Comparison of Two Bayesian-MCMC Inversion Methods for Laboratory Infiltration and Field Irrigation Experiments

Abstract
:1. Introduction
2. Materials and Methods
2.1. Basic Theory
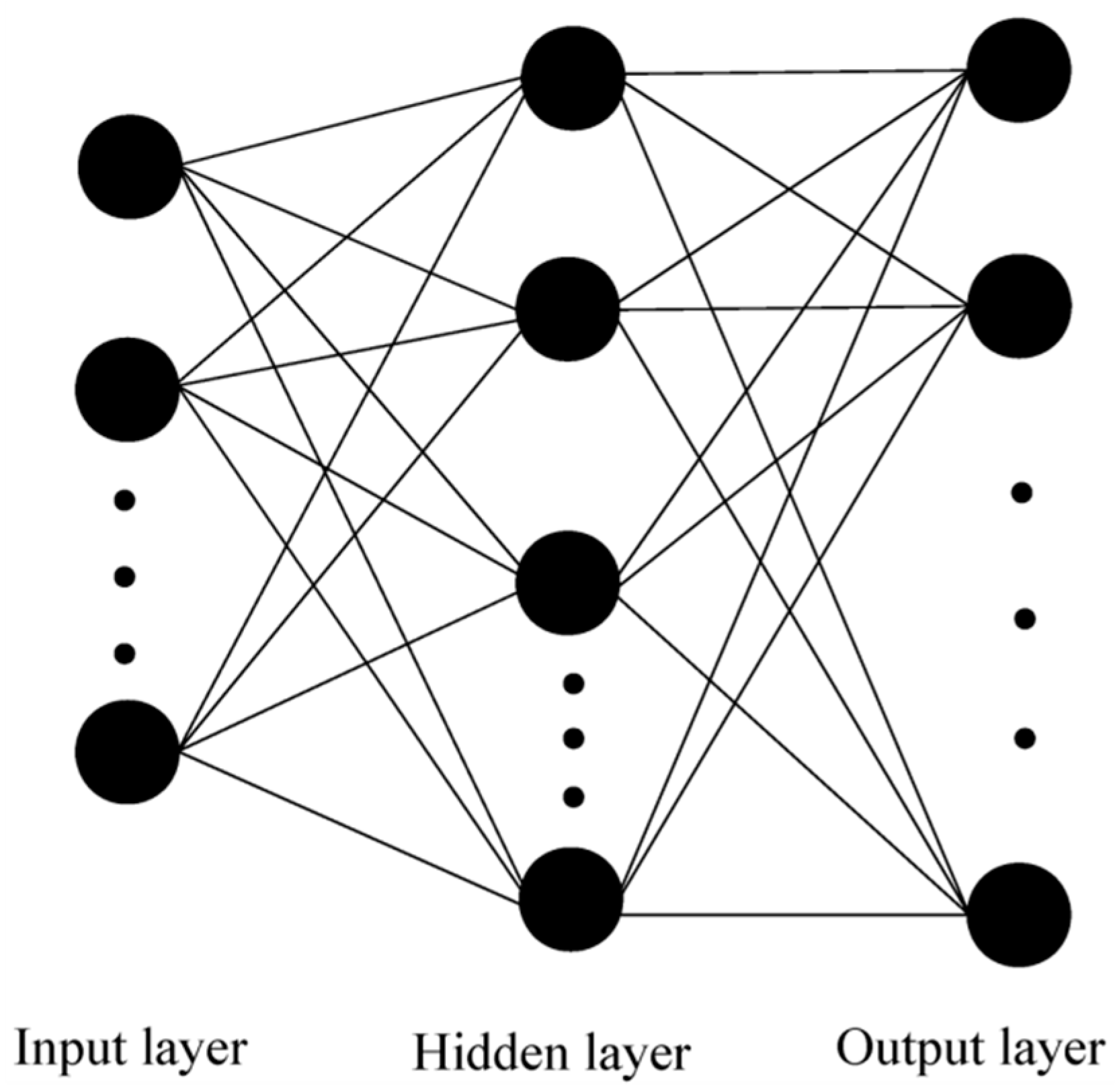
2.2. ANN Appropriate System
2.2.1. ANN Optimized by the Particle Swarm Optimization (PSO) Algorithm
2.2.2. Procedures for the ANN-Based Bayesian-MCMC Algorithm
- Generate k random sets of model parameters } from the parameter prior distributions. Compute the corresponding sets of simulated output results using the original HYDRUS-1D forward model.
- Construct a three-layer BP neural network in which the number of the unknown hydraulic parameters is the number of input layer nodes and the number of measured pressure heads during the experiments is the number of output layer nodes. A number of initial weights and threshold combinations are randomly generated using the data pairs {M, F}.
- Optimize the weights and thresholds of the neural network using the PSO algorithm, where each combination obtained in the above step is considered to be a particle. After that, the optimal neural network representing the forward analysis process is achieved.
- Compute the corresponding sets of stochastic model-error realizations }, where , ) is the corresponding output results of the ANN approximate system formed in the above step, F() is those of the original HYDRUS-1D forward model, and i = 1,…,k.
- Perform PCA on the model-error realizations } to obtain a sparse orthonormal basis } for the model error. For each set of model parameters tested within the MCMC, the model error component of the discrepancy between the measured values and the ANN simulated values is obtained by projecting the discrepancy to the orthonormal basis B.
