4.1. Dataset Description
The datasets that are used in the model for evaluation are the KDD-CUP99 and TON_IoT datasets. KDD-CUP99 [
29] is considered a benchmark in the field of Intrusion Detection developed by DARPA. It has a wide range of intrusions mixed with regular connections. It still finds its way into modern intrusion detection applications because of the significance of the dataset. DoS is one of the main targets for this research through this dataset that will be focused on primarily. Researchers use this dataset to develop and evaluate machine learning algorithms for effective intrusion detection in computer networks. More such new datasets have come up, which not only have recent data collection but also have data collection on the Internet of Things (IoT) and the Industrial Internet of Things (IIoT). The TON_IoT dataset [
30] is a new-generation dataset of such things, designed for evaluating cybersecurity applications based on AI and Machine/Deep Learning algorithms. These datasets encompass heterogeneous data from IoT and IIoT telemetry datasets, Windows and Linux operating system datasets, and network traffic datasets. Gathered from a realistic and large-scale network environment at UNSW Canberra, the datasets feature a testbed network with IoT and IIoT networks, along with simulated cyber-attacks like DoS, DDoS, and ransomware. Data sets are available for researchers to discuss and analyze cybersecurity projects. These include intrusion detection, malicious software detection, privacy protection, digital and criminal activity detection, and tracking potential security threats. The VeReMi dataset [
31] is a dataset that suits a VANET architecture and simulates it perfectly for a vehicular attack scenario. The benchmark dataset is a standard dataset that consists of various attacks, but for our use, we have combined all attacks into one class. The purpose of combining all attacks is to create an environment that has two classes: the attack class and the normal class.
It is clarified that the KDD-CUP99 is an older dataset, and the nature of the network has evolved since then. Our intention behind using it was to check our algorithm’s performance on diverse datasets, including legacy data. Similarly, the TON_IoT dataset was used as a more recent dataset to see how our algorithm performs with contemporary network traffic. It has been clarified that two of the datasets are not directly representative of the VANET environment. However, our aim was to show that our method’s applicability is not limited to a specific type or era of network traffic. To emulate the VANET environment, we have used the VeReMi dataset.
4.2. Experiment Setup
Our experimental setup is backed by a robust Intel (R) Core (TM) i7-8700 CPU (IBM India, Delhi, India) clocked at 3.20 GHz. The system boasted 16 GB of RAM, ensuring efficient multitasking and data handling. Furthermore, the presence of a 256-GB SSD is used for faster data access. The experiments were performed on a Windows 11 operating system using MATLAB 2019a. ReLU is used as an activation function. For training the model, we adopted a learning rate of 0.001 and tested with different epochs, i.e., 100, 200, 300, 400, and 500. All calculations were batch-processed in blocks of 512 for better convergence.
4.3. Performance Analysis
The performance of the CCNN-SA-BiLSTM is analyzed, and its results are compared to those of internal adaptations and variations of our proposed algorithm, i.e., CCNN-BiLSTM, CCNN-LSTM, and other established algorithms, CNN-LSTM, CNN-GRU (Gated recurrent unit), and 3-LSTM. Evaluation of the suggested model’s efficacy is carried out in terms of NPV, FPR, FNR, and MCC, as well as Accuracy, Precision, Recall, Sensitivity, and Specificity. Performance is evaluated using a Confusion Matrix, which includes metrics such as ACC (Accuracy), PRE (Precision), SEN (Sensitivity), SPE (Specificity), F_M (F-measure), NPV (Negative Predictive Value), FPR (False Positive Rate), FNR (False Negative Rate), and MCC (Matthew’s correlation coefficient). With the help of individual metrics, a confusion matrix is leveraged at the end to provide a consolidated view of the model’s performance. The methodology for calculating these metrics is described in detail in this section.
Accuracy
The percentage of accurately predicted cases in all examples is used to measure accuracy.
- 2.
Precision
Precision is a helpful indicator of how precisely the positive chemicals are expected because it indicates the percentage of correctly anticipated positive cases in all test findings.
