3.1. Ground Point Extraction
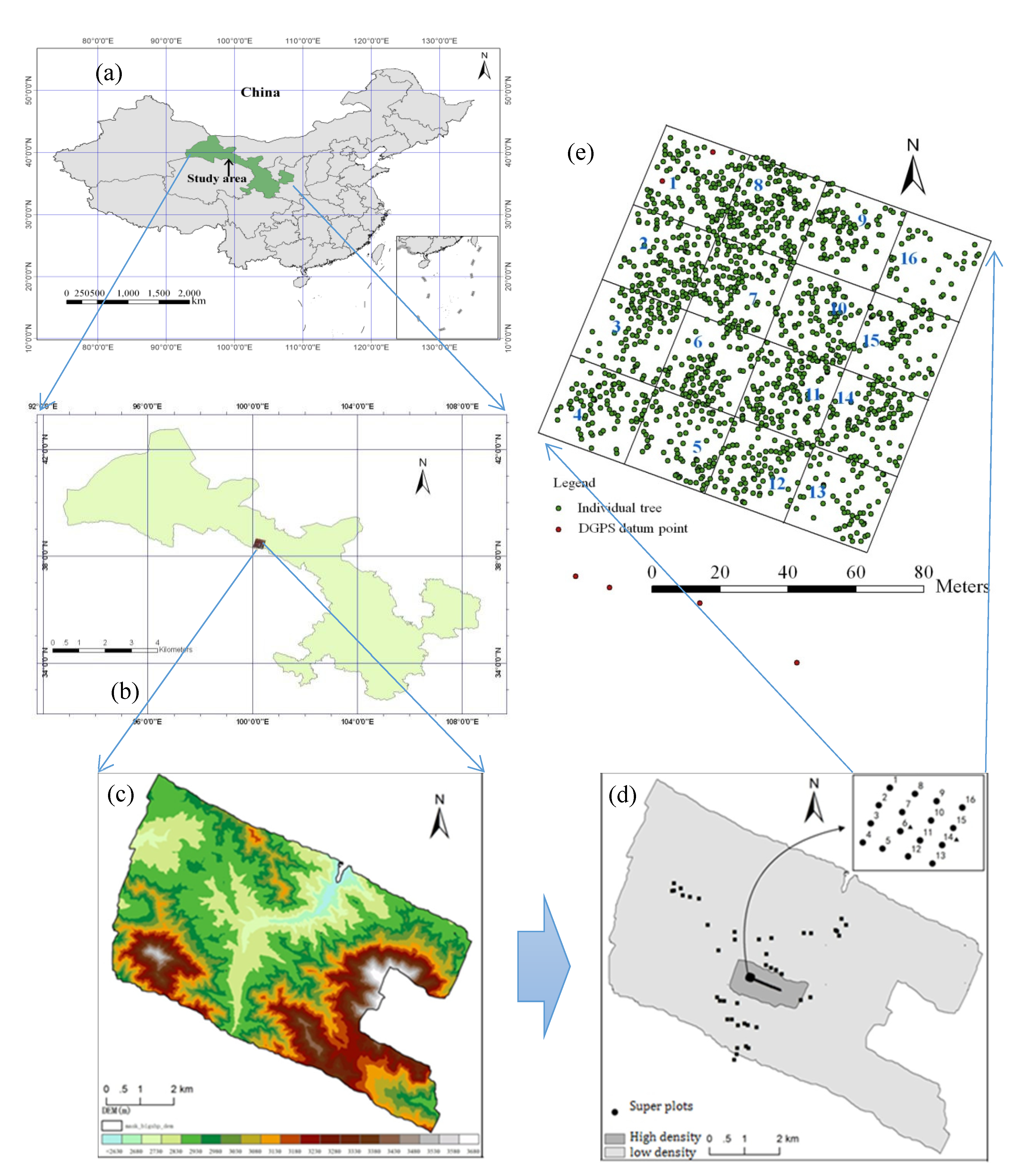
In this section, the iterative TIN algorithm was used to extract the ground points, and then four interpolation algorithms were used, and their accuracy was analyzed. In order to eliminate the influence of scanning angle, 27 LiDAR lines—each with a scanning degree of less than 10 degrees—were selected based on Terrasolid software, totaling 8,028,759 points, with an average density of 0.7 points/m
2. Iterative TIN algorithm assumes that the ground changes are smooth, and the large elevation changes in some areas are caused by buildings or vegetation [
3]. Therefore, the ground points are screened by controlling the increment of slope. The extraction of ground points is to filter ground points based on a large grid and construct a sparse irregular triangular network. Then, a new triangular network is constructed with the initial ground points, and the iteration increment is calculated. The ground points are re-screened until the termination conditions of iteration or a certain number of iterations are met, the iteration is stopped, and the output is the expected result.