- The model error component received above is subtracted from the corresponding residual of the Bayesian likelihood function. Run the Bayesian-MCMC algorithm using the ANN instead of the original HYDRUS-1D forward model to generate samples of the posterior distribution.
2.3. Basic Theory of the Gaussian Process
3. Case Studies
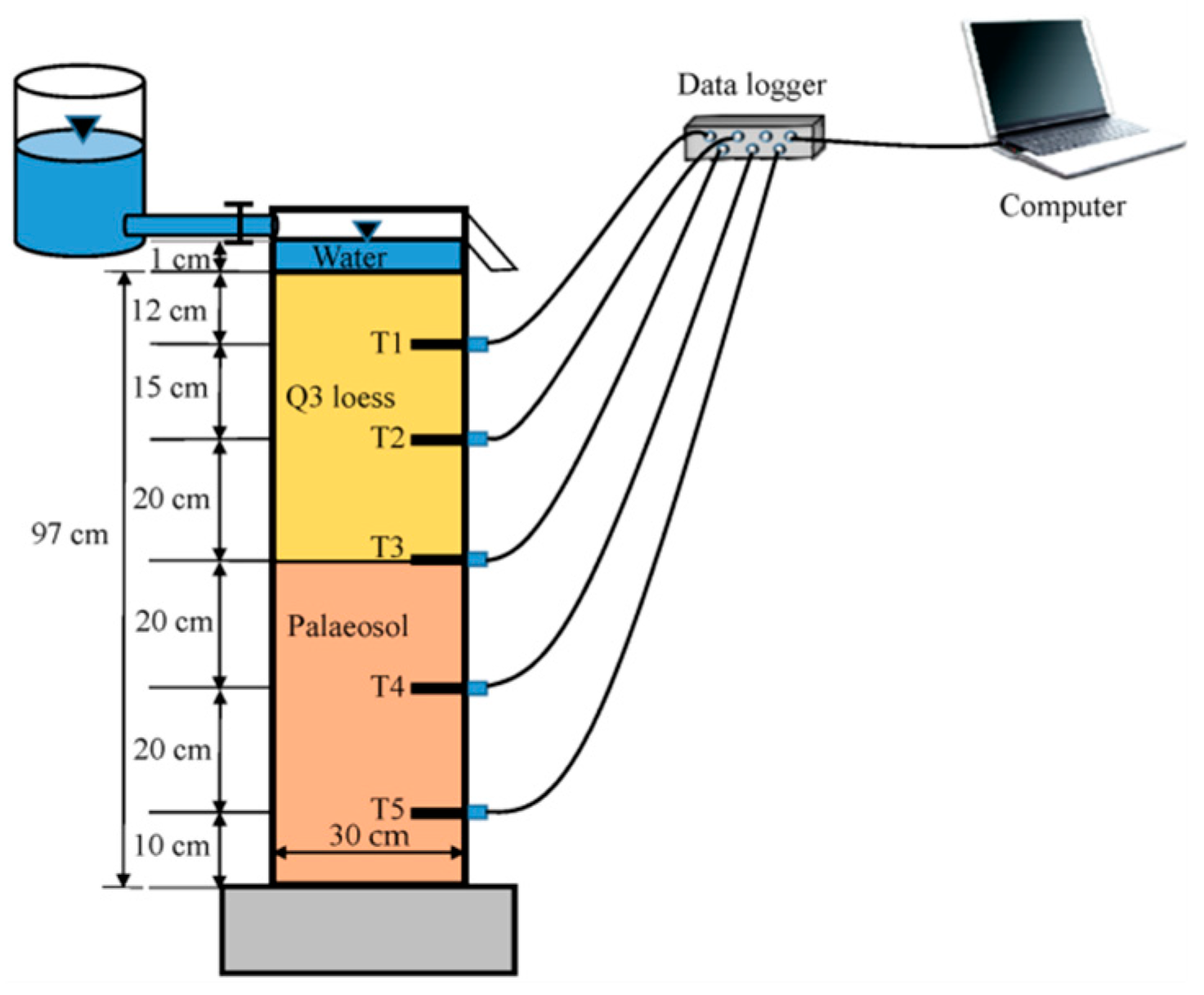
3.1. Case 1: Laboratory Infiltration Experiment
3.1.1. Obtainment of the Measurement Data
3.1.2. Construction of the Original HYDRUS model and Surrogate Systems
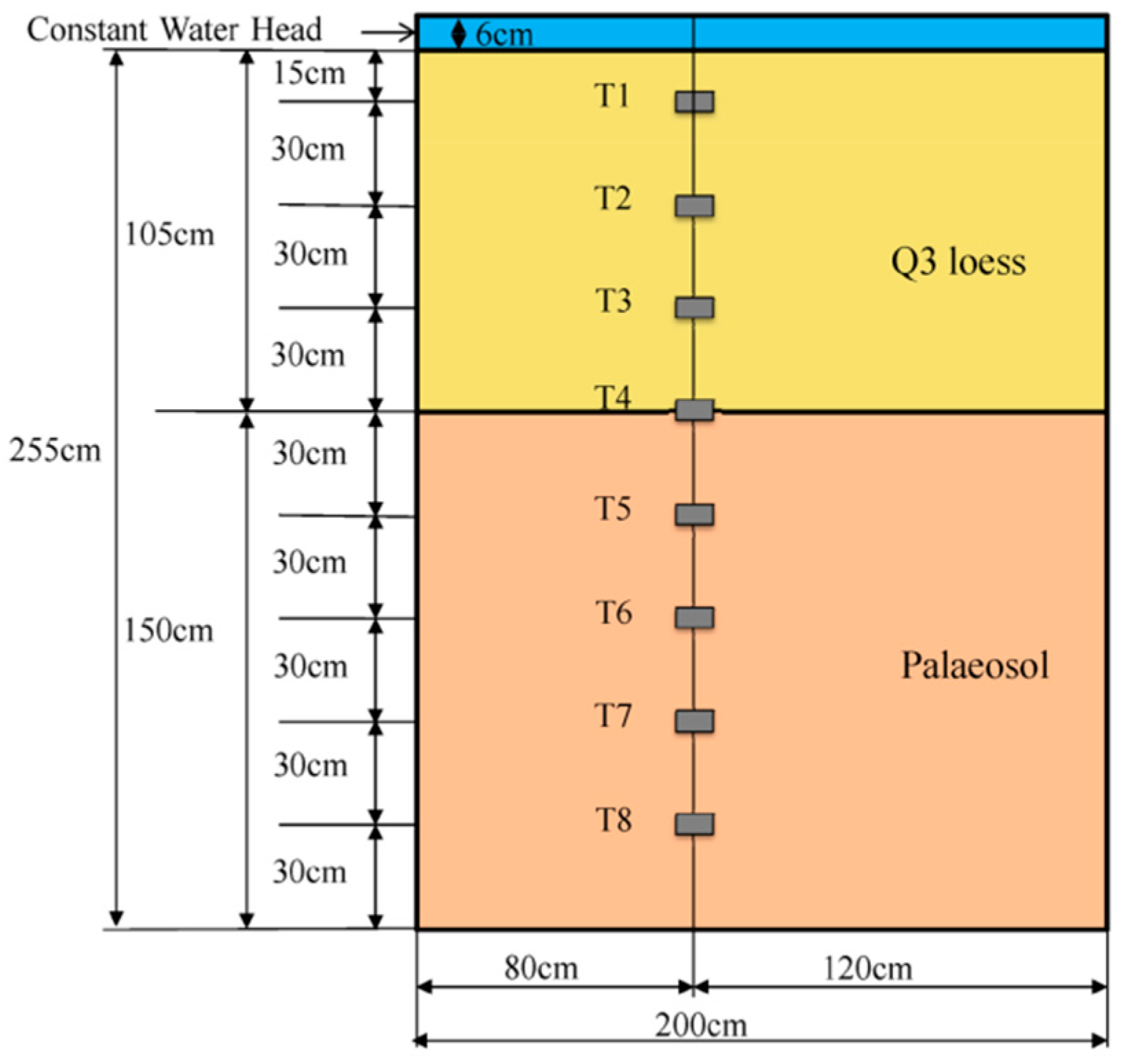
3.2. Case 2: The Field Irrigation Experiment
3.2.1. Obtainment of the Measurement Data
3.2.2. Construction of the Original HYDRUS Model and Surrogate Systems
4. Results
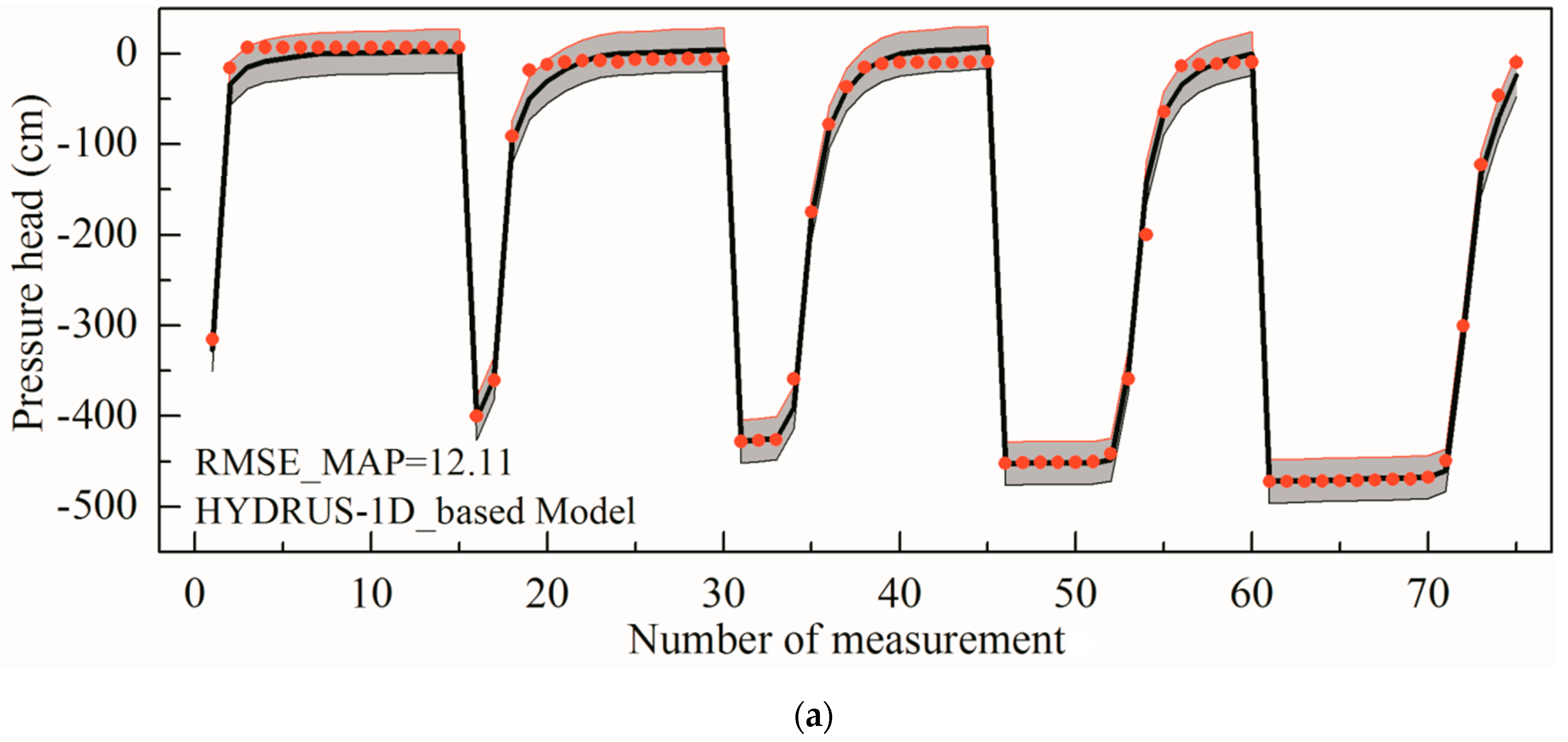
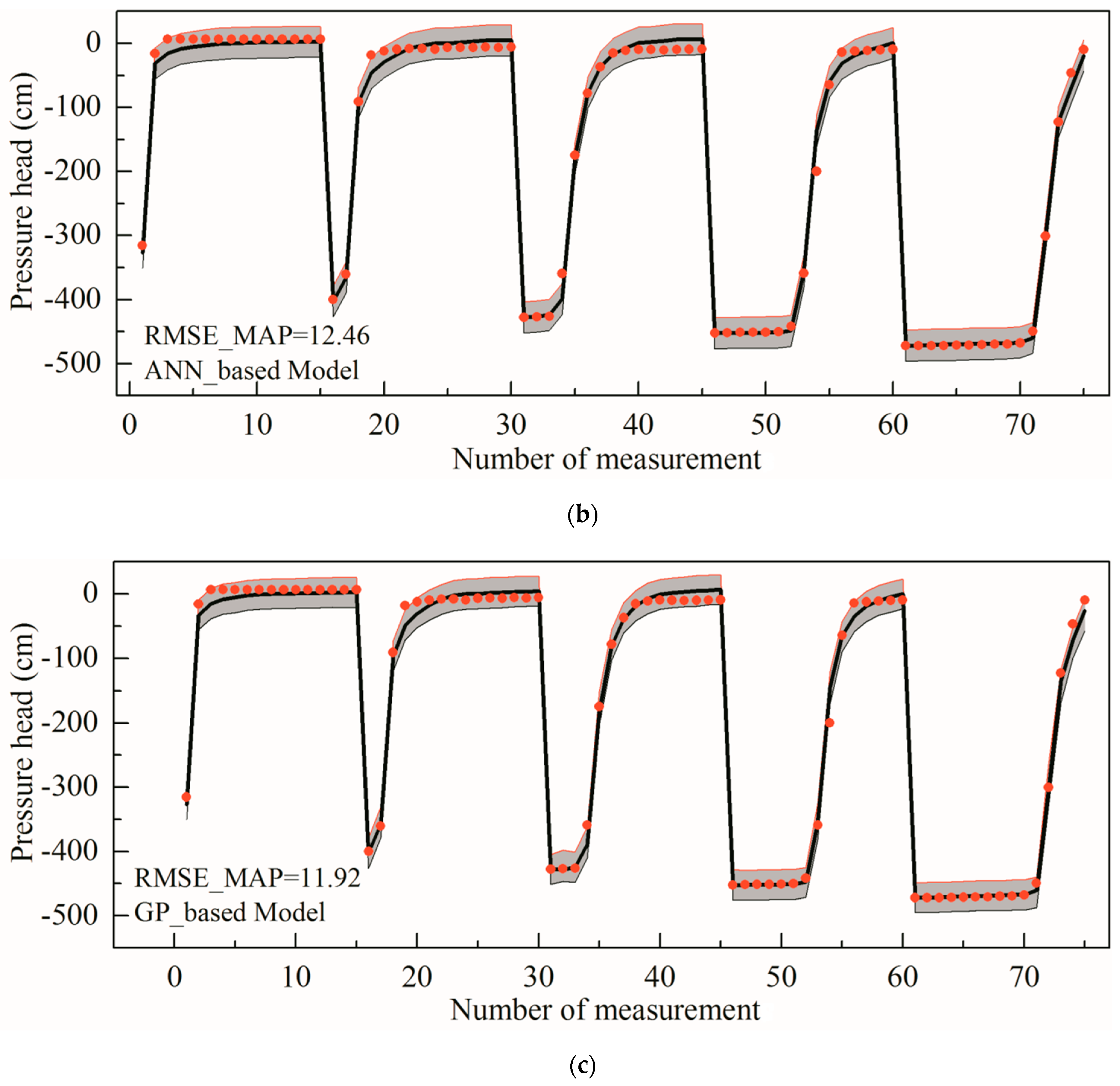
4.1. Case 1 Results
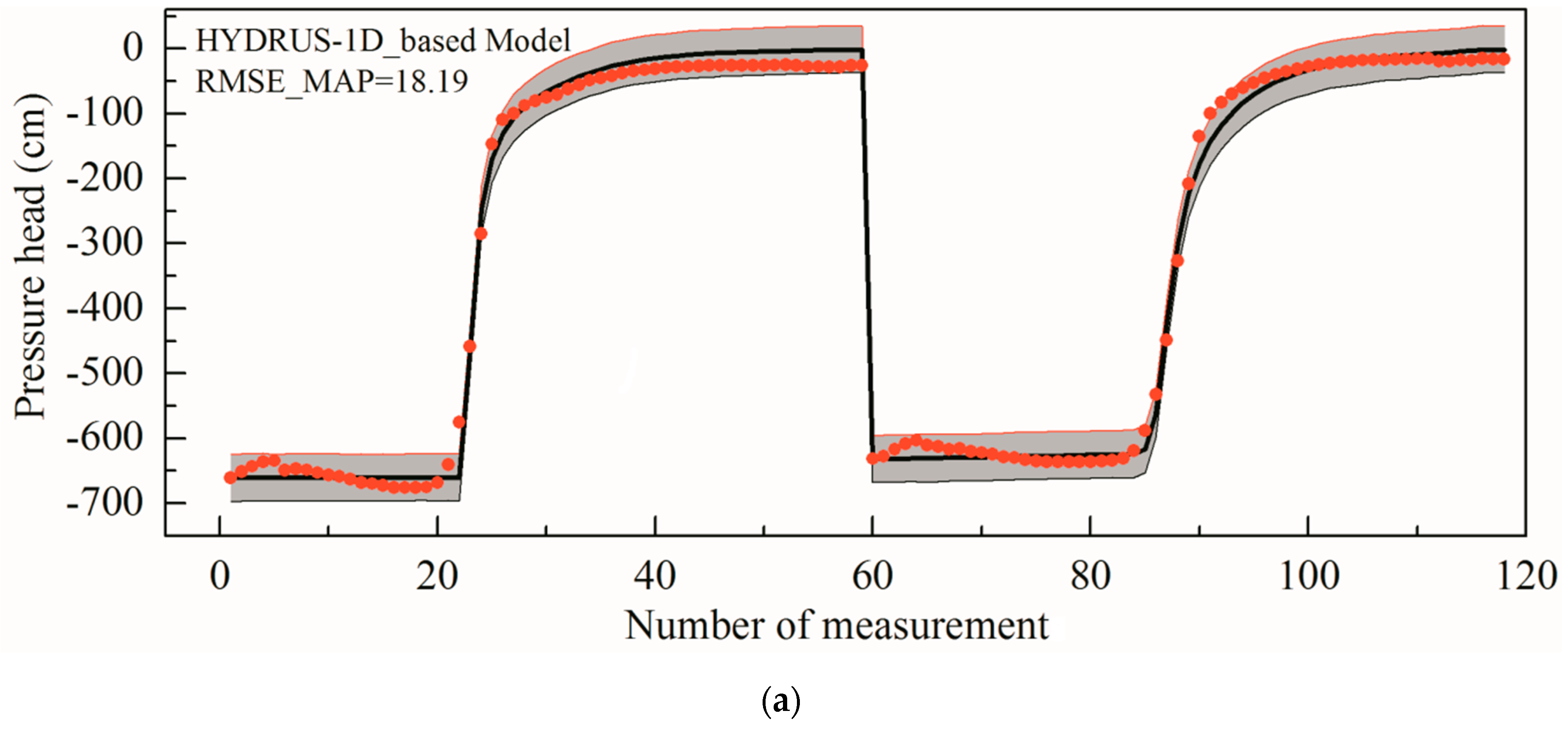
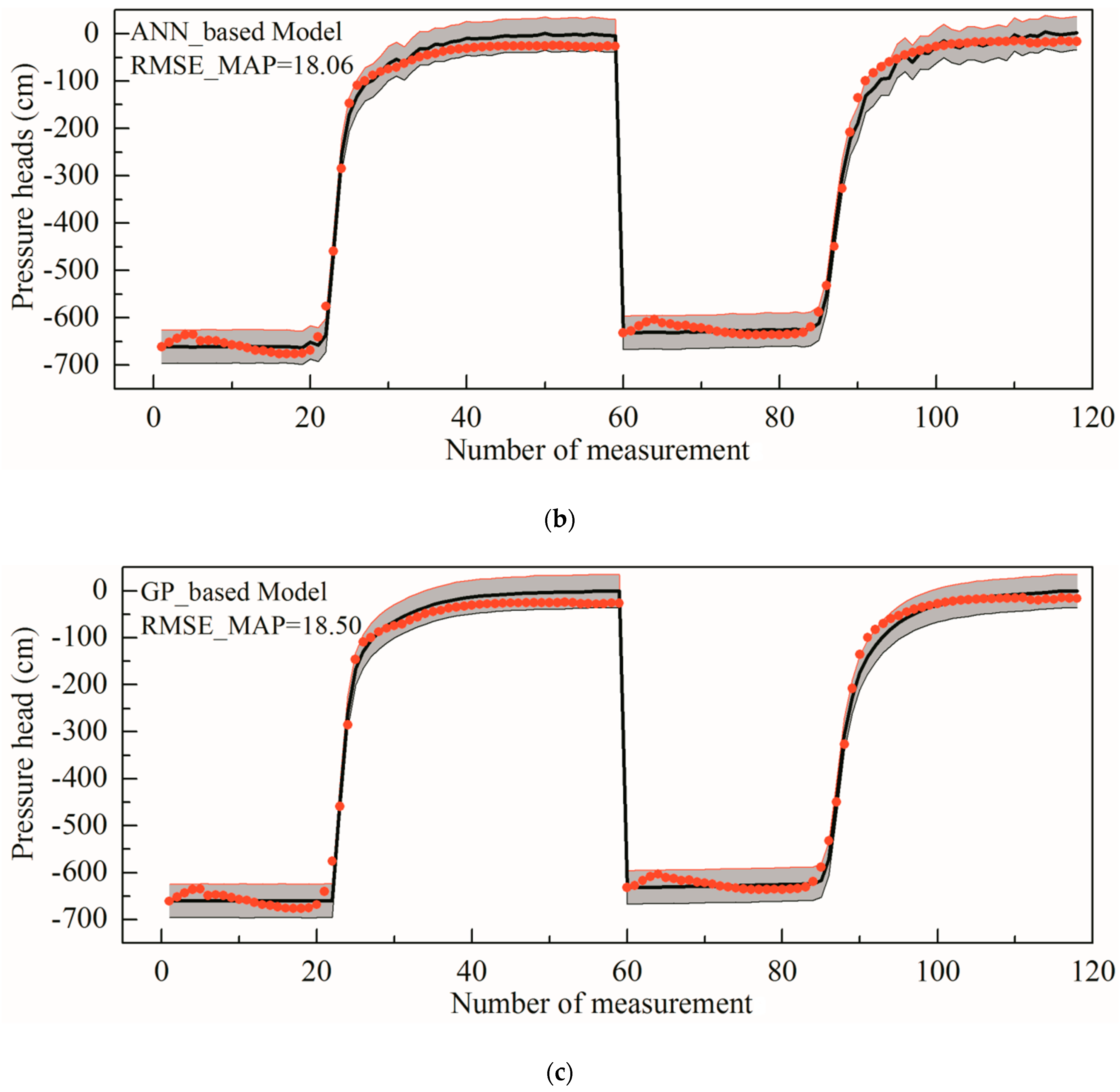
4.2. Case 2 Results
5. Discussion
6. Conclusions
- Approximate system-based MCMC methods can considerably accelerate the inverse modelling in layered loess since the computational cost of the surrogate-based MCMC simulation is rather lower. Furthermore, the optimal parameter values derived from different methods do not show a large difference, which signifies that the surrogates can yield MAP parameter estimates without marked bias compared to those obtained with the original HYDRUS model at reasonable computational costs.
- The simulated pressure head values in the layered undisturbed loess profile are consistent with the experimental results. Specifically, the simulations using the MAP parameter values are extremely close to the experimental data, which also fall in the 95% posterior confidence intervals. Uncertainty analyses of the pressure heads supported the reliability of the ANN/GP-based MCMC. The fitting effect of the field test is not as good as that of the indoor test since there are more complex conditions in the field.
