A Deep Recurrent Neural Network for Non-Intrusive Load Monitoring Based on Multi-Feature Input Space and Post-Processing


Abstract
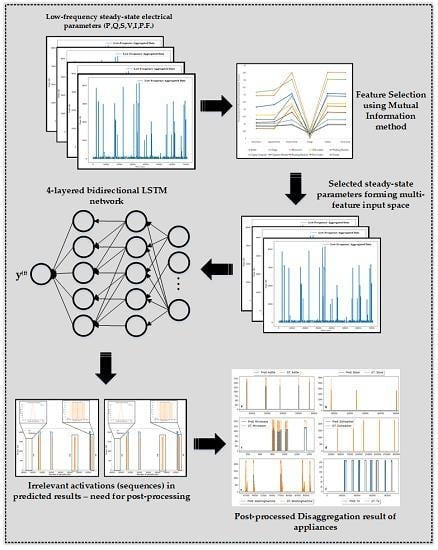
:
1. Introduction
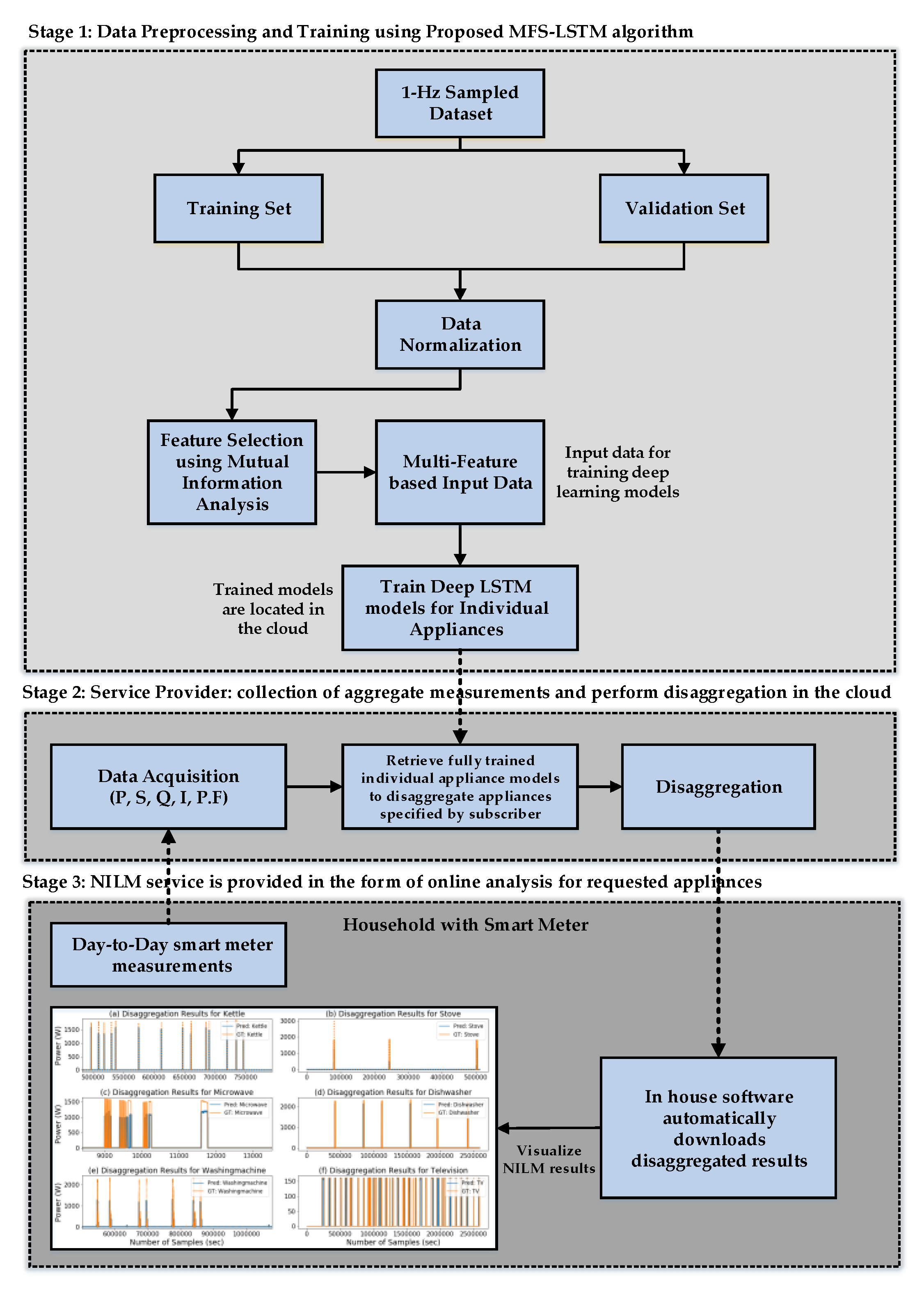
2. Proposed Energy Disaggregation Approach (MFS-LSTM Algorithm)
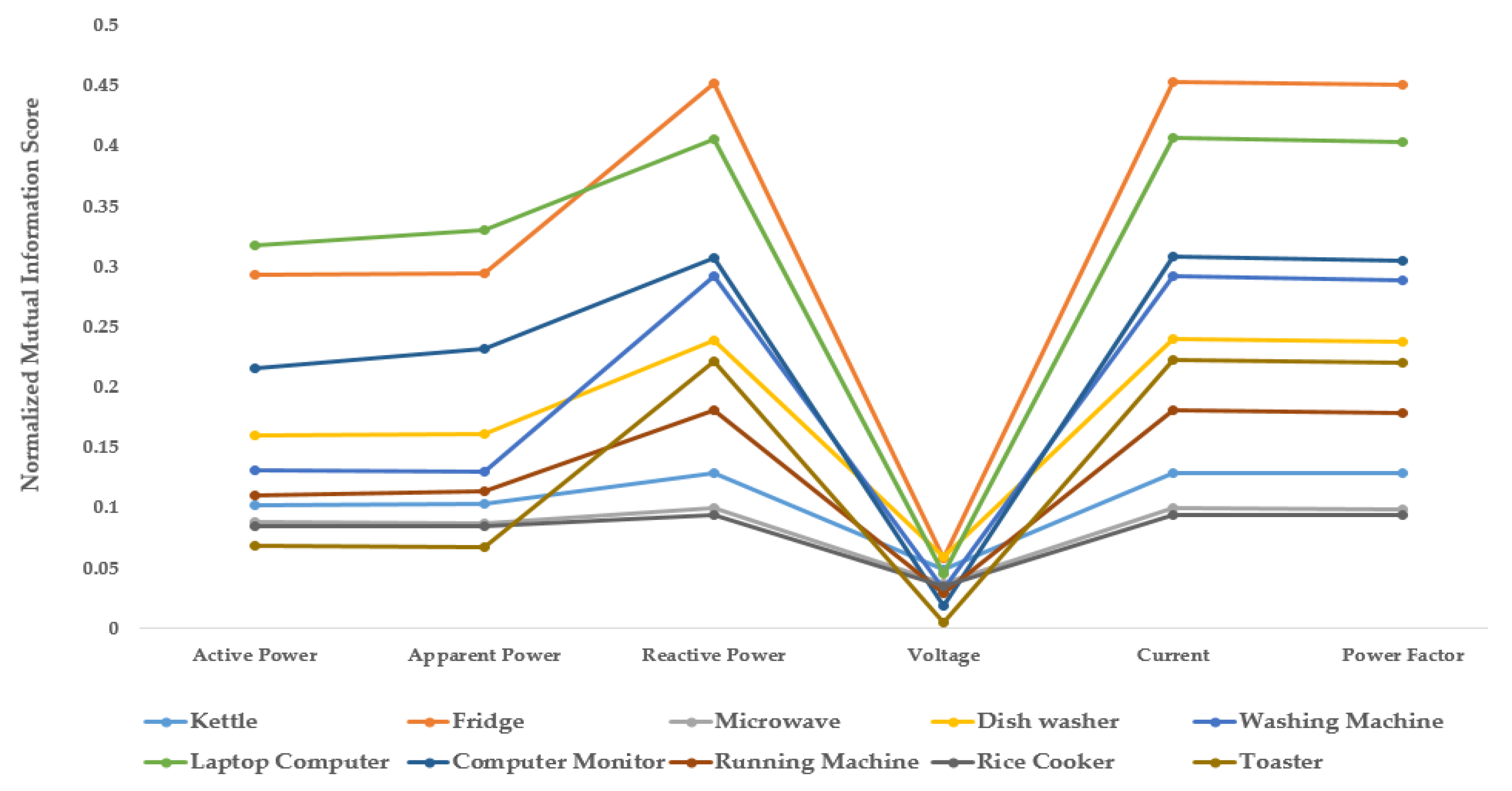
2.1. Steady-State Signatures as Multi-Feature Input Subspace
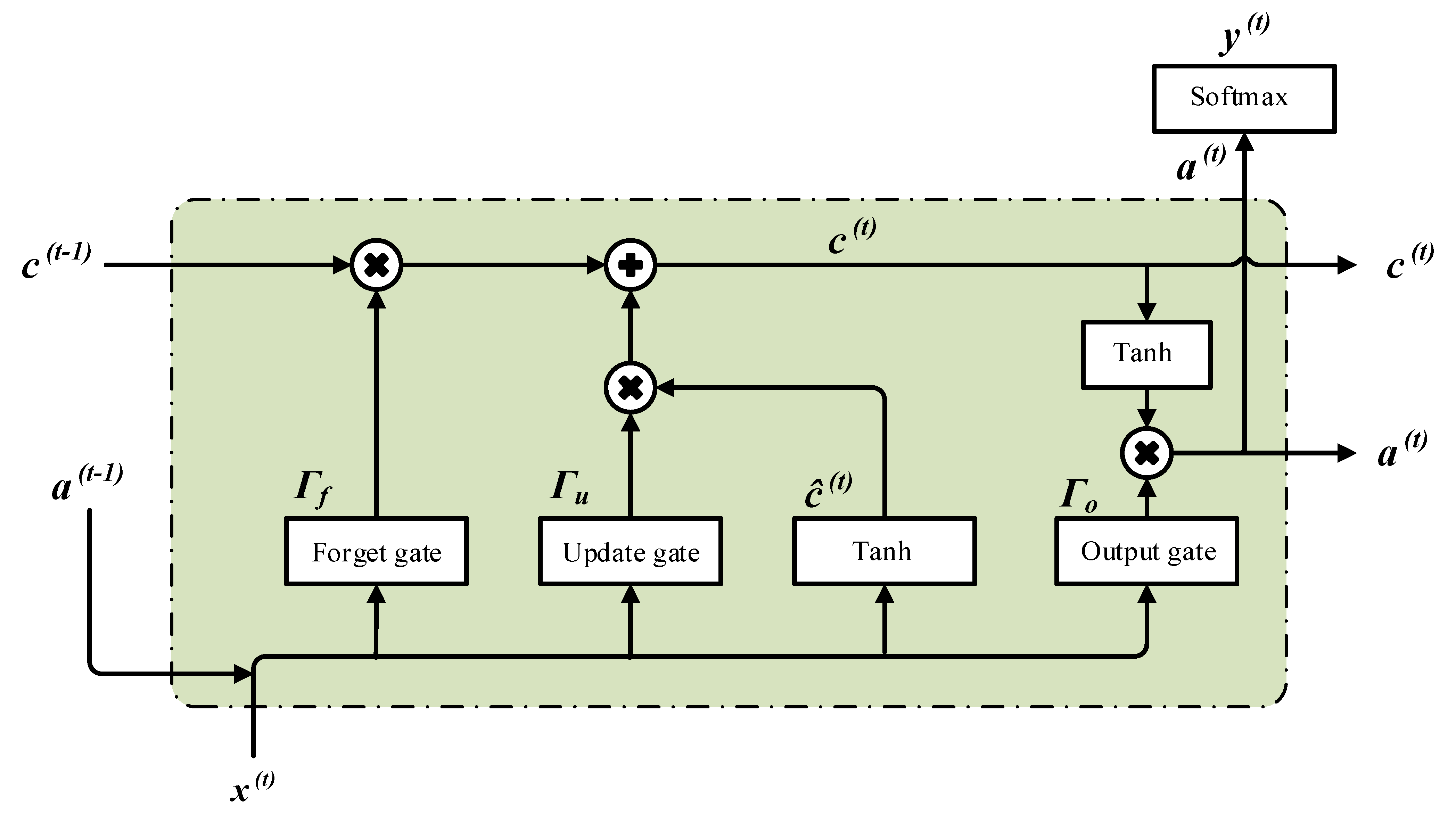
2.2. LSTM-based Deep Recurrent Neural Network
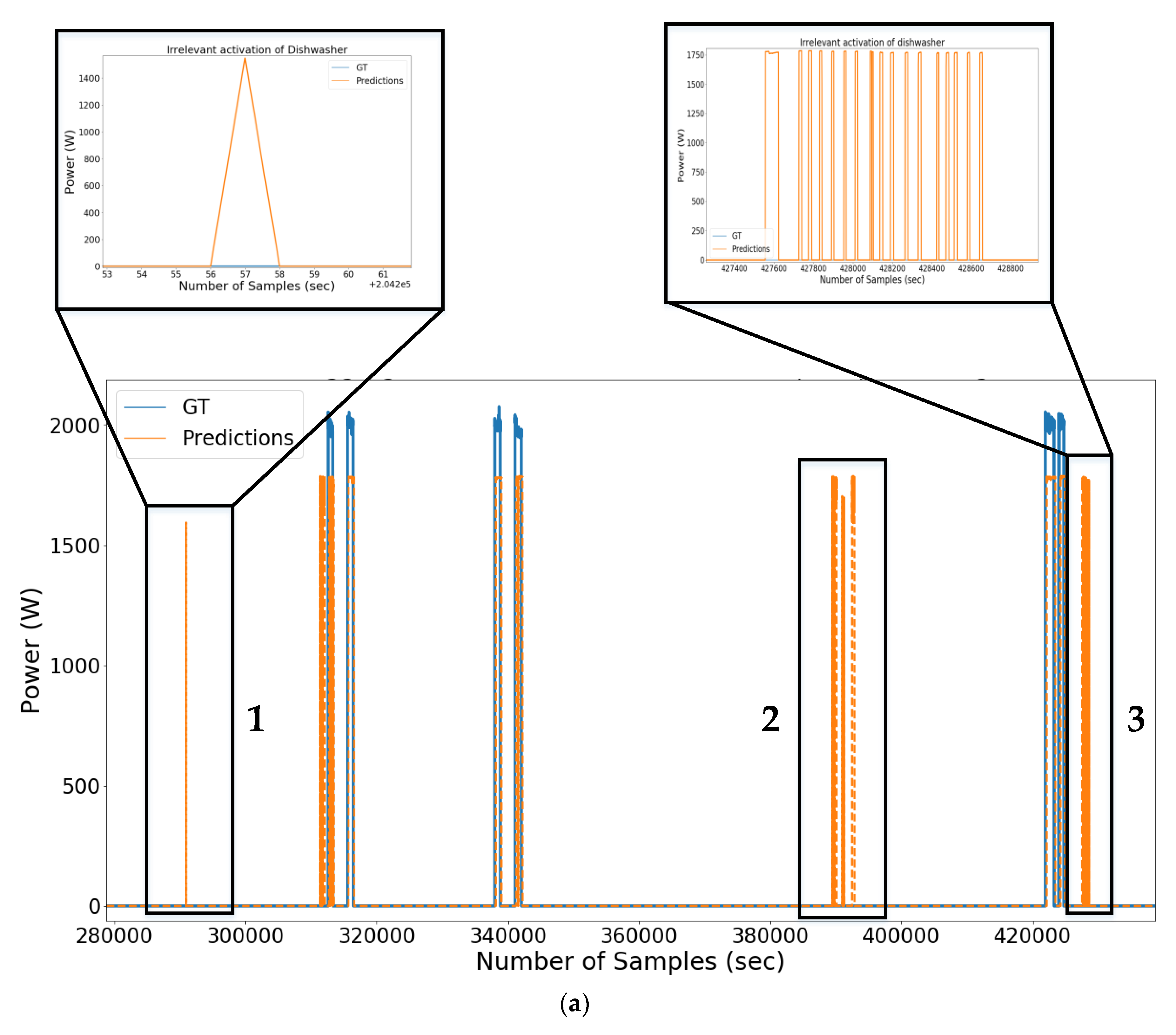
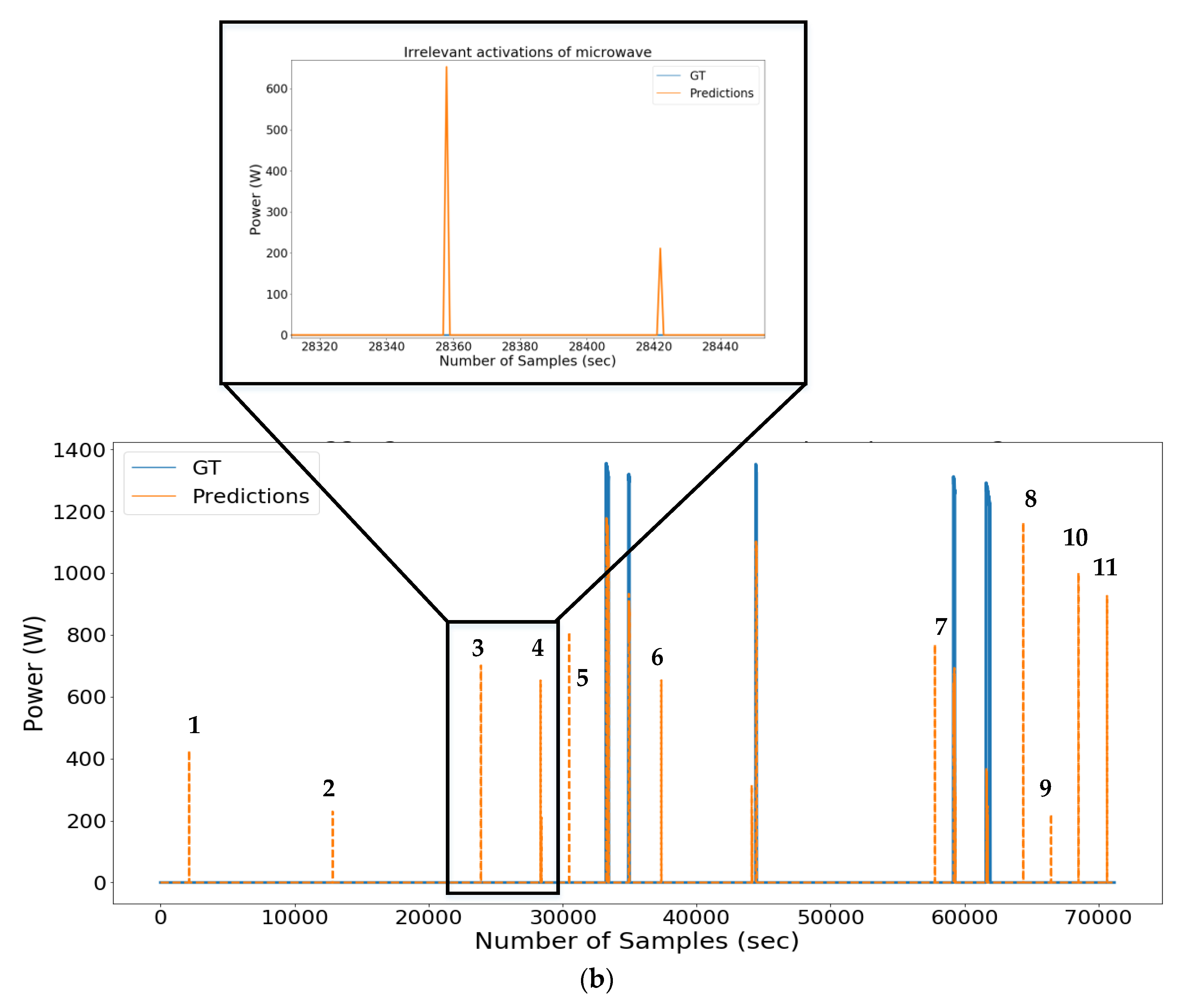
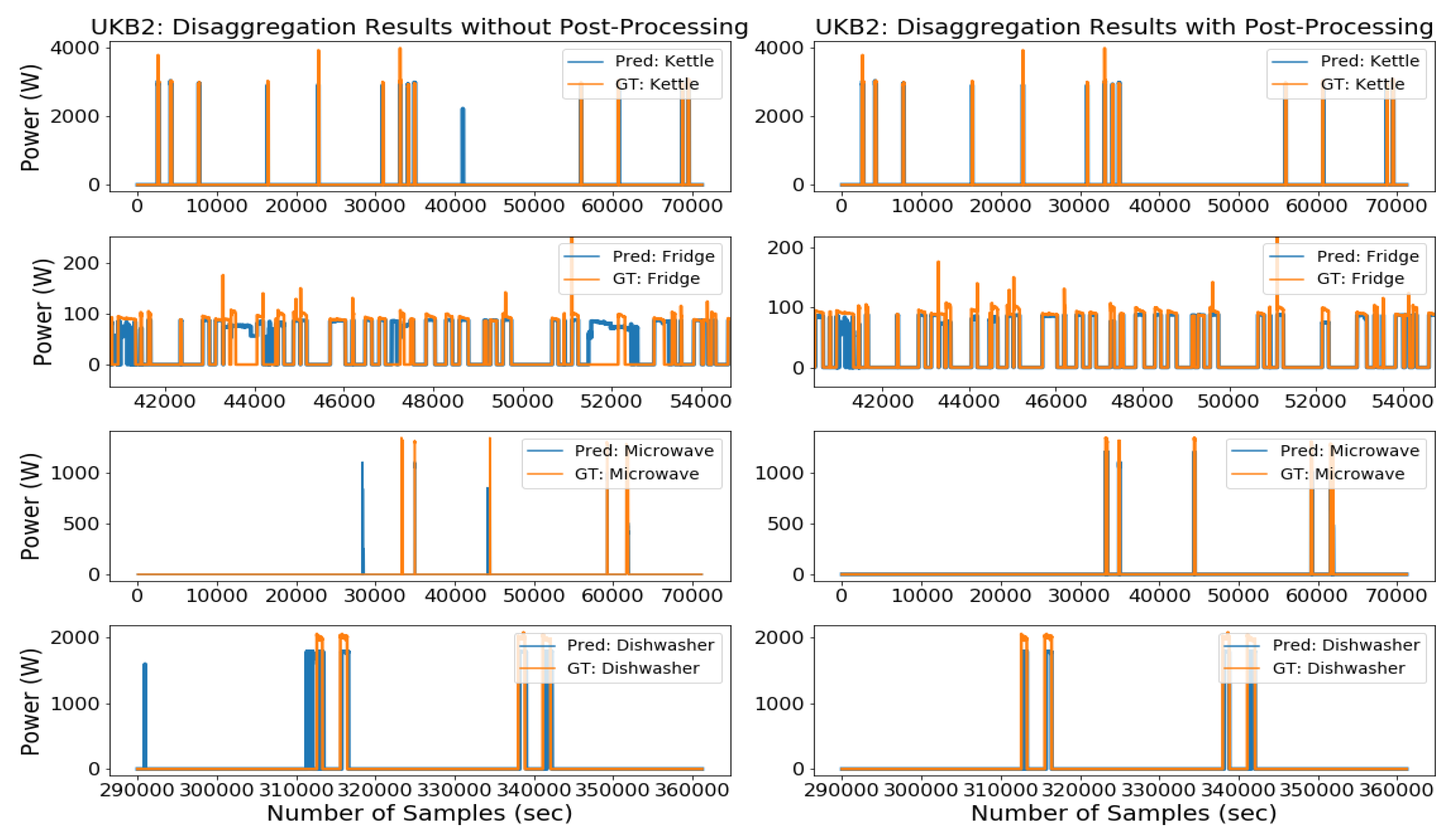
2.3. Post-Processing
2.4. Real-time Deployable NILM Framework
3. Case Study
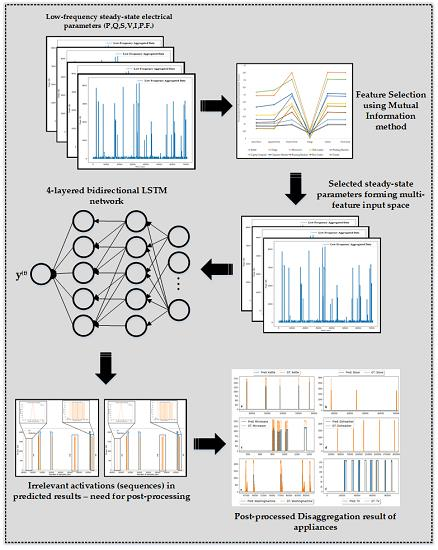
3.1. Datasets and Pre-Processing
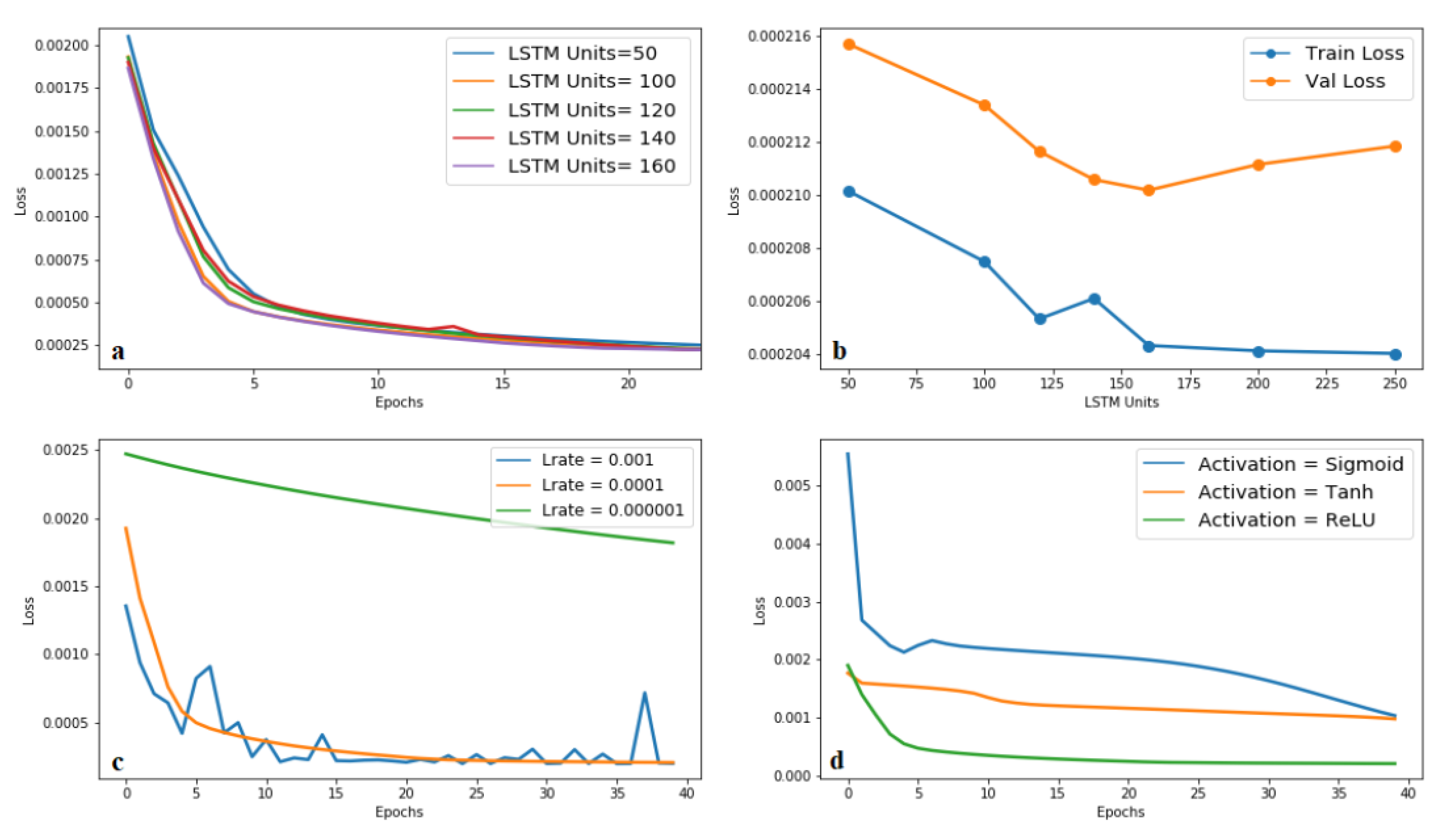
3.2. Training and Hyperparameter Optimization
- 1D convolutional layer: input shape (5, 1), filter size = 4, and number of filters = 16
- 1 bidirectional LSTM layer: number of hidden units = 150, activation = ‘ReLu’
- Dropout layer with dropout = 0.3
- 1 bidirectional LSTM layer: number of hidden units = 300, activation = ‘ReLu’
- Dropout layer with dropout = 0.3
- Fully connected dense layer: number of units = 1, activation = ‘linear’
3.3. Performance Evaluation Metrics
4. Results and Discussion
4.1. Testing in Seen Scenario (Unseen Data from UKDALE House-2 and ECO House-1,2,5)
4.1.1. Results with the UKDALE Dataset
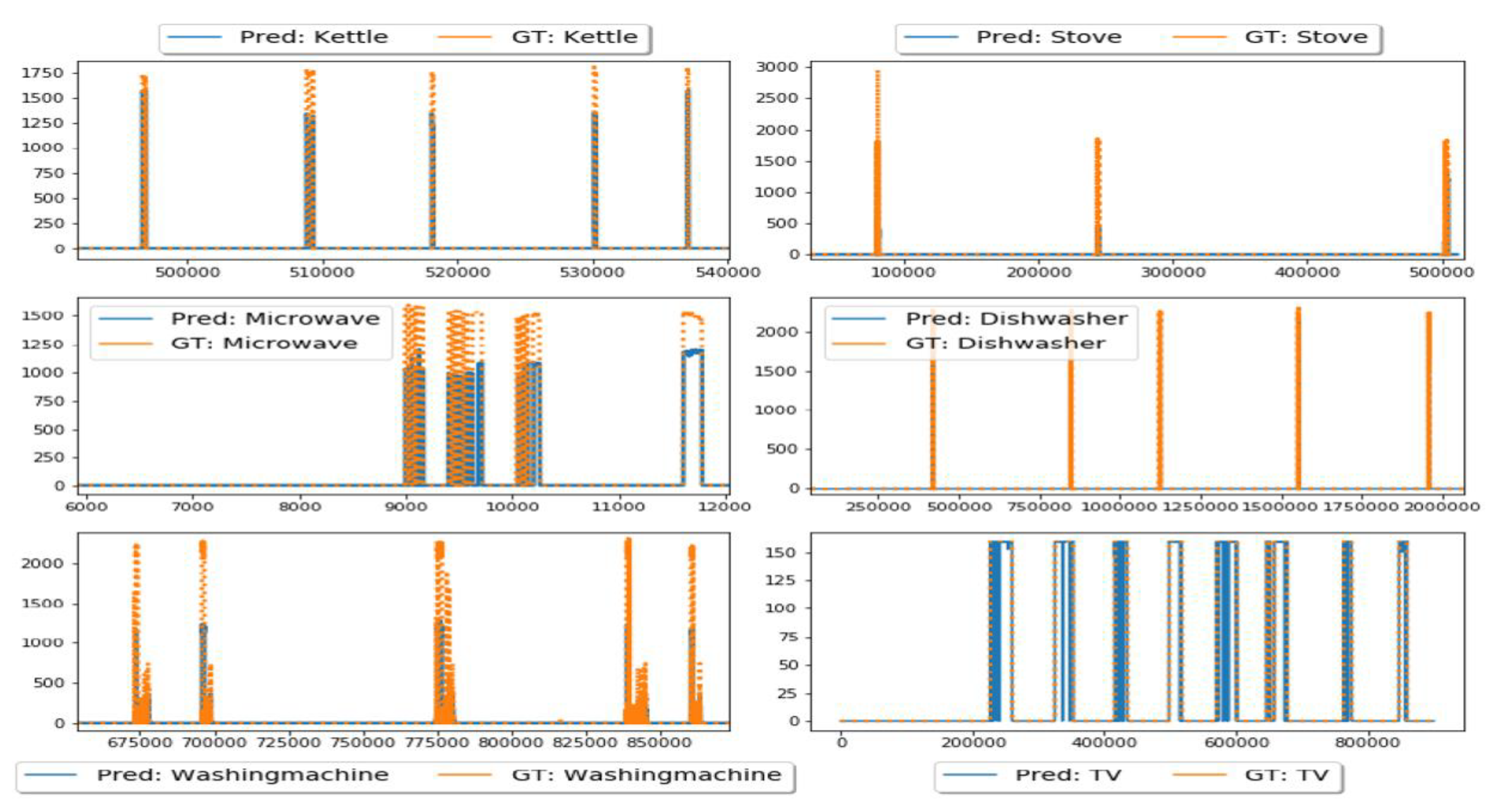
4.1.2. Results with the ECO Dataset
4.2. Testing in an Unseen Scenario (Unseen Data from UKDALE House-5)
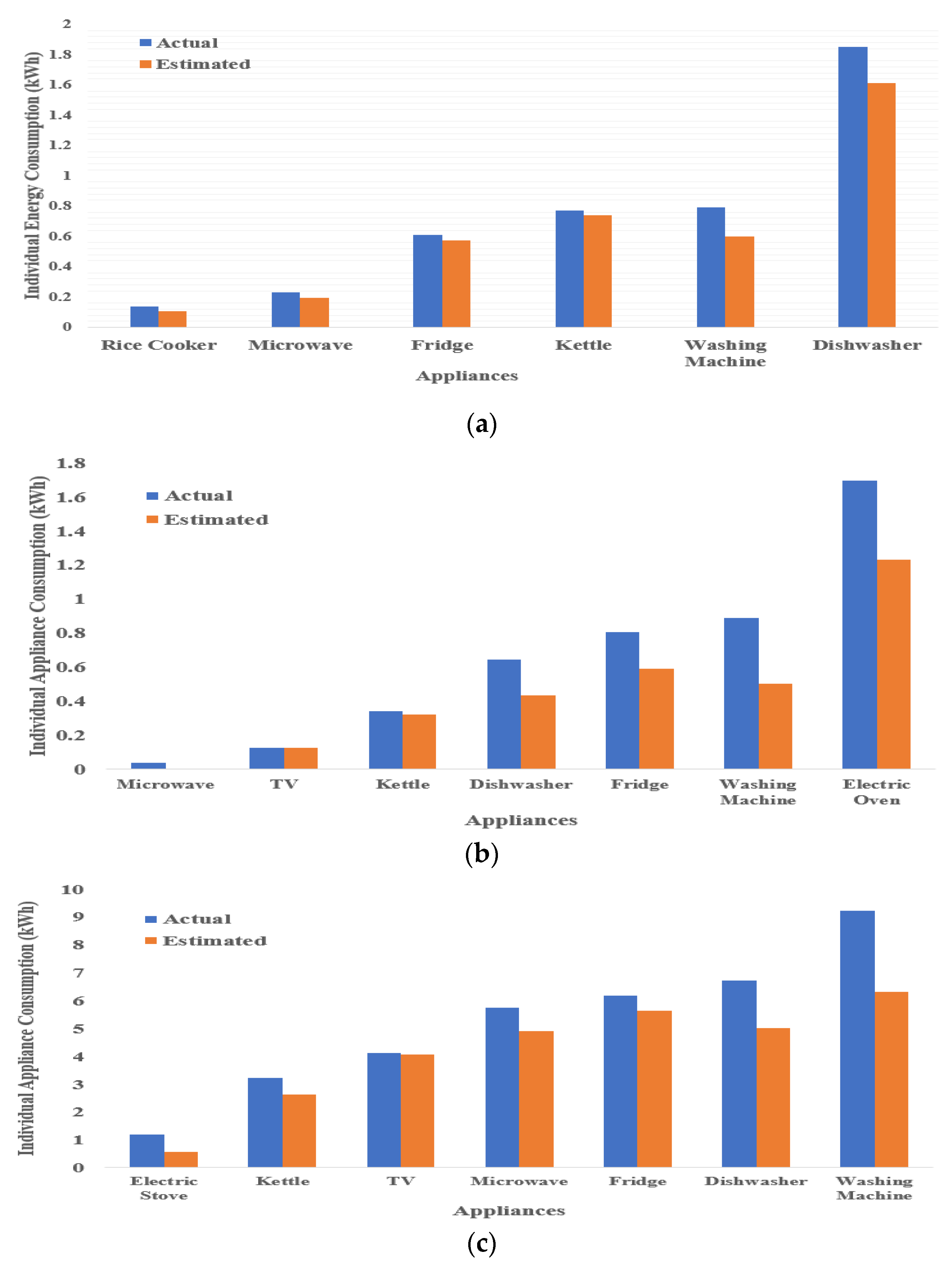
4.3. Energy Contributions by Target Appliances
4.4. Performance Comparison with State-of-the-Art Disaggregation Algorithms
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Nomenclature
| %-NR | Percentage Noise Ratio |
| Sigmoid function | |
| Forget gate | |
| Output gate | |
| Update gate | |
| AFHMM | Additive Factorial Hidden Markov Model |
| The activation value at time index ‘t’ | |
| The activation value at time index ‘t-1′ | |
| The nth-activation from ground-truth activations list | |
| The nth activations from predicted appliance activation list | |
| The list of ground-truth activations | |
| The list of predicted appliance activations | |
| The updated predicted activation profile | |
| The bias value for Tanh layer | |
| The bias value for forget layer | |
| The bias value for output layer | |
| The bias value for update layer | |
| The new cell state | |
| The output of Tanh layer | |
| The previous cell state | |
| CAD | Consumer Access Device |
| CNN | Convolutional Neural Network |
| CNN(S-S) | Sequence-to-Sequence Convolutional Neural Network |
| CO | Combinatorial Optimization algorithm |
| The cosine of angle between RMS line voltage and line current. | |
| DAE | Denoised Autoencoder |
