
Fine-Grained Large-Scale Vulnerable Communities Mapping via Satellite Imagery and Population Census Using Deep Learning

 , , and
, , and
Abstract
:1. Introduction
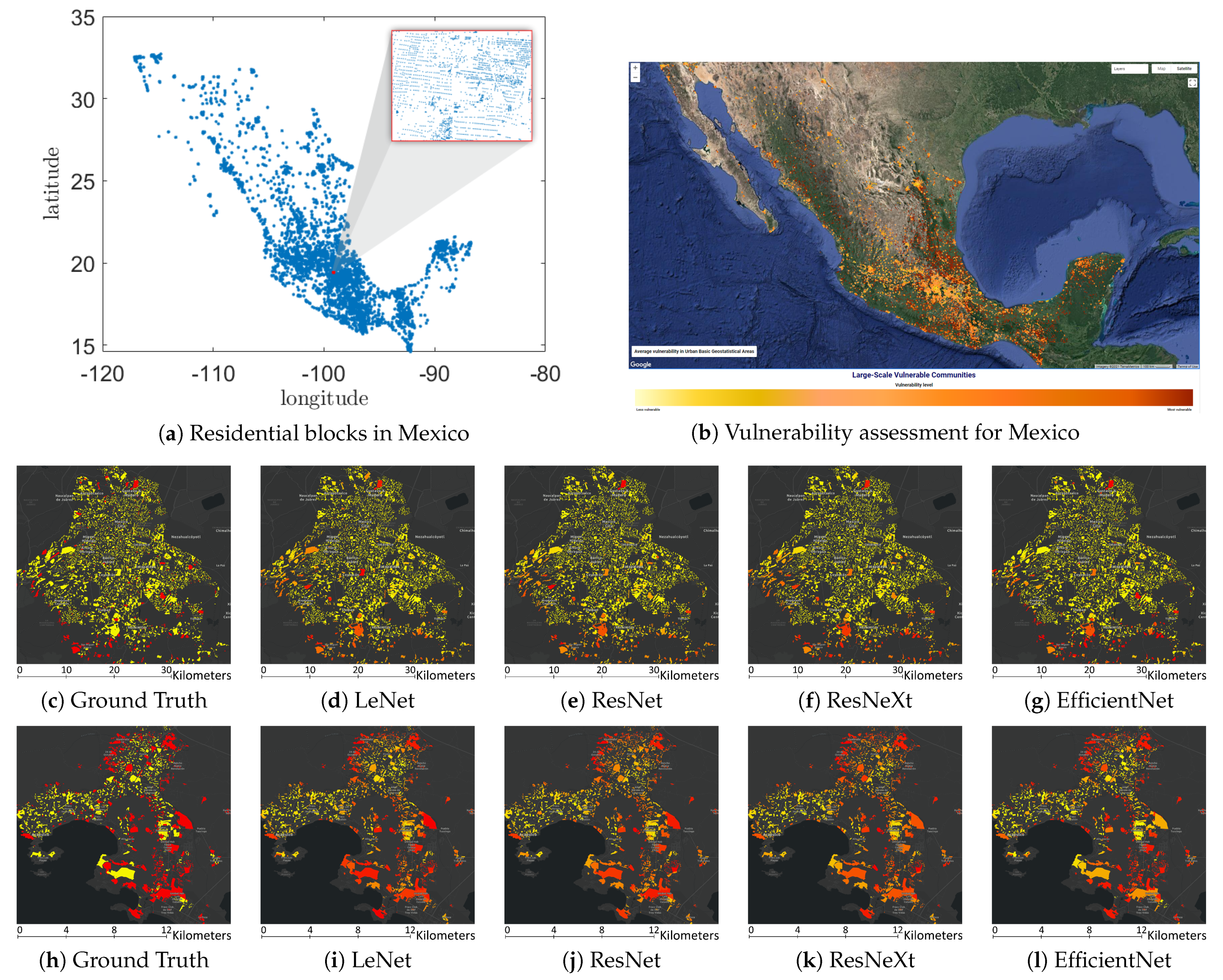
- A nationwide assessment of settlements’ vulnerability for Mexico is conducted at the residential block level.
