

Short-Term Load Forecasting of the Greek Power System Using a Dynamic Block-Diagonal Fuzzy Neural Network
 , and
, and
Abstract
:1. Introduction
2. The Architecture of DBD-FELF
- For the general case of a multiple-input-simple-output model, the fuzzy rules base has r fuzzy rules in the form:where denotes the i-th rule, is the input vector, n represents the sample index, and corresponds to the fuzzy set of the j-th input for the i-th rule.
- The fuzzy sets are implemented by Gaussian membership functions as follows:
- The tuning parameters of the premise parts are the mean values, , and the standard deviations, , of the membership functions. It becomes evident from Equation (2) that the premise parts of the fuzzy rules are of a static nature.
- The degree of fulfillment of each rule is the algebraic product of the Gaussian membership functions:
- Equation (3) is an m-dimensional Gaussian function. Therefore, the degree of fulfillment corresponds to the membership function of a fuzzy hyper-region. The fuzzy rule-base partitions the input space into operating regions, where each rule can be considered as a local sub-model, which contributes to the overall fuzzy system’s output according to the degree of fulfillment, and produces its own output as a result of the operation of its BDRNN.
- The consequent parts of the rules are block-diagonal recurrent neural networks. The structure of a two-block BDRNN is presented in Figure 1. The input signal is fed to the blocks of neurons, where each block contains a pair of neurons. There are no connections between neurons that belong to different blocks, while neurons of the same block feedback both to themselves and to each other, with unit delays. This network structure is of a dynamic nature, having internal recurrence (local output feedback, [30]).For a BDRNN with N neurons, the outputs of the neurons are given by the following state equations:.The output of the BDRNN for the i-th fuzzy rule is calculated as follows:where the notation given below is used:
- ➢
- The typical sigmoid function, , implements the activation functions and .
- ➢
- and are the outputs of neurons that form the k-th block when the n-th sample is processed.
- ➢
- is the output of the i-th fuzzy rule.
- ➢
- and are the synaptic weights of the neurons that form the k-th block, and j is the dimension index of the input vector.
- ➢
- are the synaptic weights of the output neuron.
- ➢
- are the feedback weights of the k-th block of neurons of BDRNN. In order to reduce the number of tuning parameters by half, the scaled orthogonal form is selected. As described in [24], the feedback weights of each block comprise the following feedback matrix:
- The defuzzification part of DBD-FELF produces the model’s output. The weighted average defuzzification scheme is employed, since it is the most popular in TSK fuzzy models, requiring a low computational burden:
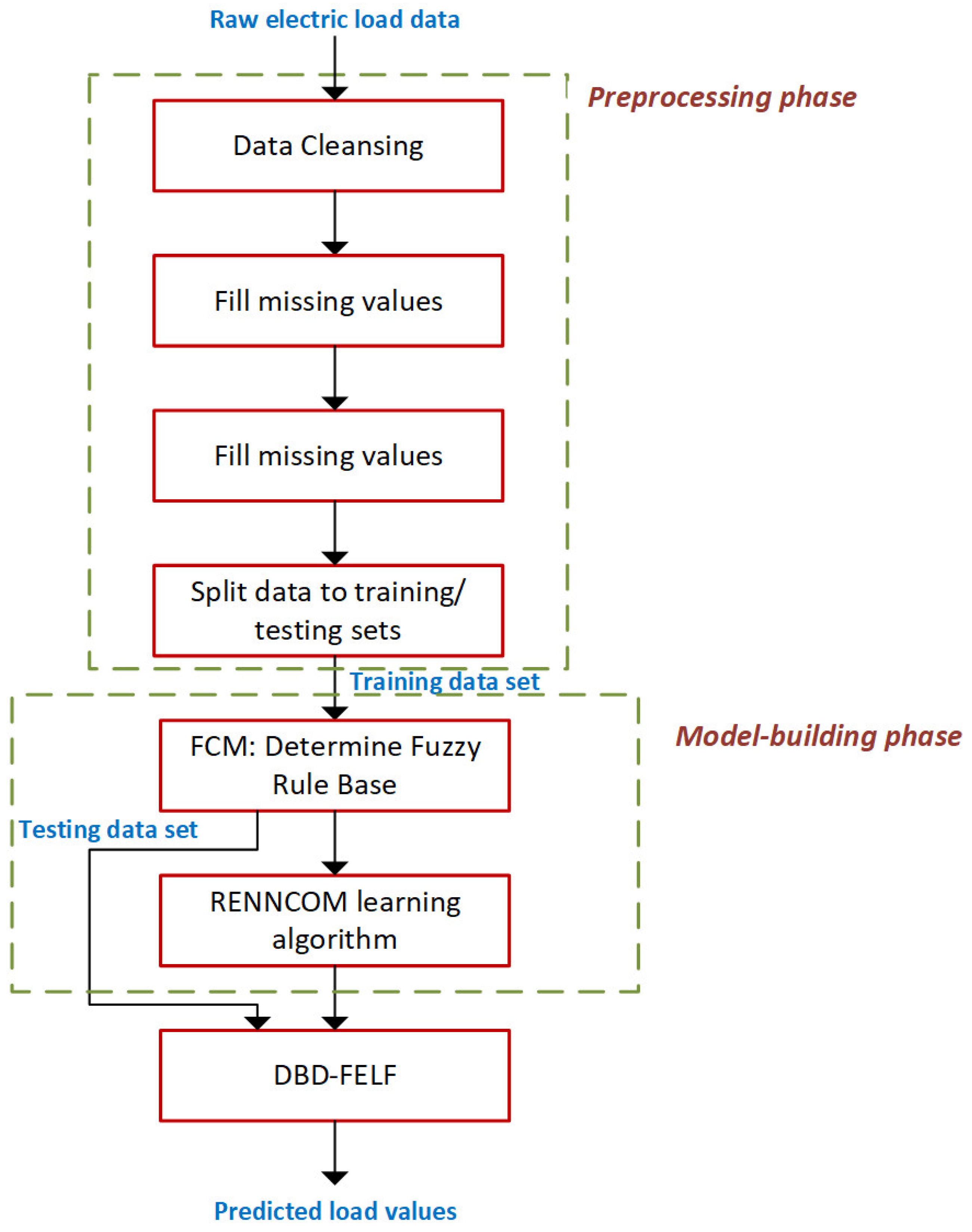
3. The Model-Building Process
- (1)
- The error measure, E, should be minimized so that the electric load time-series, , is identified. The Mean Squared Error is selected to be the error measure:The error measure is minimized through an iterative process, where, at each iteration, is decremented by a certain amount, . This change is selected in an adaptive way so that, after a succession of iterations, the accumulated changes lead to the establishment of an accurate input-output representation.
- (2)
- A second function, called the pay-off function, Φ, should be minimized so that stability during the learning process is preserved. In the present case, the pay-off function includes the constraints given by Equation (12) and has the following form:From Equation (15), it can be inferred that minimizing Φ means maximizing the denominators and, consequently, forcing the sums to be negative. Therefore, the consequent weights are updated so that the eigenvalues of the block submatrices lie within the unit circle.
- (3)
- An extra condition is imposed, which facilitates a search in the weight space [43]:is the amount by which the consequent parameter vector is changed at each iteration. Matrix Δ is a diagonal matrix that hosts the maximum parameter change (MPC) of each weight. Equation (16) describes a hyper-ellipsoid, which is centered on the current consequent weight vector, and a search for the new values of the weights is restricted by this hyper-ellipsoid. For given values of and Δ, the optimal is the vector that maximizes .
4. Experimental Results
4.1. Problem Statement—Data Preprocessing Phase
- (a)
- The data set is not divided into seasons and the whole annual electric load time-series is examined. Moreover, there is no separation between working days and weekends.
