
Comparison of Prediction Models for Mortality Related to Injuries from Road Traffic Accidents after Correcting for Undersampling

Abstract
:1. Introduction
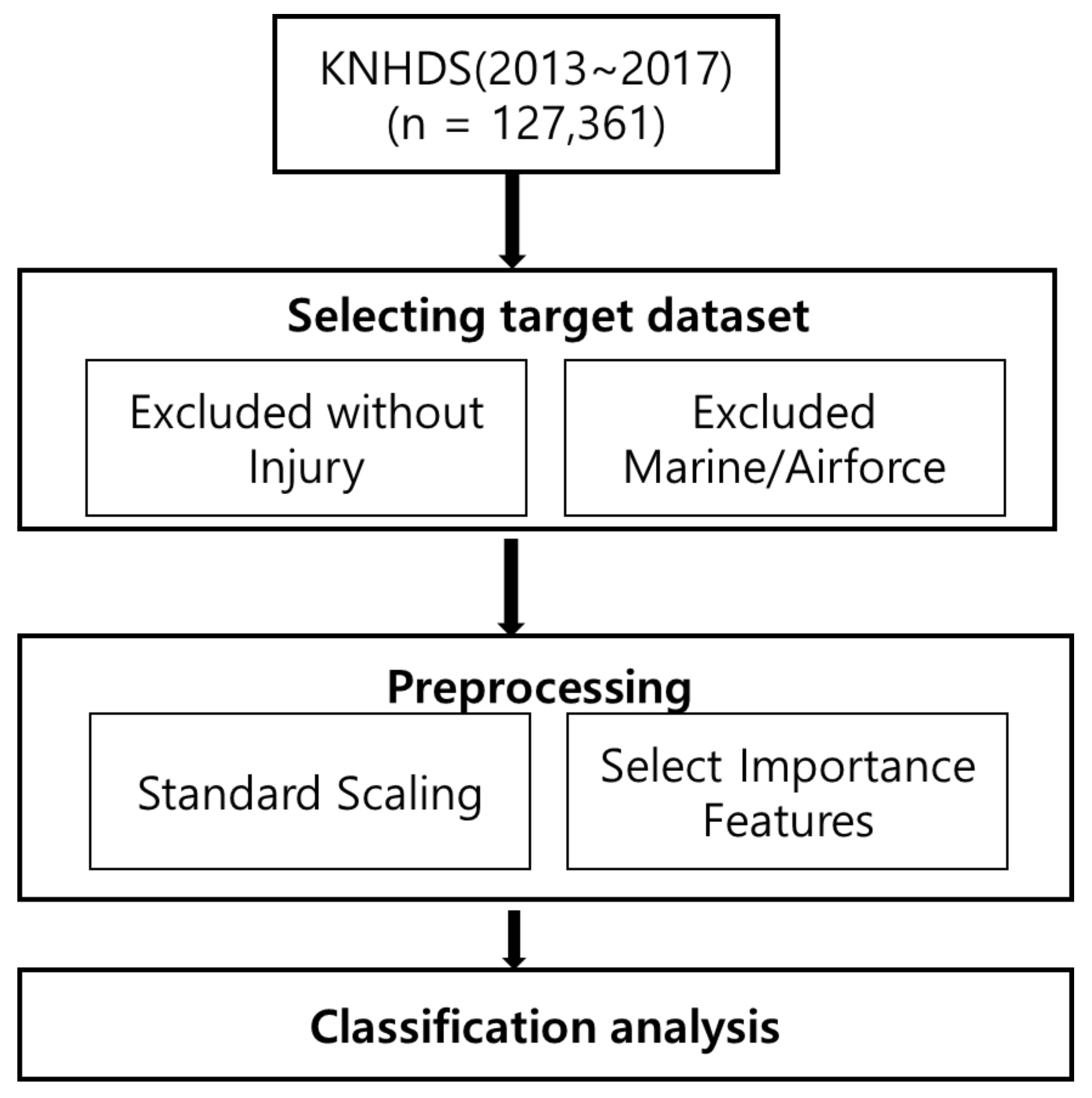
2. Materials and Methods
2.1. Research Sample
- If the principal diagnosis does not have an injury code, use the injury code of the other diagnosis as that of the principal diagnosis to match the injury with the external cause of injury code;
- If the principal or secondary diagnosis does not have an injury code, exclude it as not being an injury (1587 cases);
- Exclude cases if there is no injury code and there are only complications of medical and surgical treatments (T80–T88);
- Exclude cases if there is no injury code, and there are only the sequelae of injuries and addictions (T90–T98);
- If there are multiple types of injuries to one anatomical site, consider it a single site.
