
Bagging and Boosting Ensemble Classifiers for Classification of Multispectral, Hyperspectral and PolSAR Data: A Comparative Evaluation

 ,
,  ,
, 

Abstract
:1. Introduction
2. Ensemble Learning Classifiers
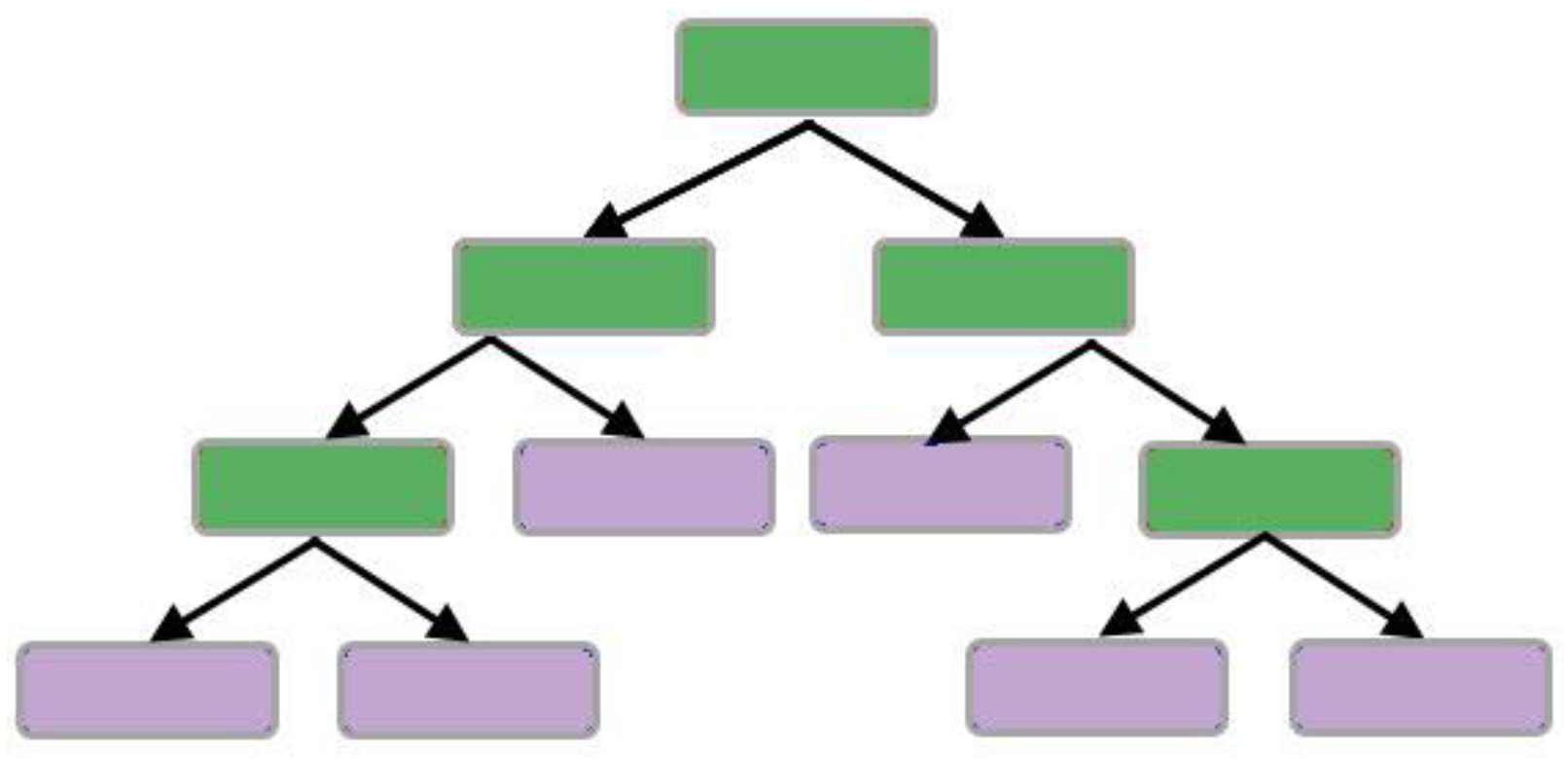
2.1. Decision Tree (DT)
2.2. Adaptive Boosting (AdaBoost)
2.3. Gradient Boosting Machine (GBM)
2.4. Extreme Gradient Boosting (XGBoost)
2.5. Light Gradient Boosting Machine (LightGBM)
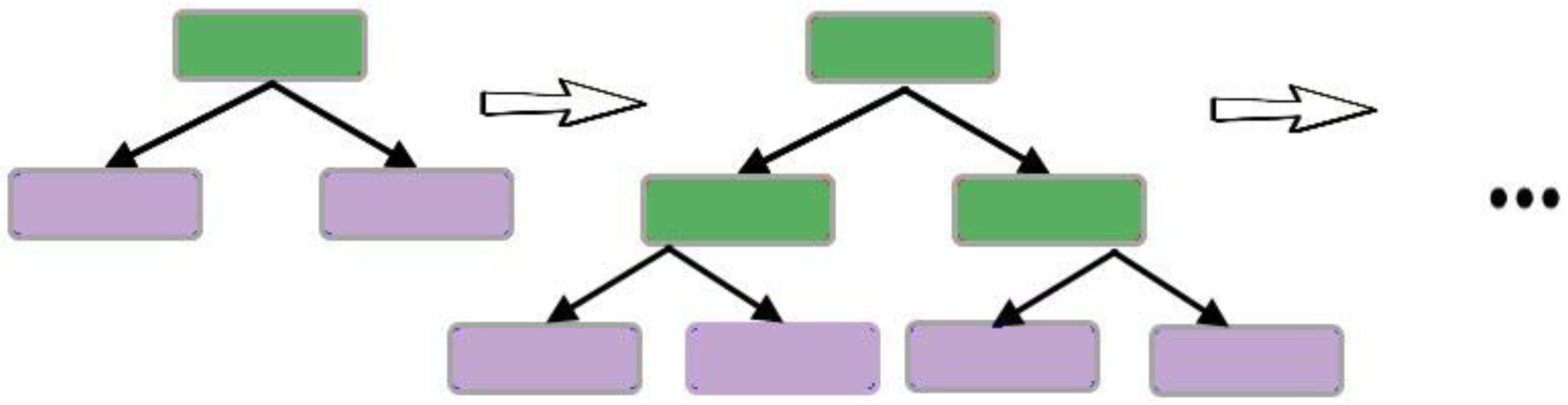
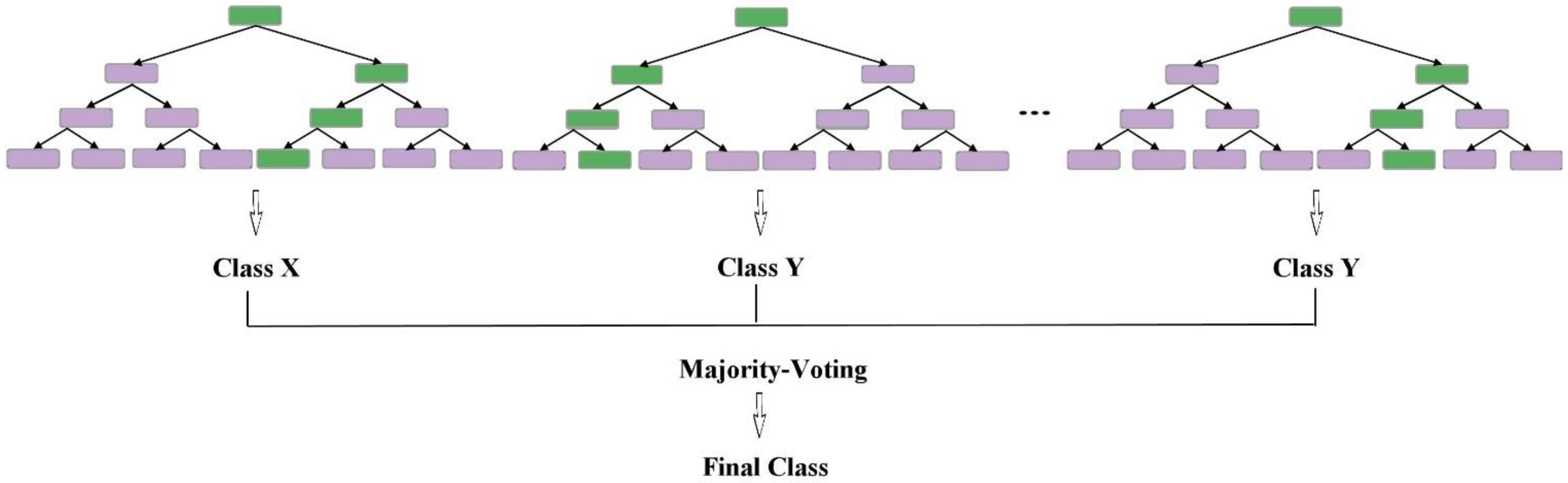
2.6. Random Forest (RF)
3. Remote Sensing Datasets
3.1. ISPRS Vaihingen Dataset
3.2. Pavia University Scene
3.3. San Francisco Bay SAR Data
4. Experiments and Results
4.1. User-Set Parameters
4.1.1. Hyper-Parameter Tuning for Multispectral Data
4.1.2. Hyper-Parameter Tuning for Hyperspectral Data
4.1.3. Hyper-Parameter Tuning for PolSAR Data
4.2. Classification Results
4.2.1. Land-Cover Mapping from Multispectral Data
4.2.2. Classification Results of Hyperspectral Data
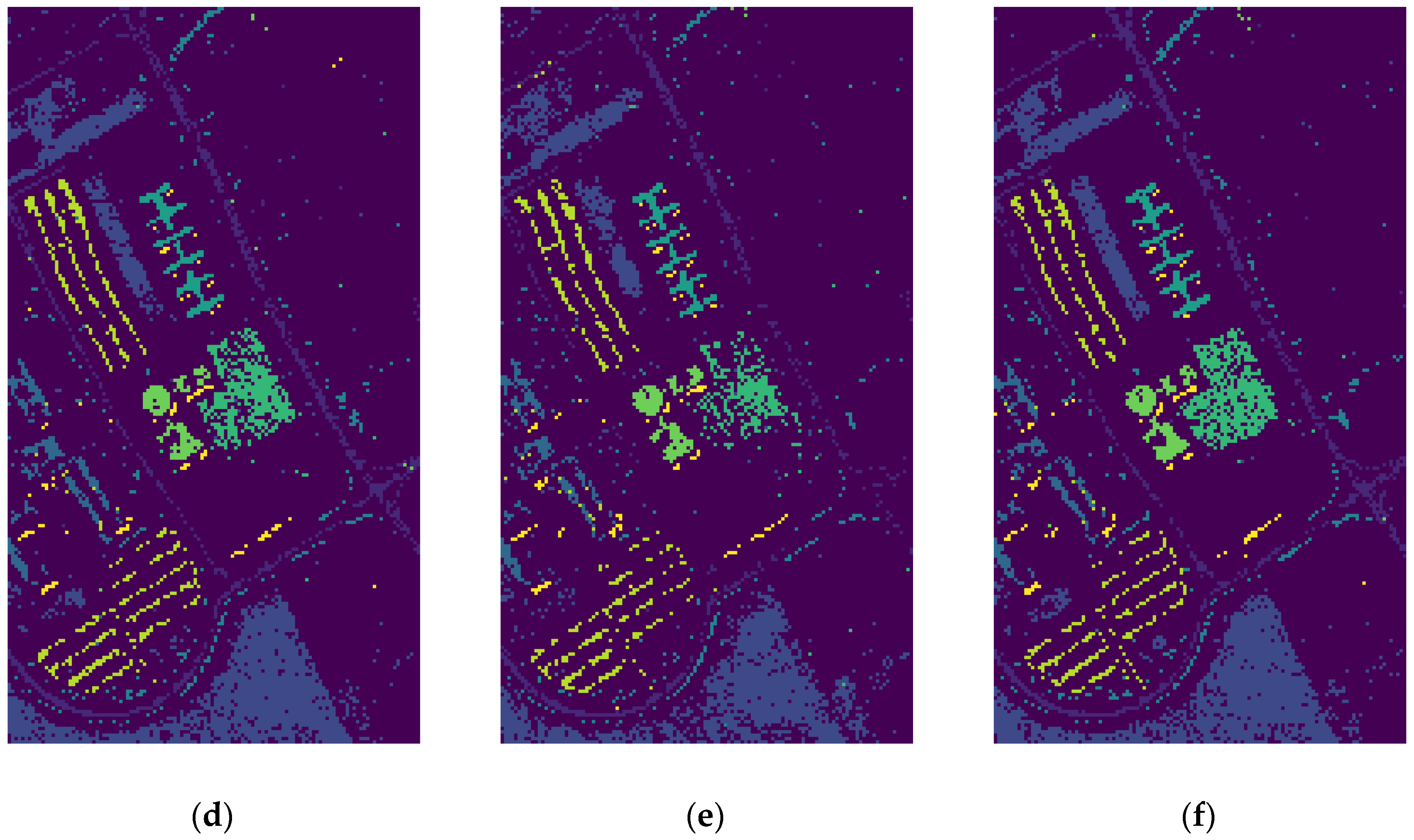
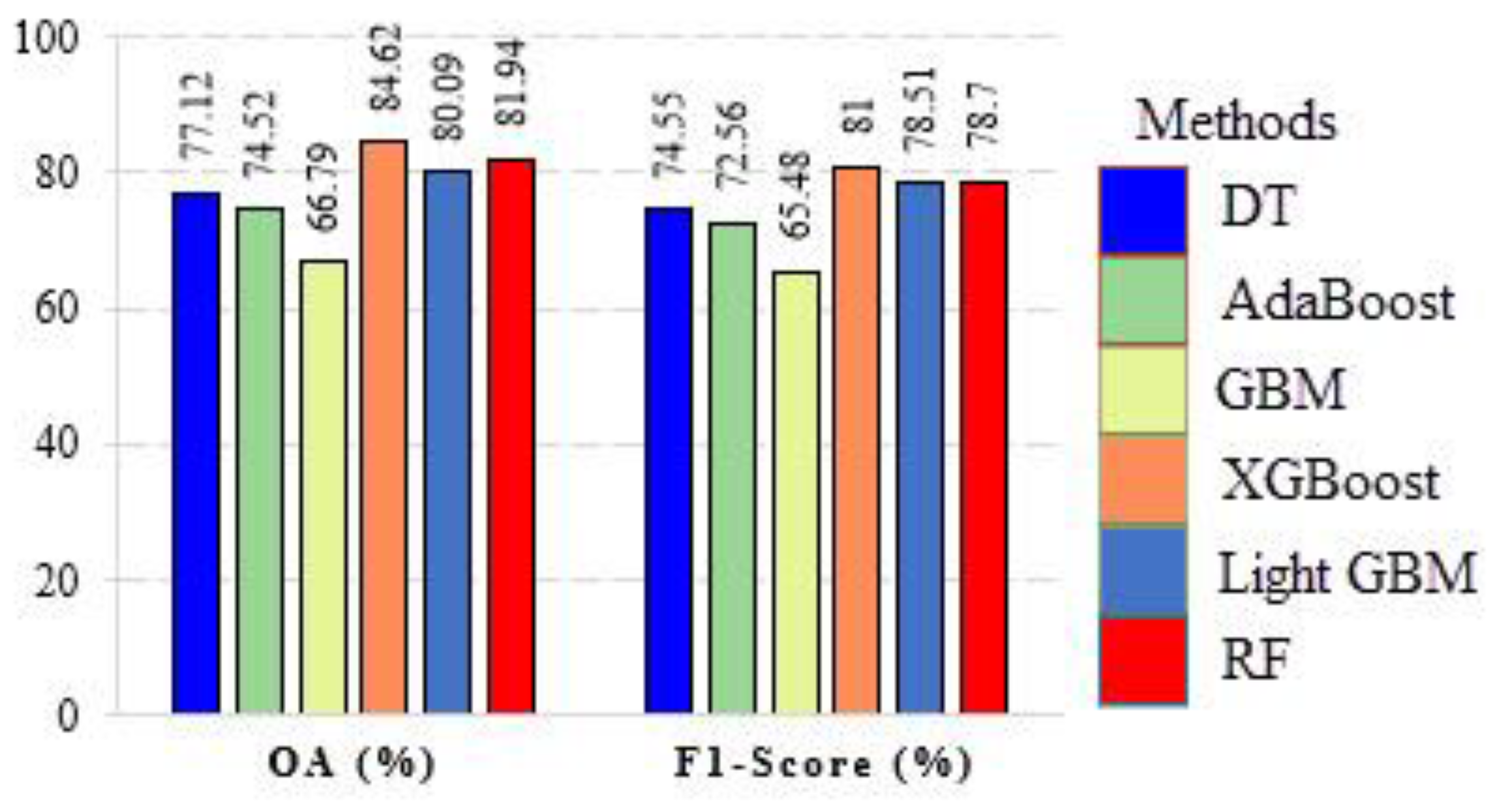
4.2.3. Classification Results of PolSAR Dataset
4.2.4. The Final Summary of Classification Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| RS | Remote Sensing |
| EO | Earth observations |
| LULC | Land Use/Land Cover |
| ML | Machine Learning |
| EL | Ensemble Learning |
| DT | Decision Tree |
| AdaBoost | Adaptive Boosting |
| GBM | Gradient boosting machine |
| XGBoost | Extreme Gradient Boosting |
| LightGBM | Light Gradient Boosting Machine |
| RF | Random Forest |
| MTD | Maximum Tree Depth |
| NBCs | Number of Base Classifiers |
| LR | Learning Rate |
| MTA | Mean Test Accuracy |
| MSS | Minimum Sample Split |
References
- Aredehey, G.; Mezgebu, A.; Girma, A. Land-Use Land-Cover Classification Analysis of Giba Catchment Using Hyper Temporal MODIS NDVI Satellite Images. Int. J. Remote Sens. 2018, 39, 810–821. [Google Scholar] [CrossRef]
- Xia, M.; Tian, N.; Zhang, Y.; Xu, Y.; Zhang, X. Dilated Multi-Scale Cascade Forest for Satellite Image Classification. Int. J. Remote Sens. 2020, 41, 7779–7800. [Google Scholar] [CrossRef]
