, for this dataset, the following features were selected: age quantile, hematocrit, hemoglobin, platelets, and red blood cells (
Table 4). Predicting whether a patient ends up with pneumonia or not due to COVID-19 implications requires the patient’s laboratory data, because the laboratory indicators are quite important for making new decisions from health professionals.
Breast cancer is the most frequent malignancy in women worldwide. It is responsible for 25% of all cancer incidences and afflicted approximately 2.1 million individuals in 2015. The main obstacle to its detection is determining whether tumors are malignant (cancerous) or benign (non-cancerous). The chosen characteristics are included in
Table 5, which are quite important for the broad picture of the patient, and thus for training the models in order to produce the most accurate outcome predictions.
Finally, the last of the datasets is that of kidney disease. The corresponding data for this scenario were collected from a competition of the electronic repository Kaggle, with the amount of this data reaching 399 patient records with the control of various laboratory elements deemed necessary for training the models and safely making decisions about kidney disease predictions. The characteristics that were selected for investigating whether there is a risk of developing kidney disease or not are related to age, blood pressure, specific gravity, albumin, etc. (
Table 6).
3.3. Evaluation Results
To perform a prediction on a given patient, the ML algorithms were already trained with the datasets described in
Section 3.1. As a result, for a new prediction based on the trained models, specific information for this patient is uploaded through one of the forms provided by the UI of the mechanism, as shown in
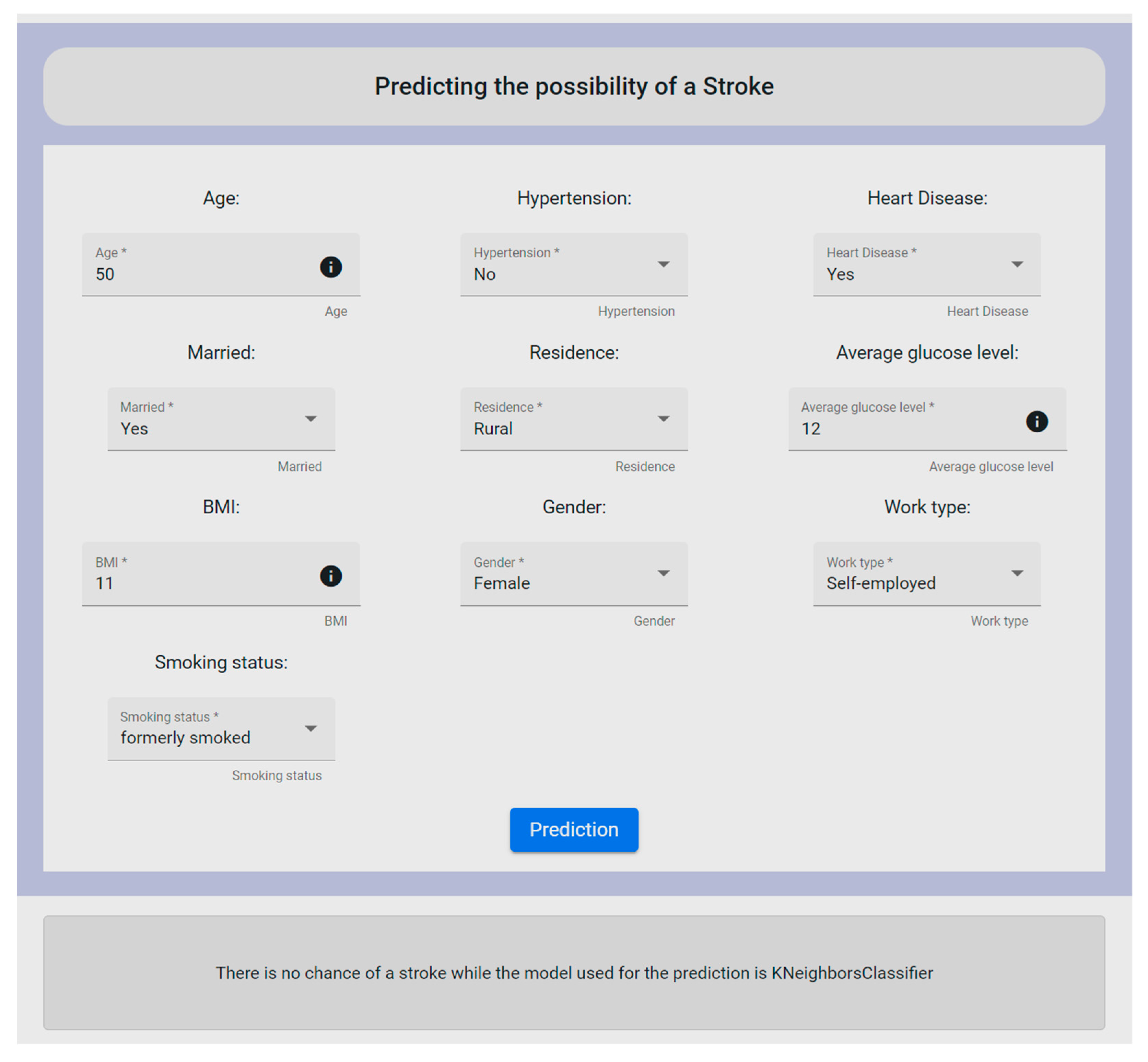
Figure 10. More specifically, the form depicted in
Figure 10 deals with the stroke dataset, where the user is requested to fill in the provided fields in order to proceed with the needed data analysis. To this end, it should be noted that all form’s fields are required to be filled in by the user.
The fields that make up the form refer to the id, gender, age, hypertension, heart_disease, ever_married, work_type, residence_type, avg_glucose_level, bmi, and smoking_status. By clicking the prediction button, the user could see whether the patient had a chance of having a stroke or not, based on the provided data. Firstly, the data were cleaned to remove outliers or other similar cases such as missing values of some fields, and then the data were properly orchestrated through the execution of the Orchestrated Experiment microservice. Consequently, the ML models were trained by exploiting the inserted data via the Model Training microservice and then exporting the appropriate metrics via the Model Evaluation and Model Validation microservices. After completing this procedure, to check the performance of the developed models on both the training data and the test data, the Model Serving microservice was applied for the prediction results. At the end, all these mechanisms were optimized into one page within the UI. Additionally, along with the final decision, the UI revealed to the user the most suitable ML model used for the prediction. In this experiment, the mechanism revealed that there was not any possibility of the patient to have a stroke, whereas the KNN algorithm was outlined to have produced the most reliable and efficient results. To be more specific, KNN was chosen for the stroke case since it produced the highest accuracy rate (96%), and also in relation to the remaining metric functions (further analyzed in Table 15).
Following the same concept, the mechanism supports the same functionalities for the other five datasets (i.e., diabetes, heart failure, COVID-19, breast cancer, kidney disease). In deeper detail, as for the case of diabetes, the form’s features were: age, admission_type, discharge_type, timeHospital, admission_source_type, num_medication_type, num_inpatient_type, number_diagnoses, num_procedure, race, gender, glu_serum, A1C, and change. For the heart failure prediction, the form’s features were age, anaemia, diabetes, ejection_fraction, creatinine_phosphokinase, serum_creatinine, sex, high_blood_pressure, platelets, smoking, serum_sodium, and time. In addition, the features for the COVID-19 case were: age, hematocrit, hemoglobin, platelets, redBloodCells, lymphocytes, leukocytes, basophils, eosinophils, monocytes, serumGlucose, neutrophils, creatinine, urea, sodium, proteina, potassium, alanineTransaminase, and aspartateTransaminase. Furthermore, in the case of breast cancer, the form’s feature were: radius_mean, texture_mean, perimeter_mean, area_mean, smoothness_mean, compactness_mean, concavity_mean, concave points_mean, symmetry_mean, fractal_dimension_mean, radius_se, texture_se, perimeter_se, area_se, smoothness_se, compactness_se, concavity_se, concave points_se, symmetry_se, fractal_dimension_se, radius_worst, texture_worst, perimeter_worst, area_worst, smoothness_worst, compactness_worst, concavity_worst, concave points_worst, symmetry_worst, and fractal_dimension_worst. Finally, for the kidney disease scenario, the form’s features were sg, al, sc, pcv, and htn.
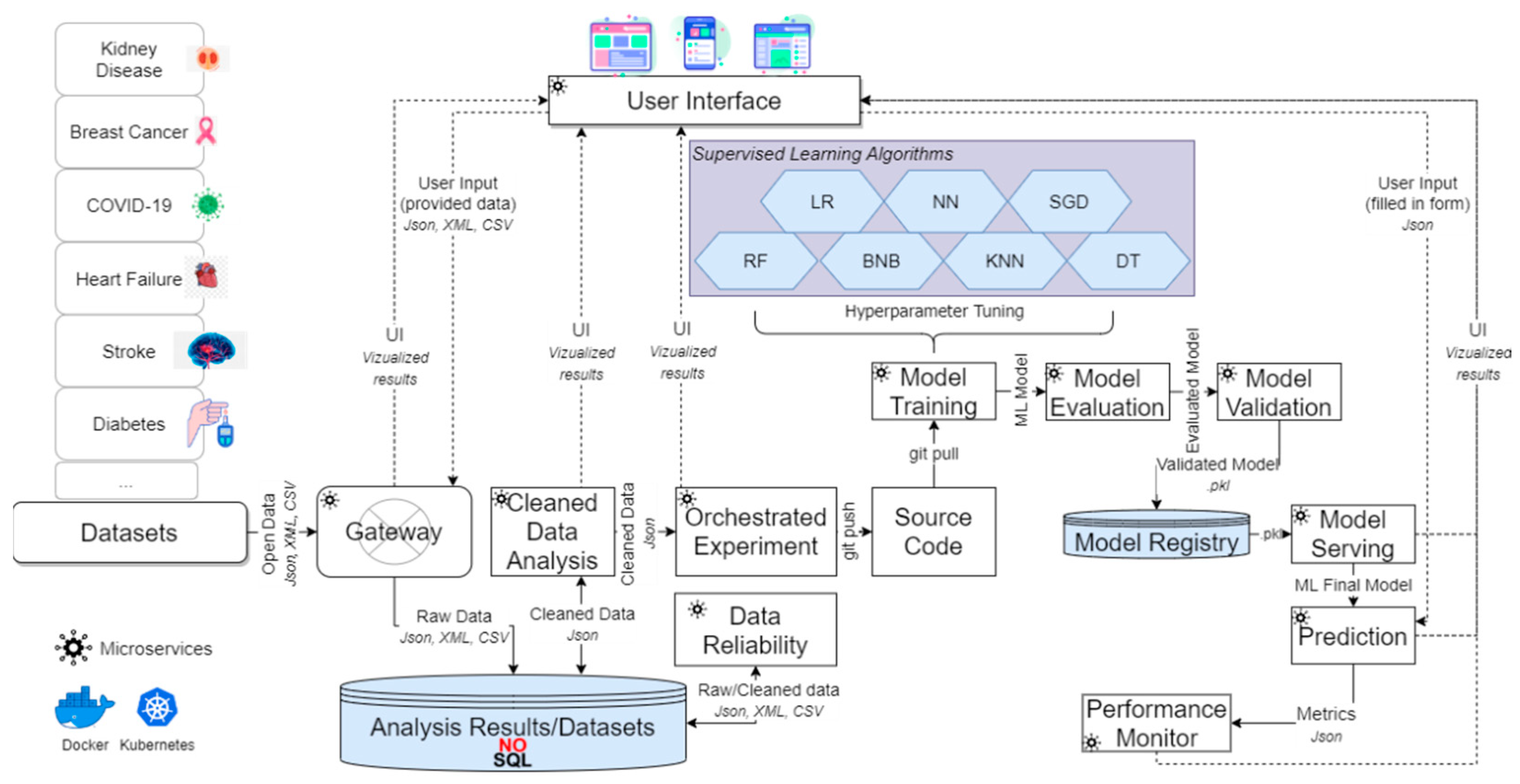
To effectively capture all the aforementioned results for all the different chosen scenarios, as stated above, the proposed mechanism applied the procedure described in
Section 2.2, following the sequence of the described processes (i.e., microservices). Hence, during the Data Reliability process, various corrective actions took place upon the diverse datasets, resulting into the results of
Table 7. Each row of this table showcases the data inconsistencies that were traced and fixed per dataset, to secure that the performance of the ML algorithms applied in the following step would be the best possible, since it is highly correlated to the quality of the given data.
Then, each ML algorithm was applied upon the inserted user’s data and the respective cleaned dataset. More specifically, the exploited algorithms had been set based on the parameters that are depicted in the following tables (
Table 8,
Table 9,
Table 10,
Table 11,
Table 12,
Table 13 and
Table 14), for each different algorithm. Initially, the models’ training began with each algorithm’s parameters being initialized to random values or zeros. An optimization technique was then used to change the initial values as training/learning continued (e.g., gradient descent). The learning method constantly updated the parameter values as learning progressed, whilst the model’s hyperparameter values stayed static.