- An alternative vulnerability indicator is developed using the UN-Habitat factors related to settlements [27].
- Using data composed of hundreds of thousands of records, different convolutional neural network (CNN) architectures are assessed in the task of mapping satellite images to the vulnerability index.
- The computer code for this project is made available to the research community. This should permit the evaluation of this work and serve as a stepping stone for further progress in the field.
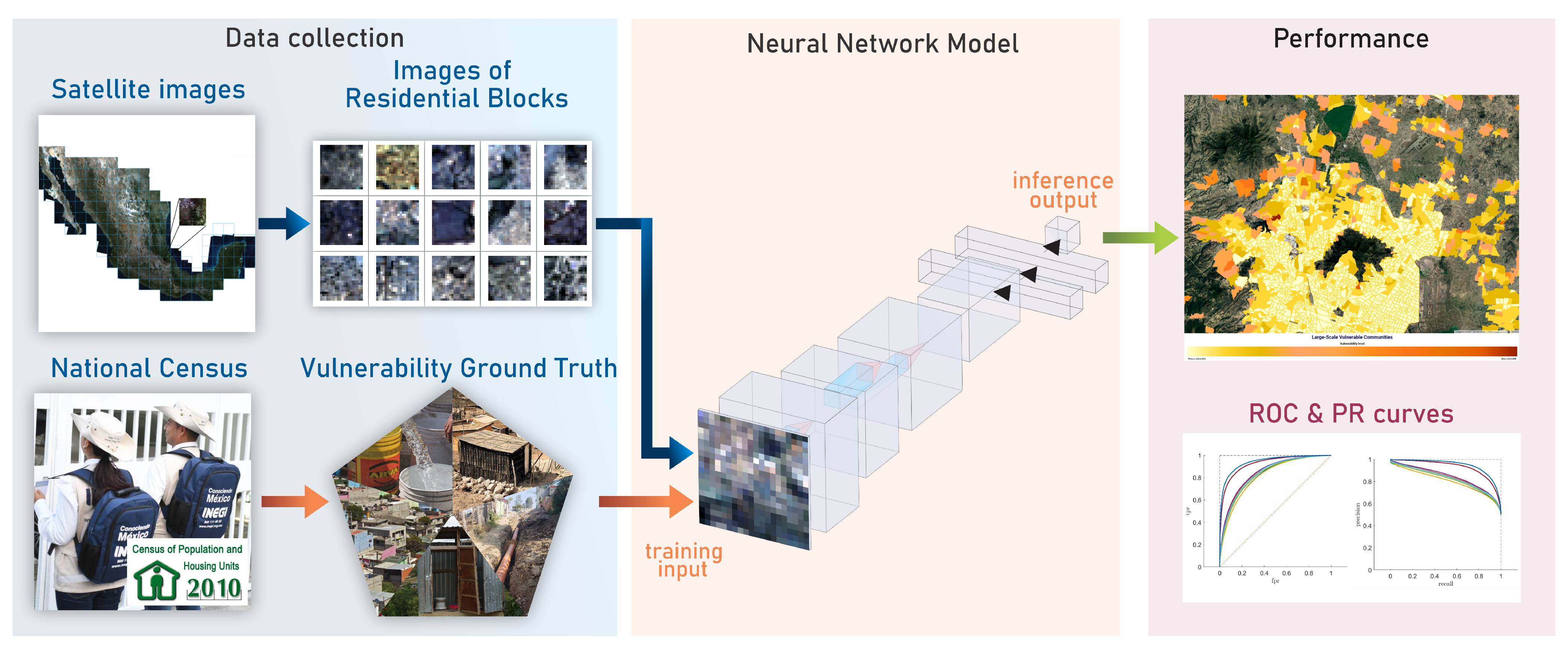
2. Materials and Methods
