The Role of Improved Ground Positioning and Forest Structural Complexity When Performing Forest Inventory Using Airborne Laser Scanning


Abstract
:
1. Introduction
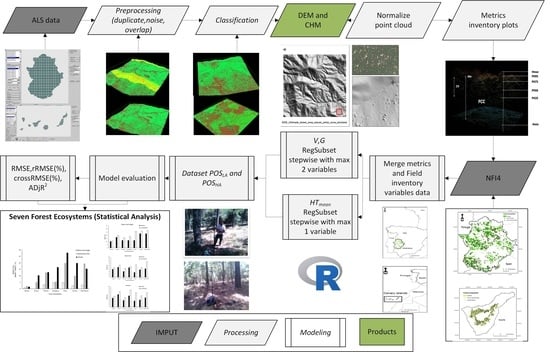
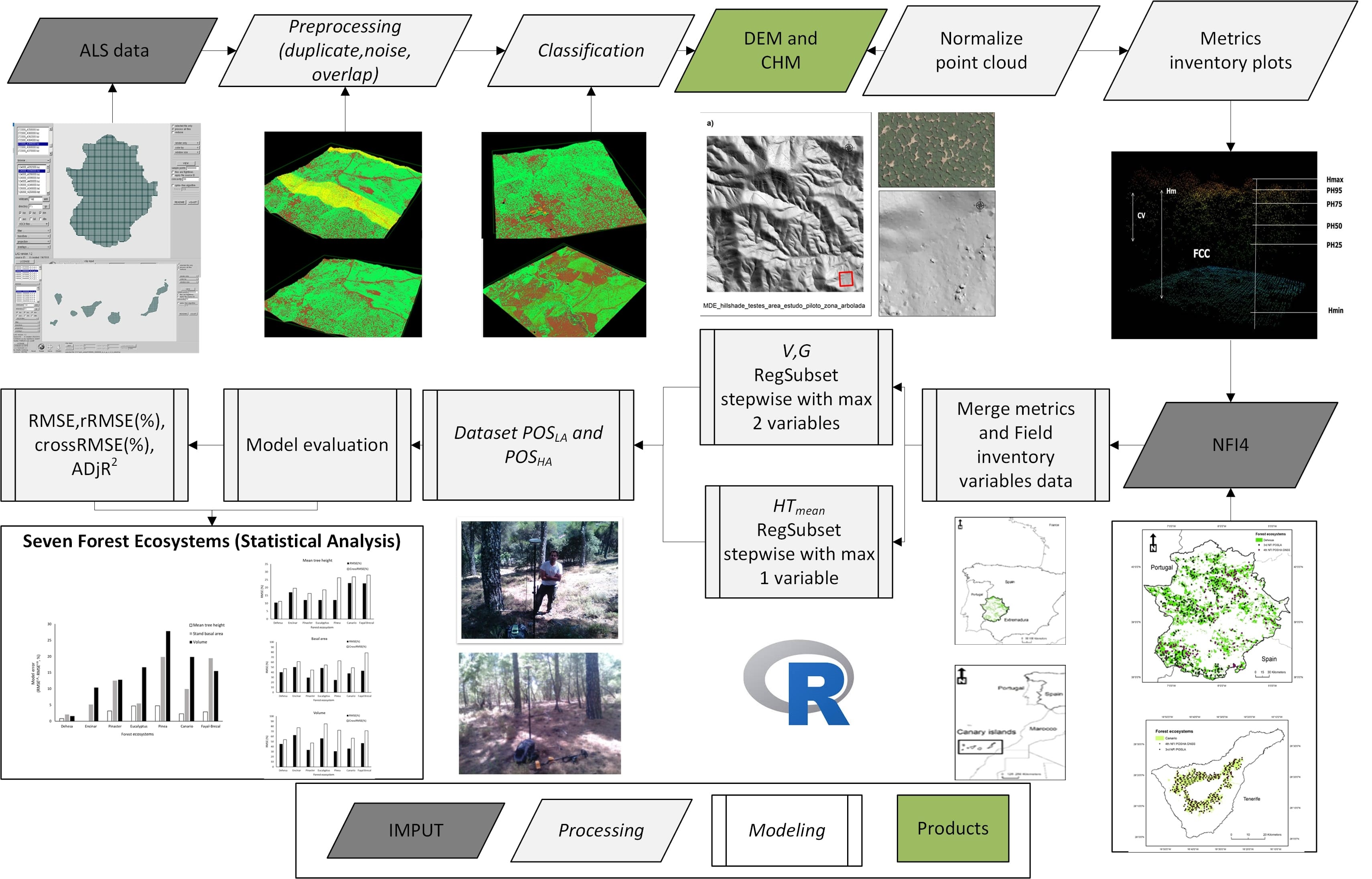
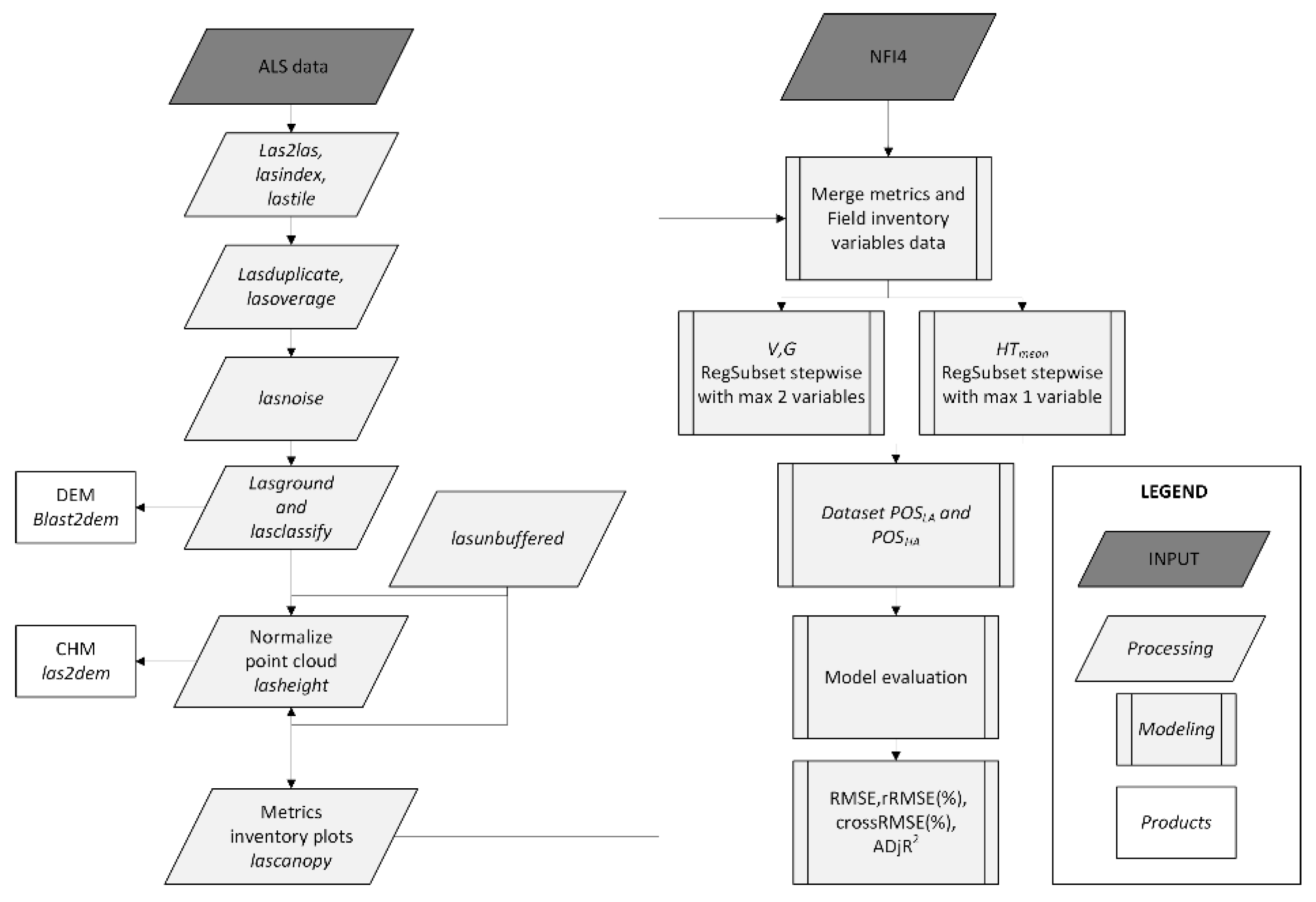
2. Materials and Methods
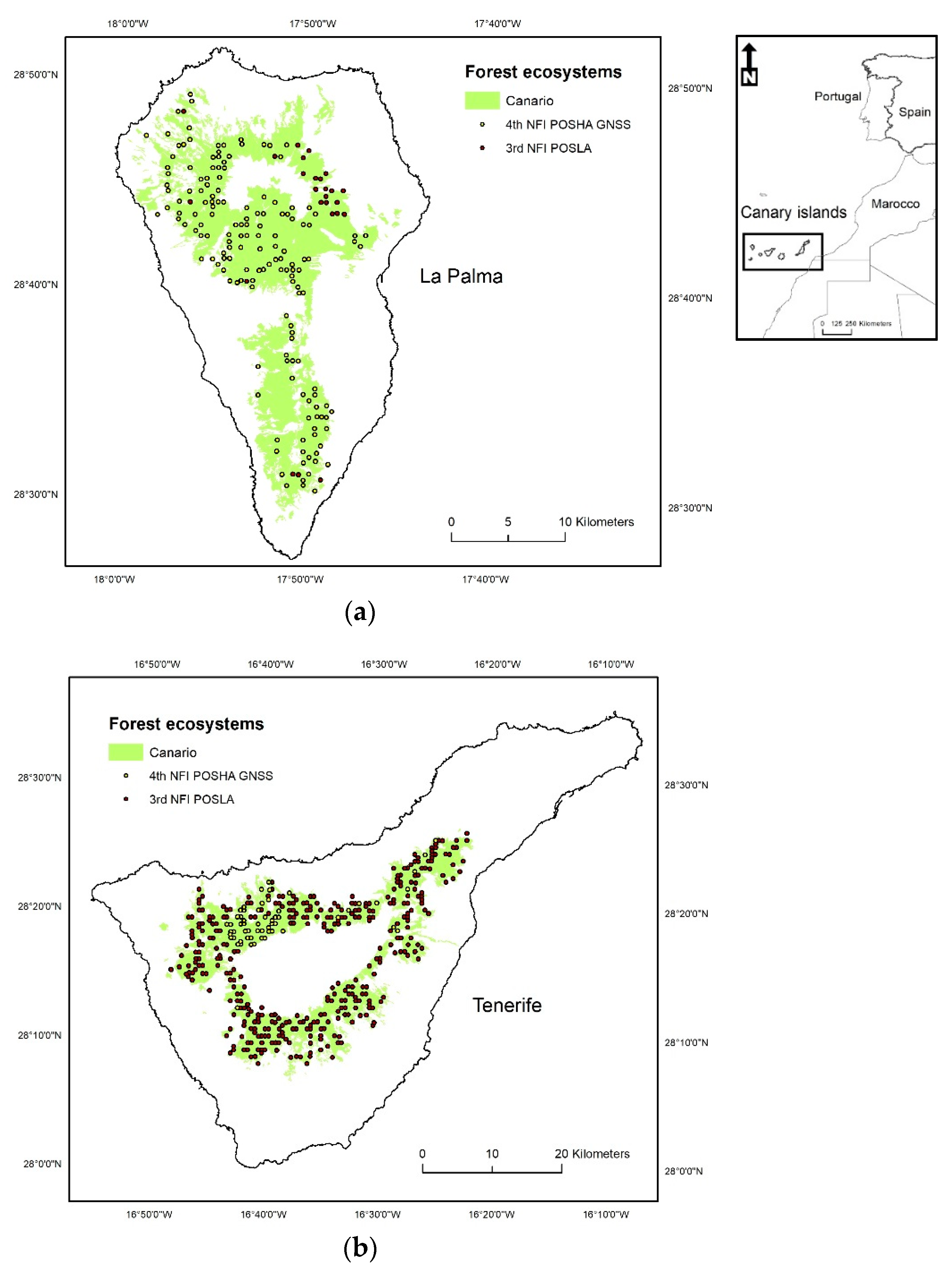
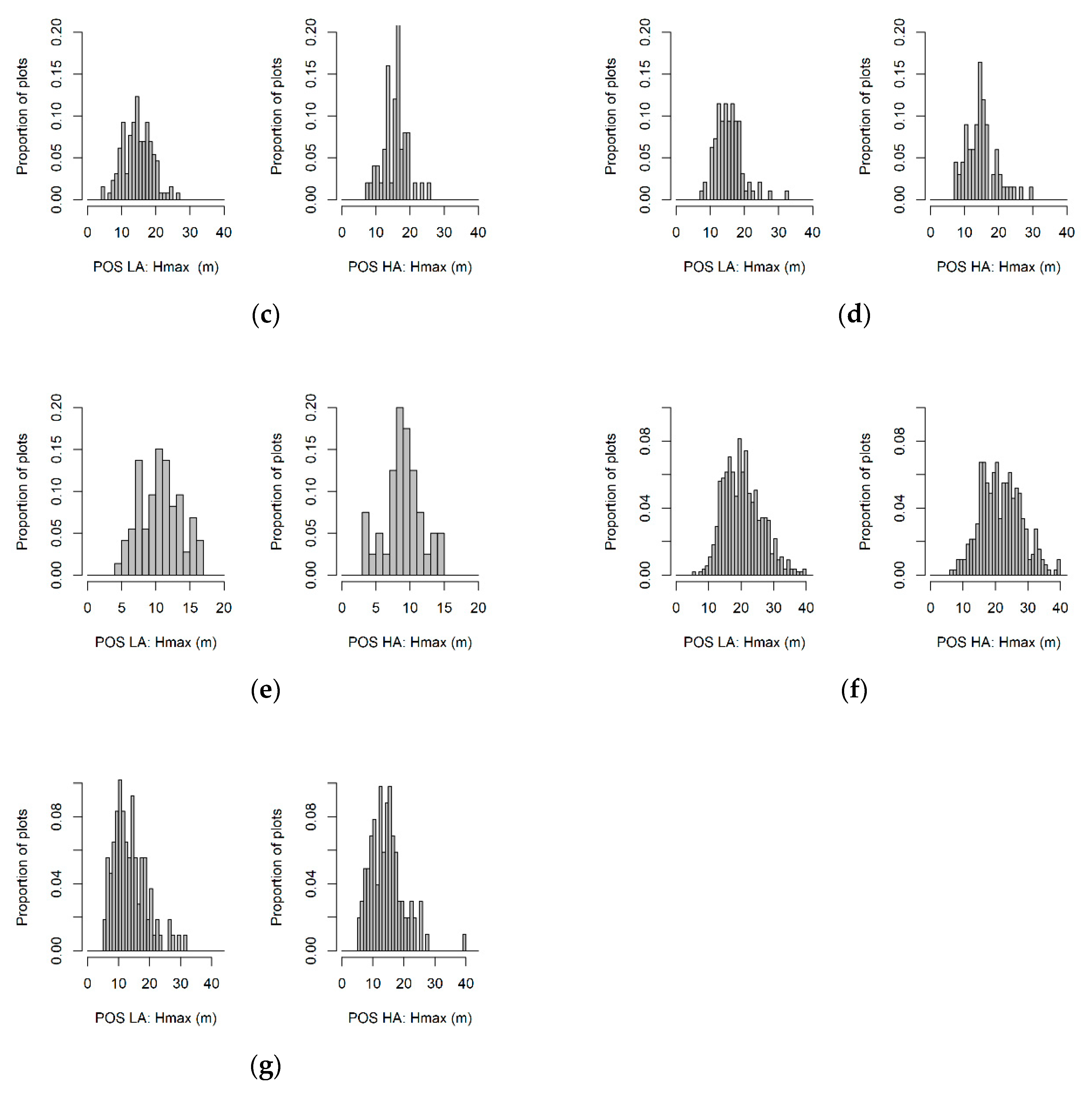
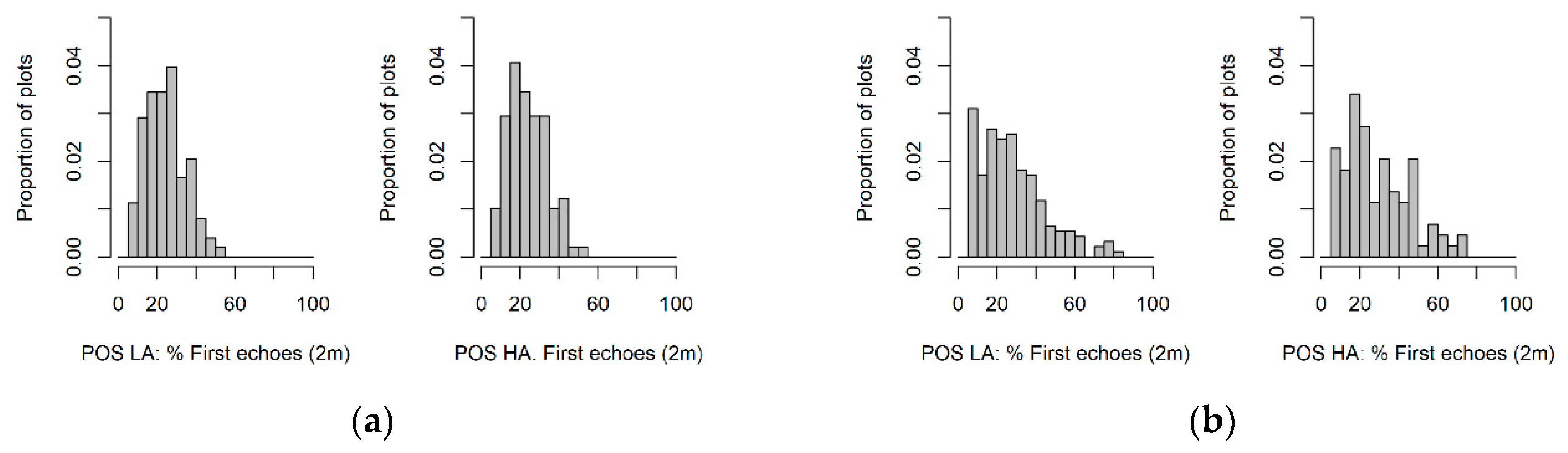