Table 15 depicts the prediction results of each algorithm in combination with its percentage of accuracy (%). The values in the first sub-field (inside parenthesis) for the cases of heart failure, stroke, COVID-19, and kidney disease refer that there is a possibility of the anomaly to happen (Yes as Y) or not (No as N). In the case of diabetes, it states if there is a need for the patient to uptake insulin (Yes as Y) or if there is a need to uptake insulin along with other medicine (No as N). As for the case of breast cancer, it states if there is a chance of the cancer type being malignant (as M) or being benign (as B). For example, in the case of the first conducted experiment (i.e., stroke), the result indicated that there was not any chance of the patient to have a stroke (N) and the accuracy of the prediction of KNN was 96%. Even though the rest of the algorithms had also high levels of accuracy, as for example the BNB that had an accuracy of 95%, such a small difference in the world of ML is quite important, since in real-world scenarios, such differences are of crucial importance. Additionally, in the case of breast cancer, the results of most algorithms indicated that a large percentage of patient samples have benign breast cancer, so it is not considered as a problem of great concern. This is positive, because it is observed that the LR algorithm scores an accuracy rate equal to 100%, outlining that the patients were dealing with a benign breast cancer. However, this was also proven with additional related parameters that are mentioned in the following sections.
In sequel, to conclude to the best suitable training algorithm for the prediction, during the training phase, the mechanism considered the metric of accuracy along with the metrics of precision, recall, F1-score, and confusion matrix (described in
Section 2.2).
Concerning precision, this metric refers to the ratio between the true positive and all the positive values. Thus, for the first experiment (i.e., stroke), this referred to the measure of the patients correctly identified of having a chance to have a stroke from all the patients who actually had.
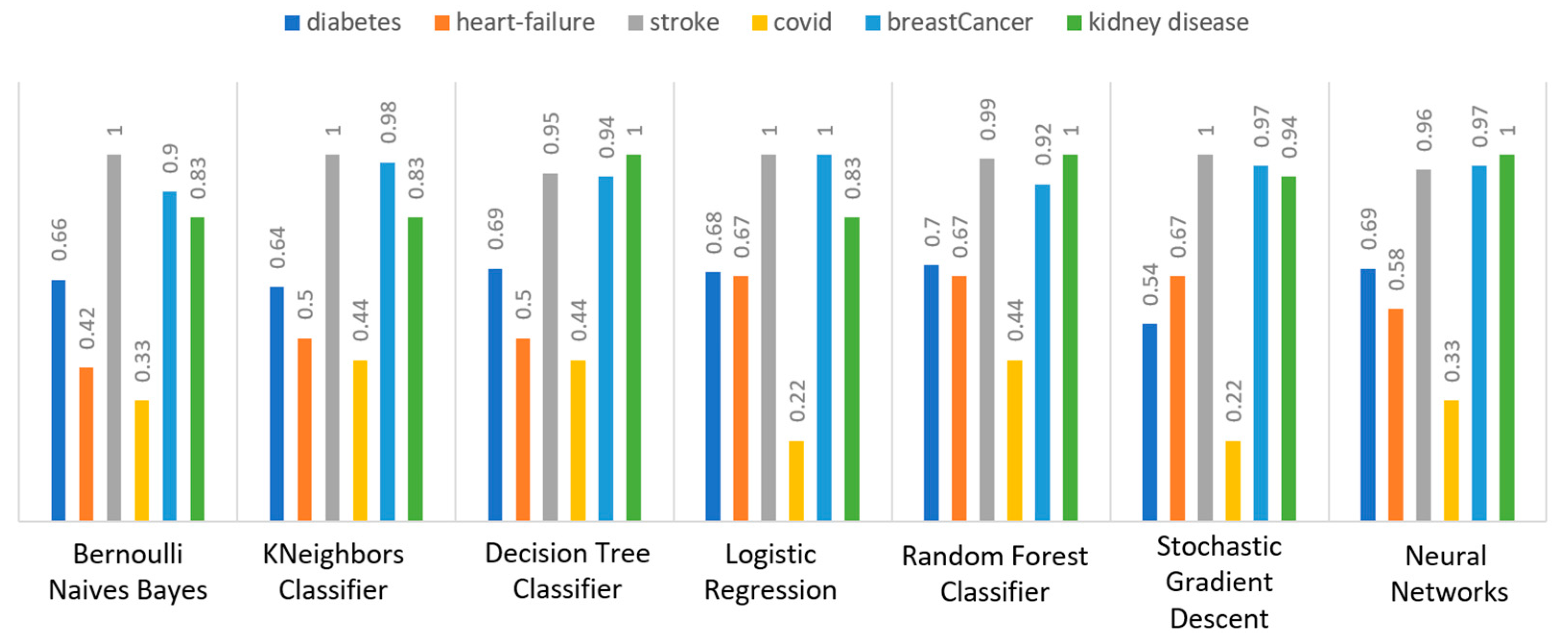
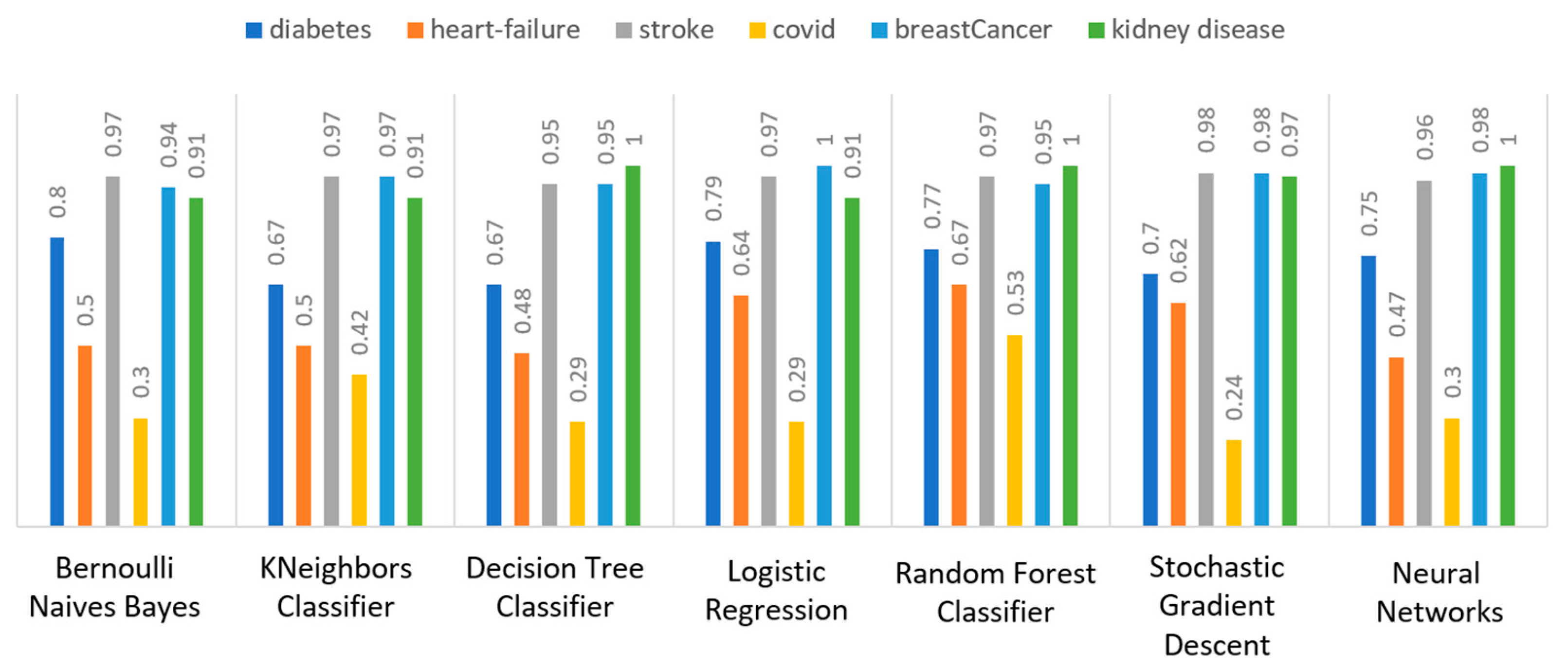
Figure 11 depicts this metric for all the algorithms applied upon the different chosen datasets, where in the case of diabetes the best algorithm was RF (70%), in the case of heart failure both LR, RF, and SGD produced the best results with 67% precision, in the case of stroke BNB, KNN, LR, and SGD had perfect precision (i.e., 100%), whilst in the case of COVID-19 the best performing algorithms were KNN and RF, with 44% precision. For the case of breast cancer, the best algorithm was LR (100%). Finally, as for the kidney disease use case, the best algorithms were DT, RF, and NN, which resulted into 100% precision.
Regarding recall, this metric depicts the correctly identified true positive values.
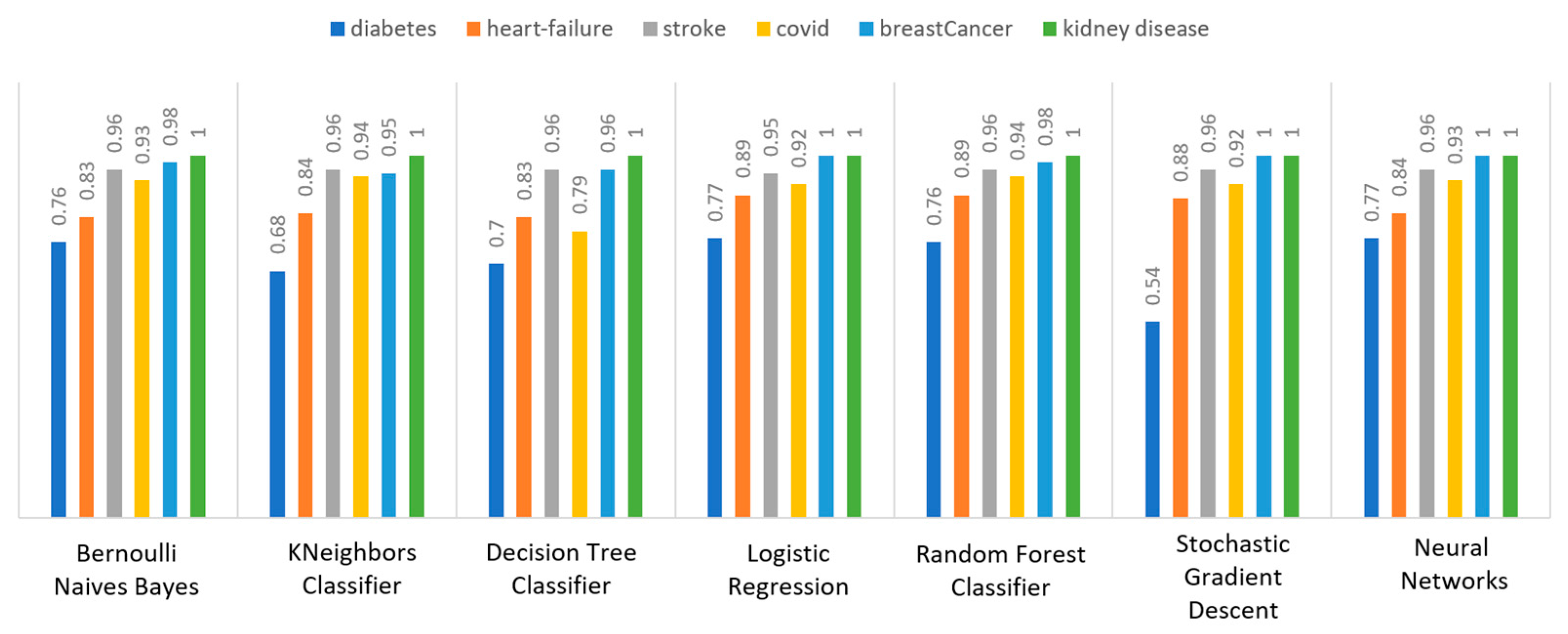
Figure 12 depicts this metric for all the algorithms applied upon the different chosen datasets. In the case of diabetes, the best algorithms were LR and NN (77%). When applied on the heart failure dataset both LR and RF had 89% recall, while in the case of the stroke dataset all algorithms had a very high percentage of recall (96%). In the case of COVID-19 the best performing algorithms were KNN and NN with 100% recall, whereas in the same notion, in the case of breast cancer the best algorithms were LR and NN with 100% recall as well. Finally, in the case of kidney disease, DT, RF, and NN also had a perfect recall (100%).
To this end, it should be noted that achieving high recall can be considered more important than obtaining high accuracy. For other kind of ML models, such as the classification ones, whether a patient is suffering from an anomaly or not, it is desirable to have high accuracy. Therefore,
Figure 13 portrays the F1-score metric for all the algorithms applied upon all the different selected datasets. In the case of the diabetes dataset, the best algorithm was BNB with 80% F1-score. In the case of heart failure RF had 67% F1-score, while in the case of the stroke dataset BNB, KNN, LR, and RF achieved 97% F1-score. Regarding the COVID-19 dataset, the best algorithm was RF with 53% F1-score. Moreover, in the case of breast cancer dataset LR had 100% F1-score, whilst in the case of the kidney disease dataset DT, RF and NN achieved 100% F1-score as well. It is worth mentioning that SGD algorithm achieved equally accurate results with 97% F1-score.
