
Comparison of Missing Data Infilling Mechanisms for Recovering a Real-World Single Station Streamflow Observation


 and
and
Abstract
:1. Introduction
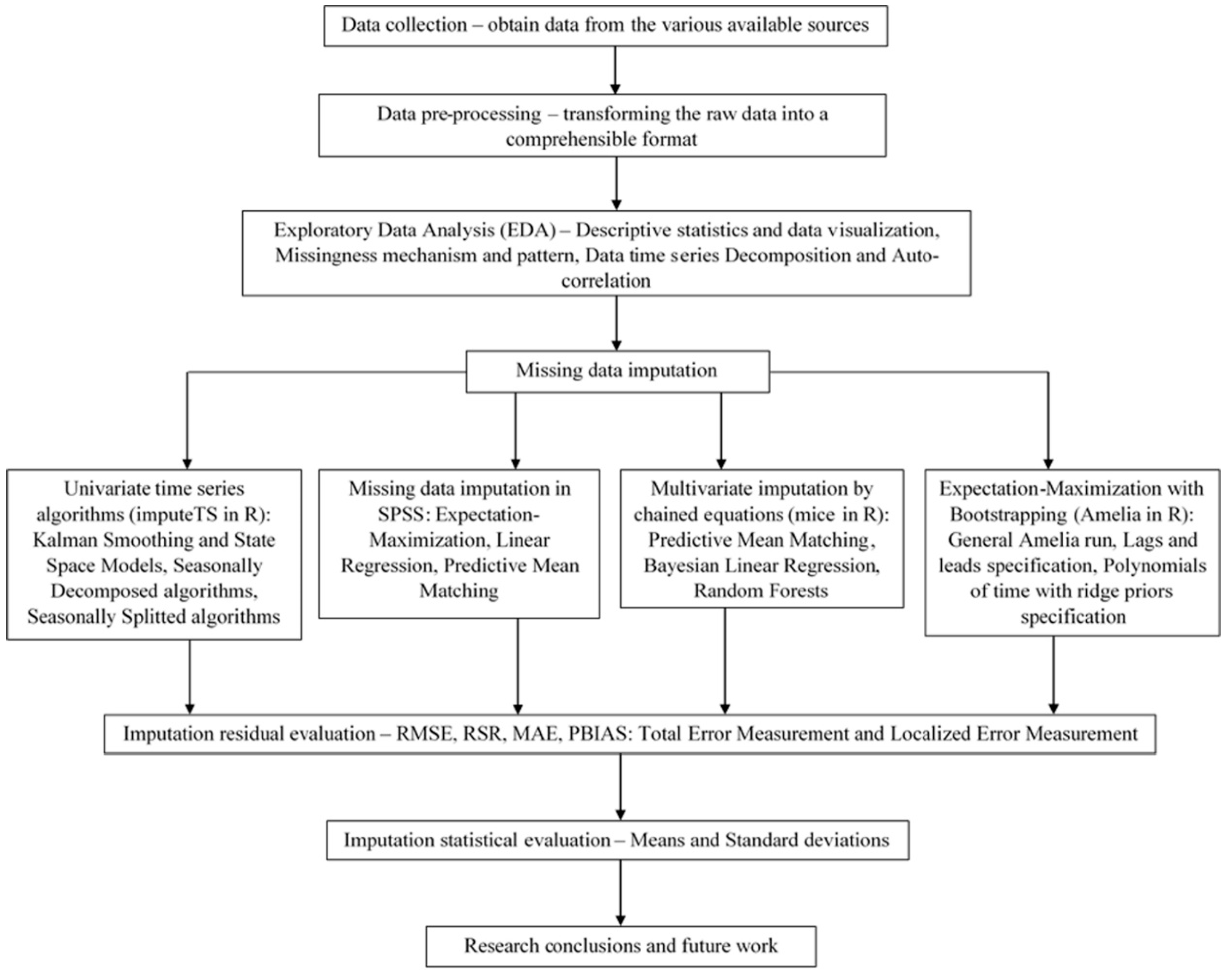
2. Materials and Methods
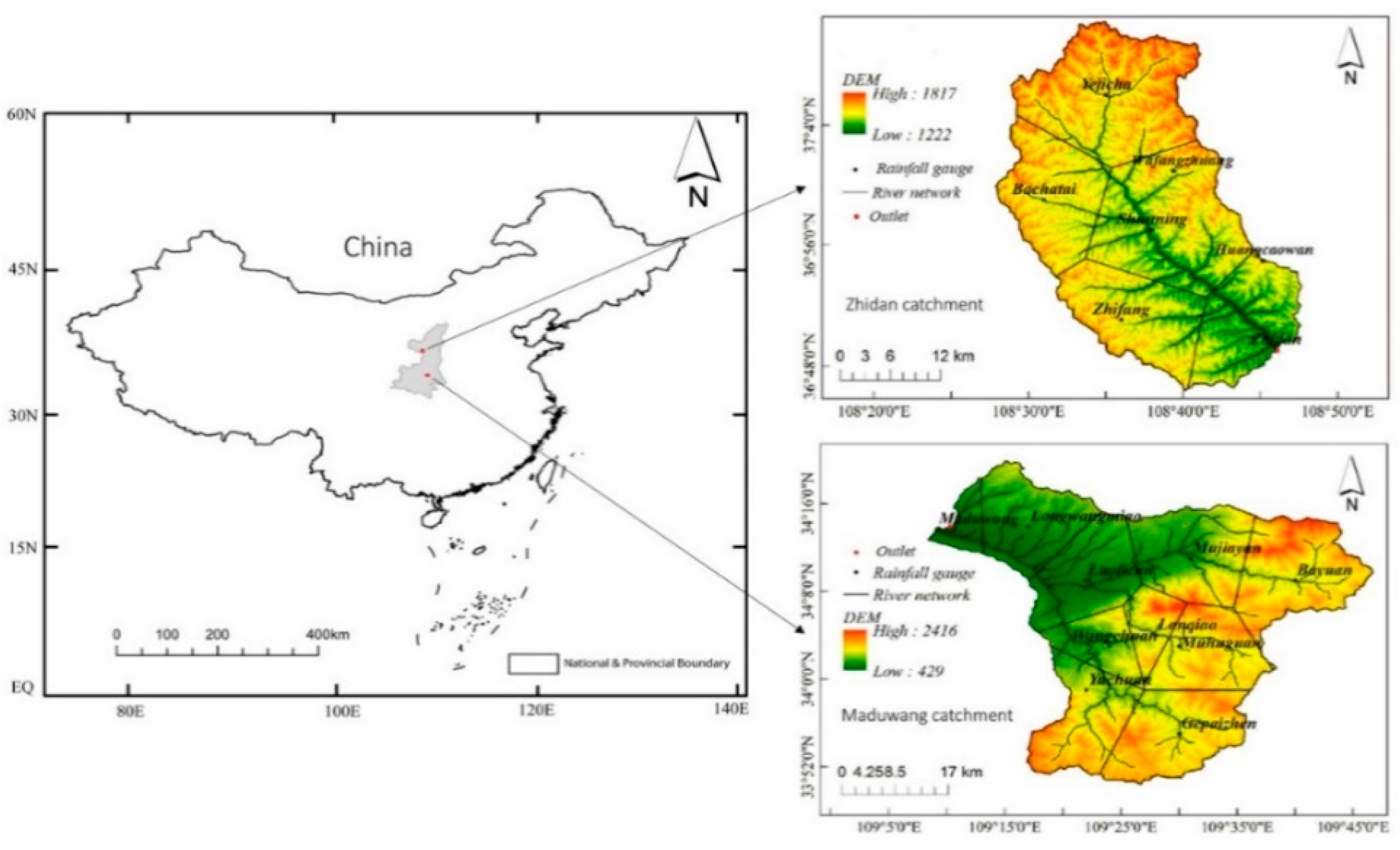
2.1. Study Areas and Data Used
2.2. Methods
2.2.1. Exploratory Data Analysis (EDA)
- Descriptive statistics
- 2.