- Briem, G.J.; Benediktsson, J.A.; Sveinsson, J.R. Boosting, Bagging, and Consensus Based Classification of Multisource Remote Sensing Data. In Proceedings of the Multiple Classifier Systems; Kittler, J., Roli, F., Eds.; Springer: Berlin/Heidelberg, Germany, 2001; pp. 279–288. [Google Scholar]
- Jamshidpour, N.; Safari, A.; Homayouni, S. Spectral–Spatial Semisupervised Hyperspectral Classification Using Adaptive Neighborhood. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 4183–4197. [Google Scholar] [CrossRef]
- Halder, A.; Ghosh, A.; Ghosh, S. Supervised and Unsupervised Landuse Map Generation from Remotely Sensed Images Using Ant Based Systems. Appl. Soft Comput. 2011, 11, 5770–5781. [Google Scholar] [CrossRef]
- Chen, Y.; Dou, P.; Yang, X. Improving Land Use/Cover Classification with a Multiple Classifier System Using AdaBoost Integration Technique. Remote Sens. 2017, 9, 1055. [Google Scholar] [CrossRef] [Green Version]
- Maulik, U.; Chakraborty, D. A Robust Multiple Classifier System for Pixel Classification of Remote Sensing Images. Fundam. Inform. 2010, 101, 286–304. [Google Scholar] [CrossRef]
- Nowakowski, A. Remote Sensing Data Binary Classification Using Boosting with Simple Classifiers. Acta Geophys. 2015, 63, 1447–1462. [Google Scholar] [CrossRef] [Green Version]
- Kavzoglu, T.; Colkesen, I.; Yomralioglu, T. Object-Based Classification with Rotation Forest Ensemble Learning Algorithm Using Very-High-Resolution WorldView-2 Image. Remote Sens. Lett. 2015, 6, 834–843. [Google Scholar] [CrossRef]
- Rokach, L. Ensemble Methods for Classifiers. In Data Mining and Knowledge Discovery Handbook; Maimon, O., Rokach, L., Eds.; Springer US: Boston, MA, USA, 2005; pp. 957–980. ISBN 978-0-387-25465-4. [Google Scholar]
- Dietterich, T.G. An Experimental Comparison of Three Methods for Constructing Ensembles of Decision Trees: Bagging, Boosting, and Randomization. Mach. Learn. 2000, 40, 139–157. [Google Scholar] [CrossRef]
- Miao, X.; Heaton, J.S.; Zheng, S.; Charlet, D.A.; Liu, H. Applying Tree-Based Ensemble Algorithms to the Classification of Ecological Zones Using Multi-Temporal Multi-Source Remote-Sensing Data. Int. J. Remote Sens. 2012, 33, 1823–1849. [Google Scholar] [CrossRef]
