1. Introduction
The steady accessibility of remote sensing data, particularly high resolution images, has animated remarkable research outputs in the remote sensing community. Two of the most active topics in this regard refer to image classification and retrieval [
1,
2,
3,
4,
5]. Image classification aims to assign scene images to a discrete set of land use/land cover classes depending on the image content [
6,
7,
8,
9,
10]. Recently, with rapidly expanded remote sensing acquisition technologies, both quantity and quality of remote sensing data have been increased. In this context, content-based image retrieval (CBIR) has become a paramount research subject in order to meet the increasing need for the efficient organization and management of massive volumes of remote sensing data, which has been a long lasting challenge in the community of remote sensing.
In the last decades, great efforts have been made to develop effective and precise retrieval approaches to search for interest information across large archives of remote sensing. A typical CBIR system involves two main steps [
11], namely feature extraction and matching, where the most relevant images from the archive are retrieved. In this regard, both extraction of features as well as matching play a pivotal role in controlling the efficiency of a retrieval system [
12].
Content-based remote sensing image retrieval is a particular application of CBIR, in the field of remote sensing. However, the remote sensing community seems to put the emphasis more on devising powerful features due to the fact that image retrieval systems performance relies greatly on the effectiveness of the extracted features [
13]. In this respect, remote sensing image retrieval approaches rely on handcrafted features and deep-learning.
As per handcrafted features, low-level features are harnessed to depict the semantic tenor of remote sensing images, and it is possible to draw them from either local or global regions of the image. Color features [
14,
15], texture features [
2,
16,
17], and shape features [
18] are widely applied as global features. On other hand, local features tend to emphasize the description on local regions instead of looking at the image as a whole. There are various algorithms for describing local image regions such as the scale-invariant feature transform (SIFT) and speed up robust features (SURF) [
19,
20]. The bag-of-word (BOW) model [
21], and the vector of aggregated local descriptors (VLAD) [
22] are generally proposed to encode local features into a fixed-size image signature via a codebook/dictionary of keypoint/feature vectors.
Recently, remote sensing images have been witnessing a steady increase due to the prominent technological progress of remote sensors [
23]. Therefore, huge volumes of data with various spatial dimensions and spectral channels can be availed [
24]. On this point, handcrafted features may be personalized and successfully tailored to small chunks of data; they do not meet, however, the standards of practical contexts where the size and complexity of data increases. Nowadays, deep learning strategies, which aim to learn automatically the discriminative and representative features, are highly effective in large-scale image recognition [
25,
26,
27], object detection [
28,
29], semantic segmentation [
30,
31], and scene classification [
32]. Furthermore, recurrent neural networks (RNNs) have achieved immense success with various tasks in sequential data analysis as recognition of action [
33,
34] and image captioning [
35]. Recent research shows that image retrieval approaches work particularly well by exploiting deep neural networks. For example, the authors in [
36] introduced a content-based remote sensing image retrieval approach depending on deep metric learning using a triplet network. The proposed approach has shown promising results compared to prior state-of-the-art approaches. The work in [
37] presented an unsupervised deep feature learning method for the retrieval task of remote sensing images. Yang et al. [
38] proposed a dynamic kernel with a deep convolutional neural network (CNN) for image retrieval. It focuses on matching patches between the filters and relevant images and removing the ones for irrelevant pairs. Furthermore, deep hashing neural network strategies are adopted in some works for large-scale remote sensing image retrieval [
39]. Li et al. [
40] presented a new unsupervised hashing method, the aim of which is to build an effective hash function. In another work, Li et al. [
41], investigated cross-source remote sensing image retrieval via source-invariant deep hashing CNNs, which automatically extract the semantic feature for multispectral data.
It is worthwhile mentioning that the aforementioned image retrieval methods are single label retrieval approaches, where the query image and the images to be retrieved are labelled by a single class label. Although these approaches have been applied with a certain amount of success, they tend to abstract the rich semantic tenor of a remote sensing image into a single label.
