
Clinical Concept Extraction with Lexical Semantics to Support Automatic Annotation

 ,
,  ,
,  , ,
, ,
Abstract
:1. Introduction
2. Related Work
2.1. Information Extraction Clinical Tools
2.2. Clinical Information Classification and Extraction Methods
2.2.1. Rule-Based Approach
2.2.2. Medical-Related Terminology
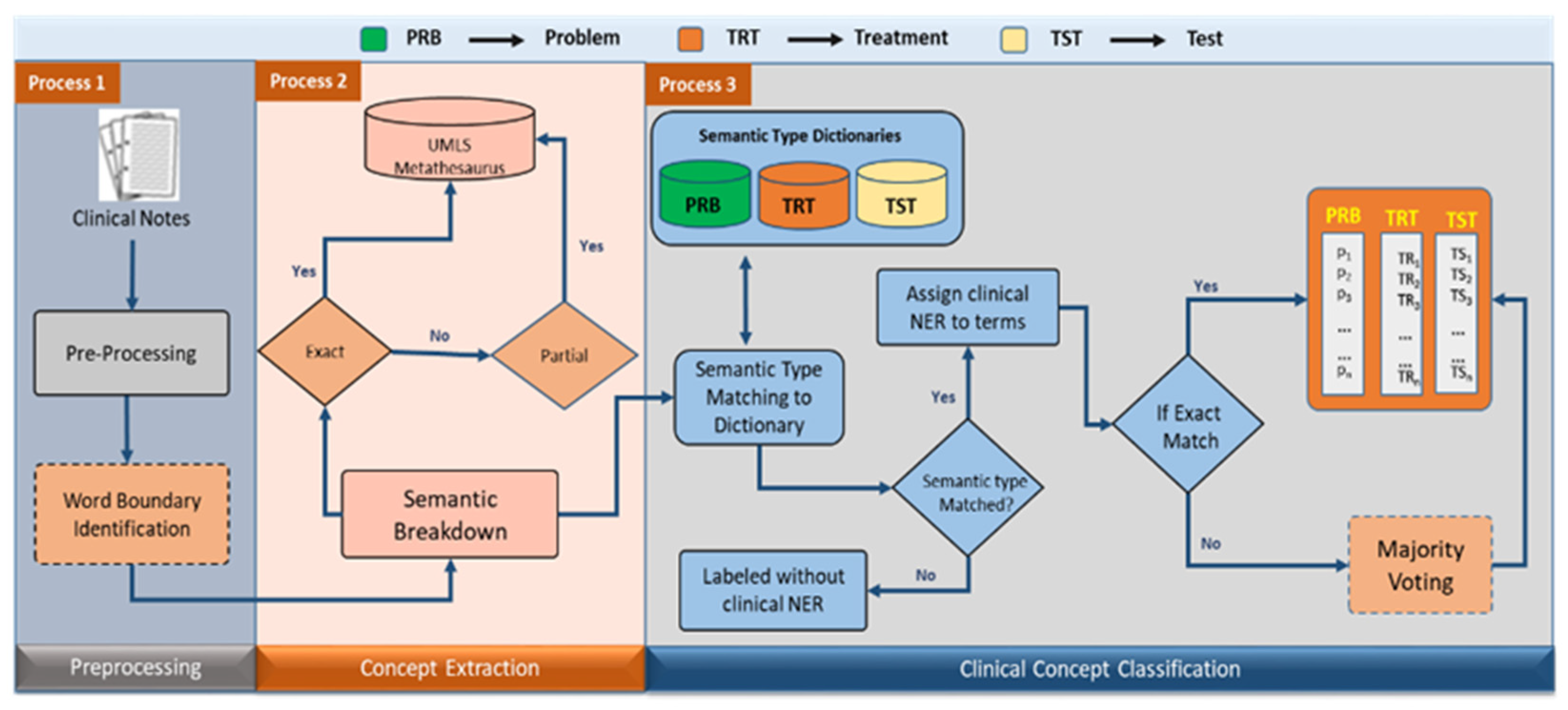
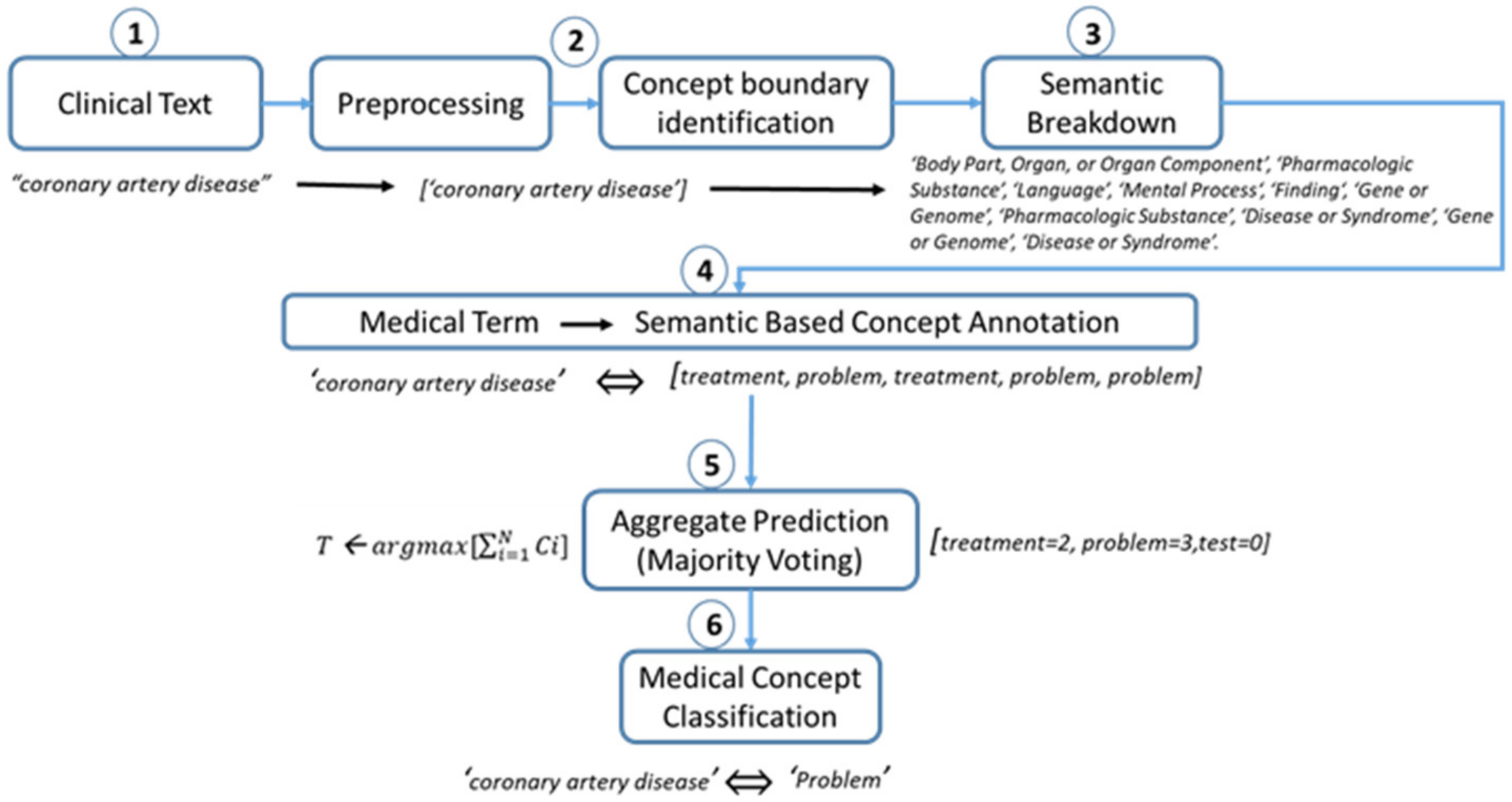
3. Proposed Methodology
3.1. Document Preprocessing
- (a)
- Tokenization: Sentences are tokenized in each document into a set of words wi. All the stop words that convey no meaning, such as “the”, “this”, “from”, “on”, “off”, etc. are removed from the set W.
- (b)
- Lemmatization: Words’ lemmas are identified to improve performance on ambiguous and invisible words. Lemmatization is preferred as it produces more accurate output compared to stemming in some instances, such as lemmatizing the word ‘caring’, it returns ‘care’, while stemming returns’ car’, and this is erroneous. We utilized the NLTK [23] WordNetLemmatizer package that provides a comprehensive and robust word-lemmatization solution.