- The similar RMSE_MAPs of both the ANN and GP approximate systems indicates that they offer almost equally good performances. These results are, of course, related to the models and special experimental conditions considered. The suggested methods should be verified and improved for different types of soils and more complex conditions.
- The main shortcoming of the suggested surrogate methods is that the construction time of the approximate system is strongly related to the number of training samples. The computational costs of the GP construction cubically increase as the amount of training data increases. For a high-dimensional and complex system, training ANN/GP surrogates would be extremely time-consuming. Moreover, the substitute systems can only predict the fixed elements used in the training samples of mapping relationships.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Refsgaard, J.C.; Christensen, S.; Sonnenborg, T.O.; Seifert, D.; Højberg, A.L.; Troldborg, L. Review of strategies for handling geological uncertainty in groundwater flow and transport modeling. Adv. Water Resour. 2012, 36, 36–50. [Google Scholar] [CrossRef]
- Wöhling, T.; Vrugt, J.A. Multiresponse multilayer vadose zone model calibration using Markov chain Monte Carlo simulation and field water retention data. Water Resour. Res. 2011, 47, 1–9. [Google Scholar] [CrossRef] [Green Version]
- Vrugt, J.A. Markov chain Monte Carlo simulation using the DREAM software package: Theory, concepts, and MATLAB implementation. Environ. Model. Softw. 2016, 75, 273–316. [Google Scholar] [CrossRef] [Green Version]