- Missingness mechanism and missingness pattern
- 3.
- Decomposition and Auto-correlation
2.2.2. Missing Data Imputation
- Imputation methods
- 2.
- Imputation Accuracy statistics
3. Results
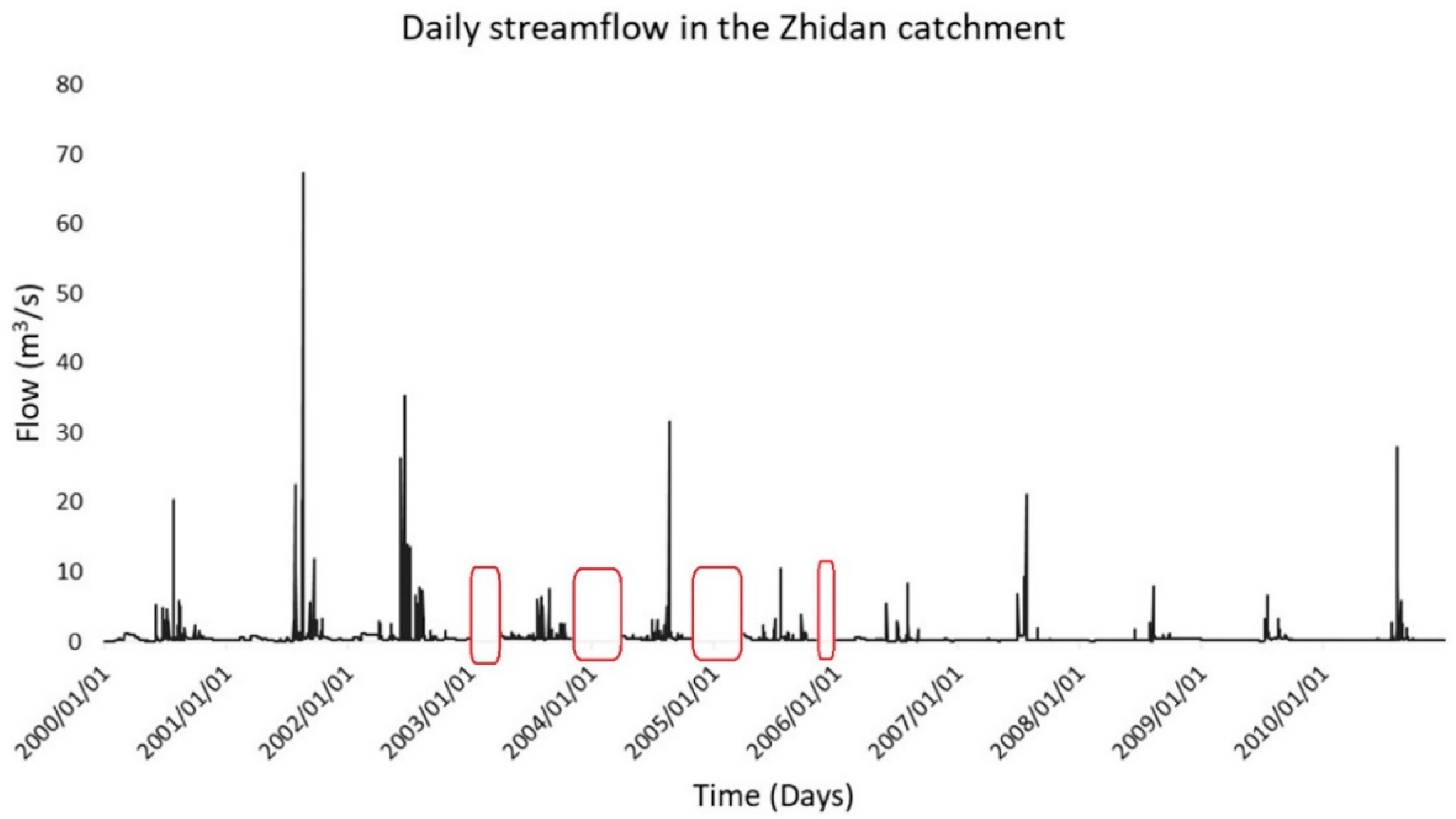
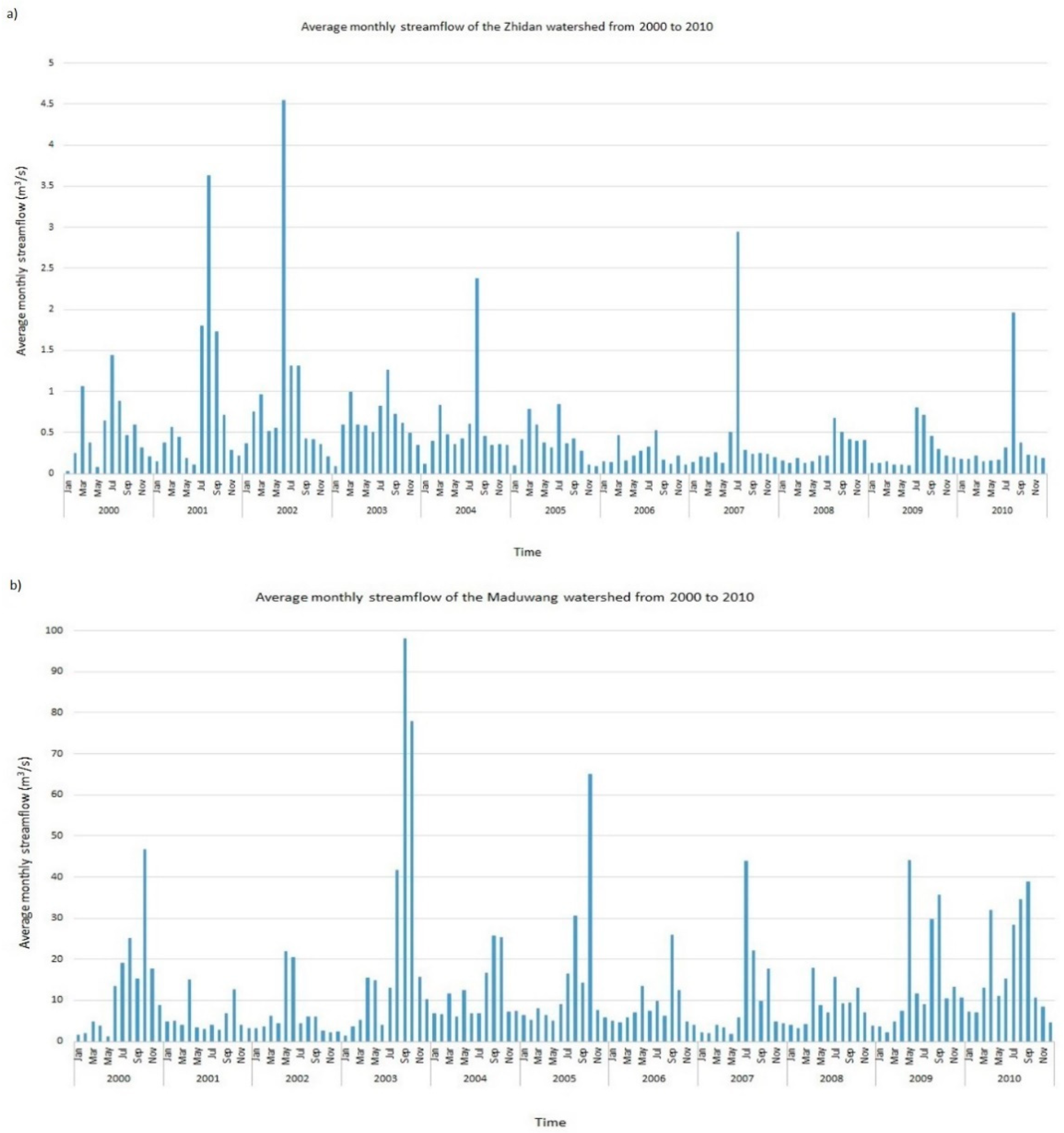
3.1. EDA Results
3.2. Imputation Results
- The PMM method of the Monotone multiple imputation mechanism in SPSS surpassed the PMM method of the MICE algorithm in all of the error metrics across the TEM and the LEM. However, both use the same predictive mean matching method of missing data imputation, with the Monotone PMM in SPSS underestimating the missing values. At the same time, the PMM of MICE overestimates the missing values.
- Although the interpolation method of the seasonally decomposed algorithm outperforms all of the applied methods in RMSE, RSR, and MAE, it is overtaken in terms of the bias by the Kalman method of the same algorithm, the structural time series of the Kalman smoothing algorithm across both the TEM and LEM, and the PMM method of the Monotone multiple imputation mechanism in SPSS with the LEM while having the same underestimation bias with the TEM.
- The PMM method of the Monotone multiple imputation mechanism in SPSS, although having a better RMSE value, possesses the same RSR value and is outdone in MAE and percentage bias across the TEM and LEM by the structural time series of the Kalman smoothing algorithm.
- Similarly, the PMM method of the Monotone multiple imputation mechanism in SPSS, although having better RMSE and RSR values than the Kalman method of the seasonally decomposed algorithm, shows the same MAE value and is outdone in the estimation percentage bias by the latter method across both the TEM and LEM.