In order to moderate the semantic gap and enhance the retrieval performance, recent remote sensing research proposed multi-label approaches. For instance, the work in [
12] presented a multi-label method, making use of a semi-supervised graph-theoretic technique in order to improve the region-based retrieval method [
42]. Zhou et al. [
43] proposed a multi-label retrieval technique by training a CNN for semantic segmentation and feature generation. Shao et al. [
11] constructed a dense labeling remote sensing dataset to evaluate the performance of retrieval techniques based on traditional handcrafted feature as well as deep learning-based ones. Dai et al. [
44] discussed the use of multiple hyperspectral image retrieval labels and introduced a multi-label scheme that incorporates spatial and spectral features.
It is evident that the multi-label scenario is generally favored (over the single label case) on account of its abundant semantic information. However, it remains limited due to the discrete nature of labels pertaining to a given image. This suggests a further endeavor to model the relation among objects/labels using an image description. With the rapid advancement of computer vision and natural language processing (NLP), machines began to understand, slowly but surely, the semantics of images.
Current computer vision literature suggests that, instead of tackling the problem from an image-to-image matching perspective, cross-modal text-image learning seems to offer a more concrete alternative. This concept has manifested itself lately in the form of image captioning, which stems as a crossover where computer vision meets NLP. Basically, it consists of generating a sequential textual narration of visual data, similar to how humans perceive it. In fact, image captioning is considered as a subtle aid for image grasping, as a description generation model should capture not only the objects/scenes presented in the image, but it should also be capable of expressing how the objects/scenes relate to each other in a textual sentence.
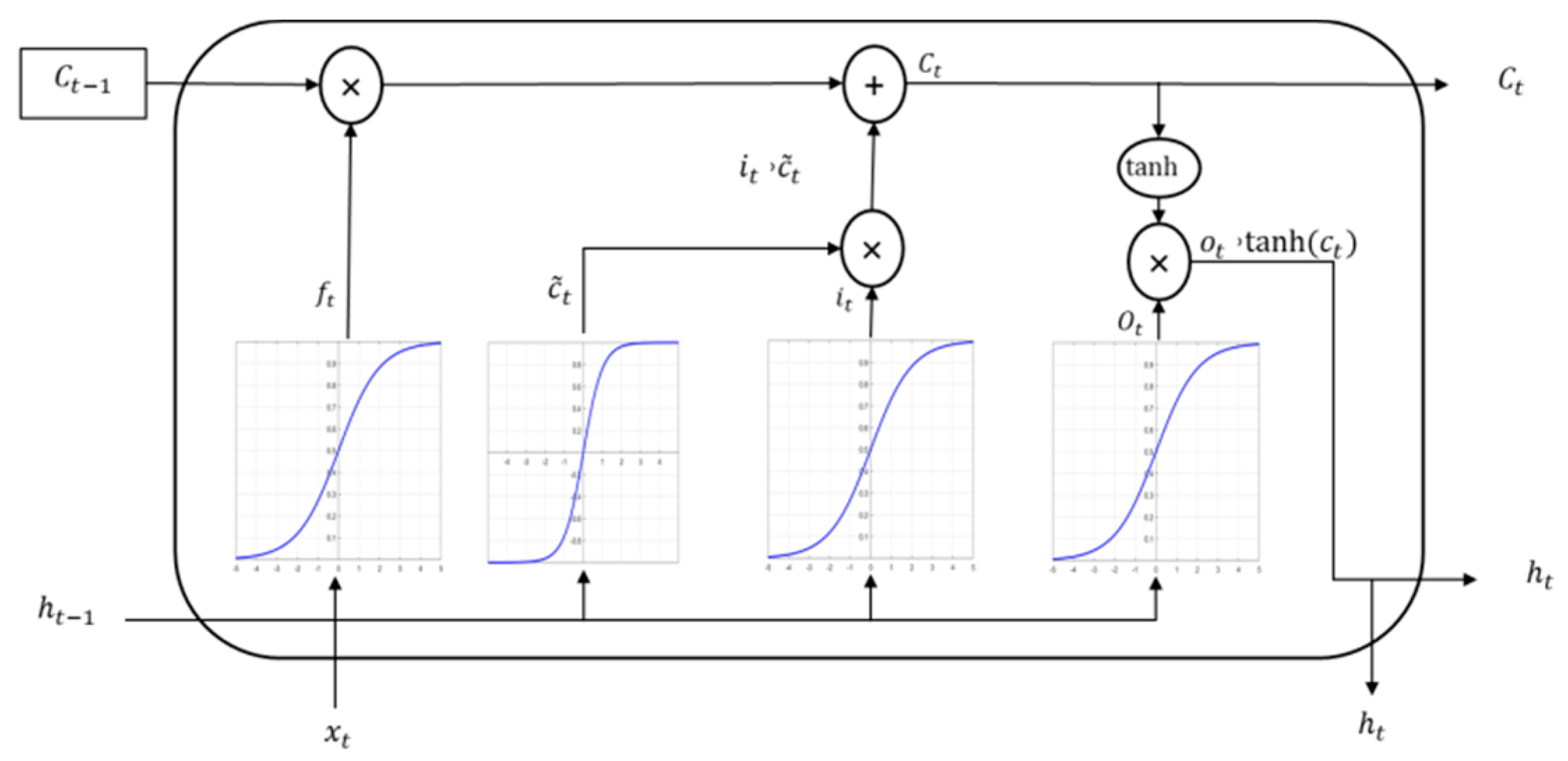
The leading deep learning techniques, for image captioning, can be categorized into two streams. One stream adopts encoder–decoder, an end-to-end fashion [
45,
46] where a CNN is typically considered as the encoder and an RNN as the decoder, often a Long-Short Term Memory (LSTM) [
47]. Rather than translating between various languages, such techniques translate from a visual representation to language. The visual representation is extracted via a pre-trained CNN [
48]. Translation is achieved by RNNs based language models. The major usefulness of this method is that the whole system adopts end to end learning [
47]. Xu et al. [
35] went one step further by introducing the attention mechanism, which enables the decoder to concentrate on specific portions of the input image when generating a word. The other stream adopts a compositional framework, such as [
