Automatic Acquisition of Failure Mode and Effect Analysis Ontology for Sustainable Risk Management

 ,
,
Abstract
:1. Introduction
2. Related Work
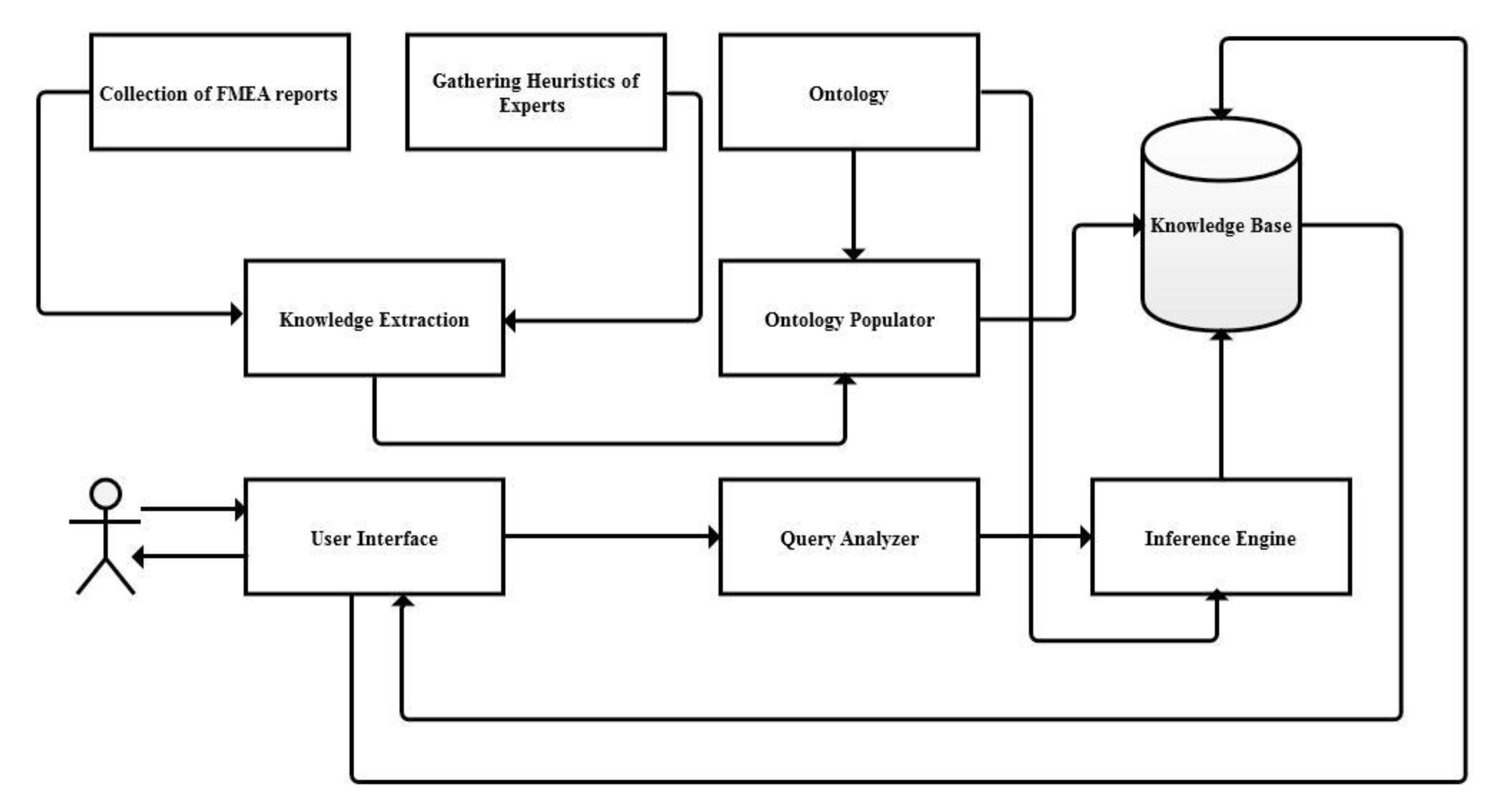
2.1. Ontology-Based Content Management Systems
2.2. Ontology Population Approaches
2.3. Comma Separated Values (CSV) to RDF Conversion Approaches
- A fully automated approach without human intervention.
- Involvement of domain ontology for rapid mapping between CSV file and ontology language.
- More than one instance could be defined from one row as it is not necessary for a row to have only a single instance.
- Rows or columns can have multivalued attributes, which should be properly handled and have assigned relations with their correspondent instances correctly (without human intervention).
- Empty attributes should also be handled.
- Special characters, which can cause conflict with XML tags, should be converted properly.
