1. Introduction
The coastline of the Antarctic continent consists not only of solid rock but also dynamic glacier and ice shelf fronts. Iceberg calving and recent disintegration events of ice shelves make the Antarctic coastline a constantly changing boundary between land ice and ocean. Ice shelf and glacier fronts are sensitive indicators for glaciological processes and play an important role for ice sheet dynamics and mass balance. Changes in ice front position can influence ice sheet discharge as retreating fronts may enhance ice sheet flow through reduced buttressing effects [
1]. If we want to understand the sea level rise contribution of Antarctica, besides many other parameters, current calving front dynamics have to be tracked. Only in this way, recent changes in glacier and ice shelf front movement can be detected. Additionally, our understanding of forces controlling calving front location (CFL) change is still limited as continuous Antarctic coastal-change time series are scarce [
2]. This is attributed to the lack of suitable amounts of remote sensing imagery and the time-consuming manual delineation of calving fronts. But since the launch of Sentinel-1 year-round, medium-resolution and weather independent imagery over the Antarctic coastline with weekly revisit times is available. To exploit this abundance of data, a novel automatic approach for coastline extraction is needed to continuously track glacier and ice front fluctuations. But, so far, no automatic method exists to track dynamic glacier and ice shelf front change intra-annually.
Automatic coastline extraction from SAR (Synthetic Aperture Radar) imagery has been a challenging task for several decades [
3]. Speckle and wind roughed sea lower the intensity contrast between sea and land and other object boundaries may have higher contrast than the actual coastline [
4,
5,
6]. For the Antarctic coastline and polar coastlines in general, additional difficulties arise. The Antarctic coastline is defined as the boundary between the ice sheet (including floating ice shelves and glacier tongues) and the ocean [
7]. In many cases, the Antarctic coastline can be difficult to detect on remote sensing imagery. For example, fast ice is fastened to the ice sheet, has similar backscatter values as the ice shelf surface but has originally developed from sea ice. Additionally, icebergs enclosed by slushy sea ice reduce the contrast between sea ice and the glacier tongue which makes the delineation more difficult. Therefore, most general image processing techniques like segmentation and edge detection don’t perform accurate enough [
8]. Besides edge detection, classification-based approaches are used to extract the coastline, sometimes additionally with active contours [
6,
9,
10,
11,
12]. For polar regions, classification approaches on SAR imagery are difficult to apply as backscatter varies exceptionally over the same spot throughout the year. Seasonal changes in sea ice and snow properties and melt modify backscatter characteristics over the ocean and ice sheet [
13,
14,
15,
16]. For example, the higher parts of the ice sheet may have the same backscatter intensity as open water and ice mélange scatters similar to a rough glacier surface.
Despite the many challenges that have to be faced to extract polar coastlines from SAR imagery, a few (semi-)automated approaches exist. Sohn and Jezek 1999 [
15] applied the Roberts operator for edge extraction after edge enhancement and local thresholding for the Jacobshavn Glacier in Greenland based on ERS-1 imagery. They extracted the calving front of Jacobshavn Glacier with an accuracy of 2–3 pixels (200–300 m) for the year 1992. Liu and Jezek 2004 [
4,
8] developed an image processing chain for the RADARSAT mosaic from 1997 (later on also for 2000). After speckle reduction and edge enhancement, the image is segmented by using local adaptive thresholding. In the post-processing step, the Antarctic coastline is extracted by the canny edge detector. Errors occur in areas with wind roughened sea, wet snow, and fast ice. Their developed approach was very successful as it could be applied on a Circum-Antarctic RADARSAT mosaic, even though the accuracy was inferior in areas with fast ice and mélange and manual correction had to be applied. Krieger and Floricioiu [
17] combined a simple Canny edge detector with a pixel tracing technique to delineate the calving front location of Zachariae Isstroem from TerraSAR-X and Sentinel-1 imagery for two dates. Compared to manual delineation, the results deviated on average 159 m and 246 m, respectively. All described approaches perform well for the selected scenes and acquisition times, but unfortunately were not tested for large-scale applications, spatial transferability, or dense temporal analysis which we pursued.
