
Wildfire Prediction Model Based on Spatial and Temporal Characteristics: A Case Study of a Wildfire in Portugal’s Montesinho Natural Park


Abstract
:1. Introduction
2. Materials and Methods
2.1. Study Area
2.2. Data
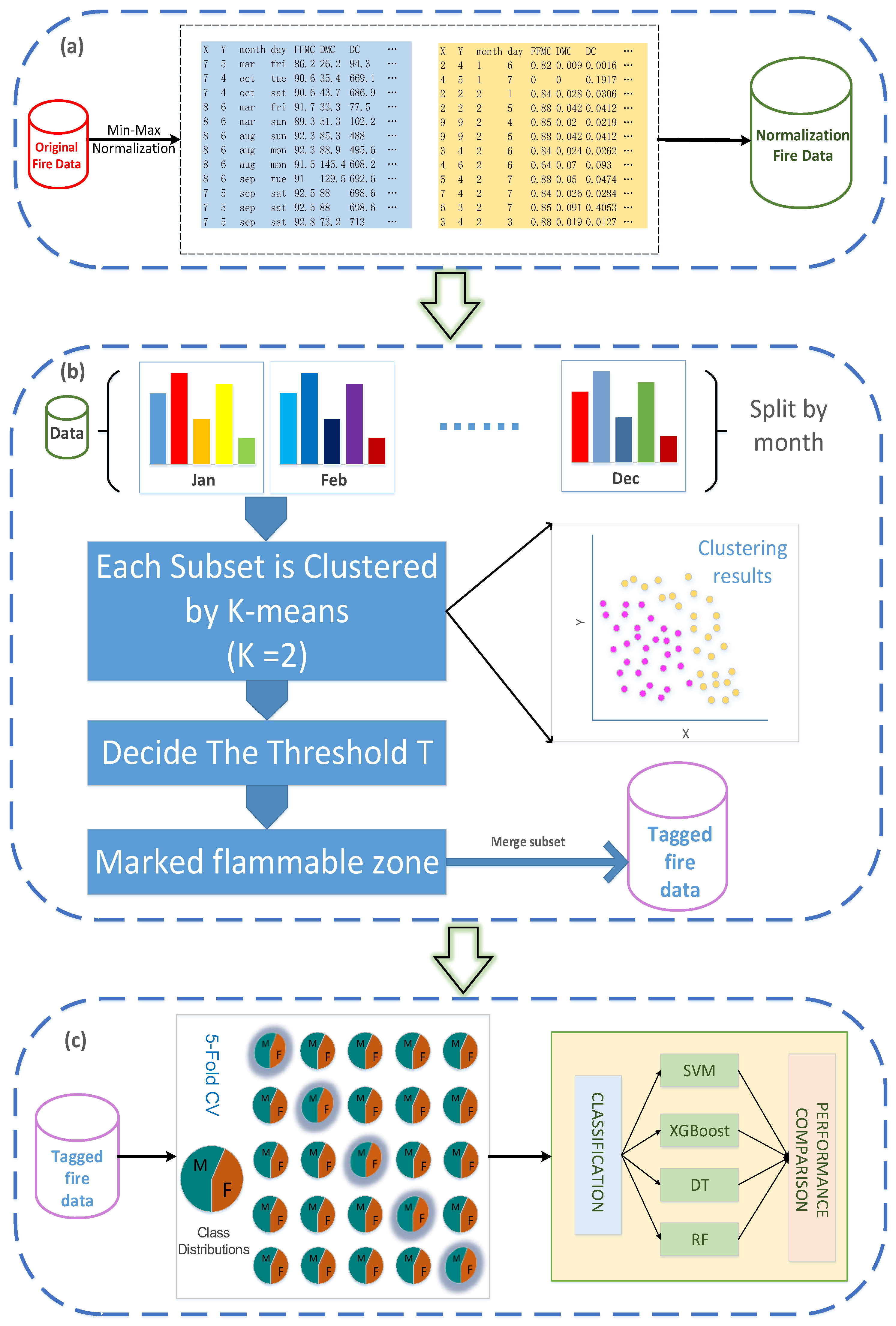
2.3. Data Preprocessing
2.4. Grouping the Datasets
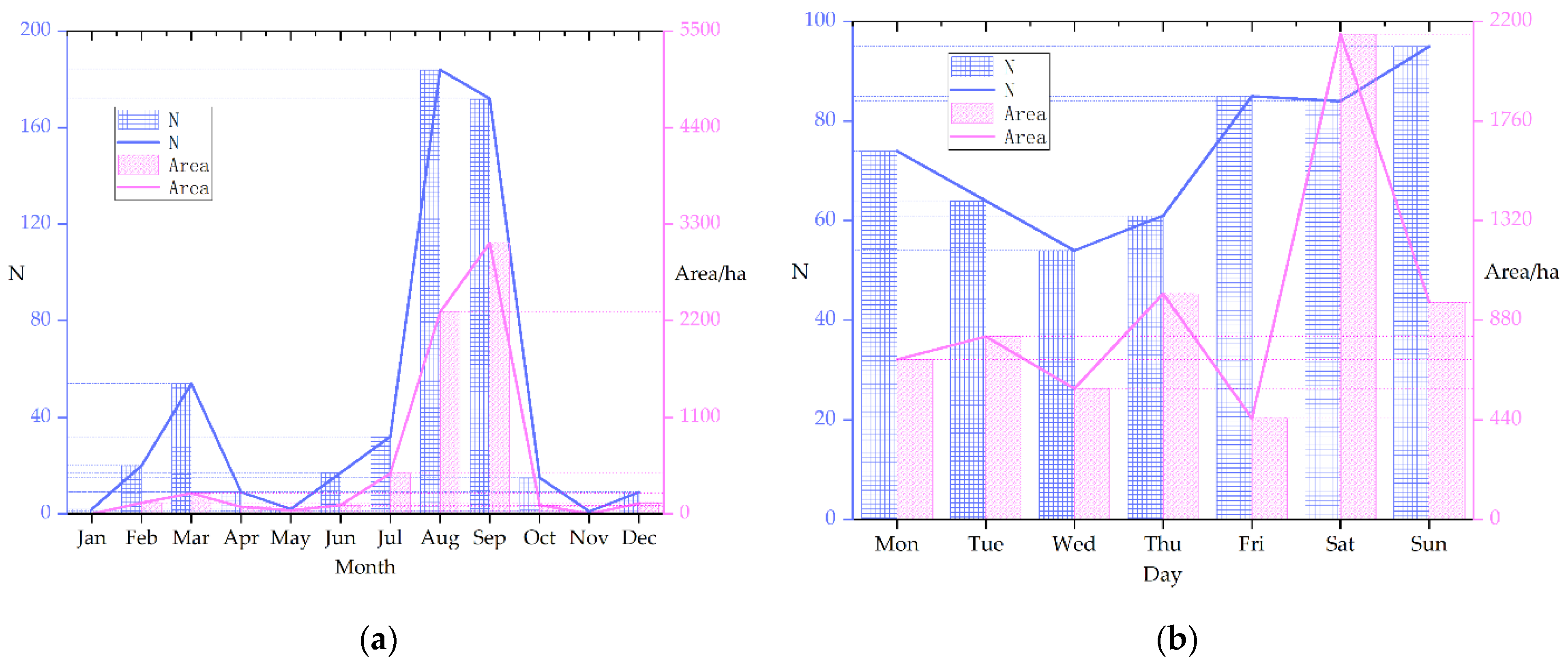
2.4.1. Time Series
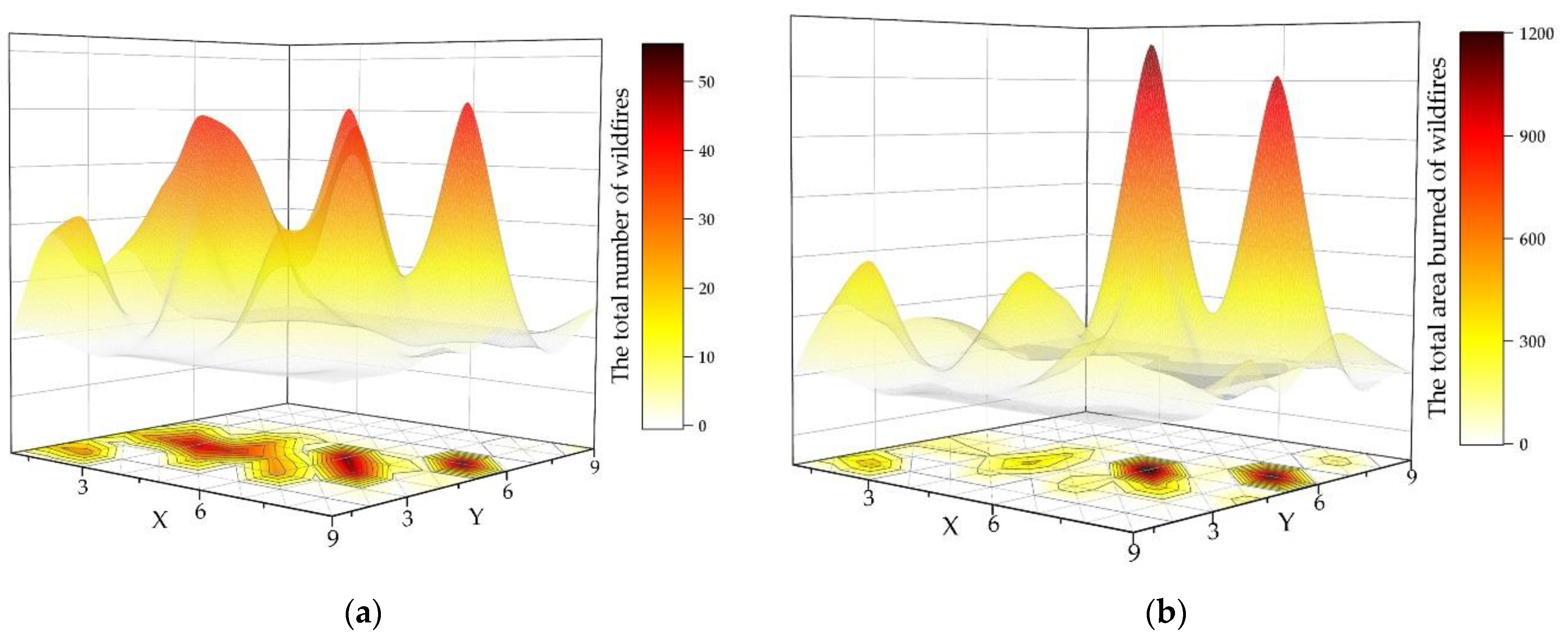