- The RF method of the MICE algorithm overtakes the ARIMA state-space representation method of the Kalman smoothing algorithm, all of the methods of the seasonally splitted algorithm in MAE and bias results across all of the measurements regardless of its worse RMSE and RSR results, and overestimates the missing values, while the others underestimate the missing values.
- The PMM method of the MICE algorithm and the Kalman method of the seasonally splitted algorithm possess similar and opposite bias estimation of the missing values, with the PMM overestimating while the Kalman underestimates, although the Kalman method displays better RMSE, RSR, and MAE results.
- The BLR method of the MICE algorithm also outperforms the LR method of the Monotone multiple imputation mechanism in SPSS and all of the methods of the EMB algorithm in MAE and percentage bias across both the TEM and LEM, although the LR method and the EMB algorithms display better RMSE and RSR values.
- The mean of the original Zhidan dataset containing missing data is a greater mean than the mean of the entire dataset without missing data. Therefore, the algorithms which resulted in lower means than the original dataset provide better missing data imputation methods for this real-world dataset.
- The seasonally splitted algorithm did not impute one missing value also of the Zhidan watershed in Table 8, similar to the case displayed in Table 7. Therefore, it can be rightly assumed that the means produced by this algorithm would be below the actual mean of the Zhidan dataset without missing values.