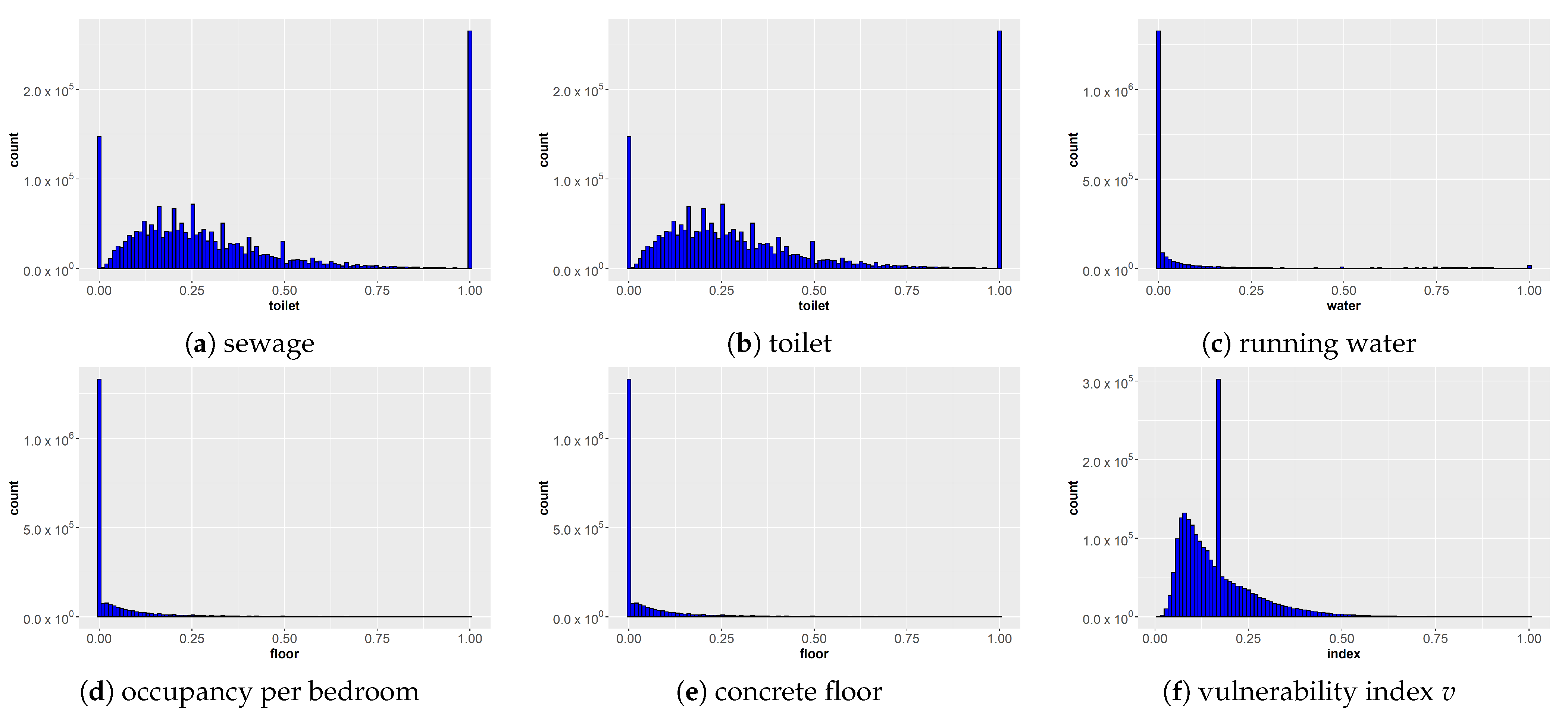
2.1. Characterizing Vulnerability
2.2. Setup
2.3. Selecting a Learning Architecture
2.4. Detecting Vulnerability
3. Results
3.1. Learning
- LeNet:
- [39] Current LeNet-5 implementations adopt hyperbolic tangents activation functions in the inner layers and softmax in the last layer. Our best training results were obtained by employing Stochastic Gradient Descent (SGD) as the optimizer with a constant learning rate of with a momentum equal to 0.9, a batch size of 128, and training during 100 epochs. For this CNN, we resize the images to pixels.