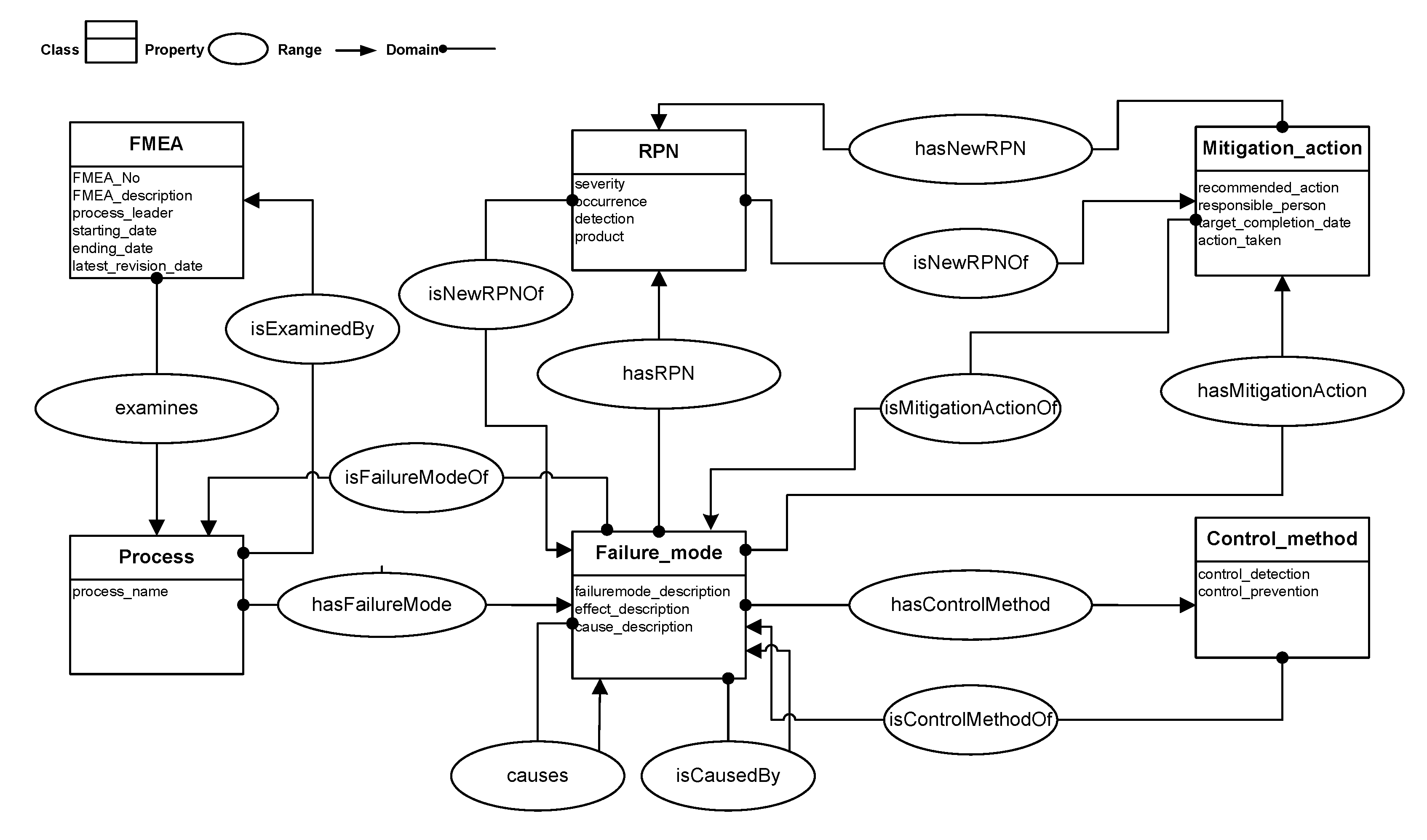
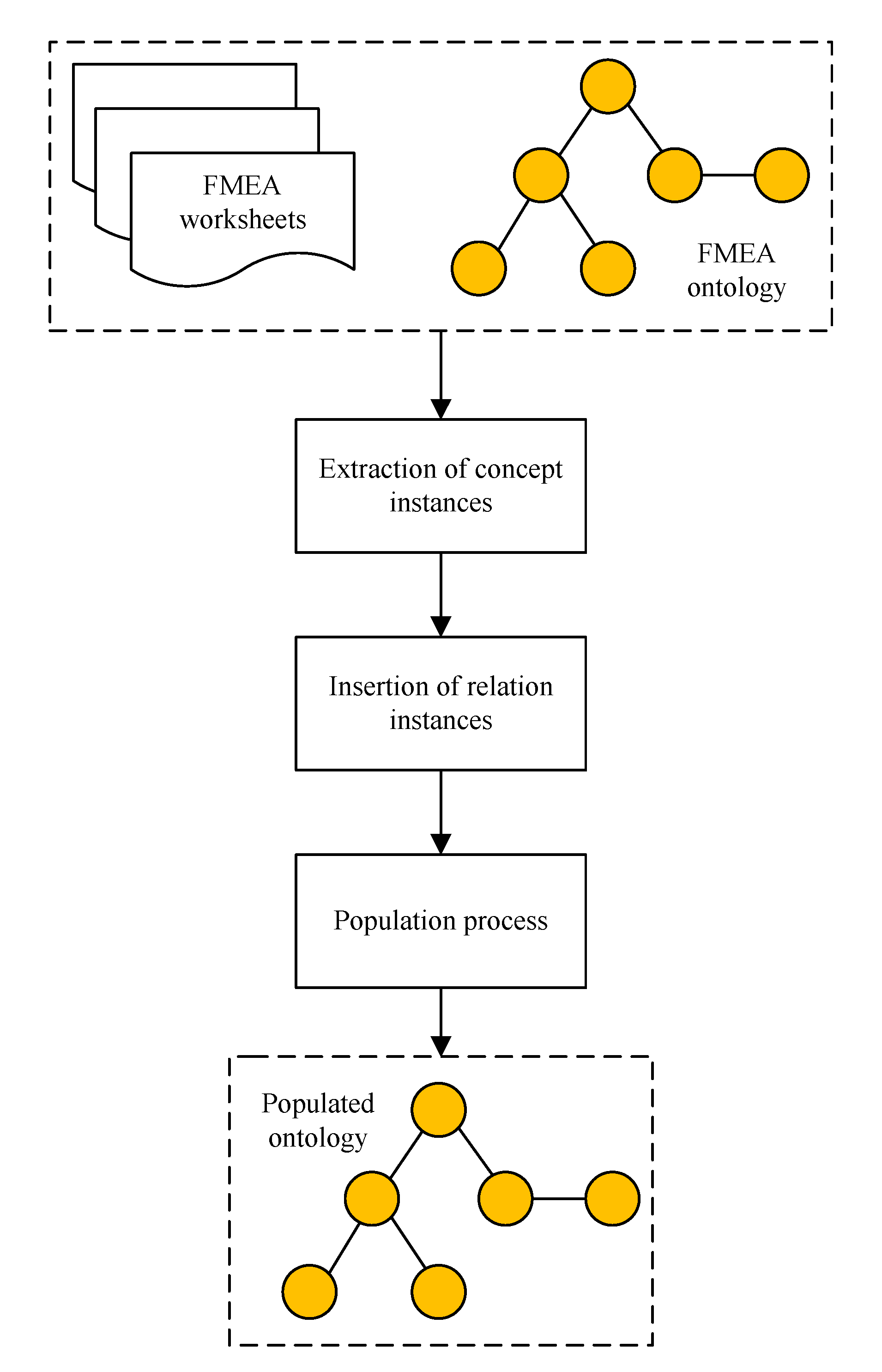
3. Proposed Work
Proposed Algorithm
- Load CSV file and read its contents in a 2D array named “FMEA table.”
- Read an existing OWL file and remove its end of file tag.
- For each process in FMEA table:
- For each failure mode
- Read each effect
- Read each cause
- Read each mitigation action
- Read RPN
- Create a complete RDF instance including process description, failure mode, effect, cause, mitigation action, and RPN by inducing class relationships.
- Embed this RDF instance as an OWL-named individual in existing OWL file.
- Add end of file tag to the existing OWL file.
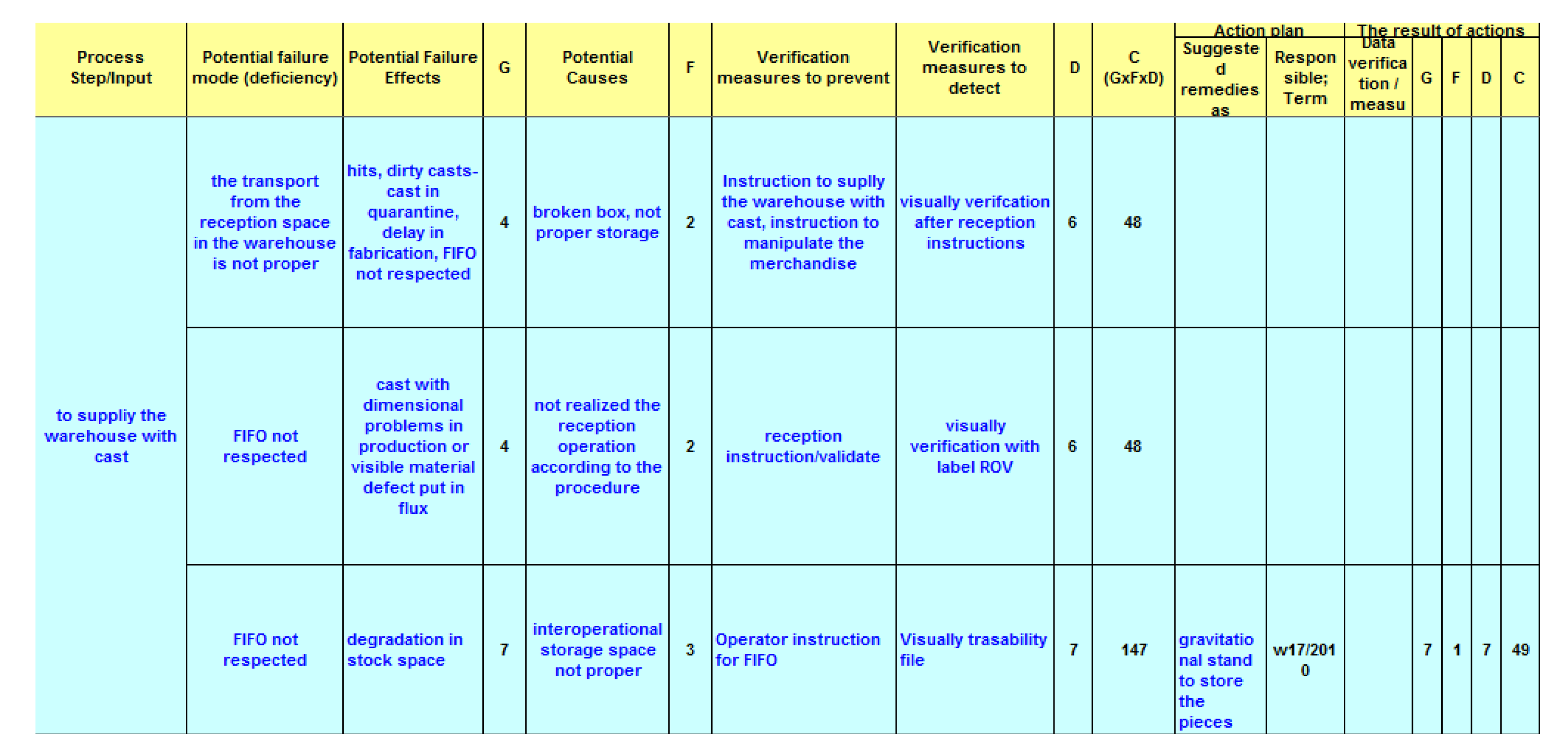
4. Evaluation
4.1. Ontology Validation Using OntoQA Features
4.1.1. Schema Features
- Relationship Richness (RR)
= 0.25.
4.1.2. Attribute Richness (AR)
= 2.5.
4.1.3. Knowledge Base Features
- Class Richness (CR)
= 100.
