

A Comprehensive Review of Machine Learning Approaches for Anomaly Detection in Smart Homes: Experimental Analysis and Future Directions

Abstract
:
1. Introduction and Motivation
- We generated 50,000 abnormal activities by considering all potential anomalies that could occur in a two-resident home, significantly enhancing the reliability of our research findings.
- Our research includes a comprehensive guide that examines how varying the training–test splitting ratios and implementing k-fold cross-validation impact the performance of these classifiers.
- In our study, we also present a detailed analysis of the computational complexity of these classifiers, spanning from the training phase to making predictions. This analysis effectively illustrates the trade-off between performance and computational costs associated with these algorithms.
- Our research entails a rigorous comparative analysis of these classifiers using the activity recognition using ambient sensing (ARAS) multi-resident smart home dataset. Additionally, we offer valuable insights and recommendations for future researchers in this field, aiming to guide and inform their work on similar topics or within the same domain.
2. Background and Related Work
2.1. Machine Learning-Based Human Activity Anomaly Detection
2.2. Machine Learning-Based Anomaly Detection in Other Domains
3. Analysis and Comparison of Machine Learning-Based Anomaly Detection
3.1. Machine Learning Models
3.1.1. Decision Tree (DT)
3.1.2. Support Vector Machine (SVM)
3.1.3. Naïve Bayes (NB) Classifier
3.1.4. Gradient Boosting (GB) Classifier
3.1.5. Light Gradient Boosting Machine (LGBM) Classifier
3.1.6. Random Forest (RF) Classifier
3.1.7. k-Nearest Neighbors (KNN) Classifier
3.1.8. Logistic Regression (LR) Classifier
3.2. Deep Learning Techniques
3.2.1. Long Short-Term Memory (LSTM) Model
3.2.2. Gated Recurrent Unit (GRU) Model
3.3. Dataset
3.4. Experiments
3.5. Computing Platform
3.6. Evaluation
- Accuracy: For the accuracy, we measured the proportion of correctly classified predictions among the total number of predictions.where TP refers to the number of true positives, TN refers to the number of true negatives, FP represents the number of false positives, and FN denotes the number of false negatives. These measures refer to the actual number of instances a classifier model has correctly (referring to true) or incorrectly (falsely) predicted in the positive or negative class (where positive and negative in this context refer to being or not being in a defined class, respectively).
- Precision: Precision measures the proportion of instances that are correctly classified as positive (TP) among all positive predictions made.
- Recall: This score measures the proportion of true positive predictions among all actual positive instances, whether they are correctly classified as positive or incorrectly classified as negative (FN). Recall is, thus, calculated as the number of true positive predictions divided by the sum of true positive and false negative predictions.F-1 score: The F-1 score is the harmonic mean of the precision and recall.
- Macro average F-1: This score calculates the F-1 score for each class independently and then takes the unweighted average of these scores. Unweighted average means that this score will treat all the classes equally regardless of the number of instances they have.
- Weighted average F-1: This score calculates the F-1 score for each class independently and then takes the weighted average of these scores, weighted by the number of true instances for each class. In this score, the classes with more instances will receive a higher weight in the calculation.In the above measures, TP, TN, FN, FP, N, and w denote the number of true positives, the number of true negatives, the number of false negatives, the number of false positives, the number of classes, and the weight assigned to each class, respectively.