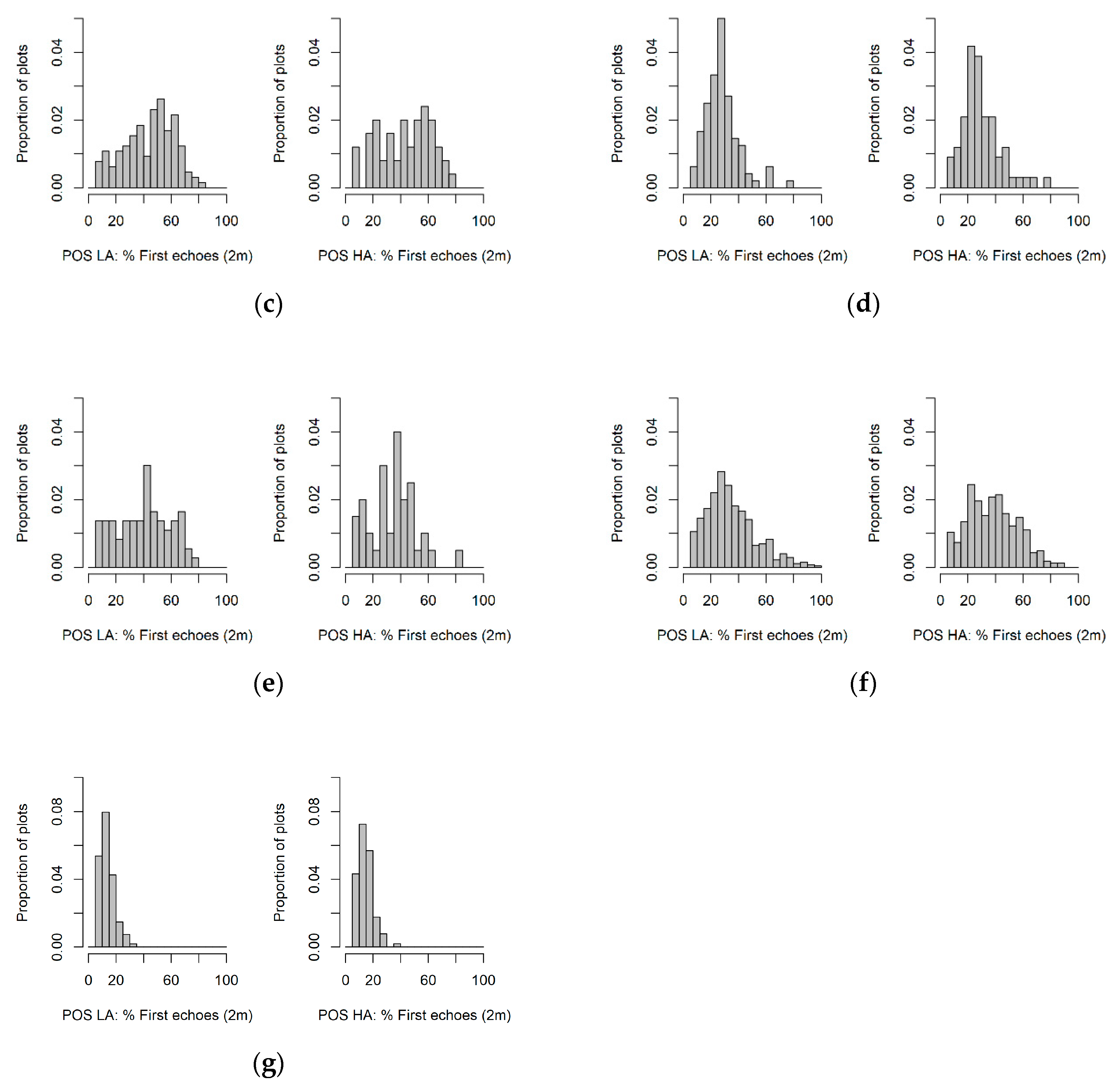
2.1. Study Area, Sampling Design and Ground Data
- Dehesa: sparse old-growth cork oak forests (Quercus suber L.) of low tree density, “Dehesas”, traditionally managed to produce cork and provide grazing for domestic and wild livestock.
- Encinar: sparse oak forest (Quercus ilex subsp. ballota (Desf.) Samp.) managed in a coppice rotation system to produce firewood and grazing for domestic and wild livestock.
- Pinaster: even-aged forests of Pinus pinaster subsp. mesogeensis Aiton.
- Eucalyptus: commercial forests of Eucalyptus spp.; the dominant especies is Eucalyptus camaldulensis Dehnh., which is used to be managed for pulp.
- Pinea: even-aged forests of Pinus pinea L. managed for cone production and oriented to provide important ecosystem services over sandy soils, such as soil erosion control.