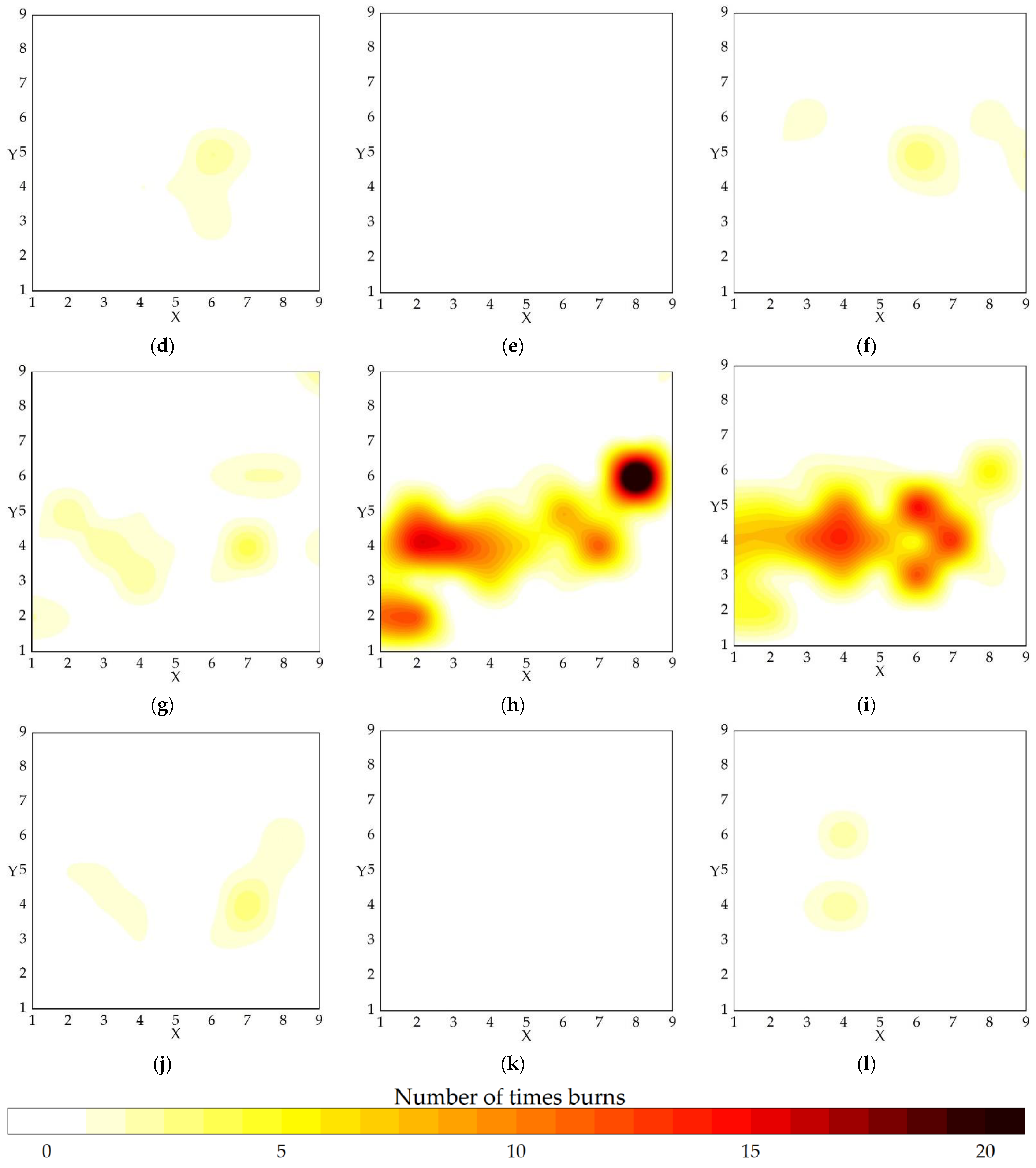
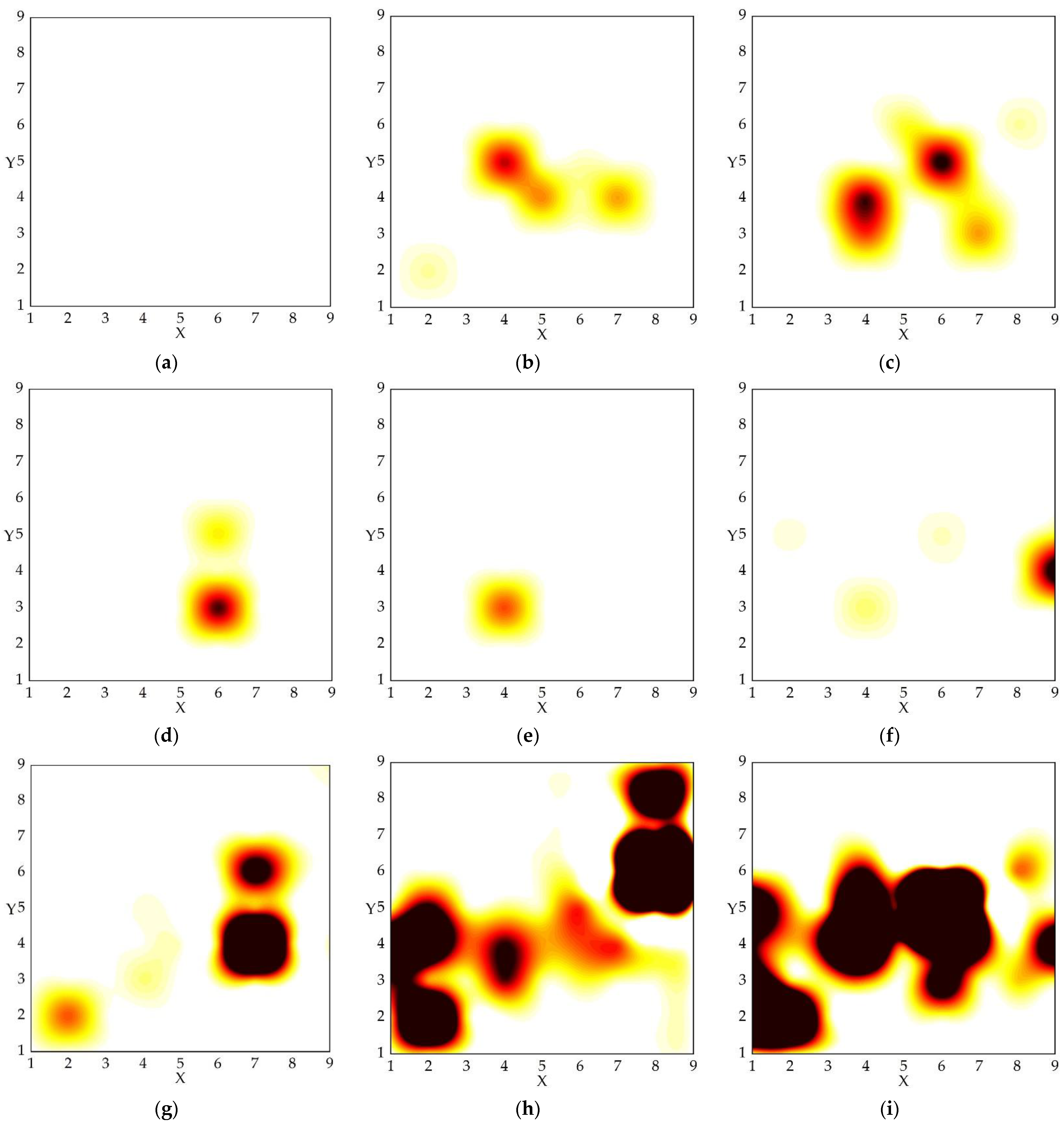
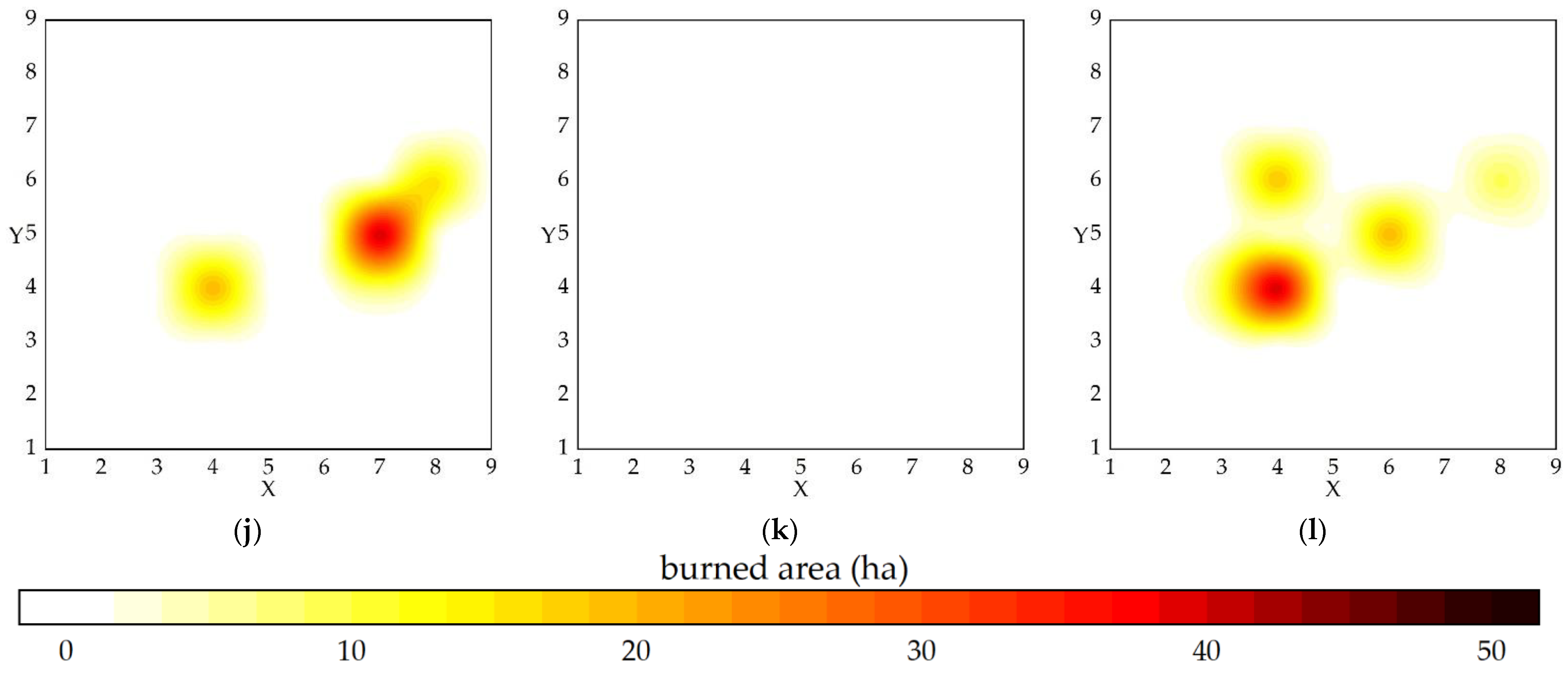
2.4.2. Spatial Series
2.4.3. Time and Space Division
2.5. K-Means Cluster
2.6. Machine Learning Models
2.6.1. XGBoost
2.6.2. Support Vector Machine
2.6.3. Decision Tree
2.6.4. Random Forest
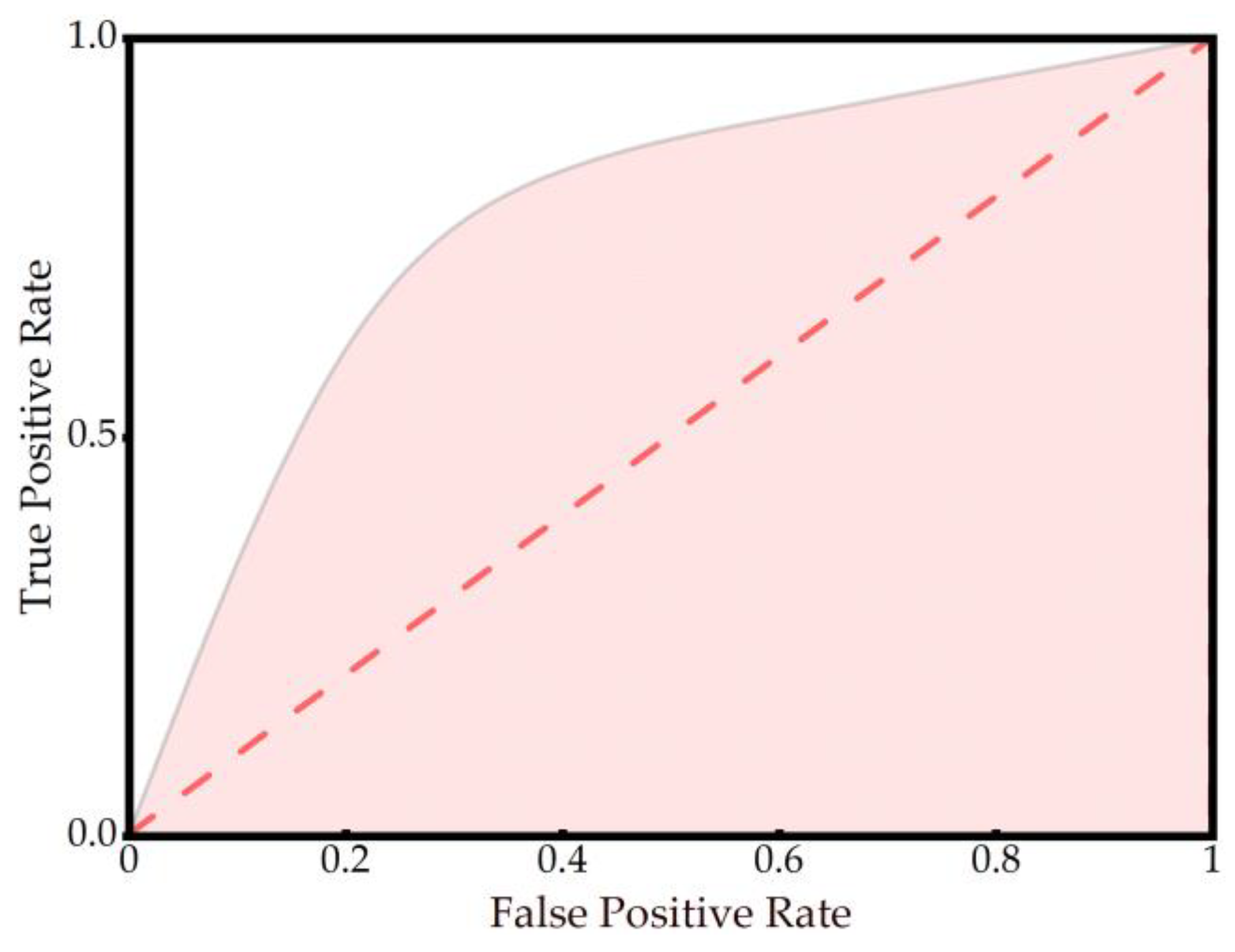
2.7. Performance Evaluation Metrics
