1. Introduction
Forest ecosystems are essential providers of services like food, water, timber, and the regulation of climate, floods, water quality, as well as biodiversity and recreation [
1]. Sustainable adaptation and management of forests has become vital under current conditions of human development and climate change. Remote sensing technologies have been widely used in forest inventory and monitoring to support forest management [
2]. Among various remote sensing technologies, laser scanning, or light detection and ranging (lidar), has attracted particular interest due to its unique advantage, i.e., the ability to penetrate through the foliage and capture both tree structures and the ground [
3].
Lidar has been integrated into various platforms to study the forest at different scales, including space-borne satellites (e.g., Global Ecosystem Dynamics Investigation) [
4], airborne systems (e.g., helicopter or plane) [
5], unmanned aerial vehicles (UAVs) [
6], ground mobile platforms (e.g., vehicle, backpack, handheld) [
7], and ground stationary tripods [
8]. Each of those lidar systems can produce point clouds with different characteristics in terms of coverage, point density, field of view, and accuracy, making them best suited for different purposes.
Airborne lidar or airborne laser scanning (ALS) systems normally consist of three main components: A global navigation satellite system (GNSS) receiver for absolute positioning, an inertial measurement unit for both positioning and orientation, and a laser scanner that measures the ground by distance and angle in the form of 3D points [
9,
10]. They are usually mounted on airplanes for a large coverage while maintaining a good (cm) level of accuracy. The point density is dependent upon a few factors, e.g., scanner measurement rate and scanning mechanism, flight height and speed, swath width, and strip overlaps, hence it may vary from less than 1 point per m
2 to more than 50 points per m
2. But in general, the maximum point density is getting higher with the development of airborne laser scanners.
Early studies have mostly focused on the characteristics at stand-level, such as canopy cover and height, from airborne lidar data, due to limited point density [
11,
12,
13]. Now the point density is high enough to capture a sufficient number of points on each individual tree, so that individual tree detection or delineation (ITD), including tree location, size, shape and number, has drawn considerable attention [
5,
14,
15,
16]. Vertical distribution, above ground biomass and other secondary properties, can be derived from those accurate delineation parameters. Therefore, ALS has been increasingly used for precise forest mapping and monitoring at landscape or regional scale [
10].
Although ITD from airborne lidar is an important research topic for forest studies, it still remains as a challenge due to the complexity and heterogeneity of the forest structure and its composition. The main difficulty of ITD is tree segmentation, a step to segment the overall points into clusters that represent individual trees. There are two main strategies for tree segmentation: Raster-based and point-based [
17,
18]. Earlier methods mostly adopted the first strategy, converting the 3D point clouds into canopy height models (CHMs), a raster image, then detecting tree tops using 2D image processing techniques such as local maxima, region growing and watershed [
5]. The second strategy segments the trees based directly on 3D points [
14,
19]. Examples include rule-based distance and height thresholding [
16,
20,
21], voxel-based [
22], graph-based [
23], and kernel-based [
24] methods. Some tried to combine both strategies to separately detect tree tops and trunks, then segment in the voxel space [
25]. Segmentation methods based directly on 3D point clouds are proven to outperform those based on 2D raster conversions, such as CHM, especially for multi-layered forests [
14,
19]. One of the 3D methods, mean shift, a classical 2D clustering approach that can easily be adapted to 3D scenarios, has drawn considerable attention for direct 3D point cloud segmentation [
24,
25].
Mean shift had been successfully used in computer vison and image processing for mode-seeking in feature space. The mode is the maxima of a density function, and is located iteratively by shifting the weighted mean determined by a kernel, hence the name mean shift. The kernel can be easily expanded into 3D, so the mean can be calculated directly from the 3D points. It has shown promising results for different types of tree conditions, such as multi-layered temperate [
24] and tropical forests [
26], mixed-species urban trees [
27], and boreal coniferous forest [
28]. However, there are a few factors to be considered, such as the kernel shape, size, and weight, to better implement it to segment trees.
As an in depth analysis of the kernel function and weighting are inadequate from the literature, this paper aims at providing a detailed assessment of the mean shift algorithm for ITD from airborne lidar data to clarify the influence of the variations to the performance.
2. Related Work
Proposed by Fukunaga and Hostetler [
29], the original mean shift algorithm was applied to clustering and data noise filtering. It was further proven to be effective by Cheng [
30] for clustering and global optimization. Then it was widely exploited as a robust approach of image segmentation in feature space [
31]. Moreover, it was intensively used for non-rigid object tracking in real time [
32]. Due to its clear advances in image segmentation, mean shift was soon applied to remote sensing imageries [
33,
34,
35]. For example, Huang and Zhang [
33] used means shift with an adaptive bandwidth to extract object-based features for high dimensional hyperspectral image urban classification by support vector machine (SVM).