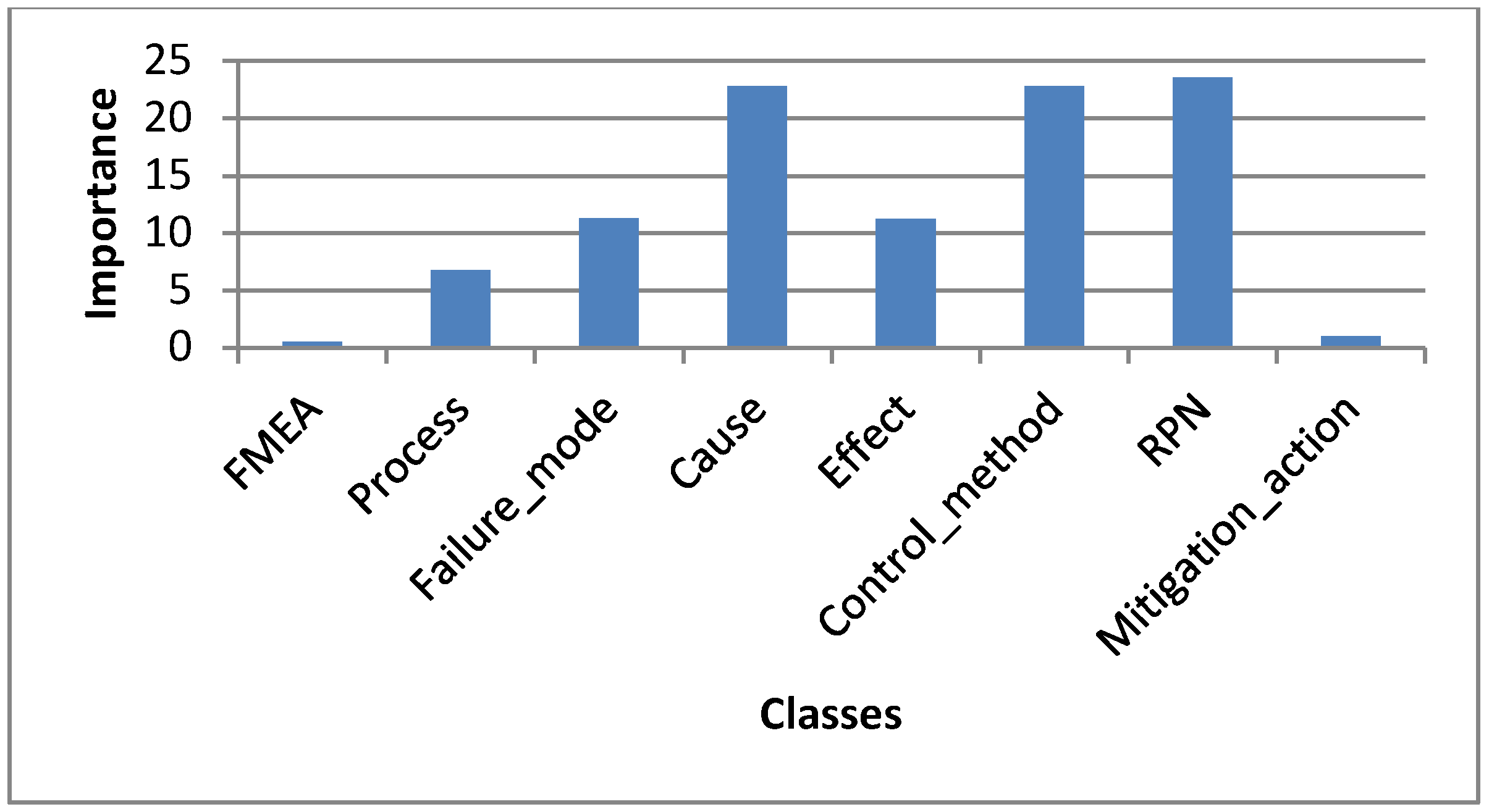
- Class Connectivity (Conn)
- Class Importance (Imp)
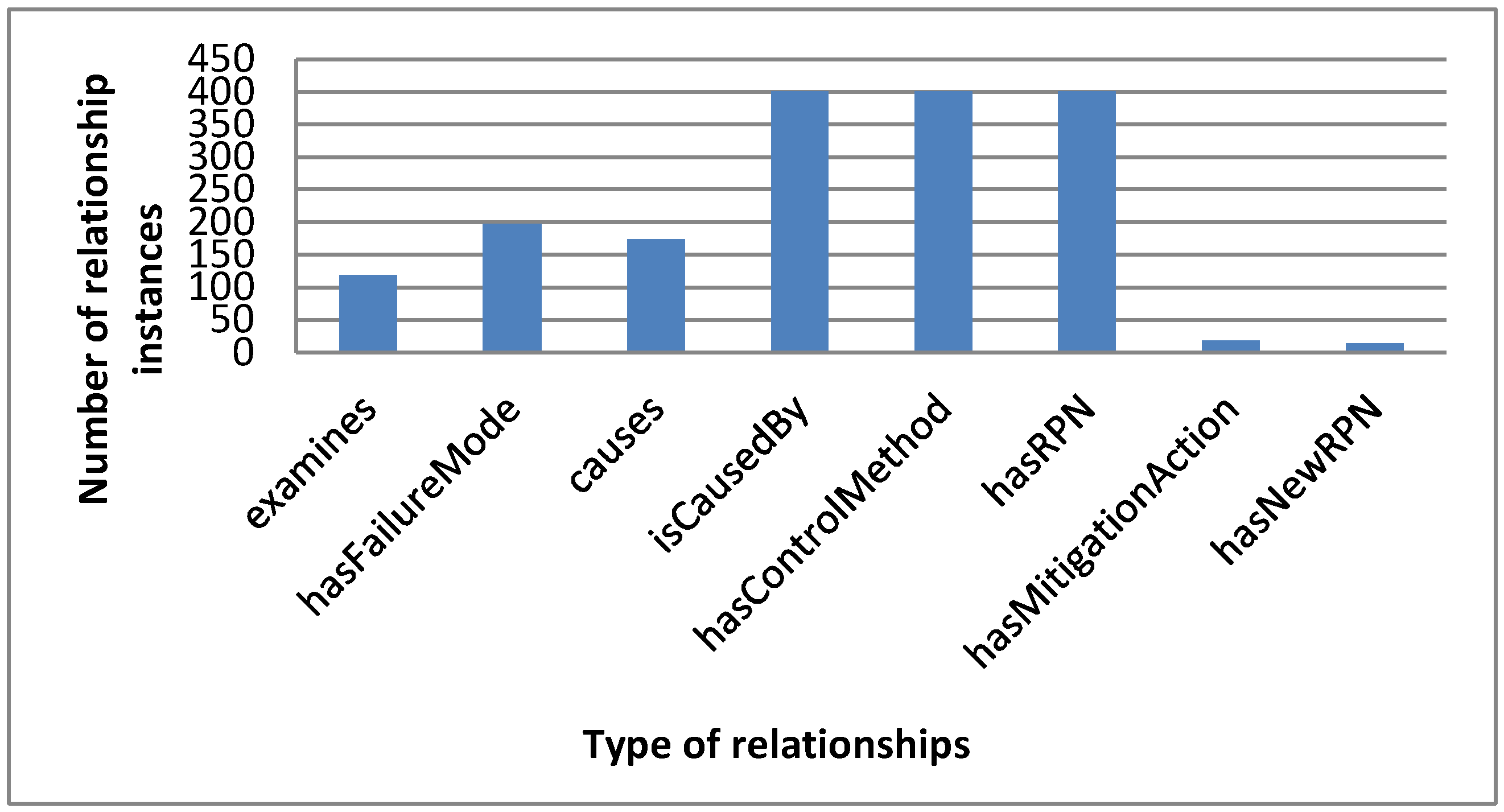
- Relationship Richness (RRkb)
= 100.