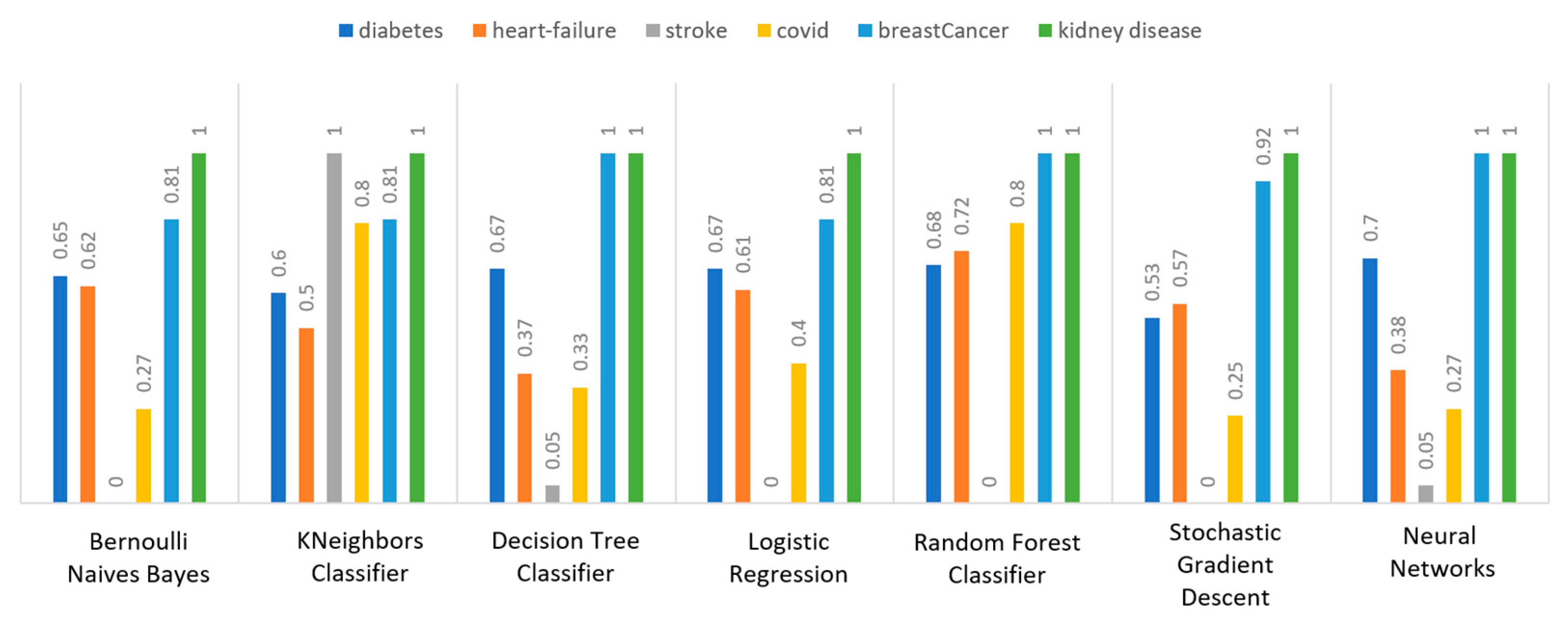
Additionally, regarding the specificity metric, in the scope of the utilized datasets, it refers to the percentage of people who do not have a disease and are tested as negative.
Figure 14 depicts this metric for all the algorithms applied upon the different chosen datasets, where in the case of the diabetes dataset the best algorithm was NN (70%), while in the case of the heart failure dataset RF achieved 72% specificity. In the case of the stroke dataset the best choice of algorithm was KNN, since it had 100% recall, whilst in the case of the COVID-19 dataset the best performing algorithms were KNN and RF with 80% specificity. Moreover, regarding the case of breast cancer dataset, the best algorithms were DT, RF, and NN with a perfect (100%) specificity, whereas in the case of the kidney disease dataset all the algorithms achieved a perfect (100%) specificity as well.
3.3.1. Diabetes Use Case
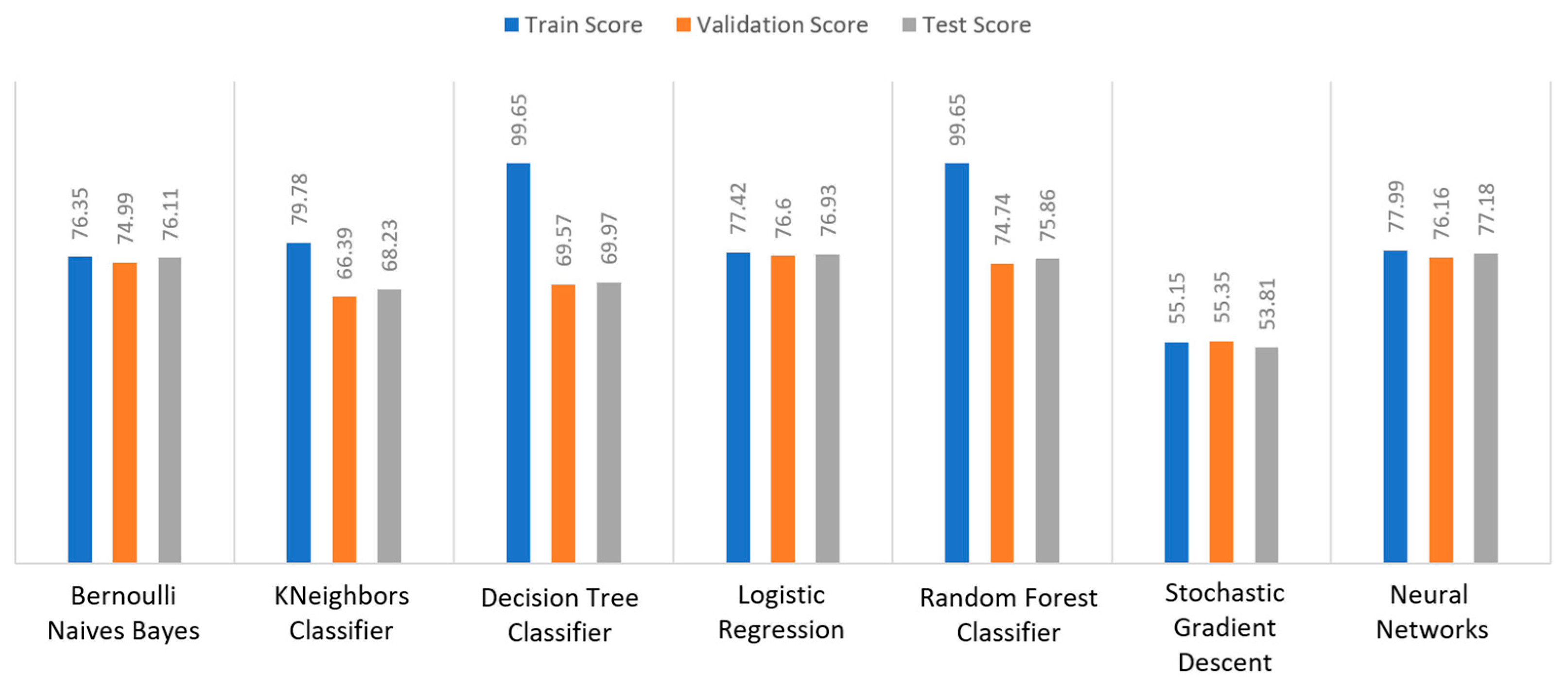
Apart from the abovementioned metrics, the train, validation, and test scores were used for the models’ evaluation, as described in
Section 2.2. For the diabetes dataset, in
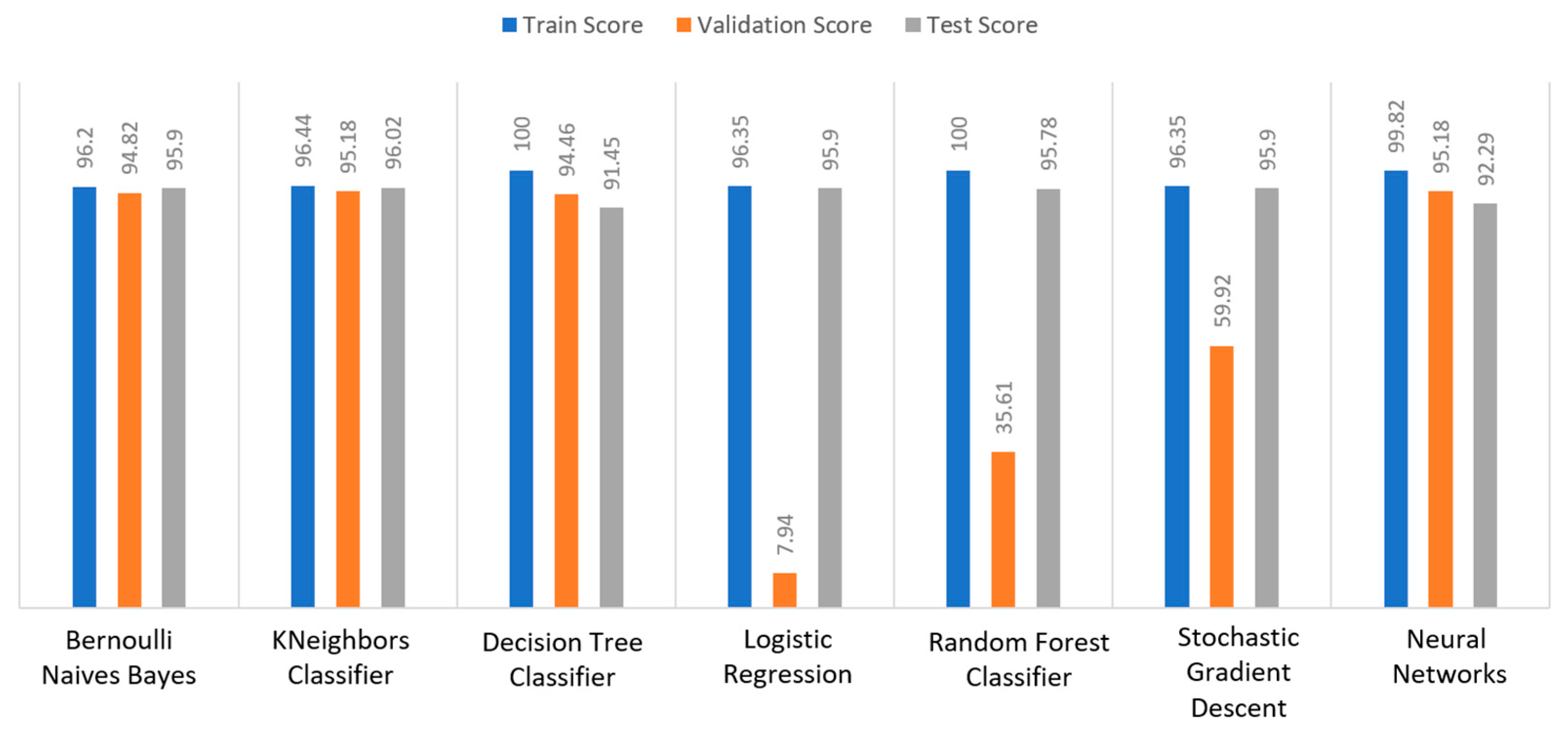
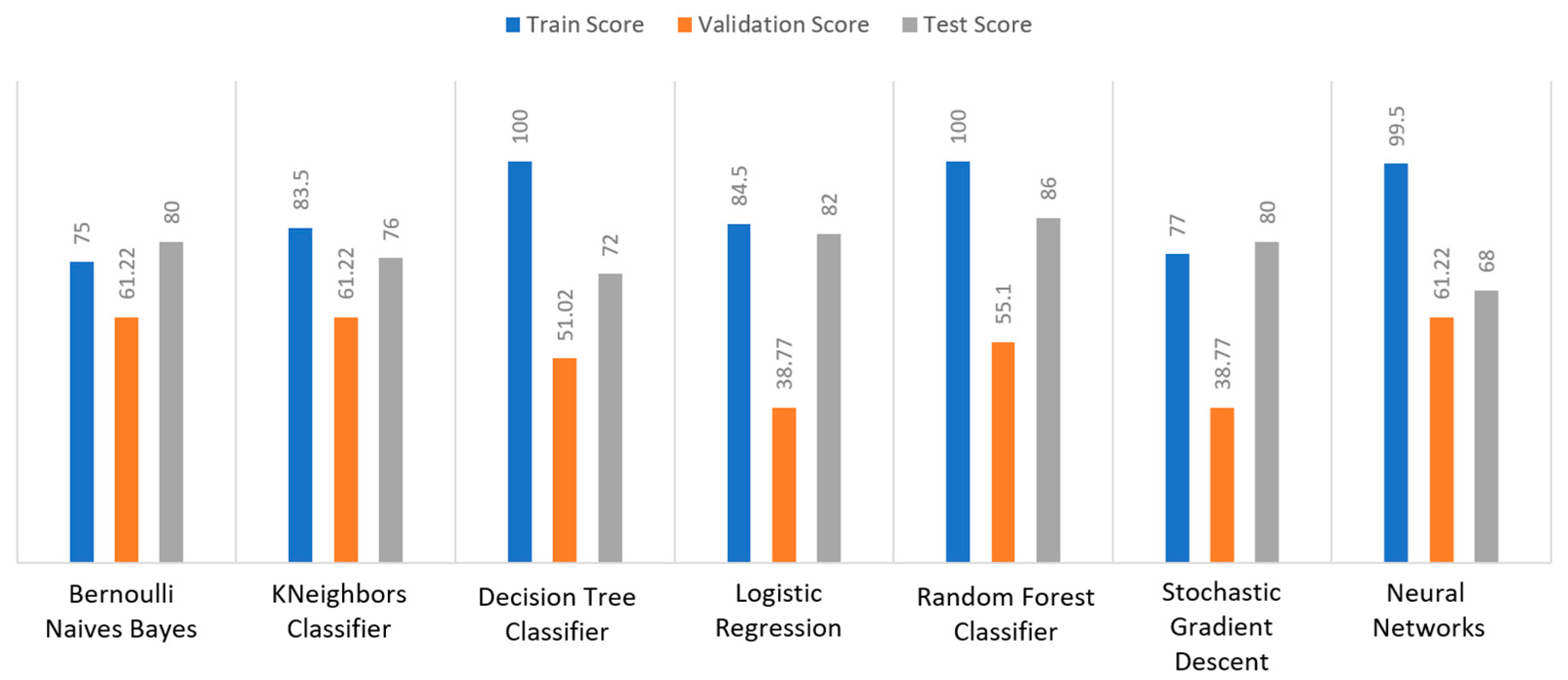
Figure 15, DT and RF achieved a train score percentage equal to 99.65%, while the rest of the algorithms achieved a score under 80%. Moreover, it was observed that BNB (76.35%) or KNN (79.78%) could not be properly trained, due to the training data. As for the validation score, only three algorithms achieved a score above 60%. These algorithms were BNB, KNN, and NN, with a percentage equal to 61.22%. Regarding the test score, RF achieved a score of 86%, while all the other algorithms had scores under 85%. The next highest score was 82% by LR. In conclusion, for the diabetes dataset, the best algorithm was BNB, since all the metrics in all training, validation, and test data did not differ from each other.
