
A Novel Virtual Sensor Modeling Method Based on Deep Learning and Its Application in Heating, Ventilation, and Air-Conditioning System


School of Automation, Wuhan University of technology, Wuhan 430070, China
*
Author to whom correspondence should be addressed.
Energies 2022, 15(15), 5743; https://0-doi-org.brum.beds.ac.uk/10.3390/en15155743
Submission received: 16 June 2022
/
Revised: 27 July 2022
/
Accepted: 29 July 2022
/
Published: 8 August 2022
(This article belongs to the Special Issue Designing, Modeling and Optimizing Energy and Environmental Systems for Buildings)
Abstract
:Realizing the dynamic redundancy of sensors is of great significance to ensure the energy saving and normal operation of the heating, ventilation, and air-conditioning (HVAC) system. Building a virtual sensor model is an effective method of redundancy and fault tolerance for hardware sensors. In this paper, a virtual sensor modeling method combining the maximum information coefficient (MIC) and the spatial–temporal attention long short-term memory (STA-LSTM) is proposed, which is named MIC-STALSTM, to achieve the dynamic and nonlinear modeling of the supply and return water temperature at both ends of the chiller. First, MIC can extract the influencing factors highly related to the target variables. Then, the extracted impact factors via MIC are used as the input variables of the STA-LSTM algorithm in order to construct an accurate virtual sensor model. The STA-LSTM algorithm not only makes full use of the LSTM algorithm’s advantages in handling historical data series information, but also achieves adaptive estimation of different input variable feature weights and different hidden layer temporal correlations through the attention mechanism. Finally, the effectiveness and feasibility of the proposed method are verified by establishing two virtual sensors for different temperature variables in the HVAC system.
1. Introduction
Heating, ventilation, and air-conditioning (HVAC) systems, which ensure a good indoor environment and air quality, are frequently used in commercial, residential, and industrial buildings. HVAC systems can be thought of as a complex network of several interrelated subsystems, each of which includes several mechanical components and a large number of sensors. Common sensors used in HVAC systems include humidity sensors, CO sensors, temperature sensors, and particulate matter (PM) sensors, etc. [1]. These sensors are constantly monitoring the real-time operation of the system and feeding the monitored information back to the control system. Correct sensor values are the basis for the control system to be capable of making appropriate decisions. However, sensors used in HVAC systems are inevitably prone to different types of faults (e.g., bias, drift, and abrupt failures). Errors generated by faulty sensors have considerable effects on the control behavior of HVAC systems, and lead to increased energy consumption and reduced thermal comfort [2]. Therefore, it is essential to construct virtual sensors as effective alternatives to faulty sensors in HVAC systems.
Generally, the modeling methods of virtual sensors are divided into two categories, including model-based methods and data-driven methods. Model-based methods require mathematical equations to define the relationship between input and output variables. However, due to the complexity of modern HVAC systems, it is difficult to use mathematical equations to establish an accurate virtual sensor model. In contrast, data-driven methods do not need to establish an accurate mathematical model, and only need to obtain a decision function through the processing of historical observation data. The accuracy of the final results is ensured by adjusting the decision function continuously. Plenty of multivariate statistical methods and machine learning methods based on data-driven are widely used in the development of virtual sensors, such as principal component regression (PCR) [3], partial least squares regression (PLSR) [4], support vector regression (SVR) [5], and multilayer perceptron (MLP) [6]. However, multivariate statistical methods for virtual sensor modeling have significant limitations in dealing with non-linear data. Moreover, MLP frequently suffers from gradient explosion, which may lead to poor modeling performance when the network structure becomes too large and complex. In response to the many problems in multivariate statistical methods and machine learning methods, deep learning has been gradually developed over the past decade and has been very successful in a variety of areas [7,8,9,10], including the modeling of virtual sensors. For example, the gated stacked target-related autoencoder (GSTAE) for virtual sensor modeling was proposed and applied to an industrial case to measure the butane concentration at the bottom of a de-butane tower [11]. An adaptive deep belief network (OAFDBN) was used to build a virtual sensor for the sake of estimating the cetane content in diesel [12].
Among the vast range of deep learning algorithms, the long short-term memory (LSTM), with its unique storage unit and gate structure, can effectively avoid the gradient vanishing in neural networks and better capture the non-linear and dynamic correlations of data in industrial processes. There is no doubt that the superiority shown by LSTM has attracted countless researchers working in the field of virtual sensors. For example, a virtual sensor based on LSTM has been put forward and used in sulfur recovery units (SRU) [13]. As sensors in SRU are highly susceptible to corrosion, the virtual sensor built is an effective alternative to the hardware sensor for estimating the concentration of SO and HS in the output gas stream. At the same time, improved algorithms based on LSTM are constantly being proposed. A supervised long short-term memory (SLSTM) capable of dynamically learning hidden states using target and input variables was proposed and the effectiveness of the virtual sensor model built by SLSTM was demonstrated on the penicillin fermentation process [14]. A variable attention-based long short-term memory (VA-LSTM) was proposed for virtual sensor modeling, which focuses on capturing correlations between input variables and the target variable [15]. In the proposed model, different weights are assigned to each input variable depending on the magnitude of the correlation. Ultimately, satisfactory performance for the final distillation point prediction of the heavy naphtha in the hydrocracking process has been achieved.
However, to the best of our knowledge, few studies have been carried out on virtual sensor modeling for HVAC systems. This is because there are still some problems that need to be overcome. For instance, a large amount of sensor data are stored during the operation of HVAC systems, but not all of them contribute to the modeling of virtual sensors. Furthermore, HVAC systems are always in switching operating states. This switching between operating conditions will lead to sudden changes in some sensor data, which have a great impact on the subsequent predictions of virtual sensors. Therefore, this paper proposes an MIC-STALSTM method for handling the two problems described above and frequently encountered in the operation of HVAC systems. The method combines the maximal information coefficient (MIC) and the spatio-temporal attention long short-term memory (STA-LSTM). According to the data collected by the HVAC system, the method uses the MIC to explore the correlation between the remaining variables and the target variables, which are the supply and return water temperature variable at both ends of the chiller. Moreover, the highly correlated impact factors filtered by the MIC are used as the input variables of the subsequent STA-LSTM algorithm to construct a virtual sensor. Finally, the MIC-STALSTM algorithm is validated on a real HVAC system and compared with the LSTM, TA-LSTM, and STA-LSTM for analysis.
The remainder of this paper is organized as follows. In Section 2, the relevant fundamentals of the maximal information coefficient (MIC) and the spatio-temporal attention long short-term memory (STA-LSTM) are briefly summarized. In Section 3, the MIC-STALSTM model combining MIC and STA-LSTM is proposed, and a virtual sensor modeling framework based on MIC-STALSTM is presented. In Section 4, the effectiveness and feasibility of the proposed method are verified in a case study of an HVAC system by constructing virtual sensors for two target temperature variables. Finally, conclusions are drawn in the last section, Section 5.
2. Methodology
In this section, the deep learning framework and some basic algorithms that make up the MIC-STALSTM method are presented in detail.
2.1. Maximal Information Coefficient
When exploring relationships in datasets, traditional correlation coefficient-based methods can only effectively estimate the linear relationships between variables. In contrast, non-linear relationships are more common in actual industrial datasets. MIC is a powerful method to measure the correlation between two variables, which can not only discover linear correlations in datasets, but also explore potential non-linear and non-functional correlations between variables [16,17]. For two variables X and Y, their correlation is calculated via MIC. The first step is to draw a scatter plot of the dataset (where n is the number of samples) on a two-dimensional space. Along the x-axis and y-axis directions, i grids and j grids are, respectively, divided, and the two-dimensional space is divided into small grids. The scatter plot formed by the dataset D has a corresponding probability distribution on each small grid G [18]. Since there is more than one way to divide the dataset by grid, all existing grid possibilities can be explored through different partitioning schemes. An optimal discretization method can be found and the maximum mutual information (MI) corresponding to the optimal discretization method can be obtained.
where represents the mutual information when the probability distribution is . The maximum mutual information value is normalized to the interval , which can be expressed as:
Then, we select the largest mutual information value after normalization as the MIC value. The calculation of MIC can be expressed as:
where the resolution of the grid is restricted to and .
The variables X and Y are independent of each other when the value of MIC equals 0; when the MIC is equal to 1, there is a functional relationship that can be described between the variables X and Y. A prominent feature of MIC is that when MIC is used to detect the correlation between variables, the value measured by MIC will be more concentrated at either ends of the range [0, 1]. Such characteristics allow MIC to better explore the potential relationships between variables than traditional feature selection methods such as the Pearson or Spearman correlation coefficient.
2.2. Spatio-Temporal Attention Long Short-Term Memory
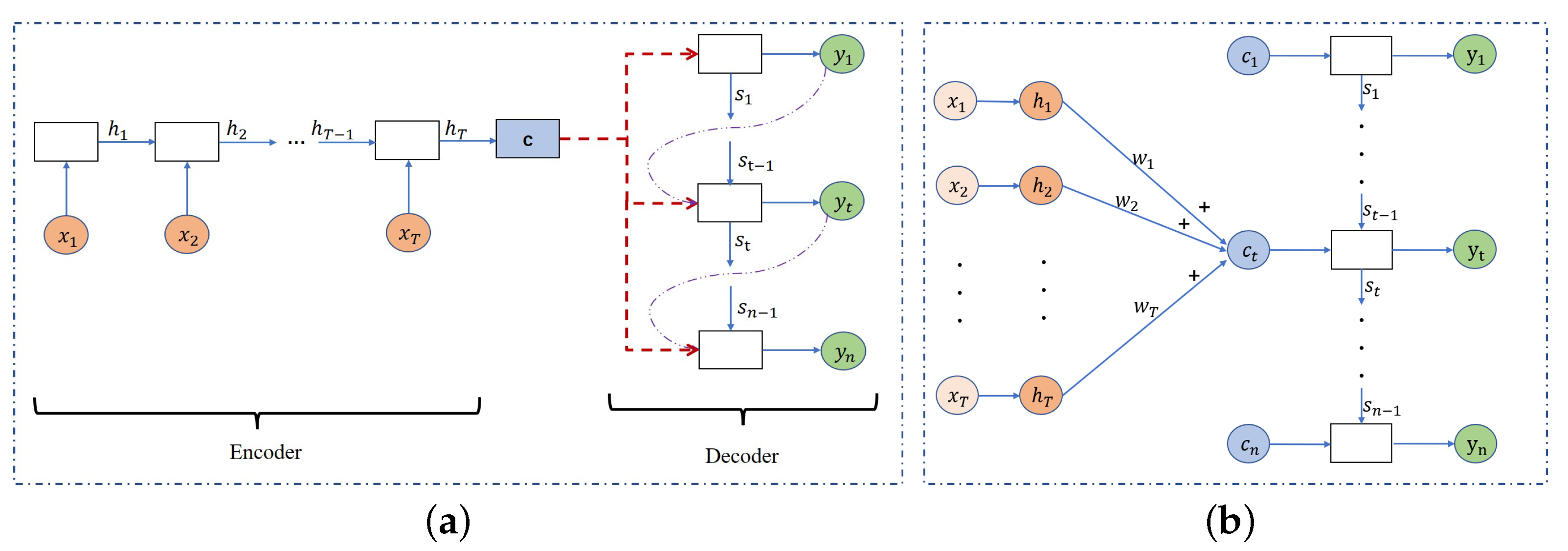
The encoder–decoder (Seq2Seq) is a deep learning framework that is widely used to process time series, which provides a powerful solution for the problem processing of dynamic sequences, and its basic structure is shown in Figure 1a. The encoder–decoder structure firstly needs to compress all the information of the input data sequence into an intermediate vector c with a fixed length through an encoder unit, and then decode the intermediate vector c through a decoder unit to obtain the desired output sequence: . The encoder unit and decoder unit in the framework can use any basic neural network framework, such as RNN, GRU, LSTM, and so on.
