
A Framework for the Optimization of Complex Cyber-Physical Systems via Directed Acyclic Graph

 , , , and
, , , and {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Data Leakage in ML Experiments
3. Library Design
3.1. Project Management
3.2. Implementation Details
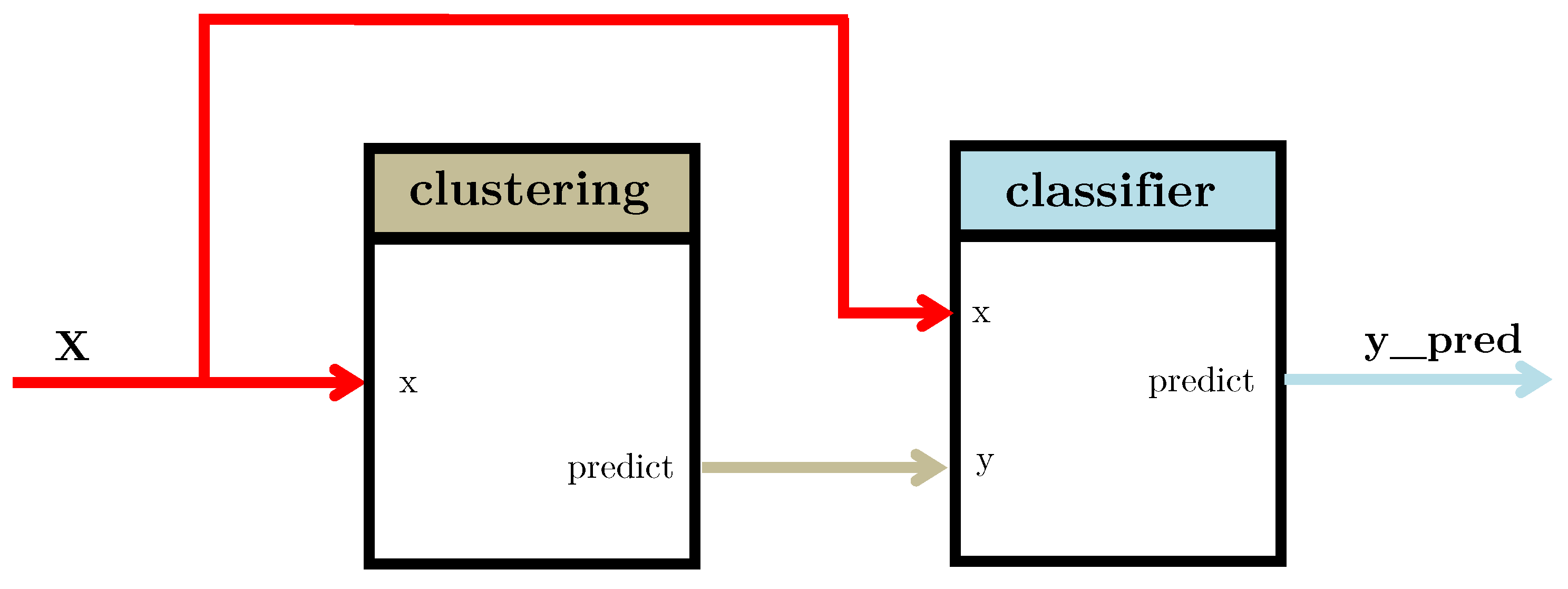
3.3. Example
- scaler: A scikit-learn MinMaxScaler data preprocessor in charge of scaling the dataset.
- classifier: A scikit-learn GaussianMixture classifier in charge of performing the clustering of the dataset and the classification of any new sample.
- demux: A custom Demultiplexer class in charge of splitting the input arrays accordingly to the selection input vector. This block is provided by PipeGraph.
- lm_0, lm_1, lm_2: A set of scikit-learn LinearRegression objects
- mux: A custom Multiplexer class in charge of combining different input arrays into a single one accordingly to the selection input vector. This block is provided by PipeGraph.
3.4. Implemented Methods
- inject(sink, sink_var, source, source_var) Defines a connection between two nodes of the graph declaring which variable (source_var) from the origin node (source) is passed to the destination node (sink) with new variable name sink_name).
- decision_function(X) Applies PipeGraphClasifier’s predict method and returns the decision_function output of the final estimator.
- fit(X, y=None, fit_params) Fits the PipeGraph steps one after the other and following the topological order of the graph defined by the connections attribute.
- fit_predict(X, y=None, fit_params) Applies predict of a PipeGraph to the data following the topological order of the graph, followed by the fit_predict method of the final step in the PipeGraph. Valid only if the final step implements fit_predict.
- get_params(deep=True) Gets parameters for an estimator.
- predict(X) Predicts the PipeGraph steps one after the other and following the topological order defined by the alternative_connections attribute, in case it is not None, or the connections attribute otherwise.
- predict_log_proba(X) Applies PipeGraphRegressor’s predict method and returns the predict_log_proba output of the final estimator.
