Multi-Scale Geospatial Object Detection Based on Shallow-Deep Feature Extraction

 , ,
, ,  and
and
Abstract
:
1. Introduction
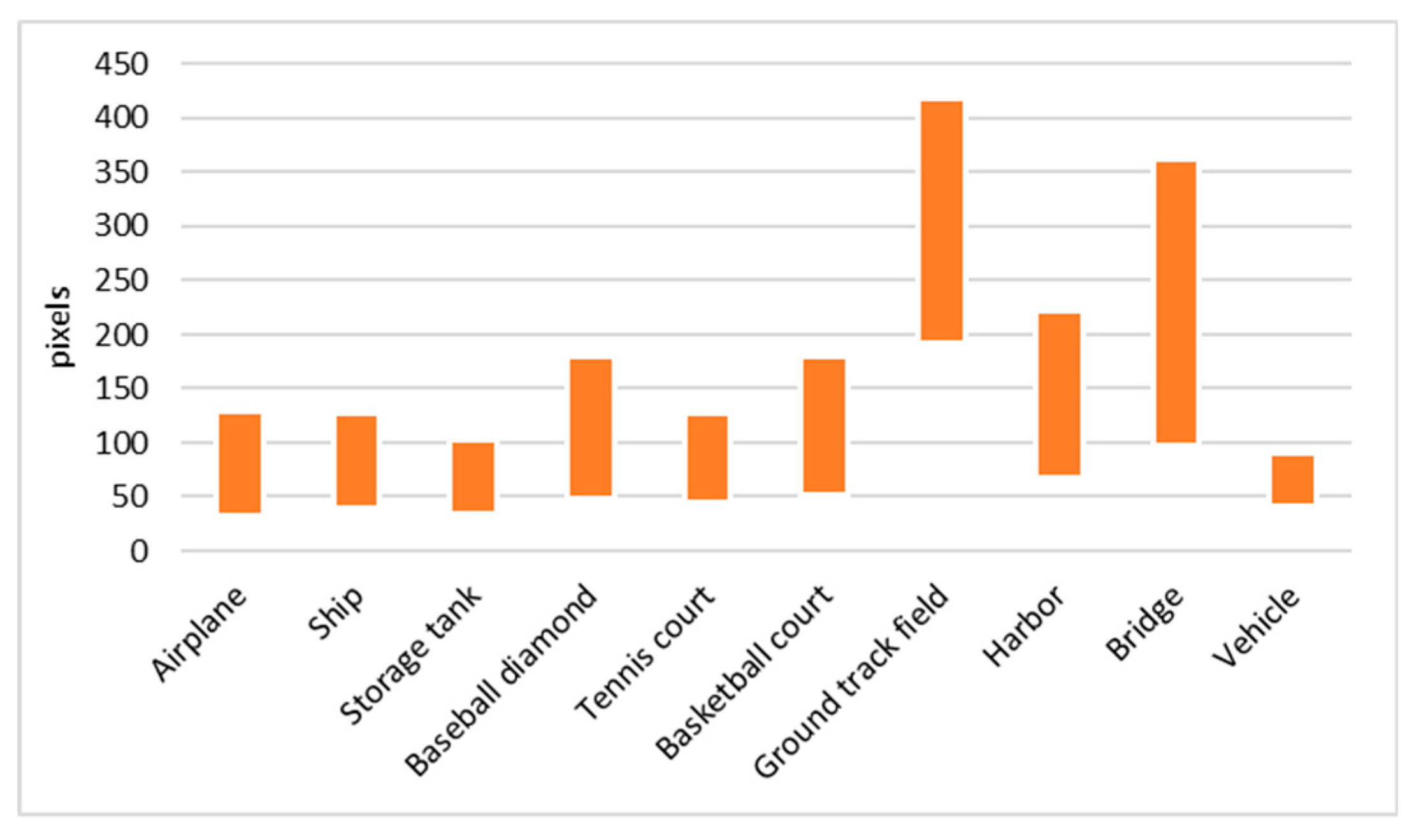
- In remote sensing images, each object does not have a fixed size and often appears at various scales. Further, the datasets mostly were collected from different resources with different resolutions.
- The remote sensing image is very large and contains a lot of small objects that sometimes appear in dense groups, such as vehicles and storage tanks. This adds significant challenges for geospatial object detection methods. By using normal object detection methods, the loss of small objects in RSI is very large, so there is an urgent need to optimize the detection methods.
- The aerial images are enormous and overcrowded with many kinds of small objects. Therefore, the manual annotation of objects is very complex and costly. Additionally, object detection in RSIs is a small sample setting problem. Although there are methods specifically designed for small sample setting problems, like rank-1 feedforward neural network (FNN) in [40], deep learning architectures are data hungry and thus, the training samples for object detection from RSIs are inadequate for training them.
- The surrounding area of each different class is not the same as can be seen in Figure 1. For example, ships and airplanes mostly have a clear background and also have special colors and shapes that make them distinguishable. In contrast, many objects like vehicles and harbors do not have a special appearance or properties, so they need to be treated differently.
- A novel framework suitable for VHR remote sensing imagery was designed, which can detect the multi-scale and multi-class object in large-scale complex scenes.