The encoder–decoder framework has distinct advantages in some areas, such as machine translation, in that this framework can handle the problem of unequal lengths of input and output sequences. However, as the length of the processing sequence increases, the intermediate vector c may lose some key valid information, resulting in a decrease in the accuracy of subsequent decoding. Therefore, for the purpose of addressing the challenge of information loss in the encoder–decoder framework, the attention mechanism was introduced to the basic encoder–decoder framework structure [19]. In this attention-based structure, shown in Figure 1b, the original fixed-length vector c is replaced by a changing vector determined by the current desired output .
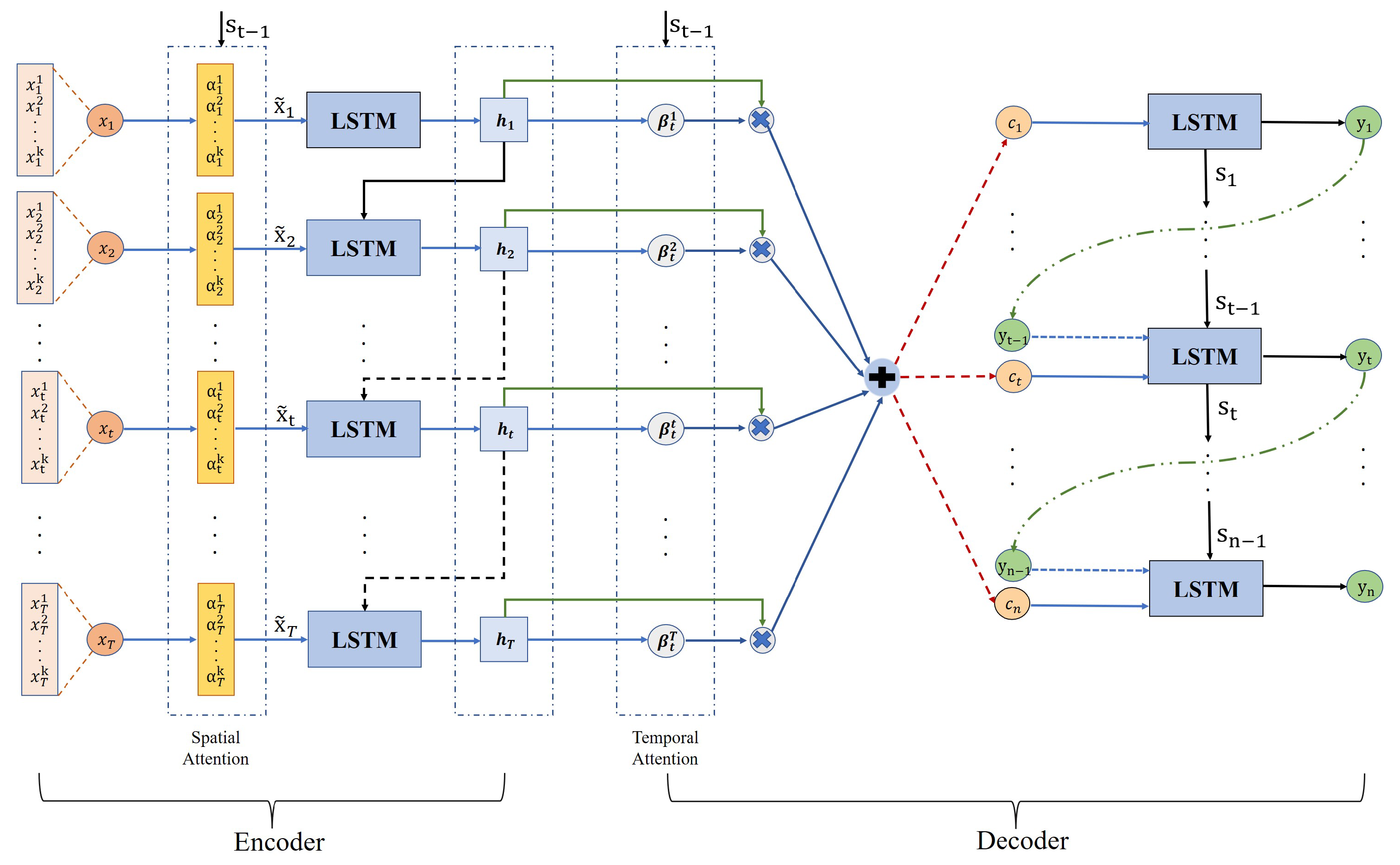
This paper adopts the spatio-temporal attention long short-term memory (STA-LSTM) model; its structure is shown in Figure 2, which introduces the spatial attention mechanism and the temporal attention mechanism on the basic encoder–decoder framework. Firstly, STA-LSTM introduces a spatial attention mechanism on the encoder side, which can assign different spatial attention weights to input variables at different time steps. Its calculation process is as follows.
In time step t, there are samples of k variables: , where , the spatial weight corresponding to k variables ], where the formula for calculating the spatial weight corresponding to the ith variable is as follows:
where , , , are the parameters that the network needs to learn through training, is the bias, is the hidden variable from the LSTM hidden layer, and is the double curve activation function. We normalize the spatial attention weight of the ith variable by Equation (6) in order to ensure that the sum of the spatial attention weight of all input variables is 1 at time step t.
The spatial weights assigned to different inputs finally determine the amount of information flowing to the encoder part of the LSTM network. The larger the spatial weight, the more important the corresponding input features are for predicting the output. Then, we assign their corresponding weights to the input variables, , and obtain a new input sequence by weighting, as shown in Equation (7).
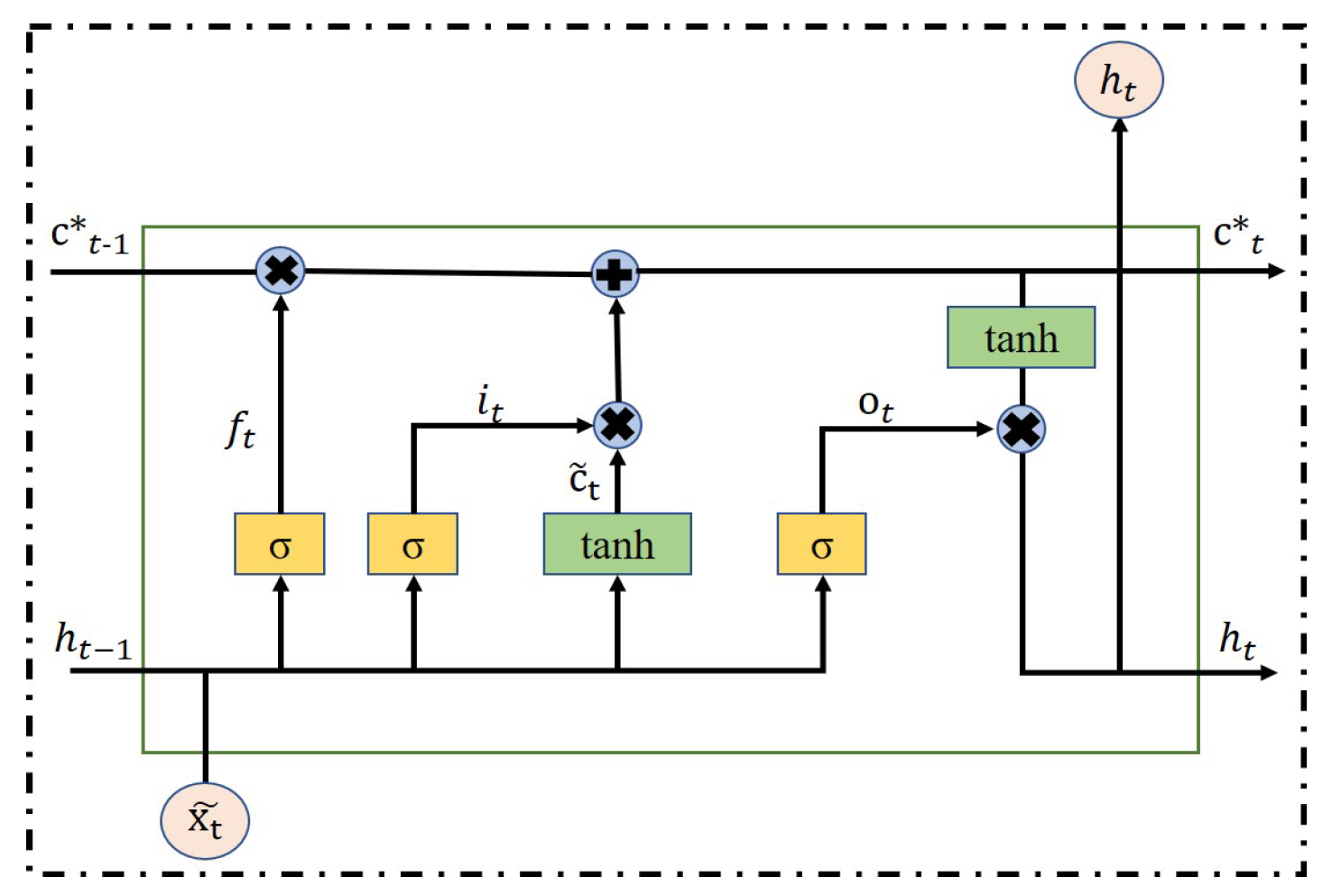
The new input sequence finally enters the LSTM network of the encoder part with different input variable information, and obtains the hidden state at time step t. The structure of LSTM is shown in Figure 3, and its definition can be expressed as:
Moreover, the hidden state of the encoder part can be expressed as:
Subsequently, a temporal attention mechanism is introduced after the LSTM network of the encoder, which assigns a temporal attention weight to the hidden state in each LSTM network, as shown in Equation (10), and is weighted by the latter hidden states that adaptively determine the hidden states generated instantaneously by the encoder LSTM at all moments.
where , , , are the parameters that the network needs to learn through training, and the assignment of the temporal attention weight depends on the current input and the LSTM hidden variable from time step . The non-linear function tanh is used as the activation function due to its good convergence performance. Then, is obtained after normalizing :
Calculating the hidden sequence and the temporal attention weight can finally obtain the changing intermediate vector :
The LSTM hidden layer of the decoder part can be represented as:
Finally, the predicted output is obtained from the intermediate vector and the hidden layer output updated by the decoder at moment :
where , and are the model parameters that the neural network can learn.
