Accurate Building Extraction from Fused DSM and UAV Images Using a Chain Fully Convolutional Neural Network

 ,
,  and
and
Abstract
:
1. Introduction
2. Materials and Methods
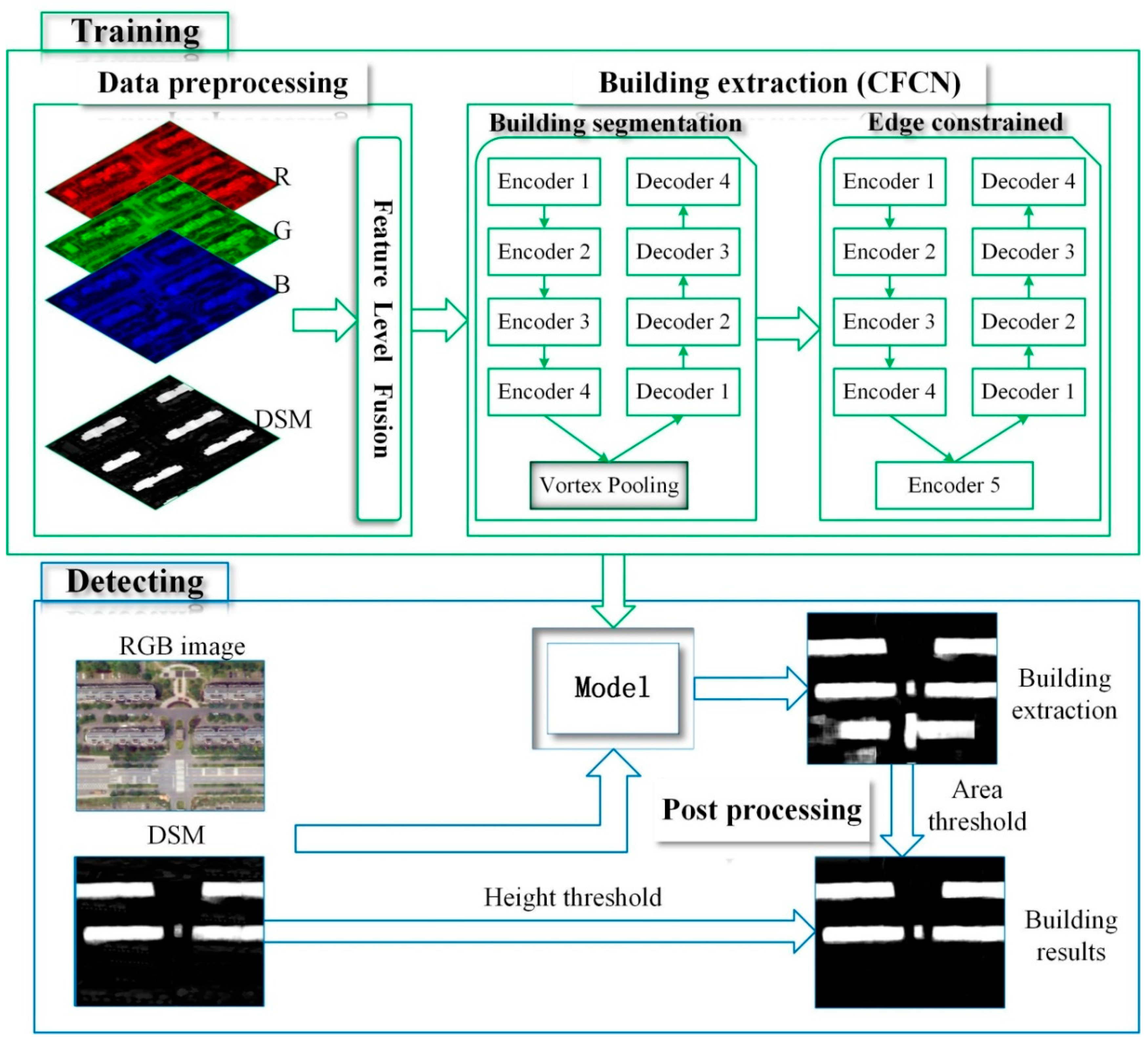
2.1. Overview of the Method
2.2. Data Preprocessing
2.3. Building Extraction
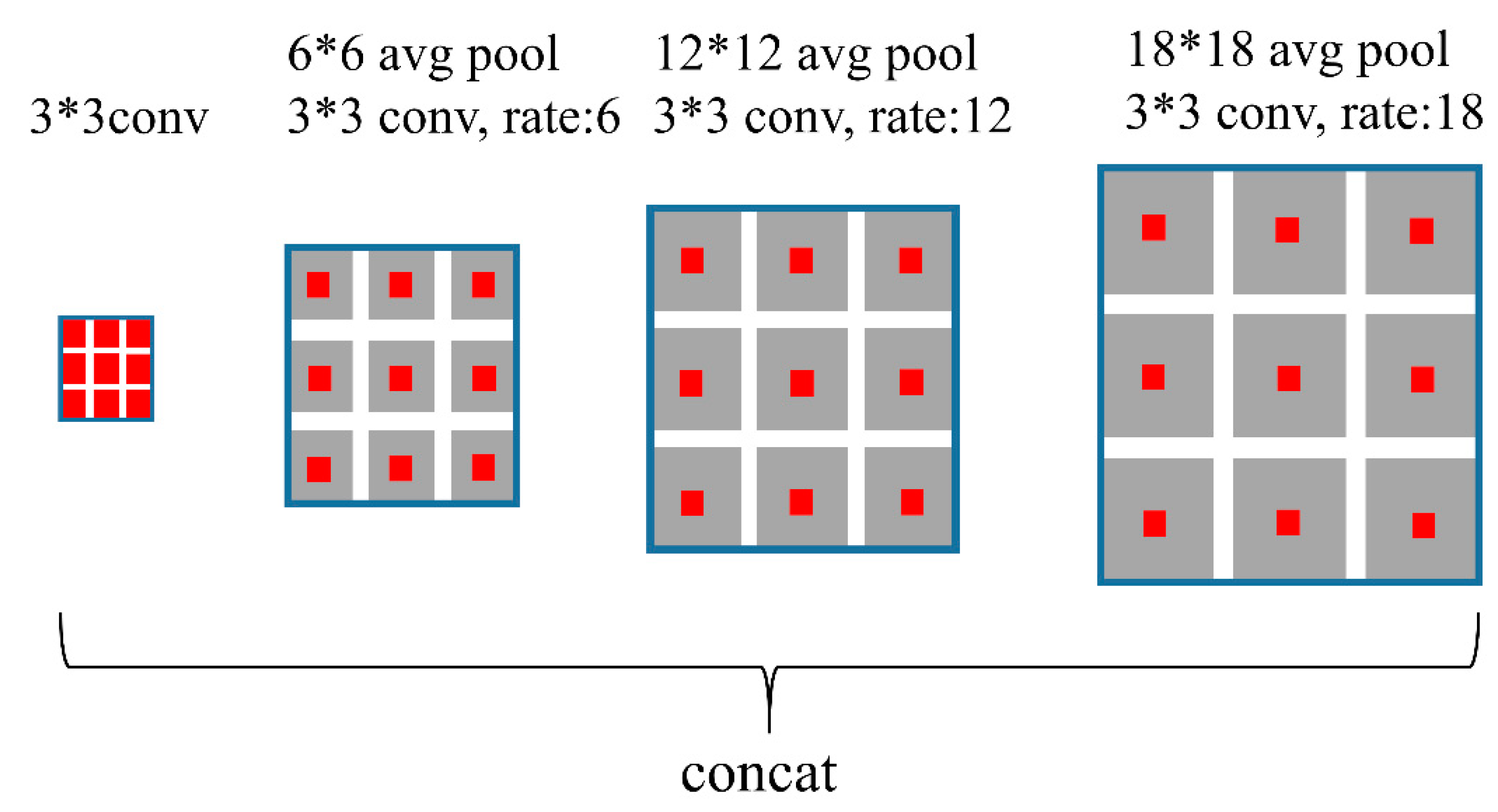
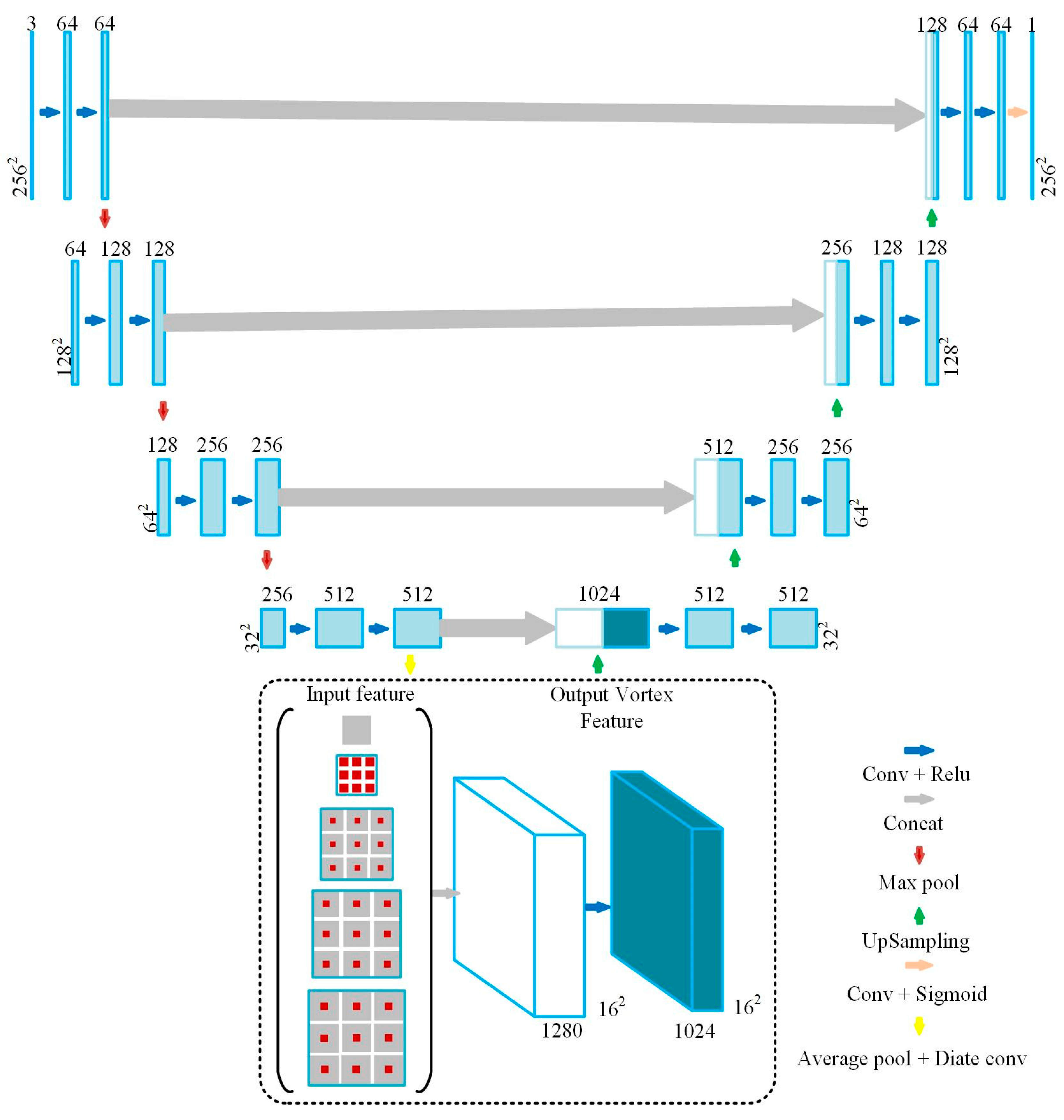
2.3.1. Building Segmentation
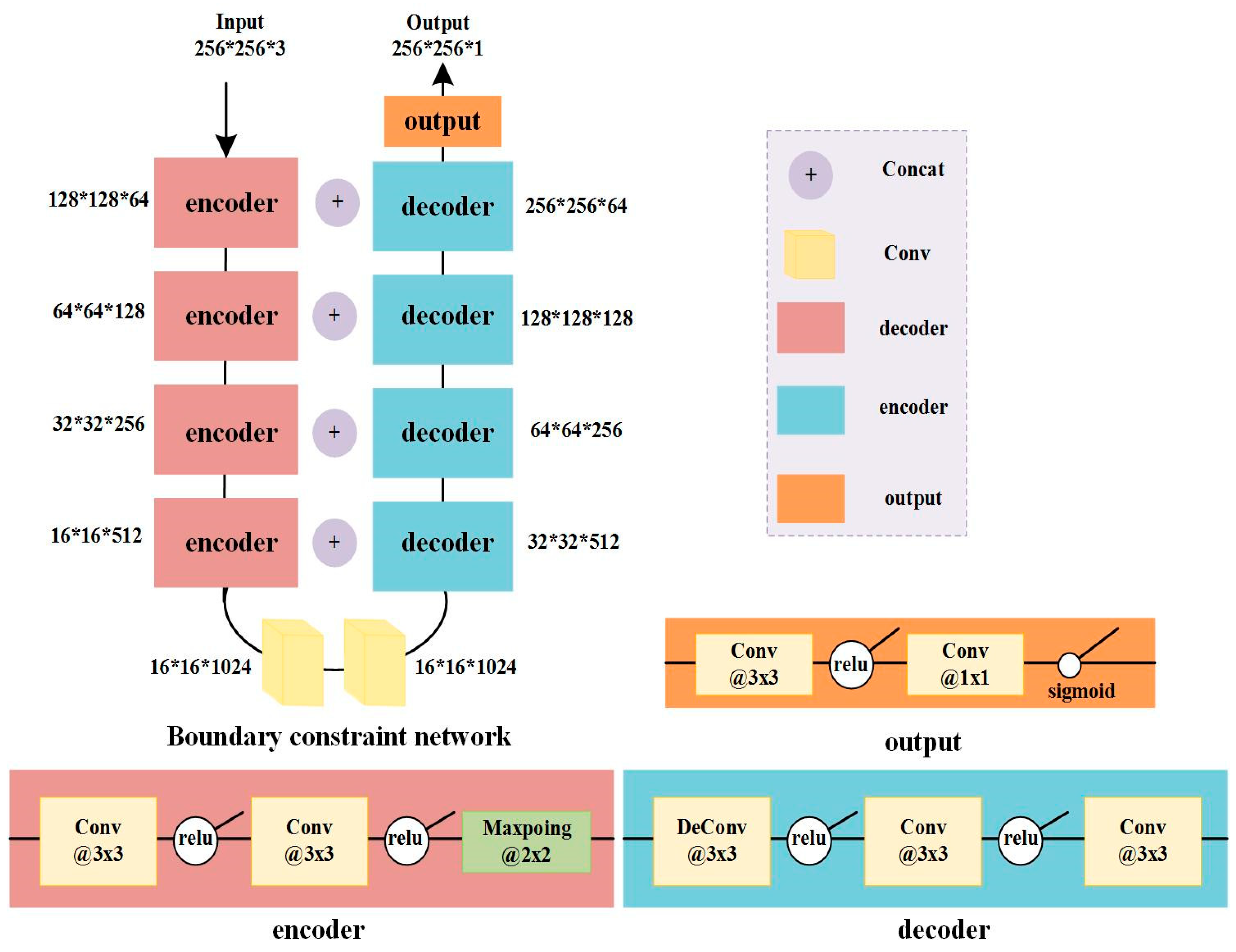
2.3.2. Boundary Constraint
2.4. Post Processing
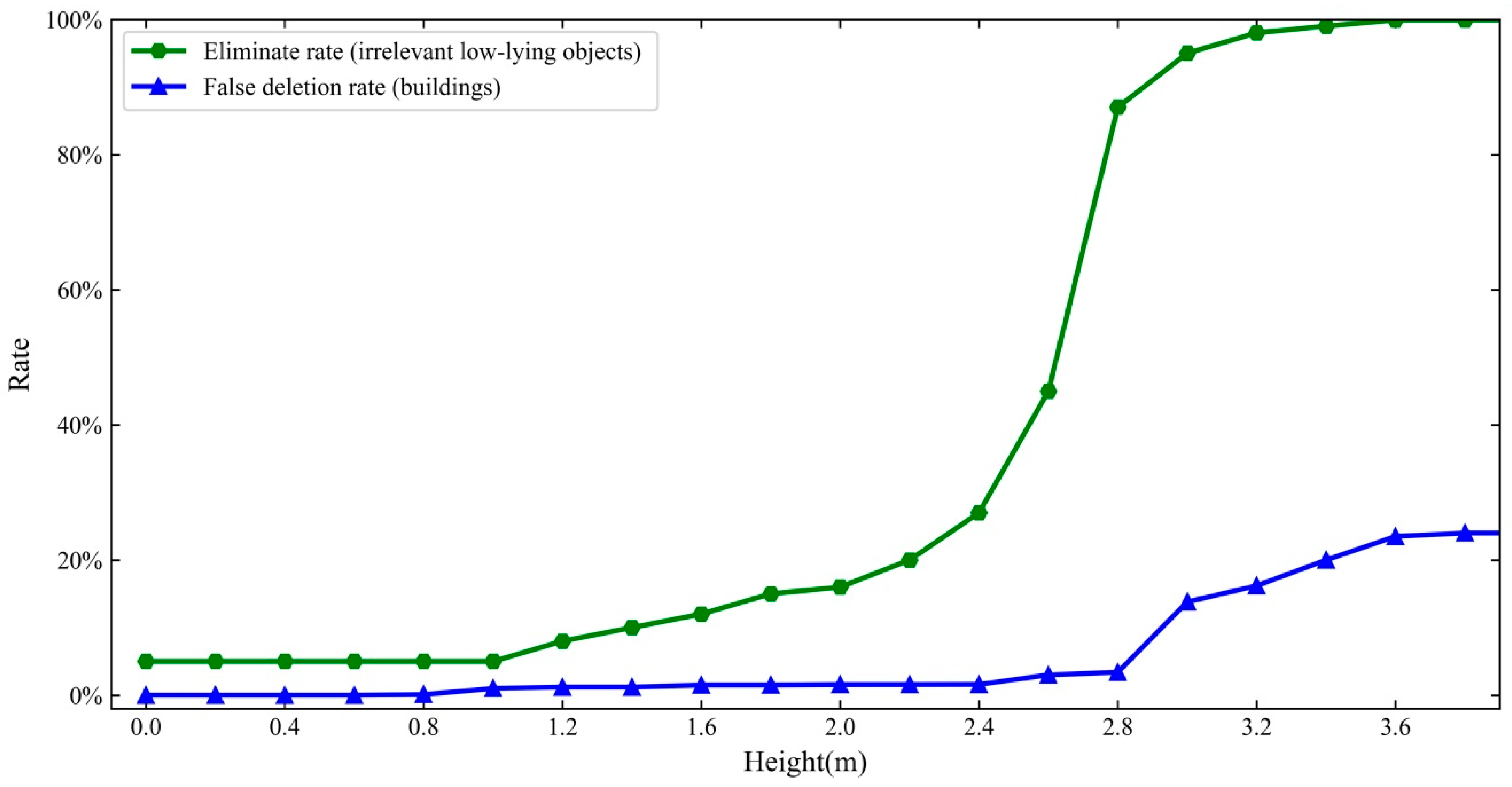
2.4.1. Height Filtration
2.4.2. Area Filtration
3. Experiments and Results
3.1. Experimental Design
3.1.1. Experimental Setting
3.1.2. Evaluation Metrics
3.2. Experimental Results
4. Discussion
4.1. Effects of Fusing DSM Data for Building Extraction
4.2. Effects of Adding a U-NET Chain for Building Extraction
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Karsli, F.; Dihkan, M.; Acar, H.; Ozturk, A. Automatic building extraction from very high-resolution image and LiDAR data with SVM algorithm. Arab. J. Geosci. 2016, 9, 635. [Google Scholar] [CrossRef]
- Du, S.; Zhang, Y.; Zou, Z.; Xu, S.; Chen, S. Automatic building extraction from LiDAR data fusion of point and grid-based features. ISPRS J. Photogramm. Remote. Sens. 2017, 130, 294–307. [Google Scholar] [CrossRef]
- Alshehhi, R.; Marpu, P.R.; Wei, L.W.; Mura, M.D. Simultaneous extraction of roads and buildings in remote sensing imagery with convolutional neural networks. ISPRS J. Photogramm. Remote. Sens. 2017, 130, 139–149. [Google Scholar] [CrossRef]