- (b)
- A single input is used—the actual load value at hour h of the previous day, (MW)—with DBD-FELF predicting the load at the same hour of day d. In this way, the forecaster attempts to identify the mappingwithout resorting to climate and temperature variables. d = 1, …, 365 and h = 1, …, 24 are the day and hour indices, respectively. This decision is made to provide a very economical model in terms of parameters and computational burden. Therefore, no feature selection (a rather demanding preprocessing step) is required based either on the expertise of the system operators or on statistical methods and regression models [45]. DBD-FELF intends to model the dependence of current load on past loads by taking advantage of the recurrent nature of BDRNNs.
4.2. DBD-FELF’s Features
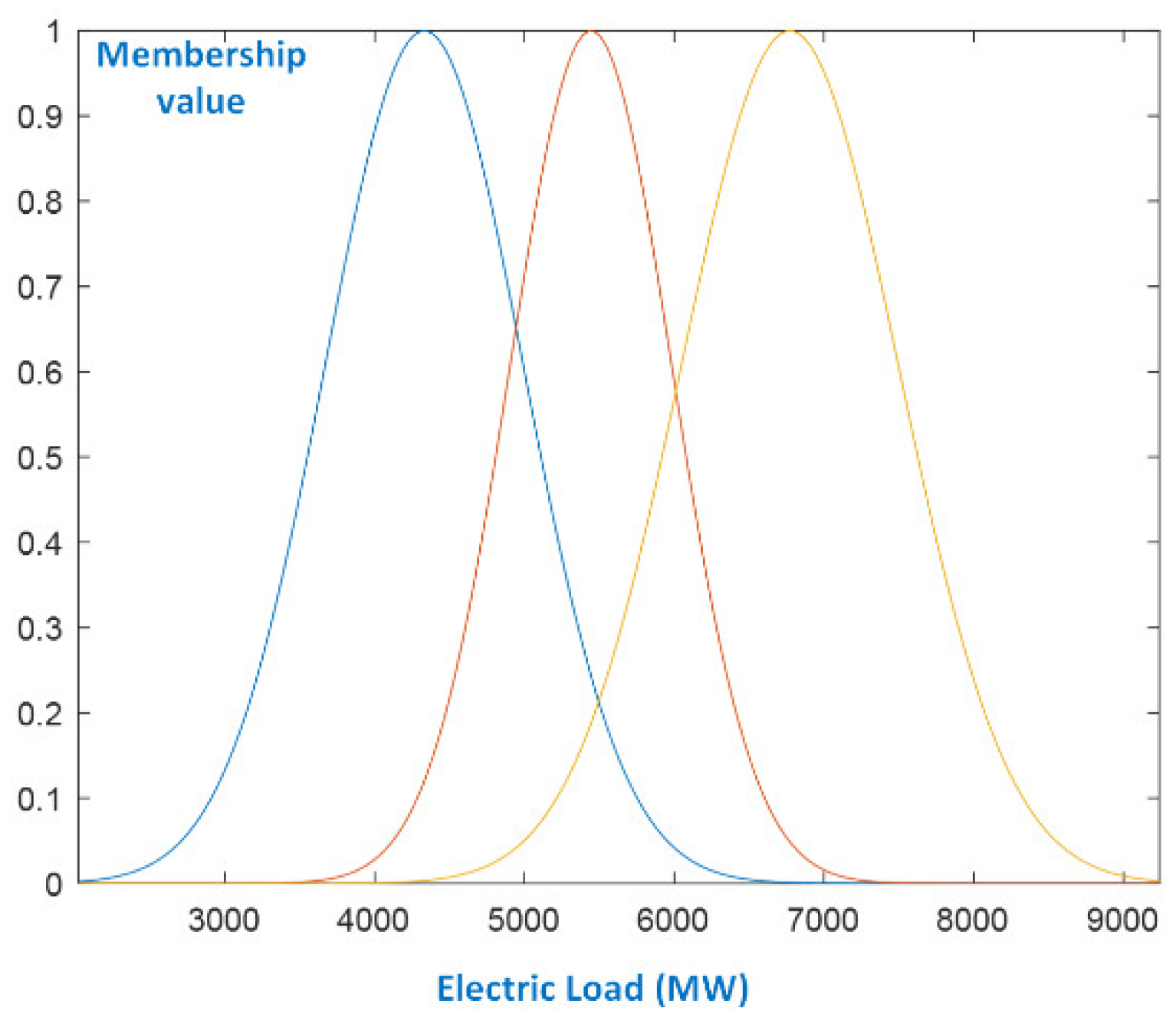
4.3. Experimental Results
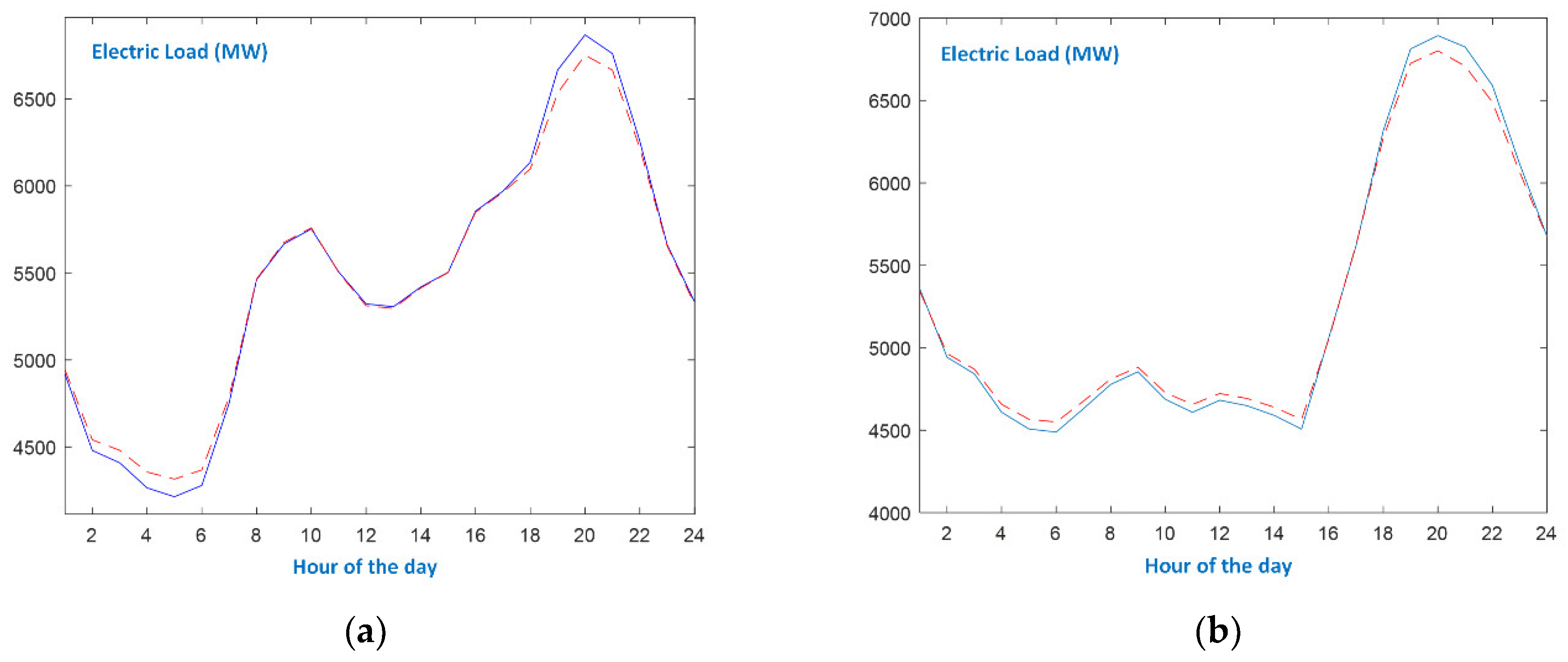
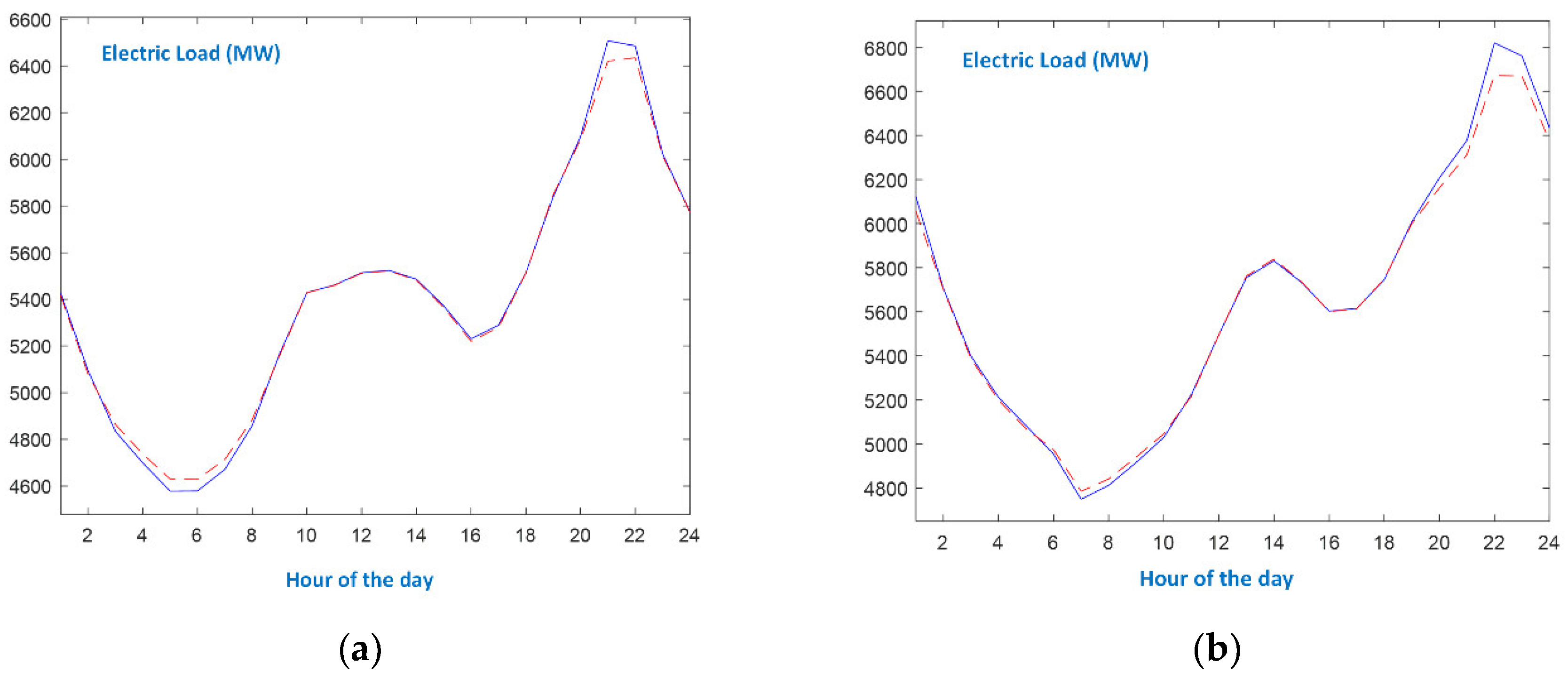
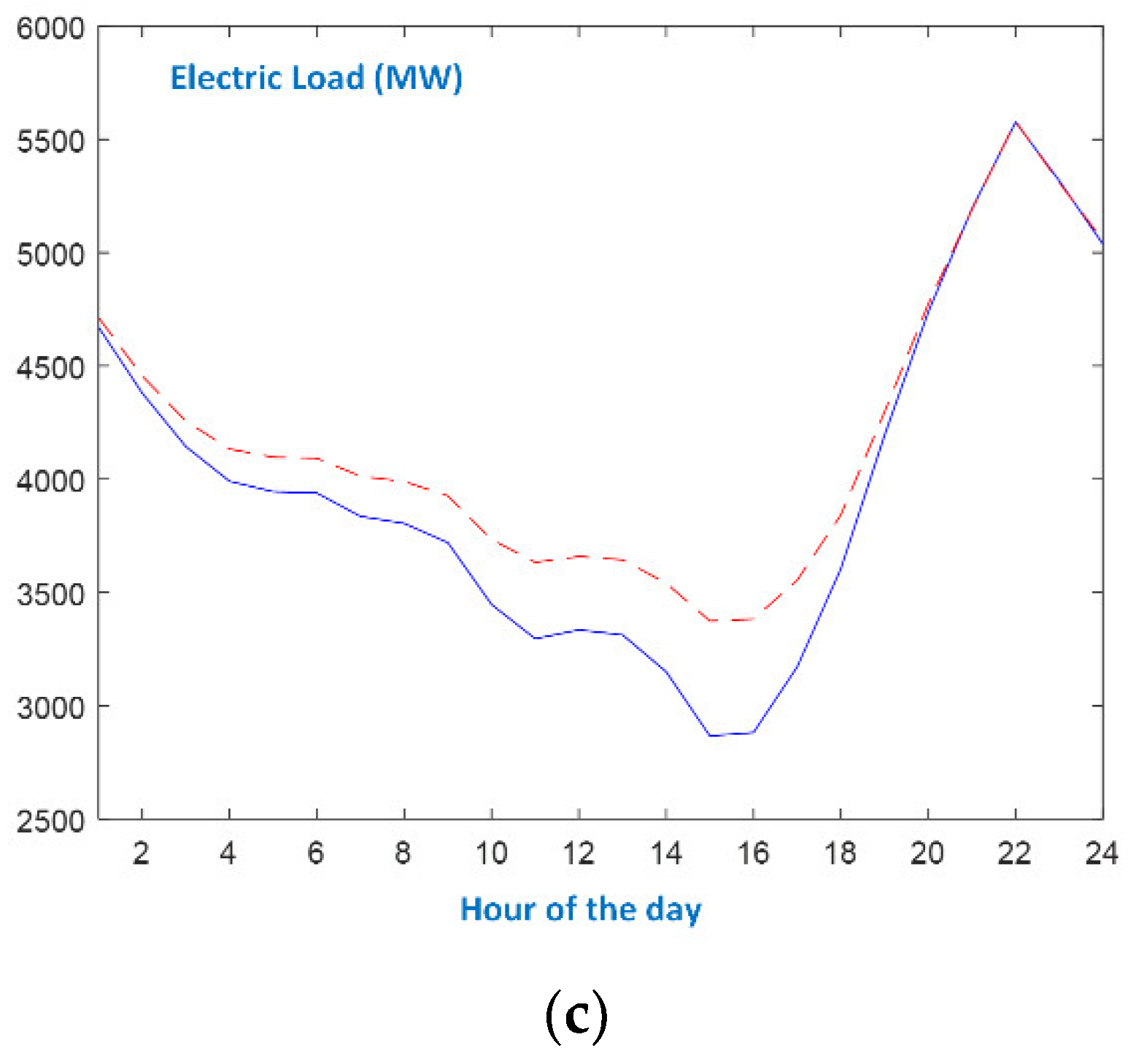
- In the case of working days, the appearances of morning and evening peaks, as well as the first minimum load, are similar at all seasons. During Spring and Autumn working days, the evening minimum is more discrete than during Winter and Summer.