2.2. Variable Definitions
3. Results
3.1. Sample Characteristics
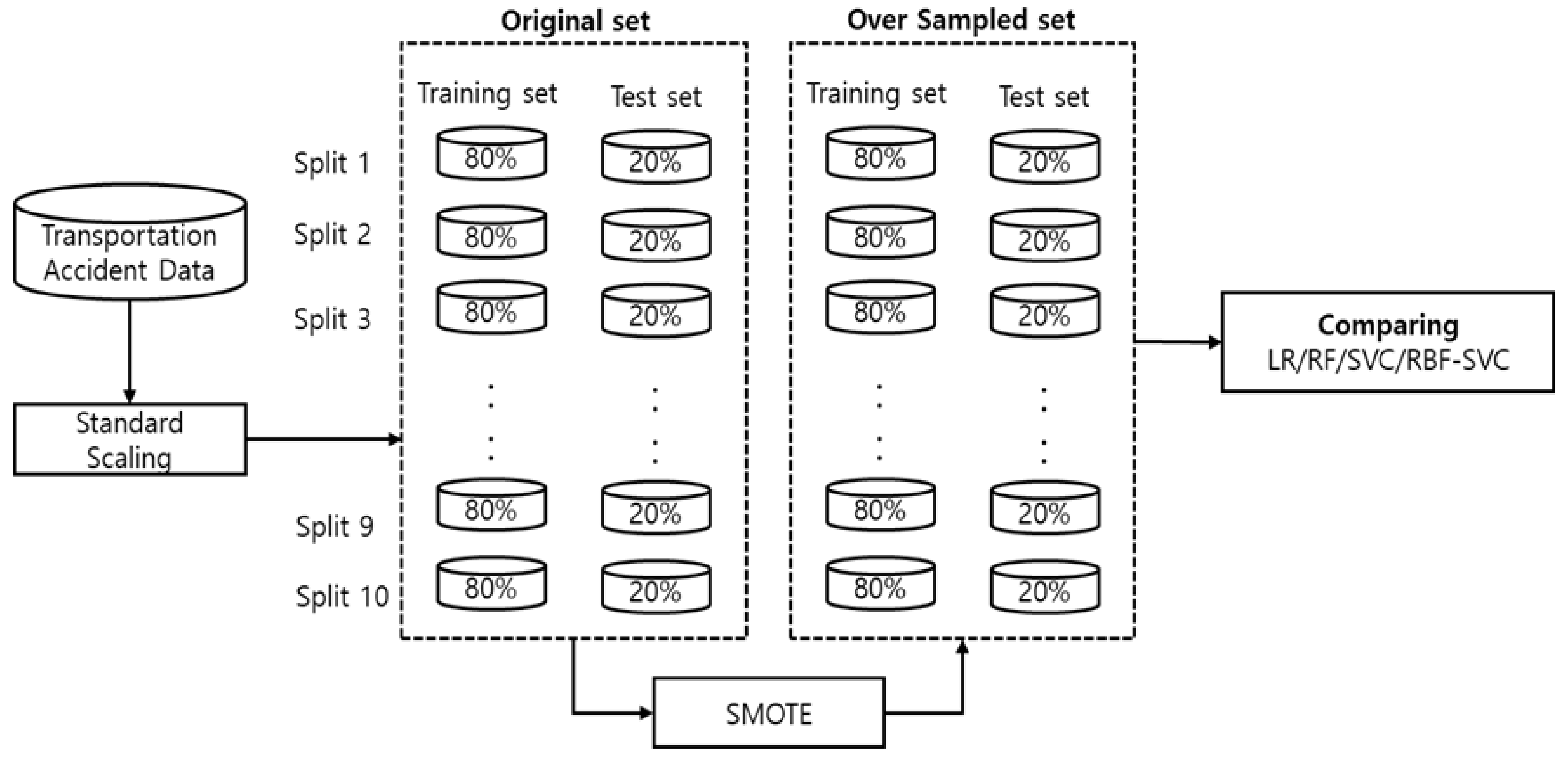
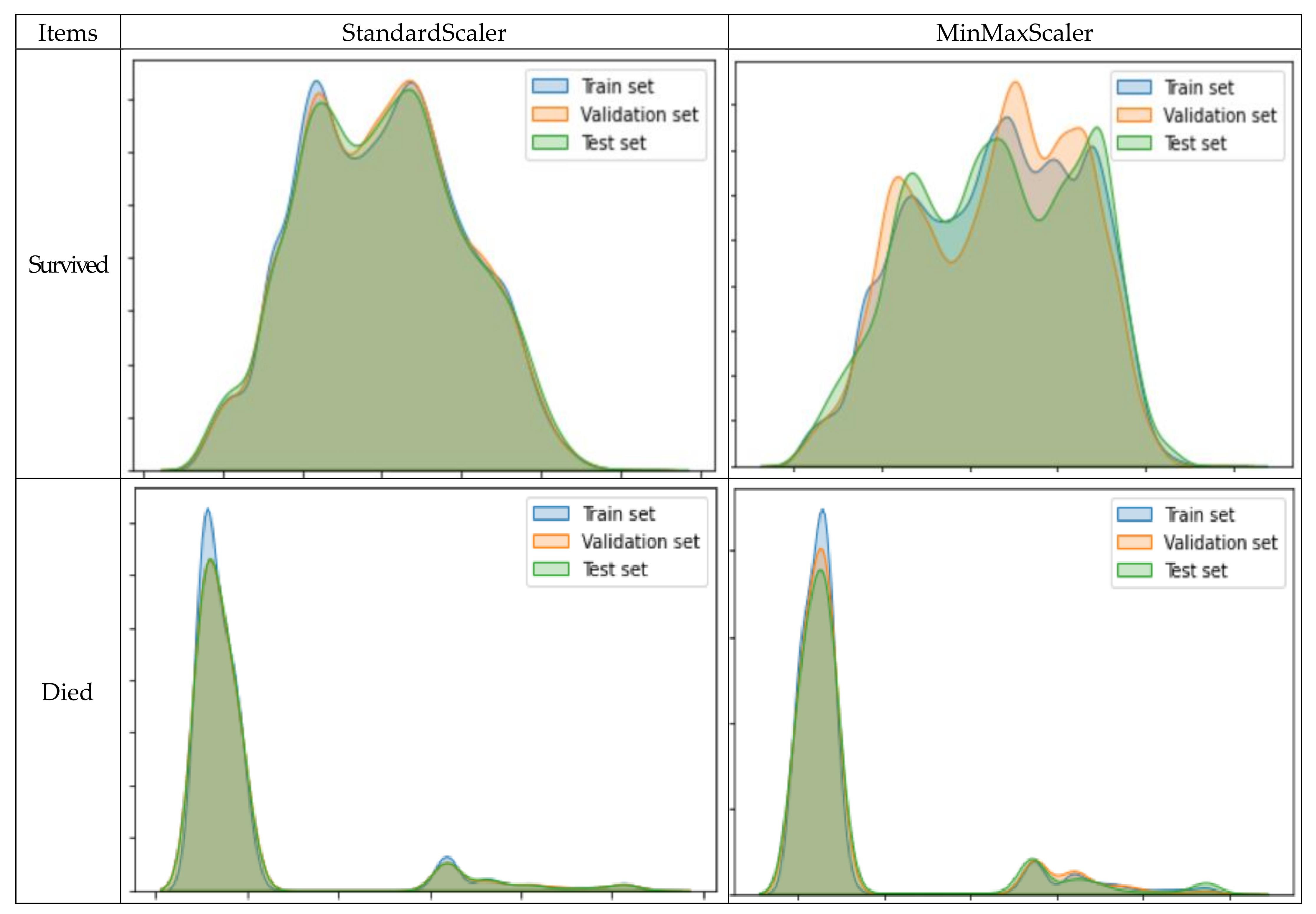
3.2. Classification Analysis
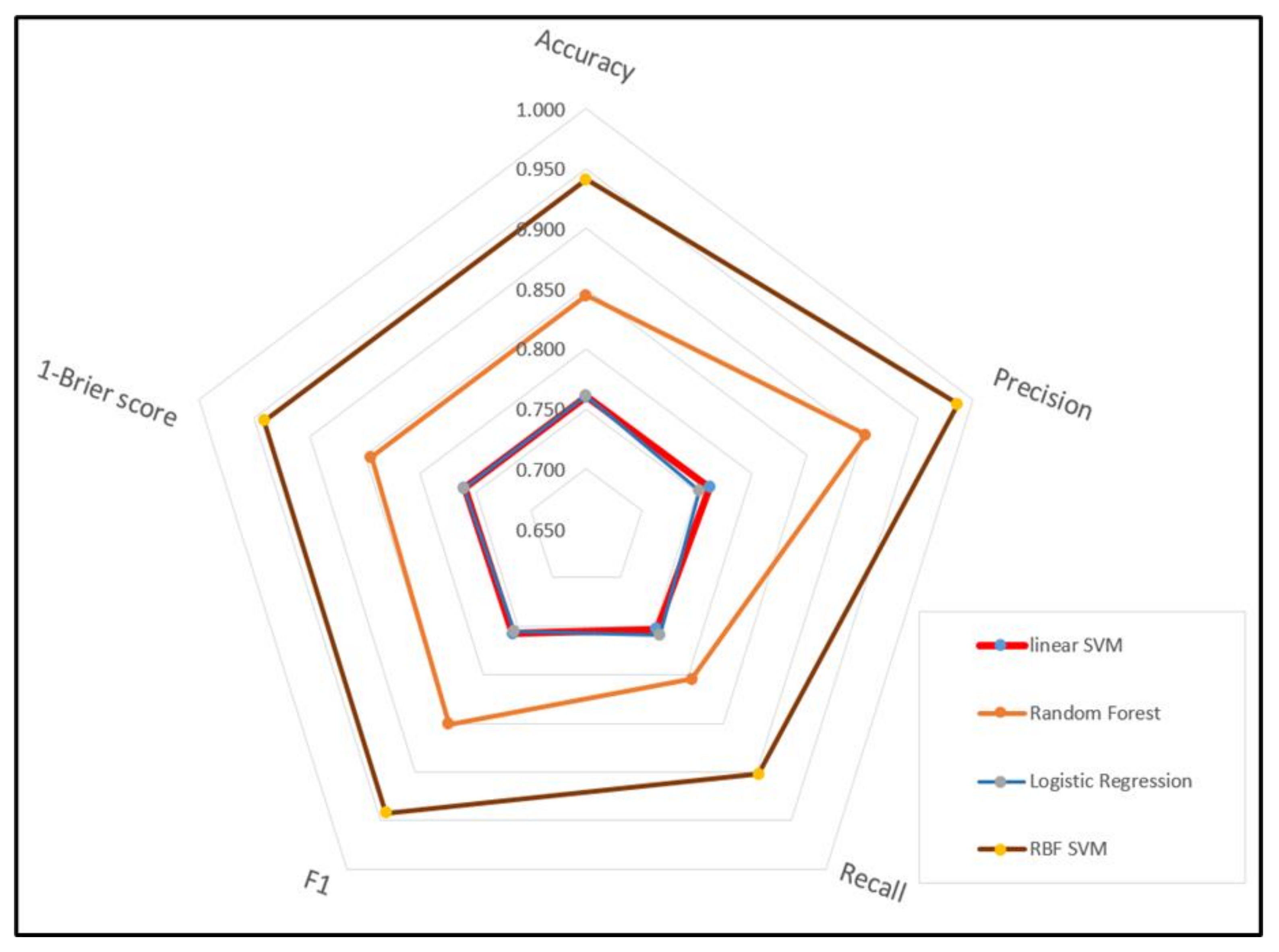
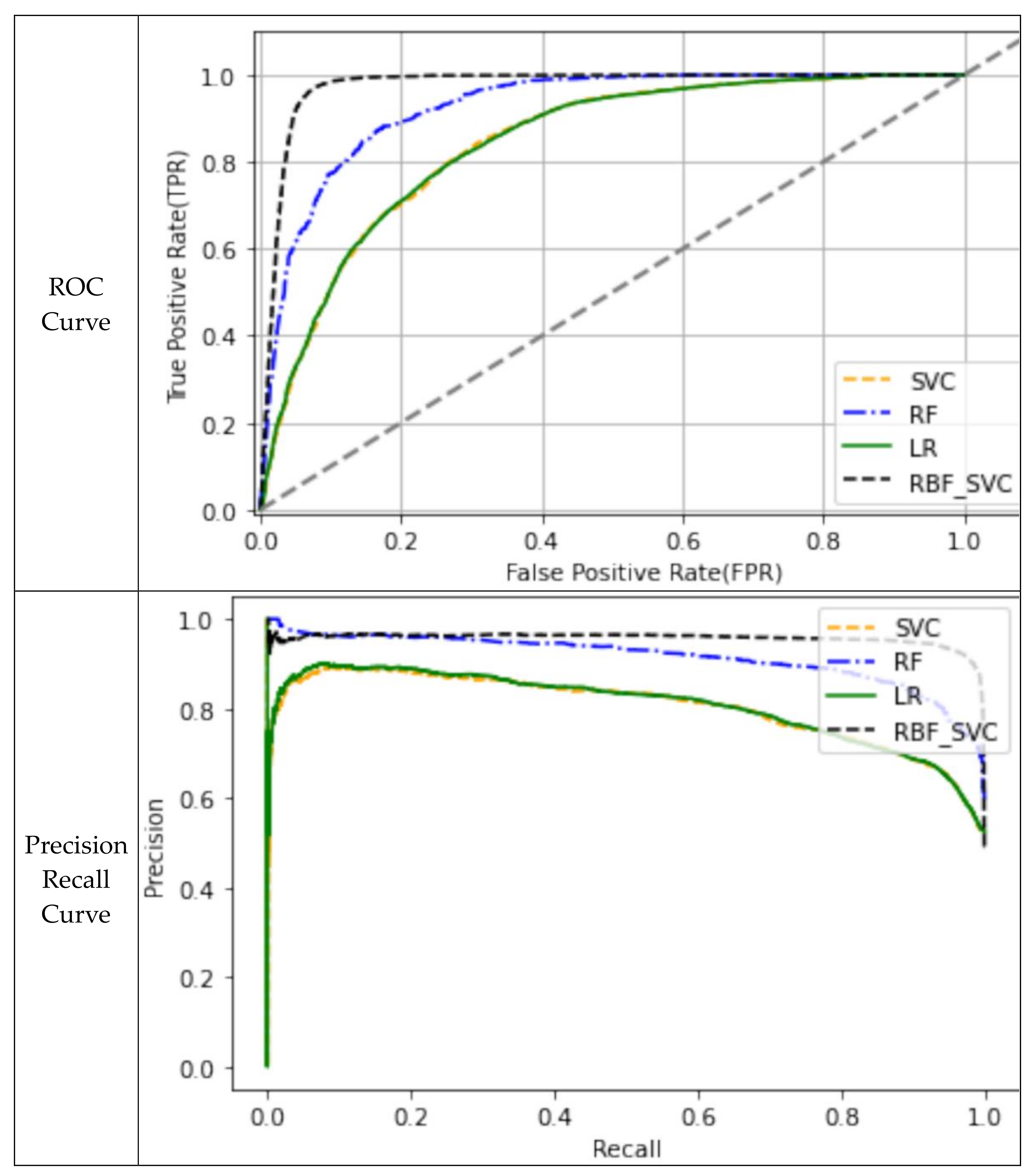
3.3. Model Evaluation
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- MacKenzie, E.J.; Fowler, C.J. Epidemiology. In Trauma, 4th ed.; Mattox, K.L., Feliciano, D.V., Moore, E.E., Eds.; McGraw-Hill: New York, NY, USA, 2000; Volume 22, p. 8. [Google Scholar]
- Gebresenbet, R.F.; Aliyu, A.D. Injury severity level and associated factors among road traffic accident victims attending emergency department of Tirunesh Beijing Hospital, Addis Ababa, Ethiopia: A cross sectional hospital-based study. PLoS ONE 2019, 14, e0222793. [Google Scholar] [CrossRef]
- OECD. International Transport Forum. In Road Safety Annual Report 2015; OECD Publishing: Paris, France, 2015. [Google Scholar] [CrossRef]
- Chen, S.; Kuhn, M.; Prettner, K.; E Bloom, D. The global macroeconomic burden of road injuries: Estimates and projections for 166 countries. Lancet Planet. Health 2019, 3, e390–e398. [Google Scholar] [CrossRef]
- Ranki, L.; Parkes, H. Better than Cure: Injury Prevention Policy, Institute for Public Policy Research. 2020. Available online: https://www.ippr.org/research/publications/better-than-cure-injury-prevention-policy (accessed on 10 May 2021).