| DFHMM | Differential Factorial Hidden Markov Model |
| DNN | Deep Neural Network |
| Total ground-truth energy | |
| Total predicted energy | |
| The updated predicted energy profile | |
| EA | Estimation Accuracy |
| ECO | Electricity Consumption & Occupancy dataset |
| FHMM | Factorial Hidden Markov Model |
| The accumulated False-Negatives | |
| The accumulated False-Positives | |
| GPU | Graphics Processing Unit |
| HMM | Hidden Markov Model |
| The RMS line current | |
| K | The total number of target appliances |
| The length of ground-truth activations | |
| The length of predicted appliance activations | |
| MAE | Mean Absolute Error (calculated in watts) |
| MAP | Maximum a Posteriori algorithm |
| MFS-LSTM | Multi-Feature Subspace based Long Short-Term Memory Network |
| Neural-LSTM | Deep Neural Network based Long Short-Term Memory Network |
| NILM | Non-Intrusive Load Monitoring |
| P | The measured active power |
| P.F | The measured Power Factor |
| The probability density function of variable ‘x’ | |
| The probability density function of variable ‘y’ | |
| The joint probability density functions of variable ‘x’ and ‘y’ | |
| Q | The measured reactive power |
| ReLU | Rectified Linear Unit |
| RNN | Recurrent Neural Network |
| S | The measured apparent power |
| The sine of angle between RMS line voltage and line current | |
| SVM | Support Vector Machine |
| T | The total time sequence used for training/testing |
| Tanh | The hyperbolic tangent function |
| The accumulated True-Positives | |
| UKDALE | UK Domestic Appliance-Level Electricity dataset |
| The RMS line voltage | |
| The weight value for Tanh layer | |
| The weight value for forget layer | |
| The weight value for output layer | |
| The weight value for update layer | |
| The input power sequence at time step ‘t’ | |
| The ground-truth power at time step ‘t’ | |
| The ground-truth power for appliance ‘k’ at time step ‘t’ | |
| The predicted power at time step ‘t’ | |
| The predicted power for appliance ‘k’ at time step ‘t’ |
References
- Zhang, G.; Wang, G.G.; Farhangi, H.; Palizban, A. Data Mining of Smart Meters for Load Category Based Disaggregation of Residential Power Consumption. Sustain. Energy Grids Netw. 2017, 10, 92–103. [Google Scholar] [CrossRef]
- Singhal, V.; Maggu, J.; Majumdar, A. Simultaneous Detection of Multiple Appliances from Smart-Meter Measurements via Multi-Label Consistent Deep Dictionary Learning and Deep Transform Learning. IEEE Trans. Smart Grid. 2018, 10, 2969–2978. [Google Scholar] [CrossRef] [Green Version]
- IEC. Coping with the Energy Challenge The IEC’s Role from 2010 to 2030; International Electrotechnical Commission: Geneva, Switzerland, September 2010; pp. 1–75. [Google Scholar]
