1. Introduction
Occupational injuries are a significant problem in the mining industry [
1]. The Mine Safety and Health Administration (MSHA) reported that there were a total of 16,394 non-fatal lost time injuries in the US from 2015 to 2018 [
2]. A total of 104 fatalities were reported in the US from 2015–2018 [
2]. It is essential to analyze past mining injuries data to identify the factors leading to accidents and utilize them as predictors for future injuries [
3].
Several researchers in mining safety and health have examined lost time from work in studies related to occupational safety. Among underground coal and metal/non-metal miners, both age and time away from work after an injury were observed to be directly proportional [
4]. Onder used logistic regression to classify the accidents into two classes (greater than and less than three lost workdays). Maintenance personnel and workers were found to have the highest probability of exposure to accidents with greater than three lost workdays [
5]. Handling materials is the most common type of injury resulting in lost-time injuries [
6,
7]. Coleman and colleagues discussed using lost workdays as a measure to compare the performance of safety programs in the absence of denominator (number of workers exposed) data [
8]. Nouwrouzi and colleagues analyzed the top 56 annual and lifetime cited articles related to mining injuries [
9]. Seventy-three per cent of the articles described certain factors as predictors of lost-time injuries. Every injury event has some causal factors associated with it. Injury outcomes can be predicted when the causes are known [
10].
Statistical and machine learning techniques have been commonly used to analyze the importance of contributing factors toward an accident in the domain of occupation safety [
10,
11,
12,
13,
14]. Classification trees, support vector machines, and neural networks are the most widely used machine learning models in this domain.
Matias and colleagues analyzed floor-level falls in the mining, construction, and services sectors using several machine learning techniques [
11]. Bayesian networks, classification trees, support vector machines, and extreme learning machines were used in their approach. Bayesian networks were found to be the best all-round technique. Rivas and colleagues modelled incidents and accidents in two companies in the mining and construction sectors [
15]. They also reported a similar result where Bayesian networks and classification trees outperformed logistic regression. The dataset comprised of survey results and information obtained from interviews. A similar superior performance of machine learning techniques was also reported in a study done by Tixier and colleagues on construction injury data [
12]. Random forest and Stochastic Gradient Tree Boosting were used to predict three safety outcomes, namely, injury type, energy type, and body part.
Many studies in occupational safety domain use structured data to analyze the accidents [
13,
16]. Use of textual reports to predict the safety outcomes has been minimal. Marucci-Wellman and colleagues used Naive Bayes, Single word, and Bi-gram models, support vector machine, and logistic regression for classifying the event leading to injury using injury narratives of a workers compensation dataset [
16]. Sarkar and colleagues used topic modelling on the injury text data to extract topics or classes [
10]. A topic or class is a cluster of similar words. Davoudi Kakhki and colleagues used cluster modeling to identify high-risk groups of occupational incidents with severe injuries [
17]. Previous studies on occupational safety outcomes have shown the superior performance of machine learning techniques, such as classification trees, support vector machines, and artificial neural networks (ANNs) [
18,
19].
The potential benefits of machine learning algorithms can not only be recognized by their capability to handle multi-dimensional and large amounts of data, but also from (i) their ability to generate actionable insights to improve decision-making, and (ii) their capacity to improve over time with exposure to more data [
10,
12]. Due to the advantages of machine learning techniques, they have been successfully used in many fields, such as e-commerce, healthcare, and banking [
20,
21,
22]. Studies on occupational safety studies have also used machine learning techniques to analyze and generate actionable insights [
12,
15,
18,
23]. Similarly, the use of machine learning techniques can significantly benefit the mining industry. Large amounts of safety-related data related to mining is available, and humans cannot review all the data. The machine learning techniques can be leveraged to analyze safety data and provide actionable insights. However, the use of machine learning methods in the mining industry has been minimal [
23,
24]. Use of text narratives in the predictive analysis is infrequent [
16]. Similarly, not many studies use days away from work as an outcome while analyzing mining injuries using machine learning techniques. Modelling the outcome of the injury and days away from work is vital to identify the factors leading to these outcomes. Days away from work (DAFW) is also an indicator of the severity of the injury. The purpose of this study is to identify the potential of text narratives to predict the outcome of the injury and days away from work. We used logistic regression, decision trees, random forests, and ANNs to find answers to the following questions: (1) Do text narratives have enough information to predict the outcome of the injury compared to the tabular data, and (2) can text narratives be used to predict days away from work? Decision trees, random forest, and ANN were selected based on the superior performance of these models in the studies related to occupational safety [
10,
12,
13,
15,
16]. The performance of these models were compared to the performance of logistic regression.