- (c)
- N-gramming: A word of n-gram is applied to represent a set of co-occurring words in a sentence, as described by Equation (1):where ~ represents the subtraction of a scalar (N − 1) from each element of the vector . expresses the number of words in a sentence. We utilize four n-gram parameters because a medical concept can be a compound word such as “overall left ventricular systolic function”.
- (d)
- Deduplication: Duplicate words are removed to reduce the data dimensionality and avoid ambiguity. We utilized a set of built-in data type functions with characteristics to store data in an unordered and unchangeable way that would not allow duplicate values.
- (e)
- POS tagging: The part of speech (POS) tagging using NLTK NLP library was employed and then we constructed a regular expression pattern to filter only meaningful information such as nouns, adjectives, and adverbs from a list of words, as shown in Equation (2). <NN*> denotes all the noun phrases, “<JJ*>” represents all the adjectives, and “<RB*> shows the adverb phrases from X, where X represents the “bag of words” list attained through regular expression.X = Bag of words = “< NN∗ >< JJ∗ >< RB∗ >”
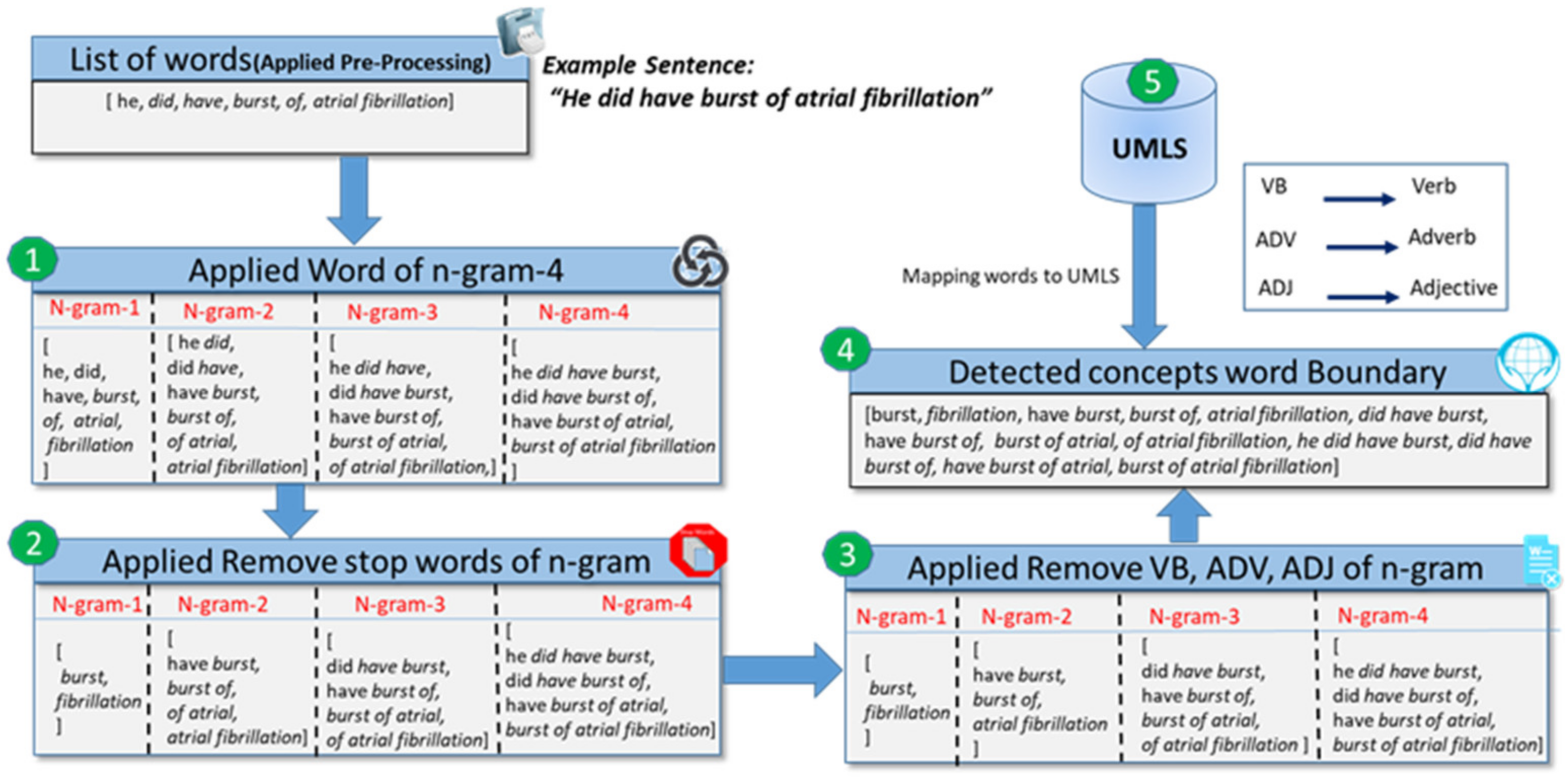
Word Boundary Detection
- (a)
- Preprocessing: A preProcessing procedure is created that accepts an unstructured clinical document as an input ingredient to preprocess. Subsequently, this is applied to preprocessing steps such as tokenization, lemmatization, etc. We obtained a bag of words with a size of n-gram-4, as described in Section 3.1.
- (b)
- Stop-words removal: In the preprocessing step in Section 3.1, we did not apply the stop-word removal operation because multiple adjacent word concepts also contained stop words such as “a pelvic fracture,” where “a” is a stop word. In the second step, we removed stop words of n-gram from the list of n-gram words such as “is the”, “did have of”, etc.
- (c)
- Stop words and POS filtering: A word that appears with a combination of stop word, verb, adjective, and adverb that does not convey a domain knowledge discarded such as “of atrial”, “good effect”, or “very good effect”, as described in Algorithm 1, step 9.
- (d)
- Detected words boundary: We retained a list of alternate words that contains either stop words or not, such as “have burst”, “burst of atrial”, etc., because these words convey a domain of knowledge related to a heart problem. In another method, we identified noun phrases and eliminated all other phrases.
- (e)
- Word mapping to UMLS: Finally, we mapped each word to the UMLS to extract semantic information, practicing exact and approximate word matching.
