1. Introduction
With the development of remote sensing technology, remote sensing data and techniques have been widely applied to marine monitoring and surveys with the purpose of national defense and resource exploitation [
1,
2,
3,
4,
5]. As major transportation modes and typical targets in seas, ships have been paid more and more attention in applications based on remote sensing images. The detection of ships plays an important role in both civilian and military applications, such as port management, maritime rescue, battlefield surveillance and strategic deployment [
6,
7].
Many ship detection methods have been proposed based on images produced by different sensors. Synthetic aperture radar (SAR) images were used earlier and technologies are relatively mature. Compared to SAR images, high-resolution images contain more detailed structure and texture information, which have attracted more and more research interests in recent years [
8,
9]. According to the location and background of ships, ship detection methods using high-resolution images can be divided into offshore ship detection and inshore ship detection. Offshore ships are located in the sea, whose background is almost the sea surface only. Since offshore ship targets usually differ significantly from backgrounds on grey levels and textures, this kind of study has already made great progress [
10,
11]. On the contrary, inshore ships lie in ports which have complex land environments and a great number of disturbance objects similar to ships. Moreover, inshore ships in very high-resolution images exhibit various sizes and shapes, and some of them are densely arranged near the coast. As a result, the detection of inshore ships is still a challenging task [
12].
In the traditional methods of inshore ship detection, two major steps are usually employed [
13]. First, sea–land segmentation based on texture and shape features is implemented to eliminate land interference and improve target searching efficiency, and then, ship targets are detected with feature extraction and machine learning approaches. However, most of these methods are carried out based on artificially designed features [
14], which show limitations on performance in practical applications [
15].
With the advancement of deep learning methods, Convolutional Neural Networks (CNNs) have achieved great success in image processing, especially in object detection tasks, where a great number of CNN-based methods have been proposed. Region proposals with CNN (R-CNN) [
16] is the first benchmark framework that successfully applies CNN to object detection. Based on the idea of Region Proposal Network (RPN), Spatial Pyramid Pooling Network (SSP-Net) [
17], Fast R-CNN [
18] and Faster R-CNN [
19] are presented in succession to improve the performance and efficiency of R-CNN. All of these methods first generate region proposals by RPN, then use Non-Maximum Suppression (NMS) to select candidates with high confidence, and finally implement classification and location regression on these region proposals to obtain accurate detection results. With the preference to speed, some other one-step structures (without RPN step) are proposed as well, representatives of which include YOLO (You Only Look Once) [
20] and SSD (Single Shot Multibox Detector) [
21]. They take the object detection task as a problem of regression, and directly employ classification and regression on the feature map without consideration of region proposals.
Since the networks mentioned above have been proven to be effective in object detection of natural images, researchers in remote sensing have made efforts to utilize them in the application of inshore ship detection. Zhang et al., realize ship detection based on a Faster R-CNN framework [
22]. Wu et al., employ ship head searching, RPN, mutli-task network and NMS for inshore ship detection [
23]. The advantage of a deep neural network is its strong capability of feature description, which is exactly essential for the challenging task of inshore ship detection. Therefore, many model-transplanting methods easily outperform the traditional ones by means of deep learning [
24].