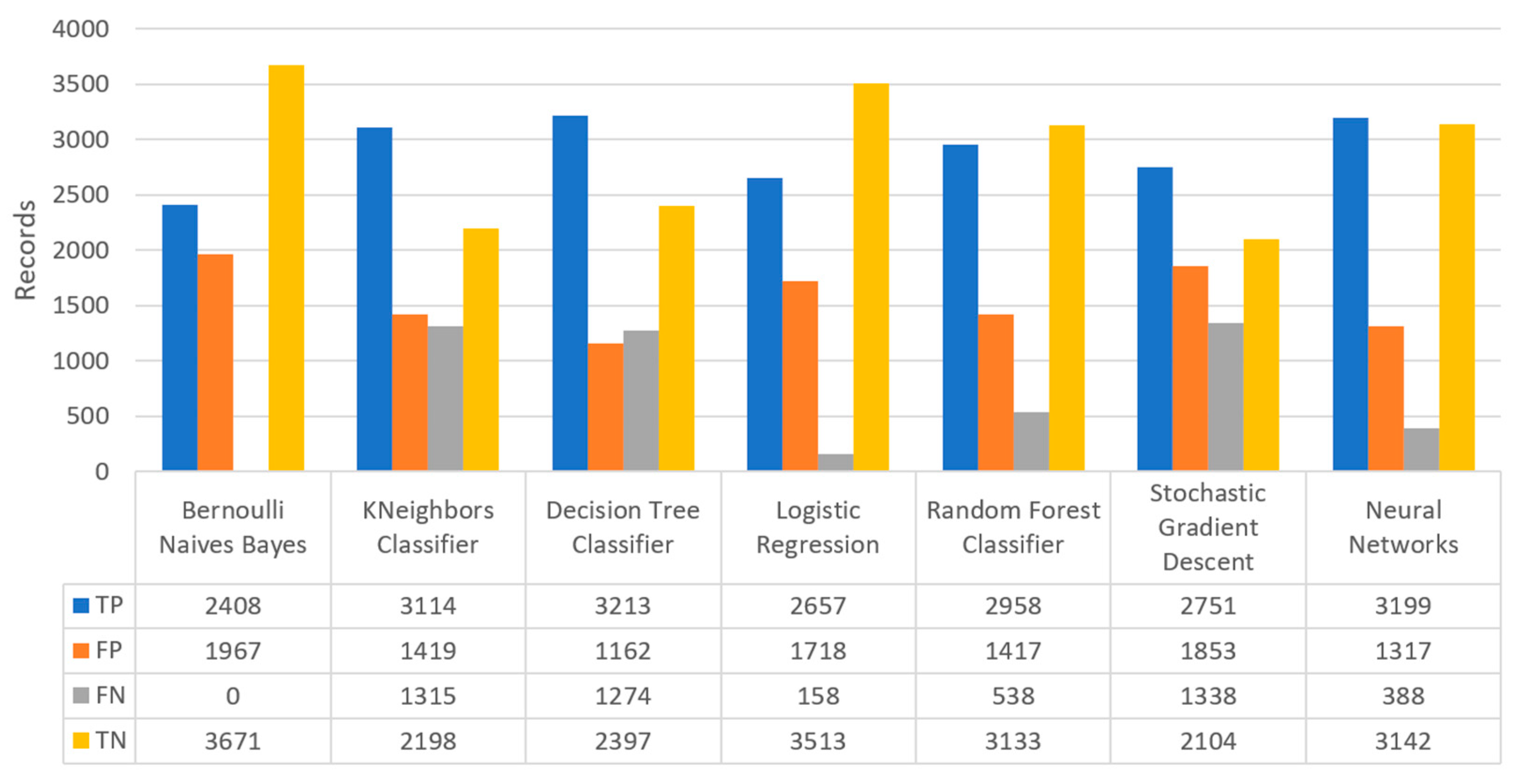
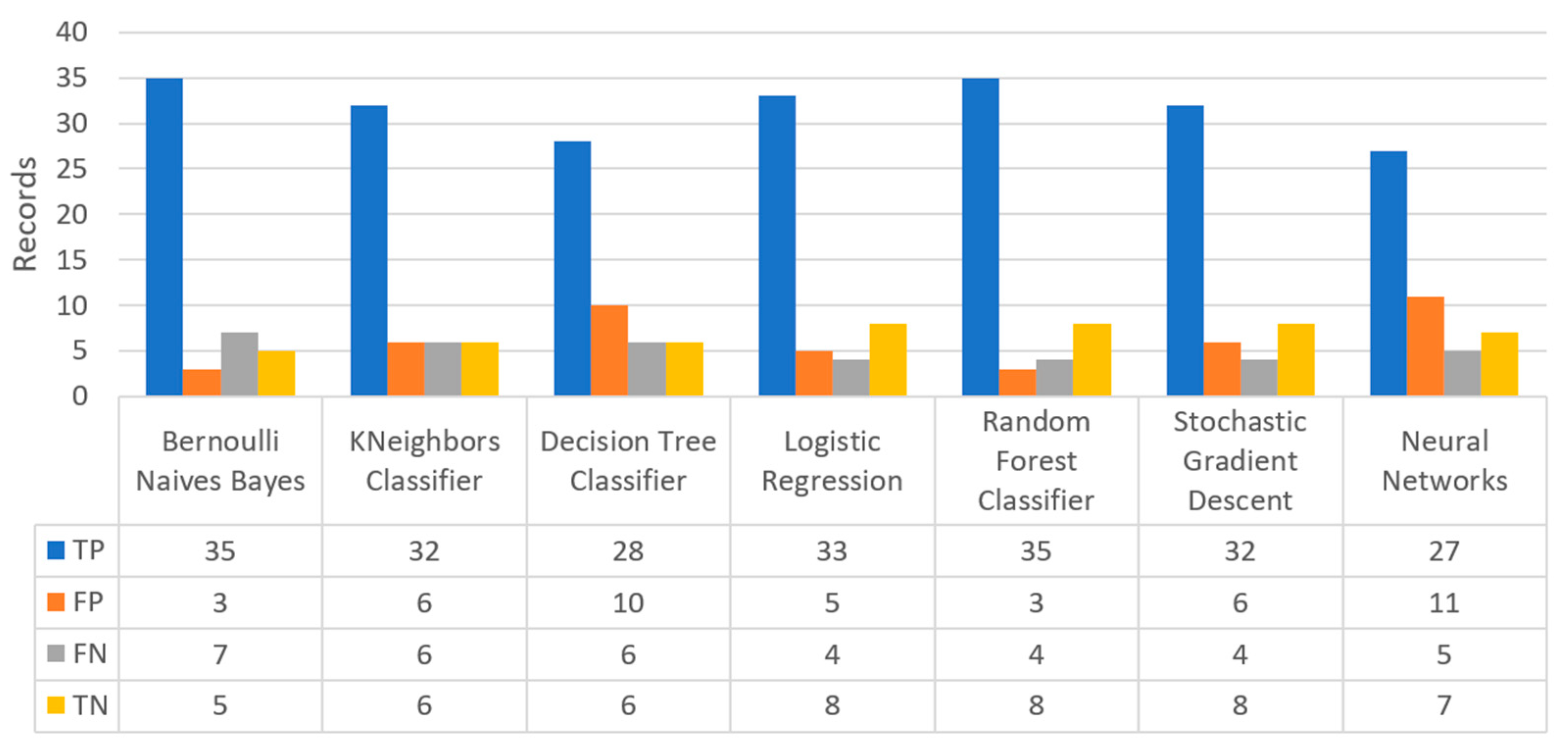
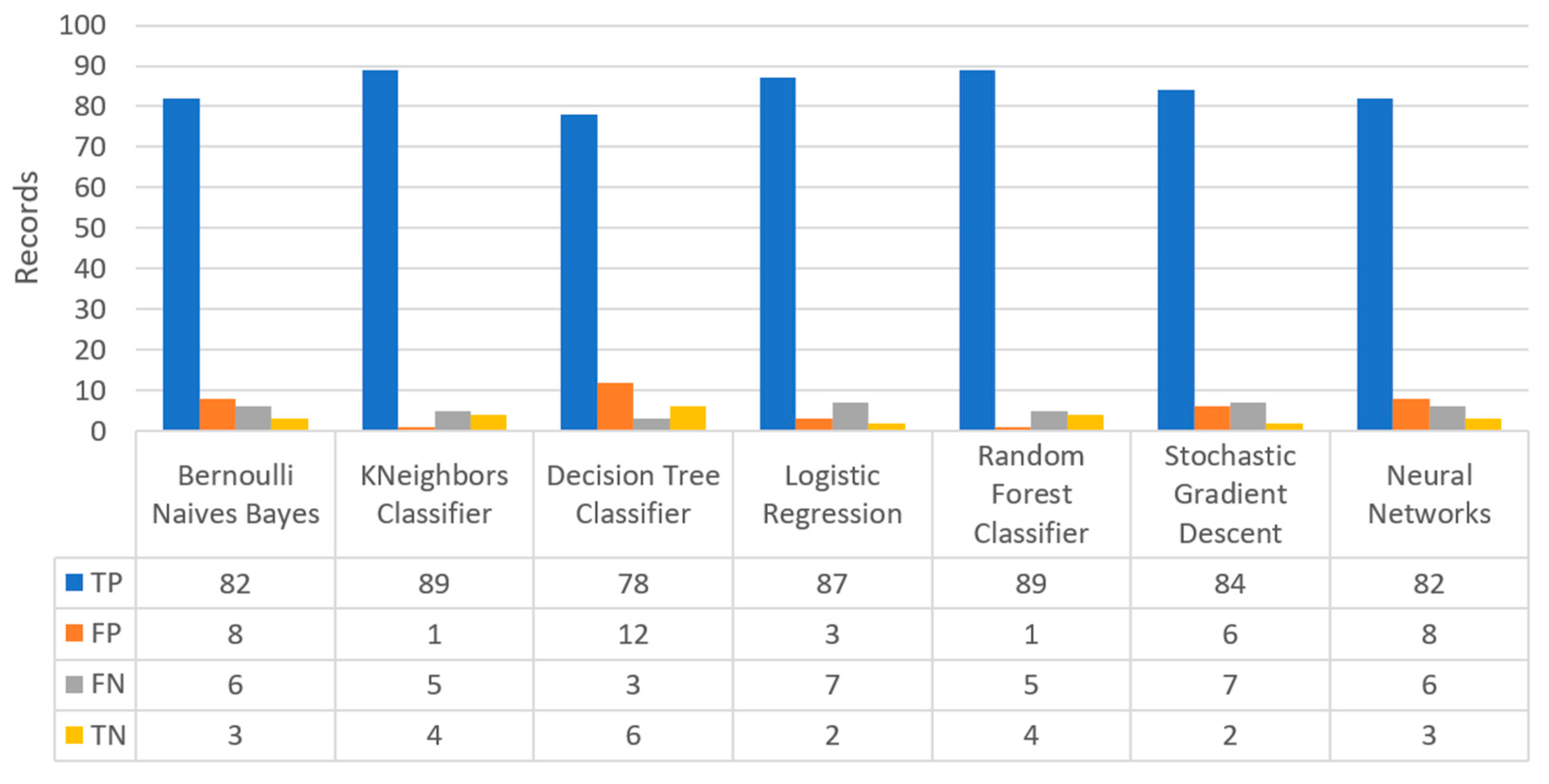
Finally, the confusion matrix for the diabetes scenario’s predictions was estimated, showing the distribution of records based on the four different combinations of predicted and actual values of the diabetes dataset.
Figure 16 depicts the confusion matrix for the diabetes dataset, where NN predicted that there was a true probability that insulin would be granted in 3199 records (TP), while insulin in combination with some other medicine would be granted in 3142 records (TN). In addition, the next best algorithm was LR with 2657 records in which insulin would be administered, and 3513 records in which insulin with other medicine would be administered.