| Algorithm 1: Clinical concepts—word-boundary identification. |
| Input: Unstructured Clinical Document2. |
| Output: Word boundary identification |
| 1. wordList ← new ArrayList< > |
| 2. wordSet ← new ArrayList< > |
| 3. Doc: Read Document |
| 4. bagOfWords ← preProcessing(Doc) |
| 5. for each word in bagOfWords, do |
| 6. if word Not Equal to Null, do |
| 7. for each word_2 in word.split(), do |
| 8. w_tag ← pos_tag(word_2) |
| 9. if word_2 in (stopWords) OR w_tag == (Verb, Adjective, Adverb), do |
| 10. wordSet ← word_2 |
| 11. end if |
| 12. end for |
| 13. if len(wordSet) Not Equal to len(word.split()), do |
| 14. wordList ← word |
| 15. wordSet.clear() |
| 16. end if |
| 17. end if |
| 18. end for |
3.2. Clinical Concept Extraction
3.2.1. Finding Terms
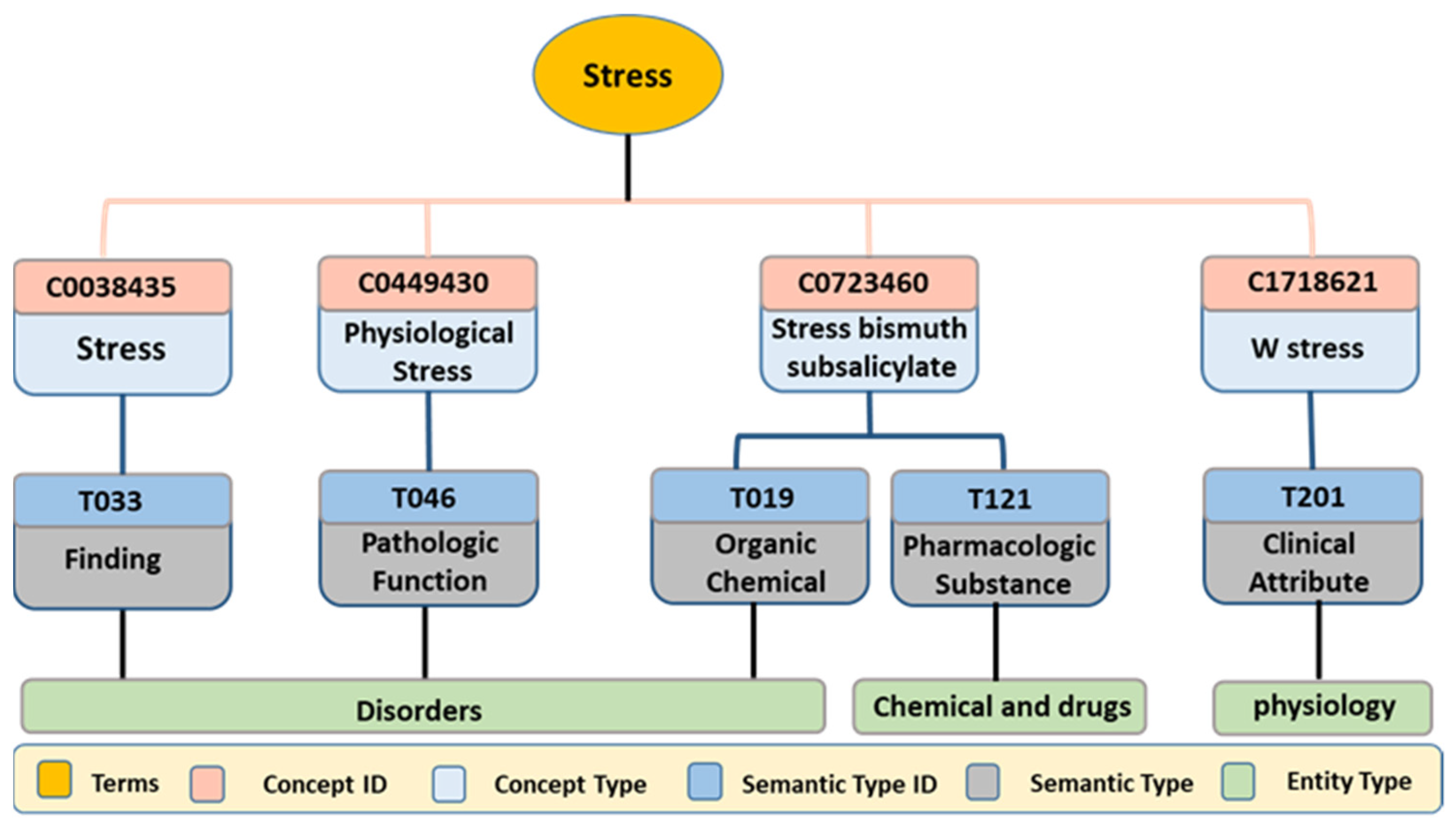
3.2.2. Concept Identification
| Algorithm 2: Concept Identification from UMLS. |
| Input: Clinical Document D ← {d1, d2, d3.... dn} # set of documents di |
| Output: set of Terms and Concepts |
| 1. wordlist ← newArrayList<> |
| 2. conceptMap ← newMultiMap<term, concept > |
| 3. Doc: Read Document |
| 4. wordList ← Pre-Processing(Doc) |
| 5. for each term in wordList, do |
| 6. String: cui, concept ← searchConceptUMLS (parameter: term) |
| 7. If size(cui) > 0, do |
| 8. conceptMap<k, v> ← term, concept |
| 9. cuiList ← cui |
| 10. Nextterm |
| 11. end if |
| 12. end for |
3.2.3. Semantic-Type Identification
| Algorithm 3: Semantic-Type Identification from UMLS. |
| Input: List of Concepts ID’s C ← {c1, c2, c3 … cn} |
| Output: set of Concepts ID’s (cui) and Semantic types |