- ResNet:
- [37] Models based on ResNet-50 v2 architecture were trained, replacing the top layer with a flattened layer, and inserting a drop out layer with probability, a dense layer of 256 units with ReLU activation function, and a dense layer with the softmax activation function for two classes. For one model, the bands of the images were used, and for the other, the + IR bands were used. In both cases, the images were resized to pixels. Transfer learning with ImageNet [35] weights was applied and then the CNN was trained during 100 epochs with a batch size of 128. When using + IR bands, the input layer of the model was modified. Then, the ImageNet pre-trained weights were copied to the other layers before performing training, initializing the input layer with Xavier [47]. The best results for this CNN were obtained optimizing with SGD with a learning rate of and momentum 0.9.
- ResNeXt:
- [21] The images were resized to pixels and the models were based on the ResNeXt-50 architecture. As in the ResNet-based models, the top layer was replaced with a flatten layer, and inserted a drop out layer with probability, a dense layer of 256 units with ReLU activation function, and a dense layer with softmax activation function for two classes. The models were initialized using the weights of the ResNeXt network pre-trained with ImageNet [35] and then fine-tuned by training throughout 100 epochs using SGD with momentum 0.9 and a batch size of 128. For the model trained with the + IR bands’ images, the input layer was modified to accept those images and used the ImageNet weights only on the non-modified layers.
- EfficientNet:
- [38] For efficientNet, the images were resized to , applying transfer learning with ImageNet [35] weights. When the bands were used, the transference was immediate. Otherwise, when the + IR bands were used, accommodating the extended number of channels in the CNN input. Correspondingly, the input layer was initialized using Xavier [47]. Correspondingly, the top layer of the EfficientNet architecture was removed and replaced with a global average pooling layer. A a drop out layer with a 0.5 probability, along with a dense layer with softmax activation function for two classes. The best results for this CNN were obtained training during 20 epochs using the Adam optimization method with and . During the first 18 epochs, a learning rate of 0.001 was applied and 0.0001 for the last two. For there experiments, the EfficientNet-B3 architecture was employed.
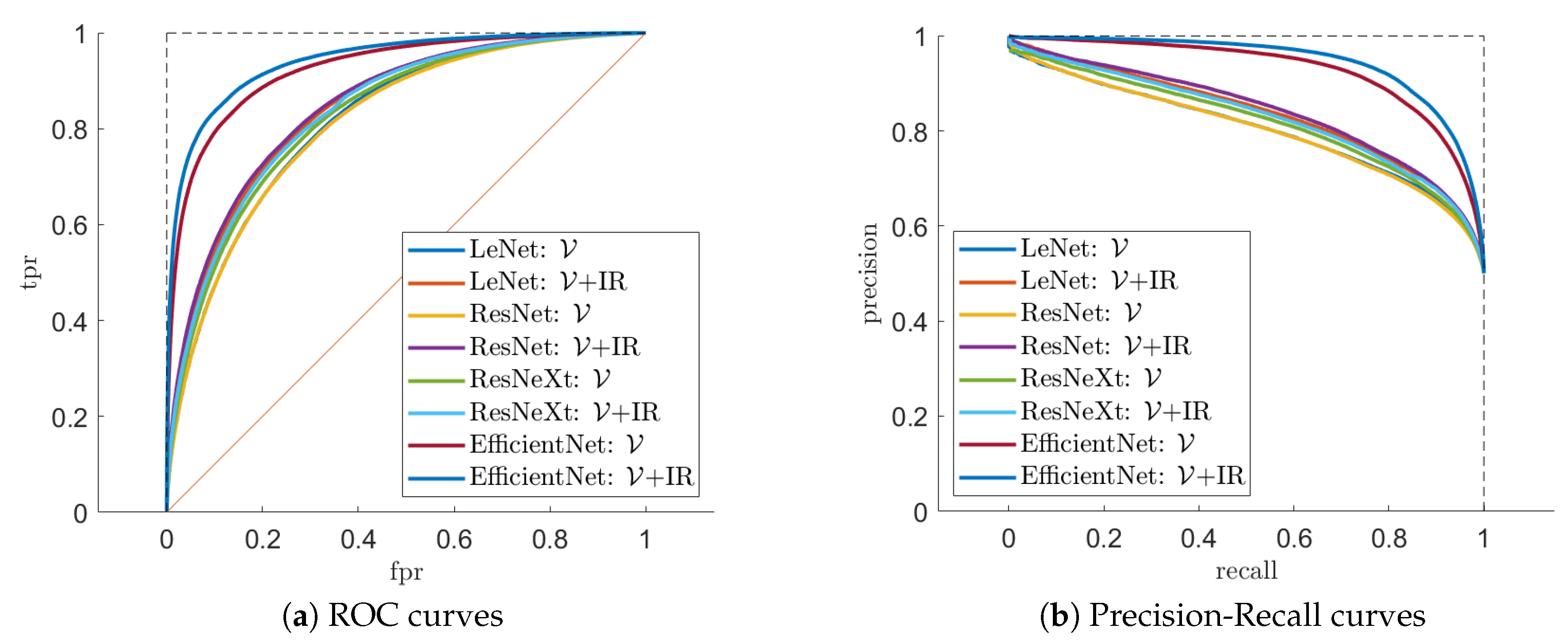
3.2. Classification Performance
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Atamanov, A.; Lakner, C.; Mahler, D.G.; Tetteh Baah, S.K.; Yang, J. The Effect of New PPP Estimates on Global Poverty; Technical Report; World Bank: Washington, DC, USA, 2020. [Google Scholar]
- Akova, F. Effective Altruism and Extreme Poverty; Technical Report; University of Warwick: Coventry, UK, 2021. [Google Scholar]
- Solt, F. Measuring Income Inequality Across Countries and Over Time: The Standardized World Income Inequality Database. Soc. Sci. Q. 2020, 101, 1183–1199. [Google Scholar] [CrossRef]
- Scheuer, F.; Slemrod, J. Taxation and the Superrich. Annu. Rev. Econ. 2020, 12, 189–211. [Google Scholar] [CrossRef]
- Roser, M.; Ortiz-Ospina, E.; Global Extreme Poverty. In Our World in Data. 2013. Available online: https://ourworldindata.org/extreme-poverty (accessed on 8 August 2021).