49] for instance, which divided the task of generating the caption into various parts: detection of the words by a CNN, generating the caption candidates, and re-ranking the sentence by a deep multimodal similarity model.
With respect to image captioning, the computer vision literature suggests several contributions mainly based on deep learning. For instance, You et al. [
50] combined top-down (i.e., image-to-words) and bottom-up (i.e., joining several relevant words into a meaningful image description) approaches via CNN and RNN models for image captioning, which revealed interesting experimental results. Chen et al. [
51] proposed an alternative architecture based on spatial and channel-wise attention for image captioning. In other works, a common deep model called a bi-directional spatial–semantic attention network was introduced [
52,
53], where an embedding and a similarity network were adopted to model the bidirectional relations between pairs of text and image. Zhang and Lu [
54] proposed a projection classification loss that classified the vector projection of representations from one form to another by improving the norm-softmax loss. Huang et al. [
52] addressed the problem of image text matching in bi-direction by making use of attention networks.
So far, it can be noted that computer vision has been accumulating a steady research basis in the context of image captioning [
47,
50,
55]. In remote sensing, however, contributions have barely begun to move in this direction, often regarded as the ‘next frontier’ in computer vision. Lu et al. [
56] for instance, proposed a similar concept as in [
51] by combining CNNs (for image representation) and LSTM network for sentence generation in remote sensing images. Shi et al. [
57] leveraged a fully convolutional architecture for remote sensing image description. Zhang et al. [
58] adopted an attribute attention strategy to produce remote sensing image description, and investigated the effect of the attributes derived from remote sensing images on the attention system.
As we have previously reviewed, the mainstream of the remote sensing works focuses mainly on scenarios of single label, whereas in practice images may contain many classes simultaneously. In the quest for tackling this bottleneck, recent works attempted to allocate multiple labels to a single query image. Nevertheless, coherence among the labels in such cases remains questionable since multiple labels are assigned to an image regardless of their relativity. Therefore, these methods do not specify (or else model) explicitly the relation between the different objects in a given image for a better understanding of its content. Evidently, remote sensing image description has witnessed rather scarce attention in this sense. This may be explained by the fact that remote sensing images exhibit a wide range of morphological complexities and scale changes, which render text to/from image retrieval intricate.
