
Transferable Deep Learning from Time Series of Landsat Data for National Land-Cover Mapping with Noisy Labels: A Case Study of China



Abstract
:1. Introduction
- (1)
- To the best of our knowledge, this is the first time that a mutual deep-learning model of this type—that is, a MTNet that can be used for national-level land cover mapping—has been developed.
- (2)
- A novel interactive training strategy was proposed, and this was embedded into our MTNet to produce large-scale land cover maps with unbalanced training samples and noisy labels.
- (3)
- Extensive experiments conducted on national land-cover datasets for 2005 and 2010 demonstrated the effectiveness and superiority of the proposed MTNet, yielding national land-cover maps with high accuracy.
2. Previous Studies
2.1. CNN-Based Land-Cover Mapping
2.2. Noisy Label Problem
3. Data Description
3.1. Data Sources
3.2. Data Pre-Processing
3.3. Study Area and Training Sets
3.3.1. Training Samples for the Jing-Jin-Ji Region with Different Composition
- TS-1: This set consisted of 1280 training samples covering all the classes present in the study area, namely, forest, grassland, wetland, water body, cultivated land, artificial surface and bare land.
- TS-2: As there exists serious confusion in the labels of grassland and forest in TS-1, these two classes were merged to decrease the impact of labeling errors in this set.
- TS-3: In this set, the grassland was oversampled so that the impact of the proportion of inaccurate classes on the final land-cover map could be explored.
3.3.2. Typical Regions
3.3.3. The Whole Nation of China
4. Methodology
5. Experiments and Analysis on Typical Regions
5.1. Experiments on Different Compositions of Training Samples
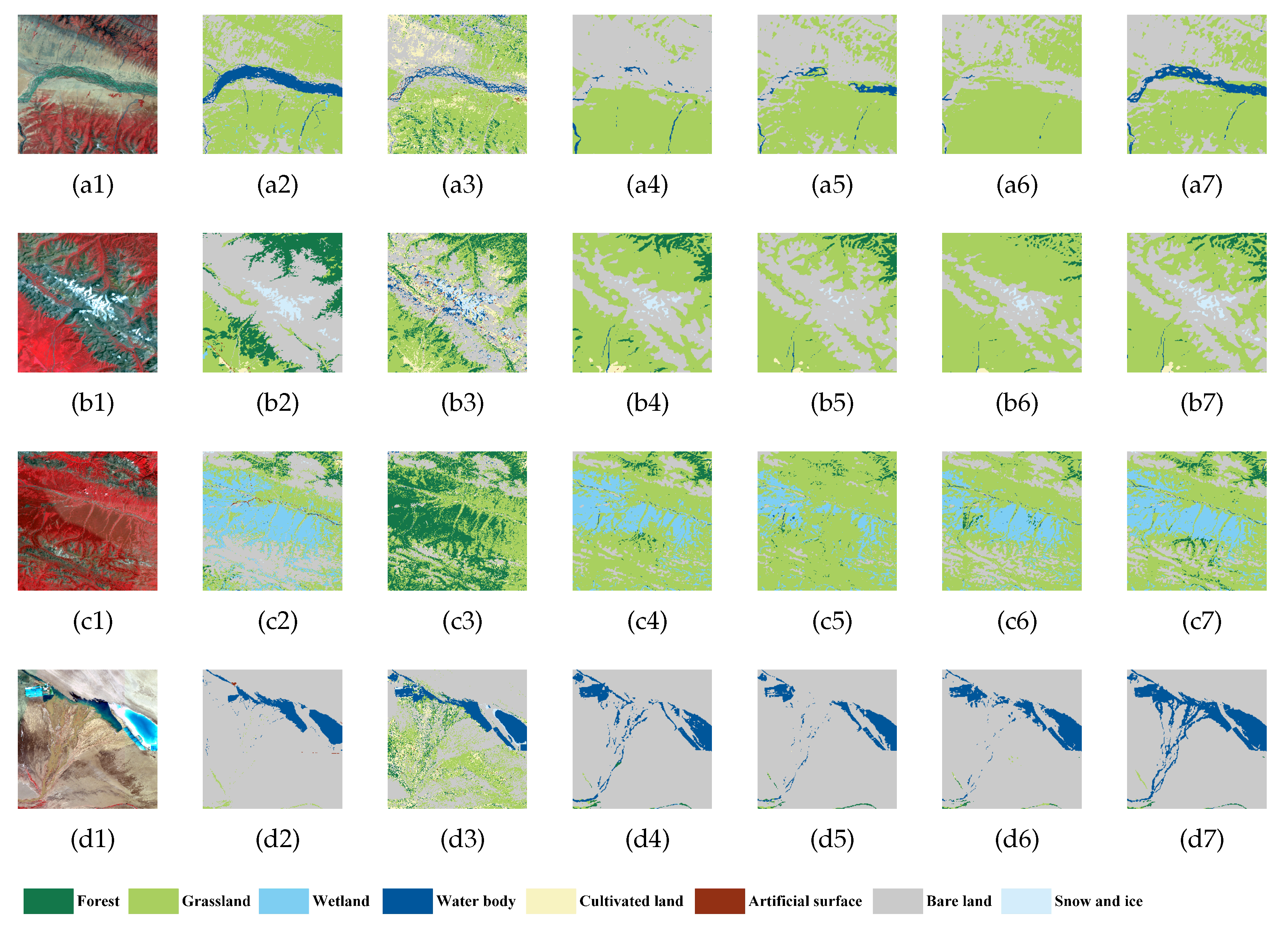
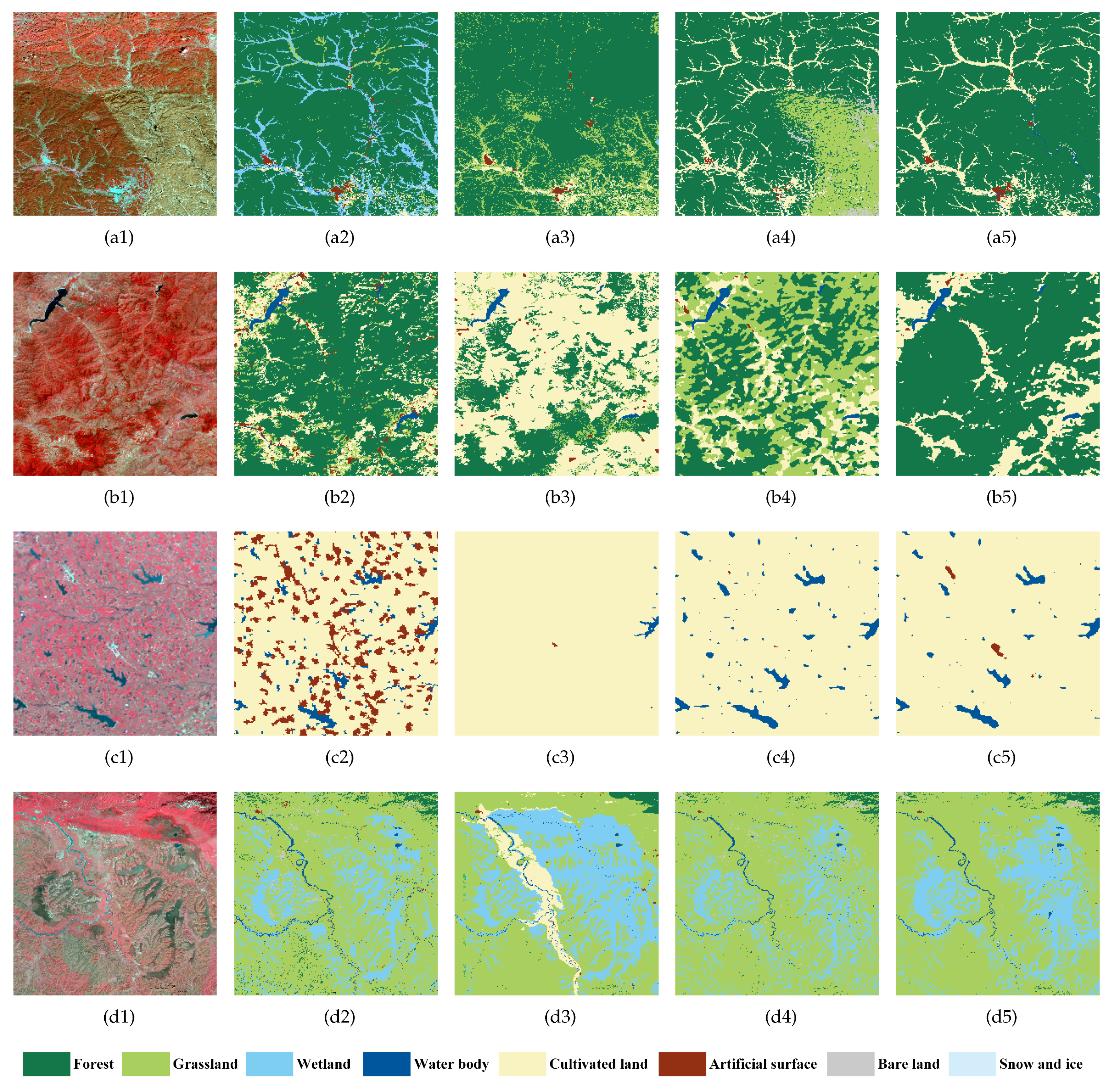
5.2. Qualitative Results for Typical Regions
5.3. Quantitative Results for Typical Region
- (1)
- Among all the methods: RF obtained the lowest accuracy. Influenced by the independence in training samples, RF cannot effectively learn the relationship between pixels and thus is sensitive to noise. Accordingly, both the precision and the F1_score were significantly lower than DL-based methods.