- 3.
Sensitivity
By dividing the total positives by the percentage of genuine positive forecasts, one may determine the sensitivity number, also referred to as Recall.
- 4.
Specificity
The percentage of successfully predicted negative outcomes over all negative outcomes is known as specificity.
- 5.
F-Measure
In order to ensure that each class only contains a single sort of data item, the F-Measure number strikes a compromise between fully identifying all data bits and doing so.
- 6.
Matthew’s correlation coefficient (MCC)
A binary two-by-two variable association measure is the MCC, also called the Phi Coefficient.
- 7.
Negative Prediction Value (NPV)
The performance of a diagnostic test or similar quantitative metric is described by NPV.
- 8.
False Positive Ratio (FPR)
The false positive rate is derived by dividing the total number of negative events by the total number of negative events that were incorrectly labeled as positive (false positives).
- 9.
False Negative Ratio (FNR)
The “false-negative rate,” sometimes known as the “miss rate,” is the probability that the test will fail to identify a real positive.
The results in
Table 2 show that the proposed CCNN-SA-BiLSTM model outperforms all other models on the KDD’99 dataset. It achieves a high sensitivity of 99% and a high specificity of 100%, indicating its ability to accurately detect both true positive and true negative instances. The overall accuracy of the proposed model is 99%, demonstrating its capability to correctly classify intrusion and non-intrusion instances. Furthermore, the precision of CCNN-SA-BiLSTM is 99%, indicating that the model is effective at identifying positive instances while minimizing false positives. The F-measure of 99% confirms the model’s balanced performance between precision and sensitivity. Additionally, the NPV of 99% suggests that the model accurately identifies non-intrusion instances. The proposed model also exhibits an exceptional MCC of 98%, indicating a strong correlation between predicted and true values. Moreover, the FPR and FNR values are impressively low at 0% and 1%, respectively, signifying minimal misclassifications of positive and negative cases.
Table 3 presents the performance comparison of intrusion detection models on the TON_IoT dataset. The results demonstrate that the proposed CCNN-SA-BiLSTM model maintains a high level of performance on the TON_IoT dataset. It achieves a sensitivity of 99% and a specificity of 99%, indicating its ability to accurately detect both positive and negative instances of intrusion. The overall accuracy of the model is 99%, showcasing its capability to correctly classify instances in the dataset. Moreover, the precision of CCNN-SA-BiLSTM is 99%, highlighting its effectiveness in identifying positive instances while minimizing false positives. The F-measure of 99% further corroborates the model’s balanced performance between precision and sensitivity. Additionally, the NPV of 99% indicates its proficiency in accurately identifying non-intrusion instances. Furthermore, the MCC value of 98% suggests a strong correlation between the predicted and true values, indicating the model’s reliability in making accurate predictions. The FPR and FNR values are both low at 1%, indicating a minimal rate of misclassification for both positive and negative instances. Among the existing models, CCNN-BiLSTM shows the closest performance to the proposed model, with high sensitivity, specificity, and accuracy scores. However, the proposed CCNN-SA-BiLSTM model outperforms all other models across most metrics, demonstrating its superior intrusion detection capability on the TON_IoT dataset.
Table 4 presents the performance comparison of various algorithms; the Proposed Algorithm exhibited an accuracy of 98.6%. Its precision and sensitivity stood at 97.8%, with an F-measure of 96.1% [
35]. While CNN-LSTM [
36] registered a high precision of 99.6%, its sensitivity was slightly lower at 95.6%, resulting in an F-measure of 97.6%. The CCNN-BiLSTM method followed closely, with metrics showing 97.2% accuracy, 96.3% precision and sensitivity, and a 93.4% F-measure. The CCNN-LSTM showed a similar performance, with 97.1% accuracy and an F-measure of 92.1%. Among the methods, 3-LSTM [
36] had the lowest metrics, with 95% accuracy and an F-measure equal to its sensitivity of 94.95%.
It is evident that while the Proposed Algorithm and CNN-LSTM [
36] perform closely, the former provides a more balanced performance across all metrics.