- Ghanea, M.; Moallem, P.; Momeni, M. Building extraction from high-resolution satellite images in urban areas: Recent methods and strategies against significant challenges. Int. J. Remote Sens. 2016, 37, 5234–5248. [Google Scholar] [CrossRef]
- Liu, Y.; Fan, B.; Wang, L.; Bai, J.; Xiang, S.; Pan, C. Semantic labeling in very high resolution images via a self-cascaded convolutional neural network. ISPRS J. Photogramm. Remote Sens. 2018, 145, 78–95, S0924271617303854. [Google Scholar] [CrossRef] [Green Version]
- Huang, J.; Zhang, X.; Xin, Q.; Sun, Y. Automatic building extraction from high-resolution aerial images and LiDAR data using gated residual refinement network. ISPRS J. Photogramm. Remote Sens. 2019, 151, 91–105. [Google Scholar] [CrossRef]
- Lin, X.; Zhang, J.X. Object-based morphological building index for building extraction from high resolution remote sensing imagery. Acta Geod. Cartogr. Sin 2017, 46, 724–733. [Google Scholar]
- Jin, X.; Davis, C.H. Automated building extraction from high-resolution satellite imagery in urban areas using structural, contextual, and spectral information. Eurasip J. Adv. Signal Process. 2005, 2005, 745309. [Google Scholar] [CrossRef] [Green Version]
- Kabolizade, M.; Ebadi, H.; Ahmadi, S. An improved snake model for automatic extraction of buildings from urban aerial images and LiDAR data. Comput. Environ. Urban Syst. 2010, 34, 435–441. [Google Scholar] [CrossRef]
- Tames-Noriega, A.; Rodriguez-Cuenca, B.; Alonso, M.C. Automatic extraction of buildings and trees using fuzzy K-means classification on high-resolution satellite imagery and LiDAR data. In Proceedings of the 2015 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Milan, Italy, 26–31 July 2015; pp. 593–596. [Google Scholar]