| 1. semanticTypeMap ← new MultiMap<conceptID, sematnicType > |
| 2. semanticTypleList ← new ArrayList<> |
| 3. cuiList: Read cuiList from Algorithm.2 |
| 4. for each cui in cuiList, do |
| 5. String: conceptName, semanticType ← searchSemanticTypeUMLS (parameter: cui) |
| 6. semanticTypeMap<k, v> ← conceptName, semanticType |
| 7. semanticTypeList ← semanticType |
| 8. Next:cui |
| 9. end |
3.2.4. Entity-Type Identification
| Algorithm 4: Entity-Type Identification from UMLS. |
| Input: List of Semantic Types S ← {s1, s2, s3 … sn} |
| Output: set of Semantic Types (STY’s) and Entity types |
| 1. entityTypeMap ← new MultiMap<semanticType, entityType > |
| 2. semanticTypeList: Read semanticTypeList from Algorithm.3 |
| 3. for each type in semanticTypeList, do |
| 4. String: sematnicType, entityType ← searchEntityTypeUMLS (parameter: type) |
| 5. entityTypeMap<k, v> ← semanticType, entityType |
| 6. Next:type |
| 7. end |
3.2.5. Example Case Study
3.3. Clinical Concept Classification
- Rule 1:If the number of any concept type (c1, c2, c3) is greater for the term T, then classify the term with the majority-threshold concept.For instance, if c1 > c2 AND c1 > c3 then T ← c1, else if c2 > c1 AND c2 > c3 then T ← c2 else if c3 > c1 AND c3 > c2 then T ← c3.
- Rule 2:If the number of any concept type (c1, c2, c3) is similar for term T, then presume a first-class (c1) as a majority threshold.Such as: IF frequency of c1 == c2 == c3 then T ← c1 OR c2 OR c3, which means that the class that is on the first index in a list will be selected as a perfect class for a concept.