Maschler et al. [
36] applied mean shift to airborne hyperspectral image twice: Firstly to differentiate short and tall stands, and secondly to segment individual tree crowns, to classify a temperate forest.
Melzer [
37] pioneered the adoption of mean shift for ALS point cloud segmentation, by which power lines and vegetation were differentiated in an urban area. Yao et al. [
38] combined mean shift with normalized cuts, to segment and classify 3D airborne lidar data in urban areas. Lee et al. [
39] extracted shorelines from integrated airborne lidar point clouds and aerial orthophotos using mean-shift segmentation.
Table 1 lists the usage of mean shift for tree segmentation from airborne lidar data, and the settings used in the studies. Ferraz et al. [
40] firstly used mean shift to stratify forest vertical structure in 3D. The Epanechnikov kernel, implemented as a Cylinder shape, was chosen, and three discrete kernel bandwidths were empirically selected to stratify the forest into three layers. The algorithm was then used to extract individual trees [
24]. As the kernel shape and the ratio between horizontal and vertical components were fixed, there was only one parameter, kernel bandwidth, to be tuned. Ferraz et al. [
26] then adapted the method to detect individual tree crowns at different layers within tropical forests. Based on the previous method, an adaptive mean shift 3D segmentation (AMS3D) using an allometric function that defines the relationship between tree height and crown width and depth was proposed. The bandwidth model was adaptive to the allometric function; for example it would increase as the kernel moves upwards on higher trees.
Yao et al. [
41] also used the cylindrical kernel with a horizontal Gaussian profile to extract local dense modes of points using a fixed bandwidth. Those local modes were intentionally oversegmented, and features were derived from those segmented clusters, then grouped via normalized cuts by measuring the similarity of clusters in terms of their spatial distribution and features. This methodology was further investigated to estimate the regeneration coverage under 5 m in a temperate forest [
42]. The radius and height of the cylinder-shaped kernel were both set independently, and the sensitivity of radius and height were further tested.
Apart from forest trees, the mean shift algorithm was also applied to urban trees by Xiao et al. [
27]. To fit the general tree shape, a tree crown model, i.e., the Pollock model, which can vary from a cone to an ellipsoid, was proposed as the mean shift kernel. In addition, the continuous adaptive mean shift (CamShift) concept was adopted with the assumption that higher trees would have wider crowns, and would benefit from a larger bandwidth. Therefore the bandwidth was set to be continuously adaptive to the tree height with a constant ratio, which was insensitive to tree size, shape and species, as found in the experiments.
The advantage of adaptive mean shift for individual tree identification was further proved by Hu et al. [
43]. Instead of using an allometric function, the points were roughly segmented by a fixed bandwidth mean shift first, and the crown sizes were estimated by an iterative region growing at multiple layers of different heights. Then the varying crown size was used to guide the kernel bandwidth in the second round of mean shift segmentation. A spherical kernel was chosen instead of a cylinder-shaped kernel, as in previous studies. Both the segmentation and localization results were improved by detecting the tree trunks first, in order to complement the adaptive mean shift segmentation [
44].
In addition to monochromatic wavelength lidar points, the algorithm was also employed for multispectral airborne lidar data by Dai et al. [
28], who firstly segmented the trees only in the spatial domain, then the SVM was used to detect those which had been undersegmented, which were then refined by a second round of mean shift segmentation, considering the multispectral domain. The cylindrical kernel followed the same design as in [
24], apart from an extra weight on higher points in the kernel, which guided the kernel to move upwards.
In summary, the mean shift algorithm has been a popular and effective method to segment individual trees from airborne lidar data of different types of forests. However, there are variations in terms of kernel shape, adaptiveness of kernel size, and weighting. Therefore, this paper will focus on a systematic assessment of the algorithm to provide a better understanding of the performance under different configurations and data conditions.
