
A Joint Resource Allocation, Security with Efficient Task Scheduling in Cloud Computing Using Hybrid Machine Learning Techniques


 , , and
, , and
Abstract
:1. Introduction
- In order to manage resource crunches in the cloud environment, we proposed scheduling user tasks by employing the advanced Cat optimization algorithm.
- The proposed resource allocation and security with efficient computer operational planning use hybrid machine learning to optimize the task.
- ICS-TS is introduced to improve passive resources by partitioning the cloud environment into the workspace and state space. GO-DNN based resource management further reduces resource usage in a large-scale cloud environment, with multiple servers receiving multiple requests per day from users.
- On successfully completing the system, an in-depth neural network based on optimization is implemented, setting tasks on appropriate virtual machines. Consequently, the source forecast and reset forecast measures virtual machine processors, memory, and I/O usage.
2. Related Work
3. Problem Formulation and Network Model
3.1. Research Gap
3.2. Research Objectives
- To design and develop dynamic resource allocation and task scheduling process
- To minimize the expected total makespan and maximize throughput through optimal scheduling.
3.3. Network Model
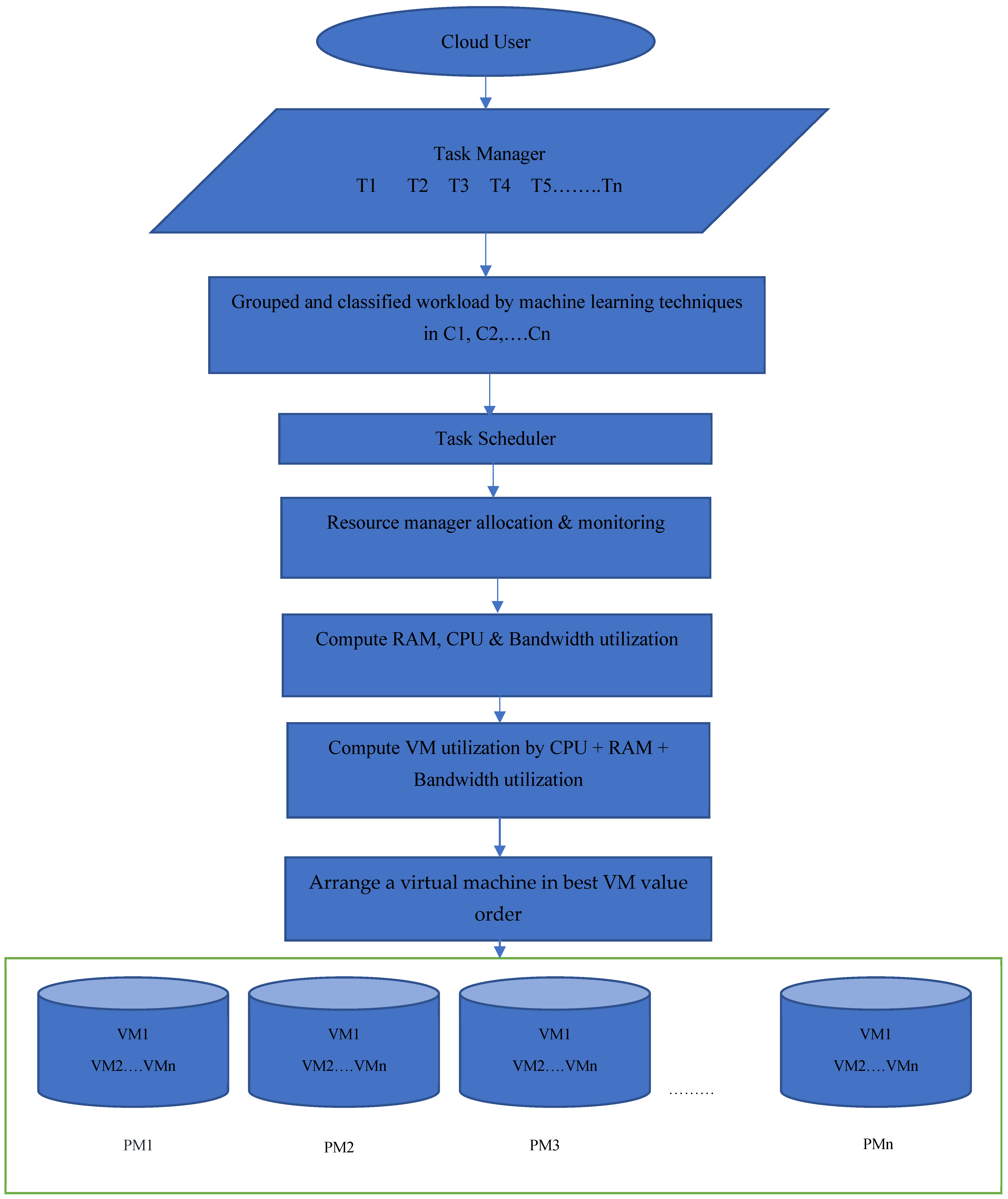
4. Proposed OEQRM Scheme
4.1. Task Scheduling with ICS-TS Algorithm
- ecological and physiological environments,
- genetic potentiality,
- the social conditions of the colony, as well as various earlier and ongoing interactions between these three parameters.
