1. Introduction
Diagnosis of chronic diseases is essential in the healthcare field as these diseases persist for a long time. The major chronic diseases include diabetes, cardiovascular disease, kidney problem, cancer, and stoke. Classification of the disease helps in taking precautionary actions, and effective treatment at an initial stage found to be helpful for patients [
1].
Principal component analysis (PCA) a trendy method for data reduction, found to be a useful step in classification [
2]. PCA and machine learning methods were successfully applied in medical domains, for example, in the diagnosis of diabetes aspects, therapy, prognostics of recurrence of breast cancer, localization of a primary tumor, and diagnosis of thyroid diseases. Polytomization of variables may occur in situation categorical variables are of multiple outcomes, for more subjective assessment and evaluation, as the factors scores obtained from binary variables are linearly related [
1,
2,
3].
As a chronic disease, diabetes mellitus is assuming pestilence proportion worldwide, by affecting developed and underdeveloped countries at the same time [
4]. The most recent prevalence figure published by the International Diabetes Federation is 425 million people living with diabetes mellitus worldwide, with almost 50% non-diagnosed cases [
5].
The disease is characterized by high blood glucose. Failure of the pancreas to produce enough insulin and the body’s inefficient use insulin are both pathologic causes of diabetes. Diabetes cannot currently be cured, but only controlled through medication and treatment. Other chronic diseases include hypertension, cardiovascular diseases, kidney problems, and eye problems [
6].
Some factors might cause diabetes or increase the risk of the disease. Treatment options can be scientifically advanced on a microscopic and genetic level, through interactions of glucose and insulin in the metabolic system and to macroscopic factors such as social and lifestyle elements, all of which contribute to the disease itself [
7].
According to the authors of [
8,
9], obesity is one of the contributory factors for diabetes. Obesity is a situation of having a body mass index (BMI) more than 30.
Nevertheless, those with a lower BMI but who have a large percentage of body fat, mainly centered on their waist, are also at high risk. Besides this, additional contributory factors of diabetes include high blood pressure history patents, heart attack, or stroke [
10,
11]. Also, if a family member has had diabetes, the risk is increased [
12].
Higher risk of cardiovascular diseases including heart disease, angina and stroke, among others, could be associated with diabetes. As a result of excess glucose in the blood, leaving the body via kidneys may increase risk of kidney problem and related diseases. Kidney problems account for almost 16% of all deaths in diabetics [
13].
Eye problem-related diseases, as well as being affected by diabetes and retinopathy, are persistent in patients with long term history of diabetes as the leading cause of preventable loss of sight [
14].
PCA is a popular technique for data dimension reduction, which, in turn, is a necessary step in classification [
15]. By predicting the data onto the dominant eigenvectors, the dimension of the original dataset can be reduced with little or no loss of information.
Asymptotic theory for principal component analysis was developed by [
16]. The method demonstrates the uses of principal component analysis. The steps include selecting and measuring a set of variables, preparing the correlation matrix, extracting a set of factors from the correlation matrix, determining the number of factors, rotating the elements, and interpreting the results.
In his book [
17], PCA was presented in different fields such as agriculture, biology, ecology, finance, health, taxonomy, and architecture. In the same way, PCA also was applied to multispectral-multimodal optical image analysis for malaria diagnostics [
18].
In this paper, we consider an approach that combines data mining techniques and PCA, to approaches polytomous variable-based classification of diabetes mellitus and other chronic diseases. The remaining paper is structured as follows.
Section 2 presents the material and methodology; after,
Section 3 reviews the results,
Section 4 discusses the results, and
Section 5 concludes the findings.
2. Materials and Methods
2.1. Ethical Approval
The Research approved by the Natural Science Foundation of China Hebei province, the Yanshan University ethics committee. Also, all procedures performed in studies involving human participants were under the 1964 Helsinki declaration.
Besides, ethical clearance was also granted by the seven northwestern states of Nigeria. From their respective Ministry of Health; Jigawa, Kano, Kaduna, Katsina, Kebbi, Sokoto, and Zamfara States, with grant codes FMC/BKD/CLN/HREC/138, MOH/ADM/744/VOL.I/558, MOH/OH/797/T.I/456, MOH/ADM/SUB/1152/214, MOH/SUB/4679/I, SMH/1580/V.IV, and HSMB/SUB/540/VOL.I, respectively. All participants provided written informed consent after having all procedures explained to them.
2.2. Data Source
Real-life data were collected from both primary and secondary sources, in the northwestern states of Nigeria. The author distributes questionnaires to both diabetes and other chronic diseases patients. He also asked the verbal interview to those who could not write, with the help from the hospital staff.
Some part of the hospital’s record related to diseases symptoms and their complications also used. The dataset comprises 281 observations and 34 attributes for this particular research.
2.3. Data Description
The dataset used for this research purpose contains 281 observations and 34 attributes on the diabetes mellitus and other chronic diseases patients.
The attributes’ information is as follows.
AGE—Patient’s age (numeric).
GLU—Patient’s glucose level (numeric with range of 3.9 to 7.2 mmol/L normal and >7.2 mmol/L diabetic).
DBP—Patient’s diastolic blood pressure (numeric: <80 mmHg normal, 80 to 120 mmHg hypertensive and >120 mmHg crisis).
BMI—Patient’s body mass index (numeric: <18.5 kg/msq underweight, from 18.5 to 25 kg/msq normal, 25 to 30 kg/msq overweight, and >30 kg/msq obese).
