

Hosting Capacity Assessment Strategies and Reinforcement Learning Methods for Coordinated Voltage Control in Electricity Distribution Networks: A Review


Abstract
:1. Introduction
- It categorizes and explains the major RL-based algorithms that are applicable to the power system domain and especially distribution network management;
- It explores a wide range of recent publications on RL-based coordinated voltage control algorithms and highlights the significance of such control methods in enhancing the performance of electricity distribution networks;
- It compares the main features of these algorithms and reviews their advantages and disadvantages;
- It explains the HC assessment methods and the application of RL-based algorithms for enhancing the HC of distribution networks.
2. Hosting Capacity Analysis
- Overvoltage problems;
- Overloading and power loss problems;
- Power quality problems;
- Protection problems.
2.1. Deterministic Methods
2.2. Probabilistic Load Flow Methods
2.3. Quasi-Static Time Series Methods
2.4. Voltage Control
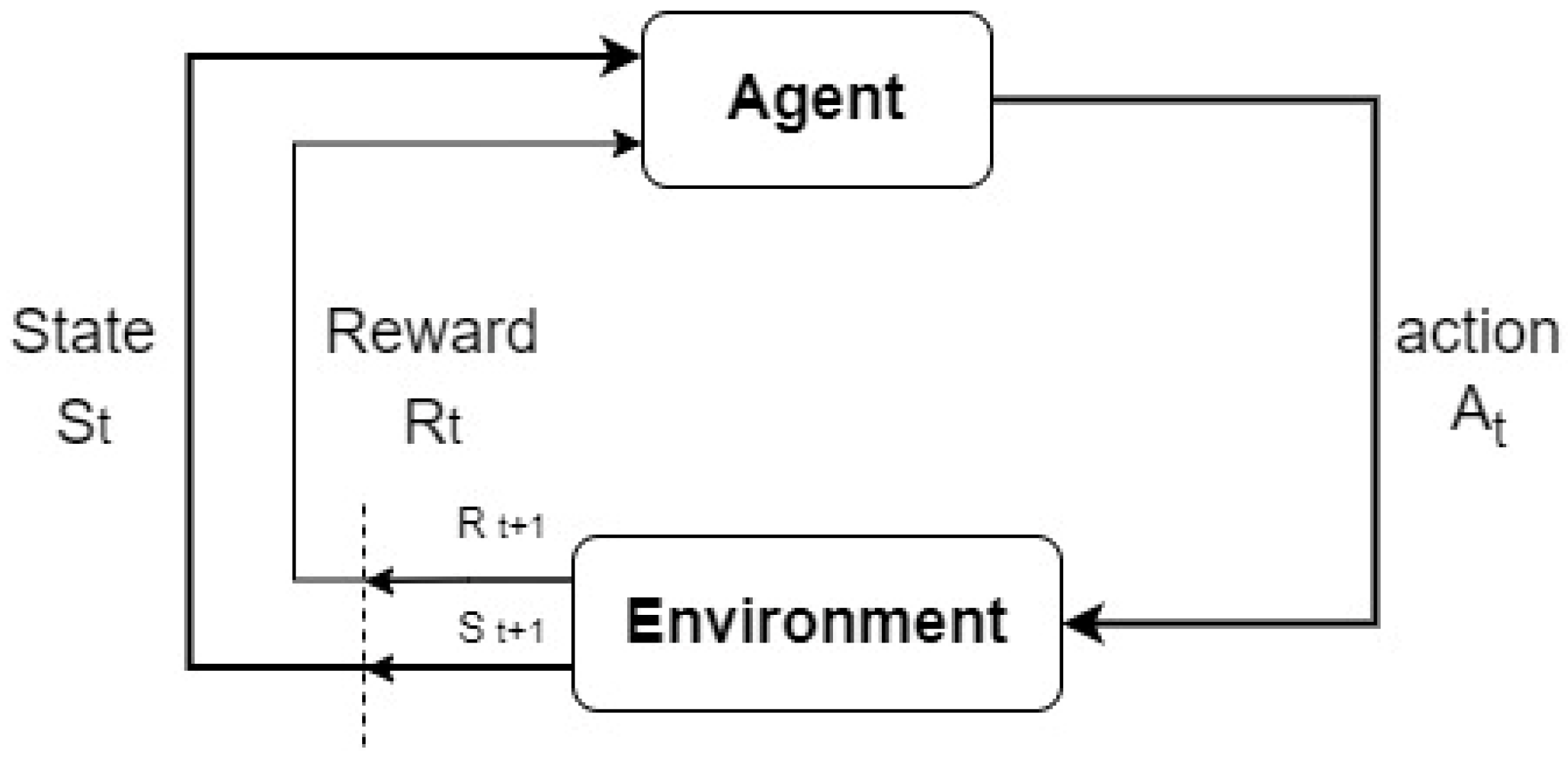
3. An Introduction to Reinforcement Learning
3.1. Markov Decision Process
3.2. Artificial Neural Networks
3.2.1. Deep Neural Networks
3.2.2. Convolutional Neural Networks
3.2.3. Recurrent Neural Networks
3.2.4. Graph Neural Networks
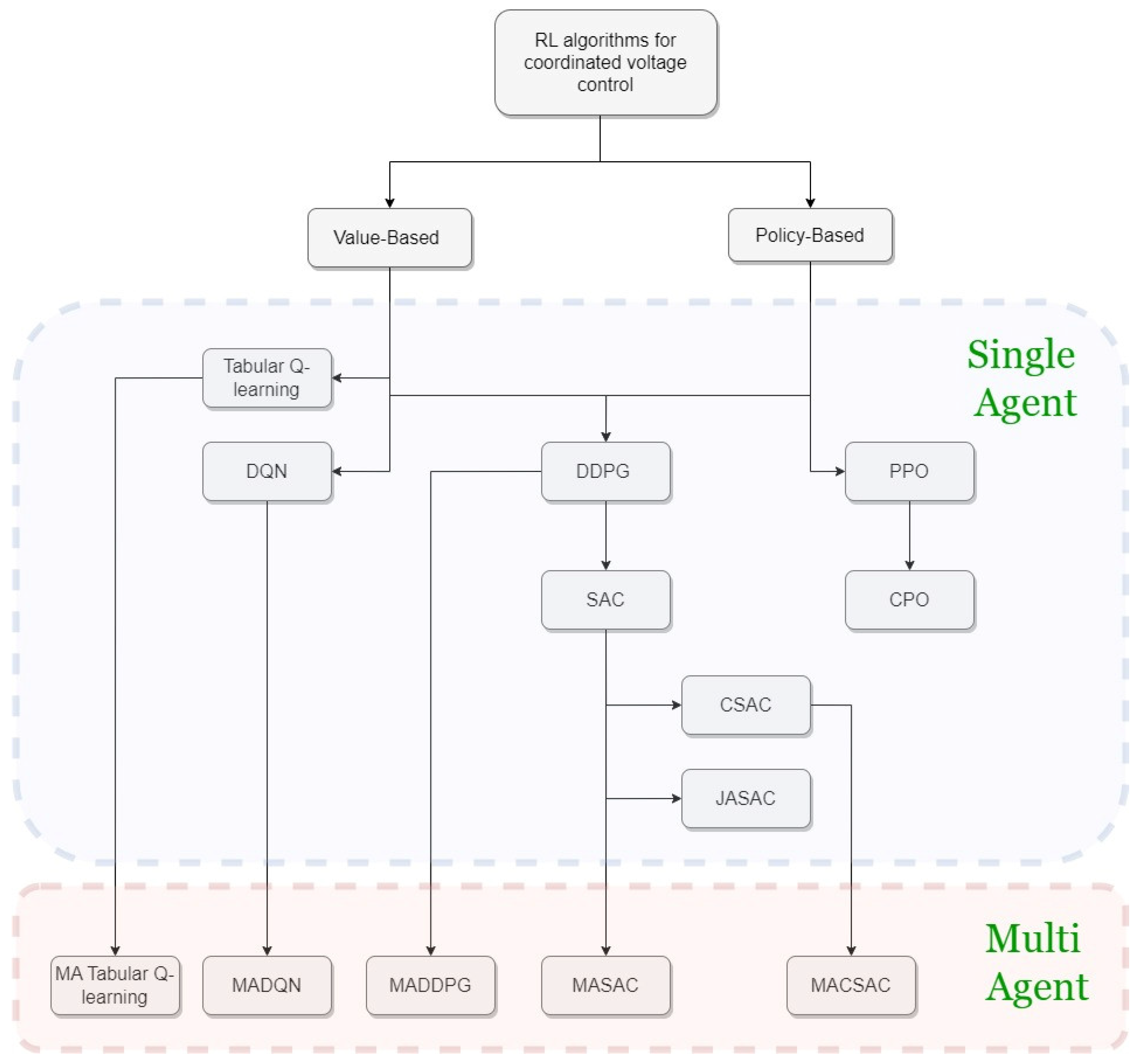
4. A Classification of Reinforcement Learning Algorithms
4.1. Value-Based Methods
4.1.1. Q-Learning
4.1.2. Deep Q-Learning
4.2. Policy-Based Methods
4.3. Actor-Critic Algorithms
4.3.1. Deep Deterministic Policy Gradient
- The replay buffer size—The performance of DDPG increases with the size of the replay buffer, but converges after a certain value. Identification of the correct replay buffer size is key in maximizing the performance of DDPG while utilizing less memory.
- Exploration strategy—DDPG algorithms are deterministic and do not explore the environment as do other stochastic algorithms, and they often converge to a local optimum. One of the strategies to achieve exploration in DDPG algorithms is to add Gaussian noise to the actions during the training process.