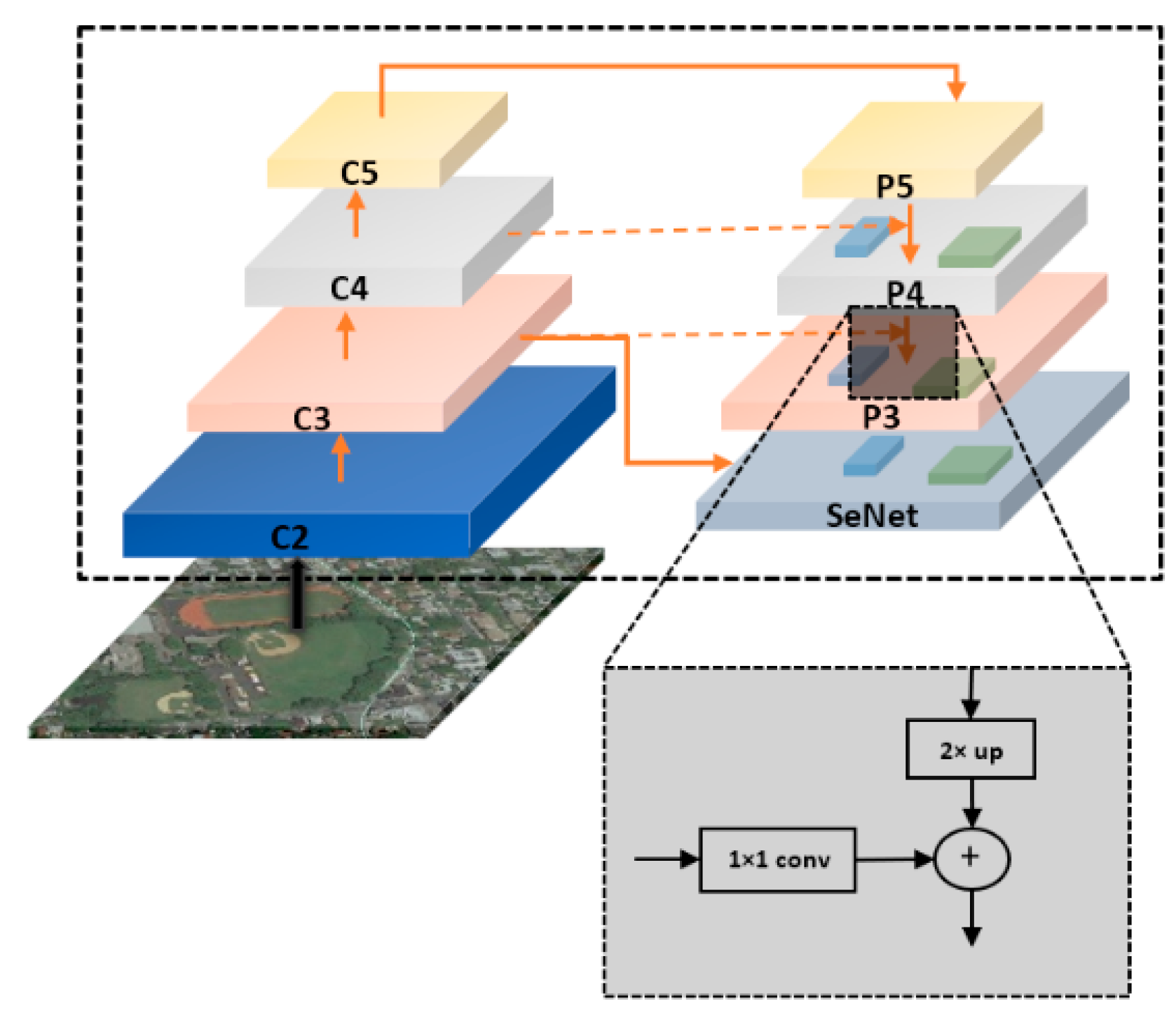
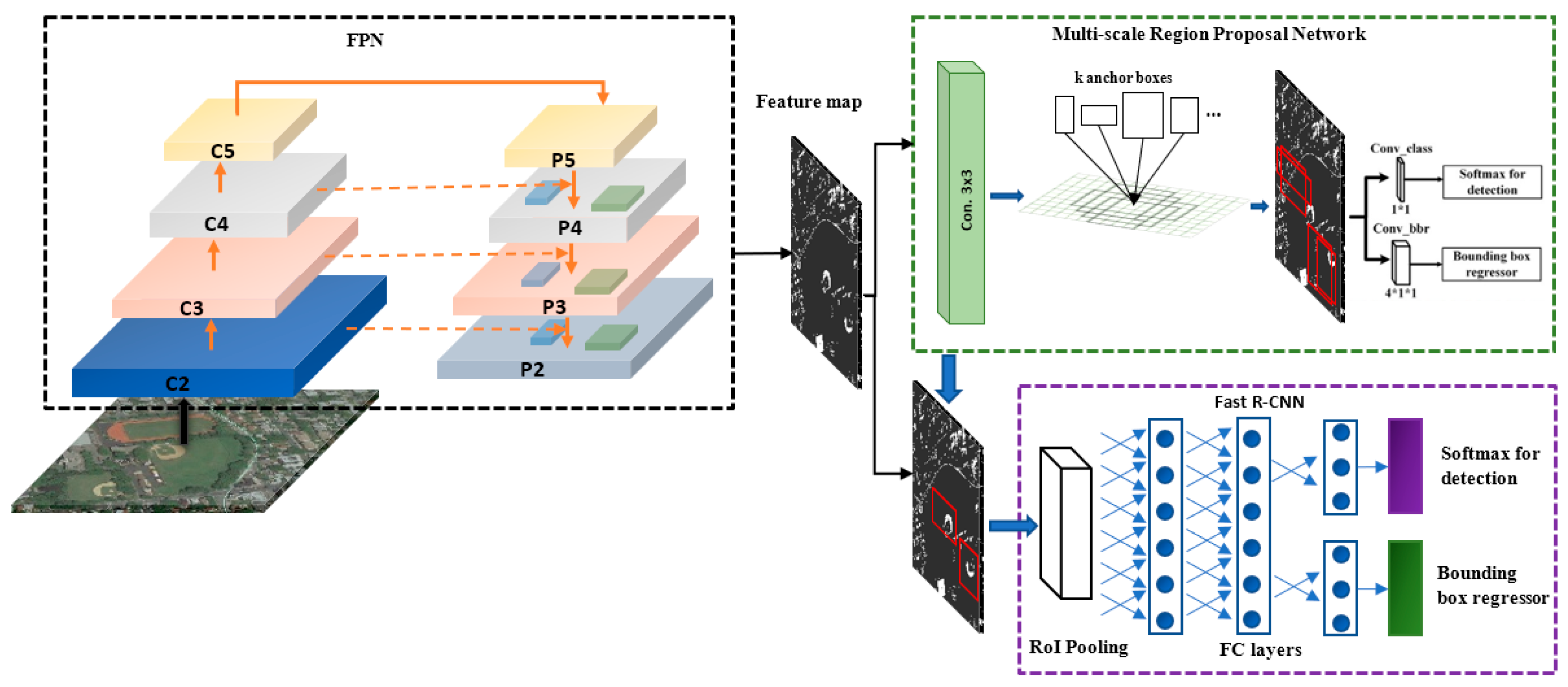
- A feature pyramid extraction was designed which has a button-up pathway (BU), top-down pathway (TD) and many lateral connections to connect between the BU and TD layers to get higher semantic and resolution information to correspond with the situation of remote sensing images, which contain various sizes of objects.
