Extensive experiments were conducted on public hyperspectral data to evaluate the classification performance of our proposed transfer learning method.
3.1. Datasets
Six widely known hyperspectral datasets were used in this experiment. These hyperspectral scenes included Indian Pines, Botswana, Salinas, DC Mall, Pavia University (i.e., PaviaU), and Houston from the 2013 IEEE Data Fusion Contest (referred as Houston 2013 hereafter). The Indian Pines and Salinas were collected by the 224-band Airborne Visible/Infrared Imaging Spectrometer (AVIRIS). Botswana was acquired by the Hyperion sensor onboard the EO-1 satellite, with the data acquisition ability of 242 bands covering the 0.4–2.5 μm. DC Mall was gathered by the Hyperspectral digital imagery collection experiment (HYDICE). PaviaU and Houston 2013 were acquired by the ROSIS and CASI sensor, respectively. Detailed information about these data are listed in
Table 1: uncalibrated or noisy bands covering the region of water absorption have been removed from these datasets.
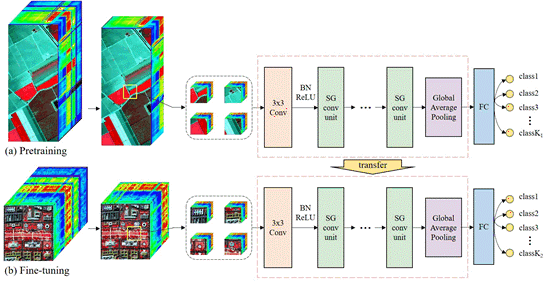
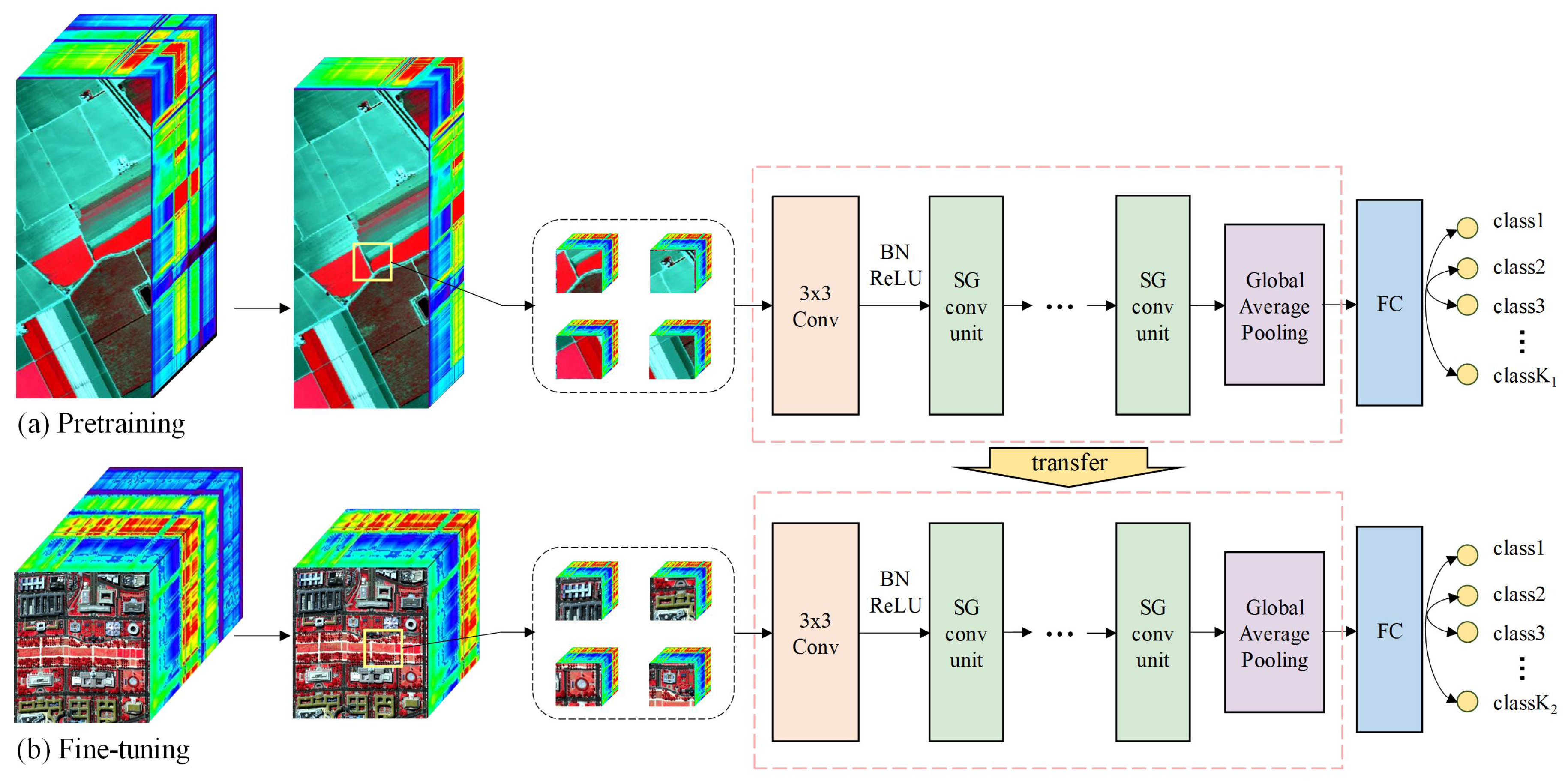
Three pairs of transfer learning experiments were designed using these six datasets: (1) pretrain on the Indian Pines, and fine-tune on the Botswana scene; (2) pretrain on the PaviaU scene, and fine-tune on the Houston 2013 scene; (3) pretrain on the Salinas scene, and fine-tune on the DC Mall scene. The experiments were designed as above for two reasons: (1) the source data and target data were collected by different sensors, but they were similar in terms of spatial resolution and the spectral range; (2) the source data have more labeled samples in each class than those of the target data. Despite that slight differences of band wavelengths may exist between the source and target data, SG-CNNs will automatically adapt its parameters to extract spectral features for the target data in the fine-tuning process.