- Halmy, M.W.A.; Gessler, P.E. The Application of Ensemble Techniques for Land-Cover Classification in Arid Lands. Int. J. Remote Sens. 2015, 36, 5613–5636. [Google Scholar] [CrossRef]
- Briem, G.J.; Benediktsson, J.A.; Sveinsson, J.R. Multiple Classifiers Applied to Multisource Remote Sensing Data. IEEE Trans. Geosci. Remote Sens. 2002, 40, 2291–2299. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Bagging Predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef] [Green Version]
- Benediktsson, J.A.; Chanussot, J.; Fauvel, M. Multiple Classifier Systems in Remote Sensing: From Basics to Recent Developments. In Proceedings of the Multiple Classifier Systems; Haindl, M., Kittler, J., Roli, F., Eds.; Springer: Berlin/Heidelberg, Germany, 2007; pp. 501–512. [Google Scholar]
- Pal, M. Ensemble Learning with Decision Tree for Remote Sensing Classification. Int. J. Comput. Inf. Eng. 2007, 1, 3852–3854. [Google Scholar]
- Mahdianpari, M.; Jafarzadeh, H.; Granger, J.E.; Mohammadimanesh, F.; Brisco, B.; Salehi, B.; Homayouni, S.; Weng, Q. A Large-Scale Change Monitoring of Wetlands Using Time Series Landsat Imagery on Google Earth Engine: A Case Study in Newfoundland. GISci. Remote Sens. 2020, 57, 1102–1124. [Google Scholar] [CrossRef]
- Georganos, S.; Grippa, T.; Vanhuysse, S.; Lennert, M.; Shimoni, M.; Kalogirou, S.; Wolff, E. Less Is More: Optimizing Classification Performance through Feature Selection in a Very-High-Resolution Remote Sensing Object-Based Urban Application. GISci. Remote Sens. 2018, 55, 221–242. [Google Scholar] [CrossRef]
- Ustuner, M.; Balik Sanli, F. Polarimetric Target Decompositions and Light Gradient Boosting Machine for Crop Classification: A Comparative Evaluation. ISPRS Int. J. Geo-Inf. 2019, 8, 97. [Google Scholar] [CrossRef] [Green Version]
- Abdi, A.M. Land Cover and Land Use Classification Performance of Machine Learning Algorithms in a Boreal Landscape Using Sentinel-2 Data. GISci. Remote Sens. 2020, 57, 1–20. [Google Scholar] [CrossRef] [Green Version]