An alternative to established image processing techniques using hand crafted feature extraction algorithms (e.g., filter for edge detection) can be a deep learning approach. Deep learning was applied successfully to solve complex image processing tasks, even for complex remote sensing imagery, with outstanding accuracies, and further developments are still improving this state-of-the-art technique [
18]. In recent years, deep convolutional neural networks (DCNN) outperformed conventional machine learning classifiers such as random forest and support vector machine in many cases [
18,
19]. Specifically, fully convolutional networks (FCN) proved to perform best for semantic segmentation tasks, where for each pixel a semantic label is created based on contextual and pixel information of an image (e.g., [
20,
21,
22]). This general technique from computer vision is perfectly transferable to classify remote sensing images [
23,
24,
25]. For coastline extraction, traditional thresholding and segmentation approaches were tested against different FCN architectures. The latter outperformed the traditional image processing techniques with better accuracies [
26]. The best performance for segmentation in coastal areas was performed by FCNs based on the U-Net architecture [
19] introduced by Ronneberger et al. [
22]. The initial U-Net got very popular as it performed very well on medical gray scale imagery even in low contrast areas with only a low amount of training imagery [
22]. The key features are skip connections between the down- and up-sampling blocks allowing accurate located pixel by pixel classification. So far, two studies exist on the application of the U-Net for calving front delineation for selected Greenlandic glaciers. Mohajerani et al. [
27] used optical Landsat imagery to extract the calving front of Jakobshavn, Sverdrup, Kangerlussuaq, and Helheim Glacier. The FCN results outperform common edge detection techniques with a mean deviation of 96.3 m (approx. 2 pixels). Major drawbacks of this approach are the low resolution of the input image, rotation of the input image into flow direction, and training on the edge only. For a continuous coastline, a low cost path has to be found between the classified edge pieces within a 500 m buffer which might not cover huge calving events occurring in Antarctica. The second study focused on the multi-temporal analysis of glacier front change and created a dense time series for Jakobshavn Isbrae glacier based on TerraSAR-X imagery [
28]. Zhang et al. created a very dense time series with a mean difference of 104 m (17.3 pixels) with respect to manual delineated ones. Nevertheless, their approach was only tested for a single glacier and required many high resolution training images.
In this study we use a modified U-Net to create a framework for Antarctic glacier and ice shelf front extraction that is able to create dense CFL time series for large-scale areas. For the first time, we propose a modified U-Net that can handle radar remote sensing data of different polarizations and elevation information. Our approach allows to track coastal change along the Antarctic coastline and to assess the fluctuations of glacier and ice shelf fronts automatically. In this paper, we first describe our study areas used for training and also later for testing to prove transferability. Afterwards, we