- predict_proba(X) Applies PipeGraphClassifier’s predict method and returns the predict_proba output of the final estimator.
- score(X, y=None, sample_weight=None) Applies PipeGraphRegressor’s predict method and returns the score output of the final estimator.
- set_params(kwargs) Sets the parameters of this estimator. Valid parameter keys can be listed with get_params().
4. Case Studies
4.1. Anomaly Detection in Manufacturing Processes
4.2. Heat Exchanger Modeling
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
| Listing A1. Example code for the PipeGraph shown in Figure 2. |
|
References
- Lee, J.; Bagheri, B.; Kao, H.A. A Cyber-Physical Systems architecture for Industry 4.0-based manufacturing systems. Manuf. Lett. 2015, 3, 18–23. [Google Scholar] [CrossRef]
- Pereira, A.; Romero, F. A review of the meanings and the implications of the Industry 4.0 concept. Procedia Manuf. 2017, 13, 1206–1214. [Google Scholar] [CrossRef]
- Nawanir, G.; Lim, K.T.; Othman, S.N.; Adeleke, A.Q. Developing and validating lean manufacturing constructs: An SEM approach. Benchmark. Int. J. 2018, 25, 1382–1405. [Google Scholar] [CrossRef]
- Antony, J.; Psomas, E.; Garza-Reyes, J.A.; Hines, P. Practical implications and future research agenda of lean manufacturing: A systematic literature review. Prod. Plan. Control 2021, 32, 889–925. [Google Scholar] [CrossRef]
- Ghobadian, A.; Talavera, I.; Bhattacharya, A.; Kumar, V.; Garza-Reyes, J.A.; O’Regan, N. Examining legitimatisation of additive manufacturing in the interplay between innovation, lean manufacturing and sustainability. Int. J. Prod. Econ. 2020, 219, 457–468. [Google Scholar] [CrossRef]
- Maware, C.; Okwu, M.O.; Adetunji, O. A systematic literature review of lean manufacturing implementation in manufacturing-based sectors of the developing and developed countries. Int. J. Lean Six Sigma 2021. ahead-of-print. [Google Scholar] [CrossRef]
- Psomas, E. Future research methodologies of lean manufacturing: A systematic literature review. Int. J. Lean Six Sigma 2021, 12, 1146–1183. [Google Scholar] [CrossRef]
- Azadeh, A.; Yazdanparast, R.; Zadeh, S.A.; Zadeh, A.E. Performance optimization of integrated resilience engineering and lean production principles. Expert Syst. Appl. 2017, 84, 155–170. [Google Scholar] [CrossRef] [Green Version]
- Kravets, A.G.; Bolshakov, A.A.; Shcherbakov, M.V. (Eds.) Cyber-Physical Systems: Advances in Design & Modelling; Springer International Publishing: Cham, Switzerland, 2020; Volume 259. [Google Scholar] [CrossRef]
- Kirchhof, J.C.; Michael, J.; Rumpe, B.; Varga, S.; Wortmann, A. Model-Driven Digital Twin Construction: Synthesizing the Integration of Cyber-Physical Systems with Their Information Systems. In Proceedings of the 23rd ACM/IEEE International Conference on Model Driven Engineering Languages and Systems, MODELS ’20, Virtual, 16–23 October 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 90–101. [Google Scholar] [CrossRef]
- Wang, T.; Wang, X.; Ma, R.; Li, X.; Hu, X.; Chan, F.T.S.; Ruan, J. Random Forest-Bayesian Optimization for Product Quality Prediction With Large-Scale Dimensions in Process Industrial Cyber–Physical Systems. IEEE Internet Things J. 2020, 7, 8641–8653. [Google Scholar] [CrossRef]
- Banerjee, S.; Balas, V.E.; Pandey, A.; Bouzefrane, S. Towards Intelligent Optimization of Design Strategies of Cyber-Physical Systems: Measuring Efficacy through Evolutionary Computations. In Computational Intelligence in Emerging Technologies for Engineering Applications; Springer International Publishing: Cham, Switzerland, 2020; pp. 73–101. [Google Scholar] [CrossRef]
- Tran, H.D.; Yang, X.; Manzanas Lopez, D.; Musau, P.; Nguyen, L.V.; Xiang, W.; Bak, S.; Johnson, T.T. NNV: The Neural Network Verification Tool for Deep Neural Networks and Learning-Enabled Cyber-Physical Systems. In Computer Aided Verification; Lahiri, S.K., Wang, C., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 3–17. [Google Scholar]