- Canario: dense even-aged forests of Pinus canariensis C. Sm. that provide important forest ecosystems services, such as erosion control in steep terrains. Fayal-Brezal: the wax myrtle-tree heath (‘Fayal-Brezal’) forest is a mixture of laurel tree (Familia Lauraceae) and Myrica faya Ait. trees and Erica arborea L. arboreal shrubs.
2.2. Positioning Equipment and Co-Registration Assessment
2.3. Airborne Laser Scanning
2.4. Estimation of Forest Attributes
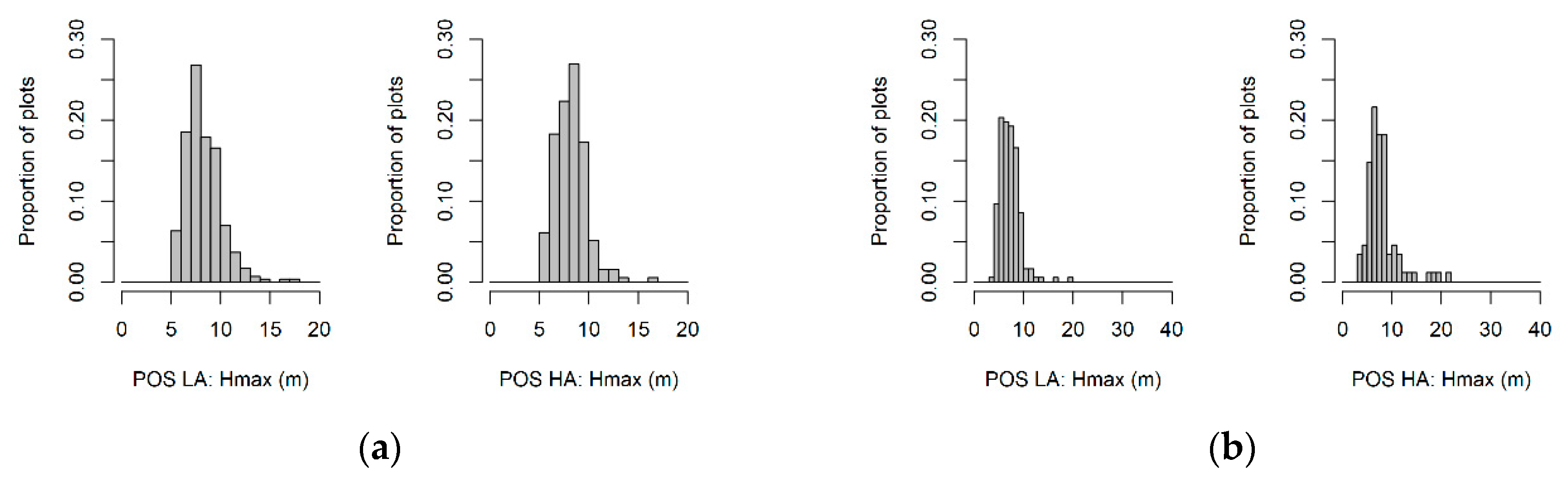
2.5. Inoptimality-Losses Approach and Co-Registration Assessment
3. Results
3.1. Selection of Predictor Variables and Model Building
3.2. Selection of Predictor Variables and Model Building
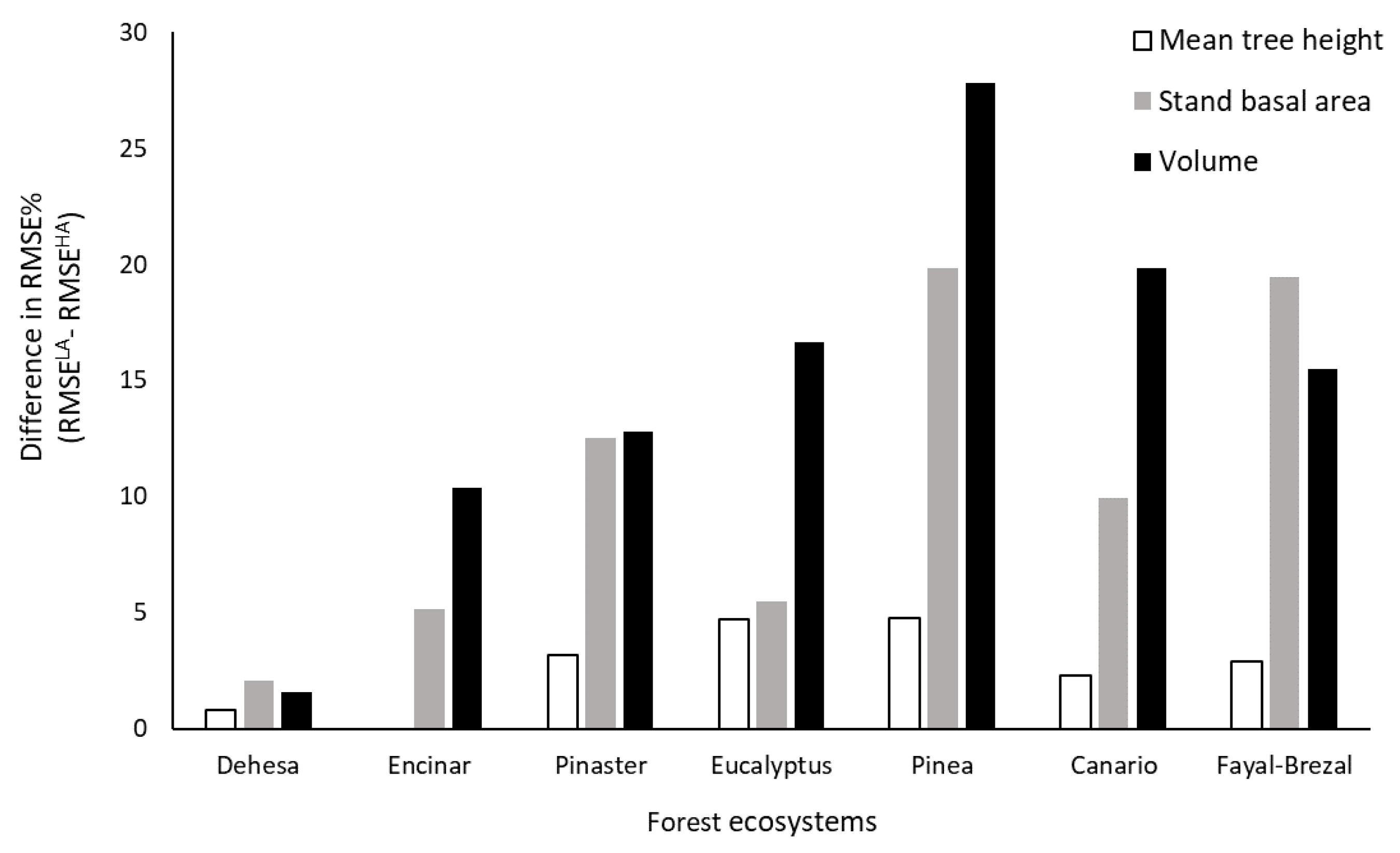
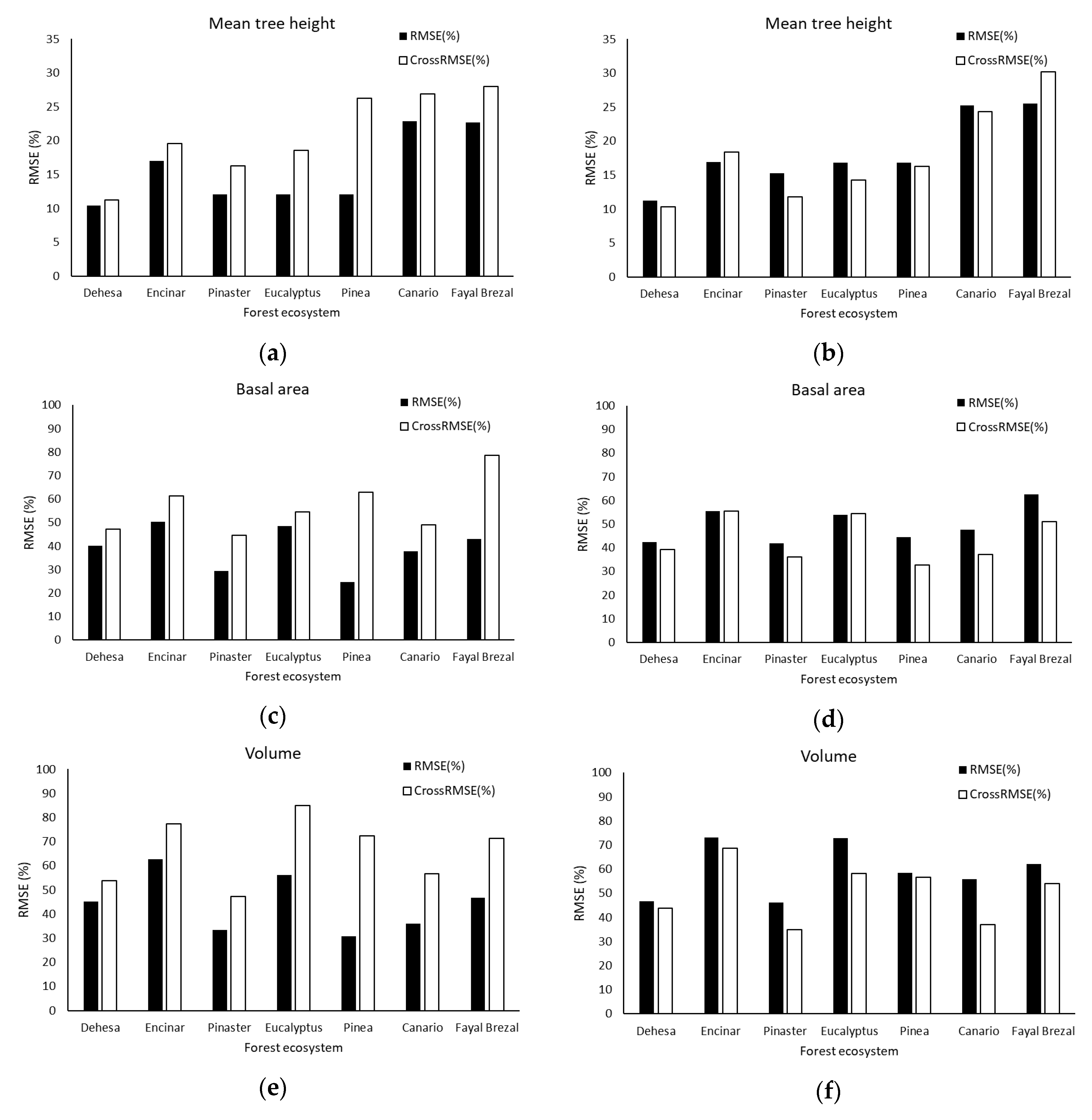
3.3. Assessing the Transferability Approach
3.3.1. Mean Tree Height Models
3.3.2. Stand Basal Area Models
3.3.3. Growing Stock Volume Models
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
Availability of Data and Materials
Appendix A




Appendix B

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Forest Attributes | POSHA Models | POSLA Models |
|---|---|---|
| G Mean tree height (HTmean, m) | ||
| HTmean = 0.760* + 1.319 Hmean*** | HTmean = 0.728** + 1.333 Hmean*** | |
| Encinar | HTmean = 0.896* + 1.324 H50*** | HTmean = 2.312*** + 0.795 H70*** |
| Pinaster | HTmean = 3.678*** + 0.789 H80*** | HTmean = 5.447*** + 0.729 H70*** |
| Eucalyptus | HTmean = 2.261*** + 0.934 H80*** | HTmean = 2.731*** + 0.744 H90*** |
| Pinea | HTmean = 4.552** + 0.097 Hstd*** | HTmean = 4.198** + 0.794 Hmean*** |
| Canario | HTmean = 1.940*** + 0.982 H50*** | HTmean = 3.244*** + 0.952 Hmean*** |
| Fayal-Brezal | HTmean = 3.995*** + 0.601 H40*** | HTmean = 3.256*** + 0.403 H99*** |
| Stand basal area (G, m2 ha−1) | ||
| Dehesa | G = −1.308 + 1.379 H01*** + 0.139 FCfirst*** | G = 0.668 + 0.038 Hstd** + 0.168 FCfirst*** |
| Encinar | G = −3.028* + 1.607 H40*** + 0.087 FCfirst*** | G = −5.023*** + 2.214 H10*** + 0.141 FCfirst*** |
| Pinaster | G = −10.097*** + 1.966 H10*** + 0.548 FCall*** | G = −14.256*** + 5.361 H01*** + 0.439 FCfirst*** |
| Eucalyptus | G = −7.585*** + 0.922 H50*** + 0.276 FCall*** | G = −4.578*** + 0.059 Hstd*** + 0.258 FCall*** |
| Pinea | G = −10.024** + 5.474 H01** + 0.264 FCfirst*** | G = −0.306 + 1.054 FCfirst *** - 0.803 FCall** |
| Canario | G = −11.28*** + 0.462 FCfirst *** + 24.338 CRR*** | G = −5.743*** + 0.747 H25*** + 0.440 FCfirst*** |
| Fayal-Brezal | G = −26.429*** + 0.367 FCfirst*** + 68.722 CRR*** | G = −9.437*** + 3.341 H30*** + 0.166 FCfirst *** |
| Growing stock volume (V, m3 ha−1) | ||
| Dehesa | V = 0.742 + 0.58 H99 + 0.327 FCfirst*** | V = −6.75*** + 1.214 H99*** + 0.437 FCfirst*** |
| Encinar | V = −6.709* + 1.783 H95* + 0.434 FCall*** | V = −6.186* + 1.944 Hkur* + 0.559 FCfirst*** |
| Pinaster | V = −85.719*** + 13.508 H25*** + 2.601 FCfirst*** | V = −66.684*** + 14.99 H10*** + 2.524 FCfirst*** |
| Eucalyptus | V = −39.306*** + 0.53 Hstd*** + 1.585 FCall*** | V = 96.374*** - 23.842 Hstd*** + 1.709 Hmean*** |
| Pinea | V = −33.442*** + 10.621 H20***- 1.052 FC first *** | V = −6.493 + 6.456 FCfirst *** - 5.432FCall** |
| Canario | V = −102.659*** + 11.647 H40***+ 2.875 FC first *** | V = −106.582*** + 9.825 H50*** + 3.193 FCfirst*** |
| Fayal-Brezal | V = −102.761*** + 31.997 H20*** + 0.867 FCfirst** | V = 21.305*** - 47.229 H01* + 36.030 H25*** |
References
- Corona, P.; Chirici, G.; McRoberts, R.E.; Winter, S.; Barbati, A. Contribution of large-scale forest inventories to biodiversity assessment and monitoring. For. Ecol. Manag. 2011, 262, 2061–2069. [Google Scholar] [CrossRef] [Green Version]
- Alberdi, I.; Condés, S.; Mcroberts, R.E.; Winter, S. Mean species cover: A harmonized indicator of shrub cover for forest inventories. Eur. J. For. Res. 2018, 137, 265–278. [Google Scholar] [CrossRef] [Green Version]
- Fernández-Landa, A.; Fernández-Moya, J.; Tomé, J.L.; Algeet-Abarquero, N.; Guillén-Climent, M.L.; Vallejo, R.; Sandoval, V.; Marchamalo, M. High resolution forest inventory of pure and mixed stands at regional level combining national forest inventory field plots, Landsat, and low density lidar. Int. J. Remote Sens. 2018, 39, 14. [Google Scholar] [CrossRef]
- Shang, C.; Coops, N.C.; Wulder, M.A.; White, J.C.; Hermosilla, T. Update and spatial extension of strategic forest inventories using time series remote sensing and modeling. Int. J. Appl. Earth Obs. 2020, 84, 101956. [Google Scholar] [CrossRef]