3. Virtual Sensor Modeling Based on MIC-STALSTM
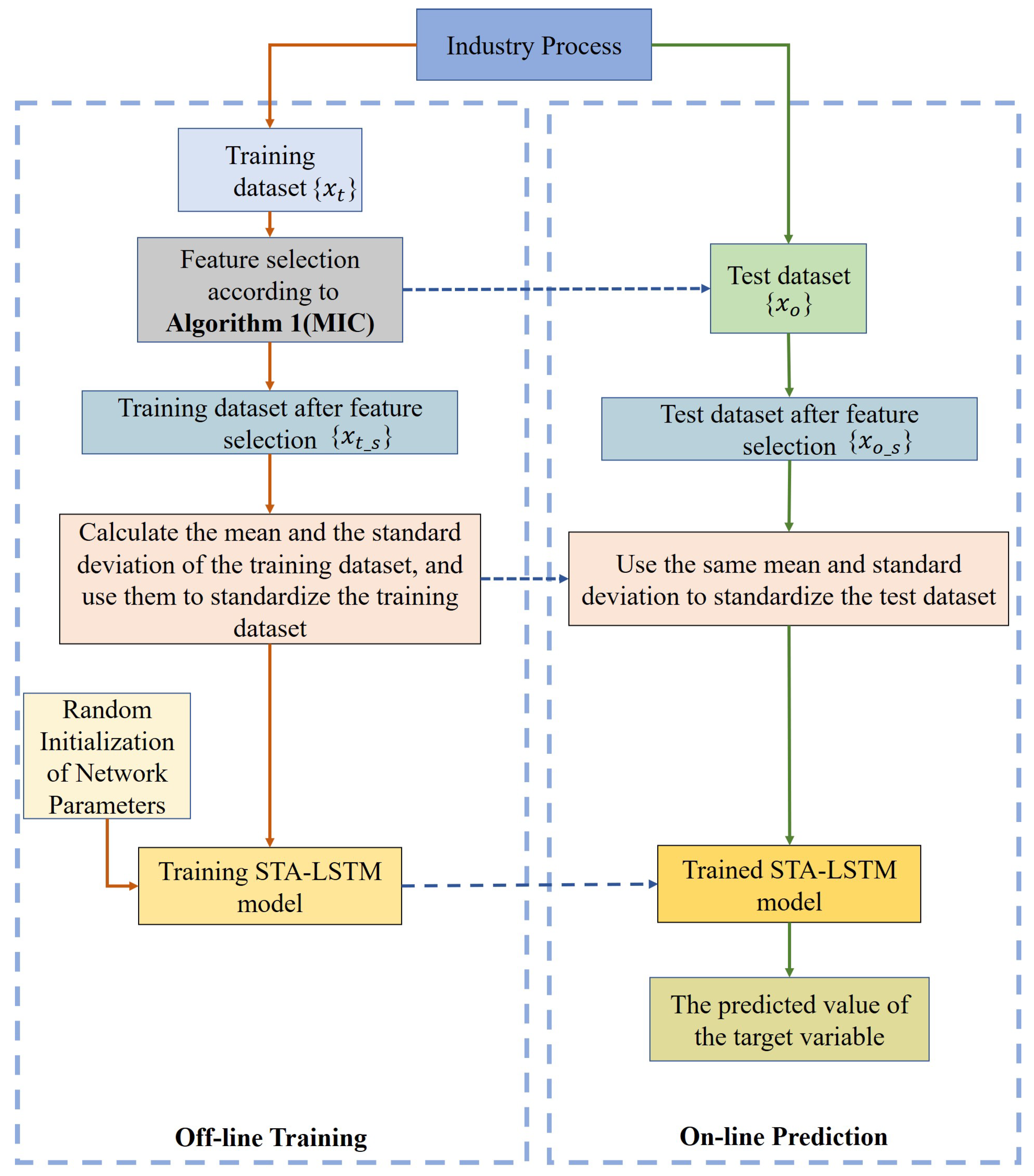
This section introduces the virtual sensor modeling process based on the MIC-STALSTM algorithm, and its framework is shown in Figure 4. In the following subsections, we will introduce the process of using the virtual sensor model to predict the temperature variables. The process includes offline training, online prediction, and evaluation of the prediction performance of the virtual sensors through three different indicators.
3.1. Offline Training
The dataset collected in an industrial process is divided into a training dataset and test dataset . The detailed steps of the offline model training of MIC-STALSTM are shown below.
Step 1: Through Algorithm 1, perform feature selection on the training dataset to obtain the dataset ;
Step 2: Normalize the dataset ;
Step 3: Input the pre-processed training dataset and the network hyperparameter set in advance into the model to train the STA-LSTM model.
3.2. Online Prediction
When the training dataset obtains relatively satisfactory results and performance on the model MIC-STALSTM, the network parameters are saved and used for the online prediction of target variables. The steps are described as follows.
Step 1: Through the MIC value obtained from the training dataset, perform the same feature selection on the test dataset to obtain the dimension-reduced test dataset ;
Step 2: Use the normalization parameter of to normalize the test dataset ;
Step 3: Place the test dataset after preprocessing into the trained STA-LSTM model to obtain the final prediction outputs.
| Algorithm 1 Feature selection through maximal information coefficient |
|
3.3. Performance Indicators
The prediction performance of the model is evaluated by three indicators: root mean square error (RMSE), mean absolute value error (MAE), and coefficient of determination (). The root mean square error (RMSE) and mean absolute value error (MAE) are defined as follows:
In the above two equations, N is the total number of training samples, is the true value of the test data, and is the predicted value of the data output by the model. Among them, RMSE focuses on calculating the prediction error of the entire test dataset according to the above definition. Furthermore, MAE can also better reflect the real situation of the predicted value error. This is because the errors are absolute values, and there is no situation where positive and negative errors cancel each other out. It can be seen from the definitions of RMSE and MAE that the smaller the values of RMSE and MAE, the smaller the model prediction error and the more accurate the prediction. Moreover, another indicator that is widely used in forecasting problems is the coefficient of determination , which is defined as follows:
where represents the average of all training samples. represents the squared correlation between the true and predicted outputs. With being closer to 1, better predictive performance of the model is indicated.
4. Case Study
In this section, the working principle of the HVAC system and the dataset used for the algorithm performance comparison are described in detail. Moreover, the performance of the proposed MIC-STALSTM algorithm is validated for the prediction of two temperature variables in the HVAC system. The two temperature variables are the chilled water return temperature variable and the chilled water supply temperature variable . For , we aim at demonstrating the effectiveness of the MIC-STALSTM when there are switches in operating conditions in the HVAC system. For , the superiority of MIC-STALSTM is verified when there is no work switching in the HVAC system.
4.1. Description of HVAC Systems
4.1.1. The Working Principles of HVAC Systems
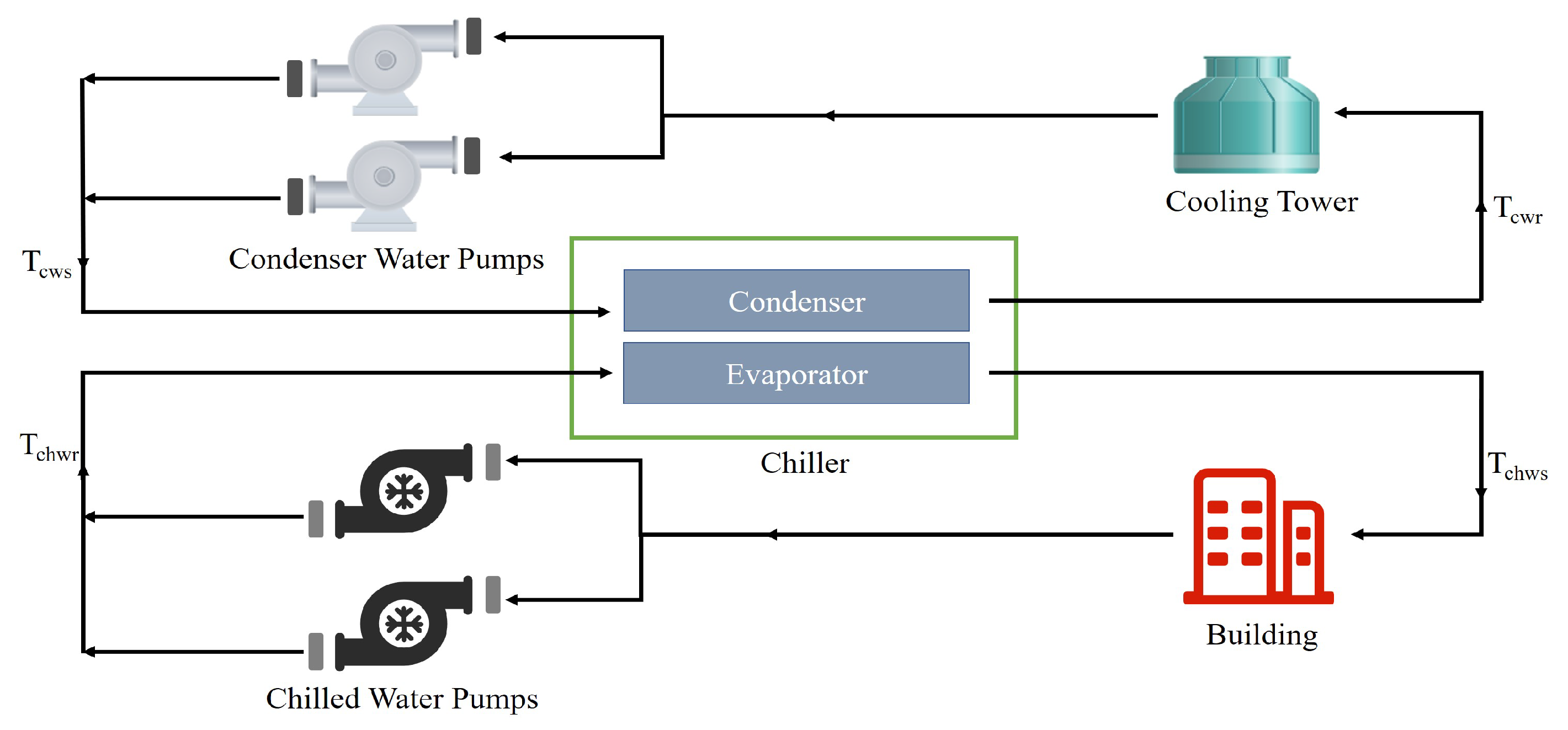
Figure 5 gives the basic working principle of a heating, ventilation, and air-conditioning (HVAC) system that contains two heat exchange circulation systems, internal and external circulation. In the internal circulation (bottom half of Figure 5), chilled water pumps push cold water cooled by a chiller into the building to cool and dehumidify the air inside the building through heat exchange. The circulating water, which has absorbed the heat of the air inside the building and increased in temperature to , is returned to the chiller for cooling, and its heat is transferred to the external circulation via the condenser. In the external circulation (top half of Figure 5), the condenser water pumps drive the water in the condenser to absorb the heat generated by the evaporator to the cooling tower, which discharges the heat from the water to the outdoor air, where it flows back to the condenser and so on. The evaporator in the internal circulation and the condenser in the external circulation are encapsulated together, and this whole is known as the chiller. The HVAC system absorbs the heat from the indoor environment and transports it to the outdoors through energy conversion, so as to achieve air exchange and cooling.