| Algorithm 1 ICS-TS algorithm | |
| Input: | Din, Ur, Tt, BW |
| Output: | Multiple Service Providers To Optimize Scheduling |
| |
| Return: Multiple Service Providers To Optimize Scheduling | |
4.2. Resource Allocation Using GO-DNN
| Algorithm 2 Multi-objective Rule Set | |
| Input: | d, N, Nc, Ns, Nre, Ned, Ped, S (i) |
| Output: | Optimal Resource utilization |
| |
| Return: Optimized Resource Utilization | |
4.3. Data Encryption Using Lightweight Scheme
4.3.1. Initial Transformation
4.3.2. Final Transformation
5. Results and Discussion
5.1. Performance Metrics
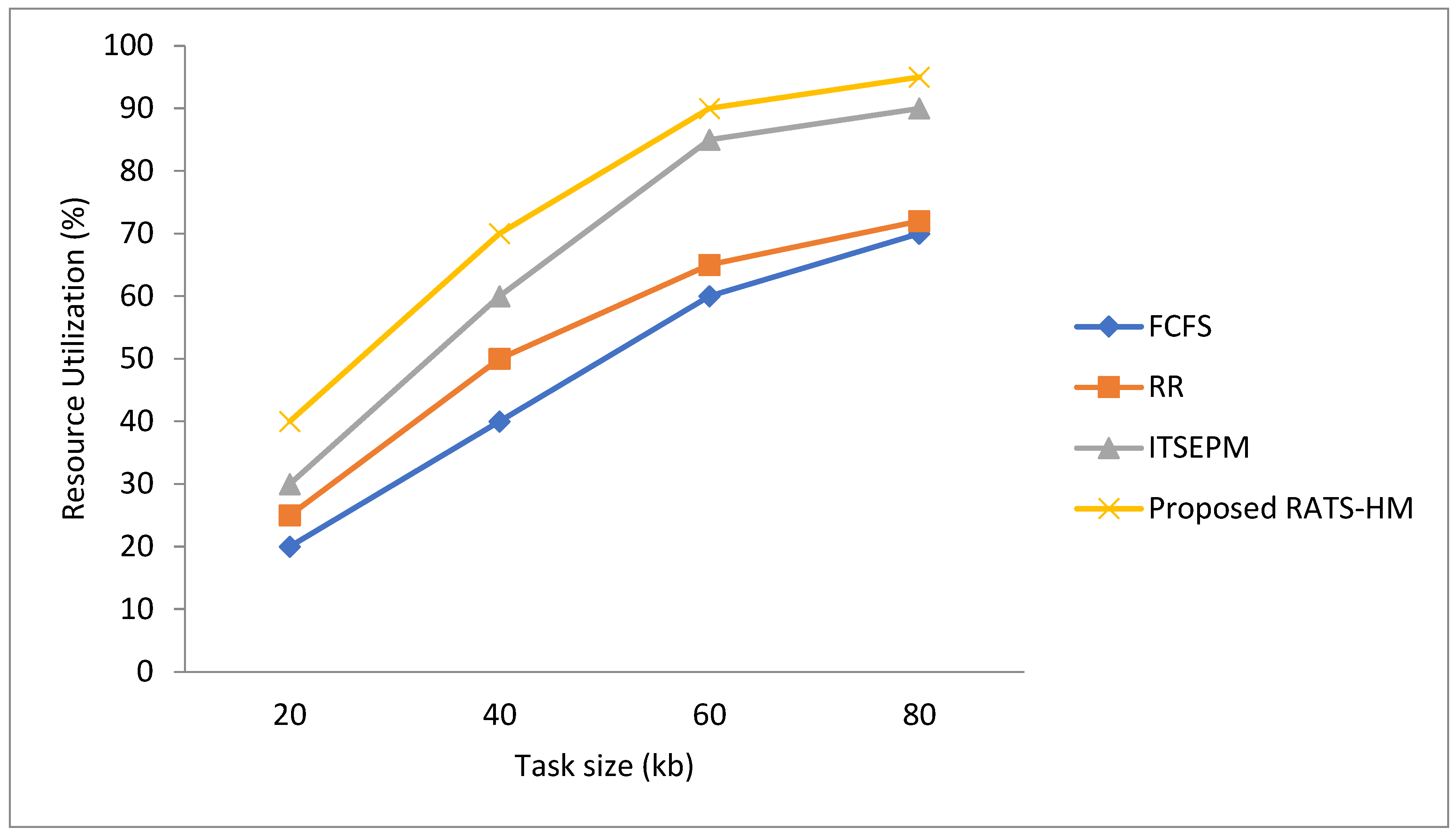
5.1.1. Evaluation of Resource Utilization
5.1.2. Evaluation of Response Time
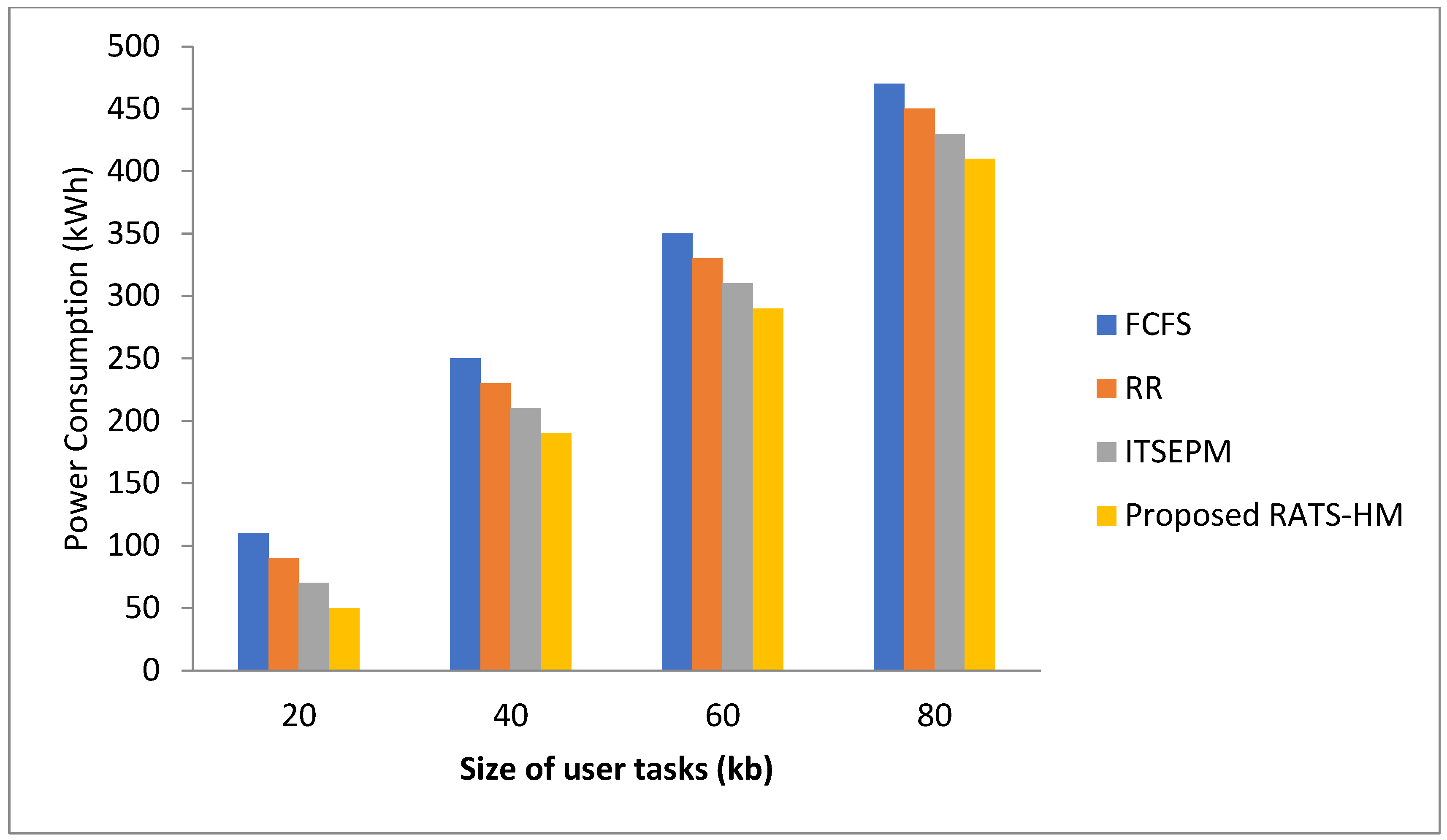
5.1.3. Evaluation of Power Consumption
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Papagianni, C.; Leivadeas, A.; Papavassiliou, S.; Maglaris, V.; Cervello-Pastor, C.; Monje, A. On the optimal allo-cation of virtual resources in cloud computing networks. IEEE Trans. Comput. 2013, 62, 1060–1071. [Google Scholar] [CrossRef]
- Kaewpuang, R.; Niyato, D.; Wang, P.; Hossain, E. A Framework for Cooperative Resource Management in Mobile Cloud Computing. IEEE J. Sel. Areas Commun. 2013, 31, 2685–2700. [Google Scholar] [CrossRef]
- Xiao, Z.; Song, W.; Chen, Q. Dynamic resource allocation using virtual machines for cloud computing environ-ment. IEEE Trans. Parallel Distrib. Syst. 2012, 24, 1107–1117. [Google Scholar] [CrossRef]
- Warneke, D.; Kao, O. Exploiting Dynamic Resource Allocation for Efficient Parallel Data Processing in the Cloud. IEEE Trans. Parallel Distrib. Syst. 2011, 22, 985–997. [Google Scholar] [CrossRef] [Green Version]
- Son, S.; Jung, G.; Jun, S.C. An SLA-based cloud computing that facilitates resource allocation in the distributed data centers of a cloud provider. J. Supercomput. 2013, 64, 606–637. [Google Scholar] [CrossRef]
