
Small-Scale Urban Object Anomaly Detection Using Convolutional Neural Networks with Probability Estimation

 , , and
, , and
Abstract
:1. Introduction
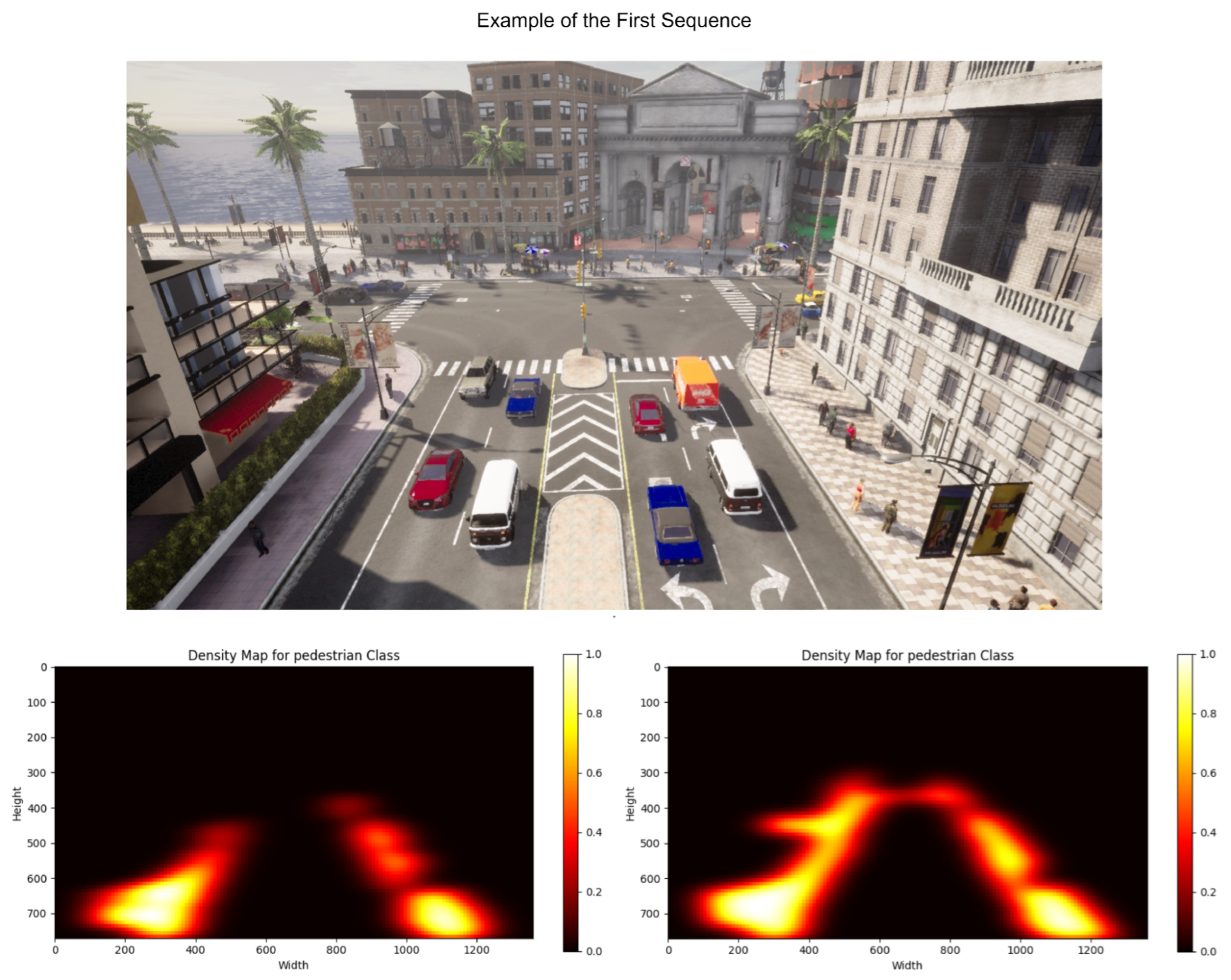
- The creation and collection of a synthetic dataset to test the proposed methodology. This set consists of urban sequences where pedestrians and vehicles of variable dimensions transit. The training set is composed of sequences to learn the typical patterns of these elements, while sequences conform to the test set with multiple anomalies to be identified.
- Applying the described methodology using several pre-trained object detection and super-resolution models to improve the elements’ mean average precision (mAP).
- Testing and evaluation of the described technique using various metrics.