- Accuracy of the training model—DDPG algorithms are often trained offline before their implementation in the online distribution network to minimize the undesirable costs associated with the start-up stage. Therefore, the distribution network model used for training must be accurate to achieve a good level of performance and low costs during the online execution.
4.3.2. Soft Actor Critic
5. Multi-Agent Reinforcement Learning
6. Environment Model and MDP Parameters
6.1. Environment
6.2. State Space
6.3. Action Space
6.4. Reward Function and Constraints
7. Risk Factors and Challenges
7.1. Centralized and Decentralized Control
7.2. Safety and Scalability
- The JASAC algorithm proposed in [100] makes use of an adversarial agent to learn the control policies that are robust to the transfer gap. The protagonist actor and the adversary actor share a joint critic in the proposed JASAC algorithm that promotes the efficiency and the convergence of the training process, especially for large state-action spaces.
- The SAC algorithm proposed in [94] utilizes a probabilistic ensemble deep neural network (PEDNN) model of the actual distribution network that captures the aleatoric and epistemic uncertainties of voltage. Some of the aleatoric uncertainties of the distribution network are the resistance and reactance of lines that change according to external factors such as humidity and temperature. Epistemic uncertainties account for the uncertainty of the model due to the lack of sufficient data.
- The DDPG algorithm proposed in [92] makes use of a data-driven DNN model that acts as a substitute to the actual electricity distribution network. The constructed DNN model is used to generate the training samples required for the DDPG algorithm without interacting with the actual distribution network.
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- International Energy Agency. Renewables 2022 Analysis and Forecast to 2027; International Energy Agency: Paris, France, 2022. Available online: https://www.iea.org/reports/renewables-2022 (accessed on 10 November 2022).