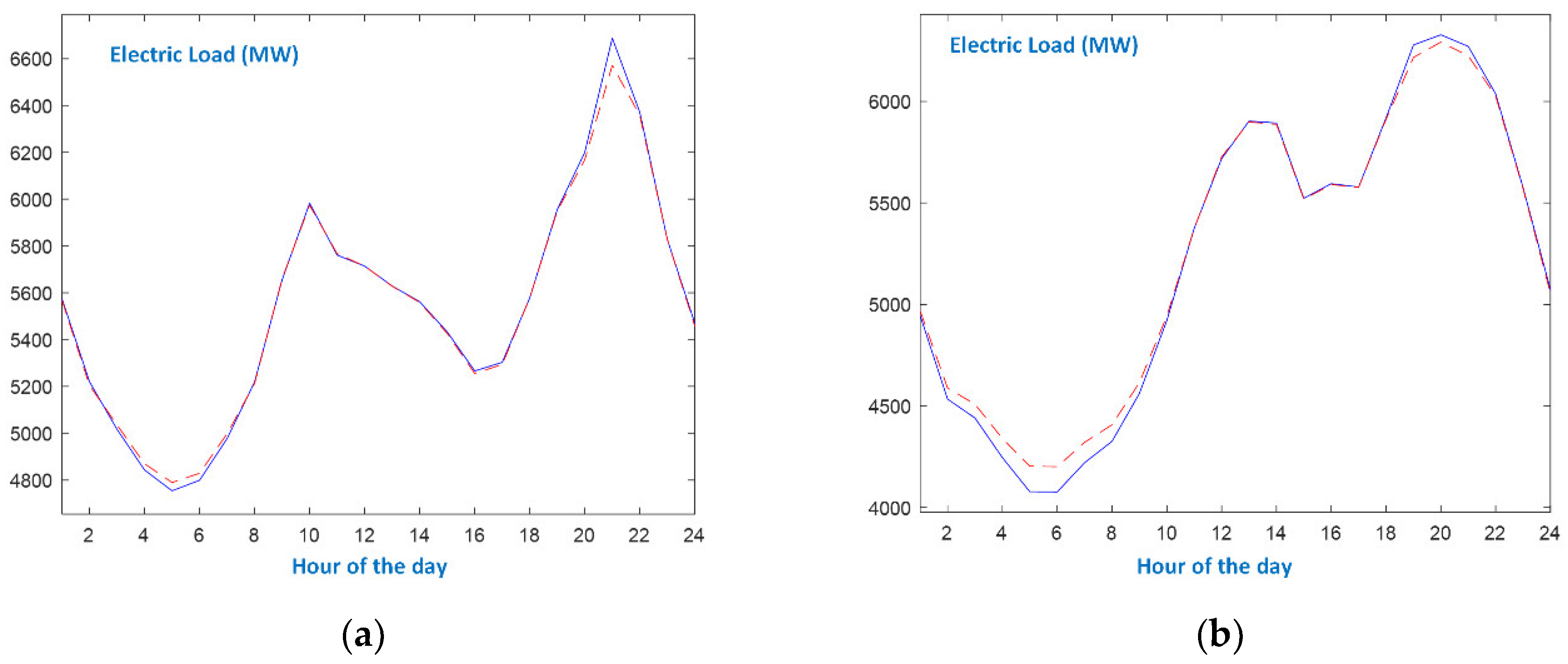
- As expected, the evolution of the load curve on Sundays is quite different from the one of working days. Additionally, the seasonal patterns are also different. Autumn and Spring Sundays follow the evolution of the respective working day load curves after 6 p.m.
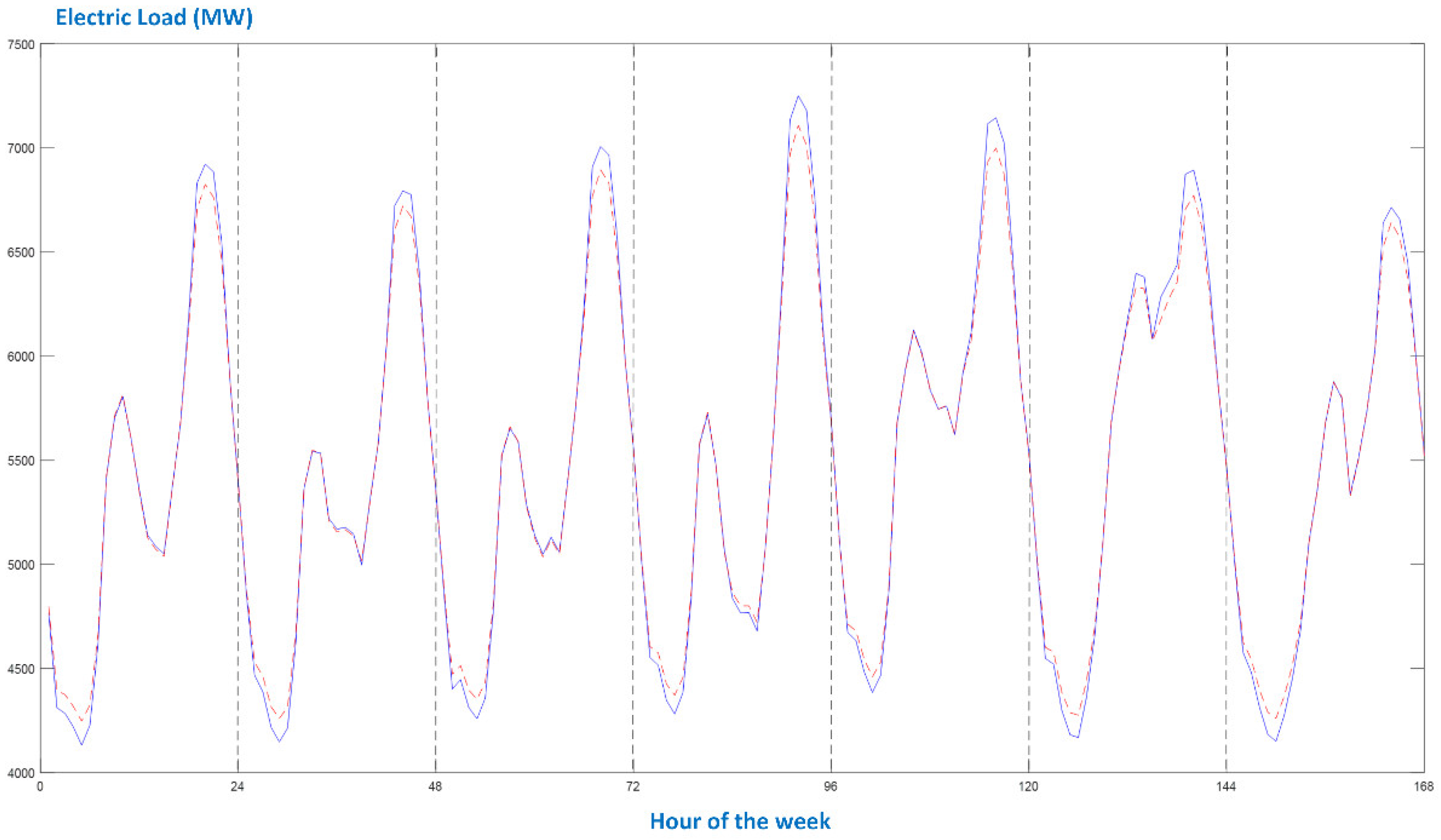
- Even though there exist differences between seasonal patterns, as well as between the types of days, the proposed forecaster efficiently models the actual load curves since it identifies the peaks and the minimum loads and accurately predicts the values at the slopes. As shown in Figure 8, the single-input forecaster is capable of tracking the transition from weekend days to working days and vice versa.