3.2. Experimental Setup
To evaluate the performance of the proposed classification framework, classification results of three target datasets were compared with those predicted from two baseline models, i.e., ShuffleNet V2 (abbreviated as ShuffleNet2) [
40] and ResNeXt [
45]. ShuffleNet2 is well-known for its speed and accuracy tradeoff. ResNeXt consists of building blocks with group convolution and shortcut connections, which are also used in the SG-CNN. It is worth noting that we used ShuffleNet2 and ResNeXt with fewer building blocks rather than their original models, considering the limited samples of HSIs. Specifically, convolution layers in Stages 3 and 4 of ShuffleNet2 were removed, and output channels was set to 48 for Stage 2 layers; for the ResNeXt model, only one building block was retained. For further details on ShuffleNet2 and ResNeXt architectures, the reader is referred to [
40,
45]. In addition, simplified ShuffleNet2 and ResNeXt were both trained on the original target HSI data as well as fine-tuned on the 64-band target data using a corresponding pretrained network from the 64-band source data. Classification results obtained from the transfer learning of baseline models were referred to ShuffleNet2_T and ResNeXt_T, respectively. In addition, we performed transfer learning with SG-CNNs throughout the experiment.
Three SG-CNNs with three levels of complexity were tested for evaluation (see
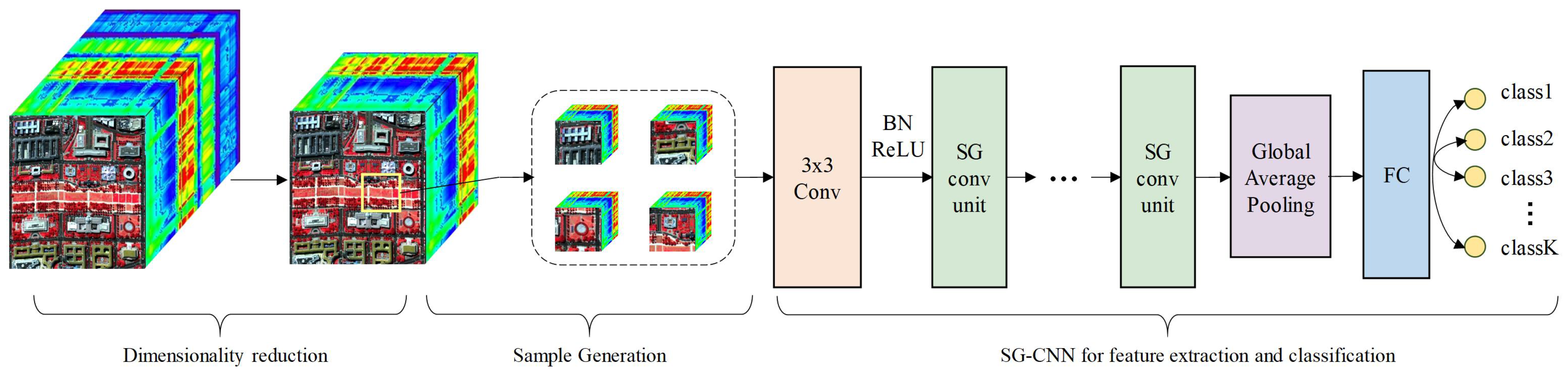
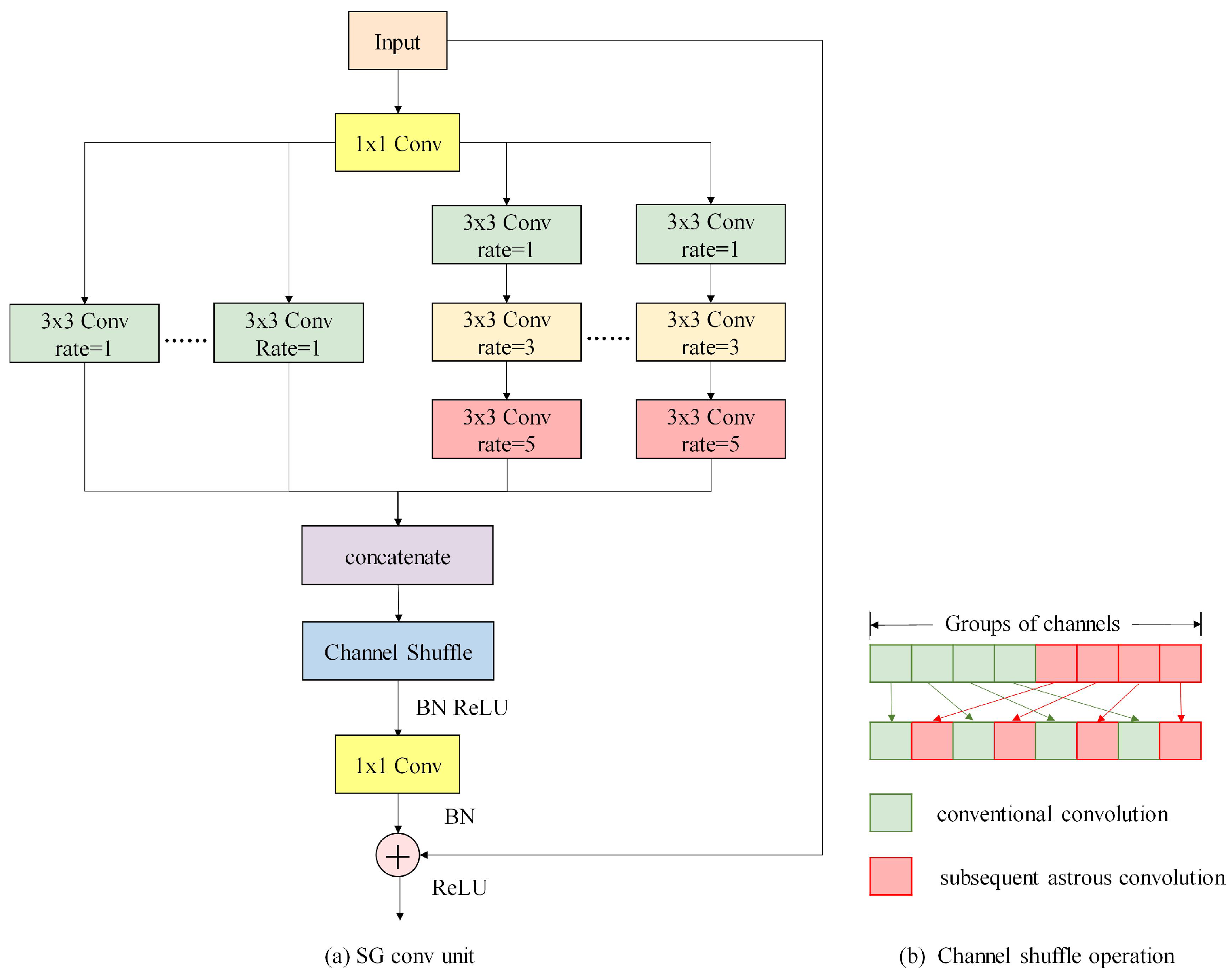
Table 2). SG-CNN-X represents the SG-CNN with X layers of convolution. It is worth noting that ResNeXt and SG-CNN-8 have the same number of layers, and the only difference between their structure is the introduction of atrous convolution for half the groups and shuffle operation in the SG-CNN-8 model. The number of groups was fixed to eight for both the SG-CNNs and ResNeXt, and the sample size was set to 19 × 19. In the SG conv unit, the dilation rates of three atrous convolutions were set to 1, 3, and 5 to get a receptive field of 19 (i.e., the full size of a sample).