- Zhou, G.; Du, S. Mining parameter information for building extraction and change detection with very high-resolution imagery and GIS data. Mapp. Sci. Remote Sens. 2017, 54, 26. [Google Scholar]
- Mahdianpari, M.; Salehi, B.; Mohammadimanesh, F.; Homayouni, S.; Gill, E. The first wetland inventory map of newfoundland at a spatial resolution of 10 m using sentinel-1 and sentinel-2 data on the google earth engine cloud computing platform. Remote Sens. 2018, 11, 43. [Google Scholar] [CrossRef] [Green Version]
- Han, J.; Zhang, D.; Cheng, G.; Guo, L.; Ren, J. Object detection in optical remote sensing images based on weakly supervised learning and high-level feature learning. IEEE Trans. Geosci. Remote Sens. 2015, 53, 3325–3337. [Google Scholar] [CrossRef] [Green Version]
- Cohen, J.P.; Wei, D.; Kuhlman, C.; Chen, A.; Di, L. Rapid building detection using machine learning. Appl. Intell. 2016, 45, 443–457. [Google Scholar] [CrossRef] [Green Version]
- Volpi, M.; Tuia, D. Dense semantic labeling of subdecimeter resolution images with convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2016, 55, 881–893. [Google Scholar] [CrossRef] [Green Version]
- Liheng, Z.; Lina, H.; Hang, Z. Deep learning based multi-temporal crop classification. Remote Sens. Environ. 2019, 221, 430–443. [Google Scholar]
- Zhang, C.; Sargent, I.; Xin, P.; Li, H.; Atkinson, P.M. An object-based convolutional neural network (OCNN) for urban land use classification. Remote Sens. Environ. 2018, 216, 57–70. [Google Scholar] [CrossRef] [Green Version]
- Cheng, G.; Han, J. A Survey on Object Detection in Optical Remote Sensing Images. ISPRS J. Photogramm. Remote Sens. 2016, 117, 11–28. [Google Scholar] [CrossRef] [Green Version]