WGT—Patient’s weight (numeric).
OCP—Patient’s occupation status (numeric: 1—student, 2—housewife, 3—others, 4—civil servant).
SEX—Patient’s sex (categorical: M—male and F—female).
DIT—Diet took by the patient (categorical: NBD—not a balanced diet; BLD—balanced diet).
MST—Patient’s marital status (categorical: SG—single, MR—married, SP—separated, DV—divorced, and WD—widowed).
DCD—Patient’s diabetes condition (categorical: IND—insulin dependent, NID—non-insulin-dependent and GTD—gestational).
RSB—Patient’s residential Suburb (categorical: VL—village, TW—town and CY—city).
LOE—Patient’s level of education (categorical: NE—not go to school, PE—primary school, HE—high school, CE—college/university, PG—postgraduate, and IE—Islamic school).
EXT—Excessive thirst (binary yes or no).
FRU—Frequent urination (binary yes or no).
WLG—Weight loss or gain (binary yes or no).
FLS—Flulike symptoms (binary yes or no).
BRV—Blurred vision (binary yes or no).
IRT—Irritability (binary yes or no).
SHC—Slow healings on cut or bruise (binary yes or no).
TLF—Tingling or loss of feeling in hand or feet (binary yes or no).
RIV—Recurring infection on gum or skin (binary yes or no).
RIV—Recurring vaginal/bladder infection (binary yes or no).
SFH—Swelling on the ankle, fit or hand (binary yes or no).
VMT—Vomiting (binary yes or no).
FTG—Fatigue (binary yes or no).
SCE—Spiders, cobwebs or specks in the eye (binary yes or no).
DRV—Dark streaks or red that blocks vision (binary yes or no).
EYP—Eye pain (binary yes or no).
PCJ—Pain in chest, jaw, or arm (binary yes or no).
SOB—Shortness of breath (binary yes or no).
SWG—Swelling (edema) (binary yes or no).
NRV—Nervousness (binary yes or no).
HIT—Heat intolerance (binary yes or no).
SBF—Slowing in body function (binary yes or no).
2.4. Diabetes Mellitus
Diabetes is a chronic disease that occurs either when the pancreas does not produce enough insulin or when the body cannot efficiently use the insulin it produces. Insulin is a hormone that controls blood sugar. Hyperglycemia or higher blood sugar is a common effect of uncontrolled diabetes and, over time, leads to severe damages in the entire human body’s systems [
19].
The diabetes conditions include type I diabetes, also known as “Insulin-dependent” (IND). It is characterized by beta cell destruction caused by an autoimmune process, typically leading to absolute insulin deficiency. Ultimately, all IND patients will require insulin remedy to maintain normglycemia.
Type II diabetes is also known as “Non-insulin-dependent” (NID). The most common form of diabetes mellitus and is highly associated with a family history of diabetes, older age, obesity and lack of exercise. NID comprises 80% to 90% of all cases of diabetes mellitus. Primarily individuals with Type 2 diabetes exhibit intra-abdominal (visceral) obesity, which is directly related to the presence of insulin resistance, in addition to hypertension and dyslipidemia.
The disorder identified in women who develop IND during pregnancy, and women with undiagnosed asymptomatic NID discovered during pregnancy classified as Gestational Diabetes (GTD) [
19,
20].
Diagnostic criteria for diabetes: fasting plasma glucose ≥ 7.0 mmol/L or 2-hour post-load plasma glucose ≥ 11.1 mmol/L or Hba1c ≥ 48 mmol/mol. For gestational diabetes: fasting plasma glucose 5.1–6.9 mmol/L or 1-hour post-load plasma glucose ≥ 10.0 mmol/L or 2-hour post-load plasma glucose 8.5–11.0 mmol/L [
19].
In some countries of low and middle incomes, use the most straightforward test that does not require fasting before taking the test, if 200 or more than 200 mg/dl of blood glucose it probably indicates diabetes but has to be reconfirmed [
20].
2.5. Sampling Procedure
The sampling procedure used in distributing the questionnaires and determining the sample sizes is a probability cluster sampling process at the beginning. The entire populations were divided into clusters, which is allied with a selection of a subset of individuals from the populace to estimate the characteristics of the entire population [
21]. All the attributes determine one or more properties of the observable subjects distinguished as independent individuals.
The nonprobability sampling procedure was also applied. It is a process by which a researcher selects a sample based on subjective judgment rather than random selection. Thus, not all the members of the population have the same equal chance of participating in the study, unlike the probabilistic method.
The northwestern part of Nigeria comprises of seven states. We divide each state into three clusters according to their senatorial zones (i.e., central, north, and south). Own government hospitals were chosen in each group from the six states; whereas, in Kano State, we double the number due to its population.
This particular research is ongoing from 2017 until 2019. Presently, we collected the data from Jigawa, Kano, Katsina, Zamfara, and some part of Sokoto states. The hospitals covered Ajingi General Hospital (Kano State), Murtala Muhammad Specialist Hospital (Kano State), Abdullahi Wase Specialist Hospital (Kano State), Sir Muhammad Sunusi General Hospital (Kano State), Gaya General Hospital (Kano State), Gwarzo General Hospital (Kano State), Federal Medical Centre Birnin-Kudu (Jigawa State), Hadejia General Hospital (Jigawa State), Gumel General Hospital (Jigawa State), Katsina General Hospital (Katsina State), Daura General Hospital (Katsina State), Malumfashi General Hospital (Katsina State), Gusau General Hospital (Zamfara State), TalataMafara General Hospital (Zamfara State), KauraNamoda General Hospital (Zamfara State), and Bodinga General Hospital (Sokoto State).