describe our input data and explain the developed processing chain. The performance of our approach is tested for transferability in space and time in two ways. First, the classification accuracy and distance difference compared to a manual delineated coastline is calculated for four training and four test sites. Second, transferability in time and space is assessed by the creation of a monthly CFL time series for a part of Marie Byrd Land, which has not been in the training areas and is compared to manual delineations of the coastline.
2. Study Areas
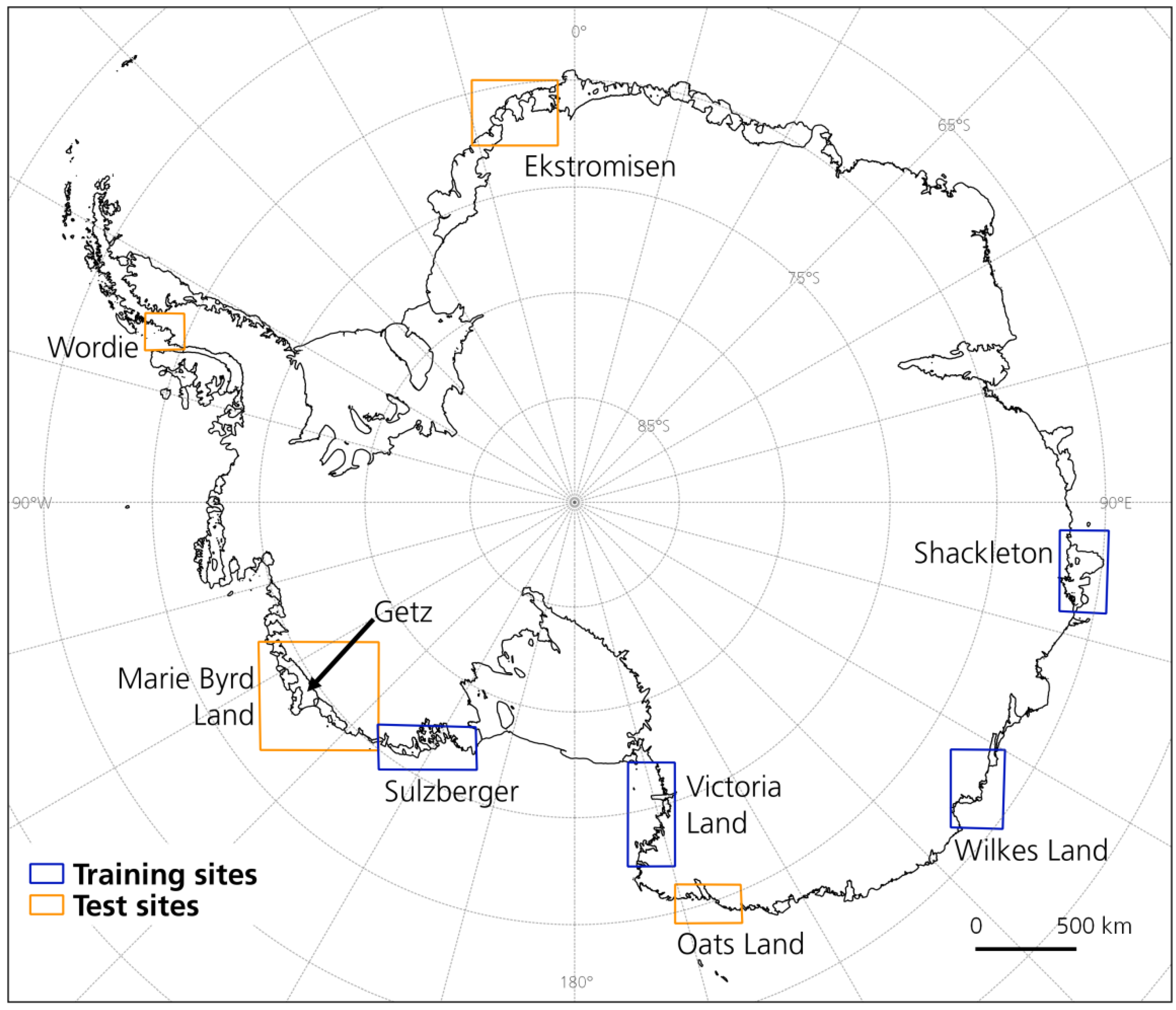
To develop a glacier and ice shelf front extraction algorithm, it needs to handle all kinds of different Antarctic coastline morphologies such as huge ice shelves, ridged glacier tongues, and solid rock. Therefore, we chose eight different training and test sites with different characteristics. The training areas are used to train the model and test it later on with new scenes over this region. Test areas are only used for testing the model and are not presented to the network before. All locations of the training and test sites are shown in
Figure 1 and described in the following.
The area around the Sulzberger Ice Shelf is characterized by the fast moving Land Glacier (about 1.6 km/yr) and the slower moving glaciers (10-200 m/yr) flowing into the Nickerson (60 km wide) and Sulzberger Ice Shelf (more than 100 km wide) [
29,
30]. A huge ice shelf with a length of 400 km is represented by the Shackleton Ice Shelf site [
31] with changing sea ice conditions. The part of Wilkes Land consists mostly of dynamic glaciers with myriads of icebergs and ridged glacier tongues. Additionally, sea ice conditions and mélange are challenging in this area. Finally, along Victoria Land, long glacier tongues enter the ocean between steep terrain. Later on, the developed workflow shall be tested on the following four test sites to demonstrate the transferability of our approach. Ekstromisen is a 143 km wide ice shelf along Queen Maud Land, far away from any training sites. The disintegrated Wordie Ice Shelf and the surrounding glaciers lay along the Antarctic Peninsula within steep terrain. The third test site is at Oats Land with long glacier tongues and ice shelves in different shapes. Lastly, a part of Marie Byrd Land is selected because of the multi-year ice areas. Within this area, the Getz Ice Shelf was also chosen to test our algorithm on time series generation as little is known about the current frontal fluctuations [
2]. The Getz Ice Shelf is the largest ice shelf along West Antarctica with an area of 33,395 km
2 and pinned with islands along the front [
32]. Getz experienced the highest mass loss compared to all other ice shelves along West Antarctica with −67.6 ±12 Gt per year between 2003 and 2008 [
33]. Basal melt accounts for about three quarter of the mass loss and calving for one quarter [
33] but can vary as Getz is subject to changeable ocean forcing conditions [
32]. Between 2008 and 2013/2015 the glacier flow of glaciers feeding the Getz Ice Shelf increased by 10 to 100 m/yr at the grounding line (6% increase of discharge) [
34]. The grounding line itself of the Getz Ice Shelf retreated 100–200 m per year between 2010 and 2016 [
35]. Taken together, those factors indicate that Getz Ice Shelf is exposed to changing environmental conditions.