3. Materials and Methods
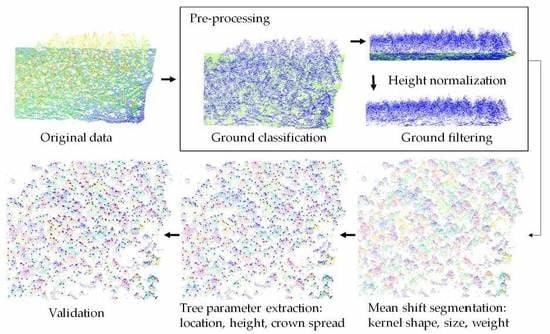
The full workflow of individual forest tree delineation from raw airborne laser scanning data is presented in
Figure 1. First, the original point cloud is pre-processed to prepare for the segmentation. Ground points are classified, then the aboveground points are normalized to avoid influence from terrain relief during the segmentation step. In addition, points below 1 m are considered as noise, and thus filtered out. Next, a point-based segmentation method, mean shift, is used to segment the whole point cloud into individual trees. This paper will focus on the assessment of tree segmentation using mean shift, which is an important step that affects the following tree parameter extraction. Other representative methods, such as marker-controlled watershed segmentation [
15], are also implemented for comparison. Then for each segment, tree parameters are extracted, such as the location (x, y), height (h), longest crown spread (l) and longest crown cross-spread (l’). Finally, the extractions are validated against field measurements so that the accuracies of the variants of the mean shift algorithm are evaluated.
3.1. Test Data
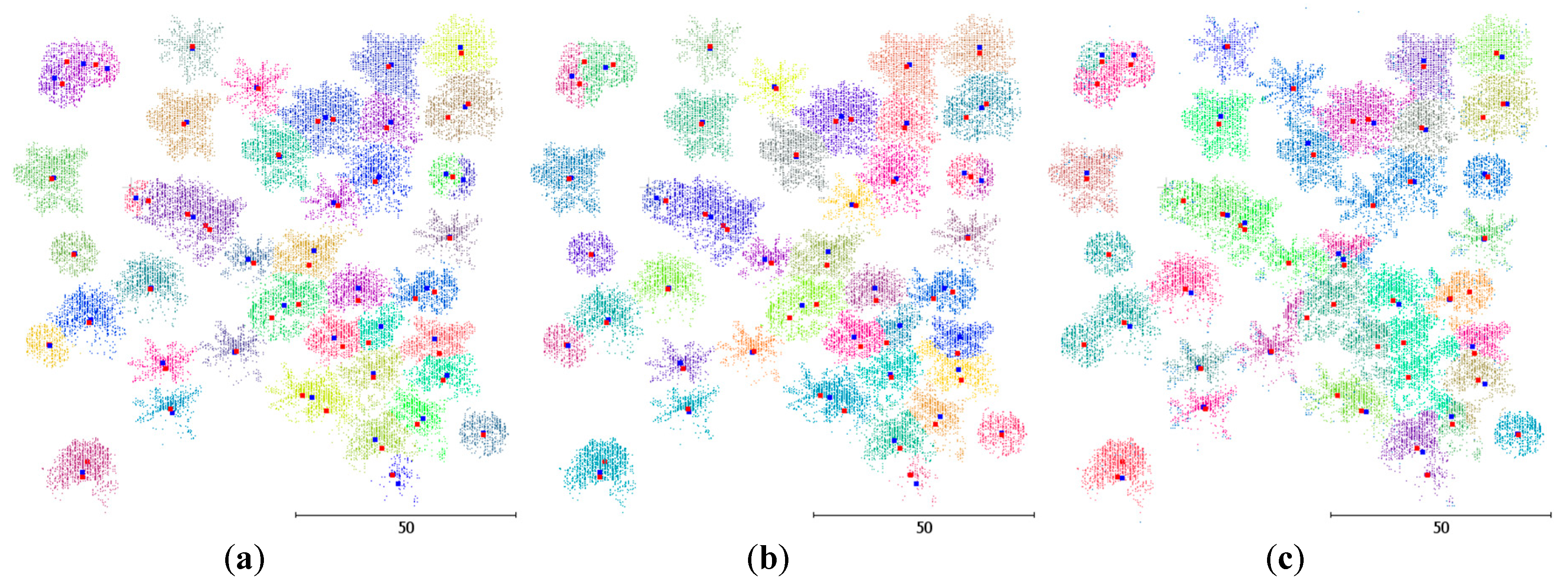
Three types of plots were used in this study to test the tree segmentation methods: a) A synthetically generated mixed-deciduous woodland, b) a monoculture coniferous stand, and c) two forest plots with a mixture of coniferous and deciduous species.