- The feature map of each different layer was allocated to objects of specific scales, which increase the detection accuracy.
- The multiple feature maps produced were combined. Therefore, the resolution increased, and multiple levels of details could be considered simultaneously. Additionally, it is more accurate to detect various sizes of objects and densely packed objects.
- A shallow network was used which improves the localization and the time of performance (training and testing time).
2. Methods
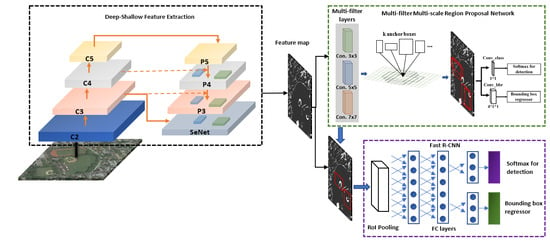
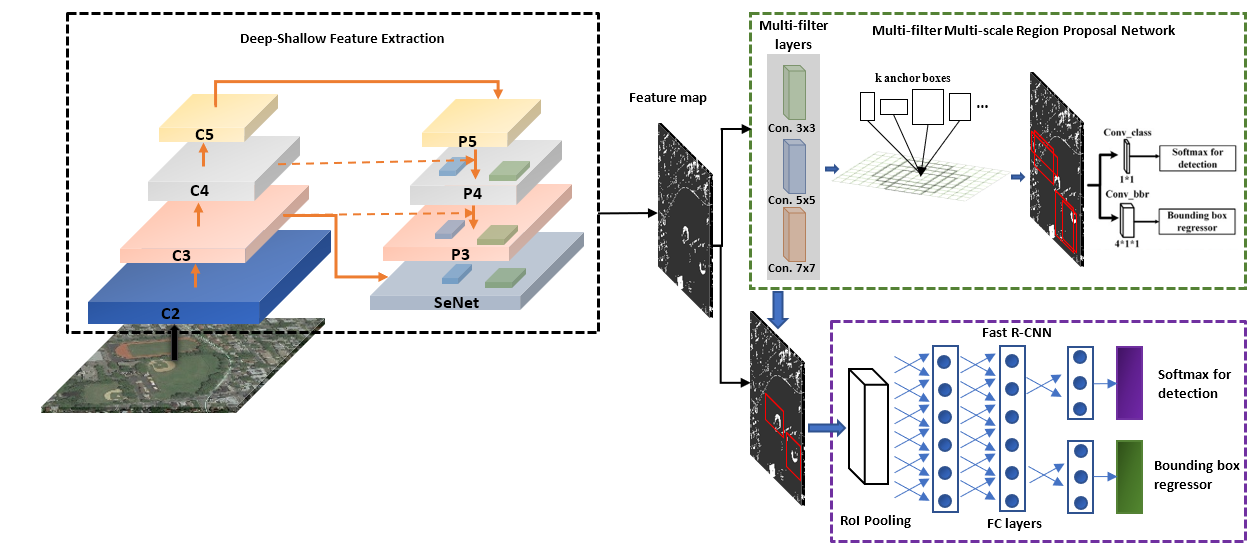
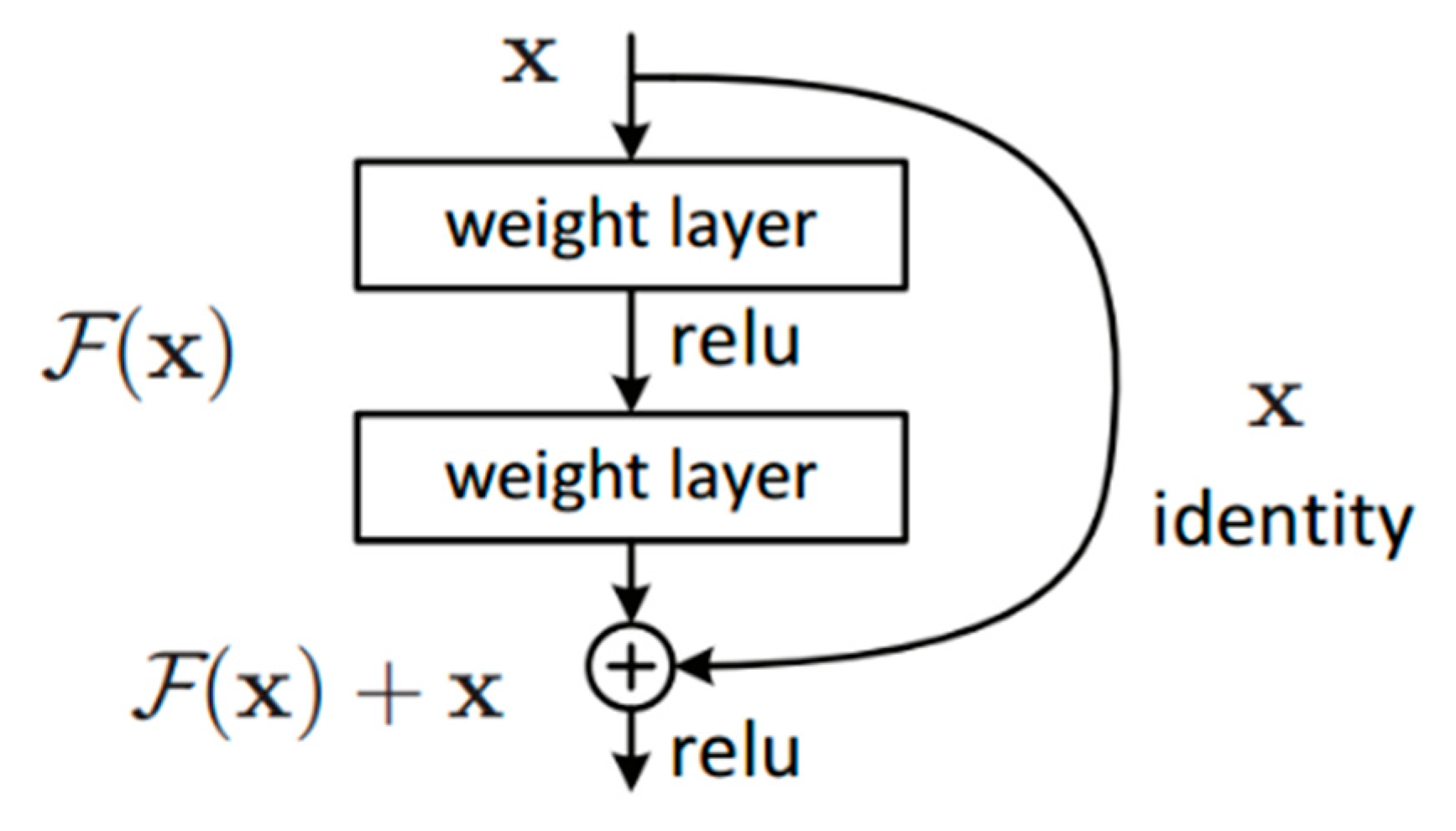
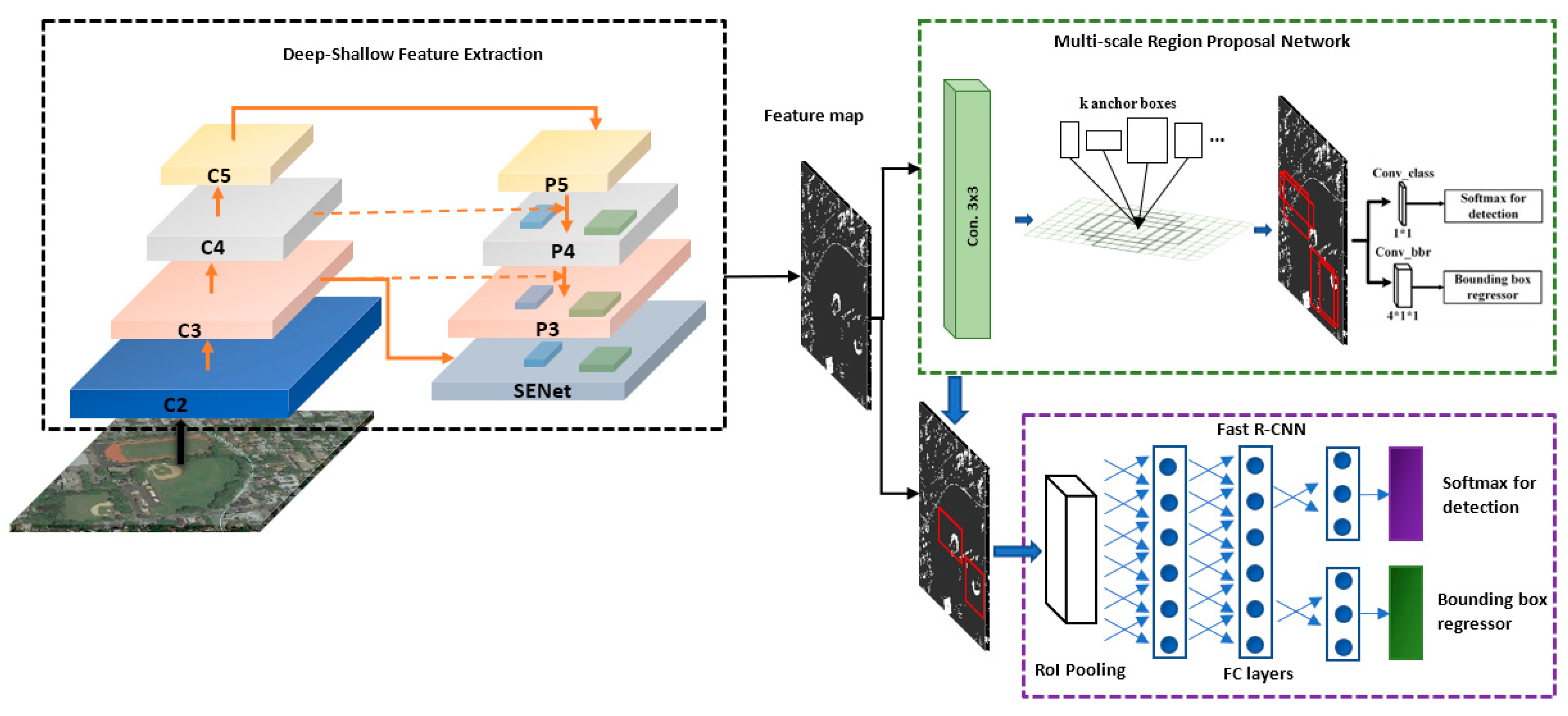
2.1. Shallow-Deep Feature Extraction Network (SDFE)
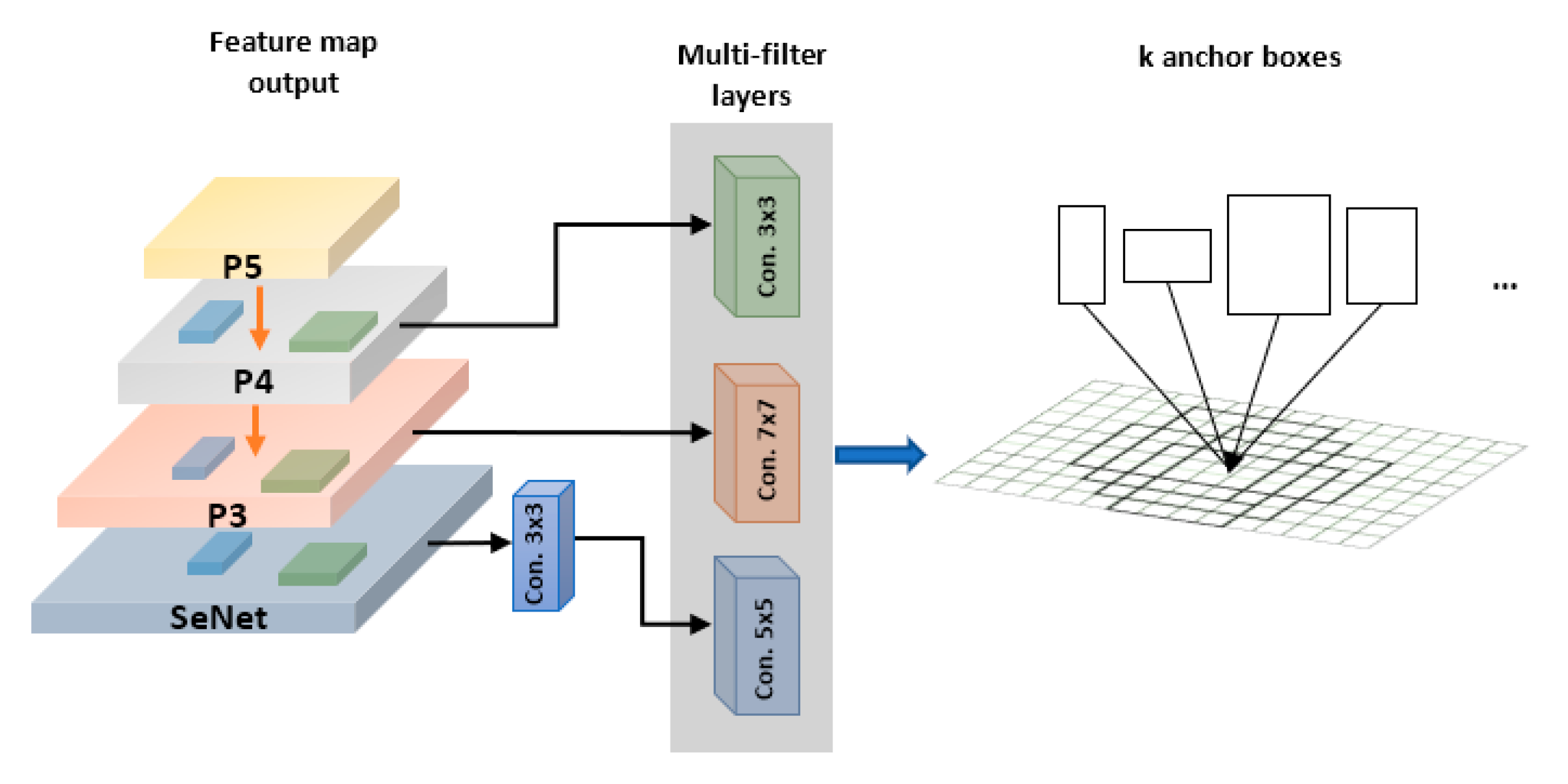
2.2. MS-MF Region Proposal Network
