
Novel Recommendation-Based Approach for Multidisciplinary Development of Future Universities


1
Library, Fudan University, Shanghai 200433, China
2
Commonwealth Scientific and Industrial Research Organisation, Sydney, NSW 2122, Australia
3
Department of Communication Science and Engineering, Fudan University, Shanghai 200433, China
*
Author to whom correspondence should be addressed.
Sustainability 2022, 14(10), 5881; https://0-doi-org.brum.beds.ac.uk/10.3390/su14105881
Submission received: 7 April 2022
/
Revised: 5 May 2022
/
Accepted: 11 May 2022
/
Published: 12 May 2022
(This article belongs to the Special Issue Social Innovation at Higher Education Institutions: Promoting Sustainable Development Objectives)
Abstract
:Multidisciplinary sustainable development is an important and complex system for comprehensive universities. Typically, a comprehensive university’s objective is to create a free, open, and diversified ecosystem of disciplines. Given finite available resources, e.g., funding or investment, configuring the formation of disciplines is critical. Understanding the interrelationships among different disciplines is challenging. Rather than directly wading through massive high-dimensional interrelated data, we judiciously formulate the cumbersome configurations of disciplines as a discipline recommendation problem. In this paper, we propose a novel data-driven approach to the configuration of disciplines based on a recommendation to predict and recommend an appropriate configuration of disciplines. The proposed approach exhibits good performance against standard metrics on real-world public data sets. It can be implemented as an attractive engine for constructing disciplines for universities.
1. Introduction
Multidisciplinary sustainable development of a university, which is responsible for the social innovation [1,2,3], is a critical and complex engineering system involving combinations of knowledge domains to optimize the configuration of the existing discipline structure [4]. A typical objective of a comprehensive university is to cater to a free, open, and diversified ecosystem of disciplines. However, subject to the constraints of funds and other factors, e.g., geographical location, a university bearing the weight of both talent cultivation and scientific research cannot be unconditionally supported to invest evenly across all disciplines [5]. In other words, a university must construct its disciplines with a well-directed configuration schedule to make the most of its finite resources. An adequate configuration of resource usage consequently leads to better competitiveness of both university and discipline. Top universities with better competitiveness are inclined to have more opportunities of receiving industrial investment or government grants [6,7]. In this sense, the developments of both universities and disciplines cannot be decoupled but inextricably linked and mutually enhanced.
Recently, multidisciplinary sustainable development has been stressed as having more and more important effects on social innovation and development. In [8], multidisciplinary innovation for social change (SHINE) was proposed to utilize multidisciplinary innovation methods to solve the social problems. As discussed in [9], multidisciplinary collaboration and development for higher education should be encouraged and advocated for social innovation and sustainable development. The work in [10] focused the interdisciplinary doctoral education to investigate the systemic solutions and professional competency for the sustainability of society from the viewpoint of pedagogical methodology. Under such a key role of multidisciplinary sustainable development for social innovation, there indeed needs to be more attention paid to the evaluation and discussions for realizing an appropriate multidisciplinary configuration for universities. In [5], the authors argued that multidisciplinary production can be evaluated via the collaborative settings of research funds, projects, and teams. In [11], the authors focused on the technical level as the indicator to evaluate the importance of disciplines for further multidisciplinary construction. In [7], the authors proposed a multiple-criteria decision-making method based on the nonradial super efficiency data envelopment analysis to model the discipline construction problem as a resource distribution optimization problem, which emphasized the Malmquist productivity index as the evaluation metric. In [12], a multi-criteria decision-making model was proposed, using a D-number preference matrix to evaluate the efficiencies of different disciplines with several discipline features as the selected evaluation indexes.
However, there exist high-dimensional features for the disciplines, and how to optimally identify the high-dimensional feature relationship among the different disciplines for universities also with the high-dimensional feature is still an open issue. From this perspective, it is thus imperative to efficiently clarify the relationship among the different disciplines and construct a well-directed multidisciplinary configuration. Facing such a classical information overload problem that arose in handling the high-dimensional feature of discipline and university, the recommendation-based ideology relies on the collaborative intelligence to solve such a high-dimensional information-overload problem typically involving two parties (namely, the university and discipline), rather than inefficiently focusing on one or several discipline features as the evaluation indicator for a specific university.
Generally, the discipline competitiveness can be evaluated in terms of rankings or scores published by the well-known third parties, e.g., QS [13], THE [14], and USNEWS [15], and the general structure of evaluation data of disciplines is shown in Table 1. For the sake of simplicity, we only consider the top-2 list, where only the two highest-ranked universities are considered for each selected discipline. It can be seen that the score earned by the physics discipline of university 3 is remarkably higher than the score achieved by physics discipline of university 4, which manifests in the competitiveness of the physics discipline of university 3 over that of university 4. From Table 1, we also observe that the score for discipline mathematics of university 1 is remarkably high. However, the other disciplines of university 1 do not exist in the top-2 list, indicating that only the predominant ones are endowed in the published list. This caters to the fact that many non-advantaged disciplines are not considered in the evaluation scope of the third party in practice.
Based on the above discussions on the objective of becoming a university with significant comprehensive competitiveness of disciplines, a rational configuration of disciplines can be thus a critical issue. However, the decision process of a sensible configuration of disciplines for a university is generally based on the cumbersome data analysis of the incredibly gigantic amount and high-dimensional data, which includes both the university feature and the discipline feature data, e.g., the university feature data in China includes whether a university is included in Project 985 [16], Project 211 [17], Project double first-class [18], or the other projects from local government, the numbers of faculty members, researchers, supporting and administrative staff, the number of public service staffs, the number of current students and new enrollment, the age structure of faculties, the granted funding from government and other third parties, the existing essential experimental equipment, the current basic educational facilities, and geographical locations [19]. The discipline feature of discipline can be the specific feature such as whether a discipline is science–engineering based or humanity–social-science based, whether the discipline is included in Project 985, Project 211, Project double first-class, or the other projects from local government, the granted funding from government or the other third parties, the historical evolution, the number of involved faculties and students, and the existing basic experimental equipment [19]. It is difficult to determine an appropriate configuration of disciplines for a university based on the above high-dimensional features for universities and disciplines.
The traditional approaches mainly include two aspects: one is to attempt to analyze by synthesis based on the aforementioned high-dimensional data, and the other is to empirically and intuitively select one or several dimensions as the research target [11,12,20,21,22,23,24,25,26]. Using this method it is not possible to provide an efficient solution for optimizing the configurations of disciplines under such a massive amount of high-dimensional data. In contrast to the traditional brute-force or empirical methods, we provide a novel data-driven approach for the construction of disciplines by reformulating the problem of optimizing the configurations of disciplines as a discipline recommendation problem. The proposed approach performs better than existing approaches in terms of standard metrics, upon a real-world data set. It can be implemented as a critical engine for the recommendations of disciplines for future universities.
Our contributions can be summarized as follows:
- Rather than directly wading through massive high-dimensional data, we judiciously formulate the cumbersome configurations of disciplines as a discipline recommendation problem.
- An efficient non-negative matrix factorization-based algorithm is developed to solve the resultant recommendation problem with a low (polynomial-time) complexity.
- A promising off-the-shelf subject list can be readily given by the proposed recommendation engine and used as a cost-effective, powerful and practical tool in the decision process of discipline configuration for a future university.
Numerical results based on collected real-world data demonstrate that our proposed approach can achieve superior performance in terms of accuracy and robustness, compared to existing alternative algorithms.
This paper is organized as follows. Section 2 presents the judicious mapping from the problem of interest to the data-driven recommendation problem, formulates the problem, and develops an efficient non-negative matrix factorization approach to solve the recommendation problem. Section 3 provides the details on the data set used to be trained and validated, followed by numerical results to evaluate the proposed approach. Section 4 concludes the paper.
2. Problem Formulation
Inspired by the paradigm application of the recommender system [27,28], we interpret the problem of discipline configuration to a recommender system. The similarities and the mappings between the two problems are listed as follows.