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- van Buuren, S. Flexible Imputation of Missing Data, 2nd ed.; Keiding, N., Morgan, B.J.T., Wikle, C.K., van der Heijden, P., Eds.; Chapman and Hall/CRC: Boca Raton, FL, USA, 2018; ISBN 9780429492259. [Google Scholar]
- Starrett, S.K.; Starrett, S.K.; Heierm, T.; Su, Y.; Tuan, D.; Bandurraga, M. Filling in missing peakflow data using artificial neural networks. ARPN J. Eng. Appl. Sci. 2010, 5, 49–55. [Google Scholar]
- Di Piazza, A. The Problem of Missing Data in Hydroclimatic Time Series. Application of Spatial Interpolation Techniques to Construct a Comprehensive of Hydroclimatic Data in Sicily, Italy. Ph.D. Thesis, Università di Palermo, Palermo, Italy, 2011. [Google Scholar]
- Moritz, S.; Sardá, A.; Bartz-Beielstein, T.; Zaefferer, M.; Stork, J. Comparison of different Methods for Univariate Time Series Imputation in R. arXiv 2015, arXiv:1510.03924. [Google Scholar]
- Ng, W.W.; Panu, U.S.; Lennox, W.C. Comparative studies in problems of missing extreme daily streamflow records. J. Hydrol. Eng. 2009, 14, 91–100. [Google Scholar] [CrossRef]
- Little, T.D.; Jorgensen, T.D.; Lang, K.M.; Moore, E.W.G. On the joys of missing data. J. Pediatr. Psychol. 2014, 39, 151–162. [Google Scholar] [CrossRef] [Green Version]
- Kim, M.; Baek, S.; Ligaray, M.; Pyo, J.; Park, M.; Cho, K.H. Comparative studies of different imputation methods for recovering streamflow observation. Water 2015, 7, 6847–6860. [Google Scholar] [CrossRef] [Green Version]
- Kim, J.-W.; Pachepsky, Y.A. Reconstructing missing daily precipitation data using regression trees and artificial neural networks for SWAT streamflow simulation. J. Hydrol. 2010, 394, 305–314. [Google Scholar] [CrossRef]
- Chandrasekaran, S.; Moritz, S.; Zaefferer, M.; Stork, J.; Bartz-Beielstein, T.; Bartz-Beielstein, T. Data Preprocessing: A New Algorithm for Univariate Imputation Designed Specifically for Industrial Needs. In Proceedings of the Workshop Computational Intelligence, Dortmund, Germany, 24–25 November 2016; Hoffmann, F., Hüllermeier, E., Eds.; pp. 1–20. [Google Scholar]
- Moritz, S.; Bartz-Beielstein, T. imputeTS: Time series missing value imputation in R. R J. 2017, 9, 207–218. [Google Scholar] [CrossRef] [Green Version]
- Misztal, M.A. Comparison of Selected Multiple Imputation Methods for Continuous Variables—Preliminary Simulation Study Results. Acta Univ. Lodz. Folia Oeconomica 2019, 6, 73–98. [Google Scholar] [CrossRef]
- Rubin, D.B. Multiple Imputation for Nonresponse in Surveys; John Wiley & Sons: New York, NY, USA, 1987; ISBN 0-471-08705-X. [Google Scholar]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum Likelihood from Incomplete Data via the EM Algorithm. J. R. Stat. Soc. Ser. B 1977, 39, 1–38. [Google Scholar]
- Rantou, K.-E.; Karagrigoriou, A.; Vonta, I. On imputation methods in univariate time series. MESA 2017, 8, 239–251. [Google Scholar]
- Albano, G.; La Rocca, M.; Perna, C. On the Imputation of Missing Values in Univariate PM10 Time Series. In Proceedings of the Computer Aided Systems Theory—EUROCAST 2017 (16th International Conference, Revised Selected Papers, Part II), Las Palmas de Gran Canaria, Spain, 19–24 February 2017; Moreno-Díaz, R., Pichler, F., Quesada-Arencibia, A., Eds.; Springer: Las Palmas de Gran Canaria, Spain, 2017; Volume LNCS 10672, pp. 12–19. [Google Scholar]
- Chaudhry, A.; Li, W.; Basri, A.; Patenaude, F. A Method for Improving Imputation and Prediction Accuracy of Highly Seasonal Univariate Data with Large Periods of Missingness. Wirel. Commun. Mob. Comput. 2019, 2019, 1–13. [Google Scholar] [CrossRef]
- Phan, T.T.H.; Poisson Caillault, É.; Lefebvre, A.; Bigand, A. Dynamic time warping-based imputation for univariate time series data. Pattern Recognit. Lett. 2020, 139, 139–147. [Google Scholar] [CrossRef] [Green Version]
- Flores, A.; Tito, H.; Centty, D. Recurrent neural networks for meteorological time series imputation. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 482–487. [Google Scholar] [CrossRef]
- Nanda, T.; Sahoo, B.; Chatterjee, C. Enhancing the applicability of Kohonen Self-Organizing Map (KSOM) estimator for gap-filling in hydrometeorological timeseries data. J. Hydrol. 2017, 549, 133–147. [Google Scholar] [CrossRef]
- Norazizi, N.A.A.; Deni, S.M. Comparison of Artificial Neural Network (ANN) and Other Imputation Methods in Estimating Missing Rainfall Data at Kuantan Station. In Proceedings of the Communications in Computer and Information Science, 5th International Conference, SCDS 2019, Iizuka, Japan, 28–29 August 2019; Springer Nature Singapore Pte Ltd.: Singapore, 2019; Volume 1100, pp. 298–306. [Google Scholar]
- Baraldi, A.N.; Enders, C.K. An introduction to modern missing data analyses. J. Sch. Psychol. 2010, 48, 5–37. [Google Scholar] [CrossRef]
- de Souza, G.R.; Bello, I.P.; Corrêa, F.V.; de Oliveira, L.F.C. Artificial Neural Networks for Filling Missing Streamflow Data in Rio do Carmo Basin, Minas Gerais, Brazil. Brazilian Arch. Biol. Technol. 2020, 63, 1–8. [Google Scholar] [CrossRef]
- Dembélé, M.; Oriani, F.; Tumbulto, J.; Mariéthoz, G.; Schaefli, B. Gap-filling of daily streamflow time series using Direct Sampling in various hydroclimatic settings. J. Hydrol. 2019, 569, 573–586. [Google Scholar] [CrossRef]
- Mesta, B.; Akgun, O.B.; Kentel, E. Alternative solutions for long missing streamflow data for sustainable water resources management. Int. J. Water Resour. Dev. 2020, 1–24. [Google Scholar] [CrossRef]
- Sidibe, M.; Dieppois, B.; Mahé, G.; Paturel, J.E.; Amoussou, E.; Anifowose, B.; Lawler, D. Trend and variability in a new, reconstructed streamflow dataset for West and Central Africa, and climatic interactions, 1950–2005. J. Hydrol. 2018, 561, 478–493. [Google Scholar] [CrossRef] [Green Version]
- Tencaliec, P.; Favre, A.C.; Prieur, C.; Mathevet, T. Reconstruction of missing daily streamflow data using dynamic regression models. Water Resour. Res. 2015, 51, 9447–9463. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Post, D. How good are hydrological models for gap-filling streamflow data? Hydrol. Earth Syst. Sci. 2018, 22, 4593–4604. [Google Scholar] [CrossRef] [Green Version]
- Flores, A.; Tito, H.; Silva, C. Local average of nearest neighbors: Univariate time series imputation. Int. J. Adv. Comput. Sci. Appl. 2019, 10, 45–50. [Google Scholar] [CrossRef]