4.4. Graphical Representation
The performance comparison between the current models and the suggested model for KDD’99, TON_IoT, and VeReMi datasets are shown graphically in
Figure 4,
Figure 5,
Figure 6,
Figure 7,
Figure 8,
Figure 9,
Figure 10,
Figure 11 and
Figure 12. The
y-axis displays the values of the performance metrics, while the
x-axis indicates the various models. Each statistic is represented by two subplots in the graph, one for KDD’99 and the other for the TON_IoT dataset. The graph shows that the suggested model performs better than the current models across all performance criteria for the two datasets. The suggested model’s accuracy is superior to the current models for both datasets. For both datasets, the suggested model’s FNR and FPR are lower than those of the current models. For KDD’99, the suggested model outperforms the current models in terms of MCC and NPV, but for the TON_IoT dataset, the proposed model outperforms the existing models in terms of MCC and NPV. The suggested model has better Precision, Sensitivity, and Specificity than the current models for both datasets. The VeReMi dataset is considered in
Figure 9.
Figure 4a, b represents the sensitivity and specificity of the KDD’99 and TON_IoT Datasets. The balance between true positive and true negative is shown using this graph, wherein the proposed model (CCNN-SA-BiLSTM) performed better than others.
Figure 5a, b represents the accuracy and precision of the different models on different datasets. It shows the overall classification of the model. The accuracy of the proposed model is the best among all the models, which is attributed to the Bidirectional nature of the model, which considers both past and future data and results in good predictions.