2.1. Problem Mapping
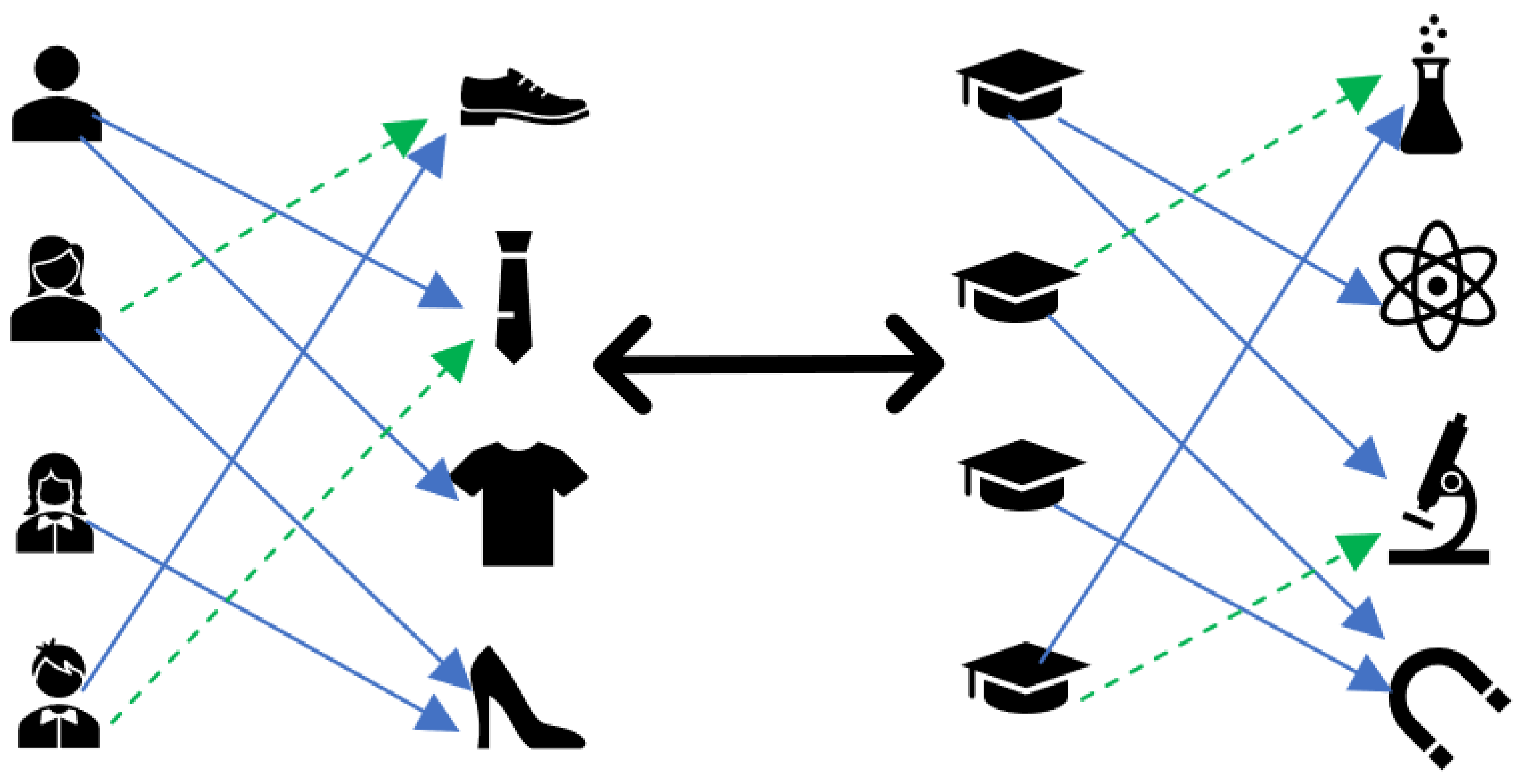
- In the classical recommendation-based problem of retail business, there are two types of roles: users and items. As shown in the left subfigure of Figure 1, the solid blue line refers to an actual purchase of an item by a user, and the green dashed line refers to a recommended item by the recommendation engine. In such a scenario, the users freely purchase the preferred ones from thousands of items. Typically, it can be inefficient for the user to fetch the mostly matched targets via brute-force search in many high-dimensional candidates. This induces the so-called information overload problem. To solve the problem, the recommendation engine is utilized to transform the cumbersome high-dimensional searching space into the low-dimensional space, and based on neighborhood or historical data similarities and correlations in the low-dimensional space, further recommend a Top-K (K is usually a small number) number of most needed items to users [29,30].As for the configuration of disciplines for universities, there are also two types of roles: universities and disciplines. As shown in the right sub-figure of Figure 1, the solid blue line refers to a preponderant discipline included in published data by a third party for a university, and the green dashed line refers to a recommended discipline by the recommendation engine to be the promising discipline for a university. In such a case, the objective of a university is to determine a series of disciplines as the focus of further developments. Correspondingly, we resort to the recommendation engine to transform the original high-dimensional features of both universities and disciplines into the low-dimensional ones. Based on neighborhood or historical data similarities and correlations in the low-dimensional space, we subsequently recommend an adequate configuration of disciplines to direct the decision process on the development of disciplines.
- In the recommendation case of retail business, the recommendation engine often relies on the explicit feedback of users, e.g., the rating for a specific item given by users. Based on a specific item’s neighborhood or historical usage rating data, the recommendation engine can readily provide the recommendation list of items with a neighborhood-based collaborative filtering approach or model-based approach [31]. As for the problem of discipline configuration for universities, the score on a specific discipline by a third party can be seen as a preferred configuration of the discipline for a university. Based on the scores on disciplines by the third party, the recommendation engine can be readily used to handle the recommendation task as in retail business scenarios and provide an appropriate list of disciplines for universities.
2.2. Discipline Recommendation Problem
Generally, the classical recommendation-based problem is solved based on a rating matrix, in which the rows represent the users, and the columns represent the items. Correspondingly, in the discipline recommendation case, a discipline score table, as shown in Table 2, can be reconstructed from the raw data as shown in Table 1.
Based on Table 2, we can further construct an incomplete score matrix, denoted by , as
where M and N are the number of universities and the number of disciplines, respectively, and represents the rated score earned by the j-th discipline of the i-th university, e.g., in the case in Table 2, , , , and .
Note that some entries of are missing, e.g., , and in (1), since only the preponderant disciplines of a university are rated and included, as discussed earlier. In practice, the values of M and N are generally large, since there is a large number of universities and disciplines in the published list by the third party [13,14,15,19], and is typically sparse due to a large number of missing entries. This implies a relatively small number of common disciplines rated for pairwise universities. The classical neighborhood-based similarity technique, which utilizes the weighted pairwise similarity to predict the missing entry [31,32], is not applicable to predict the missing entries of . This is because the pairwise inner product can be approximately zero with few rated disciplines in common when using the cosine similarity approach to compute the neighborhood-based similarity.
By resorting to the state-of-the-art latent factor model-based approach [33,34], the sparsity of and the subsequent series of problems can be robustly alleviated. The latent factor model-based approach can provide a robust approximation of to achieve a low-dimensional (low-rank) representation space of universities and disciplines. In the low-dimensional (low-rank) space, the imperceptible pairwise correlations in the original sparse space can be conveniently captured in the dense low-dimensional (low-rank) space. Based on the sparsity and the pairwise rows or columns correlations of , we proceed to propose an efficient dimensionality reduction approach to approximate the original matrix , by using non-negative matrix factorization.
Let denote the latent factor matrix of the universities, and the latent factor matrix of the disciplines, where d ( and ) is the number of key factors considered. The ranks of both the row space of and the column space of are d.
The approximation of is used to minimize the Frobenius norm of the difference between and , i.e.,
Since the score data published by the third parties is generally quantized in a non-negative metric, e.g., , or {100, 99, …, 1}, it is reasonable to consider a non-negative latent factor matrix of the universities, i.e., , and a non-negative latent factor matrix of disciplines, i.e., .
As discussed in Section 2.1, only the leading disciplines of a university are endowed in the published list. This leads to the sparsity of , which indicates the number of observed entries is relatively small. Overfitting can then arise when solving problem (2). For this reason, we add a regularization on and to the objective of (2) [31,35].
The non-negative matrix optimization problem based on partial observations of the entries of can be formulated as
where is the regularization parameter, and in both parts of the objective function is for the convenience of calculating differentiation in each iteration.
We next propose an iterative descent algorithm to solve the non-negative constrained problem (3), as summarized in Algorithm 1.
| Algorithm 1 The proposed iterative-based algorithm to solve problem (3) |
| Initialize: Randomly initialize and with each entry in (0, 1), fill the unknown entries of as 0, an accuracy level , select a step size , a regularization parameter , and set . |
Repeat:
|
Here, the rationality of initializing the unknown entries as zero is due to the fact that the unspecified entries can be reasonably set to zero when the prior probability of entries being zero is significantly high. This is also due to the fact that a model can generally undergo overfitting with limited training data based on classical machine learning. It is thus more efficient to enlarge the training set by specifying the unknown ones as zero. As such, the variance can be efficiently reduced with a more extensive training set, and the model generalizes better [31]. The maximum function max{x, 0} in step (3) is to enforce the non-negativity of each entry.
After the solutions are output by the proposed approach, we can reconstruct the estimated rating matrix , as follows.
where each unrated entry of original has been predicted in . Considering a specific university, it is convenient to output Top-K recommended disciplines with the highest predicted scores from the corresponding row of .
