

Multi-Microgrid Collaborative Optimization Scheduling Using an Improved Multi-Agent Soft Actor-Critic Algorithm

Abstract
:1. Introduction
- To address the issue of the transaction and complementarity of electric energy among multi-microgrids, we constructed a collaborative optimization scheduling model for MMG based on a multi-agent centralized training distributed execution framework. This model effectively facilitates energy transactions between different entities and reduces the MMG system operating cost.
- To enhance the generalization performance of the algorithm to cope with renewable energy uncertainties, we proposed an AutoML-based MASAC analysis method for MMG energy management. This approach eliminates the reliance on mathematical probability distributions for renewable energy outputs and increases the adaptability of the method to complex MMG scenarios.
- Simulation tests have demonstrated that the proposed method can effectively manage the demand between different microgrids and promote the consumption of renewable energy, while achieving power complementarity. Moreover, the proposed method has better economy and computational efficiency than other RL algorithms.
- The remaining sections of this paper are organized as follows: Section 2 mainly introduces the MMG energy management model, while Section 3 presents the solution method of the proposed model. In Section 4, we conduct a comprehensive case analysis to demonstrate the effectiveness of the proposed method. Finally, Section 5 summarizes the paper.
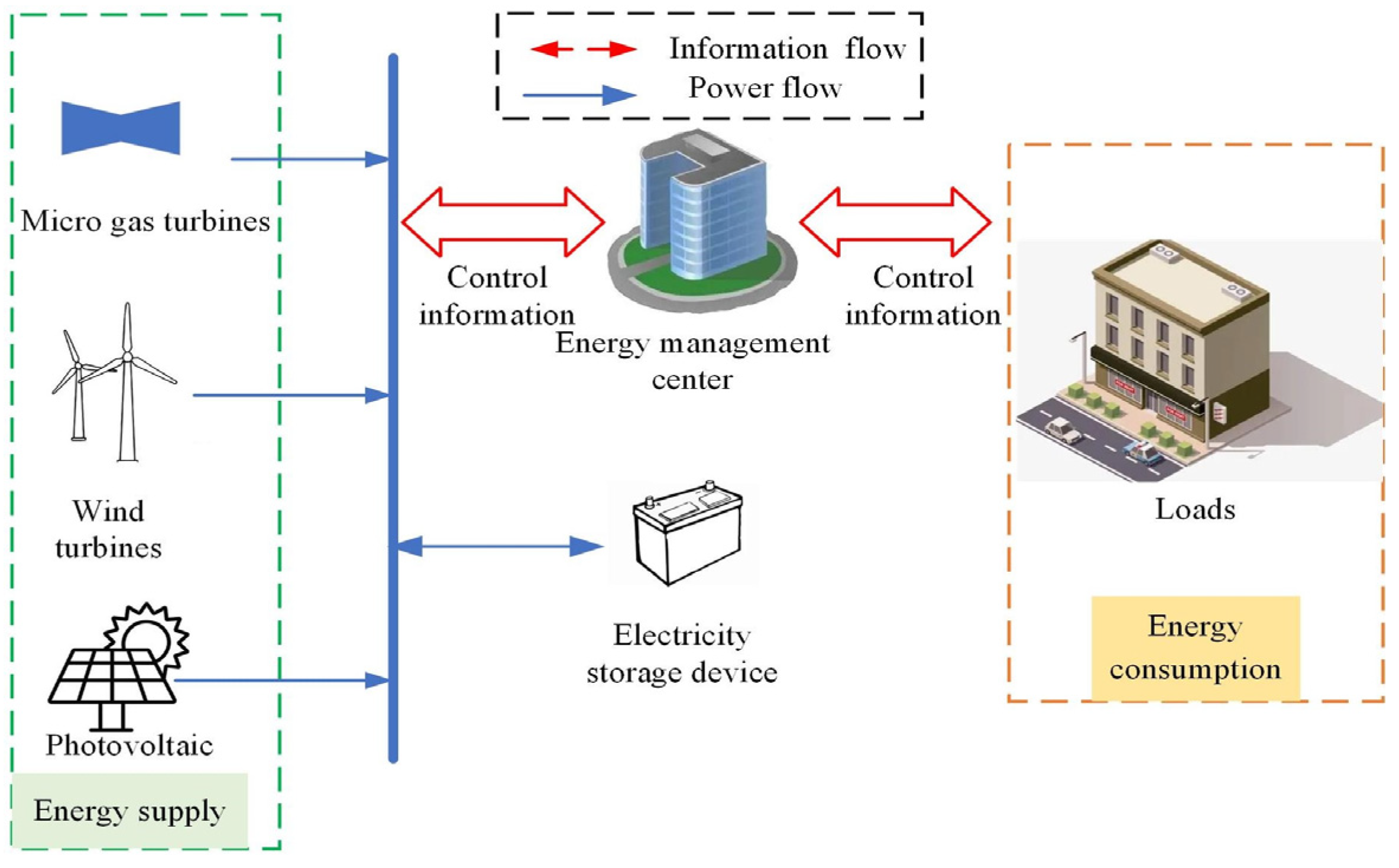
2. Multi-Microgrid Energy Management Model
2.1. Optimal Modeling of the Individual Microgrid
2.1.1. Distributed Generation
2.1.2. Micro-Gas Turbines
2.1.3. Electricity Storage Devices
2.2. Multi-Microgrid Energy Management Model
2.2.1. Objective Function
Transaction Cost between Microgrids
Transaction Cost of MGs and Distribution Network
Microgrid Power Loss
Power Imbalance between Energy Supply and Consumption
2.2.2. Constraints
Electrical Balance Constraint
Constraints of Electricity Storage Devices
Constraints on Power Trading between MGs and Distribution Network
Constraints on Electricity Traded between Microgrids
3. Model Solving
3.1. Automated Machine Learning
3.2. MASAC Methodology
| Algorithm 1: MASAC Algorithm Based on AutoML for Multi-Microgrid Optimal Scheduling |
| 1: Initialize the neural network parameters φ and ξ of actor and critic. 2: Initialize the replay buffer ℜ with size . 3: for trial = 1: M do 4: Select a set of hyperparameters from the search space according to the Metis Tuner. 5: for episode = 1: E do 6: Select random action from the action space. 7: Select the initial state from the state space. 8: for t = 1: H do 9: Each agent i selects action ai from the action space. 