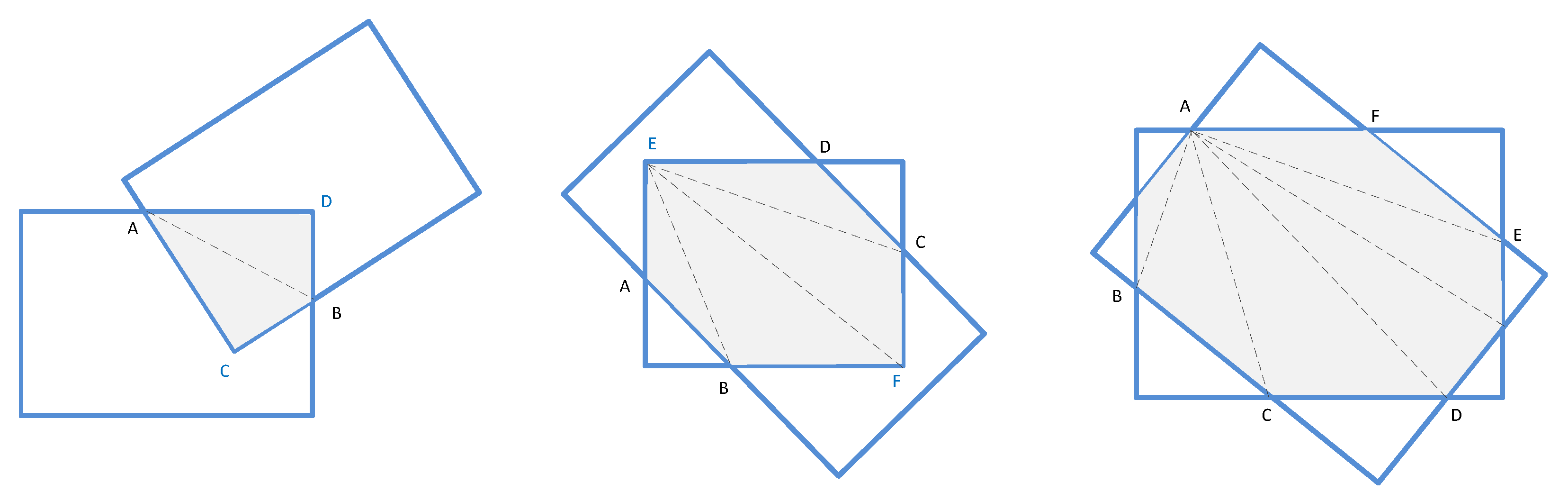
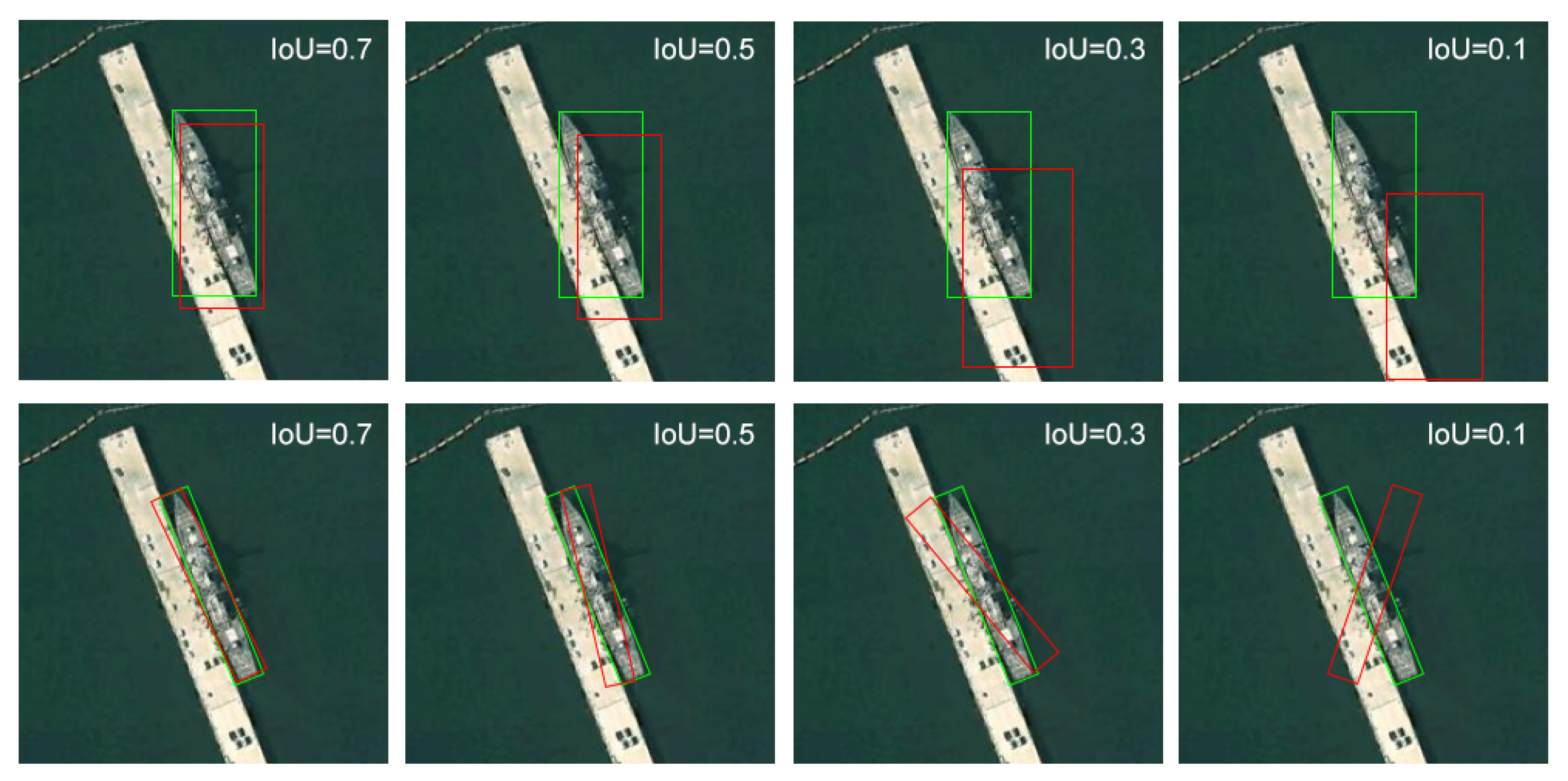
The above-mentioned methods all utilize horizontal bounding boxes to mark the location of ship targets. Although a horizontal bounding box is applicable for most object detections in natural images, it cannot locate inshore ships accurately because of their unique shapes. Since ships usually have a large aspect ratio and obvious inclined angle, a horizontal bounding box is not able to estimate the orientation of a ship. Moreover, after region proposals are generated, non-maximum suppression is usually applied as a vital step to reduce the number of candidates and increase detection efficiency. If inclined inshore ships lie densely near the port, the overlap of their horizontal bounding boxes will be very large, which will result in targets being missed when NMS is applied to screen region proposals.