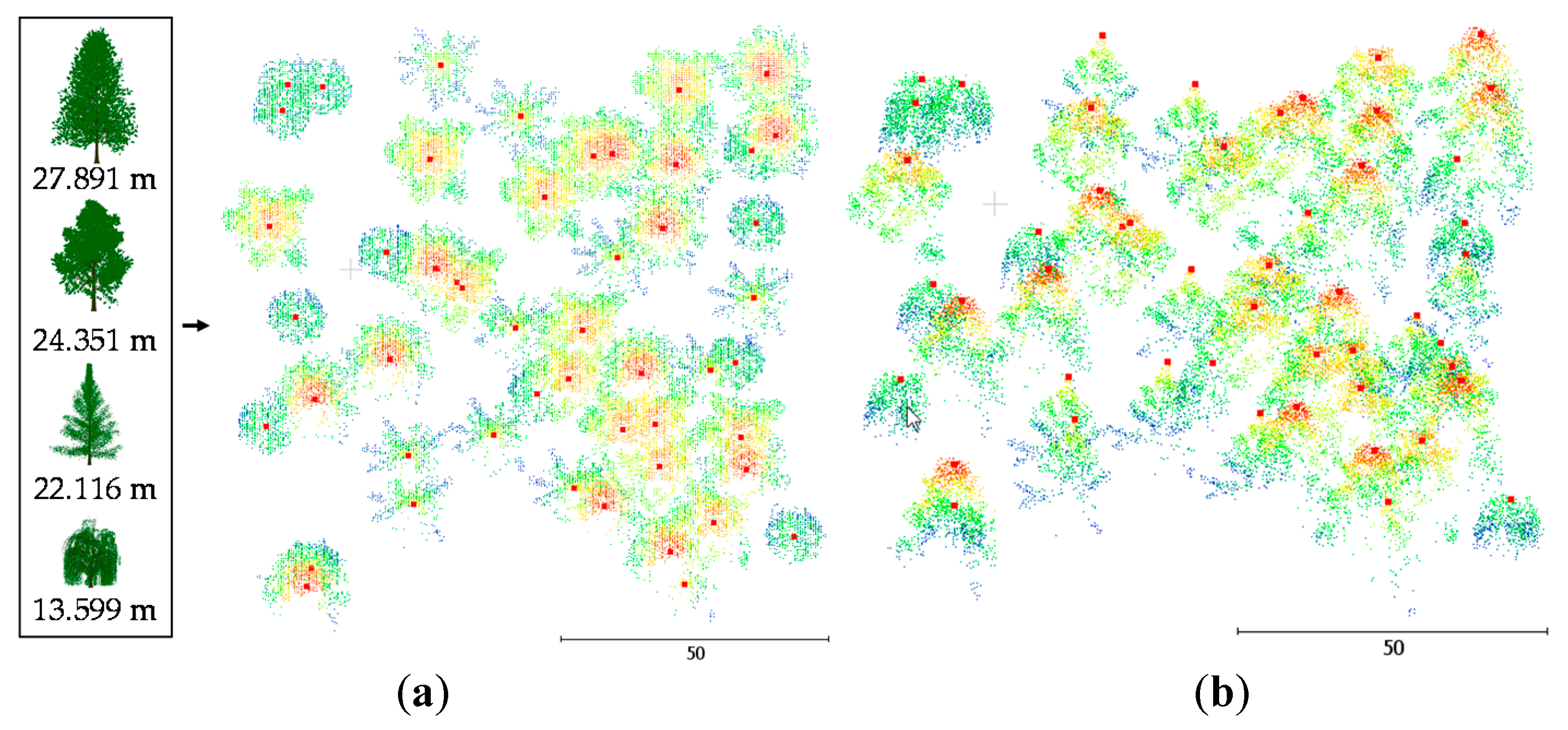
The synthetic dataset (
Figure 2) was simulated by the open-source software HELIOS [
45]. Main advantages of using synthetic data include: a) Accurate knowledge on the tree locations and crown parameters, and b) control over the number and species of trees. Four species, black tupelo (Nyssa sylvatica Marshall), sassafras (Sassafras albidum), tamarack (Larix laricina (Du Roi) K.Koch), and weeping willow (Salix babylonica L.), were fed into the RIEGL LMS-Q780 simulator to simulate fifty trees randomly located on a 100 m by 100 m square (one hectare). Their heights are 27.891 m, 24.351 m, 22.116 m, and 13.599 m, respectively.