4. Discussion
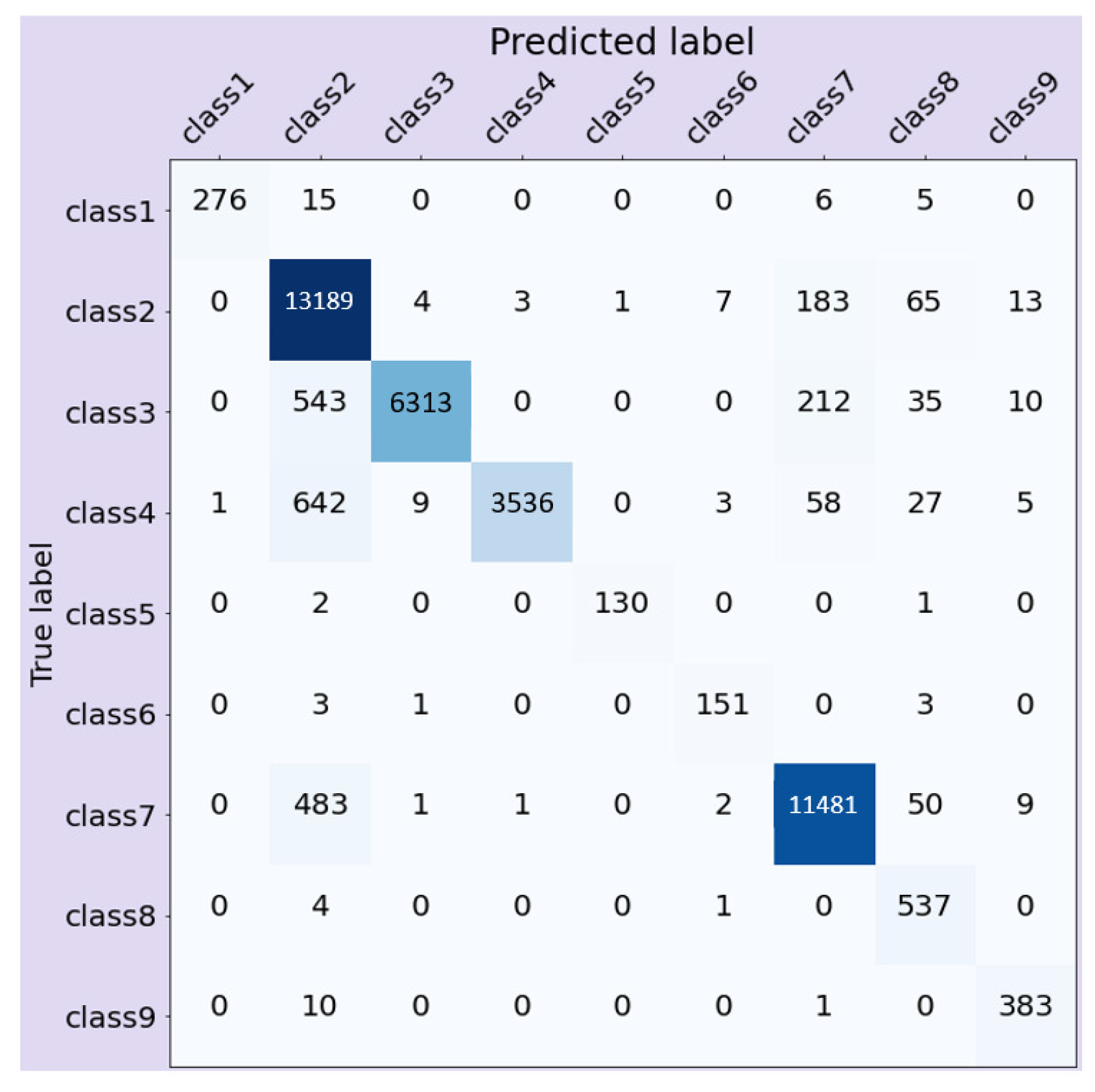
This study used supervised machine learning techniques, such as logistic regression, decision tree, random forest, and ANN to predict injury outcome and days away from work in mining operations. Fixed field entries (structured data) and injury narratives (unstructured data) were used to train the models. The experiments done in this study show that random forest trained on the vector representation of injury narratives performed better than all other models. The high accuracy and an F1 score of random forest even when there exists a class imbalance shows the effectiveness of ensemble learning methods. The most plausible conclusion for the superior performance of random forest on narratives is the information present in the narrative, which is not present in the fixed field entries. One example would be the narrative, “Employee was grinding off metal that had been cut on flop gate. A piece of metal must have got under employee’s safety shield and safety glasses, causing an abrasion to eye. Employee did not notice discomfort until employee got home”. The model trained on fixed field entries classified this incident as “Days restricted activity only”. The tabular data does not have any mention of safety glasses or safety shield that the employee was wearing. However, the model trained on narratives has information about the safety equipment. This could be one of the reasons why the model trained on narratives classified this incident correctly, which is “No days away from work, No restricted activity”. ANN performed relatively better than other models when the input was fixed field entries. However, underrepresented classes were removed from the dataset when fixed field entries were used. This study forms a foundation for the future research in utilizing text narratives in the predictive analysis of injury outcomes.