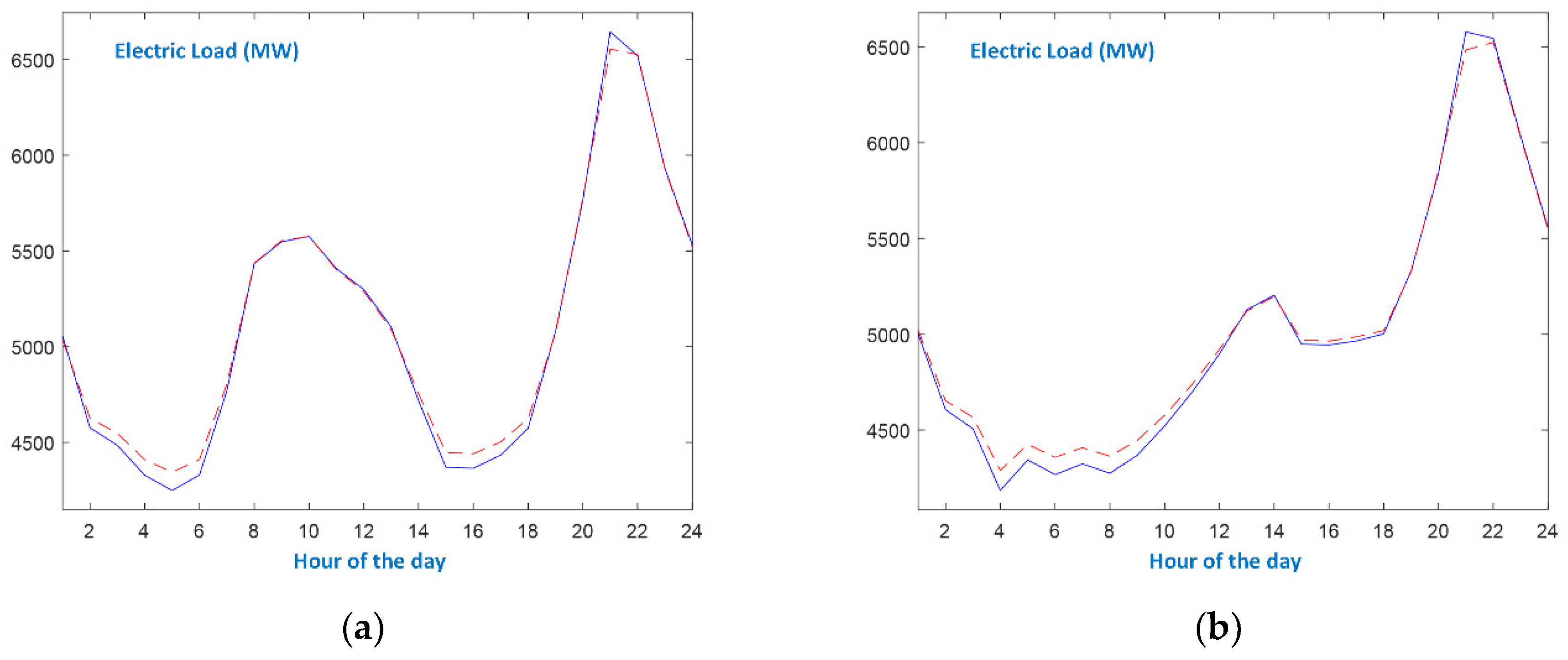
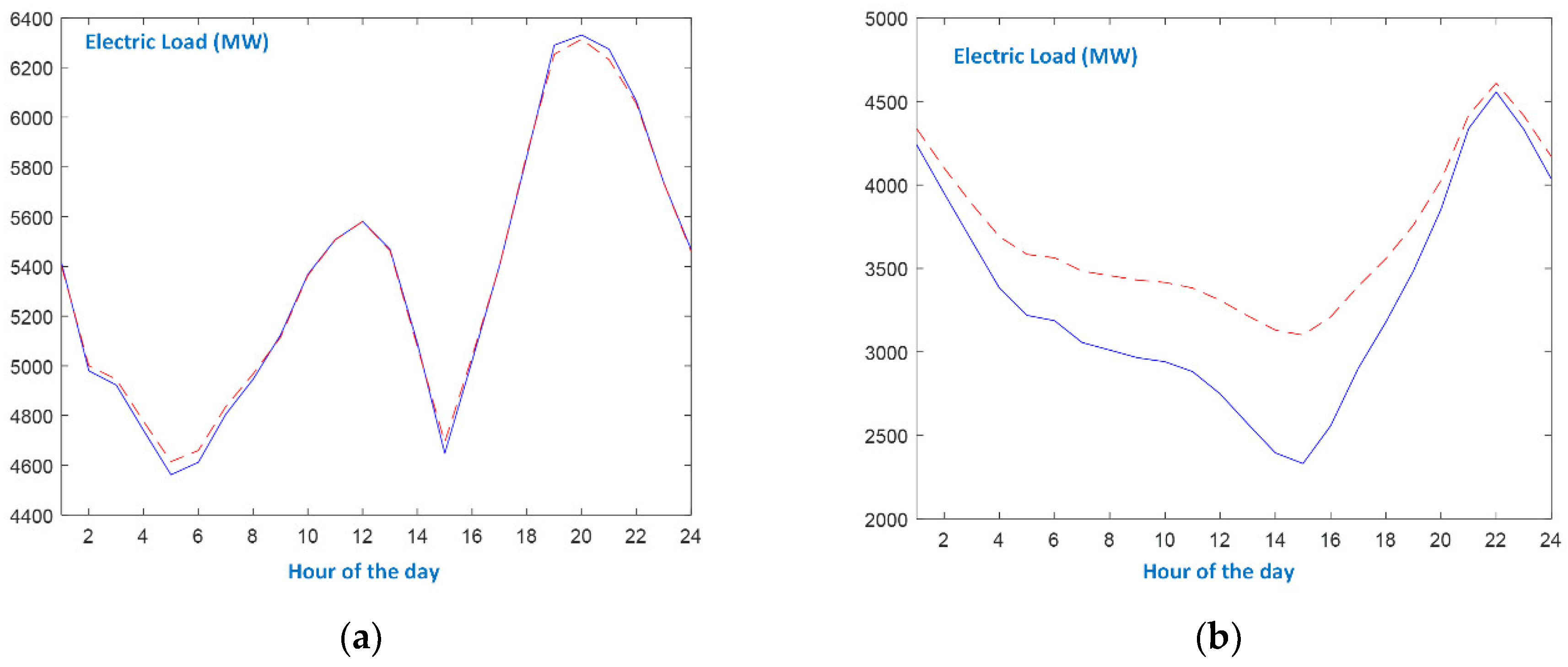
- As far as Holidays are concerned, it can be seen in Figure 9a that the Christmas load curve is tracked by DBD-FELF very efficiently. The average percentage error for Christmas day is 0.31%. This behavior can be attributed to the fact that, during Christmas, Greeks stay at home or pay visits; therefore, the household loads compensate the industrial ones. The two minima occur at 5 a.m. and 3 p.m., and the first peak load at 10 a.m., at the same hours as the previous day. Moreover, the load evolution is quite similar on these two days, leading to the conclusion that the temporal relation of past loads has been effectively identified.
- On the contrary, the Easter and Assumption holidays are quite a different story. The day of Easter is a highly irregular day, as shown in Figure 9b. There is no morning peak, and there is a continuous decrease in load demand until 3 p.m. Moreover, the load values are significantly reduced (2331 MW at 3 p.m.) with respect to the previous day (3405 MW) and to the previous Sunday (3392 MW), leading to enormous errors, including the following: 735.9 MW at 2 p.m., 770 MW at 3 p.m. and 652.6 at 4 p.m., and an average percentage error of 8.11%. This unusual load curve reflects the fact that, during Easter, no industrial activity takes place, and Greek people leave their homes and celebrate outdoors. The evening peak attains 4500 MW, whereas, in a typical Spring Sunday, the respective peak is around 6500 MW (Figure 5b). In the case of 15 August (Assumption day), DBD-FELF is not accurate, at least until 6p.m. Even though it tracks the dynamics, the predicted load takes fairly bigger values, leading to errors up to 507 MW. The load curve is quite similar to that of Easter, as there is no morning peak as well, and load keeps more or less reducing to a minimum below 3000 MW around 3 p.m. (lunch time). Assumption day is at the heart of summer vacations for Greek people; most are on leave and spend the morning at the beach, returning to their summer houses or to hotels late in the evening. However, the load profile returns to normal at around 6 p.m., and the performance DBD-FELF is significantly ameliorated. The average percentage error for 15 August is 3.53%.