4. Results and Discussion
4.1. Performance on House A
4.2. Performance on House B
4.3. Computational Cost Analysis
5. Conclusions and Future Directions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Bakar, U.A.B.U.A.; Ghayvat, H.; Hasanm, S.F.; Mukhopadhyay, S.C. Activity and Anomaly Detection in Smart Home: A Survey; Springer International Publishing: Cham, Switzerland, 2016; Volume 16, pp. 191–220. [Google Scholar] [CrossRef]
- Ramapatruni, S.; Narayanan, S.N.; Mittal, S.; Joshi, A.; Joshi, K. Anomaly Detection Models for Smart Home Security. In Proceedings of the 2019 IEEE 5th Intl Conference on Big Data Security on Cloud (BigDataSecurity), IEEE International Conference on High Performance and Smart Computing, (HPSC) and IEEE International Conference on Intelligent Data and Security (IDS), Washington, DC, USA, 27–29 May 2019; pp. 19–24. [Google Scholar] [CrossRef]
- Rahim, A.; Zhong, Y.; Ahmad, T.; Ahmad, S.; Pławiak, P.; Hammad, M. Enhancing Smart Home Security: Anomaly Detection and Face Recognition in Smart Home IoT Devices Using Logit-Boosted CNN Models. Sensors 2023, 23, 6979. [Google Scholar] [CrossRef] [PubMed]
- Alghayadh, F.; Debnath, D. A Hybrid Intrusion Detection System for Smart Home Security Based on Machine Learning and User Behavior. Adv. Internet Things 2021, 11, 10–25. [Google Scholar] [CrossRef]
- Malaisé, A.; Maurice, P.; Colas, F.; Charpillet, F.; Ivaldi, S. Activity Recognition with Multiple Wearable Sensors for Industrial Applications. In Proceedings of the ACHI 2018—Eleventh International Conference on Advances in Computer-Human Interactions, Rome, Italy, 25–29 March 2018. [Google Scholar]
- Howedi, A.; Lotfi, A.; Pourabdollah, A. An Entropy-Based Approach for Anomaly Detection in Activities of Daily Living in the Presence of a Visitor. Entropy 2020, 22, 845. [Google Scholar] [CrossRef] [PubMed]
- Alemdar, H.; Ertan, H.; Incel, O.D.; Ersoy, C. ARAS human activity datasets in multiple homes with multiple residents. In Proceedings of the 2013 7th International Conference on Pervasive Computing Technologies for Healthcare and Workshops, Venice, Italy, 5–8 May 2013; pp. 232–235. [Google Scholar]
- Han, S.; Wu, Q.; Yang, Y. Machine learning for Internet of things anomaly detection under low-quality data. Int. J. Distrib. Sens. Netw. 2022, 18, 15501329221133765. [Google Scholar] [CrossRef]
- Liang, J.M.; Chung, P.L.; Ye, Y.J.; Mishra, S. Applying Machine Learning Technologies Based on Historical Activity Features for Multi-Resident Activity Recognition. Sensors 2021, 21, 2520. [Google Scholar] [CrossRef]
- Jakkula, V.; Cook, D.J. Anomaly detection using temporal data mining in a smart home environment. Methods Inf. Med. 2008, 47, 70–75. [Google Scholar] [CrossRef]
- Zamani, S.; Talebi, H.; Stevens, G. Time Series Anomaly Detection in Smart Homes: A Deep Learning Approach. arXiv 2023, arXiv:2302.14781. [Google Scholar] [CrossRef]
- Priyadarshini, I.; Alkhayyat, A.; Gehlot, A.; Kumar, R. Time series analysis and anomaly detection for trustworthy smart homes. Comput. Electr. Eng. 2022, 102, 108193. [Google Scholar] [CrossRef]