3. Numerical Results
3.1. Evaluation on a Local Authoritative Data Set
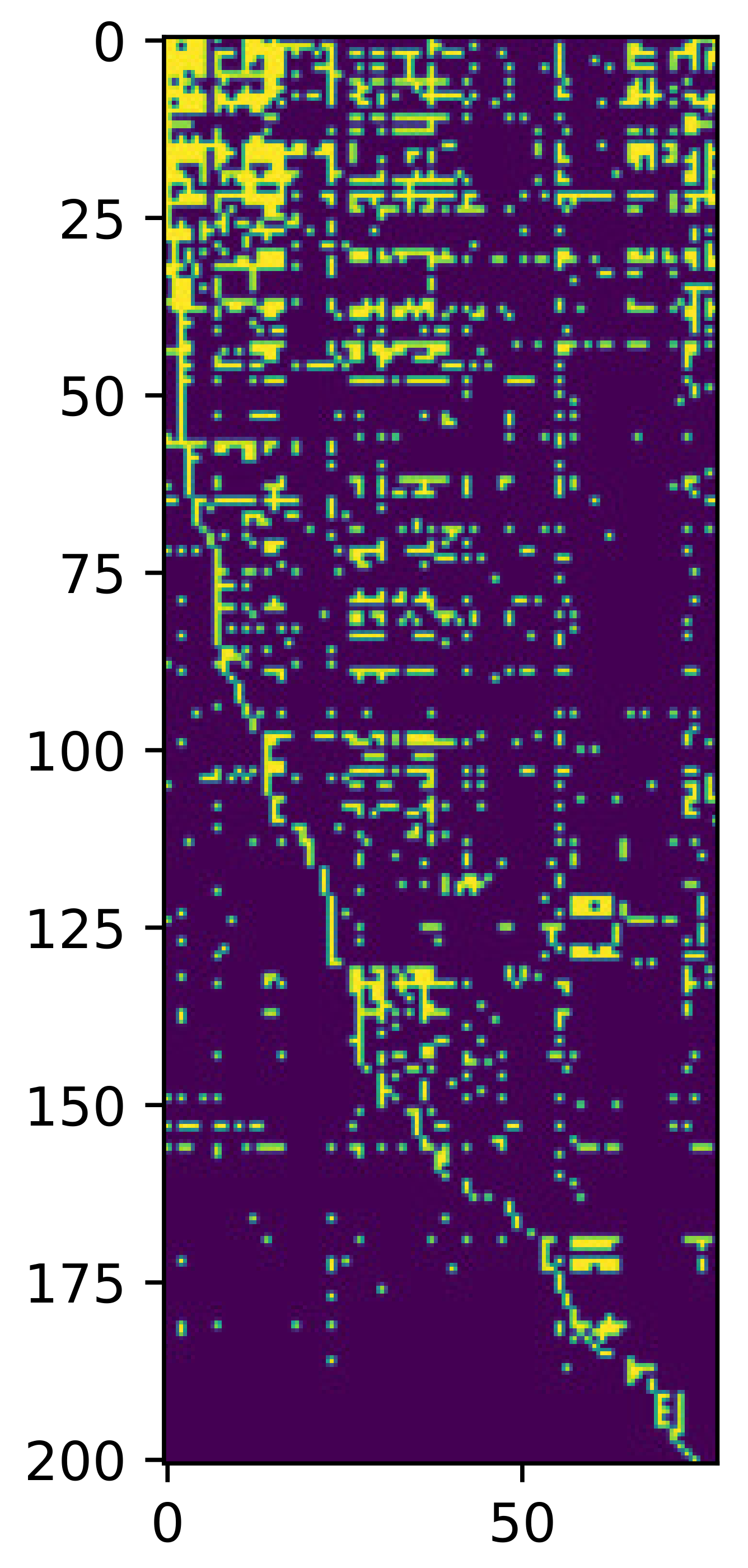
In order to get the objective and authoritative assessment data on disciplines of universities, we have collected official discipline assessment data for universities from the website of the Ministry of Education of China. The collected data includes the second-round nationwide discipline assessment data and the third-round discipline assessment data. The duration of the second-round data ranges from the year 2007 to the year 2009. The duration of third-round data varies from the year 2011 to the year 2012. The collected two-round data can thus have an inherently sequential form. The second-round data can be used as the training set. The third-round data can be used as the test set to validate the recommendation performance of the proposed algorithms. The collected two-round raw sample data is shown separately in Table 3 and Table 4. As discussed in the earlier sections, only a small part of disciplines are rated and captured in the assessment data, and this can be incarnated as the sparsity of the collected data, as shown in Figure 2.
The filtered training matrix is shown in Figure 2. The information of the filtered training matrix is shown in Table 5.
Since our focus is on utilizing the recommendation-based solution to provide constructive suggestions on the discipline configurations of universities, we adopt the Top-K recommendation evaluation to exhibit the recommendation performance. As a general way to test the performance of recommendation algorithms, the Top-K recommendation has been widely adopted in the retail business. The general idea of the Top-K recommendation is to recommend a number (K) of the most promising items based on the outcome of the recommendation engine for further investigation on whether the recommended items are actually adopted. As for our interest in recommending promising disciplines for universities, the proposed approach outputs a Top-K number of prosperous disciplines based on the sparse training matrix. Then we investigate whether some of the recommended disciplines are included in the test set.
In order to formally evaluate the performance of discipline recommendations, we adopt two well-known evaluation metrics for the Top-K recommendation: Precision and Recall; the expressions of the two metrics are given by [38,39]
where stands for the total number of distinct universities in both training and test sets, stands for the i-th university, and and stand for the set of predicted list for and the set of test list for , respectively.
The Precision metric stands for the ratio on the scale of predicted targets truly hit in the test set to the scale of total predicted targets. It mainly reflects how many truly hit targets occupied in the total predicted targets list. The Recall metric stands for the ratio of predicted targets that are hit in the test set to the scale of total test targets. It reflects the extent of how many truly hit targets occupied in the total test targets list. As for our problem, we make the proposed algorithm perform with a high Recall; i.e., we would like the proposed algorithms to recommend more ground-truth disciplines. The university can thus make more confident and flexible decisions on the configurations of disciplines based on more effective recommended candidates.
To illustrate the recommendation performance of the proposed approach, Table 6 shows a sample of disciplines hit in the Top-5 recommendation, where the disciplines in bold font represent the recommended disciplines hit in the test set, and the test set represents the set that the disciplines appeared in the third-round data but did not appear in the second-round data. It can be observed that the hit probability for these universities is 0.8. In addition, the hit probability can be up to 1 in some universities. These universities have a common feature on a considerable number of test sets; hence, we choose not to exhibit these for conciseness. The reason why these universities in Table 6 are sampled for the exhibition is that they are all specialist universities, e.g., polytechnic, mining, traffic-related, and agriculture. It is consistent with the objective of discipline development, which is to cater to a free, open, and diversified ecosystem of disciplines.
Based on (5) and (6), we proceed to evaluate the performance of discipline recommendations with the metrics of Recall and Precision, respectively. The baseline approaches used for comparisons are the random recommendation approach, naive truncated singular value decomposition (NSVD) approach [40], and partial non-negative matrix factorization (PNNMF) approach. The random recommendation approach randomly chooses the K number of unrated disciplines in the training data as the recommended disciplines. The NSVD approach is based on the direct SVD of the original sparse matrix with unrated ones as zero, and the PNNMF approach is the same as the proposed approach, except that only the known part, is updated in the iterations.
