
BiLSTM-I: A Deep Learning-Based Long Interval Gap-Filling Method for Meteorological Observation Data


Abstract
:1. Introduction
2. Materials and Methods
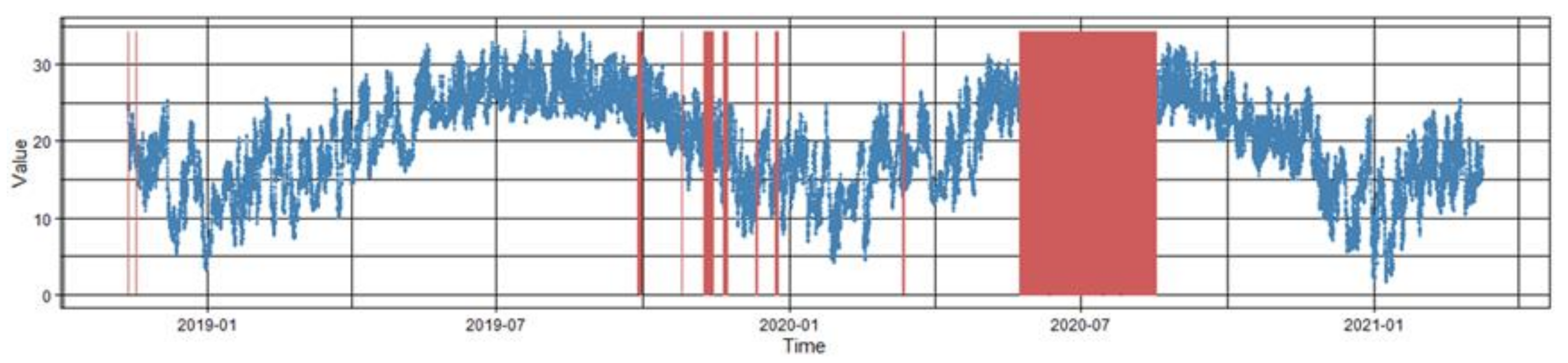
2.1. Meteorological Temperature Observation Data
2.2. Baseline Methods
2.2.1. Time Series Data Imputation with Kalman Smoothing
- (1)
- Structured time series model (Kalman-S)
- (2)
- ARIMA-based state space model (Kalman-A)
2.2.2. BRITS-I Time Series Imputation Method Based on Deep Learning
2.3. BiLSTM-I Model Development
2.3.1. Basic Definition
2.3.2. Rolling Window Sampling
2.3.3. Design of Deep Learning Models
- (1)
- Encoder
- (2)
- Decoder
2.4. Accuracy Evaluation
3. Results and Discussion
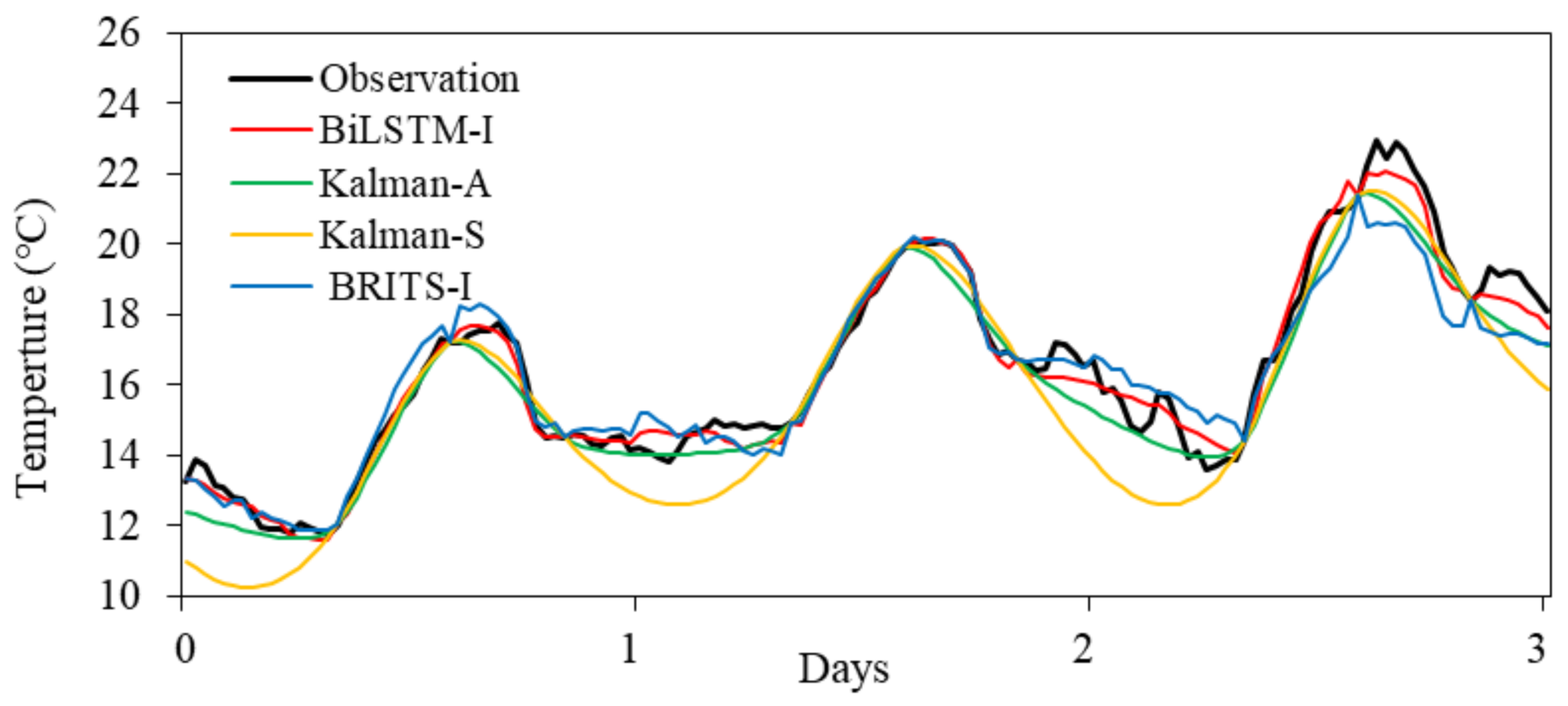
3.1. BiLSTM-I vs. BRITS-I
3.2. BiLSTM-I vs. Kalman Smoothing
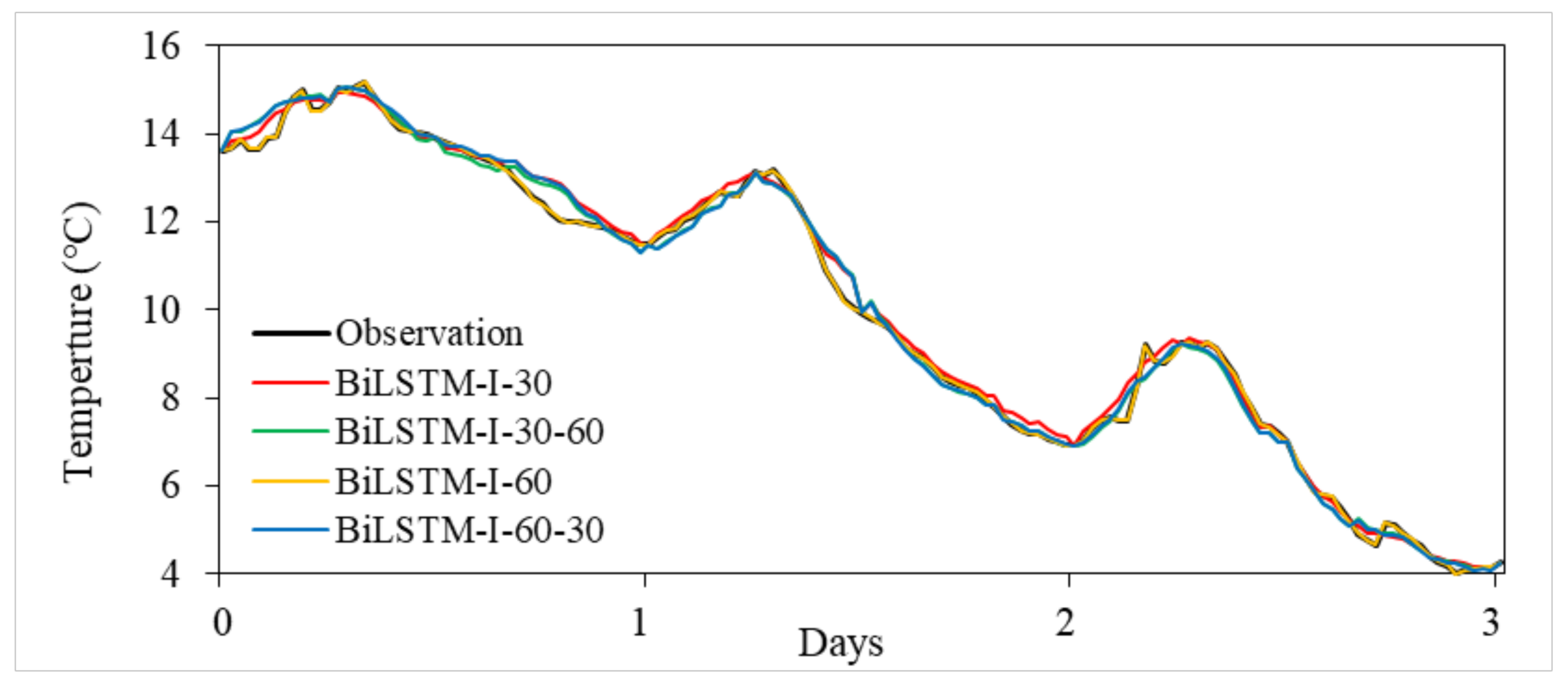
3.3. The Generalization Ability of BiLSTM-I
4. Summary
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lara-Estrada, L.; Rasche, L.; Sucar, E.; Schneider, U.A. Inferring missing climate data for agricultural planning using Bayesian network. Land 2018, 7, 4. [Google Scholar] [CrossRef] [Green Version]
- Huang, M.T.; Piao, S.L.; Ciais, P.; Peñuelas, J.; Wang, X.H.; Keenan, T.F.; Peng, S.S.; Berry, J.A.; Wang, K.; Mao, J.F. Air temperature optima of vegetation productivity across global biomes. Nat. Ecol. Evol. 2019, 3, 772–779. [Google Scholar] [CrossRef]
- Hu, L.W.; He, H.L.; Shen, Y.; Ren, X.L.; Yan, S.K.; Xiang, W.H.; Ge, R.; Niu, Z.E.; Xu, Q.; Zhu, X.B. Modeling the Carbon Cycle of a Subtropical Chinese Fir Plantation Using a Multi-Source Data Fusion Approach. Forests 2020, 11, 369. [Google Scholar] [CrossRef] [Green Version]
- Luedeling, E. Interpolating hourly temperatures for computing agroclimatic metrics. Int. J. Biometeorol. 2018, 62, 1799–1807. [Google Scholar] [CrossRef]
- Afrifa-Yamoah, E.; Mueller, U.A.; Taylor, S.M.; Fisher, A.J. Missing data imputation of high-resolution temporal climate time series data. Meteorol. Appl. 2020, 27, e1873. [Google Scholar] [CrossRef]