2.6. Categorization of Continuous Variables
Continuous variables (CVs) encountered in many situations. CVs such as age, body mass index, blood glucose level, blood pressure, and many other things were measured. To relate an outcome variable to a single continuous variable, an appropriate regression model is essential.
CVs may be converted into categorical variables by grouping values into two or more categories. Dichotomize continuous variables occur in one of two possible states, which can label as zero and one, e.g., “improved/not improved”, “completed task/failed to complete the task”, etc. In a situation whereby the grouping of variables is more than two categories, referred to as polytomous continuous variables [
22].
There are several advantages of dichotomizing continuous variables, but these no statistical grounds [
23]. The most common argument seems to be simplicity. Placing all individuals into two groups is extensively perceived to greatly simplify statistical analysis and lead to straightforward interpretation and presentation of results.
From the literature point of view, it has observed that dichotomization of variable had been criticized extensively [
22,
23,
24,
25,
26]. According to the authors of [
27], when the real risk increases (or decreases) monotonically with the level of the variable of interest, the apparent spread of risk will increase with the number of groups used. With only two groups, one may seriously underestimate the extent of variation in risk. This means that when individuals are divided into just two groups, considerable variability may subsume within each group.
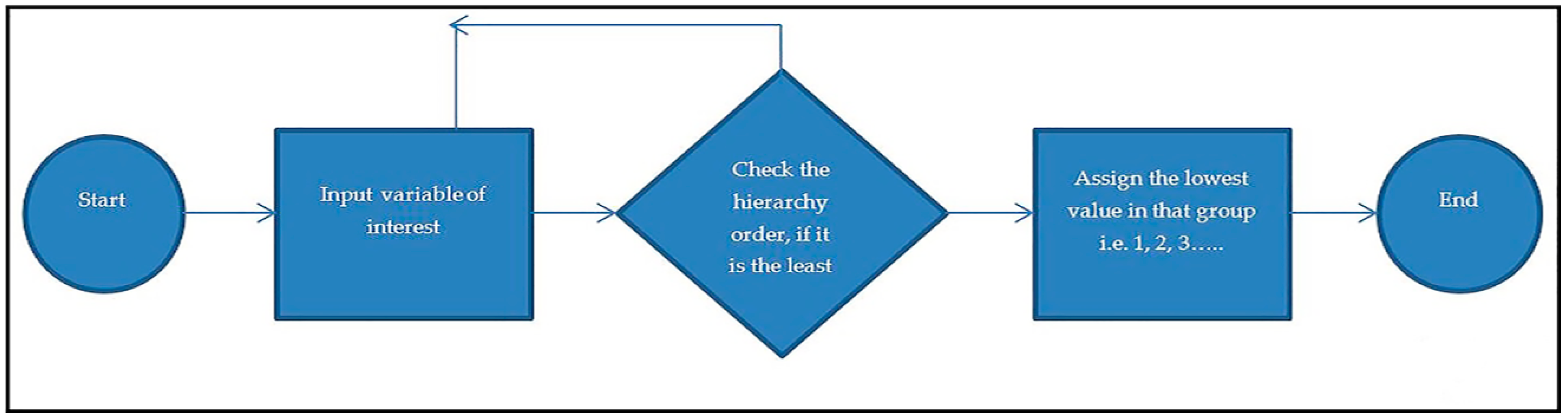
Therefore, the study adopts the grouping of categorical variables to be polytomous, except where they are naturally dichotomous. The procedures involved presented by the flowchart as in
Figure 1.
A proposed polytomous categorization of variables procedures executed in java codes, the process involved in classifying the variables implemented in “if-else-if statement” algorithm. The algorithms perform the tasks and screen each categorical variable before assign to the appropriate group.
The study achieved seven if-else-if statements for the classification process by successfully categorizing seven different categorical variables. Data flow for the categorized variables of interest presented below in
Figure 2.
2.7. Principal Component Analysis
Principal component analysis is a high utility multivariable analysis (MVA) technique used in summarizing the information contained in a continuous multivariable dataset, by reducing the dimension of the dataset without losing useful information. PCA is aimed to identify a hidden pattern in any given dataset, reduce redundancy and eliminate noise.
PCA works in a highly correlated environment. So, it selects a set of variables that are highly dependent with each other, but at the same time, they are entirely uncorrelated with different subsets of variables which are combined to form a factor.
The basic idea here is that these newly formed factors drive the fundamental process due to which the variables in the data set are thought to correlate with each other. The specific goals are to summarize patterns of correlations among observed variables, to reduce a large number of observed variables to a smaller number of factors, and to provide an outfitted definition for an underlying process by using observed variables [
28]. The PCA model is based on the following model,
where
i,
j = 1, 2, 3, …,
p.
The correlation matrix for the complete data based on the sizes of some correlation place constraints on the sizes of others. In particular,
2.8. Software Programming Language
The programming software used for the experiments are free open programming software for programming, statistics, and graphics. This was developed by Ross Ihaka and Robert Gentleman at the University of Auckland in New Zealand, the name (R) came from their respective first names [
29], and can be accessed online via
http://www.r-project.org. Also, an object-oriented programming language (java platform) was used in the process of categorizing the variables.