2. Related Work
2.1. Convolutional Neural Network Models
2.2. Super-Resolution Models
2.3. Anomaly Detection
2.4. Differences with Other Proposals
3. Models and Methods
3.1. Convolutional Neural Networks for Object Detection
- CenterNet HourGlass104 Keypoints 1024 × 1024: CenterNet Keypoints is a one-stage object detection framework that efficiently predicts object centers and regresses the bounding box size. The HourGlass104 backbone effectively captures multi-scale features. In addition to detecting object bounding boxes, this variant predicts keypoints associated with each object, making it suitable for tasks such as human pose estimation. The HourGlass architecture uses repeated down-sampling and up-sampling stages, allowing it to capture fine-grained details while maintaining a global context.
- CenterNet HourGlass104 1024 × 1024: This CenterNet variant omits the keypoint prediction branch, focusing only on object detection. Using the HourGlass104 backbone, it retains the advantages of multi-scale feature representation and precise object localization. The absence of the keypoint prediction branch reduces the model’s computational complexity, making it more efficient.
- Faster R-CNN Inception ResNet V2 1024 × 1024 (RetinaNet152): Faster R-CNN is a two-stage object detection model that separates region proposal generation and object classification. The Inception ResNet V2 backbone provides good feature extraction capabilities. The first stage generates region proposals using a Region Proposal Network (RPN), which efficiently proposes candidate object bounding boxes. In the second stage, these proposals are further refined and classified to produce the final detections.
- EfficientDet D4: EfficientDet is a scalable and efficient object detection model that balances accuracy and computational efficiency. The EfficientDet D4 variant is optimized to detect objects at different scales with high accuracy. It leverages a composite scaling method that uniformly scales the model’s depth, width and resolution.
- SSD ResNet152 V1 FPN 1024 × 1024 (RetinaNet152): SSD (Single-Shot Multibox Detector) is a one-stage object detection model that directly predicts object categories and bounding boxes at multiple scales. The ResNet152 V1 FPN backbone incorporates feature pyramid networks (FPN) for multi-scale feature extraction and improved performance. The FPN helps the model handle objects of several sizes effectively.
3.2. Convolutional Neural Networks for Super-Resolution
3.3. Methodology
4. Experiments and Results
4.1. Dataset
4.2. Metrics
4.3. Results
5. Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. arXiv 2016, arXiv:1506.01497. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. CenterNet: Keypoint Triplets for Object Detection. arXiv 2019, arXiv:1904.08189. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. arXiv 2020, arXiv:1905.11946. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Computer Vision—ECCV 2016, Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer International Publishing: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar] [CrossRef] [Green Version]
- García-Aguilar, I.; Luque-Baena, R.M.; López-Rubio, E. Improved detection of small objects in road network sequences using CNN and super resolution. Expert Syst. 2021, 39, e12930. [Google Scholar] [CrossRef]
- Jiang, K.; Wang, Z.; Yi, P.; Wang, G.; Lu, T.; Jiang, J. Edge-Enhanced GAN for Remote Sensing Image Superresolution. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5799–5812. [Google Scholar] [CrossRef]
- Zhou, J.; Vong, C.M.; Liu, Q.; Wang, Z. Scale adaptive image cropping for UAV object detection. Neurocomputing 2019, 366, 305–313. [Google Scholar] [CrossRef]
- Wang, X.; Xie, L.; Dong, C.; Shan, Y. Real-ESRGAN: Training Real-World Blind Super-Resolution with Pure Synthetic Data. arXiv 2021, arXiv:2107.10833. [Google Scholar]