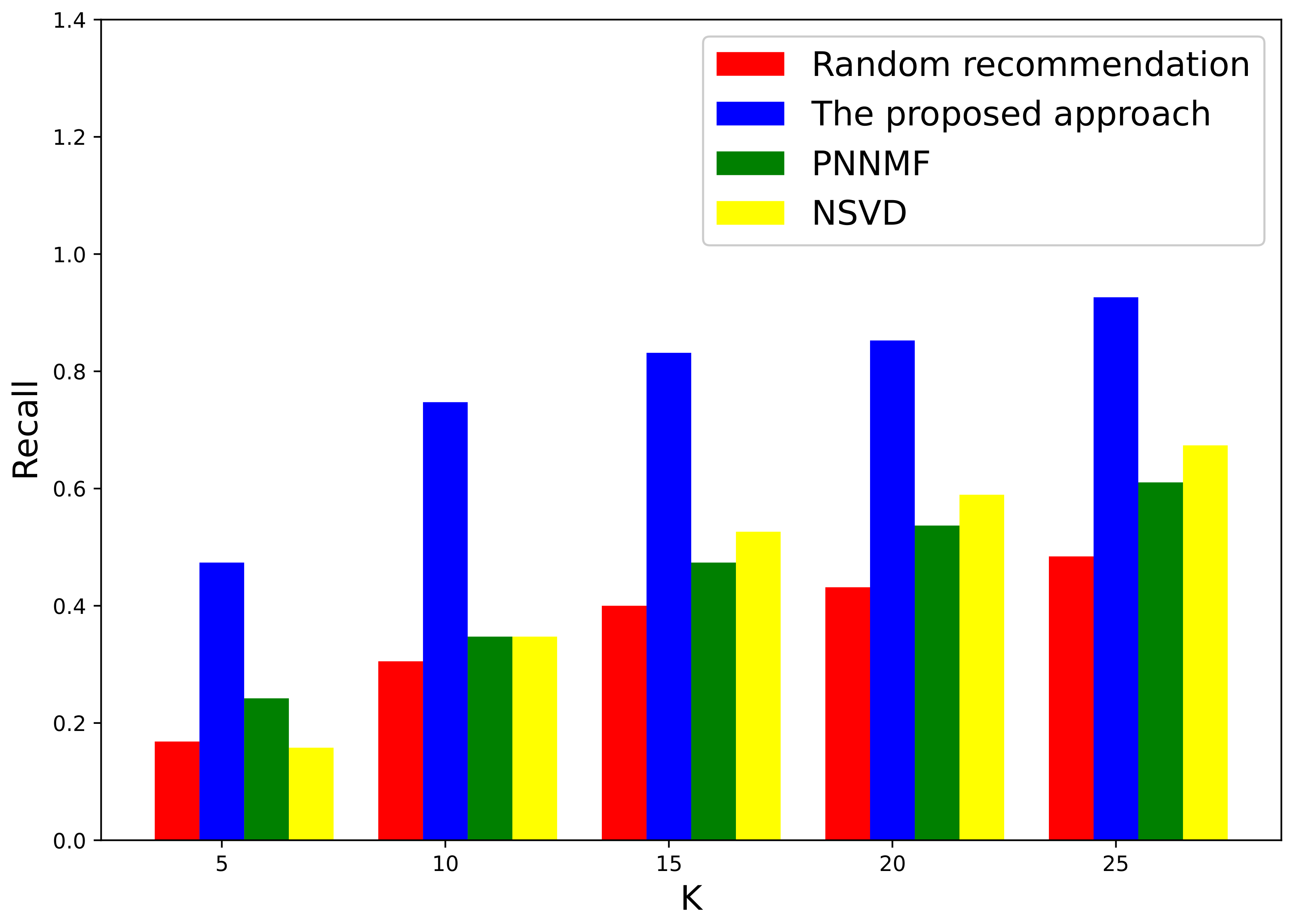
Figure 3 shows the Recall performance of discipline recommendations with the growth of K. We can observe that the proposed approach remarkably outperforms the baseline approaches for each K. The gap between the proposed approach and the baseline approaches increases with K, yet, the performance of the random recommendation deteriorates with the increasing K value, which can be shown as the slope of the random recommendation line becomes smaller. This implies that the proposed approach can recommend more useful outcomes than the random recommendation approach with the same number of test sets and it can perform satisfactory robustness under each K. In contrast, the random recommendation approach is more susceptible to noise in the larger recommendation list. The NSVD performs slightly better than the random recommendation. This is because there indeed exists a potential statistical pattern in the development of disciplines. The worst performance of PNNMF is due to the overfitting induced by the insufficient training set.
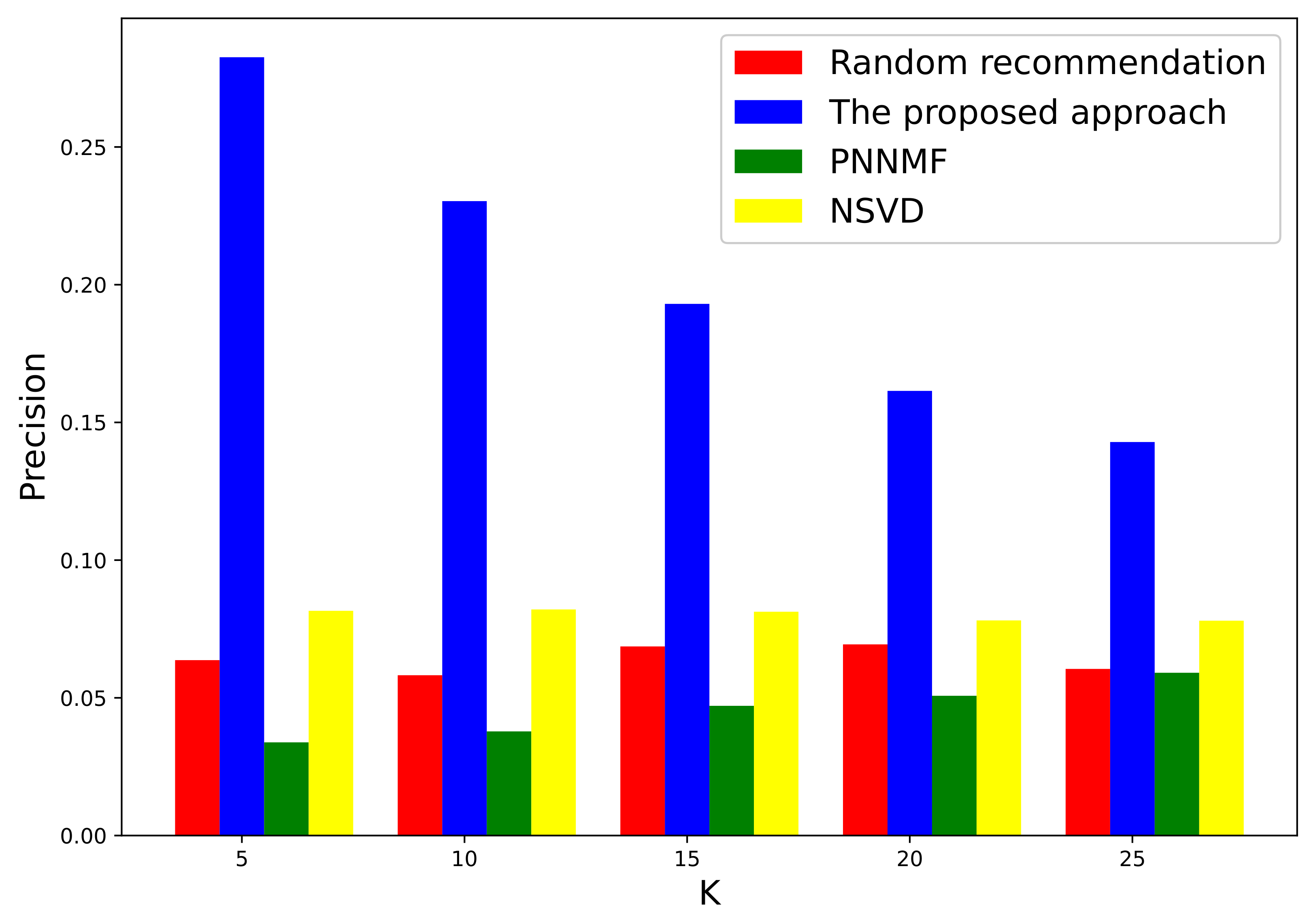
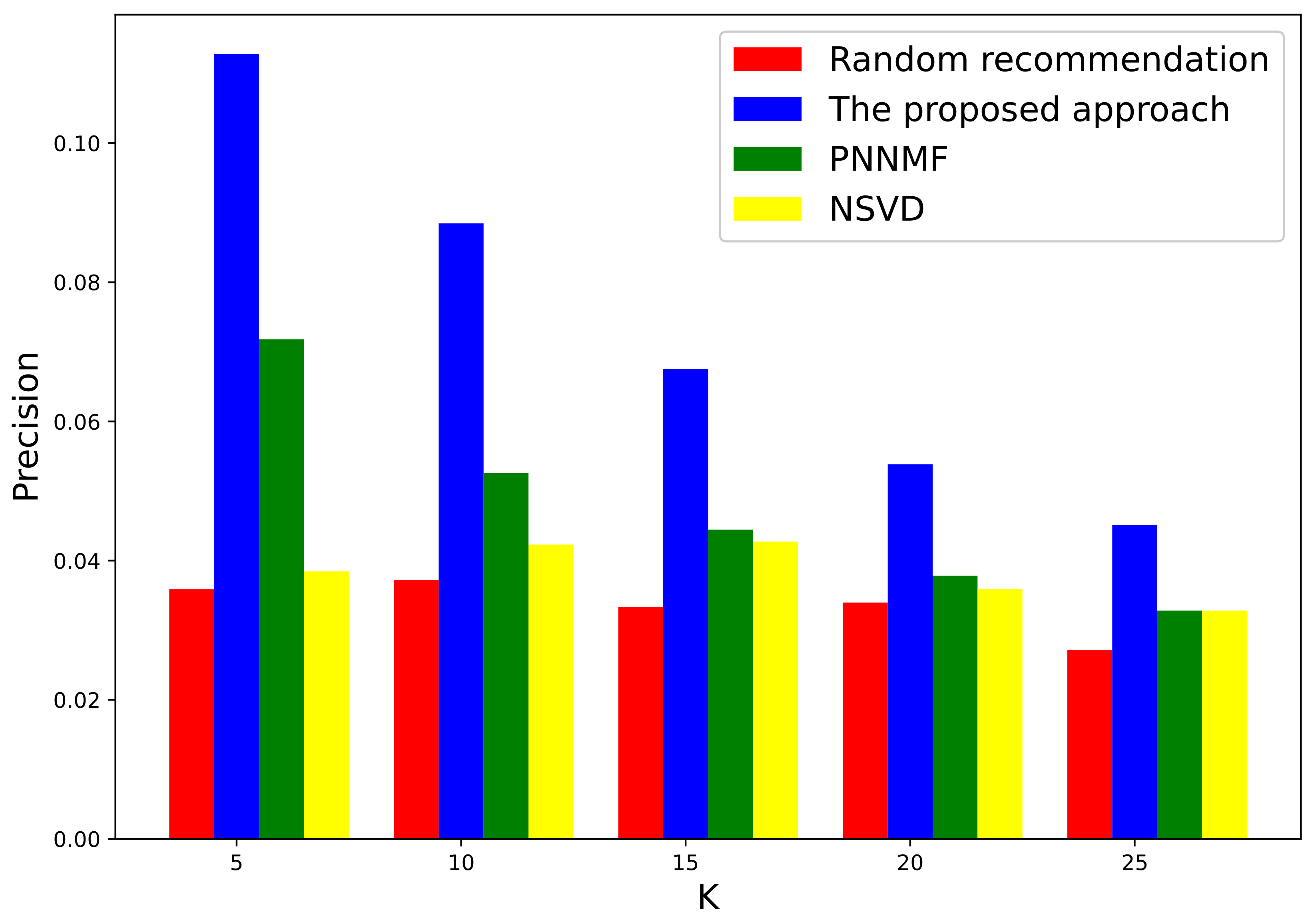
Figure 4 shows the Precision performance of discipline recommendation with the growth of K. We can observe that the Precision decreases with the increase of K under both the proposed and the baseline recommendations. The proposed approach remarkably outperforms the baseline methods on Precision under each K. It is interesting to observe that the proposed approach exhibits relatively good performance when K is 5. This is because the distribution of top recommendation disciplines output by the proposed approach exhibits reasonable concentration and accuracy. In contrast, the baseline approaches suffer from low efficiency and exacerbated performance under each K. Evidently, the proposed approach can provide fairly good recommendations, even when K is small.