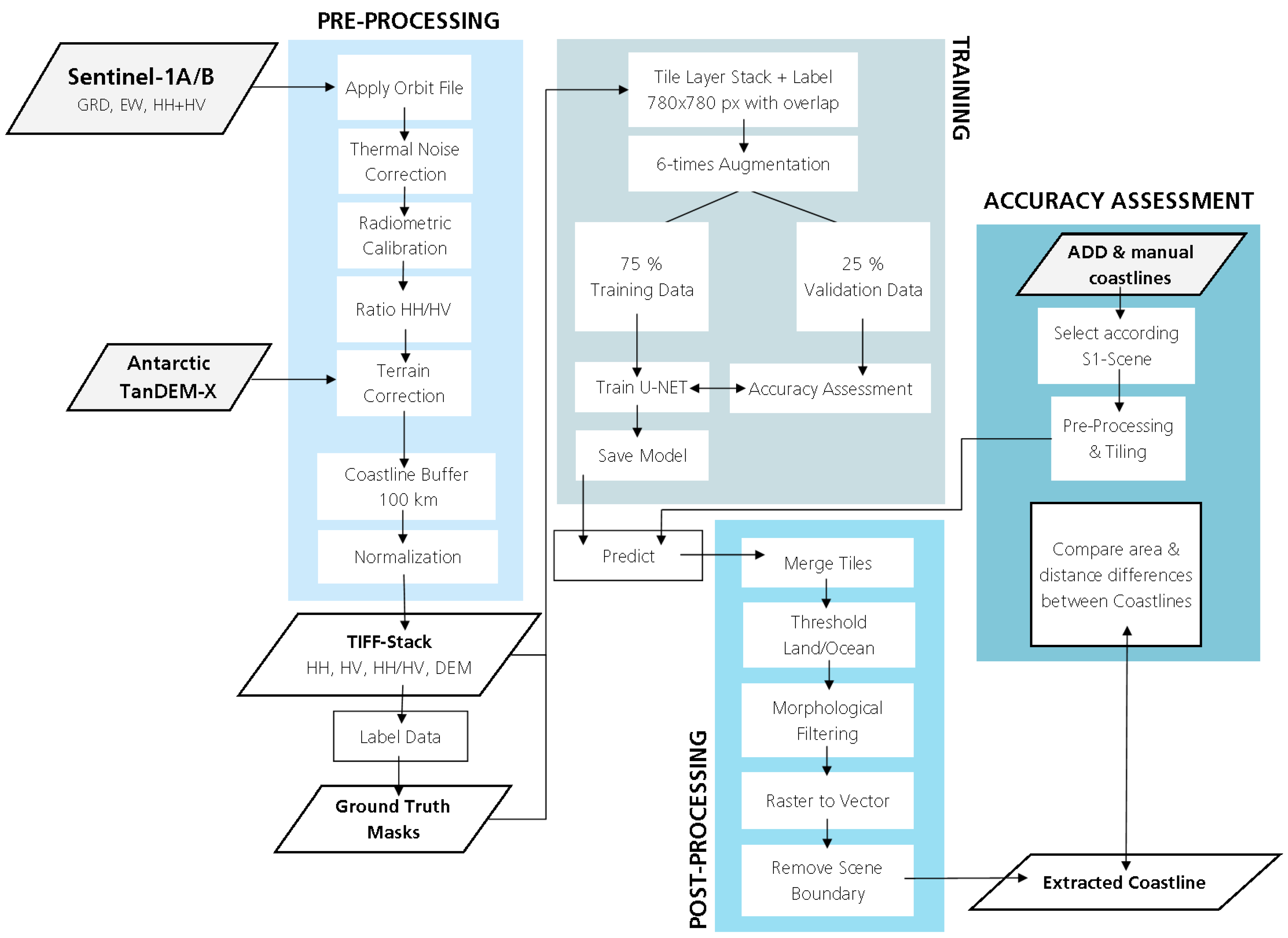
4. Method
4.1. Pre-Processing SAR Data
The pre-processing of Sentintel-1 EW GRD (Ground Range Detected) scenes was performed with the ESA SNAP (Sentinel Application Platform) software 6.0 including the following steps:
Apply Orbit File;
Thermal noise removal;
Radiometric calibration;
Geometric terrain correction with TanDEM-X 90 m;
Stacking of HH, HV, HH/HV, and TanDEM-X 90 m.
The Orbit File is applied to update satellite position and satellite velocity for more accurate orbit state vectors. Afterwards, thermal noise is reduced by the thermal noise removal. Radiometric calibration converts the backscatter intensity to the backscatter coefficient sigma nought. Now, the pixel values represent the backscatter of the reflecting surface and make comparison between different scenes possible. Usually, speckle filtering is applied afterwards but we decided to forgo this step as it might reduce the appearance of edges. Finally, to remove distance distortions in the signal due to topography, we corrected for terrain with the TanDEM-X 90 m. With the terrain corrected scene, a four-layer stack is created with the polarizations HH and HV, as well as the ratio HH/HV and the digital elevation model.