- Ding, F.; Mather, B.; Gotseff, P. Technologies to Increase PV Hosting Capacity in Distribution Feeders. In Proceedings of the 2016 IEEE Power and Energy Society General Meeting (PESGM), Boston, MA, USA, 17–21 July 2016. [Google Scholar] [CrossRef]
- Rajabi, A.; Elphick, S.; David, J.; Pors, A.; Robinson, D. Innovative approaches for assessing and enhancing the hosting capacity of PV-rich distribution networks: An Australian perspective. Renew. Sustain. Energy Rev. 2022, 161, 112365. [Google Scholar] [CrossRef]
- Chathurangi, D.; Jayatunga, U.; Perera, S.; Agalgaonkar, A.P.; Siyambalapitiya, T. Comparative evaluation of solar PV hosting capacity enhancement using Volt-VAr and Volt-Watt control strategies. Renew. Energy 2021, 177, 1063–1075. [Google Scholar] [CrossRef]
- Liu, J.; Li, Y.; Rehtanz, C.; Cao, Y.; Qiao, X.; Lin, G.; Song, Y.; Sun, C. An OLTC-inverter coordinated voltage regulation method for distribution network with high penetration of PV generations. Electr. Power Energy Syst. 2019, 113, 991–1001. [Google Scholar] [CrossRef]
- Li, C.; Chen, Y.A.; Jin, C.; Sharma, R.; Kleissl, J. Online PV Smart Inverter Coordination using Deep Deterministic Policy Gradient. Electr. Power Syst. Res. 2022, 209, 107988. [Google Scholar] [CrossRef]
- Tomin, N.; Voropai, N.; Kurbatsky, V.; Rehtanz, C. Management of voltage flexibility from inverter-based distributed generation using multi-agent reinforcement learning. Energies 2021, 14, 8270. [Google Scholar] [CrossRef]
- Breker, S.; Rentmeister, J.; Sick, B.; Braun, M. Hosting capacity of low-voltage grids for distributed generation: Classification by means of machine learning techniques. Appl. Soft Comput. J. 2018, 70, 195–207. [Google Scholar] [CrossRef]
- Wu, J.; Yuan, J.; Weng, Y.; Ayyanar, R. Spatial-Temporal Deep Learning for Hosting Capacity Analysis in Distribution Grids. IEEE Trans. Smart Grid 2022, 14, 354–364. [Google Scholar] [CrossRef]
- Mulenga, E.; Bollen, M.H.J.; Etherden, N. A review of hosting capacity quantification methods for photovoltaics in low-voltage distribution grids. Int. J. Electr. Power Energy Syst. 2020, 115, 105445. [Google Scholar] [CrossRef]
- Ismael, S.M.; Abdel Aleem, S.H.E.; Abdelaziz, A.Y.; Zobaa, A.F. State-of-the-art of hosting capacity in modern power systems with distributed generation. Renew. Energy 2019, 130, 1002–1020. [Google Scholar] [CrossRef]
- Chen, X.; Qu, G.; Tang, Y.; Low, S.; Li, N. Reinforcement Learning for Selective Key Applications in Power Systems: Recent Advances and Future Challenges. IEEE Trans. Smart Grid 2022, 13, 2935–2958. [Google Scholar] [CrossRef]
- Wu, M.; Hong, L.; Wang, Y.; Yan, Z.; Chen, Z. Volt-VAR control for distribution networks with high penetration of DGs: An overview. Electr. J. 2022, 35, 107130. [Google Scholar] [CrossRef]
- Yang, T.; Zhao, L.; Li, W.; Zomaya, A.Y. Reinforcement learning in sustainable energy and electric systems: A survey. Annu. Rev. Control 2020, 49, 145–163. [Google Scholar] [CrossRef]
- Cao, D.; Hu, W.; Zhao, J.; Zhang, G.; Zhang, B.; Liu, Z.; Chen, Z.; Blaabjerg, F. Reinforcement Learning and Its Applications in Modern Power and Energy Systems: A Review. J. Mod. Power Syst. Clean Energy 2020, 8, 1029–1042. [Google Scholar] [CrossRef]
- Kharrazi, A.; Sreeram, V.; Mishra, Y. Assessment techniques of the impact of grid-tied rooftop photovoltaic generation on the power quality of low voltage distribution network—A review. Renew. Sustain. Energy Rev. 2019, 120, 109643. [Google Scholar] [CrossRef]
- Electric Power Research Institute. EPRI Stochastic Analysis to Determine Feeder Hosting Capacity for Distributed Solar PV; EPRI Technical Update; Product ID 1026640; Electric Power Research Institute: Washington, DC, USA, 2012; pp. 1–50. [Google Scholar]
- Torquato, R.; Salles, D.; Pereira, C.O.; Meira, P.C.M.; Freitas, W. A Comprehensive Assessment of PV Hosting Capacity on Low-Voltage Distribution Systems. IEEE Trans. Power Deliv. 2018, 33, 1002–1012. [Google Scholar] [CrossRef]
- Zubo, R.H.A.; Mokryani, G.; Rajamani, H.S.; Aghaei, J.; Niknam, T.; Pillai, P. Operation and planning of distribution networks with integration of renewable distributed generators considering uncertainties: A review. Renew. Sustain. Energy Rev. 2017, 72, 1177–1198. [Google Scholar] [CrossRef] [Green Version]
- Ebe, F.; Idlbi, B.; Morris, J.; Heilscher, G.; Meier, F. Evaluation of PV hosting capacities of distribution grids with utilisation of solar roof potential analyses. CIRED Open Access Proc. J. 2017, 2017, 2265–2269. [Google Scholar] [CrossRef]
- Ebe, F.; Idlbi, B.; Morris, J.; Heilscher, G.; Meier, F. Evaluation of PV Hosting Capacity of Distribuion Grids Considering a Solar Roof Potential Analysis—Comparison of Different Algorithms. In Proceedings of the 2017 IEEE Manchester PowerTech, Powertech, Manchester, UK, 18–22 June 2017. [Google Scholar] [CrossRef]
- Heslop, S.; Macgill, I.; Fletcher, J.; Lewis, S. Method for determining a PV generation limit on low voltage feeders for evenly distributed PV and Load. Energy Procedia 2014, 57, 207–216. [Google Scholar] [CrossRef] [Green Version]
- Carollo, R.; Chaudhary, S.K.; Pillai, J.R. Hosting Capacity of Solar Photovoltaics in Distribution Grids under Different Pricing Schemes. In Proceedings of the 2015 IEEE PES Asia-Pacific Power and Energy Engineering Conference (APPEEC), Brisbane, QLD, Australia, 15–18 November 2015; pp. 5–9. [Google Scholar] [CrossRef] [Green Version]
- Heslop, S.; MacGill, I.; Fletcher, J. Maximum PV generation estimation method for residential low voltage feeders. Sustain. Energy Grids Netw. 2016, 7, 58–69. [Google Scholar] [CrossRef]
- Papaioannou, I.T.; Purvins, A. A methodology to calculate maximum generation capacity in low voltage distribution feeders. Int. J. Electr. Power Energy Syst. 2014, 57, 141–147. [Google Scholar] [CrossRef]
- Sexauer, J.M.; Mohagheghi, S. Voltage quality assessment in a distribution system with distributed generation—A probabilistic load flow approach. IEEE Trans. Power Deliv. 2013, 28, 1652–1662. [Google Scholar] [CrossRef]