3. Results
Performance Evaluation Results
4. Discussion
4.1. Drivers of Wildfire
4.2. Limitations and Future Work
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Santos, S.; Bento-Gonçalves, A.; Vieira, A. Research on Wildfires and Remote Sensing in the Last Three Decades: A Bibliometric Analysis. Forests 2021, 12, 604. [Google Scholar] [CrossRef]
- Ribeiro-Kumara, C.; Köster, E.; Aaltonen, H.; Köster, K. How do forest fires affect soil greenhouse gas emissions in upland boreal forests? A review. Environ. Res. 2020, 184, 109328. [Google Scholar] [CrossRef]
- Seidl, R.; Thom, D.; Kautz, M.; Martin-Benito, D.; Peltoniemi, M.; Vacchiano, G.; Wild, J.; Ascoli, D.; Petr, M.; Honkaniemi, J.; et al. Forest disturbances under climate change. Nat. Clim. Chang. 2017, 7, 395–402. [Google Scholar] [CrossRef] [PubMed]
- Shukla, P.R.; Skea, J.; Buendia, E.C.; Masson-Delmotte, V.; Portner, H.-O.; Roberts, D.C.; Zhai, P.; Slade, R.; Connors, S.; van Diemen, R.; et al. (Eds.) Change and Land: An IPCC Special Report on Climate Change, Desertification, Land Degradation, Sustainable Land Management, Food Security, and Greenhouse Gas Fluxes in Terrestrial Ecosystems; in press.