- Flores, A.; Tito, H.; Centty, D. Model for time series imputation based on average of historical vectors, fitting and smoothing. Int. J. Adv. Comput. Sci. Appl. 2019, 10, 346–352. [Google Scholar] [CrossRef]
- Flores, A.; Tito, H.; Centty, D. Improving gated recurrent unit predictions with univariate time series imputation techniques. Int. J. Adv. Comput. Sci. Appl. 2019, 10, 708–714. [Google Scholar] [CrossRef] [Green Version]
- Flores, A.; Tito, H.; Silva, C. CBRi: A Case Based Reasoning-Inspired Approach for Univariate Time Series Imputation. In Proceedings of the 2019 IEEE Latin American Conference on Computational Intelligence (LA-CCI), Guayaquil, Ecuador, 11–15 November 2019; Institute of Electrical and Electronics Engineers Inc.: Piscataway Township, NJ, USA, 2019; pp. 1–6. [Google Scholar]
- Savarimuthu, N.; Karesiddaiah, S. An unsupervised neural network approach for imputation of missing values in univariate time series data. Concurr. Comput. Pract. Exp. 2021, 33, 1–16. [Google Scholar] [CrossRef]
- Phan, T.T.H. Machine Learning for Univariate Time Series Imputation. In Proceedings of the 2020 International Conference on Multimedia Analysis and Pattern Recognition, MAPR 2020, Hanoi, Vietnam, 8–9 October 2020; Institute of Electrical and Electronics Engineers Inc.: Piscataway Township, NJ, USA, 2020; pp. 1–6. [Google Scholar]
- Habibi Khalifeloo, M.; Mohammad, M.; Heydari, M. Application of Different Statistical Methods to Recover Missing Rainfall Data in the Klang River Catchment. Int. J. Innov. Sci. Math. 2015, 3, 2347–9051. [Google Scholar]
- Mbungu, W.B.; Kashaigili, J.J. Assessing the Hydrology of a Data-Scarce Tropical Watershed Using the Soil and Water Assessment Tool: Case of the Little Ruaha River Watershed in Iringa, Tanzania. Open J. Mod. Hydrol. 2017, 7, 65–89. [Google Scholar] [CrossRef] [Green Version]
- Tfwala, S.S.; Wang, Y.M.; Lin, Y.C. Prediction of missing flow records using multilayer perceptron and coactive neurofuzzy inference system. Sci. World J. 2013, 2013, 1–7. [Google Scholar] [CrossRef] [Green Version]
- Vieira, F.; Cavalcante, G.; Campos, E.; Taveira-Pinto, F. A methodology for data gap filling in wave records using Artificial Neural Networks. Appl. Ocean Res. 2020, 98, 1–9. [Google Scholar] [CrossRef]
- Huang, P.; Li, Z.; Chen, J.; Li, Q.; Yao, C. Event-based hydrological modeling for detecting dominant hydrological process and suitable model strategy for semi-arid catchments. J. Hydrol. 2016, 542, 292–303. [Google Scholar] [CrossRef]
- Miao, Q.; Yang, D.; Yang, H.; Li, Z. Establishing a rainfall threshold for flash flood warnings in China’s mountainous areas based on a distributed hydrological model. J. Hydrol. 2016, 541, 371–386. [Google Scholar] [CrossRef]
- Kan, G.; Yao, C.; Li, Q.; Li, Z.; Yu, Z.; Liu, Z.; Ding, L.; He, X.; Liang, K. Improving event-based rainfall-runoff simulation using an ensemble artificial neural network based hybrid data-driven model. Stoch. Environ. Res. Risk Assess. 2015, 29, 1345–1370. [Google Scholar] [CrossRef]
- Liu, Y.; Li, Z.; Liu, Z.; Zhang, Y. TOPKAPI-based flood simulation in semi-humid and semi-arid regions. Water Power 2016, 42, 18–22. [Google Scholar]
- Li, Z.; Jiang, T.; Huang, P.; Liu, Z.; An, D.; Yao, C.; Ju, X. Impact and analysis of watershed precipitation and topography characteristics on model simulation results. Adv. Water Sci. 2015, 26, 473–480. [Google Scholar]
- Angele, G.; Bilgram, S. IBM SPSS Statistics 23. Release Notes 2015, 23, 25–84. [Google Scholar]
- Enders, C.K. Applied Missing Data Analysis, 1st ed.; Kenny, D.A., Little, T.D., Eds.; The Guilford Press: New York, NY, USA, 2010; ISBN 9781606236390. [Google Scholar]
- Hui, D.; Wan, S.; Su, B.; Katul, G.; Monson, R.; Luo, Y. Gap-filling missing data in eddy covariance measurements using multiple imputation (MI) for annual estimations. Agric. For. Meteorol. 2004, 121, 93–111. [Google Scholar] [CrossRef]
- Little, R.J.A.; Rubin, D.B. Statistical Analysis with Missing Data: Second Edition, 2nd ed.; Barnet, V., Hunder, J.S., Kendall, D.G., Balding, D.J., Bloomfield, P., Cressie, N.A.C., Fisher, N.I., Johnstone, I.M., Kadane, J.B., Ryan, L.M., et al., Eds.; John Wiley Sons: Hoboken, NJ, USA, 2002; ISBN 0471183865. [Google Scholar]
- Carpenter, J.R.; Smuk, M. Missing data: A statistical framework for practice. Biom. J. 2021, 63, 915–947. [Google Scholar] [CrossRef]
- Little, R.J. A test of missing completely at random for multivariate data with missing values. J. Am. Stat. Assoc. 1988, 83, 1198–1202. [Google Scholar] [CrossRef]
- Little, R.J.A.; Rubin, D.B. Statistical Analysis with Missing Data, 2nd ed.; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2014; ISBN 978-1-119-01356-3. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2018; Available online: https://www.R-project.org/ (accessed on 4 August 2021).
- Cleveland, R.B.; Cleveland, W.S.; McRae, J.E.; Terpenning, I. STL: A Seasonal-Trend Decomposition Procedure Based on Loess (with Discussion). J. Off. Stat. 1990, 6, 3–73. [Google Scholar]
- Hafen, R. stlplus: Enhanced Seasonal Decomposition of Time Series by Loess. CRAN Repos. 2016. Available online: https://cran.r-project.org/web/packages/stlplus/stlplus.pdf (accessed on 4 August 2021).
- Brockwell, P.J.; Davis, R.A. Time Series: Theory and Methods, 2nd ed.; Springer: New York, NY, USA, 1991; ISBN 1441903194. [Google Scholar]
- Moritz, S.; Gatscha, S.; Wang, E. Package “ imputeTS ”. Time Series Missing Value Imputation. 2021, pp. 1–36. Available online: https://cran.microsoft.com/snapshot/2015-11-26/web/packages/imputeTS/imputeTS.pdf (accessed on 4 August 2021).
- IBM. SPSS Statistics Documentation. Available online: https://www.ibm.com/docs/en/spss-statistics/23.0.0?topic=imputation-method-multiple (accessed on 15 January 2019).
- van Buuren, S.; Groothuis-Oudshoorn, K. MICE: Multivariate Imputation by Chained Equations in R. J. Stat. Softw. 2013, 30, 2–20. [Google Scholar]
- van Buuren, S.; Groothuis-Oudshoorn, K.; Vink, G.; Schouten, R.; Robitzsch, A.; Rockenschaub, P.; Doove, L.; Jolani, S.; Moreno-Betancur, M. Package “mice”. 2021, pp. 1–188. Available online: https://cran.r-project.org/web/packages/mice/mice.pdf (accessed on 4 August 2021).
