

Fight Fire with Fire: Detecting Forest Fires with Embedded Machine Learning Models Dealing with Audio and Images on Low Power IoT Devices


Abstract
:1. Introduction
- Collect two ad hoc datasets to train and preliminary test the developed ML models. In particular, the former is a dataset containing audio files labelled into two classes, “Fire” and “No-Fire”, on the basis of the presence of fire-related sounds mixed with sundry environmental noises typical of forests (e.g., wind, insects, animals). Conversely, the latter is a dataset containing pictures labelled into the same classes discriminating the presence of fires within forest environments in a wide range of weather conditions and moments of the day (i.e., at night and in daylight).
- Present a ML-enabled embedded VSU prototype that simultaneously runs two classifiers dealing with audio and picture data in turn in order to recognise forest fires.
- Test and select the devised embedded ML algorithms and propose alarm conditions in order to enhance the classification capability of the VSU prototype, and finally measure the latency and current absorption of the prototype.
2. Related Works
3. Datasets Description
3.1. Audio Dataset
- Clean Fire—the sound of fire was the only audible noise
- Fire with Animal Sounds—the sound of fire was superimposed on sounds coming from animals living in forests (e.g., birds)
- Fire with Insect Sounds—the sound of fire was superimposed on sounds coming from insects living in forests (e.g., cicadas)
- Fire with Wind Noise—the sound of fire was superimposed on the noise of wind or of shaking leaves
- Additional Fire Samples—digitally mounted samples in which the sound of fire was superimposed on the samples belonging to the “No-Fire” class with different intensity levels, with the aim of improving generalisation capability of the relative trained NN
- Recordings—samples recorded according to the procedure explained above during the combustion of plant residues at a variable distance from the flames.
- Animal Sounds—samples of sounds from animals living in forests (e.g., birds) that were not exploited as background for the “Fire with Animal Sounds” typology of the “Fire” class
- Insect Sounds—samples of sounds from insects living in forests (e.g., cicadas) that were not exploited as background for the “Fire with Insect Sounds” typology of the “Fire” class
- Wind Noise—samples of wind noise or of shaking leaves that were not exploited as background for the “Fire with Wind Noise” typology of the “Fire” class
- Rain Noise—samples of rain noise or thunder
- Sundry Samples—a set of samples belonging to events that are marginal with respect to the context of interest, but which could be recorded by the device (e.g., sounds produced by agricultural machinery, the sound of aircraft, the buzz of people talking in the distance), included in order to augment the generalisation capability of the relative trained NN.
3.2. Picture Dataset
4. System Overview
4.1. Hardware
4.2. Embedded ML Model: Audio NN
4.2.1. Audio Feature Extraction
4.2.2. Convolutional Neural Network Classifier
4.2.3. Model Quantisation for Deployment
4.3. Embedded ML Model: Picture NN
4.3.1. Picture Feature Extraction
4.3.2. Convolutional Neural Network Classifier
4.3.3. Model Quantisation for Deployment
4.4. VSU Functioning Scheme
5. Laboratory Tests and Results
- Assessing the classification performance on the relative test set for audio NN #1, audio NN #2, and the picture NN;
- Assessing the hardware performance of audio NN #1, audio NN #2, and the picture NN;
- Selecting one model between audio NN #1 and audio NN #2 on the basis of their performance on an ad hoc edited video;
- Choosing and on the basis of the performance of the selected audio NN and the picture NN on the same video mentioned above;
- Assessing the performance of the VSU prototype from the point of view of classification and latency, making use of the same video as above;
- Measuring the current drawn by the VSU prototype.