Figure 1 shows the differences between horizontal bounding boxes and rotated bounding boxes when detecting densely arranged inshore ships based on region proposals. It is seen from the figure that the horizontal bounding box ground truth (
Figure 1b) covers more redundancy regions than the rotated one (
Figure 1d), and large overlaps of region proposals may cause side effects of NMS; target regions are not separated appropriately or some are even missed out (
Figure 1c).
Rotation bounding boxes are first presented and studied in the research of text detection, which has a similar requirement of detecting text of arbitrary orientations. Rotational Region CNN (R
CNN) [
25] introduces inclined angle information in classification and regression networks and employs skew NMS to select region proposals. Rotation RPN (RRPN) [
26] creates rotation anchors to improve the quality of proposals at the stage of RPN, and improves the performance of R
CNN.
With the achievement these methods have made, rotated region proposals have been applied to ship detection as well. Liu et al., introduce pooling of a Rotation Region of Interest (RRoI) and rotation bounding box regression in the framework [
27]. Yang et al., integrate a dense feature pyramid network, RRPN and Fast R-CNN to inclined results [
6]. Zhou et al., use a semantic segmentation network to recognize part of ships for rotated region proposals [
28,
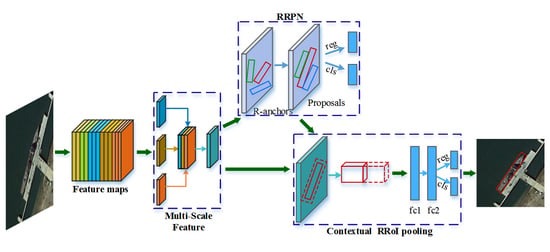
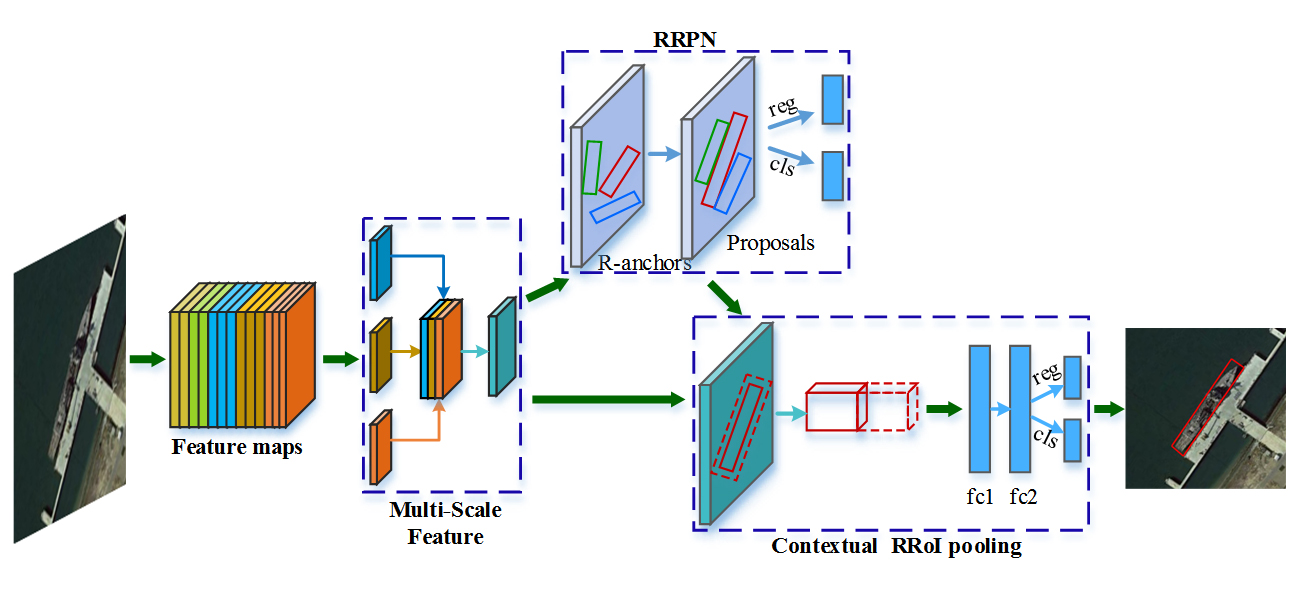
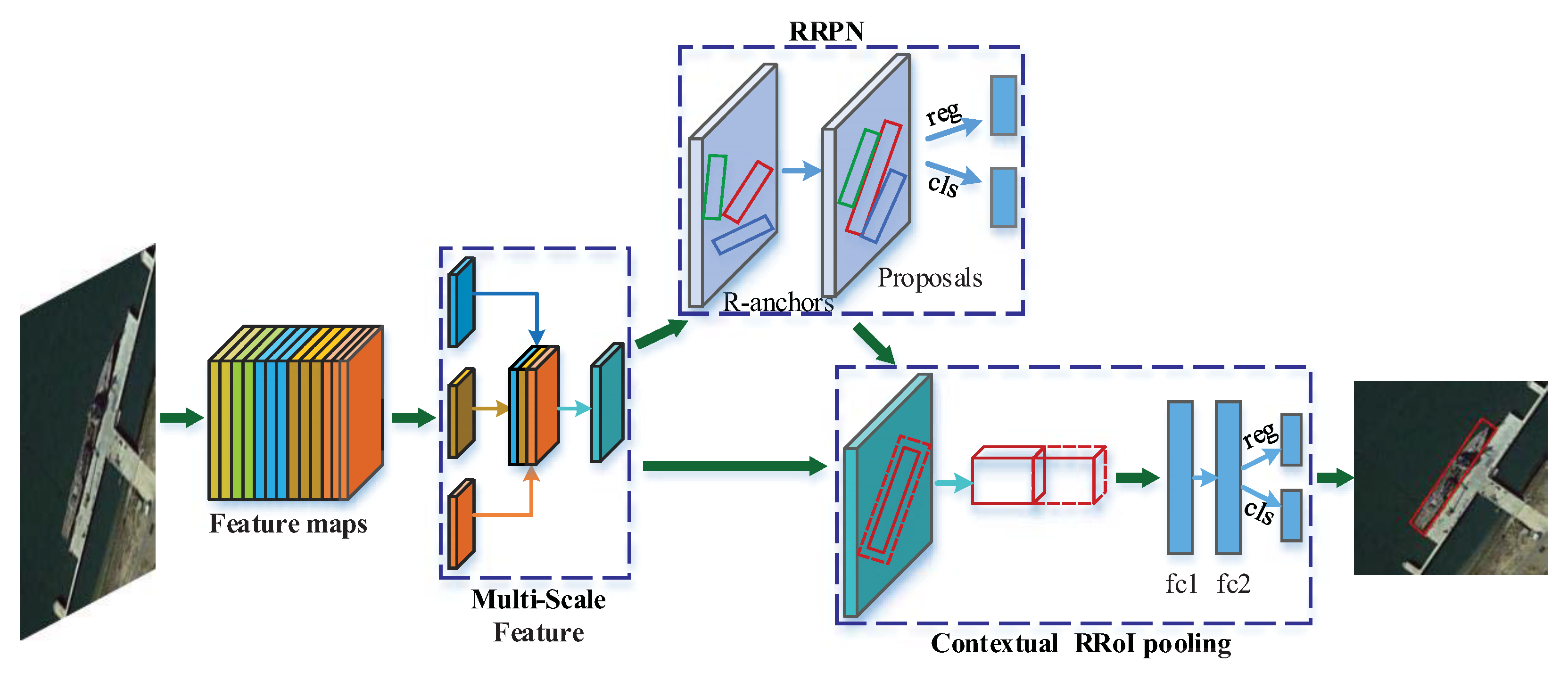
29]. Although methods adopting a rotation bounding box have already been proposed during the past two years, the problem of accurate rotated region proposal and the consequent information loss of employing rotated boxes are not yet well solved. To generate appropriate rotated region proposals for inshore ships of various locations and sizes with a concise end-to-end model is still challenging. Moreover, although a horizontal box is inferior to a rotated one, redundancy regions that a horizontal box contains can provide beneficial contextual information in some sense. The RRoI pooling of a rotated box aims to obtain an accurate description of objects for detection, however, it excludes very useful contextual information, which will result in more false alarms than traditional RPN methods. In consideration of all the above, in this paper, we propose a concise end-to-end framework for arbitrary-oriented inshore ship detection. Our method uses the baseline backbone feature extraction network in accordance with popular deep learning work of object detection. Nevertheless, state-of-the-art feature pyramid processing based on backbone network is employed to implement multi-scale feature fusion. Then, a rotation region proposal network is adopted to generate rotated region proposals for ships of various sizes and locations. Finally, a rotated contextual RRoI pooling is applied to correct the information loss of the rotated box for an accurate description of target detection. The main contributions of this paper are as follows:
We propose a novel and concise framework for arbitrary-oriented inshore ship detection which can handle complex port scenes and targets of different sizes.