- Honaker, J.; King, G.; Blackwell, M. Amelia II: A Program for Missing Data. 2015. Available online: https://mran.microsoft.com/snapshot/2017-02-04/web/packages/Amelia/Amelia.pdf (accessed on 4 August 2021).
- Honaker, J.; King, G.; Blackwell, M. Package “Amelia”: A Program for Missing Data. 2021. Available online: https://cran.r-project.org/web/packages/Amelia/Amelia.pdf (accessed on 4 August 2021).
- van Buuren, S.; Brand, J.P.L.; Groothuis-Oudshoorn, C.G.M.; Rubin, D.B. Fully conditional specification in multivariate imputation. J. Stat. Comput. Simul. 2006, 76, 1049–1064. [Google Scholar] [CrossRef]
- van Buuren, S. Multiple imputation of discrete and continuous data by fully conditional specification. Stat. Methods Med. Res. 2007, 16, 219–242. [Google Scholar] [CrossRef]
- van Buuren, S.; Groothuis-Oudshoorn, K. mice: Multivariate imputation by chained equations in R. J. Stat. Softw. 2011, 45, 1–67. [Google Scholar]
- Honaker, J.; King, G.; Blackwell, M. Amelia II: A program for missing data. J. Stat. Softw. 2011, 45, 1–47. [Google Scholar]
- Harvey, A.C. Forecasting, Structural Time Series Models and the Kalman Filter; Reprint; Cambridge University Press: Cambridge, UK, 1990; ISBN 9781107049994. [Google Scholar]
- Welch, G.; Bishop, G. An Introduction to the Kalman Filter. Department of Computer Science; University of North Carolina: Chapel Hill, TR, USA, 2006; pp. 1–16. [Google Scholar]
- Grewal, M.S.; Andrews, A.P. Kalman Filtering: Theory and Practice with MATLAB®, 4th ed.; Wiley-IEEE Press: Hoboken, NJ, USA, 2014; ISBN 9781118984987. [Google Scholar]
- Schafer, J.L. Analysis of Incomplete Multivariate Data, 1st ed.; Chapman and Hall/CRC: New York, NY, USA, 1997; ISBN 1439821860. [Google Scholar]
- Khan, S.I.; Hoque, A.S.M.L. SICE: An improved missing data imputation technique. J. Big Data 2020, 7, 1–21. [Google Scholar] [CrossRef]
- Chhabra, G.; Vashisht, V.; Ranjan, J. A Comparison of Multiple Imputation Methods for Data with Missing Values. Indian J. Sci. Technol. 2017, 10, 1–7. [Google Scholar] [CrossRef]
- Castillo, I.; Schmidt-Hieber, J.; Van Der Vaart, A. Bayesian linear regression with sparse priors. Ann. Stat. 2015, 43, 1986–2018. [Google Scholar] [CrossRef] [Green Version]
- Schafer, J.L. Multiple imputation in multivariate problems when the imputation and analysis models differ. Stat. Neerl. 2003, 57, 19–35. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Hapfelmeier, A.; Hothorn, T.; Ulm, K. Recursive partitioning on incomplete data using surrogate decisions and multiple imputation. Comput. Stat. Data Anal. 2012, 56, 1552–1565. [Google Scholar] [CrossRef]
- Booker, D.J.; Woods, R.A. Comparing and combining physically-based and empirically-based approaches for estimating the hydrology of ungauged catchments. J. Hydrol. 2014, 508, 227–239. [Google Scholar] [CrossRef] [Green Version]
- Berk, R.A. An Introduction to Ensemble Methods for Data Analysis. Sociol. Methods Res. 2006, 34, 263–295. [Google Scholar] [CrossRef] [Green Version]
- Schoppa, L.; Disse, M.; Bachmair, S. Evaluating the performance of random forest for large-scale flood discharge simulation. J. Hydrol. 2020, 590, 1–13. [Google Scholar] [CrossRef]
- Yapo, P.O.; Gupta, H.V.; Sorooshian, S. Automatic calibration of conceptual rainfall-runoff models: Sensitivity to calibration data. J. Hydrol. 1996, 181, 23–48. [Google Scholar] [CrossRef]
- Moriasi, D.N.; Arnold, J.G.; Van Liew, M.W.; Bingner, R.L.; Harmel, R.D.; Veith, T.L. Model evaluation guidelines for systematic quantification of accuracy in watershed simulations. Trans. ASABE 2007, 50, 885–900. [Google Scholar] [CrossRef]
- Dembélé, M.; Zwart, S.J. Evaluation and comparison of satellite-based rainfall products in Burkina Faso, West Africa. Int. J. Remote Sens. 2016, 37, 3995–4014. [Google Scholar] [CrossRef] [Green Version]
- Thiemig, V.; Rojas, R.; Zambrano-Bigiarini, M.; Levizzani, V.; De Roo, A. Validation of Satellite-Based Precipitation Products over Sparsely Gauged African River Basins. J. Hydrometeorol. 2012, 13, 1760–1783. [Google Scholar] [CrossRef]
- Beck, M.W.; Bokde, N.; Asencio-Cortés, G.; Kulat, K. R package imputetestbench to compare imputation methods for Univariate time series. R J. 2018, 10, 218–233. [Google Scholar] [CrossRef] [Green Version]
- Singh, J.; Knapp, H.V.; Demissie, M. Hydrologic Modeling of the Iroquois River Watershed Using HSPF and SWAT; Illinois State Water Survey Contract Report; Illinois State Water Survey: Champaign, IL, USA, 2004; Volume 8, pp. 1–24. [Google Scholar]
- Venables, W.N.; Ripley, B.D. Modern Applied Statistics with S, 4th ed.; Springer: New York, NY, USA, 2002; Volume 53, ISBN 978-0-387-21706-2. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Imputation Method | Method | Multiple Imputation | Description of Imputation Methods and Methods |
|---|---|---|---|
| imputeTS (univariate time series algorithms) | |||
| Kalman Smoothing and State Space Models (na_kalman) | Structural Model & Kalman Smoothing (StructTS) | No | It implements Kalman Smoothing on structural time series models or on the state space representation of an ARIMA model for imputation [54]. Details on the Kalman Filtering and State Space Models can be found in Harvey [64], Welch and Bishop [65], and Grewal and Andrews [66]. |
| ARIMA State Space Representation & Kalman Smoothing (auto.arima) | No | ||
| Seasonally Decomposed Missing Value Imputation (na_seadec) | Imputation by Interpolation algorithm after decomposition (interpolation) | No | This method, as a preprocessing step, firstly decomposes the data and removes the seasonal component from the time series. Then performs imputation on the trend and irregular components and afterwards adds the seasonal component again [9,54]. |