- Halofsky, J.E.; Peterson, D.L.; Harvey, B.J. Changing wildfire, changing forests: The effects of climate change on fire regimes and vegetation in the Pacific Northwest, USA. Fire Ecol. 2020, 16, 4. [Google Scholar] [CrossRef]
- Huffman, D.W.; Roccaforte, J.P.; Springer, J.D.; Crouse, J.E. Restoration applications of resource objective wildfires in western US forests: A status of knowledge review. Fire Ecol. 2020, 16, 1–13. [Google Scholar] [CrossRef]
- Sirin, A.; Medvedeva, M. Remote Sensing Mapping of Peat-Fire-Burnt Areas: Identification among Other Wildfires. Remote Sens. 2022, 14, 194. [Google Scholar] [CrossRef]
- Ma, W.; Feng, Z.; Cheng, Z.; Chen, S.; Wang, F. Identifying Forest Fire Driving Factors and Related Impacts in China Using Random Forest Algorithm. Forests 2020, 11, 507. [Google Scholar] [CrossRef]
- Abram, N.J.; Henley, B.J.; Gupta, A.S.; Lippmann, T.J.R.; Clarke, H.; Dowdy, A.J.; Sharples, J.J.; Nolan, R.H.; Zhang, T.; Wooster, M.J.; et al. Connections of climate change and variability to large and extreme forest fires in southeast Australia. Commun. Earth Environ. 2021, 2, 1–17. [Google Scholar] [CrossRef]
- Sulova, A.; Arsanjani, J.J. Exploratory Analysis of Driving Force of Wildfires in Australia: An Application of Machine Learning within Google Earth Engine. Remote. Sens. 2021, 13, 10. [Google Scholar] [CrossRef]
- Fernandez-Anez, N.; Krasovskiy, A.; Müller, M.; Vacik, H.; Baetens, J.; Hukić, E.; Solomun, M.K.; Atanassova, I.; Glushkova, M.; Bogunović, I.; et al. Current Wildland Fire Patterns and Challenges in Europe: A Synthesis of National Perspectives. Air, Soil Water Res. 2021, 14, 11786221211028185. [Google Scholar] [CrossRef]
- Febriandhika, A.I.; Rahman, C.T.; Ramdani, F.; Saputra, M.C.; IEEE. Tangible Landscape: Simulation of Estimation of Wildfire Spread in Arjuno Mountain Tahura R. Soerjo Region. In Proceedings of the 4th International Symposium on Geoinformatics (ISyG), Malang, Indonesia, 10–12 November 2018. [Google Scholar]
- Jain, P.; Coogan, S.C.P.; Subramanian, S.G.; Crowley, M.; Taylor, S.W.; Flannigan, M.D. A review of machine learning applications in wildfire science and management. Environ. Rev. 2020, 28, 478–505. [Google Scholar] [CrossRef]
- Jaafari, A.; Zenner, E.K.; Pham, B.T. Wildfire spatial pattern analysis in the Zagros Mountains, Iran: A comparative study of decision tree based classifiers. Ecol. Inform. 2018, 43, 200–211. [Google Scholar] [CrossRef]
- Gigović, L.; Pourghasemi, H.R.; Drobnjak, S.; Bai, S. Testing a New Ensemble Model Based on SVM and Random Forest in Forest Fire Susceptibility Assessment and Its Mapping in Serbia’s Tara National Park. Forests 2019, 10, 408. [Google Scholar] [CrossRef]
- Collins, L.; McCarthy, G.; Mellor, A.; Newell, G.; Smith, L. Training data requirements for fire severity mapping using Landsat imagery and random forest. Remote Sens. Environ. 2020, 245, 111839. [Google Scholar] [CrossRef]
- Michael, Y.; Helman, D.; Glickman, O.; Gabay, D.; Brenner, S.; Lensky, I.M. Forecasting fire risk with machine learning and dynamic information derived from satellite vegetation index time-series. Sci. Total Environ. 2020, 764, 142844. [Google Scholar] [CrossRef]
- Hantson, S.; Arneth, A.; Harrison, S.P.; Kelley, D.I.; Prentice, I.C.; Rabin, S.S.; Archibald, S.; Mouillot, F.; Arnold, S.R.; Artaxo, P.; et al. The status and challenge of global fire modelling. Biogeosciences 2016, 13, 3359–3375. [Google Scholar] [CrossRef]
- Saha, M.V.; Scanlon, T.M.; D’Odorico, P. Climate seasonality as an essential predictor of global fire activity. Glob. Ecol. Biogeogr. 2018, 28, 198–210. [Google Scholar] [CrossRef]
- Spitz, D.B.; Clark, D.A.; Wisdom, M.J.; Rowland, M.M.; Johnson, B.K.; Long, R.A.; Levi, T. Fire history influences large-herbivore behavior at circadian, seasonal, and successional scales. Ecol. Appl. 2018, 28, 2082–2091. [Google Scholar] [CrossRef] [PubMed]
- Abouali, A.; Raposo, J.R.; Viegas, D.X. The role of the terrain-modified wind on driving the fire behaviour over hills-an Experimental and Numerical Analysis. In Proceedings of the 8th International Conference on Forest Fire Research, Coimbra, Portugal, 9–16 November 2018; pp. 677–694. [Google Scholar] [CrossRef]
- LeVine, D.; Crews, K. Time series harmonic regression analysis reveals seasonal vegetation productivity trends in semi-arid savannas. Int. J. Appl. Earth Obs. Geoinf. ITC J. 2019, 80, 94–101. [Google Scholar] [CrossRef]