In order to further evaluate the overall performance of the proposed approach, we adopt the well-known F1 metric (7), which is the harmonic mean of Precision and Recall, to exhibit the overall performance of recommendation, i.e.,
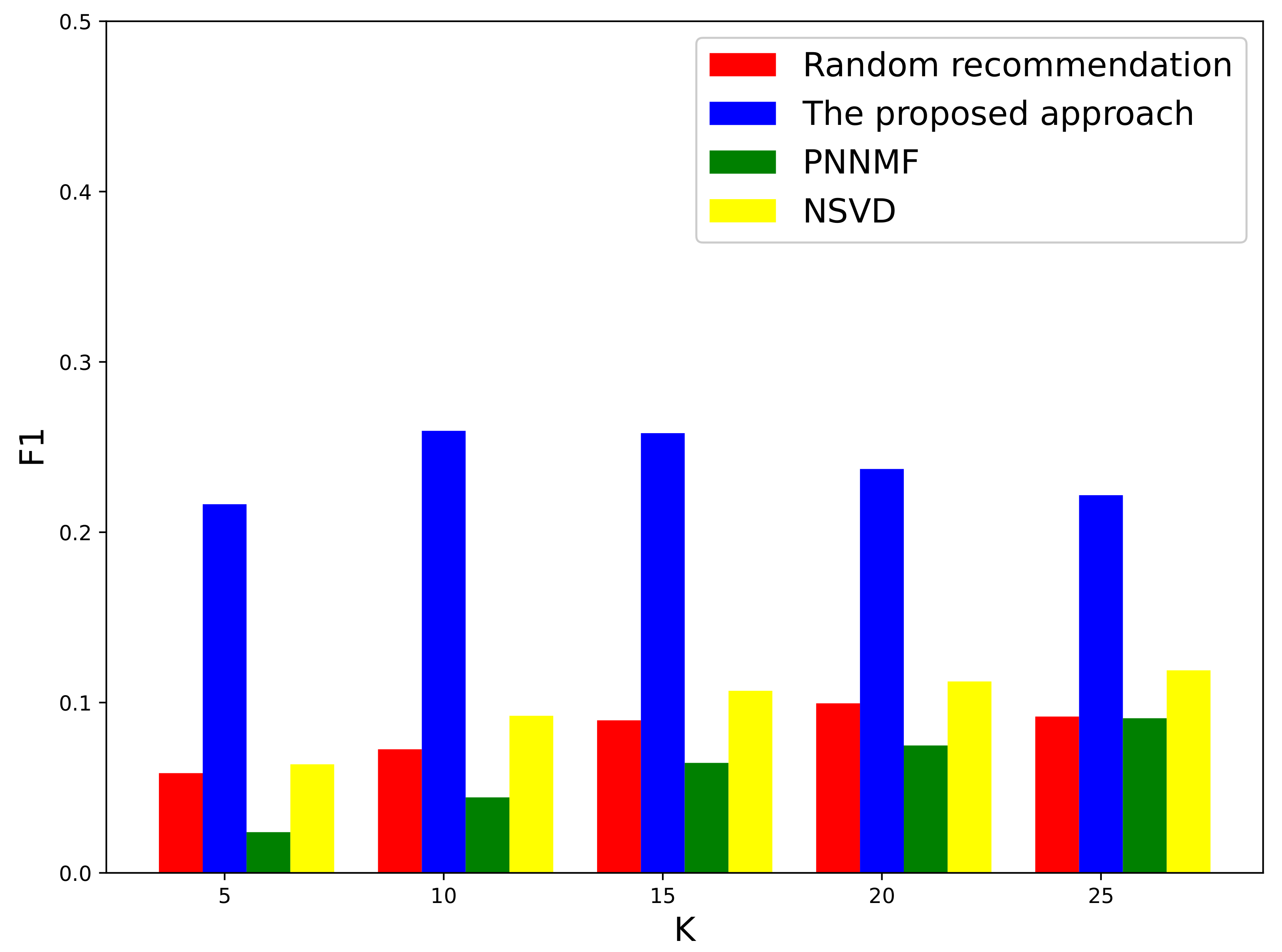
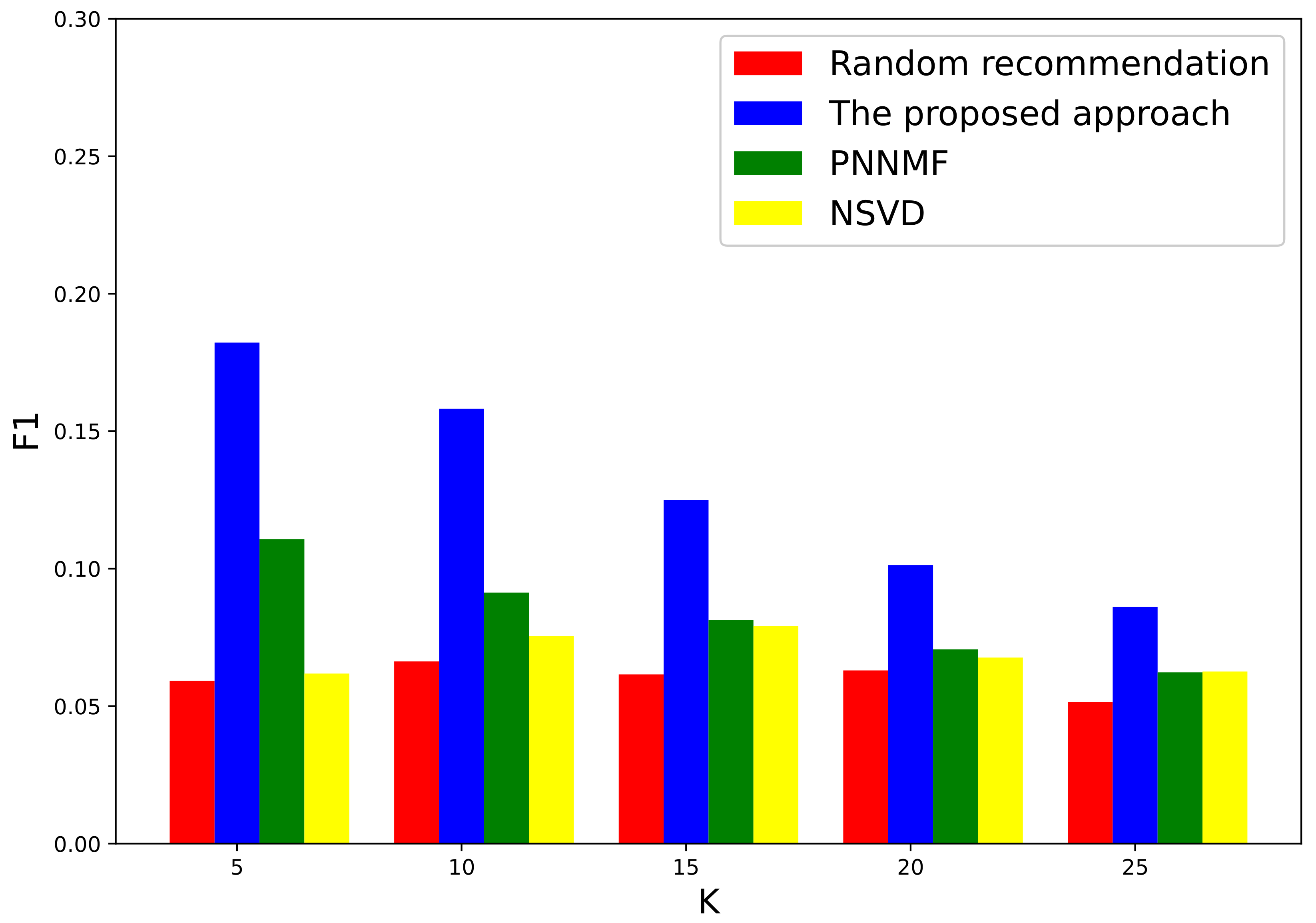
In general, the larger the F1 value is, the better the model’s overall performance is. Figure 5 shows the F1 performance of discipline recommendations with the increase of K. We observe that the F1 increases with K within the range from to achieves the peak at , and then gradually deteriorates. As discussed above, we can choose suitable metrics among Precision, Recall, and F1 to evaluate for a specific purpose. Here, we take when assessing the metric of F1, to balance the trade-off between Precision and Recall.