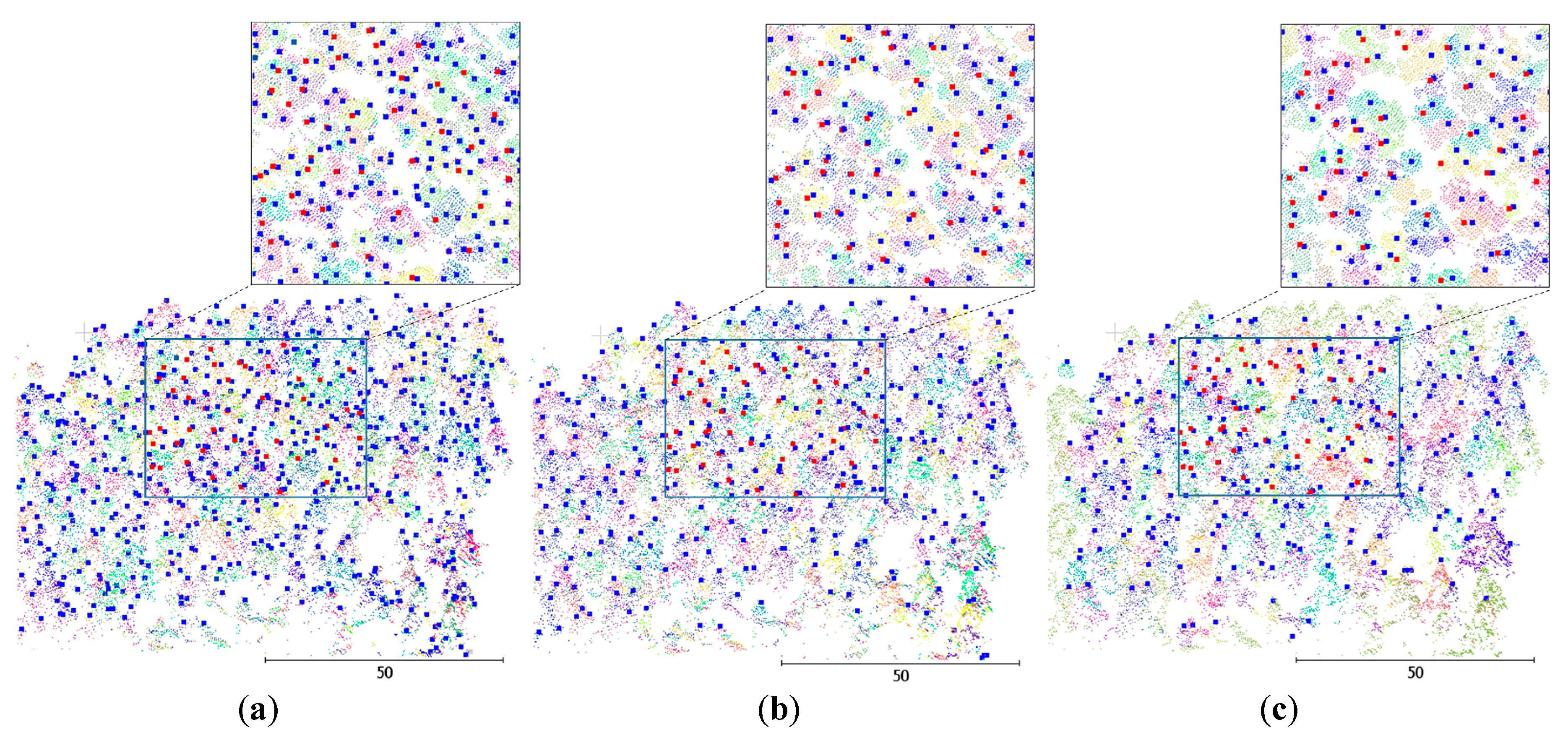
Apart from the synthetic data, an airborne laser scanning (ALS) dataset (8.4 points per m
2) of a monoculture plantation stand located in the Queen Elizabeth Forest Park (Aberfoyle, UK) is used for the experiment (
Figure 3a). The data were collected by the UK Natural Environment Research Council Airborne Research Facility using the Leica ALS50 Scanner in August 2014. The plot was planted in year 1965, and was composed of lodgepole pine (Pinus contorta Dougl.). Tree parameters, including locations and heights of 45 trees, were surveyed during the field campaign. Tree locations were measured by total station at the bottoms of trees, whilst heights were measured using a vertex hypsometer [
46]. The average recorded tree height was 16.18 m, with a standard deviation of 2.12 m. Note that the whole plot contains much more trees, but only this subset covering different tree sizes and densities was measured for validation. Ideally, given a valid tree delineation approach, only a small plot needs to be ground measured to validate the approach and to choose parameters or configurations, which will then be applied to the whole area without further parameter tuning.
The final data of two plots (Plots B1
Figure 3b and B2
Figure 3c, approx. 8 points per m
2 ) were taken from an international benchmark [
22]. They both have a mixture of species, including Norway spruce (Picea abies L.), Scots pine (Pinus sylvestris L.), Downy birch (Betula sp. L.), and Aspen (Populus tremula L.). Plot B1 is predominantly composed of Norway spruce (80%), and the average tree height is 16.8 m with a standard deviation of 6.4 m. Plot B2 has around 55% Norway spruce, and the average tree height is 16.1 m with a standard deviation of 7.31 m. Both plots have multiple crown layers, i.e., dominant, co-dominant, intermediate, and suppressed. The ALS data were collected in June 2004 using an Optech 2033 airborne scanner. Field measurements were collected with a terrestrial laser scanner (TLS), Faro LS880HE. The locations and heights of trees were manually measured from the TLS data.