4.2. U-Net Architecture for Image Segmentation
To extract the border between the two classes, land ice and ocean, we use a classifier which takes the pixel value as well as the spatial context into account. We chose the basic structure from the originally developed U-Net from Ronneberger et al. [
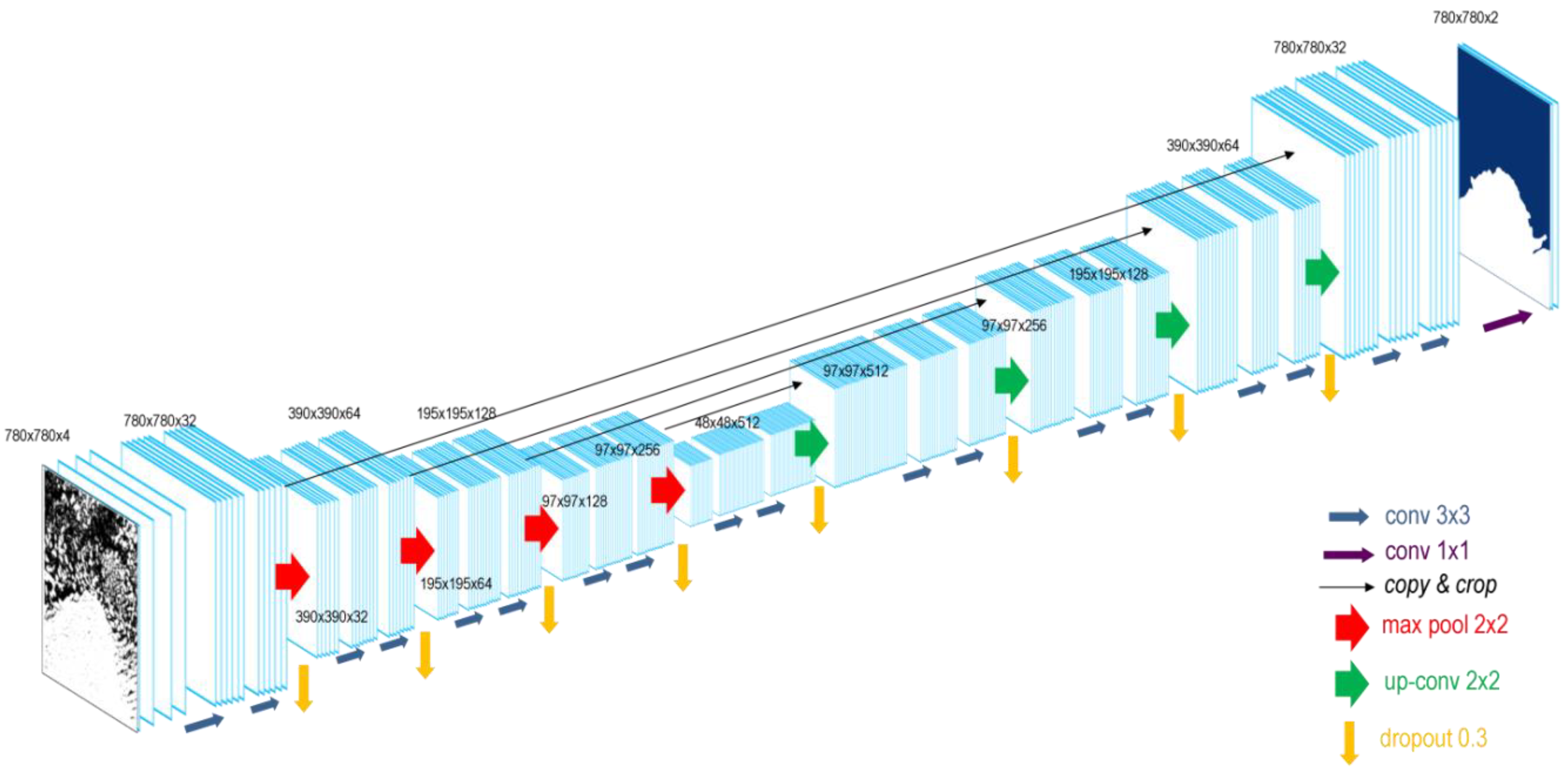
22] and modified the architecture for our purpose. Main modifications include (1) the usage of bigger input tiles; (2) starting with 32 feature channels (instead of 64) and increasing only to 512 (instead of 1024); (3) including drop out; and (4) feeding four input channels instead of one.
Figure 2 visualizes our modified U-net architecture with four down-sampling units (red arrows) in the encoder block and four up-sampling units (green arrows) in the decoder block as well as skip-connections (black arrows). In the following, we explain the basic function of the U-Net, hyperparameter selection, and why we entered modifications.
To train the network, we feed 780 x 780 pixel tiles with four input channels (HH, HV, DEM, HH/HV). Four input channels were selected to be able to not only use gray scale images but to include different polarizations and elevation information. The tile size was increased compared to the initial U-Net as bigger tiles include more spatial context, which is crucial for feature detection along the Antarctic coastline. For training, each of the input tiles is convoluted by a 3 x 3 kernel with stride 1. The kernel consists of a 3 x 3 matrix of random initialized weights which gets updated during the training process using the Adam optimizer in TensorFlow 1.12 with the default learning rate of 0.001, the default cost function categorical cross entropy and the activation function ReLU (rectified linear units). Also, bigger kernels were tested but increased the computational cost and were neglected. The trained weights can be seen as a filter that extracts specific features of the input image. Hence, after each convolution, feature maps are generated from the input image for the number of available filters. In our case, the four input channels are convoluted to 32, 64, 265, and 512 feature maps. As our input tiles and the glacial features are bigger than the cells in the medical imagery from the initial U-Net, we selected less but bigger feature maps. This keeps the computational cost low, whereas still enough trainable parameters are obtained. With each down-sampling block, the number of feature maps increases whereas the tile size decreases by a 2 × 2 max pooling operation. This technique allows reducing the image size and computational cost by taking the maximum value of each 2 × 2 pixel matrix. This extracts the most important information. After each pooling, dropout is applied to randomly exclude a given amount of the trained weights (for each training step) to prevent overfitting. Finally, at the end of the encoding block, 512 feature maps of the size 48 × 48 pixel exist.