- Froehlich, J.; Larson, E.; Gupta, S.; Cohn, G.; Reynolds, M.; Patel, S. Disaggregated End-Use Energy Sensing for the Smart Grid. IEEE Pervasive Comput. 2011, 10, 28–39. [Google Scholar] [CrossRef]
- Laitner, J.; Erhardt-Martinez, K. Examining the Scale of the Behaviour Energy Efficiency Continuum. In People-Centred Initiatives for Increasing Energy Savings; American Council for Energy Efficient Economy: Washington, DC, USA, 2010; pp. 20–31. [Google Scholar]
- Carrie Armel, K.; Gupta, A.; Shrimali, G.; Albert, A. Is Disaggregation the Holy Grail of Energy Efficiency? The Case of Electricity. Energy Policy 2013, 52, 213–223. [Google Scholar] [CrossRef] [Green Version]
- Paterakis, N.G.; Erdinç, O.; Bakirtzis, A.G.; Catalão, J.P.S. Optimal Household Appliances Scheduling under Day-Ahead Pricing and Load-Shaping Demand Response Strategies. IEEE Trans. Ind. Informa. 2015, 11, 1509–1519. [Google Scholar] [CrossRef]
- De Baets, L.; Develder, C.; Dhaene, T.; Deschrijver, D. Detection of Unidentified Appliances in Non-Intrusive Load Monitoring Using Siamese Neural Networks. Int. J. Electr. Power Energy Syst. 2019, 104, 645–653. [Google Scholar] [CrossRef]
- Zoha, A.; Gluhak, A.; Imran, M.A.; Rajasegarar, S. Non-Intrusive Load Monitoring Approaches for Disaggregated Energy Sensing: A Survey. Sensors 2012, 12, 16838–16866. [Google Scholar] [CrossRef] [Green Version]
- Zeifman, M. Disaggregation of Home Energy Display Data Using Probabilistic Approach. IEEE Trans. Consum. Electron. 2012, 58, 23–31. [Google Scholar] [CrossRef]
- Nalmpantis, C.; Vrakas, D. Machine Learning Approaches for Non-Intrusive Load Monitoring: From Qualitative to Quantitative Comparation. Artif. Intell. Rev. 2018, 52, 1–27. [Google Scholar] [CrossRef]
- Hart, G.W. Nonintrusive Appliance Load Monitoring. Proc. IEEE 1992, 80, 1870–1891. [Google Scholar] [CrossRef]
- Figueiredo, M.B.; De Almeida, A.; Ribeiro, B. An Experimental Study on Electrical Signature Identification of Non-Intrusive Load Monitoring (NILM) Systems. In Proceedings of the International Conference on Adaptive and Natural Computing Algorithms, ICANNGA, Ljubljana, Slovenia, 14–16 April 2011; pp. 31–40. [Google Scholar] [CrossRef]
- Chang, H.H. Non-Intrusive Demand Monitoring and Load Identification for Energy Management Systems Based on Transient Feature Analyses. Energies 2012, 5, 4569–4589. [Google Scholar] [CrossRef] [Green Version]
- Jiang, L.; Luo, S.H.; Li, J.M. Intelligent Electrical Appliance Event Recognition Using Multi-Load Decomposition. Adv. Mater. Res. 2013, 805–806, 1039–1045. [Google Scholar] [CrossRef]
- Meehan, P.; McArdle, C.; Daniels, S. An Efficient, Scalable Time-Frequency Method for Tracking Energy Usage of Domestic Appliances Using a Two-Step Classification Algorithm. Energies 2014, 7, 7041–7066. [Google Scholar] [CrossRef] [Green Version]