4.2. Evaluation of the Populated Ontology by Querying It
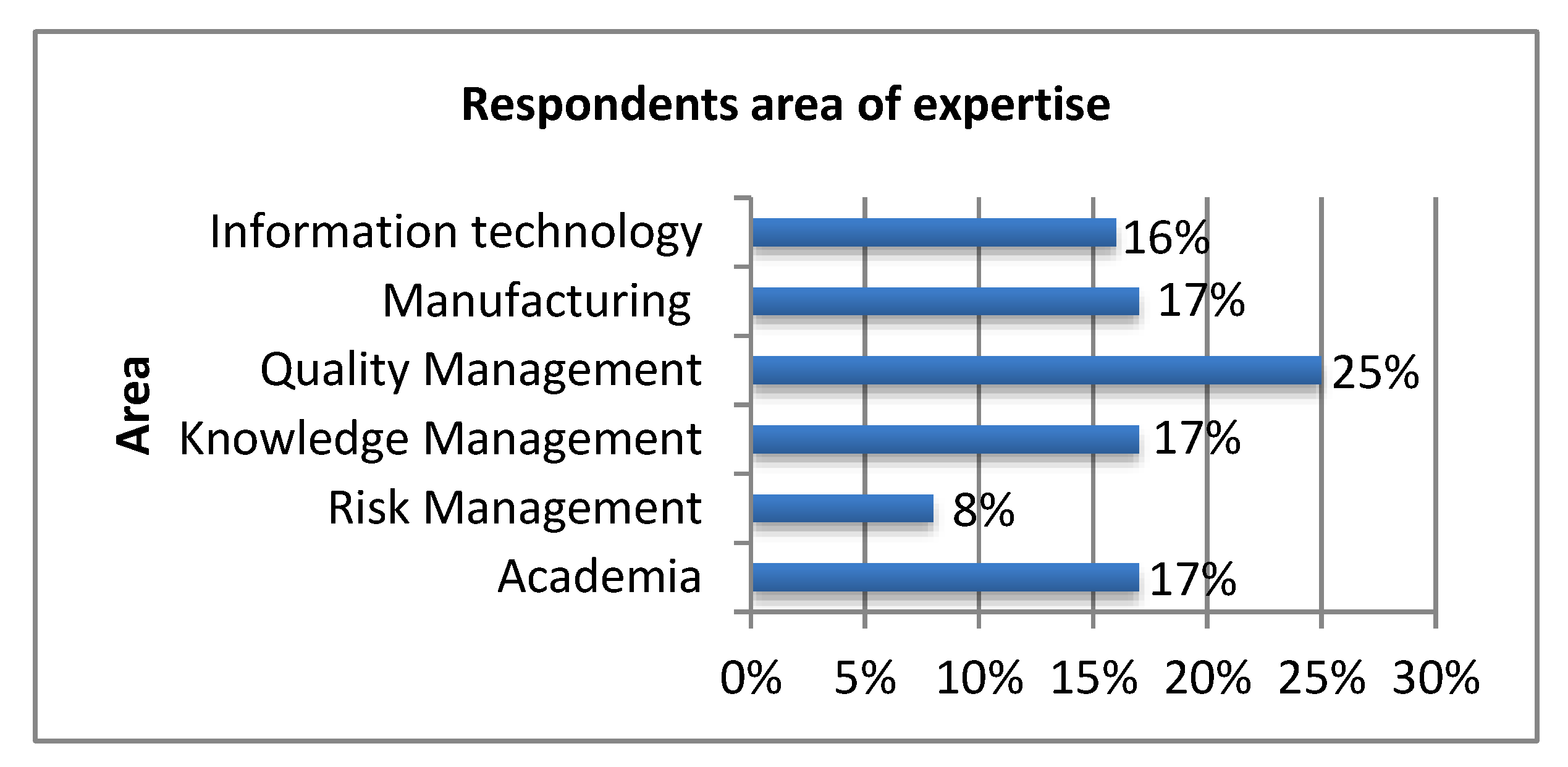
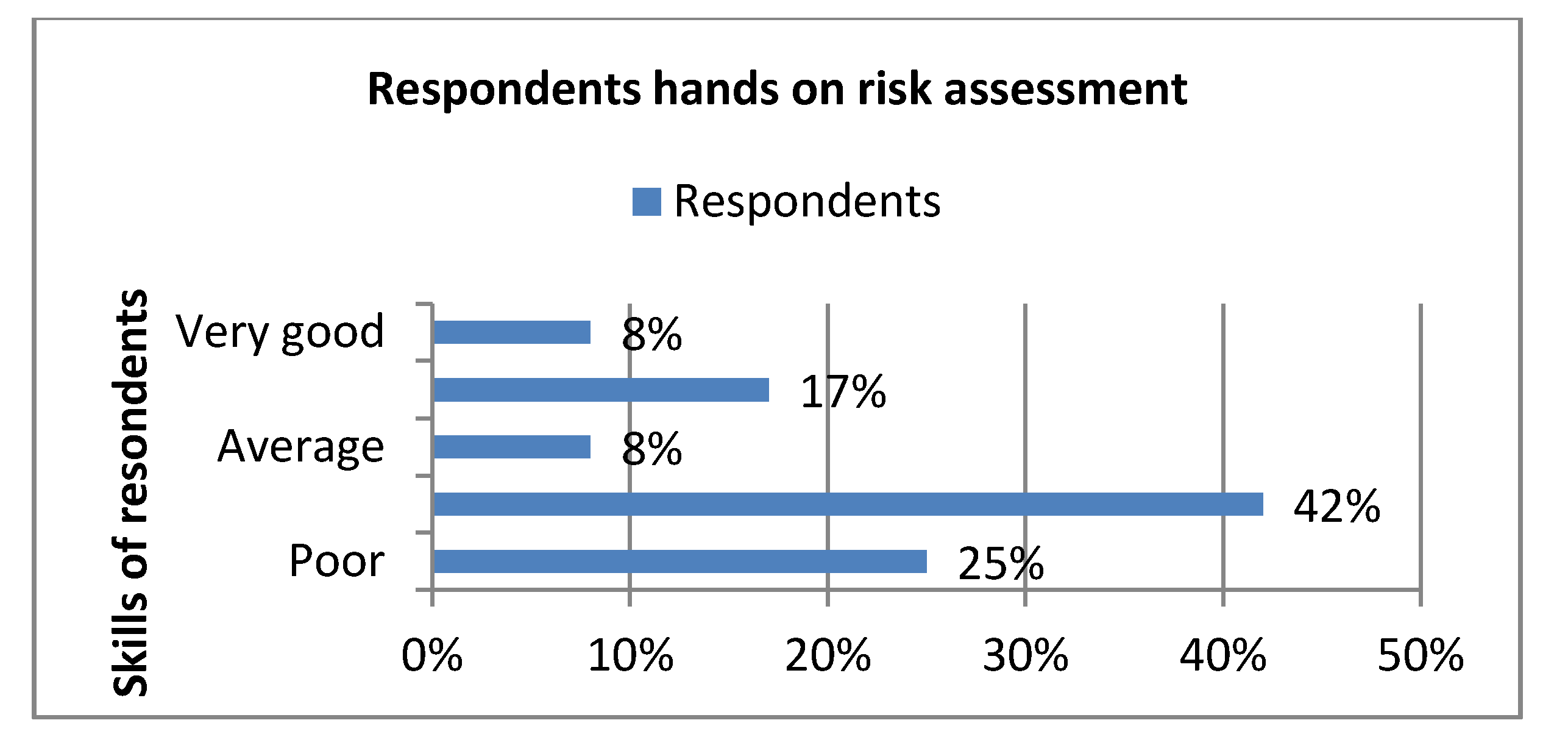
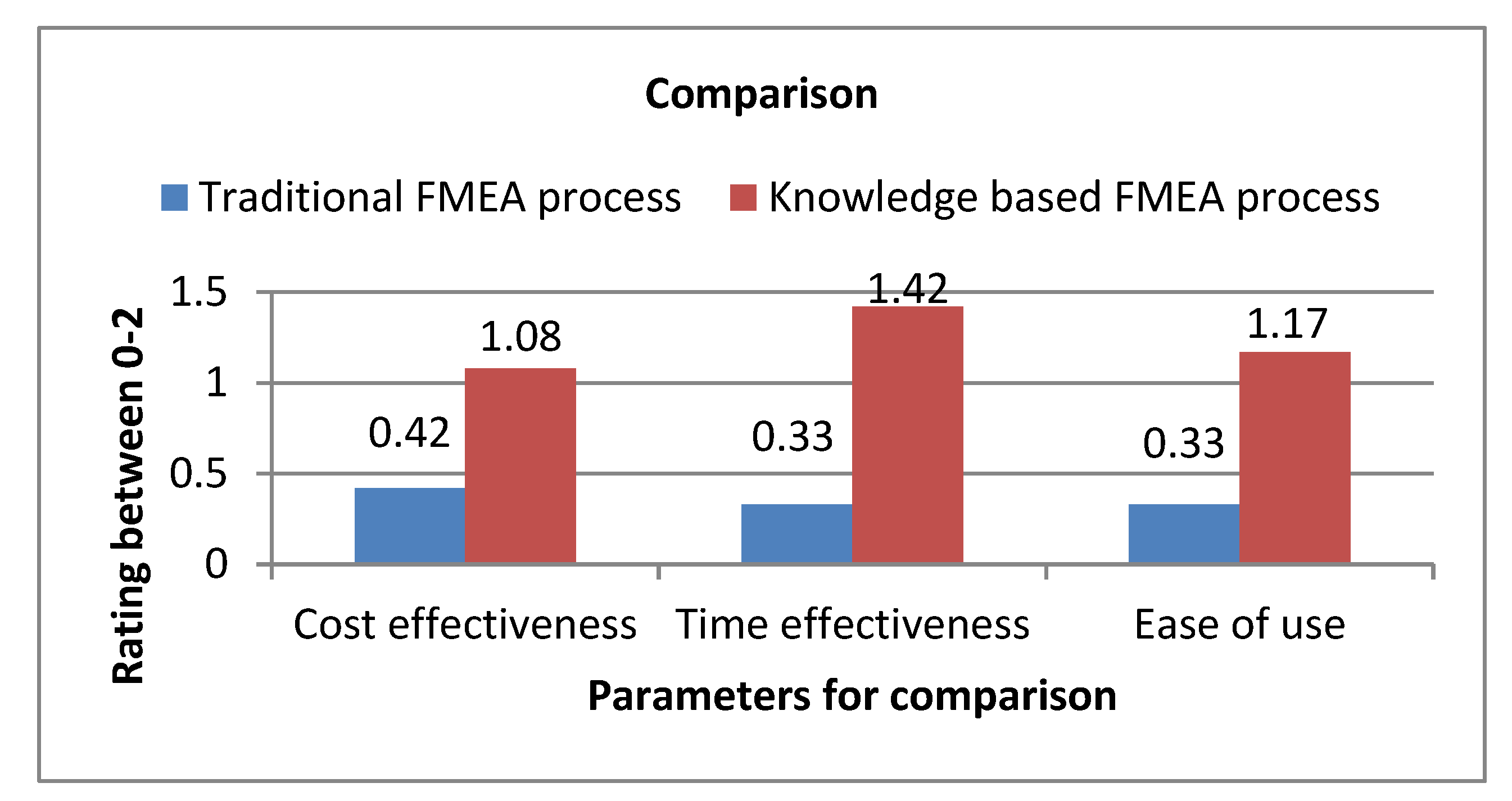
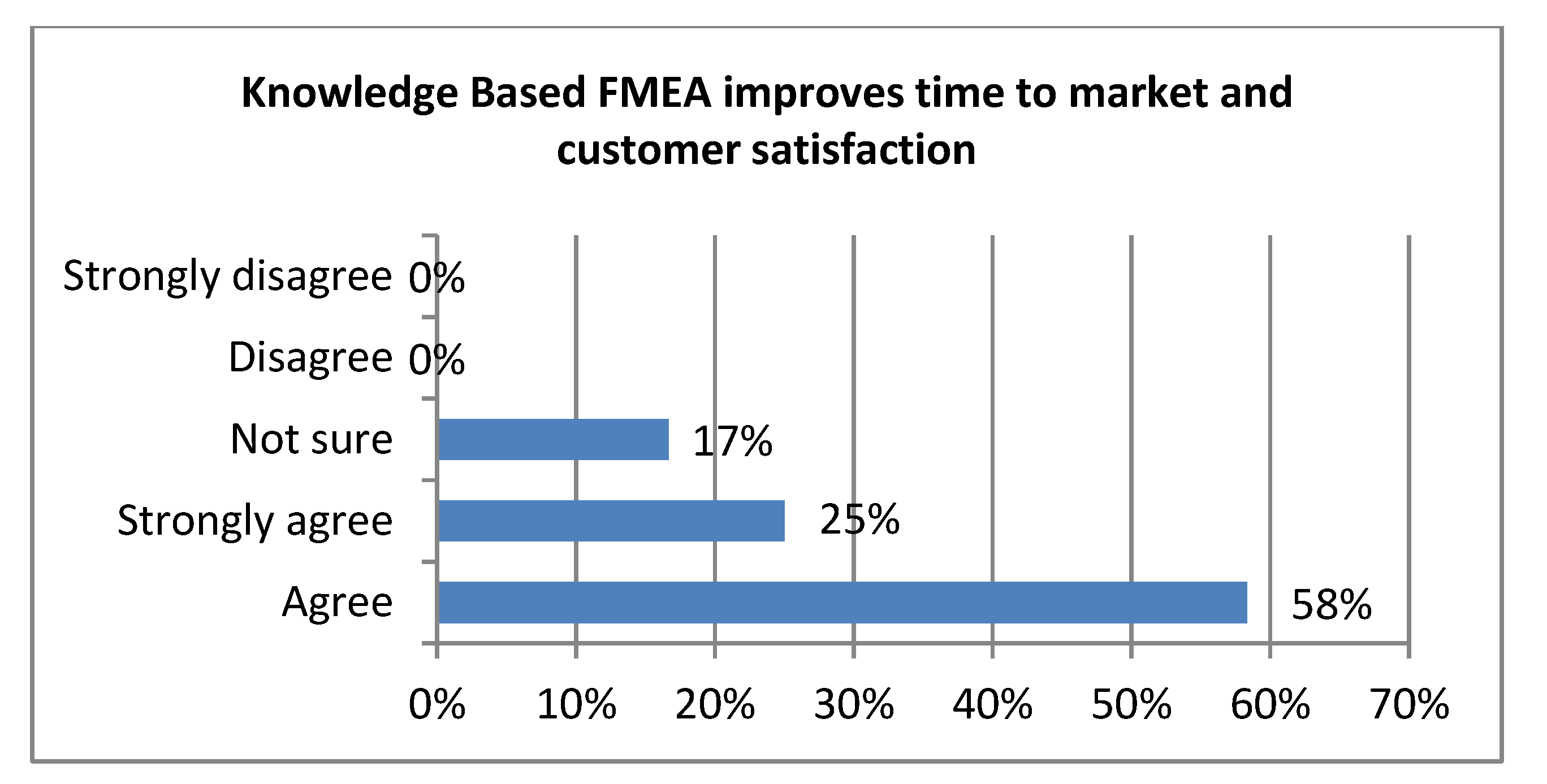
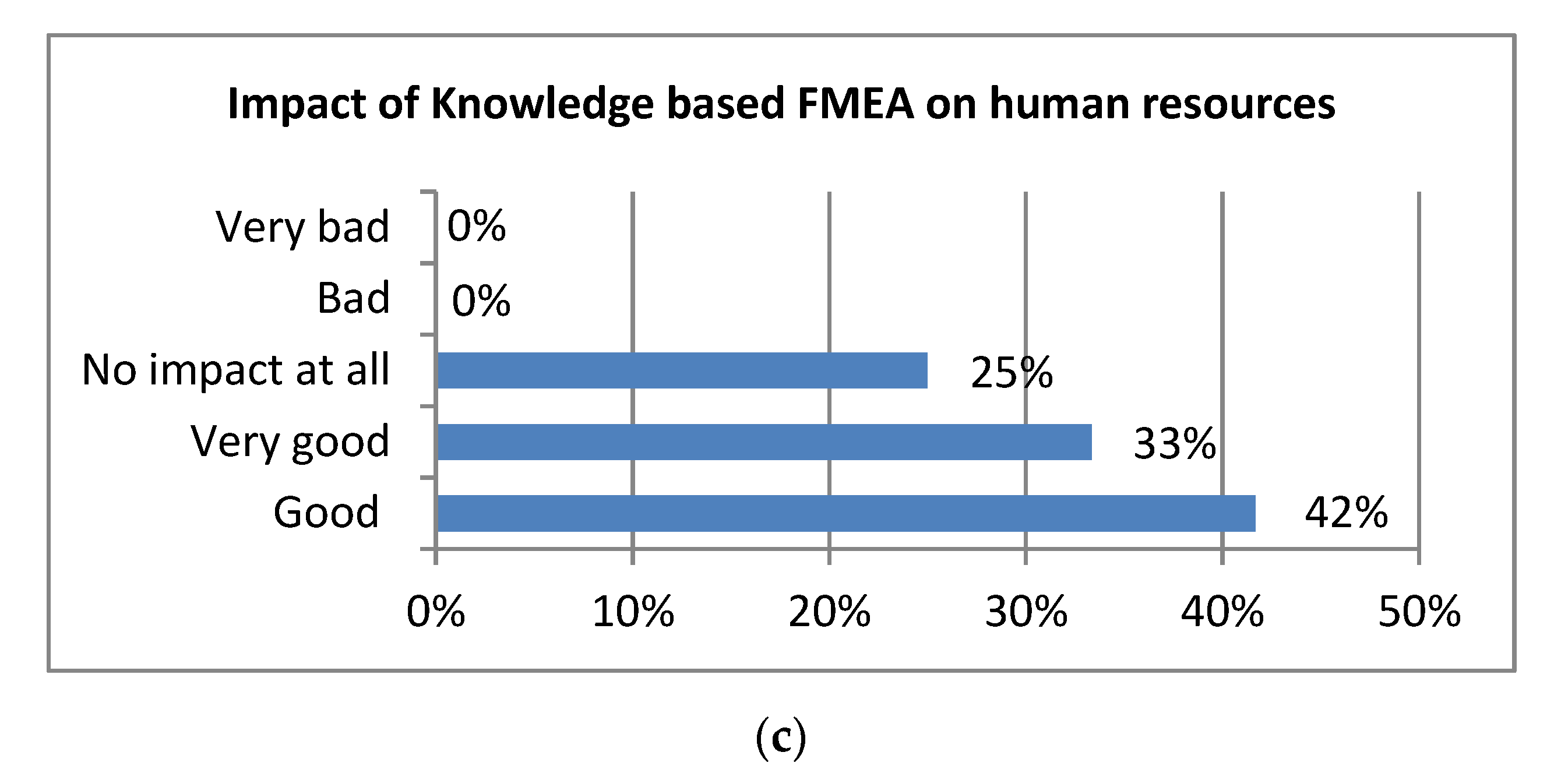
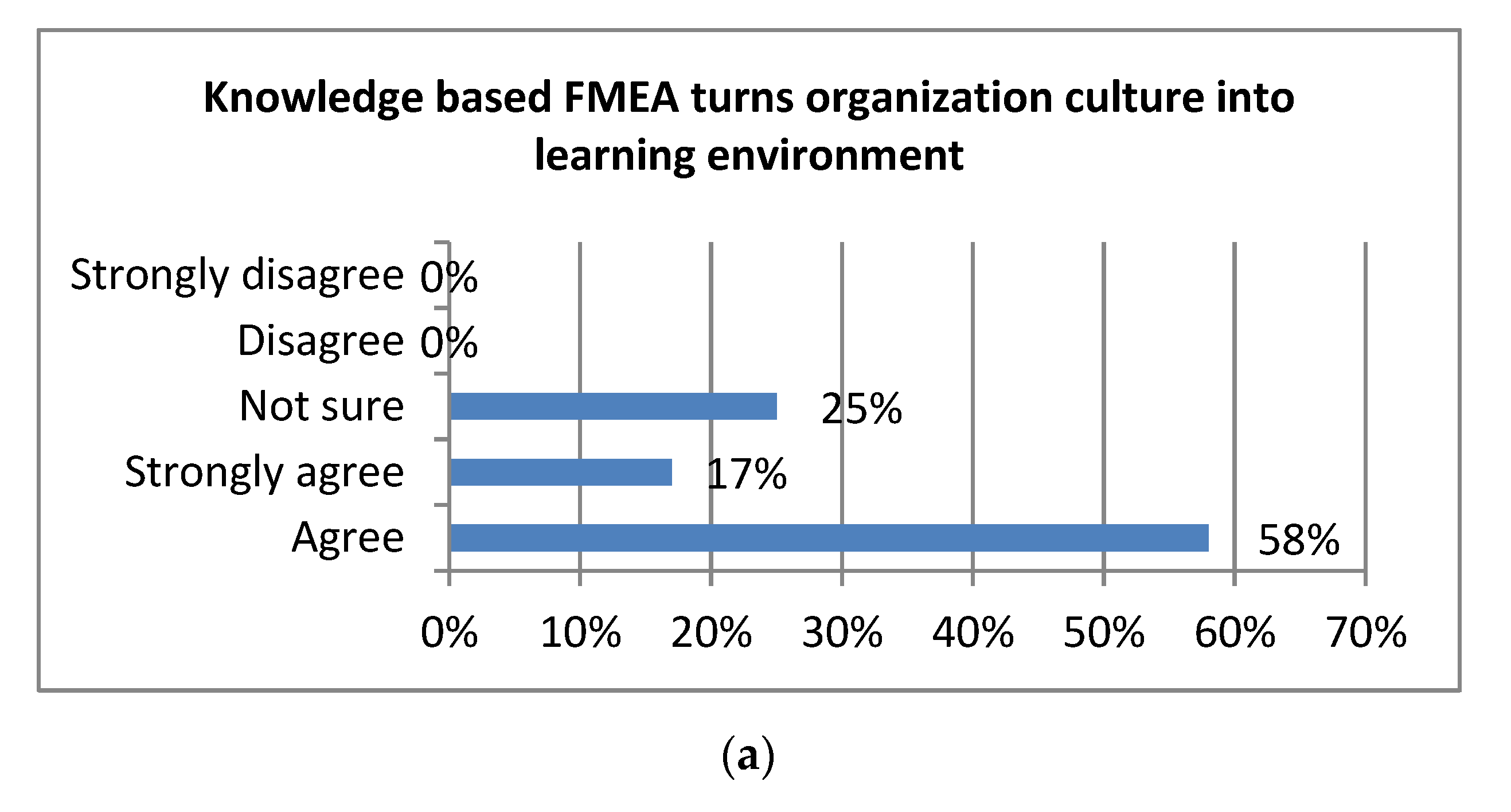
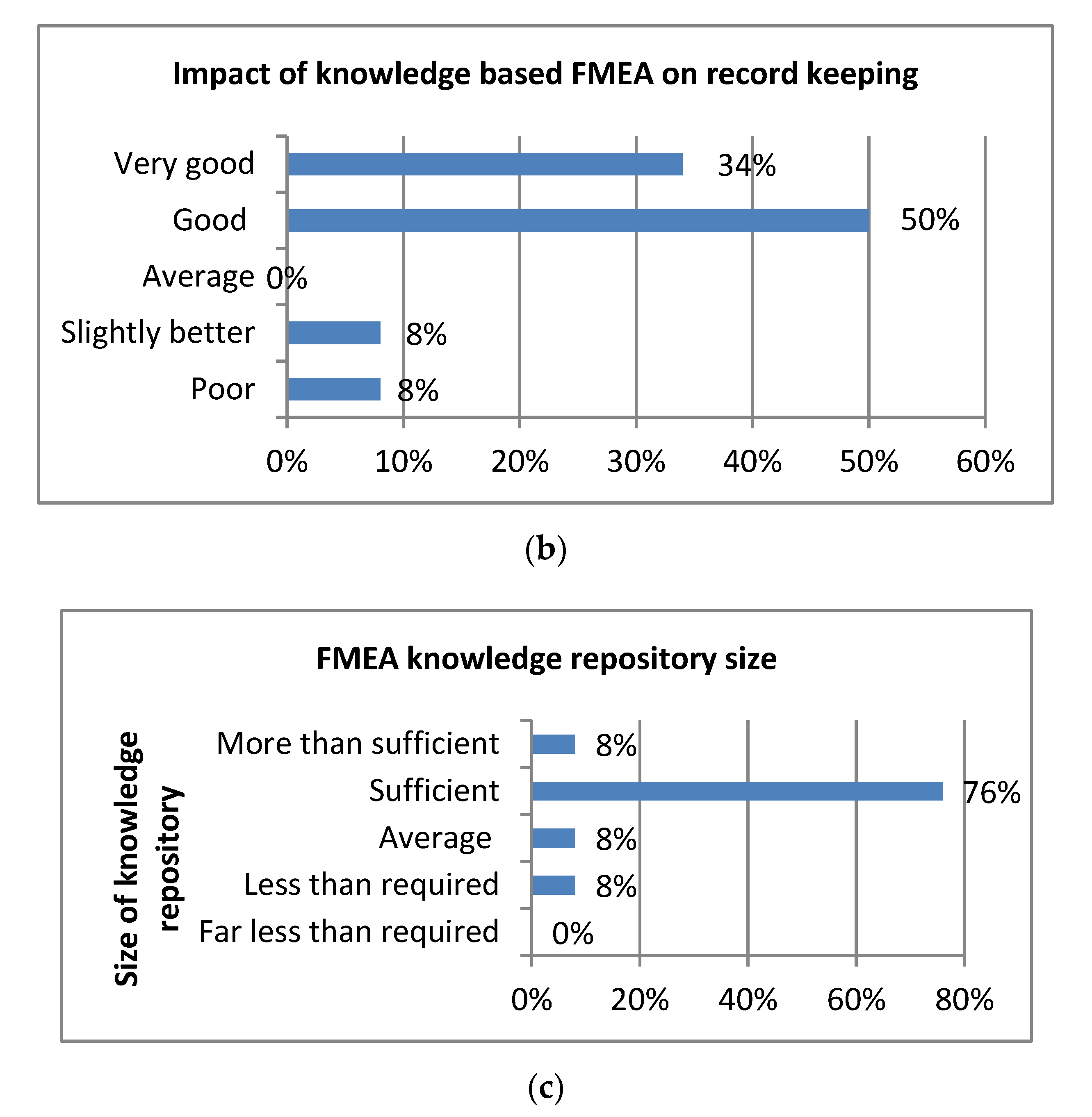
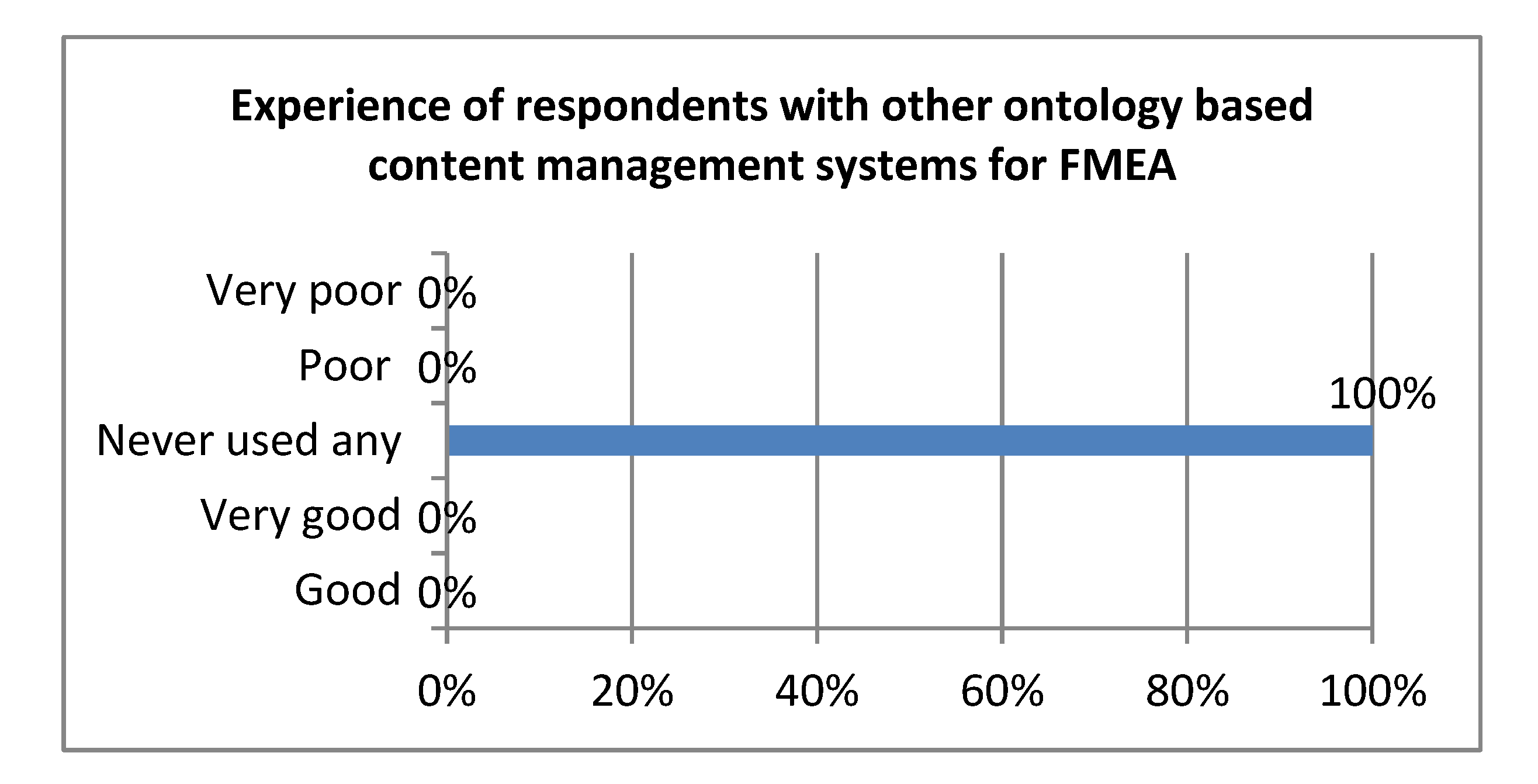
4.3. Evaluation in the Light of Expert’s Opinion
4.4. Comparison with Existing Ontology-Based KMS for FMEA
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
|
|
|
|
|
| Please give here your comments to support your answer for question 5: |
|
|
|
|
|
|
|
|
|
|
|
References
- Rehman, Z.; Kifor, C. An Ontology to Support Semantic Management of FMEA Knowledge. Int. J. Comput. Commun. Control 2016, 11, 507–521. [Google Scholar] [CrossRef] [Green Version]
- Wu, J.; Lo, M.F.; Ng, A.W. Knowledge Management and Sustainable Developmen. In Encyclopedia of Sustainability in Higher Education; Leal, F.W., Ed.; Springer International Publishing: Cham, Swizerland, 2018; pp. 1–9. [Google Scholar]
- Lai, F.W.; Samad, F. Enterprise Risk Management Framework and Empirical Determinants of Its Implementation. In Proceedings of the International Conference on Business and Economics Research, Kuala Lumpur, Malaysia, 26–28 November 2010. [Google Scholar]
- Nguyen, T.L.; Shu, M.H.; Hsu, B.M. Extended FMEA for Sustainable Manufacturing: An Empirical Study in Non-Wooven Fabric Industry. Sustainability 2016, 8, 939. [Google Scholar] [CrossRef]
- Jaroslava, K.; Ivana, R. Enterprise Content Management Implementation and Risk. Acta Univ. Agric. Silvic. Mendel. Brun. 2015, 63, 1687–1695. [Google Scholar]
- Mika, P.; Iosif, V.; Sure, Y.; Akkermans, H. Ontology-based Content Management in a Virtual Organization. In Handbook on Ontologies. International Handbooks on Information Systems; Springer: Berlin/Heidelberg, Germany, 2004. [Google Scholar]
- Rehman, Z.; Kifor, S. A Conceptual Architecture of Ontology Based KM System for Failure Mode and Effects Analysis. Int. J. Comput. Commun. Contol 2014, 9, 463–470. [Google Scholar] [CrossRef] [Green Version]