- Rule 3:If the number of two concept types (c1, c2) is similar, we ignored the third concept type (c3) and assigned the first concept type(c1) to the term between two similar concept types (c1, c2).Such as: IF number of c1 == c2 AND c3 < c1 AND c2, ignore c3 and assigned T← c1 OR c2, else if number of c2 == c3 AND c1 < c2 AND c3, ignore c1 and assigned T← c2 OR c3, else if number of c1 == c3 AND c2 < c1 AND c3, ignore c2 and assigned T← c1 OR c3.
4. Results and Discussion
4.1. Performance Measures
4.2. Datasets
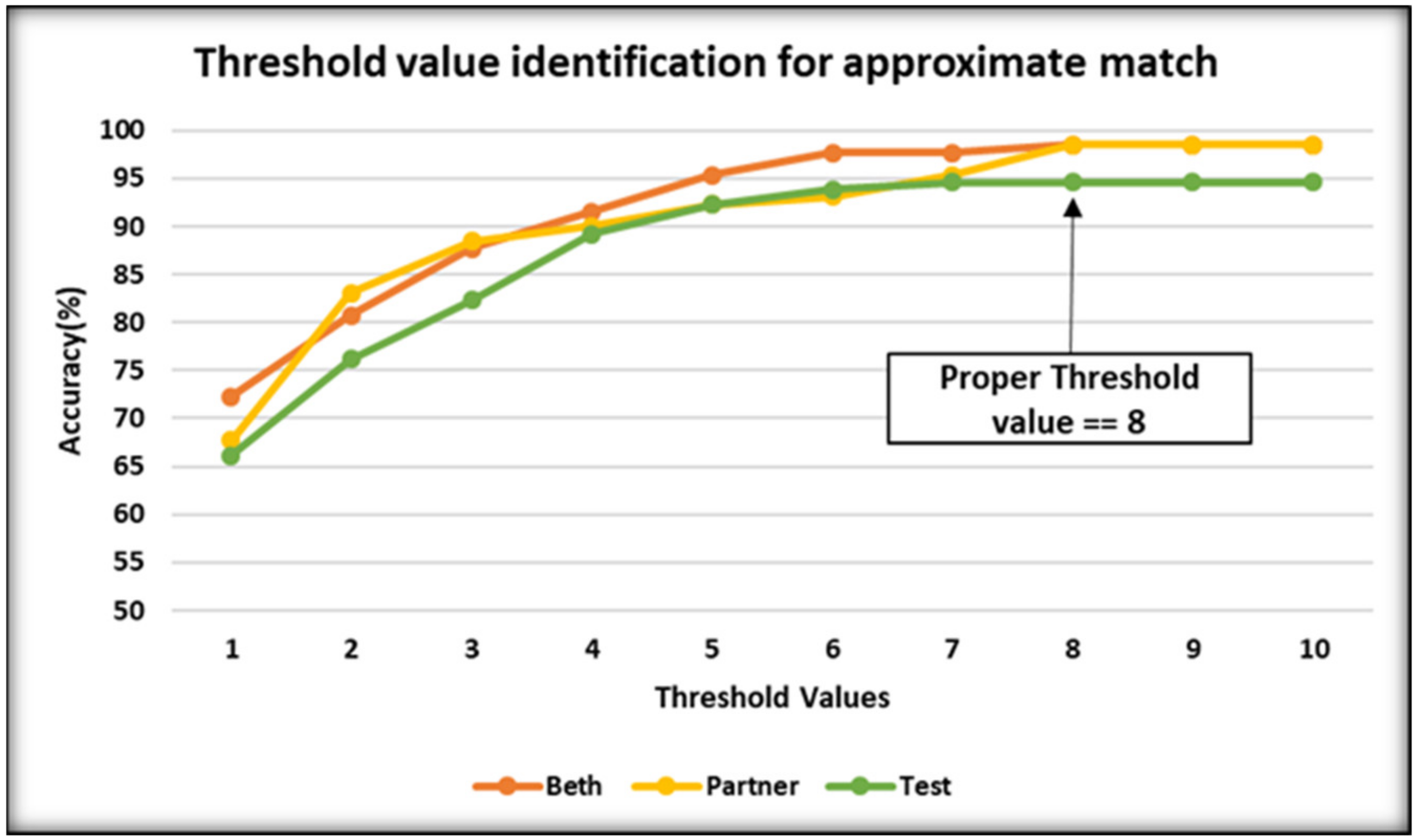
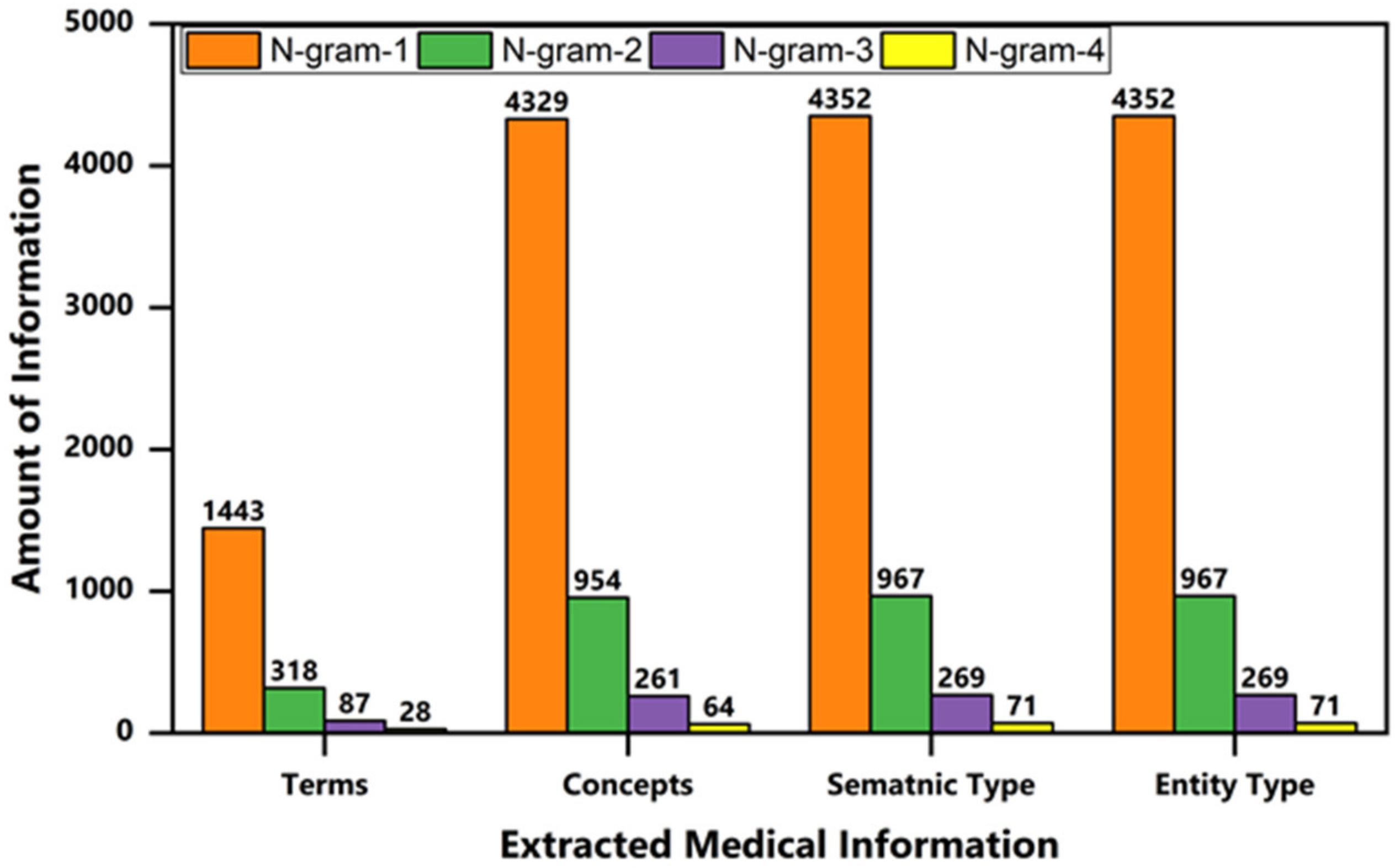
4.3. Word-Boundary Identification Algorithm Performance
4.4. Semantic Breaking
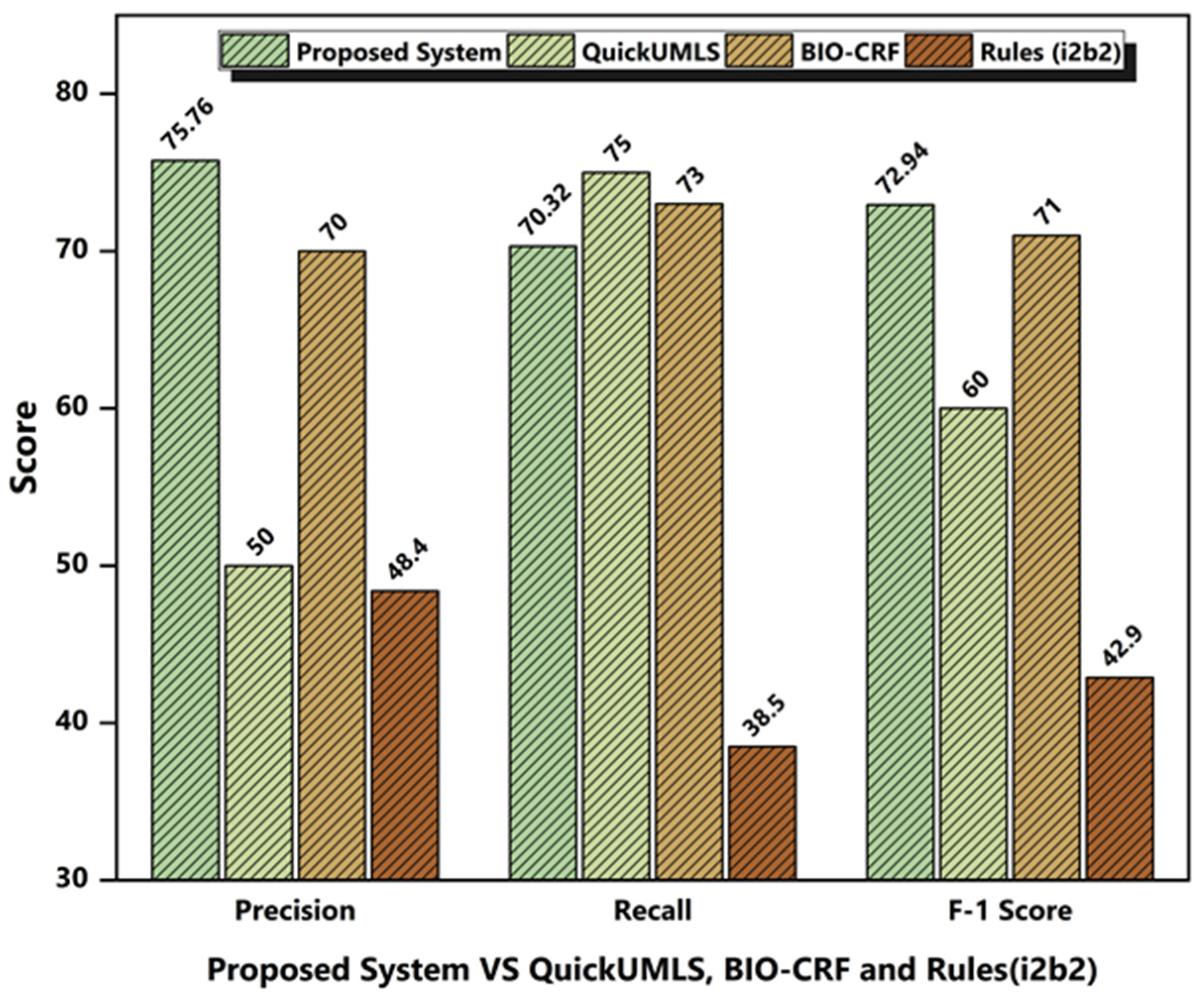
4.4.1. System Performance Comparison with Competitors
4.4.2. Performance Comparison on Individual Concept Extraction
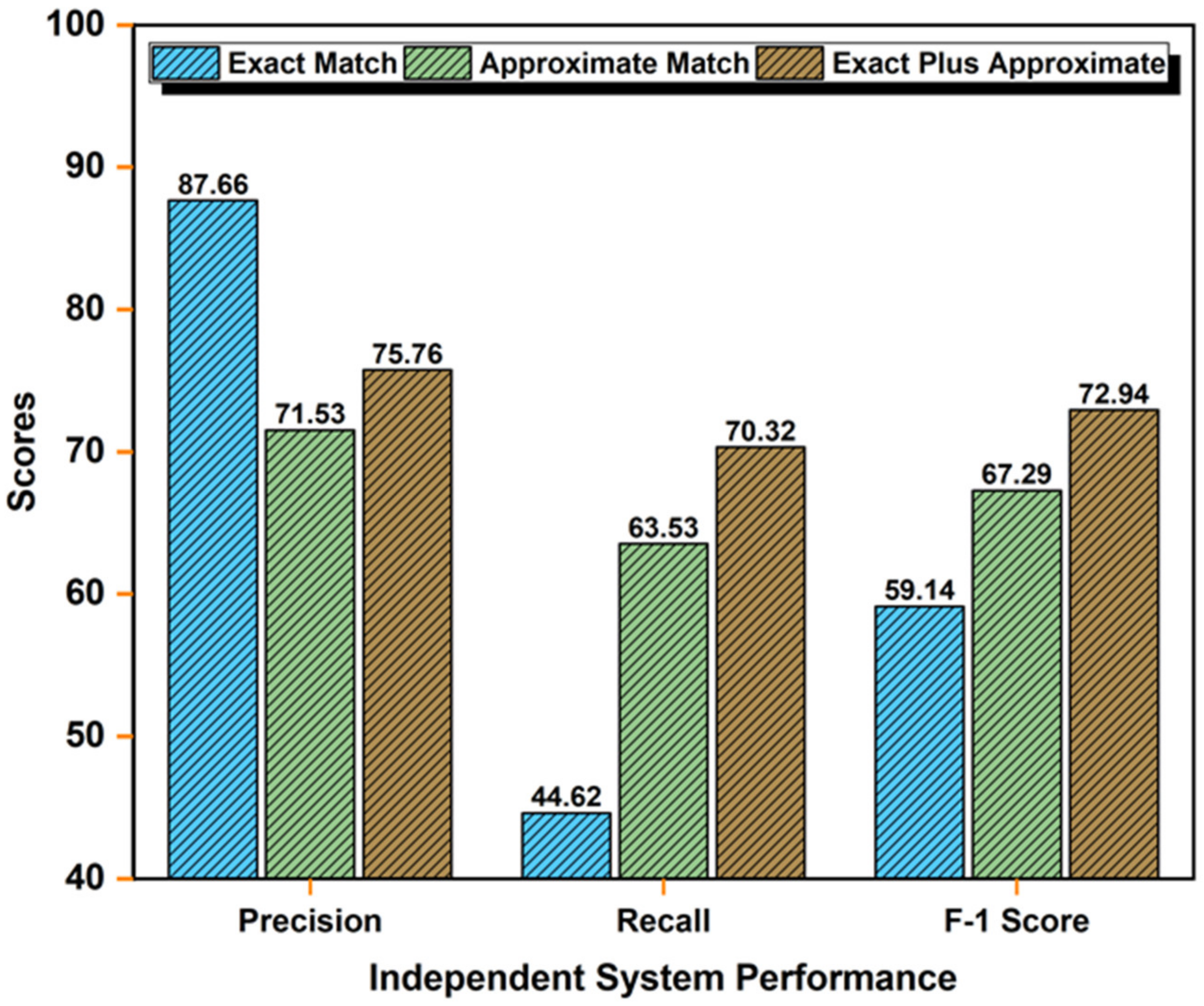
4.4.3. Independent System Performance
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
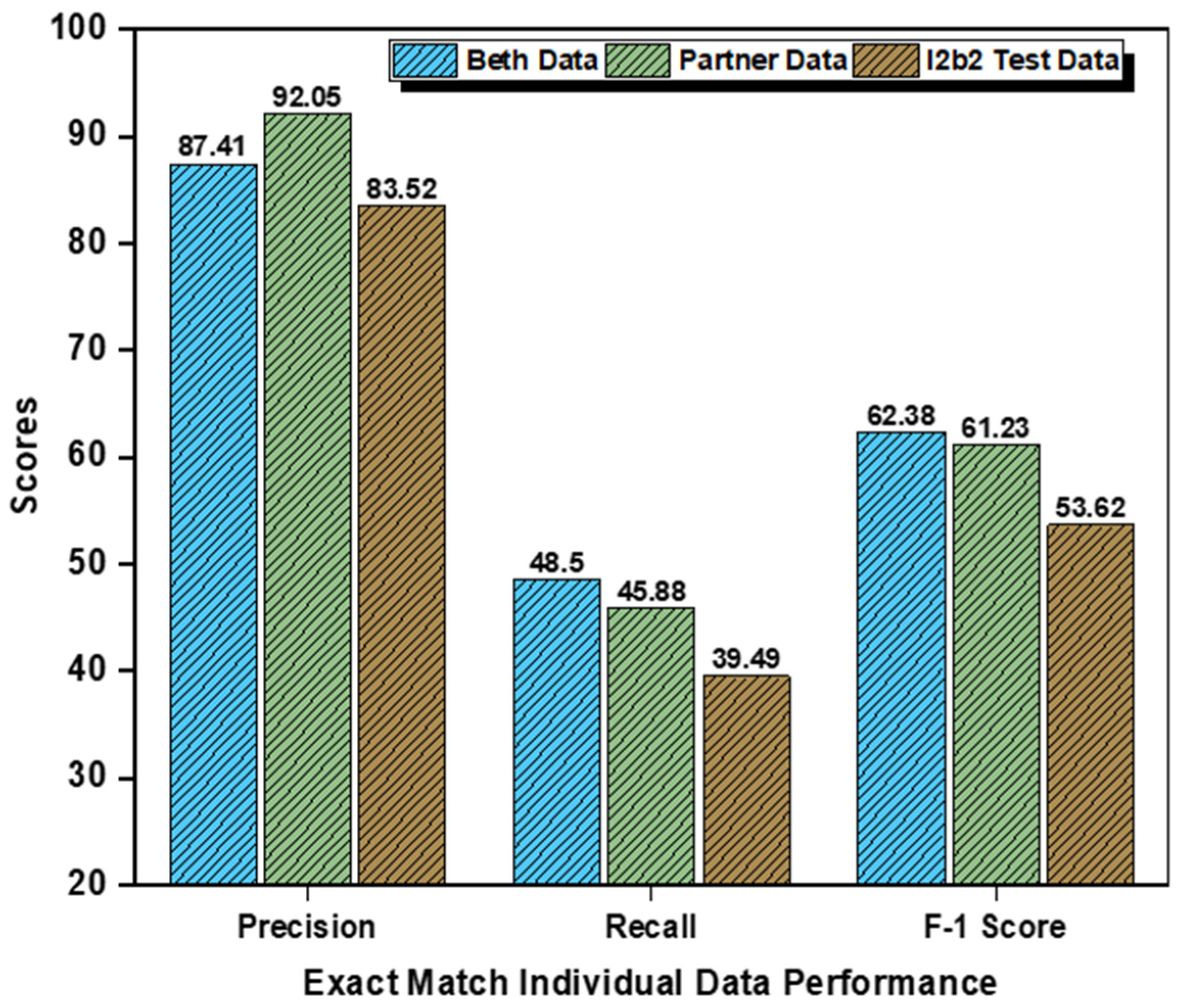
Appendix A.1. Performance on Individual Datasets Using Exact Matching


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Categories | Precision (%) | Recall (%) | F1-Score (%) |
|---|---|---|---|---|
| Beth Medical Center | Problem | 94.83% | 49.55% | 65.09% |
| Treatment | 78.13% | 54.95% | 64.52% | |
| Test | 89.27% | 40.99% | 56.19% | |
| Partners Healthcare | Problem | 93.33% | 47.93% | 63.34% |
| Treatment | 93.91% | 56.37% | 70.46% | |
| Test | 88.89% | 33.33% | 48.48% | |
| i2b2 Test Data set | Problem | 93.33% | 36.27% | 54.24% |