- Shi, X.; Cheng, Y.; Xue, D. Classification Algorithm of Urban Point Cloud Data Based on LightGBM. IOP Conf. Ser. Mater. Sci. Eng. 2019, 631, 052041. [Google Scholar] [CrossRef]
- Jiang, H.; Li, D.; Jing, W.; Xu, J.; Huang, J.; Yang, J.; Chen, S. Early Season Mapping of Sugarcane by Applying Machine Learning Algorithms to Sentinel-1A/2 Time Series Data: A Case Study in Zhanjiang City, China. Remote Sens. 2019, 11, 861. [Google Scholar] [CrossRef] [Green Version]
- Krishna Moorthy, S.M.; Calders, K.; Vicari, M.B.; Verbeeck, H. Improved Supervised Learning-Based Approach for Leaf and Wood Classification from LiDAR Point Clouds of Forests. IEEE Trans. Geosci. Remote Sens. 2020, 58, 3057–3070. [Google Scholar] [CrossRef] [Green Version]
- Zhong, L.; Hu, L.; Zhou, H. Deep Learning Based Multi-Temporal Crop Classification. Remote Sens. Environ. 2019, 221, 430–443. [Google Scholar] [CrossRef]
- Saini, R.; Ghosh, S.K. Crop Classification in a Heterogeneous Agricultural Environment Using Ensemble Classifiers and Single-Date Sentinel-2A Imagery. Geocarto Int. 2019, 1–19. [Google Scholar] [CrossRef]
- Dey, S.; Mandal, D.; Robertson, L.D.; Banerjee, B.; Kumar, V.; McNairn, H.; Bhattacharya, A.; Rao, Y.S. In-Season Crop Classification Using Elements of the Kennaugh Matrix Derived from Polarimetric RADARSAT-2 SAR Data. Int. J. Appl. Earth Obs. Geoinf. 2020, 88, 102059. [Google Scholar] [CrossRef]
- Gašparović, M.; Dobrinić, D. Comparative Assessment of Machine Learning Methods for Urban Vegetation Mapping Using Multitemporal Sentinel-1 Imagery. Remote Sens. 2020, 12, 1952. [Google Scholar] [CrossRef]
- Chan, J.C.W.; Huang, C.; Defries, R. Enhanced Algorithm Performance for Land Cover Classification from Remotely Sensed Data Using Bagging and Boosting. IEEE Trans. Geosci. Remote Sens. 2001, 39, 693–695. [Google Scholar] [CrossRef]
- Friedl, M.A.; Brodley, C.E. Decision Tree Classification of Land Cover from Remotely Sensed Data. Remote Sens. Environ. 1997, 61, 399–409. [Google Scholar] [CrossRef]
- Song, Y.Y.; Ying, L.U. Decision Tree Methods: Applications for Classification and Prediction. Shanghai Arch. Psychiatry 2015, 27, 130–135. [Google Scholar] [CrossRef]