5.1. Performance on Test Set and Hardware
5.2. Ad Hoc Edited Test Video
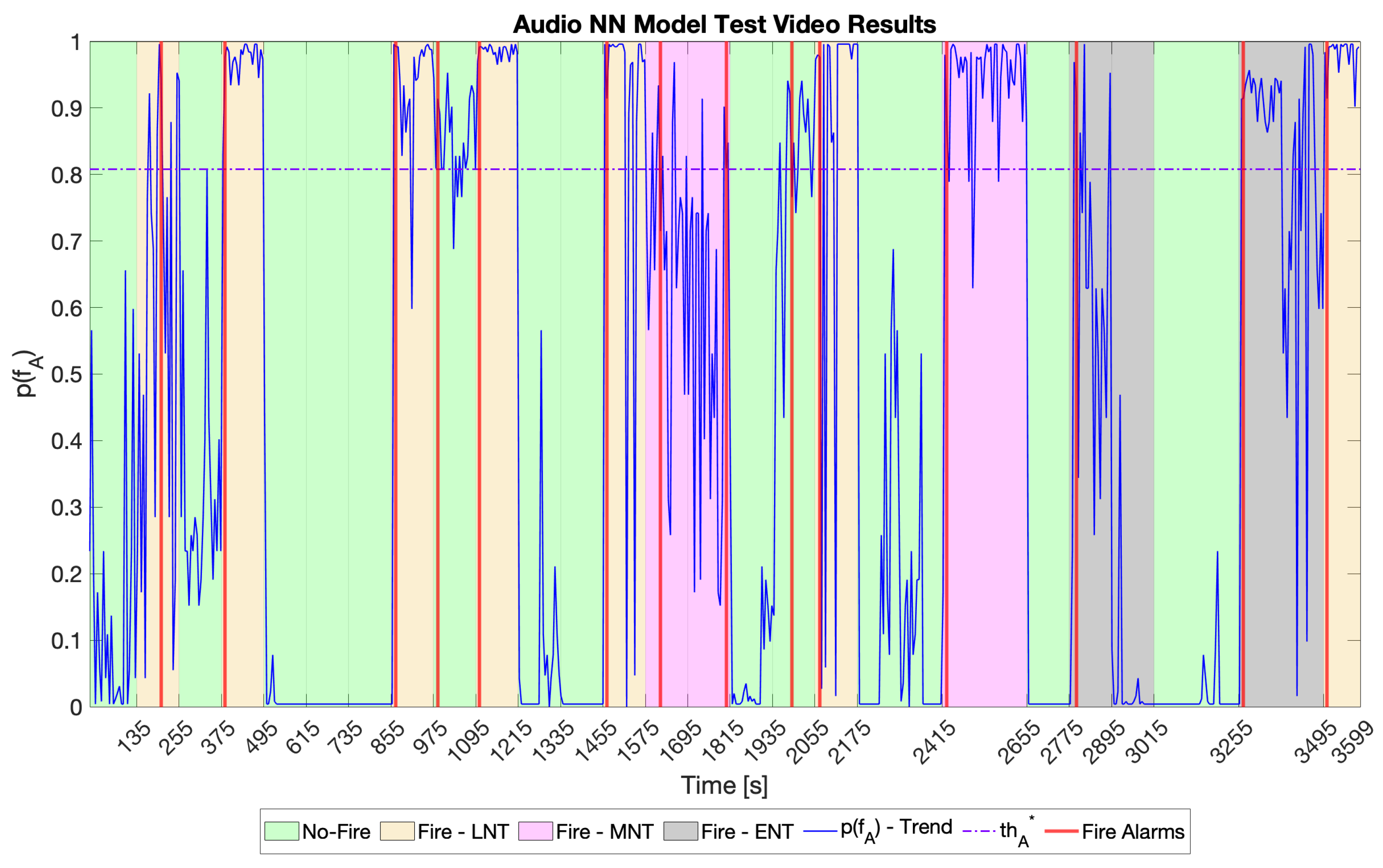
5.3. Performance on Test Video, Audio NN Model Selection, and Condition of Fire Definition
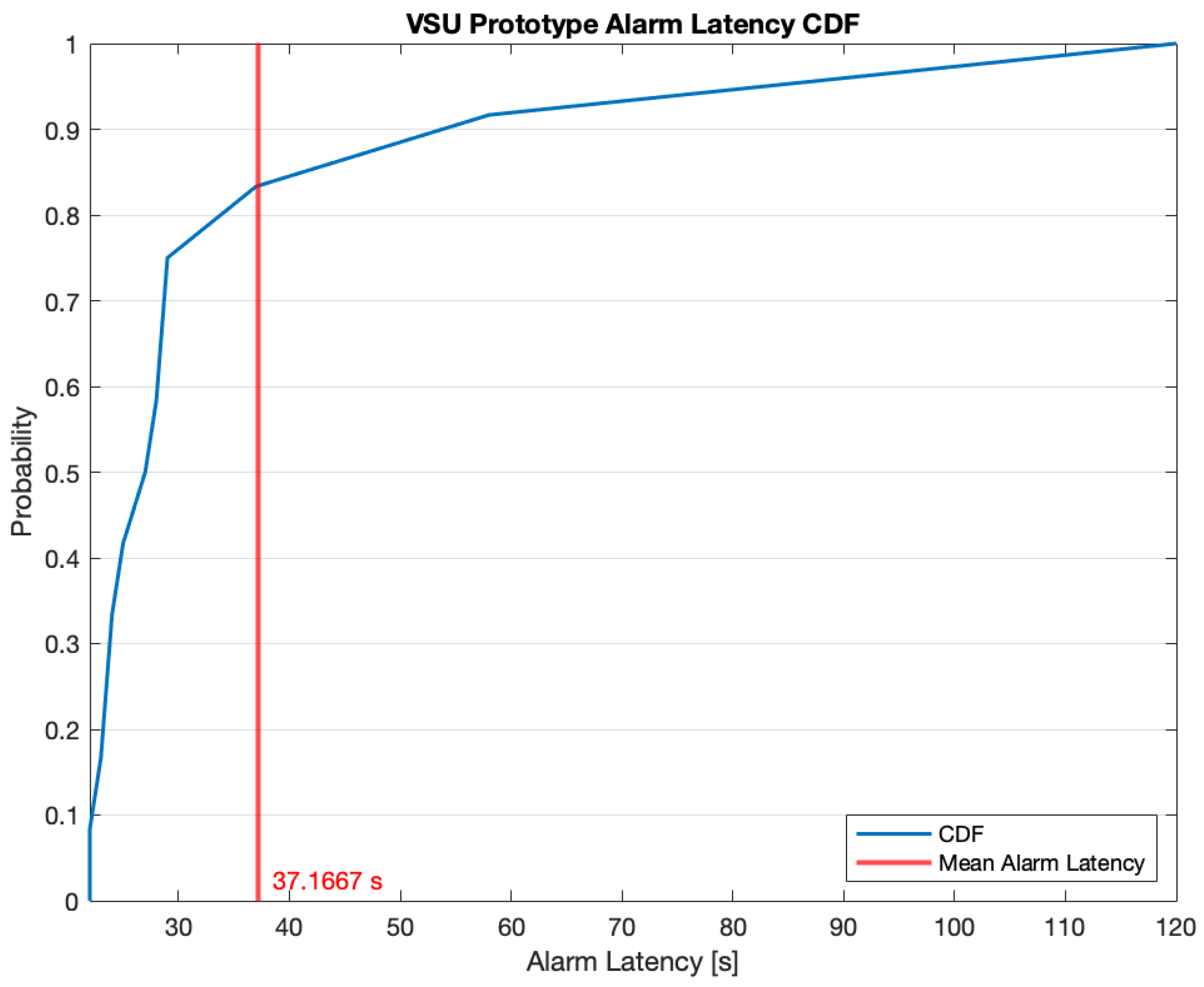
5.4. Performance of the VSU Prototype
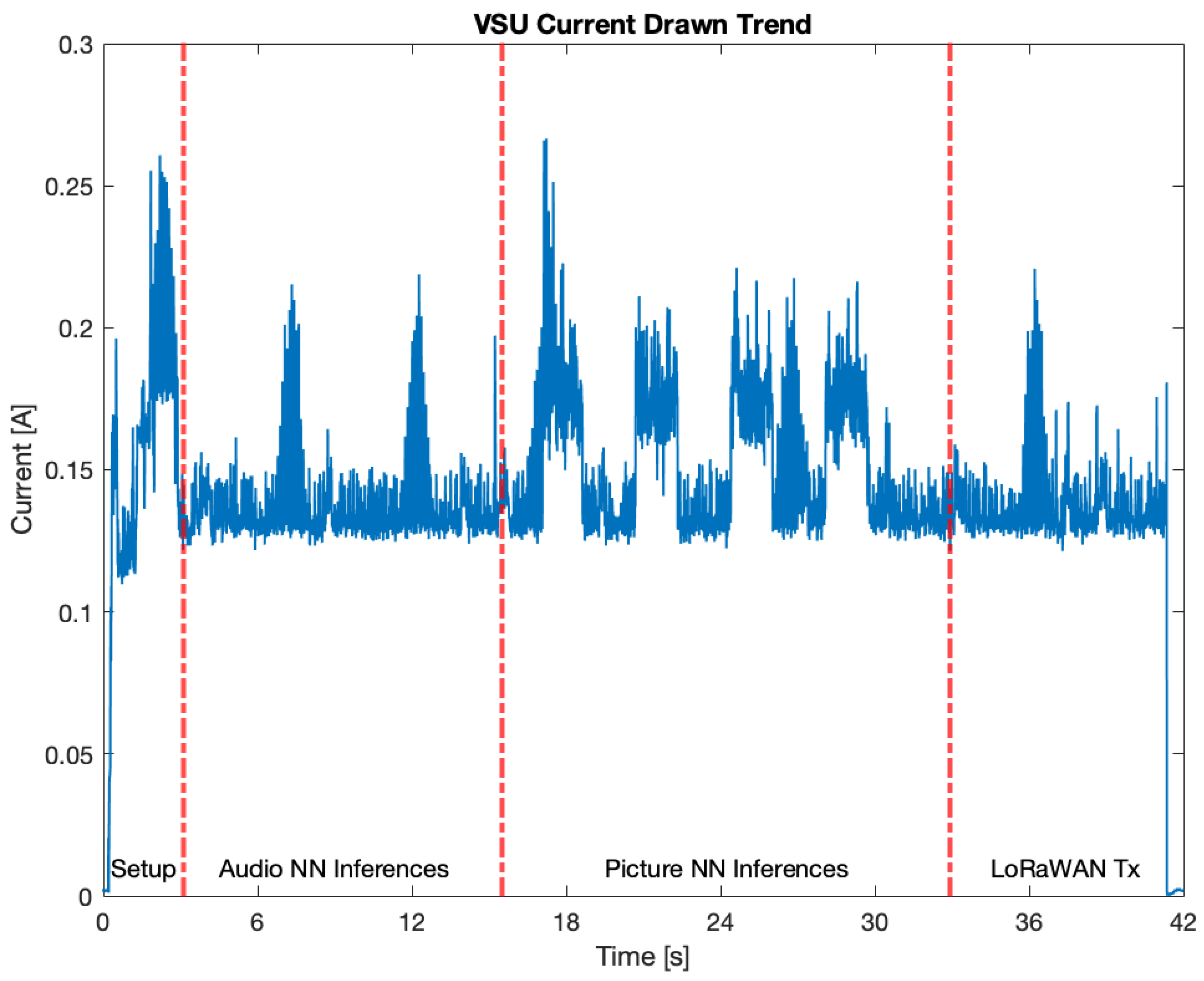
5.5. Current Drawn by the VSU Prototype
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- San-Miguel-Ayanz, J.; Durrant, T.; Boca, R.; Maianti, P.; Liberta, G.; Artes Vivancos, T.; Jacome Felix Oom, D.; Branco, A.; de Rigo, D.; Ferrari, D.; et al. Advance Report on Wildfires in Europe, Middle East and North Africa; Publications Office of the European Union: Luxembourg, 2021. [Google Scholar]
- Pham, H.T.; Nguyen, M.A.; Sun, C.C. AIoT solution survey and comparison in machine learning on low-cost microcontroller. In Proceedings of the 2019 International Symposium on Intelligent Signal Processing and Communication Systems (ISPACS), Taipei, Taiwan, 3–6 December 2019; pp. 1–2. [Google Scholar]
- Merenda, M.; Porcaro, C.; Iero, D. Edge machine learning for ai-enabled iot devices: A review. Sensors 2020, 20, 2533. [Google Scholar] [CrossRef] [PubMed]
- Hu, X.; Li, Y.; Jia, L.; Qiu, M. A novel two-stage unsupervised fault recognition framework combining feature extraction and fuzzy clustering for collaborative AIoT. IEEE Trans. Ind. Inform. 2021, 18, 1291–1300. [Google Scholar] [CrossRef]
- Wang, Y.; Ho, I.W.H.; Chen, Y.; Wang, Y.; Lin, Y. Real-time water quality monitoring and estimation in AIoT for freshwater biodiversity conservation. IEEE Internet Things J. 2021, 9, 14366–14374. [Google Scholar] [CrossRef]
- Zualkernan, I.; Judas, J.; Mahbub, T.; Bhagwagar, A.; Chand, P. An aiot system for bat species classification. In Proceedings of the 2020 IEEE International Conference on Internet of Things and Intelligence System (IoTaIS), Bali, Indonesia, 27–28 January 2021; pp. 155–160. [Google Scholar]