| Treatment | 71.80% | 56.57% | 63.28% | |
| Test | 85.41% | 25.63% | 39.43% |
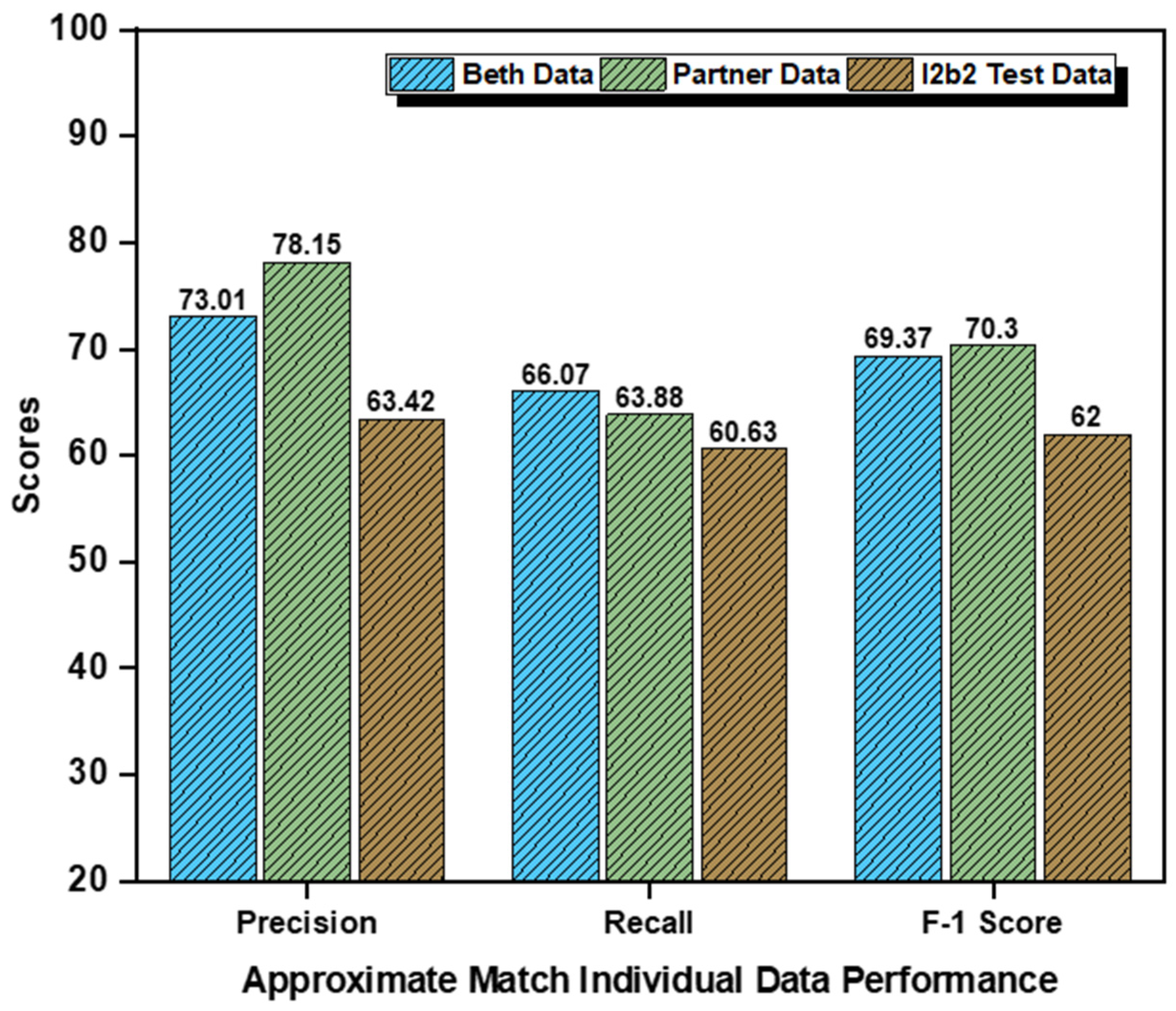
Appendix A.2. Individual Datasets and Concept-Wise Performance Approximate Matching

| Datasets | Categories | Precision (%) | Recall (%) | F1-Score (5) |
|---|---|---|---|---|
| Beth Medical Center | Problem | 62.73% | 83.47% | 71.63% |
| Treatment | 71.31% | 75.65% | 73.42% | |
| Test | 85% | 39.08% | 53.54% | |
| Partners Healthcare | Problem | 84.46% | 86.23% | 85.34% |
| Treatment | 75% | 94.29% | 83.55% | |
| Test | 75% | 11.11% | 19.35% | |
| i2b2 Test Dataset | Problem | 67.05% | 78.28% | 72.23% |
| Treatment | 50.81% | 77.04% | 61.23% | |
| Test | 72.41% | 26.58% | 38.89% |
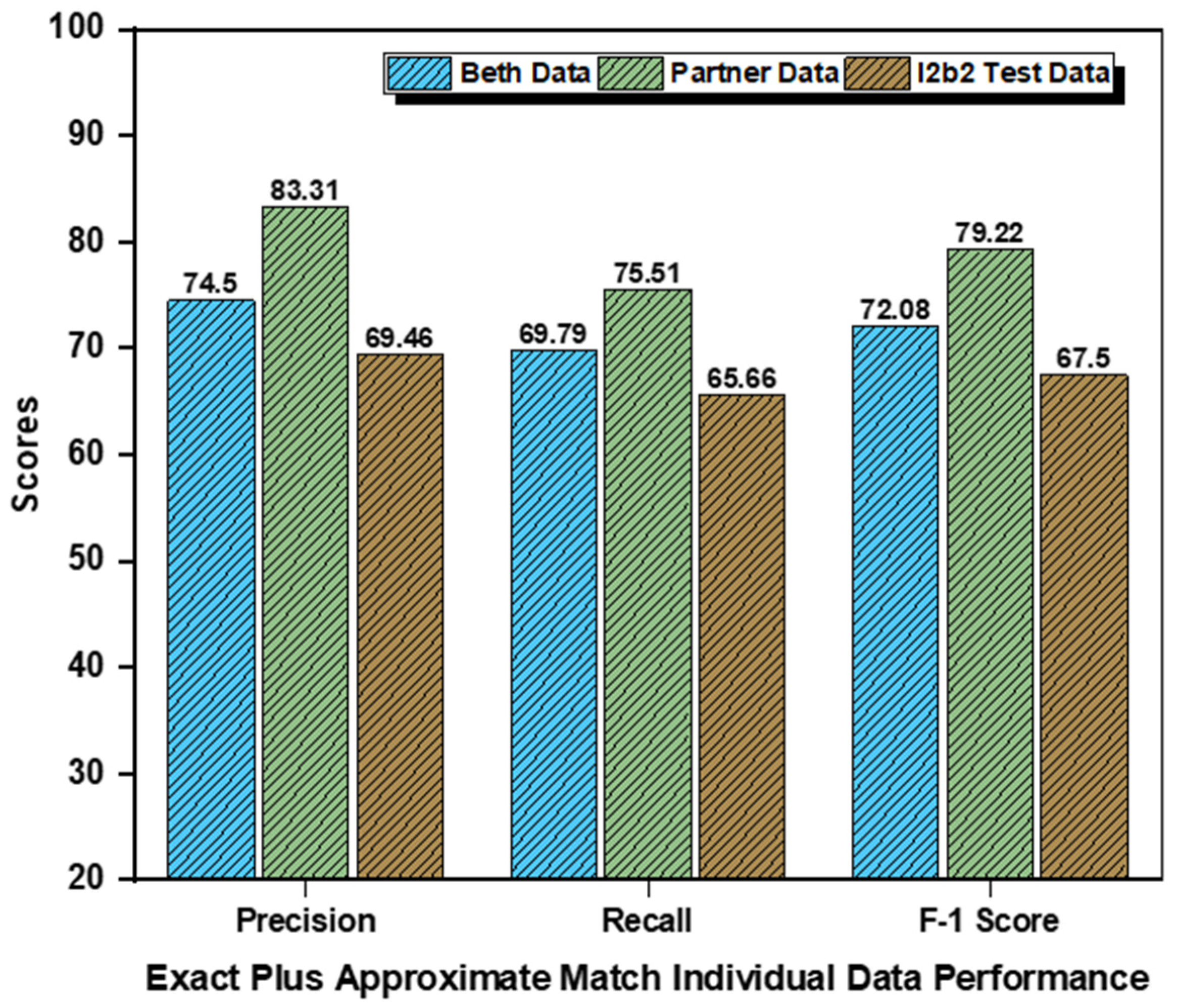
Appendix A.3. Individual Datasets and Concept-Wise Performance: Exact-Plus-Approximate Matching

| Datasets | Categories | Precision (%) | Recall (%) | F1-Score (5) |
|---|---|---|---|---|
| Beth Medical Center | Problem | 73.81% | 83.78% | 78.48% |
| Treatment | 72.55% | 81.32% | 76.68% | |
| Test | 77.14% | 44.26% | 56.25% | |
| Partners Healthcare | Problem | 91.67% | 86.52% | 89.02% |
| Treatment | 78.26% | 100% | 87.80% | |
| Test | 80% | 40% | 53.33% | |
| i2b2 Test Dataset | Problem | 70.15% | 77.05% | 73.44% |
| Treatment | 52.81% | 78.12% | 63.03% | |
| Test | 85.42% | 41.79% | 56.12% |
References
- Soldaini, L.; Goharian, N. Quickumls: A Fast, Unsupervised Approach for Medical Concept Extraction. MedIR Workshop, Sigir. 2016. Available online: http://medir2016.imag.fr/data/MEDIR_2016_paper_16.pdf (accessed on 29 September 2021).