- Kharrazi, A.; Sreeram, V.; Mishra, Y. Assessment of Voltage Unbalance Due to Single Phase Rooftop Photovoltaic Panels in Residential Low Voltage Distribution Network: A Study on a Real LV Network in Western Australia. In Proceedings of the 2017 Australasian Universities Power Engineering Conference (AUPEC), Melbourne, VIC, Australia, 19–22 November 2018; pp. 1–6. [Google Scholar] [CrossRef] [Green Version]
- Vallée, F.; Klonari, V.; Lisiecki, T.; Durieux, O.; Moiny, F.; Lobry, J. Development of a probabilistic tool using Monte Carlo simulation and smart meters measurements for the long term analysis of low voltage distribution grids with photovoltaic generation. Int. J. Electr. Power Energy Syst. 2013, 53, 468–477. [Google Scholar] [CrossRef]
- Bracale, A.; Caramia, P.; Carpinelli, G.; Di Fazio, A.R.; Varilone, P. A bayesian-based approach for a short-term steady-state forecast of a smart grid. IEEE Trans. Smart Grid 2013, 4, 1760–1771. [Google Scholar] [CrossRef]
- Panigrahi, B.K.; Sahu, S.K.; Nandi, R.; Nayak, S. Probablistic Load Flow of a Distributed Generation Connected Power System by Two Point Estimate Method. In Proceedings of the 2017 International Conference on Circuit, Power and Computing Technologies (ICCPCT), Kollam, India, 20–21 April 2017; pp. 1–5. [Google Scholar]
- Aien, M.; Fotuhi-Firuzabad, M.; Aminifar, F. Probabilistic load flow in correlated uncertain environment using unscented transformation. IEEE Trans. Power Syst. 2012, 27, 2233–2241. [Google Scholar] [CrossRef]
- Schwippe, J.; Krause, O.; Rehtanz, C. Extension of a Probabilistic Load Flow Calculation Based on an Enhanced Convolution Technique. In Proceedings of the 2009 IEEE PES/IAS Conference on Sustainable Alternative Energy (SAE), Valencia, Spain, 28–30 September 2009; pp. 1–6. [Google Scholar] [CrossRef] [Green Version]
- Schellenberg, A.; Rosehart, W.; Aguado, J. Cumulant-based probabilistic optimal power flow (P-OPF) with Gaussian and Gamma distributions. IEEE Trans. Power Syst. 2005, 20, 773–781. [Google Scholar] [CrossRef] [Green Version]
- Chen, W.; Li, X.; Pei, X. Probabilistic Load Flow Calculation Method Based on Polynomial Normal Transformation and Extended Latin hypercube. In Proceedings of the 2019 IEEE 3rd Conference on Energy Internet and Energy System Integration (EI2), Changsha, China, 8–10 November 2019; pp. 1369–1374. [Google Scholar] [CrossRef]
- Kabir, M.N.; Mishra, Y.; Bansal, R.C. Probabilistic load flow for distribution systems with uncertain PV generation. Appl. Energy 2016, 163, 343–351. [Google Scholar] [CrossRef]
- IEEE Std 1547.7-2013; IEEE Guide for Conducting Distribution Impact Studies for Distributed Resource Interconnection. Institute of Electrical and Electronics Engineers: Piscataway, NJ, USA, 2014; pp. 1–137. [CrossRef]
- Reno, M.J.; Deboever, J.; Mather, B. Motivation and Requirements for Quasi-Static Time Series (QSTS) for Distribution System Analysis. In Proceedings of the 2017 IEEE Power & Energy Society General Meeting, Chicago, IL, USA, 16–20 July 2017; pp. 1–5. [Google Scholar]
- Quiroz, J.E.; Reno, M.J.; Broderick, R.J. Time Series Simulation of Voltage Regulation Device Control Modes. In Proceedings of the 2013 IEEE 39th Photovoltaic Specialists Conference (PVSC), Tampa, FL, USA, 16–21 June 2013; pp. 1700–1705. [Google Scholar] [CrossRef]
- Pecenak, Z.K.; Disfani, V.R.; Reno, M.J.; Kleissl, J. Multiphase Distribution Feeder Reduction. IEEE Trans. Power Syst. 2018, 33, 1320–1328. [Google Scholar] [CrossRef]
- Deboever, J.; Grijalva, S.; Reno, M.J.; Broderick, R.J. Fast Quasi-Static Time-Series (QSTS) for yearlong PV impact studies using vector quantization. Sol. Energy 2018, 159, 538–547. [Google Scholar] [CrossRef]
- López, C.D.; Idlbi, B.; Stetz, T.; Braun, M. Shortening Quasi-Static Time-Series Simulations for Cost-Benefit Analysis of Low Voltage Network Operation with Photovoltaic Feed-In. In Proceedings of the Power and Energy Student Summit (PESS) 2015, Dortmund, Germany, 13–14 January 2015. [Google Scholar] [CrossRef]
- Qureshi, M.U.; Grijalva, S.; Reno, M.J.; Deboever, J.; Zhang, X.; Broderick, R.J. A Fast Scalable Quasi-Static Time Series Analysis Method for PV Impact Studies Using Linear Sensitivity Model. IEEE Trans. Sustain. Energy 2019, 10, 301–310. [Google Scholar] [CrossRef]
- Jain, A.K.; Horowitz, K.; Ding, F.; Sedzro, K.S.; Palmintier, B.; Mather, B.; Jain, H. Dynamic hosting capacity analysis for distributed photovoltaic resources—Framework and case study. Appl. Energy 2020, 280, 115633. [Google Scholar] [CrossRef]
- Antoniadou-Plytaria, K.E.; Kouveliotis-Lysikatos, I.N.; Georgilakis, P.S.; Hatziargyriou, N.D. Distributed and Decentralized Voltage Control of Smart Distribution Networks: Models, Methods, and Future Research. IEEE Trans. Smart Grid 2017, 8, 2999–3008. [Google Scholar] [CrossRef]
- Pippi, K.D.; Kryonidis, G.C.; Nousdilis, A.I.; Papadopoulos, T.A. A unified control strategy for voltage regulation and congestion management in active distribution networks. Electr. Power Syst. Res. 2022, 212, 108648. [Google Scholar] [CrossRef]
- Xu, T.; Wade, N.S.; Davidson, E.M.; Taylor, P.C.; McArthur, S.D.J.; Garlick, W.G. Case-based reasoning for coordinated voltage control on distribution networks. Electr. Power Syst. Res. 2011, 81, 2088–2098. [Google Scholar] [CrossRef]
- Jabr, R.A. Linear Decision Rules for Control of Reactive Power by Distributed Photovoltaic Generators. IEEE Trans. Power Syst. 2018, 33, 2165–2174. [Google Scholar] [CrossRef]
- Li, P.; Zhang, C.; Wu, Z.; Xu, Y.; Hu, M.; Dong, Z. Distributed Adaptive Robust Voltage/VAR Control with Network Partition in Active Distribution Networks. IEEE Trans. Smart Grid 2020, 11, 2245–2256. [Google Scholar] [CrossRef]
- Li, J.; Liu, C.; Khodayar, M.E.; Wang, M.H.; Xu, Z.; Zhou, B.; Li, C. Distributed Online VAR Control for Unbalanced Distribution Networks with Photovoltaic Generation. IEEE Trans. Smart Grid 2020, 11, 4760–4772. [Google Scholar] [CrossRef]