- Kim, S.-S.; Kim, W.-J.; Kang, S.-H. A study on the variation of severity adjusted LOS on Injry inpatient in Korea. J. Korea Acad. Coop. Soc. 2011, 12, 2668–2676. [Google Scholar] [CrossRef] [Green Version]
- Nghiem, H.S.; Connelly, L.B.; Gargett, S. Are road traffic crash fatality rates converging among OECD countries? Accid. Anal. Prev. 2013, 52, 162–170. [Google Scholar] [CrossRef] [PubMed]
- Williams, S.; Gousen, S.; DeFrances, C. National hospital care survey demonstration projects: Pneumonia inpatient hospitali-zations and emergency department visits. Nat. Health Sta. Rep. 2018, 116, 1–11. [Google Scholar] [PubMed]
- Jeong, H.; Jang, Y.; Bowman, P.J.; Masoud, N. Classification of motor vehicle crash injury severity: A hybrid approach for imbalanced data. Accid. Anal. Prev. 2018, 120, 250–261. [Google Scholar] [CrossRef] [PubMed]
- Han, H.; Wang, W.-Y.; Mao, B.-H. Borderline-SMOTE: A New Over-Sampling Method in Imbalanced Data Sets Learning. In Proceedings of the Transactions on Petri Nets and Other Models of Concurrency XV, Hefei, China, 23–26 August 2005; Volume 3644, pp. 878–887. [Google Scholar]
- Fernandez, A.; Garcia, S.; Herrera, F.; Chawla, N.V. SMOTE for Learning from Imbalanced Data: Progress and Challenges, Marking the 15-year Anniversary. J. Artif. Intell. Res. 2018, 61, 863–905. [Google Scholar] [CrossRef]
- Yau, K.K. Risk factors affecting the severity of single vehicle traffic accidents in Hong Kong. Accid. Anal. Prev. 2004, 36, 333–340. [Google Scholar] [CrossRef]
- McKenna, F.P. Do safety measures really work? An examination of risk homeostasis theory. Ergonomics 1985, 28, 489–498. [Google Scholar] [CrossRef]
- Hosseinzadeh, A.; Moeinaddini, A.; Ghasemzadeh, A. Investigating factors affecting severity of large truck-involved crashes: Comparison of the SVM and random parameter logit model. J. Saf. Res. 2021. [Google Scholar] [CrossRef]
- Rezapour, M.; Moomen, M.; Ksaibati, K. Ordered logistic models of influencing factors on crash injury severity of single and multiple-vehicle downgrade crashes: A case study in Wyoming. J. Saf. Res. 2019, 68, 107–118. [Google Scholar] [CrossRef] [PubMed]
- Wei, C.-P.; Chiu, I.-T. Turning telecommunications call details to churn prediction: A data mining approach. Expert Syst. Appl. 2002, 23, 103–112. [Google Scholar] [CrossRef]
- Coussement, K.; Poel, D.V.D. Churn prediction in subscription services: An application of support vector machines while comparing two parameter-selection techniques. Expert Syst. Appl. 2008, 34, 313–327. [Google Scholar] [CrossRef]
- Mozer, M.C.; Wolniewicz, R.; Grimes, D.B.; Johnson, E.; Kaushansky, H. Predicting subscriber dissatisfaction and improving retention in the wireless telecommunications industry. IEEE Trans. Neural Netw. 2000, 11, 690–696. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lord, D.; Mannering, F. The statistical analysis of crash-frequency data: A review and assessment of methodological alternatives. Transp. Res. Part A Policy Pract. 2010, 44, 291–305. [Google Scholar] [CrossRef] [Green Version]
- Savolainen, P.T.; Mannering, F.L.; Lord, D.; Quddus, M.A. The statistical analysis of highway crash-injury severities: A review and assessment of methodological alternatives. Accid. Anal. Prev. 2011, 43, 1666–1676. [Google Scholar] [CrossRef] [Green Version]