- Bertocco, M.; Fort, A.; Landi, E.; Mugnaini, M.; Parri, L.; Peruzzi, G.; Pozzebon, A. Roller Bearing Failures Classification with Low Computational Cost Embedded Machine Learning. In Proceedings of the 2022 IEEE International Workshop on Metrology for Automotive (MetroAutomotive), Modena, Italy, 4–6 July 2022; pp. 12–17. [Google Scholar]
- Arif, M.; Alghamdi, K.; Sahel, S.; Alosaimi, S.; Alsahaft, M.; Alharthi, M.; Arif, M. Role of machine learning algorithms in forest fire management: A literature review. J. Robot. Autom. 2021, 5, 212–226. [Google Scholar]
- Basu, M.T.; Karthik, R.; Mahitha, J.; Reddy, V.L. IoT based forest fire detection system. Int. J. Eng. Technol. 2018, 7, 124–126. [Google Scholar] [CrossRef] [Green Version]
- Deve, K.; Hancke, G.P.; Silva, B.J. Design of a smart fire detection system. In Proceedings of the IECON 2016-42nd Annual Conference of the IEEE Industrial Electronics Society, Florence, Italy, 23–26 October 2016; pp. 6205–6210. [Google Scholar]
- Alqourabah, H.; Muneer, A.; Fati, S.M. A smart fire detection system using IoT technology with automatic water sprinkler. Int. J. Electr. Comput. Eng. 2021, 11, 2994–3002. [Google Scholar] [CrossRef]
- Kadri, B.; Bouyeddou, B.; Moussaoui, D. Early fire detection system using wireless sensor networks. In Proceedings of the 2018 International Conference on Applied Smart Systems (ICASS), Medea, Algeria, 24–25 November 2018; pp. 1–4. [Google Scholar]
- Baldo, D.; Mecocci, A.; Parrino, S.; Peruzzi, G.; Pozzebon, A. A multi-layer lorawan infrastructure for smart waste management. Sensors 2021, 21, 2600. [Google Scholar] [CrossRef]
- Sharma, A.; Singh, P.K.; Kumar, Y. An integrated fire detection system using IoT and image processing technique for smart cities. Sustain. Cities Soc. 2020, 61, 102332. [Google Scholar] [CrossRef]
- Kinaneva, D.; Hristov, G.; Raychev, J.; Zahariev, P. Early forest fire detection using drones and artificial intelligence. In Proceedings of the 2019 42nd International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 20–24 May 2019; pp. 1060–1065. [Google Scholar]
