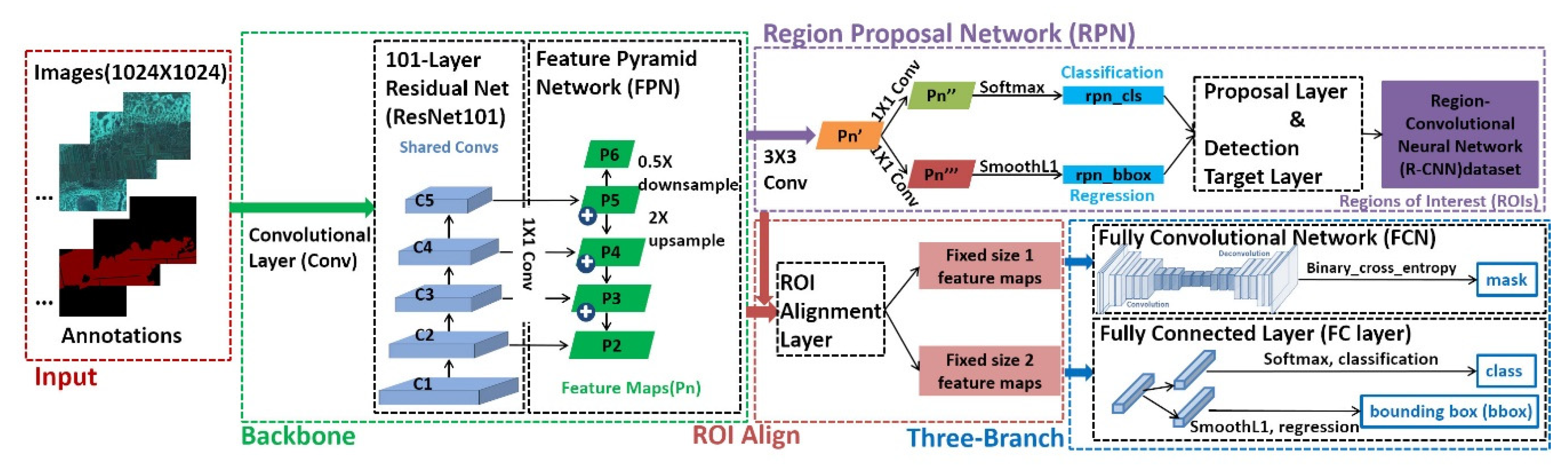
3.1.1. Network structure and working process of Mask R-CNN
Mask R-CNN is developed from Faster Region-Convolutional Neural Networks (Faster R-CNN) [
48,
49], and Faster R-CNN is inherited from Fast Region-Convolutional Neural Networks (Fast R-CNN) [
50]. Fast R-CNN is formed on the basis of Region-Convolutional Neural Networks (R-CNN) [
51]. The architecture of Mask R-CNN is shown in
Figure 3, including the feature extraction module, region proposal network (RPN), the region of interest (ROI) alignment layer, the classification-regression-mask prediction module (three-branch module), etc.
The backbone of the feature extraction module is a 101-layer residual net (ResNet101) [
52], while the framework includes feature pyramid networks (FPN) [
53]. The essence of ResNet101 is a series of shared convolutional layers (Shared Convs) that are used to extract multi-layer feature maps of the input images from the bottom-up. The bottom-up process is a common forward propagation for extracting feature maps using neural networks. The convolution kernels in a neural network are usually arranged from a large size to a small size in the same order as the convolution computation process. The FPN is a network connection form for combining and enhancing the semantic information in multi-layer feature maps, which is effective for solving multi-scale problems in object detection. The process of FPN has three steps: (1) the nearest neighbor up-sample is carried out for every layer except the 1st and 2nd based on a multi-layer feature map from ResNet101; (2) the up-sample results are horizontally connected to the Conv1D [
54] results of the upper layer for summation. Conv1D means a one-dimensional convolution, which is used for parameter reduction and data simplification in a neural network; (3) the nearest neighbor down-sample is carried out for the last layer. As a result, the feature pyramid is constructed so that each feature layer features strong semantic and spatial information.
Based on the FPN, ROIs are generated by two sub-modules (classification and regression) of the RPN. The purpose of the RPN is to identify the possible targets, while specific types are temporarily ignored. The processing steps are as follows: (1) traversing each pixel in every feature layer to generate the anchors per center pixel. An anchor is a rectangular target box on the corresponding center pixel on a feature map. The target box is an optional item of object detection. The area of the anchor is determined by the corresponding feature map, which is equal to the square value of the relative step size between the feature map and the original image. There are three anchors generated on each central pixel with three horizontal-vertical ratios of 0.5, 1, and 2. Then, the anchors are divided into positive and negative classes with a ratio of about 1:1 according to the threshold screening of the intersection over union (IOU). The IOU is calculated between each anchor and ground truth box:
where
and
represent the predicted area and the ground truth area, respectively; (2) for the positive and negative anchors, the foreground or background score of every anchor and coordinate offset between each anchor and the corresponding ground truth are calculated by forward propagation; (3) updating the weights of the network by back propagation. For the classification sub-module, the binary cross-entropy loss of the Softmax function is adopted in the RPN:
where
represents the score of category
calculated through network forward propagation;
is the total number of categories;
expresses the probability of category
covered by the Softmax function;
means the classification loss of RPN; and
stands for the true class label. The difference between
and
is calculated as a gradient of each feature layer when
is transmitted back, and is used to guide the weight parameter update of the network at the next forward propagation. For the bounding box (bbox) regression sub-module, the loss function of the Smooth
L1 function is employed in RPN, whose derivative is used to guide the weight updating of the feature layer:
where
expresses the bbox regression loss of RPN;
/
/
/
,
/
/
/
, and
/
/
/
, respectively, represent the coordinates of the prediction box calculated by forward propagation, the anchor and truth box;
is a vector that stands for the offset between the anchor and prediction box from RPN;
is a vector that has the same dimension as
and indicates an offset between the anchor and truth box. (4) On the proposal layer, a number of anchors at the top of the list are considered to be ROIs in descending order of foreground scores. The coordinates of the ROIs are adjusted to obtain more accurate prediction boxes by offset from forward propagation. Redundant boxes are removed by non-maximum suppression (NMS) to obtain the final ROIs. (5) On the detection target layer, the truth boxes containing multiple objects are deleted. The IOUs between the retained ROIs and truth boxes are calculated, while the ROIs are divided into positive samples and negative samples by the IOU threshold. For each positive sample, the category, regression offset and mask information from the closest truth box are calculated to form the R-CNN dataset.
The ROI alignment layer is used to map every ROI to a multi-layer feature map according to uniform alignment rules: (1) determining the corresponding feature layer of each ROI through the width-height size; (2) defining the relevant step size from the corresponding feature layer; (3) calculating the mapping size of the ROI to the feature layer based on the width-height size of the ROI and the step size from the feature layer; (4) setting the fixed alignment rules, where the mapping result on the feature layer per ROI is split, recombined, and interpolated to receive the corresponding fixed size feature map and to meet the input requirements of the subsequent fully connected layer (FC layer).