- Sheth, A.; Fisher, M. Semantic Enterprise Content Management; CRC Press: Boca Raton, FL, USA, 2004. [Google Scholar]
- Konys, A. An Ontology-Based Knowledge Modelling for a Sustainability Assessment Domain. Sustainability 2018, 10, 300. [Google Scholar] [CrossRef] [Green Version]
- Ivanova, A.; Deliyska, B.; Todorov, V. Domain ontology of sustainable development in economy. In AIP Conference Proceedings; AIP Publisher LLC.: Melville, NY, USA, 2018. [Google Scholar]
- Wijesooriya, C.; Heales, J.; McCoy, S. Multi-Dimensional Views for Sustainability: Ontological approach. In Proceedings of the Twenty-first Americas Conference on Information Systems, Fajardo, Puerto Rico, 13–15 August 2015. [Google Scholar]
- Ali, N.; Hong, J.-E. Failure Detection and Prevention for Cyber-Physical Systems Using Ontology-Based Knowledge Base. Computers. 2018, 7, 68. [Google Scholar] [CrossRef] [Green Version]
- Paliouras, G.; Karkaletsis, V.; Paliouras, G.; Krithara, A.; Zavitsanos, E. Ontology Population and Enrichment: State of the Art. In Knowledge-Driven Multimedia Information Extraction and Ontology Evolution, Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2011; pp. 134–166. [Google Scholar]
- Makki, J.; Alquier, A.-M.; Prince, V. Ontology Population via NLP Techniques in Risk Management. Int. J. Hum. Soc. Sci. 2009, III, 212–217. [Google Scholar]
- Kim, S.; Alani, H.; Hall, W.; Lewis, P.; Millard, D.; Shadbolt, N.; Weal, M. Artequakt: Generating Tailored Biographies from Automatically Annotated Fragments from the Web. In Proceedings of Workshop on Semantic Authoring, Annotation & Knowledge Markup (SAAKM’02), the 15th European Conference on Artificial Intelligence, Lyon, France, 21–26 July 2002; pp. 1–6. [Google Scholar]
- Alani, H.; Kim, S.; Millard, D.E.; Weal, M.J.; Lewis, P.H.; Hall, W.; Shadbolt, N.R. Automatic Extraction of Knowledge from Web Documents. In Proceedings of the 2nd International Semantic Web Conference—Workshop on Human Language Technology for the Semantic Web abd Web Services, Sanibel Island, FL, USA, 19–22 October 2003. [Google Scholar]