- (2)
- Generally, PSPNet-RL obtained better accuracies than the PSPNet, due to the introduced robust loss function. This means the robust loss proposed in [54] does have the ability of improving the robustness to noisy labels. However, as shown in Figure 6, Figure 7 and Figure 8, this improvement in the classification accuracy is at the cost of decreasing the recognition ability of complex features. Unfortunately, for most applications, object recognition ability is much more important than accuracy.
- (3)
- For Liaoning province at different time periods, the difference in the precision and F1_score for the years 2005 and 2010 were all notable: this was caused by the quality of the original images. The Landsat imagery of the west of Liaoning that was acquired in 2005 included some images from outside the growing season; this had a great impact on the ability to recognize vegetation types. Therefore, both the precision and the F1_score for 2005 were obviously lower than those for 2010.
- (4)
- For Hubei and Qinghai provinces at different time periods, all the accuracies of Liaoning in 2010 were higher than those in 2005, since the training samples contained images obtained in non-growing seasons. Accordingly, models trained by the 2010 training set had higher accuracies than those trained by the 2005 training set. This phenomenon was not found in Hubei and Qinghai. This demonstrates that models trained using high-quality training samples are more general than models trained using poorer-quality training samples.
- (5)
- For the same study area in the same year, PSPNet-RL outperformed PSPNet, and PSPNet outperformed PSPNet-TF, while all the classification accuracies of the MTNet were higher than the others. The MTNet performed well even when the training samples were not balanced and noisy labels were included. The use of interactive training samples from time-series data significantly improved the performance of the networks. This demonstrates the efficiency of the mutual training strategy used in the MTNet.
- (6)
- For different study areas, the overall accuracies were affected by the quality of the original images and labels, and so they varied with the study areas. This was a result of the different proportions of each class that were present in the training samples. For example, the main classes made up a large proportion of the training samples for Liaoning and Hubei. As a result, the overall accuracies for these areas were higher than for Qinghai, for which the samples corresponding to the main classes were of poor quality or contained noisy labels.
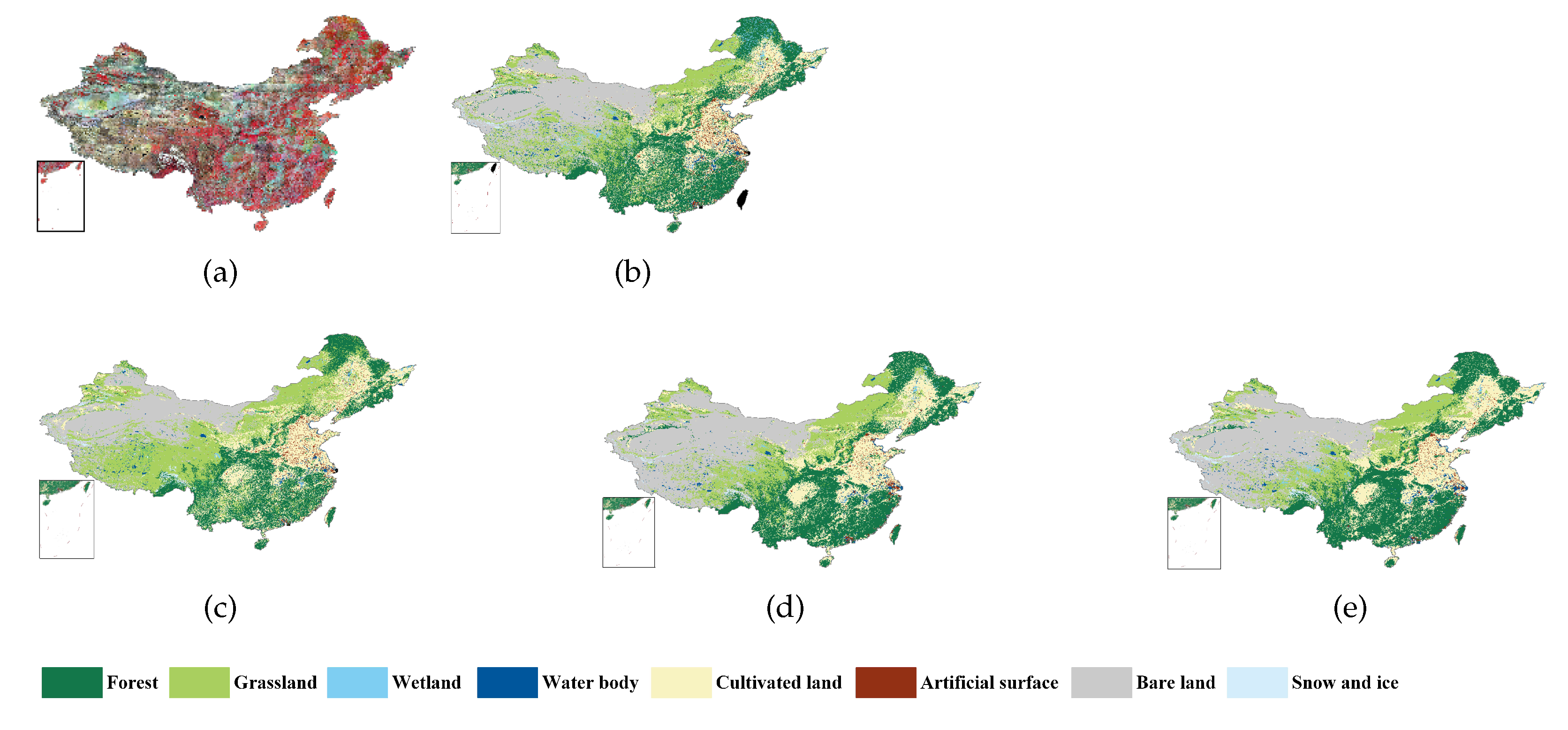
6. Extension to Land Cover Maps of China
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Kwan, C.; Gribben, D.; Ayhan, B.; Li, J.; Bernabe, S.; Plaza, A. An Accurate Vegetation and Non-Vegetation Differentiation Approach Based on Land Cover Classification. Remote Sens. 2020, 12, 3880. [Google Scholar] [CrossRef]
- Hong, D.; Hu, J.; Yao, J.; Chanussot, J.; Zhu, X.X. Multimodal remote sensing benchmark datasets for land cover classification with a shared and specific feature learning model. ISPRS J. Photogramm. Remote Sens. 2021, 178, 68–80. [Google Scholar] [CrossRef] [PubMed]
- Vogelmann, J.E.; Howard, S.M.; Yang, L.; Larson, C.R.; Wylie, B.K.; Van Driel, N. Completion of the 1990s National Land Cover Data Set for the conterminous United States from Landsat Thematic Mapper data and ancillary data sources. Photogramm. Eng. Remote Sens. 2001, 67, 650–662. [Google Scholar]