There are three types of parameters that need to be set in this algorithm: one is the initial mesh size, the other is the increment of iteration, and the third is the termination condition. According to the study area conditions, the parameters of the algorithm were set as follows: the initial mesh size was set to 60 m × 60 m; the termination conditions included terrain angle, iteration angle, and iteration distance, which were set to 88 degrees, 9 degrees, and 1.4 m, respectively; and the classification option was to stop iteration when the distance became less than 5 m. After calculation, 1,996,001 ground points were selected. One profile is shown in
Figure 2. It showed that the algorithm did not detect all the ground points, but it was enough to construct high-precision DEM.
3.2. DEM Extraction Based on Interpolation Algorithms
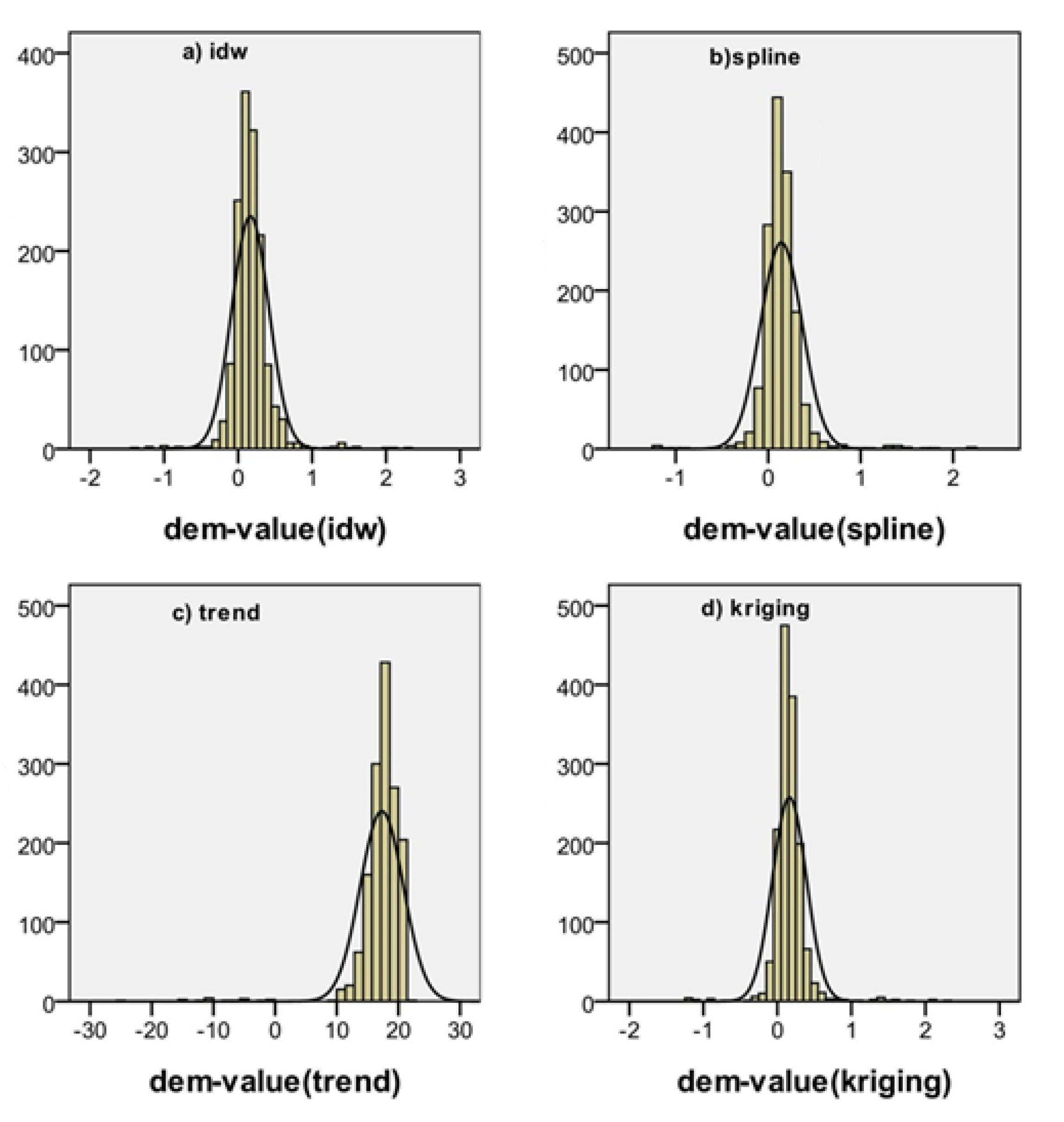
Based on the extracted ground points, DEM were generated, using an inverse distance weighted algorithm (IDW), a thin spline algorithm, a trend surface interpolation algorithm, and a Kriging algorithm.