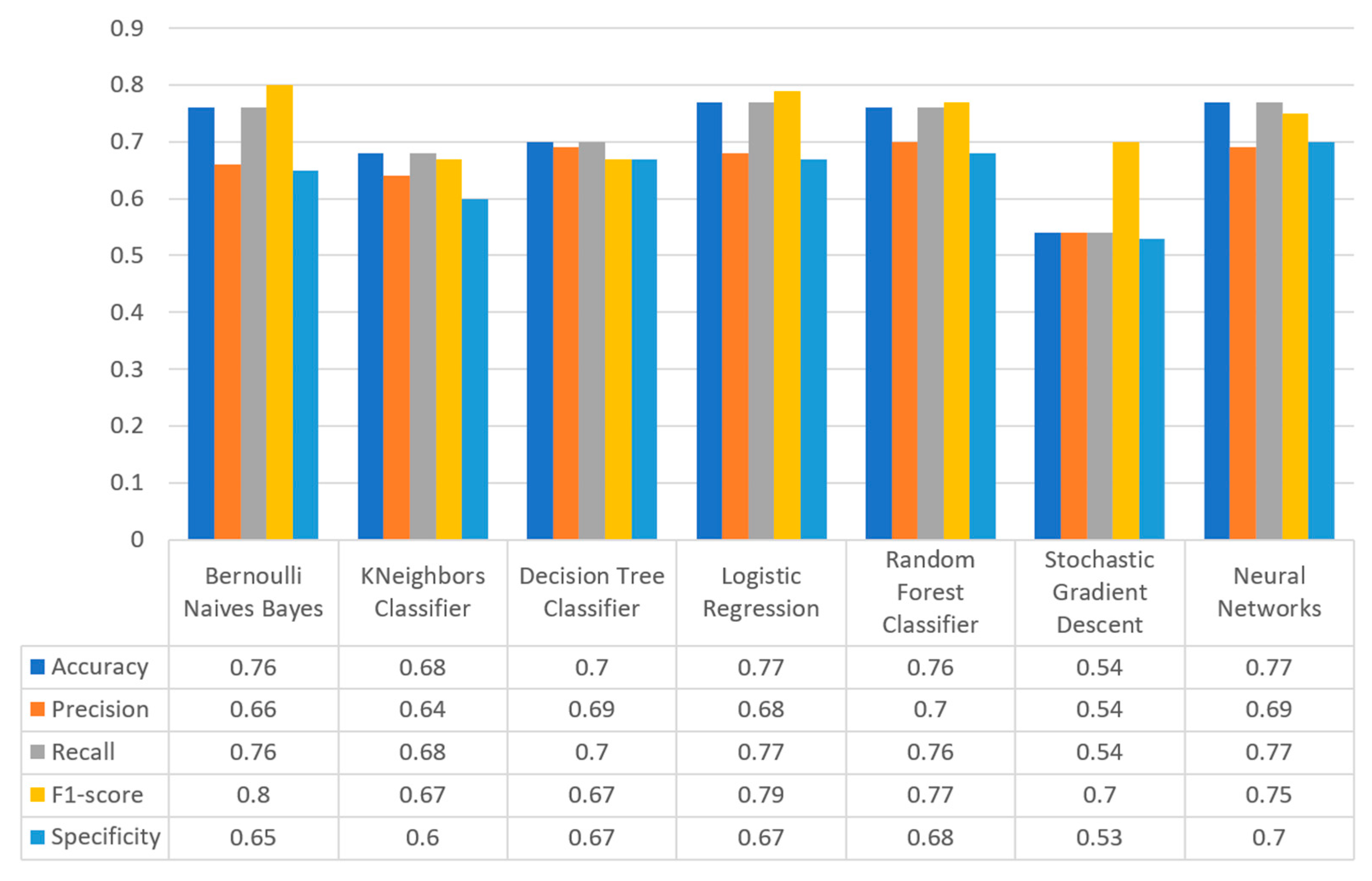
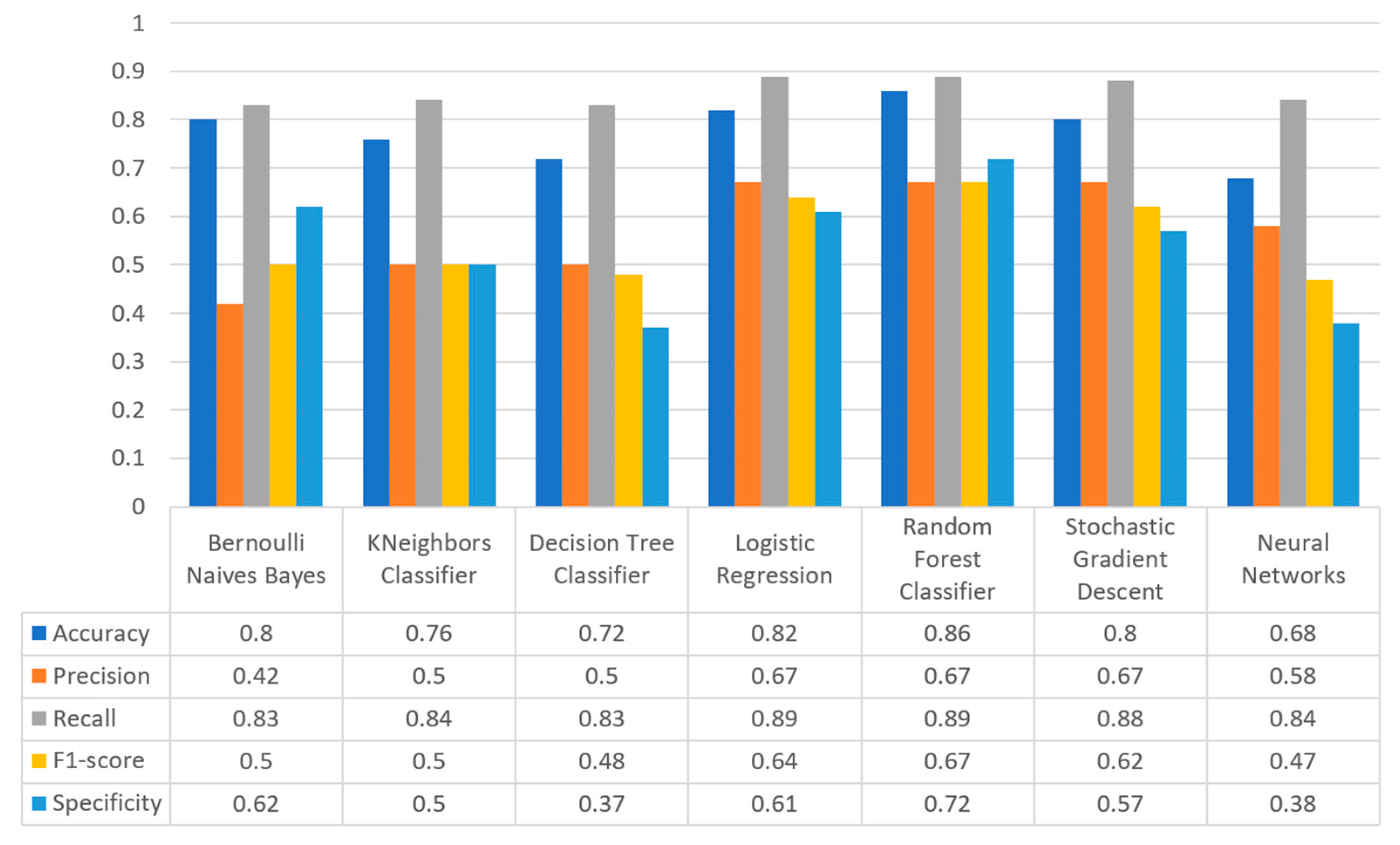
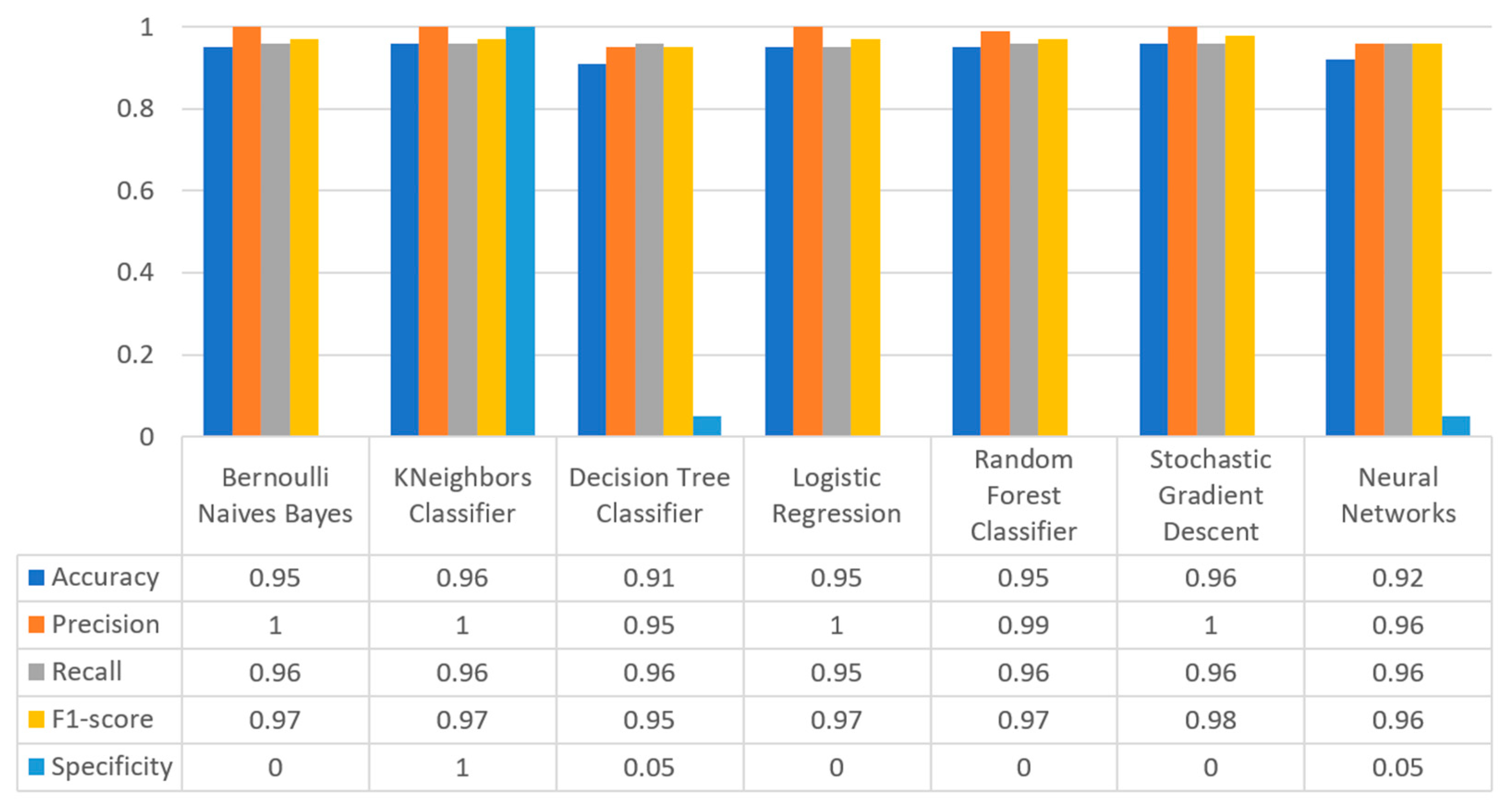
Figure 17 summarizes the comparison in terms of accuracy, precision, recall, F1-score, and specificity for the diabetes dataset. It can be observed that LR and NN produced the best prediction in terms of accuracy in comparison with BNB and the rest of the algorithms. Furthermore, the highest value of precision was observed for RF, which was equal to 0.7, followed by LR and NN with values equal to 0.68 and 0.69, respectively. In addition, as for the recall metric, the highest value was noted for the LR and NN algorithms. For the F1 score it was observed that the highest value was that of BNB, which was equal to 0.8, while LR, RF, and NN were the next ones. Finally, another important metric was that of specificity in which it is observed that the highest value was noted for NN algorithm, being equal to 0.7. Therefore, it is understood that for this case the most suitable algorithm for the diabetes scenario was NN.
3.3.2. Stroke Use Case
Regarding the stroke dataset, as shown in
Figure 18, KNN achieved a validation percentage equal to 95.18%, BNB 94.82%, and DT 94.46%, while the worst results were those of LR (7.94%) and RF (35.61%), due to the fact that they could not properly validate the received data. Additionally, it is observed that DT and RF, by considering a percentage of data from 65%–70% of the original (training) dataset, achieved a perfect (100%) score, while KNN achieved 96.44%. Additionally, most algorithms produced quite high test scores, however KNN achieved a percentage equal to 96.02%, followed by BNB with a percentage of 95.9%.