- Jiao, Z.; Zhang, Y.; Xin, J.; Mu, L.; Yi, Y.; Liu, H.; Liu, D. A deep learning based forest fire detection approach using UAV and YOLOv3. In Proceedings of the 2019 1st International Conference on Industrial Artificial Intelligence (IAI), Shenyang, China, 23–27 July 2019; pp. 1–5. [Google Scholar]
- Liu, Z.; Zhang, K.; Wang, C.; Huang, S. Research on the identification method for the forest fire based on deep learning. Optik 2020, 223, 165491. [Google Scholar] [CrossRef]
- Xu, R.; Lin, H.; Lu, K.; Cao, L.; Liu, Y. A forest fire detection system based on ensemble learning. Forests 2021, 12, 217. [Google Scholar] [CrossRef]
- Benzekri, W.; El Moussati, A.; Moussaoui, O.; Berrajaa, M. Early forest fire detection system using wireless sensor network and deep learning. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 496–503. [Google Scholar] [CrossRef]
- Harjoko, A.; Dharmawan, A.; Adhinata, F.D.; Kosala, G.; Jo, K.H. Real-time forest fire detection framework based on artificial intelligence using color probability model and motion feature analysis. Fire 2022, 5, 23. [Google Scholar]
- Zhang, S.; Gao, D.; Lin, H.; Sun, Q. Wildfire detection using sound spectrum analysis based on the internet of things. Sensors 2019, 19, 5093. [Google Scholar] [CrossRef] [Green Version]
- Li, M.; Zhang, Y.; Mu, L.; Xin, J.; Yu, Z.; Liu, H.; Xie, G. Early Forest Fire Detection Based on Deep Learning. In Proceedings of the 2021 3rd International Conference on Industrial Artificial Intelligence (IAI), Shenyang, China, 8–11 November 2021; pp. 1–5. [Google Scholar]
- Alves, J.; Soares, C.; Torres, J.M.; Sobral, P.; Moreira, R.S. Automatic forest fire detection based on a machine learning and image analysis pipeline. In Proceedings of the World Conference on Information Systems and Technologies, Cairo, Egypt, 24–26 March 2019; pp. 240–251. [Google Scholar]