- Zeifman, M.; Roth, K. Nonintrusive Appliance Load Monitoring: Review and Outlook. IEEE Trans. Consum. Electron. 2011, 57, 76–84. [Google Scholar] [CrossRef]
- Altrabalsi, H.; Stankovic, L.; Liao, J.; Stankovic, V. A Low-Complexity Energy Disaggregation Method: Performance and Robustness. In Proceedings of the IEEE Symposium on Computational Intelligence Applications in Smart Grid, CIASG, Orlando, FL, USA, 9–12 December 2014; pp. 1–8. [Google Scholar] [CrossRef] [Green Version]
- Faustine, A.; Mvungi, N.H.; Kaijage, S.; Michael, K. A Survey on Non-Intrusive Load Monitoring Methodies and Techniques for Energy Disaggregation Problem. ArXiv 2017, arXiv:1703.00785. [Google Scholar]
- Esa, N.F.; Abdullah, M.P.; Hassan, M.Y. A Review Disaggregation Method in Non-Intrusive Appliance Load Monitoring. Renew. Sustain. Energy Rev. 2016, 66, 163–173. [Google Scholar] [CrossRef]
- Kolter, J.Z.; Johnson, M.J. REDD: A Public Data Set for Energy Disaggregation Research. In Proceedings of the ACM Workshop on Data Mining Applications in Sustainability (SustKDD), San Diego, California, 21 August 2011; pp. 1–6. [Google Scholar]
- Kolter, Z.; Jaakkola, T.; Kolter, J.Z. Approximate Inference in Additive Factorial HMMs with Application to Energy Disaggregation. J. Mach. Learn. Res. 2012, 22, 1472–1482. [Google Scholar]
- Zoha, A.; Gluhak, A.; Nati, M.; Imran, M.A. Low-Power Appliance Monitoring Using Factorial Hidden Markov Models. In Proceedings of the 2013 IEEE 8th International Conference on Intelligent Sensors, Sensor Networks and Information Processing: Sensing the Future, ISSNIP 2013, Melbourne, Australia, 2–5 April 2013; Volume 1, pp. 527–532. [Google Scholar] [CrossRef] [Green Version]
- Bonfigli, R.; Principi, E.; Fagiani, M.; Severini, M.; Squartini, S.; Piazza, F. Non-Intrusive Load Monitoring by Using Active and Reactive Power in Additive Factorial Hidden Markov Models. Appl. Energy 2017, 208, 1590–1607. [Google Scholar] [CrossRef]
- Ruzzelli, A.G.; Nicolas, C.; Schoofs, A.; O’Hare, G.M.P. Real-Time Recognition and Profiling of Appliances through a Single Electricity Sensor. In Proceedings of the SECON 2010—2010 7th Annual IEEE Communications Society Conference on Sensor, Mesh and Ad Hoc Communications and Networks, Boston, MA, USA, 21–25 June 2010. [Google Scholar] [CrossRef] [Green Version]
- Lin, G.Y.; Lee, S.C.; Hsu, J.Y.J.; Jih, W.R. Applying Power Meters for Appliance Recognition on the Electric Panel. In Proceedings of the 2010 5th IEEE Conference on Industrial Electronics and Applications, ICIEA 2010, Taichung, Taiwan, 15–17 June 2010; pp. 2254–2259. [Google Scholar] [CrossRef]
- Mauch, L.; Yang, B. A New Approach for Supervised Power Disaggregation by Using a Deep Recurrent LSTM Network. In Proceedings of the 2015 IEEE Global Conference on Signal and Information Processing, GlobalSIP 2015, Orlando, FL, USA, 14–16 December 2015; pp. 63–67. [Google Scholar] [CrossRef]