- Liu, H.J.; Shi, W.; Zhu, H. Distributed voltage control in distribution networks: Online and robust implementations. IEEE Trans. Smart Grid 2018, 9, 6106–6117. [Google Scholar] [CrossRef]
- Li, Z.; Wu, Q.; Chen, J.; Huang, S.; Shen, F. Double-time-scale distributed voltage control for unbalanced distribution networks based on MPC and ADMM. Int. J. Electr. Power Energy Syst. 2023, 145, 108665. [Google Scholar] [CrossRef]
- Li, P.; Ji, H.; Yu, H.; Zhao, J.; Wang, C.; Song, G.; Wu, J. Combined decentralized and local voltage control strategy of soft open points in active distribution networks. Appl. Energy 2019, 241, 613–624. [Google Scholar] [CrossRef]
- Farina, M.; Guagliardi, A.; Mariani, F.; Sandroni, C.; Scattolini, R. Model predictive control of voltage profiles in MV networks with distributed generation. Control Eng. Pract. 2015, 34, 18–29. [Google Scholar] [CrossRef] [Green Version]
- Papadimitrakis, M.; Kapnopoulos, A.; Tsavartzidis, S.; Alexandridis, A. A cooperative PSO algorithm for Volt-VAR optimization in smart distribution grids. Electr. Power Syst. Res. 2022, 212, 108618. [Google Scholar] [CrossRef]
- Nayeripour, M.; Fallahzadeh-Abarghouei, H.; Waffenschmidt, E.; Hasanvand, S. Coordinated online voltage management of distributed generation using network partitioning. Electr. Power Syst. Res. 2016, 141, 202–209. [Google Scholar] [CrossRef]
- Zhao, B.; Xu, Z.; Xu, C.; Wang, C.; Lin, F. Network Partition-Based Zonal Voltage Control for Distribution Networks With Distributed PV Systems. IEEE Trans. Smart Grid 2018, 9, 4087–4098. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, X.; Wang, J.; Zhang, Y. Deep Reinforcement Learning Based Volt-VAR Optimization in Smart Distribution Systems. IEEE Trans. Smart Grid 2021, 12, 361–371. [Google Scholar] [CrossRef]
- El Helou, R.; Kalathil, D.; Xie, L. Fully Decentralized Reinforcement Learning-Based Control of Photovoltaics in Distribution Grids for Joint Provision of Real and Reactive Power. IEEE Open Access J. Power Energy 2021, 8, 175–185. [Google Scholar] [CrossRef]
- Liu, H.; Wu, W. Federated Reinforcement Learning for Decentralized Voltage Control in Distribution Networks. IEEE Trans. Smart Grid 2022, 13, 3840–3843. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Adaptive Computation and Machine Learning. In Reinforcement Learning: An Introduction, 2nd ed; The MIT Press: Cambridge, MA, USA, 2018; ISBN 9780262039246. [Google Scholar]
- Gupta, N.; Chandwani, V. Artificial Neural Networks as Universal Function Approximators. Int. J. Emerg. Trends Eng. Dev. 2012, 4, 456–464. [Google Scholar]
- Ghayoumi, M. Deep Learning in Practice, 1st ed; CRC Press: Boca Raton, FL, USA, 2022; ISBN 9781003025818. [Google Scholar]
- Zhang, Y.; Chen, D.; Ye, C. Toward Deep Neural Networks: WASD Neuronet Models, Algorithms, and Applications; Chapman & Hall/CRC Artificial Intelligence and Robotics Series; CRC Press: Boca Raton, FL, USA, 2019; ISBN 0-429-76098-1. [Google Scholar]
- Lotfi, A.; Pirnia, M. Constraint-guided Deep Neural Network for solving Optimal Power Flow. Electr. Power Syst. Res. 2022, 211, 108353. [Google Scholar] [CrossRef]
- Sun, R. Optimization for Deep Learning: Theory and Algorithms. arXiv 2019, arXiv:1912.08957. [Google Scholar]
- Shi, Z.; Yao, W.; Zeng, L.; Wen, J.; Fang, J.; Ai, X.; Wen, J. Convolutional neural network-based power system transient stability assessment and instability mode prediction. Appl. Energy 2020, 263, 114586. [Google Scholar] [CrossRef]
- Zou, M.; Zhao, Y.; Yan, D.; Tang, X.; Duan, P.; Liu, S. Double convolutional neural network for fault identification of power distribution network. Electr. Power Syst. Res. 2022, 210, 108085. [Google Scholar] [CrossRef]
- Wang, S.; Chen, H. A novel deep learning method for the classification of power quality disturbances using deep convolutional neural network. Appl. Energy 2019, 235, 1126–1140. [Google Scholar] [CrossRef]
- Schuster, M.; Paliwal, K.K. Bidirectional recurrent neural networks. IEEE Trans. Signal Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef] [Green Version]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations Using RNN Encoder-Decoder for Statistical Machine Translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1724–1734. [Google Scholar] [CrossRef]
- Dong, H.; Zhu, J.; Li, S.; Wu, W.; Zhu, H.; Fan, J. Short-term residential household reactive power forecasting considering active power demand via deep Transformer sequence-to-sequence networks. Appl. Energy 2023, 329, 120281. [Google Scholar] [CrossRef]
- Mellit, A.; Pavan, A.M.; Lughi, V. Deep learning neural networks for short-term photovoltaic power forecasting. Renew. Energy 2021, 172, 276–288. [Google Scholar] [CrossRef]
- Zhou, J.; Cui, G.; Hu, S.; Zhang, Z.; Yang, C.; Liu, Z.; Wang, L.; Li, C.; Sun, M. Graph neural networks: A review of methods and applications. AI Open 2020, 1, 57–81. [Google Scholar] [CrossRef]
- Lee, X.Y.; Sarkar, S.; Wang, Y. A graph policy network approach for Volt-Var Control in power distribution systems. Appl. Energy 2022, 323, 119530. [Google Scholar] [CrossRef]
- Hossain, R.R.; Huang, Q.; Huang, R. Graph convolutional network-based topology embedded deep reinforcement learning for voltage stability control. IEEE Trans. Power Syst. 2021, 36, 4848–4851. [Google Scholar] [CrossRef]
- Xing, Q.; Chen, Z.; Zhang, T.; Li, X.; Sun, K.H. Real-time optimal scheduling for active distribution networks: A graph reinforcement learning method. Int. J. Electr. Power Energy Syst. 2023, 145, 108637. [Google Scholar] [CrossRef]
- Zhang, H.; Yu, T. Taxonomy of Reinforcement Learning Algorithms BT—Deep Reinforcement Learning: Fundamentals, Research and Applications; Dong, H., Ding, Z., Zhang, S., Eds.; Springer: Singapore, 2020; pp. 125–133. ISBN 978-981-15-4095-0. [Google Scholar]
- Vlachogiannis, J.G.; Hatziargyriou, N.D. Reinforcement learning for reactive power control. IEEE Trans. Power Syst. 2004, 19, 1317–1325. [Google Scholar] [CrossRef]
- Van Hasselt, H.; Guez, A.; Silver, D. Deep Reinforcement Learning with Double Q-Learning. AAAI Conf. Artif. Intell. 2016, 30, 2094–2100. [Google Scholar] [CrossRef]