- Hsu, K.C.; Chiang, Y.T.; Lin, G.Y.; Lu, C.H.; Hsu, J.Y.J.; Fu, L.C. Strategies for Inference Mechanism of Conditional Random Fields for Multiple-Resident Activity Recognition in a Smart Home. In Trends in Applied Intelligent Systems; García-Pedrajas, N., Herrera, F., Fyfe, C., Benítez, J.M., Ali, M., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2010; pp. 417–426. [Google Scholar] [CrossRef]
- Tran, S.N.; Ngo, T.S.; Zhang, Q.; Karunanithi, M. Mixed-dependency models for multi-resident activity recognition in smart homes. Multimed. Tools Appl. 2020, 79, 23445–23460. [Google Scholar] [CrossRef]
- Gupta, D.; Gupta, M.; Bhatt, S.; Tosun, A.S. Detecting Anomalous User Behavior in Remote Patient Monitoring. In Proceedings of the 2021 IEEE 22nd International Conference on Information Reuse and Integration for Data Science (IRI), Las Vegas, NV, USA, 10–12 August 2021; pp. 33–40. [Google Scholar] [CrossRef]
- Jiang, C.; Fu, C.; Zhao, Z.; Du, X. Effective Anomaly Detection in Smart Home by Integrating Event Time Intervals. Procedia Comput. Sci. 2022, 210, 53–60. [Google Scholar] [CrossRef]
- Hao, J.; Bouzouane, A.; Gaboury, S. Recognizing multi-resident activities in non-intrusive sensor-based smart homes by formal concept analysis. Neurocomputing 2018, 318, 75–89. [Google Scholar] [CrossRef]
- Panja, S.; Yadav, K.; Nag, A. Anomaly Detection at the IoT Edge in IoT-Based Smart Home Environment Using Deep Learning. In Proceedings of the International Conference on Advanced Computing Applications, Singapore, 4–5 March 2022; Mandal, J.K., Buyya, R., De, D., Eds.; Advances in Intelligent Systems and Computing; Springer: Singapore, 2022; pp. 119–125. [Google Scholar] [CrossRef]
- Gupta, D.; Kayode, O.; Bhatt, S.; Gupta, M.; Tosun, A.S. Hierarchical Federated Learning based Anomaly Detection using Digital Twins for Smart Healthcare. In Proceedings of the 2021 IEEE 7th International Conference on Collaboration and Internet Computing (CIC), Atlanta, GA, USA, 13–15 December 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 16–25. [Google Scholar] [CrossRef]
- Gupta, D.; Moni, S.S.; Tosun, A.S. Integration of Digital Twin and Federated Learning for Securing Vehicular Internet of Things. In Proceedings of the 2023 International Conference on Research in Adaptive and Convergent Systems, Gdansk, Poland, 6–10 August 2023; pp. 1–8. [Google Scholar]
- Aversano, L.; Bernardi, M.L.; Cimitile, M.; Pecori, R.; Veltri, L. Effective Anomaly Detection Using Deep Learning in IoT Systems. Wirel. Commun. Mob. Comput. 2021, 2021, e9054336. [Google Scholar] [CrossRef]
- Abusitta, A.; de Carvalho, G.H.S.; Wahab, O.A.; Halabi, T.; Fung, B.C.M.; Mamoori, S.A. Deep learning-enabled anomaly detection for IoT systems. Internet Things 2023, 21, 100656. [Google Scholar] [CrossRef]
- Li, G.; Jung, J.J. Deep learning for anomaly detection in multivariate time series: Approaches, applications, and challenges. Inf. Fusion 2023, 91, 93–102. [Google Scholar] [CrossRef]
- Lawal, I.A.; Bano, S. Deep Human Activity Recognition With Localisation of Wearable Sensors. IEEE Access 2020, 8, 155060–155070. [Google Scholar] [CrossRef]
- Ahmad, Z.; Shahid Khan, A.; Nisar, K.; Haider, I.; Hassan, R.; Haque, M.R.; Tarmizi, S.; Rodrigues, J.J.P.C. Anomaly Detection Using Deep Neural Network for IoT Architecture. Appl. Sci. 2021, 11, 7050. [Google Scholar] [CrossRef]