- Lepot, M.; Aubin, J.B.; Clemens, F. Interpolation in Time Series: An Introductive Overview of Existing Methods, Their Performance Criteria and Uncertainty Assessment. Water 2017, 9, 796. [Google Scholar] [CrossRef] [Green Version]
- Carrizosa, E.; Olivares-Nadal, N.V.; Ramirez-Cobo, P. Times series interpolation via global optimization of moments fitting. Eur. J. Oper. Res. 2013, 230, 97–112. [Google Scholar] [CrossRef]
- Schlegel, S.; Korn, N.; Scheuermann, G. On the interpolation of data with normally distributed uncertainty for visualization. Vis. Comput. Graph. 2012, 18, 2305–2314. [Google Scholar] [CrossRef]
- Žliobaitė, I.; Hollmén, J. Optimizing regression models for data streams with missing values. Mach. Learn. 2015, 99, 47–73. [Google Scholar] [CrossRef]
- Yang, H.M.; Pan, Z.S.; Tao, Q. Online Learning for Time Series Prediction of AR Model with Missing Data. Neural Process. Lett. 2019, 50, 2247–2263. [Google Scholar] [CrossRef]
- Bashir, F.; Wei, H.L. Handling missing data in multivariate time series using a vector autoregressive model-imputation (VAR-IM) algorithm. Neurocomputing 2017, 276, 23–30. [Google Scholar] [CrossRef]
- Beck, M.W.; Bokde, N.; Asencio-Cortés, G.; Kulat, K. R Package imputeTestbench to Compare Imputation Methods for Univariate Time Series. R J. 2018, 10, 218–233. [Google Scholar] [CrossRef] [Green Version]
- John, C.; Emmanuel, J.E.; Nworu, C.C. Imputation of Missing Values in Economic and Financial Time Series Data Using Five Principal Component Analysis Approaches. CBN J. Appl. Stat. 2019, 10, 51–73. [Google Scholar] [CrossRef]
- Hwang, W.S.; Li, S.Y.; Kim, S.W.; Lee, K. Data Imputation Using a Trust Network for Recommendation via Matrix Factorization. Comput. Sci. Inf. Syst. 2014, 15, 347–368. [Google Scholar] [CrossRef] [Green Version]
- Tripathi, S.; Govindajaru, R.S. On selection of kernel parameters in relevance vector machines for hydrologic applications. Stoch. Environ. Res. Risk Assess. 2007, 21, 747–764. [Google Scholar] [CrossRef]