- Sharma, R.; Ghosh, A.; Joshi, P.K. Decision Tree Approach for Classification of Remotely Sensed Satellite Data Using Open Source Support. J. Earth Syst. Sci. 2013, 122, 1237–1247. [Google Scholar] [CrossRef] [Green Version]
- Maxwell, A.E.; Warner, T.A.; Fang, F. Implementation of Machine-Learning Classification in Remote Sensing: An Applied Review. Int. J. Remote Sens. 2018, 39, 2784–2817. [Google Scholar] [CrossRef] [Green Version]
- Pal, M.; Mather, P.M. An Assessment of the Effectiveness of Decision Tree Methods for Land Cover Classification. Remote Sens. Environ. 2003, 86, 554–565. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R.E. Experiments with a New Boosting Algorithm. In Proceedings of the Thirteenth International Conference on International Conference on Machine Learning, Bari, Italy, 3 July 1996; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1996; pp. 148–156. [Google Scholar]
- Chan, J.C.-W.; Paelinckx, D. Evaluation of Random Forest and Adaboost Tree-Based Ensemble Classification and Spectral Band Selection for Ecotope Mapping Using Airborne Hyperspectral Imagery. Remote Sens. Environ. 2008, 112, 2999–3011. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R.E. A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef] [Green Version]
- Dou, P.; Chen, Y. Dynamic Monitoring of Land-Use/Land-Cover Change and Urban Expansion in Shenzhen Using Landsat Imagery from 1988 to 2015. Int. J. Remote Sens. 2017, 38, 5388–5407. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy Function Approximation: A Gradient Boosting Machine. Ann. Statist. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Biau, G.; Cadre, B.; Rouvìère, L. Accelerated Gradient Boosting. arXiv 2018, arXiv:1803.02042. [Google Scholar] [CrossRef] [Green Version]
- Prioritizing Influential Factors for Freeway Incident Clearance Time Prediction Using the Gradient Boosting Decision Trees Method—IEEE Journals & Magazine. Available online: https://0-ieeexplore-ieee-org.brum.beds.ac.uk/document/7811191 (accessed on 16 January 2021).