- X is the predicted probability anchor,
- is the balancing parameter = 1,
- is used to evaluate to 1 when Y ≥ 1 and 0 otherwise,
- and is the bounding box regression area.
2.3. Object Detection Network
3. Experiments
3.1. Dataset Description
3.2. Evaluation Metrics
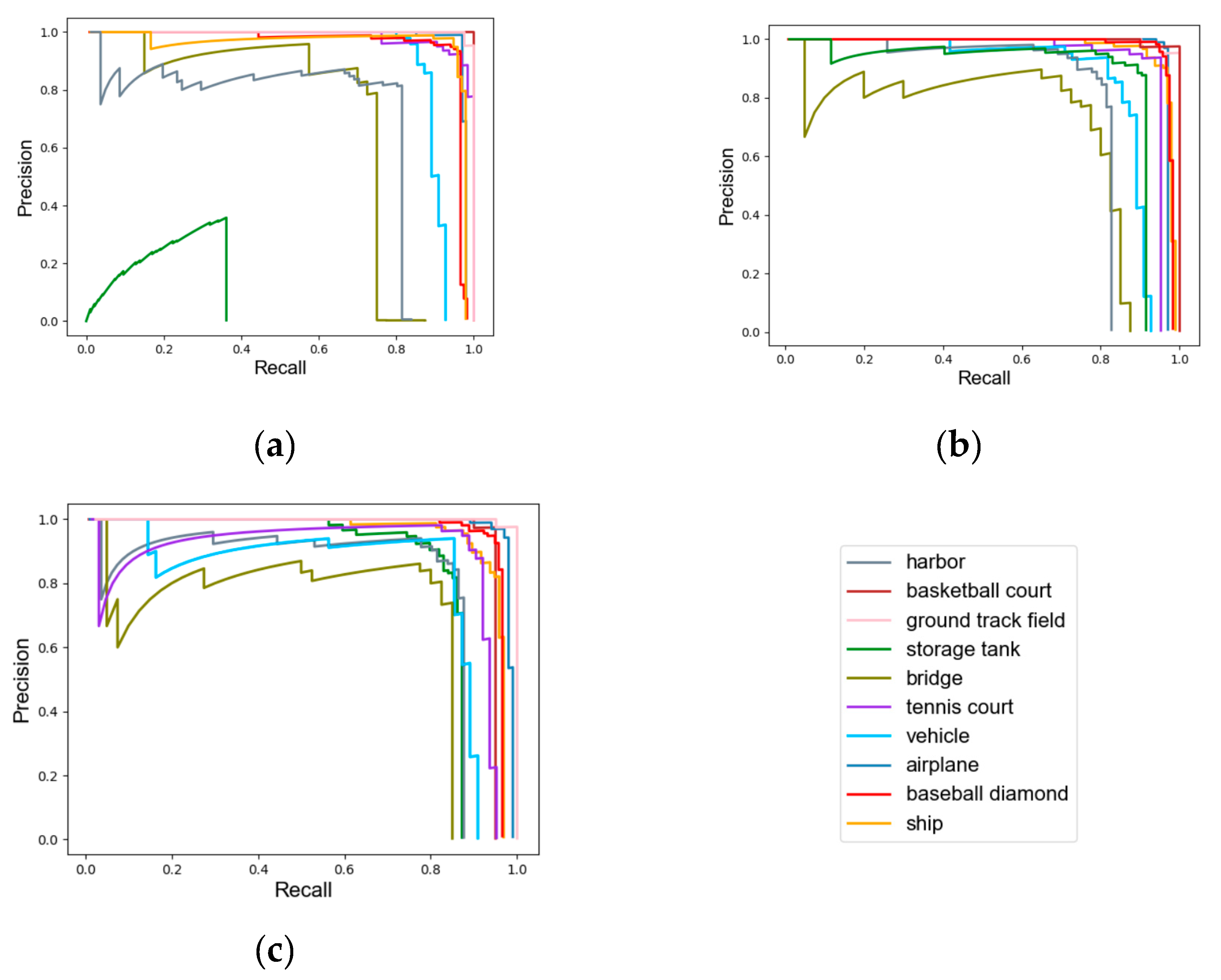
3.3. Experimental Results and Comparisons
- As known, VHR images take a long time for processing.