- Laloy, E.; Rogier, B.; Vrugt, J.A.; Mallants, D.; Jacques, D. Efficient posterior exploration of a high-dimensional groundwater model from two-stage Markov chain Monte Carlo simulation and polynomial chaos expansion. Water Resour. Res. 2013, 49, 2664–2682. [Google Scholar] [CrossRef] [Green Version]
- Khu, S.T.; Werner, M.G.F. Reduction of Monte-Carlo simulation runs for uncertainty estimation in hydrological modelling. Hydrol. Earth Syst. Sci. 2003, 7, 680–692. [Google Scholar] [CrossRef] [Green Version]
- Zeng, L.; Shi, L.; Zhang, D.; Wu, L. A sparse grid based Bayesian method for contaminant source identification. Adv. Water Resour. 2012, 37, 1–9. [Google Scholar] [CrossRef]
- Watson, T.A.; Doherty, J.E.; Christensen, S. Parameter and predictive outcomes of model simplification. Water Resour. Res. 2013, 49, 3952–3977. [Google Scholar] [CrossRef]
- Asher, M.J.; Croke, B.F.W.; Jakeman, A.J.; Peeters, L.J.M. A review of surrogate models and their application to groundwater modeling. Water Resour. Res. 2015, 51, 5957–5973. [Google Scholar] [CrossRef]
- Scholer, M.; Irving, J.; Looms, M.C.; Nielsen, L.; Holliger, K. Examining the information content of time-lapse crosshole GPR data collected under different infiltration conditions to estimate unsaturated soil hydraulic properties. Adv. Water Resour. 2013, 54, 38–56. [Google Scholar] [CrossRef]
- Brynjarsdóttir, J.; O’Hagan, A. Learning about physical parameters: The importance of model discrepancy. Inverse Probl. 2014, 30, 114007. [Google Scholar] [CrossRef]
- Del Giudice, D.; Honti, M.; Scheidegger, A.; Albert, C.; Reichert, P.; Rieckermann, J. Improving uncertainty estimation in urban hydrological modeling by statistically describing bias. Hydrol. Earth Syst. Sci. 2013, 17, 4209–4225. [Google Scholar] [CrossRef] [Green Version]