It can be observed that the F1 decreases with K for both the proposed and the baseline recommendations. The proposed approach remarkably outperforms the baseline approaches under each K. It is interesting to observe that the proposed method exhibits good performance when K is 5, in contrast to the low efficiency and exacerbated performance of the baseline approaches under each K. This again demonstrates that the proposed approach can give reasonable recommendations even when K is small since the distribution of top recommendation disciplines output by the proposed approach exhibits accuracy.
As the aim of this study is to give constructive suggestions on discipline configuration to universities, the accurate and efficient solutions output by the proposed approach can be readily used to provide constructive suggestions on the discipline configurations of universities, e.g., rendering more policy supports or financial supports on the accordingly Top-K disciplines output by the proposed approach. In addition, the data used for evaluation are focused on Chinese universities; yet, the proposed approach can be readily generalized to the discipline recommendation based on any open access discipline ranking data, e.g., international data, such as QS, THE, USNEWS, or the regional discipline ranking data for a specific country.
3.2. Further Evaluation of Well-Known International Data Set
For the sake of conducting a more convincing evaluation of the performance of the proposed approach, we have selected the “QS World University Rankings by Subject” data, “QS” for short, as the international evaluation data set. Since different countries often have distinct education systems, regulations, and funding mechanisms, we focus on universities in China by filtering the collected QS data, in contrast to the aforementioned local authoritative data set.
As the reconfiguration of disciplines is a comparatively slow systematic evolution process, as can be referred to as the period of time for the aforementioned two-round discipline assessment data, and also for the sake of observing a more remarkable result, the first stage data used as the training data set is expected to be as early as possible. Yet, also considering the uniformity of the structure of the disciplines, we choose the data published in 2020 and the data published in 2022 as the training data set and the evaluation data set, respectively, rather than the earlier data published in 2019 as the training data set for the reason of different structure of the disciplines. As done in the earlier case, we also identify the sparsity of the training data set. The QS data set used for training is still sparse based on Table 7, which again corroborates the aforementioned discussions on the sparsity of general ranking data, and also implies the necessity for the proposed approach.
As done in the aforementioned evaluation on the local authoritative data, we also adopt the Top-K recommendation evaluation to exhibit the recommendation performance. Based on the structured sparse training matrix on QS data, where the process for generating the sparse training matrix has already been discussed in Section 2, we further investigate the performance of the proposed approach under the well-known evaluation metrics for the Top-K recommendation: Precision, Recall, and F1, as done in the former case. The baseline approaches used for comparisons are the random recommendation approach, NSVD approach, and PNNMF approach, as also done in the former case.
Figure 6 shows the Recall performance of discipline recommendations with the growth of K. We can observe that the proposed approach remarkably outperforms the baseline approaches for each K. This implies that the proposed approach can recommend more useful outcomes than the random recommendation approach with the same number of test sets and it can perform satisfactory robustness under each K. The NSVD performs slightly better than PNNMF. The overfitting of PNNMF is remarkably mitigated due to the smaller proportion of sparsity of the training set, which implies that more data can be used for training, in contrast to the former local data case. In contrast, the worst random recommendation approach is more susceptible to noise in the larger recommendation list, since the slope becomes flat with the growth of K. Compared to the random recommendation approach, the performances of the proposed approach and the other two baselines manifest that there indeed exists a potential statistical pattern in the development of disciplines when evaluated on the QS data. It is also interesting to observe that the Recall of the proposed approach can even nearly up to 1 when , which reflects that the university can flexibly configure the structure of disciplines with more confident candidates output by the proposed approach.
Figure 7 shows the Precision performance of discipline recommendation with the growth of K. We can observe that the Precision decreases with the increase of K under both the proposed and the baseline recommendations. The proposed approach remarkably outperforms the baseline methods on Precision under each K. It is interesting to observe that the proposed approach exhibits relatively good performance when K is 5. This is because the distribution of top recommendation disciplines output by the proposed approach exhibits reasonable concentration and accuracy, as already discussed in the local data case. In contrast, the baseline approaches suffer from low efficiency and exacerbated performance under each K. It is also worth noting that PNNMF performs better than the other baselines due to the eased overfitting, in contrast to the worst case in the local data case.
Figure 8 shows that the F1 decreases with K for both the proposed and the baseline recommendations. The proposed approach remarkably outperforms the baseline approaches under each K. It is interesting to observe that the proposed method exhibits good performance when K is 5, in contrast to the low efficiency and exacerbated performance of the baseline approaches under each K. This again demonstrates that the proposed approach can give reasonable recommendations even when K is small since the distribution of top recommendation disciplines output by the proposed approach exhibits accuracy. It is also worth noting that the performance on F1 follows a similar trend as Precision, which can be elaborated that the Precision dominates the performance of F1 when equally considering the effect of Recall and Precision.
As for the “supply” side of disciplines, the role of disciplines can be seen as an ultimate educational product provided by the universities to the higher education marketplace, which can be an analogy with the supply–demand relationship that arose in economic theory. The entities responsible for the construction of disciplines mainly involve the government, the university itself, and also society. During the process of the construction of disciplines, the government plays an important role in the macro policy guidance, the university is responsible for the educational service with the existing disciplines, and the society is responsible for the objective evaluation of the educational discipline service. Each role in the whole supply chain for disciplines can be interconnected with each other [41]. Since the proposed approach is based on the published third-party evaluation data set to provide an appropriate configuration of disciplines for future universities, the collected and adopted data set for evaluation from the Ministry of Education of China and the well-known third-party, namely, QS, represent the aforementioned governmental aspect and societal aspect, respectively, the objectivity and rationality of selected data set is thus a key issue. However, the two adopted data sets have already stood the test of time for several decades [12,42,43], these data sets can thus be the effective data sets for evaluation.
So far, we have conducted the performance evaluation of the proposed approach on both the local authoritative data and well-known international data, the proposed approach remarkably outperforms all the baselines under the overall metrics, which significantly indicates that the proposed approach can be used as an attractive engine for providing a promising configuration of disciplines. In reality, the university can benefit a lot from the recommended configuration of disciplines based on both local and international data. Meanwhile, the university can make an appropriate trade-off between the two types of data set, or adapt a rational weight for practical applications, e.g., for the university with relatively low overall strength which never has a chance to appear in the international data set, such a university can fully utilize the local authoritative data to conduct the appropriate configuration of disciplines for striving for the chance to be adopted by the international data. Yet, for the university with originally relatively high overall strength, which has already been involved in both local and international data, it can thus have more potential chances to make rational decisions on the configuration of disciplines according to the practical needs.
4. Discussions and Conclusions
In this paper, multidisciplinary collaboration and development for higher education is a key issue for social innovation and sustainable development. However, there exist high-dimensional features for the disciplines, it is thus imperative to efficiently clarify the relationship among the different disciplines and construct a well-directed multidisciplinary configuration. Through judicious problem mapping, the discipline configuration was cast as a data-driven recommendation-based problem. In reality, the recommendation-based ideology can naturally rely on collaborative intelligence to solve such a typical high-dimensional information overload problem involving two parties (namely, discipline and university). Based on the formulated recommendation-based problem, we further developed an efficient recommendation-based approach for the discipline configurations of universities.
As the proposed approach is based on the data-driven methodology, the data set used for evaluating the performance of the proposed approach is thus a key issue. In order to ensure the collected data is authoritative, objective, and scientific, we successively collected the data from the Ministry of Education of China, which can be seen as an authoritative local data set for higher education, and the discipline ranking data for China from QS, which can be seen as an objective and well-known international data set, since this paper aims at providing efficient suggestions on the appropriate configuration of the disciplines to the universities for a specific country.
Aiming at providing an objective evaluation metric, we specifically collected a two-stage data set, which has a natural sequential feature, so that the first-stage data set can be used as the training data set, and the second-stage data set can be used as the evaluation data set. Under the natural sequential partition of collected data, the performance on the evaluation data set can thus be seen as a convincing generalization indicator for the proposed approach. In addition, we also emphasize the sparsity of data, which can be seen as another necessity for the proposed non-negative matrix factorization-based algorithm, as already discussed in Section 2.