3.2. Methods
3.2.1. Pre-processing
The Z coordinates of points on trees also contains the elevation of terrain, which can affect the segmentation when the parameters are relevant to the tree height. A common procedure is to normalize the elevation with respect to the ground. Ground classification from airborne light detection and ranging (lidar) data is a well-studied topic [
47], and there are both proprietary and free and open-source software available for ground filtering. Lastools (
https://rapidlasso.com/lastools/) is adopted here to identify ground points, which are used to normalize other points, so that tree bases are at zero height, and the Z coordinate corresponds to the tree height. After ground filtering, extra points can be observed at ground level, resulting from understory vegetation, e.g., grass or small bushes. As these are not of interest and can affect the segmentation, a 1 m buffer is applied to filter out these points, as suggested by Wang et al. [
22]. This height buffer can vary depending on the vertical structure of studied forests. A bigger buffer might be more appropriate if the understory vegetation is higher [
28]. The remaining points are considered to be on trees of interest, and will be segmented.
3.2.2. Mean Shift Segmentation
Mean shift has been widely used for image clustering in feature space, which can be multi-dimensional. This section will explain the different adaptations of mean shift for 3D point cloud segmentation. Given a lidar data of n points
, i = 1,…,n in a 3D space, the mean shift vector can be derived as the gradient of a multivariate kernel density estimator as follows:
in which
defines the kernel profile, and h is the bandwidth parameter that determines the size of the kernel. The vector
is the difference between weighted mean, using the kernel for weights, and point x, the center of the kernel, and is pointing toward the direction of the maximum increase in the density, so that the modes of density can be reached iteratively by translating the kernel (window) by the vector. [
30,
31] can be referred to for more details. The algorithm has been adapted to a best fit for tree segmentation in terms of kernel shape, size and weight.
Kernel shape: the simplest kernel shape in 3D is a sphere [
42], and it is adapted to different shapes to better segment trees, such as a Cylinder [
24]. The Pollock model has also been used as the kernel since the model represents the crown shape which can be adjusted by an extra parameter [
27].
The model is defined as follows:
in which x = (X, Y, Z) with respect to the model center, a is the radius of the crown circle in the XY-plane, b is the radius along the Z-axis and m is the crown shape parameter. When m = 1, the model is a cone, and it becomes an ellipsoid as m increases to 2. These three kernel shapes, sphere, cylinder, and Pollock model, will be tested to determine their effects on tree segmentation.
Kernel size: it has been shown that different kernel sizes can be used to segment trees of different sizes and at different layers of the canopy [
24], but the settings of the kernel size are mostly trial and error based. Both the Cylinder and Pollock model kernels have two bandwidth/size parameters (a, b) along the horizontal and vertical axes, respectively. Most commonly, the ratio between the two bandwidth parameters b/a is kept fixed during the shifting process, and only one is tuned. Another approach is to adapt the kernel size to the height of trees under the assumption that taller trees will favor a larger kernel, whereas shorter and smaller trees will favor a smaller kernel. This approach is known as continuous adaptive mean shift (Camshift) [
27]. In the tests, the kernel size (bandwidth) is tested in two regards, namely, (1) the effects of horizontal bandwidth (a
, and the ratio between the two bandwidth parameters (b/a
, and (2) whether the kernel is continuously adaptive to the height of the tree (Y or N).
Kernel weight: in addition to the shape of the kernel, different weighting strategies can be applied to the kernel, including weight in the XY-plane, weight in Z, or simply a flat kernel without any weight. Horizontal kernel weights, such as a Gaussian function [
24], will put more weight on the center points, meaning the kernel tends to move around less, which will result in more isolated points as standalone clusters. Vertical kernel weights, such as weighting on higher points in the kernel, will lead the kernel to move upwards to converge at the top of a tree [
28]. The combination of vertical weight in height
and horizontal Gaussian weight for the Pollock kernel can be expressed as follows:
where
is set to 0.5 for normal distribution weight in XY, and 0 for weight only in height. Since the dominant direction of a tree is along the vertical axis, weighting in height should facilitate the separation of trees horizontally. Therefore, it will be compared with the Gaussian weight and a flat kernel (no weight) to test its effect on segmentation.
Apart from the kernel configurations, when implementing the mean shift algorithm for segmentation, one rigid but time-consuming practice is to compute the shift for every single point. Another practice is to randomly select seed points to compute the shift. All other points that are covered by the kernel during the shifting process will be assigned the same mode/cluster as the seed points. These two implementations will also be tested for speed and accuracy assessment.