- Evin, G.; Thyer, M.; Kavetski, D.; Mclnerney, D.; Kuczera, G. Comparison of joint versus postprocessor approaches for hydrological uncertainty estimation accounting for error autocorrelation and heteroscedasticity. Water Resour. Res. 2014, 50, 2350–2375. [Google Scholar] [CrossRef]
- Josset, L.; Ginsbourger, D.; Lunati, I. Functional error modeling for uncertainty quantification in hydrogeology. Water Resour. Res. 2015, 51, 1050–1068. [Google Scholar] [CrossRef] [Green Version]
- Del Giudice, D.; Löwe, R.; Madsen, H.; Mikkelsen, P.S.; Rieckermann, J. Comparison of two stochastic techniques for reliable urban runoff prediction by modeling systematic errors. Water Resour. Res. 2015, 51, 5004–5022. [Google Scholar] [CrossRef] [Green Version]
- Doherty, J.; Christensen, S. Use of paired simple and complex models to reduce predictive bias and quantify uncertainty. Water Resour. Res. 2011, 47, 1–21. [Google Scholar] [CrossRef] [Green Version]
- Arridge, S.R.; Kaipio, J.P.; Kolehmainen, V.; Schweiger, M.; Somersalo, E.; Tarvainen, T.; Vauhkonen, M. Approximation errors and model reduction with an application in optical diffusion tomography. Inverse Probl. 2006, 22, 175–195. [Google Scholar] [CrossRef] [Green Version]
- Xu, T.; Valocchi, A.J. A Bayesian approach to improved calibration and prediction of groundwater models with structural error. Water Resour. Res. 2015, 51, 9290–9311. [Google Scholar] [CrossRef]
- Zhang, J.; Man, J.; Lin, G.; Wu, L.; Zeng, L. Inverse modeling of hydrologic systems with adaptive multi-fidelity Markov chain Monte Carlo simulations. Water Resour. Res. 2018, 54, 4867–4886. [Google Scholar] [CrossRef]
- O’Sullivan, A.; Christie, M. Simulation error models for improved reservoir prediction. Reliab. Eng. Syst. Saf. 2006, 91, 1382–1389. [Google Scholar] [CrossRef]