Based on the aforementioned discussion on the problem formulation and data set structure and details description, we then formally compared the proposed approach with the random recommendation approach, NSVD approach, and PNNMF approach under the Top-K principle. We firstly provided an intuitive sample of disciplines hit in the Top-5 recommendation, which can conveniently aid an understanding of the performance of the proposed approach. We have made the comparisons under the metric of Recall, Precision, and F1, all of which can be the classical metrics when evaluating the recommendation-based approach. Based on the numerical results from both the local authoritative governmental data and the well-known data by QS, the performance of the proposed approach is superior to the other baselines. Under the superior performance of the proposed approach, the university can efficiently, conveniently, and readily make decisions on the configuration of disciplines with the promising discipline list provided by the proposed approach, which can thus be an attractive engine for the decision process of sustainable configurations of disciplines.
In our future work, we will construct the university-discipline knowledge graph [44] by fusing context information and side information and then employing a graph-based framework to enhance the recommendation outcomes. Specifically, we will first try to model the universities and the disciplines as individual entities, respectively. We will then try to collect more context information and side information such as geographical location, cooperative relationship between pairwise universities, etc. Under the structured and enhanced university–discipline knowledge graph, the recommendation problem can be further modeled as a relation/link (university–discipline) completion problem [45], we will further employ a graph-based [46] framework to predict the missing relation/link between the university entity and the discipline entity. In addition, we can also further enhance the recommendation outcomes and performance via ensemble learning which combines the proposed approach with the graph-based approach.
Author Contributions
Conceptualization, S.B., X.W. and W.N.; methodology, S.B.; investigation, S.B.; writing—original draft preparation, S.B. and W.N.; writing—review and editing, W.N., Y.J. and X.W.; visualization, S.B.; supervision, W.N. and X.W.; funding acquisition, X.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Innovation Program of Shanghai Municipal Science and Technology Commission Grant: 20JC1416400; The open project of CAS Key Laboratory of Wireless Sensor Networks and Communications.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Monteiro, S.; Isusi-Fagoaga, R.; Almeida, L.; García-Aracil, A. Contribution of Higher Education Institutions to Social Innovation: Practices in Two Southern European Universities. Sustainability 2021, 13, 3594. [Google Scholar] [CrossRef]
- García-Aracil, A.; Monteiro, S.; Almeida, L.S. Students’ Perceptions of Their Preparedness for Transition to Work after Graduation. Act. Learn. High. Educ. 2021, 22, 49–62. [Google Scholar] [CrossRef]
- Puente, C.; Fabra, M.E.; Mason, C.; Puente-Rueda, C.; Sáenz-Nuño, M.A.; Viñuales, R. Role of the Universities as Drivers of Social Innovation. Sustainability 2021, 13, 13727. [Google Scholar] [CrossRef]
- Huang, Z.; Kougianos, E.; Ge, X.; Wang, S.; Chen, P.D.; Cai, L. A Systematic Interdisciplinary Engineering and Technology Model using Cutting-Edge Technologies for STEM Education. IEEE Trans. Educ. 2021, 64, 390–397. [Google Scholar] [CrossRef]
- Corazza, L.; Saluto, P. Universities and Multistakeholder Engagement for Sustainable Development: A Research and Technology Perspective. IEEE Trans. Eng. Manag. 2021, 68, 1173–1178. [Google Scholar] [CrossRef]
- García-Aracil, A. Understanding Productivity Changes in Public Universities: Evidence from Spain. Res. Eval. 2013, 22, 351–368. [Google Scholar] [CrossRef] [Green Version]
- Su, W.; Wang, D.; Xu, L.; Zeng, S.; Zhang, C. A Nonradial Super Efficiency DEA Framework using a MCDM to Measure the Research Efficiency of Disciplines at Chinese Universities. IEEE Access 2020, 8, 86388–86399. [Google Scholar] [CrossRef]
- Baturina, D. Pathways towards Enhancing HEI’s Role in the Local Social İnnovation Ecosystem. In Social Innovation in Higher Education: Landscape, Practices, and Opportunities; Springer: Cham, Switzerland, 2022; pp. 37–60. [Google Scholar]
- Dryjanska, L.; Kostalova, J.; Vidović, D. Higher Education Practices for Social Innovation and Sustainable Development. In Social Innovation in Higher Education: Landscape, Practices, and Opportunities; Springer: Cham, Switzerland, 2022; pp. 107–128. [Google Scholar]
- Piccardo, C.; Goto, Y.; Koca, D.; Aalto, P.; Hughes, M. Challenge-based, Interdisciplinary Learning for Sustainability in Doctoral Education. Int. J. Sustain. High. Educ. 2022, in press. [Google Scholar] [CrossRef]
- Xu, Z.; Xia, M.; Yang, Z. Interactive research of university discipline construction and development of science park. In Proceedings of the International Conference on Information Management, Innovation Management and Industrial Engineering, Shenzhen, China, 26–27 November 2011; pp. 499–502. [Google Scholar]
- Zong, F.; Hou, J.; Yang, Y. Evaluation of the first-class engineering discipline construction: A method based on d-number preference relation matrix. In Proceedings of the IEEE 4th International Conference on Electronic Information and Communication Technology (ICEICT), Xi’an, China, 18–20 August 2021; pp. 914–923. [Google Scholar]
- QS World University Rankings by Subject. Available online: https://www.topuniversities.com/subject-rankings/2021 (accessed on 28 March 2022).
- THE World University Rankings by Subject. Available online: https://www.timeshighereducation.com/world-university-rankings/by-subject (accessed on 28 March 2022).
- Best-Global-Universities. Available online: https://www.usnews.com/education/best-global-universities (accessed on 28 March 2022).
- Project 985. Available online: http://www.moe.gov.cn/srcsite/A22/s7065/200612/t20061206_128833.html (accessed on 16 March 2022).
- Project 211. Available online: http://www.moe.gov.cn/srcsite/A22/s7065/200512/t20051223_82762.html (accessed on 16 March 2022).
- Double-First. Available online: http://www.moe.gov.cn/srcsite/A22/s7065/202202/t20220211_598710.html (accessed on 16 March 2022).
- MOE. Available online: http://www.moe.gov.cn/srcsite/A11/s7057/202102/t20210205_512709.html (accessed on 16 March 2022).
- World Bank. Available online: https://ieg.worldbankgroup.org/sites/default/files/Data/Evaluation/files/highereducation.pdf (accessed on 20 February 2022).
- Sun, F. Higher education quality evaluation: A game-theory approach. In Proceedings of the 7th International Conference on Information Technology in Medicine and Education (ITME), Huangshan, China, 13–15 November 2015; pp. 473–475. [Google Scholar]
- Deng, H.; Wang, J.; Liu, X.; Liu, B.; Lei, J. Evaluating the Outcomes of Medical Informatics Development as a Discipline in China: A Publication Perspective. Comput. Methods Programs Biomed. 2018, 164, 75–85. [Google Scholar] [CrossRef]
- Zhou, M.; Zhou, J. Discipline construction plan of undergraduate studies in applied universities for China’s guangdong baiyun university based on the McKinsey 7S model. In Proceedings of the 2020 International Conference on Modern Education and Information Management (ICMEIM), Dalian, China, 25–27 September 2020; pp. 68–71. [Google Scholar]
- Zhang, Y.; Cen, G.; Feng, T. University discipline construction progress monitoring system. In Proceedings of the 14th International Conference on Computer Science & Education (ICCSE), Toronto, ON, Canada, 19–21 August 2019; pp. 176–179. [Google Scholar]
- Uhoman, A. Level of Discipline among University Academic Staff as a Correlate of University Development in Nigeria. J. Educ. Pract. 2017, 8, 21–29. [Google Scholar]
- Tongji. Available online: https://en.tongji.edu.cn/Academic_Research/Discipline_Development.htm (accessed on 14 March 2022).