- Sabokrou, M.; Fathy, M.; Hoseini, M.; Klette, R. Real-time anomaly detection and localization in crowded scenes. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Boston, MA, USA, 7–12 June 2015; pp. 56–62. [Google Scholar] [CrossRef] [Green Version]
- Cong, Y.; Yuan, J.; Liu, J. Sparse reconstruction cost for abnormal event detection. In Proceedings of the CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011; pp. 3449–3456. [Google Scholar] [CrossRef] [Green Version]
- Zhao, B.; Li, F.-F.; Xing, E.P. Online detection of unusual events in videos via dynamic sparse coding. In Proceedings of the CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011; pp. 3313–3320. [Google Scholar] [CrossRef] [Green Version]
- Mahadevan, V.; Li, W.; Bhalodia, V.; Vasconcelos, N. Anomaly detection in crowded scenes. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 1975–1981. [Google Scholar] [CrossRef]
- Shen, M.; Jiang, X.; Sun, T. Anomaly Detection by Analyzing the Pedestrian Behavior and the Dynamic Changes of Behavior. In Intelligent Computing Theories and Application, Proceedings of the 13th International Conference, ICIC 2017, Liverpool, UK, 7–10 August 2017; Huang, D.S., Bevilacqua, V., Premaratne, P., Gupta, P., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 211–222. [Google Scholar]
- Pustokhina, I.V.; Pustokhin, D.A.; Vaiyapuri, T.; Gupta, D.; Kumar, S.; Shankar, K. An automated deep learning based anomaly detection in pedestrian walkways for vulnerable road users safety. Saf. Sci. 2021, 142, 105356. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar] [CrossRef]
- Hu, X.; Dai, J.; Huang, Y.; Yang, H.; Zhang, L.; Chen, W.; Yang, G.; Zhang, D. A weakly supervised framework for abnormal behavior detection and localization in crowded scenes. Neurocomputing 2020, 383, 270–281. [Google Scholar] [CrossRef]
- Kanu-Asiegbu, A.M.; Vasudevan, R.; Du, X. Leveraging Trajectory Prediction for Pedestrian Video Anomaly Detection. In Proceedings of the 2021 IEEE Symposium Series on Computational Intelligence (SSCI), Orlando, FL, USA, 5–7 December 2021. [Google Scholar] [CrossRef]
- Chang, C.W.; Chang, C.Y.; Lin, Y.Y. A hybrid CNN and LSTM-based deep learning model for abnormal behavior detection. Multimed. Tools Appl. 2022, 81, 11825–11843. [Google Scholar] [CrossRef]
- Gayal, B.S.; Patil, S.R. Detection and localization of anomalies in video surveillance using novel optimization based deep convolutional neural network. Multimed. Tools Appl. 2023, 82, 28895–28915. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Ros, G.; Codevilla, F.; Lopez, A.; Koltun, V. CARLA: An Open Urban Driving Simulator. arXiv 2017, arXiv:1711.03938. [Google Scholar]
- Sophia, B.; Chitra, D. Segmentation Based Real Time Anomaly Detection and Tracking Model for Pedestrian Walkways. Intell. Autom. Soft Comput. 2023, 36, 2491–2504. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C.L.; Dollár, P. Microsoft COCO: Common Objects in Context. arXiv 2015, arXiv:cs.CV/1405.0312. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyper-Parameter | Value |
|---|---|
| Selected Model | Efficientdet D4 |
| IoU Threshold | 0.25 |
| Anomaly Threshold | 0.5 |
| Tiling Factor | 2 |
| Pedestrian Class | Car Class | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Sequence 1 | Sequence 2 | Sequence 1 | Sequence 2 | ||||||
| Model | Metric | RAW | OURS | RAW | OURS | RAW | OURS | RAW | OURS |
| CenterNet HourGlass104 Keypoints 1024 × 1024 | IoU = 0.50:0.95|area = all | 0.087 | 0.119 | 0.038 | 0.056 | 0.197 | 0.237 | 0.109 | 0.158 |
| IoU > 0.50|area = all | 0.272 | 0.346 | 0.095 | 0.150 | 0.386 | 0.449 | 0.278 | 0.374 | |
| IoU > 0.75|area = all | 0.028 | 0.045 | 0.018 | 0.024 | 0.120 | 0.180 | 0.030 | 0.051 | |
| IoU = 0.50:0.95|area = Small | 0.081 | 0.101 | 0.033 | 0.051 | 0.190 | 0.494 | 0.020 | 0.058 | |