- Lara, A.; Mayor, V.; Estepa, R.; Estepa, A.; Díaz-Verdejo, J.E. Smart home anomaly-based IDS: Architecture proposal and case study. Internet Things 2023, 22, 100773. [Google Scholar] [CrossRef]
- S, M.; M, R. MUD enabled deep learning framework for anomaly detection in IoT integrated smart building. e-Prime—Adv. Electr. Eng. Electron. Energy 2023, 5, 100186. [Google Scholar] [CrossRef]
- Sohail, S.; Fan, Z.; Gu, X.; Sabrina, F. Multi-tiered Artificial Neural Networks model for intrusion detection in smart homes. Intell. Syst. Appl. 2022, 16, 200152. [Google Scholar] [CrossRef]
- Araya, J.I.I.; Rifà-Pous, H. Anomaly-based cyberattacks detection for smart homes: A systematic literature review. Internet Things 2023, 22, 100792. [Google Scholar] [CrossRef]
- Du, W.; Li, A.; Zhou, P.; Niu, B.; Wu, D. PrivacyEye: A Privacy-Preserving and Computationally Efficient Deep Learning-Based Mobile Video Analytics System. IEEE Trans. Mob. Comput. 2022, 21, 3263–3279. [Google Scholar] [CrossRef]
- Wang, L.; Huynh, D.Q.; Mansour, M.R. Loss switching fusion with similarity search for video classification. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 974–978. [Google Scholar]
- Zhang, X.; Yang, S.; Zhang, J.; Zhang, W. Video anomaly detection and localization using motion-field shape description and homogeneity testing. Pattern Recognit. 2020, 105, 107394. [Google Scholar] [CrossRef]
- Yang, Y.; Angelini, F.; Naqvi, S.M. Pose-driven human activity anomaly detection in a CCTV-like environment. IET Image Process. 2023, 17, 674–686. [Google Scholar] [CrossRef]
- Ali, A.; Samara, W.; Alhaddad, D.; Ware, A.; Saraereh, O.A. Human activity and motion pattern recognition within indoor environment using convolutional neural networks clustering and naive bayes classification algorithms. Sensors 2022, 22, 1016. [Google Scholar] [CrossRef] [PubMed]
- Kumar, M.; Patel, A.K.; Biswas, M.; Shitharth, S. Attention-based bidirectional-long short-term memory for abnormal human activity detection. Sci. Rep. 2023, 13, 14442. [Google Scholar] [CrossRef] [PubMed]
- Fahad, L.G.; Tahir, S.F. Activity recognition and anomaly detection in smart homes. Neurocomputing 2021, 423, 362–372. [Google Scholar] [CrossRef]
- Jakkula, V.R.; Crandall, A.S.; Cook, D.J. Enhancing Anomaly Detection Using Temporal Pattern Discovery. In Advanced Intelligent Environments; Kameas, A.D., Callagan, V., Hagras, H., Weber, M., Minker, W., Eds.; Springer: Boston, MA, USA, 2009; pp. 175–194. [Google Scholar] [CrossRef]
- Jadidi, Z.; Pal, S.; K, N.N.; Selvakkumar, A.; Chang, C.C.; Beheshti, M.; Jolfaei, A. Security of Machine Learning-Based Anomaly Detection in Cyber Physical Systems. arXiv 2022, arXiv:2206.05678. [Google Scholar] [CrossRef]
- Vávra, J.; Hromada, M.; Lukáš, L.; Dworzecki, J. Adaptive anomaly detection system based on machine learning algorithms in an industrial control environment. Int. J. Crit. Infrastruct. Prot. 2021, 34, 100446. [Google Scholar] [CrossRef]
- Stoian, N. Machine Learning for Anomaly Detection in IoT Networks: Malware Analysis on the IoT-23 Data Set. Bachelor’s Thesis, University of Twente, Enschede, The Netherlands, 2020. [Google Scholar]