- Wei, G.; Vasilakos, A.V.; Zheng, Y.; Xiong, N. A game-theoretic method of fair resource allocation for cloud com-puting services. J. Supercomput. 2010, 54, 252–269. [Google Scholar] [CrossRef]
- Laili, Y.; Tao, F.; Zhang, L.; Sarker, B.R. A study of optimal allocation of computing resources in cloud manufacturing systems. Int. J. Adv. Manuf. Technol. 2012, 63, 671–690. [Google Scholar] [CrossRef]
- Buyya, R.; Yeo, C.S.; Venugopal, S.; Broberg, J.; Brandic, I. Cloud computing and emerging IT platforms: Vision, hype, and reality for delivering computing as the 5th utility. Futur. Gener. Comput. Syst. 2009, 25, 599–616. [Google Scholar] [CrossRef]
- Almeida, J.; Almeida, V.; Ardagna, D.; Cunha, Í.; Francalanci, C.; Trubian, M. Joint admission control and resource allocation in virtualized servers. J. Parallel Distrib. Comput. 2010, 70, 344–362. [Google Scholar] [CrossRef]
- Beloglazov, A.; Abawajy, J.; Buyya, R. Energy-aware resource allocation heuristics for efficient management of data centers for Cloud computing. Futur. Gener. Comput. Syst. 2012, 28, 755–768. [Google Scholar] [CrossRef] [Green Version]
- Nathani, A.; Chaudhary, S.; Somani, G. Policy based resource allocation in IaaS cloud. Futur. Gener. Comput. Syst. 2012, 28, 94–103. [Google Scholar] [CrossRef]
- Lin, C. A Novel College Network Resource Management Method using Cloud Computing. Phys. Procedia 2012, 24, 2293–2297. [Google Scholar] [CrossRef] [Green Version]
- Mei, H.; Wang, K.; Yang, K. Multi-Layer Cloud-RAN With Cooperative Resource Allocations for Low-Latency Computing and Communication Services. IEEE Access 2017, 5, 19023–19032. [Google Scholar] [CrossRef]
- Salhaoui, M.; Guerrero-González, A.; Arioua, M.; Ortiz, F.J.; El Oualkadi, A.; Torregrosa, C.L. Smart industrial iot monitoring and control system based on UAV and cloud computing applied to a concrete plant. Sensors 2019, 19, 3316. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Khasnabish, J.N.; Mithani, M.F.; Rao, S. Tier-Centric Resource Allocation in Multi-Tier Cloud Systems. IEEE Trans. Cloud Comput. 2015, 5, 576–589. [Google Scholar] [CrossRef]