- Silveira, E.M.D.O.; Espírito-Santo, F.D.B.; Acerbi-Júnior, F.W.; Galvão, L.S.; Withey, K.D.; Blackburn, G.A.; De Mello, J.M.; Shimabukuro, Y.E.; Domingues, T.; Scolforo, J.R.S. Reducing the effects of vegetation phenology on change detection in tropical seasonal biomes. GIScience Remote Sens. 2018, 56, 699–717. [Google Scholar] [CrossRef]
- Freitas, W.; Gois, G.; Pereira, E.; Junior, J.O.; Magalhães, L.; Brasil, F.; Sobral, B. Influence of fire foci on forest cover in the Atlantic Forest in Rio de Janeiro, Brazil. Ecol. Indic. 2020, 115, 106340. [Google Scholar] [CrossRef]
- Rakhmatulina, E.; Stephens, S.; Thompson, S. Soil moisture influences on Sierra Nevada dead fuel moisture content and fire risks. For. Ecol. Manag. 2021, 496, 119379. [Google Scholar] [CrossRef]
- Varela, V.; Vlachogiannis, D.; Sfetsos, A.; Karozis, S.; Politi, N.; Giroud, F. Projection of Forest Fire Danger due to Climate Change in the French Mediterranean Region. Sustainability 2019, 11, 4284. [Google Scholar] [CrossRef]
- Jang, E.; Kang, Y.; Im, J.; Lee, D.-W.; Yoon, J.; Kim, S.-K. Detection and Monitoring of Forest Fires Using Himawari-8 Geostationary Satellite Data in South Korea. Remote Sens. 2019, 11, 271. [Google Scholar] [CrossRef]
- Chen, Y.; Randerson, J.T.; Coffield, S.R.; Foufoula-Georgiou, E.; Smyth, P.; Graff, C.A.; Morton, D.C.; Andela, N.; van der Werf, G.R.; Giglio, L.; et al. Forecasting Global Fire Emissions on Subseasonal to Seasonal (S2S) Time Scales. J. Adv. Model. Earth Syst. 2020, 12, e2019MS001955. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.; Wang, D.; Maeda, E.E.; Pellikka, P.K.E.; Heiskanen, J. Mapping Cropland Burned Area in Northeastern China by Integrating Landsat Time Series and Multi-Harmonic Model. Remote Sens. 2021, 13, 5131. [Google Scholar] [CrossRef]
- Zhou, Q.; Rover, J.; Brown, J.; Worstell, B.; Howard, D.; Wu, Z.; Gallant, A.L.; Rundquist, B.; Burke, M. Monitoring Landscape Dynamics in Central U.S. Grasslands with Harmonized Landsat-8 and Sentinel-2 Time Series Data. Remote Sens. 2019, 11, 328. [Google Scholar] [CrossRef]
- Carvalho, N.S.; Anderson, L.O.; Nunes, C.A.; Pessôa, A.C.M.; Junior, C.H.L.S.; dos Reis, J.B.C.; Shimabukuro, Y.E.; Berenguer, E.; Barlow, J.; Aragao, L.E. Spatio-temporal variation in dry season determines the Amazonian fire calendar. Environ. Res. Lett. 2021, 16, 125009. [Google Scholar] [CrossRef]
- Xie, Y.; Peng, M. Forest fire forecasting using ensemble learning approaches. Neural Comput. Appl. 2018, 31, 4541–4550. [Google Scholar] [CrossRef]
- Evelpidou, N.; de Figueiredo, T.; Mauro, F.; Tecim, V.; Vassilopoulos, A. Natural Heritage from East to West: Case Studies from 6 EU Countries; Springer: Berlin/Heidelberg, Germany, 2010; pp. 119–132. [Google Scholar]
- Neves, J.M.; Santos, M.F.; Machado, J.M. (Eds.) New trends in artificial intelligence. In Proceedings of the 13th Portuguese Conference on Artificial Intelligence (EPIA 2007), Guimarães, Portugal, 3–7 December 2007; APPIA: Lisaboa, Portugal, 2007; pp. 512–523, ISBN 978-989-95618-0-9. [Google Scholar]
- Van Wagner, C.E. Development and Structure of the Canadian Forest Fire Weather Index System; Forestry Technical Report 35; Canadian Forestry Service, Headquarters: Ottawa, ON, Canada, 1987; 35p. [Google Scholar]
- Jiménez-Ruano, A.; Mimbrero, M.R.; Jolly, W.M.; Fernández, J.D.L.R. The role of short-term weather conditions in temporal dynamics of fire regime features in mainland Spain. J. Environ. Manag. 2018, 241, 575–586. [Google Scholar] [CrossRef]
- MacQueen, J. Some methods for classification and analysis of multivariate observations. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability; University of California Press: Berkeley, CA, USA, 1967; Volume 1, pp. 281–297. [Google Scholar]
- Arthur, D.; Vassilvitskii, S. k-means plus plus: The Advantages of Careful Seeding. In Proceedings of the 18th ACM-SIAM Symposium on Discrete Algorithms, New Orleans, LA, USA, 7–9 January 2007. [Google Scholar]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD), San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Vapnik, V.N. The Nature of Statistical Learning Theory, 2nd ed.; Springer: New York, NY, USA, 2000; p. 314. [Google Scholar]
- Salzberg, S.L. Book Review: C4.5: Programs for Machine Learning by J. Ross Quinlan. Morgan Kaufmann Publishers, Inc., 1993. Mach. Learn. 1994, 16, 235–240. [Google Scholar] [CrossRef]