4.1.2. Data Description
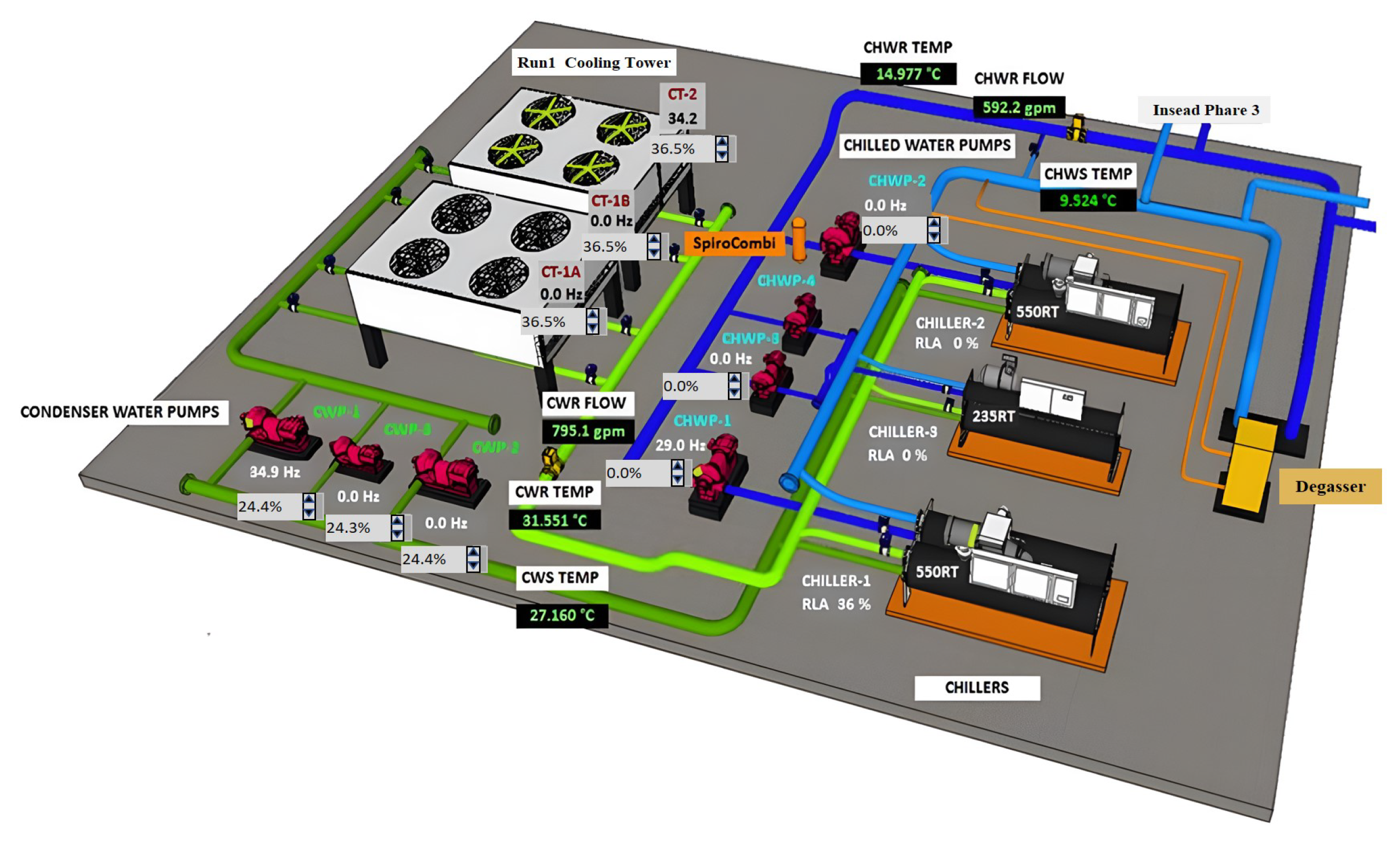
The HVAC system selected for analysis is applied to the space cooling of a high-rise office building located in a city in the tropical region of China. The city’s annual average temperature is in the range of 25–32 °C, and the average humidity is around 85%. Figure 6 presents the schematic of the HVAC system, which employs three chillers, two cooling towers, three condenser water pumps, and four chilled water pumps. The three chillers are rated at 550 RT, 550 RT, and 235 RT, respectively (RT is the cooling tonne, i.e., a unit of power indicating cooling capacity, 1RT = 3.517 kW).
The overall dataset was sampled from the operational data of the HVAC system at the actual site from 0:00 on 30 January 2017 to 23:13 on 14 February 2017, with a total sampling duration of 16 days. The sampling interval was 1 min and data were collected for a total of 50 parameters, with detailed parameters’ descriptions shown in Table 1. Emphasis needs to be placed on the fact that the values taken for all HVAC parameters are point data and not the averaged data over 1 min. A total of 18,292 samples were stored during the sampling process and the overall sample dataset was divided into two separate data subsets, a training dataset containing 5000 sample points and a test dataset containing 13,292 sample points. At the same time, the HVAC system has the characteristic of operating under variable conditions over a long period of time, and this characteristic is reflected in the dataset. At sample point 6125, the change in state of variables and triggers a change in condition from chilled water pump No. 1 to chilled water pump No. 2, which continues until sample point 9965. At sample point 9665, chilled water pump No. 2 switches to chilled water pump No. 1 again. Similarly, at sample points 12,885 and 14,910, the increase in the state variables and leads to a change in the flow rate and an increase in the head of the condenser and chilled water pumps.
4.2. MIC-STALSTM for Temperature Prediction
4.2.1. Pre-Processing of Variables in the HVAC System by MIC
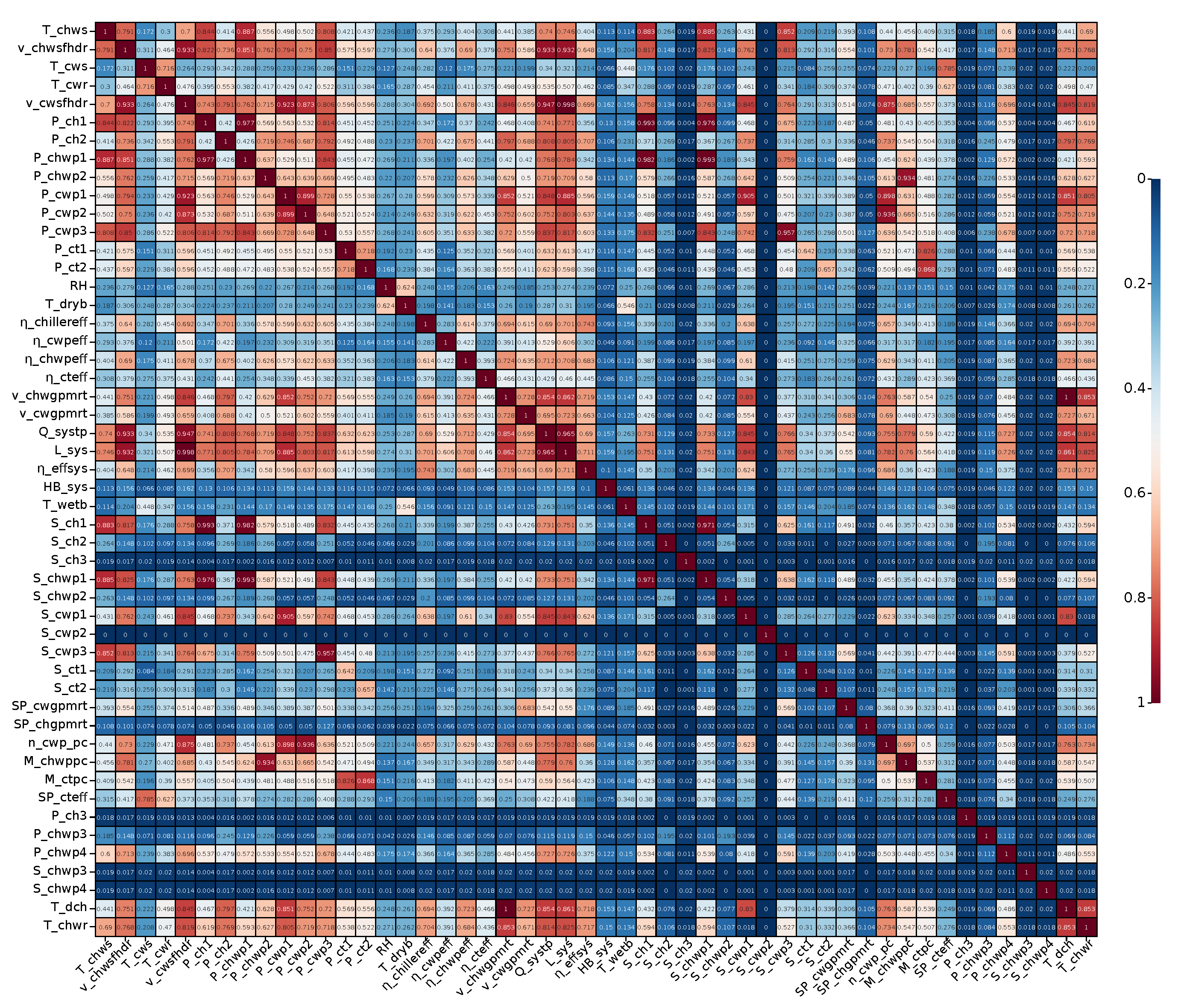
Due to the complex coupling between variables in the HVAC system, inputting all variables into the prediction model at the same time can easily lead to problems such as duplication of information and invalid features. These problems may have a negative impact on the accuracy of the virtual sensor model. Moreover, the 50 variables involved in the HVAC system are frequently faced with switching conditions, which can lead to drastic changes in sensor values. Sudden changes in sensor values can also have a significant impact on model accuracy. For the purpose of solving the above two problems and further improving the prediction accuracy of the virtual sensors, MIC values were calculated in order to prepare for subsequent variable selection. Figure 7 shows the coefficient matrix calculated by MIC, and the values in the coefficient matrix represent the MIC metric between the variables two by two in the HVAC system.