- Deng, Z.; Hao, S.; Zhou, S.; Zhao, J.; Lin, L.; Zou, H. Multi-scale object detection in remote sensing imagery with convolutional neural networks. ISPRS J. Photogramm. Remote Sens. 2018, 145, 3–22. [Google Scholar] [CrossRef]
- Liu, W.; Cheng, D.; Yin, P.; Yang, M.; Zhang, L. Small manhole cover detection in remote sensing imagery with deep convolutional neural networks. ISPRS Int. J. Geo Inf. 2019, 8, 49. [Google Scholar] [CrossRef] [Green Version]
- Mohammadimanesh, F.; Salehi, B.; Mahdianpari, M.; Gill, E.; Molinier, M. A new fully convolutional neural network for semantic segmentation of polarimetric SAR imagery in complex land cover ecosystem. ISPRS J. Photogramm. Remote Sens. 2019, 151, 223–236. [Google Scholar] [CrossRef]
- Kemker, R.; Salvaggio, C.; Kanan, C. Algorithms for semantic segmentation of multispectral remote sensing imagery using deep learning. ISPRS J. Photogramm. Remote Sens. 2018, 145, 60–77, S0924271618301229. [Google Scholar] [CrossRef] [Green Version]
- Zhao, W.; Du, S.; Qiao, W.; Emery, W.J. Contextually guided very-high-resolution imagery classification with semantic segments. ISPRS J. Photogramm. Remote Sens. 2017, 132, 48–60. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A deep convolutional encoder-decoder architecture for scene segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, PP, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Marmanis, D.; Schindler, K.; Wegner, J.D.; Galliani, S.; Datcu, M.; Stilla, U. Classification with an edge: Improving semantic image segmentation with boundary detection. ISPRS J. Photogramm. Remote Sens. 2016, 135, 158–172. [Google Scholar] [CrossRef] [Green Version]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Germany, 2015. [Google Scholar]