- Sovilj, D.; Eirola, E.; Miche, Y.; Björk, K.M.; Nian, R.; Akusok, A.; Lendasse, A. Extreme learning machine for missing data using multiple imputations. Neurocomputing 2016, 174, 220–231. [Google Scholar] [CrossRef]
- Hewamalage, H.; Bergmeir, C.; Bandara, K. Recurrent Neural Networks for Time Series Forecasting: Current status and future directions. Int. J. Forecast. 2021, 37, 388–427. [Google Scholar] [CrossRef]
- Ma, J.; Cheng, J.C.P.; Ding, Y.X.; Lin, C.Q.; Jiang, F.F.; Wang, M.Z.; Zhai, C. Transfer learning for long-interval consecutive missing values imputation without external features in air pollution time series. Adv. Eng. Inform. 2020, 44, 101092. [Google Scholar] [CrossRef]
- Song, W.; Gao, C.; Zhao, Y.; Zhao, Y.D. A Time Series Data Filling Method Based on LSTM-Taking the Stem Moisture as an Example. Sensors 2020, 20, 5045. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhou, B.H.; Cai, X.R.; Guo, W.Y.; Ding, X.K.; Yuan, X.J. Missing value imputation in multivariate time series with end-to-end generative adversarial networks. Inf. Sci. 2021, 551, 67–82. [Google Scholar] [CrossRef]
- Li, Z.N.; Yu, H.; Zhang, G.H.; Wang, J. A Bayesian vector autoregression-based data analytics approach to enable irregularly-spaced mixed-frequency traffic collision data imputation with missing values. Transp. Res. Part C Emerg. Technol. 2019, 108, 302–319. [Google Scholar] [CrossRef]
- Tsay, R.S. Analysis of Financial Time Series; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2010. [Google Scholar]
- Fernando, T. Kalman Filtering in R. J. Stat. Softw. 2011, 39, 1–27. [Google Scholar]
- Einicke, G. Smoothing, Filtering and Prediction Estimating the Past, Present and Future; InTechOpen: London, UK, 2012. [Google Scholar]
- Harvey, C.; Peters, S. Estimation Procedures for Structural Time Series Models. J. Forecast. 1990, 9, 89–108. [Google Scholar] [CrossRef]
- Durbin, J.; Koopman, S.J. Time Series Analysis by State Space Methods; Oxford Statistical Science Series; Oxford University Press: Oxford, UK, 2001. [Google Scholar]