- Hong, D.; Yokoya, N.; Chanussot, J.; Zhu, X.X. An Augmented Linear Mixing Model to Address Spectral Variability for Hyperspectral Unmixing. IEEE Trans. Image Process. 2019, 28, 1923–1938. [Google Scholar] [CrossRef] [Green Version]
- Ma, L.; Li, M.; Ma, X.; Cheng, L.; Du, P.; Liu, Y. A review of supervised object-based land-cover image classification. ISPRS J. Photogramm. Remote Sens. 2017, 130, 277–293. [Google Scholar] [CrossRef]
- Maselli, F.; Conese, C.; De Filippis, T.; Romani, M. Integration of ancillary data into a maximum-likelihood classifier with nonparametric priors. ISPRS J. Photogramm. Remote Sens. 1995, 50, 2–11. [Google Scholar] [CrossRef]
- Bruzzone, L.; Prieto, D.F. Unsupervised retraining of a maximum likelihood classifier for the analysis of multitemporal remote sensing images. IEEE Trans. Geosci. Remote Sens. 2001, 39, 456–460. [Google Scholar] [CrossRef] [Green Version]
- Quinlan, J.R. Induction of Decision Trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef] [Green Version]
- Quinlan, J.R. C4.5: Programs for Machine Learning; Mach Learn; Morgan Kaufmann Publishers: Burlington, MA, USA, 1994; Volume 16, pp. 235–240. [Google Scholar]
- Colditz, R.R. An Evaluation of Different Training Sample Allocation Schemes for Discrete and Continuous Land Cover Classification Using Decision Tree-Based Algorithms. Remote Sens. 2015, 7, 9655–9681. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random forest. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Belgiu, M.; Drăguţ, L. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Sain, S.R. The Nature of Statistical Learning Theory. Technometrics 1996, 38, 409-409. [Google Scholar] [CrossRef]
- Mountrakis, G.; Im, J.; Ogole, C. Support vector machines in remote sensing: A review. ISPRS J. Photogramm. Remote Sens. 2011, 66, 247–259. [Google Scholar] [CrossRef]
- Hong, D.; Gao, L.; Yao, J.; Zhang, B.; Plaza, A.; Chanussot, J. Graph Convolutional Networks for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2020, 59, 5966–5978. [Google Scholar] [CrossRef]
- Hong, D.; Gao, L.; Yokoya, N.; Yao, J.; Chanussot, J.; Du, Q.; Zhang, B. More Diverse Means Better: Multimodal Deep Learning Meets Remote-Sensing Imagery Classification. IEEE Trans. Geosci. Remote Sens. 2021, 59, 4340–4354. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer International Publishing: Cham, Munich, Germany, 2015; pp. 234–241. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6230–6239. [Google Scholar]
- Gong, P.; Yu, L.; Li, C.; Wang, J.; Liang, L.; Li, X.; Ji, L.; Bai, Y.; Cheng, Y.; Zhu, Z. A new research paradigm for global land cover mapping. Ann. GIS 2016, 22, 87–102. [Google Scholar] [CrossRef] [Green Version]
- Li, C.; Wang, J.; Wang, L.; Hu, L.; Gong, P. Comparison of Classification Algorithms and Training Sample Sizes in Urban Land Classification with Landsat Thematic Mapper Imagery. Remote Sens. 2014, 6, 964–983. [Google Scholar] [CrossRef] [Green Version]
- Radoux, J.; Lamarche, C.; Van Bogaert, E.; Bontemps, S.; Brockmann, C.; Defourny, P. Automated Training Sample Extraction for Global Land Cover Mapping. Remote Sens. 2014, 6, 3965–3987. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Liu, L.; Chen, X.; Xie, S.; Gao, Y. Fine Land-Cover Mapping in China Using Landsat Datacube and an Operational SPECLib-Based Approach. Remote Sens. 2019, 11, 1056. [Google Scholar] [CrossRef] [Green Version]