(1) Inverse Distance Weighted Algorithm
The first law of geography states that the similarity between two objects decreases as their distance increases. Therefore, the closer to the target point, the higher the similarity with it, the higher the weight when estimating. Inverse Distance Weighted interpolation (IDW) is based on this model. The general equation of IDW is as follows:
In the formula, Z0 is the estimated value of point 0; Zi is the Z value of point i; di is the distance between point i and point 0; s is the number of points involved in the estimation; and k is the power. Moreover, k denotes the relationship between similarity and distance of spatial objects. The larger the k value, the faster the similarity of things decays with increasing distance.
This method is simple, intuitive, and efficient. The interpolation effect of the algorithm is good when the distribution of known points is uniform. The interpolation results are between the maximum and minimum values of the interpolate data and are susceptible to extreme values.
(2) Thin Spline Algorithm
Thin spline function is based on known points, and a smooth interpolation curve is generated by using the polynomial fitting method. It has the feature that all points are on the surface, and the surface slope changes least. The approximate expression of the thin spline function is as follows:
Here, x and y indicate the abscissa and ordinate of the interpolation points;
represents the square of the distance from the known point i to the point to be interpolated; x
i and y
i are the abscissa and ordinate of control point i, respectively. Thin spline functions include two parts: (
) is a local trend function whose expression is similar to the first order linear trend surface;
is a basic function used to generate a surface with minimum curvature. The coefficients of
, a, b, and c are derived from the following linear equations.
In the formula, n is the number of control points, fi is the known value of control point i, and the estimation of coefficients is a solution of an equation system consisting of n+3 equations.
Unlike IDW, the predicted values of thin spline function method are not limited to the maximum and minimum values of control points. This method has the advantages of easy operation and small computation [
18]. However, it is difficult to estimate the error, and the interpolation effect is poor when the sampling points are scarce.
(3) Trend Surface Interpolation Algorithm
Trend surface analysis is based on the principle of regression analysis. Least squares method is used to fit a binary nonlinear function, to simulate the spatial distribution of geographical elements, and to show their change trend.
In field measurement, only discrete data can be obtained. Trend surface analysis builds polynomials based on these known points and estimates the values of other points. The first-order trend surface is expressed as follows:
In the formula, the attribute value Z is a function of coordinates x and y, and the coefficient bi is estimated by known points. The model uses the least square method to estimate bi, thus the fitting degree of the model can be measured.
Actually, the spatial distribution of geographic objects is more complex than the inclined surface generated by the first-order trend surface, such as the third-order surface containing mountains and valleys. This model is based on the following formula:
The first-order trend surface needs three coefficients, while the third-order trend surface needs to estimate 10 coefficients (bi), to predict the value of unmeasured points. The higher the order of the trend surface model is, the higher the accuracy is, and the larger the calculation amount is. Therefore, it is necessary to choose the appropriate model order according to the research complexity.
(4) Kriging Algorithm
Kriging is a geostatistical method for spatial interpolation. Compared with the previous three interpolation methods, Kriging can evaluate the prediction quality by estimating the prediction error. This study adopted the ordinary Kriging method. Assuming that there is no drift, the ordinary Kriging method only considers the spatially correlated factors and interpolates directly with the fitting semivariogram. The equation for estimating the Z value of a measurement point is as follows:
In the formula, Z
0 is the value to be estimated; Z
x is the known value of x; w
x is the weight of x; and s is the number of sample points. The weight can be obtained by solving a set of simultaneous equations. For example, when estimating the value of an unknown point (0) from three known points (1, 2, 3), the three equations in (7) need to be combined.
Here, γ(hij) is the semivariogram between known points i and j; γ(hi0) is the semivariogram between the known point i and the unknown point; and λ is the introduced Lagrange coefficient to ensure the minimum estimation error.
After calculating the weight, Z0 can be estimated by Equation (8):
The abovementioned equations indicate that Kriging method considers not only the relationship between estimated points and known points, but also the semivariogram between known points when calculating weights. Compared with other local fitting methods, Kriging calculates the variation of each estimated point, and the interpolation accuracy is higher.