- Castano, S.; Peraldi, I.S.E.; Ferrara, A.; Karkaletsis, V.; Kaya, A.; Möller, R.; Montanelli, S.; Petasis, G.; Wessel, M. Multimedia Interpretation for Dynamic Ontology Evolution. J. Log. Comput. 2009, 19, 859–897. [Google Scholar] [CrossRef]
- Suchanek, F.M. LEILA: Learning to Extract Information by Linguistic Analysis. In Proceedings of the 2nd Workshop on Ontology Learning and Population: Bridging the Gap between Text and Knowledge, Sydney, Australia, 22 July 2006; pp. 18–25. [Google Scholar]
- Buitelaar, P.; Cimiano, P.; Racioppa, S.; Siegel, M. Ontology-based Information Extraction with SOBA. In Proceedings of the International Conference on Language Resources and Evaluation, Genoa, Italy, 22–28 May 2006; pp. 2321–2324. [Google Scholar]
- Navigli, R.; Velardi, P. Enriching a Formal Ontology with a Thesaurus: An Application in the Cultural Heritage Domain. In Proceedings of the 2nd Workshop on Ontology Learning and Population, Bridging the Gap between Text and Knowledge, Sydney, Australia, 22 July 2006; pp. 1–9. [Google Scholar]
- Sang, S.K.; Jeong-Woo, S.; Seong-Bae, P.; Lee, J.H.C.; Myung-Gil, J.; Hyung-Geun, P. PTIMA: A System for Semi Automatic and Large Scale Ontology Population. In Proceedings of the 3rd Workshop on Ontology Learning and Population, Patras, Greece, 21–22 July 2008; 2008. [Google Scholar]
- Weber, N.; Buitelaar, P. Web-based Ontology Learning with ISOLDE. In Proceedings of the ISWC2006 Workshop on Web Content Mining with Human Language Technologies, Athens, GA, USA, 5–9 November 2006. [Google Scholar]
- Brewster, C.; Ciravegna, F.; Wilks, Y. User-Centred Ontology Learning for Knowledge management. In Proceedings of the NLDB ‘02: 6th International Conference on Applications of Natural Language to Information Systems-Revised, Stockholm, Sweden, 27–28 June 2002; Springer: London, UK, 2002; pp. 203–207. [Google Scholar]
- Helmut, S. Probabilistic Part-of-Speech Tagging Using Decision Trees. In Proceedings of the International Conference on New Methods in Language Processing, Manchester, UK, 1994; Available online: http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.28.1139 (accessed on 30 November 2020).