3. Result
In this study, a combine data mining and PCA techniques prompted on the real-life dataset. The dataset of 281 patients suffering from diabetes mellitus and related diseases were collected from the northwestern part of Nigeria. The results presented in both figures and tables below.
Table 1 presents descriptive statistics of some attributes and their prevalence among 281 instances. These are diabetic conditions (DCD) with three different states, average patients’ weight in respect to DCD, and patients’ age grouped with DCD.
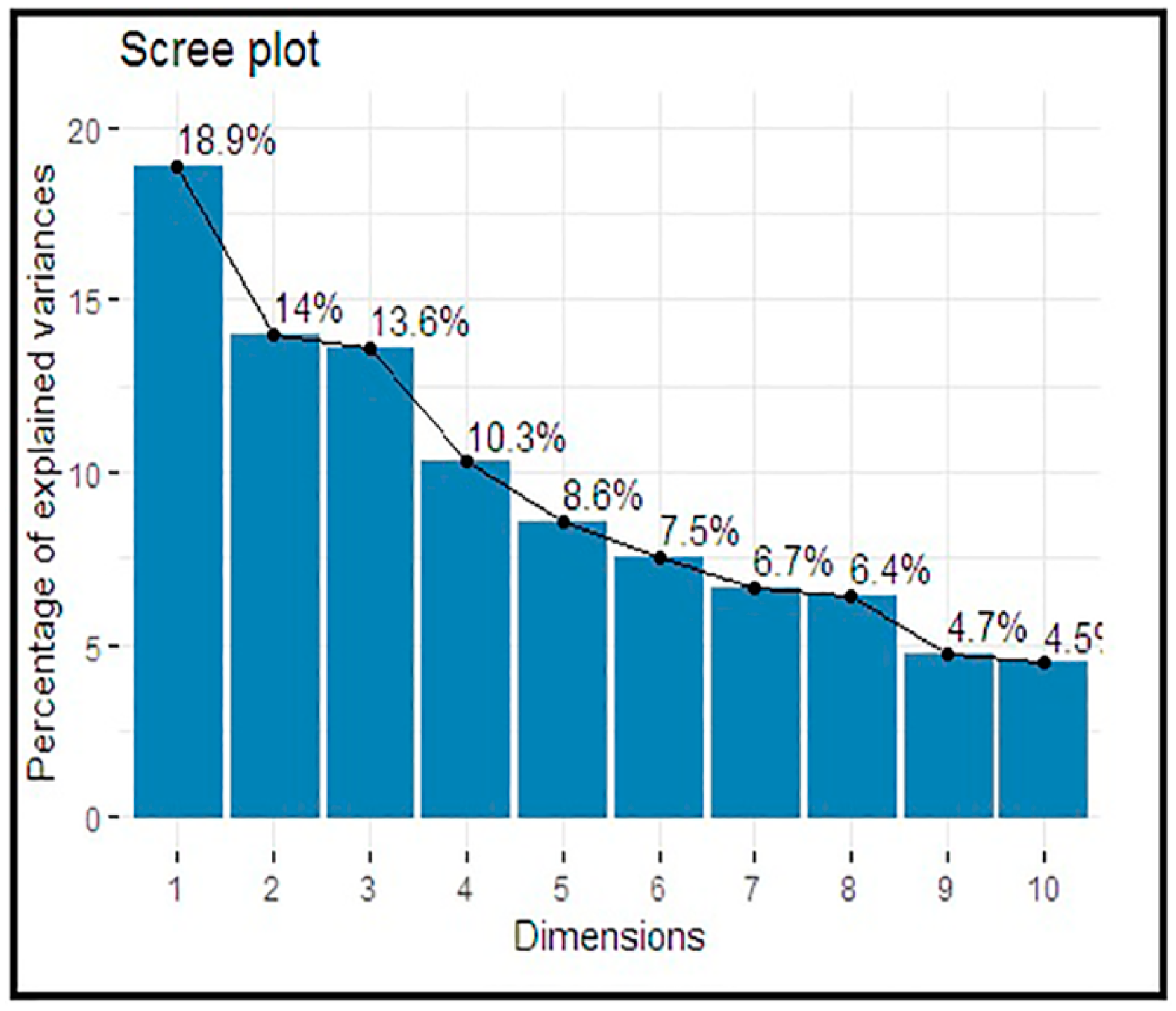
Table 2 presents the eigenvalues and the percentages of the explained variances for the principal component analysis results accounted in each principal component (PC). The amount of variation defined by each eigenvalue has shown in the second column. The value 2.264 divided by 12 equals 0.189, or the first eigenvalue explains ~18.9% of the variation.
The cumulative percentage explained is given in the last column. The first five (5) components out of twelve (12) have their eigenvalue above one (1) and are large enough to be retained. Their explained variances are 18.9%, 14.0%, 13.6%, 10.3%, and 8.6%, respectively, and thus described 65.38% of the total variance.
Figure 3 represents a Scree plot for the percentage of explained variances by each component.