Thereafter, the decoder block up-samples this densified information again to assign each pixel of the input image a classification result. Rows and columns of the input feature maps are repeated to increase the tile size to the initial input size. This step is connected to the previous feature map via convolution. The contextual information is derived from the encoder via the copy and crop skip connections. The last 32 feature channels are pooled by a 1 × 1 convolution with the Sigmoid activation function to obtain prediction probabilities for each class. Finally, the output image has the same size as the input image with two channels for the classification probabilities for each class (land ice/ocean). Our fully convolutional network consists of 7.8 million trainable parameters.
4.3. Training
For training, the final 38 scene stacks are normalized and then tiled into 780 × 780 pixel patches. The patch size is limited by GPU RAM and batch size. We chose the biggest possible tile size for a higher spatial context, accepting the drawback of small batch sizes as described by [
22]. Tiling is done with a 200 pixel overlap to reduce image borders and increase training data. To increase training effectively, we sorted our scene tiles into tiles with border areas, tiles covering only one class, and tiles with coastline. The most important tiles covering the coastline were augmented six-times by flipping and rotating for 90, 180, and 270 degrees. This creates a more intense training on the calving front. For training, we only used 30% of the border tiles, 90% of the single class tiles, and all augmented calving front tiles. Finally, we had 19,576 patches, out of them we randomly selected 25% for validation. Validation data is important as it tells after how many epochs the model converges and training has to be stopped. We trained the U-Net with a batch size of two on a GeForce GTX 1080 GPU with 12 GB RAM. The model converged after 30 epochs with a dropout value of 0.3 (30% of the weights are randomly dropped after updating). This was empirically calculated and outperformed dropout with the values 0.0, 0.2, and 0.5. Also, batch normalization was tested but resulted in worse results probably because the batch size is very small.
Figure 3 is a visualization of some of the learned filters in the down-sampling blocks. From left to right, the image size decreases from 780 to 48 pixels. Low level features are recognized after the first convolution. For example, the first filter is sensitive to the HH polarization and the DEM information (R: HH, G: HV, B: DEM, alpha: ratio). After one pooling operation, the filters start to be sensitive to broader ice-related features. After more convolutions and pooling operations, the filters get much more detailed. Ice structures in various orientations can be recognized very clearly, especially for the last two down-sampling blocks. The trained weights are able to produce classification accuracies of 98.14% for the training and 98.16% for the validation data set (after 30 Epochs).
4.4. Post-Processing
The main reason for post-processing is to generate shapefiles from the classification results. First, we merge all tiles of each Sentinel-1 scene to a georeferenced raster tiff. In overlapping areas, the mean of both classification results is taken. The prediction probabilities from the U-Net are thresholded by 0.5, so every pixel classified with a 50% probability or higher is classified as land ice. Afterwards, morphological filtering is applied with the python package scikit-image. Holes in the ice area are closed before removing islands in the water (e.g., icebergs wrongly classified as land ice). The class land ice in the output raster is finally converted to a shapefile representing the extracted coastline from the initial Sentinel-1 scene. The above described framework is summarized in the flowchart of
Figure 4.
4.5. Time Series Generation
A set of extracted calving fronts over the same area can be used to analyze calving front fluctuations. We extracted a 15-month time series from Sentinel-1A/B scenes in ascending mode. The distance change was calculated relative to an offshore baseline with the Digital Shoreline Analysis System (DSAS). Along the baseline, transects with 1 km spacing were used to measure the distance to the baseline at the intersection with the front position.
5. Accuracy Assessment
The performance of our framework is tested in two ways. First, we assess the classification accuracy for the two classes, land ice and ocean, after post-processing to compare our results with other deep learning studies. Second, the error is estimated by calculating the distance between the manually labeled coastline and the automatically extracted one. This is a better indicator for the distance deviation of the automatically extracted coastline to a manual one.
For testing, we use four satellite scenes covering the training areas in June 2018 as this month had not been used for training the network. Furthermore, four satellite images (also June 2018) covering the test sites are used for testing as well. Please see
Table S1 for a list of all training and test scenes. As reference we use manually labeled coastlines for all training and test sites for June 2018. We selected this month as it was not used for training the model and because an external coastline from the ADD (Antarctic Digital Database) exists along Marie Byrd Land for June 2018.