- The CPU of the device is very slow and the RAM of the GPU and of the device are both small, only 8 GB. These were important factors that slowed down processing.
- The structure of SDFE makes the process work in a straight line, happening one after the other in a series from C1 to P2. This also slows down the speed of the feature extraction. Therefore, a good way to improve the speed is by having the feature extraction structures work in parallel.
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Zou, Z.; Shi, Z.; Guo, Y.; Ye, J. Object Detection in 20 Years: A Survey. arXiv 2019, arXiv:1905.05055v1. [Google Scholar]
- Zhu, C.; Zhou, H.; Wang, R.; Guo, J. A Novel Hierarchical Method of Ship Detection from Spaceborne Optical Image Based on Shape and Texture Features. IEEE Trans. Geosci. Remote Sens. 2010, 48, 3446–3456. [Google Scholar] [CrossRef]
- Qi, S.; Ma, J.; Lin, J.; Li, Y.; Tian, J. Unsupervised Ship Detection Based on Saliency and S-HOG Descriptor from Optical Satellite Images. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1451–1455. [Google Scholar]
- Han, J.; Zhou, P.; Zhang, D.; Cheng, G.; Guo, L.; Liu, Z.; Bu, S.; Wu, J. Efficient, simultaneous detection of multi-class geospatial targets based on visual saliency modeling and discriminative learning of sparse coding. ISPRS J. Photogramm. Remote Sens. 2014, 89, 37–48. [Google Scholar] [CrossRef]
- Han, J.; Zhang, D.; Cheng, G.; Guo, L.; Ren, J. Object Detection in Optical Remote Sensing Images Based on Weakly Supervised Learning and High-Level Feature Learning. IEEE Trans. Geosci. Remote Sens. 2015, 6, 53. [Google Scholar] [CrossRef]
- Shi, Z.; Yu, X.; Jiang, Z.; Li, B. Ship Detection in High-Resolution Optical Imagery Based on Anomaly Detector and Local Shape Feature. IEEE Trans. Geosci. Remote Sens. 2014, 52, 4511–4523. [Google Scholar]
- Tang, J.; Deng, C.; Huang, G.-B.; Zhao, B. Compressed-Domain Ship Detection on Spaceborne Optical Image Using Deep Neural Network and Extreme Learning Machine. IEEE Trans. Geosci. Remote Sens. 2015, 53, 1174–1185. [Google Scholar] [CrossRef]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit. 2001, 1, 511–518. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–26 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Zhao, Z.; Zheng, P.; Xu, S.; Wu, X. Object Detection with Deep Learning: A Review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 1–21. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Zhou, P.; Guo, L. Multi-class geospatial object detection and geographic image classification based on collection of part detectors. ISPRS J. Photogramm. Remote Sens. 2014, 98, 119–132. [Google Scholar] [CrossRef]
- Wan, L.; Zheng, L.; Huo, H.; Fang, T. Affine Invariant Description and Large-Margin Dimensionality Reduction for Target Detection in Optical Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1116–1120. [Google Scholar] [CrossRef]
- Yuan, Y.; Hu, X. Bag-of-Words and Object-Based Classification for Cloud Extraction from Satellite Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 4197–4205. [Google Scholar] [CrossRef]
- Zhang, F.; Du, B.; Zhang, L.; Xu, M. Weakly Supervised Learning Based on Coupled Convolutional Neural Networks for Aircraft Detection. IEEE Trans. Geosci. Remote Sens. 2016, 54, 5553–5563. [Google Scholar] [CrossRef]
- Cheng, G.; Zhou, P.; Han, J. Learning Rotation-Invariant Convolutional Neural Networks for Object Detection in VHR Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 7405–7415. [Google Scholar] [CrossRef]
- Deng, Z.; Sun, H.; Zhou, S.; Zhao, J.; Lei, L.; Zou, H. Multi-scale object detection in remote sensing imagery with convolutional neural networks. ISPRS J. Photogramm. Remote Sens. 2018, 145, 3–22. [Google Scholar] [CrossRef]
- Kim, K.-H.; Hong, S.; Roh, B.; Cheon, Y.; Park, M. PVANET: Deep but Lightweight Neural Networks for Real-time Object Detection. arXiv 2016, arXiv:1608.08021. [Google Scholar]
- Hong, S.; Roh, B.; Kim, K.-H.; Cheon, Y.; Park, M. PVANet: Lightweight Deep Neural Networks for Real-time Object Detection. arXiv 2016, arXiv:1611.08588. [Google Scholar]
- Guo, W.; Yang, W.; Zhang, H.; Hua, G. Geospatial Object Detection in High Resolution Satellite Images Based on Multi-Scale Convolutional Neural Network. Remote Sens. 2018, 10, 131. [Google Scholar] [CrossRef]