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining; Association for Computing Machinery, New York, NY, USA, 13 August 2016; pp. 785–794. [Google Scholar]
- Samat, A.; Li, E.; Wang, W.; Liu, S.; Lin, C.; Abuduwaili, J. Meta-XGBoost for Hyperspectral Image Classification Using Extended MSER-Guided Morphological Profiles. Remote Sens. 2020, 12, 1973. [Google Scholar] [CrossRef]
- Natekin, A.; Knoll, A. Gradient Boosting Machines, a Tutorial. Front. Neurorobot. 2013, 7, 21. [Google Scholar] [CrossRef] [Green Version]
- Zheng, Z.; Zha, H.; Zhang, T.; Chapelle, O.; Chen, K.; Sun, G. A General Boosting Method and Its Application to Learning Ranking Functions for Web Search. In Proceedings of the Advances in Neural Information Processing Systems 20: Proceedings of the 2007 Conference, Vancouver, BC, Canada, 3–6 December 2007. [Google Scholar]
- Lombardo, L.; Cama, M.; Conoscenti, C.; Märker, M.; Rotigliano, E. Binary Logistic Regression versus Stochastic Gradient Boosted Decision Trees in Assessing Landslide Susceptibility for Multiple-Occurring Landslide Events: Application to the 2009 Storm Event in Messina (Sicily, Southern Italy). Nat. Hazards 2015, 79, 1621–1648. [Google Scholar] [CrossRef]
- Li, L.; Wu, Y.; Ye, M. Multi-Class Image Classification Based on Fast Stochastic Gradient Boosting. Informatica 2014, 38, 145–153. [Google Scholar]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.-Y. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. Adv. Neural Inf. Process. Syst. 2017, 30, 3146–3154. [Google Scholar]
- Machado, M.R.; Karray, S.; Sousa, I.T. de LightGBM: An Effective Decision Tree Gradient Boosting Method to Predict Customer Loyalty in the Finance Industry. In Proceedings of the 2019 14th International Conference on Computer Science Education (ICCSE), Toronto, ON, Canada, 19–21 August 2019; pp. 1111–1116. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Cutler, D.R.; Edwards, T.C.; Beard, K.H.; Cutler, A.; Hess, K.T.; Gibson, J.; Lawler, J.J. Random Forests for Classification in Ecology. Ecology 2007, 88, 2783–2792. [Google Scholar] [CrossRef]
- Belgiu, M.; Drăguţ, L. Random Forest in Remote Sensing: A Review of Applications and Future Directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- ISPRS International Society For Photogrammetry And Remote Sensing. 2D Semantic Labeling Challenge. Available online: https://www2.isprs.org/commissions/comm2/wg4/benchmark/semantic-labeling/ (accessed on 15 January 2021).