- Bal, P.K.; Pradhan, S.K. Privacy Preserving Secure Data Storage scheme based on Adaptive ANN and Homomorphic Re-Encryption Algorithm for Cloud. In Proceedings of the 2019 International Conference on Intelligent Computing and Remote Sensing (ICICRS), Bhubaneswar, India, 19–20 July 2019. [Google Scholar]
- Oláh J, J.; Aburumman, N.; Popp, J.; Khan, M.A.; Haddad, H.; Kitukutha, N. Impact of Industry 4.0 on environmental sustainability. Sustainability 2020, 12, 4674. [Google Scholar] [CrossRef]
- Bal, P.K.; Pradhan, S.K. Multi-level authentication-based secure aware data transaction on cloud using cyclic shift transposition algorithm. In Advances in Intelligent Computing and Communication; Springer: Singapore, 2020. [Google Scholar]
- Das, T.K.; Tripathy, A.K.; Srinivasan, K. A Smart Trolley for Smart Shopping. In Proceedings of the 2020 International Conference on System, Computation, Automation and Networking (ICSCAN), Pondicherry, India, 3–4 July 2020. [Google Scholar]
- Tafsiri, S.A.; Yousefi, S. Combinatorial double auction-based resource allocation mechanism in cloud computing market. J. Syst. Softw. 2018, 137, 322–334. [Google Scholar] [CrossRef]
- Wei, W.; Fan, X.; Song, H.; Fan, X.; Yang, J. Imperfect information dynamic stackelberg game based resource allo-cation using hidden Markov for cloud computing. IEEE Trans. Serv. Comput. 2016, 11, 78–89. [Google Scholar] [CrossRef]
- Tang, S.; Lee, B.-S.; He, B. Fair Resource Allocation for Data-Intensive Computing in the Cloud. IEEE Trans. Serv. Comput. 2016, 11, 20–33. [Google Scholar] [CrossRef]
- Zhang, J.; Xie, N.; Zhang, X.; Li, W. An online auction mechanism for cloud computing resource allocation and pricing based on user evaluation and cost. Futur. Gener. Comput. Syst. 2018, 89, 286–299. [Google Scholar] [CrossRef]