The three-branch module consists of a classification-bbox regression branch and a mask prediction branch. The former is similar to the classification-regression principle in RPN. The difference is that there are only two categories (foreground and background) in RPN, while the three-branch module has more categories. The latter is described below. Based on the results of the RPN and ROI alignment layer, for every ROI, (1) forward propagation is used to obtain the prediction masks of various categories using the deconvolution of the fixed size feature maps with FCN; (2) categories and mask information are returned by the R-CNN dataset and are used as the truth masks for various categories; (3) after assigning the per-prediction mask to the appropriate category, the final prediction results of the mask are output with the weight update guided by reverse propagation using the average binary cross-entropy loss:
where
indicates prediction probability calculated from a per-pixel sigmoid;
is the true class label; and
expresses the pixel number per ROI. The mask branch outputs a T × M
2 matrix for each ROI, which means one M × M mask for each of the T categories. For an ROI associated with the ground truth class
,
is defined on the
th mask (other masks do not contribute to the loss). In addition,
is calculated only on positive ROIs. An ROI is considered positive if the IOU between the ROI and the relevant ground truth box is at least 0.5, while negative otherwise.
Finally, the loss of the Mask R-CNN (
) mainly involves multi-classification Softmax cross-entropy loss (
) and Smooth
L1 loss (
) from the classification-bbox regression branch and
from the mask branch:
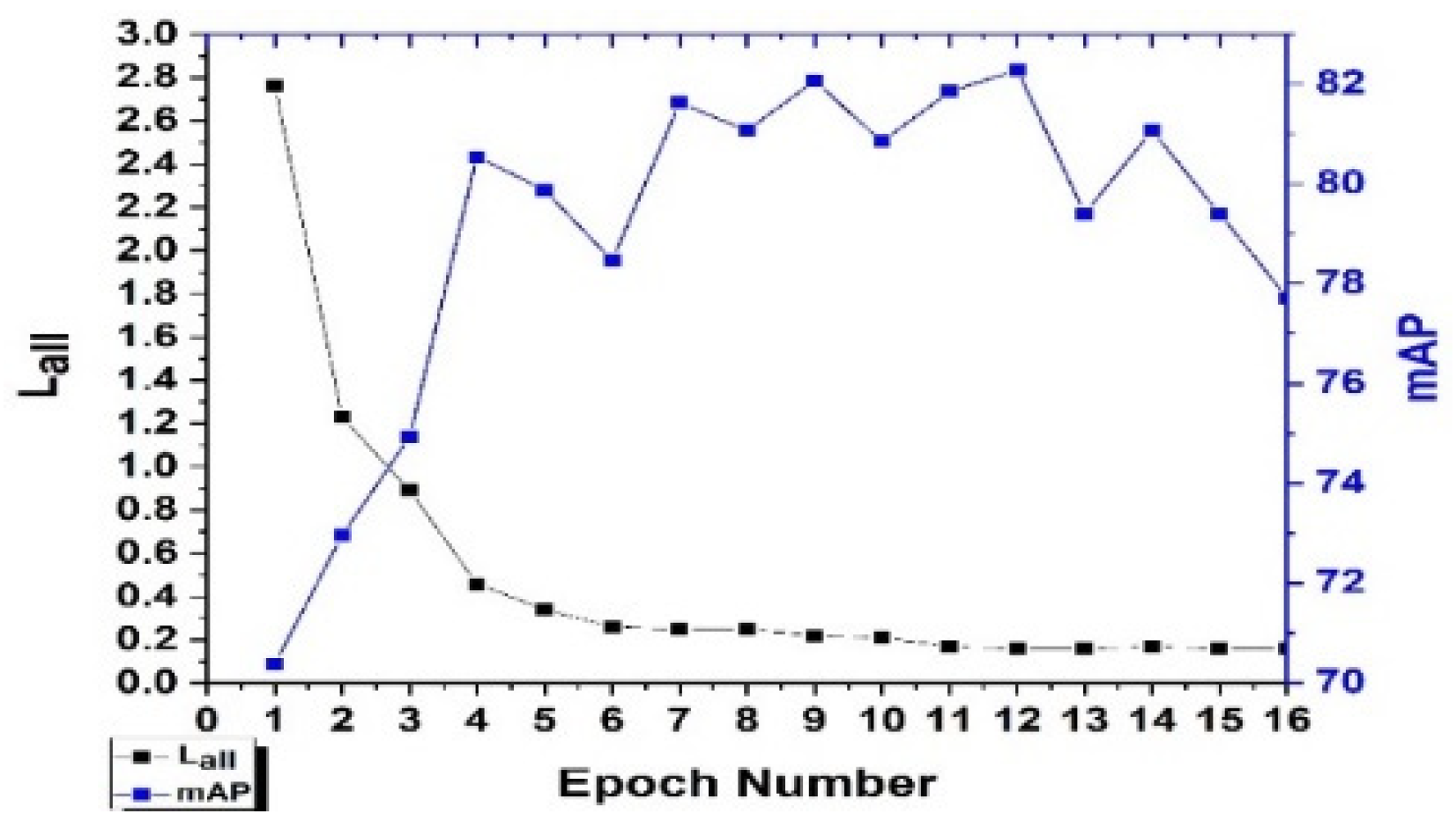
In this paper, Mask R-CNN for C-plot instance segmentation was built in Colaboratory, and the environments were configured with python3, Keras, and TensorFlow. Colaboratory is a Jupyter Notebook environment stored on Google Drive, which is run entirely on the cloud and offers free hardware accelerators (GPU or TPU) to train neural networks for developers. The parameters used in Mask R-CNN were divided into four types: (1) The 1st type was generally determined by the Mask R-CNN network structure and the default values were maintained, e.g., backbone for feature extraction, the step size of each feature layer, the length size of the anchor in RPN, fixed size for feature maps in the ROI alignment layer, the size of the mask output from the mask prediction branch, etc. (2) The 2nd type was mainly influenced by the hardware, e.g., GPU number, image number trained at once, etc. (3) The 3rd type had common value rules which were obtained in many existing studies, e.g., validation number in each epoch, the step length of the anchor generation in RPN, the horizontal–vertical ratios of the anchor in RPN, etc. Among them, partial parameters were also influenced by the characteristics of specific research objects, the situation of RS base image, and the relative relation between actual plots and image pixels, e.g., input image size, maximum ground truth instances for each image, the total number of positive and negative anchors for RPN training, the ROI number output from the proposal layer for training (inference), the ROI number exported from the detection target layer, the positive ratio of the ROI for three-branch, the maximum number of ROIs validated per image, the classification confidence of the ROIs validated, learning rate, learning momentum, etc. (4) The 4th type were carefully optimized in our research process, mainly including epoch number of training, iteration number in each epoch, the IOU threshold of NMS to filter proposals in RPN, the IOU threshold of the NMS to avoid ROI or mask stacking, etc., which was determined by comparing training loss and inference accuracy through experiments with a unified input dataset. Meanwhile, the grid search method was adopted to optimize parameters.