- Rafiq, H.; Zhang, H.; Li, H.; Ochani, M.K. Regularized LSTM Based Deep Learning Model: First Step towards Real-Time Non-Intrusive Load Monitoring. In Proceedings of the IEEE International Conference on Smart Energy Grid Engineering (SEGE), Oshawa, ON, Canada, 12–15 August 2018; pp. 234–239. [Google Scholar] [CrossRef]
- He, W.; Chai, Y. An Empirical Study on Energy Disaggregation via Deep Learning. Adv. Intell. Syst. Res. 2016, 133, 338–342. [Google Scholar] [CrossRef] [Green Version]
- Kim, J.; Le, T.-T.-H.; Kim, H. Nonintrusive Load Monitoring Based on Advanced Deep Learning and Novel Signature. Comput. Intell. Neurosci. 2017, 2017, 4216281. [Google Scholar] [CrossRef]
- Kelly, J.; Knottenbelt, W. Neural NILM: Deep Neural Networks Applied to Energy Disaggregation. In Proceedings of the ACM International Conference on Embedded Systems for Energy-Efficient Built Environments, Seoul, South Korea, 3–4 November 2015; pp. 55–64. [Google Scholar] [CrossRef] [Green Version]
- Bonfigli, R.; Felicetti, A.; Principi, E.; Fagiani, M.; Squartini, S.; Piazza, F. Denoising Autoencoders for Non-Intrusive Load Monitoring: Improvements and Comparative Evaluation. Energy Build. 2018, 158, 1461–1474. [Google Scholar] [CrossRef]
- Zhang, C.; Zhong, M.; Wang, Z.; Goddard, N.; Sutton, C. Sequence-to-Point Learning with Neural Networks for Nonintrusive Load Monitoring. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 1–8. [Google Scholar]
- Barsim, K.S.; Yang, B. On the Feasibility of Generic Deep Disaggregation for Single-Load Extraction. ArXiv 2018, arXiv:1802.02139. [Google Scholar]
- Zhang, Y.; Yin, B.; Cong, Y.; Du, Z. Multi-state Household Appliance Identification Based on Convolutional Neural Networks and Clustering. Energies 2020, 13, 792. [Google Scholar] [CrossRef] [Green Version]
- D’Incecco, M.; Squartini, S.; Zhong, M. Transfer Learning for Non-Intrusive Load Monitoring. IEEE Trans. Smart Grid 2020, 11, 1419–1429. [Google Scholar] [CrossRef]
- Singh, S.; Majumdar, A. Deep Sparse Coding for Non-Intrusive Load Monitoring. IEEE Trans. Smart Grid 2018, 9, 4669–4678. [Google Scholar] [CrossRef] [Green Version]
- Cho, J.; Hu, Z.; Sartipi, M. Non-Intrusive A/C Load Disaggregation Using Deep Learning. In Proceedings of the IEEE Power Engineering Society Transmission and Distribution Conference, Denver, CO, USA, 16–19 April 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Miao, J.; Niu, L. A Survey on Feature Selection. Procedia Comput. Sci. 2016, 91, 919–926. [Google Scholar] [CrossRef] [Green Version]
- Masoudi-Sobhanzadeh, Y.; Motieghader, H.; Masoudi-Nejad, A. FeatureSelect: A Software for Feature Selection Based on Machine Learning Approaches. BMC Bioinformatics 2019, 20, 170. [Google Scholar] [CrossRef]