- Bai, Y.; Mas, E.; Koshimura, S. Towards operational satellite-based damage-mapping using u-net convolutional network: A case study of 2011 tohoku earthquake-tsunami. Remote Sens. 2018, 10, 1626. [Google Scholar] [CrossRef] [Green Version]
- Kaiser, P.; Wegner, J.D.; Lucchi, A.; Jaggi, M.; Hofmann, T.; Schindler, K. Learning aerial image segmentation from online maps. IEEE Trans. Geosci. Remote Sens. 2017, 55, 6054–6068. [Google Scholar] [CrossRef]
- Lv, N.; Chen, C.; Qiu, T.; Sangaiah, A.K. Deep learning and superpixel feature extraction based on sparse autoencoder for change detection in sar images. IEEE Trans. Ind. Inform. 2018, 14, 5530–5538. [Google Scholar] [CrossRef]
- Raveerat, J.; Masashi, M.; Naruo, K.; Shigeki, K.; Riho, I.; Ryosuke, N. Newly built construction detection in sar images using deep learning. Remote Sens. 2019, 11, 1444. [Google Scholar]
- Mnih, V.; Hinton, G.E. Learning to detect roads in high-resolution aerial images. In Proceedings of the 11th European Conference on Computer Vision (ECCV), Crete, Greece, 11 September 2010; pp. 210–223. [Google Scholar]
- Zhen, X.; Wang, R.; Zhang, H.; Ning, L.; Lei, Z. Building extraction from high-resolution SAR imagery based on deep neural networks. Remote Sens. Lett. 2017, 8, 888–896. [Google Scholar]
- Wu, G.; Zhiling, G.; Xiaodan, S.; Qi, C.; Yongwei, X.; Ryosuke, S.; Xiaowei, S. A Boundary regulated network for accurate roof segmentation and outline extraction. Remote Sens. 2018, 10, 1195. [Google Scholar] [CrossRef] [Green Version]