- Plag, H.; Jules-Plag, S. A Goal-based Approach to the Identification of Essential Transformation Variables in Support of the Implementation of the 2030 Agenda for Sustainable Development. Int. J. Digit. Earth 2020, 13, 166–187. [Google Scholar] [CrossRef]
- Khan, M.; Blumenstock, J. Multi-GCN: Graph Convolutional Networks for Multi-View Networks, with Applications to Global Poverty. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 606–613. [Google Scholar]
- Bansal, C.; Jain, A.; Barwaria, P.; Choudhary, A.; Singh, A.; Gupta, A.; Seth, A. Temporal Prediction of Socio-economic Indicators Using Satellite Imagery. In COMAD; ACM: New York, NY, USA, 2020; pp. 73–81. [Google Scholar]
- Hoffman-Hall, A.; Loboda, T.; Hall, J.; Carroll, M.; Chen, D. Mapping Remote Rural Settlements at 30 m Spatial Resolution using Geospatial Data-Fusion. Remote Sens. Environ. 2019, 233, 111386. [Google Scholar] [CrossRef]
- Gram-Hansen, B.; Helber, P.; Varatharajan, I.; Azam, F.; Coca-Castro, A.; Kopackova, V.; Bilinski, P. Mapping informal settlements in developing countries using machine learning and low resolution multi-spectral data. In Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society, Honolulu, HI, USA, 27–28 January 2019; pp. 361–368. [Google Scholar]
- Verma, D.; Jana, A.; Ramamritham, K. Transfer Learning Approach to Map Urban Slums using High and Medium Resolution Satellite Imagery. Habitat Int. 2019, 88, 101981. [Google Scholar] [CrossRef]
- Engstrom, R.; Hersh, J.; Newhouse, D. Poverty from Space: Using High-Resolution Satellite Imagery for Estimating Economic Well-Being; World Bank: Washington, DC, USA, 2017. [Google Scholar]
- Herfort, B.; Li, H.; Fendrich, S.; Lautenbach, S.; Zipf, A. Mapping Human Settlements with Higher Accuracy and Less Volunteer Efforts by Combining Crowdsourcing and Deep Learning. Remote Sens. 2019, 11, 1799. [Google Scholar] [CrossRef] [Green Version]
- Ajami, A.; Kuffer, M.; Persello, C.; Pfeffer, K. Identifying a Slums’ Degree of Deprivation from VHR Images using Convolutional Neural Networks. Remote Sens. 2019, 11, 1282. [Google Scholar] [CrossRef] [Green Version]
- Andreano, M.S.; Benedetti, R.; Piersimoni, F.; Savio, G. Mapping Poverty of Latin American and Caribbean Countries from Heaven Through Night-Light Satellite Images. Soc. Indic. Res. 2020, 156, 533–562. [Google Scholar] [CrossRef]
- Dorji, U.J.; Plangprasopchok, A.; Surasvadi, N.; Siripanpornchana, C. A Machine Learning Approach to Estimate Median Income Levels of Sub-Districts in Thailand using Satellite and Geospatial Data. In Proceedings of the ACM SIGSPATIAL International Workshop on AI for Geographic Knowledge Discovery, Chicago, IL, USA, 5 November 2019; pp. 11–14. [Google Scholar]
- Shi, K.; Chang, Z.; Chen, Z.; Wu, J.; Yu, B. Identifying and Evaluating Poverty using Multisource Remote Sensing and Point of Interest (POI) Data: A Case Study of Chongqing, China. J. Clean. Prod. 2020, 255, 120245. [Google Scholar] [CrossRef]
- Li, G.; Chang, L.; Liu, X.; Su, S.; Cai, Z.; Huang, X.; Li, B. Monitoring the spatiotemporal dynamics of poor counties in China: Implications for global sustainable development goals. J. Clean. Prod. 2019, 227, 392–404. [Google Scholar] [CrossRef]
- Xie, M.; Jean, N.; Burke, M.; Lobell, D.; Ermon, S. Transfer Learning from Deep Features for Remote Sensing and Poverty Mapping. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Ngestrini, R. Predicting Poverty of a Region from Satellite Imagery using CNNs; Technical Report; Utrecht University: Utrecht, The Netherlands, 2019. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1492–1500. [Google Scholar]