Figure 6a, b represents the Recall and NPV results, indicating the importance of identifying True Positives and True negatives. The high result indicates the extent to which the model was able to identify both factors. CCCN-SA-BiLSTM outperforms the other models by a margin of 1%. The identification of mistakes made by the classifier is equally important, as it helps in tuning the model’s threshold for classification.
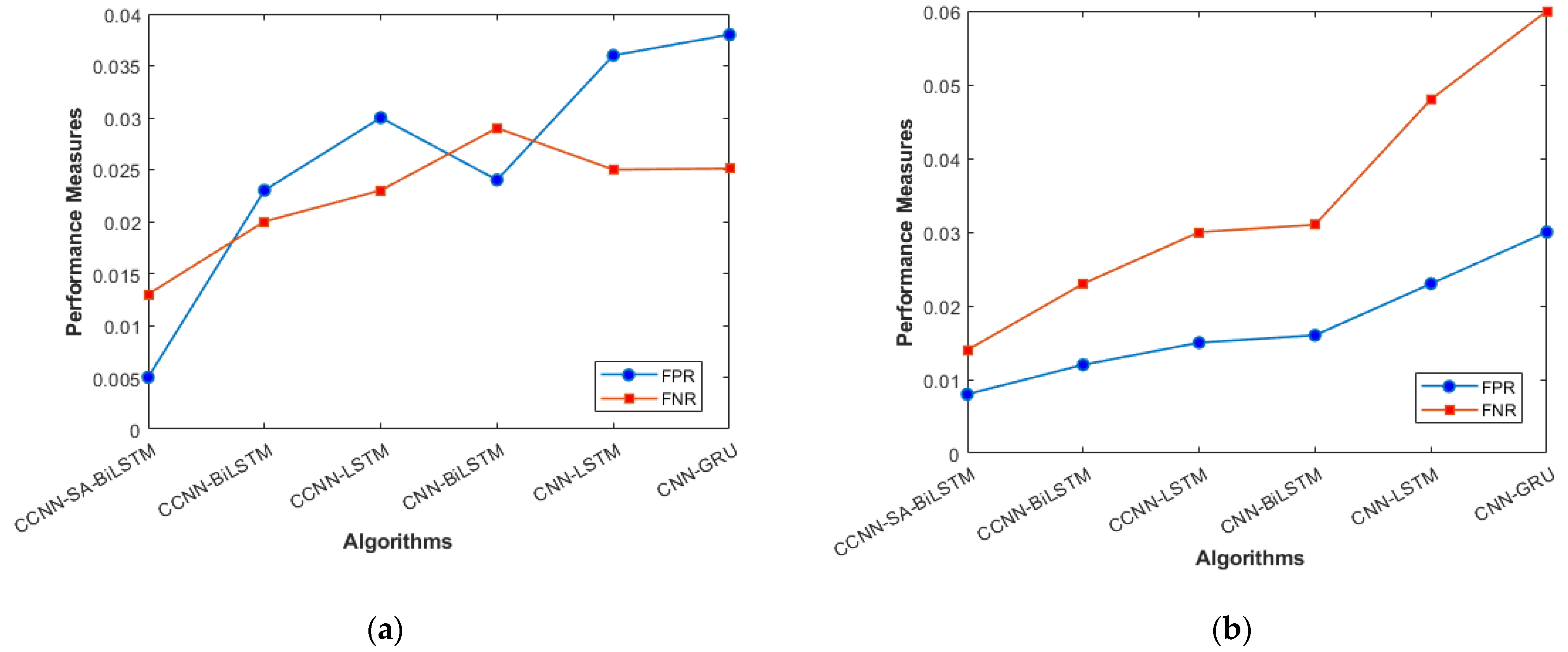
Figure 7a, b are used for this purpose, and the metrics used here are False Positive Rate and False Negative Rate.
The overall holistic view of the model is finally represented by F_Measure and MCC, which are represented in
Figure 8a, b. The overall balance between precision, Recall, and correlation is shown, and the model (CCNN-SA-BiLSTM) performed better than the others. The classes are balanced, which is one of the factors that leads to low FPR and FNR for our proposed work, which can be seen in
Figure 11 as well. The cascaded CNN captures the hierarchical features effectively, reducing the FPV and FNV significantly. The self-attention mechanism in our work enhances the long-term dependencies, which leads to better results when compared with other existing models.
Figure 9a represents the accuracy and precision of proposed and existing models. The accuracy of our model stands at 98.6%, which slightly outperformed the CNN-LSTM model by less than 1%. The LSTM model surely improves the accuracy of the model in the VANET architecture, as can be seen in