- Koziarski, M.; Woźniak, M.; Krawczyk, B. Combined Cleaning and Resampling algorithm for multi-class imbalanced data with label noise. Knowl.-Based Syst. 2020, 204, 106223. [Google Scholar] [CrossRef]
- Patrini, G.; Rozza, A.; Menon, A.K.; Nock, R.; Qu, L. Making Deep Neural Networks Robust to Label Noise: A Loss Correction Approach. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2233–2241. [Google Scholar]
- Tanaka, D.; Ikami, D.; Yamasaki, T.; Aizawa, K. Joint Optimization Framework for Learning with Noisy Labels. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5552–5560. [Google Scholar]
- Hong, D.; Yokoya, N.; Chanussot, J.; Xu, J.; Zhu, X.X. Joint and Progressive Subspace Analysis (JPSA) With Spatial–Spectral Manifold Alignment for Semisupervised Hyperspectral Dimensionality Reduction. IEEE Trans. Cybern. 2021, 51, 3602–3615. [Google Scholar] [CrossRef]
- Liu, T.; Tao, D. Classification with Noisy Labels by Importance Reweighting. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 447–461. [Google Scholar] [CrossRef] [Green Version]
- Ghosh, A.; KUmar, H.; Sastry, P. Robust loss functions under labelnoise for deep neural networks. In Proceedings of the AAAI Conference on Artificial and Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 1919–1925. [Google Scholar]
- Rezaee, M.; Mahdianpari, M.; Zhang, Y.; Salehi, B. Deep Convolutional Neural Network for Complex Wetland Classification Using Optical Remote Sensing Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 3030–3039. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet classification with deep convolutional neural networks. Commun. ACM 2012, 25, 84–90. [Google Scholar] [CrossRef]
- Huang, B.; Zhao, B.; Song, Y. Urban land-use mapping using a deep convolutional neural network with high spatial resolution multispectral remote sensing imagery. Remote Sens. Environ. 2018, 214, 73–86. [Google Scholar] [CrossRef]
- Marmanis, D.; Datcu, M.; Esch, T.; Stilla, U. Deep Learning Earth Observation Classification Using ImageNet Pretrained Networks. IEEE Geosci. Remote Sens. Lett. 2016, 13, 105–109. [Google Scholar] [CrossRef] [Green Version]
- Scott, G.J.; England, M.R.; Starms, W.A.; Marcum, R.A.; Davis, C.H. Training Deep Convolutional Neural Networks for Land–Cover Classification of High-Resolution Imagery. IEEE Geosci. Remote Sens. Lett. 2017, 14, 549–553. [Google Scholar] [CrossRef]
- Chen, Y.; Ming, D.; Lv, X. Superpixel based land cover classification of VHR satellite image combining multi-scale CNN and scale parameter estimation. Earth Sci. Inform. 2019, 12, 341–363. [Google Scholar] [CrossRef]
- Liu, S.; Qi, Z.; Li, X.; Yeh, A.G.O. Integration of Convolutional Neural Networks and Object-Based Post-Classification Refinement for Land Use and Land Cover Mapping with Optical and SAR Data. Remote Sens. 2019, 11, 690. [Google Scholar] [CrossRef] [Green Version]
- Zhang, S.; Li, C.; Qiu, S.; Gao, C.; Zhang, F.; Du, Z.; Liu, R. EMMCNN: An ETPS-Based Multi-Scale and Multi-Feature Method Using CNN for High Spatial Resolution Image Land-Cover Classification. Remote Sens. 2020, 12, 66. [Google Scholar] [CrossRef] [Green Version]
- Hu, Y.; Zhang, Q.; Zhang, Y.; Yan, H. A Deep Convolution Neural Network Method for Land Cover Mapping: A Case Study of Qinhuangdao, China. Remote Sens. 2018, 10, 2053. [Google Scholar] [CrossRef] [Green Version]