- Yi, D.H. Applied Time Series Analysis; Renmin University of China Press: Beijing, China, 2019; pp. 18–116. [Google Scholar]
- Xu, D.W.; Wang, Y.D.; Jia, L.M.; Qin, Y.; Dong, H.H. Real-time road traffic state prediction based on ARIMA and Kalman filter. Front. Inf. Technol. Electron. Eng. 2017, 18, 287–302. [Google Scholar] [CrossRef]
- Jong, P.; Penzer, J. The ARIMA model in state space form. Stat. Probab. Lett. 2004, 70, 119–125. [Google Scholar] [CrossRef]
- Tsay, R.S. State-Space Models and Kalman Filter. In Analysis of Financial Time Series, 2nd ed.; John Wiley & Sons: Hoboken, NJ, USA, 2005; pp. 490–542. [Google Scholar]
- Guo, Z.J.; Wan, Y.M.; Ye, H. A data imputation method for multivariate time series based on generative adversarial network. Neurocomputing 2019, 360, 185–197. [Google Scholar] [CrossRef]
- Cao, W.; Wang, D.; Li, J.; Zhou, H.; Li, L.; Li, Y.T. BRITS: Bidirectional Recurrent Imputation for Time Series. In Proceedings of the 32nd Conference on Neural Information Processing Systems (NeurIPS 2018), Montréal, QC, Canada, 3–8 December 2018; pp. 6776–6786. [Google Scholar]
- Lai, X.C.; Wu, X.; Zhang, L.Y.; Lu, W.; Zhong, C.Q. Imputations of missing values using a tracking-removed autoencoder trained with incomplete data. Neurocomputing 2019, 366, 54–65. [Google Scholar] [CrossRef]
- Dabrowski, J.J.; Rahman, A. Sequence-to-Sequence Imputation of Missing Sensor Data. In AI 2019: Advances in Artificial Intelligence; Springer: Cham, Switzerland, 2019; pp. 265–276. [Google Scholar]
- Zhang, Y.F.; Thorburn, P.J.; Xiang, W.; Fitch, P. SSIM-A Deep Learning Approach for Recovering Missing Time Series Sensor Data. IEEE Internet Things J. 2019, 6, 6618–6628. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Demirhan, H.; Renwick, Z. Missing value imputation for short to mid-term horizontal solar irradiance data. Appl. Energy 2018, 225, 998–1012. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Frequency | Time | Missing Values |
|---|---|---|---|
| Dataset 1 | 8 am daily | 2018/11/13–2020/2/10 | None |
| Dataset 2 | 2 pm daily | 2018/11/13–2020/2/10 | None |