- Calheiros, T.; Nunes, J.P.; Pereira, M. Recent evolution of spatial and temporal patterns of burnt areas and fire weather risk in the Iberian Peninsula. Agric. For. Meteorol. 2020, 287, 107923. [Google Scholar] [CrossRef]
- Geraldes, A.; Boavida, M. Distinct age and landscape influence on two reservoirs under the same climate. Hydrobiologia 2003, 504, 277–288. [Google Scholar] [CrossRef]
- Nagle-McNaughton, T.; Gong, X.; Constantine, J.A. Implications of the modifiable areal unit problem for wildfire analyses. Adv. Biol. Earth Sci. 2019, 4, 150–175. [Google Scholar]
- Wang, J.; Zhang, X.; Rodman, K. Land cover composition, climate, and topography drive land surface phenology in a recently burned landscape: An application of machine learning in phenological modeling. Agric. For. Meteorol. 2021, 304–305, 108432. [Google Scholar] [CrossRef]
- Parente, J.; Pereira, M.G.; Tonini, M. Space-time clustering analysis of wildfires: The influence of dataset characteristics, fire prevention policy decisions, weather and climate. Sci. Total Environ. 2016, 559, 151–165. [Google Scholar] [CrossRef]
- Fernandes, P.M. Variation in the Canadian Fire Weather Index Thresholds for Increasingly Larger Fires in Portugal. Forests 2019, 10, 838. [Google Scholar] [CrossRef]
- Banerjee, T. Impacts of Forest Thinning on Wildland Fire Behavior. Forests 2020, 11, 918. [Google Scholar] [CrossRef]
- Benali, A.; Sá, A.; Pinho, J.; Fernandes, P.; Pereira, J. Understanding the Impact of Different Landscape-Level Fuel Management Strategies on Wildfire Hazard in Central Portugal. Forests 2021, 12, 522. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Abbreviation | Variables | Explanations | |
|---|---|---|---|
| Location | X | X-axis spatial coordinates (1 ≤ X ≤ 9) | |
| Y | Y-axis spatial coordinates (1 ≤ Y ≤ 9) | ||
| Time series | Month | Months of the year (from January to December) | |
| Day | Days of the week (from Monday to Sunday) | ||
| FWI | FFMC | fine fuel moisture code | Water content of cured fine fuels (from 18.7 to 96.20), with a time period of 16 h |
| DMC | duff moisture code | Water content of surface combustible material (from 1.1 to 291.3) in the upper layer of forest humus, with a time period of 12 days | |
| DC | drought code | Index of the effect of prolonged drought on forest combustibles (7.9–860.6), with a time period of 52 days | |
| ISI | initial spread index | The initial rate of fire spread (from 0 to 56.10) | |
| Climatic conditions | temp | temperature | Temperature (Celsius) (from 2.2 to 33.30) |
| RH | relative humidity | Relative humidity (%) (from 15.0 to 100) | |
| Wind | Wind speed (km/h) (from 0.40 to 9.40) | ||
| Rain | Outdoor rainfall (mm/m2) (from 0.0 to 6.40) | ||
| Burned area | Area | Total forest burned area (ha) (0.00~1090.84) |
| Model | Parameters |
|---|---|
| XGBoost | max_depth = 3; min_child_weight = 1; gamma = 0.1 colsample_bytree = 1; scale_pos_weight = 1; learing_rate = 0.05 n_estimators = 500; silent = 1; colsample_bytree = 1 early_stopping_rounds = 100; eval_metric = “logloss” |
| RF | max_depth = 5; n_estimators = 10; max_fearure = 1 n_estimators = 500; min_samples_split = 2 |
| SVM | Kernel = ‘linear’; degree = 3; tol = 0.001 |
| DT | criterion = “gini”; min_samples_split = 2; min_samples_leaf = 1 |
| Model | Accuracy (ACC) | F1 Score (F1) | AUC 1 |
|---|---|---|---|
| XGBoost | 0.8132 | 0.7862 | 0.8052 |
| RF | 0.7204 | 0.7122 | 0.7204 |
| SVM | 0.6722 | 0.6322 | 0.6724 |
| DT | 0.7968 | 0.7880 | 0.7966 |
| Model | ACC | F1 | AUC |
|---|---|---|---|
| XGBoost | 0.6366 | 0.4484 | 0.4804 |
| RF | 0.6846 | 0.4258 | 0.4912 |
| SVM | 0.7082 | 0.4146 | 0.5000 |
| DT | 0.5322 | 0.4600 | 0.4648 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dong, H.; Wu, H.; Sun, P.; Ding, Y. Wildfire Prediction Model Based on Spatial and Temporal Characteristics: A Case Study of a Wildfire in Portugal’s Montesinho Natural Park. Sustainability 2022, 14, 10107. https://0-doi-org.brum.beds.ac.uk/10.3390/su141610107
Dong H, Wu H, Sun P, Ding Y. Wildfire Prediction Model Based on Spatial and Temporal Characteristics: A Case Study of a Wildfire in Portugal’s Montesinho Natural Park. Sustainability. 2022; 14(16):10107. https://0-doi-org.brum.beds.ac.uk/10.3390/su141610107
Chicago/Turabian StyleDong, Hao, Han Wu, Pengfei Sun, and Yunhong Ding. 2022. "Wildfire Prediction Model Based on Spatial and Temporal Characteristics: A Case Study of a Wildfire in Portugal’s Montesinho Natural Park" Sustainability 14, no. 16: 10107. https://0-doi-org.brum.beds.ac.uk/10.3390/su141610107