- Marcos, D.; Volpi, M.; Kellenberger, B.; Tuia, D. Land cover mapping at very high resolution with rotation equivariant CNNs: Towards small yet accurate models. ISPRS J. Photogramm. Remote Sens. 2018, 145, 96–107. [Google Scholar] [CrossRef] [Green Version]
- Li, W.; Dong, R.; Fu, H.; Wang, J.; Yu, L.; Gong, P. Integrating Google Earth imagery with Landsat data to improve 30-m resolution land cover mapping. Remote Sens. Environ. 2020, 237, 111563. [Google Scholar] [CrossRef]
- Hong, D.; Yokoya, N.; Xia, G.S.; Chanussot, J.; Zhu, X.X. X-ModalNet: A semi-supervised deep cross-modal network for classification of remote sensing data. ISPRS J. Photogramm. Remote. Sens. 2020, 167, 12–23. [Google Scholar] [CrossRef]
- Nijhawan, R.; Joshi, D.; Narang, N.; Mittal, A.; Mittal, A.A. A Futuristic Deep Learning Framework Approach for Land Use-Land Cover Classification Using Remote Sensing Imagery. In Advanced Computing and Communication Technologies; Mandal, J.K., Bhattacharyya, D., Auluck, N., Eds.; Springer: Singapore, 2019; pp. 87–96. [Google Scholar]
- Zhang, C.; Pan, X.; Li, H.; Gardiner, A.; Sargent, I.; Hare, J.; Atkinson, P.M. A hybrid MLP-CNN classifier for very fine resolution remotely sensed image classification. ISPRS J. Photogramm. Remote Sens. 2018, 140, 133–144. [Google Scholar] [CrossRef] [Green Version]
- Zhang, C.; Sargent, I.; Pan, X.; Li, H.; Gardiner, A.; Hare, J.; Atkinson, P.M. Joint Deep Learning for land cover and land use classification. Remote Sens. Environ. 2019, 221, 173–187. [Google Scholar] [CrossRef] [Green Version]
- Jiang, J.; Ma, J.; Wang, Z.; Chen, C.; Liu, X. Hyperspectral Image Classification in the Presence of Noisy Labels. IEEE Trans. Geosci. Remote Sens. 2019, 57, 851–865. [Google Scholar] [CrossRef] [Green Version]
- Santos, L.A.; Ferreira, K.R.; Camara, G.; Picoli, M.C.; Simoes, R.E. Quality control and class noise reduction of satellite image time series. ISPRS J. Photogramm. Remote Sens. 2021, 177, 75–88. [Google Scholar] [CrossRef]
- Algan, G.; Ulusoy, I. Image classification with deep learning in the presence of noisy labels: A survey. Knowl.-Based Syst. 2021, 215, 106771. [Google Scholar] [CrossRef]
- Zhang, J.; Dai, Y.; Zhang, T.; Harandi, M.; Barnes, N.; Hartley, R. Learning Saliency From Single Noisy Labelling: A Robust Model Fitting Perspective. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 2866–2873. [Google Scholar]
- Ji, D.; Oh, D.; Hyun, Y.; Kwon, O.M.; Park, M.J. How to handle noisy labels for robust learning from uncertainty. Neural Netw. 2021, 143, 209–217. [Google Scholar] [CrossRef]
- Deng, L.; Yang, B.; Kang, Z.; Yang, S.; Wu, S. A noisy label and negative sample robust loss function for DNN-based distant supervised relation extraction. Neural Netw. 2021, 139, 358–370. [Google Scholar] [CrossRef]
- Han, B.; Tsang, I.W.; Chen, L.; Zhou, J.T.; Yu, C.P. Beyond Majority Voting: A Coarse-to-Fine Label Filtration for Heavily Noisy Labels. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3774–3787. [Google Scholar] [CrossRef]
- Zhang, X.Y.; Liu, C.L.; Suen, C.Y. Towards Robust Pattern Recognition: A Review. Proc. IEEE 2020, 108, 894–922. [Google Scholar] [CrossRef]
- Zhang, Q.; Lee, F.; Wang, Y.; Miao, R.; Chen, L.; Chen, Q. An improved noise loss correction algorithm for learning from noisy labels. J. Vis. Commun. Image Represent. 2020, 72, 102930. [Google Scholar] [CrossRef]