- It produces accurate forecasts for the electric load data of the Greek Power System.
- It is an economical model with reduced computational complexity with regard to its rivals.
- The model-building process does not require a preprocessing step for selecting appropriate past load values.
- The model operates effectively without climate variables.
- A single model is applied for forecasting the whole year, independent of the nature of the day. The results justify this decision in general; however, the effect of highly irregular days such as Easter and 15 August (Assumption day) are clear.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Nomenclature
| fuzzy set of the j-th input for the i-th rule. | |
| membership function of the j-th input axis for the i-th fuzzy rule | |
| mean of a Gaussian membership function of the j-th input dimension for the i-th fuzzy rule | |
| standard deviation of a Gaussian membership function of the j-th input dimension for the l-th fuzzy rule | |
| degree of fulfillment of the i-th fuzzy rule | |
| N | number of neurons at the consequent parts of the fuzzy rules |
| RMSE | root mean squared error |
| APE | average percentage error |
| P | size of the electric load data set |
| maximum actual load of day d | |
| actual load at the h-th hour d-1 | |
| predicted load at the h-th hour d-1 | |
| scaled-orthogonal feedback matrix for k-th block of the i-th fuzzy rule | |
| synaptic weights at the k-th block of the i-th fuzzy rule | |
| feedback synaptic weights at the k-th block of the i-th fuzzy rule | |
| synaptic weights at the output layer of the i-th fuzzy rule | |
| the outputs of the neurons that consist the k-th block of the i-th fuzzy rule | |
| BDRNNi | the block-diagonal recurrent neural network of the i-th fuzzy rule |
| the output of the i-th fuzzy rule | |
| weight vector for the consequents parts of the fuzzy rules | |
| stability function for the k-th block of the i-th rule | |
| error decrement | |
| pay-off function | |
| MPC | maximum parameter change |
| membership degree that the n-th data sample belongs to the i-th cluster | |
| Lagrange multipliers for the outputs of the neurons that consist the k-th block of the i-th fuzzy rule | |
| Lagrange multiplier for the output of the i-th fuzzy rule | |
| increase factor for maximum parameter change | |
| decrease factor for maximum parameter change | |
| minimum parameter change | |
| maximum parameter change | |
| initial parameter change |
References
- Hoang, A.; Vo, D. The balanced enegy mix for achieving environmental and economic goals in the long run. Energies 2020, 13, 3850. [Google Scholar] [CrossRef]
- Sgouras, K.; Dimitrelos, D.; Bakirtzis, A.; Labridis, D. Quantitative risk management by demand response in distribution networks. IEEE Trans. Power Syst. 2018, 33, 1496–1506. [Google Scholar] [CrossRef]
- Halkos, G.; Gkampoura, E. Assessing fossil fuels and renewable’s impact on energy poverty conditions in Europe. Energies 2023, 16, 560. [Google Scholar] [CrossRef]
- Marneris, I.; Ntomaris, A.; Biskas, P.; Basilis, C.; Chatzigiannis, D.; Demoulias, C.; Oureilidis, K.; Bakirtzis, A. Optimal Participation of RES aggregators in energy and ancillary services markets. IEEE Trans. Ind. Appl. 2022, 59, 232–243. [Google Scholar] [CrossRef]
- Park, D.C.; El-Sharkawi, M.; Marks, R.; Atlas, L.; Damborg, M. Electric load forecasting using an artificial neural network. IEEE Trans. Power Syst. 1991, 6, 442–449. [Google Scholar] [CrossRef]
- Papalexopoulos, A.; How, S.; Peng, T. An implementation of a neural network based load forecasting model for the EMS. IEEE Trans. Power Syst. 1994, 9, 1956–1962. [Google Scholar] [CrossRef]
- Bansal, R. Bibliography on the fuzzy set theory applications in power systems. IEEE Trans. Power Syst. 2003, 18, 1291–1299. [Google Scholar] [CrossRef]
- Dash, P.; Liew, A.; Rahman, S.; Dash, S. Fuzzy and neuro-fuzzy computing models for electric load forecasting. Eng. Appl. Artif. Intell. 1995, 8, 423–433. [Google Scholar] [CrossRef]
- Shah, S.; Nagraja, H.; Chakravorty, J. ANN and ANFIS for short term load forecasting. Eng. Technol. Appl. Sci. Res. 2018, 8, 2818–2820. [Google Scholar] [CrossRef]
- Ibrahim, B.; Rabelo, L.; Gutierrez-Franco, E.; Clavijo-Buritica, N. Machine learning for short-term load forecasting in smart grids. Energies 2022, 15, 8079. [Google Scholar] [CrossRef]
- Lahouar, A.; Ben Hadj Slama, J. Day-ahead Load forecast using Random Forest and expert input selection. Energy Convers. Manag. 2015, 103, 1040–1051. [Google Scholar] [CrossRef]
- Madrid, E.; Nuno, A. Short-term electricity load forecasting with machine learning. Information 2021, 12, 50. [Google Scholar] [CrossRef]
- Zhang, S.; Zhang, N.; Zhang, Z.; Chen, Y. Electric power load forecasting method based on a support vector machine optimized by the improved seagull optimization algorithm. Energies 2022, 15, 9197. [Google Scholar] [CrossRef]
- Giasemidis, G.; Haben, S.; Lee, T.; Singleton, C.; Grindrod, P. A genetic algorithm approach for modelling low voltage network demands. Appl. Energy 2017, 203, 463–473. [Google Scholar] [CrossRef]
- Yang, Y.; Shang, Z.; Chen, Y.; Chen, Y. Multi-objective particle swarm optimization algorithm for multi-step electric load forecasting. Energies 2020, 13, 532. [Google Scholar] [CrossRef]
- Shohan, J.; Faruque, O.; Foo, S. Forecasting of electric load using a hybrid LSTM—Neural prophet model. Energies 2022, 15, 2158. [Google Scholar] [CrossRef]
- Abumohse, M.; Owda, A.; Owda, M. Electrical load forecasting using LSTM, GRU, and RNN algorithms. Energies 2023, 16, 2283. [Google Scholar] [CrossRef]