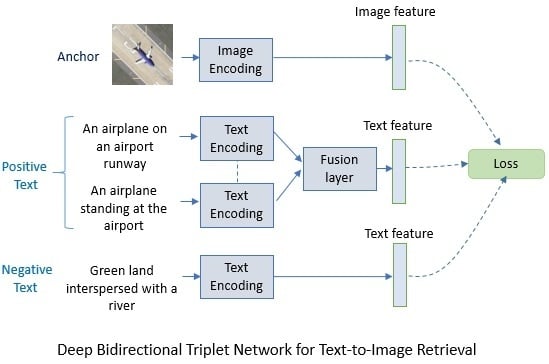
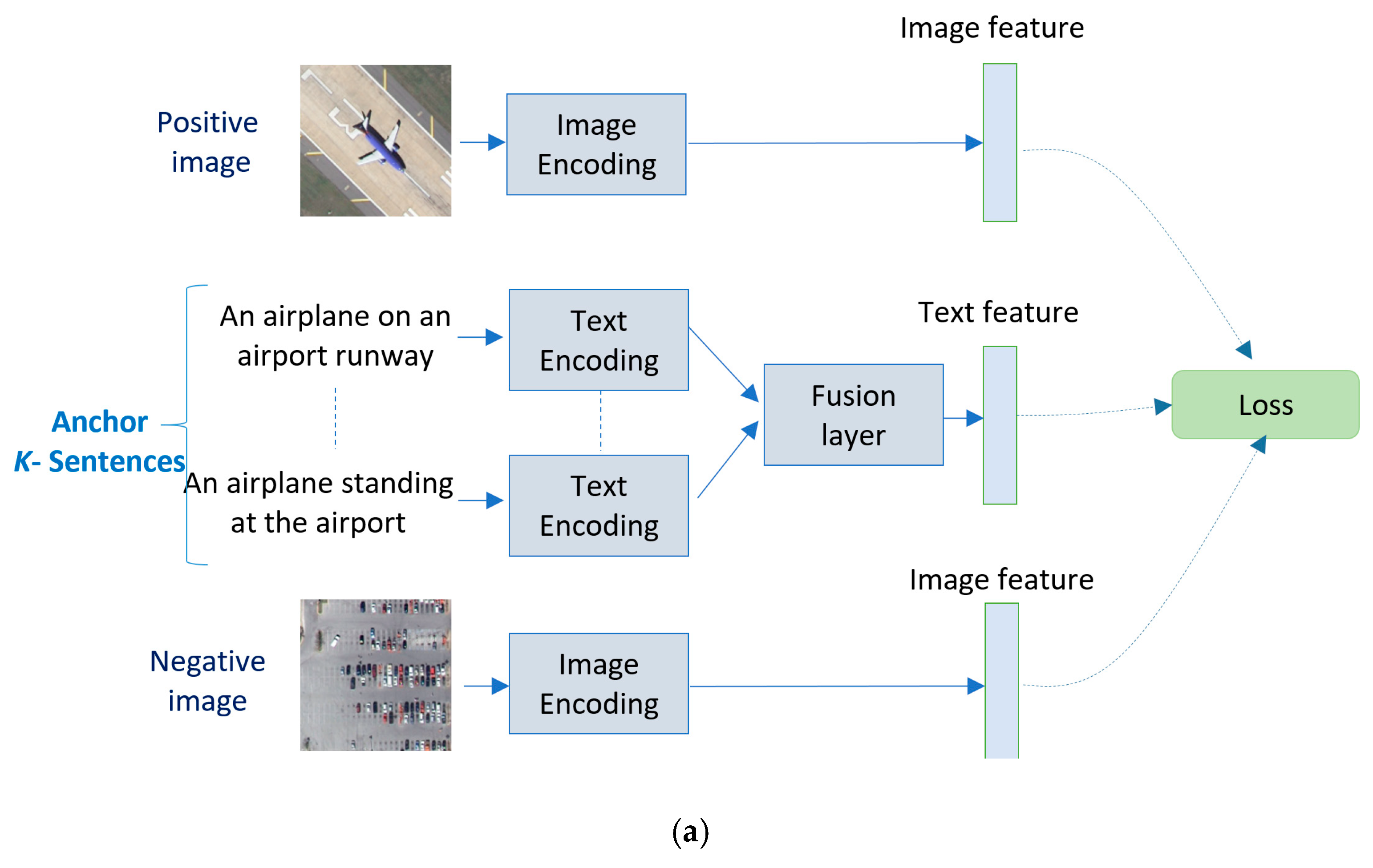
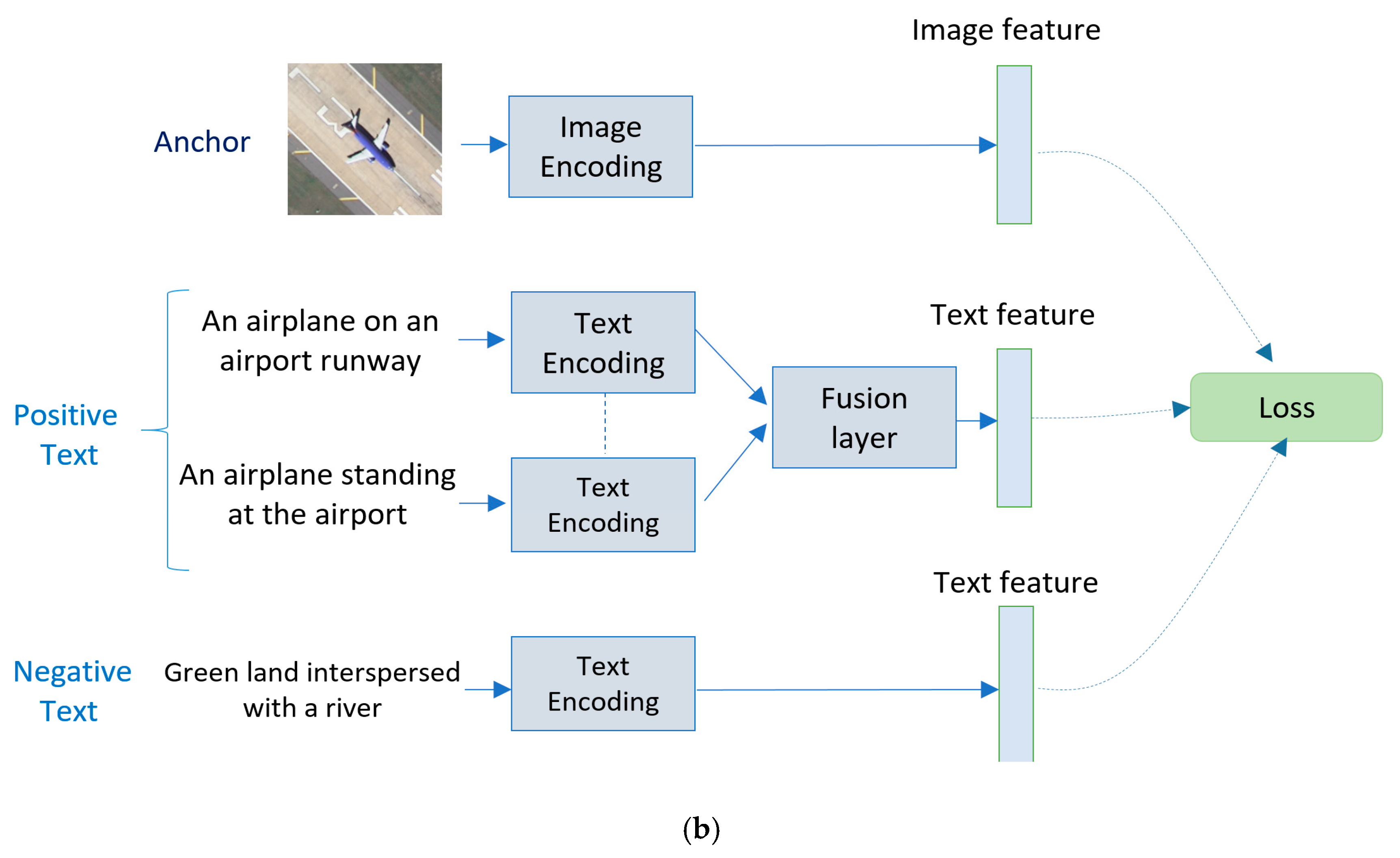
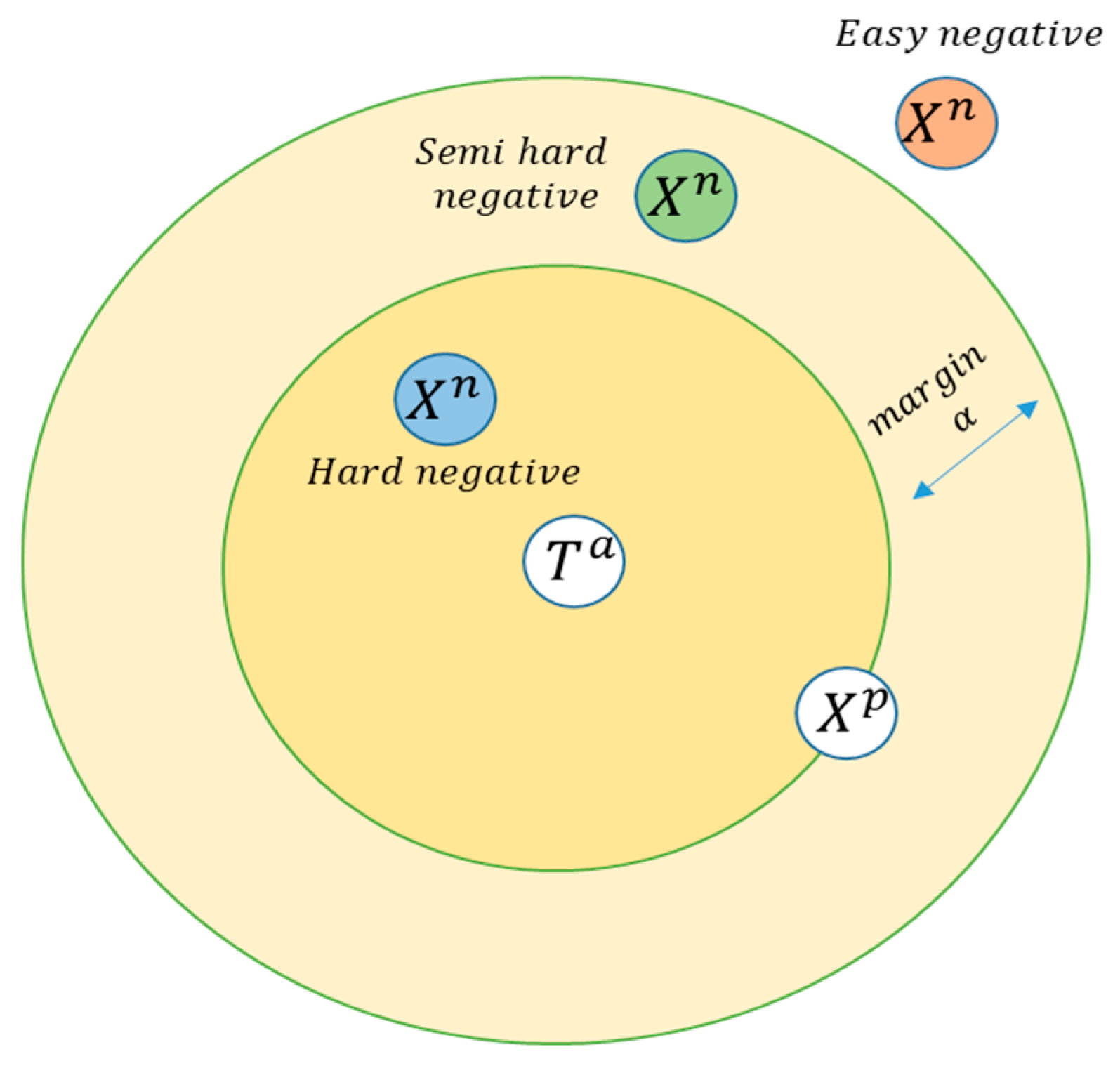
In this paper we propose a solution based DBTN for solving the text-to-image matching problem. It is worth mentioning that this work is inspired from [
53]. The major contributions of this work can be highlighted as follows:
Departing from the fact that the task of text-image retrieval/matching is a new topic in the remote sensing community, we deem it necessary to build a benchmark dataset for remote sensing image description. Our dataset will constitute a benchmark for future research in this respect.