Before network training, original data were normalized to guarantee input values within 0 to 1. Data augmentation techniques (including horizontal and vertical flip) were used to increase the training samples. All classification methods were implemented using python code with high-level APIs Tensorflow [
48] and Keras. To further alleviate possible overfitting, the sum of multi-class cross entropy and L2 regularization term was taken as the loss function, and we set the weight decay to 5 × 10
−4 in the L2 regularizer. The Adam optimizer [
49] was adopted with an initial learning rate of 0.001, and the learning rate would be reduced to one-fifth of its value if the validation loss function did not decrease for 10 epochs. We used the Adam optimizer with a mini-batch size of 32 on a NVIDIA GEFORCE RTX 2080Ti GPU. The number of epochs was set to 150–250 for different datasets, and it is determined based on the number of training samples.
3.3. Experiments on Indian Pines and Botswana Scenes
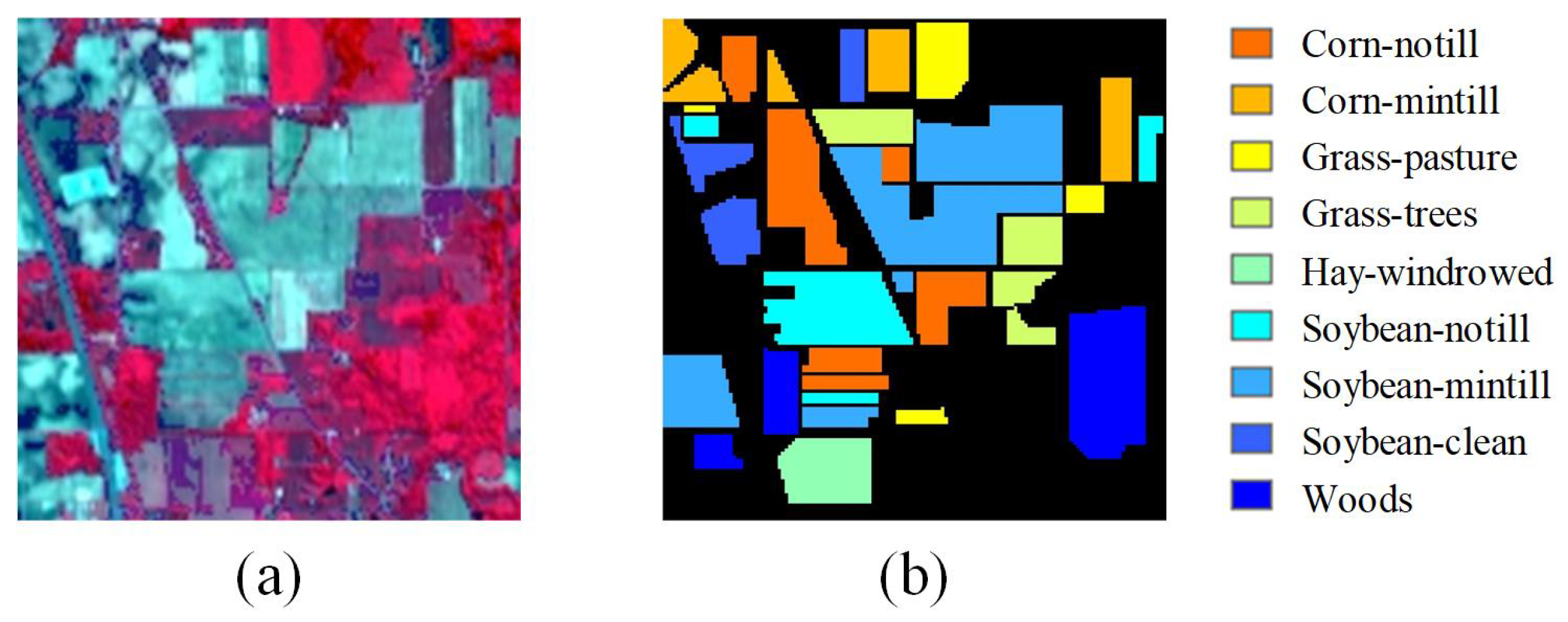
The false-color composites of the Indian Pines and Botswana scenes are displayed in
Figure 4 and
Figure 5, with their corresponding ground truth. In the pre-training and fine-tuning stage,
Table 3 gives the number of labeled pixels that were randomly selected for training, and the remaining labeled samples were used for the test.