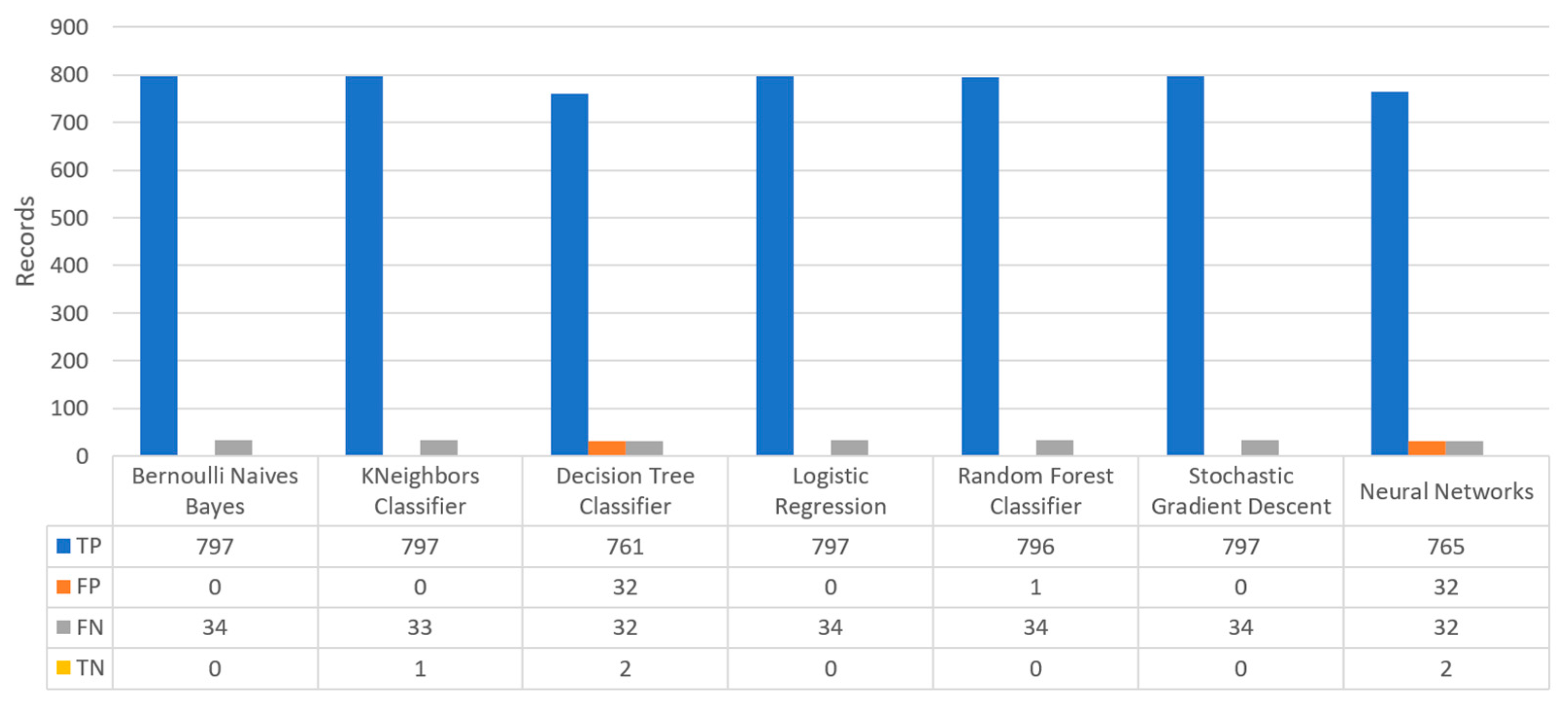
Figure 19 depicts the confusion matrix for the stroke dataset, where KNN predicted that there was a true probability that a stroke attack would occur in 797 records (TP), while in only one case (just in 1 record) it predicted that no stroke attack would occur (TN).
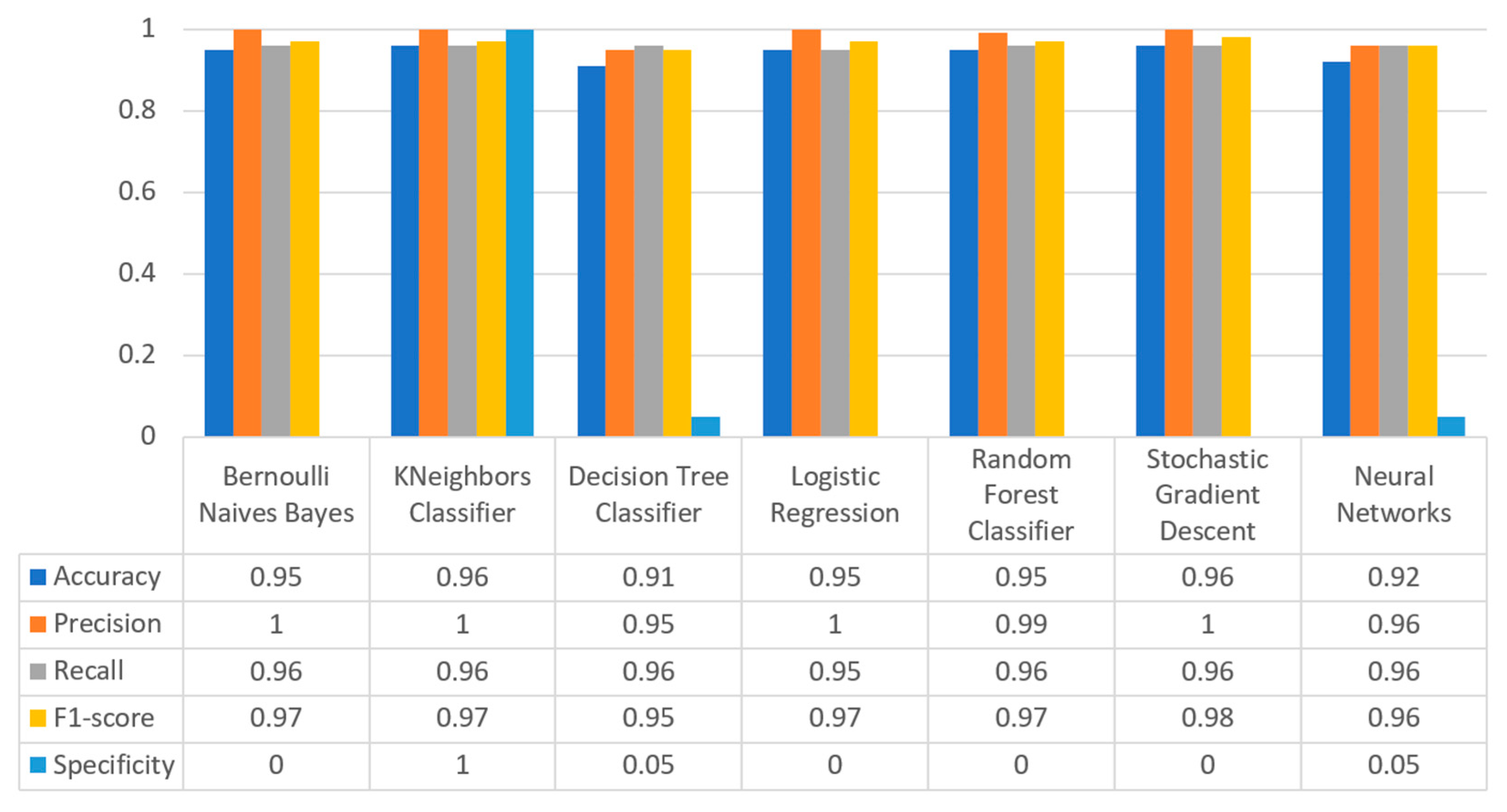
Figure 20 summarizes the comparison in the metrics of accuracy, precision, recall, F1-score, and specificity for the stroke scenario. To begin with, it can be seen that KNN and RF produced the best predictions in terms of accuracy in comparison with BNB, LR, and the rest of the algorithms. Moreover, the precision’s highest value was noted for BNB, KNN, LR, and SGD, which was equal to 1, followed by the RF algorithm. Regarding the recall metric, the highest value was noted in KNN. Moreover, regarding F1-scores, the highest value was achieved by SGD that was equal to 0.98, followed by BNB, KNN, LR, and RF. Finally, another important metric was that of specificity, in which it was observed that the highest value was noted for KNN, being equal to 1. Therefore, it is understood that for this case the most suitable algorithm for predicting whether a patient is likely to have a stroke or not was KNN.
3.3.3. Heart Failure Use Case
For the heart failure dataset, as shown in
Figure 21, DT and RF achieved a train score percentage equal to 100%, RF had also a good performance (99.50%), whilst the rest of the algorithms achieved scores between 75% and 85%. Moreover, the lowest percentages were produced by BNB (75%), KNN (83.5%), and SGD (85.32%), due to the fact that the training data could not be properly trained. Regarding the second metric, validation scores were quite low for all the algorithms, whilst only three of them achieved a score above 60%, referring to BNB, KNN, and NN. As for the test score, RF achieved a score equal to 86%, while all the other algorithms had scores below 85%, while the next highest percentage was achieved by LR (82%). In conclusion, for the case the of heart failure dataset, the best algorithm was BNB, since all the captured metrics in all the training, validation, and test data did not differ from each other.
Figure 22 shows the confusion matrix for the heart failure dataset, where RF predicted that there was a true probability that a heart failure attack would occur in 35 records (TP), while no heart failure attack would occur in eight records (TN). Additionally, the next best algorithm was LR with 33 records being predicted for having a heart failure attack, while no heart failure attack was predicted in eight records.
Figure 23 illustrates the comparison for the different metrics in the heart failure case. RF produced the best prediction in terms of accuracy (0.86) in comparison with LR (0.82) and the other algorithms. In addition, regarding precision, it is observed that the highest value was noted for RF and LR that was equal to 0.67. As for the recall metric, the highest value was noted for the LR and RF algorithms, while for F1-score, it is observed that the highest value was that of RF, being equal to 0.67, and followed by LR and SGD (<0.04). Finally, another important captured metric was that of specificity, in which it is observed that the highest value was achieved by RF, being equal to 0.72. Therefore, it is understood that the most suitable prediction regarding heart failure was produced by RF.
3.3.4. COVID-19 Use Case
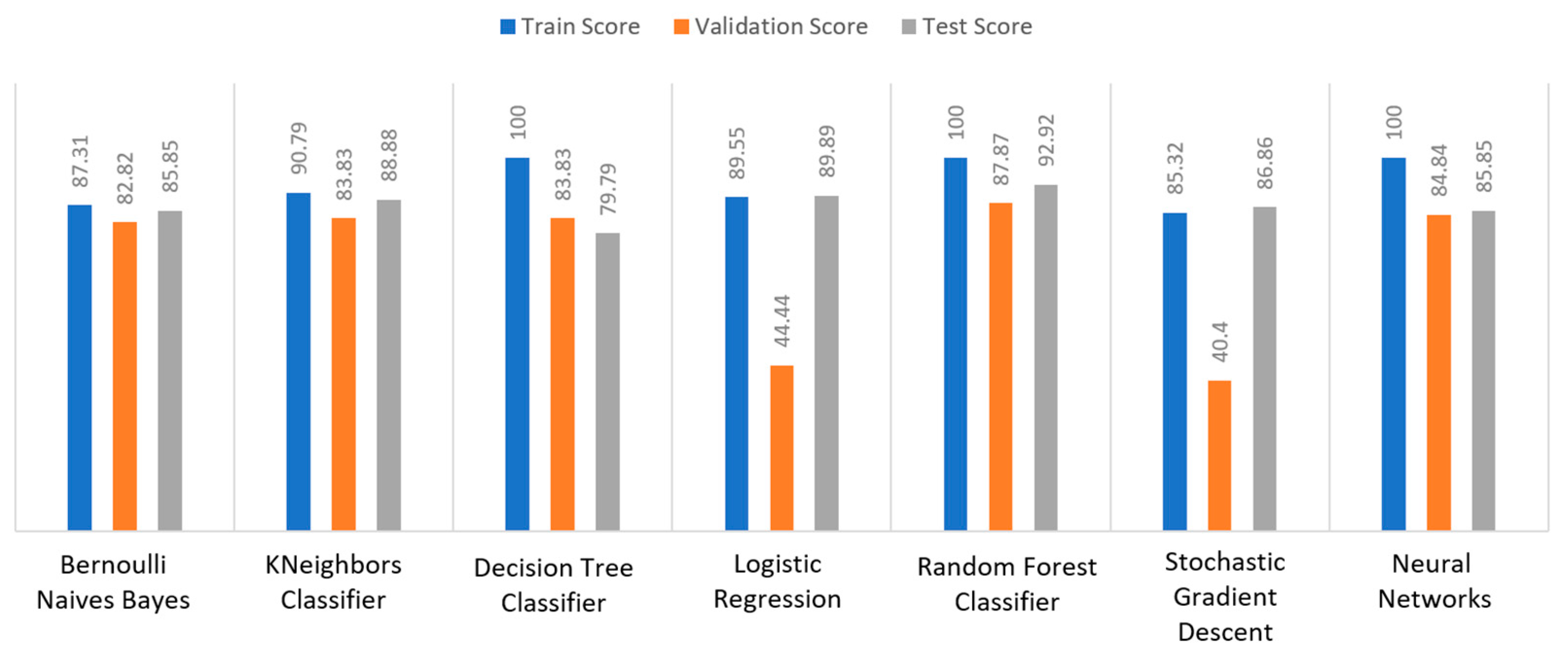
For the COVID-19 dataset, in
Figure 24 it can be seen that DT and NN achieved a train score percentage equal to 100% and KNN achieved a 90.79% score, while the rest of the algorithms reached a score not greater than 90%. For example, BNB had an 87.31% score, LR had an 89.55% score, and SGD had an 85.32% score due to the fact that the training data could not be properly trained. It was also observed that most algorithms achieved a score of around 80 to 90% (i.e., BNB (82.82%) or RF (87.87%)), while LR and SGD achieved a very low score of around 40% to 45%, respectively. Regarding the test score metric, RF achieved a score of 92.92%, while all the other algorithms had scores under 90% (i.e., BNB (85.85%) or LR (89.89%)). In conclusion, for the case of the COVID-19 dataset, the best algorithm was RF, because all the metrics in all the training, validation, and test data achieved a maximum score of approximately or equally to 100%.