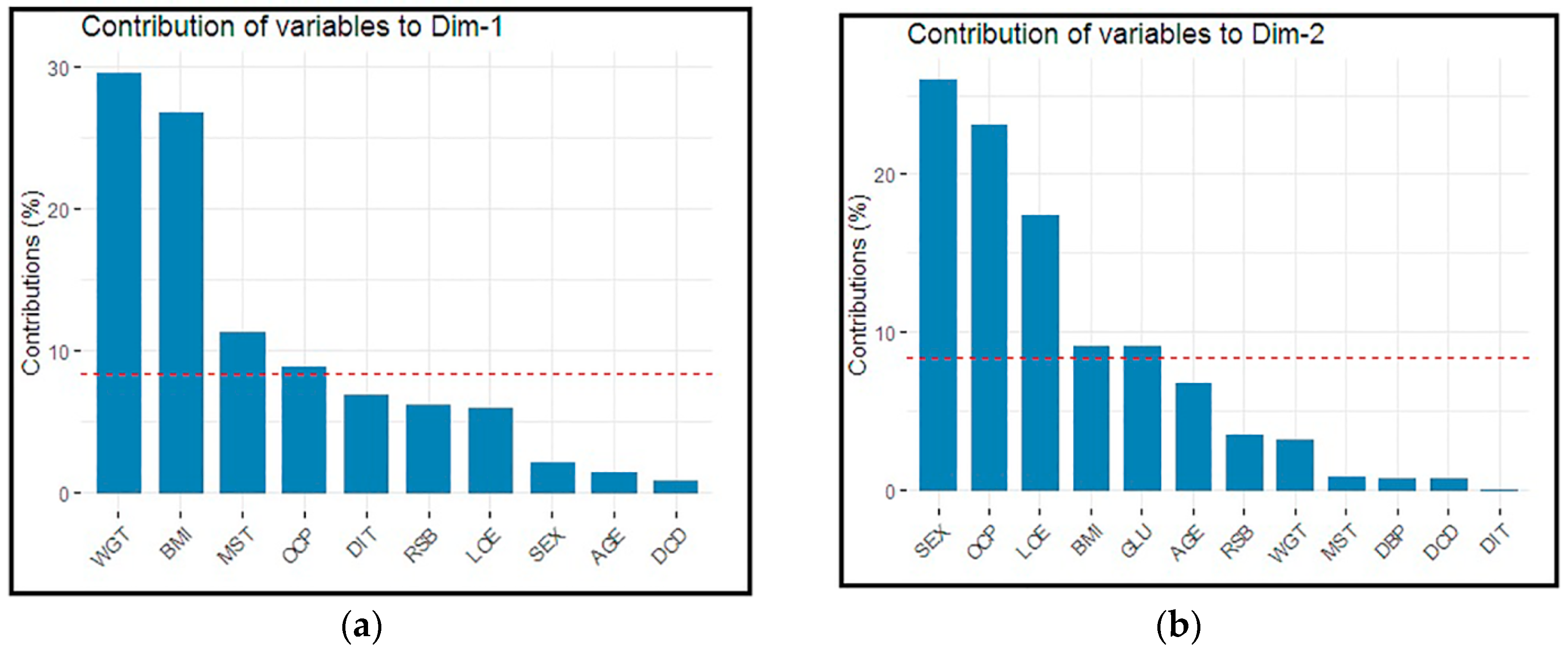
Figure 4a represents bar plots for the individual variables contribution to PCs in dimension one (Dim-1). For example, the variable “WGT” contributed the highest percentage, followed by BMI, etc.
Figure 4b represents bar plots for the individual variables contribution to PCs in dimension 2 (Dim-2). For example, the variable SEX contributed the most significant percentage followed by OCP, etc.