- Portugal, I.; Alencar, P.; Cowan, D. The use of machine learning algorithms in recommender systems: A systematic review. Expert Syst. Appl. 2018, 97, 205–227. [Google Scholar] [CrossRef] [Green Version]
- Bischl, B.; Lang, M.; Kotthoff, L.; Schiffner, J.; Richter, J.; Studerus, E.; Casalicchio, G.; Jones, Z.M. mlr: Machine Learning in R. J. Mach. Learn. Res. 2016, 17, 5938–5942. [Google Scholar]
- Meng, X.; Bradley, J.; Yavuz, B.; Sparks, E.; Venkataraman, S.; Liu, D.; Freeman, J.; Tsai, D.; Amde, M.; Owen, S.; et al. MLlib: Machine Learning in Apache Spark. J. Mach. Learn. Res. 2016, 17, 1–7. [Google Scholar]
- Heaton, J. Encog: Library of Interchangeable Machine Learning Models for Java and C#. J. Mach. Learn. Res. 2015, 16, 1243–1247. [Google Scholar]
- Curtin, R.R.; Cline, J.R.; Slagle, N.P.; March, W.B.; Ram, P.; Mehta, N.A.; Gray, A.G. mlpack: A Scalable C++ Machine Learning Library. J. Mach. Learn. Res. 2013, 14, 801–805. [Google Scholar]
- King, D.E. Dlib-ml: A Machine Learning Toolkit. J. Mach. Learn. Res. 2009, 10, 1755–1758. [Google Scholar]
- Hall, M.; Frank, E.; Holmes, G.; Pfahringer, B.; Reutemann, P.; Witten, I.H. The WEKA Data Mining Software: An Update. SIGKDD Explor. Newsl. 2009, 11, 10–18. [Google Scholar] [CrossRef]
- Abeel, T.; Van de Peer, Y.; Saeys, Y. Java-ML: A Machine Learning Library. J. Mach. Learn. Res. 2009, 10, 931–934. [Google Scholar]
- Jing, R.; Sun, J.; Wang, Y.; Li, M.; Pu, X. PML: A parallel machine learning toolbox for data classification and regression. Chemom. Intell. Lab. Syst. 2014, 138, 1–6. [Google Scholar] [CrossRef]
- Lauer, F. MLweb: A toolkit for machine learning on the web. Neurocomputing 2018, 282, 74–77. [Google Scholar] [CrossRef] [Green Version]
- Gashler, M. Waffles: A Machine Learning Toolkit. J. Mach. Learn. Res. 2011, 12, 2383–2387. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Munappy, A.R.; Mattos, D.I.; Bosch, J.; Olsson, H.H.; Dakkak, A. From Ad-Hoc Data Analytics to DataOps. In Proceedings of the International Conference on Software and System Processes, ICSSP ’20, Seoul, Korea, 26–28 June 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 165–174. [Google Scholar] [CrossRef]
- Ntalampiras, S.; Potamitis, I. A Concept Drift-Aware DAG-Based Classification Scheme for Acoustic Monitoring of Farms. Int. J. Embed. Real Time Commun. Syst. 2020, 11, 62–75. [Google Scholar] [CrossRef]
- Géron, A. Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems, 2nd ed.; O’Reilly Media: Sebastopol, CA, USA, 2019. [Google Scholar]
- Sánchez-González, L.; Riego, V.; Castejón-Limas, M.; Fernández-Robles, L. Local Binary Pattern Features to Detect Anomalies in Machined Workpiece. In Hybrid Artificial Intelligent Systems; de la Cal, E.A., Villar Flecha, J.R., Quintián, H., Corchado, E., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 665–673. [Google Scholar]
- Aláiz-Moretón, H.; Castejón-Limas, M.; Casteleiro-Roca, J.L.; Jove, E.; Fernández Robles, L.; Calvo-Rolle, J.L. A Fault Detection System for a Geothermal Heat Exchanger Sensor Based on Intelligent Techniques. Sensors 2019, 19, 2740. [Google Scholar] [CrossRef] [Green Version]





Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Castejón-Limas, M.; Fernández-Robles, L.; Alaiz-Moretón, H.; Cifuentes-Rodriguez, J.; Fernández-Llamas, C. A Framework for the Optimization of Complex Cyber-Physical Systems via Directed Acyclic Graph. Sensors 2022, 22, 1490. https://0-doi-org.brum.beds.ac.uk/10.3390/s22041490
Castejón-Limas M, Fernández-Robles L, Alaiz-Moretón H, Cifuentes-Rodriguez J, Fernández-Llamas C. A Framework for the Optimization of Complex Cyber-Physical Systems via Directed Acyclic Graph. Sensors. 2022; 22(4):1490. https://0-doi-org.brum.beds.ac.uk/10.3390/s22041490
Chicago/Turabian StyleCastejón-Limas, Manuel, Laura Fernández-Robles, Héctor Alaiz-Moretón, Jaime Cifuentes-Rodriguez, and Camino Fernández-Llamas. 2022. "A Framework for the Optimization of Complex Cyber-Physical Systems via Directed Acyclic Graph" Sensors 22, no. 4: 1490. https://0-doi-org.brum.beds.ac.uk/10.3390/s22041490