The classification accuracy is calculated for a 1 km buffer area along the manual delineated coastline. We decided to focus on the frontal area only as classification accuracies for the entire 100 km buffer area are for all training and test sites over 99% and hence, less meaningful. Common standard performance measures (recall, precision, f1-score) are derived for the classification result. Especially to monitor calving front change, it is useful to also know the distance error of an automatically extracted coastline compared to a manual one. Therefore, we created for each training and test site a baseline for 1 km spaced vertical transects. These transects are automatically generated, only in areas of crossing transects or non-perpendicular transects we corrected them manually. Along those, the distance between both lines is calculated in Antarctic Polar Stereographic Projection. Transect generation and distance calculations were performed with the Digital Shoreline Analysis System (DSAS) provided by USGS. It is a free MATLAB-based tool which can run with ArcGIS.
5.1. Classification Accuracy
The classification accuracy is tested with the three standard parameters precision, recall, and f1-score for a 1 km buffer along the manual coastline for the classes land ice and ocean. Precision is a good measure for false positives, recall for capturing real positives and f1-score is the balance between both. The accuracies are given for June 2018 (
Table 1). The average f1-score for ice in all train sites is 90% and for the test sites 91%, for water 89% and 90%, respectively. Within the different training and test areas, the accuracy varies slightly. The classification for Shackleton Ice Shelf performed best with 94% accuracy for both classes. In contrast, Sulzberger Ice Shelf only reaches 85% for ice and 83% for water. Better performance can be reached for the test site Ekstromisen with 93% (ice) and 92% (water). The area along the disintegrated Wordie Ice Shelf has slightly lower accuracies with 88% for ice and 87% for water. In general, for ice classification the true positives are captured well but the lower value in precision indicates more false positives. Hence, a slight over-classification for the class land ice exists.
5.2. Error Estimation
The error of the automated coastline is presented as the distance difference to a manual delineated coastline. The difference can either be calculated along transects or as the average width of the enclosed area between the manual and automated coastline. The advantage of using transects is twofold. Transects can be drawn for selected sections along the coastline which allows to calculate the distance error for frontal sections and stable coastline areas separately. Additionally, with calculating the median instead of the mean distance of several transects, outliers can be eliminated and the estimated frontal change is more accurate.
A second way to calculate the error in distance is to divide the area difference of both coastlines (manual and automated) by their averaged length (short A/F). This way, the calculated error in distance can be calculated quickly but extreme values are smoothed out. Nevertheless, we calculated this often-used formula for comparison with already published studies.
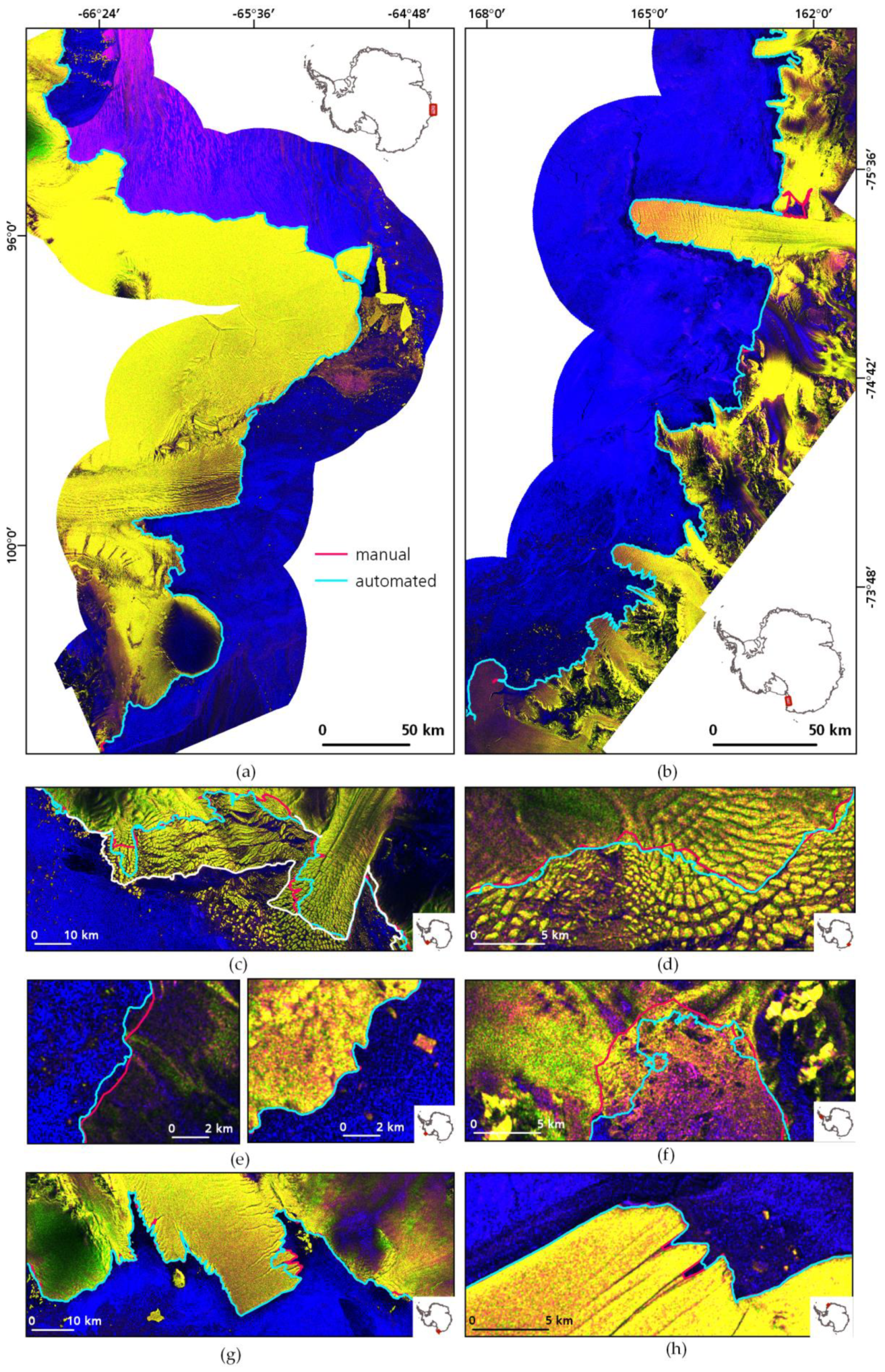