- Zhu, Z.; Wei, Z.; Yin, B.; Liu, T.; Huang, X. Feature Selection of Non-Intrusive Load Monitoring System Using RFE and RF. J. Phys. Conf. Ser. 2019, 1176, 1–8. [Google Scholar] [CrossRef]
- Schirmer, P.A.; Mporas, I. Statistical and Electrical Features Evaluation for Electrical Appliances Energy Disaggregation. Sustainability 2019, 11, 3222. [Google Scholar] [CrossRef] [Green Version]
- Valenti, M.; Bonfigli, R.; Principi, E.; Squartini, S. Exploiting the Reactive Power in Deep Neural Models for Non-Intrusive Load Monitoring. In Proceedings of the International Joint Conference on Neural Networks, Rio de Janeiro, Brazil, 8–13 July 2018; 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Harell, A.; Makonin, S.; Bajic, I.V. Wavenilm: A Causal Neural Network for Power Disaggregation from the Complex Power Signal. In Proceedings of the ICASSP, IEEE International Conference on Acoustics, Speech and Signal Processing—Proceedings, Brighton, UK, 12–17 May 2019. [Google Scholar] [CrossRef] [Green Version]
- Kong, W.; Dong, Z.Y.; Wang, B.; Zhao, J.; Huang, J. A Practical Solution for Non-Intrusive Type II Load Monitoring Based on Deep Learning and Post-Processing. IEEE Trans. Smart Grid 2020, 11, 148–160. [Google Scholar] [CrossRef]
- Beraha, M.; Metelli, A.M.; Papini, M.; Tirinzoni, A.; Restelli, M. Feature Selection via Mutual Information: New Theoretical Insights. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–9. [Google Scholar] [CrossRef] [Green Version]
- Tabatabaei, S.M. Decomposition Techniques for Non-Intrusive Home Appliance Load Monitoring; University of Alberta: Edmonton, AB, Canada, 2014. [Google Scholar] [CrossRef]
- Asif, W.; Rajarajan, M.; Lestas, M. Increasing User Controllability on Device Specific Privacy in the Internet of Things. Comput. Commun. 2018, 116, 200–211. [Google Scholar] [CrossRef] [Green Version]
- Batra, N.; Kelly, J.; Parson, O.; Dutta, H.; Knottenbelt, W.; Rogers, A.; Singh, A.; Srivastava, M. NILMTK: An Open Source Toolkit for Non-Intrusive Load Monitoring Categories and Subject Descriptors. In Proceedings of the International Conference on Future Energy Systems (ACM e-Energy), Cambridge, UK, 11–13 June 2014; pp. 1–4. [Google Scholar] [CrossRef] [Green Version]
- Kelly, J.; Knottenbelt, W. The UK-DALE Dataset, Domestic Appliance-Level Electricity Demand and Whole-House Demand from Five UK Homes. Sci. Data 2015, 2, 150007. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Beckel, C.; Kleiminger, W.; Cicchetti, R.; Staake, T.; Santini, S. The ECO Data Set and the Performance of Non-Intrusive Load Monitoring Algorithms. In Proceedings of the 1st ACM Conference on Embedded Systems for Energy-Efficient Buildings—BuildSys ’14, Memphis, TN, USA, 5–6 November 2014; pp. 80–89. [Google Scholar] [CrossRef]
- Chollet, F. Keras: The Python Deep Learning Library. Available online: https://keras.io (accessed on 8 April 2020).