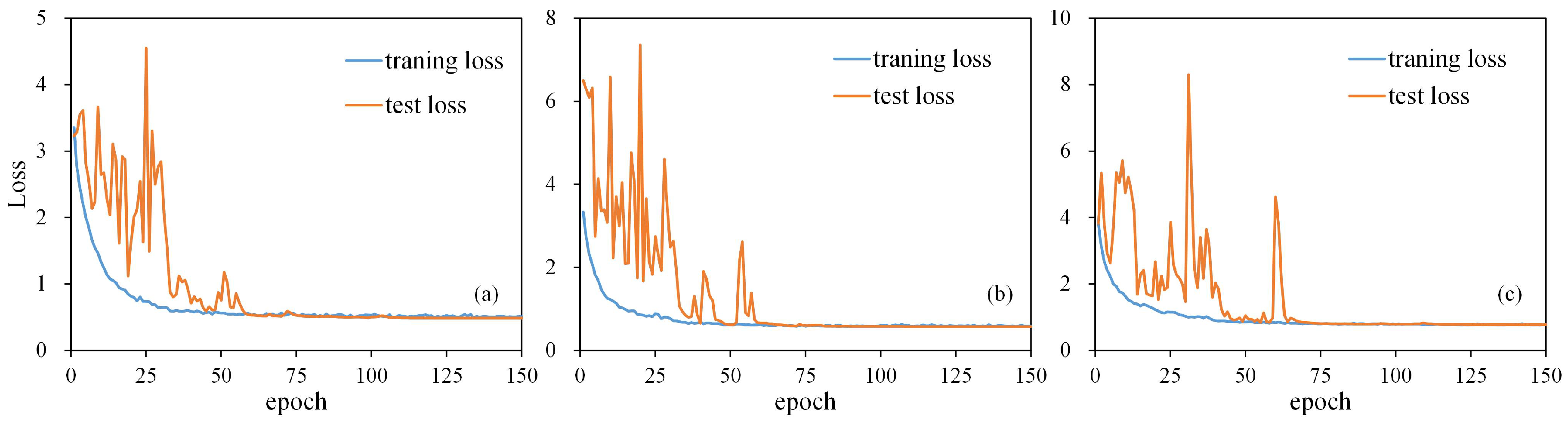
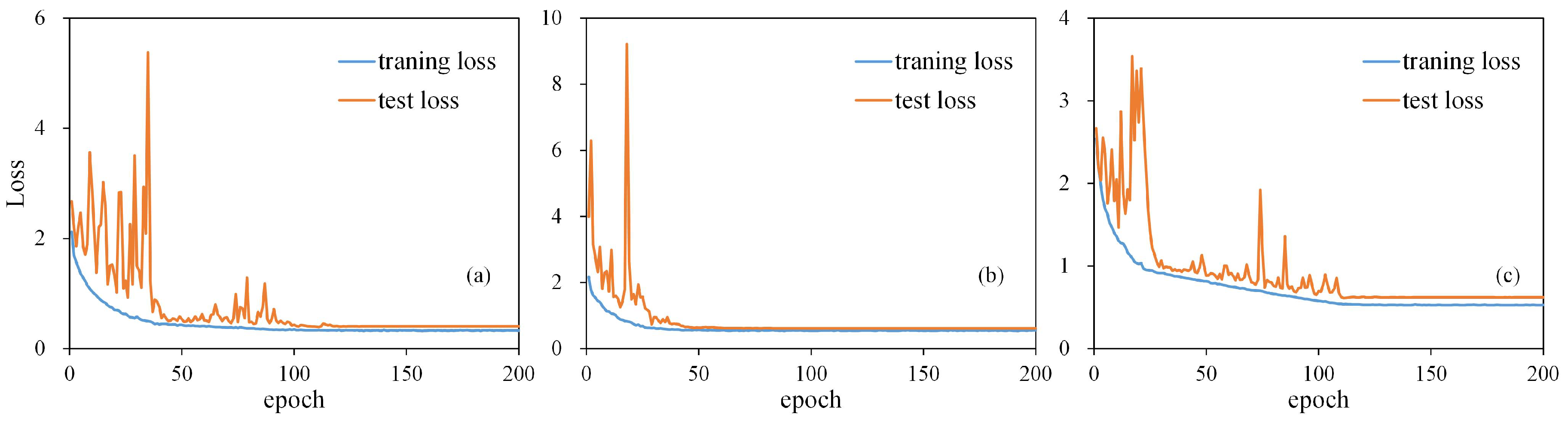
The loss function of SG-CNNs converged in the 150 epochs of training, indicating no overfitting during the fine-tuning process (see
Figure 6). Classification results obtained by SG-CNNs were then compared with other methods in
Table 4 for the Botswana scene. A range of criteria, including overall accuracy (OA), average accuracy (AA), and Kappa coefficient (K), were all reported as well as the classification accuracy of each class and training time. OA and AA are defined as below:
where
is the number of correctly predicted samples out of
samples in class
i, and
n is the number of classes.
Based on the results in
Table 4, several preliminary conclusions can be drawn as follows.
(1) Compared with baseline models, SG-CNNs typically achieve better classification performance, providing higher accuracy and spending relatively less training time. Specifically, the overall accuracy of SG-CNNs was 98.97–99.65%, which was approximately ∼1% and ∼3.5% higher, on average, than ResNeXt and ShuffleNet2 models, respectively. In addition, SG-CNN-7 and SG-CNN-8 were shown to be quite efficient, as the execution time of their fine-tuning process was comparable to that of ShuffleNet2_T and ResNeXt_T. As an effect of its complicated structure with more trainable parameters, SG-CNN-12 required a longer period of time to fine-tune.
(2) As mentioned in
Section 3.2, SG-CNN-8 can be seen as the baseline ResNeXt model that introduces atrous convolution and channel shuffle into its group convolution. Comparing the classification results of these two models, we can appreciate that the inclusion of atrous convolution and channel shuffle improved the classification.
(3) For the baseline models, both ShuffleNet2_T and ResNeXt_T, which were fine-tuned on the 64-band target data, obtained similar accuracy with much lower execution time, compared with their counterparts that were directly trained from original HSIs. This indicates that the simple band selection strategy applied in transfer learning can generally help to enhance the training efficiency.