3.1.4. Identification and post-processing
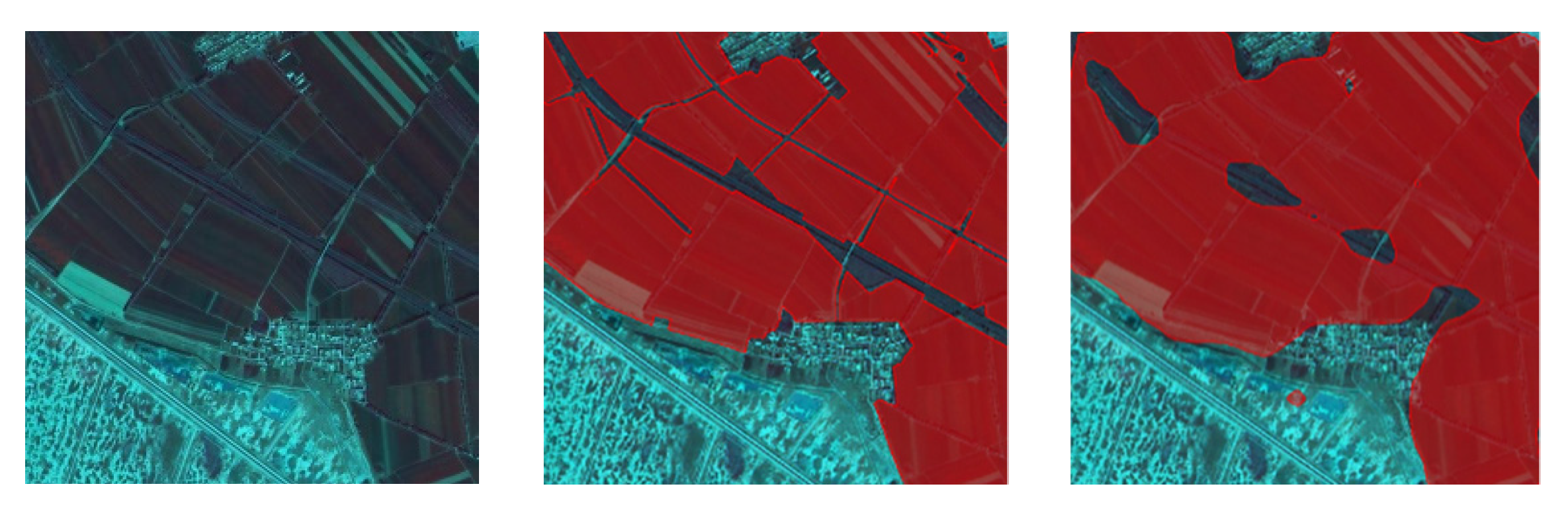
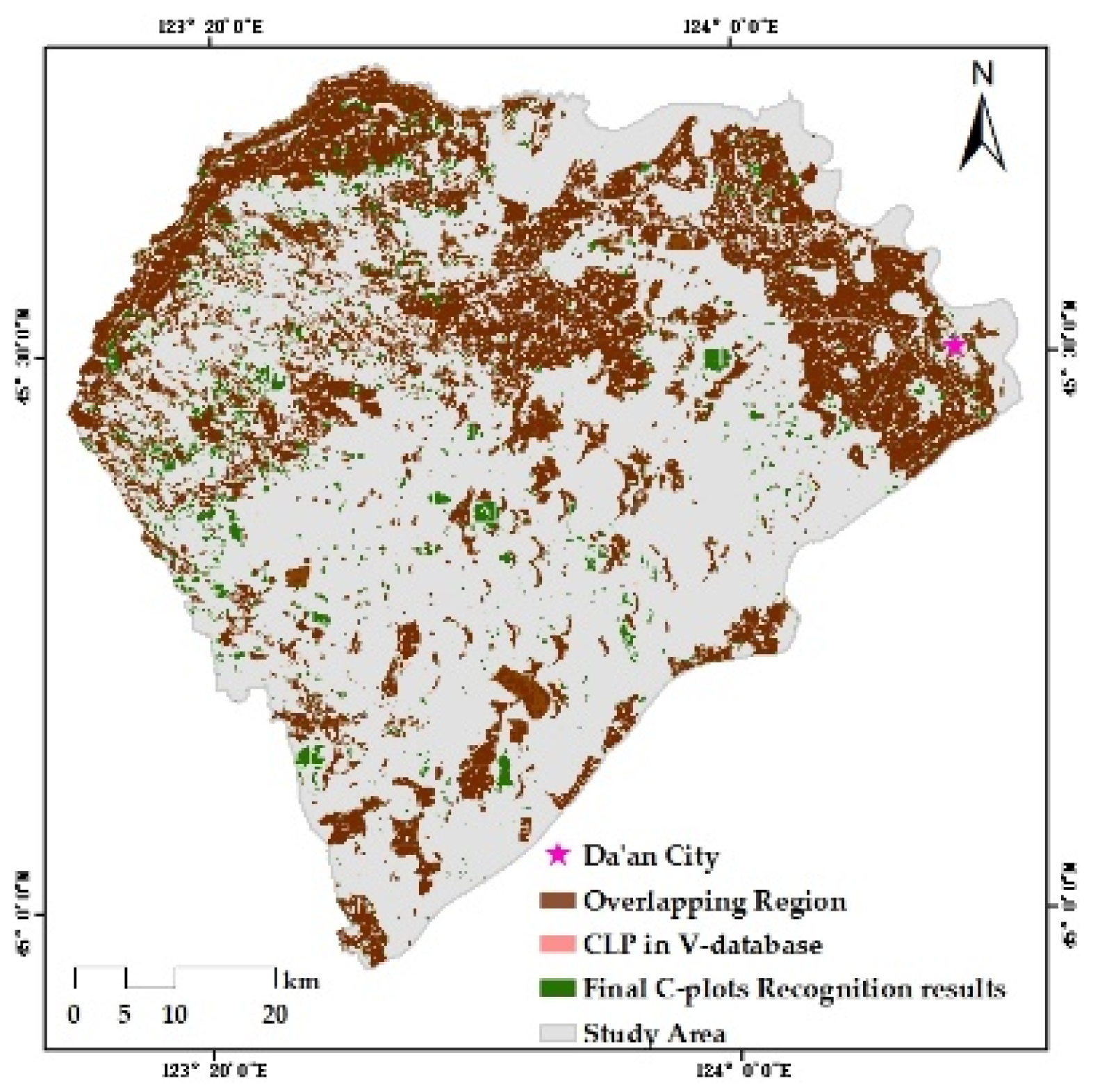
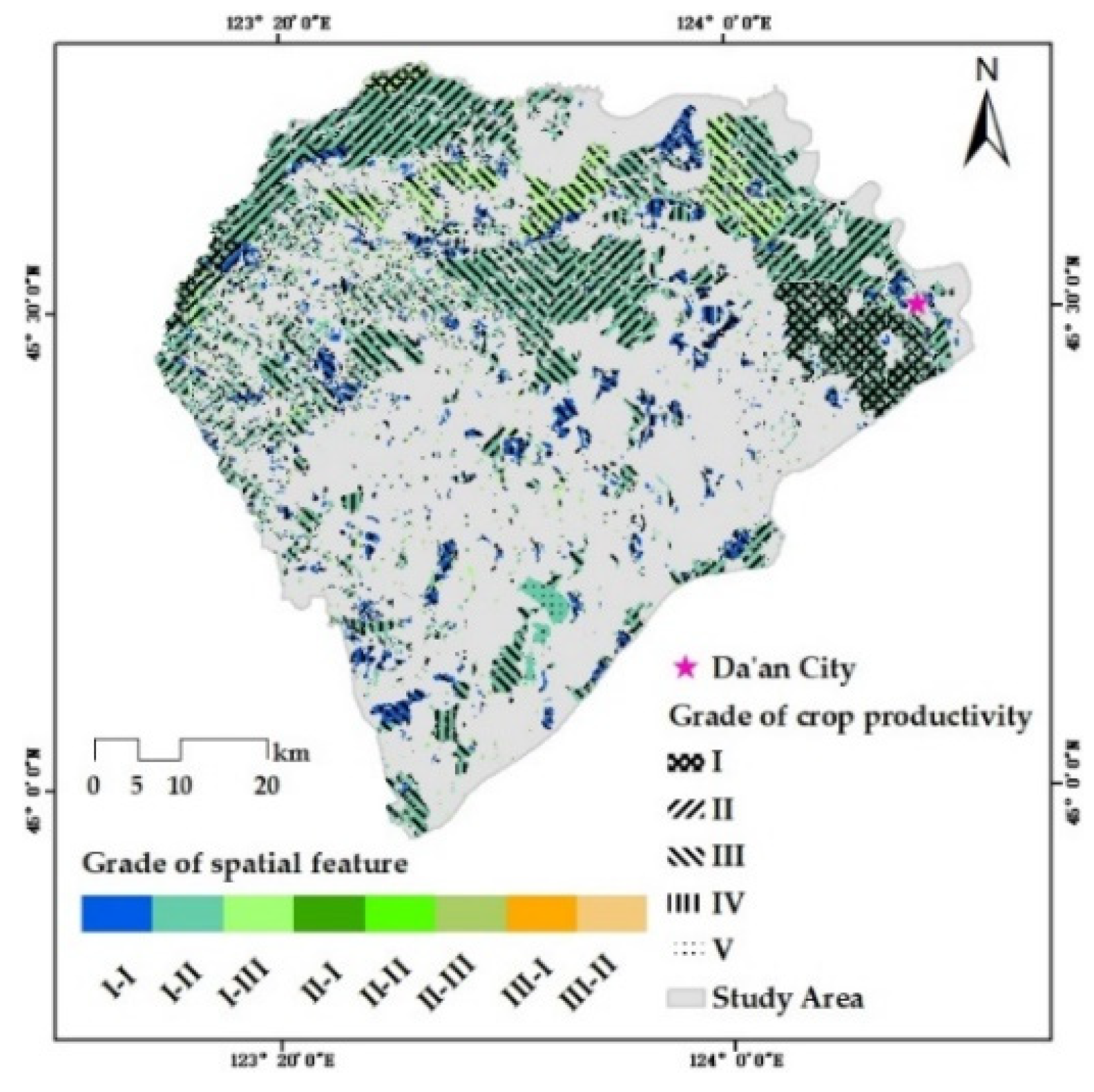
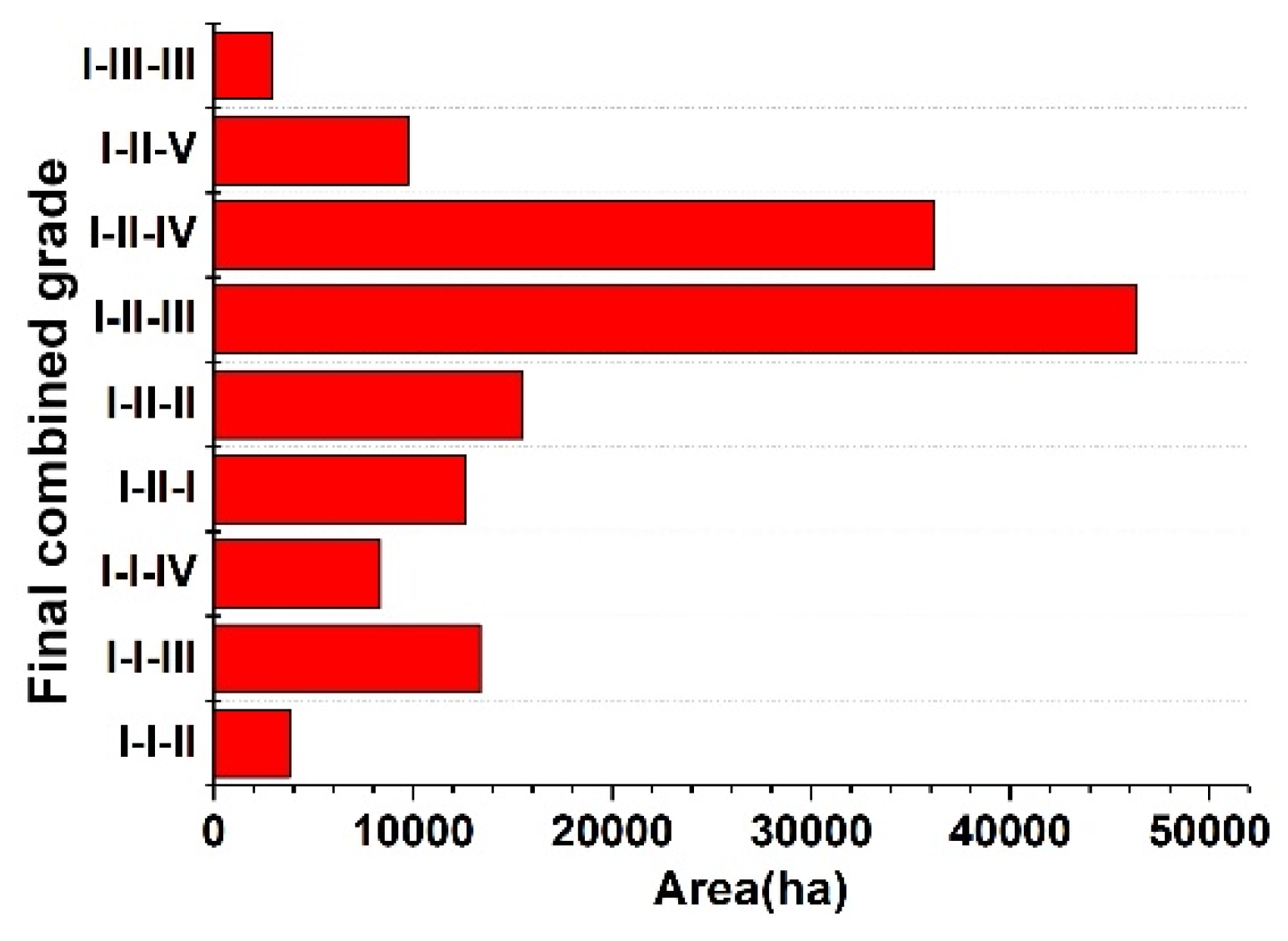
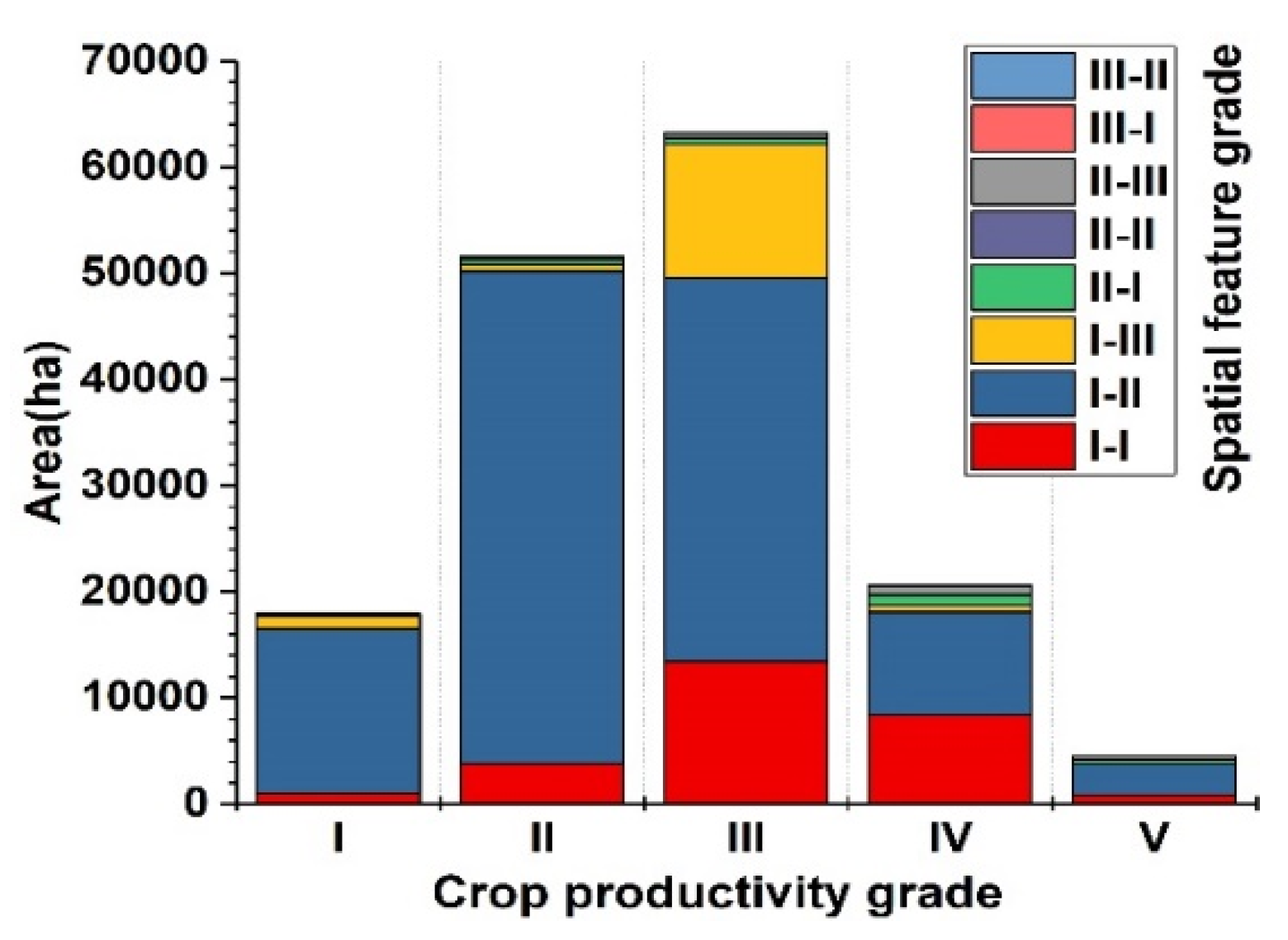
In this paper, the RS base map of the whole region (47,072 × 46,523) was separated into unified image blocks (1023 × 1011), which were put into the optimal Mask R-CNN model to receive the C-plots in every block. The recognition results of the global C-plots were