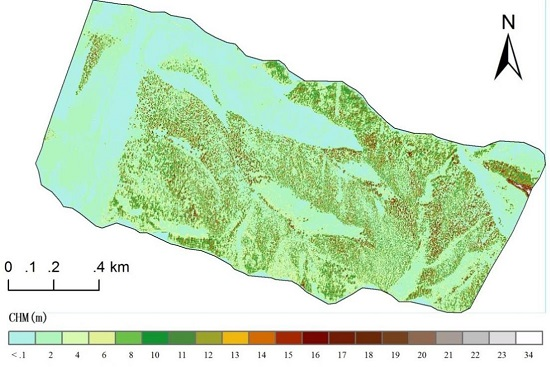
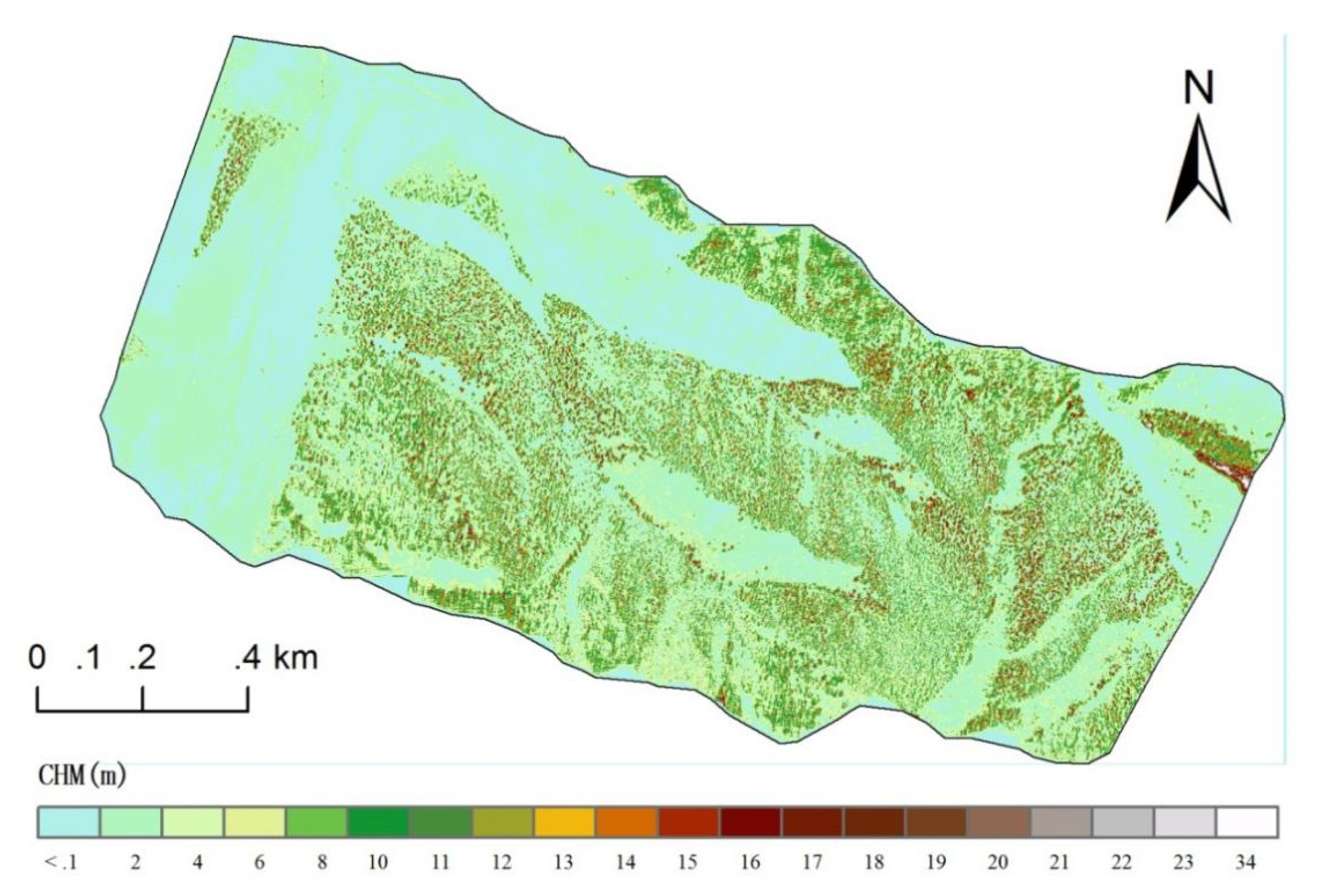
The DEM was acquired by the interpolation method. The height of the point cloud was assigned to the DSM and the CHM was acquired.