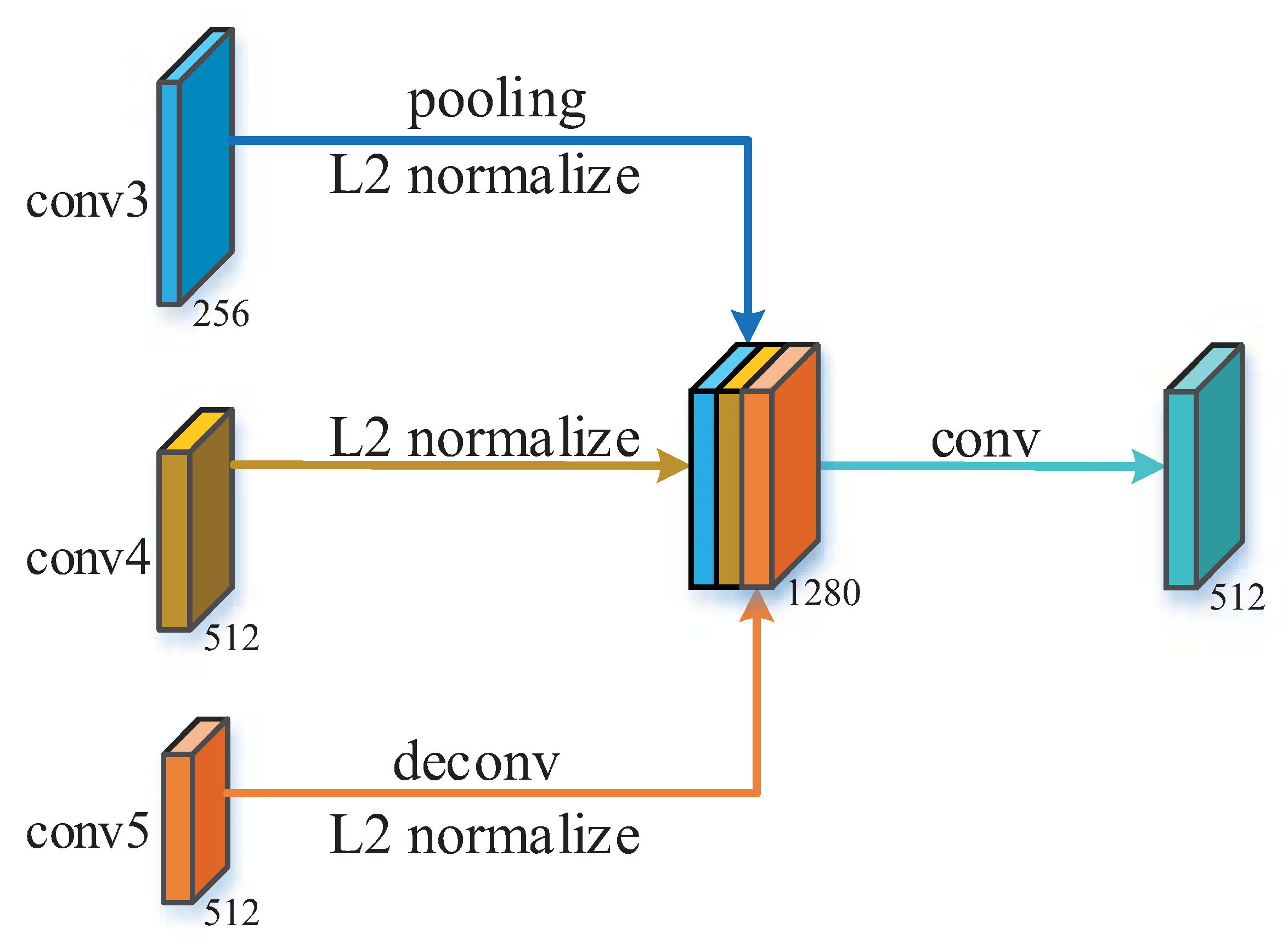
For better detection of various target sizes, we design a multi-scale feature extraction and fusion network to build the multi-scale features, which contribute to the promotion of precision on different ships.