- Chopde, A.; Magon, A.; Bhatkar, S. Forest Fire Detection and Prediction from Image Processing Using RCNN. In Proceedings of the 7th World Congress on Civil, Structural, and Environmental Engineering, Virtual, 10–12 April 2022. [Google Scholar]
- Ya’acob, N.; Najib, M.S.M.; Tajudin, N.; Yusof, A.L.; Kassim, M. Image processing based forest fire detection using infrared camera. J. Phys. Conf. Ser. 2021, 1768, 012014. [Google Scholar] [CrossRef]
- Huang, H.T.; Downey, A.R.; Bakos, J.D. Audio-Based Wildfire Detection on Embedded Systems. Electronics 2022, 11, 1417. [Google Scholar] [CrossRef]
- Fort, A.; Peruzzi, G.; Pozzebon, A. Quasi-Real Time Remote Video Surveillance Unit for LoRaWAN-based Image Transmission. In Proceedings of the 2021 IEEE International Workshop on Metrology for Industry 4.0 & IoT (MetroInd4. 0&IoT), Rome, Italy, 7–9 June 2021; pp. 588–593. [Google Scholar]
- Oroceo, P.P.; Kim, J.I.; Caliwag, E.M.F.; Kim, S.H.; Lim, W. Optimizing Face Recognition Inference with a Collaborative Edge–Cloud Network. Sensors 2022, 22, 8371. [Google Scholar] [CrossRef]
- Dhou, S.; Alnabulsi, A.; Al-Ali, A.; Arshi, M.; Darwish, F.; Almaazmi, S.; Alameeri, R. An IoT machine learning-based mobile sensors unit for visually impaired people. Sensors 2022, 22, 5202. [Google Scholar] [CrossRef]
- Munteanu, D.; Moina, D.; Zamfir, C.G.; Petrea, S.M.; Cristea, D.S.; Munteanu, N. Sea Mine Detection Framework Using YOLO, SSD and EfficientDet Deep Learning Models. Sensors 2022, 22, 9536. [Google Scholar] [CrossRef] [PubMed]
- Peruzzi, G.; Galli, A.; Pozzebon, A. A Novel Methodology to Remotely and Early Diagnose Sleep Bruxism by Leveraging on Audio Signals and Embedded Machine Learning. In Proceedings of the 2022 IEEE International Symposium on Measurements & Networking (M&N), Padua, Italy, 18–20 July 2022; pp. 1–6. [Google Scholar]
- Hemdan, E.E.D.; El-Shafai, W.; Sayed, A. CR19: A framework for preliminary detection of COVID-19 in cough audio signals using machine learning algorithms for automated medical diagnosis applications. J. Ambient. Intell. Humaniz. Comput. 2022, 1–13. [Google Scholar] [CrossRef]