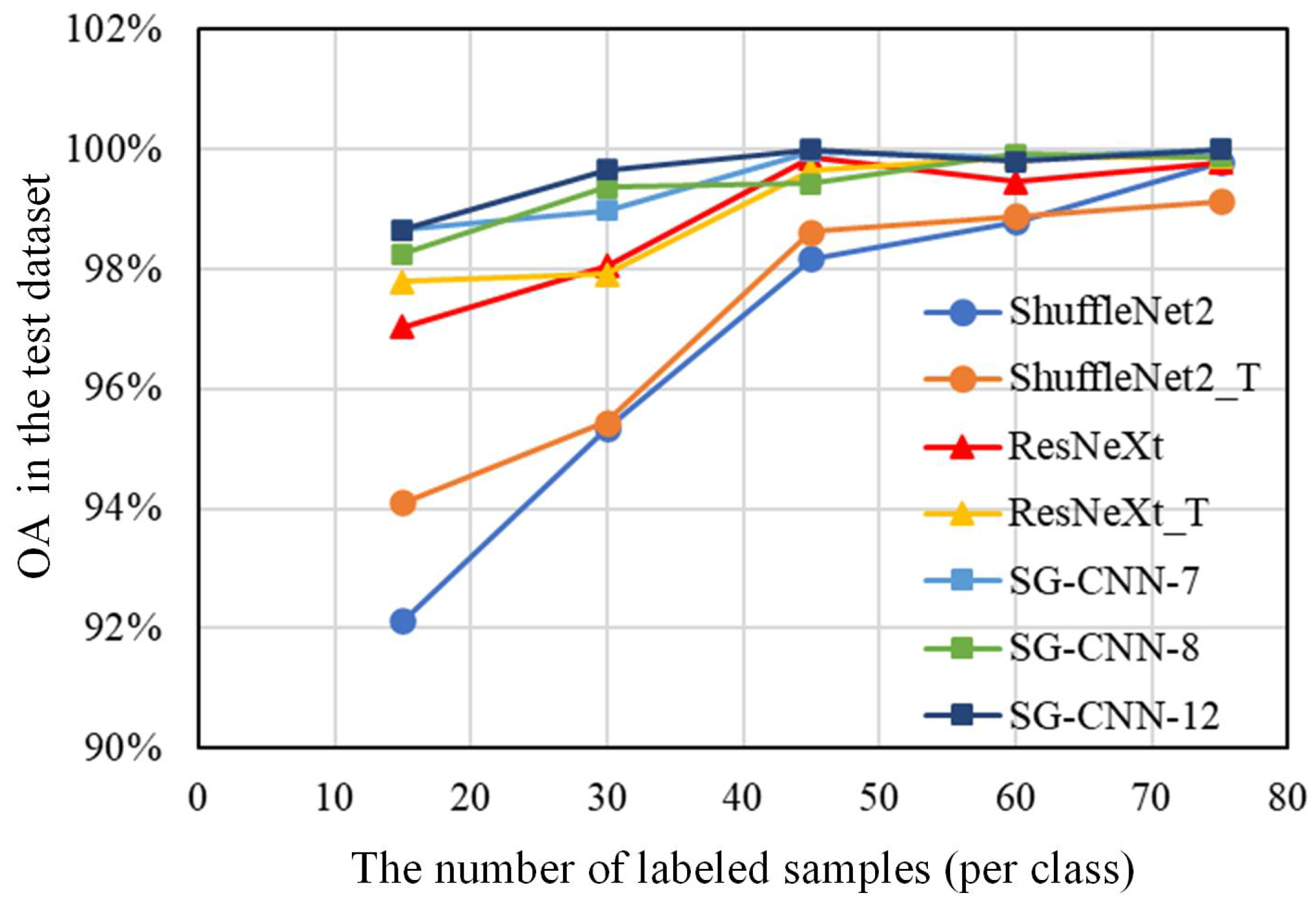
Our second test with the Botswana scene evaluated the classification performance of transfer learning with SG-CNNs using varying sizes of samples. Specifically, 15, 30, 45, 60, and 75 samples per class from the Botswana scene were used, respectively, to fine-tune the pretrained SG-CNNs, and their classification performances were evaluated from OAs of the corresponding remaining samples (i.e., the test samples). Meanwhile, the same samples used for fine-tuning SG-CNNs were utilized to train ShuffleNet2 and ResNext and fine-tune ShuffleNet2_T and ResNext_T. These models were also assessed with OA of test samples.
Figure 7 displays OAs in the test dataset from different classification methods with different numbers of training samples. Several conclusions can be drawn:
(1) Compared with ShuffleNet2, ShuffleNet2_T, and ResNeXt, SG-CNNs showed a remarkable improvement for classification by providing a higher classification accuracy, especially when labeled samples were relatively small (i.e., 15–60 samples per class).
(2) Compared with ResNeXt_T, SG-CNNs generally yielded better classification results when the training samples were limited (i.e., 15–45 per class). As the number of samples increased to 60–75 for each class, ResNeXt_T provided comparable accuracy.
(3) Although SG-CNN-12 generally achieved the best performance, its classification accuracy was merely 0.1–0.7% higher than that of SG-CNN-7 and SG-CNN-8. However, the latter two showed smaller values of execution time for the fine-tuning than the former. In other words, SG-CNN-7 and SG-CNN-8 had better tradeoffs between classification accuracy and efficiency.
3.4. Experiments on PaviaU and Houston 2013 Scenes
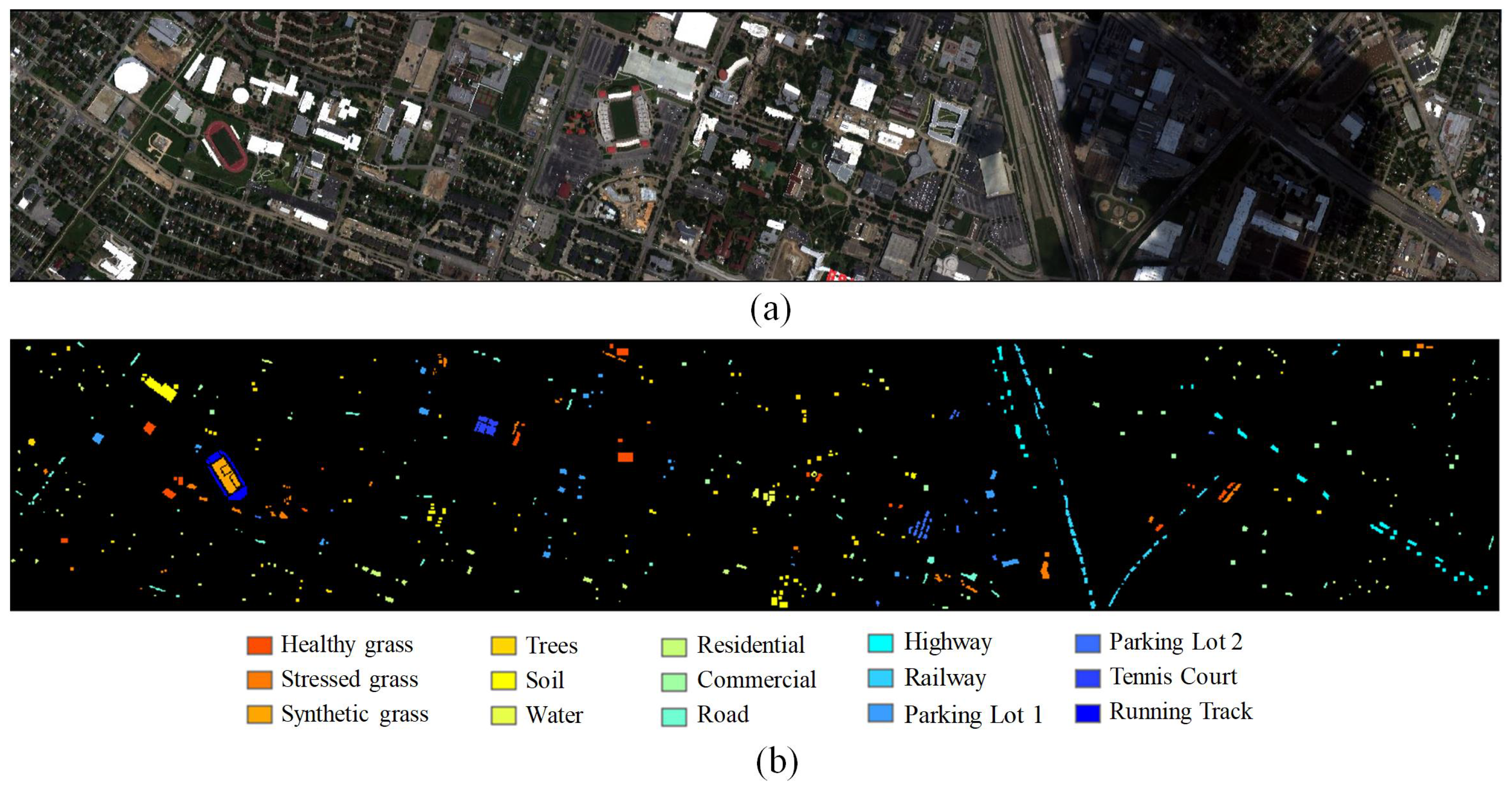
PaviaU and Houston 2013 datasets are displayed with their labeled sample distributions in
Figure 8 and
Figure 9.