3.3. Individual Tree Parameter Inversion Algorithm
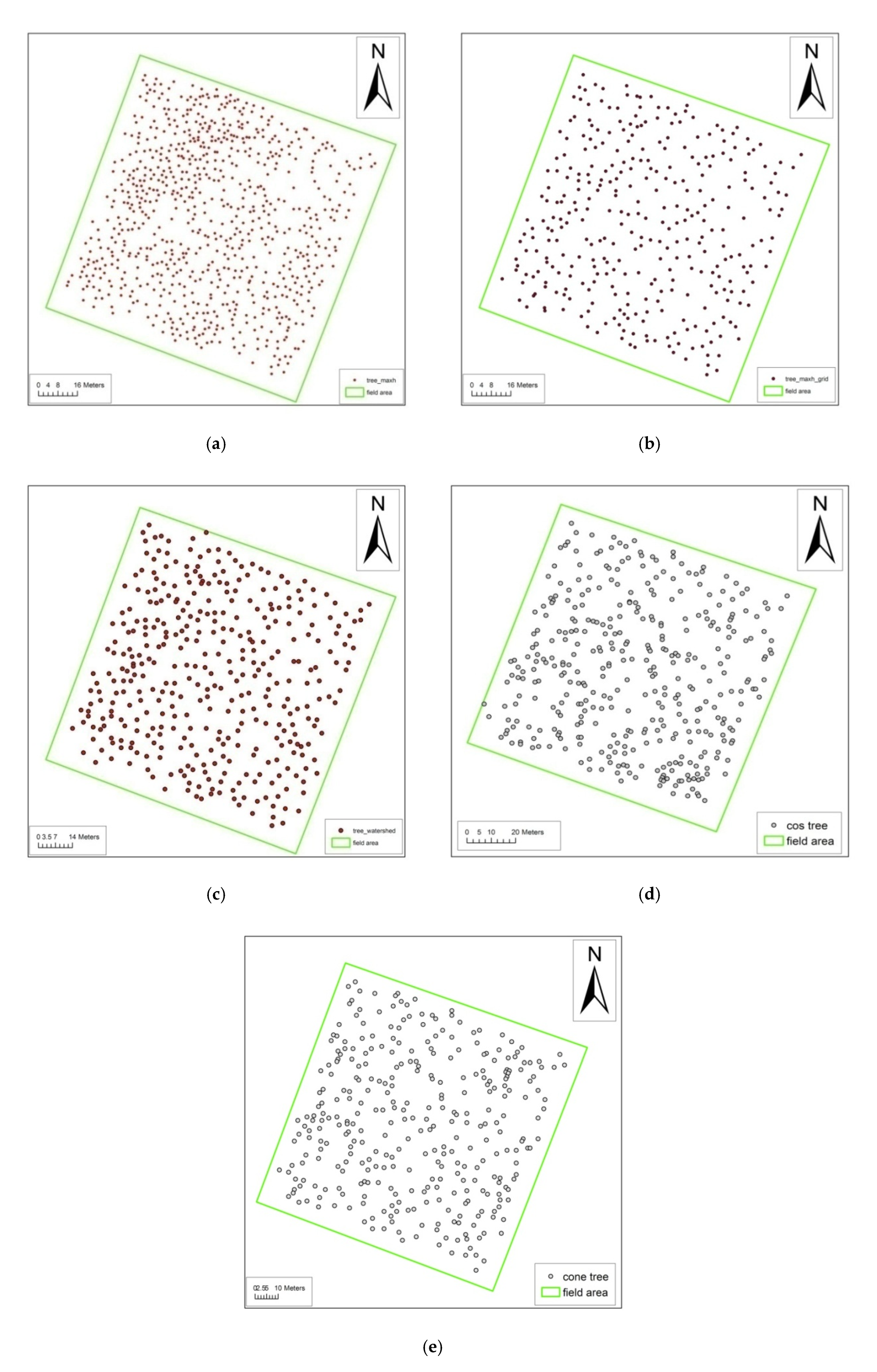
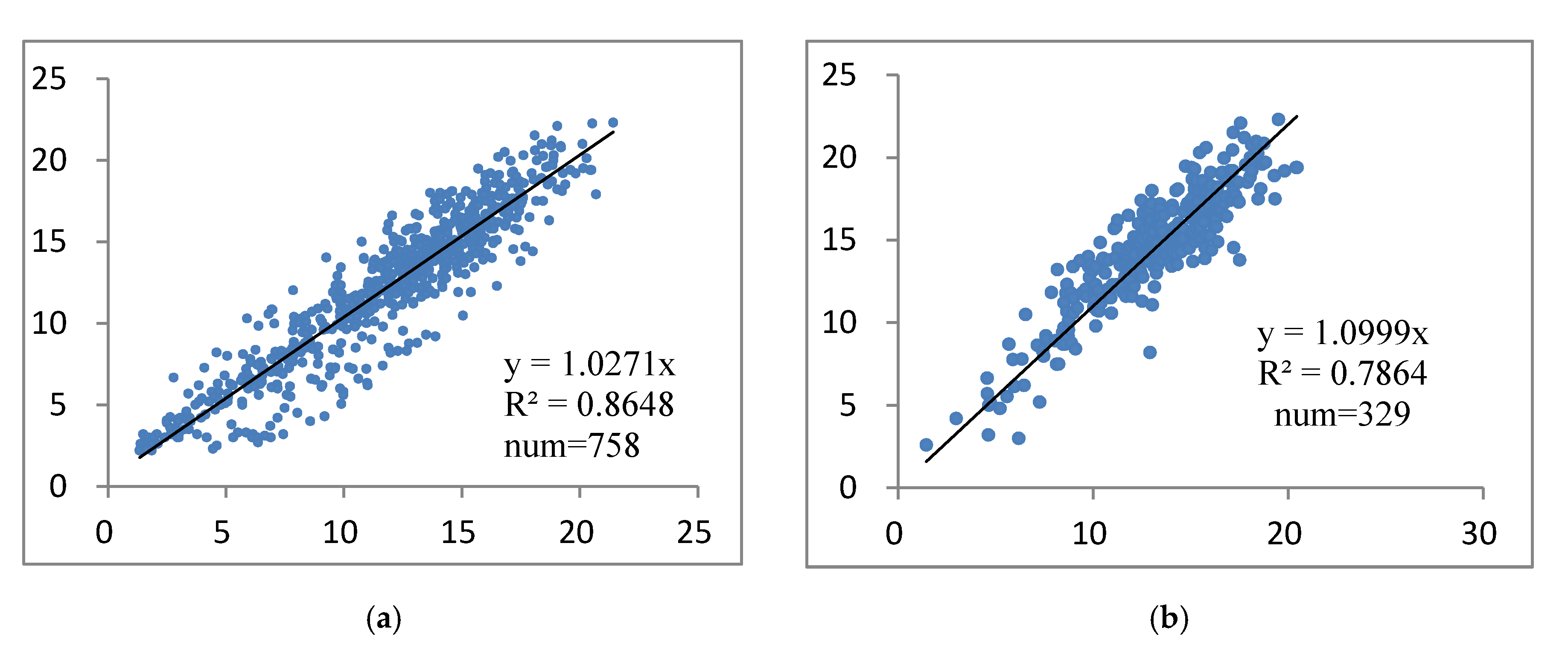
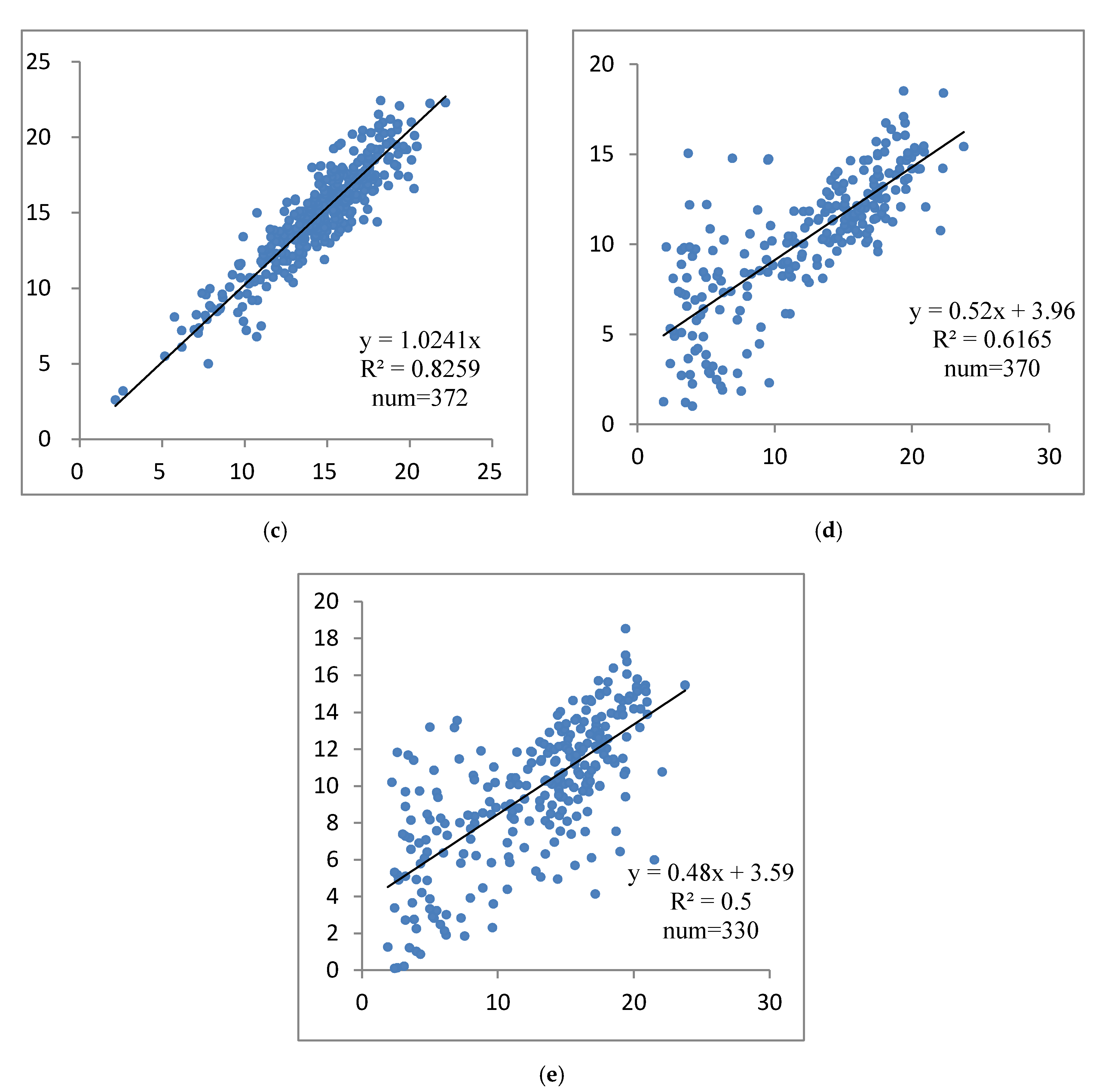
(1) Local Maximum Algorithms Based on Point Clouds
Local maximum algorithms based on point clouds searches the maximum value in a certain window size as the treetop position. It needs to set the window size according to the distribution and structure of the tree crown. For the same forest stand with uniform crown size, a fixed window size can be used. When the crown size varies greatly, the fixed search window can easily produce pseudo treetop or miss crown vertices. A feasible alternative is to determine the search window size according to the relationship between tree height and crown width [
30]. For the forest area with the same tree species of
Picea crassifolia, there is a linear relationship between tree height and crown width [
18]:
Here, X denotes tree height, and Y denotes crown width. The parameters of the equation were determined by linear regression of measured tree height and crown width in the surveyed plots.
Firstly, the LiDAR point cloud data in xyz format was transformed into shp format, and then the elevation value of DEM was extracted and assigned to each point, and the difference between the height of point cloud and DEM was calculated, so that the distance between each point and ground was obtained. Based on this, the Thiessen polygons and TIN were constructed, and the volume was calculated by taking the height of the interior point of the Thiessen polygon as the base. If the volume was 0, it indicated that the point was the highest and was reserved as an individual treetop [