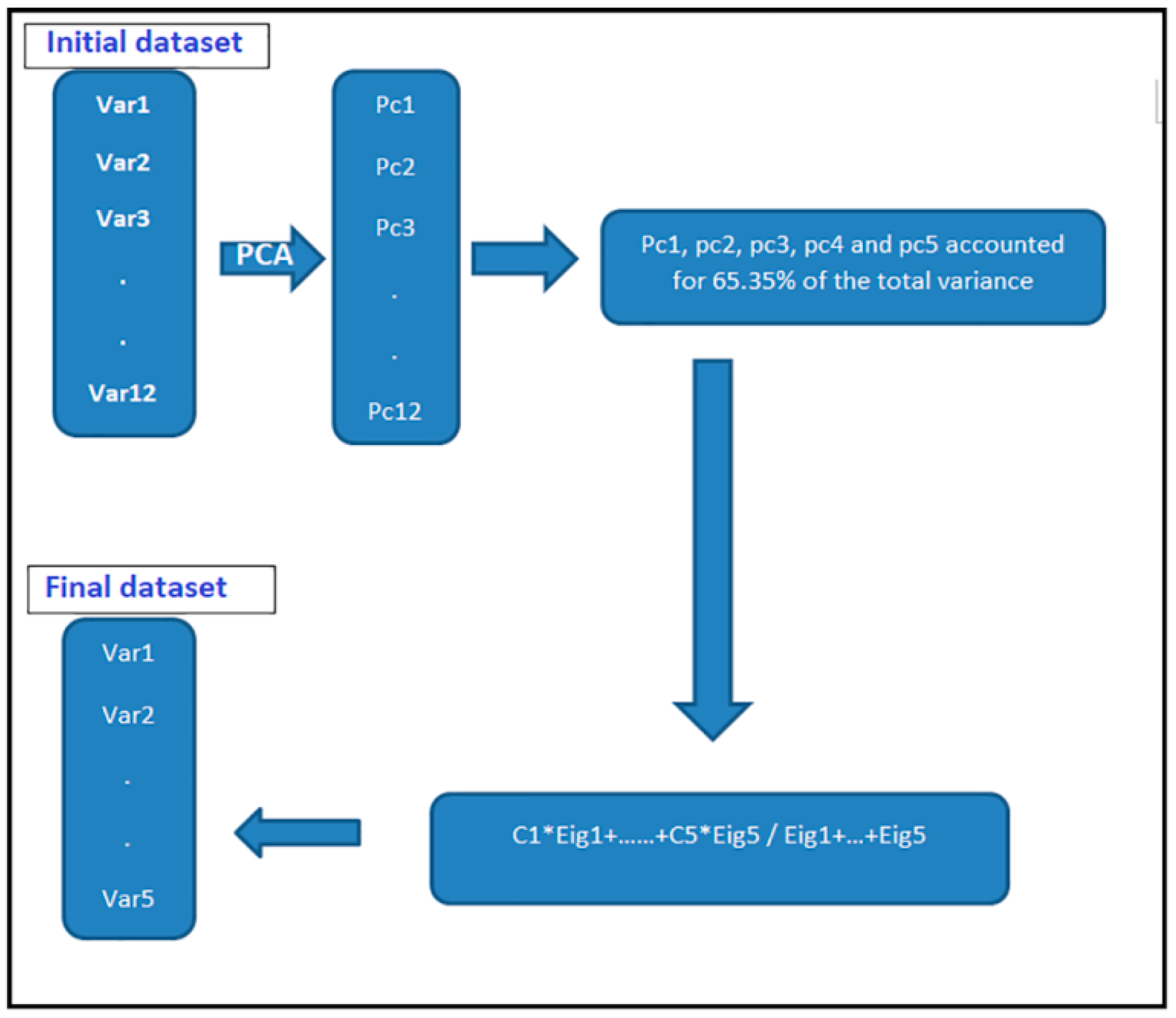
Figure 5 below, represents a data reduction process flow, at the initial stage, twelve variables entered, and in the final stage, the dataset reduced to five variables.
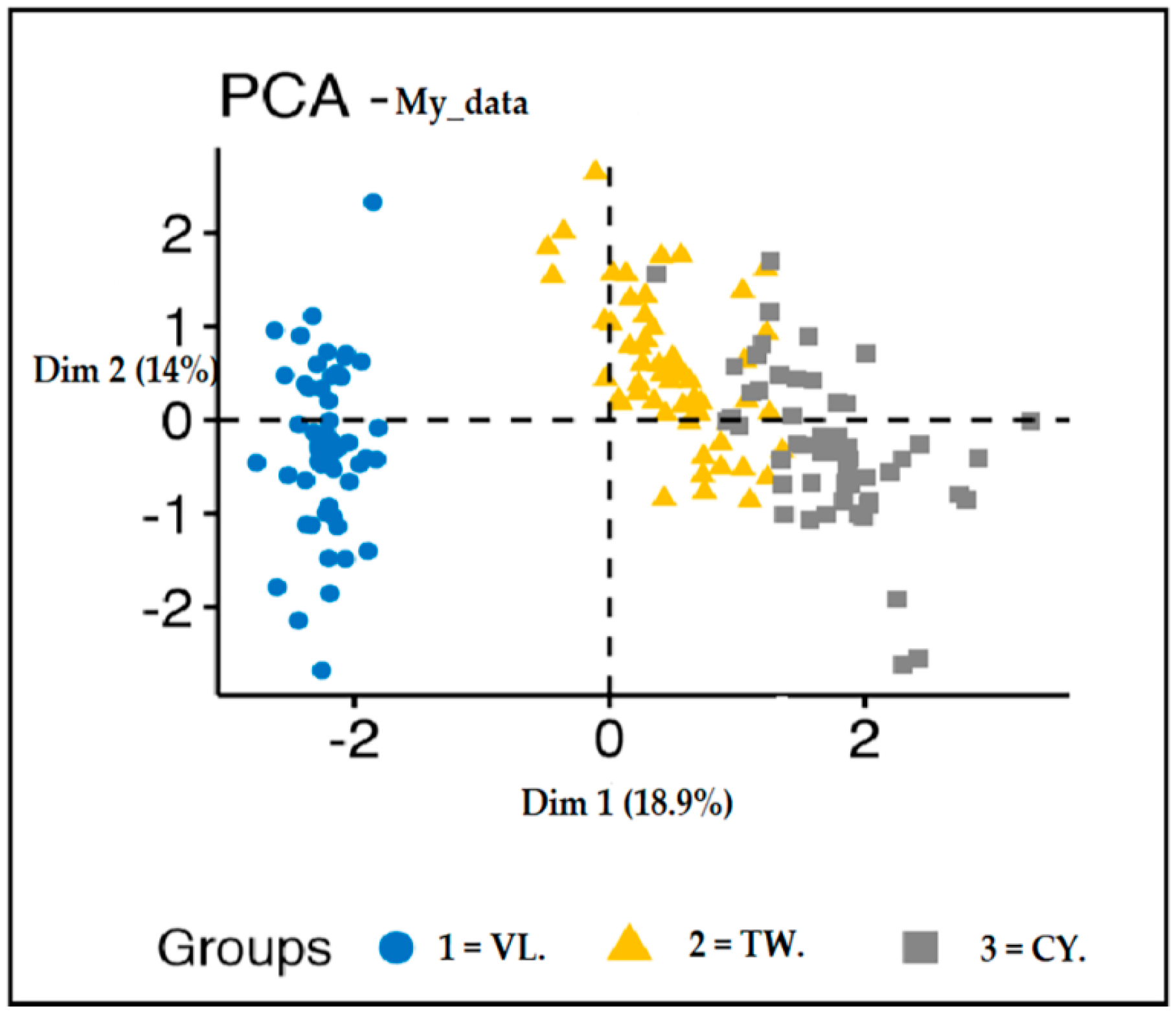
Figure 6, below, presents K-means clusters example for the attribute “Residential suburb” classified as Village, Town, and City for the 281 instances. Also, the same applies to the remaining attributes.