- Roy, D.; Bernal, D.; Lees, M. An Exploratory Factor Analysis Model for Slum Severity Index in Mexico City. Urban Stud. 2019, 789–805. [Google Scholar] [CrossRef] [Green Version]
- Ibrahim, M.; Haworth, J.; Cheng, T. Understanding Cities with Machine Eyes: A Review of Deep Computer Vision in Urban Analytics. Cities 2020, 96, 102481. [Google Scholar] [CrossRef]
- Sharma, P.; Manandhar, A.; Thomson, P.; Katuva, J.; Hope, R.; Clifton, D.A. Combining Multi-Modal Statistics for Welfare Prediction Using Deep Learning. Sustainability 2019, 11, 6312. [Google Scholar] [CrossRef] [Green Version]
- Jean, N.; Burke, M.; Xie, M.; Davis, M.; Lobell, D.; Ermon, S. Combining Satellite Imagery and Machine Learning to Predict Poverty. Science 2016, 353, 790–794. [Google Scholar] [CrossRef] [Green Version]
- Tingzon, I.; Orden, A.; Sy, S.; Sekara, V.; Weber, I.; Fatehkia, M.; Herranz, M.G.; Kim, D. Mapping Poverty in the Philippines Using Machine Learning, Satellite Imagery, and Crowd-sourced Geospatial Information. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, XLII-4/W19, 425–431. [Google Scholar] [CrossRef] [Green Version]
- United Nations Human Settlements Programme Staff. The Challenge of Slums: Global Report on Human Settlements, 2003; Earthscan Publications: London, UK; Sterling, VA, USA, 2003; ISBN 978-1-84407-037-4. [Google Scholar]
- Weeks, J.; Hill, A.; Stow, D.; Getis, A.; Fugate, D. Can We Spot a Neighborhood from the Air? Defining Neighborhood Structure in Accra, Ghana. Remote Sens. 2007, 69, 9–22. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Patel, A.; Shah, P.; Beauregard, B. Measuring Multiple Housing Deprivations in Urban India using Slum Severity Index. Habitat Int. 2020, 101, 102190. [Google Scholar] [CrossRef]
- INEGI. Censos y Conteos de Población y Vivienda; INEGI: Aguascalientes, Mexico, 2011. [Google Scholar]
- INEGI. Producción y Publicación de la Geomediana Nacional a Partir de Imágenes del Cubo de Datos Geoespaciales de México. Documento Metodológico; Technical Report; INEGI: Aguascalientes, Mexico, 2020. [Google Scholar]
- Roberts, D.; Mueller, N.; McIntyre, A. High-dimensional pixel composites from earth observation time series. IEEE Trans. Geosci. Remote Sens. 2017, 55, 6254–6264. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Li, H.; Tian, Y.; Mueller, K.; Chen, X. Beyond Saliency: Understanding Convolutional Neural Networks from Saliency Prediction on Layer-wise Relevance Propagation. Image Vis. Comput. 2019, 83, 70–86. [Google Scholar] [CrossRef] [Green Version]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A Large-Scale Hierarchical Image Database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. Software. 2015. Available online: tensorflow.org (accessed on 8 August 2021).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- LeCun, Y.; Boser, B.; Denker, J.; Henderson, D.; Howard, R.; Hubbard, W.; Jackel, L. Backpropagation Applied to Handwritten Zip Code Recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. arXiv 2014, arXiv:1406.2661. [Google Scholar]
- Perez, A.; Ganguli, S.; Ermon, S.; Azzari, G.; Burke, M.; Lobell, D. Semi-Supervised Multitask Learning on Multispectral Satellite Images using Wasserstein Generative Adversarial Networks (GANs) for Predicting Poverty. arXiv 2019, arXiv:1902.11110. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, Inception-Resnet and the Impact of Residual Connections on Learning. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNet v2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Buslaev, A.; Iglovikov, V.; Khvedchenya, E.; Parinov, A.; Druzhinin, M.; Kalinin, A. Albumentations: Fast and Flexible Image Augmentations. Information 2020, 11, 125. [Google Scholar] [CrossRef] [Green Version]