10: Interact joint actions a = {a1,a2,… anMG) with the environment to get corresponding states x′ and rewards r. 11: Store transition (x,a,r,x′) in experience replay buffer ℜ. 12: for agent = 1: nMG do 13: Sample a mini-batch of N experience (xN,aN,rN,) from the experience replay buffer ℜ. 14: Updating the critic network by minimizing the loss function. 15: Updating the actor network via gradient descent. 16: end for 17: Updating critic target network parameters using soft update. 18: end for 19: end for 20: Collect the reward and upload it to the Metis Tuner. 21: end for 22: Select the best hyperparameters and policies. |
3.3. Solving Process
4. Case Study
4.1. Settings in Test Case
4.2. Results and Analysis
4.2.1. Analyze Optimization Results Using AutoML
4.2.2. Electrical Balance Analysis of Each MG
4.2.3. Economic Analysis
4.2.4. Analysis of Transactions between MGs as Well as between MGs and the Distribution Network
4.2.5. ESD Charging and Discharging Strategy Analysis
4.2.6. Performance Comparison with other RL Algorithms
4.2.7. Analysis of Convergence and Computational Efficiency across Multiple Runs
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Parlikar, A.; Schott, M.; Godse, K.; Kucevic, D.; Jossen, A.; Hesse, H. High-power electric vehicle charging: Low-carbon grid integration pathways with stationary lithium-ion battery systems and renewable generation. Appl. Energy 2023, 333, 120541. [Google Scholar] [CrossRef]
- Li, Y.; Han, M.; Shahidehpour, M.; Li, J.Z.; Long, C. Data-driven distributionally robust scheduling of community integrated energy systems with uncertain renewable generations considering integrated demand response. Appl. Energy 2023, 335, 120749. [Google Scholar] [CrossRef]
- Kim, H.J.; Kim, M.K. A novel deep learning-based forecasting model optimized by heuristic algorithm for energy management of microgrid. Appl. Energy 2023, 332, 120525. [Google Scholar] [CrossRef]
- Feng, Z.N.; Wei, F.R.; Wu, C.T.; Sui, Q.; Lin, X.N.; Li, Z.T. Novel source-storage coordination strategy adaptive to impulsive generation characteristic suitable for isolated island microgrid scheduling. IEEE Trans. Smart Grid 2023, 2023, 3244852. [Google Scholar] [CrossRef]
- Li, Y.; Yang, Z.; Li, G.Q.; Zhao, D.B.; Tian, W. Optimal scheduling of an isolated microgrid with battery storage considering load and renewable generation uncertainties. IEEE Trans. Ind. Electr. 2018, 66, 1565–1575. [Google Scholar] [CrossRef] [Green Version]
- An, D.; Yang, Q.Y.; Li, D.H.; Wu, Z.Z. Distributed Online Incentive Scheme for Energy Trading in Multi-Microgrid Systems. IEEE Trans. Autom. Sci. Eng. 2023, 2023, 3236408. [Google Scholar] [CrossRef]
- Hakimi, S.M.; Hasankhani, A.; Shafie-khah, M.; Catalão, J.P.S. Stochastic planning of a multi-microgrid considering integration of renewable energy resources and real-time electricity market. Appl. Energy 2021, 298, 117215. [Google Scholar] [CrossRef]