| Imputation by Kalman Smoothing and State Space Models after decomposition (kalman) | No | ||
| Seasonally Splitted Missing Value Imputation (na_seasplit) | Imputation by Interpolation algorithm after split (interpolation) | No | This method, also as a preprocessing step, initially splits the times series into seasons and afterwards performs imputation separately for each of the seasons [54]. |
| Imputation by Kalman Smoothing and State Space Models after split (kalman) | No | ||
| SPSS (multivariate algorithms with time as explicit) | |||
| Expectation-Maximization (EM) | No | EM is an iterative algorithm to find maximum likelihood estimation problem for missing data. Likelihood-based approaches define a model for the observed data and the inferences are based on the likelihood or posterior distribution under the posited model [1]. The major idea of this algorithm is to calculate the values of missing variables according to the initial parameters (means, covariance) and observed data (E step). Then update the initial parameters according to the complete data set that has been calculated (M step) and repeat the two steps until convergence. Little and Rubin, and Schafer provide extensive review of the theory of the EM algorithm [46,67]. | |
| Monotone | Linear Regression (LR) | Yes | Multiple imputation using linear regression generates imputations by building a model from observed data and predicting the missing values from the fitted model using the spread around the fitted linear regression line of y given x, as fitted on the observed data [1,57]. Here, the analysis is performed by point estimates to find the single best value around the regression line [68]. |
| Predictive Mean Matching (PMM) | Yes | Predictive mean matching is a multiple imputation mechanism where the missing values are drawn from the observed data such that it always finds values that have been actually observed in the data so that it is close to the predicted mean by using an implicit model and the nearest-neighbor together to calculate the values [1,69]. Imputations are restricted to the observed values, and hence PMM can maintain non-linear relations when the structural part of the imputation model is inaccurate [62], so they are realistic and, therefore, imputations outside the observed data range will not occur, thus avoiding problems of meaningless imputations [1]. | |
| mice (multivariate algorithms with time as explicit) | |||
| Fully conditional specification (FCS) or Multivariate imputation by chained equations (MICE) | PMM (mice.impute.pmm) | Yes | As above |
| Bayesian Linear Regression (BLR) (mice.impute.norm) | Yes | Multiple imputation using Bayesian linear regression [70] is much like linear regression. However, the imputation is done within the context of Bayesian inference where the missing values are drawn from a Bayesian posterior predictive distribution for the observed data [68,71]. Thus BLR seeks to find out the posterior distribution for the model parameters rather than finding a single best value [68]. | |
| Random Forests (RF) (mice.impute.rf) | Yes | Random forests [72] use machine learning by combining many regression trees (for continuous variables) or classification trees (for discrete variables) into an ensemble by drawing several bootstrap samples (a random sample of predictors as the covariates before each node is split) [1,73,74,75]. RF consists of iteratively training a random forest on observed values for imputing the missing values [25]. Thus Random forest applies a set of observed input–output training data to create predictions of the mean output for new input data [76]. | |
| Amelia (multivariate algorithms with time as explicit, multivariate algorithms on lagged data and multivariate algorithms using polynomials of time) | |||
| Expectation-Maximization with Bootstrapping (EMB) | General Amelia run (Time as explicit) | Yes | This was run as the general form of Amelia without the specification of the time series argument but with the date variable as a date object in R |
| Lags and leads (lags and leads method) | Yes | A way of handling time-series information in Amelia is to include lags and leads of certain variables into the imputation model. Lags are variables that take the value of another variable in the previous time period while leads take the value of another variable in the next time period [4,58]. Amelia then adds covariates of lags and leads of the specified variable to the imputation model. | |
| Time series polynomials with ridge priors (ts and polytime method) | Yes | Another way Amelia allows for the consideration of time series data is with the use of the ts and polytime arguments. Using the ts and polytime arguments, Amelia can develop a general model of patterns within variables across time by creating a sequence of polynomials of the time index of time up to the user defined k-th order, (k ≤ 3). With this input, Amelia will add covariates to the model that are equivalent to time and its polynomials and these covariates will help better impute the missing values [58]. | |
| Statistic Metric | Equation | Values Range | Perfect Score |
|---|---|---|---|
| Root Mean Square Error (RMSE) | 0–∞ | 0 | |
| Ratio of RMSE to the standard deviation of the observations (RSR) | 0–1 | 0 | |
| Mean Absolute Error (MAE) | 0–∞ | 0 | |
| Percent of bias (PBIAS) | 0–100% | 0 |
| Descriptive Statistics | |||||
|---|---|---|---|---|---|
| Total | |||||
| N | % | N | Percent (%) | N | % |
| 3606 | 89.7% | 412 | 10.3% | 4018 | 100.0% |