- Giulio, G.; Domenico, L.; Massimo, M.; Federico, S. Ontology population for open-source intelligence: A GATE-based solution. J. Softw. Pract. Exp. 2018, 48, 2302–2330. [Google Scholar]
- Ali, A.; Ahmed, S.; Francois, B.B.; Cecilia, Z.-M. Ontology population with deep learning based-NLP: A case study on the Biomolecular Network Ontology. In Proceedings of the 23rd International Conference on Knowledge-Based and Intelligent Information and Engineering Systems (Elsevier Procedia Computer Science), Budapest, Hungary, 23–24 July 2019; pp. 572–581. [Google Scholar]
- Tomas, M.; Ilya, S.; Chen, K.; Corrado, G.; Jeffrey, D. Distributed representations of words and phrases and their compositionality. Adv. Neural Inf. Process. Syst. 2013, 26, 3111–3119. [Google Scholar]
- Unbehauen, J.; Hellmann, S.; Auer, S.; Stadler, C. Knowledge Extraction from Structured Sources. In Search Computing—Broadening Web Search Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2012; pp. 34–52. [Google Scholar]
- Stevens, R.; Sattler, U. Disjointness between Classes in an Ontology. Ontogenesis 2012. Available online: http://ontogenesis.knowledgeblog.org/1260 (accessed on 20 September 2019).
- Samir Tartir, I.; Arpinar, B.; Sheth, A.P. Ontological Evaluation and Validation. In Theory and Applications of Ontology: Computer Applications; Springer: New York, NY, USA, 2010; pp. 115–130. [Google Scholar]
- Dittmann, L.; Rademacher, T.; Zelewski, S. Performing FMEA using ontologies. In Proceedings of the 18th International Workshop on Qualitative Reasoning, Evanston, IL, USA, 2–4 August 2004; pp. 209–216. [Google Scholar]
- Ebrahimipour, V.; Rezaie, K.; Shokravi, S. An ontology approach to support FMEA studies. Expert Syst. Appl. 2010, 37, 671–677. [Google Scholar] [CrossRef]
- Mikos, W.L.; Ferreira, J.C.; Botura, P.E.; Freitas, L.S. A system for distributed sharing and reuse of design and manufacturing. J. Manuf. Syst. 2011, 30, 133–143. [Google Scholar] [CrossRef]


