- Wang, Z.; Schaul, T.; Hessel, M.; Van Hasselt, H.; Lanctot, M.; De Frcitas, N. Dueling Network Architectures for Deep Reinforcement Learning. In Proceedings of the 33rd International Conference on International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; Volume 48, pp. 2939–2947. [Google Scholar]
- Fortunato, M.; Azar, M.G.; Piot, B.; Menick, J.; Hessel, M.; Osband, I.; Graves, A.; Mnih, V.; Munos, R.; Hassabis, D.; et al. Noisy Networks for Exploration. In Proceedings of the 6th International Conference on Learning Representations (ICLR 2018), Vancouver, BC, Canada, 30 April–3 May 2018; pp. 1–21. [Google Scholar]
- Bellemare, M.G.; Dabney, W.; Munos, R. A Distributional Perspective on Reinforcement Learning. In Proceedings of the 34th International Conference on Machine Learning, Sydney, NSW, Australia, 6–11 August 2017; Volume 70, pp. 693–711. [Google Scholar]
- Yang, Q.; Wang, G.; Sadeghi, A.; Giannakis, G.B.; Sun, J. Two-Timescale Voltage Control in Distribution Grids Using Deep Reinforcement Learning. IEEE Trans. Smart Grid 2020, 11, 2313–2323. [Google Scholar] [CrossRef] [Green Version]
- Schulman, J.; Levine, S.; Moritz, P.; Jordan, M.I.; Abbeel, P. Trust Region Policy Optimization. arXiv 2015, arXiv:1502.05477. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization Algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Sutton, R.S.; McAllester, D.; Singh, S.; Mansour, Y. Policy gradient methods for reinforcement learning with function approximation. Adv. Neural Inf. Process. Syst. 2000, 32, 1057–1063. [Google Scholar]
- Cao, D.; Hu, W.; Xu, X.; Wu, Q.; Huang, Q.; Chen, Z.; Blaabjerg, F. Deep Reinforcement Learning Based Approach for Optimal Power Flow of Distribution Networks Embedded with Renewable Energy and Storage Devices. J. Mod. Power Syst. Clean Energy 2021, 9, 1101–1110. [Google Scholar] [CrossRef]
- Silver, D.; Lever, G.; Heess, N.; Degris, T.; Wierstra, D.; Riedmiller, M. Deterministic policy gradient algorithms. In Proceedings of the 31st International Conference on International Conference on Machine Learning, Beijing China, 21–26 June 2014; Volume 1, pp. 605–619. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous Control with Deep Reinforcement Learning. In Proceedings of the 4th International Conference on Learning Representations (ICLR 2016), San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Cao, D.; Zhao, J.; Hu, W.; Ding, F.; Yu, N.; Huang, Q.; Chen, Z. Model-free voltage control of active distribution system with PVs using surrogate model-based deep reinforcement learning. Appl. Energy 2022, 306, 117982. [Google Scholar] [CrossRef]
- Kou, P.; Liang, D.; Wang, C.; Wu, Z.; Gao, L. Safe deep reinforcement learning-based constrained optimal control scheme for active distribution networks. Appl. Energy 2020, 264, 114772. [Google Scholar] [CrossRef]
- Haarnoja, T.; Zhou, A.; Abbeel, P.; Levine, S. Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor. arXiv 2018, arXiv:1801.01290. [Google Scholar]
- Liu, Q.; Guo, Y.; Deng, L.; Tang, W.; Sun, H.; Huang, W. Robust Offline Deep Reinforcement Learning for Volt-Var Control in Active Distribution Networks. In Proceedings of the 2021 IEEE 5th Conference on Energy Internet and Energy System Integration (EI2), Taiyuan, China, 22–24 October 2021; pp. 442–448. [Google Scholar] [CrossRef]
- Liu, H.; Wu, W.; Wang, Y. Bi-level Off-policy Reinforcement Learning for Two-Timescale Volt/VAR Control in Active Distribution Networks. IEEE Trans. Power Syst. 2022, 38, 385–395. [Google Scholar] [CrossRef]
- Yang, Q.; Simão, T.D.; Tindemans, S.; Spaan, M.T.J. WCSAC: Worst-Case Soft Actor Critic for Safety-Constrained Reinforcement Learning. AAAI Conf. Artif. Intell. 2021, 35, 10639–10646. [Google Scholar] [CrossRef]
- Ha, S.; Xu, P.; Tan, Z.; Levine, S.; Tan, J. Learning to Walk in the Real World with Minimal Human Effort. arXiv 2020, arXiv:2002.08550. [Google Scholar]
- Wang, W.; Yu, N.; Gao, Y.; Shi, J. Safe Off-Policy Deep Reinforcement Learning Algorithm for Volt-VAR Control in Power Distribution Systems. IEEE Trans. Smart Grid 2020, 11, 3008–3018. [Google Scholar] [CrossRef]
- Wang, W.; Yu, N.; Shi, J.; Gao, Y. Volt-VAR Control in Power Distribution Systems with Deep Reinforcement Learning. In Proceedings of the 2019 IEEE International Conference on Communications, Control, and Computing Technologies for Smart Grids (SmartGridComm), Beijing, China, 21–23 October 2019. [Google Scholar] [CrossRef]
- Liu, H.; Wu, W. Two-Stage Deep Reinforcement Learning for Inverter-Based Volt-VAR Control in Active Distribution Networks. IEEE Trans. Smart Grid 2021, 12, 2037–2047. [Google Scholar] [CrossRef]
- Gao, Y.; Wang, W.; Yu, N. Consensus Multi-Agent Reinforcement Learning for Volt-VAR Control in Power Distribution Networks. IEEE Trans. Smart Grid 2021, 12, 3594–3604. [Google Scholar] [CrossRef]
- Xu, Y.; Zhang, W.; Liu, W.; Ferrese, F. Multiagent-Based Reinforcement Learning for Optimal Reactive Power Dispatch. IEEE Trans. Syst. Man, Cybern. Part C Appl. Rev. 2012, 42, 1742–1751. [Google Scholar] [CrossRef]
- Nguyen, T.T.; Nguyen, N.D.; Nahavandi, S. Deep Reinforcement Learning for Multiagent Systems: A Review of Challenges, Solutions, and Applications. IEEE Trans. Cybern. 2020, 50, 3826–3839. [Google Scholar] [CrossRef] [Green Version]
- Lowe, R.; Wu, Y.; Tamar, A.; Harb, J.; Abbeel, P.; Mordatch, I. Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments. arXiv 2017, arXiv:1706.02275. [Google Scholar]
- Sun, X.; Qiu, J. Two-Stage Volt/Var Control in Active Distribution Networks with Multi-Agent Deep Reinforcement Learning Method. IEEE Trans. Smart Grid 2021, 12, 2903–2912. [Google Scholar] [CrossRef]
- Wang, S.; Duan, J.; Shi, D.; Xu, C.; Li, H.; Diao, R.; Wang, Z. A Data-Driven Multi-Agent Autonomous Voltage Control Framework Using Deep Reinforcement Learning. IEEE Trans. Power Syst. 2020, 35, 4644–4654. [Google Scholar] [CrossRef]