- Köpke, C.; Irving, J.; Elsheikh, A.H. Accounting for model error in Bayesian solutions to hydrogeophysical inverse problems using a local basis approach. Adv. Water Resour. 2018, 116, 195–207. [Google Scholar] [CrossRef] [Green Version]
- Younes, A.; Zaouali, J.; Fahs, M.; Slama, F.; Grunberger, O.; Mara, T.A. Bayesian soil parameter estimation: Results of percolation-drainage vs infiltration laboratory experiments. J. Hydrol. 2018, 565, 770–778. [Google Scholar] [CrossRef]
- Rammay, M.H.; Elsheikh, A.H.; Chen, Y. Quantification of prediction uncertainty using imperfect subsurface models with model error estimation. J. Hydrol. 2019, 576, 764–783. [Google Scholar] [CrossRef]
- Silva, P.C.; Maschio, C.; Schiozer, D.J. Use of Neuro-Simulation techniques as proxies to reservoir simulator: Application in production history matching. J. Pet. Sci. Eng. 2007, 57, 273–280. [Google Scholar] [CrossRef]
- Yoon, H.; Jun, S.C.; Hyun, Y.; Bae, G.O.; Lee, K.K. A comparative study of artificial neural networks and support vector machines for predicting groundwater levels in a coastal aquifer. J. Hydrol. 2011, 396, 128–138. [Google Scholar] [CrossRef]
- Daliakopoulos, I.N.; Coulibaly, P.; Tsanis, I.K. Groundwater level forecasting using artificial neural networks. J. Hydrol. 2005, 309, 229–240. [Google Scholar] [CrossRef]
- Wang, D.; Tan, D.; Liu, L. Particle swarm optimization algorithm: An overview. Soft Comput. 2018, 22, 387–408. [Google Scholar] [CrossRef]
- Sun, W.; Durlofsky, L.J. A New Data-Space Inversion Procedure for Efficient Uncertainty Quantification in Subsurface Flow Problems. Math. Geosci. 2017, 49, 679–715. [Google Scholar] [CrossRef]