Figure 25 shows the confusion matrix for the COVID-19 dataset, where KNN predicted that there was a true probability that a pneumonia attack would occur in 89 records (TP), while no pneumonia attack would occur in just four records (TN). However, it is worth mentioning that RF also depicted the same results.
Figure 26 summarizes the comparison for all the captured metrics of COVID-19 dataset. As it can be seen, KNN produced the best prediction in terms of accuracy (0.96) in comparison with LR (0.95) and the other algorithms. In addition, precision’s highest value was noted for BNB, KNN, LR, and SGD, which was equal to 1. Moreover, as for the recall metric, the highest value was noted for BNB and KNN (0.96). For F1-score it was observed that the highest value was that of SGD that was equal to 0.98. Finally, for the specificity metric, it was observed that the highest value was captured for KNN, being equal to 1. Therefore, it is understood that for this case, the most suitable prediction for having a pneumonia or not was the KNN algorithm.
3.3.5. Breast Cancer Use Case
For the breast cancer scenario, in
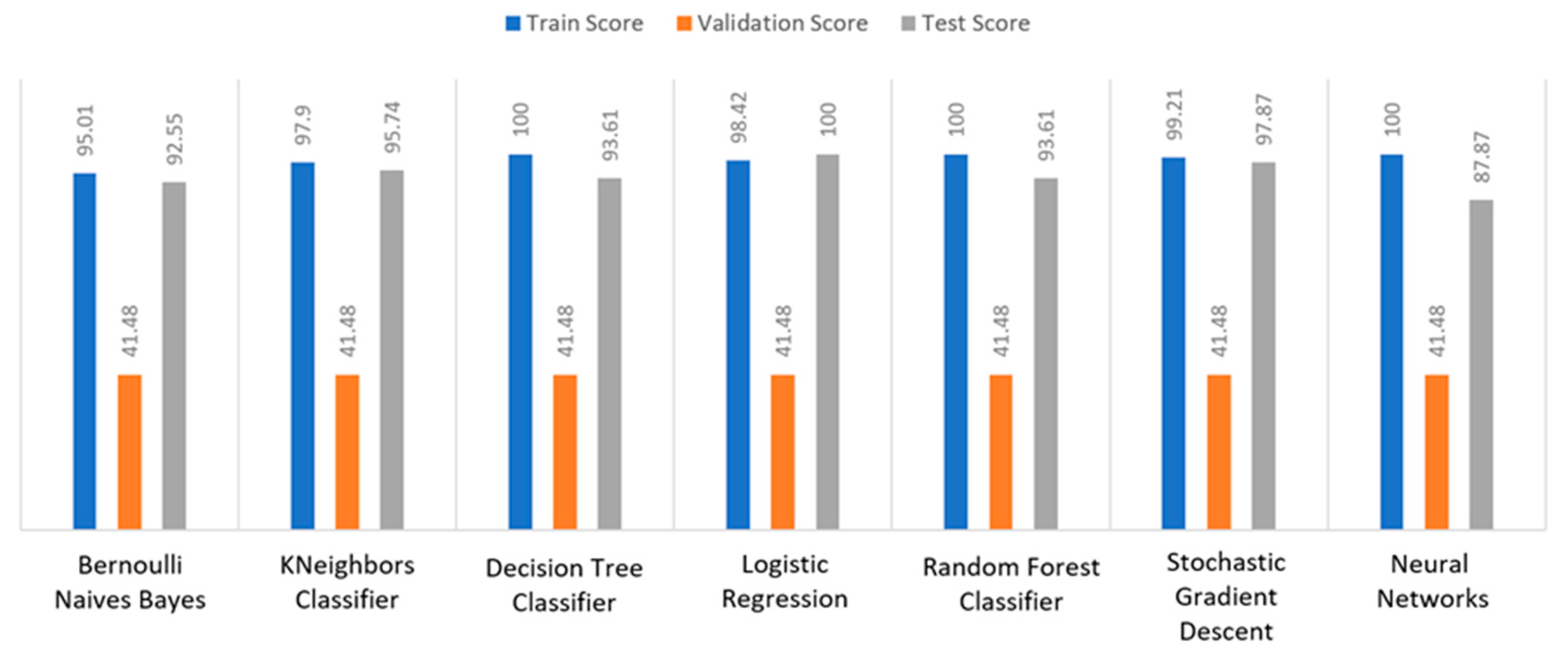
Figure 27 it is illustrated that all the algorithms achieved an almost perfect train score percentage between 95% to 100%. For example, DT, RF and NN had a percentage equal to 100%, while the other algorithms achieved more than 95% (i.e., BNB (95.01%) or KNN (97.9%)). However, regarding the validation score, all the algorithms achieved a low percentage at 41.48%. As for the test score, LR achieved 100% score, whereas the second better algorithm was SGD with 97.87%. In addition, the next better algorithm was KNN with 95.74%. All the other algorithms had scores below 95%. Thus, it appeared that the best algorithm was LR, since the minimum deviation was observed between the training and test metrics.
Figure 28 presents the confusion matrix for the breast cancer dataset, where LR predicted that there was a true probability that benign cancer would be in 62 records (TP), while malignant cancer would be in 32 records (TN). Moreover, the next best two algorithms were SGD and NN, which predicted that 60 records would have benign cancer, while 32 records would have malignant cancer.
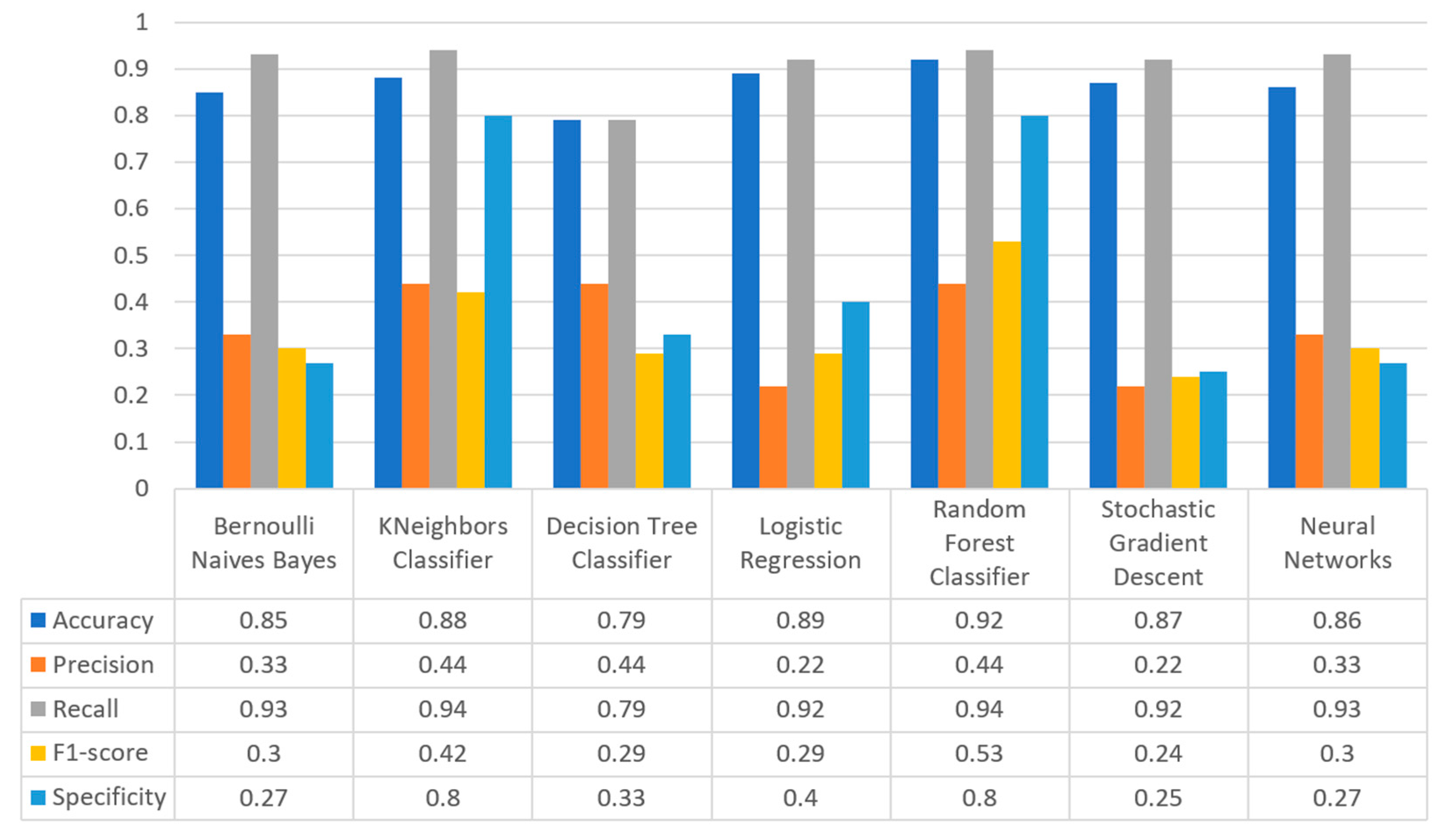
Figure 29 synopsizes the comparison in the captured metrics of accuracy, precision, recall, F1-score, and specificity for the breast cancer case. More specifically, RF produced the best prediction in terms of accuracy (0.92) in comparison with LR (0.89) and KNN (0.88). Moreover, precision’s highest value was noted for RF which was equal to 0.44. As for the recall metric, the highest value was noted for the RF and KNN (0.94), whilst for F1-score it is observed that the highest value was that of algorithm RF, being equal to 0.53. Finally, as for specificity, it was observed that the highest value was noted for RF, being equal to 0.8. Therefore, it is understood that for this case the most suitable algorithm regarding the prediction of whether the patient is likely to have a benign or malignant cancer for the breast cancer was RF.
3.3.6. Kidney Disease Use Case
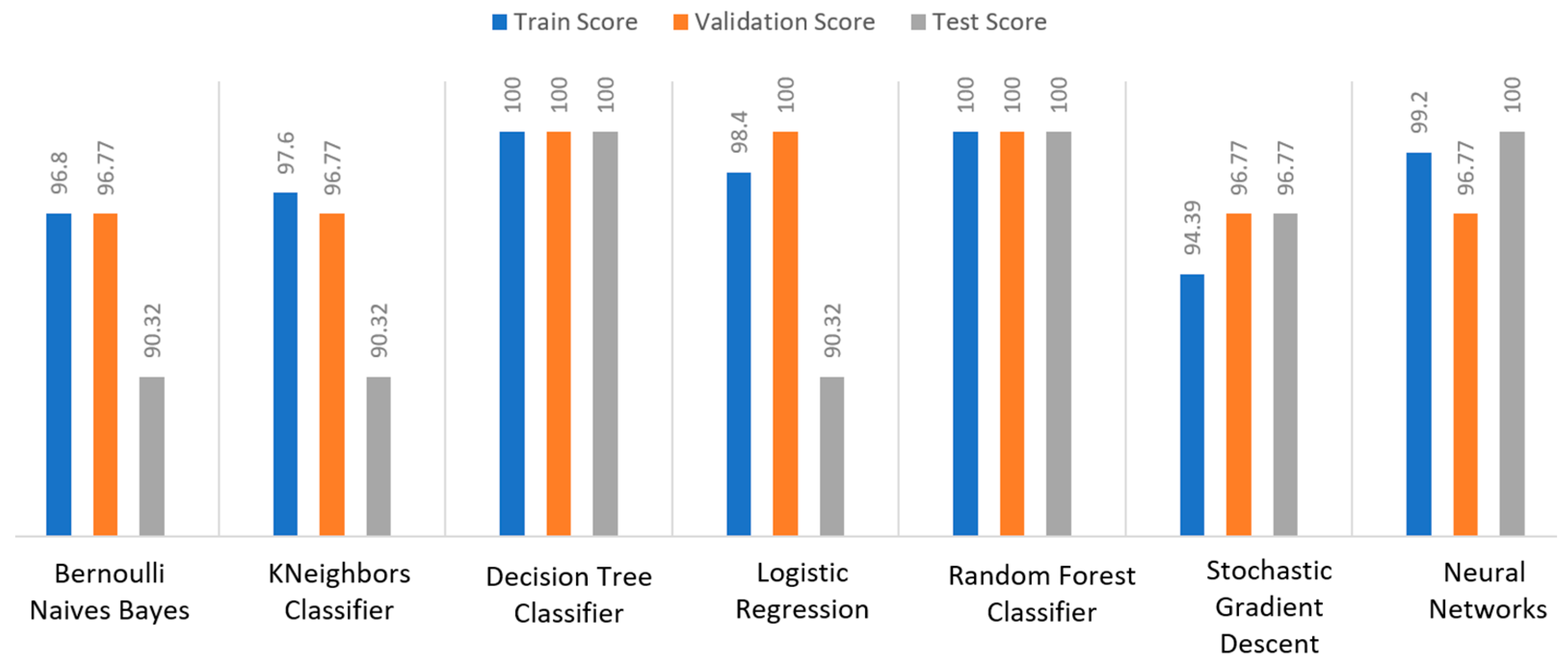
For the kidney disease dataset, as it is depicted in
Figure 30, DT and RF achieved a train score percentage equal to 100%, while NN scored an equally high percentage equal to 99.2%. However, it should be emphasized that the scores of the rest of the algorithms were also quite high (90%). Regarding the validation score, DT, LR, and RF achieved a tremendously high score (100%), whilst the other algorithms achieved quite high scores as well, equal to 96.77%. Regarding the test score metric, DT, RF, and NN achieved an equal score at 100%, whilst the next highest score was that of SGD (96.77%). In conclusion, for the kidney disease dataset, the best algorithms were DT and RF, since all the metrics in all the training, validation, and testing data did not differ from each other, being equal to 100%.