- Bakumenko, A.; Elragal, A. Detecting Anomalies in Financial Data Using Machine Learning Algorithms. Systems 2022, 10, 130. [Google Scholar] [CrossRef]
- Schlegl, T.; Schlegl, S.; West, N.; Deuse, J. Scalable anomaly detection in manufacturing systems using an interpretable deep learning approach. Procedia CIRP 2021, 104, 1547–1552. [Google Scholar] [CrossRef]
- Dash, S.; Decision Trees Explained—Entropy, Information Gain, Gini Index, CCP Pruning. Towards Data Sci. 2022. Available online: https://towardsdatascience.com/decision-trees-explained-entropy-information-gain-gini-index-ccp-pruning-4d78070db36c (accessed on 1 March 2024).
- Li, M. Application of CART decision tree combined with PCA algorithm in intrusion detection. In Proceedings of the 2017 8th IEEE International Conference on Software Engineering and Service Science (ICSESS), Beijing, China, 24–26 November 2017; pp. 38–41. [Google Scholar] [CrossRef]
- Lawrence Berkeley National Laboratory; United States Department of Energy Office of Science; United States Department of Energy Office of Scientific and Technical Information. A One-Class Support Vector Machine Calibration Method for Time Series Change Point Detection; United States Department of Energy Office of Science: Washington, DC, USA, 2019. [Google Scholar]
- Pramila, P.V.; Gayathri, M. Analysis of Accuracy in Anomaly Detection of Intrusion Detection System Using Naïve Bayes Algorithm Compared Over Gaussian Model. ECS Trans. 2022, 107, 13977–13991. [Google Scholar] [CrossRef]
- Anjum, A.; Agbaje, P.; Hounsinou, S.; Olufowobi, H. In-Vehicle Network Anomaly Detection Using Extreme Gradient Boosting Machine. In Proceedings of the 2022 11th Mediterranean Conference on Embedded Computing (MECO), Budva, Montenegro, 7–10 June 2022; IEEE: Piscataway, NJ, USA, 2022. [Google Scholar] [CrossRef]
- Sarıkaya, A.; Günel Kılıç, B.; Demirci, M. GRU-GBM: A combined intrusion detection model using LightGBM and gated recurrent unit. Expert Syst. 2022, 39, e13067. [Google Scholar] [CrossRef]
- Marteau, P.F. Random Partitioning Forest for Point-Wise and Collective Anomaly Detection-Application to Network Intrusion Detection. IEEE Trans. Inf. Forensics Secur. 2021, 16, 2157–2172. [Google Scholar] [CrossRef]
- Saleh, A.I.; Talaat, F.M.; Labib, L.M. A hybrid intrusion detection system (HIDS) based on prioritized k-nearest neighbors and optimized SVM classifiers. Artif. Intell. Rev. 2019, 51, 403–443. [Google Scholar] [CrossRef]
- Palmieri, F. Network anomaly detection based on logistic regression of nonlinear chaotic invariants. J. Netw. Comput. Appl. 2019, 148, 102460. [Google Scholar] [CrossRef]
- Poh, S.C.; Tan, Y.F.; Guo, X.; Cheong, S.N.; Ooi, C.P.; Tan, W.H. LSTM and HMM Comparison for Home Activity Anomaly Detection. In Proceedings of the 2019 IEEE 3rd Information Technology, Networking, Electronic and Automation Control Conference (ITNEC), Chengdu, China, 15–17 March 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1564–1568. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Paper | Objectives | Contributions | Limitations |
|---|---|---|---|