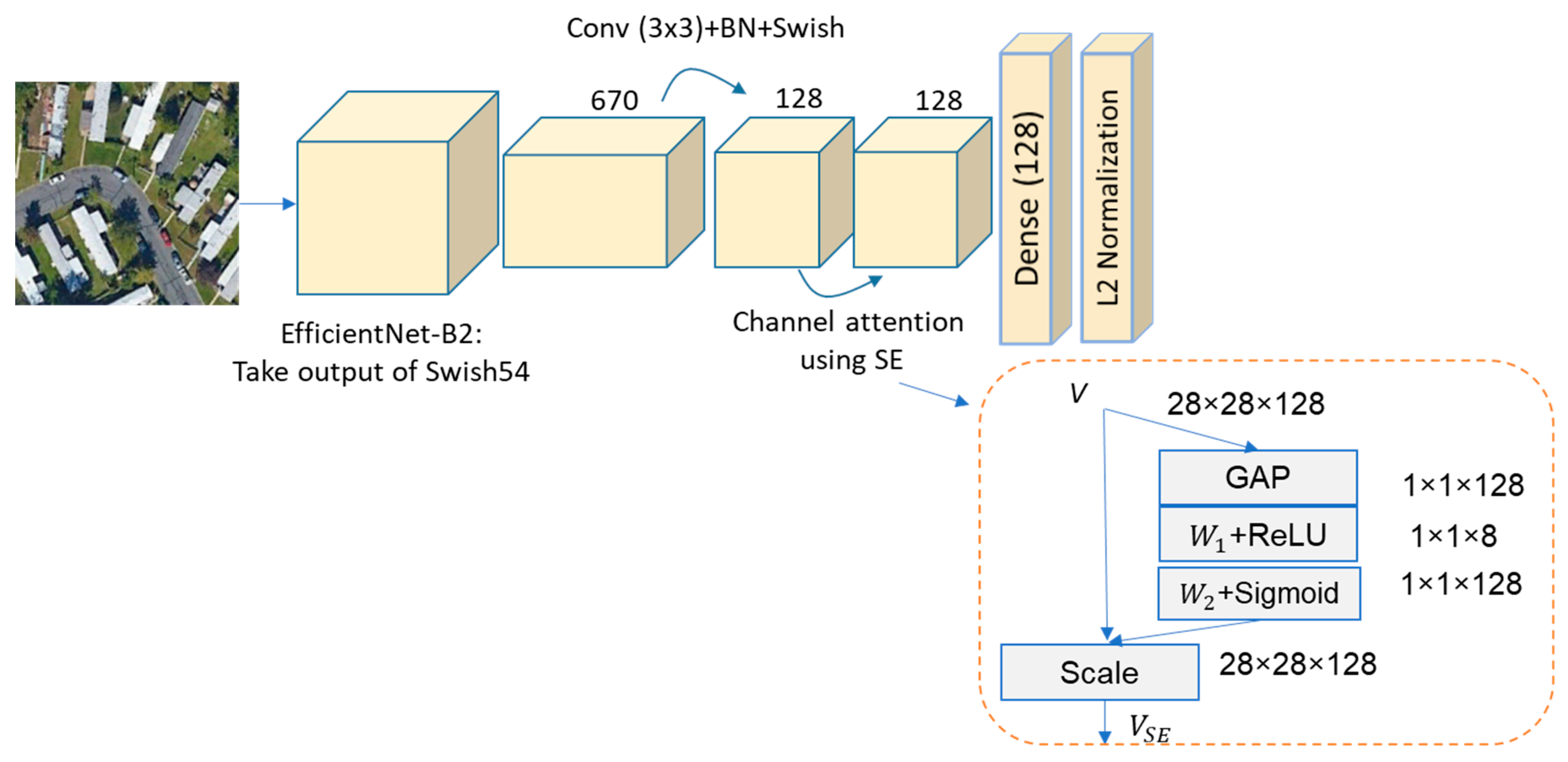
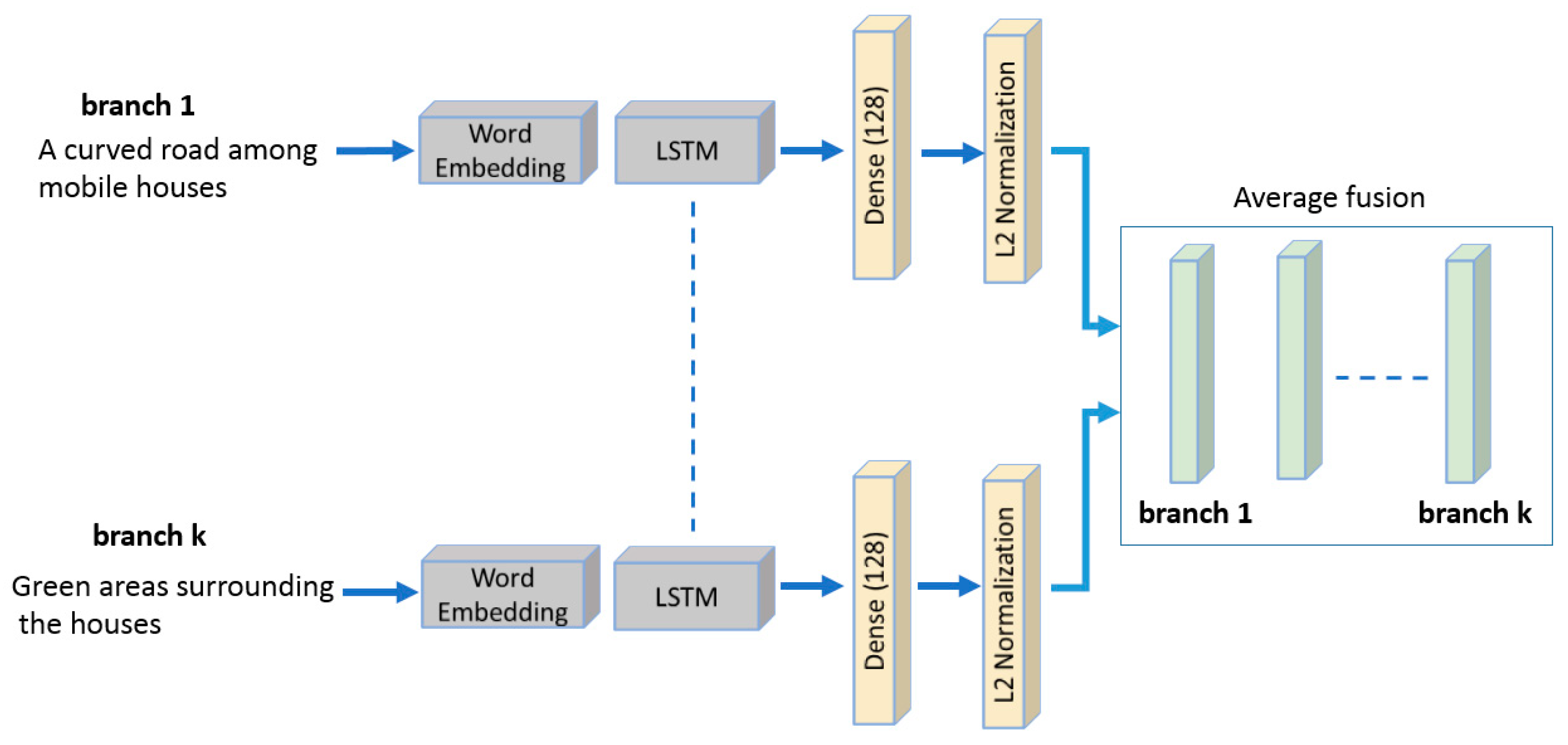
We propose a DBTN architecture to address the problem of text image matching, which to the best of our knowledge, has never been posed in remote sensing prior-art thus far.
We tie the single models into fusion schemes that can improve the overall performance through adopting the five sentences.
The paper includes five sections, where the structure of the paper is as follows. In
Section 2, we introduce the proposed DBTN method.
Section 3 presents the TextRS dataset and the experimental results followed by discussions in
Section 4. Finally,
Section 5 provides conclusions and directions for future developments.


 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}