| Dataset 3 | 8 pm daily | 2018/11/13–2020/2/10 | None |
| Dataset 4 | Every half hour | 2018/11/13–2020/2/10 | Short time interval gaps and one long time interval gap |
| Time | Temperature Value | Mask |
|---|---|---|
| 1 | Na | 0 |
| 2 | Na | 0 |
| … | … | … |
| 17 | 17.14 | 1 |
| 18 | Na | 0 |
| … | … | … |
| 27 | Na | 0 |
| 28 | 21.78 | 1 |
| 29 | Na | 0 |
| … | … | … |
| 39 | Na | 0 |
| 40 | 19.86 | 1 |
| 41 | Na | 0 |
| … | … | … |
| 47 | Na | 0 |
| 48 | Na | 0 |
| Method | RMSE (°C) | MAE (°C) | MRE | PCC |
|---|---|---|---|---|
| BiLSTM-I-60 | 0.4929 | 0.3319 | 0.0173 | 0.9963 |
| BiLSTM-I-30 | 0.4686 | 0.3215 | 0.0170 | 0.9968 |
| BRITS-I | 1.3959 | 1.0300 | 0.0537 | 0.9697 |
| Kalman-Struct | 1.1742 | 0.8449 | 0.0472 | 0.9873 |
| Kalman-ARIMA | 0.7514 | 0.5469 | 0.0306 | 0.9934 |
| Missing Value Gap | Model | RMSE | MAE | MRE | PCC |
|---|---|---|---|---|---|
| 30 Days | BiLSTM-I-30 | 0.4686 | 0.3215 | 0.0170 | 0.9968 |
| BiLSTM-I-60 | 0.4865 | 0.3326 | 0.0176 | 0.9966 | |
| 60 Days | BiLSTM-I-60 | 0.4929 | 0.3319 | 0.0173 | 0.9963 |
| BiLSTM-I-30 | 0.4834 | 0.3293 | 0.0172 | 0.9964 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xie, C.; Huang, C.; Zhang, D.; He, W. BiLSTM-I: A Deep Learning-Based Long Interval Gap-Filling Method for Meteorological Observation Data. Int. J. Environ. Res. Public Health 2021, 18, 10321. https://0-doi-org.brum.beds.ac.uk/10.3390/ijerph181910321
Xie C, Huang C, Zhang D, He W. BiLSTM-I: A Deep Learning-Based Long Interval Gap-Filling Method for Meteorological Observation Data. International Journal of Environmental Research and Public Health. 2021; 18(19):10321. https://0-doi-org.brum.beds.ac.uk/10.3390/ijerph181910321
Chicago/Turabian StyleXie, Chuanjie, Chong Huang, Deqiang Zhang, and Wei He. 2021. "BiLSTM-I: A Deep Learning-Based Long Interval Gap-Filling Method for Meteorological Observation Data" International Journal of Environmental Research and Public Health 18, no. 19: 10321. https://0-doi-org.brum.beds.ac.uk/10.3390/ijerph181910321