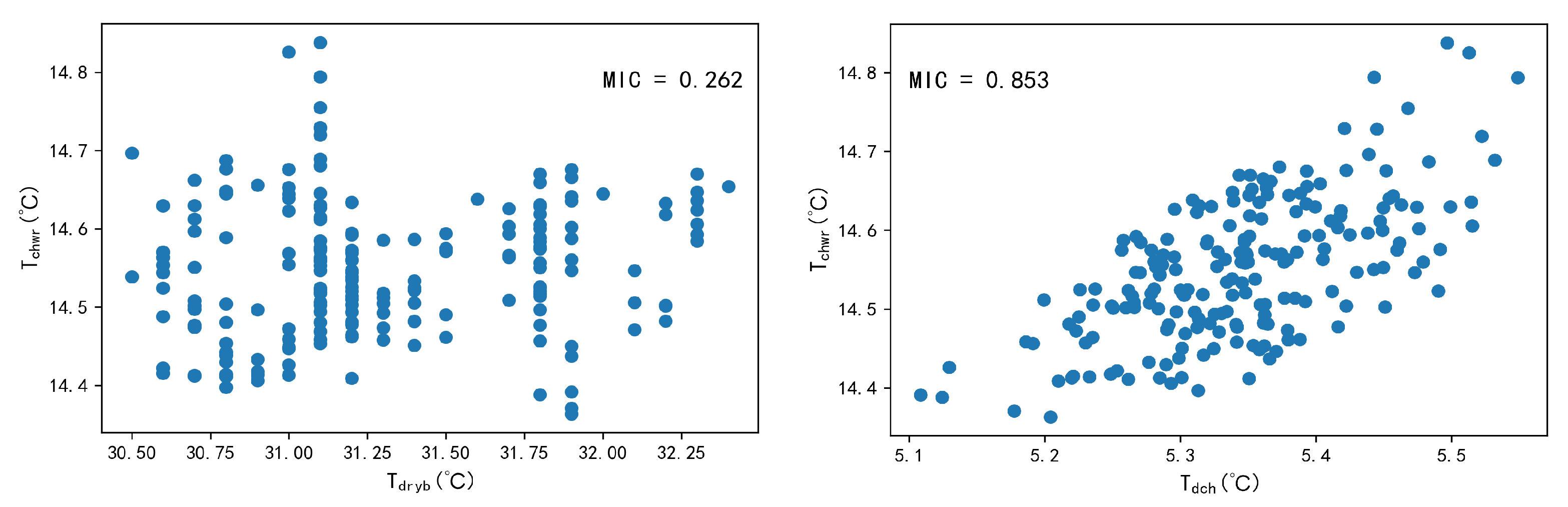
In order to verify that the relationships between the variables corresponding to different MIC values are significantly different, Figure 8 shows the scatter plots between the dry bulb temperature and the return water temperature ; the cooling effect and the return water temperature . As can be seen in Figure 8, and , whose MIC vaule is equal to 0.262, are independent of each other. Moreover, there is a linear correlation between and for an MIC value equal to 0.853, although there are a few outliers due to variations in operating conditions and loads. The larger the MIC value, the higher the correlation between the variable and the target variable, and the more information about the target variable it contains. Therefore, by choosing an MIC value greater than a certain threshold, it is ensured that the feature variables selected for prediction remain highly correlated with the target variables. Ultimately, the threshold for MIC was determined to be 0.7 based on empirical selection [21]. For , 11 variables with MIC values greater than 0.7 were selected as the input feature variables, as shown in Equation (18). For , 10 variables were selected as the input feature variables, as shown in Equation (19).
4.2.2. The Selection of Hyperparameters of STA-LSTM
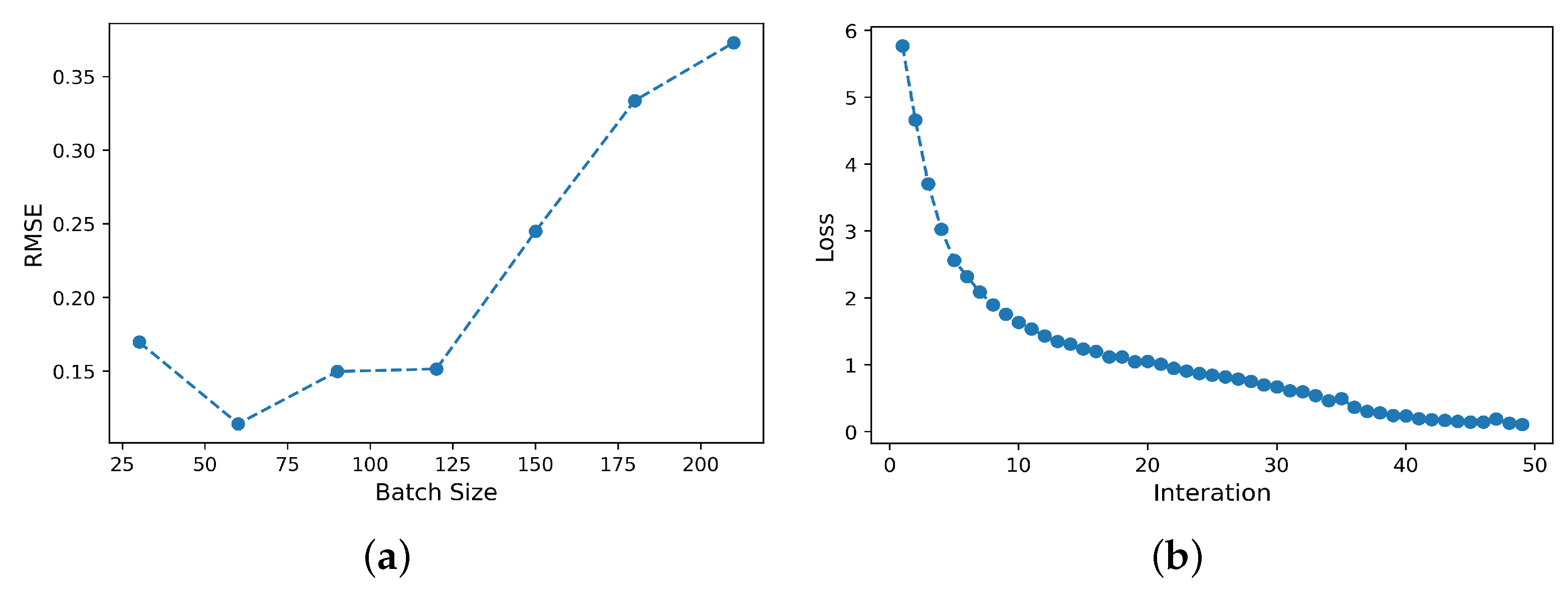
After pre-processing the variables in the HVAC system by MIC, the filtered variables are used as feature variables for the training and prediction of the STA-LSTM network. Then, for STA-LSTM, several hyperparameters in the algorithm need to be determined rationally in order to achieve high accuracy. Some of the most commonly used methods for determining hyperparameters include trial and error, grid search, random search, and Bayesian optimization. For the STA-LSTM studied in this paper, the hyperparameters to be optimized include batch size, the number of neurons, and iterations, etc. In this paper, the optimal set of parameters is confirmed by a combination of random search and trial and error. Firstly, by randomly generating several different sets of hyperparameters to obtain different experimental results, the approximate optimal interval is gradually found. Subsequently, the detailed optimal parameter set is found by the trial and error method. For , different batches in the range [30, 60, 90, 120, 150, 180, 210] show the performance trend of the STA-LSTM-based virtual sensor model. As shown in Figure 9a, with the increase in the batch size, the general trend of RMSE first decreases and then moves upwards, and remains relatively stable. The appropriate batch size should preferably be set between 30 and 90. In this paper, it is set to 64. As another important hyperparameter, the number of iterations is set to 50. At this number of iterations, the loss function of the STA-LSTM network converges on the training dataset, as shown in Figure 9b.
All of the neural network models used in this paper have approximately the same structure. Therefore, the neural network models were all placed under the same hyperparameters for training, which helps to compare the differences between the different models. Similar to the method for determining the batch size, the hyperparameters used for all algorithms were finally determined, as shown in Table 2.