- Makonin, S.; Popowich, F. Nonintrusive Load Monitoring (NILM) Performance Evaluation A Unified Approach for Accuracy Reporting. Energy Effic. 2015, 8, 809–814. [Google Scholar] [CrossRef]
- Gomes, E.; Pereira, L. PB-NILM: Pinball Guided Deep Non-Intrusive Load Monitoring. IEEE Access 2020, 8, 48386–48398. [Google Scholar] [CrossRef]
- Xia, M.; Liu, W.; Wang, K.; Zhang, X.; Xu, Y. Non-Intrusive Load Disaggregation Based on Deep Dilated Residual Network. Electr. Power Syst. Res. 2019, 170, 277–285. [Google Scholar] [CrossRef]
- Manivannan, M.; Najafi, B.; Rinaldi, F. Machine Learning-Based Short-Term Prediction of Air-Conditioning Load through Smart Meter Analytics. Energies 2017, 11, 1905. [Google Scholar] [CrossRef] [Green Version]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
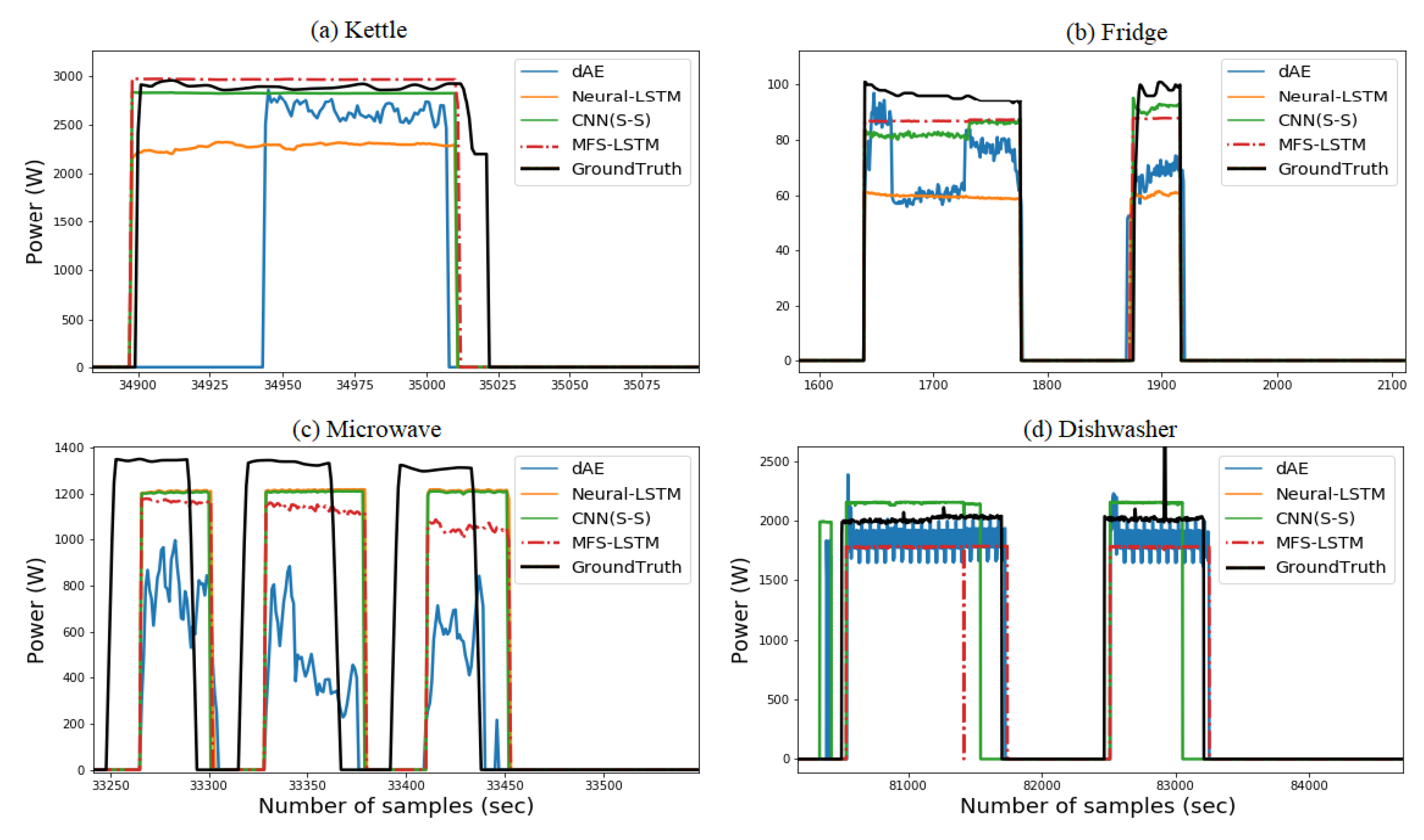{kind=link}
| Algorithm 1: Post-processing to eliminate irrelevant activations | |
| 1 | Inputs: target appliance ground-truth activations set and predicted activations set |
| 2 | Zero initialization of updated predicted activation profile (), and updated predicted energy profile () |
| 3 | Calculate lengths of each activation from and : and |
| 4 | Determine minimum length from list of actual activations lengths: min{} |
| 5 | Set pointer j = 0 |
| 6 | For |
| 7 | If : |
| 8 | ; |
| 9 | Update and ; |
| 10 | End if |
| 11 | End For |
| 12 | Return |
| House # | Appliances | Without Post-Processing | With Post-Processing | ||||||
|---|---|---|---|---|---|---|---|---|---|
| F1 | MAE (W) | SAE | EA | F1 | MAE (W) | SAE | EA | ||
| 1 | Kettle | 0.658 | 2.162 | 0.179 | 0.911 | 0.995 | 1.837 | 0.217 | 0.891 |
| 1 | Fridge | 0.497 | 13.980 | 0.138 | 0.919 | 0.997 | 5.679 | 0.347 | 0.826 |
| 5 | Microwave | 0.535 | 65.090 | 0.028 | 0.986 | 0.719 | 21.450 | 0.515 | 0.743 |
| 2 | Dishwasher | 0.559 | 13.076 | 0.094 | 0.953 | 0.749 | 5.877 | 0.419 | 0.790 |
| 1 | Washing Machine | 0.322 | 65.720 | 1.010 | 0.492 | 0.795 | 18.870 | 0.655 | 0.673 |
| 2 | Electric Stove | 0.886 | 3.519 | 0.623 | 0.688 | 0.981 | 0.240 | 0.005 | 0.997 |
| 2 | Television | 0.976 | 0.976 | 0.018 | 0.991 | 0.995 | 0.497 | 0.012 | 0.994 |
| Overall | 0.633 | 23.503 | 0.298 | 0.848 | 0.890 | 7.778 | 0.310 | 0.845 | |
| House # | Appliances | Without Post-Processing | With Post-Processing | ||||||
|---|---|---|---|---|---|---|---|---|---|
| F1 | MAE (W) | SAE | EA | F1 | MAE (W) | SAE | EA | ||
| 2 | Kettle | 0.961 | 3.906 | 0.004 | 0.998 | 0.981 | 2.353 | 0.043 | 0.978 |
| 2 | Fridge | 0.838 | 13.667 | 0.170 | 0.915 | 0.995 | 4.039 | 0.121 | 0.939 |
| 2 | Microwave | 0.721 | 7.285 | 0.276 | 0.862 | 0.869 | 5.402 | 0.437 | 0.781 |
| 2 | Dishwasher | 0.745 | 25.736 | 0.024 | 0.988 | 0.891 | 12.346 | 0.288 | 0.856 |
| 2 | Washing Machine | 0.189 | 30.990 | 0.686 | −0.09 | 0.701 | 5.400 | 0.641 | 0.679 |
| 2 | Rice Cooker | 0.299 | 8.900 | 0.699 | −0.161 | 0.781 | 1.115 | 0.378 | 0.811 |
| 5 | Electric Oven | 0.550 | 68.611 | 0.448 | 0.594 | 0.736 | 28.911 | 0.013 | 0.993 |
| 5 | Television | 0.512 | 5.695 | 0.219 | 0.890 | 0.879 | 3.428 | 0.649 | 0.675 |
| Overall | 0.688 | 23.541 | 0.361 | 0.714 | 0.976 | 8.999 | 0.367 | 0.959 | |
| House # | Appliances | Without Post-Processing | With Post-Processing | ||||||
|---|---|---|---|---|---|---|---|---|---|
| F1 | MAE (W) | SAE | EA | F1 | MAE (W) | SAE | EA | ||
| 5 | Kettle | 0.701 | 14.973 | 0.685 | 0.657 | 0.965 | 1.966 | 0.058 | 0.971 |
| 5 | Fridge | 0.732 | 27.863 | 0.270 | 0.865 | 0.872 | 19.608 | 0.467 | 0.766 |
| 5 | Microwave | 0.242 | 0.546 | 0.504 | 0.748 | 0.317 | 0.392 | 0.828 | 0.586 |
| 5 | Dishwasher | 0.554 | 35.129 | 0.273 | 0.863 | 0.809 | 15.275 | 0.323 | 0.838 |
| 5 | Washing Machine | 0.189 | 30.990 | 2.18 | −0.09 | 0.765 | 14.422 | 0.512 | 0.744 |
| Overall | 0.484 | 21.900 | 0.782 | 0.609 | 0.746 | 10.333 | 0.438 | 0.781 | |
| Metrics | UKDALE H-2 | UKDALE H-5 | ECO H-1 | ECO H-2 |
|---|---|---|---|---|
| Noise Ratio (%) | 19.34 | 72.08 | 83.76 | 70.51 |
| Actual Disaggregated Energy (%) | 80.66 | 27.92 | 16.24 | 29.49 |
| Predicted Energy (%) | 63.15 | 21.57 | 12.99 | 24.53 |
| Estimation Accuracy | 0.891 | 0.886 | 0.900 | 0.916 |
| Algorithms | Training (133 Days) | Testing (10 Days) |
|---|---|---|
| CO | 11 | 1.00 |
| FHMM | 166 | 50.63 |
| dAE | 300 | 0.02 |
| Neural-LSTM | 1280 | 0.68 |
| CNN (S-S) | 1899 | 1.19 |
| MFS-LSTM | 908 | 0.65 |