Figure 8 shows that the PaviaU scene contained five manmade types, two types of vegetation, and one type for soil and shadow. As shown in
Figure 9, the Houston 2013 scene had nine manmade types, four types of vegetation, and one type for soil and water. Surface types distributions were similar in these two scenes. ShuffleNet2, ResNeXt, and SG-CNNs were fine-tuned on the Houston 2013 scene, with pretrained models acquired from training with the PaviaU dataset.
Table 5 displays the number of samples used in the experiment, respectively. Six hundred labeled samples per class in the PaviaU scene were utilized to pretrain the models, whereas 100 randomly selected samples per class in the Houston scene were used for fine-tuning.
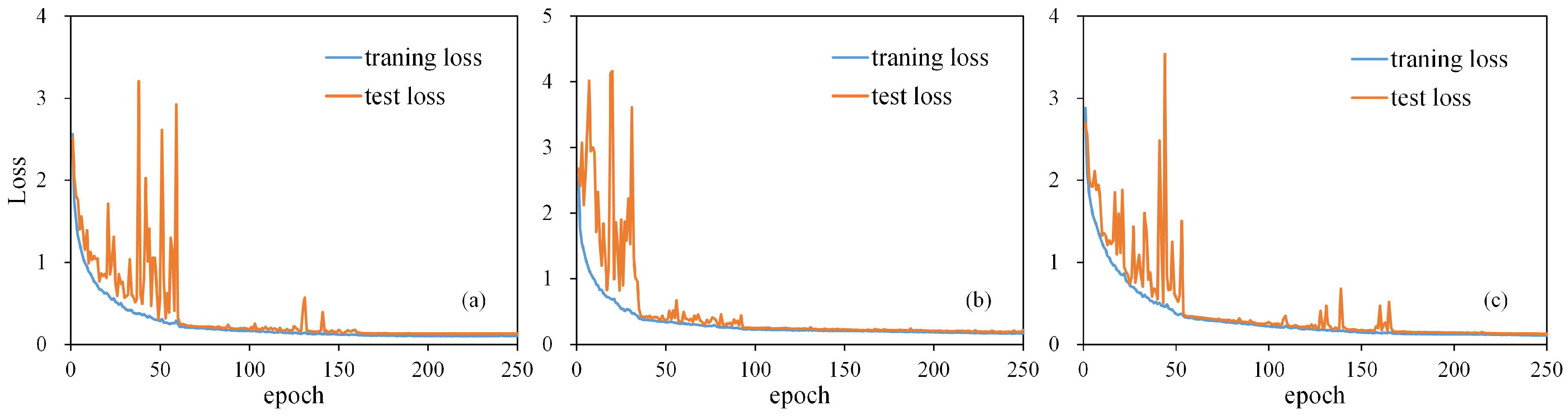
Convergence curves of the loss function are shown in
Figure 10 for the fine-tuning of SG-CNNs applied to the Houston 2013 scene. Classification results acquired from SG-CNNs and baseline models are detailed in
Table 6. As shown in
Table 6, SG-CNNs with different levels of complexity achieved higher classification accuracies than those of ShuffleNet2, ShuffleNet2_T, ResNeXt, and ResNeXt_T. Specifically, SG-CNN-12 provided the best classification results with the highest OA (99.45%), AA (99.40%), and Kappa coefficient (99.35%), and it also achieved the highest classification accuracy for eight classes in the test samples. Comparing the results from SG-CNN-8 and ResNeXt_T, the former obtained a slightly higher OA than the latter but spent less than half the training time, indicating the SG conv unit’s effectiveness for classification improvement. In addition, fine-tuned ResNeXt_T and ShuffleNet2_T yielded better results than the original ResNeXt and ShuffleNet2. Hence, this confirms the previous conclusion that our band selection strategy applied in transfer learning boosts the classification performance.