3.2.3. Other Segmentation Methods
A canopy height model (CHM)-based method, marker-controlled watershed [
15], was implemented to have an independent reference of the mean shift’s performance. Watershed is also a classical image segmentation method as mean shift. A typical procedure of watershed segmentation of a CHM image is first detecting local maxima in the image, and then segmenting the image by watershed transform. However, the local maxima can be erroneous. To improve the detection, an allometric function of tree height and crown size was introduced to adapt the search window to detect canopy maxima, which were then smoothed by a Gaussian filter. The refined tree tops were used as markers to control the watershed segmentation. Parameters, including search radius and merge radius, as implemented by [
48], were fine-tuned for each dataset to produce the best results.
A more recent method from Dalponte et al. [
49] was also implemented for comparison. Instead of using watershed, a moving window is used to locate local maxima, which then serve as the ‘initial region’ for region growing, considering the vertical height difference of neighboring pixels. The final regions are approximated by convex hulls, and are treated as tree crowns. In addition, the point-based method proposed for the benchmark data in [
22] are tested for further comparison. The point clouds are first voxelized, and some structure elements are proposed for tree top detection, which are constrained by certain rules based on tree morphological characteristics.
3.2.4. Tree Crown Parameter Extraction
Four tree crown parameters (location, height, longest crown spread and longest crown cross-spread) are extracted for the segmented trees following each of the investigated processing variants. The height can be simply taken from the highest point [
26]. Tree crown locations will be extracted from the segmented points to evaluate the segmentation step.
There are two main strategies to identify tree crown locations. The first is simply taking the location of the highest point as the location of a tree, which is based on the assumption that the top of the tree is where the tree is located. This is generally true when a tree has a clear peak and is straight upright. The second strategy is to fit a geometric shape to the points on the crown, either in 2D or 3D, which is supposed to be more robust to outliers. To identify the crown location and spreads, the crown base was firstly determined by computing a convex hull around all the tree points in 2D. The average height of the points on the convex hull can be considered as the crown height [
27]. Then the crown location, longest spread and longest cross-spread can be determined by fitting an ellipse to these points, where the ellipse center is the crown location, and the two semi-axes represent the two crown spreads. These two strategies will be assessed in this paper to investigate the effects of crown parameter extraction on segmentation validation.
3.3. Validation and Assessment Criteira
In practice, the segmentation is normally validated by checking the locations of segmented trees. That is why the influence of the tree localization method is also investigated. In addition to horizontal locations, the heights of trees can be affected by segmentation, especially when the tree canopy is multistoried or the segmentation method is in 3D. Hence, tree tops (composed of locations and heights) extracted from segmented tree crowns were compared with ground measurements. Even though the segmentation is processed at point-level, the validation is conducted at object-level.
To determine if a tree is oversegmented or undersegmented, the criteria proposed by [
22] is followed. In general, if there is only one segmented tree top within a certain range (e.g., 2 m) in 3D from a ground measured tree top, this segment is considered correct (noted as a match). If there is more than one segment in this range or no segment, then the tree is either oversegmented or undersegmented. When all the tested trees have ground truth, such as in the simulated data, the precision, recall and F
1-score can then be calculated as follows:
in which TP (True Positive) is the number of matches, FP (False Positive) is the number of oversegmentations inside or outside of the assessment range, FN (False Negative) is the number of undersegmentations.
The horizontal position accuracy and height accuracy are assessed by the root mean square error (RMSE) calculated from the horizontal and vertical distances, respectively, between the detected tree tops and ground measurements.
5. Discussion
The mean shift algorithm was tested on three different airborne lidar datasets. The settings generating the best results varied slightly across the data. Nevertheless, certain recommendations can be made based on the tests.
The Pollock model as the kernel produced the best results for all three datasets. This proves the assumption that a kernel that ensembles the crown shape will facilitate crown segmentation. Although there is one more parameter to be tuned, i.e., the crown shape, it only needs to be tested once on a subset of data, even if the data are of mixed species. For example, for the benchmark data, the same crown shape (m = 2) was set for both plots in the same forest. The Cylinder kernel also produced good results for all the tested data, similar to those demonstrated in previous studies [
26,
28]. There are two kernel bandwidth parameters to be tested (a and b), and they can be reduced to one if the ratio (b/a) is pre-defined [
24]. The spherical kernel was the simplest, but yielded the worst results apart from the benchmark plot B2. Given the fact that the Cylinder kernel is not much more complex, a first attempt to directly use the Cylinder would be recommended. The Pollock kernel would be preferred for better results with slightly more parameter tuning.