- Xu, Y.; Li, Z.; Li, W.; Du, Q.; Liu, C.; Fang, Z.; Zhai, L. Dual-Channel Residual Network for Hyperspectral Image Classification With Noisy Labels. IEEE Trans. Geosci. Remote Sens. 2021. [Google Scholar] [CrossRef]
- Zhang, Q.; Lee, F.; Wang, Y.; Ding, D.; Yao, W.; Chen, L.; Chen, Q. An joint end-to-end framework for learning with noisy labels. Appl. Soft Comput. 2021, 108, 107426. [Google Scholar] [CrossRef]
- Dube, T.; Mutanga, O.; Ismail, R. Quantifying aboveground biomass in African environments: A review of the trade-offs between sensor estimation accuracy and costs. Trop. Ecol. 2016, 57, 393–405. [Google Scholar]
- Massetti, A.; Gil, A. Mapping and assessing land cover/land use and aboveground carbon stocks rapid changes in small oceanic islands’ terrestrial ecosystems: A case study of Madeira Island, Portugal (2009–2011). Remote Sens. Environ. 2020, 239, 111625. [Google Scholar] [CrossRef]
- Jiang, M.; Yong, B.; Tian, X.; Malhotra, R.; Hu, R.; Li, Z.; Yu, Z.; Zhang, X. The potential of more accurate InSAR covariance matrix estimation for land cover mapping. ISPRS J. Photogramm. Remote Sens. 2017, 126, 120–128. [Google Scholar] [CrossRef]
- Sánchez-Espinosa, A.; Schröder, C. Land use and land cover mapping in wetlands one step closer to the ground: Sentinel-2 versus landsat 8. J. Environ. Manag. 2019, 247, 484–498. [Google Scholar] [CrossRef]
- Gong, P.; Wang, J.; Yu, L.; Zhao, Y.; Zhao, Y.; Liang, L.; Niu, Z.; Huang, X.; Fu, H.; Liu, S.; et al. Finer resolution observation and monitoring of global land cover: First mapping results with Landsat TM and ETM+ data. Int. J. Remote Sens. 2013, 34, 2607–2654. [Google Scholar] [CrossRef] [Green Version]
- Huang, H.; Wang, J.; Liu, C.; Liang, L.; Li, C.; Gong, P. The migration of training samples towards dynamic global land cover mapping. ISPRS J. Photogramm. Remote Sens. 2020, 161, 27–36. [Google Scholar] [CrossRef]
- Gong, P.; Liu, H.; Zhang, M.; Li, C.; Wang, J.; Huang, H.; Clinton, N.; Ji, L.; Li, W.; Bai, Y.; et al. Stable classification with limited sample: Transferring a 30-m resolution sample set collected in 2015 to mapping 10-m resolution global land cover in 2017. Sci. Bull. 2019, 64, 370–373. [Google Scholar] [CrossRef] [Green Version]
- Chen, J.; Chen, J.; Liao, A.; Cao, X.; Chen, L.; Chen, X.; He, C.; Han, G.; Peng, S.; Lu, M.; et al. Global land cover mapping at 30m resolution: A POK-based operational approach. ISPRS J. Photogramm. Remote Sens. 2015, 103, 7–27. [Google Scholar] [CrossRef] [Green Version]
- Liu, S.; Su, H.; Cao, G.; Wang, S.; Guan, Q. Learning from data: A post classification method for annual land cover analysis in urban areas. ISPRS J. Photogramm. Remote Sens. 2019, 154, 202–215. [Google Scholar] [CrossRef]
- Maus, V.; Câmara, G.; Cartaxo, R.; Sanchez, A.; Ramos, F.M.; de Queiroz, G.R. A Time-Weighted Dynamic Time Warping Method for Land-Use and Land-Cover Mapping. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 3729–3739. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| First-Level Classes | Second-Level Classes |
|---|---|
| Forest | Evergreen broad-leaved forest, deciduous broad-leaved forest, evergreen needle-leaved forest, deciduous needle-leaved forest, |
| Mixed-leaved forest, evergreen broad-leaved shrub, deciduous broad-leaved shrub, evergreen needle-leaved shrub, arbor garden, | |
| Shrub garden, arbor green space, shrub field | |