The mining industry exceeds many industries in terms of workplace injuries and fatalities [
50,
51,
52]. It is, therefore, essential to study the characteristics of the mining injuries in order to find the factors leading to an injury. Once the factors associated with the injuries are identified, safety programs can be designed to address those issues. This study used ANN trained on fixed field entries to find the feature importance. According to
Table 5, the nature of the injury is the most influential feature in the dataset. The nature of the injury was also found to be a significant variable in the prediction of injury severity level in the agribusiness industry [
13]. Since our focus was on injuries causing lost days of work, we analyzed the nature of injury variables for the injuries resulting in DAFW. The highest number of nature of injuries resulting in DAFW were sprain, disc rupture, fracture, cut, laceration, and bruise. The second most influential variable was an injured body part. The injuries to the back, spine, Scord, and tailbone were among the highest to result in DAFW. Occupation was also one of the essential features. An injury to the workers having the following occupations: Maintenance man, Mechanic, Repair/Serviceman, Boilermaker, Fueler, Tire tech, and Field Service tech had the highest probability to result in DAFW class. Maintenance personnel and workers were also found to have the highest risk of occupational injuries among opencast coal mine workers [
5]. Job experience was among the top five important variables which were important in predicting the outcome of the injury. It is interesting to note that job experience had much higher feature importance compared to mine experience and total experience when predicting the outcome of the injury. Margolis analyzed how age and experience were related to days away from work in underground coal mining injuries. It was found that the total mining experience has an influence on the severity of the injury [
4]. Mine experience and job experience were found to have no effect on the severity of the injury. However, it needs to be noted that the dependent variable was the number of days away from work, whereas in our study, the dependent variable was the outcome of the injury.
Given the high predictive power of the model, the above variables are significant in predicting the outcome of the injury. The nature of the injury is the most important predictor, and sprain, disc rupture, and fracture result in the most days away from work. Safety programs can be designed specifically to reduce accidents of this nature. These safety programs should also concentrate on other influential variables found in this study, such as injured body parts and occupation. Since job experience was found to be more important in predicting the outcome of the injury than mine experience and job experience, emphasis should be given to job-related safety.
Although the model with the best performance cannot be used to analyze feature importance, it can certainly help to answer questions such as, “if this kind of injury were to happen, what would it result in?”, and, “What if a different body part was injured rather than the body part mentioned in the narrative?” Answers to such questions would help safety managers to plan for accidents that could occur in the future.
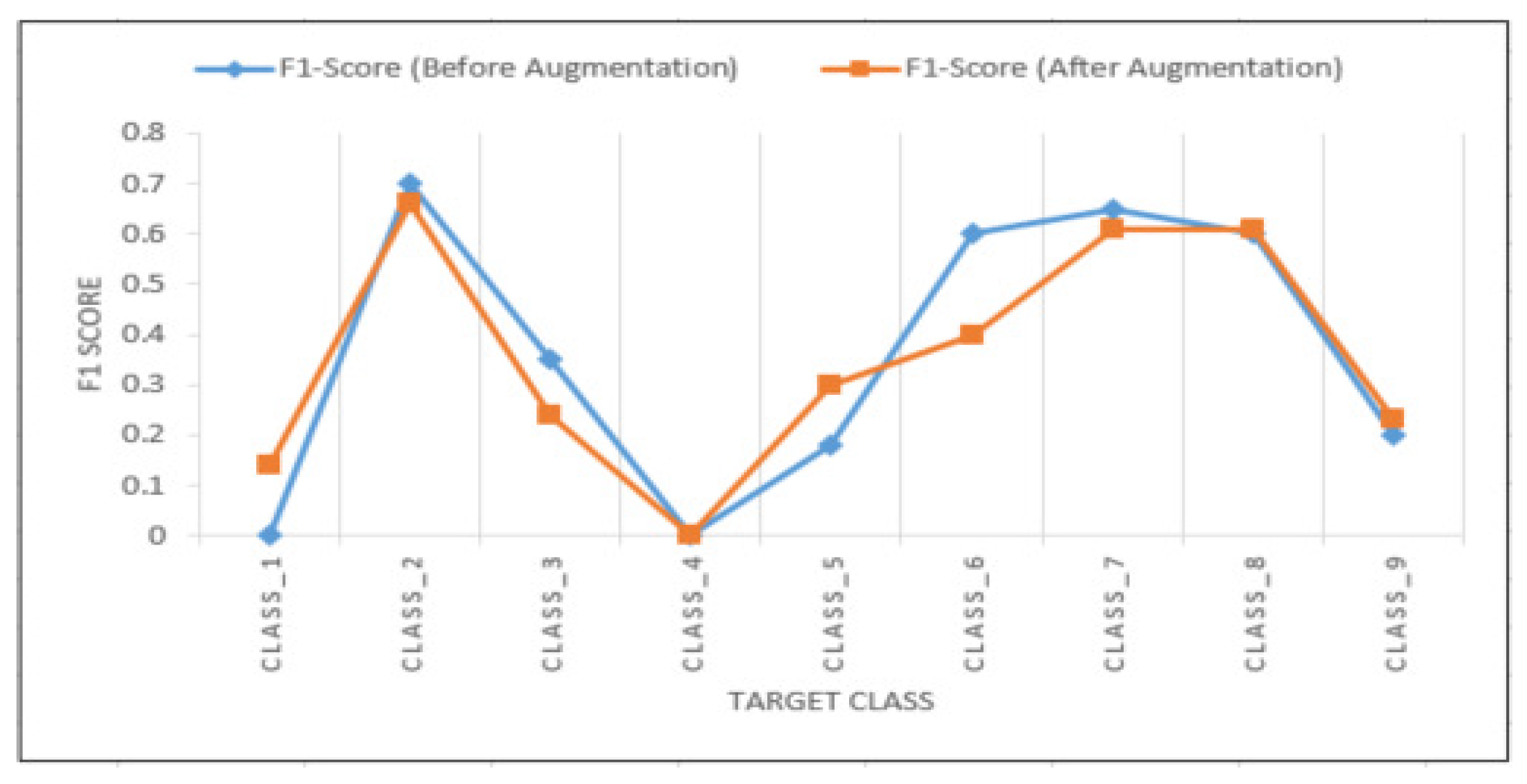
The data augmentation using word embedding increased the F1 score of ANN for unbalanced classes, except for one class. Although the overall F1 score of the model decreased from 0.60 to 0.58, the decrease in the performance was not very significant. One of the reasons for the decrease in the overall accuracy could be the way the words to be replaced were chosen. Since they were chosen randomly, the target class of the fake narrative could have changed from the target class of the original narrative. Having longer narratives would have helped in generating more accurate synthetic narratives generation.