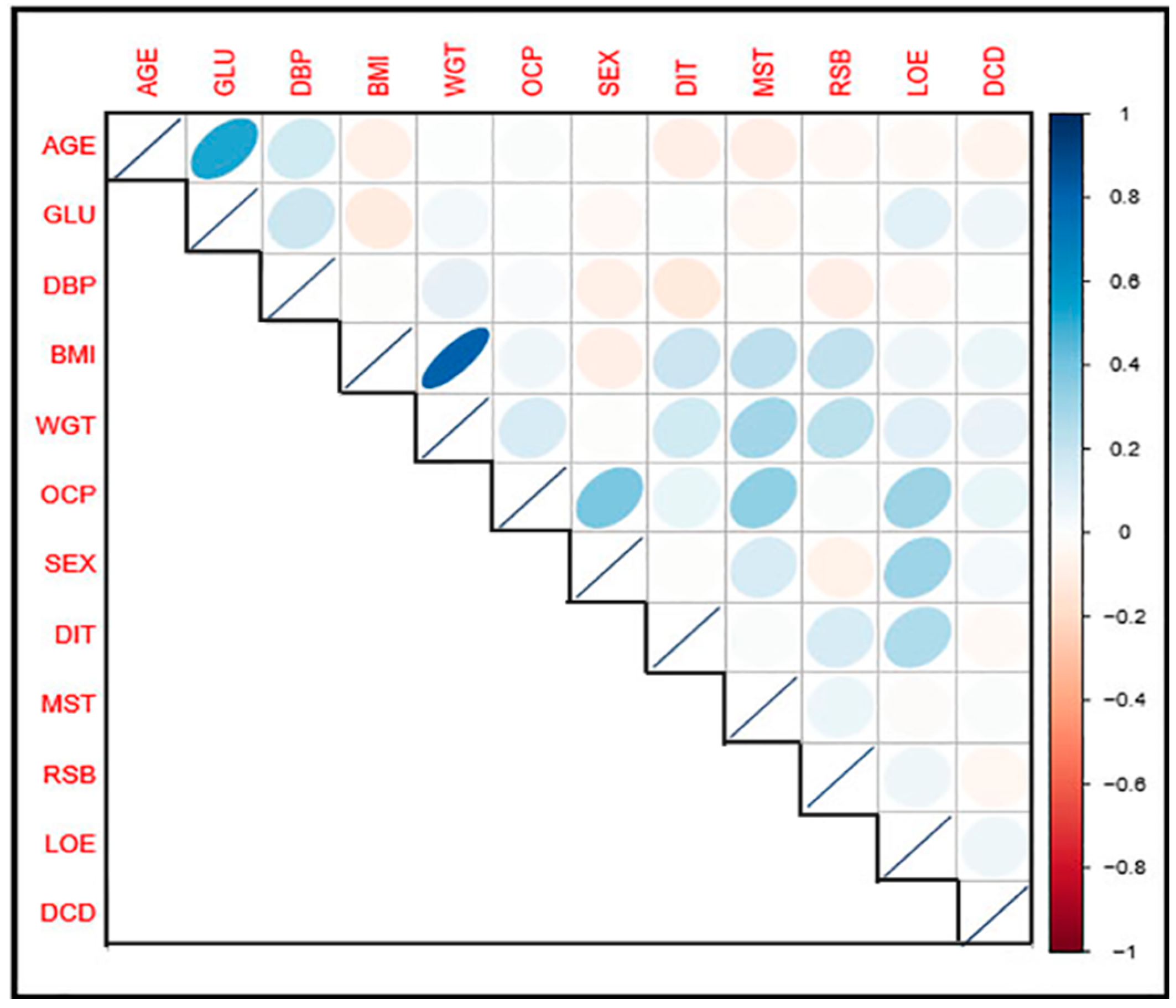
Table 3 presents a correlation matrix for the variables involves in the study to check the degree of relationship between them. It was observed that the principal diagonal leading elements are all equals 1.
Besides, variable BMI and WGT have the highest correlation value of 0.81, indicating strong positive relation. Variable AGE and GLU, SEX and OCP, MST and OCP, LOA and OCP, and SEX and LOE with their respective correlation values of 0.52, 0.39, 0.33, 0.32, and 0.30, respectively, were all are positively correlated.
Figure 7 presents a pictorial representation of a correlation matrix. The darker the color, the more strongly the relationship is, and vice versa.