4.2.3. Performance Comparison
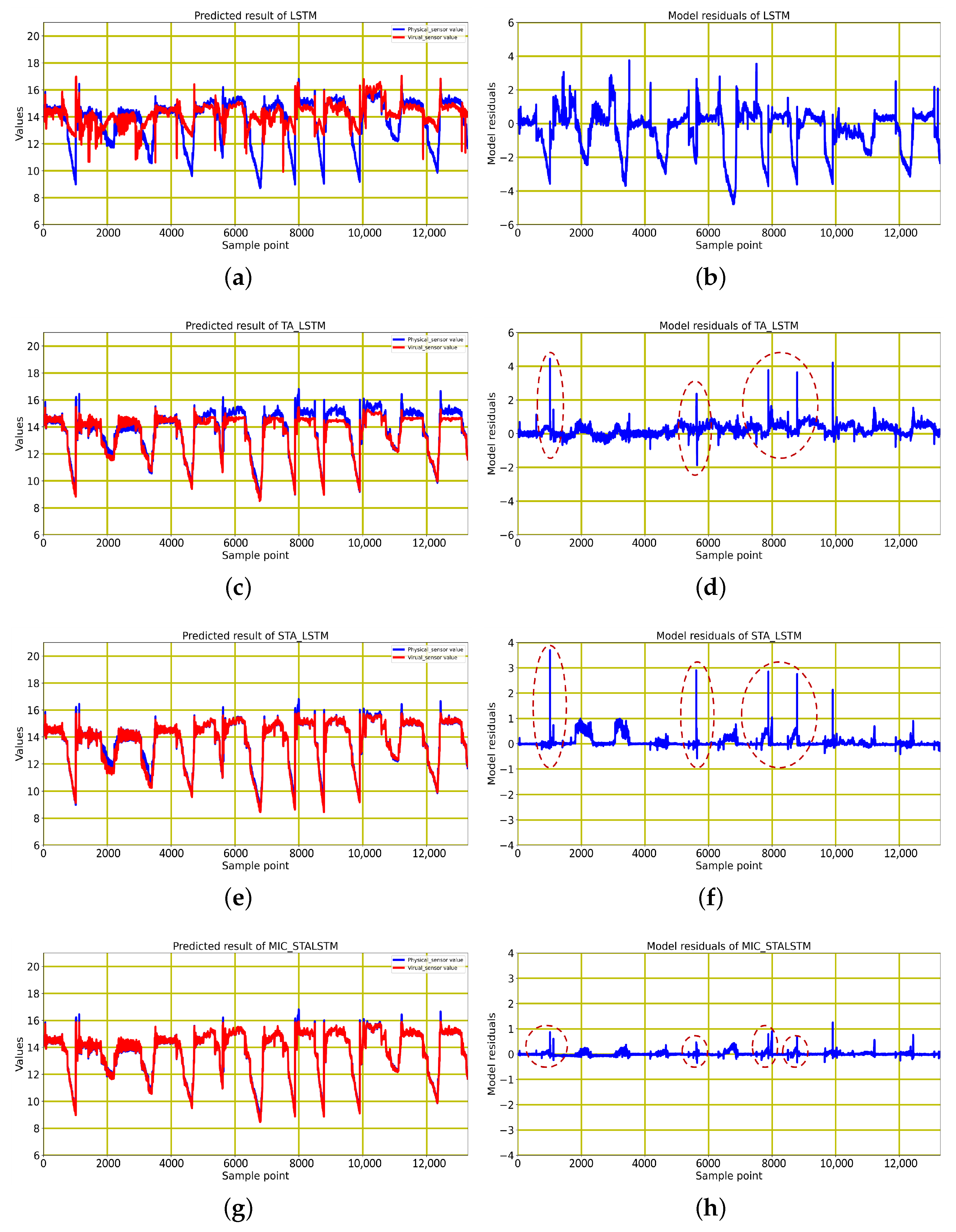
To demonstrate the effectiveness of combining MIC with STA-LSTM, the algorithm of MIC-STALSTM is used with LSTM, TA-LSTM, and STA-LSTM for the predictions of the temperature variable on the test dataset, as shown in Figure 10. Moreover, in Figure 10, the model deviation corresponding to each model for the temperature prediction is given. In the prediction images corresponding to the four algorithms, the red solid line denotes the predicted value given by the virtual sensor, and the blue solid line denotes the true value of the actual hardware sensor. It can be seen that large deviations exist between the predicted and actual curves for LSTM. The predicted curve of the TA-LSTM-based model can roughly track the trend of the actual curve. Then, the prediction curve of the virtual sensor based on the STA-LSTM algorithm is more closely aligned with the blue curve of the actual sensor value compared with the previous two algorithms. However, from the area circled by the red dotted line in Figure 10f, it can be seen that the predictions of the STA-LSTM-based model at some fixed sampling points still have large prediction errors, such as at sample point 1125, at sample point 4665, at sample point 7885, and at sample point 9910 in the test data. These coarse prediction errors are caused by the switching among different operating conditions in the HVAC system.
In general, the attention-based TA-LSTM and STA-LSTM are able to adjust the influence of different input variables on the target variable by adaptively adjusting the weights to ensure the accuracy of prediction. However, due to the abruptness of the HVAC system’s operating condition transitions, the attention-based TA-LSTM and STA-LSTM are unable to adjust the weights to accurately predict the target temperature variable in a timely manner. Therefore, the predicted values of the virtual sensors are inaccurate compared to the measured values of the actual sensors. In contrast, the improved MIC-STALSTM algorithm first extracts the influences highly correlated with by MIC before proceeding with the virtual sensor modeling. As can be seen in Equation (18), the variables that have an impact on the operating conditions at the four sampling points, , , , and , are not among the filtered feature variables. Thus, by displaying the area outlined by the red dotted line in Figure 10h, the MIC-STALSTM algorithm is more accurate in predicting the variable at the four sampling points of the work condition switch.
The MAE, RMSE, and of the four different algorithms for the variable on the test dataset are given in Table 3. As can be seen from Table 3, LSTM has the worst prediction performance, with the largest MAE and RMSE and the smallest metrics among the four algorithms. With the feature selection of the dataset by MIC and the introduction of the spatial–temporal attention mechanism, MIC-STALSTM is able to capture the data features and information in the industrial time series more effectively. It provides the best prediction accuracy of the four algorithms, as evidenced by the smallest values of the MAE and RMSE metrics and the largest values of the .
At the same time, as there are 50 variables involved in the HVAC system, too many input variables or the presence of covariance may have a negative impact on the model accuracy. Since MIC-STALSTM is capable of filtering highly correlated characteristic variables by MIC, its prediction performance is better than the LSTM, TA-LSTM, and STA-LSTM algorithms even without the conditional switching problem. To further validate the superior performance of MIC-STALSTM, the states of the variables are modified in the dataset. The four sample points for the switching of operating conditions described before no longer switch, and continue to maintain the original state at the previous moment. For example, at sample point 1125 of the test data, instead of switching from chilled water pump No. 1 to chilled water pump No. 2, the condition of chilled water pump No. 1 is maintained.
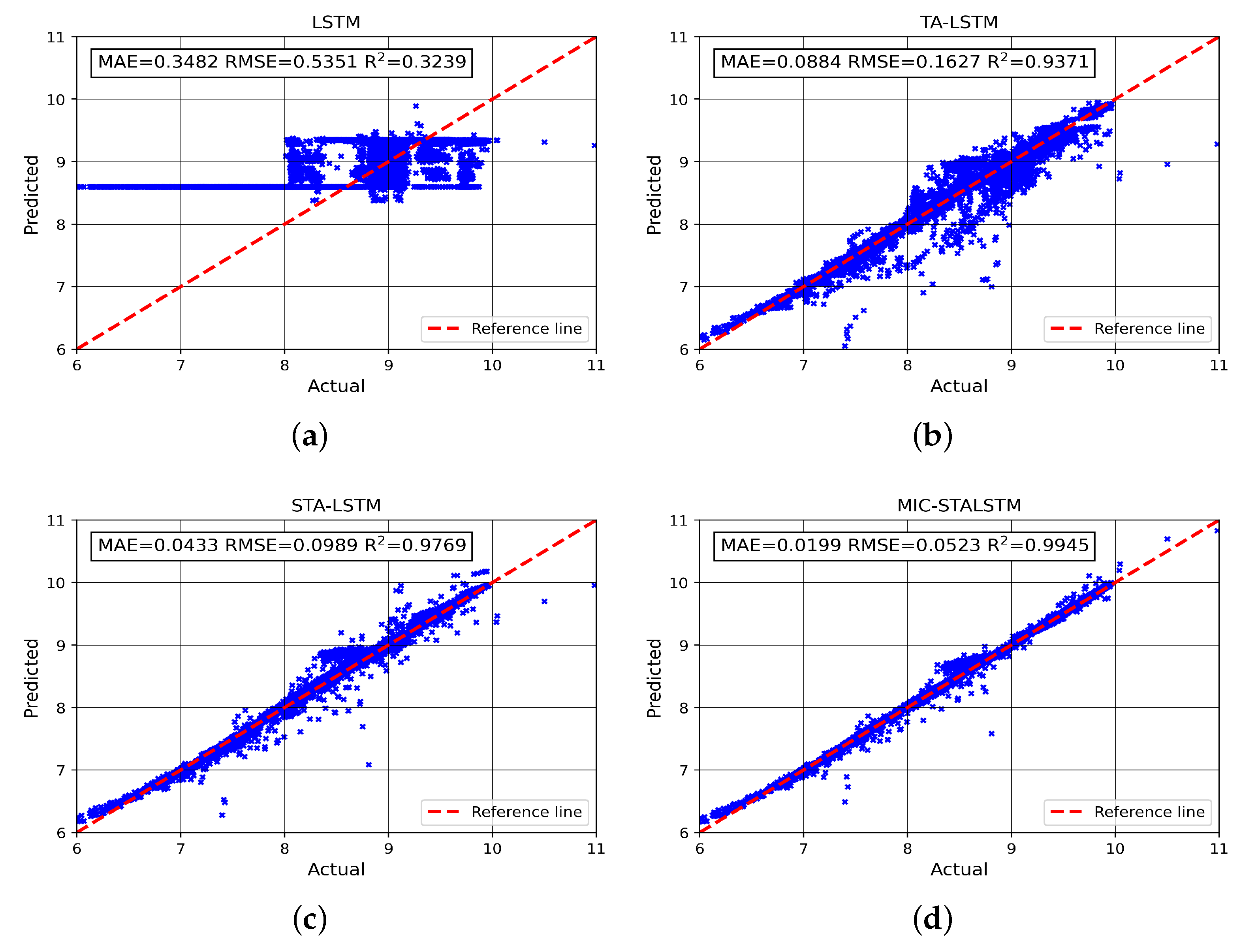
For , the prediction results of the four different algorithms without frequent switching of operating conditions are shown in Figure 11. In Figure 11, the horizontal axis is the labeled value and the vertical axis is the predicted value. The closer the scatter is to the main diagonal (red reference line), the better the prediction performance. Thus, the MIC-STALSTM shows the best prediction for compared to the other three algorithms, because the scatter distribution of MIC-STALSTM is more concentrated near the main diagonal line throughout the prediction interval .