- Bischke, B.; Helber, P.; Folz, J.; Borth, D.; Dengel, A. Multi-task learning for segmentation of building footprints with deep neural networks. arXiv 2017, arXiv:1709.05932. [Google Scholar]
- Lin, G.; Milan, A.; Shen, C.; Reid, I. RefineNet: Multi-path refinement networks with identity mappings for high-resolution semantic segmentation. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition (Cvpr 2017), Honolulu, HI, USA, 21–26 July 2016; pp. 5168–5177. [Google Scholar]
- Xie, C.W.; Zhou, H.Y.; Wu, J. Vortex pooling: Improving context representation in semantic segmentation. arXiv 2018, arXiv:1804.06242. [Google Scholar]
- Yaning, Y.; Zhang, Z.; Zhang, W.; Zhang, C.; Li, W.; Zhao, T. Semantic Segmentation of urban buildings from vhr remote sensing imagery using a deep convolutional neural network. Remote Sens. 2019, 11, 1774. [Google Scholar]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Garcia-Rodriguez, J. A review on deep learning techniques applied to semantic segmentation. arXiv 2017, arXiv:1704.06857. [Google Scholar]
- Xu, Y.; Wu, L.; Xie, Z.; Chen, Z. Building Extraction in very high resolution remote sensing imagery using deep learning and guided filters. Remote Sens. 2018, 10, 144. [Google Scholar] [CrossRef] [Green Version]
- Galvanin, E.A.D.S.; Poz, A.P.D. Extraction of building roof contours from Lidar data using a markov-random-field-based approach. IEEE Trans. Geosci. Remote Sens. 2012, 50, 981–987. [Google Scholar] [CrossRef]