- Glorot, X.; Bengio, Y. Understanding the Difficulty of Training Deep Feedforward Neural Networks. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- Limongi, G.; Galderisi, A. Twenty Years of European and International Research on Vulnerability: A Multi-Faceted Concept for Better Dealing with Evolving Risk Landscapes. Int. J. Disaster Risk Reduct. 2021, 63, 102451. [Google Scholar] [CrossRef]
- Wang, P.; Liu, X.; Berzin, T.; Brown, J.; Liu, P.; Zhou, C.; Lei, L.; Li, L.; Guo, Z.; Lei, S. Effect of a Deep-Learning Computer-Aided Detection System on Adenoma Detection during Colonoscopy (CADe-DB Trial): A Double-Blind Randomised Study. Lancet Gastroenterol. Hepatol. 2020, 5, 343–351. [Google Scholar] [CrossRef]
- Dickson, I. A Trial of Deep-Learning Detection in Colonoscopy. Nat. Rev. Gastroenterol. Hepatol. 2020, 17, 194. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Han, L.; Chen, Y.; Cheng, W.; Bai, H.; Wang, J.; Yu, M. Deep Learning-Based CT Image Characteristics and Postoperative Anal Function Restoration for Patients with Complex Anal Fistula. J. Healthc. Eng. 2021, 2021. [Google Scholar] [CrossRef]
- Torralba, A.; Fergus, R.; Freeman, W. 80 Million Tiny Images: A Large Data Set for Nonparametric Object and Scene Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 1958–1970. [Google Scholar] [CrossRef]
- Xie, N.; Ras, G.; van Gerven, M.; Doran, D. Explainable Deep Learning: A Field Guide for the Uninitiated. arXiv 2020, arXiv:2004.14545. [Google Scholar]
- Birhane, A.; Prabhu, V. Large Image Datasets: A Pyrrhic Win for Computer Vision? In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January2021; pp. 1536–1546. [Google Scholar]
- Sun, C.; Shrivastava, A.; Singh, S.; Gupta, A. Revisiting Unreasonable Effectiveness of Data in Deep Learning Era. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 843–852. [Google Scholar]
- Malach, E.; Shalev-Shwartz, S. Is Deeper Better only when Shallow is Good? arXiv 2019, arXiv:1903.03488. [Google Scholar]
- Alves Carvalho Nascimento, L.; Shandas, V. Integrating Diverse Perspectives for Managing Neighborhood Trees and Urban Ecosystem Services in Portland, OR (US). Land 2021, 10, 48. [Google Scholar] [CrossRef]
- Saverino, K.; Routman, E.; Lookingbill, T.; Eanes, A.; Hoffman, J.; Bao, R. Thermal Inequity in Richmond, VA: The Effect of an Unjust Evolution of the Urban Landscape on Urban Heat Islands. Sustainability 2021, 13, 1511. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Bands | + IR Bands | |||
|---|---|---|---|---|
| CNN | ROC | Precision-Recall | ROC | Precision-Recall |
| LeNet-5 | 0.8164 | 0.8032 | 0.8422 | 0.8351 |
| ResNet | 0.8138 | 0.8022 | 0.8475 | 0.8417 |
| ResNeXt | 0.8284 | 0.8189 | 0.8376 | 0.8293 |
| EfficientNet | 0.9256 | 0.9286 | 0.9421 | 0.9457 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Salas, J.; Vera, P.; Zea-Ortiz, M.; Villaseñor, E.-A.; Pulido, D.; Figueroa, A. Fine-Grained Large-Scale Vulnerable Communities Mapping via Satellite Imagery and Population Census Using Deep Learning. Remote Sens. 2021, 13, 3603. https://0-doi-org.brum.beds.ac.uk/10.3390/rs13183603
Salas J, Vera P, Zea-Ortiz M, Villaseñor E-A, Pulido D, Figueroa A. Fine-Grained Large-Scale Vulnerable Communities Mapping via Satellite Imagery and Population Census Using Deep Learning. Remote Sensing. 2021; 13(18):3603. https://0-doi-org.brum.beds.ac.uk/10.3390/rs13183603
Chicago/Turabian StyleSalas, Joaquín, Pablo Vera, Marivel Zea-Ortiz, Elio-Atenogenes Villaseñor, Dagoberto Pulido, and Alejandra Figueroa. 2021. "Fine-Grained Large-Scale Vulnerable Communities Mapping via Satellite Imagery and Population Census Using Deep Learning" Remote Sensing 13, no. 18: 3603. https://0-doi-org.brum.beds.ac.uk/10.3390/rs13183603