In order to obtain accurate target locating and an arbitrary-oriented bounding box, we adopt the rotation region proposal network and skew non-maximum suppression. Consequently, densely moored ships are able to be distinguished, which results in an increase of recall rates.
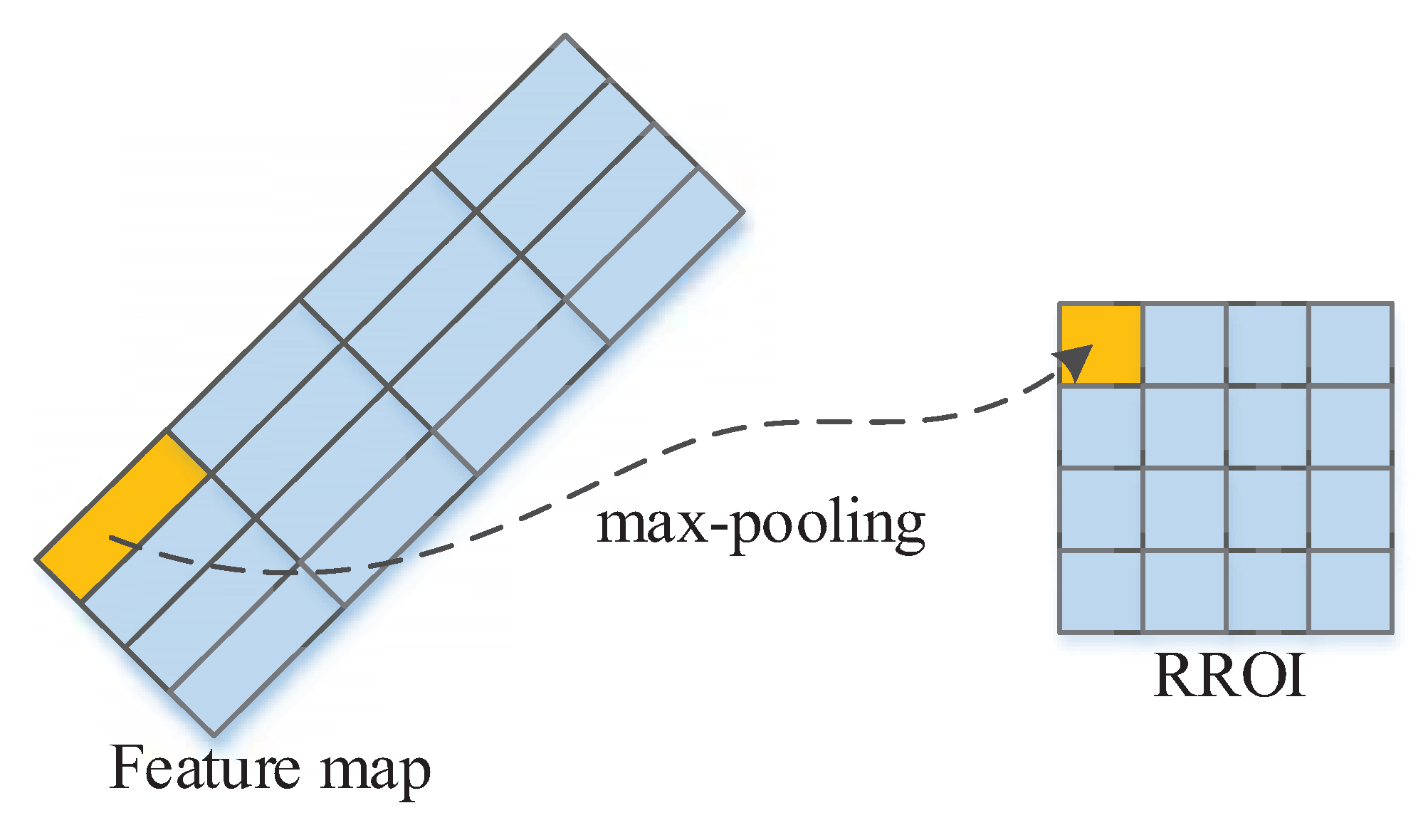
We implement rotated contextual feature pooling of a rotation region of interest to better describe ship targets and their surrounding backgrounds. As a result, the description weakness of rotation bounding boxes is improved with a decrease of false alarms.