- Cheng, W.; Yang, W.; Wang, M.; Wang, G.; Chen, J. Context Aggregation Network for Semantic Labeling in Aerial Images. Remote Sens. 2019, 11, 1158. [Google Scholar] [CrossRef] [Green Version]
- Audebert, N.; Saux, B.L.; Lefevre, S. Deep Learning for Classification of Hyperspectral Data: A Comparative Review. IEEE Geosci. Remote Sens. Mag. 2019, 7, 159–173. [Google Scholar] [CrossRef] [Green Version]
- Gao, F.; Wang, Q.; Dong, J.; Xu, Q. Spectral and Spatial Classification of Hyperspectral Images Based on Random Multi-Graphs. Remote Sens. 2018, 10, 1271. [Google Scholar] [CrossRef] [Green Version]
- Uhlmann, S.; Kiranyaz, S. Integrating Color Features in Polarimetric SAR Image Classification. IEEE Trans. Geosci. Remote Sens. 2014, 52, 2197–2216. [Google Scholar] [CrossRef]
- Quinlan, J.R. Induction of Decision Trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef] [Green Version]
- Zhang, F.; Du, B.; Zhang, L. Scene Classification via a Gradient Boosting Random Convolutional Network Framework. IEEE Trans. Geosci. Remote Sens. 2016, 54, 1793–1802. [Google Scholar] [CrossRef]
- Jafarzadeh, H.; Hasanlou, M. An Unsupervised Binary and Multiple Change Detection Approach for Hyperspectral Imagery Based on Spectral Unmixing. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 4888–4906. [Google Scholar] [CrossRef]
- Cramer, M. The DGPF-Test on Digital Airborne Camera Evaluation Overview and Test Design. Photogramm. Fernerkund. Geoinf. 2010, 73–82. [Google Scholar] [CrossRef] [PubMed]























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Bagging | Boosting |
|---|---|
| Predictors/models are independent of each other. | Predictors/models are not independent of each other. |
| There is no concept of learning from each other. | Each of the individual predictors in the chain learns to fix or minimize the prediction error of the previous one while moving sequentially forward. |
| Aims to decrease variance. | Seeks to lower the bias. |
| Advantages | Disadvantages |
|---|---|
| Generates rules which are easy to understand and interpret without any statistical knowledge. | Over fitting is a common flaw of DT. |
| Can make classifications based on both numerical and categorical variables. | Less applicable for estimation tasks, in the case of predicting the value of a continuous feature. |
| Performs the classification with less computational complexity. | Results in a loss of information when applying DT to continuous values. |
| Non-parametric | Non-optimal solution |
| Advantages | Disadvantages |
|---|---|
| Easy to understand and to visualize | Extremely sensitive to noisy data. |
| Has only a few hyper-parameters that need to be tuned. | Operates poorer than RF and XGBoost when irrelevant features are included. |
| Relatively robust to overfitting in low noise datasets. | Is not optimized for speed. |
| Can be used in both regression and classification problems. |
| Advantages | Disadvantages |
|---|---|
| Works great with categorical and numerical values. | Can cause overfitting. |
| Can be used in both regression and classification problems. | Less interpretable. |
| Can be time and memory exhaustive. |
| Advantages | Disadvantages |
|---|---|
| Supports parallel processing to be much faster than GBM. | Less interpretable, difficult to visualize and to tune compared to AdaBoost and RF. |
| Continuous splitting until the MTD specified and then starts pruning the tree backwards to eliminate extra splits beyond which there is no positive gain | It cannot handle categorical values by itself. |
| Can be used in both regression and classification problems. | Only numerical values are accepted for processing. |
| Advantages | Disadvantages |
|---|---|
| Avoids overfitting. | It is less used than other ensemble learning methods due to less documentation available. |
| Better accuracy than other boosting methods. | |
| Get better trees with smaller computational cost. | |