- McRoberts, R.E.; Andersen, H.E.; Næsset, E. Using airborne laser scanning data to support forest sample surveys. In Forestry Applications of Airborne Laser Scanning; Maltamo, M., Næsset, E., Vauhkonen, J., Eds.; Managing Forest Ecosystems Book Series Volume 27; Springer: Dordrecht, The Netherlands, 2014. [Google Scholar]
- Gschwantner, T.; Lanz, A.; Vidal, C.; Bosela, M.; Di Cosmo, L.; Fridman, J.; Gasparini, P.; Kuliešis, A.; Tomter, S.; Schadauer, K. Comparison of methods used in European national forest inventories for the estimation of volume increment: Towards harmonisation. Ann. For. Sci. 2016, 73, 807–821. [Google Scholar] [CrossRef] [Green Version]
- Tomppo, E.; Haakana, M.; Katila, M.; Peräsaari, J. Multi-Source National Forest Inventory: Methods and Applications; Springer: New York, NY, USA, 2008; Volume 18. [Google Scholar]
- White, J.C.; Coops, N.C.; Wulder, M.A.; Vastaranta, M.; Hilker, T.; Tompalski, P. Remote sensing technologies for enhancing forest inventories: A review. Can. J. Remote Sens. 2016, 42, 619–641. [Google Scholar] [CrossRef] [Green Version]
- Wulder, M.A.; White, J.C.; Nelson, R.F.; Næsset, E.; Ørka, H.O.; Coops, N.C.; Hilker, T.; Bater, C.W.; Gobakken, T. Lidar sampling for large-area forest characterization: A review. Remote Sens. Environ. 2012, 121, 196–209. [Google Scholar] [CrossRef] [Green Version]
- Vauhkonen, J.; Maltamo, M.; McRoberts, R.E.; Næsset, E. Introduction to forestry applications of airborne laser scanning. In Forestry Applications of Airborne Laser Scanning: Concepts and Case Studies; Maltamo, M., Næsset, E., Vauhkonen, J., Eds.; Managing Forest Ecosystems Book Series Volume 27; Springer: Amsterdam, The Netherlands, 2014. [Google Scholar]
- Gobakken, T.; Næsset, E. Assessing effects of positioning errors and sample plot size on biophysical stand properties derived from airborne laser scanner data. Can. J. For. Res. 2009, 39, 1036–1052. [Google Scholar] [CrossRef]
- Pascual, A.; Pukkala, T.; de-Miguel, S. Effects of plot positioning errors on the optimality of harvest prescriptions when spatial forest planning relies on ALS data. Forests 2018, 9, 371. [Google Scholar] [CrossRef] [Green Version]
- Johnson, C.E.; Barton, C.C. Where in the world are my field plots? Using GPS effectively in environmental field studies. Front. Ecol. Environ. 2004, 2, 475–482. [Google Scholar] [CrossRef]
- Pascual, A.; Bravo, F.; Ordoñez, C. Assessing the robustness of variable selection methods when accounting for co-registration errors in the estimation of forest biophysical and ecological attributes. Ecol. Model. 2019, 403, 11–19. [Google Scholar] [CrossRef]
- Frazer, G.W.; Magnussen, S.; Wulder, M.A.; Niemann, K.O. Simulated impact of sample plot size and co-registration error on the accuracy and uncertainty of LiDAR-derived estimates of forest stand biomass. Remote Sens. Environ. 2011, 115, 636–649. [Google Scholar] [CrossRef]
- Næsset, E.; Jonmeister, T. Assessing point accuracy of DGPS under forest canopy before data acquisition, in the field, and after postprocessing. Scan. J. For. Res. 2002, 17, 351–358. [Google Scholar] [CrossRef]
- Pascual, A. Using tree detection based on airborne laser scanning to improve forest inventory considering edge effects and the co-registration factor. Remote Sens. 2019, 11, 2675. [Google Scholar] [CrossRef] [Green Version]
- Mauro, F.; Valbuena, R.; Manzanera, J.A.; García-Abril, A. Influence of global navigation satellite system errors in positioning inventory plots for tree-height distribution studies. Can. J. For. Res. 2011, 41, 11–23. [Google Scholar] [CrossRef]
- Gopalakrishnan, R.; Thomas, V.A.; Coulston, J.W.; Wynne, R.H. Prediction of canopy heights over a large region using heterogeneous lidar datasets: Efficacy and challenges. Remote Sens. 2015, 7, 11036–11060. [Google Scholar] [CrossRef] [Green Version]
- Guerra-Hernández, J.; Bastos Görgens, E.; García-Gutiérrez, J.; Estraviz Rodriguez, L.C.; Tomé, M.; González-Ferreiro, E. Comparison of ALS based models for estimating aboveground biomass in three types of Mediterranean forest. Eur. J. Remote Sens. 2016, 49, 185–204. [Google Scholar] [CrossRef]
- Junttila, V.; Finley, A.O.; Bradford, J.B.; Kauranne, T. Strategies for minimizing sample size for use in airborne LiDAR-based forest inventory. For. Ecol. Manag. 2011, 292, 75–85. [Google Scholar] [CrossRef]