- Cao, D.; Hu, W.; Zhao, J.; Huang, Q.; Chen, Z.; Blaabjerg, F. A Multi-Agent deep reinforcement learning based voltage regulation using coordinated pv inverters. IEEE Trans. Power Syst. 2020, 35, 4120–4123. [Google Scholar] [CrossRef]
- Liu, H.; Wu, W. Online Multi-Agent Reinforcement Learning for Decentralized Inverter-Based Volt-VAR Control. IEEE Trans. Smart Grid 2021, 12, 2980–2990. [Google Scholar] [CrossRef]
- Li, C.; Jin, C.; Sharma, R. Coordination of PV Smart Inverters using Deep Reinforcement Learning for Grid Voltage Regulation. In Proceedings of the 18th IEEE International Conference On Machine Learning And Applications (ICMLA), Boca Raton, FL, USA, 16–19 December 2019; pp. 1930–1937. [Google Scholar] [CrossRef] [Green Version]
- Cao, D.; Zhao, J.; Hu, W.; Ding, F.; Huang, Q.; Chen, Z.; Blaabjerg, F. Data-Driven Multi-Agent Deep Reinforcement Learning for Distribution System Decentralized Voltage Control with High Penetration of PVs. IEEE Trans. Smart Grid 2021, 12, 4137–4150. [Google Scholar] [CrossRef]
- Zhang, X.; Liu, Y.; Duan, J.; Qiu, G.; Liu, T.; Liu, J. DDPG-Based Multi-Agent Framework for SVC Tuning in Urban Power Grid with Renewable Energy Resources. IEEE Trans. Power Syst. 2021, 36, 5465–5475. [Google Scholar] [CrossRef]
- Cao, D.; Zhao, J.; Hu, W.; Yu, N.; Ding, F.; Huang, Q.; Chen, Z. Deep Reinforcement Learning Enabled Physical-Model-Free Two-Timescale Voltage Control Method for Active Distribution Systems. IEEE Trans. Smart Grid 2022, 13, 149–165. [Google Scholar] [CrossRef]
- Li, H.; He, H. Learning to Operate Distribution Networks With Safe Deep Reinforcement Learning. IEEE Trans. Smart Grid 2022, 13, 1860–1872. [Google Scholar] [CrossRef]
- Hu, D.; Peng, Y.; Yang, J.; Deng, Q.; Cai, T. Deep Reinforcement Learning Based Coordinated Voltage Control in Smart Distribution Network. In Proceedings of the 2021 International Conference on Power System Technology (POWERCON), Haikou, China, 8–9 December 2021; pp. 1030–1034. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| Features | [10] | [11] | [12] | [13] | [14] | [15] | Current Work |
|---|---|---|---|---|---|---|---|
| HC assessment methods | ✓ | ✓ | x | x | x | x | ✓ |
| HC enhancement techniques | x | ✓ | x | x | x | x | P |
| An overview of reinforcement learning algorithms | x | x | ✓ | ✓ | ✓ | ✓ | ✓ |
| Coordinated voltage control using reinforcement learning methods | x | x | ✓ | ✓ | ✓ | P | ✓ |
| Identification of various challenges in using reinforcement learning methods | x | x | ✓ | x | ✓ | P | ✓ |
| Algorithm | Ref. | Sample Efficiency | Scalability | Constraint Satisfaction and Safety | Robustness to Network Changes | Centralized/Decentralized |
|---|---|---|---|---|---|---|
| Tabular Q-learning | [79] | High | Low | Low | Low | Centralized |
| DQN | [84] | High | Low | Low | Low | Centralized |
| PPO | [75,88] | Low | High | Medium | Low | Centralized |
| DDPG | [77,91,92] | High | High | Medium | Low | Centralized |
| SAC | [94,95] | High | High | Medium | Low | Centralized |
| CSAC | [98,99] | High | High | High | Low | Centralized |
| JASAC | [100] | High | High | High | High | Centralized |
| MA Tabular Q-learning | [102] | High | High | Low | Medium | Decentralized |
| MADQN | [57] | High | High | Low | Medium | Decentralized |
| MADDPG | [105,106,111] | High | High | Medium | High | Decentralized |
| MASAC | [101,110,112] | High | High | Medium | High | Decentralized |
| MACSAC | [108] | High | High | High | High | Decentralized |
| Ref. | RL Algorithm | State Space | Action Space | Algorithm(s) Used for Benchmarking | Implemented Network(s) | Description |
|---|---|---|---|---|---|---|
| [79] | Tabular Q-learning | Constraint violations of busbars | Discretized actions for OLTCs and reactive power compensation devices | Probabilistic constrained load flow and genetic algorithm | IEEE 14-bus system and IEEE 136-bus system | A tabular Q-learning algorithm is proposed to provide offline control settings while satisfying operational limits of the constraint variables |
| [84] | DQN | Active power of busbars and current capacitor configurations | Discretized actions for capacitor banks (on/off) | Nil | IEEE 123-bus system and a real-world 47 bus network | A two-timescale voltage control algorithm is proposed with slow-timescale learning for optimal capacitor settings using DQN and fast timescale optimization for smart inverter reactive power using optimal power flow models |
| [75] | GCN-PPO | Minimum-phase voltage at every bus and the control status of voltage regulators, capacitor banks and batteries | Discretized actions for the tap positions of voltage regulators, capacitor banks (on/off) and batteries (charging/discharging) | Dense-PPO | IEEE 13-bus system, IEEE 123-bus system, IEEE 34-bus system and 8500 node system | GCN-based policy network is used in the PPO algorithm to capture the topological information of the distribution network and regulate the voltage |
| [77] | GAT-DDPG | Connection relations and power information of the distribution network are mapped to graph-structured vertices and edges | Power outputs of PV systems, flexible loads, battery energy systems and SVCs | DDPG GCN-DDPG | IEEE 33-bus system | A GAT-based policy network is combined with DDPG algorithm to optimally schedule controllable devices while being robust to network topology variations |
| [91] | DDPG | Active and reactive power of customer nodes and active power outputs of PV systems | Active power curtailed in PV systems and reactive power outputs of SVCs and PV systems | Double-DQN, model-predictive control (MPC) | IEEE 123-bus system | A model-free voltage control method is proposed using a DNN-based surrogate model of the distribution network with a DDPG algorithm |
| [92] | DDPG | Voltage magnitudes of bus voltages | Smart transformer reactive power adjustments | MPC | IEEE 33-bus system and IEEE 123-bus system | A DDPG algorithm is utilized with a safety layer technique to achieve the objectives of system power loss reduction and voltage regulation by realizing optimal control policies for smart transformers |