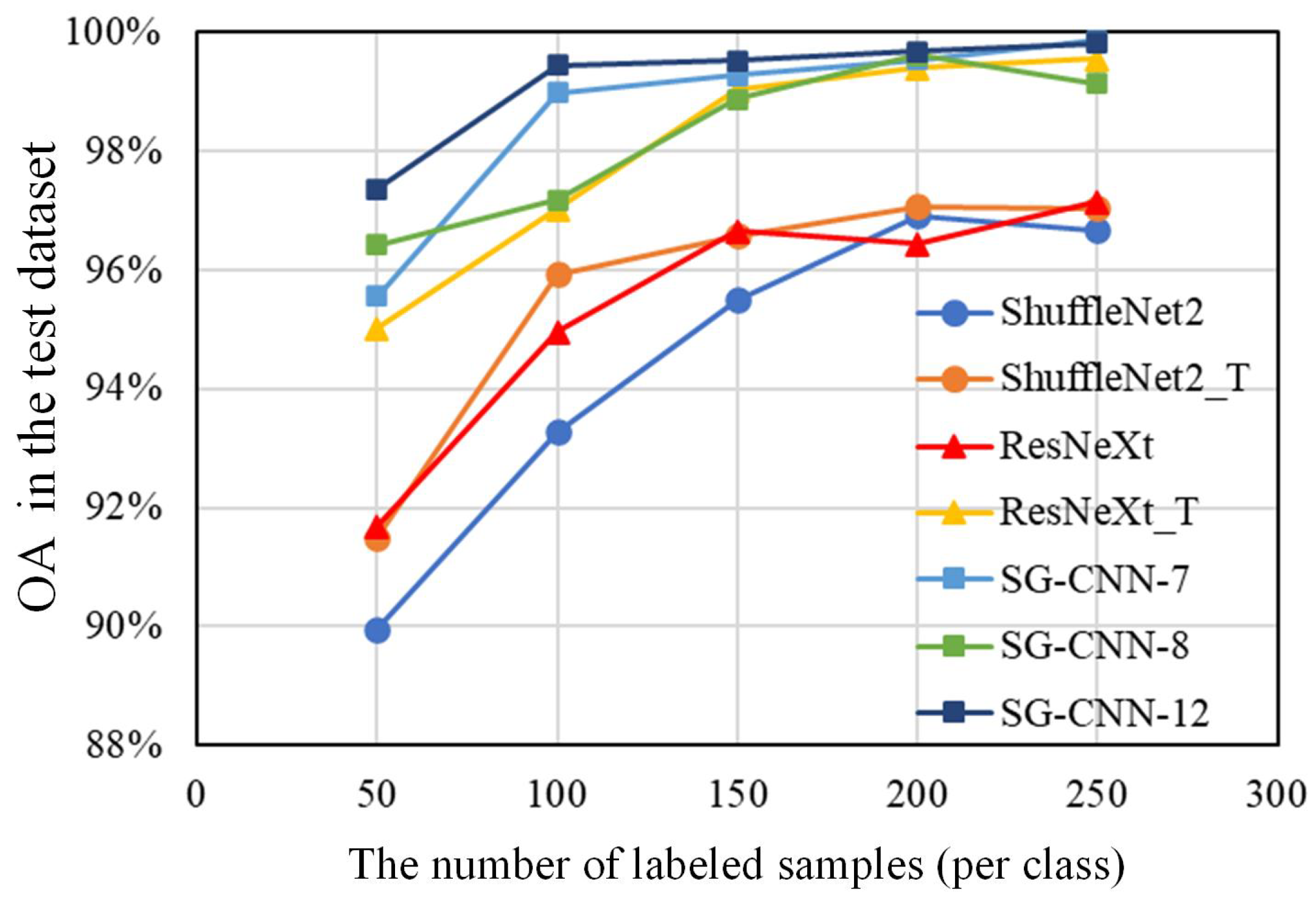
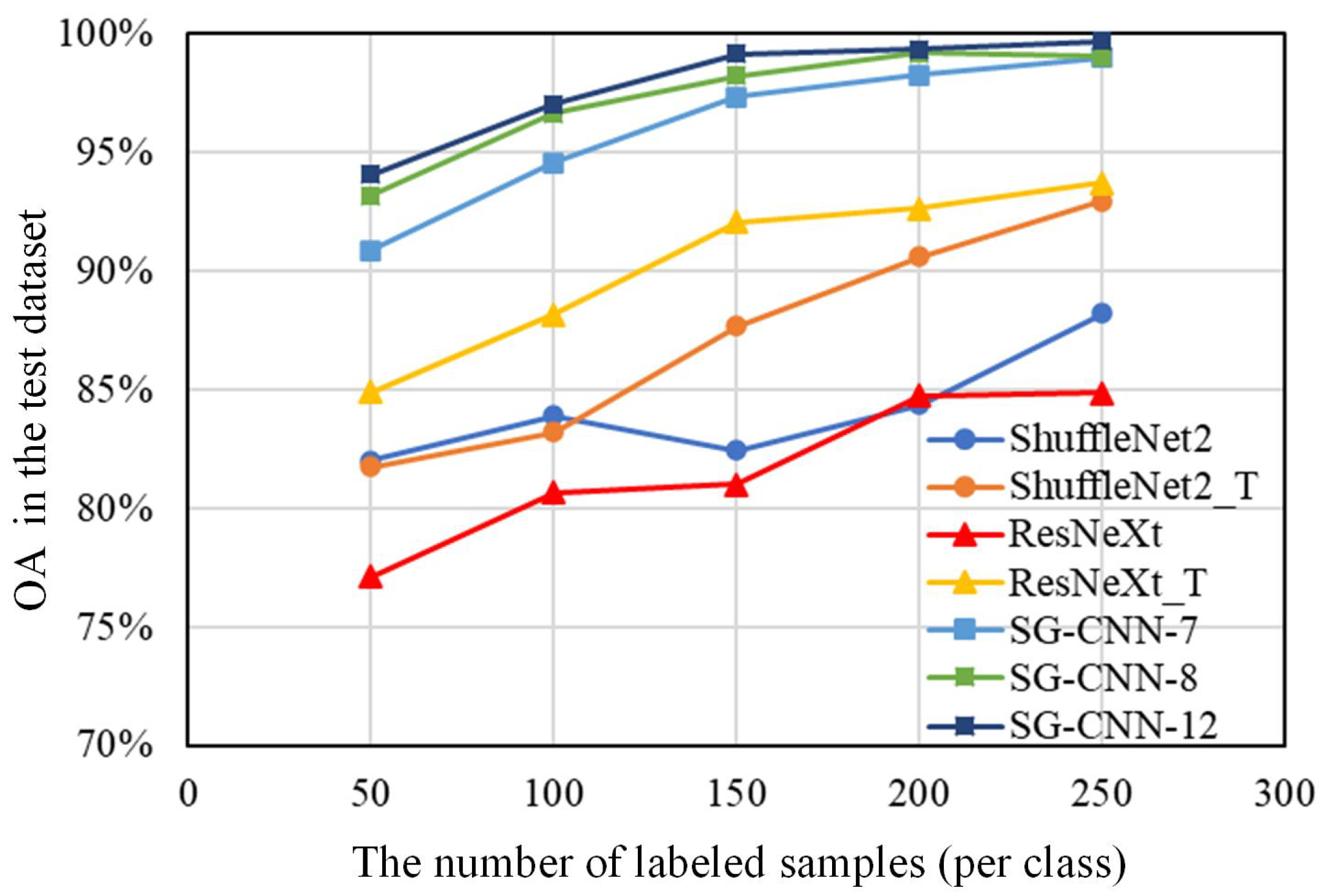
Classification experiments with varying numbers of training samples were also conducted. Specifically, 50–250 samples per class in the Houston scene were used for fine-tuning the SG-CNNs, as well as for training or fine-tuning the baseline networks. OAs of the remaining test samples are shown in
Figure 11 for all the methods. Some conclusions can be reached from making comparisons between these results:
(1) As training samples varied from 50 to 250 per class, SG-CNNs outperformed ShuffleNet2, ShuffleNet2_T, and ResNeXt for the Houston 2013 scene classification. The accuracies of the fine-tuned SG-CNNs are ∼1.3–7.4% higher than that of the other three baseline networks, indicating that SG-CNNs greatly improved the classification performance with both limited and sufficient samples.