22]. Then, the points with height less than 1.3 m were removed. Finally, using the relationship between tree height and crown width (Equation (9)), the pseudo-single-tree points which did not satisfy the conditions were gradually eliminated.
(2) Local Maximum Algorithms Based on CHM
In order to eliminate the noise in CHM, a 3 × 3 pixel mean filtering operation was performed on CHM, and then the local maximum of 3 × 3 pixel windows was searched as the candidate point of the treetop [
6,
18]. Finally, the theoretical crown width was calculated according to the tree height and Equation (9) of the candidate points. When the distance between the two candidate points was less than half of the theoretical crown width, the points with a smaller tree height were removed until the distance among all the points was greater than half of the theoretical crown width.
(3) Watershed Algorithm
A watershed is a mountain or plateau that separates two adjacent basins from which the river flows in two opposite directions. The watershed algorithm is the watershed transform based on the overflow model. It regards the gray value of the image as the elevation, and the water immerses the surface from the water-accumulation point, and gradually submerges the image at the same speed. When the rising water level from different minimum values meets, a dam is constructed to block it. Until only the top of the dam is above the water surface, the procedure is terminated and the segmentation is completed.
Taking two pixels as radius, the mean filtering of CHM (with a spatial resolution of 0.5 m) was carried out, and the inverse was obtained. In this way, a large number of small gullies were obtained. On this basis, basin function embedded in ArcGIS tool was used to extract watershed. The highest value of each basin was taken as the height of an individual tree, and the location was taken as the position of an individual tree.
(4) Template-Matching Algorithm
Template-matching algorithm is a method to find objects similar to the template from the original images according to the distance or correlation. This technology is often used in image registration, interferometric SAR, and other remote-sensing data processing. The correlation coefficient can be used as an index to measure the matching degree of the template and graph (Equation (10)).
Here, xi represents the gray value of the template, and yi represents the gray value of the detected image. When r = 1, it indicates that the current position is positively correlated with the template and the matching is successful; when r = 0, they are completely unrelated, or not the search target; if r = −1, this means that they are negatively correlated and need to be re-detected by rotation or other operations.