| Grassland | meadow, grassland, grass, herbaceous green land |
| Wetland | Forest wetland, shrub wetland, herbal wetland |
| Water body | Lakes, reservoirs/ponds, rivers, canals |
| Cultivated land | Irrigated farmland, farmland |
| Artificial surface | Residential land, industrial land, transportation land |
| Bare land | Mining land, sparse forest, sparse shrub, sparse grassland, moss/lichen, bare rock, bare soil, desert/sandy land, saline-alkali land |
| Snow and ice | Glacier/permanent snow cover |
| Training Samples | Test Samples | Patch Size | Channels | |
|---|---|---|---|---|
| Typical region | 15,000 | 4000 | 512 | 6 |
| Whole nation | 19,200 | 4800 | 6 |
| Forest | Grassland | Wetland | Water Body | Cultivated Land | Build-Up Land | Bare Land | Overall Accuracy | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| (%) | Precision | F1_Score | Precision | F1_Score | Precision | F1_Score | Precision | F1_Score | Precision | F1_Score | Precision | F1_Score | Precision | F1_Score | Precision | F1_Score |
| TS-1 | 81.54 | 76.34 | 36.05 | 49.80 | 41.82 | 57.23 | 71.66 | 16.89 | 90.34 | 81.79 | 47.50 | 58.61 | 37.73 | 49.63 | 75.25 | 71.83 |
| TS-2 | 87.61 78.94 | 48.43 | 60.17 | 72.48 | 29.11 | 85.05 | 83.22 | 56.49 | 76.20 | 41.90 | 38.90 | 83.16 | 78.32 | |||
| TS-3 | 81.74 | 77.16 | 54.61 | 56.99 | 49.60 | 63.21 | 75.39 | 34.11 | 87.17 | 78.45 | 58.11 | 63.92 | 45.98 | 49.40 | 77.65 | 72.43 |
| Time Period | RF | PSPNet-RL | PSPNet | PSPNet-TF | MTNet | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| (%) | Precision | F1_Score | Precision | F1_Score | Precision | F1_Score | Precision | F1_Score | |||
| Liaoning | 2005 | 47.76 | 49.79 | 71.80 | 71.39 | 72.97 | 72.44 | 71.69 | 71.80 | 73.58 | 73.21 |
| 2010 | 54.04 | 54.04 | 84.52 | 83.31 | 83.39 | 82.94 | 81.14 | 80.98 | 83.94 | 83.04 | |
| Hubei | 2005 | 51.16 | 58.02 | 80.91 | 79.47 | 81.13 | 79.78 | 79.10 | 77.70 | 81.32 | 80.04 |
| 2010 | 52.40 | 59.06 | 77.70 | 76.60 | 76.96 | 75.82 | 77.50 | 76.26 | 80.68 | 80.09 | |
| Qinghai | 2005 | 51.40 | 55.81 | 73.97 | 74.16 | 71.57 | 72.16 | 71.89 | 72.03 | 74.49 | 74.62 |
| 2010 | 52.79 | 56.92 | 71.86 | 72.24 | 65.77 | 65.57 | 68.03 | 67.77 | 75.48 | 75.36 | |
| Base | GLC30 | LCMPRC | PSPNet | MTNet | ||||
|---|---|---|---|---|---|---|---|---|
| Precision | F1_Score | Precision | F1_Score | Precision | F1_Score | Precision | F1_Score | |
| GLC30 | - | 74.21 | 62.63 | 77.05 | 63.74 | 77.55 | 64.03 | |
| LCMPRC | 74.50 | 59.77 | - | 82.51 | 64.38 | 82.61 | 64.41 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, X.; Hong, D.; Gao, L.; Zhang, B.; Chanussot, J. Transferable Deep Learning from Time Series of Landsat Data for National Land-Cover Mapping with Noisy Labels: A Case Study of China. Remote Sens. 2021, 13, 4194. https://0-doi-org.brum.beds.ac.uk/10.3390/rs13214194
Zhao X, Hong D, Gao L, Zhang B, Chanussot J. Transferable Deep Learning from Time Series of Landsat Data for National Land-Cover Mapping with Noisy Labels: A Case Study of China. Remote Sensing. 2021; 13(21):4194. https://0-doi-org.brum.beds.ac.uk/10.3390/rs13214194
Chicago/Turabian StyleZhao, Xuemei, Danfeng Hong, Lianru Gao, Bing Zhang, and Jocelyn Chanussot. 2021. "Transferable Deep Learning from Time Series of Landsat Data for National Land-Cover Mapping with Noisy Labels: A Case Study of China" Remote Sensing 13, no. 21: 4194. https://0-doi-org.brum.beds.ac.uk/10.3390/rs13214194