Adapting the kernel to the crown size is considered to be a valid improvement of mean shift. However, whether or not to make the kernel continuously adaptive, for instance to the tree height, is dependent on the data as demonstrated by the results. Considering that the continuous adaptiveness will cost twice the computing time, and not necessarily generate better outcome, a fixed kernel is recommended. This adaptiveness is based on the assumption that taller trees have larger crown sizes, which may not be true for mixed species forests. One possible improvement is to adapt the kernel to the individual tree crown size rather than the height. There have been attempts to extract information of the crown size from either allometric approximations [
26] or crown detection [
42]. In both cases, the kernel was adapted to the targeted crown sizes generated from extra steps.
The weighting in the vertical direction is proved to be beneficial in some cases but not always. Higher points in the kernel have higher weights, which helps the kernel to move upwards, so that the shift can be converged at the top of the tree. In this paper the weight is normalized to [0, 1], so the highest point has weight 1, and the lowest has weight 0. Other types of weighting strategy can be designed, such as the one in [
28]. The weighting in the horizontal plane did not improve the results as assumed, hence was not presented in the tables. The Gaussian function puts more weight on points near the center point, i.e., the mean, and less weight on points near the boundary of the kernel, so that the kernel is less likely to shift if there are not enough points outside of the center area of the kernel. Therefore, weighting in either height or in the XY plane should be further investigated before implementing for each specific data.
Crown localization is assessed because crown tops are used to validate the segmentation results. Crown tops can be simply decided by the highest points of the segmented crowns. But the tree locations can be inaccurate, as real trees are normally not perfectly straight upwards. An alternative approach is to fit the segmented crowns with ellipses and take the ellipse centers as crown locations. The results varied in this regard. The results of the simulated data showed clear advantage when simply using the highest points as tree tops, giving better segmentation results and lower RMSEs, whereas the results of the Aberfoyle data showed the contrary, better segmentation results and lower RMSEs when fitting the crowns with ellipses. This is because the first simulated data are perfectly upright trees with almost symmetric crowns, whereas the second is from a plantation forest where most trees are naturally inclined, and have more diverse crown structures. The benchmark data also showed better segmentation results when fitting the crowns, hence crown fitting for tree top detection is recommended for real forests. The localization accuracy itself can be further assessed when accurate ground truth of crown locations are available, which can be difficult by either field measurements or other sensing techniques [
50].
The compared marker-controlled watershed method performed well on the simulated data, with a particularly high precision. Similarly, the raster-based region growing method produced the best results for the simulated data. However, both were outperformed by the two point-based methods. For such a simple and single-layered plot, raster-based methods are expected to have a good performance. However, it clearly struggled with a more natural data, especially with the multi-layered benchmark plots. The advantage is that they are extremely fast, thus are still worth trying for less structurally complicated forests. Even though the focus of the paper is on the thorough assessment of the mean shift method itself, the comparisons with other raster- and point-based methods prove the value of such assessment, as mean shift is able to produce competitive results.
There are other possible improvements of mean shift segmentation for ITD. For example, the Pollock model crown parameter can be adaptive from prior knowledge, or classification from other data sources. Raster-based methods can be combined with mean shift to approximately estimate the crown size, which can then feed into the kernel. Moreover, a hierarchical approach can be adopted, similar to [
28], where the data is segmented by mean shift in two rounds. The first round segments the original data into plausible individual trees. A pre-trained classifier is then used to detect the oversegmented and undersegmented trees, which are refined by a second round of mean shift segmentation with appropriate parameter settings derived from the classification. As these approaches require extra steps other than the mean shift algorithm, they are considered to be out of the scope of the paper, which is focusing on the assessment of the method itself.
6. Conclusions
This paper conducted a thorough performance assessment of the mean shift algorithm for individual tree delineation from airborne lidar data. Three main factors considered are kernel shape, kernel size adaptiveness, and kernel weighting. They were assessed in three different datasets, one simulated data, one UK forest data, and one benchmark data from Finland.
The results suggested that the Pollock model used as the mean shift kernel can improve the segmentation, though there are a few parameters that would have to be fine-tuned. On the other hand, the Cylinder kernel, commonly used in other studies, can generate good results while maintaining simplicity. The continuous adaptive strategy works for certain data, but might not be reliable due to the complexity of crown structures, whilst being time consuming. The weighting in height is recommended to be tested for different datasets, whereas horizontal weighting should be undertaken with caution. Finally, the validation results can be affected by the ground truth quality, as real crown positions are difficult to determine from neither ground survey nor other data sources.
The effectiveness of mean shift is proved by comparing with two raster-based methods, marker-controlled watershed and region growing, which performed well on single-layered data, and were extremely fast. Further improvements to the segmentation workflow by introducing additional steps, such as integrating point-based and raster-based methods, will be investigated in future work.

 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}