comprised of the image blocks’ result graphs according to the order of the image blocks and the original size of whole base map. However, the resulting graph was superposition of the instance mask and the initial RS base map, where the values of the overlapping pixels were changed significantly and regularly. The regular differences were used in the decision tree (DT) solely to extract the instance mask. The preliminary C-plot identification results in a vector format were obtained by several types of spatial analyses such as vectorization, area screening, clip, etc.
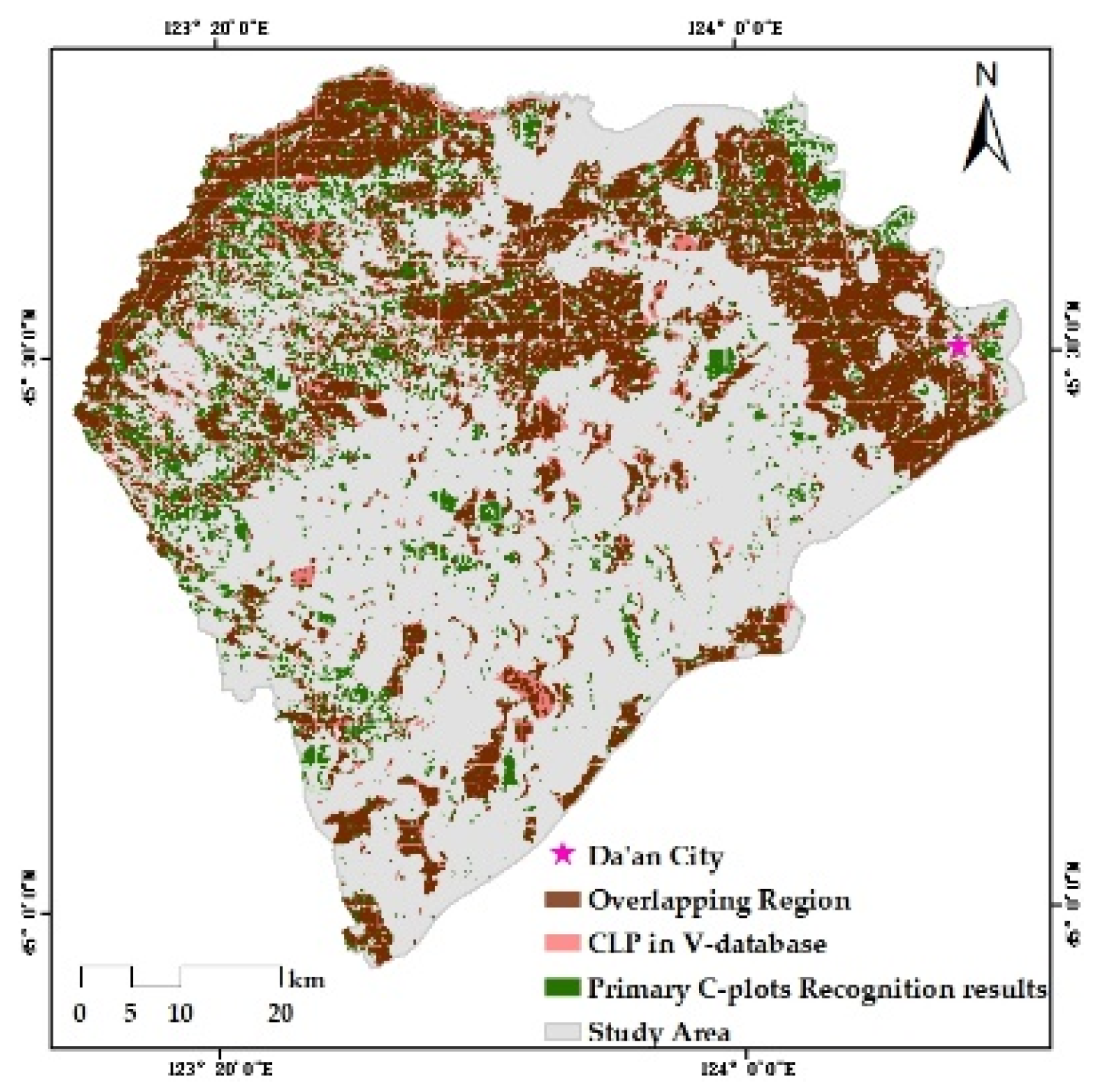
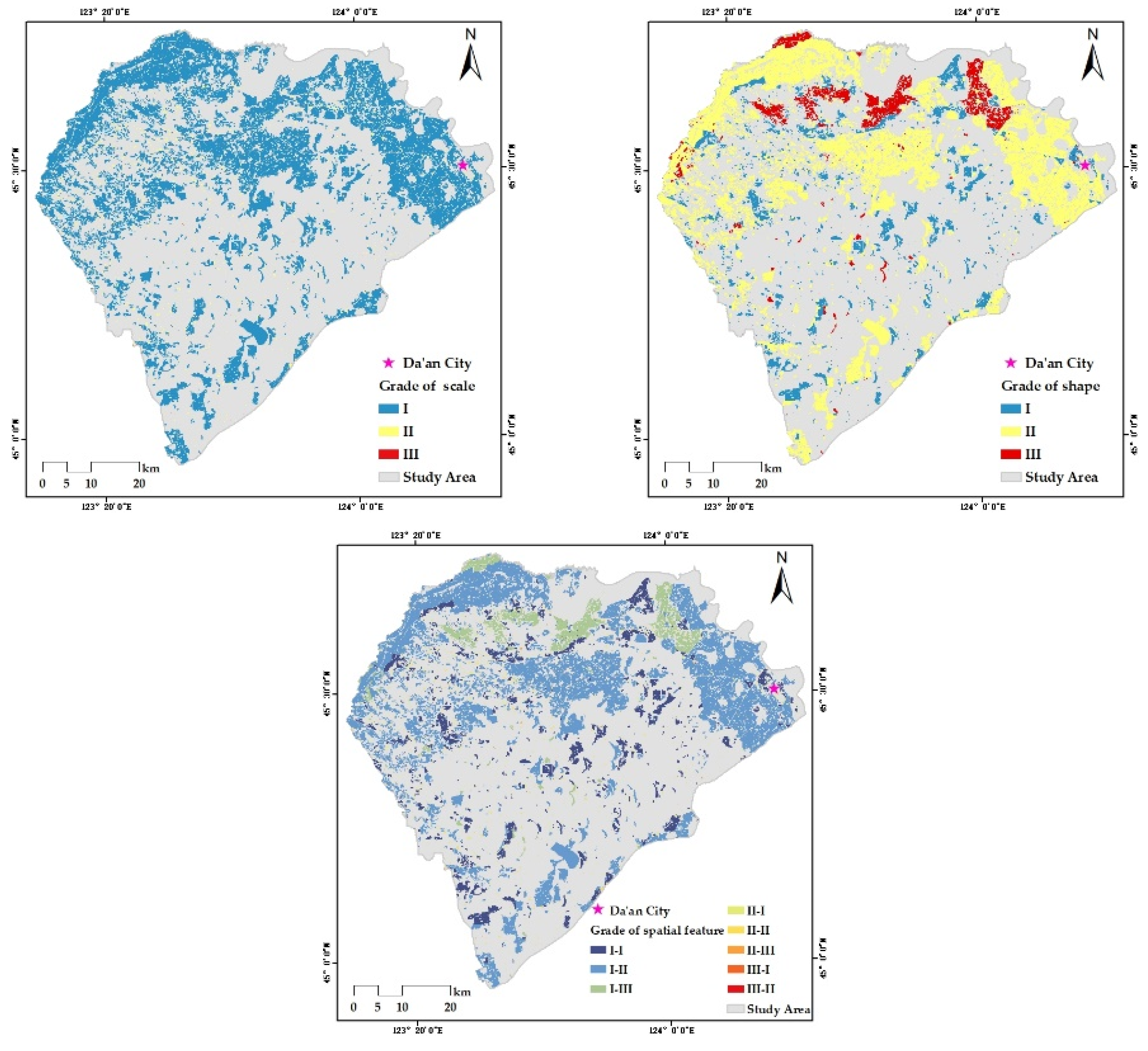
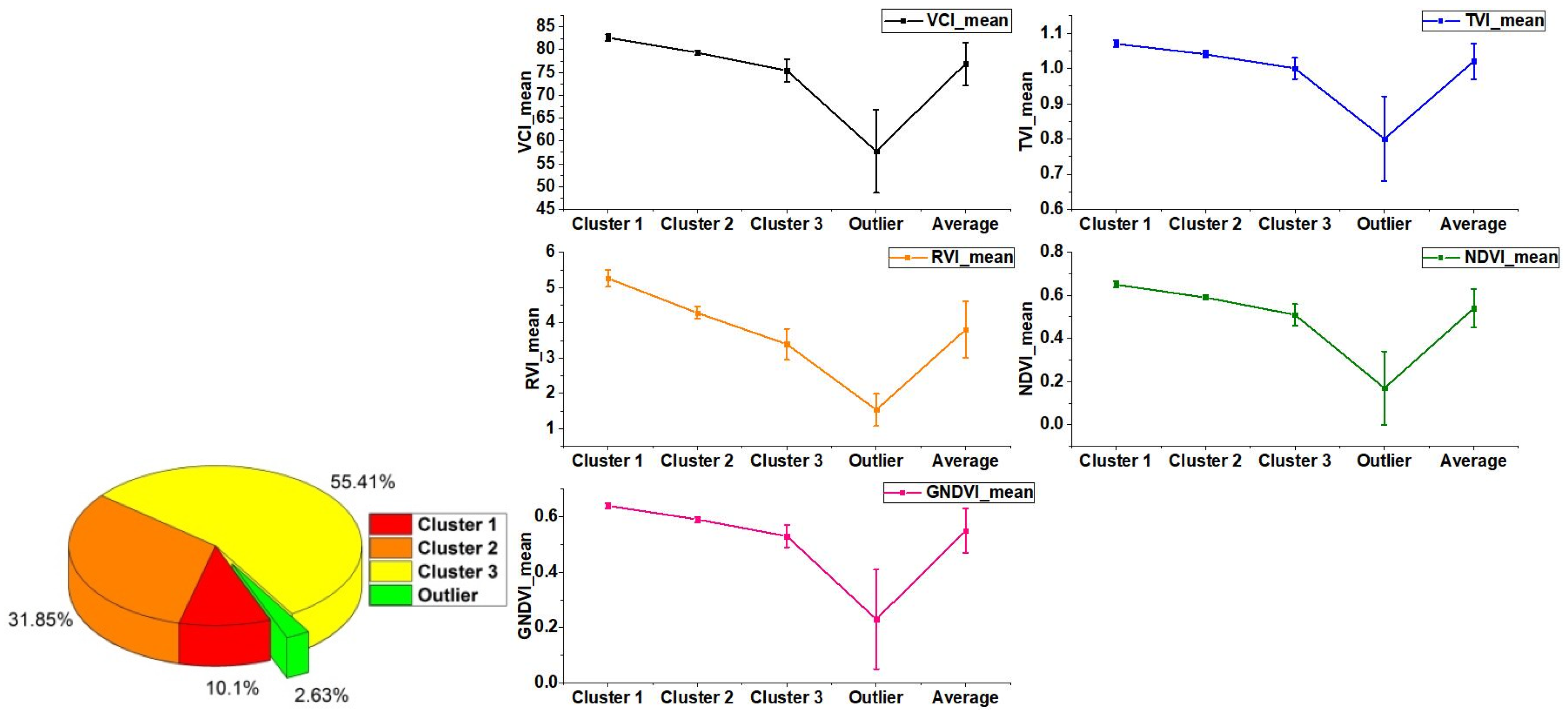
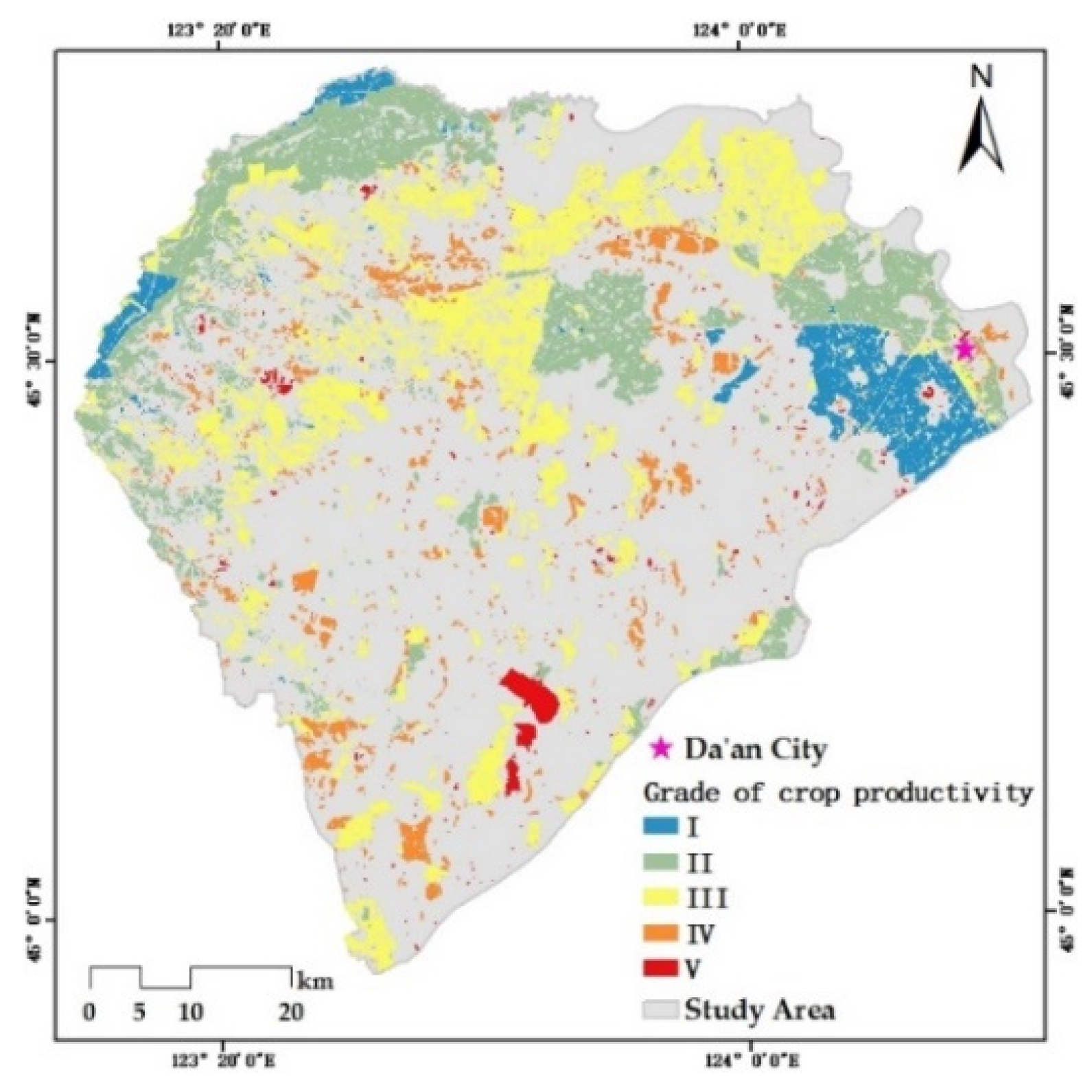
Verifying the Mask R-CNN model mainly concerns the prediction performance of the model in the target category and the group’s spatial distribution, while the ability to distinguish intra-class individuals is not fully tested. The discrimination ability of C-plot instances is further improved