| Mean (SE) | Std. Dev. | Minimum | Maximum | Skewness | Kurtosis |
| 0.523 (0.032) | 1.906 | 0.023 | 67.40 | 18.836 | 510.412 |
| Test of Normality | |||||
| Kolmogorov-Smirnov a | Shapiro-Wilk | ||||
| Statistic | df | Sig | Statistic | df | Sig. |
| 0.397 | 3606 | 0.000 | 0.153 | 3606 | 0.000 |
| Little’s MCAR Test | |||||
| Chi-Square | df | Sig. | |||
| 50.239 | 1 | 0.000 | |||
| Total | |||||
|---|---|---|---|---|---|
| N | % | N | Percent (%) | N | % |
| 4018 | 100% | 0 | 0% | 4018 | 100.0% |
| Mean (SE) | Std. Dev. | Minimum | Maximum | Skewness | Kurtosis |
| 12.557 (0.462) | 29.310 | 0.22 | 575.00 | 8.543 | 101.410 |
| Test of Normality | |||||
| Kolmogorov-Smirnov a | Shapiro-Wilk | ||||
| Statistic | df | Sig | Statistic | df | Sig. |
| 0.337 | 4018 | 0.000 | 0.316 | 4018 | 0.000 |
| Total | |||||
|---|---|---|---|---|---|
| N | % | N | Percent (%) | N | % |
| 3606 | 89.7% | 412 | 10.3% | 4018 | 100.0% |
| Mean (SE) | Std. Dev. | Minimum | Maximum | Skewness | Kurtosis |
| 13.161(0.514) | 30.857 | 0.22 | 575.00 | 8.102 | 91.096 |
| Test of Normality | |||||
| Kolmogorov-Smirnov a | Shapiro-Wilk | ||||
| Statistic | df | Sig | Statistic | df | Sig. |
| 0.337 | 3606 | 0.000 | 0.328 | 3606 | 0.000 |
| Total Error Measurement (TEM) | Localized Error Measurement (LEM) | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Imputation Method | Method | RMSE (m3/s) | RSR | MAE (m3/s) | PBIAS | RMSE (m3/s) | RSR | MAE (m3/s) | PBIAS (%) |
| imputeTS | |||||||||
| na_kalman | StructTS | 0.541 | 0.018 | 0.089 | 0 | 1.036 | 0.025 | 0.326 | 0.1 |
| auto.arima | 1.690 | 0.058 | 0.458 | −3.6 | 3.237 | 0.079 | 1.680 | −9.7 | |
| na_seadec | interpolation | 0.465 | 0.016 | 0.081 | −0.1 | 0.890 | 0.022 | 0.298 | −0.3 |
| kalman | 0.575 | 0.020 | 0.095 | 0 | 1.100 | 0.027 | 0.347 | 0 | |
| na_seasplit | interpolation | 1.690 | 0.058 | 0.407 | −2.6 | 3.237 | 0.079 | 1.494 | −6.9 |
| kalman | 1.655 | 0.056 | 0.401 | −2.8 | 3.170 | 0.077 | 1.471 | −7.5 | |
| SPSS | |||||||||
| EM | 2.126 | 0.073 | 0.623 | 4.5 | 4.071 | 0.099 | 2.283 | 12 | |
| Monotone | LR | 7.827 | 0.267 | 2.280 | 18.1 | 14.986 | 0.364 | 8.357 | 48.2 |
| PMM | 0.537 | 0.018 | 0.095 | −0.1 | 1.028 | 0.025 | 0.347 | −0.2 | |
| mice | |||||||||
| FCS or MICE | PMM | 5.172 | 0.176 | 0.616 | 2.8 | 9.902 | 0.241 | 2.257 | 7.5 |
| BLR | 8.352 | 0.285 | 1.946 | 12 | 15.991 | 0.389 | 7.134 | 31.9 | |
| RF | 1.727 | 0.059 | 0.227 | 0.3 | 3.307 | 0.080 | 0.834 | 0.9 | |
| Amelia | |||||||||
| EMB | Time as explicit | 8.056 | 0.275 | 2.362 | 18.8 | 15.425 | 0.375 | 8.658 | 50 |
| Lags and leads | 7.185 | 0.245 | 2.057 | 16.3 | 13.757 | 0.334 | 7.543 | 43.5 | |
| ts and polytime | 7.830 | 0.267 | 2.300 | 18.3 | 14.993 | 0.364 | 8.431 | 48.8 | |
| Data | N | Mean | Std. Dev. | Variance | |
|---|---|---|---|---|---|
| Complete | 4018 | 12.557 | 29.310 | 859.096 | |
| Transformed | 3606 | 13.161 | 30.857 | 952.128 | |
| na_kalman | StructTS | 4018 | 12.560 | 29.309 | 858.993 |
| auto.arima | 4018 | 12.099 | 29.409 | 864.899 | |
| na_seadec | interpolation | 4018 | 12.544 | 29.310 | 859.104 |
| kalman | 4018 | 12.557 | 29.310 | 859.047 | |
| na_seasplit | interpolation | 4017 | 12.232 | 29.368 | 862.486 |
| kalman | 4017 | 12.205 | 29.374 | 862.827 | |
| EM | 4018 | 13.121 | 29.232 | 854.497 | |
| Monotone | LR | 4018 | 14.830 | 29.793 | 887.619 |
| PMM | 4018 | 12.548 | 29.312 | 859.197 | |
| FCS or MICE | PMM | 4018 | 12.910 | 29.712 | 882.828 |
| BLR | 4018 | 14.060 | 30.144 | 908.644 | |
| RF | 4018 | 12.594 | 29.341 | 860.913 | |
| EMB | Time as explicit | 4018 | 14.915 | 29.841 | 890.514 |
| Lags and leads | 4018 | 14.607 | 29.700 | 882.105 | |
| ts and polytime | 4018 | 14.856 | 29.802 | 888.174 | |
| Data | N | Mean | Std. Dev. | Variance | |
|---|---|---|---|---|---|
| Original dataset | 3606 | 0.523 | 1.907 | 3.635 | |
| na_kalman | StructTS | 4018 | 0.513 | 1.807 | 3.266 |
| auto.arima | 4018 | 0.512 | 1.809 | 3.272 | |
| na_seadec | interpolation | 4018 | 0.514 | 1.810 | 3.276 |
| kalman | 4018 | 0.515 | 1.808 | 3.270 | |
| na_seasplit | interpolation | 4017 | 0.507 | 1.809 | 3.271 |
| kalman | 4017 | 0.506 | 1.808 | 3.269 | |
| EM | 4018 | 0.530 | 1.806 | 3.263 | |
| Monotone | LR | 4018 | 0.653 | 1.855 | 3.442 |
| PMM | 4018 | 0.513 | 1.810 | 3.276 | |
| FCS or MICE | PMM | 4018 | 0.527 | 1.839 | 3.383 |
| BLR | 4018 | 0.593 | 1.862 | 3.469 | |
| RF | 4018 | 0.511 | 1.810 | 3.275 | |
| EMB | Time as explicit | 4018 | 0.643 | 1.849 | 3.419 |
| Lags and leads | 4018 | 0.636 | 1.845 | 3.404 | |
| ts and polytime | 4018 | 0.652 | 1.854 | 3.438 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Baddoo, T.D.; Li, Z.; Odai, S.N.; Boni, K.R.C.; Nooni, I.K.; Andam-Akorful, S.A. Comparison of Missing Data Infilling Mechanisms for Recovering a Real-World Single Station Streamflow Observation. Int. J. Environ. Res. Public Health 2021, 18, 8375. https://0-doi-org.brum.beds.ac.uk/10.3390/ijerph18168375
Baddoo TD, Li Z, Odai SN, Boni KRC, Nooni IK, Andam-Akorful SA. Comparison of Missing Data Infilling Mechanisms for Recovering a Real-World Single Station Streamflow Observation. International Journal of Environmental Research and Public Health. 2021; 18(16):8375. https://0-doi-org.brum.beds.ac.uk/10.3390/ijerph18168375
Chicago/Turabian StyleBaddoo, Thelma Dede, Zhijia Li, Samuel Nii Odai, Kenneth Rodolphe Chabi Boni, Isaac Kwesi Nooni, and Samuel Ato Andam-Akorful. 2021. "Comparison of Missing Data Infilling Mechanisms for Recovering a Real-World Single Station Streamflow Observation" International Journal of Environmental Research and Public Health 18, no. 16: 8375. https://0-doi-org.brum.beds.ac.uk/10.3390/ijerph18168375