Models trained on fixed field entries performed better than the models trained on narratives when predicting the DAFW. ANN trained on fixed field entries had the least MSE. It is interesting to note that the only information missing from the narratives that is present in the fixed field entries is the shift start time, accident time, and the experience of the miner. The presence of the above variables in the fixed field entries could have helped the model in predicting the DAFW better. Accurately predicting DAFW could help the supervisors managing the workforce to plan for replacements when an injury occurs. DAFW is also an indicator of the severity of the injury. These models are not a replacement to an expert in safety; instead, they are tools to help safety experts to act proactively to reduce workplace injuries.
5. Conclusions
We explored a new research problem of predicting the outcome of the injury and the number of days away from work in the mining industry using machine learning models. Target-based statistics were used to encode categorical variables. This technique helped to tackle the problem of high cardinality categorical variables. Random forest trained on injury narratives performed better than all the models. The high predictive power of the model trained on narratives suggests that the narratives contain additional important information compared to the fixed field entries. The synthetic data augmentation with word embedding was used to tackle the data imbalance problem. This technique improved the F1 score of ANN for the underrepresented classes. However, the overall accuracy and F1 score of the model decreased after augmentation. There is a lot of unstructured data available compared to the structured data, and the results of this study show that using unstructured data, such as text narratives, could be useful in understanding the injuries better. This study shows that there is a potential for using NLP and text analytics in this field.
Regarding the application of predictive modeling in occupational injury analysis, this study not only confirms the findings from previous work on the effectiveness of data mining techniques in analyzing occupational incidents in the mining industry [
53], but also adds new methods for dealing with limited data, and yet extracting useful practical information for improving safety of mining operations. However, there are some limitations in this work. There are no weather-related features in the data, and it makes it hard to analyze if the severity of days-away-from-work classes could be impacted by weather conditions. In addition, the data lacks information about demographics of the injured workers, and thus, does not explore the role of age and experience of the worker on the days-away-from-work severity classes. Furthermore, some studies have analyzed and compared the risk of occupational incidents in mining based on workers’ genders [
54]. Therefore, another limitation to this study is a lack of probabilistic risk analysis based on the injured worker’s gender. Future direction of this research includes exploring new data collection methods to improve the quality and features of mining occupational incidents and further building models for estimating probability of each days-away-from-work class based on the features of the incident. Deep learning techniques, such as convolutional neural networks (CNNs) and recurrent neural networks, have shown promising results in text classification [
55,
56]. Future studies can expand on this study by using such deep learning models. Generative adversarial networks (GANs) have been used in recent works for text generation [
57]. The use of GANs to tackle data imbalance problems in the domain of occupational safety could be explored.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}