| IoU > 0.50|area = Medium | 0.114 | 0.203 | 0.208 | 0.237 | 0.184 | 0.236 | 0.225 | 0.292 | |
| CenterNet HourGlass104 1024 × 1024 | IoU = 0.50:0.95|area = all | 0.081 | 0.122 | 0.043 | 0.056 | 0.186 | 0.241 | 0.086 | 0.142 |
| IoU > 0.50|area = all | 0.259 | 0.351 | 0.106 | 0.149 | 0.389 | 0.457 | 0.256 | 0.365 | |
| IoU > 0.75|area = all | 0.024 | 0.044 | 0.025 | 0.026 | 0.093 | 0.171 | 0.024 | 0.034 | |
| IoU = 0.50:0.95|area = Small | 0.077 | 0.105 | 0.036 | 0.052 | 0.345 | 0.497 | 0.010 | 0.054 | |
| IoU > 0.50|area = Medium | 0.105 | 0.203 | 0.208 | 0.231 | 0.180 | 0.235 | 0.194 | 0.268 | |
| Faster R-CNN Inception ResNet V2 1024 × 1024 | IoU = 0.50:0.95|area = all | 0.033 | 0.071 | 0.097 | 0.130 | 0.015 | 0.033 | 0.055 | 0.068 |
| IoU > 0.50|area = all | 0.112 | 0.228 | 0.255 | 0.299 | 0.033 | 0.087 | 0.212 | 0.219 | |
| IoU > 0.75|area = all | 0.008 | 0.017 | 0.045 | 0.097 | 0.010 | 0.017 | 0.016 | 0.018 | |
| IoU = 0.50:0.95|area = Small | 0.024 | 0.055 | 0.150 | 0.157 | 0.008 | 0.027 | 0.010 | 0.020 | |
| IoU > 0.50|area = Medium | 0.086 | 0.157 | 0.102 | 0.140 | 0.151 | 0.207 | 0.126 | 0.147 | |
| EfficientDet D4 | IoU = 0.50:0.95|area = all | 0.018 | 0.128 | 0.010 | 0.052 | 0.133 | 0.226 | 0.062 | 0.124 |
| IoU > 0.50|area = all | 0.051 | 0.350 | 0.018 | 0.114 | 0.262 | 0.417 | 0.147 | 0.296 | |
| IoU > 0.75|area = all | 0.007 | 0.047 | 0.010 | 0.034 | 0.092 | 0.211 | 0.014 | 0.040 | |
| IoU = 0.50:0.95|area = Small | 0.010 | 0.104 | 0.006 | 0.042 | 0.258 | 0.346 | 0.013 | 0.040 | |
| IoU > 0.50|area = Medium | 0.073 | 0.249 | 0.151 | 0.268 | 0.115 | 0.206 | 0.138 | 0.255 | |
| SSD ResNet152 V1 FPN 1024 × 1024 (RetinaNet152) | IoU = 0.50:0.95|area = all | 0.007 | 0.085 | 0.137 | 0.211 | 0.010 | 0.035 | 0.022 | 0.100 |
| IoU > 0.50|area = all | 0.020 | 0.260 | 0.301 | 0.446 | 0.017 | 0.083 | 0.067 | 0.253 | |
| IoU > 0.75|area = all | 0.003 | 0.021 | 0.083 | 0.143 | 0.010 | 0.021 | 0.007 | 0.032 | |
| IoU = 0.50:0.95|area = Small | 0.008 | 0.069 | 0.007 | 0.235 | 0.006 | 0.029 | 0.002 | 0.018 | |
| IoU > 0.50|area = Medium | 0.023 | 0.175 | 0.157 | 0.220 | 0.079 | 0.196 | 0.041 | 0.208 | |
| Model | Sequence | Methodology | Number of Anomalies | Number of Anomalies Detected |
|---|---|---|---|---|
| CenterNet HourGlass 104 Keypoints 1024 × 1024 | Sequence 1 | RAW | 712 | 243 |
| OURS | 335 | |||
| Sequence 2 | RAW | 370 | 4 | |
| OURS | 84 | |||
| CenterNet HourGlass 104 1024 × 1024 | Sequence 1 | RAW | 712 | 221 |
| OURS | 288 | |||
| Sequence 2 | RAW | 370 | 60 | |
| OURS | 123 | |||
| Faster R-CNN Inception ResNet V2 1024 × 1024 | Sequence 1 | RAW | 712 | 57 |
| OURS | 222 | |||
| Sequence 2 | RAW | 370 | 4 | |
| OURS | 60 | |||
| EfficientDet D4 | Sequence 1 | RAW | 712 | 12 |
| OURS | 217 | |||
| Sequence 2 | RAW | 370 | 0 | |
| OURS | 81 | |||
| SSD ResNet152 V1 FPN 1024 × 1024 (RetinaNet 152) | Sequence 1 | RAW | 712 | 4 |
| OURS | 208 | |||
| Sequence 2 | RAW | 370 | 1 | |
| OURS | 24 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
García-Aguilar, I.; Luque-Baena, R.M.; Domínguez, E.; López-Rubio, E. Small-Scale Urban Object Anomaly Detection Using Convolutional Neural Networks with Probability Estimation. Sensors 2023, 23, 7185. https://0-doi-org.brum.beds.ac.uk/10.3390/s23167185
García-Aguilar I, Luque-Baena RM, Domínguez E, López-Rubio E. Small-Scale Urban Object Anomaly Detection Using Convolutional Neural Networks with Probability Estimation. Sensors. 2023; 23(16):7185. https://0-doi-org.brum.beds.ac.uk/10.3390/s23167185
Chicago/Turabian StyleGarcía-Aguilar, Iván, Rafael Marcos Luque-Baena, Enrique Domínguez, and Ezequiel López-Rubio. 2023. "Small-Scale Urban Object Anomaly Detection Using Convolutional Neural Networks with Probability Estimation" Sensors 23, no. 16: 7185. https://0-doi-org.brum.beds.ac.uk/10.3390/s23167185