| Adrien et al. [5] | Recognizing the activity based on the wearable sensors’ data. | Proposed probabilistic model based on HMM for single activity detection. | The dataset contains one activity and the manual extraction and selection of features. |
| Lawal, I. A. et al. [24] | Activity recognition based on the motion signals (accelerometer and gyroscope). | Converted the signals into frequency images and applied CNN models for recognizing activities. | The model cannot differentiate closely related activities. |
| Fahad et al. [36] | Identifying anomalies based on the number of activities performed each day. | Identified anomalies by considering missing or excess subevents and an unusual duration of an activity using the H20 autoencoder. | Works well for single residents while not tested for multiple residents; ground truths were generated, but not validated. |
| Gupta et al. [15] | Classifying human behavior anomalies by utilizing the Internet of Medical Things and smart homes. | Applied the HMM model for identifying anomalies where data were collected from the authors’ set test bed. | HMM works well when the hidden states are few and requires effective feature engineering for better performance. |
| Liang et al. [9] | Activity recognition of multiple residents using historical activity features. | Different machine learning models like random forest (RF), decision tree (DT), Support Vector Machine (SVM), and k-nearest neighbor (KNN) and neural network models such as Multilayer Perceptron (MLP) and Long Short-term Memory (LSTM) were used to classify human activities. | The considered features are not enough to classify all activities, including anomalies, accurately. |
| Howedi et al. [6] | Detecting anomalies in human activity in the presence of visitors. | Applied entropy-based models to classify the samples and identify anomalies. | Finding the optimal threshold for classification is difficult and significantly impacts the performance. |
| Jakkula et al. [37] | Enhancing the human activities’ anomaly detection accuracy. | Used temporal features in conjunction with the machine learning model to detect the anomalies in human activities. Generated synthetic data to increase the size of the dataset. | The quality of the synthetic data was not validated, and finding the temporal pattern, including the interval, is challenging. |
| Activity | Sensor Placements |
|---|---|
| Other | Wardrobe |
| Going Out | Convertible Couch (Used as Bed for Resident 2) |
| Preparing Breakfast | TV Receiver |
| Having Breakfast | Couch |
| Preparing Lunch | Couch |
| Having Lunch | Chair |
| Preparing Dinner | Chair |
| Having Dinner | Fridge |
| Washing Dishes | Kitchen Drawer |
| Having Snack | Wardrobe |
| Sleeping | Bathroom Cabinet |
| Watching TV | House Door |
| Studying | Bathroom Door |
| Having Shower | Shower Cabinet Door |
| Toileting | Hall |
| Napping | Kitchen |
| Using Internet | Tap |
| Reading Book | Water Closet |
| Laundry | Kitchen |
| Shaving | Bed |
| Brushing Teeth | |
| Talking on the Phone | |
| Listening to Music | |
| Cleaning | |
| Having Conversation | |
| Having Guest | |
| Changing Clothes |
| Models | Hyper-Parameters |
|---|---|