- Dadgar, M.; Hamzeh, A. How to Boost the Performance of Recommender Systems by Social Trust? Studying the Challenges and Proposing a Solution. IEEE Access 2022, 10, 13768–13779. [Google Scholar] [CrossRef]
- Coba, L.; Confalonieri, R.; Zanker, M. RecoXplainer: A Library for Development and Offline Evaluation of Explainable Recommender Rystems. IEEE Comput. Intell. Mag. 2022, 17, 46–58. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, L.; He, X.; Peng, J.; Zheng, Z.; Tang, J. Modelling High-Order Social Relations for Item Recommendation. IEEE Trans. Knowl. Data Eng. 2022, in press. [Google Scholar] [CrossRef]
- Chang, J.; Gao, C.; He, X.; Jin, D.; Li, Y. Bundle Recommendation and Generation with Graph Neural Networks. IEEE Trans. Knowl. Data Eng. 2022, in press. [Google Scholar] [CrossRef]
- Aggarwal, C. Recommender Systems; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Luo, X.; Zhou, M.; Xia, Y.; Zhu, Q. An Efficient Non-Negative Matrix-Factorization-Based Approach to Collaborative Filtering for Recommender Systems. IEEE Trans. Industr. Inform. 2014, 10, 1273–1284. [Google Scholar]
- Li, W.; He, Q.; Luo, X.; Wang, Z. Assimilating Second-Order Information for Building Non-Negative Latent Factor Analysis-based Recommenders. IEEE Trans. Syst. Man. Cybern. 2022, 52, 485–497. [Google Scholar] [CrossRef]
- Song, Y.; Li, M.; Zhu, Z.; Yang, G.; Luo, X. Non-Negative Latent Factor Analysis-Incorporated and Feature-Weighted Fuzzy Double C-Means Clustering for Incomplete Data. IEEE Trans. Fuzzy Syst. 2022, in press. [CrossRef]
- Selesnick, I. Sparse Regularization via Convex Analysis. IEEE Trans. Signal Process. 2017, 65, 4481–4494. [Google Scholar] [CrossRef]
- Second Round Discipline Assessment. Available online: http://www.chinadegrees.cn/xwyyjsjyxx/zlpj/xksppm/ (accessed on 12 January 2022).
- Third Round Discipline Assessment. Available online: http://www.chinadegrees.cn/xwyyjsjyxx/xxsbdxz/index.shtml (accessed on 12 January 2022).
- Gao, X.; Feng, F.; He, X.; Huang, H.; Guan, X.; Feng, C.; Ming, Z.; Chua, T. Hierarchical Attention Network for Visually-Aware Food Recommendation. IEEE Trans. Multimed. 2020, 22, 1647–1659. [Google Scholar] [CrossRef] [Green Version]
- Wu, B.; He, X.; Chen, Y.; Nie, L. Modeling Product’s Visual and Functional Characteristics for Recommender Systems. IEEE Trans. Knowl. Data Eng. 2022, 34, 1330–1343. [Google Scholar] [CrossRef]
- Yan, C.; Zhang, Y.; Zhong, W.; Zhang, C.; Xin, B. A Truncated SVD-based ARIMA Model for Multiple QoS Prediction in Mobile Edge Computing. Tsinghua Sci. Technol. 2022, 27, 315–324. [Google Scholar] [CrossRef]
- Wu, Y.; Tong, T. The First-Class Discipline Construction from the Perspective of Supply Side Reform. Univ. Educ. Sci. 2017, 4, 10–16. [Google Scholar]
- Chinadegrees. Available online: http://www.chinadegrees.cn/xwyyjsjyxx/cde/en/ (accessed on 5 May 2022).
- QS Methodology. Available online: https://www.topuniversities.com/qs-world-university-rankings/methodology (accessed on 5 May 2022).
- Liu, X.; Song, R.; Wang, Y.; Xu, H. A Multi-Granular Aggregation-Enhanced Knowledge Graph Representation for Recommendation. Information 2022, 13, 229. [Google Scholar] [CrossRef]
- Gao, M.; Lu, J.; Chen, F. Medical Knowledge Graph Completion Based on Word Embeddings. Information 2022, 13, 205. [Google Scholar] [CrossRef]
- Najafi, B.; Parsaeefard, S.; Leon-Garcia, A. Missing Data Estimation in Temporal Multilayer Position-Aware Graph Neural Network (TMP-GNN). Mach. Learn. Knowl. Extr. 2022, 4, 397–417. [Google Scholar] [CrossRef]
Figure 1.
The mapping from classical business recommendation to discipline recommendation.

Figure 2.
The sparsity of the training matrix with universities as rows and disciplines as columns, where the deep-blue portion stands for the unrated data, and the deep-green portion stands for the rated data.
Figure 2.
The sparsity of the training matrix with universities as rows and disciplines as columns, where the deep-blue portion stands for the unrated data, and the deep-green portion stands for the rated data.

Figure 3.
The Recall of discipline recommendations under different K values.

Figure 4.
The Precision of discipline recommendations under different K values.

Figure 5.
The F1 of discipline recommendations under different K values.

Figure 6.
The Recall of discipline recommendations evaluated on the QS data under different K values.
Figure 6.
The Recall of discipline recommendations evaluated on the QS data under different K values.

Figure 7.
The Precision of discipline recommendations evaluated on the QS data under different K values.
Figure 7.
The Precision of discipline recommendations evaluated on the QS data under different K values.

Figure 8.
The F1 ofdiscipline recommendations evaluated on the QS data under different K values.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
An example of the general structure of evaluation data of disciplines.
| University | Discipline | Scores |
|---|---|---|
| University 1 | mathematics | 89 |
| University 2 | mathematics | 82 |
| University 3 | physics | 85 |
| University 4 | physics | 75 |
| University 2 | chemistry | 82 |
| University 3 | chemistry | 81 |
Table 2.
The score table corresponding to Table 1, where ? represents the originally missing data for a specific discipline of a specific university.
Table 2.
The score table corresponding to Table 1, where ? represents the originally missing data for a specific discipline of a specific university.
| Discipline | Mathematics | Physics | Chemistry |
|---|---|---|---|
| University | |||
| University 1 | 89 | ? | ? |
| University 2 | 82 | ? | 82 |
| University 3 | ? | 85 | 81 |
| University 4 | ? | 75 | ? |
Table 3.
A raw sample (philosophy discipline) in the second round nationwide discipline assessment data [36].
Table 3.
A raw sample (philosophy discipline) in the second round nationwide discipline assessment data [36].
| Rank | University | Rating |
|---|---|---|
| 1 | Peking University | 90 |
| 2 | Renmin University of China | 89 |
| 3 | Sun Yat-sen University | 84 |
| 4 | Fudan University | 83 |
| 5 | Nanjing University | 81 |
| 6 | Wuhan University | 79 |
| 7 | Beijing Normal University | 77 |
| 8 | Nankai University | 76 |
| 9 | Jilin University | 75 |
| Zhejiang University | ||
| 10 | Tsinghua University | 74 |
| 11 | East China Normal University Xiamen University | 72 |
Table 4.
A raw sample (philosophy discipline) in the third round nationwide discipline assessment data [37].
Table 4.
A raw sample (philosophy discipline) in the third round nationwide discipline assessment data [37].
| Rank | University | Rating |
|---|---|---|
| 1 | Peking University | 95 |
| 2 | Renmin University of China | 92 |
| 3 | Fudan University Sun Yat-sen University | 87 |
| 4 | Nanjing University Wuhan University | 85 |
| 5 | Beijing Normal University | 83 |
| 6 | Nankai University Jilin University | 79 |
| 7 | Tsinghua University Heilongjiang University Zhejiang University | 78 |
| 8 | Shanxi University East China Normal University | 76 |
Table 5.
The general information of the filtered training matrix.
| The Scale of Universities | The Scale of Disciplines | Sparsity |
|---|---|---|
| 201 | 78 | 86.8% |
Table 6.
Disciplines hit in the top-5 recommendation, where the disciplines in bold font represent the recommended disciplines hit in the test set, and the test set represents the set that the disciplines appeared in the third round data but did not appear in the second round data.
Table 6.
Disciplines hit in the top-5 recommendation, where the disciplines in bold font represent the recommended disciplines hit in the test set, and the test set represents the set that the disciplines appeared in the third round data but did not appear in the second round data.
| University | Disciplines Hit in the Top-5 Recommendation |
|---|---|
| Northwestern Polytechnical University | business administration biomedical engineering electrical engineering public administration software engineering biology design |
| China University of Mining and Technology | mechanics material science and engineering information and communication engineering mechanical engineering physical education physics safety science and engineering Marxist theory |
| Dalian Jiaotong University | management science and engineering mechanics computer science and technology control science and engineering business administration mathematics software engineering transportation engineering environmental science and engineering Marxist theory |
| Shandong Agricultural University | agricultural engineering horticulture biology agricultural and forestry economic management ecology landscape architecture agricultural resources and environment foreign language and literature |
Table 7.
The general information of the filtered training matrix for QS data set.
| The Scale of Universities | The Scale of Disciplines | Sparsity |
|---|---|---|
| 78 | 49 | 81.9% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Bi, S.; Ni, W.; Jiang, Y.; Wang, X. Novel Recommendation-Based Approach for Multidisciplinary Development of Future Universities. Sustainability 2022, 14, 5881. https://0-doi-org.brum.beds.ac.uk/10.3390/su14105881
AMA Style
Bi S, Ni W, Jiang Y, Wang X. Novel Recommendation-Based Approach for Multidisciplinary Development of Future Universities. Sustainability. 2022; 14(10):5881. https://0-doi-org.brum.beds.ac.uk/10.3390/su14105881
Chicago/Turabian StyleBi, Siguo, Wei Ni, Yi Jiang, and Xin Wang. 2022. "Novel Recommendation-Based Approach for Multidisciplinary Development of Future Universities" Sustainability 14, no. 10: 5881. https://0-doi-org.brum.beds.ac.uk/10.3390/su14105881
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.