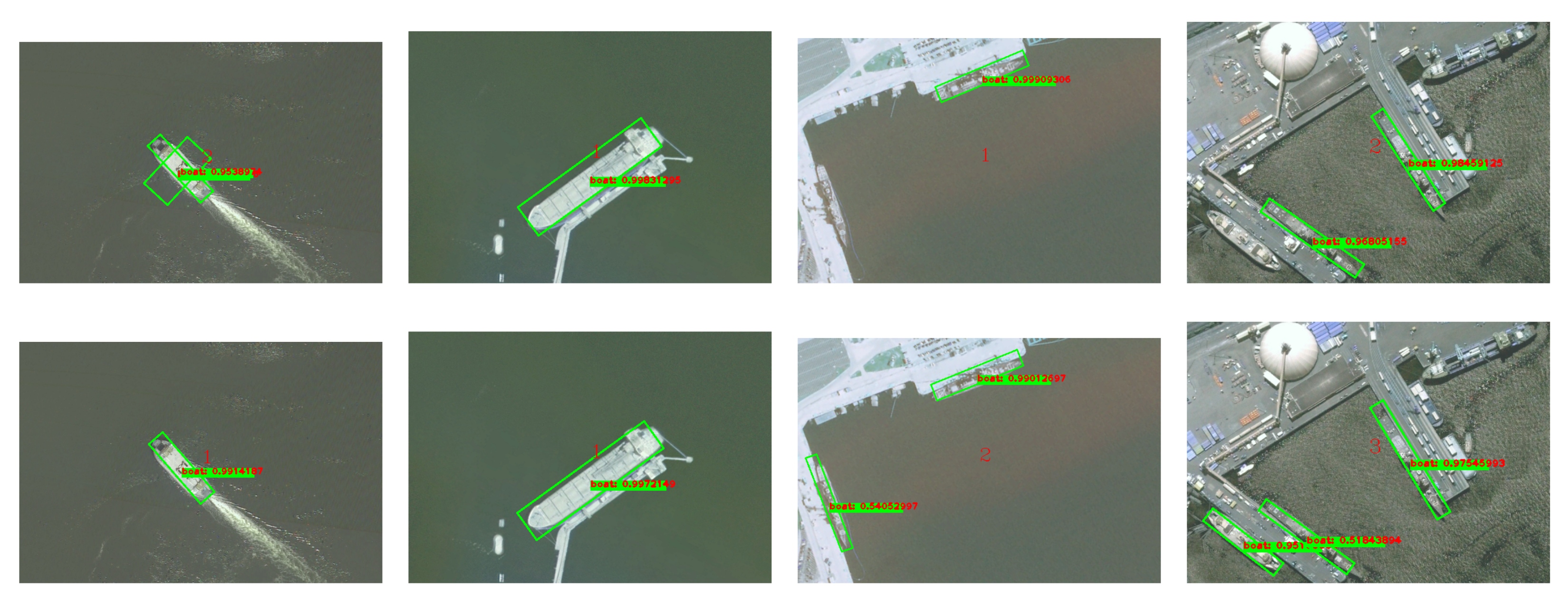
Experimental results on remote sensing port images collected from Google Earth validate the effectiveness of the proposed method. It is robust for ship targets of various sizes and types, outperforming other methods on indicators of precision, recall and false alarm criteria. Results on the public ship dataset HRCS2016 provide a parallel comparison of the proposed pipeline, which show its state-of-the-art performance compared to other advanced approaches. The rest of this paper is organized as follows:
Section 2 introduces more detailed state-of-the-art studies concerning this application.
Section 3 describes the overall framework and details of each part of our method.
Section 4 presents experiments of model analysis and contrast methods to validate the effectiveness of the proposed method. Finally,
Section 5 concludes the paper.