| Handle both categorical and continuous values. | |
| Outperforms XGBoost in terms of computational speed and memory consumptions. | |
| Speeds up the training process of conventional GBM. | |
| Parallel learning supported. |
| Advantages | Disadvantages |
|---|---|
| Handling overfitting and helps to improve the accuracy. | May change considerably by a small change in the data. |
| Flexible to both classification and regression problems. | Computations may go far more complex. |
| Handles both categorical and continuous values. | Not easily interpretable. |
| The power of handle large data sets with higher dimensionality. | Only numerical values are accepted for processing. |
| # | Class | Samples | Color Code |
|---|---|---|---|
| 1 | Impervious surfaces | 2,059,368 | |
| 2 | Building | 1,632,260 | |
| 3 | Low vegetation | 1,157,157 | |
| 4 | Tree | 1,127,394 | |
| 5 | Car | 55,863 |
| # | Class | Samples | Color Code |
|---|---|---|---|
| 1 | Asphalt | 6631 | |
| 2 | Meadows | 18,649 | |
| 3 | Gravel | 2099 | |
| 4 | Trees | 3064 | |
| 5 | Painted metal sheets | 1345 | |
| 6 | Bare Soil | 5029 | |
| 7 | Bitumen | 1330 | |
| 8 | Self-Blocking Bricks | 3682 | |
| 9 | Shadows | 947 |
| # | Class | Samples | Color Code |
|---|---|---|---|
| 1 | Water | 852,078 | |
| 2 | Vegetation | 237,237 | |
| 3 | High-Density Urban | 351,181 | |
| 4 | Low-Density Urban | 282,975 | |
| 5 | Developed | 80,616 |
| Algorithm | Most Important User-Defined Parameters | Example References |
|---|---|---|
| DT | maximum tree depth ([0, ∞]) | [33,58] |
| minimum sample split ([0, ∞]) | ||
| minimum sample split ([0, ∞]) | ||
| minimum number of samples at a leaf node | ||
| AdaBoost | learning rate ([0, 1]) | [35] |
| number of boosted trees ([0, ∞]) | ||
| GBM | maximum tree depth ([0, ∞]) | [59] |
| number of gradient boosted trees | ||
| minimum sample split ([0, ∞]) | ||
| learning rate ([0, 1]) | ||
| XGBoost | maximum tree depth ([0, ∞]) | [43] |
| number of gradient boosted trees ([0, ∞]) | ||
| minimum sample split ([0, ∞]) | ||
| learning rate ([0, 1]) | ||
| LightGBM | maximum tree depth ([0, ∞]) | [22,24] |
| number of boosted trees ([0, ∞]) | ||
| learning rate ([0, 1]) | ||
| RF | number of decision trees ([0, ∞]) | [18,50] |
| maximum tree depth ([0, ∞]) | ||
| number of variables in each node split | ||
| minimum number of samples at a leaf node | ||
| minimum sample split ([0, ∞]) |
| Datasets | Metrics | Methods | |||||
|---|---|---|---|---|---|---|---|
| DT | AdaBoost | GBM | XGBoost | LightGBM | RF | ||
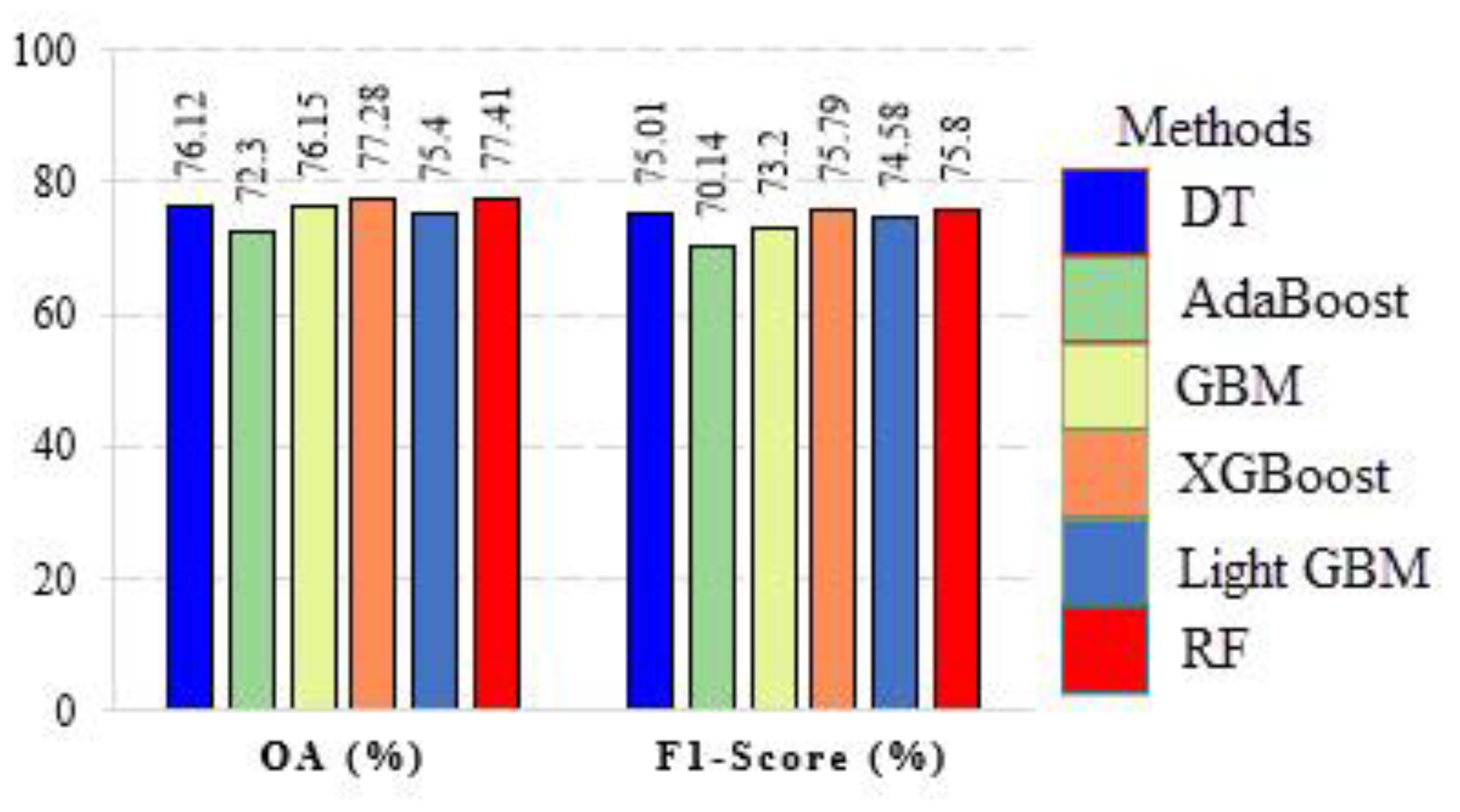
| Multispectral | OA | 76.12% | 72.3% | 76.15% | 77.28% | 75.4% | 77.41% |
| F1-Score | 75.01% | 70.14% | 73.2% | 75.79% | 74.58% | 75.8% | |
| Hyperspectral | OA | 80.51% | 78.29% | 83.84% | 85.94% | 86.34% | 85.52% |
| F1-Score | 79% | 72.8% | 82.21% | 84.48% | 83.01% | 83.44% | |
| PolSAR | OA | 77.12% | 74.52% | 66.79% | 84.62% | 80.09% | 81.94% |
| F1-Score | 74.55% | 72.56% | 65.48% | 81% | 78.51% | 78.7% | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jafarzadeh, H.; Mahdianpari, M.; Gill, E.; Mohammadimanesh, F.; Homayouni, S. Bagging and Boosting Ensemble Classifiers for Classification of Multispectral, Hyperspectral and PolSAR Data: A Comparative Evaluation. Remote Sens. 2021, 13, 4405. https://0-doi-org.brum.beds.ac.uk/10.3390/rs13214405
Jafarzadeh H, Mahdianpari M, Gill E, Mohammadimanesh F, Homayouni S. Bagging and Boosting Ensemble Classifiers for Classification of Multispectral, Hyperspectral and PolSAR Data: A Comparative Evaluation. Remote Sensing. 2021; 13(21):4405. https://0-doi-org.brum.beds.ac.uk/10.3390/rs13214405
Chicago/Turabian StyleJafarzadeh, Hamid, Masoud Mahdianpari, Eric Gill, Fariba Mohammadimanesh, and Saeid Homayouni. 2021. "Bagging and Boosting Ensemble Classifiers for Classification of Multispectral, Hyperspectral and PolSAR Data: A Comparative Evaluation" Remote Sensing 13, no. 21: 4405. https://0-doi-org.brum.beds.ac.uk/10.3390/rs13214405