| Performance Metrics | Algorithms | Kettle | Fridge | Microwave | Dishwasher | Washing Machine | Overall |
|---|---|---|---|---|---|---|---|
| F1 | CO | 0.291 | 0.493 | 0.322 | 0.125 | 0.067 | 0.259 |
| FHMM | 0.263 | 0.442 | 0.397 | 0.053 | 0.112 | 0.253 | |
| dAE | 0.641 | 0.735 | 0.786 | 0.746 | 0.485 | 0.679 | |
| Neural-LSTM | 0.961 | 0.791 | 0.774 | 0.419 | 0.152 | 0.619 | |
| CNN(S-S) | 0.940 | 0.912 | 0.923 | 0.708 | 0.759 | 0.848 | |
| MFS-LSTM | 0.981 | 0.995 | 0.869 | 0.891 | 0.701 | 0.887 | |
| MAE (Watts) | CO | 61.892 | 53.200 | 59.141 | 71.776 | 121.541 | 73.510 |
| FHMM | 84.270 | 67.244 | 53.472 | 107.655 | 147.330 | 91.994 | |
| dAE | 22.913 | 23.356 | 9.591 | 24.193 | 27.339 | 21.478 | |
| Neural-LSTM | 7.324 | 22.571 | 7.449 | 19.465 | 109.144 | 33.190 | |
| CNN(S-S) | 5.033 | 13.501 | 7.004 | 26.516 | 8.414 | 12.094 | |
| MFS-LSTM | 2.353 | 4.039 | 5.402 | 12.346 | 5.400 | 5.908 | |
| SAE | CO | 0.438 | 0.358 | 0.747 | 0.472 | 0.611 | 0.525 |
| FHMM | 0.463 | 0.516 | 0.849 | 0.594 | 0.523 | 0.589 | |
| dAE | 0.576 | 0.108 | 0.681 | 0.028 | 0.217 | 0.322 | |
| Neural-LSTM | 0.114 | 0.028 | 0.309 | 0.711 | 0.695 | 0.371 | |
| CNN(S-S) | 0.052 | 0.154 | 0.368 | 0.575 | 0.433 | 0.316 | |
| MFS-LSTM | 0.043 | 0.121 | 0.437 | 0.288 | 0.641 | 0.306 | |
| EA | CO | 0.926 | 0.915 | 0.838 | 0.581 | 0.847 | 0.821 |
| FHMM | 0.902 | 0.912 | 0.829 | 0.543 | 0.802 | 0.798 | |
| dAE | 0.711 | 0.946 | 0.659 | 0.986 | 0.723 | 0.805 | |
| Neural-LSTM | 0.943 | 0.940 | 0.845 | 0.645 | 0.614 | 0.797 | |
| CNN(S-S) | 0.972 | 0.930 | 0.717 | 0.723 | 0.745 | 0.817 | |
| MFS-LSTM | 0.978 | 0.939 | 0.781 | 0.856 | 0.679 | 0.847 |
| Performance Metrics | Algorithms | Kettle | Fridge | Microwave | Dishwasher | Washing Machine | Overall |
|---|---|---|---|---|---|---|---|
| F1 | CO | 0.327 | 0.382 | 0.086 | 0.128 | 0.124 | 0.209 |
| FHMM | 0.181 | 0.539 | 0.022 | 0.047 | 0.101 | 0.178 | |
| dAE | 0.746 | 0.671 | 0.432 | 0.652 | 0.415 | 0.583 | |
| Neural-LSTM | 0.331 | 0.364 | 0.216 | 0.165 | 0.113 | 0.238 | |
| CNN(S-S) | 0.783 | 0.684 | 0.226 | 0.495 | 0.533 | 0.544 | |
| MFS-LSTM | 0.965 | 0.872 | 0.317 | 0.809 | 0.765 | 0.746 | |
| MAE (Watts) | CO | 113.457 | 89.922 | 77.264 | 81.131 | 77.902 | 87.935 |
| FHMM | 174.744 | 78.511 | 183.472 | 105.626 | 128.756 | 134.222 | |
| dAE | 64.864 | 56.785 | 19.283 | 164.931 | 23.958 | 65.964 | |
| Neural-LSTM | 89.514 | 58.562 | 14.841 | 106.390 | 103.654 | 74.592 | |
| CNN(S-S) | 54.244 | 23.675 | 21.191 | 113.447 | 115.783 | 65.668 | |
| MFS-LSTM | 1.966 | 19.608 | 0.392 | 15.275 | 14.422 | 10.333 | |
| SAE | CO | 0.813 | 0.374 | 0.951 | 0.625 | 0.715 | 0.696 |
| FHMM | 0.871 | 0.569 | 0.982 | 0.754 | 0.763 | 0.788 | |
| dAE | 0.581 | 0.552 | 0.867 | 2.112 | 0.585 | 0.939 | |
| Neural-LSTM | 1.588 | 0.573 | 0.815 | 0.505 | 0.614 | 0.819 | |
| CNN(S-S) | 0.523 | 0.624 | 0.843 | 0.339 | 0.691 | 0.604 | |
| MFS-LSTM | 0.058 | 0.467 | 0.828 | 0.323 | 0.512 | 0.438 | |
| EA | CO | 0.608 | 0.633 | 0.405 | 0.443 | 0.431 | 0.504 |
| FHMM | 0.589 | 0.551 | 0.336 | 0.417 | 0.584 | 0.495 | |
| dAE | 0.709 | 0.724 | 0.566 | −0.061 | 0.375 | 0.463 | |
| Neural-LSTM | 0.209 | 0.713 | 0.592 | 0.749 | 0.540 | 0.561 | |
| CNN(S-S) | 0.581 | 0.778 | 0.533 | 0.417 | 0.634 | 0.589 | |
| MFS-LSTM | 0.971 | 0.766 | 0.586 | 0.838 | 0.744 | 0.781 |
| Algorithms | Estimation Accuracy (EA) | |
|---|---|---|
| Seen Scenario | Unseen Scenario | |
| CO | 0.907 | 0.544 |
| FHMM | 0.813 | 0.536 |
| dAE | 0.888 | 0.518 |
| Neural-LSTM | 0.891 | 0.289 |
| CNN (S-S) | 0.924 | 0.633 |
| MFS-LSTM | 0.964 | 0.856 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rafiq, H.; Shi, X.; Zhang, H.; Li, H.; Ochani, M.K. A Deep Recurrent Neural Network for Non-Intrusive Load Monitoring Based on Multi-Feature Input Space and Post-Processing. Energies 2020, 13, 2195. https://0-doi-org.brum.beds.ac.uk/10.3390/en13092195
Rafiq H, Shi X, Zhang H, Li H, Ochani MK. A Deep Recurrent Neural Network for Non-Intrusive Load Monitoring Based on Multi-Feature Input Space and Post-Processing. Energies. 2020; 13(9):2195. https://0-doi-org.brum.beds.ac.uk/10.3390/en13092195
Chicago/Turabian StyleRafiq, Hasan, Xiaohan Shi, Hengxu Zhang, Huimin Li, and Manesh Kumar Ochani. 2020. "A Deep Recurrent Neural Network for Non-Intrusive Load Monitoring Based on Multi-Feature Input Space and Post-Processing" Energies 13, no. 9: 2195. https://0-doi-org.brum.beds.ac.uk/10.3390/en13092195