- Guo, Z.; Luo, L.; Wang, W.; Du, S. Data fusion of high-resolution satellite imagery and GIS data for automatic building extraction. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2013, XL-7/W1, 23–28. [Google Scholar] [CrossRef] [Green Version]
- Li, Y. Automatic edge extraction by lidar-optical data fusion adaptive for complex building shapes. Proc.SPIE Int. Soc. Opt. Eng. 2011, 8286, 393–403. [Google Scholar]
- Sohn, G.; Dowman, I. Data fusion of high-resolution satellite imagery and Lidar data for automatic building extraction. ISPRS J. Photogramm. Remote Sens. 2007, 62, 43–63. [Google Scholar] [CrossRef]
- Wen, M.A.; Yue, J.P.; Cao, S. Building edge extraction from Lidar data based on images segmentation. Geogr. Geo Inf. Sci. 2010, 8286, 828613–828616. [Google Scholar]
- Shi, W.; Mao, Z. Building extraction from panchromatic high-resolution remotely sensed imagery based on potential histogram and neighborhood total variation. Earth Sci. Inform. 2016, 9, 1–13. [Google Scholar] [CrossRef]
- Xin, H.; Zhang, L. An SVM ensemble approach combining spectral, structural, and semantic features for the classification of high-resolution remotely sensed imagery. IEEE Trans. Geosci. Remote Sens. 2013, 51, 257–272. [Google Scholar]
- Rongshuang, F.; Yang, C.; Qiheng, X.U.; Jingxue, W.; Geomatics, S.O.; University, L.T. A high-resolution remote sensing image building extraction method based on deep learning. Acta Geod. Cartogr. Sin. 2019, 48, 34–41. [Google Scholar]
- Vakalopoulou, M.; Karantzalos, K.; Komodakis, N.; Paragios, N. Building detection in very high resolution multispectral data with deep learning features. In Proceedings of the 2015 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Milan, Italy, 26–31 July 2015; pp. 1873–1876. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Precision | Recall | F1 | IoU |