In this study, the mean filtering of 3 × 3 was performed, and then the maximum value in the neighborhood of 3 × 3 was extracted. With this point as the center, the correlation coefficients were obtained by using two-dimensional cosine function and conic function whose diameter was 3, 5, 7, 9, 11, 13, 15, 17, and 19 pixels and height was equal to the height of the treetop. Finally, the maximum value of correlation coefficient greater than 0.8 was retained as the single tree position, and the diameter of the maximum deceleration rate of correlation coefficient was used as the crown width.
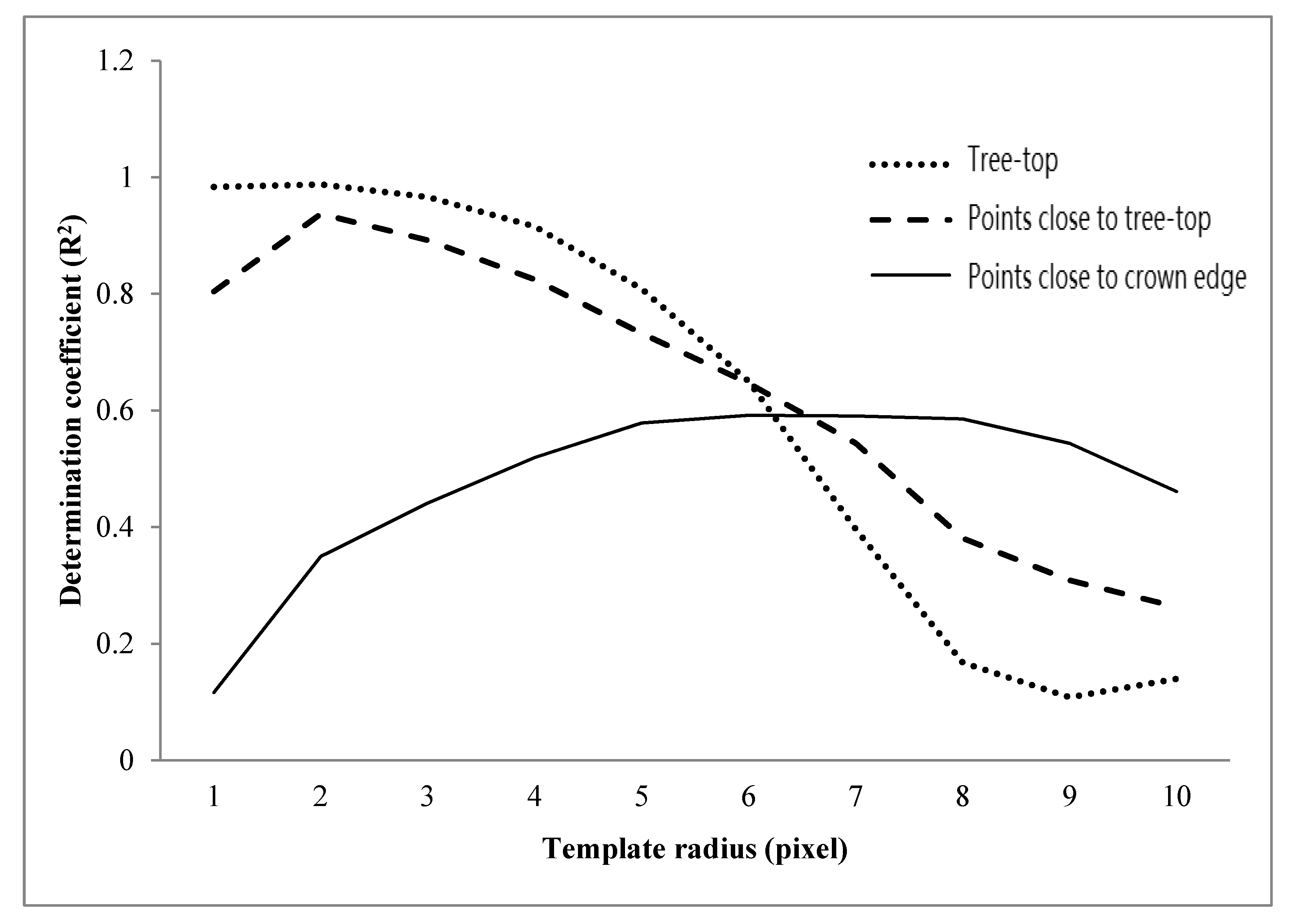
As shown in
Figure 3, when the matching point is located at the top of the tree, the matching point extends gradually to the ground and the surrounding crown, and the determination coefficient of the crown and the model decreases gradually. When the matching points are located in the canopy around the treetop, with the increase in the radius, the matching points gradually extend to the ground and the surrounding canopy, and the correlation coefficient between the canopy and the model decreases first, then increases, and finally decreases. This rule can be used to extract the crown width of individual trees.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}