- Jiang, H.-P.; Chen, W.-M. Self-adaptive resource allocation for energy-aware virtual machine placement in dynamic computing cloud. J. Netw. Comput. Appl. 2018, 120, 119–129. [Google Scholar] [CrossRef]
- Gong, S.; Yin, B.; Zheng, Z.; Cai, K.-Y. Adaptive Multivariable Control for Multiple Resource Allocation of Service-Based Systems in Cloud Computing. IEEE Access 2019, 7, 13817–13831. [Google Scholar] [CrossRef]
- Wu, X.; Wang, H.; Wei, D.; Shi, M. ANFIS with natural language processing and gray relational analysis based cloud computing framework for real time energy efficient resource allocation. Comput. Commun. 2019, 150, 122–130. [Google Scholar] [CrossRef]
- Zhao, J.; Li, Q.; Gong, Y.; Zhang, K. Computation Offloading and Resource Allocation For Cloud Assisted Mobile Edge Computing in Vehicular Networks. IEEE Trans. Veh. Technol. 2019, 68, 7944–7956. [Google Scholar] [CrossRef]
- Abbasi, M.; Yaghoobikia, M.; Rafiee, M.; Jolfaei, A.; Khosravi, M.R. Efficient resource management and workload allocation in fog–cloud computing paradigm in IoT using learning classifier systems. Comput. Commun. 2020, 153, 217–228. [Google Scholar] [CrossRef]
- Reis, T.; Teixeira, M.; Almeida, J.; Paiva, A. A Recommender for Resource Allocation in Compute Clouds Using Genetic Algorithms and SVR. IEEE Lat. Am. Trans. 2020, 18, 1049–1056. [Google Scholar] [CrossRef]
- Zhang, Q.; Gui, L.; Hou, F.; Chen, J.; Zhu, S.; Tian, F. Dynamic Task Offloading and Resource Allocation for Mo-bile-Edge Computing in Dense Cloud RAN. IEEE Internet Things J. 2020, 7, 3282–3299. [Google Scholar] [CrossRef]
- Praveenchandar, J.; Tamilarasi, A. Dynamic resource allocation with optimized task scheduling and improved power management in cloud computing. J. Ambient. Intell. Humaniz. Comput. 2021, 12, 4147–4159. [Google Scholar] [CrossRef]