|---|---|---|---|---|
| U-net | 92.14 | 93.24 | 92.69 | 89.62 |
| U-net-V | 93.82 | 95.43 | 94.62 | 90.53 |
| U-net-VDSM | 95.14 | 98.86 | 96.96 | 92.61 |
| CFCN | 97.25 | 98.67 | 97.95 | 96.23 |
| Model | Precision | Recall | F1 | IoU |
|---|---|---|---|---|
| U-net | 96.47 | 98.15 | 97.30 | 91.12 |
| U-net-V | 96.82 | 98.74 | 97.78 | 92.84 |
| U-net-VDSM | 96.94 | 99.57 | 98.24 | 92.23 |
| CFCN | 97.22 | 99.52 | 98.36 | 96.43 |
| Model | Precision | Recall | F1 | IoU |
|---|---|---|---|---|
| U-net | 92.67 | 93.41 | 93.04 | 89.31 |
| U-net-V | 92.74 | 94.62 | 93.67 | 90.74 |
| U-net-VDSM | 94.62 | 98.75 | 96.64 | 92.32 |
| CFCN | 95.35 | 98.62 | 96.96 | 95.76 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, W.; Yang, M.; Xie, M.; Guo, Z.; Li, E.; Zhang, L.; Pei, T.; Wang, D. Accurate Building Extraction from Fused DSM and UAV Images Using a Chain Fully Convolutional Neural Network. Remote Sens. 2019, 11, 2912. https://0-doi-org.brum.beds.ac.uk/10.3390/rs11242912
Liu W, Yang M, Xie M, Guo Z, Li E, Zhang L, Pei T, Wang D. Accurate Building Extraction from Fused DSM and UAV Images Using a Chain Fully Convolutional Neural Network. Remote Sensing. 2019; 11(24):2912. https://0-doi-org.brum.beds.ac.uk/10.3390/rs11242912
Chicago/Turabian StyleLiu, Wei, MengYuan Yang, Meng Xie, Zihui Guo, ErZhu Li, Lianpeng Zhang, Tao Pei, and Dong Wang. 2019. "Accurate Building Extraction from Fused DSM and UAV Images Using a Chain Fully Convolutional Neural Network" Remote Sensing 11, no. 24: 2912. https://0-doi-org.brum.beds.ac.uk/10.3390/rs11242912