(2) Comparing with ResNeXt_T, SG-CNNs obtained better results when few samples were provided (i.e., 50–100 per class). As the number of samples increased to 150–250 per class, the ResNeXt_T and SG-CNNs achieved comparable accuracy. This suggests that SG-CNNs have better performance with limited samples.
(3) In general, SG-CNN-12 provided the highest classification accuracy among the three SG-CNNs. However, as the number of training samples increased, the performance of SG-CNN-12 showed no obvious improvement compared to SG-CNN-7 and SG-CNN-8, which are more efficient and require less computing time.
3.5. Experiments on Salinas and DC Mall Scenes
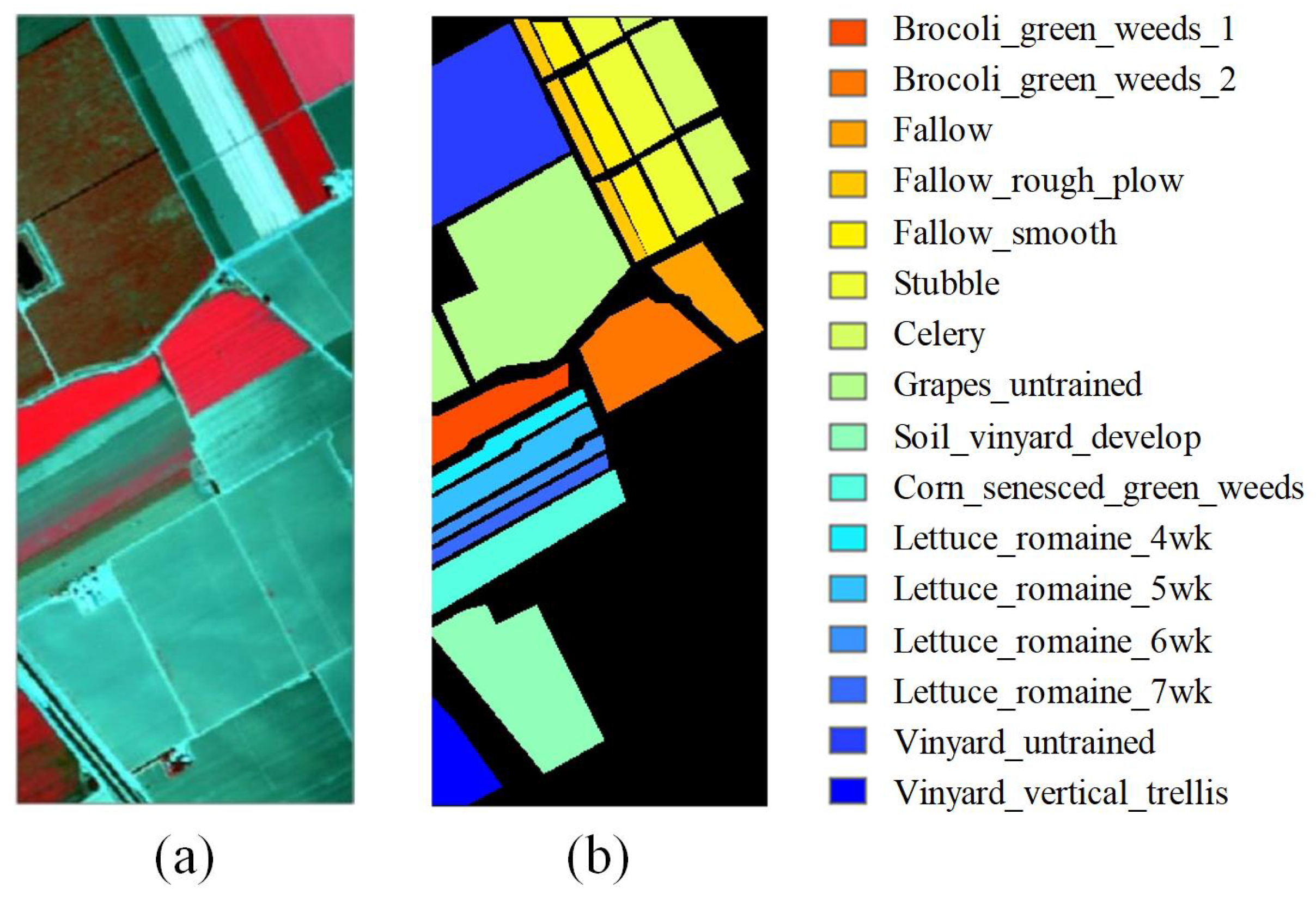
Salinas and DC Mall images and their labeled samples are shown in
Figure 12 and
Figure 13, respectively. It is important to note that surface types were quite different between these two scenes. The Salinas scene mainly consisted of natural materials (i.e., vegetation and three types of fallow), whereas the DC Mall scene included grass, trees, shadows, and three manmade materials.
Table 7 provides the number of samples used as training and test datasets. Five hundred samples of each class in the Salinas scene were randomly selected for base network training, whereas 100 samples of each class in the DC Mall scene were used for fine-tuning.
The loss function of SG-CNNs converged during the fine-tuning for the DC Mall scene (see
Figure 14). The classification results of both baseline models and SG-CNNs are listed in
Table 8 with their corresponding training time. As shown in
Table 8, similar conclusions can be reached from the DC Mall experiment. First, SG-CNNs outperformed the baseline models in terms of classification results. Moreover, SG-CNN-8 had an OA nearly 10% higher than that of ResNeXt_T, indicating the improvement brought by the proposed SG conv unit. Furthermore, although the target data and source data had different surface types, transfer learning on the SG-CNNs led to major improvement in the classification accuracy.
Analogously, our second test on the DC Mall scene evaluated the classification performance of the proposed method with varying sizes of labeled samples. We used 50–250 samples per class at an interval of 50 to train ShuffleNet2 and ResNeXt and to fine-tune SG-CNNs, ShuffleNet2_T, and ResNeXt_T.
Figure 15 shows the OAs for the test samples from all methods. In the DC Mall experiment, SG-CNNs outperformed all baseline models, including the ResNeXt_T, when a large number of training samples (e.g., 250 samples per class) was provided. Specifically, the OA of SG-CNNs was higher than that of other methods by 5.3–18.2%, which confirmed the superiority of our proposed method. For the DC Mall dataset, SG-CNN-12 achieved better results when samples were relatively limited (i.e., 50–150 samples per class). With 200–250 training samples in each category, SG-CNN-7 and SG-CNN-8 required less time to obtain a comparable accuracy to that of SG-CNN-12.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}