- Zhao, Z.L.; Guo, J.T.; Luo, X.; Lai, C.S.; Yang, P.; Lai, L.L.; Li, P.; Guerrero, J.M.; Shahidehpour, M. Distributed robust model predictive control-based energy management strategy for islanded multi-microgrids considering uncertainty. IEEE Trans. Smart Grid 2022, 13, 2107–2120. [Google Scholar] [CrossRef]
- Li, Y.Z.; He, S.Y.; Li, Y.; Shi, Y.; Zeng, Z.G. Federated multiagent deep reinforcement learning approach via physics-informed reward for multimicrogrid energy management. IEEE Trans. Neur. Netw. Learn. Syst. 2023, 2023, 3232630. [Google Scholar] [CrossRef]
- Lin, S.F.; Liu, C.T.; Li, D.D.; Fu, Y. Bi-level multiple scenarios collaborative optimization configuration of CCHP regional multi-microgrid system considering power interaction among microgrids. Proc. CSEE 2020, 40, 1409–1421. [Google Scholar] [CrossRef]
- Xia, Y.X.; Xu, Q.S.; Huang, Y.; Liu, Y.H.; Li, F.X. Preserving privacy in nested peer-to-peer energy trading in networked microgrids considering incomplete rationality. IEEE Trans. Smart Grid 2022, 14, 606–622. [Google Scholar] [CrossRef]
- Ali, L.; Muyeen, S.M.; Bizhani, H.; Simoes, M.G. Economic planning and comparative analysis of market-driven multi-microgrid system for peer-to-peer energy trading. IEEE Trans. Ind. Appl. 2022, 58, 4025–4036. [Google Scholar] [CrossRef]
- Xie, P.L.; Tan, S.; Bazmohammadi, N.; Guerrero, J.M.; Vasquez, J.C.; Alcala, J.M.; Carreño, J.E.M. A distributed real-time power management scheme for shipboard zonal multi-microgrid system. Appl. Energy 2022, 317, 119072. [Google Scholar] [CrossRef]
- Daneshvar, M.; Mohammadi-Ivatloo, B.; Abapour, M.; Asadi, S. Energy exchange control in multiple microgrids with transactive energy management. J. Mod. Power Syst. Clean Energy 2020, 8, 719–726. [Google Scholar] [CrossRef]
- Jiang, H.Y.; Ning, S.Y.; Ge, Q.B.; Yun, W.; Xu, J.Q.; Bin, Y. Optimal economic dispatching of multi-microgrids by an improved genetic algorithm. IET Cyber-Syst. Robot. 2021, 3, 68–76. [Google Scholar] [CrossRef]
- Zhang, X.Z.; Wang, Z.Y.; Lu, Z.Y. Multi-objective load dispatch for microgrid with electric vehicles using modified gravitational search and particle swarm optimization algorithm. Appl. Energy 2022, 306, 118018. [Google Scholar] [CrossRef]
- Nawaz, A.; Wu, J.; Ye, J.; Dong, Y.D.; Long, C.N. Distributed MPC-based energy scheduling for islanded multi-microgrid considering battery degradation and cyclic life deterioration. Appl. Energy 2023, 329, 120168. [Google Scholar] [CrossRef]
- Chen, W.D.; Wang, J.N.; Yu, G.Y.; Chen, J.J.; Hu, Y.M. Research on day-ahead transactions between multi-microgrid based on cooperative game model. Appl. Energy 2022, 316, 119106. [Google Scholar] [CrossRef]