through post-processing. In this paper, the preliminary C-plot identification results were constrained and corrected by the V-database with authoritative auxiliary data regarded as the approximate ground truth. Specifically, the barrier factor patches of the V-database (some roads, rivers, etc.) were used for the erase operation. Cultivated land patches (CLPs) in the V-database were used to update the preliminary results and modify the instance boundaries. More detailed identification results were obtained, which are the data foundation for the delineation and grading of ACPUs.
There were three steps in the updating process: (1) the elementary recognition results were identified by CLPs to obtain the overlapping region between each CLP and C-plot instance; (2) the area ratio of every overlapping region was counted to determine the spatial fit degree between each C-plot instance and the corresponding CLP with IOU; (3) various update rules were determined by setting IOU thresholds. If IOU = 0 or 0.3 ≤ IOU < 0.6, the corresponding CLP would be preserved. If 0 < IOU < 0.3, the C-plot instance would be retained. If 0.6 ≤ IOU ≤ 1.0, the union of relevant C-plot instance and CLP would be reserved. If the C-plot instance did not overlap with any CLP, it would also be retained.

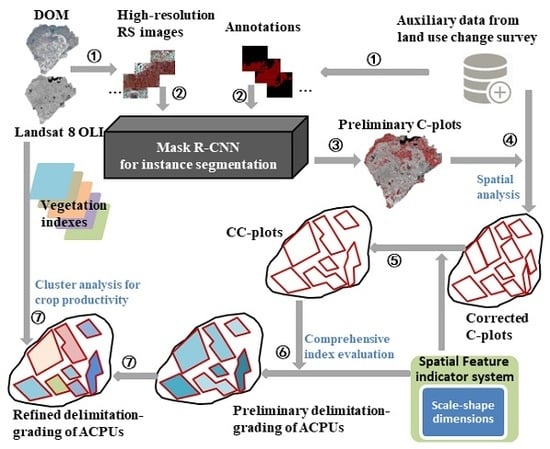















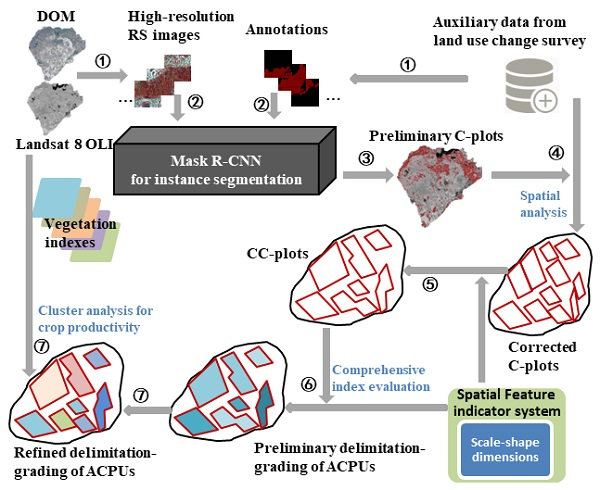{kind=link}
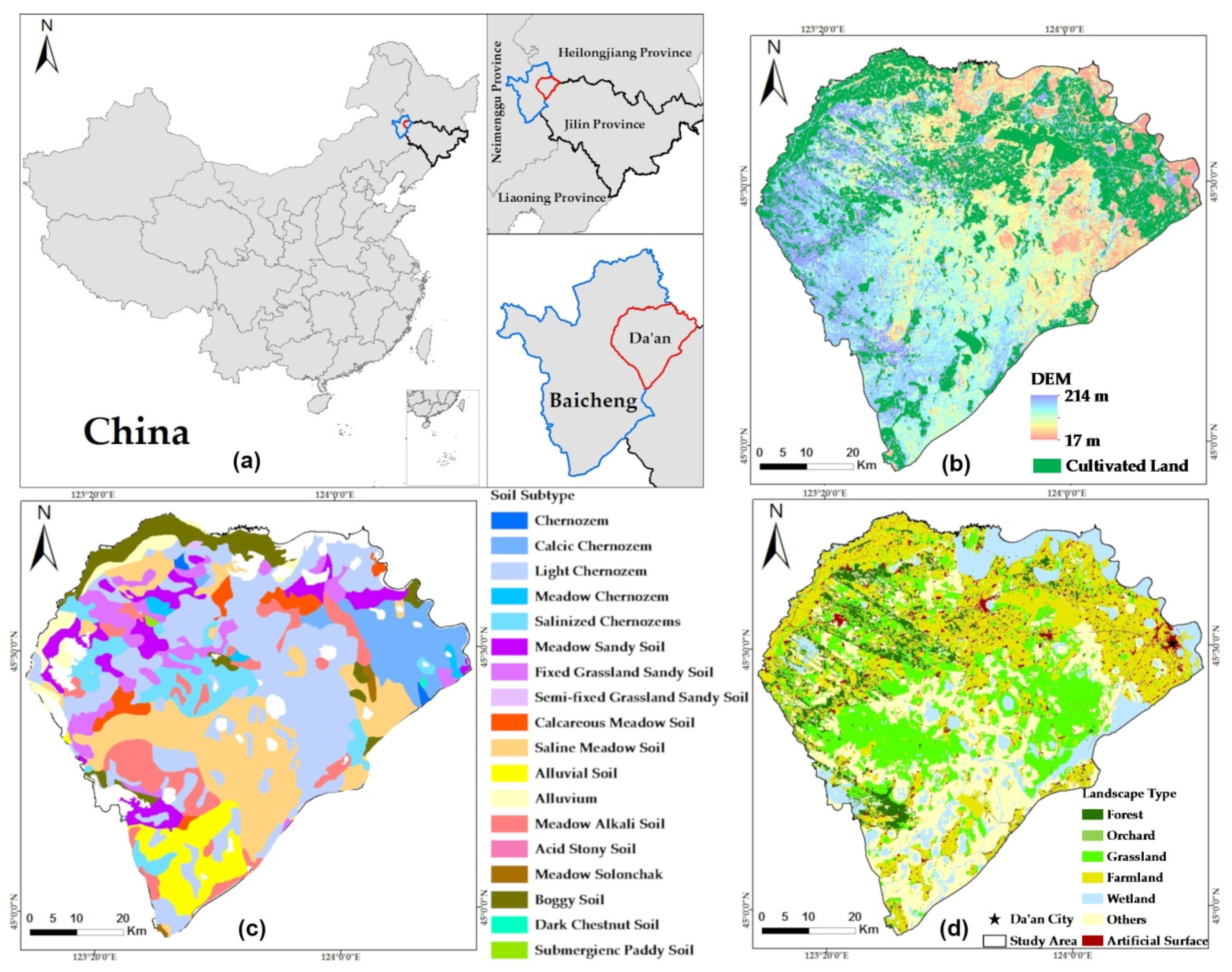{kind=link}
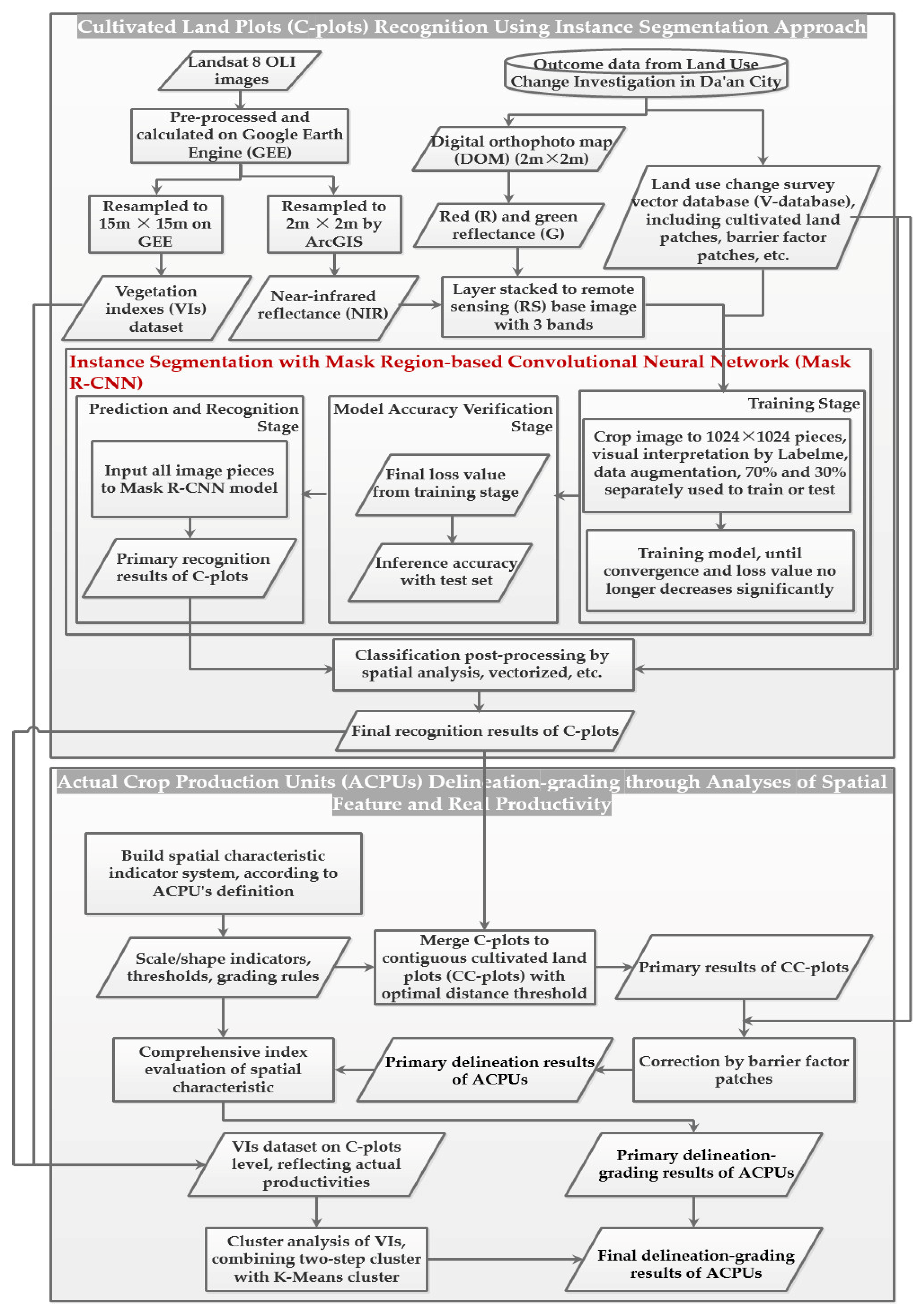{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}