- Pahar, M.; Niesler, T. Machine Learning Based COVID-19 Detection from Smartphone Recordings: Cough, Breath and Speech. 2021. Available online: https://www.researchgate.net/publication/350673813_Machine_Learning_based_COVID-19_Detection_from_Smartphone_Recordings_Cough_Breath_and_Speech (accessed on 3 January 2023).
- da Silva, B.; Happi, A.W.; Braeken, A.; Touhafi, A. Evaluation of classical machine learning techniques towards urban sound recognition on embedded systems. Appl. Sci. 2019, 9, 3885. [Google Scholar] [CrossRef] [Green Version]
- Ravi, P.; Syam, U.; Kapre, N. Preventive detection of mosquito populations using embedded machine learning on low power iot platforms. In Proceedings of the 7th Annual Symposium on Computing for Development, Nairobi, Kenya, 17–22 November 2016; pp. 1–10. [Google Scholar]
- Antonini, M.; Vecchio, M.; Antonelli, F.; Ducange, P.; Perera, C. Smart audio sensors in the internet of things edge for anomaly detection. IEEE Access 2018, 6, 67594–67610. [Google Scholar] [CrossRef]
- Fonseca, E.; Favory, X.; Pons, J.; Font, F.; Serra, X. FSD50K: An open dataset of human-labeled sound events. IEEE/ACM Trans. Audio Speech Lang. Process. 2022, 30, 829–852. [Google Scholar] [CrossRef]
- Piczak, K.J. ESC: Dataset for Environmental Sound Classification. In Proceedings of the 23rd Annual ACM Conference on Multimedia, Brisbane, Australia, 26–30 October 2015; pp. 1015–1018. [Google Scholar] [CrossRef]
- Peruzzi, G.; Pozzebon, A.; Van Der Meer, M. Audio Dataset. Available online: https://drive.google.com/file/d/15PQ-my8cA1blUIbAGRY8Jhq_d8Z7qim7/view (accessed on 18 November 2022).
- Dincer, B. Wildfire Detection Image Dataset. Available online: https://www.kaggle.com/datasets/brsdincer/wildfire-detection-image-data (accessed on 23 November 2022).
- Peruzzi, G.; Pozzebon, A.; Van Der Meer, M. Picture Dataset. Available online: https://drive.google.com/file/d/1QEAt4JiNxu5zZpXkWVnJm5sgtZm15Cf4/view?usp=share_link (accessed on 18 November 2022).