- Li, Y.; Bu, F.J.; Li, Y.Z.; Long, C. Optimal scheduling of island integrated energy systems considering multi-uncertainties and hydrothermal simultaneous transmission: A deep reinforcement learning approach. Appl. Energy 2023, 333, 120540. [Google Scholar] [CrossRef]
- Alahyari, A.; Jooshaki, M. Fast energy management approach for the aggregated residential load and storage under uncertainty. J. Energy Storage 2023, 62, 106848. [Google Scholar] [CrossRef]
- Zou, H.L.; Wang, Y.; Mao, S.W.; Zhang, F.H.; Chen, X. Distributed online energy management in interconnected microgrids. IEEE Intern. Things J. 2019, 7, 2738–2750. [Google Scholar] [CrossRef]
- Fan, Z.; Zhang, W.; Liu, W.X. Multi-agent deep reinforcement learning based distributed optimal generation control of DC microgrids. IEEE Trans. Smart Grid 2023, 2023, 3237200. [Google Scholar] [CrossRef]
- Wang, Y.; Qiu, D.W.; Teng, F.; Strbac, G. Towards microgrid resilience enhancement via mobile power sources and repair crews: A multi-agent reinforcement learning approach. IEEE Trans. Power Syst. 2023, 2023, 3240479. [Google Scholar] [CrossRef]
- Hu, C.F.; Wen, G.H.; Wang, S.; Fu, J.J.; Yu, W.W. Distributed Multiagent Reinforcement Learning with Action Networks for Dynamic Economic Dispatch. IEEE Trans. Neur. Netw. Learn. Syst. 2023, 2023, 3234049. [Google Scholar] [CrossRef]
- Qiu, D.W.; Wang, Y.; Sun, M.Y.; Strbac, G. Multi-service provision for electric vehicles in power-transportation networks towards a low-carbon transition: A hierarchical and hybrid multi-agent reinforcement learning approach. Appl. Energy 2022, 313, 118790. [Google Scholar] [CrossRef]
- Wang, Y.; Wu, Y.K.; Tang, Y.J.; Li, Q.; He, H.W. Cooperative energy management and eco-driving of plug-in hybrid electric vehicle via multi-agent reinforcement learning. Appl. Energy 2023, 332, 120563. [Google Scholar] [CrossRef]
- Gao, Y.; Matsunami, Y.; Miyata, S.; Akashi, Y. Multi-agent reinforcement learning dealing with hybrid action spaces: A case study for off-grid oriented renewable building energy system. Appl. Energy 2022, 326, 120021. [Google Scholar] [CrossRef]
- Park, K.; Moon, I. Multi-agent deep reinforcement learning approach for EV charging scheduling in a smart grid. Appl. Energy 2022, 328, 120111. [Google Scholar] [CrossRef]
- Yu, Y.; Liu, G.P.; Hu, W.S. Learning-based secure control for multichannel networked systems under smart attacks. IEEE Trans. Ind. Electr. 2022, 70, 7183–7193. [Google Scholar] [CrossRef]
- Xia, Y.; Xu, Y.; Wang, Y.; Mondal, S.; Dasgupta, S.; Gupta, A.K.; Gupta, G.M. A safe policy learning-based method for decentralized and economic frequency control in isolated net-worked-microgrid systems. IEEE Trans. Sustain. Energy 2022, 13, 1982–1993. [Google Scholar] [CrossRef]
- Soleimanzade, M.A.; Kumar, A.; Sadrzadeh, M. Novel data-driven energy management of a hybrid photovoltaic-reverse osmosis desalination system using deep reinforcement learning. Appl. Energy 2022, 317, 119184. [Google Scholar] [CrossRef]