- Zhong, Y.; Han, X.; Zhang, L. Multi-class geospatial object detection based on a position-sensitive balancing framework for high spatial resolution remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2018, 138, 281–294. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Advances in Neural Information, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object Detection via Region-based Fully Convolutional Networks. arXiv 2016, arXiv:1605.06409v1. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. arXiv 2017, arXiv:1612.03144. [Google Scholar]
- Wei Liu, D.A.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. Proc. Eur. Conf. Comput. Vis. 2016, 2016, 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Shen, Z.; Liu, Z.; Li, J.; Jiang, Y.-G.; Chen, Y.; Xue, X. DSOD: Learning Deeply Supervised Object Detectors from Scratch. arXiv 2018, arXiv:1708.01241. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Region-Based Convolutional Networks for Accurate Object Detection and Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 142–158. [Google Scholar] [CrossRef] [PubMed]
- Uijlings, J.R.R.; Van De Sande, K.E.; Gevers, T.; Smeulders, A.W.M. Selective Search for Object Recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef] [Green Version]
- Cortes, C.; Vapnik, V. Support vector machine. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [Green Version]
- Lazebnik, S.; Schmid, C.; Ponce, J. Beyond Bags of Features: Spatial Pyramid Matching for Recognizing Natural Scene Categories. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; pp. 2169–2178. [Google Scholar]
- Perronnin, F.; Sánchez, J.; Mensink, T. Improving the Fisher Kernel for Large-Scale Image Classification. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2010; pp. 143–156. [Google Scholar] [Green Version]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Roy, A.G.; Navab, N.; Wachinger, C. Recalibrating Fully Convolutional Networks with Spatial and Channel “Squeeze and Excitation” Blocks. IEEE Trans. Med. Imaging 2019, 38, 540–549. [Google Scholar] [CrossRef]
- Lin, Z.; Ji, K.; Leng, X.; Kuang, G. Squeeze and Excitation Rank Faster R-CNN for Ship Detection in SAR Images. IEEE Geosci. Remote Sens. Lett. 2019, 16, 751–755. [Google Scholar] [CrossRef]
- Liu, F.; Chen, C.; Gu, D.; Zheng, J. FTPN: Scene Text Detection with Feature Pyramid Based Text Proposal Network. IEEE Access 2019, 7, 44219–44228. [Google Scholar] [CrossRef]
- Makantasis, K.; Doulamis, A.D.; Doulamis, N.D.; Nikitakis, A. Tensor-Based Classification Models for Hyperspectral Data Analysis. IEEE Trans. Geosci. Remote Sens. 2018, 56, 6884–6898. [Google Scholar] [CrossRef]
- Yang, X.; Fu, K.; Sun, H.; Yang, J.; Guo, Z.; Yan, M.; Zhang, T.; Xian, S. R2CNN++: Multi-Dimensional Attention Based Rotation Invariant Detector with Robust Anchor Strategy. arXiv 2018, arXiv:1811.07126. [Google Scholar]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object Detection with Discriminatively Trained Part-Based Models. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1627–1645. [Google Scholar] [CrossRef]
- Kong, T.; Sun, F.; Yao, A.; Liu, H.; Lu, M.; Chen, Y. RON: Reverse Connection with Objectness Prior Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5244–5252. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2019. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Neubeck, A.; Gool, L.V. Efficient Non-Maximum Suppression. In Proceedings of the International Conference on Pattern Recognition (ICPR’06), Hong Kong, China, 20–24 August 2006; pp. 850–855. [Google Scholar]
- Wan, L.; Eigen, D.; Fergus, R. End-to-end integration of a Convolutional Network, Deformable Parts Model and non-maximum suppression. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 851–859. [Google Scholar]
- Han, J.; Zhang, D.; Cheng, G.; Liu, N.; Xu, D. Advanced Deep-Learning Techniques for Salient and Category-Specific Object Detection: A Survey. IEEE Signal Process. Mag. 2018, 35, 84–100. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J. A survey on object detection in optical remote sensing images. ISPRS J. Photogramm. Remote Sens. 2016, 117, 11–28. [Google Scholar] [CrossRef] [Green Version]
- Han, X.; Zhong, Y.; Zhang, L. An Efficient and Robust Integrated Geospatial Object Detection Framework for High Spatial Resolution Remote Sensing Imagery. Remote Sens. 2017, 9, 666. [Google Scholar] [CrossRef]
- Xu, Z.; Xu, X.; Wang, L.; Yang, R.; Pu, F. Deformable ConvNet with Aspect Ratio Constrained NMS for Object Detection in Remote Sensing Imagery. Remote Sens. 2017, 9, 1312. [Google Scholar] [CrossRef]