| [94] | SAC | Voltage, active and reactive power of nodes and the previous action | Reactive power outputs of inverter-based energy resources and SVCs | Without Volt-VAr control, online trained SAC | IEEE 33-bus system and | A PEDNN is utilized to learn the power flow model of the distribution network and then incorporated in the training process of the SAC-based polices that is used to regulate the voltage in the distribution network |
| [95] | SAC | Active and reactive power injections of buses, voltage magnitudes and tap positions of OLTCs and capacitor banks | Discrete actions for tap positions in the SAC agent controlling slow timescale devices; continuous actions for reactive power injections in the SAC agent controlling fast timescale devices | DQN | IEEE 33-bus system and IEEE 123-bus system | The proposed two-timescale SAC based algorithm learns control policies for both fast timescale and slow timescale network elements to optimize voltage regulation in the distribution network in a coordinated manner |
| [98] | CSAC | Active and reactive power injections of buses and current tap positions of controlled devices | Discrete actions for tap positions of voltage regulators, OLTCs and capacitor banks. | SAC, DQN and CPO | IEEE 4-bus, 34-bus and 123-bus distribution test feeders | A safe model-free CSAC algorithm is proposed to regulate the voltage in the distribution network and achieve operational constraint satisfaction |
| [100] | JASAC | Voltage magnitude, active and reactive power of buses in the network | Reactive power outputs of inverter-based energy resources and SVCs | SAC | IEEE 33-bus, 69-bus and 123-bus test feeders | A two-stage deep RL algorithm that is robust to network variations is proposed to regulate the voltage in the distribution network |
| [102] | MA tabular Q-learning | The local observations for every agent are the active power flows to neighbouring buses | Voltage regulators, capacitor banks and OLTCs are considered as agents and the action space is dependent on the type of controlling device | Discrete particle swarm optimization algorithm and interior point method | Ward-Hale 6-bus system, IEEE 30-bus system and the IEEE 162-bus system | MA tabular Q-learning algorithm is proposed to regulate the voltage of the distribution network and minimize the real power loss while satisfying the operational constraints |
| [57] | MADQN | Three-phase voltages at all buses in the distribution network | Control actions of smart inverters, autonomous voltage regulators and capacitor banks | Nil. | IEEE 13-bus and 123-bus distribution systems | A MADQN algorithm is proposed to regulate the voltage and reduce power loss in an unbalance distribution network |
| [105] | MADDPG | Local measurements of PV systems combined with dispatch results of OLTC and capacitor banks | Difference in PV reactive power between two consecutive time steps | One-timescale centralized, double-timescale local and combined centralized and local Volt-VAr | IEEE 33-bus system | A MADDPG algorithm is proposed to regulate the voltage that features offline centralized training and online decentralized execution |
| [106] | MADDPG | States are defined as a vector including system bus voltages, phase angles and power flows | Action space is defined as a vector of generator bus voltage magnitudes | DDPG | Illinois 200-bus system | A data-driven MADDPG algorithm that is robust to a weak communication environment is proposed to solve the autonomous voltage control problem |
| [107] | MADDPG | A set of local observations consisting of active and reactive power of loads and active power injections of PV systems | The action space is a set of actions by all agents consisting of reactive power outputs of the inverters | QV-droop control and MADDPG without attention critic | IEEE 33-bus system and IEEE 123-bus system | A MADDPG algorithm is developed by incorporating an attention critic model that allows intelligent learning and identifies certain information that is the most relevant to the rewards |
| [101] | MASAC | State is a set of network active and reactive power injections and the status of the controlled devices in the previous step | Action space is a set of tap positions of OLTCs, capacitor banks and voltage regulators | SAC, MPC and mixed-integer conic programming | IEEE 4-bus, 34-bus and 123-bus distribution test feeders | A randomization-based consensus algorithm is developed utilizing MASAC by establishing communication of each agent with its neighbours to regulate the voltage in the distribution network |
| [108] | MACSAC | State space is defined as a vector that consists of active and reactive power injections of buses and voltage magnitudes | Action space is defined as vector containing the reactive power outputs of PV inverters and SVCs | CSAC, MASAC and MADDPG | 33-bus, 141-bus and IEEE 37-bus distribution test feeders | The distribution network is divided into several areas and each area is given a local controller that act as an agent in the implemented MACSAC algorithm; each agent controls the reactive power of the controllable devices locally in the respective area |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Suchithra, J.; Robinson, D.; Rajabi, A. Hosting Capacity Assessment Strategies and Reinforcement Learning Methods for Coordinated Voltage Control in Electricity Distribution Networks: A Review. Energies 2023, 16, 2371. https://0-doi-org.brum.beds.ac.uk/10.3390/en16052371
Suchithra J, Robinson D, Rajabi A. Hosting Capacity Assessment Strategies and Reinforcement Learning Methods for Coordinated Voltage Control in Electricity Distribution Networks: A Review. Energies. 2023; 16(5):2371. https://0-doi-org.brum.beds.ac.uk/10.3390/en16052371
Chicago/Turabian StyleSuchithra, Jude, Duane Robinson, and Amin Rajabi. 2023. "Hosting Capacity Assessment Strategies and Reinforcement Learning Methods for Coordinated Voltage Control in Electricity Distribution Networks: A Review" Energies 16, no. 5: 2371. https://0-doi-org.brum.beds.ac.uk/10.3390/en16052371