- Christos, L.; Stergiou, K.; Psannis, E.; Gupta, B.B. IoT-based Big Data secure management in the Fog over a 6G Wireless Network. IEEE Internet Things J. 2021, 8, 5164–5171. [Google Scholar]
- Stergiou, C.L.; Psannis, K.E.; Gupta, B.B. InFeMo: Flexible Big Data Management Through a Federated Cloud System. ACM Trans. Internet Technol. 2022, 22, 1–22. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
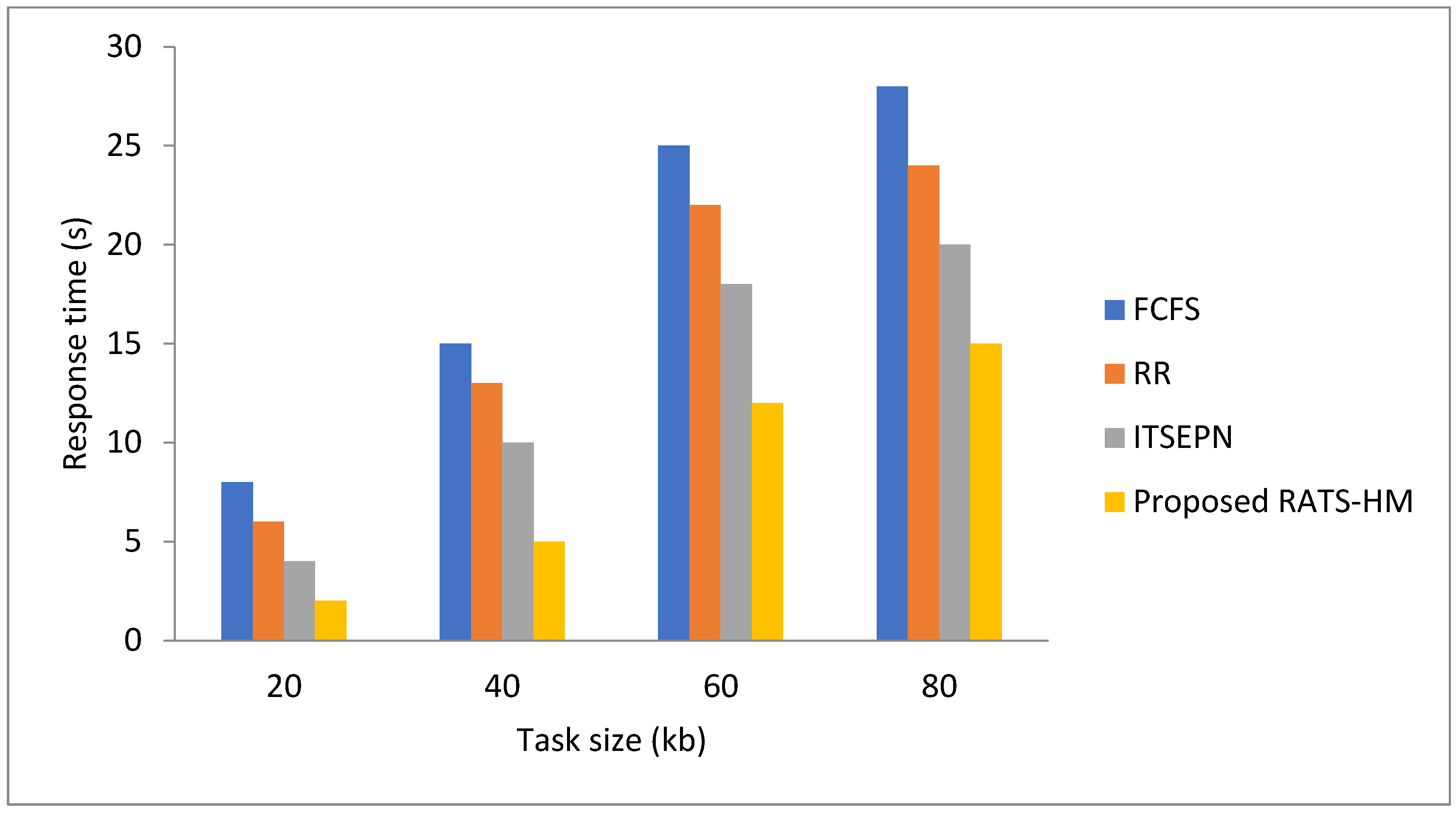{kind=link}
{kind=link}
| Citation | Author | Title | Propose Solutions | Environment | Open Issue |
|---|---|---|---|---|---|
| [21] | Wei et al. | Imperfect information dynamic Stackelberg game based resource allocation using hidden Markov for cloud computing | The assessed cost of CSAMIISG is near the genuine exchange cost and the exchange cost is not exactly the real exchange esteem | Huawei | Application framework and change settings to make it more effective |
| [22] | Tang et al. | Fair resource allocation for data-intensive computing in the cloud | The technique offers various leveled long haul asset reasonableness (H-LTRF) with the option of the LTRF expansion to add progressive sources, for example, the LTRF and H-LTRF. | Amazon EC2 | LTYARN open source at |
| http://sourceforge.net/projects/ltyarn/ (accessed on 22 August 2021) | |||||
| [23] | Zhang et al. | An online auction mechanism for cloud computing resource | The author proposes the online virtual resource allocation and payment (OVRAP) algorithm | IBM CPLEX12 | C++ is used for algorithm implementation |
| allocation and pricing based on user evaluation and cost | |||||
| [24] | Jiang et al. | Self-adaptive resource allocation for energy-aware virtual machine placement in a dynamic computing cloud | proposed method first groups the servers with a shorter path length using the given DCN topology | Google cluster trace | Lacks a large amount of practical data |