- Bianchi, F.; Maiorino, E.; Kampffmeyer, M.; Rizzi, A.; Jenssen, R. Recurrent Neural Networks for Short-Term Load Forecasting—An Overview and Comparative Analysis; Springer: Cham, Switzerland, 2017. [Google Scholar] [CrossRef]
- Vanting, N.; Ma, Z.; Jorgensen, B. A scoping review of deep neural networks for electric load forecasting. Energy Inform. 2021, 4, 49. [Google Scholar] [CrossRef]
- Farsi, B.; Amayri, M.; Bouguila, N.; Eicker, U. On short-term load forecasting using machine learning techniques and a novel parallel deep LSTM-CNN approach. IEEE Access 2021, 9, 31191–31212. [Google Scholar] [CrossRef]
- Pirbazari, A.; Chakravorty, A.; Rong, C. Evaluating feature selection methods for short-term load forecasting. In Proceedings of the 2019 IEEE International Conference on Big Data and Smart Computing, Kyoto, Japan, 27 February–2 March 2009. [Google Scholar] [CrossRef]
- Yang, Y.; Wang, Z.; Gao, Y.; Wu, J.; Zhao, S.; Ding, Z. An effective dimensionality reduction approach for short-term load forecasting. Electr. Power Syst. Res. 2022, 210, 108150. [Google Scholar] [CrossRef]
- Takagi, T.; Sugeno, M. Fuzzy identification of systems and its applications. IEEE Trans. Syst. Man Cybern. 1985, 15, 116–132. [Google Scholar] [CrossRef]
- Sivakumar, S.; Robertson, W.; Phillips, W. On-line stabilization of block-diagonal recurrent neural networks. IEEE Trans. Neural Netw. 1999, 10, 167–175. [Google Scholar] [CrossRef]
- Mastorocostas, P. A Block-diagonal recurrent fuzzy neural network for dynamic system identification. In Proceedings of the 16th IEEE International Conference on Fuzzy Systems, London, UK, 23–26 July 2007. [Google Scholar] [CrossRef]
- Mastorocostas, P.; Hilas, C. A block-diagonal recurrent fuzzy neural network for system identification. Neural Comput. Appl. 2009, 18, 707–717. [Google Scholar] [CrossRef]
- Mastorocostas, P.; Hilas, C. A Block-diagonal dynamic fuzzy filter for adaptive noise cancellation. In Innovations and Advanced Techniques in Systems, Computing Sciences and Software Engineering; Springer: Dordrecht, The Netherlands, 2007. [Google Scholar] [CrossRef]
- Mastorocostas, P.; Hilas, C.; Varsamis, D.; Dova, S. A telecommunications call volume forecasting system based on a recurrent fuzzy neural network. In Proceedings of the 2013 IEEE International Joint Conference on Neural Networks, Dallas, TX, USA, 4–9 August 2013. [Google Scholar] [CrossRef]
- Mastorocostas, P.; Hilas, C.; Varsamis, D.; Dova, S. Telecommunications call volume forecasting with a block-diagonal recurrent fuzzy neural network. Telecommun. Syst. 2016, 63, 15–25. [Google Scholar] [CrossRef]
- Tsoi, A.; Back, A. Locally recurrent Ggobally feedforward networks: A critical review of architectures. IEEE Trans. Neural Netw. 1994, 5, 229–239. [Google Scholar] [CrossRef]
- Shihabudheen, K.; Pillai, G. Recent advances in neuro-fuzzy system: A Survey. Knowl. Based Syst. 2018, 152, 136–162. [Google Scholar] [CrossRef]
- Ojha, V.; Abraham, A.; Snasel, V. Heuristic design of fuzzy inference systems: A review of three decades of research. Eng. Appl. Artif. Intel. 2019, 85, 845–864. [Google Scholar] [CrossRef]
- Jassar, S.; Liao, Z.; Zhao, L. A recurrent neuro-fuzzy system and its application in inferential sensing. Appl. Soft Comput. 2011, 11, 2935–2945. [Google Scholar] [CrossRef]
- Juang, C.-F.; Lin, Y.-Y.; Tu, C.-C. A recurrent self-evolving fuzzy neural network with local feedbacks and its application to dynamic system processing. Fuzzy Sets Syst. 2010, 161, 2552–2568. [Google Scholar] [CrossRef]
- Stavrakoudis, D.; Theocharis, J. Pipelined recurrent fuzzy networks for nonlinear adaptive speech prediction. IEEE Trans. Syst. Man Cybern. B Cybern. 2007, 37, 1305–1320. [Google Scholar] [CrossRef]
- Mastorocostas, P.; Theocharis, J. A Recurrent fuzzy neural model for dynamic system identification. IEEE Trans. Syst. Man Cybern. B Cybern. 2002, 32, 176–190. [Google Scholar] [CrossRef] [PubMed]
- Samanta, S.; Suresh, S.; Senthilnath, J.; Sundararajan, N. A new neuro-fuzzy inference system with dynamic neurons (NFIS-DN) for system identification and time series forecasting. Appl. Soft Comput. 2019, 82, 105567. [Google Scholar] [CrossRef]
- Mastorocostas, P.; Hilas, C. ReNFFor: A recurrent neurofuzzy forecaster for telecommunications data. Neural Comput. Appl. 2013, 22, 1727–1734. [Google Scholar] [CrossRef]
- Kandilogiannakis, G.; Mastorocostas, P.; Voulodimos, A. ReNFuzz-LF: A recurrent neurofuzzy system for short-term load forecasting. Energies 2022, 15, 3637. [Google Scholar] [CrossRef]
- Dunn, J. A fuzzy relative of the ISODATA process and its use in detecting compact, well-separated clusters. J. Cybernet. 1974, 3, 32–57. [Google Scholar] [CrossRef]
- Bezdek, J. Cluster validity with fuzzy sets. J. Cybernet. 1973, 3, 58–73. [Google Scholar] [CrossRef]
- Zhou, T.; Chung, F.-L.; Wang, S. Deep TSK fuzzy classifier with stacked generalization and triplely concise interpretability guarantee for large data. IEEE Trans. Fuzzy Syst. 2017, 25, 1207–1221. [Google Scholar] [CrossRef]
- Mastorocostas, P.; Theocharis, J. A stable learning method for block-diagonal recurrent neural networks: Application to the analysis of lung sounds. IEEE Trans. Syst. Man. Cybern. B Cybern. 2006, 36, 242–254. [Google Scholar] [CrossRef]
- Werbos, P. Beyond Regression: New Tools for Prediction and Analysis in the Behavioral Sciences. Ph.D. Thesis, Harvard University, Cambridge, MA, USA, 1974. [Google Scholar]
- Veeramsetty, V.; Chandra, D.R.; Grimaccia, F.; Mussetta, M. Short term electric load forecasting using principal component analysis and recurrent neural networks. Forecasting 2022, 4, 149–164. [Google Scholar] [CrossRef]
- Greek Independent Power Transmission Operator. Available online: https://www.admie.gr/en/market/market-statistics/detail-data (accessed on 22 April 2023).