- Nord-Larsen, T.; Schumacher, J. Estimation of forest resources from a country wide laser scanning survey and national forest inventory data. Remote Sens. Environ. 2012, 119, 148–157. [Google Scholar] [CrossRef]
- Novo-Fernández, A.; Barrio-Anta, M.; Recondo, C.; Cámara-Obregón, A.; López-Sánchez, C.A. Integration of national forest inventory and nationwide airborne laser scanning data to improve forest yield predictions in north-western Spain. Remote Sens. 2019, 11, 1693. [Google Scholar] [CrossRef] [Green Version]
- Bontemps, J.D.; Bouriaud, O. Predictive approaches to forest site productivity: Recent trends, challenges and future perspectives. Forestry 2013, 87, 109–128. [Google Scholar] [CrossRef]
- Korhonen, L.; Repola, J.; Karjalainen, T.; Packalen, P.; Maltamo, M. Transferability and calibration of airborne laser scanning based mixed-effects models to estimate the attributes of sawlog-sized Scots pines. Silva Fenn. 2019, 53, 1–18. [Google Scholar] [CrossRef] [Green Version]
- Tompalski, P.; White, J.C.; Coops, N.C.; Wulder, M.A. Demonstrating the transferability of forest inventory attribute models derived using airborne laser scanning data. Remote Sens. Environ. 2019, 227, 110–124. [Google Scholar] [CrossRef]
- Domingo, D.; Alonso, R.; Lamelas, M.T.; Montealegre, A.L.; Rodríguez, F.; de la Riva, J. Temporal transferability of pine forest attributes modeling using low-density airborne laser scanning data. Remote Sens. 2019, 11, 261. [Google Scholar] [CrossRef] [Green Version]
- Fekety, P.A.; Falkowski, M.J.; Hudak, A.T.; Jain, T.B.; Evans, J.S. Transferability of lidar-derived basal area and stem density models within a northern Idaho ecoregion. Can. J. Remote Res. 2018, 44, 131–143. [Google Scholar] [CrossRef]
- Kangas, A.; Gobakken, T.; Puliti, S.; Hauglin, M.; Naesset, E. Value of airborne laser scanning and digital aerial photogrammetry data in forest decision making. Silva Fenn. 2018, 52, 9923. [Google Scholar] [CrossRef] [Green Version]
- Lindgren, N.; Christensen, P.; Nilsson, B.; Åkerholm, M.; Allard, A.; Reese, H.; Olsson, H. Using optical satellite data and airborne lidar data for a nationwide sampling survey. Remote Sens. 2015, 7, 4253–4267. [Google Scholar] [CrossRef] [Green Version]
- Sankey, T.; Donager, J.; McVay, J.; Sankey, J.B. UAV lidar and hyperspectral fusion for forest monitoring in the southwestern USA. Remote Sens. Environ. 2017, 195, 30–43. [Google Scholar] [CrossRef]
- Iglhaut, J.; Cabo, C.; Puliti, S. Structure from motion photogrammetry in forestry: A review. Curr. For. Rep. 2019, 5, 155–168. [Google Scholar] [CrossRef] [Green Version]
- Bravo, F.; Gabriel, J.; del Rio, M.; Barrio, M.; Bonet Lledos, J.A.; Bravo Olviedo, A.; Calama, R.; Castedo Dorado, F.; Crecente Campo, F.; Condes, S.; et al. Growth and yield models in Spain: Historical overview, contemporary examples and perspectives. For. Syst. 2012, 20, 315–328. [Google Scholar] [CrossRef] [Green Version]
- Alberdi, I.; Cañellas, I.; Vallejo, R. The Spanish national forest inventory: History, development, challenges and perspectives. Pesquisa Florestral Brasileira 2017, 37, 361. [Google Scholar] [CrossRef]
- Chirici, G.; Giannetti, F.; McRoberts, R.E.; Travaglini, D.; Pecchi, M.; Maselli, F.; Chiesi, M.; Corona, P. Wall-to-wall spatial prediction of growing stock volume based on Italian national forest inventory plots and remotely sensed data. Int. J. Appl. Earth Obs. 2020, 84, 101959. [Google Scholar] [CrossRef]
- Bolton, D.K.; Coops, N.C.; Wulder, M.A. Measuring forest structure along productivity gradients in the Canadian boreal with small-footprint Lidar. Environ. Monit. Assess. 2013, 185, 6617. [Google Scholar] [CrossRef]
- Shin, J.; Temesgen, H.; Strunk, J.L.; Hilker, T. Comparing modeling methods for predicting forest attributes using LiDAR metrics and ground measurements. Can. J. Remote Sens. 2016, 42, 739–765. [Google Scholar] [CrossRef]
- McRoberts, R.E.; Chen, Q.; Gormanson, D.D.; Walters, B.F. The shelf-life of airborne laser scanning data for enhancing forest inventory inferences. Remote Sens. Environ. 2018, 206, 254–259. [Google Scholar] [CrossRef]
- Isenburg, M. LAStools-Efficient LiDAR Processing Software, version 14101; rapidlasso GmbH: Gilching, Germany, 2018; Available online: http://rapidlasso.com/LAStools (accessed on 24 April 2018).
- Maltamo, M.; Næsset, E.; Vauhkonen, J. (Eds.) Forestry Applications of Airborne Laser Scanning: Concepts and Case Studies; Managing Forest Ecosystems Book Series Volume 27; Springer: Dordrecht, The Netherlands, 2014. [Google Scholar]