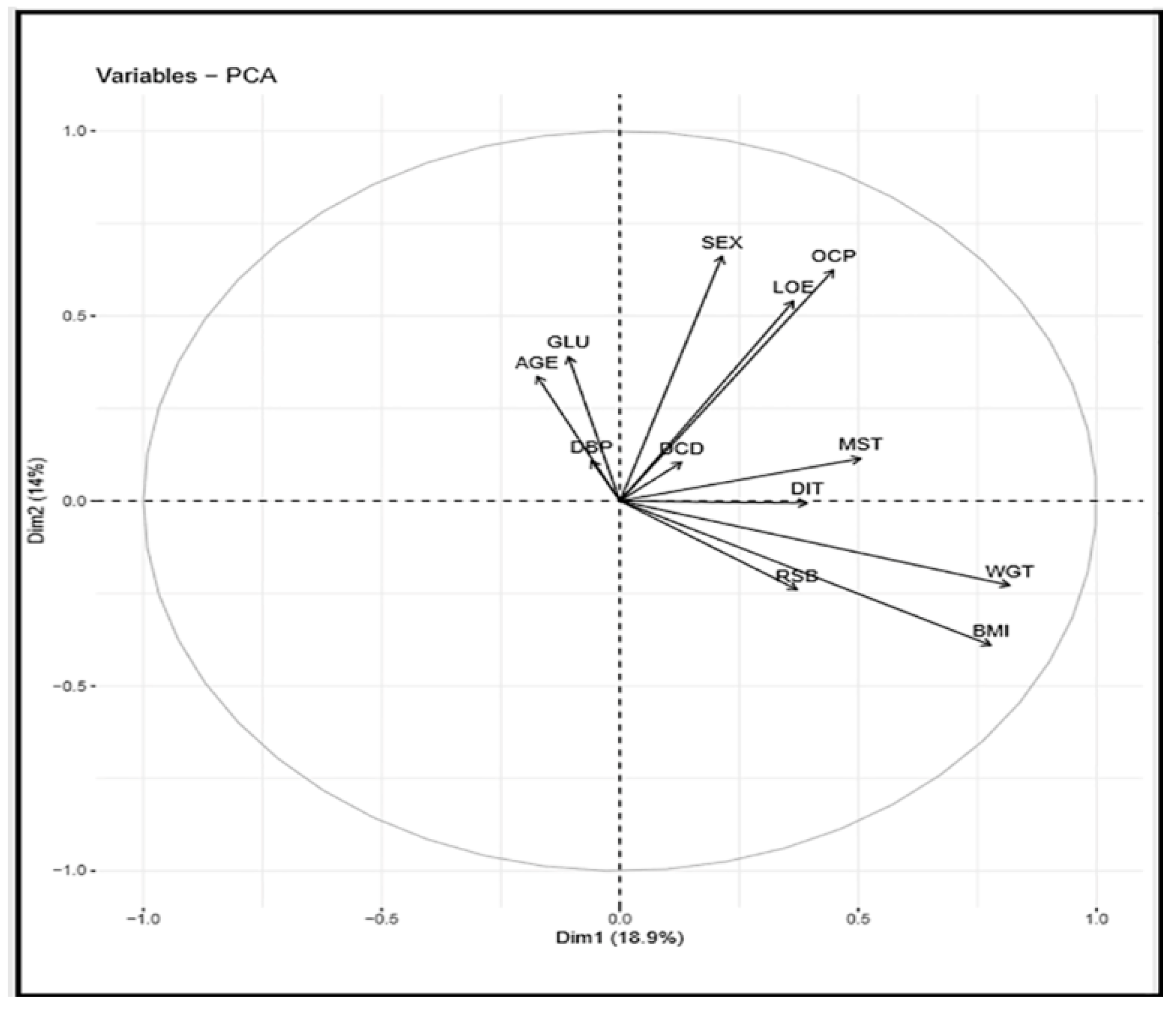
Figure 8 presents a correlation circle between the variables and PCs in dimensions 1 and 2, serving as the coordinate of the variables on the PCs.
Table 4, below, presents a correlation coefficient result for some selected symptoms of diabetes mellitus and other chronic diseases; the first column represents diabetes mellitus symptoms, and the first raw represents symptoms from four different chronic diseases involved in the study. The chronic diseases include high blood pressure, kidney problems, cardiovascular problems, and eye problems.
It was observed that the symptoms (FTG) related to kidney problems and high blood pressure has a relatively high correlation value of (0.43). Symptom (SOB) related cardiovascular problem, symptom (SCE) related to eye problem and symptoms (NRV) of high blood pressure with their correlation values of (0.42), (0.37), and (0.30), respectively.
On the other hand, the study recorded negative correlations between some symptoms among chronic diseases and diabetes mellitus. Also, symptoms (SFH) related to kidney problems and (DRV) associated with eye problems, with correlation values of (−0.01) and (0.01), respectively, show no relationship.
5. Conclusions
The study proposed a polytomous method of categorizing variables. The process was applied to classify all the categorical variables of interest in a real-life dataset. The result in
Table 2 shows eigenvalues, and the total variance explained for the principal components (PCs) solution.
There were twelve (12) variables involved in the study, and the aim was to predict the pattern of the correlation with minimum factors as possible. Similarly, the resultant eigenvalues correspond to a different factor, and, usually, factors with large eigenvalues are to be retained.
It is quite clear that from
Table 2 above, the first five (5) components out of twelve (12) have their eigenvalue above one (1) and thus, are large enough to be retained. Their variances are 18.9%, 14.0%, 13.6%, 10.3%, and 8.6%, respectively. These five (5) components describe 65.38% of the total variance.
Besides, from the retrained PCs, the first two PCs were used in the assessment of K-means clusters for the attribute residential suburb.
Moreover, from the correlation results, it has been revealed that diabetes patients are more likely to have kidney or hypertensive problem with the correlation value of (0.43). Rather than having an eye and cardiovascular issues. Therefore, the study validates the proposed categorization method for classification techniques.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}