- Divita, G.; Zeng, Q.T.; Gundlapalli, A.V.; Duvall, S.; Nebeker, J.; Samore, M.H. Sophia: A expedient 797 UMLS concept extraction annotator. In Proceedings of the AMIA Annual Symposium; American Medical Informatics Association: Rockville, MD, USA, 2014; Volume 2014, p. 467. Available online: https://0-www-ncbi-nlm-nih-gov.brum.beds.ac.uk/pmc/articles/PMC4420011/ (accessed on 29 September 2021).
- Savova, G.K.; Masanz, J.; Ogren, P.V.; Zheng, J.; Sohn, S.; Kipper-Schuler, K.C.; Chute, C.G. Mayo clinical Text Analysis and Knowledge Extraction System (cTAKES): Architecture, component evaluation and applications. J. Am. Med. Inform. Assoc. 2010, 17, 507–513. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Uzuner, Ö.; South, B.R.; Shen, S.; DuVall, S.L. 2010 i2b2/VA challenge on concepts, assertions, and relations in clinical text. J. Am. Med. Inform. Assoc. 2011, 18, 552–556. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tran LT, T.; Divita, G.; Carter, M.E.; Judd, J.; Samore, M.H.; Gundlapalli, A. V Exploiting the UMLS Metathesaurus for extracting and categorizing concepts representing signs and symptoms to anatomically related organ systems. J. Biomed. Inform. 2015, 58, 19–27. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Guo, Y.; Kakrania, D.; Baldwin, T.; Syeda-Mahmood, T. Efficient clinical concept extraction in electronic medical records. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Available online: https://www.aaai.org/ocs/index.php/AAAI/AAAI17/paper/view/14794/14029 (accessed on 29 September 2021).
- Wang, Y.; Wang, L.; Rastegar-Mojarad, M.; Moon, S.; Shen, F.; Afzal, N.; Liu, S.; Zeng, Y.; Mehrabi, S.; Sohn, S.; et al. Clinical information extraction applications: A literature review. J. Biomed. Inform. 2018, 77, 34–49. [Google Scholar] [CrossRef] [PubMed]
- Aronson, A.R.; Lang, F.M. An overview of MetaMap: Historical perspective and recent advances. J. Am. Med. Inform. Assoc. 2010, 17, 229–236. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Suominen, H.; Salanterä, S.; Velupillai, S.; Chapman, W.W.; Savova, G.; Elhadad, N.; Pradhan, S.; South, B.R.; Mowery, D.L.; Jones, G.J.F.; et al. Overview of the ShARe/CLEF eHealth evaluation lab 2013. In Proceedings of the International Conference of the Cross-Language Evaluation Forum for European Languages; Springer: Berlin/Heidelberg, Germany, 2013; pp. 212–231. [Google Scholar] [CrossRef] [Green Version]
- Kelly, L.; Goeuriot, L.; Suominen, H.; Schreck, T.; Leroy, G.; Mowery, D.L.; Velupillai, S.; Chapman, W.W.; Martinez, D.; Zuccon, G.; et al. Overview of the share/clef ehealth evaluation lab 2014. In International Conference of the Cross-Language Evaluation Forum for European Languages; Springer: Cham, Switzerland, 2014; pp. 172–191. [Google Scholar] [CrossRef] [Green Version]
- Sahu, R. Rule-Based Method for Automatic Medical Concept Extraction from Unstructured Clinical Text. In Recent Findings in Intelligent Computing Techniques; Springer: Singapore, 2018; pp. 261–267. [Google Scholar] [CrossRef]
- Kang, N.; Afzal, Z.; Singh, B.; van Mulligen, E.; Kors, J.A. Using an ensemble system to improve concept extraction from clinical records. J. Biomed. Inform. 2012, 45, 423–428. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Minard, A.-L.; Ligozat, A.-L.; Ben Abacha, A.; Bernhard, D.; Cartoni, B.; Deleger, L.; Grau, B.; Rosset, S.; Zweigenbaum, P.; Grouin, C. Hybrid methods for improving information access in clinical documents: Concept, assertion, and relation identification. J. Am. Med. Inform. Assoc. 2011, 18, 588–593. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xu, H.; AbdelRahman, S.; Jiang, M.; Fan, J.W.; Huang, Y. An initial study of full parsing of clinical text using the Stanford Parser. In Proceedings of the 2011 IEEE International Conference on Bioinformatics and Biomedicine Workshops (BIBMW), Atlanta, GA, USA , 12–15 November 2011; pp. 607–614. [Google Scholar] [CrossRef]
- Available online: http://www.alias-i.com/lingpipe/index.html (accessed on 15 March 2021).
- Bodenreider, O. The unified medical language system (UMLS): Integrating biomedical terminology. Nucleic Acids Res. 2004, 32 (Suppl. 1), D267–D270. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, S.; Elhadad, N. Unsupervised biomedical named entity recognition: Experiments with clinical and biological texts. J. Biomed. Inform. 2013, 46, 1088–1098. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Friedman, C.; Alderson, P.O.; Austin, J.H.; Cimino, J.J.; Johnson, S.B. A general natural-language text processor for clinical radiology. J. Am. Med. Inform. Assoc. 1994, 1, 161–174. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Aronson, A.R.; Mork, J.G.; Névéol, A.; Shooshan, S.E.; Demner-Fushman, D. Methodology for creating UMLS content views appropriate for biomedical natural language processing. In AMIA Annual Symposium Proceedings; American Medical Informatics Association: Rockville, MD, USA, 2008; Volume 2008, p. 21. Available online: https://0-www-ncbi-nlm-nih-gov.brum.beds.ac.uk/pmc/articles/PMC2655934/ (accessed on 29 September 2021).
- Salmasian, H.; Freedberg, D.E.; Abrams, J.A.; Friedman, C. An automated tool for detecting medication overuse based on the electronic health records. Pharmacoepidemiol. Drug Saf. 2013, 22, 183–189. [Google Scholar] [CrossRef] [PubMed]
- Kim, Y.; Riloff, E.; Hurdle, J. A study of concept extraction across different types of clinical notes. In AMIA Annual Symposium Proceedings; American Medical Informatics Association: Rockville, MD, USA, 2015; Volume 2015, p. 737. [Google Scholar]
- Morton, T.; Kottmann, J.; Baldridge, J.; Bierner, G. Opennlp: A Java-Based Nlp Toolkit. 2005. (accessed on 12 April 2021).
- Bird, S. NLTK: The natural language toolkit. In Proceedings of the COLING/ACL 2006 Interactive Presentation Sessions, Sydney, Australia, 17–18 July 2006. [Google Scholar] [CrossRef]
- He, Y.; Kayaalp, M. A Comparison of 13 Tokenizers on MEDLINE; The Lister Hill National Center for Biomedical Communications: Bethesda, MD, USA, 2006; Volume 48.
- Allen, J.F. Towards a general theory of action and time. Artif. Intell. 1984, 23, 123–154. [Google Scholar] [CrossRef]
- Savova, G.K.; Fan, J.; Ye, Z.; Murphy, S.P.; Zheng, J.; Chute, C.G.; Kullo, I.J. Discovering peripheral arterial disease cases from radiology notes using natural language processing. In AMIA Annual Symposium Proceedings; American Medical Informatics Association: Rockville, MD, USA, 2010; Volume 2010, p. 722. Available online: https://0-www-ncbi-nlm-nih-gov.brum.beds.ac.uk/pmc/articles/PMC3041293/ (accessed on 29 September 2021).