- Parri, L.; Parrino, S.; Peruzzi, G.; Pozzebon, A. A LoRaWAN network infrastructure for the remote monitoring of offshore sea farms. In Proceedings of the 2020 IEEE International Instrumentation and Measurement Technology Conference (I2MTC), Dubrovnik, Croatia, 25–28 May 2020; pp. 1–6. [Google Scholar]
- Miranda, I.D.; Diacon, A.H.; Niesler, T.R. A comparative study of features for acoustic cough detection using deep architectures. In Proceedings of the 2019 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Berlin, Germany, 23–27 July 2019; pp. 2601–2605. [Google Scholar]
- Koike, T.; Qian, K.; Kong, Q.; Plumbley, M.D.; Schuller, B.W.; Yamamoto, Y. Audio for audio is better? An investigation on transfer learning models for heart sound classification. In Proceedings of the 2020 42nd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Montreal, QC, Canada, 20–24 July 2020; pp. 74–77. [Google Scholar]
- Kutsumi, Y.; Kanegawa, N.; Zeida, M.; Matsubara, H.; Murayama, N. Automated Bowel Sound and Motility Analysis with CNN Using a Smartphone. Sensors 2023, 23, 407. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Liu, K.; Tzanetakis, G.; Pan, J. Cooperative abnormal sound event detection in end-edge-cloud orchestrated systems. CCF Trans. Netw. 2020, 3, 158–170. [Google Scholar] [CrossRef]
- Wu, J.; Liu, Q.; Zhang, M.; Pan, Z.; Li, H.; Tan, K.C. HuRAI: A brain-inspired computational model for human-robot auditory interface. Neurocomputing 2021, 465, 103–113. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Addabbo, T.; Fort, A.; Mugnaini, M.; Vignoli, V.; Intravaia, M.; Tani, M.; Bianchini, M.; Scarselli, F.; Corradini, B.T. Smart Gravimetric System for Enhanced Security of Accesses to Public Places Embedding a MobileNet Neural Network Classifier. IEEE Trans. Instrum. Meas. 2022, 71, 1–10. [Google Scholar] [CrossRef]
- Sineglazov, V.; Khotsyanovsky, V. Camera Image Processing on ESP32 Microcontroller with Help of Convolutional Neural Network. Electron. Control Syst. 2022, 2, 26–31. [Google Scholar]
- Bilang, J.M.D.; Balbuena, P.A.A.L.; Villaverde, J.F. Cactaceae Detection Using MobileNet Architecture. In Proceedings of the 2021 IEEE 13th International Conference on Humanoid, Nanotechnology, Information Technology, Communication and Control, Environment, and Management (HNICEM), Manila, Philippines, 28–30 November 2021; pp. 1–5. [Google Scholar]
- Audy, Z. Analysis Quality of Corn Based on IoT, SSD Mobilenet Models and Histogram. J. Nas. Tek. Elektro Dan Teknol. Inf. Vol. 2022, 11, 79–87. [Google Scholar]
- Zheng, W.C.; Lee, J.S.; Sun, Y.H. Development of AI-based Recycling Bins Using MobileNet-SSD Networks. In Proceedings of the 2021 IEEE International Conference on Consumer Electronics-Taiwan (ICCE-TW), Penghu, Taiwan, 15–17 September 2021; pp. 1–2. [Google Scholar]
- Rabano, S.L.; Cabatuan, M.K.; Sybingco, E.; Dadios, E.P.; Calilung, E.J. Common garbage classification using mobilenet. In Proceedings of the 2018 IEEE 10th International Conference on Humanoid, Nanotechnology, Information Technology, Communication and Control, Environment and Management (HNICEM), Baguio City, Philippines, 29 November–2 December 2018; pp. 1–4. [Google Scholar]
- Kokilavani, V. Intelligent Face Mask and Body Temperature Detection System using Machine Learning Algorithm. In Proceedings of the 2022 International Conference on Innovative Computing, Intelligent Communication and Smart Electrical Systems (ICSES), Chennai, India, 15–16 July 2022; pp. 1–6. [Google Scholar]
- Hossain, D.; Imtiaz, M.H.; Ghosh, T.; Bhaskar, V.; Sazonov, E. Real-time food intake monitoring using wearable egocnetric camera. In Proceedings of the 2020 42nd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Montreal, QC, Canada, 20–24 July 2020; pp. 4191–4195. [Google Scholar]
- Peruzzi, G.; Pozzebon, A.; Van Der Meer, M. Test Video. Available online: https://drive.google.com/file/d/1Hi2gs4mkrFibULaHfVDzgJZgVaVUYf6L/view?usp=share_link (accessed on 1 December 2022).