- Li, Y.; Wang, R.N.; Li, Y.Z.; Zhang, M.; Long, C. Wind power forecasting considering data privacy protection: A federated deep reinforcement learning approach. Appl. Energy 2023, 329, 120291. [Google Scholar] [CrossRef]
- Li, Y.; Wang, B.; Yang, Z.; Li, J.Z.; Li, G.Q. Optimal scheduling of integrated demand response-enabled community-integrated energy systems in uncertain environments. IEEE Trans. Ind. Appl. 2021, 58, 2640–2651. [Google Scholar] [CrossRef]
- Li, Y.; Feng, B.; Wang, B.; Sun, S.C. Joint planning of distributed generations and energy storage in active distribution networks: A Bi-Level programming approach. Energy 2022, 245, 123226. [Google Scholar] [CrossRef]
- Hutter, F.; Kotthoff, L.; Vanschoren, J. Automated Machine Learning: Methods, Systems, Challenges; Springer: Cham, Switzerland, 2019. [Google Scholar]
- Awad, M.; Khanna, R. Machine Learning and Knowledge Discovery. In Efficient Learning Machines: Theories, Concepts, and Applications for Engineers and System Designers; Awad, M., Khanna, R., Eds.; Apress: Berkeley, CA, USA, 2015; pp. 19–38. [Google Scholar]
- He, X.; Zhao, K.Y.; Chu, X.W. AutoML: A survey of the state-of-the-art. Knowl. Based Syst. 2021, 212, 106622. [Google Scholar] [CrossRef]
- Li, Z.L.; Liang, C.J.M.; He, W.J.; Zhu, L.J.; Dai, W.J.; Jiang, J.; Sun, G.Z. Metis: Robustly tuning tail latencies of cloud systems. In Proceedings of the 2018 USENIX Annual Technical Conference (USENIX ATC ’18), Boston, MA, USA, 11–13 July 2018; pp. 981–992. [Google Scholar]
- Li, Y.; Wang, R.N.; Yang, Z. Optimal scheduling of isolated microgrids using automated reinforcement learning-based multi-period forecasting. IEEE Trans. Sustain. Energy 2021, 13, 159–169. [Google Scholar] [CrossRef]
- McKay, M.D.; Beckman, R.J.; Conover, W.J. A comparison of three methods for selecting values of input variables in the analysis of output from a computer code. Technometrics 2000, 42, 55–61. [Google Scholar] [CrossRef]
- Buşoniu, L.; Babuška, R.; De Schutter, B. Multi-Agent Reinforcement Learning: An Overview. In Innovations in Multi-Agent Systems and Applications-1; Srinivasan, D., Jain, L.C., Eds.; Studies in Computational Intelligence; Springer: Berlin, Heidelberg, 2010; Volume 310, pp. 183–221. [Google Scholar]
- Lowe, R.; Wu, Y.I.; Tamar, A.; Harb, J.; Pieter Abbeel, O.; Mordatch, I. Multi-agent actor-critic for mixed cooperative-competitive environments. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 1–12. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Logenthiran, T.; Srinivasan, D.; Khambadkone, A.M.; Aung, H.N. Multiagent system for real-time operation of a microgrid in real-time digital simulator. IEEE Trans. Smart Grid 2012, 3, 925–933. [Google Scholar] [CrossRef]