2. Related Work
From the perspective of different scenes that targets lie in, ship detection methods can be roughly divided into offshore and inshore ship detection; by the types of methodology of detection framework, they can be divided into traditional methods and deep learning ones. An offshore ship scene usually contains small at-sea targets and the detection task mainly aims to resist disturbance of sea surface background. Inshore ship targets are usually relatively larger, where complex similar land confusions of ports are the major challenges. Traditional ship detection methods usually design shape and texture features for classifying the target and background, which may be more applicable to offshore ship detection since offshore scenes are relatively simple compared to coasts and ports. Representative features adopted for offshore ship detection include shape and texture features [
10], S-HOG features [
30], edge and contour features [
11], and topology structure and LBP features [
31,
32]. Inshore ship detection with traditional methods usually focuses on special characteristics of ships to design features and recognize targets. He et al., adopt weighted voting and rotation-scale-invariant pose to detect ships [
12], and Bi et al. [
8] employ an omnidirectional intersected two-dimension scanning strategy and decision mixture model to detect ships. Since artificially designed features cannot cope with complex port background, as a result, more and more deep learning methods are proposed in the inshore ship detection task during the most recent three years while non-deep-learning ones are seldom presented.
Object detection frameworks using deep neural networks have been applied to remote sensing applications [
33,
34] since they were proved to outperform traditional methods in natural images. In the field of inshore ship detection, many researchers have delved into the development of target detection with deep learning methods. A fully convolutional network is applied to detect ships in the literature [
35], but facing the problem that localization is not accurate enough. Methods based on R-CNN and its improved variants (especially Fast R-CNN and Faster R-CNN) are highly favored for their better detection effects [
22]. Moreover, various improvements on the detection framework are employed, including the addition of ship head detection [
23] and contextual information [
1].
In consideration of the characteristics of inshore ships that targets are always inclined or even closely arranged, rotation bounding boxes are proposed to further improve the localization accuracy of ships. Liu et al. [
27] bring in a rotated region CNN and rotation ROI pooling to detect inclined ships, but the skew proposals are generated by the method like a selective search presented by [
11] (not end-to-end model). Li et al. [
36] employ a five-box method to produce rotation proposals, which is not a region proposal network. In order to build an end-to-end model, Zhang et al., introduce a rotation region proposal network instead of the above rotation proposal generation methods to generate rotated bounding boxes [
37]. However, this work is a direct application from text detection [
26] to the remote sensing field. Yang et al. [
6] further supplement a dense feature pyramid network based on RRPN and RoI align to improve performance. However, the authors declare that this framework using rotation region proposals has a defect of higher false alarms. Zhou et al. [
28,
29] propose approaches to use semantic segmentation networks to recognize parts of ships for rotated region proposal, where additional semantic pixel labels of ship parts have to be provided. On the basis of different RPN design to produce rotated bounding boxes, many approaches are being used to improve the performance of inshore ship detection. As far as we know, very few studies, except for [
6,
28], have simultaneously employed a multi-scale feature, rotation region proposal network and contextual pooling in one uniform end-to-end model.
5. Conclusions
In this paper, we propose an inshore ship detection framework based on a multi-scale feature pyramid fusion network, rotation region proposal network and contextual rotation region of interest pooling. In consideration of various sizes of inshore ships, the proposed method fuses multi-scale features from a pyramid of a backbone feature extraction network to better describe targets of different sizes. In order to locate inshore ships more accurately and distinguish targets that are densely arranged, a rotation region proposal network with skew non-maximum suppression is introduced to generate region proposals. Moreover, to offset the context loss impact of inclined region proposal, a contextual region alongside the rotation RoI is added to supplement effective information of inshore ships. Experiments of model analysis validate that each step mentioned above contributes to the final results of detection, and the proposed model with all three steps achieves state-of-the-art performance compared to other methods.
In the future work, the following aspects are worth further investigation and should be improved for the detection of inshore ships: (1) Backbone detection framework. Currently, Faster R-CNN is employed as the most popular backbone detection network, and improved efficient and concise models may be used as the backbone in the future. (2) A Method of multi-scale feature extraction and fusion. Many approaches aim to extract multi-scale features, whereas more accurate and faster methods are still in demand. (3) An Approach to produce region proposals. How to generate effective region proposals of reasonable quantity is a key step in object detection, which will affect the efficiency and performance of the whole model. (4) The selection of pooling method, loss function and context addition method. All of these details will influence the model performance especially under conditions of imbalanced samples and complex interferences. (5) Detection and other methods in combination, for example, with semantic segmentation and visual saliency may all contribute to the detection of ships.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}