- Köpke, C.; Irving, J.; Roubinet, D. Stochastic inversion for soil hydraulic parameters in the presence of model error: An example involving ground-penetrating radar monitoring of infiltration. J. Hydrol. 2019, 569, 829–843. [Google Scholar] [CrossRef] [Green Version]
- Gao, H.; Zhang, J.; Liu, C.; Man, J.; Chen, C.; Wu, L.; Zeng, L. Efficient bayesian inverse modeling of water infiltration in layered soils. Vadose Zone J. 2019, 18. [Google Scholar] [CrossRef] [Green Version]
- Dai, F.C.; Lee, C.F.; Ngai, Y.Y. Landslide risk assessment and management: An overview. Eng. Geol. 2002, 64, 65–87. [Google Scholar] [CrossRef]
- Xu, L.; Dai, F.; Tu, X.; Tham, L.G.; Zhou, Y.; Iqbal, J. Landslides in a loess platform, North-West China. Landslides 2014, 11, 993–1005. [Google Scholar] [CrossRef]
- Gelman, A.; Rubin, D.B. Inference from Iterative Simulation Using Multiple Sequences. Stat. Sci. 1992, 7, 457–511. [Google Scholar] [CrossRef]
- Zheng, Q.; Zhang, J.; Xu, W.; Wu, L.; Zeng, L. Adaptive Multifidelity Data Assimilation for Nonlinear Subsurface Flow Problems. Water Resour. Res. 2019, 55, 203–217. [Google Scholar] [CrossRef]
- Laloy, E.; Jacques, D. Emulation of CPU-demanding reactive transport models: A comparison of Gaussian processes, polynomial chaos expansion, and deep neural networks. Comput. Geosci. 2019, 23, 1193–1215. [Google Scholar] [CrossRef] [Green Version]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type of Parameters | n | Ks (m/min) | ||||
|---|---|---|---|---|---|---|
| Q3 | Parameter Ranges | [0.15, 0.2] | [0.45,0.55] | [0.003, 0.01] | [1.5, 2.5] | [0.005, 0.02] |
| HYDRUS-Based-MAP | 0.1702 | 0.4791 | 0.0063 | 1.5003 | 0.0156 | |
| ANN-Based-MAP | 0.2 | 0.45 | 0.0044 | 1.5031 | 0.02 | |
| GP-Based-MAP | 0.1719 | 0.4795 | 0.0099 | 1.5199 | 0.0154 | |