- Luca, M.D.; Mauro, R.; Russo, F.; Acqua, G.D. Road Safety Management Using Bayesian and Clustering Analysis. Soc. Behav. Sci. 2012, 54, 1260–1269. [Google Scholar] [CrossRef] [Green Version]
- Ona, J.D.; Lopez, Z.; Mujalli, R.; Calvo, F.J. Analysis of Traffic Accident on Rural Highway Using Latent Class Clustering and Bayesian Networks. Accid. Anal. Prev. 2013, 51, 1–10. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhou, X.; Lu, P.; Zheng, Z.; Tolliver, D.; Keramati, A. Accident prediction accuracy assessment for highway-rail grade crossings using random forest algorithm compared with decision tree. Reliab. Eng. Syst. Saf. 2020, 200, 106931. [Google Scholar] [CrossRef]
- Kashani, A.T.; Rabieyan, R.; Besharati, M.M. A data mining approach to investigate the factors influencing the crash severity of motorcycle pillion passengers. J. Saf. Res. 2014, 51, 93–98. [Google Scholar] [CrossRef]
- Assim, K. raffic crash severity prediction—A synergy by hybrid principal component analysis and machine learning models. Int. J. Environ. Res. Pub. Health 2020, 17, 7598. [Google Scholar] [CrossRef]
- Guo, L.; Ge, P.-S.; Zhang, M.-H.; Li, L.-H.; Zhao, Y.-B. Pedestrian detection for intelligent transportation systems com-bining AdaBoost algorithm and supportvector machine. Expert Syst. Appl. 2012, 39, 4274–4286. [Google Scholar] [CrossRef]
- Chen, C.; Zhang, G.; Qian, Z.; Tarefder, R.A.; Tian, Z. Investigating driver injury severity patterns in rollover crashes using support vector machine models. Accid. Anal. Prev. 2016, 90, 128–139. [Google Scholar] [CrossRef] [PubMed]
- Jung, H.-N.; Lee, J.H.; Jun, C.-H. A data mining procedure for unbalanced binary classification. J. Korean Inst. Ind. Eng. 2010, 36, 13–21. [Google Scholar]
- Kim, Y.; Hong, S.-O.; Kim, B.-A.; Jo, J.-H.; Kwon, Y.-H.; Lee, Y.-K. The main results of Korea national discharge in-depth injury survey 2004-2016. Epidemiol. Heal. 2020, 42, e2020044. [Google Scholar] [CrossRef] [PubMed]
- Faraway, J.J. Data splitting strategies for reducing the effect of model selection on inference. Comput. Sci. Stat. 1995, 30, 332–341. [Google Scholar]
- Diez, D.M.; Barr, C.D.; Cetinkaya-Rundel, M. CreateSpace Independent Publishing Platform. In OpenIntro Statistics; Openintro: San Francisco, CA, USA, 2012; Volume 12. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Leonard, K.J.; Rauner, M.S.; Schaffhauser-Linzatti, M.-M.; Yap, R. The effect of funding policy on day of week admissions and discharges in hospitals: The cases of Austria and Canada. Health Policy 2003, 63, 239–257. [Google Scholar] [CrossRef]
- Song, Y.R.; Lee, M.S.; Kim, D.R.; Kim, K.H. A convergence study on the characteristics of length of hospital stays of injured and traumatic death patients-Based on the Korea National Hospital Discharge Injury Survey data. J. Korea Converg. Soc. 2017, 8, 87–96. [Google Scholar] [CrossRef]
- Douzas, G.; Bacao, F.; Last, F. Improving imbalanced learning through a heuristic oversampling method based on k-means and SMOTE. Inf. Sci. 2018, 465, 1–20. [Google Scholar] [CrossRef] [Green Version]
- Kuo, B.-C.; Ho, H.-H.; Li, C.-H.; Hung, C.-C.; Taur, J.-S. A Kernel-Based Feature Selection Method for SVM With RBF Kernel for Hyperspectral Image Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 317–326. [Google Scholar] [CrossRef]