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Audio Type | Number of Samples | Total Time [s] |
|---|---|---|---|
| Fire | Clean Fire | 272 | 1360 |
| Fire with Animals Sounds | 272 | 1360 | |
| Fire with Insects Sounds | 272 | 1360 | |
| Fire with Wind Noise | 272 | 1360 | |
| Additional Fire Samples | 272 | 1360 | |
| Recordings | 72 | 360 | |
| No-Fire | Animals Sounds | 276 | 1380 |
| Insects Sounds | 200 | 1000 | |
| Wind Noise | 345 | 1725 | |
| Rain Noise | 211 | 1055 | |
| Sundry Samples | 400 | 2000 |
| Class | Picture Type | Number of Samples |
|---|---|---|
| Fire | Daylight | 1108 |
| Fire | Night | 1212 |
| No-Fire | Snow | 389 |
| No-Fire | Daylight | 1297 |
| No-Fire | Fog | 658 |
| Rain | ||
| Night | ||
| No-Fire | Noise | 396 |
| Audio | Audio | ||
|---|---|---|---|
| NN #1 | NN #2 | ||
| Input Data: | Window Size [s] | 4 | 2 |
| Sliding Temporal | Sliding Step [s] | 2 | 2 |
| Windows | Sampling Frequency [kHz] | 16 | 16 |
| Feature Extraction: Mel-scaled Spectrograms | Temporal Frame Length [s] | 0.050 | 0.050 |
| Sliding Step [s] | 0.025 | 0.025 | |
| FFT Points | 1024 | 1024 | |
| Filterbanks | 40 | 40 | |
| Filterbanks Lowest Frequency [Hz] | 300 | 300 | |
| Noise Floor [dB] | −52 | −72 | |
| CNN Classifier | Architecture | 1-D | 2-D |
| Convolutional-Pooling Layers | 2 | 4 | |
| Convolutional Neurons | 8-16 | 8-16-32-64 | |
| Fully Connected Layers/Neurons | 1/64 | 1/64 | |
| Dropout Layers/Rate | 2/0.5 | 2/0.5 | |
| Activation Function | ReLU | ReLU | |
| Training Algorithm: Backpropagation | Loss Function | CCE | CCE |
| Dataset Rate for Training Set | 0.6 | 0.6 | |
| Dataset Rate for Validation Set | 0.2 | 0.2 | |
| Dataset Rate for Test Set | 0.2 | 0.2 | |
| Learning Rate | 0.005 | 0.005 |
| Model | RAM | Flash | Execution | Overall |
|---|---|---|---|---|
| Occupancy [kB] | Occupancy [kB] | Time [ms] | Accuracy [%] | |
| Audio NN #1 | 16.8 | 72.5 | 6 | 90.890 |
| Audio NN #2 | 38.0 | 119.6 | 89 | 95.375 |
| Picture NN | 283.0 | 162.6 | 43 | 87.495 |
| Audio NN #1 | Audio NN #2 | |
|---|---|---|
| 2 | 2 | |
| 0.808 | 0.940 | |
| TPs | 12/13 | 12/13 |
| TNs | 11/13 | 11/13 |
| FPs | 2/13 | 2/13 |
| FNs | 1/13 | 1/13 |
| Accuracy | 88.5% | 88.5% |
| Recall | 92.3% | 92.3% |
| Precision | 85.7% | 85.7% |
| F score | 88.9% | 88.9% |
| Picture NN | |
|---|---|
| 4 | |
| 0.823 | |
| TPs | 13/13 |
| TNs | 9/13 |
| FPs | 4/13 |
| FNs | 0/13 |
| Accuracy | 84.6% |
| Recall | 100.0% |
| Precision | 76.5% |
| F score | 86.7% |
| Audio NN | Picture NN | VSU Prototype | |
|---|---|---|---|
| TPs | 12/13 | 13/13 | 12/13 |
| TNs | 11/13 | 9/13 | 13/13 |
| FPs | 2/13 | 4/13 | 1/13 |
| FNs | 1/13 | 0/13 | 0/13 |
| Accuracy | 88.50% | 84.60% | 96.15% |
| Recall | 92.30% | 100.00% | 92.30% |
| Precision | 85.70% | 76.50% | 100.00% |
| F score | 88.90% | 86.70% | 96.00% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peruzzi, G.; Pozzebon, A.; Van Der Meer, M. Fight Fire with Fire: Detecting Forest Fires with Embedded Machine Learning Models Dealing with Audio and Images on Low Power IoT Devices. Sensors 2023, 23, 783. https://0-doi-org.brum.beds.ac.uk/10.3390/s23020783
Peruzzi G, Pozzebon A, Van Der Meer M. Fight Fire with Fire: Detecting Forest Fires with Embedded Machine Learning Models Dealing with Audio and Images on Low Power IoT Devices. Sensors. 2023; 23(2):783. https://0-doi-org.brum.beds.ac.uk/10.3390/s23020783
Chicago/Turabian StylePeruzzi, Giacomo, Alessandro Pozzebon, and Mattia Van Der Meer. 2023. "Fight Fire with Fire: Detecting Forest Fires with Embedded Machine Learning Models Dealing with Audio and Images on Low Power IoT Devices" Sensors 23, no. 2: 783. https://0-doi-org.brum.beds.ac.uk/10.3390/s23020783