| S1 | Parameter Ranges | [0.15, 0.2] | [0.45, 0.55] | [0.003, 0.01] | [1.5, 2.5] | [0.005, 0.015] |
| HYDRUS-Based-MAP | 0.2 | 0.45 | 0.0073 | 1.5 | 0.01 | |
| ANN-Based-MAP | 0.1997 | 0.45 | 0.0094 | 1.6227 | 0.01 | |
| GP-Based-MAP | 0.1993 | 0.4505 | 0.0095 | 2.1504 | 0.0067 | |
| Type of Parameters | n | Ks (m/min) | ||||
|---|---|---|---|---|---|---|
| Q3 | Parameter Ranges | [0.15, 0.2] | [0.45,0.55] | [0.003, 0.01] | [1.5, 2.5] | [0.005, 0.02] |
| HYDRUS-Based-MAP | 0.1906 | 0.4638 | 0.0097 | 2.4997 | 0.0087 | |
| ANN-Based-MAP | 0.15 | 0.45 | 0.0065 | 1.585 | 0.0088 | |
| GP-Based-MAP | 0.1999 | 0.4693 | 0.003 | 2.5 | 0.008 | |
| S1 | Parameter Ranges | [0.15, 0.2] | [0.45,0.55] | [0.003, 0.01] | [1.5, 2.5] | [0.005, 0.015] |
| HYDRUS-Based-MAP | 0.2 | 0.45 | 0.0047 | 1.6335 | 0.01 | |
| ANN-Based-MAP | 0.2 | 0.45 | 0.0034 | 1.5199 | 0.008 | |
| GP-Based-MAP | 0.2 | 0.4586 | 0.003 | 1.6205 | 0.005 | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, Q.; Dai, F.; Zhao, Z. Comparison of Two Bayesian-MCMC Inversion Methods for Laboratory Infiltration and Field Irrigation Experiments. Int. J. Environ. Res. Public Health 2020, 17, 1108. https://0-doi-org.brum.beds.ac.uk/10.3390/ijerph17031108
Guo Q, Dai F, Zhao Z. Comparison of Two Bayesian-MCMC Inversion Methods for Laboratory Infiltration and Field Irrigation Experiments. International Journal of Environmental Research and Public Health. 2020; 17(3):1108. https://0-doi-org.brum.beds.ac.uk/10.3390/ijerph17031108
Chicago/Turabian StyleGuo, Qinghua, Fuchu Dai, and Zhiqiang Zhao. 2020. "Comparison of Two Bayesian-MCMC Inversion Methods for Laboratory Infiltration and Field Irrigation Experiments" International Journal of Environmental Research and Public Health 17, no. 3: 1108. https://0-doi-org.brum.beds.ac.uk/10.3390/ijerph17031108