- Gleason, C.J.; Im, J. Forest biomass estimation from airborne LiDAR data using machine learning approaches. Remote Sens. Environ. 2012, 125, 80–91. [Google Scholar] [CrossRef]
- Fassnacht, F.E.; Hartig, F.; Latifi, H.; Berger, C.; Hernández, J.; Corvalán, V.; Koch, B. Importance of sample size, data type and prediction method for remote sensing-based estimations of aboveground forest biomass. Remote Sens. Environ. 2014, 154, 102–114. [Google Scholar] [CrossRef]
- Bouvier, M.; Durrieu, S.; Fournier, R.A.; Renaud, J.P. Generalizing predictive models of forest inventory attributes using an area-based approach with airborne LiDAR data. Remote Sens. Environ. 2015, 156, 322–334. [Google Scholar] [CrossRef]
- Kuuluvainen, T. Conceptual models of forest dynamics in environmental education and management: Keep it as simple as possible, but no simpler. For. Ecosyst. 2016, 3, 18. [Google Scholar] [CrossRef] [Green Version]
- Lumley, T.; Miller, A. Leaps: Regression Subset Selection. R Package. 2017. Available online: https://CRAN.R-project.org/package=leaps (accessed on 12 May 2019).
- R Development Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2019; Available online: https://www.R-project.org/ (accessed on 12 May 2019).
- Kotivuori, E.; Korhonen, L.; Packalen, P. Nationwide airborne laser scanning based models for volume, biomass and dominant height in Finland. Silva Fenn. 2016, 50, 1–28. [Google Scholar] [CrossRef] [Green Version]
- Moser, P.; Vibrans, A.C.; McRoberts, R.E.; Næsset, E. Methods for variable selection in LiDAR-assisted forest inventories. Forestry 2017, 90, 112–124. [Google Scholar] [CrossRef] [Green Version]
- Rodríguez, F.; Lizarralde, I.; Bravo, F. Comparison of stem taper equations for eight major tree species in the Spanish Plateau. For. Syst. 2015, 24, 2. [Google Scholar] [CrossRef] [Green Version]
- Kukunda, C.B.; Duque-Lazo, J.; González-Ferreiro, E.; Thaden, H.; Kleinn, C. Ensemble classification of individual Pinus crowns from multispectral satellite imagery and airborne LiDAR. Int. J. Appl. Earth Obs. 2018, 65, 12–23. [Google Scholar] [CrossRef]
- Blázquez-Casado, A.; Calama, R.; Valbuena, M. Combining low-density LiDAR and satellite images to discriminate species in mixed Mediterranean forest. Ann. For. Sci. 2019, 76, 57. [Google Scholar] [CrossRef]
- Maltamo, M.; Peuhkurinen, J.; Malinen, J.; Vauhkonen, J.; Packalén, P.; Tokola, T. Predicting tree attributes and quality characteristics of scots pine using airborne laser scanning data. Silva Fenn. 2009, 43, 507–521. [Google Scholar] [CrossRef] [Green Version]
- Zellner, A. An efficient method of estimating seemingly unrelated regressions and tests for aggregation bias. JASA 1962, 57, 348–368. [Google Scholar] [CrossRef]
- Burkhart, H.E.; Stuck, R.D.; Leuschner, W.A.; Reynolds, M.A. Allocating inventory resources for multiple-use planning. Can. J. For. Res. 1978, 8, 100–110. [Google Scholar] [CrossRef]
- St-Onge, B.; Vepakomma, U. Assessing forest gap dynamics and growth using multi-temporal laser-scanner data. IAPRS 2004, 140, 173–178. [Google Scholar]
- Bergseng, E.; Ørka, H.O.; Næsset, E.; Gobakken, T. Assessing forest inventory information obtained from different inventory approaches and remote sensing data sources. Ann. For. Sci. 2015, 72, 33–45. [Google Scholar] [CrossRef] [Green Version]





| Forest Ecosystem | Sample Plots | Statistic | HTmean (m) | G (m2 ha−1) | V (m3 ha−1) | N (trees ha−1) |
|---|---|---|---|---|---|---|
| Dehesa | 499 | Mean | 7.7 | 6.5 | 15.3 | 85.0 |
| Max | 14.1 | 27.8 | 62.6 | 1143.0 | ||
| Min | 3.4 | 0.7 | 1.2 | 5.1 | ||
| Encinar | 275 | Mean | 5.9 | 4.9 | 15.8 | 272.0 |
| Max | 11.7 | 31.3 | 108.6 | 2132.0 | ||
| Min | 2.9 | 0.4 | 1.2 | 5.1 | ||
| Pinaster | 180 | Mean | 11.7 | 20.1 | 126.1 | 488.0 |
| Max | 13.1 | 75.8 | 452.7 | 3214.9 | ||
| Min | 4.6 | 0.4 | 1.6 | 5.1 | ||
| Eucalyptus | 163 | Mean | 11.6 | 7.2 | 42.2 | 390.7 |
| Max | 24.9 | 47.8 | 396.5 | 1651.3 | ||
| Min | 4.3 | 0.4 | 2.1 | 5.1 | ||
| Pinea | 113 | Mean | 9.2 | 13.9 | 63.7 | 360.4 |
| Max | 17.7 | 64.4 | 426.8 | 2383.7 | ||
| Min | 3.6 | 0.4 | 2.2 | 5.1 | ||
| Canario | 880 | Mean | 13.3 | 18.4 | 132.6 | 302.7 |
| Max | 31.3 | 84.9 | 784.4 | 2574.7 | ||
| Min | 2.8 | 0.4 | 1.6 | 5.1 | ||
| Fayal-Brezal | 210 | Mean | 8.1 | 23.8 | 105.6 | 1527.8 |
| Max | 17.7 | 85.8 | 423.0 | 4806.8 | ||
| Min | 3.4 | 0.4 | 1.5 | 5.1 |
| Positioning Accuracy | Forest Ecosystem | ||||||
|---|---|---|---|---|---|---|---|