- Davies, D.; Bouldin, D. A clustering separation measure. IEEE Trans. Pattern Anal. Mach. Intell. 1979, 1, 224–227. [Google Scholar] [CrossRef]
- Jang, J.-S.R. ANFIS: Adaptive-network-based fuzzy inference system. IEEE Trans. Syst. Man Cybern. 1993, 23, 665–685. [Google Scholar] [CrossRef]
- Veeramsetty, V.; Chandra, D.R.; Salkuti, S.R. Short-term electric power load forecasting using factor analysis and long short-term memory for smart cities. Int. J. Circuit Theory Appl. 2021, 49, 1678–1703. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Number |
|---|---|
| m | r |
| σ | r |
| a | r·N |
| b | r·N |
| w | r·N |
| Premise | 2·r |
| Consequent | 3·r·N |
| Total | 2·r +3·r·N |
| Iterations | |||||||
|---|---|---|---|---|---|---|---|
| 1.05 | 0.5 | 1 × 10−4 | 0.5 | 1 × 10−2 | 6 | 0.9 | 1000 |
| No of Blocks | APE Training | RMSE Training | APE Testing | RMSE Testing | No of Param. |
|---|---|---|---|---|---|
| 1 | 1.05% | 107 | 1.18% | 112 | 24 |
| 2 | 1.10% | 104 | 1.22% | 110 | 42 |
| 3 | 1.09% | 107 | 1.20% | 110 | 60 |
| 4 | 1.05% | 107 | 1.18% | 111 | 78 |
| 5 | 1.13% | 108 | 1.18% | 108 | 96 |
| Season | APE Training | RMSE Training | APE Testing | RMSE Testing |
|---|---|---|---|---|
| Winter | 1.03% | 125 | 1.04% | 121 |
| Spring | 1.36% | 118 | 1.66% | 131 |
| Summer | 0.81% | 90 | 0.96% | 104 |
| Autumn | 1.00% | 88 | 1.03% | 88 |
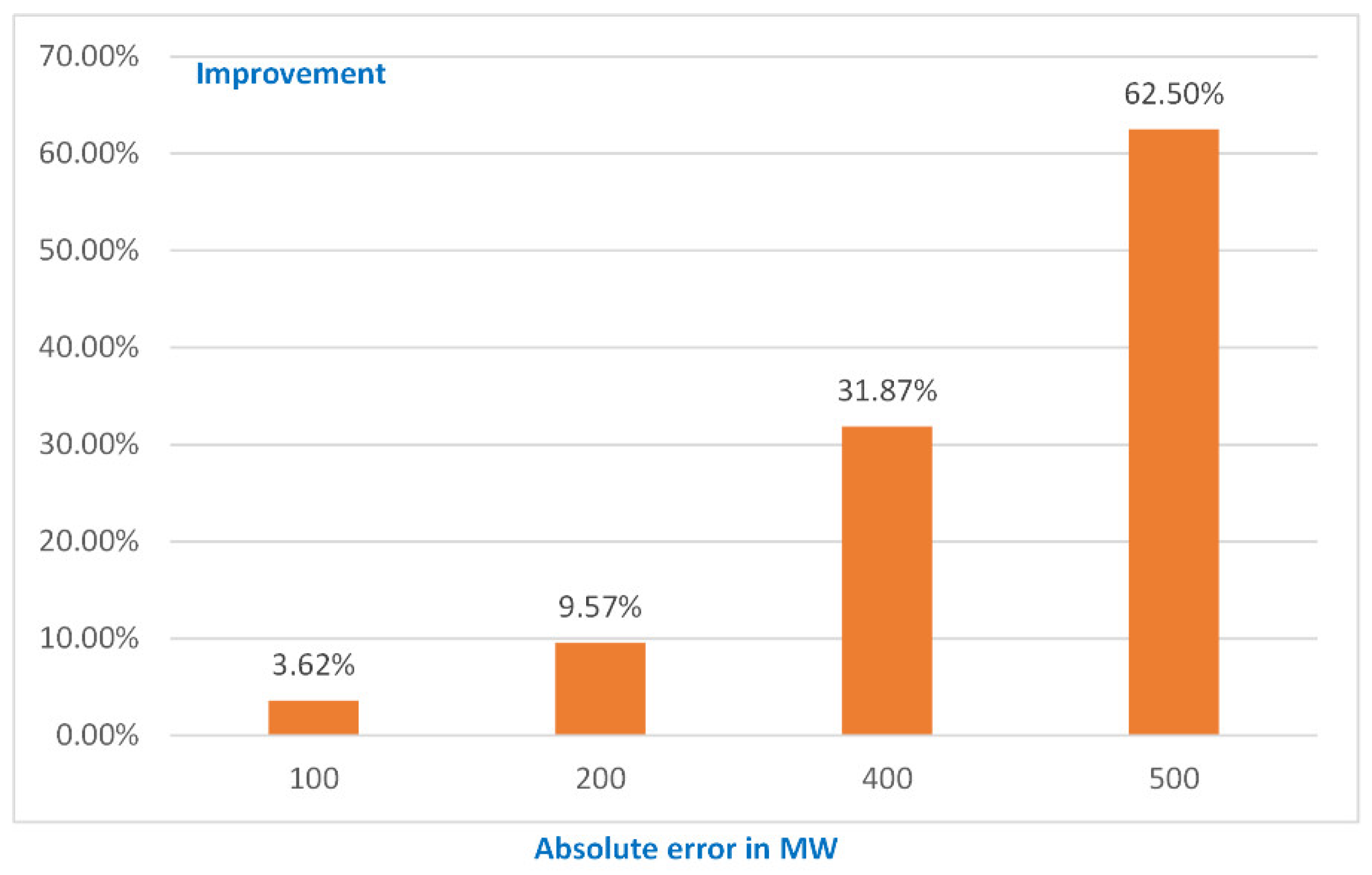
| Electric Load | >100 MW | >200 MW | >400 MW | >500 MW |
|---|---|---|---|---|
| Hours | 2686 | 718 | 62 | 15 |
| Time | 30.58% | 8.17% | 0.70% | 0.18% |
| DFNN | Structural Parameters | |||||
|---|---|---|---|---|---|---|
| H | Membership function | Activation function | ||||
| 1 | 2 | 2 | 1 | 2 | Gaussian | tanh |
| Learning parameters | ||||||
| 1.05 | 0.5 | 0.0001 | 0.01 | 0.85 | ||
| ReNFuzz-LF | Structural Parameters | |||||
| H | Membership function | Activation function | ||||
| 2 | Gaussian | tanh | ||||
| Learning parameters | ||||||
| Temp | ||||||
| 1.2 | 0.01 | 0.4 | 1.05 | 0.5 | 0.0001 | 0.01 |
| ANFIS | Learning parameters | |||||
| Initial Step size | Step size increase rate | Step size decrease rate | ||||
| 0.01 | 1.1 | 0.9 | ||||
| Membership function: Gaussian | ||||||
| GRU | Hyperparameters | |||||
| Activation function | Bias | Dropout | Batch size | Optimizer | learning rate | |
| tanh | Yes | 0.35 | 16 | Adam | 0.001 | |
| LSTM-1 | Hyperparameters | |||||
| Activation function | Bias | Dropout | Batch size | Optimizer | learning rate | |
| tanh | Yes | 0.35 | 16 | Adam | 0.001 | |
| LSTM-2,3,4 | Hyperparameters | |||||
| Activation function | Bias | Dropout | Batch size | Optimizer | learning rate | |
| tanh | Yes | 0.2 | 24 | Adam | 0.001 | |
| RNN-1 | Hyperparameters | |||||
| Activation function | Bias | Dropout | Batch size | Optimizer | learning rate | |
| tanh | Yes | 0.35 | 80 | Adam | 0.001 | |
| RNN-2 | Hyperparameters | |||||
| Activation function | Bias | Dropout | Batch size | Optimizer | learning rate | |
| tanh | Yes | 0.35 | 24 | Adam | 0.001 | |
| Model | APE (Testing) | No. of Parameters |
|---|---|---|
| DBD-FELF | 1.18% | 24 |
| ReNFuzz-LF | 1.35% | 33 |
| DFNN | 1.36% | 48 |
| ANFIS | 1.48% | 279 |
| LSTM-4 (1 layer, 25 units) | 1.73% | 2726 |
| RNN-2 (40 neurons) | 1.72% | 4961 |
| LSTM-3 (1 layer, 50 units) | 1.51% | 10,451 |
| LSTM-2 (2 layers, 50 units) | 1.23% | 30,651 |
| RNN-1 (200 neurons) | 1.71% | 120,801 |
| GRU | 1.17% | 2,258,001 |
| LSTM-1 (2 layers, 500 units) | 1.18% | 3,006,501 |
| Model | Training Phase (Seconds) | Testing Phase (Seconds) |
|---|---|---|
| DBD-FELF | 49.87 | 0.72 |
| GRU | 347.8 | 7.187 |
| LSTM-1 (2 layers, 500 units) | 584.4 | 8.973 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kandilogiannakis, G.; Mastorocostas, P.; Voulodimos, A.; Hilas, C. Short-Term Load Forecasting of the Greek Power System Using a Dynamic Block-Diagonal Fuzzy Neural Network. Energies 2023, 16, 4227. https://0-doi-org.brum.beds.ac.uk/10.3390/en16104227
Kandilogiannakis G, Mastorocostas P, Voulodimos A, Hilas C. Short-Term Load Forecasting of the Greek Power System Using a Dynamic Block-Diagonal Fuzzy Neural Network. Energies. 2023; 16(10):4227. https://0-doi-org.brum.beds.ac.uk/10.3390/en16104227
Chicago/Turabian StyleKandilogiannakis, George, Paris Mastorocostas, Athanasios Voulodimos, and Constantinos Hilas. 2023. "Short-Term Load Forecasting of the Greek Power System Using a Dynamic Block-Diagonal Fuzzy Neural Network" Energies 16, no. 10: 4227. https://0-doi-org.brum.beds.ac.uk/10.3390/en16104227