| Decision Tree | Criterion: Gini |
| Random Forest | Default Parameters |
| Gaussian Naïve Bayes | No Hyper-parameters |
| LGBM Classifier | Default Parameters |
| Support Vector Machine | Kernel: RBF, , |
| Logistic Regression | Default Parameters |
| k-Nearest Neighbors | Number of Neighbors: 5 |
| Gradient Boosting Classifier | Default Parameters |
| LSTM | Sequence Length: 1, |
| Hidden Dimension: 64, | |
| Number of Layers: 2, | |
| Optimizer: Adam, | |
| Loss Function: Cross-Entropy Loss, | |
| Batch Size: 32, | |
| Epoch: 100 | |
| GRU | Input Size: 22, |
| Hidden Size: 64, | |
| Number of Layers: 2, | |
| Optimizer: Adam, | |
| Loss Function: Cross-Entropy Loss, | |
| Batch Size: 32, | |
| Epoch: 100 |
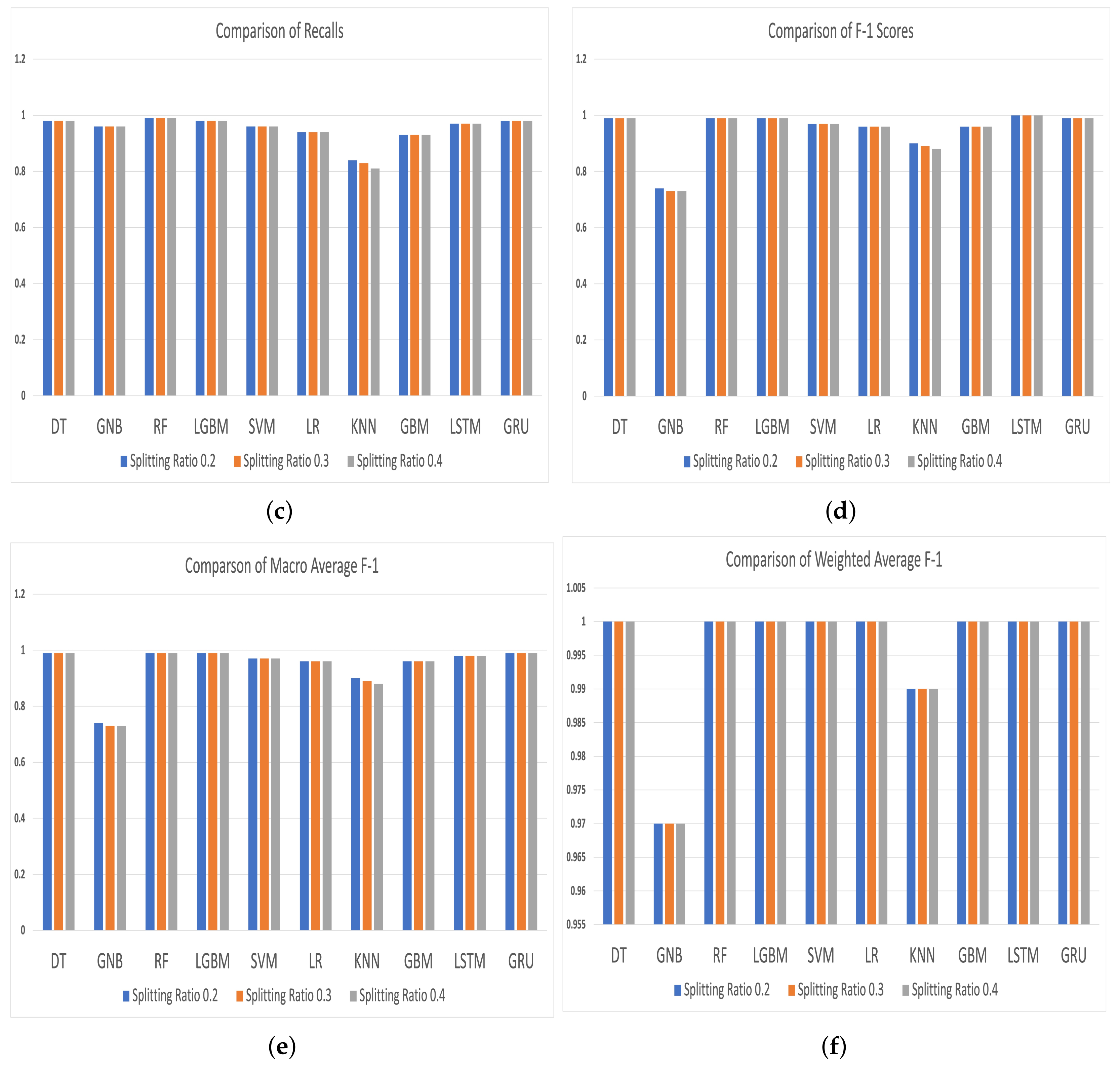
| Models | Accuracy | Precision | Recall | F-1 Score | Macro Average F-1 | Weighted Average F-1 |
|---|---|---|---|---|---|---|
| Decision Tree | 1.0 | 0.99 | 0.97 | 0.98 | 0.99 | 1.0 |
| Gaussian Naïve Bayes + | 0.96 | 0.33 | 0.96 | 0.49 | 0.73 | 0.97 |
| Random Forest ** | 1.0 | 0.99 | 0.98 | 0.99 | 0.99 | 1.0 |
| LGBM | 1.0 | 0.99 | 0.96 | 0.98 | 0.99 | 1.0 |
| Support Vector Machine | 1.0 | 0.99 | 0.96 | 0.98 | 0.97 | 0.99 |
| Logistic Regression | 1.0 | 0.94 | 0.90 | 0.92 | 0.96 | 1.0 |
| k-Nearest Neighbors | 0.99 | 0.98 | 0.84 | 0.90 | 0.89 | 0.98 |
| Gradient Boosting Machine | 1.0 | 0.98 | 0.87 | 0.92 | 0.96 | 1.0 |
| LSTM Technique | 1.0 | 0.99 | 0.97 | 0.98 | 0.98 | 1.0 |
| GRU Technique * | 1.0 | 0.99 | 0.99 | 0.99 | 0.99 | 1.0 |
| Models | Accuracy | Precision | Recall | F-1 Score | Macro Average F-1 | Weighted Average F-1 |
|---|---|---|---|---|---|---|
| Decision Tree ** | 1.0 | 0.98 | 0.98 | 0.98 | 0.99 | 1.0 |
| Gaussian Naïve Bayes + | 0.95 | 0.35 | 0.94 | 0.49 | 0.74 | 0.96 |
| Random Forest | 0.99 | 0.99 | 0.96 | 0.98 | 0.98 | 1.0 |
| LGBM | 1.0 | 0.97 | 0.96 | 0.98 | 0.98 | 1.0 |
| Support Vector Machine | 1.0 | 0.99 | 0.95 | 0.97 | 0.95 | 0.99 |
| Logistic Regression | 1.0 | 0.93 | 0.92 | 0.91 | 0.97 | 1.0 |
| k-Nearest Neighbors | 0.99 | 0.97 | 0.85 | 0.90 | 0.89 | 0.98 |
| Gradient Boosting Machine | 1.0 | 0.97 | 0.86 | 0.93 | 0.95 | 1.0 |
| LSTM | 1.0 | 0.98 | 0.97 | 0.98 | 0.98 | 1.0 |
| GRU Technique * | 1.0 | 0.99 | 0.99 | 0.99 | 0.99 | 1.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rahman, M.M.; Gupta, D.; Bhatt, S.; Shokouhmand, S.; Faezipour, M. A Comprehensive Review of Machine Learning Approaches for Anomaly Detection in Smart Homes: Experimental Analysis and Future Directions. Future Internet 2024, 16, 139. https://0-doi-org.brum.beds.ac.uk/10.3390/fi16040139
Rahman MM, Gupta D, Bhatt S, Shokouhmand S, Faezipour M. A Comprehensive Review of Machine Learning Approaches for Anomaly Detection in Smart Homes: Experimental Analysis and Future Directions. Future Internet. 2024; 16(4):139. https://0-doi-org.brum.beds.ac.uk/10.3390/fi16040139
Chicago/Turabian StyleRahman, Md Motiur, Deepti Gupta, Smriti Bhatt, Shiva Shokouhmand, and Miad Faezipour. 2024. "A Comprehensive Review of Machine Learning Approaches for Anomaly Detection in Smart Homes: Experimental Analysis and Future Directions" Future Internet 16, no. 4: 139. https://0-doi-org.brum.beds.ac.uk/10.3390/fi16040139