| Dehesa | Encinar | Pinaster | Eucalyptus | Pinea | Canario | Fayal Brezal | |
| POSLA only | 302 | 187 | 130 | 96 | 73 | 553 | 102 |
| POSLA and POSHA | 197 | 88 | 50 | 67 | 40 | 327 | 108 |
| Re-measurement (%) | 39.5 | 32.0 | 27.8 | 41.1 | 35.4 | 37.2 | 51.5 |
| Total samples | 499 | 275 | 180 | 163 | 113 | 880 | 210 |
| *Statistic | Symbol | Description |
|---|---|---|
| Moment statistics | ||
| Central tendency | Hmean | Mean elevation of ALS echoes. |
| Skewness | Hskew | Skewness of the distribution of ALS echoes. |
| Kurtosis | Hkurt | Kurtosis of the distribution of ALS echoes. |
| Order statistics | Hmax HMin | Maximum and minimum elevation of ALS echoes. |
| CRR | Canopy Relief Ratio defined as (Hmean − HMin)/(Hmax − HMin). | |
| Height percentiles | Hi for i = 1, 5, 10, 20, 25, 30, 40, 50, 60, 70, 75, 80, 90, 95, 99 | Height percentiles of the ALS echoes distribution. |
| Density metric | ||
| Percent all > 2 m | FCall | Number of all points above 2 m divided by the number of all returns. |
| Cover metric | ||
| Percent first > 2 m | FCfirst | Number of first returns above 2 m divided by the number of all first returns as a percentage. |
| Forest Ecosystem | Mean Distance (m) | Distance Range (m) | Standard Deviation (m) |
|---|---|---|---|
| Dehesa | 21.1 | 0.5–90.6 | 12.9 |
| Encinar | 21.4 | 4.0–63.5 | 13.4 |
| Pinaster | 29.5 | 0.8–85.5 | 19.2 |
| Pinea | 22.9 | 0.7–57.8 | 16.9 |
| Eucalyptus | 22.5 | 2.3–90.6 | 14.4 |
| Canario | 29.5 | 1.6–249.7 | 35.2 |
| Fayal-Brezal | 30.1 | 2.3–119.5 | 28.0 |
| Forest Attribute | Forest Ecosystem | ||||||
|---|---|---|---|---|---|---|---|
| Dehesa | Encinar | Pinaster | Eucalyptus | Pinea | Canario | Fayal Brezal | |
| POSLA | |||||||
| Mean tree height (HTmean, m) | Hmean | H40 | H70 | H90 | Hmean | Hmean | H99 |
| Basal area (G, m2 ha−1) | Hmax | Hkur | H10 | Hstd | FCfirst | H50 | H01 |
| FCfirst | FCfirst | FCfirst | FCall | FCall | FCfirst | H25 | |
| Volume (V, m3 ha−1) | Hstd | H10 | H01 | Hstd | FCfirst | H25 | H30 |
| FCfirst | FCfirst | FCfirst | FCall | FCall | FCfirst | FCfirst | |
| POSHA | |||||||
| Mean tree height (HTmean, m) | Hmean | H99 | H80 | H80 | Hstd | H50 | H40 |
| Basal area (G, m2 ha−1) | H99 | H95 | H25 | Hstd | FCfirst | FCfirst | FCfirst |
| FCall | FCall | FCall | FCall | H20 | H40 | H20 | |
| Volume (V, m3 ha−1) | H01 | H40 | H10 | H50 | H10 | CRR | FCall |
| FCfirst | FCfirst | FCall | FCall | FCfirst | FCfirst | FCfirst | |
| Forest Attribute | Forest Ecosystem | ||||||
|---|---|---|---|---|---|---|---|
| Dehesa | Encinar | Pinaster | Eucalyptus | Pinea | Canario | Fayal Brezal | |
| POSLA | |||||||
| Mean tree height (HTmean, m) | 0.70 | 0.45 | 0.65 | 0.62 | 0.59 | 0.49 | 0.46 |
| (11.2) | (16.9) | (15.2) | (16.8) | (16.8) | (25.1) | (25.5) | |
| Basal area (G, m2 ha−1) | 0.45 | 0.57 | 0.66 | 0.60 | 0.69 | 0.65 | 0.45 |
| (42.3) | (55.4) | (41.8) | (54.0) | (44.3) | (47.6) | (62.4) | |
| Volume (V, m3 ha−1) | 0.50 | 0.46 | 0.67 | 0.57 | 0.61 | 0.67 | 0.61 |
| (46.6) | (73.0) | (46.0) | (72.7) | (58.5) | (55.8) | (62.2) | |
| POSHA | |||||||
| Mean tree height (HTmean, m) | 0.70 | 0.65 | 0.69 | 0.81 | 0.81 | 0.67 | 0.46 |
| (11.2) | (17.0) | (12.0) | (12.1) | (12.1) | (22.9) | (22.6) | |
| Basal area (G, m2 ha−1) | 0.35 | 0.40 | 0.79 | 0.71 | 0.83 | 0.65 | 0.68 |
| (40.1) | (50.3) | (29.3) | (48.5) | (24.6) | (37.7) | (43.0) | |
| Volume (V, m3 ha−1) | 0.31 | 0.50 | 0.78 | 0.78 | 0.83 | 0.77 | 0.74 |
| (45.0) | (62.6) | (33.2) | (56.1) | (30.7) | (35.9) | (46.7) | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pascual, A.; Guerra-Hernández, J.; Cosenza, D.N.; Sandoval, V. The Role of Improved Ground Positioning and Forest Structural Complexity When Performing Forest Inventory Using Airborne Laser Scanning. Remote Sens. 2020, 12, 413. https://0-doi-org.brum.beds.ac.uk/10.3390/rs12030413
Pascual A, Guerra-Hernández J, Cosenza DN, Sandoval V. The Role of Improved Ground Positioning and Forest Structural Complexity When Performing Forest Inventory Using Airborne Laser Scanning. Remote Sensing. 2020; 12(3):413. https://0-doi-org.brum.beds.ac.uk/10.3390/rs12030413
Chicago/Turabian StylePascual, Adrián, Juan Guerra-Hernández, Diogo N. Cosenza, and Vicente Sandoval. 2020. "The Role of Improved Ground Positioning and Forest Structural Complexity When Performing Forest Inventory Using Airborne Laser Scanning" Remote Sensing 12, no. 3: 413. https://0-doi-org.brum.beds.ac.uk/10.3390/rs12030413