- Chang, L.; Chien, J. Analysis of driver injury severity in truck-involved accidents using a non-parametric classification tree model. Saf. Sci. 2013, 51, 17–22. [Google Scholar] [CrossRef]
- Glance, L.G.; Osler, T.M.; Mukamel, D.B. TMPM-ICD9: A trauma mortality prediction model based on ICD-9-CM codes. Ann. Surg. 2009, 249, 1032–1039. [Google Scholar] [CrossRef] [PubMed]
- Cios, K.J.; Moore, G.W. Uniqueness of medical data mining. Artif. Intell. Med. 2002, 26, 1–24. [Google Scholar] [CrossRef]
- Lavrač, N.; Keravnou, E.T.; Zupan, B. Intelligent data analysis in medicine and pharmacology: An overview. In Intelligent Data Analysis in Medicine and Pharmacology; Wolters Kluwer: Alphen on the Rhine, The Netherlands, 1997; pp. 1–13. [Google Scholar]
- Road Safety Annual Report 2015, OECD/International Transport Forum. Available online: https://www.itf-oecd.org/sites/default/files/docs/15irtadannualreport_0.pdf (accessed on 10 May 2021).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Items | Freq. (%) | Items | Freq. (%) | ||
|---|---|---|---|---|---|
| Mean age | 42.72 (18.401) * | Patterns of principal injury | Superficial injury | 9037 (16.3) | |
| Sex | Male | 32,936 (59.6) | Open wound | 1825 (3.3) | |
| Female | 22,343 (40.4) | Fracture | 11,035 (20.0) | ||
| Role in accident | Pedestrian | 9411 (17.0) | Sprain/dislocation | 24,049 (43.5) | |
| Driver | 22,358(40.4) | Nerve injury | 289 (0.5) | ||
| Public transit Passenger | 8818 (16.0) | Blood vessel injury | 87 (0.2) | ||
| Person injured while boarding or exiting vehicle | 5699 (10.3) | Internal organ injury ** | 8147 (14.7) | ||
| Person outside of vehicle | 218 (0.4) | Muscle injury | 457 (0.8) | ||
| Car passenger | 5795 (10.5) | Crush injury | 119 (0.2) | ||
| Other Injured person | 2980(5.4) | Amputation | 34 (0.1) | ||
| Primary site of injury | Head | 11,050 (20.0) | Other and unspecified injury | 200 (0.4) | |
| Neck | 10,523 (19.0) | Type of injury | Multiple site | 2481 (4.5) | |
| Spine | 7 (0.0) | Single site | 52,726 (95.4) | ||
| Chest | 4625 (8.4) | Unspecified | 72 (0.1) | ||
| Abdomen/back | 11,129 (20.1) | Operation | Yes | 11,788 (21.3) | |
| Shoulder/upper arm | 4125 (7.5) | No | 43,491 (78.7) | ||
| Forearm | 1660 (3.0) | Treatment outcome | Survived | 54,609 (98.8) | |
| Wrist/hand | 1669 (3.0) | Died | 670 (1.2) | ||
| Hip/thigh | 1580 (2.9) | ||||
| Knee/lower leg | 5756 (10.4) | ||||
| Ankle/foot | 2136 (3.9) | ||||
| Multiple site | 933 (1.7) | ||||
| Unknown site | 86 (0.1) | ||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Boo, Y.; Choi, Y. Comparison of Prediction Models for Mortality Related to Injuries from Road Traffic Accidents after Correcting for Undersampling. Int. J. Environ. Res. Public Health 2021, 18, 5604. https://0-doi-org.brum.beds.ac.uk/10.3390/ijerph18115604
Boo Y, Choi Y. Comparison of Prediction Models for Mortality Related to Injuries from Road Traffic Accidents after Correcting for Undersampling. International Journal of Environmental Research and Public Health. 2021; 18(11):5604. https://0-doi-org.brum.beds.ac.uk/10.3390/ijerph18115604
Chicago/Turabian StyleBoo, Yookyung, and Youngjin Choi. 2021. "Comparison of Prediction Models for Mortality Related to Injuries from Road Traffic Accidents after Correcting for Undersampling" International Journal of Environmental Research and Public Health 18, no. 11: 5604. https://0-doi-org.brum.beds.ac.uk/10.3390/ijerph18115604