The error estimation results are presented in
Table 2 with the absolute mean, the median, and the A/F value. The difference between the automatically extracted coastline and the manual delineation is on average 151 m for areas included in training and 154 m for test areas. For stable coastline areas, the error is lower as for frontal areas. Taking the median instead of the mean of all transect measurements, the error reduces to -16 m for training and -2 m for test areas. Best results are performed for the Shackleton and Ekstromisen Ice Shelf. Larger errors occur in the area of the Sulzberger Ice Shelf and the disintegrated Wordie Ice Shelf. To compare the achieved differences to the error between two manually delineated coastlines, we chose the ADD coastline for Marie Byrd Land which was delineated manually on the same Sentinel-1 scenes. Unfortunately, the error is quite huge as the ADD coastline was not very accurately delineated, including many areas of fast ice and calved glacier ice (see
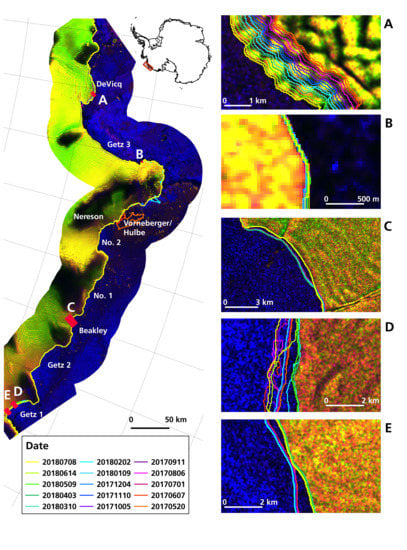
Figure 5 and
Figure S1). Hence, the error for frontal areas only and the entire coastline is overestimated. The error in stable areas could still be a good indicator of a manual delineation error as the subjectivity in glacier and ice shelf front definition is excluded. The average error between two manual delineations is 180 m and 186 m for the Sulzberger Ice Shelf and the remaining Marie Byrd Land, respectively.
In general, the average width of the enclosed area is lower than the error calculated with transect-measurements. For training areas, the error is less than 2 px (78 m) for training, and 2.69 px (108 m) for test areas.
5.3. Time Series Evaluation
To assess how good calving front change can be tracked with our approach, we compare the presented 15-month time series with five manual delineated coastlines (see
Table 3 for dates) covering different months. The error is presented in
Table 3 and
Table 4 as the absolute mean and the median of the differences between the five reference coastlines and the automatic extracted one. The median is a more robust measure as it compensates errors and extreme values. The comparison of absolute mean and median calculations in
Table 2 and
Table 3 demonstrate that the difference between the automated and manual coastlines is smaller when using the median. We also present the absolute mean error with standard deviation for each glacier/ice shelf. Overall, the distance error is 1-2 px with some exceptions for the Vorneberger/Hulbe Glacier and Getz 1 (see
Table 3 and
Table 4).
To assure the reliability of our generated time series, we added a quality threshold. In some months with difficult sea ice conditions, extreme over estimations of land ice can occur. To exclude those miss-classifications, we added an outlier detection that removes extreme front positions with a distance greater than the one and a half times of the upper interquartile range plus the 90%-quantile. Additionally, we calculate the R2 of the calculated regression through the time series for each glacier. In case the frontal change shows a clear signal in advance or retreat, the R2 value will be high. Low values can indicate that a front experienced a major calving event or periodic calving.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}