- Li, Y.; Wang, B.; Yang, Z.; Li, J.Z.; Chen, C. Hierarchical stochastic scheduling of multi-community integrated energy systems in uncertain environments via Stackelberg game. Appl. Energy 2022, 308, 118392. [Google Scholar] [CrossRef]
- Sun, J.Z.; Deng, J.H.; Li, Y. Indicator & crowding distance-based evolutionary algorithm for combined heat and power economic emission dispatch. Appl. Soft Comput. 2020, 90, 106158. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.; Chen, Y.B.; Ma, J.; Zhao, D.W.; Qian, M.H.; Li, D.; Wang, D.; Zhao, L.H.; Zhou, M. Stochastic optimal dispatch of combined heat and power integrated AA-CAES power station considering thermal inertia of DHN. Int. J. Electr. Power Energy Syst. 2022, 141, 108151. [Google Scholar] [CrossRef]
- Li, Y.; Wei, X.H.; Li, Y.Z.; Dong, Z.Y.; Shahidehpour, M. Detection of false data injection attacks in smart grid: A secure federated deep learning approach. IEEE Trans. Smart Grid 2022, 13, 4862–4872. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value | Parameter | Value |
|---|---|---|---|
| (kW) | 100 | ($/kWh) | 1.3 |
| (kW) | 100 | ($/kWh) | 1.5 |
| (kWh) | 200 | ($/kWh) | 1.35 |
| 0.9 | 0.5 | ||
| (kW) | 5 | 2 | |
| (kW) | 30 | 0.02 | |
| ($/kWh) | 0.5 |
| Parameter | Value | Parameter | Value |
|---|---|---|---|
| (kW) | 100 | ($/kWh) | 0.1 |
| (kW) | 100 | ($/kWh) | 0.2 |
| (kWh) | 200 | ($/kWh) | 0.15 |
| 0.9 | 0.5 | ||
| (kW) | 5 | 2 | |
| (kW) | 30 | 0.02 | |
| ($/kWh) | 0.06 |
| N | |||||
|---|---|---|---|---|---|
| Experiment 1 | 0.916 | 0.0004 | 0.0006 | 512 | 0.159 |
| Experiment 2 | 0.877 | 0.0002 | 0.0007 | 128 | 0.269 |
| Model 1 (USD) | Model 2 (USD) | |
|---|---|---|
| MMG | 63624.00 | 58942.00 |
| Solution Method | Number of Episodes | Convergence Time (s) |
|---|---|---|
| Proposed method | 545 | 236.43 |
| MAPPO | 771 | 267.67 |
| MAA2C | 995 | 339.24 |
| Run Number | Total Reward (10−4) | Computation Time (s) |
|---|---|---|
| 1 | −5.89 | 442.00 |
| 2 | −5.89 | 449.11 |
| 3 | −5.89 | 451.78 |
| 4 | −5.89 | 447.33 |
| 5 | −5.89 | 444.08 |
| 6 | −5.89 | 439.77 |
| 7 | −5.89 | 447.56 |
| 8 | −5.89 | 439.99 |
| 9 | −5.89 | 449.42 |
| 10 | −5.89 | 450.68 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, J.; Li, Y.; Wang, B.; Wu, H. Multi-Microgrid Collaborative Optimization Scheduling Using an Improved Multi-Agent Soft Actor-Critic Algorithm. Energies 2023, 16, 3248. https://0-doi-org.brum.beds.ac.uk/10.3390/en16073248
Gao J, Li Y, Wang B, Wu H. Multi-Microgrid Collaborative Optimization Scheduling Using an Improved Multi-Agent Soft Actor-Critic Algorithm. Energies. 2023; 16(7):3248. https://0-doi-org.brum.beds.ac.uk/10.3390/en16073248
Chicago/Turabian StyleGao, Jiankai, Yang Li, Bin Wang, and Haibo Wu. 2023. "Multi-Microgrid Collaborative Optimization Scheduling Using an Improved Multi-Agent Soft Actor-Critic Algorithm" Energies 16, no. 7: 3248. https://0-doi-org.brum.beds.ac.uk/10.3390/en16073248