| Name | Data Source | Mapping Language | Mapping | Requires Domain Ontology | Uses GUI |
|---|---|---|---|---|---|
| CSV2RDF4LOD | CSV | RDF | Manual | False | False |
| Convert2RDF | Delimited text file | RDF/DAML | Manual | False | True |
| Google Refine RDF Extension | CSV and XML | None | Semiautomatic | False | True |
| Mapping Master | CSV | Mapping Master | GUI | False | True |
| OntoWiki CSV Importer | CSV | RDF Data Cube Vocabulary | Semiautomatic | False | True |
| RDF 123 | CSV | – | Manual | False | True |
| T2LD | CSV | – | Automatic | False | False |
| TopBraid Composer | CSV | SKOS | Semiautomatic | False | True |
| XLWrap: Spreadsheet to RDF | CSV | TriG Syntax | Manual | False | False |
| Approach | Domain | Ontology Methodology | Tools | Knowledge Base Acquisition | Size of Knowledge Base |
|---|---|---|---|---|---|
| [31] | Unknown | TOVE methodology | F-logic | Manual | Not mentioned |
| [32] | Tehran Subway Project | Not mentioned | Protégé, ARP Servlet | Not mentioned | Not mentioned |
| [33] | Company project that produces cage component in bearings | Methontology | Protégé, RacerPro | Manual | Not mentioned |
| Proposed approach | Automotive processes | Hybrid (Methontology and OTK) | Protégé, Hermit, Python | Automatic | 1357 instances |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rehman, Z.; Kifor, C.V.; Jabeen, F.; Naz, S.; Waqar, M. Automatic Acquisition of Failure Mode and Effect Analysis Ontology for Sustainable Risk Management. Sustainability 2020, 12, 10208. https://0-doi-org.brum.beds.ac.uk/10.3390/su122310208
Rehman Z, Kifor CV, Jabeen F, Naz S, Waqar M. Automatic Acquisition of Failure Mode and Effect Analysis Ontology for Sustainable Risk Management. Sustainability. 2020; 12(23):10208. https://0-doi-org.brum.beds.ac.uk/10.3390/su122310208
Chicago/Turabian StyleRehman, Zobia, Claudiu Vasile Kifor, Farhana Jabeen, Sheneela Naz, and Muhammad Waqar. 2020. "Automatic Acquisition of Failure Mode and Effect Analysis Ontology for Sustainable Risk Management" Sustainability 12, no. 23: 10208. https://0-doi-org.brum.beds.ac.uk/10.3390/su122310208