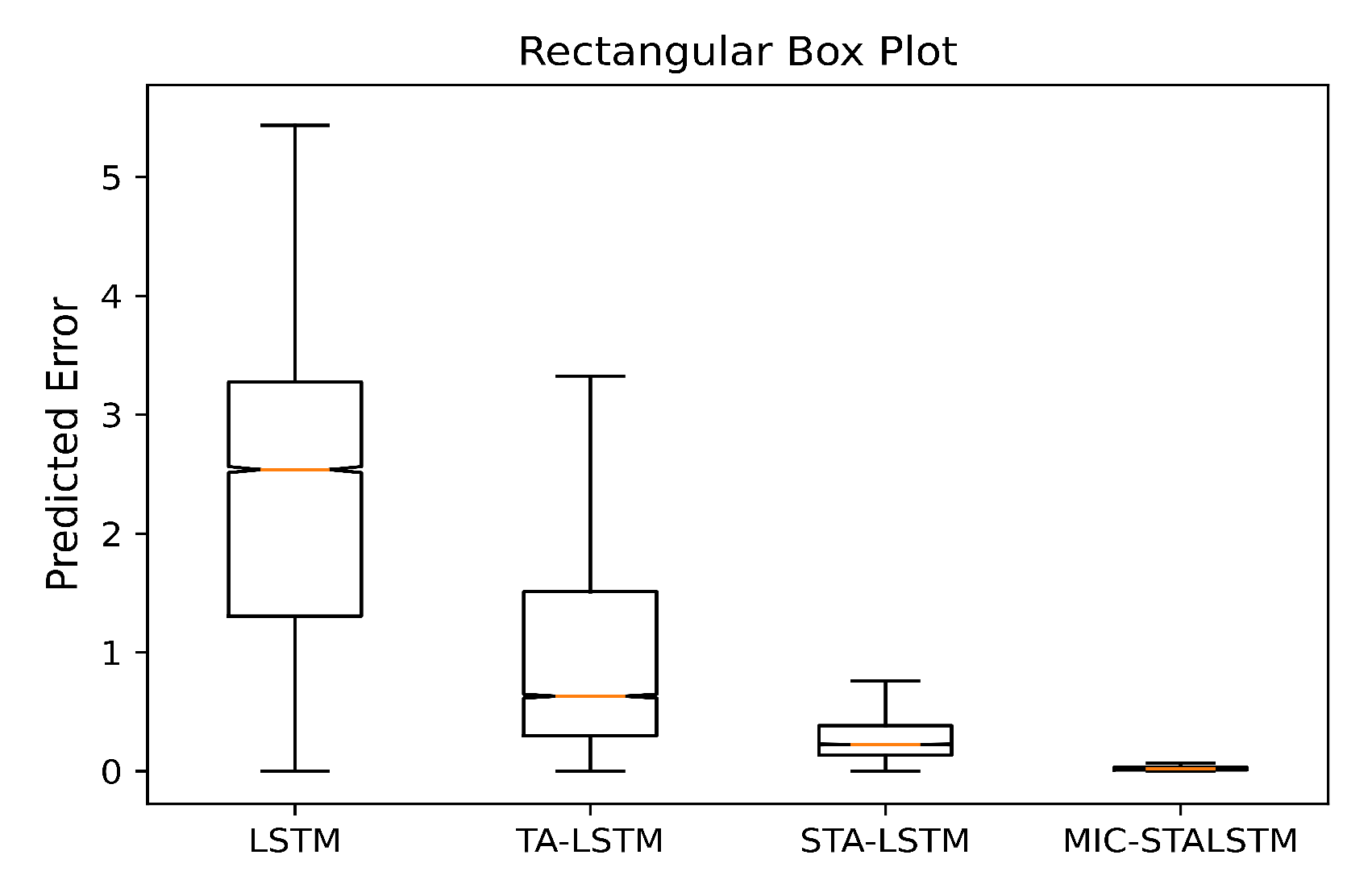
In order to show more intuitively the prediction performance of the four different algorithms for the target variable , box plots of the absolute prediction errors for the four methods are given in Figure 12, which can effectively reflect the data distribution characteristics of the absolute errors. In each box plot, the medians of the absolute prediction errors are indicated by the orange markers in the boxes. Moreover, the bottom and top of the box, respectively, represent the lower and upper quartiles of the absolute error of the different algorithms. In addition, the normal distribution parameters for the four algorithms and the intervals corresponding to the different normal distribution parameters are presented in Table 4. From Figure 12 as well as from Table 4, it can be seen that the prediction errors of MIC-STALSTM are more densely distributed around 0 and have the narrowest confidence intervals .
Therefore, when there is no frequent switching of operating conditions in the HVAC system, MIC-STALSTM still achieves a further improvement in prediction accuracy for the temperature variable compared to the remaining three algorithms.
5. Conclusions
This paper mainly presents a virtual sensor modeling method for the temperature of supply and return water at both ends of the chiller in an HVAC system. The traditional STA-LSTM algorithm can adaptively adjust spatial attention to change the corresponding weights of different input variables at different time steps. Moreover, it is capable of adjusting the temporal attention to change the temporal correlation of the hidden state of the neural network. However, the model based on STA-LSTM is not suitable for the target variable prediction of the HVAC system, which is due to the following problems in virtual sensor modeling in HVAC systems: (1) not all variables contribute positively to the modeling of virtual sensors, due to the complex coupling between variables; (2) the total HVAC system is constantly faced with changes in system conditions and operating loads, which will lead to sudden changes in different variables. The weight adaptive adjustment of STA-LSTM cannot work well under a sudden change in working conditions. At the sample points with sudden changes in operating conditions, the virtual sensor model established by the STA-LSTM algorithm has a large prediction error. Therefore, based on the deficiency of the STA-LSTM algorithm and the operational characteristics of HVAC systems, this paper proposes an MIC-STALSTM algorithm that combines MIC and STA-LSTM, which screens out the influence factors with low correlations with the target temperature variable by MIC. When the filtered influence factor is used as the main variable leading to the change in working conditions, the prediction of the temperature variable by the MIC-STALSTM algorithm will no longer be affected by the auxiliary variable. Using the MIC-STALSTM-based virtual sensor to accurately model the temperature shows that the MIC-STALSTM is a suitable modeling method when the system is faced with a change in operating conditions. At the same time, since MIC performs feature extraction on a large number of features in the original dataset, the input variables involved in subsequent prediction are highly correlated with the target variables. By establishing a virtual sensor for the supply water temperature variable of the chiller, it is verified that the prediction performance of MIC-STALSTM is more precise and effective than the other three algorithms without facing frequent switching conditions in the HVAC system.
This paper provides a comprehensive overview of the MIC-STALSTM-based approach to virtual sensor modeling. However, it has a limitation in which the modeling framework does not depart from the basic virtual sensor framework (i.e., offline training and online prediction), which makes the model completely fixed in the process of online prediction. The completely fixed model may suffer from a degradation in predictive performance for time-varying HVAC systems. For further work, more attention will be paid to online adaptive modeling for virtual sensors.
Author Contributions
Conceptualization, D.W.; methodology, D.W.; software, D.W.; validation, D.W.; formal analysis, D.W.; investigation, D.W.; resources, X.L.; data curation, D.W.; writing—original draft preparation, D.W.; writing—review and editing, X.L.; visualization, D.W.; supervision, X.L.; project administration, X.L.; funding acquisition, X.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Reppa, V.; Papadopoulos, P.; Polycarpou, M.M.; Panayiotou, C.G. A Distributed Architecture for HVAC Sensor Fault Detection and Isolation. IEEE Trans. Control Syst. Technol. 2014, 23, 1323–1337. [Google Scholar] [CrossRef] [Green Version]
- Choi, Y.; Yoon, S. Virtual sensor-assisted in situ sensor calibration in operational HVAC systems. Build. Environ. 2020, 181, 107079–107090. [Google Scholar] [CrossRef]
- Sedghi, S.; Sadeghian, A.; Huang, B. Mixture semisupervised probabilistic principal component regression model with missing inputs. Comput. Chem. Eng. 2017, 103, 176–178. [Google Scholar] [CrossRef]
- Chen, J.; Yang, C.; Zhou, C.; Li, Y.; Zhu, H.; Gui, W. Multivariate Regression Model for Industrial Process Measurement Based on Double Locally Weighted Partial Least Squares. IEEE Trans. Instrum. Meas. 2020, 69, 3962–3971. [Google Scholar] [CrossRef]
- Desai, K.; Badhe, Y.; Tambe, S.S.; Kulkarni, B.D. Soft-sensor development for fed-batch bioreactors using support vector regression. Biochem. Eng. J. 2006, 27, 225–239. [Google Scholar] [CrossRef]
- Kusiak, A.; Li, M.; Zheng, H. Virtual models of indoor-air-quality sensors. Appl. Energy 2010, 87, 2087–2094. [Google Scholar] [CrossRef]
- Lin, T.; Pan, Y.; Xue, G.; Song, J.; Qi, C. A Novel Hybrid Spatial-Temporal Attention-LSTM Model for Heat Load Prediction. IEEE Access 2020, 8, 159182–159195. [Google Scholar] [CrossRef]
- Noor, F.; Haq, S.; Rakib, M.; Ahmed, T.; Jamal, Z.; Siam, Z.S.; Hasan, R.T.; Adnan, M.S.; Dewan, A.; Rahman, R.M. Water Level Forecasting Using Spatiotemporal Attention-Based Long Short-Term Memory Network. Water 2022, 14, 612. [Google Scholar] [CrossRef]
- Song, S.; Lan, C.; Xing, J. Spatio-Temporal Attention-Based LSTM Networks for 3D Action Recognition and Detection. IEEE Trans. Image Process 2018, 27, 3459–3471. [Google Scholar] [CrossRef] [PubMed]
- Feng, L.; Zhao, C.; Sun, Y. Dual Attention-Based Encoder-Decoder: A Customized Sequence-to-Sequence Learning for Soft Sensor Development. IEEE Trans. Neur. Net. Lear 2021, 32, 3306–3317. [Google Scholar] [CrossRef] [PubMed]
- Sun, Q.; Ge, Z. Gated Stacked Target-Related Autoencoder: A Novel Deep Feature Extraction and Layerwise Ensemble Method for Industrial Soft Sensor Application. IEEE Trans. Cybern. 2020, 52, 3457–3468. [Google Scholar] [CrossRef] [PubMed]
- Yuan, X.; Rao, J.; Gu, Y.; Ye, L.; Wang, K.; Wang, Y. Online Adaptive Modeling Framework for Deep Belief Network-Based Quality Prediction in Industrial Processes. Ind. Eng. Chem. Res. 2021, 60, 15208–15218. [Google Scholar] [CrossRef]
- Ke, W.; Huang, D.; Yang, F.; Jiang, Y. Soft Sensor Development and Applications Based on LSTM in Deep Neural Networks. In Proceedings of the 2017 IEEE Symposium Series on Computational Intelligence(SSCI), Honolulu, HI, USA, 27 November–1 December 2017. [Google Scholar]
- Yuan, X.; Li, L.; Wang, Y. Nonlinear Dynamic Soft Sensor Modeling With Supervised Long Short-Term Memory Network. IEEE Trans. Ind. Informat 2020, 16, 3168–3176. [Google Scholar] [CrossRef]
- Yuan, X.; Li, L.; Wang, Y.; Yang, C.; Gui, W. Deep learning for quality prediction of Nonlinear Dynamic Processes with Variable Attention-Based Long Short-Term Memory Network. Can. J. Chem. Eng. 2019, 98, 1377–1389. [Google Scholar] [CrossRef]
- Guo, Z.; Yu, B.; Hao, M.; Wang, W.; Jiang, Y.; Zong, F. A novel hybrid method for flight departure delay prediction using Random Forest Regression and Maximal Information Coefficient. Aerosp. Sci. Technol. 2021, 116, 106822–106832. [Google Scholar] [CrossRef]
- Reshef, D.N.; Reshef, Y.A.; Finucane, H.K.; Grossman, S.R.; McVean, G.; Turnbaugh, P.J.; Lander, E.S.; Mitzenmacher, M.; Sabeti, P.C. Detecting Novel Associations in Large Data Sets. Science 2011, 334, 1518–1524. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, Y.; Yan, X. Soft Sensor Modeling Method by Maximizing Output-Related Variable Characteristics Based on a Stacked Autoencoder and Maximal Information Coefficients. Int. J. Comput. Intell. Syst. 2019, 12, 1062–1074. [Google Scholar] [CrossRef] [Green Version]
- Yuan, X.; Li, L.; Shardt, Y.A.; Wang, Y.; Yang, C. Deep Learning With Spatiotemporal Attention-Based LSTM for Industrial Soft Sensor Model Development. IEEE Trans. Ind. Electron. 2021, 68, 4404–4414. [Google Scholar] [CrossRef]
- Official of TipDM Cup, China. Available online: https://www.tipdm.org/u/cms/www/201703/09223534dgbb.pdf (accessed on 8 March 2017).