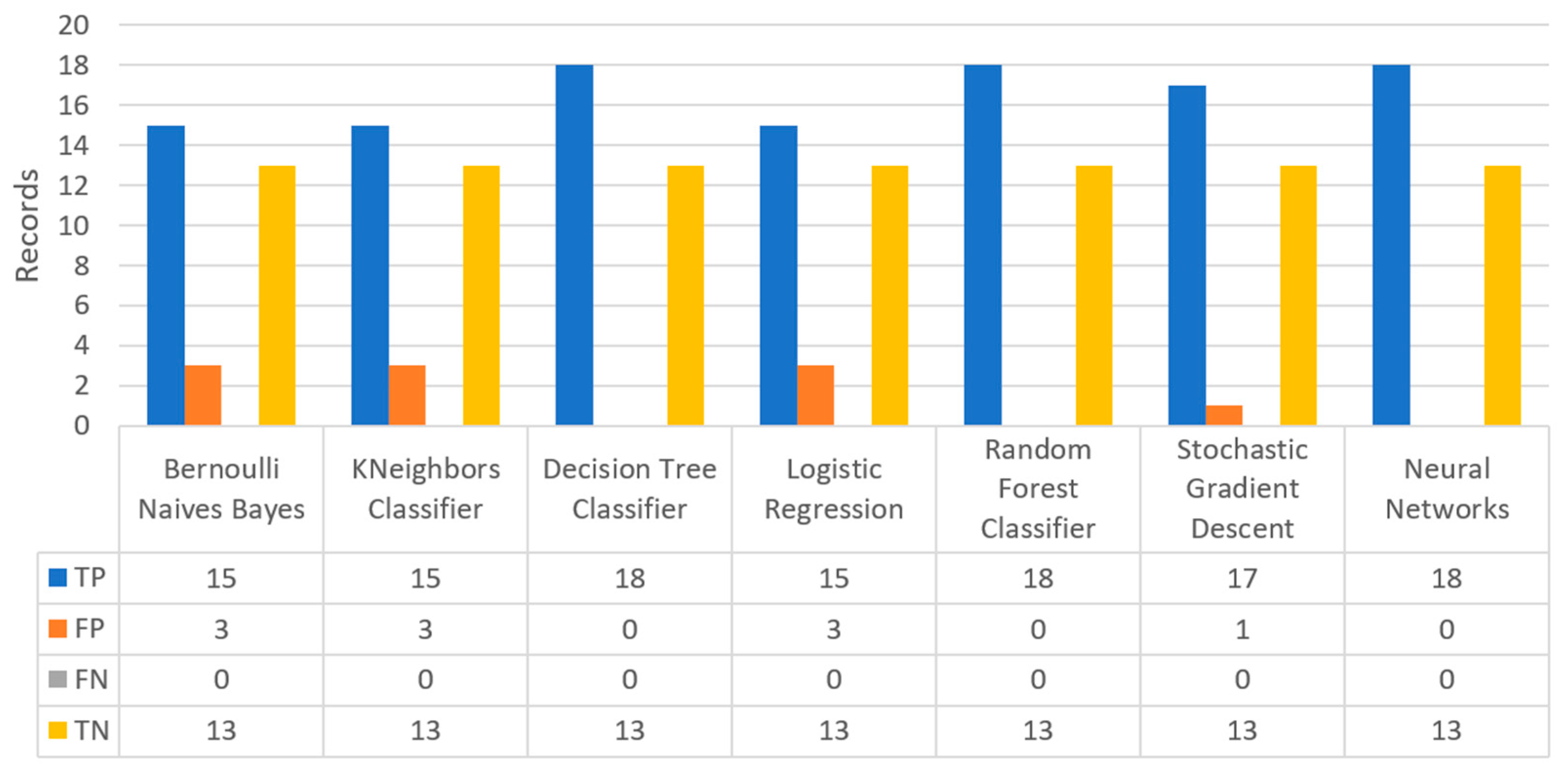
Figure 31 shows the confusion matrix for the kidney disease dataset, where DT, RF and NN predicted that there was a true probability that 18 records would refer to patients with kidney disease (TP), while 13 records would refer to patients with no kidney disease (TN).
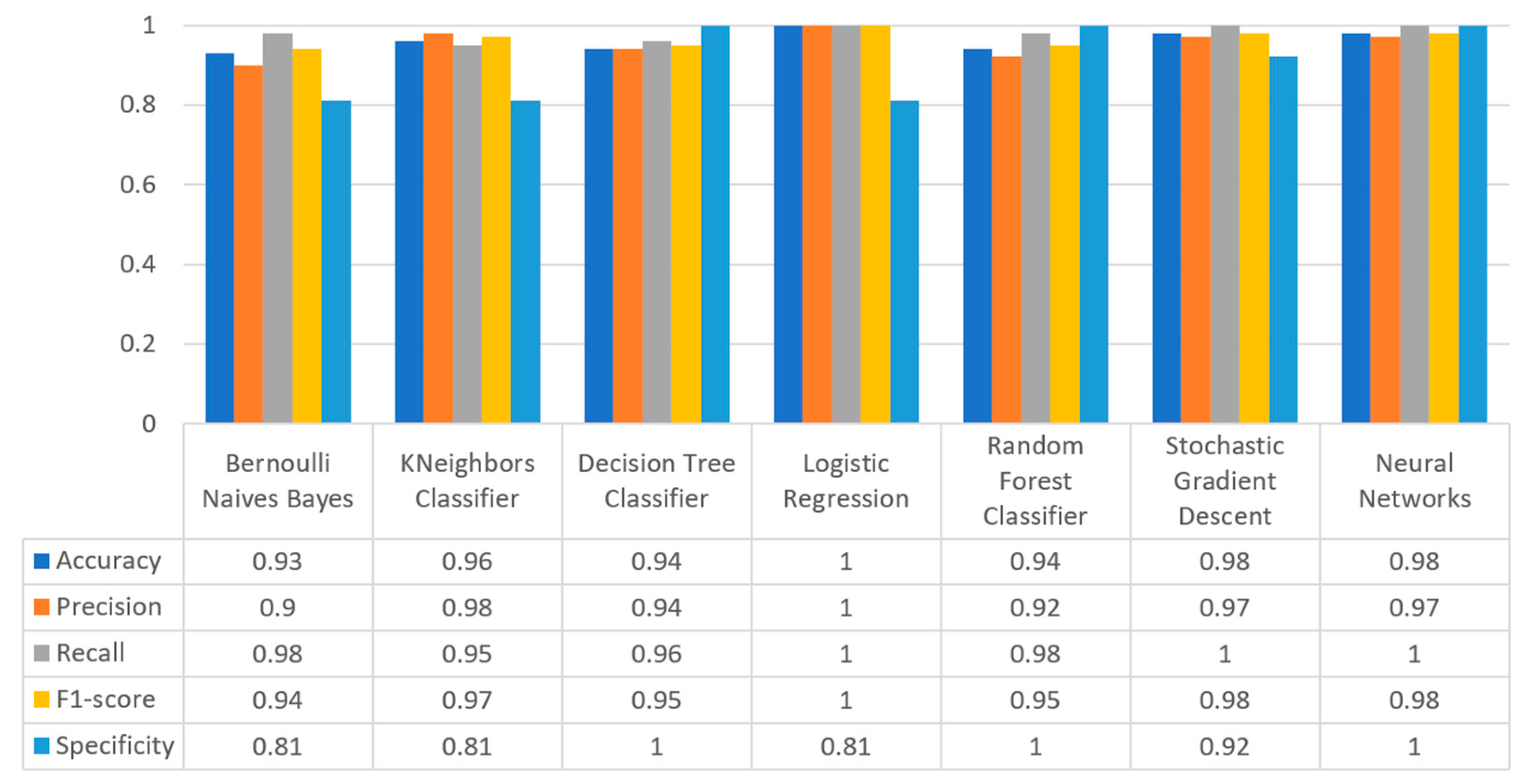
Figure 32 summarizes the comparison for all the captured metrics of the kidney disease case. In deeper detail, LR produced the best prediction in terms of accuracy (1) in comparison with LR (0.93). In addition, precision’s highest value was noted for the algorithm LR, being equal to 1, recall achieved the highest value by the LR, SGD, and NN algorithms (1), whilst F1-score had the highest value by LR, being equal to 1. Finally, regarding the specificity metric, it is observed that the highest value was achieved by the DT, RF, and NN algorithms, being equal to 1. Therefore, it is understood that in this case, the most suitable algorithm regarding the prediction of kidney disease was LR.
3.3.7. Training Performance
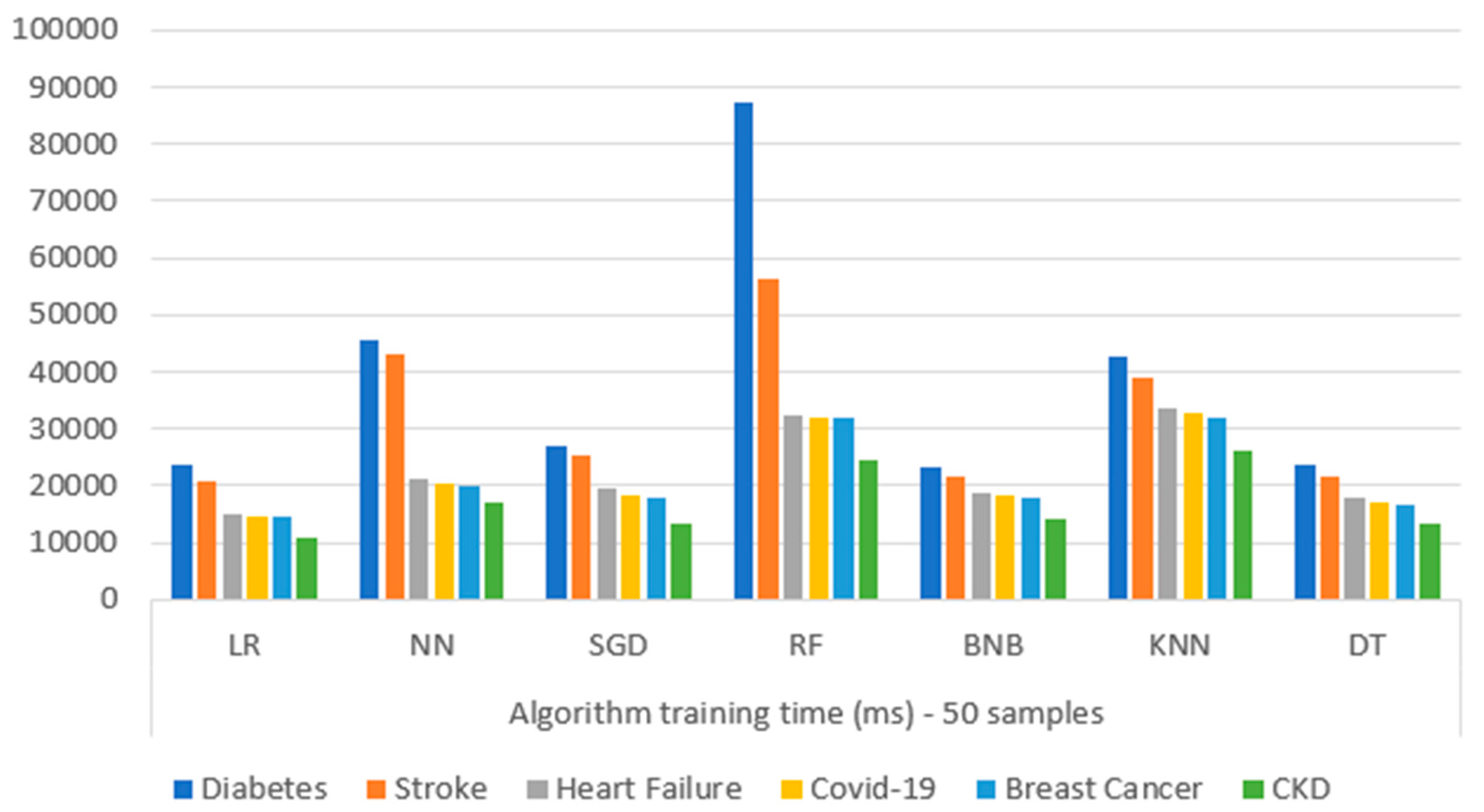
Figure 33 presents the comparison of the training performance time (in milliseconds (ms)) for each ML algorithm upon each different chosen dataset. Specifically, for each dataset, consecutive tests were performed on the Model Training microservice, implementing the different exploited ML algorithms (BNB, KNN, DT, LR, RF, NN, and SGD). Based on the captured results, it is observed that RF was more complex in its training process for the diabetes dataset, while NN followed. In general, it can be seen that the diabetes dataset, due to its high complexity (concerning its large number of features, and huge data volume), revealed the highest training time in every algorithm. As for the rest of the datasets, it can be observed that the training time was a function of data complexity, as expected, where RF took longer to train its model, while NN and KNN followed.

 ,
, 

































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}