Figure 9. The addition of the Self- attention Layer has given some edge to our model in terms of accuracy, but when compared with precision metrics, CNN-LSTM has an advantage over the proposed model.
Figure 9b talks about the sensitivity and F_Measure of the models. The stacked 3-LSTM performs the lowest among all the models. The cascaded way of using LSTM does not improve the result as much as cascaded CNN, which is evident in the graph when sensitivity is taken into consideration.
A performance comparison of accuracy between the proposed and existing models is presented in
Table 5 and
Table 6.
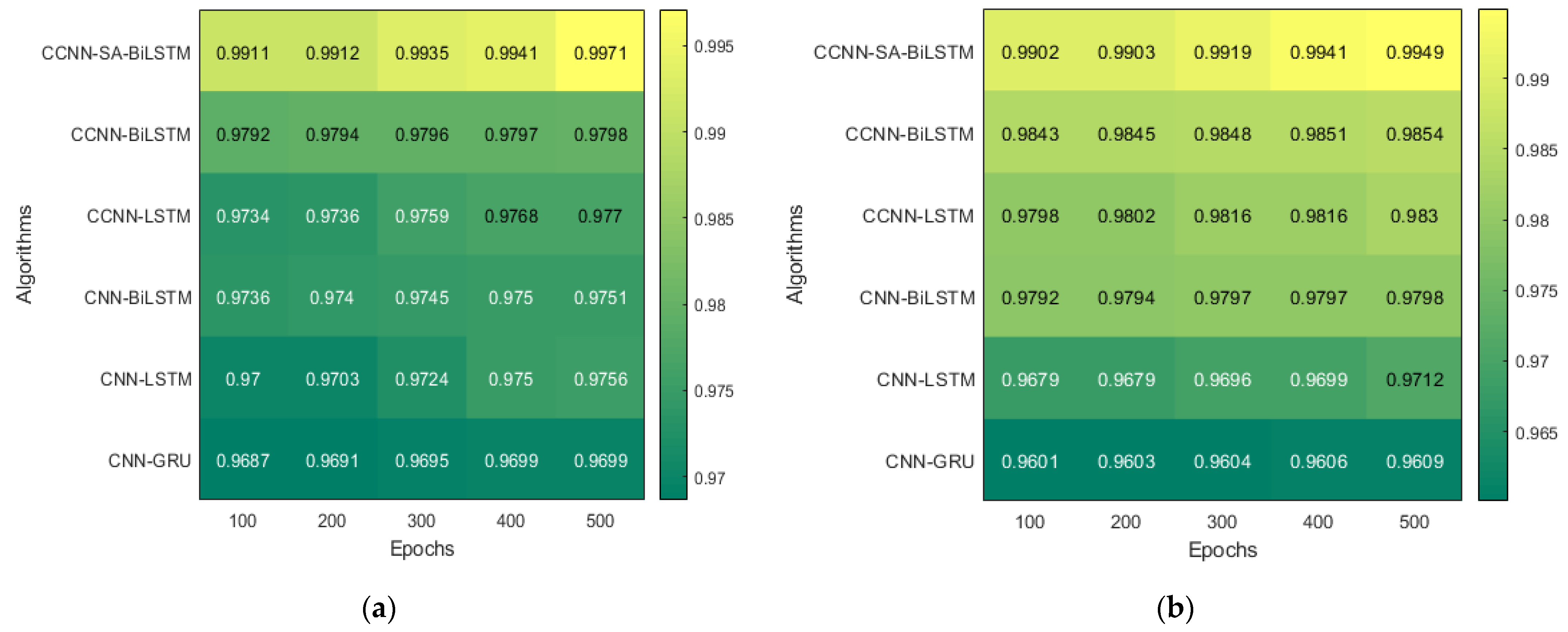
The model runs for five different Epoch values, and the result pertaining to that is mentioned above. The result with a 500-epoch value showed promising results in both datasets. These tables illustrate the variations in performance (accuracy) across different epochs for the KDD’99 and TON_IoT datasets, respectively. The accuracy improved as the epochs were increased, which helped the model converge at a better local minimum value. Further, an increase in epoch would have resulted in overfitting of the dataset.
The heatmap shown in
Figure 10, extracted from
Table 5 and
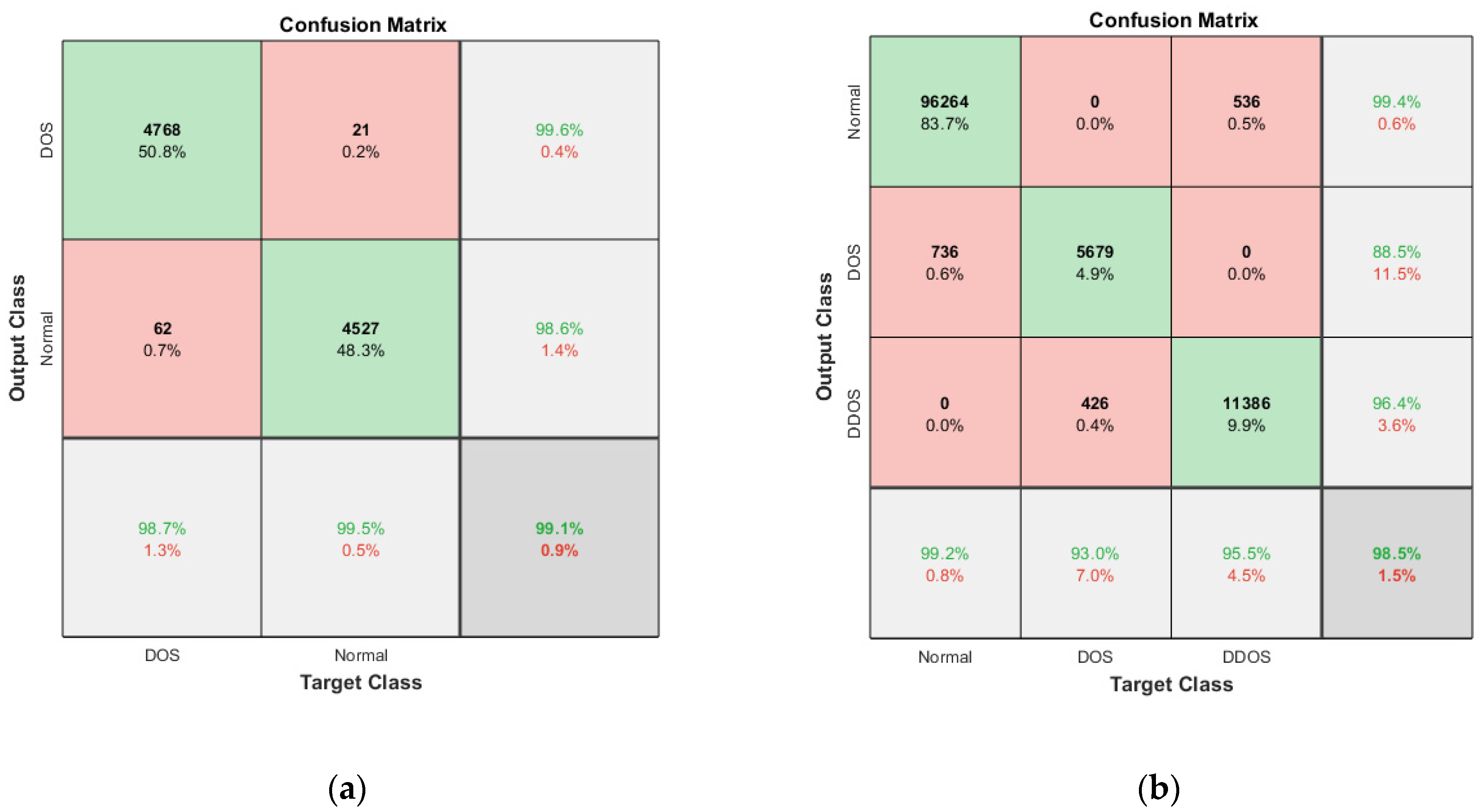
Table 6, shows the accuracy with five different epochs, where (a) represents KDD’99 and (b) represents the TON_IoT dataset. The accuracy of the DoS class in the KDD’99 dataset as per the confusion matrix is 99.6%, whereas that of the normal class is 98.6%, as represented in
Figure 10a.
Likewise, for the TON_IoT Dataset, the accuracy of the Normal class is 99.4%, and that of the DoS and DDoS classes is 88.5% and 96.4%, as represented in
Figure 11b. The low values of False Positive and False negative help achieve good performance in the model. The class imbalance factor is also taken into consideration, as can be seen in the table, where a roughly equal distribution of all the classes is present in the model. Thus, the proposed model exhibits robust performance on the given datasets.
Additionally,
Figure 12 illustrates the RoC curve, with (a) denoting KDD’99 and (b) representing TON_IoT. The RoC plots the true positive rate against the false positive rate at various thresholds. In KDD’99, the AUC value is nearing 1, representing the classifier is good at differentiating among both the classes, whereas in TON_IoT, one vs. all analysis is used, wherein the first normal class is taken as positive and the rest as negative, the next being DoS vs. all, and finally DDoS vs. all. The AUC of 0.98, 0.975, and 0.965 represent that the model is able to clearly distinguish between the classes and represents good model performance.
The performance of the CCNN-SA-BiLSTM is attributed to the integration of the SA mechanism with the BiLSTM. The self-attention mechanism enables the model to focus on the most relevant features, while the bidirectional nature of the LSTM captures patterns from both past and future time steps. This combination allows for a more comprehensive feature understanding, leading to better classification performance as compared to other methods. The result is supported by the different metrics discussed above, and the results for the same are depicted via graphs.

 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}