- Gao, L.; Li, D.; Li, D.; Yao, L.; Liang, L.; Gao, Y. A Novel Chiller Sensors Fault Diagnosis Method Based on Virtual Sensors. Sensors 2019, 19, 3013. [Google Scholar] [CrossRef] [PubMed] [Green Version]
Figure 1.
Some basic structures. (a) Structure of an encoder–decoder. (b) Structure of an attention-based encoder–decoder.
Figure 1.
Some basic structures. (a) Structure of an encoder–decoder. (b) Structure of an attention-based encoder–decoder.

Figure 2.
Structure of STA-LSTM.

Figure 3.
Structure of the LSTM unit.

Figure 4.
Framework of MIC-STALSTM-based virtual sensor modeling.

Figure 5.
Working principle diagram of HVAC systems.

Figure 6.
Schematic of the HVAC system (Reprinted from Ref. [20]. 2017, Official of TipDM Cup).
Figure 6.
Schematic of the HVAC system (Reprinted from Ref. [20]. 2017, Official of TipDM Cup).

Figure 7.
Coefficient matrix between variables of the HVAC system.

Figure 8.
Scatter plots of and , , and .

Figure 9.
The training curve of the neural networks: (a) Description of the relationship between RMSE and batch size for based on STA-LSTM. (b) Convergence curve of STA-LSTM.
Figure 9.
The training curve of the neural networks: (a) Description of the relationship between RMSE and batch size for based on STA-LSTM. (b) Convergence curve of STA-LSTM.

Figure 10.
Predicted performance of four algorithms: (a) Prediction result of LSTM. (b) Prediction residual of LSTM. (c) Prediction result of TA-LSTM. (d) Prediction residual of TA-LSTM. (e) Prediction result of STA-LSTM. (f) Prediction residual of STA-LSTM. (g) Prediction result of MIC-STALSTM. (h) Prediction residual of MIC-STALSTM.
Figure 10.
Predicted performance of four algorithms: (a) Prediction result of LSTM. (b) Prediction residual of LSTM. (c) Prediction result of TA-LSTM. (d) Prediction residual of TA-LSTM. (e) Prediction result of STA-LSTM. (f) Prediction residual of STA-LSTM. (g) Prediction result of MIC-STALSTM. (h) Prediction residual of MIC-STALSTM.

Figure 11.
The scatter plots of predicted and labeled values for with LSTM, TA-LSTM, STA-LSTM, MIC-STALSTM. (a) Prediction of based on LSTM. (b) Prediction of based on TA-LSTM. (c) Prediction of based on STA-LSTM. (d) Prediction of based on MIC-STALSTM.
Figure 11.
The scatter plots of predicted and labeled values for with LSTM, TA-LSTM, STA-LSTM, MIC-STALSTM. (a) Prediction of based on LSTM. (b) Prediction of based on TA-LSTM. (c) Prediction of based on STA-LSTM. (d) Prediction of based on MIC-STALSTM.

Figure 12.
Rectangular box plot of absolute prediction error.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
The description of the HVAC system parameters.
| No. | Variables | Descriptions | Unit |
|---|---|---|---|
| 1 | RH | Relative humidity | % |
| 2 | Dry bulb temperature | °C | |
| 3 | Wet bulb temperature | °C | |
| 4 | Status of the chiller No. 1 | ||
| 5 | Status of the chiller No. 2 | ||
| 6 | Status of the chiller No. 3 | ||
| 7 | Power of the chiller No. 1 | kW | |
| 8 | Power of the chiller No. 2 | kW | |
| 9 | Power of the chiller No. 3 | kW | |
| 10 | Efficiency of the chiller | kW/RT | |
| 11 | Status of chilled water pump No. 1 | ||
| 12 | Status of chilled water pump No. 2 | ||
| 13 | Status of chilled water pump No. 3 | ||
| 14 | Status of chilled water pump No. 4 | ||
| 15 | Power of chilled water pump No. 1 | kW | |
| 16 | Power of chilled water pump No. 2 | kW | |
| 17 | Power of chilled water pump No. 3 | kW | |
| 18 | Power of chilled water pump No. 4 | kW | |
| 19 | Speed of chilled water pump | % | |
| 20 | The temperature of water flowing out of the chiller | °C | |
| 21 | Cooling effect: temperature difference between and | °C | |
| 22 | The flow rate of cooling water in internal circulation | gal/min | |
| 23 | Load flow rate: / | gal/min·RT | |
| 24 | Setting point of | gal/min·RT | |
| 25 | Status of condenser water pump No. 1 | ||
| 26 | Status of condenser water pump No. 2 | ||
| 27 | Status of condenser water pump No. 3 | ||
| 28 | Power of condenser water pump No. 1 | kW | |
| 29 | Power of condenser water pump No. 2 | kW | |
| 30 | Power of condenser water pump No. 3 | kW | |
| 31 | Rate of condenser water pump | % | |
| 32 | Average efficiency of condenser water pump | kW/RT | |
| 33 | The temperature of the water flowing out of the condenser | °C | |
| 34 | The temperature of the water flowing into the condenser | °C | |
| 35 | The flow rate of chilled water in external circulation | gal/min | |
| 36 | Load flow rate: / | gal/min·RT | |
| 37 | Setting point of | gal/min·RT | |
| 38 | Status of cooling tower No. 1 | ||
| 39 | Status of cooling tower No. 2 | ||
| 40 | Power of cooling tower 1 | kW | |
| 41 | Power of cooling tower 2 | kW | |
| 42 | Speed of cooling tower fans | % | |
| 43 | Average efficiency of cooling tower | kW/RT | |
| 44 | Setting point of | kW/RT | |
| 45 | Power consumption of the total system | kW | |
| 46 | The cooling load of the total system | RT | |
| 47 | Efficiency of the total system | kW/RT | |
| 48 | Thermal balance of the total system | % | |
| 49 | Average efficiency of chilled water pumps | kW/RT | |
| 50 | The temperature of the water flowing into the chiller | °C |
Table 2.
The final values of the hyperparameters corresponding to different target variables.
| Method | Learning Rate | Hidden Unit | Batch Size | Time Step | Iterations |
|---|---|---|---|---|---|
| 0.001 | 60 | 64 | 4 | 50 | |
| 0.003 | 60 | 64 | 3 | 50 |
Table 3.
Prediction performance indicators of the four algorithms for the variable .
| Method | MAE | RMSE | |
|---|---|---|---|
| LSTM | 0.9029 | 1.3146 | 0.3185 |
| TA-LSTM | 0.2951 | 0.3940 | 0.9387 |
| STA-LSTM | 0.0969 | 0.2340 | 0.9784 |
| MIC-STALSTM | 0.0415 | 0.0758 | 0.9977 |
Table 4.
Confidence intervals’ prediction error.
| Parameter | LSTM | TA-LSTM | STA-LSTM | MIC-STALSTM |
|---|---|---|---|---|
| 2.2743 | 1.1471 | 0.3319 | 0.0299 | |
| 1.1468 | 1.2216 | 0.3500 | 0.0445 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Wang, D.; Li, X. A Novel Virtual Sensor Modeling Method Based on Deep Learning and Its Application in Heating, Ventilation, and Air-Conditioning System. Energies 2022, 15, 5743. https://0-doi-org.brum.beds.ac.uk/10.3390/en15155743
AMA Style
Wang D, Li X. A Novel Virtual Sensor Modeling Method Based on Deep Learning and Its Application in Heating, Ventilation, and Air-Conditioning System. Energies. 2022; 15(15):5743. https://0-doi-org.brum.beds.ac.uk/10.3390/en15155743
Chicago/Turabian StyleWang, Delin, and Xiangshun Li. 2022. "A Novel Virtual Sensor Modeling Method Based on Deep Learning and Its Application in Heating, Ventilation, and Air-Conditioning System" Energies 15, no. 15: 5743. https://0-doi-org.brum.beds.ac.uk/10.3390/en15155743
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.