- Ren, Y.; Zhu, C.; Xiao, S. Deformable Faster R-CNN with Aggregating Multi-Layer Features for Partially Occluded Object Detection in Optical Remote Sensing Images. Remote Sens. 2018, 10, 1470. [Google Scholar] [CrossRef]
- Chen, S.; Zhan, R.; Zhang, J. Geospatial Object Detection in Remote Sensing Imagery Based on Multiscale Single-Shot Detector with Activated Semantics. Remote Sens. 2018, 10, 820. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Performance Stages | Layers of Feature Map | Scales | Ratios | Filters |
|---|---|---|---|---|
| P5, P4, P3, P2 | The same two scales for each layer | [1, 0.5, 2, 1/3., 3., 1.5, 1/1.5] | - |
| P4, P3, SENet | The same two scales for each layer | [1, 0.5, 2, 1/3., 3., 1.5, 1/1.5] | - |
| P4, P3, SENet | The same two scales for each layer | [1, 0.5, 2, 1/3., 3., 1.5, 1/1.5] | 3 × 3, 5 × 5, 7 × 7 conv. |
| Training Method | SDFE | MS | MF | mAP | Recall | Average Training Time per Image (Second) | Average Test Time per Image (Second) |
|---|---|---|---|---|---|---|---|
| All FPN + MS | √ | 83.31 | 89.46 | 1.2 | 3.3 | ||
| SD-MS | √ | √ | 91.55 | 94.39 | 0.9 | 2.5 | |
| SDFE + MS-MF | √ | √ | √ | 90.09 | 93.35 | 1.1 | 3 |
| Stages | FPN + MS | SD-MS | SDFE + MS-MF | |||
|---|---|---|---|---|---|---|
| Recall | AP | Recall | AP | Recall | AP | |
| A | 98.02 | 97.60 | 97.03 | 96.98 | 99.01 | 98.36 |
| S | 97.92 | 96.54 | 98.96 | 97.31 | 96.88 | 95.07 |
| ST | 36.17 | 12.95 | 91.49 | 88.45 | 87.23 | 85.07 |
| BD | 98.29 | 95.69 | 98.29 | 97.62 | 96.58 | 96.05 |
| TC | 100.00 | 98.56 | 95.24 | 94.26 | 95.24 | 91.33 |
| BC | 100.00 | 100.00 | 100.00 | 99.76 | 95.00 | 94.87 |
| GTF | 100.00 | 99.89 | 100.00 | 99.65 | 100.00 | 99.88 |
| H | 83.95 | 71.14 | 82.72 | 80.37 | 87.65 | 82.54 |
| B | 87.50 | 70.75 | 87.50 | 73.72 | 85.00 | 73.78 |
| V | 92.73 | 90.01 | 92.73 | 87.35 | 90.91 | 83.96 |
| Mean | 89.46 | 83.31 | 94.39 | 91.55 | 93.35 | 90.09 |
| Class | RICNN | R-P-F-R-CNN | D-R-FCN | COPD | PSB | D-F-R-CNN | RDAS512 | MS-CNN | FPN + MS | SD-MS |
|---|---|---|---|---|---|---|---|---|---|---|
| A | 88.35 | 90.4 | 87.3 | 89.11 | 90.7 | 90.7 | 99.6 | 99.3 | 97.6 | 96.98 |
| S | 77.34 | 75 | 81.4 | 81.73 | 80.6 | 87.1 | 85.5 | 92 | 96.54 | 97.31 |
| ST | 85.27 | 44.4 | 63.6 | 97.32 | 80.3 | 70.5 | 89 | 83.2 | 12.95 | 88.45 |
| BD | 88.12 | 89.9 | 90.4 | 89.38 | 89.9 | 89.5 | 95 | 97.2 | 95.69 | 97.62 |
| TC | 40.83 | 79 | 81.6 | 73.27 | 75.5 | 89.3 | 89.6 | 90.8 | 98.56 | 94.26 |
| BC | 58.45 | 77.6 | 74.1 | 73.41 | 81.6 | 87.3 | 94.8 | 92.6 | 100 | 99.76 |
| GTF | 86.73 | 87.7 | 90.3 | 82.99 | 86.5 | 97.2 | 95.3 | 98.1 | 99.89 | 99.65 |
| H | 68.6 | 79.1 | 75.3 | 73.39 | 78.5 | 73.5 | 82.6 | 85.1 | 71.14 | 80.37 |
| B | 61.51 | 68.2 | 71.4 | 62.86 | 77.2 | 69.9 | 77.2 | 71.9 | 70.75 | 73.72 |
| V | 71.1 | 73.2 | 75.5 | 83.3 | 71 | 88.8 | 86.5 | 85.9 | 90.01 | 87.35 |
| mAP | 72.63 | 76.5 | 79.1 | 80.68 | 81.2 | 84.4 | 89.5 | 89.6 | 83.31 | 91.55 |
| (a) | (b) | |||||
| Class | 0.3 | 0.4 | 0.5 | 0.3 | 0.4 | 0.5 |
| A | 98.71 | 97.60 | 97.60 | 98.00 | 98.00 | 96.98 |
| S | 98.50 | 98.50 | 96.54 | 97.31 | 97.31 | 97.31 |
| ST | 92.59 | 42.90 | 12.95 | 99.52 | 96.29 | 88.45 |
| BD | 95.69 | 95.69 | 95.69 | 98.47 | 98.47 | 97.62 |
| TC | 98.56 | 98.56 | 98.56 | 94.26 | 94.26 | 94.26 |
| BC | 100.00 | 100.00 | 100.00 | 99.76 | 99.76 | 99.76 |
| GTF | 99.89 | 99.89 | 99.89 | 99.65 | 99.65 | 99.65 |
| H | 89.20 | 85.51 | 71.14 | 90.52 | 86.78 | 80.37 |
| B | 84.11 | 73.54 | 70.75 | 86.17 | 78.61 | 73.72 |
| V | 90.01 | 90.01 | 90.01 | 88.22 | 87.35 | 87.35 |
| mAP | 94.73 | 88.22 | 83.31 | 95.19 | 93.65 | 91.55 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
AL-Alimi, D.; Shao, Y.; Feng, R.; Al-qaness, M.A.A.; Elaziz, M.A.; Kim, S. Multi-Scale Geospatial Object Detection Based on Shallow-Deep Feature Extraction. Remote Sens. 2019, 11, 2525. https://0-doi-org.brum.beds.ac.uk/10.3390/rs11212525
AL-Alimi D, Shao Y, Feng R, Al-qaness MAA, Elaziz MA, Kim S. Multi-Scale Geospatial Object Detection Based on Shallow-Deep Feature Extraction. Remote Sensing. 2019; 11(21):2525. https://0-doi-org.brum.beds.ac.uk/10.3390/rs11212525
Chicago/Turabian StyleAL-Alimi, Dalal, Yuxiang Shao, Ruyi Feng, Mohammed A. A. Al-qaness, Mohamed Abd Elaziz, and Sunghwan Kim. 2019. "Multi-Scale Geospatial Object Detection Based on Shallow-Deep Feature Extraction" Remote Sensing 11, no. 21: 2525. https://0-doi-org.brum.beds.ac.uk/10.3390/rs11212525