| [26] | Wu et al. | ANFIS with natural language processing and gray relational analysis based cloud computing framework for real-time energy-efficient resource allocation | proposed aANFIS model solves the dynamical prediction problem of VM workload by training the values of feature attributes | Malleable Network System Simulator | Lacks a large amount of practical data |
| Required | Component Specification |
|---|---|
| Processor | Intel® Pentium® CPU G2030 @ 3.00 GHZ |
| Operating System | Windows (X86 ultimate) 64-bit OS |
| Hard Disk | 1 TB |
| RAM | 4 GB |
| System | 64 Bit OS System |
| Component | Specification | Values |
|---|---|---|
| Cloudlets | Length of task No of tasks | 1600–3400 30–300 |
| Virtual Machine | Host | 4 |
| Physical Machine | Memory Bandwidth Storage | 540 25,00,00 500 GB |
| Offline | Execution Time |
|---|---|
| Workload prediction online | 10 min |
| Task monitoring and scheduling | 20 min |
| Connection to agents | 0.050 s |
| Power management | 2.015 s |
| Response to users | 0.010 s |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bal, P.K.; Mohapatra, S.K.; Das, T.K.; Srinivasan, K.; Hu, Y.-C. A Joint Resource Allocation, Security with Efficient Task Scheduling in Cloud Computing Using Hybrid Machine Learning Techniques. Sensors 2022, 22, 1242. https://0-doi-org.brum.beds.ac.uk/10.3390/s22031242
Bal PK, Mohapatra SK, Das TK, Srinivasan K, Hu Y-C. A Joint Resource Allocation, Security with Efficient Task Scheduling in Cloud Computing Using Hybrid Machine Learning Techniques. Sensors. 2022; 22(3):1242. https://0-doi-org.brum.beds.ac.uk/10.3390/s22031242
Chicago/Turabian StyleBal, Prasanta Kumar, Sudhir Kumar Mohapatra, Tapan Kumar Das, Kathiravan Srinivasan, and Yuh-Chung Hu. 2022. "A Joint Resource Allocation, Security with Efficient Task Scheduling in Cloud Computing Using Hybrid Machine Learning Techniques" Sensors 22, no. 3: 1242. https://0-doi-org.brum.beds.ac.uk/10.3390/s22031242