- Sohn, S.; Savova, G.K. Mayo Clinic Smoking Status Classification System: Extensions and Improvements. In AMIA Annual Symposium Proceedings; American Medical Informatics Association: Rockville, MD, USA, 2009; Volume 2009, p. 619. Available online: https://0-www-ncbi-nlm-nih-gov.brum.beds.ac.uk/pmc/articles/PMC2815365/ (accessed on 29 September 2021).
- Khin, N.P.P.; Lynn, K.T. Medical concept extraction: A comparison of statistical and semantic methods. In Proceedings of the 2017 18th IEEE/ACIS International Conference on Software Engineering, Artificial Intelligence, Networking and Parallel/Distributed Computing (SNPD), Kanazawa, Japan, 26–28 June 2017; pp. 35–38. [Google Scholar] [CrossRef]
- Abbas, A.; Ansaar, M.Z.; Lee, S. Medical Concept Extraction using Smartphone and Natural Language Processing Techniques (poster). In Proceedings of the 17th Annual International Conference on Mobile Systems Applications, and Services, Seoul, Korea, 12 June 2019; pp. 630–631. [Google Scholar] [CrossRef]
- National Libarary of Medicine. Umls Metathesaurus. 2019. Available online: https://www.nlm.nih.gov/research/umls/new_users/online_learning/SEM_001.html (accessed on 1 December 2020).
- Segura-Bedmar, I.; Martínez, P.; Segura-Bedmar, M. Drug name recognition and classification in biomedical texts: A case study outlining approaches underpinning automated systems. Drug Discov. Today 2008, 13, 816–823. [Google Scholar] [CrossRef] [PubMed]
- Abbas, A.; Afzal, M.; Hussain, J.; Lee, S. Meaningful Information Extraction from Unstructured Clinical Documents. Proc. Asia Pac. Adv. Netw. 2019, 48, 42–47. [Google Scholar]
- Campillos, L.; Deléger, L.; Grouin, C.; Hamon, T.; Ligozat, A.L.; Névéol, A. A French clinical corpus with comprehensive semantic annotations: Development of the Medical Entity and Relation LIMSI annOtated Text corpus (MERLOT). Lang. Resour. Eval. 2018, 52, 571–601. [Google Scholar] [CrossRef]
- Liu, H.; Aronson, A.R.; Friedman, C. A study of abbreviations in MEDLINE abstracts. In Proceedings of the AMIA Symposium; American Medical Informatics Association: Rockville, MD, USA, 2002; p. 464. [Google Scholar]
- Srinivasan, S.; Rindflesch, T.C.; Hole, W.T.; Aronson, A.R.; Mork, J.G. Finding UMLS Metathesaurus concepts in MEDLINE. In Proceedings of the AMIA Symposium; American Medical Informatics Association: Rockville, MD, USA, 2002; p. 727. Available online: https://0-www-ncbi-nlm-nih-gov.brum.beds.ac.uk/pmc/articles/PMC2244184/ (accessed on 29 September 2021).
- Geller, J.; He, Z.; Perl, Y.; Morrey, C.P.; Xu, J. Rule-based support system for multiple UMLS semantic type assignments. J. Biomed. Inform. 2013, 46, 97–110. [Google Scholar] [CrossRef] [PubMed] [Green Version]








| Clinical Domain | Semantic Type |
|---|---|
| Problem | “Disease or Syndrome, Sign or Symptom, Finding, Pathologic Function, Mental or Behavioral Dysfunction, Injury or Poisoning, Cell or Molecular Dysfunction, Congenital Abnormality, Acquired Abnormality, Neoplastic Process, Anatomic Abnormality, virus/bacterium.” |
| Treatment | “Therapeutic or Preventive Procedure, Organic Chemical, Pharmacologic Substance, Biomedical and Dental material, Antibiotic, Clinical Drug, Steroid, Drug Delivery Device, Medical Device.” |
| Test | “Tissue, Cell, Laboratory or Test Result, Laboratory Procedure, diagnostic procedure, Clinical Attribute, Body Substance.” |
| Process Name | Processes |
|---|---|
| Clinical Term | beta blockers |
| Semantic Breakdown | beta blockers = [‘Pharmacologic Substance’, ‘Organic Chemical’, ‘Pathologic Function’, ‘Organic Chemical’, ‘Clinical Attribute’, ‘Injury or Poisoning’, ‘Pharmacologic Substance’] |
| Semantic-Based Concept Annotation | beta blockers = [‘Treatment’, ‘Treatment’, ‘Problem’, ‘Treatment’, ‘Test’, ‘Problem’, ‘Treatment’] |
| Majority Voting | (‘Treatment’ = 4, ‘Problem’ = 2, ‘Test’ = 1) |
| Classification | beta blockers ⇔ Treatment |
| Process Name | Processes |
|---|---|
| Clinical Term | heart rate |
| Semantic Breakdown | heart rate = [‘Clinical Attribute’, ‘Clinical Attribute’, ‘Finding’, ‘Finding’, ‘Medical Device’, ‘Medical Device’] |
| Semantic-Based Concept Annotation | heart rate = [‘Test,’ Test’, ‘Problem’, ‘Problem’, ‘Treatment’, “Treatment’] |
| Majority Voting | (‘Test’ = 2, ‘Problem’ = 2, ‘Treatment’ = 2) |
| Classification | heart rate⇔ Test |
| Process Name | Processes |
|---|---|
| Clinical Term | increased heart rate |
| Semantic Breakdown | increased heart rate = [“Finding’, ‘Finding’, ‘Clinical Attribute’, ‘Clinical Attribute’, ‘Finding’, ‘Clinical Attribute’, ‘Finding’, ‘Clinical Attribute’, ‘NONE’, ‘NONE’] |
| Semantic-Based Concept Annotation | increased heart rate = [‘Problem’, ‘Problem’, ‘Test’, ‘Test’, Problem’, ‘Test’, ‘Problem’, ‘Test’] |
| Majority Voting | (‘Problem’ = 4, ‘Test’ = 4, ‘Treatment’ = 0) |
| Classification | Increased heart rate ⇔ Problem |
| Data Source | Golden Datasets | Number of Concepts | |||
|---|---|---|---|---|---|
| Problem | Treatment | Test | Total | ||
| Beth Medical Center | 73 | 4187 | 3073 | 3036 | 10,296 |
| Partners Healthcare | 97 | 2886 | 1771 | 1572 | 6229 |
| i2b2 Test dataset | 256 | 12,592 | 9343 | 9226 | 31161 |
| Total | 426 | 19,665 | 14,187 | 13,834 | 47,686 |
| Datasets | True Positive | False Negative | Sensitivity |
|---|---|---|---|
| Beth Medical Center | 255 | 7 | 97.33% |
| Partners Healthcare | 162 | 5 | 97% |
| i2b2 Test Dataset | 400 | 13 | 96.85% |
| Overall Results | 817 | 24 | 97.14% |
| Systems | Category | Precision (%) | Recall (%) | F1-Score (%) |
|---|---|---|---|---|
| BIO-CRF | Problem | 79% | 69% | 74% |
| Treatment | 79% | 70% | 74% | |
| Test | 80% | 67% | 73% | |
| Proposed System | Problem | 79% | 83% | 81% |
| Treatment | 68% | 87% | 76% | |
| Test | 80% | 42% | 55% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abbas, A.; Afzal, M.; Hussain, J.; Ali, T.; Bilal, H.S.M.; Lee, S.; Jeon, S. Clinical Concept Extraction with Lexical Semantics to Support Automatic Annotation. Int. J. Environ. Res. Public Health 2021, 18, 10564. https://0-doi-org.brum.beds.ac.uk/10.3390/ijerph182010564
Abbas A, Afzal M, Hussain J, Ali T, Bilal HSM, Lee S, Jeon S. Clinical Concept Extraction with Lexical Semantics to Support Automatic Annotation. International Journal of Environmental Research and Public Health. 2021; 18(20):10564. https://0-doi-org.brum.beds.ac.uk/10.3390/ijerph182010564
Chicago/Turabian StyleAbbas, Asim, Muhammad Afzal, Jamil Hussain, Taqdir Ali, Hafiz Syed Muhammad Bilal, Sungyoung Lee, and Seokhee Jeon. 2021. "Clinical Concept Extraction with Lexical Semantics to Support Automatic Annotation" International Journal of Environmental Research and Public Health 18, no. 20: 10564. https://0-doi-org.brum.beds.ac.uk/10.3390/ijerph182010564